云计算历年题整理
目录
第一大题
第一大题HA计算
给出计算连接到EC2节点的EBS的高可用性(HA)的数学公式,如场景中所述;计算EC2节点上的EBS的高可用性(HA);场景中80%的AWS EC2节点用于并行处理,总共有100个虚拟中央处理单元(vCPUs)用于处理数据,使用固定工作负载和缩放工作负载来计算AWS EC2系统的系统效率(固定和缩放效率)。
一个Amazon AWS EC2 集群包含300个vCPUs。如果这些处理器的80%用于并行执行计算和处理活动,计算:使用“固定工作负载”和“扩展工作负载”的AWS EC2集群的系统效率(两个单独的计算);上面描述的AWS EC2集群还有一个为集群提供HA的AWS S3,如果集群的总平均故障间隔时间(MTTF)为500天,平均平均修复时间(MTTR)为2.5天,则计算集群的系统可用性
第一大题n个xx(只答若干个短语)
列出四种云部署模型(该题出现2次)
描述管理虚拟集群的四种方法(W1D2)
讨论四种类型的云计算部署模型,并在每种情况下描述Security和Trust的问题
描述私有云和公共云部署模型之间的三个区别(W1D1)
描述两种类型的可伸缩性度量,以及在此场景中可能出现的问题:一家银行决定在其现有的银行应用程序中添加一个新的客户关系管理(CRM)功能,还在两个国家开设了新的分行,这些新分行将使用相同的应用程序。
第一大题子网掩码计算
AWS VPC的公网子网CIDR为20.0.2.0/20,计算IP数量地址,写出子网可以拥有的最大EC2实例。
利用您在云计算方面的知识,在下述场景中,解释您认为解决方案架构师决定使用伦敦区域和两个可用区(az)的原因;描述解决方案架构师决定将Web应用程序部署在公共子网中,而将DynamoDB数据库部署在私有子网中的原因;计算Amazon VPC中可创建的最大IP地址个数和公网子网中可创建的最大虚拟机个数。
第一、二大题描述名词
第一大题描述名词
描述计算机网络中的数据完整性和数据机密性(该题出现2次)
描述 AWS CloudFront
描述AWS Regions和AWS Zones
描述AWS可信顾问(W1D3)
第二大题描述名词
描述Amazon CloudWatch和AWS CloudTrail
描述模型视图控制器(MVC)和前端控制器设计模式,为这两种设计模式在实际应用中的应用分别举出一个例子
第二大题
第二大题CUDA代码
关于GPU和CUDA:简要说明在CUDA C编程模型中使用的五个主要步骤,以解决基于主机和设备组件的GPU编程架构的异构性质;编写一个简单的CUDA C程序,打印“欢迎来到GPU编程世界!”使用myGPUKernel()作为CUDA C程序的内核名称,并使用<<< >>>分隔符启动它,以打印消息“欢迎来到GPU编程世界!”并行五次(不要使用任何C迭代循环命令)。
编写一个GPU CUDA C程序,内核名为“add”,添加两个整数变量a和显示程序将与主机(CPU)和设备(GPU)通信的所有步骤,包括内存管理活动(可以随意使用更多变量)。(该题出现2次)
关于GPU和CUDA:描述使用CUDA平台编写GPU的三种方法;描述GPU CUDA计算或编程中异构计算的两个特性。
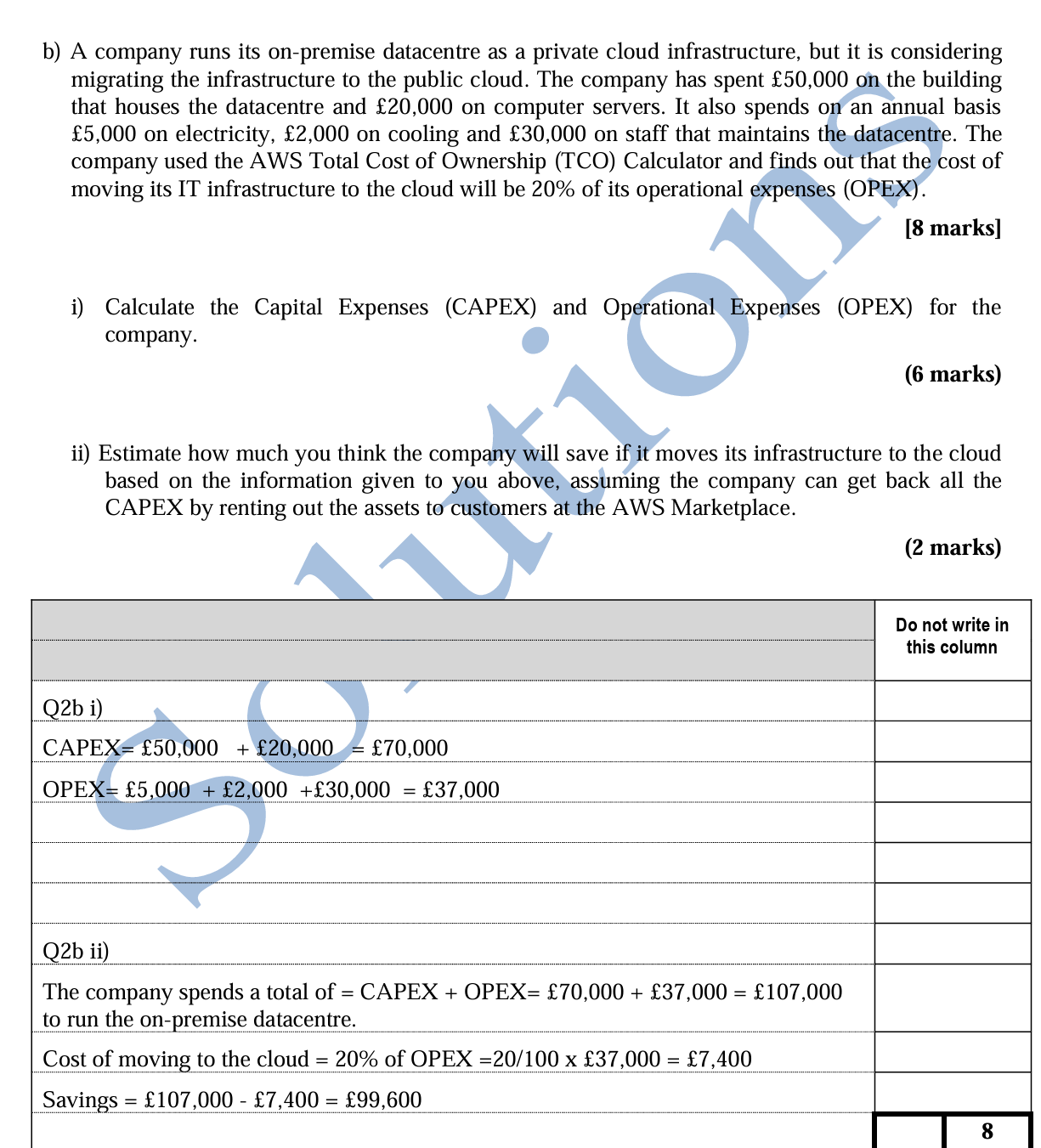
第二大题经济计算
根据上述公司收支的描述,计算资本支出(CAPEX)和运营费用;假设公司可以通过在AWS市场上向客户出租资产来收回所有的资本支出,估算一下如果公司将其基础设施迁移到云端可以节省多少成本。
关于云经济的:用图表分别描述计算传统IT成本和云计算成本的两种算法/数学模型;如果一个传统IT系统的总成本为50万英镑,那么它的前期资本成本为30万英镑,用云计算代替传统IT模式的成本是多少?
第三大题
