Kafka(五)生产者
目录
- Kafka生产者
- 1 配置生产者
- bootstrap.servers
- key.serializer
- value.serializer
- client.id=""
- acks=all
- buffer.memory=33554432(32MB)
- compression.type=none
- batch.size=16384(16KB)
- max.in.flight.requests.per.connection=5
- max.request.size=1048576(1MB)
- receive.buffer.bytes=65536 (64KB)
- send.buffer.bytes=131072 (128KB)
- enable.idempotence=true
- partitioner.class
- partitioner.ignore.keys=false
- interceptor.classes
- 2 发送时间相关配置
- max.block.ms=60000 (1 minute)
- delivery.timeout.ms=120000 (2 minutes)
- retries=2147483647
- retry.backoff.ms=100
- request.timeout.ms=30000 (30 seconds)
- linger.ms
- 3 创建生产者
- 4 发送消息到Kafka
- 4.1 发送并忘记
- 4.2 同步发送
- 4.3 异步发送
- 5 序列化器
- 5.1 自定义序列化器
- 5.1 Avro序列化器
- 7 分区
- 7 拦截器
- 8 配额和节流
Kafka生产者
Kafka 生产者是 Apache Kafka 中的一个组件,用于将数据发布到 Kafka 集群中的主题(topic)中。生产者负责将消息发送到 Kafka 集群,并且可以指定消息的键(key)和分区(partition)。生产者可以采用异步或同步的方式发送消息,并且可以配置消息的压缩、序列化和批处理等属性。
Kafka 生产者可以通过 Kafka 的 API 或者客户端库来实现,常见的客户端库包括 Java、Python、Go、C++ 等。生产者可以在分布式环境中部署,并且可以通过多个线程同时发送消息,以提高生产效率和吞吐量。
Kafka 生产者的主要作用是将数据快速、可靠地发送到 Kafka 集群中,以供消费者消费。生产者的高性能和可靠性是 Kafka 的关键特性之一,使得 Kafka 在大数据处理和实时数据流处理中得到广泛应用。
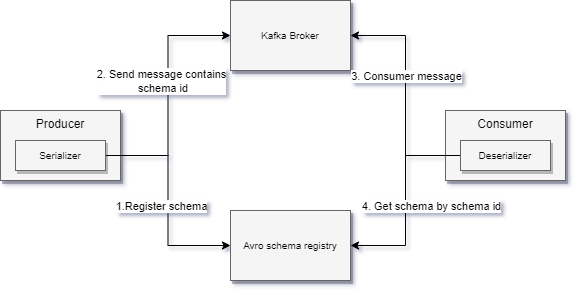
下图描述了生产者和broker之间的交互过程:

