图像去噪——CBDNet网络训练自己数据集及推理测试,模型转ONNX模型(详细图文教程)
CBDNet 主要由两个子网络组成:噪声估计子网络和去噪子网络。噪声估计子网络用于估计图像的噪声水平,而去噪子网络用于去除图像中的噪声。
CBDNet 的优势在于:
它采用了更真实的噪声模型,既考虑了泊松-高斯模型,还考虑了信号依赖噪声和 ISP 对噪声的影响。
它采用了非对称损失函数,可以提高网络的泛化能力。
它结合了合成噪声图像和真实噪声图像进行训练,可以更好地适应真实场景。
CBDNet 的劣势在于:
它需要大量的训练数据,训练过程比较耗时。
它对硬件资源要求比较高。
目录
- 一、源码包准备
- 二、环境准备
- 三、数据集准备
- 3.1 官网数据集
- 3.2 自己数据集准备
- 四、训练
- 4.1 参数修改
- 4.2 训练集路径读取
- 4.3 单卡或多卡训练
- 4.4 训练
- 4.5 保存模型权重
- 五、推理测试
- 5.1 单帧测试
- 5.1.1 命令方式
- 5.1.2 参数配置方式
- 5.2 多帧遍历文件夹测试
- 5.3 推理速度
- 5.3.1 GPU
- 5.3.2 CPU
- 六、转ONNX
- 6.1 转换代码
- 6.2 可视化网络结构
- 6.3 检验转换后的ONNX模型是否正确
- 七、测试结果
- 7.1 测试场景1
- 7.2 测试场景2
- 7.3 测试场景3
- 7.4 测试场景4
- 八、总结
一、源码包准备
官网提供了源码包,我自己也提供了一份,我在官网基础上修改了一些代码,建议学者使用我提供的源码包。本教程是Pytorch版本的。
官网链接:CNDNet
我提供的源码包:网盘,提取码为:7nlv
论文地址:论文
下载解压后的样子如下:
二、环境准备
我自己的训练和测试环境如下,供参考,其它版本也行。
三、数据集准备
3.1 官网数据集
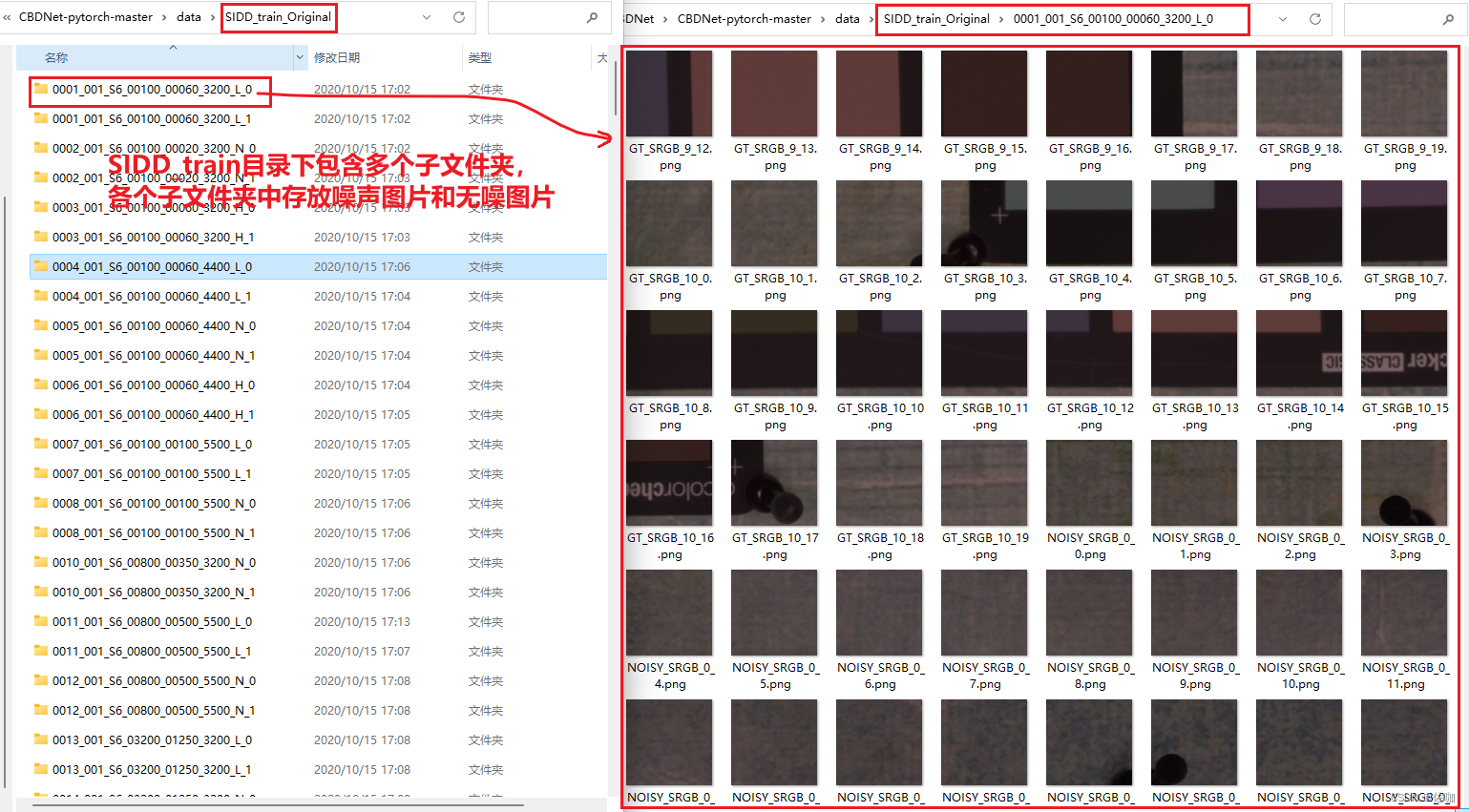
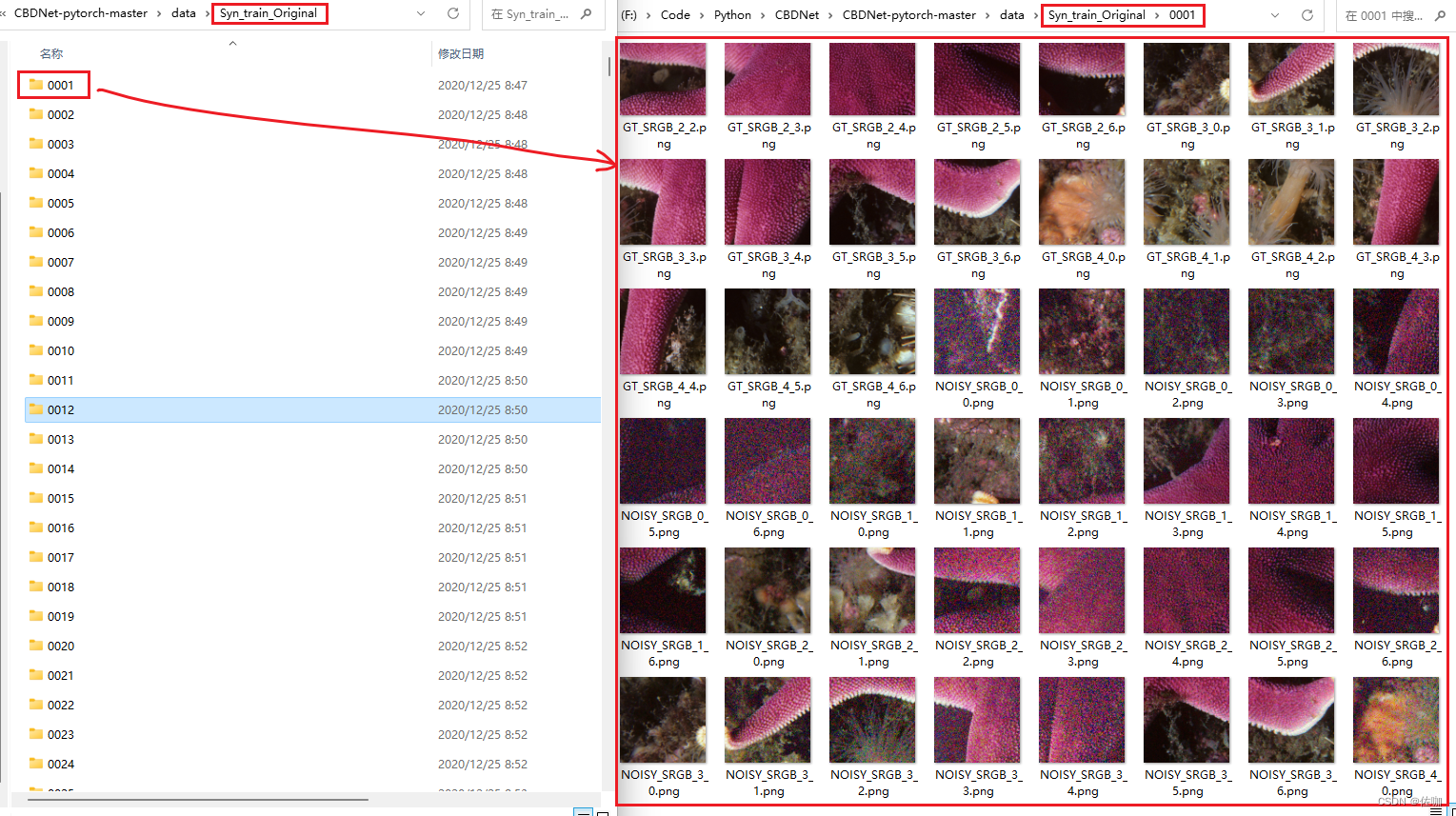
官网教程中有两个数据集,SIDD和Syn,且在链接中提供了一个已经训练好的模型权重文件。数据集和模型权重的下载链接为:SIDD Syn如下:

上面官网提供的两个数据集中,其中SIDD是真实的噪声数据集,Syn是合成噪声数据集。
下载后解压,其中SIDD数据集内容如下:
Syn数据集解压后的样子如下:
3.2 自己数据集准备
官网提供的数据集是将一副高分辨率图像裁剪为256*256大小后再加噪声,每一张高分辨率图像裁剪后得到的小图构成一个子文件夹,多个子文件夹构成整个数据集。
自己制作数据集时可以不用这么小的图片,也不用分这么多子文件夹,只需要将无噪图像和噪声图像同时放到同一个文件夹中,还要注意图片名字命名有规则,命名不一定要按照我的命名方式,自定义规则即可。如下:
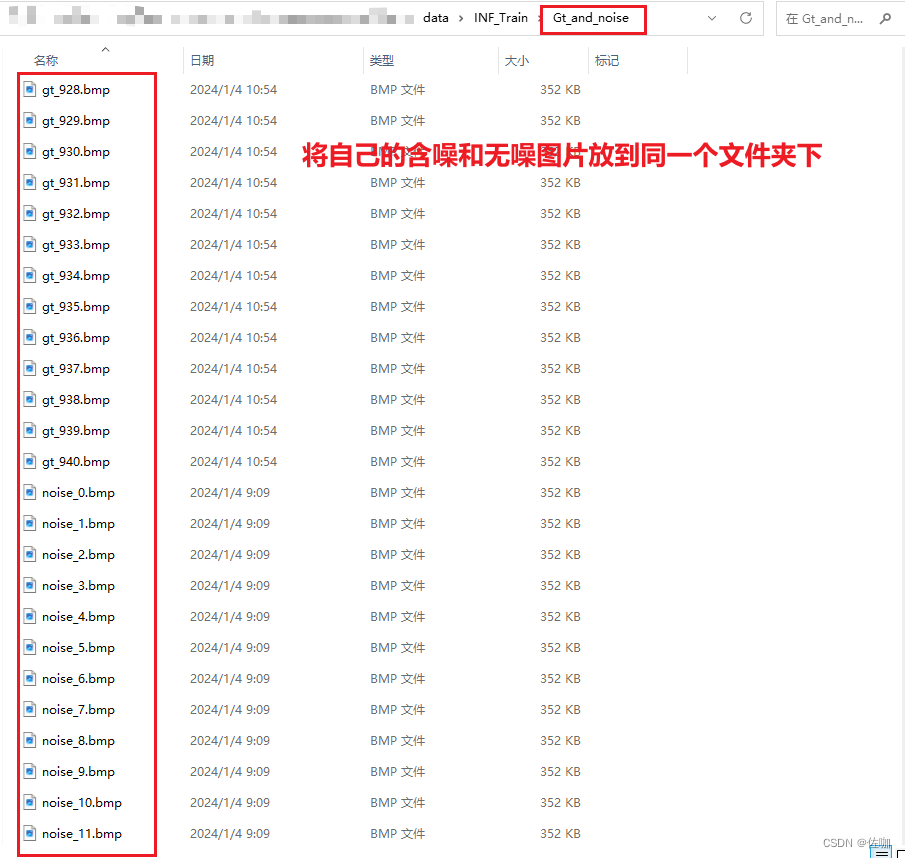
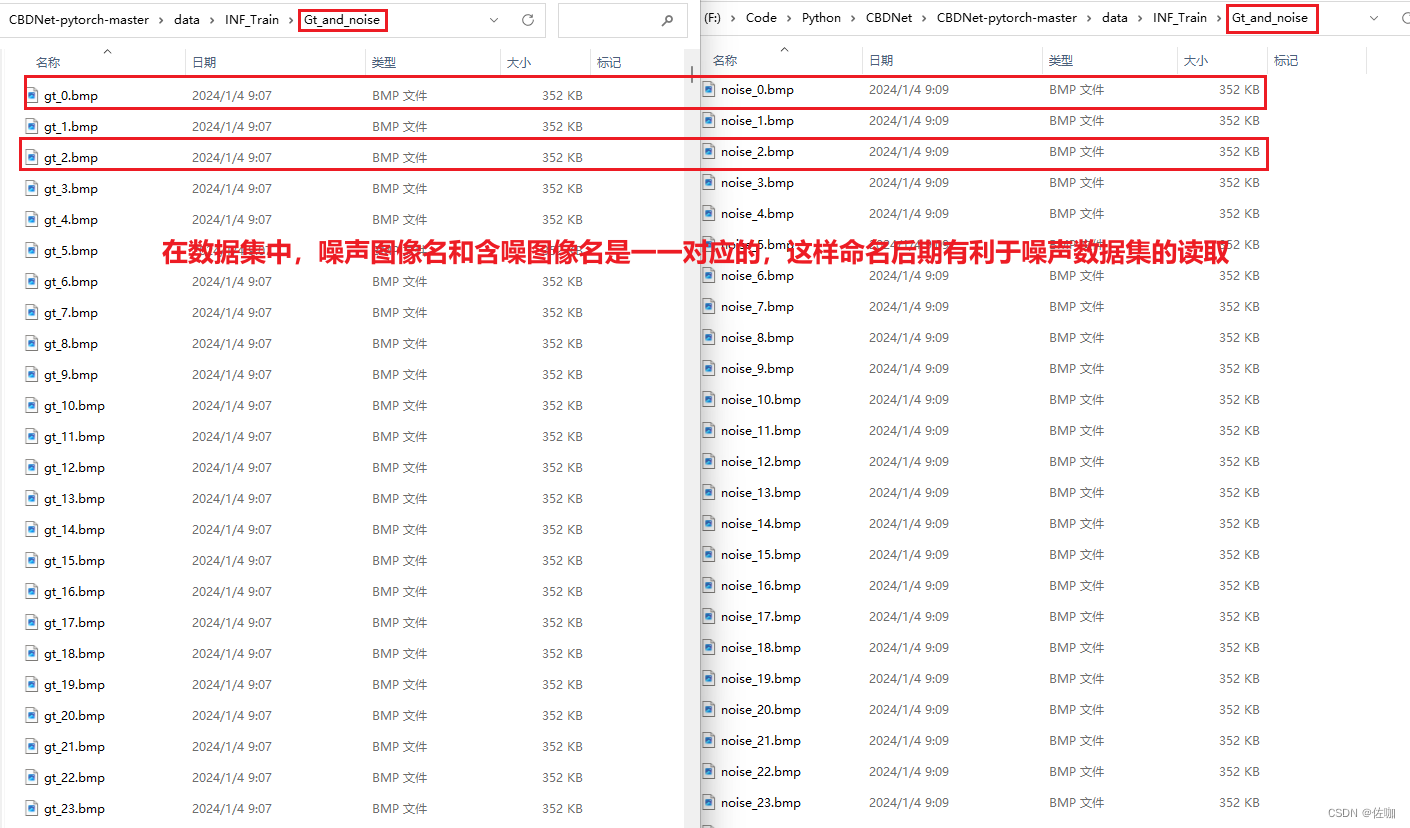
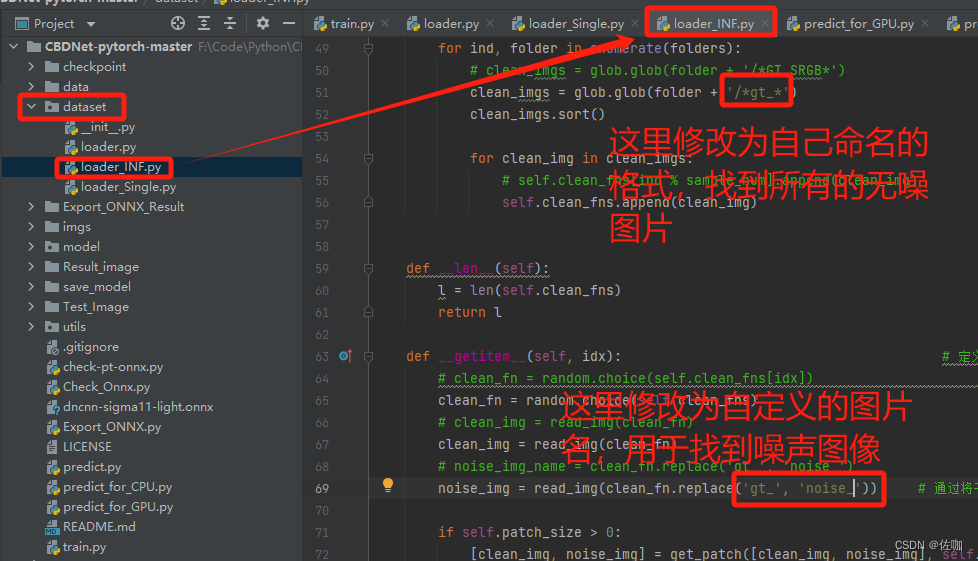
如果自己修改数据集的名字,在代码中也要对应修改,不然运行代码找不到图片,代码中具体修改的地方如下:
四、训练
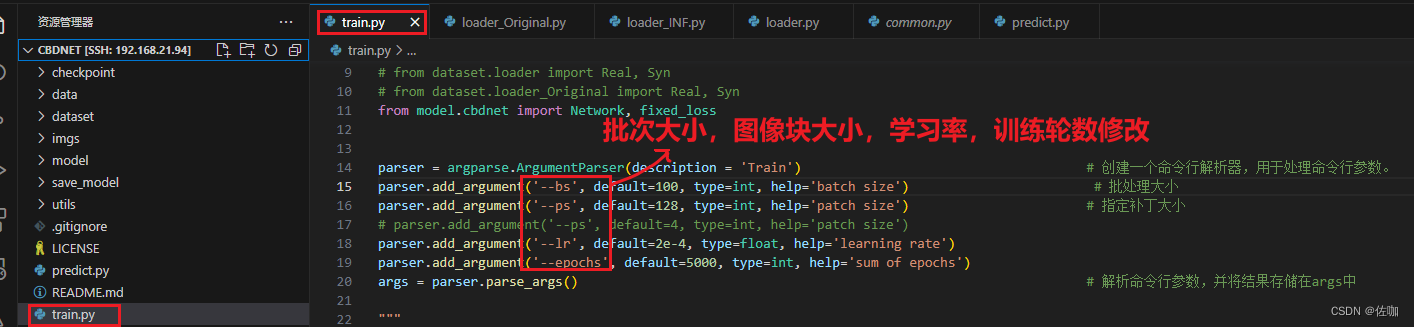
4.1 参数修改
下面是超参数修改:
4.2 训练集路径读取
下面是数据集路径读取:
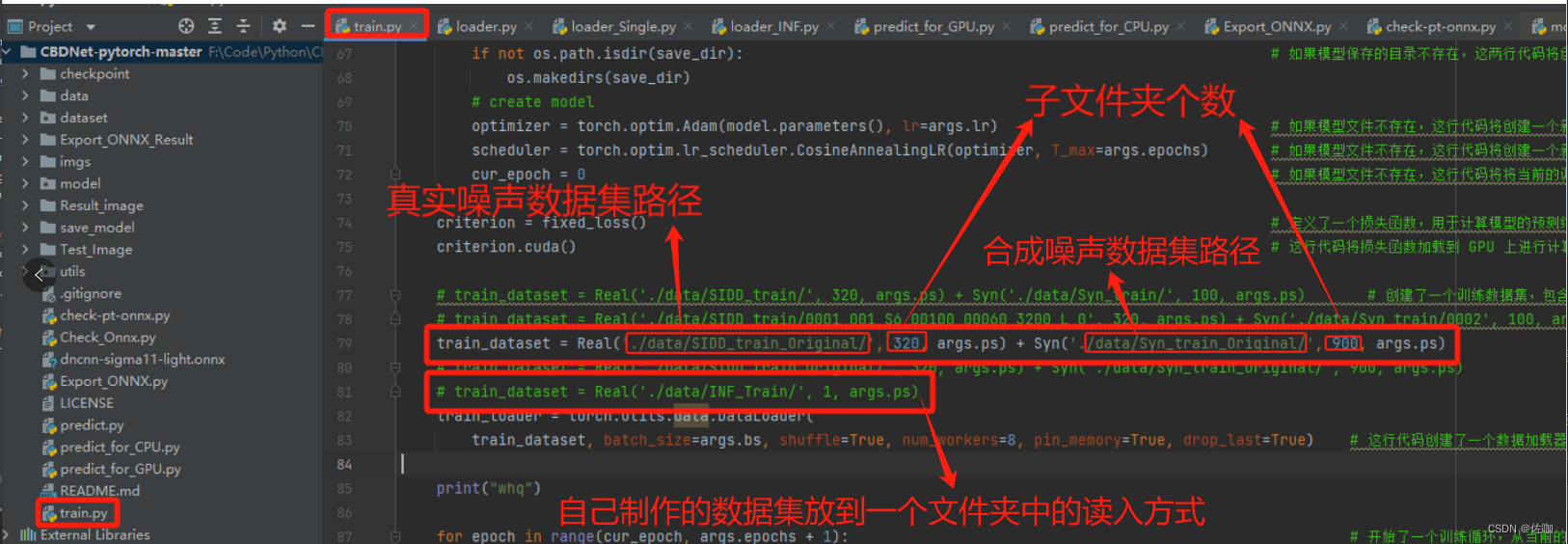
读入数据这里,batch_size的设置一定要小于子文件夹个数,不然训练时损失函数一直为0,训练结果不对。因为官网提供的源码中,如果一次喂入图片数量小于batch_size,就会被舍弃(主要是因为drop_last=True参数的设置),舍弃了就没数据训练了。