第三大题Map/Reduce项目涉及代码
下列Map/Reduce伪代码的结果是什么?解释它并举例说明映射器/还原器之间的信息交换(出现两次)
根据下列场景,如何使用 MapReduce 计算模型组织计算?请提供算法伪代码。您可以编写适用于给定输入的 Map/Reduce 程序,计算每个供应商提供的商品的平均销售价格,或者使用伪代码编写规范。
编写一个Map/Reduce Java程序来计算每个事件类别中最受欢迎的事件(即最常预订的古典音乐会,爵士音乐会,流行音乐会等)。包括注释来解释代码的作用。您还可以使用伪代码来编写规范,或者用图表来说明输入、映射、减少和输出块之间的数据流。
第三大题阿姆达尔定律计算
关于Map/Reduce的性能:定义并行计算中的加速概念;使用Amdahl定律,计算用10个处理器运行此作业时可实现的最大加速,注意8%的计算作业必须顺序执行。
关于Map/Reduce的性能:描述阿姆达尔定律,以及顺序计算和并行计算之间的区别。说出Hadoop中必须按顺序执行的一个阶段;如果95%的计算作业必须顺序执行,那么在跨8个处理器运行该作业时可实现的最大加速是多少?同样,对于同一个作业,当跨1000个处理器运行该作业时,可实现的最大加速是多少?用阿姆达尔定律来回答
描述Flynn对计算机体系结构的四种分类。(W1D1)用阿姆达尔定律计算提高使用10个处理器并行运行20%应用程序的系统的性能速度
第三大题键值对计算
假设作业是针对600万张图片的数据集执行的。Hadoop为作业分配了20个mapper和6个Reducers,一张照片中出现的汽车的平均数量是0.5:估计Mapper将发出多少个键值对;假设数据集有3000个独特的汽车型号,每个Reducer有多少个key?注意,您可以假设在reducer之间实现均衡的分区。
在该场景中,Hadoop使用10个mapper和2个reducer来完成计算,每个Mapper发出多少中间键:值对?有多少唯一的键被馈送到每个Reducer?
第三大题也与map有关但不是代码和计算
涉及到Map/Reduce的Combiner:什么是Combiner,用处?它和减速器有什么不同?使用组合器是可选的还是强制的;简要说明组合器必须遵守的两条规则。
解释在MapReduce作业的shuffle和sort阶段,由谁运行Combiner函数以及在哪个时间点执行Combiner函数。
关于Map-Reduce的数据过滤:Map-Reduce作业中数据过滤的目的是什么?给出一个数据过滤的例子;为什么数据过滤是“Mapper唯一的工作”?
第三大题HDFS描述
涉及Hadoop计算作业执行:用箭头(→)连接Hadoop计算任务对应负责的守护进程
关于Hadoop分布式文件系统的:NameNode在HDFS中的职责是什么;用合适的图表解释HDFS的写操作(例如,如何创建一个新文件并将数据写入HDFS);为什么HDFS默认为每个块存储三个单独的副本?为什么在大型集群中将三个副本分散到不同的物理机架上是有用的?
定义分布式系统和基础设施的高可用性。
在分布式系统的背景下,什么是“五九可用性”?请解释这与“单点故障”的概念之间的关系,以及这可能对分布式系统产生的负面影响(该题出现2次)
HDFS (Hadoop Distributed File System)如何检测数据块损坏
如果Map任务中的一个失败,Map/Reduce作业是否会完成?应用程序主机和节点管理器如何检测Map任务的失败并对其作出反应?
第四大题
第四大题DNS描述
什么是内容交付网络(CDN)中的DNS缓存?DNS缓存的两个好处。
关于内容分发网络(CDN):为什么网站要使用CDN?为什么CDN在世界各地放置服务器?