I will add more comments for this diagram later …
1 配置生产者
bootstrap.servers
这个参数是常用的KafkaProducer和KafkaConsumer用来连接Kafka集群的入口参数,这个参数对应的值通常是Kafka集群中部分broker的地址,比如:host1:9092,host2:9092,不同的broker地址之间用逗号隔开。这个参数使用的比较频繁,久而久之的就会认为这个参数配置的是所要连接的Kafka集群的broker地址,包括很多Kafka的初学者而言也会Keep这个观点,其实这个是不准确的。bootstrap.servers这个参数是用来配置发现Kafka集群信息的,这个意味着什么呢?
KafkaProducer与Kafka集群建立连接的过程是:
- KafkaProducer向bootstrap.servers所配置的地址指向的其中一个Server发送MetadataRequest请求;
- bootstrap.servers所配置的地址指向的Server返回MetadataResponse给KafkaProducer,MetadataResponse中包含了Kafka集群的所有元数据信息。
- KafkaProducer在元数据中找到集群的首领地址,向它发送消息
key.serializer
一个类名,用来序列化消息键为字节数组。Broker接收的键和值都是字节数组。
value.serializer
一个类名,用来序列化消息值为字节数组。
client.id=“”
发出请求时要传递给服务器的id字符串。这样做的目的是通过允许在服务器端请求日志中包含逻辑应用程序名称,能够跟踪ip/端口以外的请求源。
acks=all
此参数指定了生产者在多少个分区副本收到消息的情况下才会认为消息写入成功。允许以下设置:
acks=0。如果设置为零,则生产者根本不会等待来自服务器的任何确认。该记录将立即添加到套接字缓冲区,并被视为已发送。在这种情况下,无法保证服务器已收到记录,重试配置也不会生效(因为客户端通常不会知道任何故障)。为每条记录返回的偏移量将始终设置为-1。
acks=1。表示只要首领收到消息,并将记录成功写入其本地日志,就返回成功响应,不等待所有追随者的确认。在这种情况下,如果首领在确认成功后,追随者复制之前崩溃,则记录将会丢失。
acks=all。表示首领将等待同步复制集合中所有的副本都确认收到了记录。这保证了只要至少有一个同步复制副本保持活动状态,记录就不会丢失。这是最有力的保证。这相当于acks=-1的设置。
请注意,启用幂等性要求此配置值为“all”。如果设置了冲突的配置并且没有显式启用幂等性,则会禁用幂等性。
buffer.memory=33554432(32MB)
生产者可用于缓冲等待发送到服务器的记录的总内存字节数。如果记录的发送速度快于它们传递到服务器的速度,则生产者将阻止max.block.ms,之后将引发异常。
此设置应大致对应于生产者将使用的总内存,但不是硬绑定的,因为并非生产者使用的所有内存都用于缓冲。一些额外的内存将用于压缩(如果启用了压缩)以及维护飞行中的请求。
compression.type=none
生产者生成的所有数据的压缩类型。默认值为none(即无压缩)。有效值为none、gzip、snappy、lz4或zstd。压缩是全批数据,因此批处理的效果也会影响压缩比(批处理越多,压缩效果越好)。
batch.size=16384(16KB)
每当多个记录被发送到同一个分区时,生产者将尝试将记录批处理成更少的请求。这有助于提高客户端和服务器的性能。此配置控制以字节为单位的默认批处理大小。
不会尝试批处理大于此大小的记录。
发送到代理的请求将包含多个批,每个分区一个批,其中包含可发送的数据。
小批量会降低批处理的普遍性,并可能降低吞吐量(零批量会完全禁用批处理)。非常大的批处理大小可能会更加浪费内存,因为我们总是会分配指定批处理大小的缓冲区,以期待更多的记录。
注意:此设置提供要发送的批次大小的上限。如果我们为这个分区累积的字节少于这个数量,我们将“逗留”一段时间,等待更多记录出现。此linger.ms设置默认为0,这意味着即使累积的批量大小在此batch.size设置下,我们也会立即发送一条记录。
max.in.flight.requests.per.connection=5
这个参数指定了生产者在收到服务器响应(阻塞)之前可以向单个连接发送多少个消息批次。
请注意,如果此配置设置为大于1并且enable.idempotence设置为false,则由于重试(即,如果启用了重试)而导致发送失败后,存在消息重新排序的风险;如果禁用重试或enable.idempotence设置为true,则将保留排序。此外,启用幂等性要求该配置的值小于或等于5。如果设置了冲突的配置并且没有显式启用幂等性,则会禁用幂等性。
max.request.size=1048576(1MB)
请求的最大大小(以字节为单位)。此设置将限制生产者在单个请求中发送的记录批次数,以避免发送巨大的请求。这也是对最大未压缩记录批大小的有效限制。请注意,服务器对记录批大小有自己的上限(如果启用了压缩,则在压缩后),这可能与此不同。
receive.buffer.bytes=65536 (64KB)
TCP socket接收数据包缓冲区大小。如果值是-1,会使用操作系统默认值。
send.buffer.bytes=131072 (128KB)
TCP socket发送数据包缓冲区大小。如果值是-1,会使用操作系统默认值。
enable.idempotence=true
当设置为“true”时,生产者将确保在流中只写入每条消息的一个副本。如果为“false”,则由于代理失败等原因导致的生产者重试可能会在流中写入重试消息的副本。请注意,启用幂等性要求max.in.flight.requests.per-connection小于或等于5(为任何允许的值保留消息顺序),重试次数大于0,acks必须为“all”。
如果没有设置冲突的配置,默认情况下会启用幂等。如果设置了冲突的配置并且没有显式启用幂等性,则会禁用幂等性。如果显式启用了幂等性并设置了冲突的配置,则抛出ConfigException。
partitioner.class
确定在生成记录时将记录发送到哪个分区。可用选项包括:
- 如果未设置,则使用默认分区逻辑。此策略将记录发送到同一个粘性分区,直到该分区产生至少batch.size字节为止。它与以下策略配合使用:
- 如果没有指定分区,但存在键,根据键的哈希值选择分区。
- 如果没有分区或键,在当前粘性分区中产生至少batch.size字节后,才会切换到下一个分区。
- org.apache.kafka.clients.producer.internals.DefaultPartitioner
不推荐设置,如果要使用默认分区逻辑,删除此配置项即可。 - org.apache.kafka.clients.producer.RoundRobinPartitioner
一种分区策略,一系列连续记录中的每个记录都被发送到不同的分区,无论是否提供了键,直到分区用完,过程重新开始。 - org.apache.kafka.clients.producer.UniformStickyPartitioner
不推荐设置,使用partitioner.ignore.keys=true配合默认分区策略可以达到相同的效果。- 如果在记录中指定了分区,发送到指定分区
- 否则,在当前粘性分区中产生至少batch.size字节后,然后切换到下一个分区。注意:与DefaultPartitioner不同,记录键不作为此分区器中分区策略的一部分。具有相同密钥的记录不能保证发送到同一分区。
partitioner.ignore.keys=false
当设置为“true”时,生产者不会使用记录键来选择分区。如果为“false”,则生产者将在存在键时根据密钥的哈希来选择分区。注意:如果使用自定义分区器,则此设置无效。
interceptor.classes
要用作拦截器的类的列表。通过实现org.apache.kafka.clients.producer.ProducerInterceptor接口,您可以在生产者接收到的记录发布到kafka集群之前拦截(并可能改变)这些记录。默认情况下,没有拦截器。
2 发送时间相关配置
消息传递时间分布:

max.block.ms=60000 (1 minute)
配置控制KafkaProducer的发送消息方法的阻塞时间:send(), partitionsFor(), initTransactions(), sendOffsetsToTransaction(), commitTransaction() and abortTransaction()。对于send(),此超时限制了等待元数据获取和缓冲区分配的总时间(用户提供的序列化程序或分区程序中的阻塞不计入此超时)。对于partitionsFor(),此超时限制了在元数据不可用时等待元数据所花费的时间。与事务相关的方法总是阻塞,但如果无法发现事务协调器或在超时时间内没有响应,则可能会超时。
delivery.timeout.ms=120000 (2 minutes)
调用send()返回后报告成功或失败的时间上限。这限制了记录在发送之前延迟的总时间、等待来自代理的确认的时间(如果预期的话)以及允许重试发送失败的时间。如果遇到不可恢复的错误、重试次数已用完,或者记录被添加到提前到达交货到期截止日期的批中,则生产者可能会报告未能在该配置之前发送记录。此配置的值应大于或等于request.timeout.ms和linger.ms的总和
retries=2147483647
设置一个大于零的值将导致客户端重新发送任何发送失败并可能出现暂时错误的记录。请注意,此重试与客户端在收到错误后重新发送记录没有什么不同。如果delivery.timeout.ms配置的超时在确认成功之前首先过期,那么在重试次数用完之前,Produce请求将失败。用户通常应该不设置此配置,而是使用delivery.timeout.ms来控制重试行为。
启用幂等性要求此配置值大于0。如果设置了冲突的配置并且没有显式启用幂等性,则会禁用幂等性。
在将enable.idempotence设置为false和将max.in.flight.requests.per-connection设置为大于1时允许重试可能会更改记录的顺序,因为如果将两个批发送到单个分区,并且第一个批失败并重试,但第二个成功,则第二个批中的记录可能会首先出现。
retry.backoff.ms=100
尝试重试对给定主题分区的失败请求之前等待的时间。这避免了在某些失败场景下以紧密循环的方式重复发送请求。
request.timeout.ms=30000 (30 seconds)
配置控制客户端等待请求响应的最长时间。如果在超时之前没有收到响应,客户端将在必要时重新发送请求,或者在重试次数用完时使请求失败。
linger.ms
这个参数指定了生产者在发送消息批次之前等待更多消息加如批次的时间。通常情况下,只有当记录到达速度快于发送速度时,才会在加载时发生这种情况。然而,在某些情况下,即使在中等负载下,客户端也可能希望减少请求的数量。此设置通过添加少量人工延迟来实现这一点——也就是说,生产者将等待指定的延迟,以允许发送其他记录,从而可以将发送分批在一起,而不是立即发送记录。这可以被认为类似于TCP中的Nagle算法。此设置提供了批处理延迟的上限:一旦我们获得一个分区的batch.size大小的记录,无论此设置如何,它都将立即发送,但是,如果我们为该分区累积的字节数少于此数量,我们将“逗留”指定的时间,等待更多记录出现。此设置默认为0(即无延迟)。例如,设置linger.ms=5可以减少发送的请求数量,但在没有负载的情况下,发送记录的延迟将增加5ms。
3 创建生产者
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("acks", "all");props.put("delivery.timeout.ms", 30000);props.put("batch.size", 16384);props.put("linger.ms", 1);props.put("buffer.memory", 33554432);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);
4 发送消息到Kafka
发送消息有3种模式:
4.1 发送并忘记
把消息发送给broker,并不关心发送是否成功。
ProducerRecord<String, String> record = new ProducerRecord<String, String>("my-topic", "key", "value");try {producer.send(record);} catch (Exception e) {logger.error("", e);}producer.flush();producer.close();
4.2 同步发送
ProducerRecord<String, String> record = new ProducerRecord<String, String>("my-topic", "key", "value");try {RecordMetadata metadata = producer.send(record).get();} catch (Exception e) {logger.error("", e);}producer.close();
4.3 异步发送
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");kafkaProducer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (null == exception) {} else {logger.error("", exception);}kafkaProducer.close();}});
一般Producer会出现两种错误:
- 可重试错误
对于这种错误,producer会自动重试。例如网络连接错误。如果重试多次仍无法解决,可能会达到重试次数上限,抛出重试异常;或者达到请求超时时间,抛出超时异常。 - 不可重试错误
直接抛出异常。例如消息体超过大小限制。
5 序列化器
5.1 自定义序列化器
package com.qupeng.demo.kafka.kafkaapache.producer;import org.apache.kafka.common.serialization.Serializer;import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;public class CustomizedSerializer implements Serializer<Product> {@Overridepublic byte[] serialize(String topic, Product product) {byte[] name = product.getName().toString().getBytes(StandardCharsets.UTF_8);ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + name.length);buffer.putInt(product.getId());buffer.putInt(name.length);buffer.put(name);return buffer.array();}
}5.1 Avro序列化器
Avro是一种与语言无关的序列化格式,并使用schema来定义格式,用JSON来描述模式。因为Kafaka保存记录是不关心格式的,都作为二进制数组处理,所以Avro非常适合Kafka的客户端用来处理特定格式的消息。
使用Avro格式必须要注意:
- 格式遵循Avro的兼容性原则,用于新旧版本的兼容。
- 反序列化器需要获取写入数据时使用的模式。这就要求每一条记录都要携带模式,造成记录大小成倍增加。所以需要引入模式注册表,集中管理模式数据。
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props. put("key.serializer", "io.confluent.kafka.serializer.KafkaAvroSerializer");props.put("value.serializer", "io.confluent.kafka.serializer.KafkaAvroSerializer");props.put("schema.registry.url", "...");Producer<String, Product> producer = new KafkaProducer(props);while (true) {Product product = Product.newBuilder().build();ProducerRecord<String, Product> record = new ProducerRecord("product", product.getName(), product);producer.send(record);}
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props. put("key.serializer", "io.confluent.kafka.serializer.KafkaAvroSerializer");props.put("value.serializer", "io.confluent.kafka.serializer.KafkaAvroSerializer");props.put("schema.registry.url", "...");Producer<String, GenericRecord> producer = new KafkaProducer(props);String schemaString = "{\n" +" \"namespace\": \"com.qupeng.demo.kafka.kafkaspringbootproducer.avro\",\n" +" \"type\": \"record\",\n" +" \"name\": \"Product\",\n" +" \"fields\": [\n" +" {\n" +" \"type\": \"int\",\n" +" \"name\": \"id\",\n" +" \"default\": 0\n" +" },\n" +" {\n" +" \"type\": \"string\",\n" +" \"name\": \"name\",\n" +" \"default\": \"\"\n" +" }\n" +" ]\n" +"}";Schema.Parser parser = new Schema.Parser();Schema schema = parser.parse(schemaString);GenericRecord genericRecord = new GenericData.Record(schema);genericRecord.put("id", 0);genericRecord.put("name", "iPhone 17");ProducerRecord<String, GenericRecord> producerRecord = new ProducerRecord<>("product", "0", genericRecord);producer.send(producerRecord);
7 分区
由配置参数partitioner.class指定分区器类,除了内置分区器,还可以自定义分区器:
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;import java.util.Map;
public class MyPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {String msgValue = value.toString();return msgValue.contains("0") ? 0 : 1;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}
}
7 拦截器
使用配置参数interceptor.classes指定拦截器类。
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.nio.charset.StandardCharsets;
import java.util.Map;
import java.util.UUID;public class MyProducerInterceptor implements ProducerInterceptor {private Logger logger = LoggerFactory.getLogger(MyProducerInterceptor.class);@Overridepublic ProducerRecord onSend(ProducerRecord record) {record.headers().add("correlationId", UUID.randomUUID().toString().getBytes(StandardCharsets.UTF_8));return record;}@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {logger.info(metadata.toString());}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
8 配额和节流
覆盖默认配置的选项在3.0版本之后已经删除,只能使用动态配置来修改。
quota.producer.default=10485760
quota.consumer.default=10485760
# 用命令动态修改配额
kafka-configs.sh --bootstrap-server "172.26.143.96:9092" --alter --add-config 'producer_byte_rate=1024, consumer_byte_rate=2048' --entity-type clients --entity-name rest-api-1# 用命令查看配额
kafka-configs.sh --bootstrap-server "172.26.143.96:9092" --describe --entity-type clients --entity-name rest-api-1
相关文章:
Kafka(五)生产者
目录 Kafka生产者1 配置生产者bootstrap.serverskey.serializervalue.serializerclient.id""acksallbuffer.memory33554432(32MB)compression.typenonebatch.size16384(16KB)max.in.flight.requests.per.connection5max.request.size1048576(1MB)receive.buffer.byte…...