官网读取数据这部分原理是,假设选择SIDD数据集,batch_size设置为64,SIDD中有320个子文件夹,那么一个epoch中,就会随机选取64个子文件,并从64个子文件夹中选取一张图片,迭代5次后完成一个epoch。读取数据的代码如下,这部分代码在./dataset/loader.py脚本中第36行有:
class Real(Dataset): # 该类继承自Dataset类。Real类用于处理图像数据集,特别是用于处理含有噪声的图像和对应的干净图像def __init__(self, root_dir, sample_num, patch_size=128): # 定义了类的初始化函数,接受三个参数:root_dir(数据集的根目录),sample_num(样本数量),patch_size(图像块的大小,默认为128)。self.patch_size = patch_size # 将传入的patch_size赋值给类的成员变量self.patch_sizefolders = glob.glob(root_dir + '/*') # 获取root_dir目录下的所有文件夹folders.sort() # 对获取到的文件夹进行排序self.clean_fns = [None] * sample_num # 初始化一个长度为sample_num的列表self.clean_fns,所有元素都为nonefor i in range(sample_num): # 对于每一个样本self.clean_fns[i] = [] # 将self.clean_fns的第i个元素设置为一个空列表for ind, folder in enumerate(folders): # 对于每一个文件夹clean_imgs = glob.glob(folder + '/*GT_SRGB*')# clean_imgs = glob.glob(folder + '/*gt_*') # 获取该文件夹下所有名字中包含GT_SRGB的文件,这些文件是干净的图像。clean_imgs.sort() # 对获取到的干净图像进行排序for clean_img in clean_imgs: # 对于每一个干净的图像self.clean_fns[ind % sample_num].append(clean_img) # 将该图像的文件名添加到self.clean_fns的相应列表中def __len__(self): # 定义了类的__len__函数,该函数返回数据集的大小。l = len(self.clean_fns) # 计算self.clean_fns的长度,即数据集的大小return l # 返回数据集的大小def __getitem__(self, idx): # 定义了类的__getitem__函数,该函数用于获取数据集的第idx个样本。clean_fn = random.choice(self.clean_fns[idx]) # 中随机选择一个干净的图像clean_img = read_img(clean_fn) # 读取该干净的图像。noise_img = read_img(clean_fn.replace('GT_SRGB', 'NOISY_SRGB')) # 读取对应的含有噪声的图像# noise_img = read_img(clean_fn.replace('gt_', 'noise_')) # 读取对应的含有噪声的图像if self.patch_size > 0: # 如果patch_size大于0[clean_img, noise_img] = get_patch([clean_img, noise_img], self.patch_size) # 则从干净的图像和含有噪声的图像中获取一个大小为patch_size的图像块return hwc_to_chw(noise_img), hwc_to_chw(clean_img), np.zeros((3, self.patch_size, self.patch_size)), np.zeros((3, self.patch_size, self.patch_size)) # 返回含有噪声的图像块、干净的图像块以及两个全零的占位符官网提供的这种读取方法对于大数据集读取速度很快,如果是自己制作的小数据集,只有一个文件夹时,就没必要按照官网的方法读取,因为如果只有一个文件夹,那batch_size就只能设置为1,batch_size太小,不利于训练和模型的泛化能力。修改读入数据这部分的代码,直接将所有图片数据读取存到列表中,在遍历列表读取即可,这么做的缺点是,数据集较庞大时,前期加载数据集会比较慢。修改读数据代码如下:
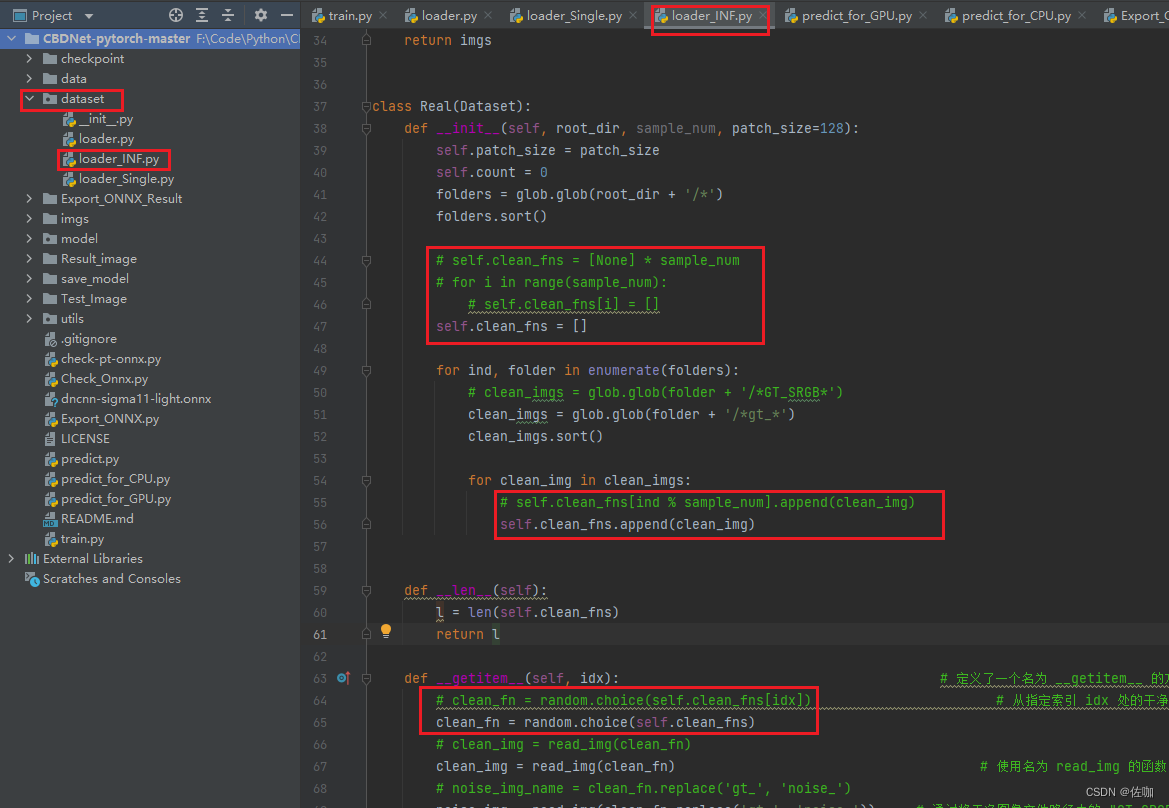
实际代码为:
class Real(Dataset):def __init__(self, root_dir, sample_num, patch_size=128):self.patch_size = patch_sizeself.count = 0folders = glob.glob(root_dir + '/*')folders.sort()# self.clean_fns = [None] * sample_num# for i in range(sample_num):# self.clean_fns[i] = []self.clean_fns = []for ind, folder in enumerate(folders):# clean_imgs = glob.glob(folder + '/*GT_SRGB*')clean_imgs = glob.glob(folder + '/*gt_*')clean_imgs.sort()for clean_img in clean_imgs:# self.clean_fns[ind % sample_num].append(clean_img)self.clean_fns.append(clean_img)def __len__(self):l = len(self.clean_fns)return ldef __getitem__(self, idx): # 定义了一个名为 __getitem__ 的方法,它通常用于实现自定义 Python 对象的索引行为,例如访问自定义数据集中的元素。