与内容交付网络(CDN)有关:什么是内容分发网络(CDN)?解释CDN是如何工作的;CDN中的DNS重定向是什么?简要解释不同的DNS重定向类型及其优缺点;点对点(P2P)网络是什么?解释P2P网络相对于客户机-服务器网络的三个好处。
第四大题数据库描述
关于Map/Reduce之外的大数据平台:什么是内存处理?讨论Hadoop Map/Reduce与现代内存处理系统(如Apache Spark)相比的的主要性能限制,用一个例子说明两者的区别;在Apache Spark的背景下,什么是弹性分布式数据集(RDD) ?解释两种类型的RDD操作,并为每种操作提供一个示例,例如,如何通过编程操作创建和修改RDD。
与云数据库有关:解释以下这些用于实现数据分区和复制的技术:内存缓存、读写分离、高可用性集群、数据分片;SQL数据库以牺牲分区为代价提供了强一致性和可用性,而不同的NoSQL数据库采用不同的基于cap的权衡,那么Dynamo做了哪些权衡?
与云数据库有关:为什么在云数据库中使用数据分区和复制很重要;在数据访问上下文中解释强一致性和最终一致性之间的区别,用例子来解释
关于分布式云数据库的:解释NoSQL数据库与传统关系数据库的区别,请在ACID事务属性上下文中解释这一点;使用NoSQL数据库的好处是什么;说出使用NoSQL数据库(例如Cassandra)而不是使用传统SQL关系数据库的两个原因;什么是布鲁尔CAP定理?解释CAP的三个特性;NoSQL数据库是否满足CAP的所有三个支柱?如果没有,解释为什么没有,以及放松这些限制的好处是什么。
这个问题是关于云数据库的:列出ACID事务属性;大多数云数据库都有ACID事务属性吗?如果不是,为什么;什么是memcached?它的功能与关系数据库(例如SQL)有什么不同?如果在没有可用存储空间的情况下,尝试在memcached中存储对象,会发生什么情况?
关于Casandra的(一个NoSQL数据库):解释卡桑德拉戒指上的复制因子是指什么,这对Cassandra数据存储的弹性有什么影响;假设你管理一个Cassandra数据库,你面临着可伸缩性问题,即当前的Cassandra节点集不足以处理你的应用程序的需求,如何增加Cassandra数据库的容量?用弹性来解释这一点,以及它对性能的影响;Cassandra有单点故障吗?
第四大题其它描述
关于Apache Spark框架计算的,它基于RDD:定义Spark RDD,解释为什么Spark是一个使用rdd概念的内存处理平台;通过回答以下问题来描述RDD的生命周期:Spark程序如何创建新的RDD?何时创建rdd?如何修改rdd?Spark框架如何以及何时销毁rdd;给出一个利用Spark作为内存处理系统的算法示例。
传统的流处理系统和微批流处理系统有什么区别?
关于分布式图处理的:解释Pregel在并行图计算时使用“像顶点一样思考”模型的方式,给出一个适合这个模型的图算法的例子;什么是图分区?为什么有必要?讨论图划分在分布式图处理系统中的作用;图分区和性能之间的关系是什么?错误的分区决策会导致更差的性能吗?如果是,为什么?
关于分布式图处理:描述谷歌Pregel背后的主要概念。它是如何并行化图计算的?它如何最小化节点之间发送消息的需求?
第一大题
第一大题HA计算
给出计算连接到EC2节点的EBS的高可用性(HA)的数学公式,如场景中所述;计算EC2节点上的EBS的高可用性(HA);场景中80%的AWS EC2节点用于并行处理,总共有100个虚拟中央处理单元(vCPUs)用于处理数据,使用固定工作负载和缩放工作负载来计算AWS EC2系统的系统效率(固定和缩放效率)。
用上述资料,分别以“固定工作量”和“扩展工作量”计算该电子商务集群的两个系统效率;如果该电子商务公司使用的集群平均平均恢复时间(MTTR)为96小时,总平均故障时间(MTTF)为900天,计算集群的高可用性(HA)