【Leetcode】242.有效的字母异位词
一、题目 1、题目描述 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 示例1: 输入: s = "anagram", t = "nagaram" 输出: true示例2: 输入: …...
关系数据理论的函数依赖)
【数据库原理】(16)关系数据理论的函数依赖
一.函数依赖的概念 函数依赖是关系数据库中核心的概念,它指的是在属性集之间存在的一种特定的关系。这种关系表明,一个属性集的值可以唯一确定另一个属性集的值。 属性子集:在关系模式中,X和Y可以是单个属性,也可以是…...

脆弱的SSL加密算法漏洞原理以及修复方法
漏洞名称:弱加密算法、脆弱的加密算法、脆弱的SSL加密算法、openssl的FREAK Attack漏洞 漏洞描述:脆弱的SSL加密算法,是一种常见的漏洞,且至今仍有大量软件支持低强度的加密协议,包括部分版本的openssl。其实…...
)
SVN迁移至GitLab,并附带历史提交记录(二)
与《SVN迁移至GitLab,并附带历史提交记录》用的 git svn clone不同,本文使用svn2git来迁移项目代码。 一、准备工作 安装Git环境,配置本地git账户信息: git config --global user.name "XXX" git config --global us…...
如何创建容器搭建节点
1.注册Discord账号 https://discord.com/这是登录网址: https://discord.com/ 2.点击startnow注册,用discord注册或者邮箱注册都可,然后登录tickhosting Tick Hosting这是登录网址:Tick Hosting 3.创建servers 4.点击你创建的servers,按照图中步骤进行...

微众区块链观察节点的架构和原理 | 科普时间
践行区块链公共精神,实现更好的公众开放与监督!2023年12月,微众区块链观察节点正式面向公众开放接入功能。从开放日起,陆续有多个观察节点在各地运行,同步区块链数据,运行区块链浏览器观察检视数据…...

React Admin 前端脚手架之ant-design-pro
文章目录 一、React Admin 前端脚手架选型二、React Admin 前端脚手架之ant-design-pro三、ant-design-pro使用步骤四、调试主题五、常用总结(持续更新)EditableProTable组件 常用组件EditableProTable组件 编辑某行后,保存时候触发发送请求EditableProTable组件,添加记录提…...