它接受一个索引 idx 作为输入,表示要获取的元素# clean_fn = random.choice(self.clean_fns[idx]) # 从指定索引 idx 处的干净图像文件路径列表中随机选择一个文件路径 干净文件路径列表存储在类的 self.clean_fns 属性中clean_fn = random.choice(self.clean_fns)# clean_img = read_img(clean_fn) clean_img = read_img(clean_fn) # 使用名为 read_img 的函数(通常用于读取图像)从选定的文件路径读取干净图像# noise_img_name = clean_fn.replace('gt_', 'noise_')noise_img = read_img(clean_fn.replace('gt_', 'noise_')) # 通过将干净图像文件路径中的 "GT_SRGB" 替换为 "NOISY_SRGB" 来读取对应的噪声图像if self.patch_size > 0: # 检查是否指定了 patch 大小[clean_img, noise_img] = get_patch([clean_img, noise_img], self.patch_size) # 如果指定了 patch 大小,则使用名为 get_patch 的函数从干净图像和噪声图像中提取指定大小的 patchreturn hwc_to_chw(noise_img), hwc_to_chw(clean_img), np.zeros((3, self.patch_size, self.patch_size)), np.zeros((3, self.patch_size, self.patch_size))
用我提供的读数据方法,就可以根据自己电脑性能,设置为较大的batch_size值进行训练。
4.3 单卡或多卡训练
官网提供的源码,默认是直接调用电脑端的所有显卡并行训练,如果想自定义在第二块单卡上训练,需要添加代码,如下:
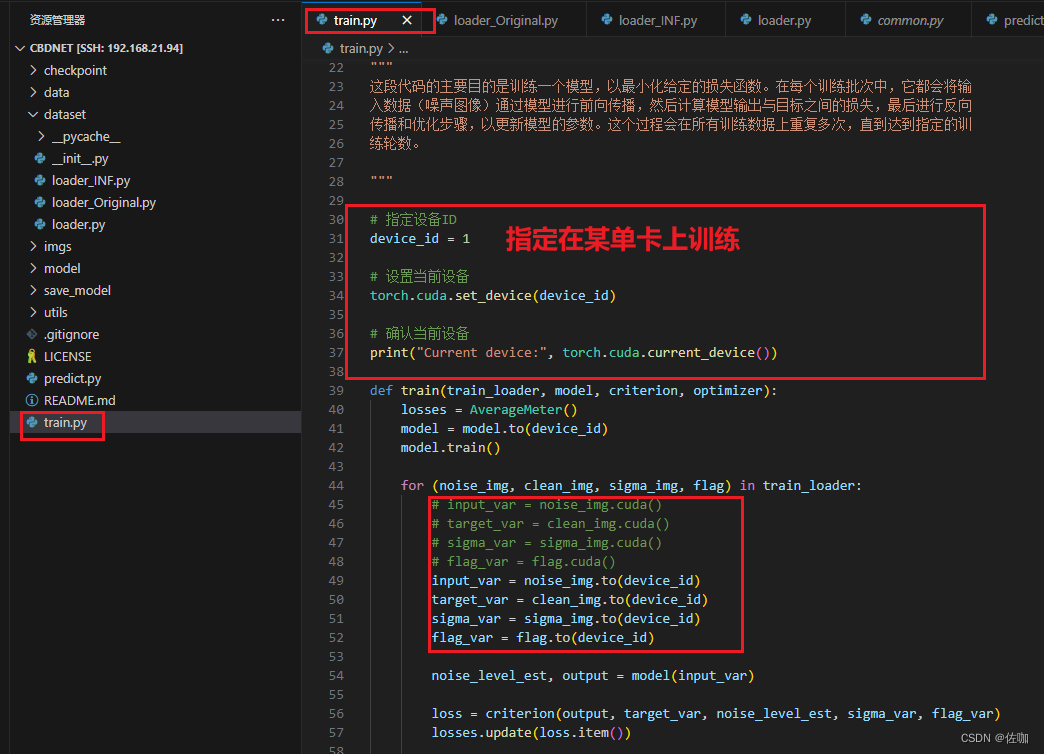
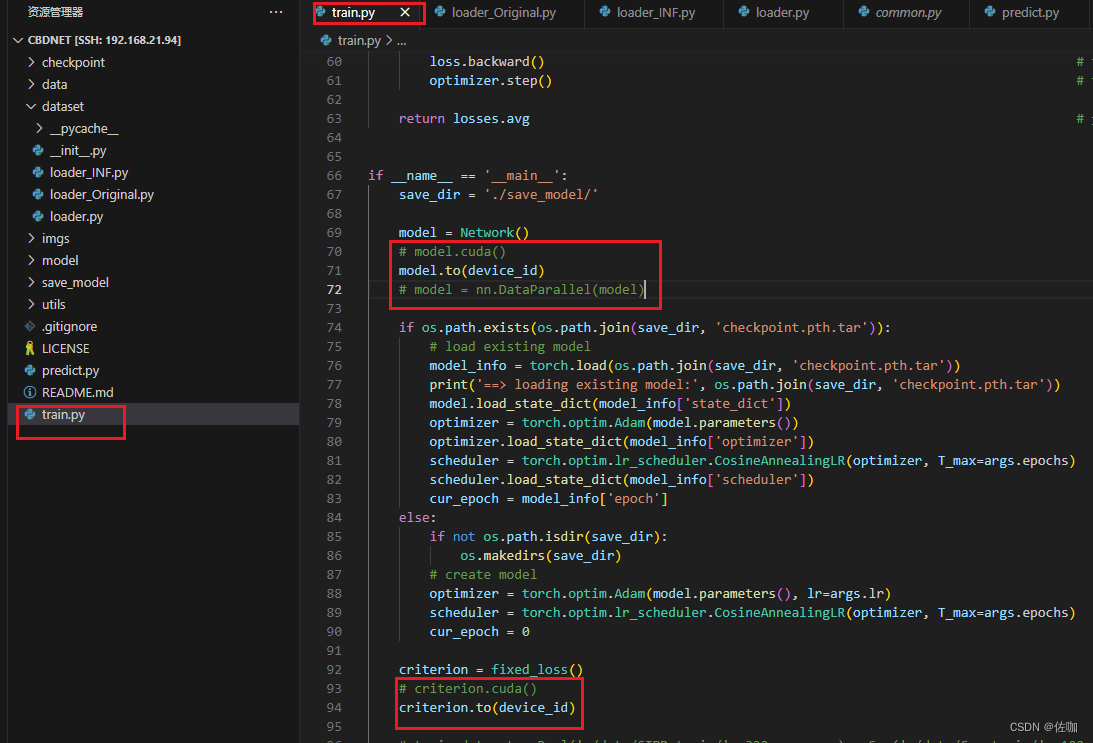
如果想要多卡并行训练,保持默认即可,不用修改。
4.4 训练
上面参数和路径都修改好后直接运行train.py脚本就开始训练了,如下:
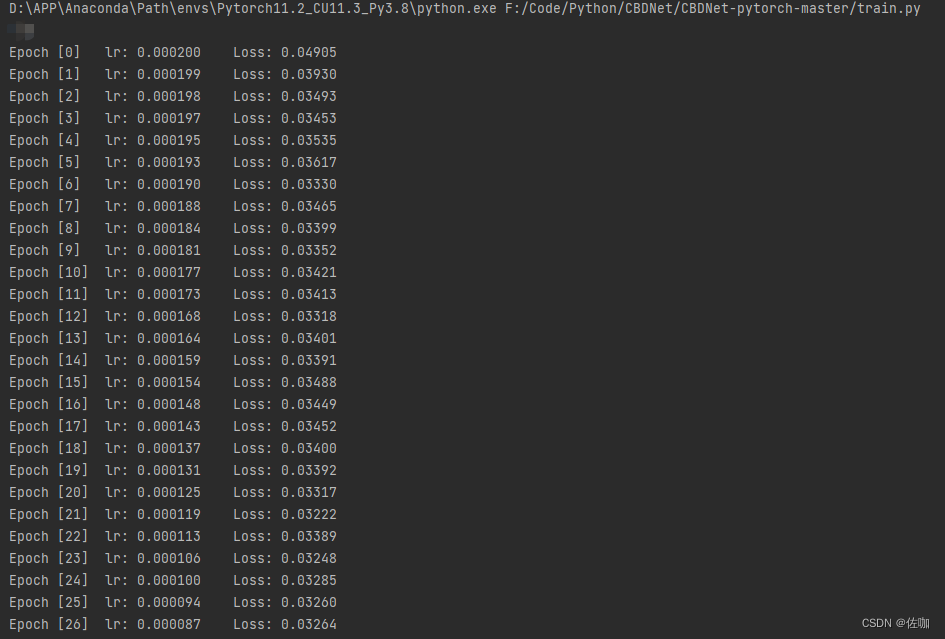
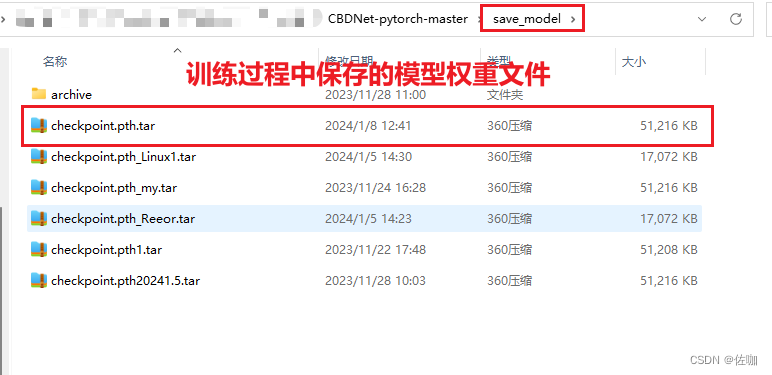
4.5 保存模型权重
训练过程中的模型权重文件会自动保存到根目录下的save_model文件夹中,如下:
五、推理测试
5.1 单帧测试
5.1.1 命令方式
如果只测试一张图片,在终端中输入下面命令:
python predict.py input_filename output_filename
其中input_filename是包含路径的图片名,output_filename是包含保存路径的图片名。实际例子命令如下:
python predict.py Test_Image/ETDS_GaoDe_X4_bmp/4_ETDS_M7C48_x4.bmp Result_image/whq/4_Train_ETDS_M7C48_x4_Denoise.bmp
5.1.2 参数配置方式
如果开发编译环境使用的是Pycharm,也可以使用Configuration参数配置方式测试,如下:
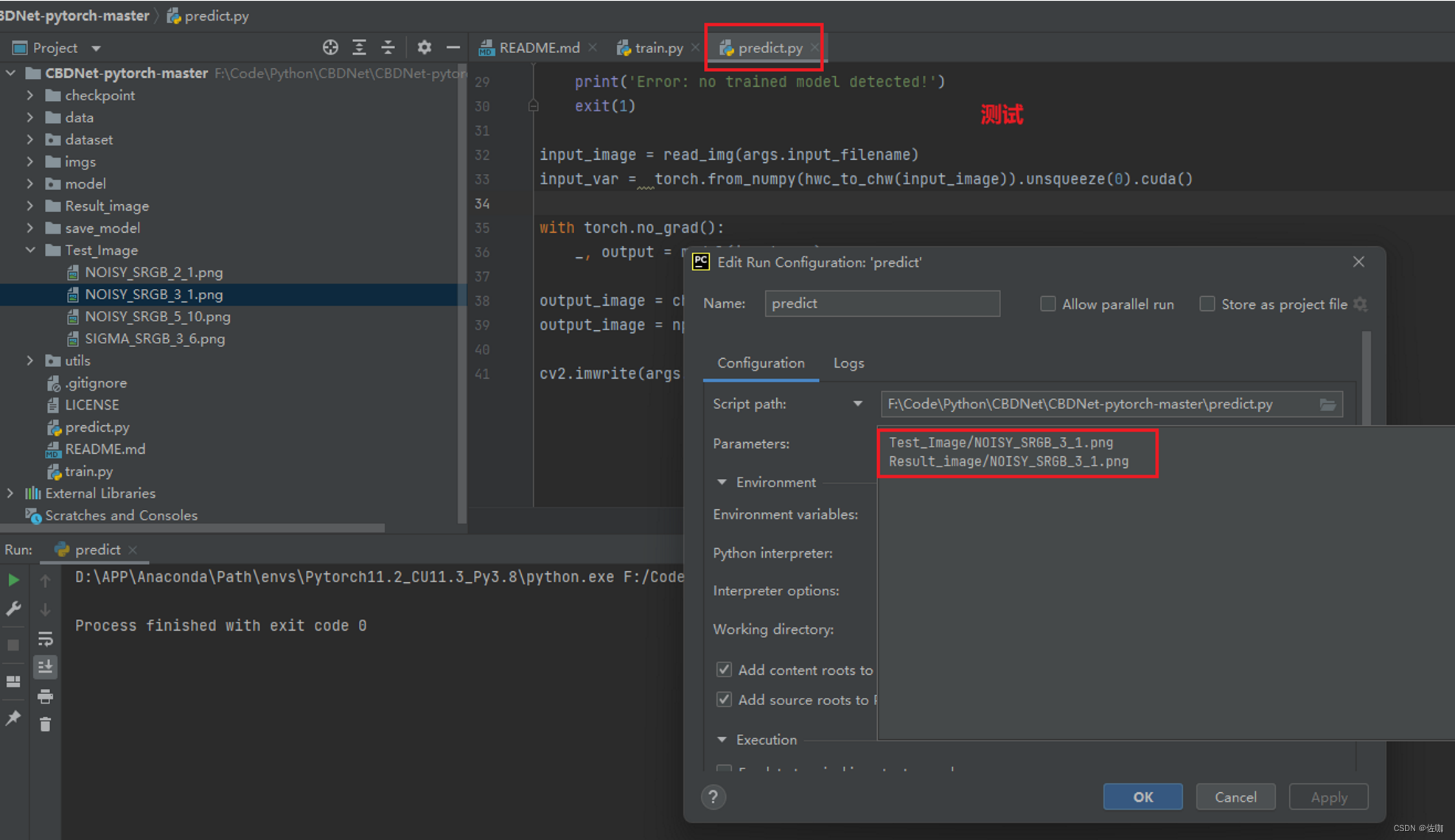
5.2 多帧遍历文件夹测试
如果想直接批量测试一个文件夹中的多张图片,运行我提供的脚本,其中predict_for_CPU.py是CPU批量处理的脚本,predict_for_GPU.py是GPU批量处理的脚本。分为两个脚本是为了下一步的推理时间测试。
批量测试的脚本具体使用如下:
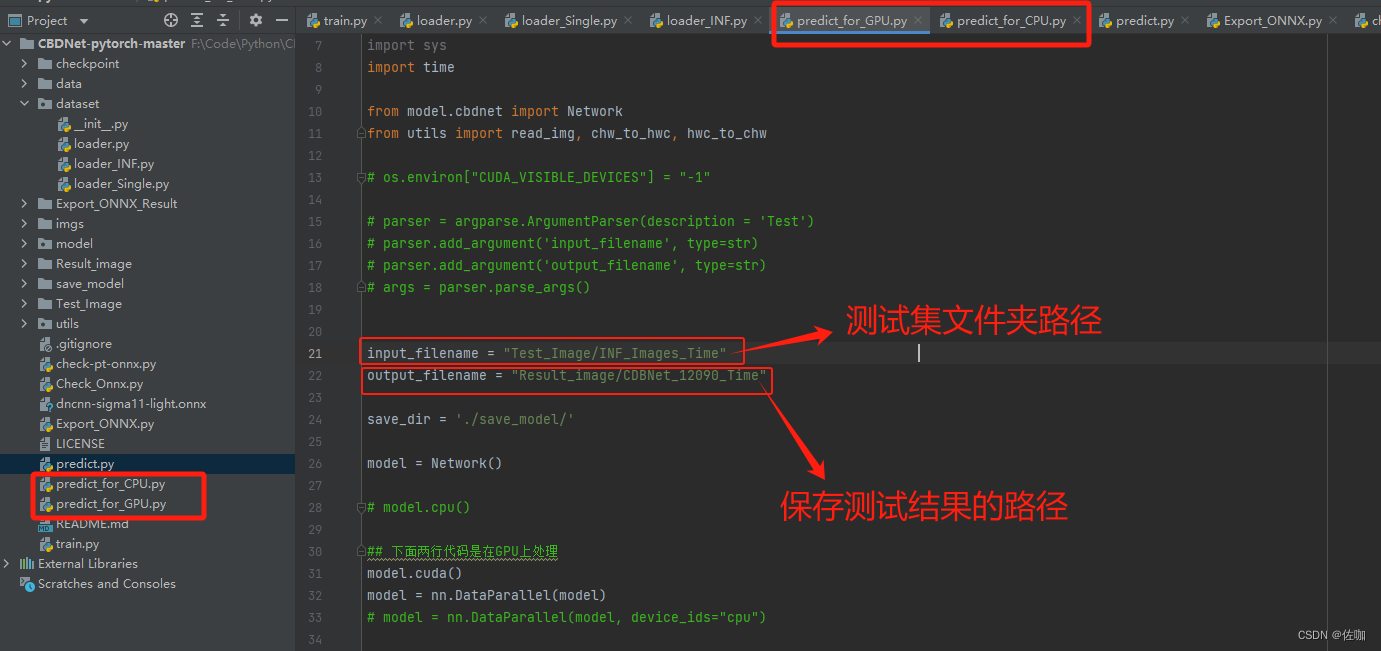
5.3 推理速度
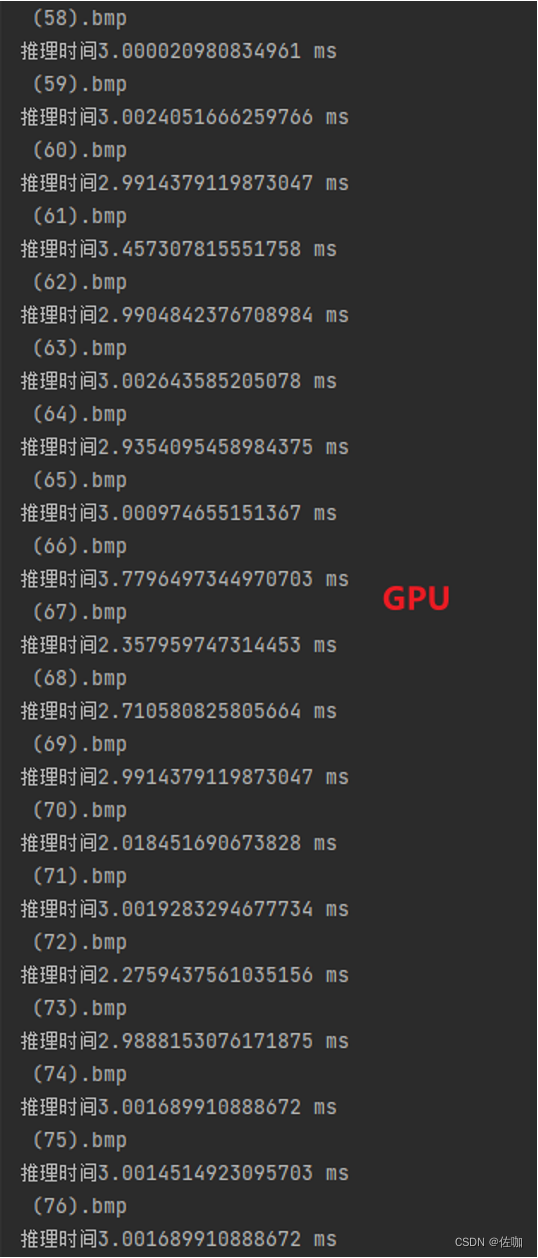
5.3.1 GPU
GPU测试环境:Nvidia GeForce RTX 3050,测试图片96*96,推理时间:2.8ms/fps
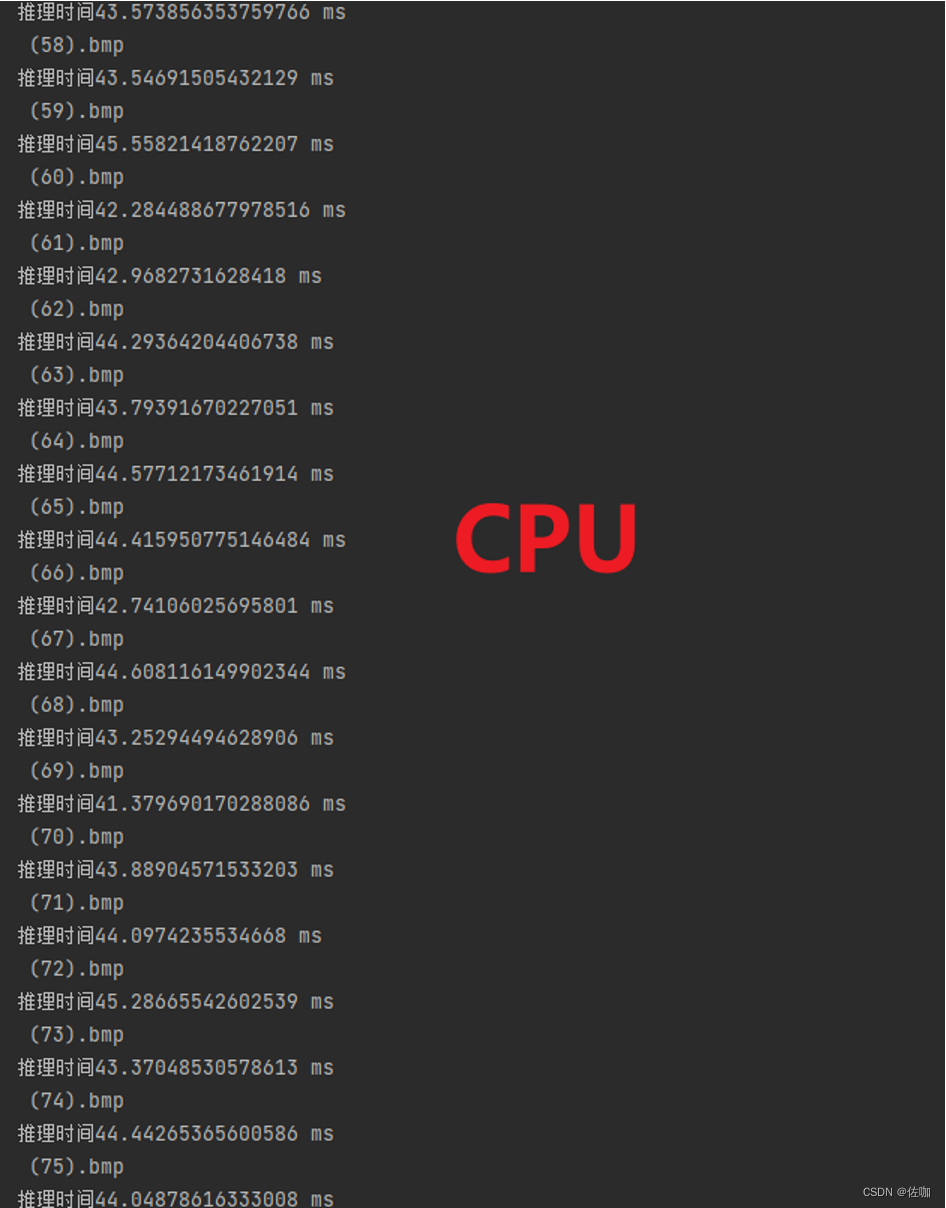
5.3.2 CPU
测试环境:12th Gen Intel® Core™ i7-12700H 2.30 GHz,测试图片96*96,推理速度:43.61ms/fps
六、转ONNX
为方便部署,将上面训练好的模型权重文件转为ONNX中间格式。
6.1 转换代码
import torch
import torch.nn as nn
import onnx
import numpy as np
from onnx import load_model, save_model
from onnx.shape_inference import infer_shapes