一个Amazon AWS EC2 集群包含300个vCPUs。如果这些处理器的80%用于并行执行计算和处理活动,计算:使用“固定工作负载”和“扩展工作负载”的AWS EC2集群的系统效率(两个单独的计算);上面描述的AWS EC2集群还有一个为集群提供HA的AWS S3,如果集群的总平均故障间隔时间(MTTF)为500天,平均平均修复时间(MTTR)为2.5天,则计算集群的系统可用性

不写答案了,和前题差不多
第一大题n个xx(只答若干个短语)
列出四种云部署模型(该题出现2次)

描述管理虚拟集群的四种方法(W1D2)


讨论四种类型的云计算部署模型,并在每种情况下描述Security和Trust的问题


描述私有云和公共云部署模型之间的三个区别(W1D1)


描述两种类型的可伸缩性度量,以及在此场景中可能出现的问题:一家银行决定在其现有的银行应用程序中添加一个新的客户关系管理(CRM)功能,还在两个国家开设了新的分行,这些新分行将使用相同的应用程序。



![]()
第一大题子网掩码计算
AWS VPC的公网子网CIDR为20.0.2.0/20,计算IP数量地址,写出子网可以拥有的最大EC2实例。

利用您在云计算方面的知识,在下述场景中,解释您认为解决方案架构师决定使用伦敦区域和两个可用区(az)的原因;描述解决方案架构师决定将Web应用程序部署在公共子网中,而将DynamoDB数据库部署在私有子网中的原因;计算Amazon VPC中可创建的最大IP地址个数和公网子网中可创建的最大虚拟机个数。
一家客户主要在伦敦的公司正在将其内部部署(私有云)服务迁移到亚马逊网络服务(AWS),他们已经聘请了一位解决方案架构师来设计他们将用于部署的AWS架构。该架构包括:Amazon VPC (Amazon Virtual Private Cloud), CIDR为10.0.0.0/16;位于伦敦地区(eu-west-2)的eu-west-2a可用区(AZ)的公网子网CIDR为10.0.1.0/20;位于伦敦地区(AZ)的eu-west-2b可用区(AZ)的私有子网CIDR为10.0.2.0/20。Web应用程序将驻留在公共子网中,DynamoDB数据库将驻留在私有子网中



第一、二大题描述名词
第一大题和第二大题的描述名词雷同所以放一起,但第三、四大题也有很多来源于前两周
第一大题描述名词
描述计算机网络中的数据完整性和数据机密性(该题出现2次)


数据机密性还可以这么写

描述 AWS CloudFront

描述AWS Regions和AWS Zones

描述AWS可信顾问(W1D3)


第二大题描述名词
描述Amazon CloudWatch和AWS CloudTrail

描述模型视图控制器(MVC)和前端控制器设计模式,为这两种设计模式在实际应用中的应用分别举出一个例子

第二大题
第二大题CUDA代码
关于GPU和CUDA:简要说明在CUDA C编程模型中使用的五个主要步骤,以解决基于主机和设备组件的GPU编程架构的异构性质;编写一个简单的CUDA C程序,打印“欢迎来到GPU编程世界!”使用myGPUKernel()作为CUDA C程序的内核名称,并使用<<< >>>分隔符启动它,以打印消息“欢迎来到GPU编程世界!”并行五次(不要使用任何C迭代循环命令)。


编写一个GPU CUDA C程序,内核名为“add”,添加两个整数变量a和显示程序将与主机(CPU)和设备(GPU)通信的所有步骤,包括内存管理活动(可以随意使用更多变量)。(该题出现2次)



上述代码补充讲解

关于GPU和CUDA:描述使用CUDA平台编写GPU的三种方法;描述GPU CUDA计算或编程中异构计算的两个特性。


两个特性找不到原文,下面三选一吧

第二大题经济计算
根据传统IT成本模型和云计算成本模型解释CAPEX和OPEX,并给出两个CAPEX下的成本例子和两个OPEX下的成本例子。在你的答案中使用数学成本模型作为例证。


根据上述公司收支的描述,计算资本支出(CAPEX)和运营费用;假设公司可以通过在AWS市场上向客户出租资产来收回所有的资本支出,估算一下如果公司将其基础设施迁移到云端可以节省多少成本。
关于云经济的:用图表分别描述计算传统IT成本和云计算成本的两种算法/数学模型;如果一个传统IT系统的总成本为50万英镑,那么它的前期资本成本为30万英镑,用云计算代替传统IT模式的成本是多少?