向爬虫而生---Redis 基石篇1 <拓展str>
前言: 本来是基于scrapy-redis进行讲解的,需要拓展一下redis; 包含用法,设计,高并发,阻塞等; 要应用到爬虫开发中,这些基础理论我觉得还是有必要了解一下; 所以,新开一栏! 把redis这个环节系统补上,再转回去scrapy-redis才好深入; 正文: Redis是一种内存数据库,…...

【野火i.MX6ULL开发板】利用microUSB线烧入Debian镜像
0、前言 烧入Debian镜像有两种方式:SD卡、USB SD卡:需要SD卡(不是所有型号都可以,建议去了解了解)、SD卡读卡器 USB:需要microUSB线 由于SD卡的网上资料很多了,又因为所需硬件(SD卡…...

“我在大A炒自己”
嘻嘻嘻,大伙儿好像还挺喜欢我闲聊,今天太忙,没得空精进技术,那咱还是接着闲聊吧😂😂 看到标题点进来的各位大A真爱粉,请先收下我的崇高敬意!!别误会,标题说的…...

js 颜色转换,RGB颜色转换为16进制,16进制颜色转为RGB格式
颜色转换,RGB颜色转换为16进制,16进制颜色转为RGB格式,可以自己设置透明度。 //十六进制颜色值的正则表达式 var reg /^#([0-9a-fA-f]{3}|[0-9a-fA-f]{6})$/; /*RGB颜色转换为16进制*/ String.prototype.colorHex function () {var that this;if (/^…...

uniapp中用户登录数据的存储方法探究
Hello大家好!我是咕噜铁蛋!作为一个博主,我们经常需要在应用程序中实现用户登录功能,并且需要将用户的登录数据进行存储,以便在多次使用应用程序时能够方便地获取用户信息。铁蛋通过科技手段帮大家收集整理了些知识&am…...
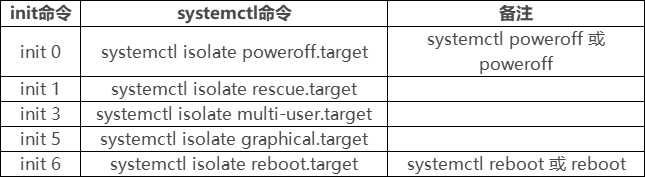
引导过程与服务控制
文章目录 一、Linux操作系统引导过程1、开机启动的完整过程1.1 开机自检(BIOS)1.2 MBR引导1.3 GRUB菜单1.4 加载内核(kernel)1.5 init进程初始化 2、系统初始化进程2.1 init进程2.2 systemdinit与systemd区别 3、Systemd单元类型4…...

《矩阵分析》笔记
来源:【《矩阵分析》期末速成 主讲人:苑长(5小时冲上90)】https://www.bilibili.com/video/BV1A24y1p76q?vd_sourcec4e1c57e5b6ca4824f87e74170ffa64d 这学期考矩阵论,使用教材是《矩阵论简明教程》,因为没…...