# from models_DnCNN import DnCNN
from model.cbdnet import Network# 加载模型
# dncnn_model = DnCNN(input_chnl=1, groups=1)
# dncnn_model = torch.load("./model_DnCNN_datav1-sigma11/model_DnCNN_datav1_epoch_500.pth")["model"]
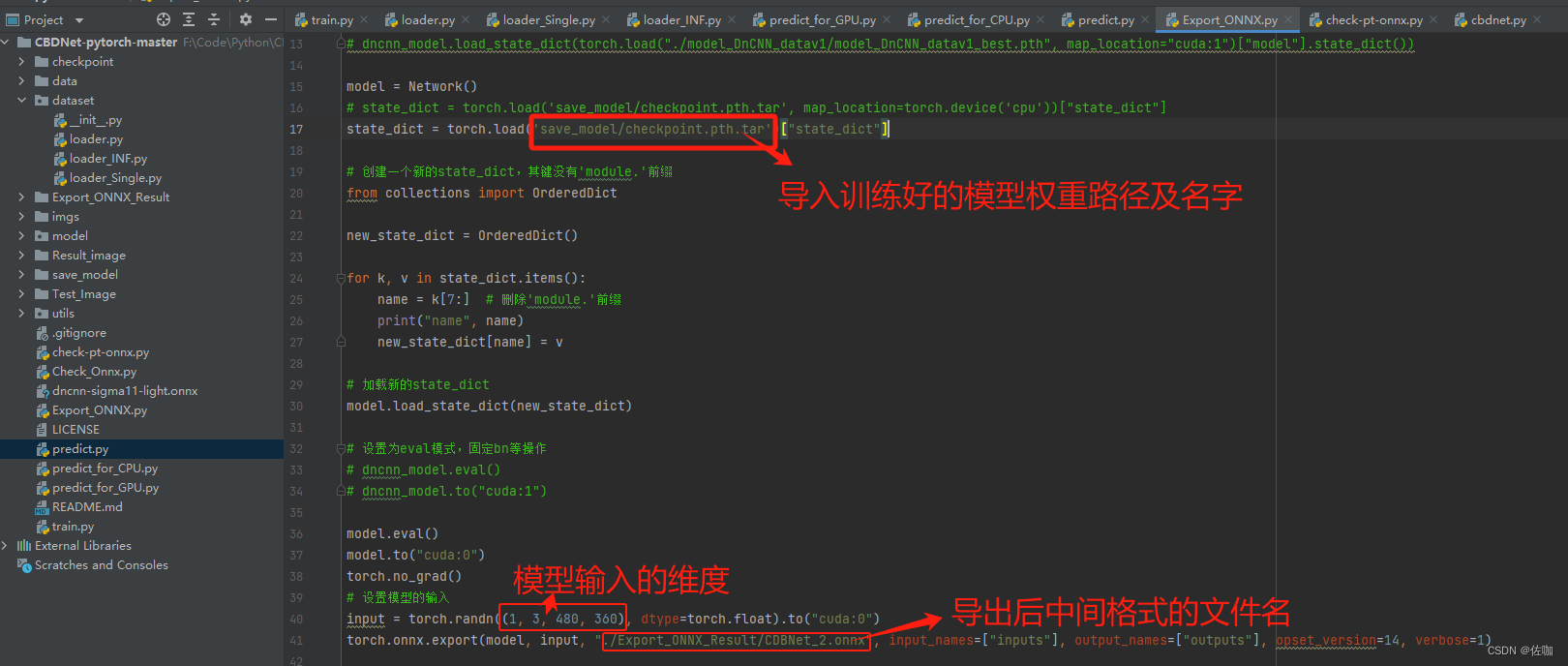
# dncnn_model.load_state_dict(torch.load("./model_DnCNN_datav1/model_DnCNN_datav1_best.pth", map_location="cuda:1")["model"].state_dict())model = Network()
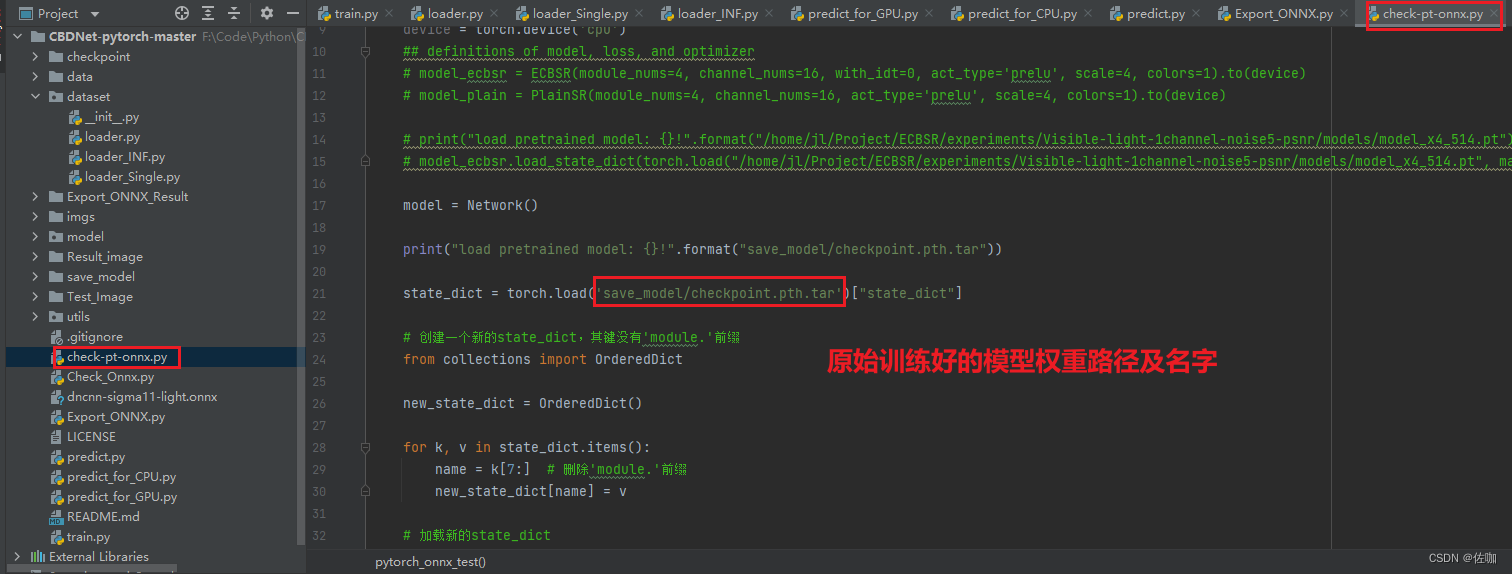
# state_dict = torch.load('save_model/checkpoint.pth.tar', map_location=torch.device('cpu'))["state_dict"]
state_dict = torch.load('save_model/checkpoint.pth.tar')["state_dict"]# 创建一个新的state_dict,其键没有'module.'前缀
from collections import OrderedDictnew_state_dict = OrderedDict()for k, v in state_dict.items():name = k[7:] # 删除'module.'前缀print("name", name)new_state_dict[name] = v# 加载新的state_dict
model.load_state_dict(new_state_dict)# 设置为eval模式,固定bn等操作
# dncnn_model.eval()
# dncnn_model.to("cuda:1")model.eval()
model.to("cuda:0")
torch.no_grad()
# 设置模型的输入
input = torch.randn((1, 3, 480, 360), dtype=torch.float).to("cuda:0")
torch.onnx.export(model, input, "./Export_ONNX_Result/CDBNet_2.onnx", input_names=["inputs"], output_names=["outputs"], opset_version=14, verbose=1)# torch.onnx.export(model, input, "./dncnn-sigma11-light.onnx", input_names=["inputs-jl"], output_names=["outputs-jl"], opset_version=14, verbose=1,
# dynamic_axes={"inputs-jl":{2:"inputs_height", 3:"inputs_weight"}, "outputs-jl":{2:"outputs_height", 3:"outputs_weight"}})print("Model has benn converted to onnx")# onnx_model = load_model("./dncnn-sigma11.onnx")
# onnx_model = infer_shapes(onnx_model)# save_model(onnx_model, "dncnn-sigma11-shape.onnx")
转后得到的中间格式如下:
6.2 可视化网络结构
可视化网络结构,使用Netron,网址:Netron
打开网络结构如下:
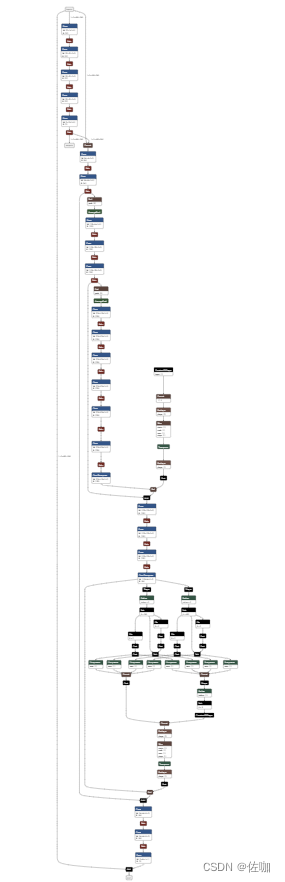
6.3 检验转换后的ONNX模型是否正确
输入同样的数据到转换后的ONNX模型中和原始训练好的模型中,比较两模型的输出差值大不大,在接受范围内就说明转换成功。使用方法及检验代码如下:
检验代码为:
import torch
import numpy as np
import onnxruntime
# from models.ecbsr import ECBSR
# from models.plainsr import PlainSR
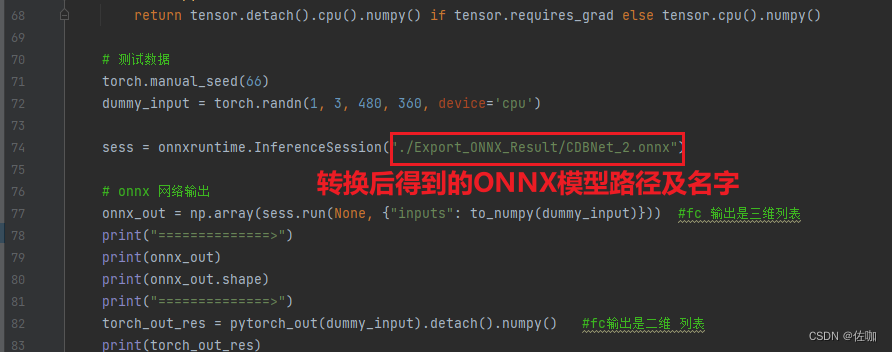
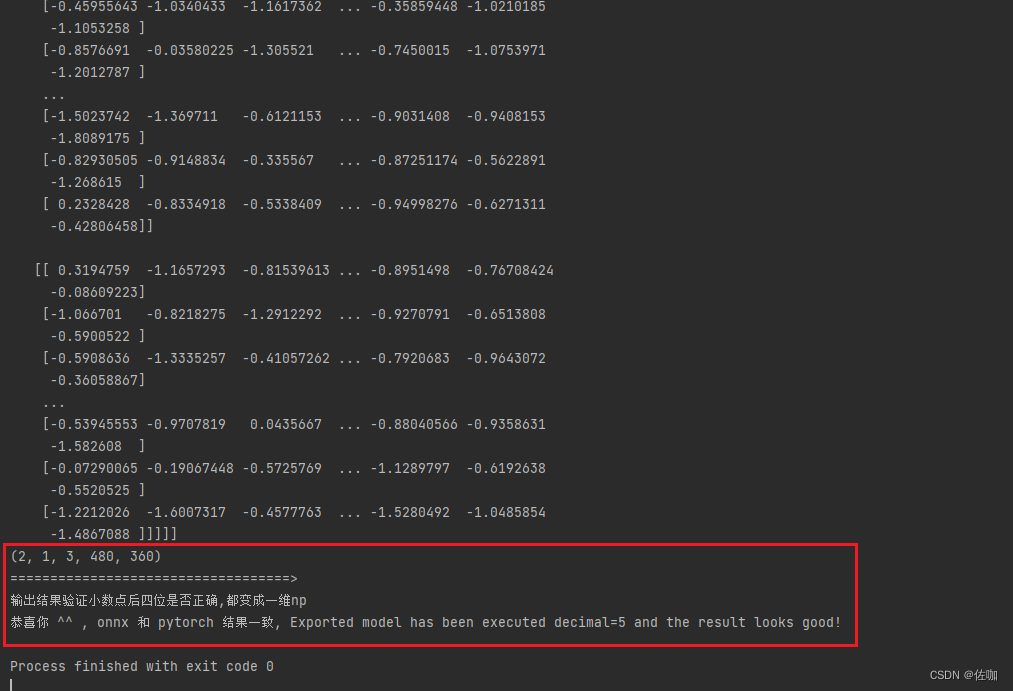
from model.cbdnet import Networkdef torch_model():device = torch.device('cpu')## definitions of model, loss, and optimizer# model_ecbsr = ECBSR(module_nums=4, channel_nums=16, with_idt=0, act_type='prelu', scale=4, colors=1).to(device)# model_plain = PlainSR(module_nums=4, channel_nums=16, act_type='prelu', scale=4, colors=1).to(device)# print("load pretrained model: {}!".format("/home/jl/Project/ECBSR/experiments/Visible-light-1channel-noise5-psnr/models/model_x4_514.pt"))# model_ecbsr.load_state_dict(torch.load("/home/jl/Project/ECBSR/experiments/Visible-light-1channel-noise5-psnr/models/model_x4_514.pt", map_location='cpu'))model = Network()print("load pretrained model: {}!".format("save_model/checkpoint.pth.tar"))state_dict = torch.load('save_model/checkpoint.pth.tar')["state_dict"]# 创建一个新的state_dict,其键没有'module.'前缀from collections import OrderedDictnew_state_dict = OrderedDict()for k, v in state_dict.items():name = k[7:] # 删除'module.'前缀new_state_dict[name] = v# 加载新的state_dictmodel.load_state_dict(new_state_dict)return model## copy weights from ecbsr to plainsr# depth = len(model_ecbsr.backbone)# for d in range(depth):# module = model_ecbsr.backbone[d]# act_type = module.act_type# RK, RB = module.rep_params()# model_plain.backbone[d].conv3x3.weight.data = RK# model_plain.backbone[d].conv3x3.bias.data = RB## if act_type == 'relu': pass# elif act_type == 'linear': pass# elif act_type == 'prelu': model_plain.backbone[d].act.weight.data = module.act.weight.data# else: raise ValueError('invalid type of activation!')# return model_ecbsrdef pytorch_out(input):model = torch_model() #model.eval# input = input.cuda()# model.cuda()torch.no_grad()model.eval()output = model(input)# print output[0].flatten()[70:80]out1 = output[0]out2 = output[1]out = torch.stack((out1, out2))return outdef pytorch_onnx_test():def to_numpy(tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()# 测试数据torch.manual_seed(66)dummy_input = torch.randn(1, 3, 480, 360, device='cpu')sess = onnxruntime.InferenceSession("./Export_ONNX_Result/CDBNet_2.onnx")# onnx 网络输出onnx_out = np.array(sess.run(None, {"inputs": to_numpy(dummy_input)})) #fc 输出是三维列表print("==============>")print(onnx_out)print(onnx_out.shape)print("==============>")torch_out_res = pytorch_out(dummy_input).detach().numpy() #fc输出是二维 列表print(torch_out_res)print(torch_out_res.shape)print("===================================>")print("输出结果验证小数点后四位是否正确,都变成一维np")torch_out_res = torch_out_res.flatten()onnx_out = onnx_out.flatten()pytor = np.array(torch_out_res,dtype="float32") #need to float32onn=np.array(onnx_out,dtype="float32") ##need to float32np.testing.assert_almost_equal(pytor,onn, decimal=5) #精确到小数点后4位,验证是否正确,不正确会自动打印信息print("恭喜你 ^^ , onnx 和 pytorch 结果一致, Exported model has been executed decimal=5 and the result looks good!")pytorch_onnx_test()
运行上面代码后,输出如下,则说明ONNX模型转换成功,可以直接放到其它平台部署了。
七、测试结果
7.1 测试场景1