第三大题
第三大题Map/Reduce项目涉及代码
下列Map/Reduce伪代码的结果是什么?解释它并举例说明映射器/还原器之间的信息交换(出现两次)

根据下列场景,如何使用 MapReduce 计算模型组织计算?请提供算法伪代码。您可以编写适用于给定输入的 Map/Reduce 程序,计算每个供应商提供的商品的平均销售价格,或者使用伪代码编写规范。
大型超市连锁店的收银柜台,对于每个售出的商品,它生成一个记录,格式如下 [方括号中为类型]
ProductId [String],Supplier [String],Price [Double]
在这里,ProductId [String] 是产品的唯一标识符,Supplier [String] 是产品的供应商名称,而 Price [Double] 是产品的销售价格。假设超市连锁店在数个月的时间里积累了数千兆字节的数据。这些数据可以作为输入提供给 MapReduce 作业,格式为一组键/值对(String ProductId,ProductRecord record)。键是字符串,表示超市连锁店产品的唯一标识符,而值是 ProductRecord 对象,包含产品的全部详细信息(以及用于访问每个字段的方法)。例如,ProductRecord.getPrice() 和 ProductRecord.getSupplier() 分别返回输入行的 Price 和 Supplier 字段。
注意:可以假设存在一个名为 computeAvg(List<Pair> values) 的方法,它返回列表中商品的平均销售价格。应该在 reduce 方法中使用这个方法。
超市连锁店的首席执行官想要一个供应商列表,列出每个供应商提供的商品的平均销售价格。

Map(String key, ProductRecord value):// key 是产品ID,value 是产品记录对象supplier = value.getSupplier() // 获取供应商price = value.getPrice() // 获取销售价格emitIntermediate(supplier, price) // 输出中间键/值对Reduce(String key, List<Double> values):// key 是供应商名称,values 是该供应商的所有销售价格列表avgPrice = computeAvg(values) // 调用computeAvg方法计算平均销售价格emit(key, avgPrice) // 输出最终键/值对,键为供应商,值为平均销售价格
编写一个Map/Reduce Java程序来计算每个事件类别中最受欢迎的事件(即最常预订的古典音乐会,爵士音乐会,流行音乐会等)。包括注释来解释代码的作用。您还可以使用伪代码来编写规范,或者用图表来说明输入、映射、减少和输出块之间的数据流。

第三大题阿姆达尔定律计算
关于Map/Reduce的性能:定义并行计算中的加速概念;使用Amdahl定律,计算用10个处理器运行此作业时可实现的最大加速,注意8%的计算作业必须顺序执行。

关于Map/Reduce的性能:描述阿姆达尔定律,以及顺序计算和并行计算之间的区别。说出Hadoop中必须按顺序执行的一个阶段;如果95%的计算作业必须顺序执行,那么在跨8个处理器运行该作业时可实现的最大加速是多少?同样,对于同一个作业,当跨1000个处理器运行该作业时,可实现的最大加速是多少?用阿姆达尔定律来回答


描述Flynn对计算机体系结构的四种分类。(W1D1)用阿姆达尔定律计算提高使用10个处理器并行运行20%应用程序的系统的性能速度


第三大题键值对计算
假设作业是针对600万张图片的数据集执行的。Hadoop为作业分配了20个mapper和6个Reducers,一张照片中出现的汽车的平均数量是0.5:估计Mapper将发出多少个键值对;假设数据集有3000个独特的汽车型号,每个Reducer有多少个key?注意,您可以假设在reducer之间实现均衡的分区。

解析:
第一题的300万个键值对是由(600万张图片)*(一张照片中出现的汽车的平均数量是0.5)得来
第二题的500个keys是由(3000个独特的汽车型号)/(6个Reducers)得来

在该场景中,Hadoop使用10个mapper和2个reducer来完成计算,每个Mapper发出多少中间键:值对?有多少唯一的键被馈送到每个Reducer?

第三大题也与map有关但不是代码和计算
涉及到Map/Reduce的Combiner:什么是Combiner,用处?它和减速器有什么不同?使用组合器是可选的还是强制的;简要说明组合器必须遵守的两条规则。


解释在MapReduce作业的shuffle和sort阶段,由谁运行Combiner函数以及在哪个时间点执行Combiner函数。

关于Map-Reduce的数据过滤:Map-Reduce作业中数据过滤的目的是什么?给出一个数据过滤的例子;为什么数据过滤是“Mapper唯一的工作”?