『App自动化测试之Appium应用篇』| Appium常用API及操作
『App自动化测试之Appium应用篇』| Appium常用API及操作 1 press_keycode1.1 键盘操作1.2 关于KeyCode1.3 press_keycode源码1.4 电话键相关1.5 控制键相关1.6 基本按键相关1.7 组合键相关1.8 符号键相关1.9 使用举例 2 swip方法2.1 swip说明2.2 swip使用方法2.3 使用示例 3 sc…...
VSCode搭建 .netcore 开发环境
一、MacOS 笔者笔记本电脑上安装的是macOS High Sierra(10.13),想要尝试一下新版本的.netcore,之前系统是10.12时,.netcore 3.1刚出来时安装过3.1版本,很久没更新了,最近.net8出来了,想试一下,…...
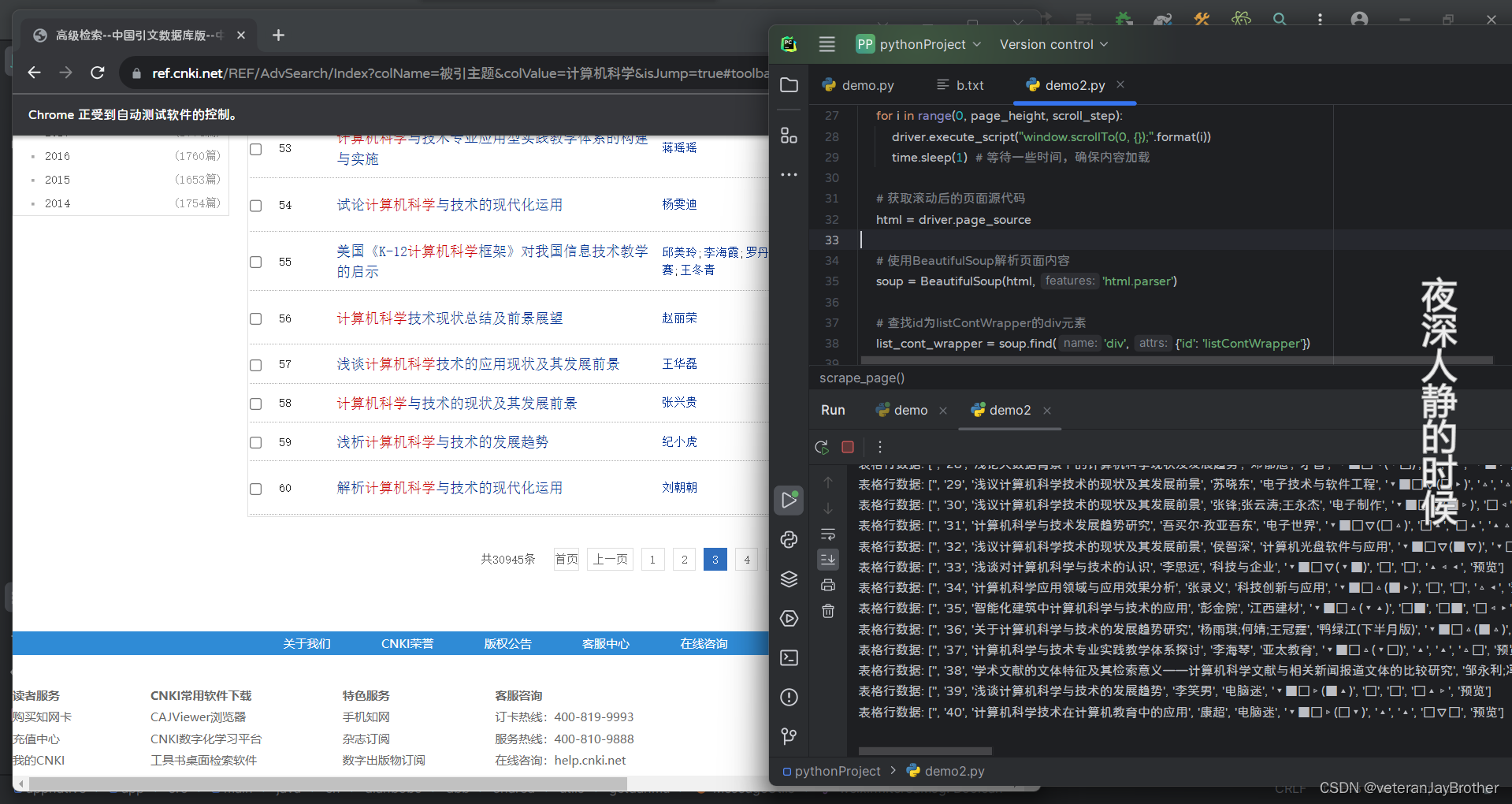
python 写自动点击爬取数据
今天来点不一样的!哥们 提示: 这里只是用于自己学习的 ,请勿用违法地方 效果图 会进行点击下一页 进行抓取 需要其他操作也可以自己写 文章目录 今天来点不一样的!哥们前言一、上代码?总结 前言 爬虫是指通过编程自动…...
CSDN博客重新更新
说来惭愧,好久没更新博客文章,导致个人博客网站:https://lenky.info/ 所在的网络空间和域名都过期了都没发觉,直到有个同事在Dim上问我我的个人博客为啥打不开了。。。幸好之前有做整站备份,后续慢慢把内容都迁回CSDN上…...
)
《剑指 Offer》专项突破版 - 面试题 5 : 单词长度的最大乘积(C++ 实现)
目录 前言 方法一 方法二 前言 题目链接:318. 最大单词长度乘积 - 力扣(LeetCode) 题目: 输入一个字符串数组 words,请计算不包含相同字符的两个字符串 words[i] 和 words[j] 的长度乘积的最大值。如果所有字符串…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...