7.2 测试场景2

7.3 测试场景3

7.4 测试场景4
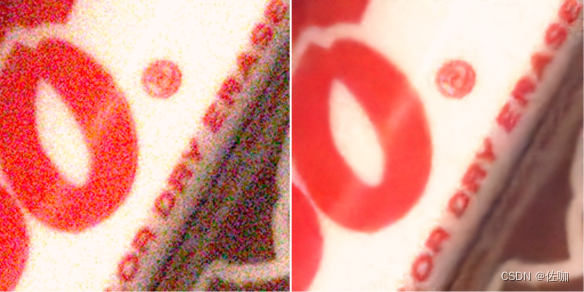
八、总结
以上就是图像去噪CBDNet网络训练自己数据集及推理测试,并将训练好的模型转ONNX模型的详细实现过程。网络架构需要花些时间解读,学者仔细研究。
总结不易,多多支持,谢谢!
相关文章:
图像去噪——CBDNet网络训练自己数据集及推理测试,模型转ONNX模型(详细图文教程)
CBDNet 主要由两个子网络组成:噪声估计子网络和去噪子网络。噪声估计子网络用于估计图像的噪声水平,而去噪子网络用于去除图像中的噪声。 CBDNet 的优势在于: 它采用了更真实的噪声模型,既考虑了泊松-高斯模型,还考虑…...
)
【Verilog】期末复习——解释下列名词(FPGA、ASIC、IP、RTL、EDA、HDL、FSM)
系列文章 数值(整数,实数,字符串)与数据类型(wire、reg、mem、parameter) 运算符 数据流建模 行为级建模 结构化建模 组合电路的设计和时序电路的设计 有限状态机的定义和分类 期末复习——数字逻辑电路分…...

计算机网络 综合(习题)
【计算机网络习题】系列文章目录 计算机网络 第一章 绪论(习题) 计算机网络 第二章 计算机网络体系结构(习题) 计算机网络 第三章 应用层(习题) 计算机网络 第四章 运输层(习题) 计算机网络 第五章 网络层(习题) 计算机网络 第六章 数据链路层(习题) 计算机网络 第七章 物…...
)
探索vue2框架的世界:简述常用的vue2选项式API (二)
组件实例 👉 $attrs 用于父组件隔代向孙组件传值 长设置在子组件中 v-bind"$attrs" (Vue2.4) parent.vue (父组件) <template><div class"outer"><h3>父组件</h3>名字:<input v-model"name"…...
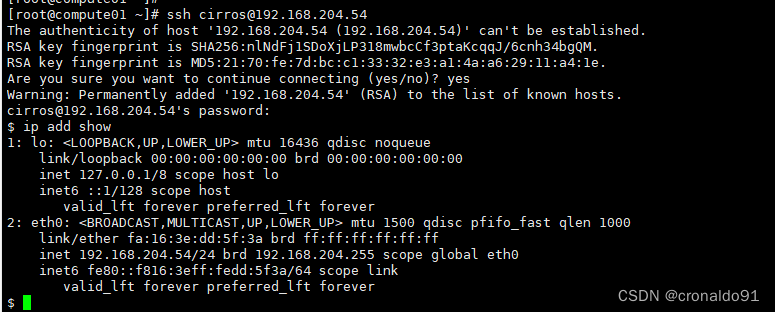
云计算:OpenStack 分布式架构管理FLAT网络(单控制节点与多计算节点)
目录 一、实验 1.环境 2.控制节点创建网络 3.控制节点创建规格 4.控制节点新增安全组入口规则 5.控制节点创建实例 二、问题 1.FLAT网络底层如何实现 2.无法SSH 云主机实例 一、实验 1.环境 (1) 主机 表1 主机 主机架构IP备注controller控制节点192.168.204.210已部…...

【深度学习】cv领域中各种loss损失介绍
文章目录 前言一、均方误差二、交叉熵损失三、二元交叉熵损失四、Smooth L1 Loss五、IOU系列的loss 前言 损失函数是度量模型的预测输出与真实标签之间的差异或误差,在深度学习算法中起着重要作用。具体作用: 1、目标优化:损失函数是优化算法…...