第三大题HDFS描述
涉及Hadoop计算作业执行:用箭头(→)连接Hadoop计算任务对应负责的守护进程


关于Hadoop分布式文件系统的:NameNode在HDFS中的职责是什么;用合适的图表解释HDFS的写操作(例如,如何创建一个新文件并将数据写入HDFS);为什么HDFS默认为每个块存储三个单独的副本?为什么在大型集群中将三个副本分散到不同的物理机架上是有用的?


定义分布式系统和基础设施的高可用性。


在分布式系统的背景下,什么是“五九可用性”?请解释这与“单点故障”的概念之间的关系,以及这可能对分布式系统产生的负面影响(该题出现2次)

“五九可用性”是指系统的可用性达到99.999%。这意味着系统每年最多只能停机5.26分钟,忍受少数错误,不能有单点误差。这是对分布式系统高可用性的极端要求,通常在需要持续运行且不容忍长时间停机的关键应用中使用。
HDFS (Hadoop Distributed File System)如何检测数据块损坏


如果Map任务中的一个失败,Map/Reduce作业是否会完成?应用程序主机和节点管理器如何检测Map任务的失败并对其作出反应?


第四大题
第四大题DNS描述
什么是内容交付网络(CDN)中的DNS缓存?DNS缓存的两个好处。

关于内容分发网络(CDN):为什么网站要使用CDN?为什么CDN在世界各地放置服务器?


与内容交付网络(CDN)有关:什么是内容分发网络(CDN)?解释CDN是如何工作的;CDN中的DNS重定向是什么?简要解释不同的DNS重定向类型及其优缺点;点对点(P2P)网络是什么?解释P2P网络相对于客户机-服务器网络的三个好处。



第四大题数据库描述
关于Map/Reduce之外的大数据平台:什么是内存处理?讨论Hadoop Map/Reduce与现代内存处理系统(如Apache Spark)相比的的主要性能限制,用一个例子说明两者的区别;在Apache Spark的背景下,什么是弹性分布式数据集(RDD) ?解释两种类型的RDD操作,并为每种操作提供一个示例,例如,如何通过编程操作创建和修改RDD。

与云数据库有关:解释以下这些用于实现数据分区和复制的技术:内存缓存、读写分离、高可用性集群、数据分片;SQL数据库以牺牲分区为代价提供了强一致性和可用性,而不同的NoSQL数据库采用不同的基于cap的权衡,那么Dynamo做了哪些权衡?

关于读写分离:所有的写操作都发生在主数据库上,确保数据的一致性。读操作可以分发到任意一个从数据库上,实现了负载均衡,提高了并发能力。优点:提高了系统的并发读能力,降低了读操作对主数据库的压力。增加了系统的可伸缩性,可以通过添加从数据库来扩展读能力。缺点:数据同步延迟:从数据库复制数据的过程是异步的,可能导致读到的数据并不是最新的。一致性问题:在某些情况下,主数据库和从数据库之间可能存在数据不一致的情况,需要采取一些措施来处理这种情况。

高可用性集群是指由多个节点组成的数据库集群,旨在提高系统的可用性和容错能力。如果一个节点出现故障,其他节点可以接管其工作,从而保持系统的正常运行。适用于读写操作都较为频繁的场景。
数据分片是为了应对大规模数据存储和处理的需求,将数据分散存储在多个节点上,每个节点负责一部分数据。数据分片的实现方式例子:垂直分片: 将不同表或列的数据存储在不同的节点上,可以根据数据的关系进行垂直拆分。水平分片: 将同一表中的不同行数据存储在不同的节点上,可以根据某个字段值的范围或哈希值进行水平拆分。
与云数据库有关:为什么在云数据库中使用数据分区和复制很重要;在数据访问上下文中解释强一致性和最终一致性之间的区别,用例子来解释


关于分布式云数据库的:解释NoSQL数据库与传统关系数据库的区别,请在ACID事务属性上下文中解释这一点;使用NoSQL数据库的好处是什么;说出使用NoSQL数据库(例如Cassandra)而不是使用传统SQL关系数据库的两个原因;什么是布鲁尔CAP定理?解释CAP的三个特性;NoSQL数据库是否满足CAP的所有三个支柱?如果没有,解释为什么没有,以及放松这些限制的好处是什么。



这个问题是关于云数据库的:列出ACID事务属性;大多数云数据库都有ACID事务属性吗?如果不是,为什么;什么是memcached?它的功能与关系数据库(例如SQL)有什么不同?如果在没有可用存储空间的情况下,尝试在memcached中存储对象,会发生什么情况?


关于Casandra的(一个NoSQL数据库):解释卡桑德拉戒指上的复制因子是指什么,这对Cassandra数据存储的弹性有什么影响;假设你管理一个Cassandra数据库,你面临着可伸缩性问题,即当前的Cassandra节点集不足以处理你的应用程序的需求,如何增加Cassandra数据库的容量?用弹性来解释这一点,以及它对性能的影响;Cassandra有单点故障吗?

或用chatgpt



第四大题其它描述
关于Apache Spark框架计算的,它基于RDD:定义Spark RDD,解释为什么Spark是一个使用rdd概念的内存处理平台;通过回答以下问题来描述RDD的生命周期:Spark程序如何创建新的RDD?何时创建rdd?如何修改rdd?Spark框架如何以及何时销毁rdd;给出一个利用Spark作为内存处理系统的算法示例。

传统的流处理系统和微批流处理系统有什么区别?

关于分布式图处理的:解释Pregel在并行图计算时使用“像顶点一样思考”模型的方式,给出一个适合这个模型的图算法的例子;什么是图分区?为什么有必要?讨论图划分在分布式图处理系统中的作用;图分区和性能之间的关系是什么?错误的分区决策会导致更差的性能吗?如果是,为什么?




关于分布式图处理:描述谷歌Pregel背后的主要概念。它是如何并行化图计算的?它如何最小化节点之间发送消息的需求?
![]()
![]()

相关文章:
云计算历年题整理
目录 第一大题 第一大题HA计算 给出计算连接到EC2节点的EBS的高可用性(HA)的数学公式,如场景中所述;计算EC2节点上的EBS的高可用性(HA);场景中80%的AWS EC2节点用于并行处理,总共有100个虚拟中央处理单元(vCPUs)用于处理数据&a…...

2401vim,vim重要修改更新大全
原文 2023 更好的UTF-16支持 添加strutf16len()和utf16idx(),并在byteidx(),byteidxcomp()和charidx()中添加utf16标志,在内置.txt文档中. 添加crypymethod xchacha20v2 与xchacha20基本相同,但更能抵御libsodium的变化. 2022 添加"smoothscroll" 用鼠标滚动…...

安卓多用户管理之Userinfo
目录 前言Userinfo----用户信息1.1 属性1.2 构造器1.3 信息的判断及获取方法1.3.1 获取默认用户类型1.3.2 基础信息判断 1.4 序列化部分 总结 前言 UserManagerService内部类UserData中有一个Userinfo类型的info参数,在UserData中并未有所体现,但在后续…...

JavaScript-流程控制-笔记
1.流程语句的分类 顺序结构 分支结构 循环结构 2.if语句 1)if结构 if( 条件 ){ // 条件成立执行的代码 } 2)if else 结构 if( 条件 ){ // 条件成立执行的代码 }else{ // 条件不成…...

springboot + vue3实现增删改查分页操作
springboot vue3实现增删改查分页操作 环境最终实现效果实现功能主要框架代码实现数据库后端前端 注意事项 环境 jdk17 vue3 最终实现效果 实现功能 添加用户,禁用,启用,删除,编辑,分页查询 主要框架 后端 spri…...

leetcode01-重复的子字符串
题目链接:459. 重复的子字符串 - 力扣(LeetCode) 一般思路: 如果存在k是S的字串,记k的长度为s,S的长度为n,则一定有n是s的倍数,且满足对于j∈[s,n],一定存在s[j]s[j-s]; …...