2024年,为什么学网络安全找不到工作?这才是重要原因!
为什么网络安全人才缺口那么大,但很多人还是找不到工作?其实大家都忽略了1个重点,那就是不清楚企业在招什么样的人。 我花了2天的时间统计了主流招聘网站的岗位信息,发现了一个惊人的真相,那就是企业都喜欢招这3种人&a…...
很有用!小企业如何从零开始制作产品手册?
对于初创公司和小企业来说,创造一份高效、吸引人的产品手册可能不是特别简单,特别是当资源和预算有限的时候。然而,一份良好的产品手册可以帮助你传达你的品牌故事,展示你的产品,甚至可以帮助你提高销售额,…...

基于OpenCV的图像缩放
基础概念 缩放是将图像的尺寸变小或变大的过程,即减少或增加原图像数据的像素个数,或者说通过增加或删除像素点来改变图像的尺寸; 基本原理:将分辨率(图片尺寸)为(w,h)的图像,缩放后其图像分辨…...

基于长短期神经网络LSTM的测量误差预测
目录 背影 摘要 代码和数据下载:基于长短期神经网络LSTM的测量误差预测(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/download/abc991835105/88714812 LSTM的基本定义 LSTM实现的步骤 基于长短期神经网络LSTM的测量误差预测 结果分析 展望 参考论文 背影 …...
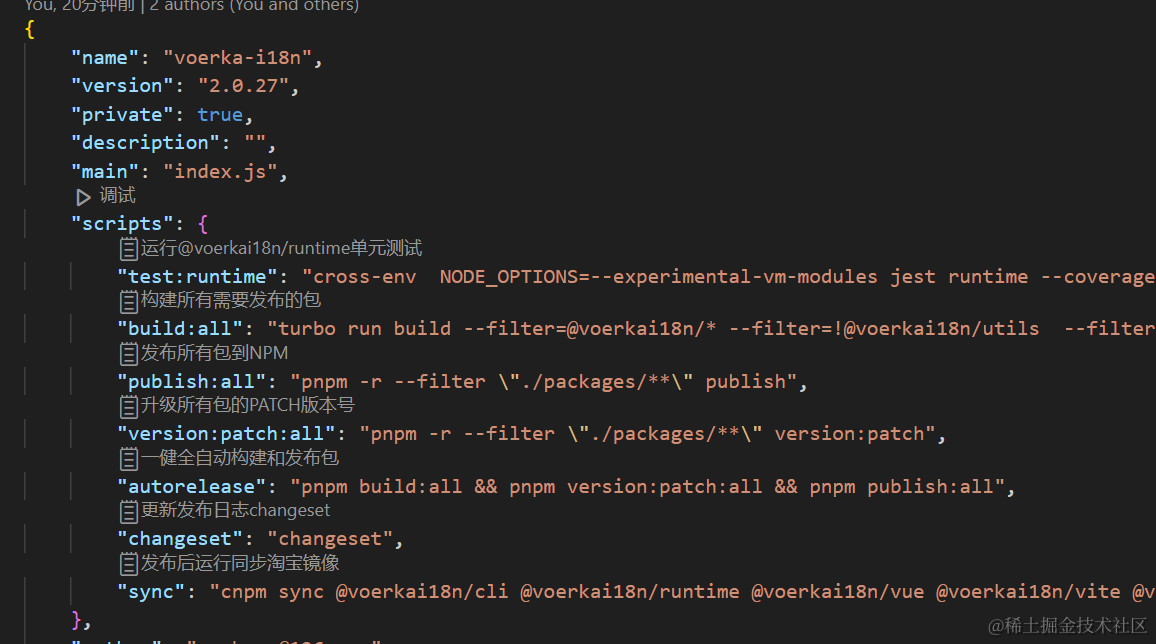
`package.json`也可以有注释了
众所周知,JSON文件是不支持注释的,除了JSON5/JSONC之外,我们在开发项目特别是前端项目时,大量会用到JSON文件,特别是在编写package.json中的scripts时,由于缺少注释,当有大量的命令脚本时,就有了…...

数学之何为数学
数学是什么 数学是绝大多数人学得最多的一门功课,但对于“数学是什么?”这一看来很普通的问题,却很难一下子给出一个使公众满意的回答。按照恩格斯的说法,数学是以现实世界的空间形式和数量关系为研究对象的。尽管人们现在对空间…...

docker容器内,将django项目数据库改为postgresql
容器为ubuntu20.04版本,新建了一套django项目,使用的默认sqllit3,换为postgresql,容器里安装postgresql方法 步骤1: 安装PostgreSQL数据库 # 打开一个bash会话在你的容器中 docker exec -it <container_id_or_name> bash#…...
【echarts】雷达图参数详细介绍
1. 详细示例 var option {tooltip: {trigger: item},radar: {startAngle: 90,//第一个指示器轴的角度,默认90indicator: [// 指示器{ name: Category A, max: 220 },// name:指示器名称{ name: Category B, max: 200 },// max:指示器的最大值,可选&…...

网络安全试题进阶——附答案
选择题 什么是CSRF攻击的全称? A. Cross-Site Request ForgeryB. Cross-Site ScriptingC. Credential Sniffing and Retrieval ForceD. Cyber Security and Risk Framework 哪种安全攻击利用用户的社交工程,诱使他们点击似乎是合法链接的恶意链接&#x…...
二刷Laravel 教程(构建页面)总结Ⅰ
L01 Laravel 教程 - Web 开发实战入门 ( Laravel 9.x ) 一、功能 1.会话控制(登录、退出、记住我) 2.用户功能(注册、用户激活、密码重设、邮件发送、个人中心、用户列表、用户删除) 3.静态页面(首页、关于、帮助&am…...
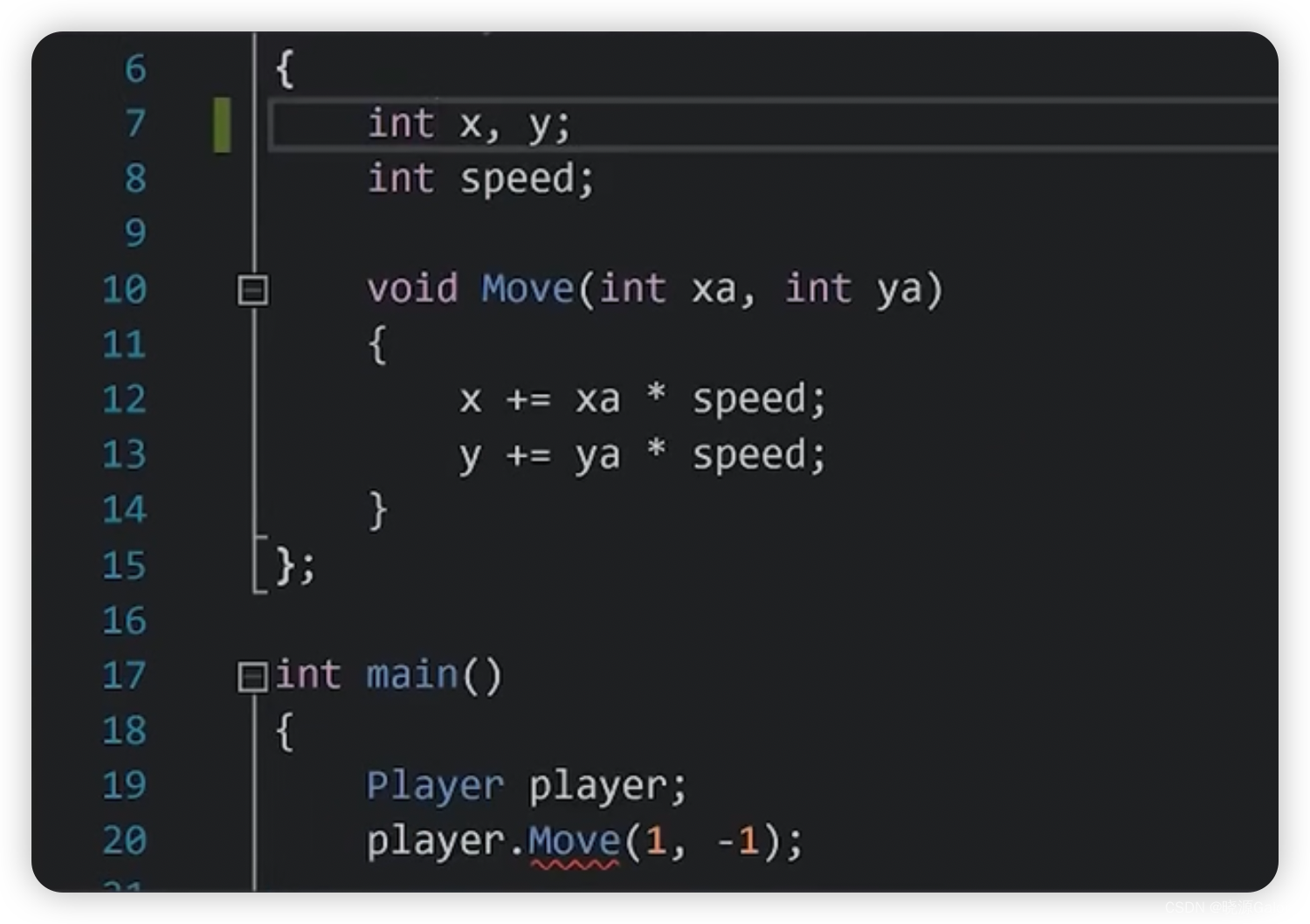
C++|19.C++类与结构体对比
类和结构体 类和结构体本质上并没有太大区别。 但两者在默认上有所区别。 类默认成员变量是私有的,而结构体默认成员变量是公有的。 也就是说,对于一个类来说,会默认使用private去保护其内部成员变量使得无法直接访问到其内部的变量。 同时从…...

Apache Camel笔记
Apache Camel笔记 1. Apache Camel概念 Apache Camel是一个轻量级的应用集成开发框架,专注于简化集成应用的开发。它基于Enterprise Integration Patterns(企业集成模式,简称EIP)的设计理念,提供了灵活的路由和中介机制…...

CSDN定制的奖品谁不想要?
各位大佬,在下真的缺一个喝水的杯子!!! 2023年即将画上句号,在这一年的技术征途上,CSDN始终陪伴在我身边,为我提供了丰富的知识资源、实用的技术文章和友好的交流平台。当我得知自己有幸获得CS…...

橄榄油行业分析:预计2029年将达到298亿美元
橄榄油是全世界公认高端食用油。橄榄油要以油橄榄树的果实为主要原料制得的植物油脂。橄榄油是世界上四大食用草本植物植物油脂之一,每年产量在260~300万吨级之间,占全球橄榄油生产量18900万吨级的1.5%上下。以其带有不饱和脂肪、角鲨烯、花青…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...