目标检测数据集 - 夜间行人检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:夜间、低光行人检测数据集,真实场景高质量图片数据,涉及场景丰富,比如夜间街景行人、夜间道路行人、夜间遮挡行人、夜间严重遮挡行人数据;适用实际项目应用:公共场所监控场景下夜间行人检测项目…...
【YOLO系列】 YOLOv4思想详解
前言 以下内容仅为个人在学习人工智能中所记录的笔记,先将目标识别算法yolo系列的整理出来分享给大家,供大家学习参考。 本文未对论文逐句逐段翻译,而是阅读全文后,总结出的YOLO V4论文的思路与实现路径。 若文中内容有误…...
查询json数组
步骤一:创建表格 首先,我们需要创建一个表格来存储包含JSON对象数组的数据。可以使用以下代码创建一个名为 my_table 的表格: CREATE TABLE my_table (id INT PRIMARY KEY AUTO_INCREMENT,json_data JSON ); 上述代码创建了一个包含两个列的…...
Docker mysql 主从复制
目录 介绍:为什么需要进行mysql的主从复制 主从复制原理: ✨主从环境搭建 主从一般面试问题: 介绍:为什么需要进行mysql的主从复制 在实际的生产中,为了解决Mysql的单点故障已经提高MySQL的整体服务性能ÿ…...
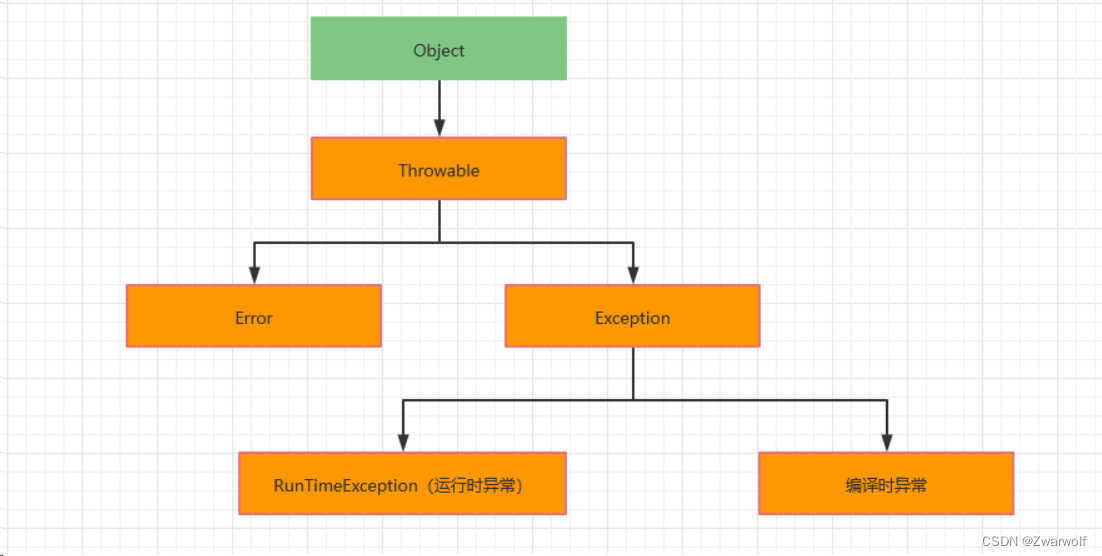
第7章-第1节-Java中的异常处理
1、异常Exception概述: 1)、异常的概念: 现实生活中万物在发展和变化会出现各种各样不正常的现象。 例如:人的成长过程中会生病。 实际工作中,遇到的情况不可能是非常完美的。 比如:你写的某个模块&…...

使用python生成一个月度账单消费金额柱状图表
阿里云月度账单根据月份、消费金额(可开票)生成一个柱状图表 import pandas as pd import matplotlib.pyplot as plt import os# 设置中文字体 plt.rcParams[font.sans-serif] [SimHei] # 用于显示中文的宋体# 获取当前工作目录下所有CSV文件 csv_fil…...

将一个独立的磁盘添加到已有的 `/` 分区
将一个独立的磁盘添加到已有的 / 分区是比较复杂的,因为 / 分区已经是一个逻辑卷(LVM)。在这种情况下,可以扩展现有的 LVM 体积组(Volume Group),然后扩展 / 逻辑卷(Logical Volume&…...

AI智能电销器人需要注意哪些问题呢
随着科技的不断发展,人们出行变得越来越方便,市面上很多产品也越来越智能化,高科技的产品不仅改变了我们的生活方式而且也改变了企业的竞争方式,很多的企业尤其是电销行业中的大佬己经意识到了AI电销机器人的好处,因此…...

呼叫中心研究分析:到2027年市场规模预计将达4966亿美元
由于业务运营中以客户为中心的方法的兴起,呼叫中心市场近年来出现了显着增长。随着对客户满意度的日益重视,全球对呼叫中心服务的需求猛增。在本次分析中,我们将从全球和中国的角度审视呼叫中心市场的发展趋势。全球市场: 到 2027…...

工业数据采集分析——工厂大脑 提升综合经济效益
随着企业对数字化的认知越来越清晰,对工业数智化的战略越来越明确,企业的诉求也在发生转变。中国的工业企业经过近几十年的发展,自动化、信息化,以及一些基础的数据系统建设在不同的行业中慢慢地推进。近几年,工业企业…...

python系列教程218——生成器表达式
朋友们,如需转载请标明出处:https://blog.csdn.net/jiangjunshow 声明:在人工智能技术教学期间,不少学生向我提一些python相关的问题,所以为了让同学们掌握更多扩展知识更好地理解AI技术,我让助理负责分享…...

jquery 实现简单的标签页效果
实现 <!DOCTYPE html> <html> <head><title>jq 实现简单的标签页效果</title><script src"/jquery/jquery-1.11.1.min.js"></script><style>.tab {cursor: pointer;width:100px;height:30px;float:left;text-align…...

C++ Web框架Drogon初体验笔记
这段时间研究了一下C的Web框架Drogon。从设计原理上面来说和Python的Web框架是大同小异的,但是难点在于编译项目上面,所以现在记录一下编译的过程。下面图是我项目的目录。其中include放的是头文件,src放的是视图文件,static放的是…...

x-cmd pkg | busybox - 嵌入式 Linux 的瑞士军刀
目录 简介首次用户功能特点竞品和相关作品 进一步阅读 简介 busybox 是一个开源的轻量级工具集合,集成了一批最常用 Unix 工具命令,只需要几 MB 大小就能覆盖绝大多数用户在 Linux 的使用,能在多款 POSIX 环境的操作系统(如 Linu…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...