【python可视化大屏】使用python实现可拖拽数据可视化大屏
介绍:
我在前几期分享了关于爬取weibo评论的爬虫,同时也分享了如何去进行数据可视化的操作。但是之前的可视化都是单独的,没有办法在一个界面上展示的。这样一来呢,大家在看的时候其实是很不方便的,就是没有办法一目了然的看到数据的规律。为了解决这个问题我使用pyecharts实现了一个可视化的大屏。接下来为大家分享一下
视频分享:
【python可视化大屏】使用python实现可拖拽数据可视化大屏
可视化大屏展示:
可视化大屏1
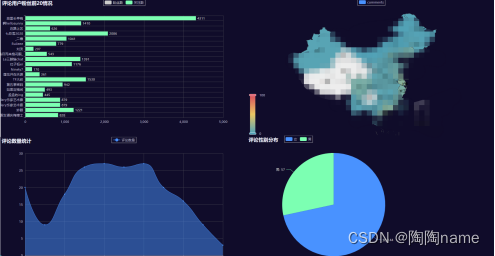
可视化大屏2:

实现流程解析:
本次实现使用的是pyecharts这个库
第一步肯定是安装pyecharts这个库了
安装可以使用pip进行安装,命令如下:
pip install pyecharts
如果安装不成功的话,可以使用清华镜像站进行安装,命令如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts
第二步就是写代码了,其实我们可以到pyecharts的官网上看一下案例的。一看就基本上知道怎么写的了。
下面的这个就是pyecharts的网站了。

我们随便点击一个案例看一下

可以看到案例代码写的非常的详细,需要哪些库,然后数据的格式是怎样的一目了然。
然后我们按照对应的代码写就可以了。
下面就是pyecharts官方给的拖拉拽的可视化效果,可以给代码拿下来运行体验一下
阅读了代码以后,我总结一下其实实现拖拉拽的数据可视化大屏就是给原来单个的可视化图表add到布局的layout就可以了。
下面是我总结的代码模板:
def bar_datazoom_slider01() -> Bar: c = ( Bar() .add_xaxis(Faker.days_attrs) .add_yaxis("商家A", Faker.days_values) .set_global_opts( title_opts=opts.TitleOpts(title="Bar-DataZoom(slider-水平)"), datazoom_opts=[opts.DataZoomOpts()], ) ) return c
def bar_datazoom_slider02() -> Bar: c = ( Bar() .add_xaxis(Faker.days_attrs) .add_yaxis("商家A", Faker.days_values) .set_global_opts( title_opts=opts.TitleOpts(title="Bar-DataZoom(slider-水平)"), datazoom_opts=[opts.DataZoomOpts()], ) ) return c
给单个的写好以后,add到layout中就可以了,像不像搭积木一样的
def page_draggable_layout(): page = Page(layout=Page.DraggablePageLayout) page.add( bar_datazoom_slider(), line_markpoint(), pie_rosetype(), grid_mutil_yaxis(), liquid_data_precision(), table_base(), ) page.render("page_draggable_layout.html")
之前我们实现了单个的可视化,具体如下:

还有词云

然后单个的代码如下:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar# 读取CSV数据
df = pd.read_csv('./weiboData.csv')# 处理粉丝数(以“万”为单位的情况)
df['粉丝数'] = df['粉丝数'].apply(lambda x: float(x.replace('万', '')) * 10000 if '万' in str(x) else float(x))# 选择粉丝数前20的用户
top20_users = df.nlargest(20, '粉丝数')c = (Bar(init_opts=opts.InitOpts(renderer='svg')).add_xaxis(list(top20_users['评论用户名'])).add_yaxis("粉丝数", list(top20_users['粉丝数'])).add_yaxis("关注数", list(top20_users['关注人数'])).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="评论用户粉丝前20情况")).render("fans.html")
)
还有其他的,我就不一一列代码了
然后我们现在的工作就是给他们整合到一起就可以了
具体,比如说我们可以先整合这个showFans.py的代码,
就是这个样子:
ef showFans() -> Bar:df = pd.read_csv('./weiboData.csv')# 处理粉丝数(以“万”为单位的情况)df['粉丝数'] = df['粉丝数'].apply(lambda x: float(x.replace('万', '')) * 10000 if '万' in str(x) else float(x))# 选择粉丝数前20的用户top20_users = df.nlargest(20, '粉丝数')c = (Bar(init_opts=opts.InitOpts(renderer='svg',theme="dark")).add_xaxis(list(top20_users['评论用户名'])).add_yaxis("粉丝数", list(top20_users['粉丝数'])).add_yaxis("关注数", list(top20_users['关注人数'])).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="评论用户粉丝前20情况")))return c # 返回图表对象而不是调用 render 函数def pageLayout():# 创建拖拽布局的页面page = Page(layout=Page.DraggablePageLayout)# 添加自定义图表函数page.add(showFans())# 渲染页面page.render("demo.html")
这样就给一个整合好了,然后后面的就是无脑操作了。
之后我们运行代码会产生一个demo.html的文件(这个文件命名自定义,我的代码里写的是demo.html,你也可以叫其他的名字,都可以的),点击这个文件就会展示我们的大屏,下面就是最终的效果了

我们可以看到在图的左上角有一个save config,这个的作用呢其实就是为了保存我拖拉拽排版大屏之后的配置文件。就是说,当我们进行拖拽各个单独的可视化文件的时候,各个子可视化文件之间会有对应的位置信息,这个config文件呢就是记录这些信息的。
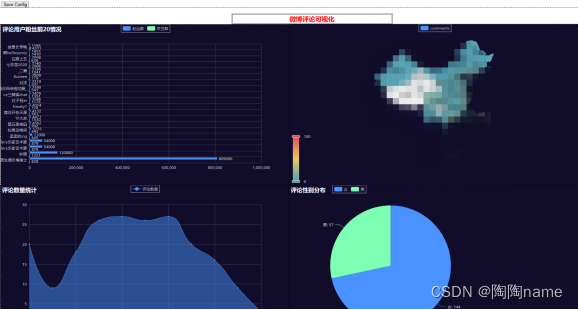
当我们进行排版好以后,我们就看可以点击save config然后保存这个config信息。
之后我们展示正式的大屏的时候时候,加载这个config文件就可以展示了。这个就是正式的版本了。

完成了上面的操作以后,然后就是使用demo.html和chart_config.json来实现正式版本的大屏。具体实现代码如下:
from pyecharts.charts import PagePage.save_resize_html(source="demo.html", cfg_file="chart_config.json", dest="final_dashboard.html")
然后我们在运行这个代码,就会产生一个final_dashboard.html文件,我们双击这个文件就会看到最终的效果了。
由于笔者能力有限,所以在阐述的时候难免有些不准确的地方,还请大家多多包涵!
完整源码【python可视化大屏】使用python实现可拖拽数据可视化大屏
相关文章:
【python可视化大屏】使用python实现可拖拽数据可视化大屏
介绍: 我在前几期分享了关于爬取weibo评论的爬虫,同时也分享了如何去进行数据可视化的操作。但是之前的可视化都是单独的,没有办法在一个界面上展示的。这样一来呢,大家在看的时候其实是很不方便的,就是没有办法一目了…...
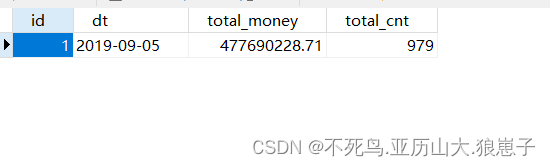
FineBI实战项目一(4):指标分析之每日订单总额/总笔数
1 明确数据分析目标 统计每天的订单总金额及订单总笔数 2 创建用于保存数据分析结果的表 use finebi_shop_bi;create table app_order_total(id int primary key auto_increment,dt date,total_money double,total_cnt int ); 3 编写SQL语句进行数据分析 selectsubstring(c…...

如何确定CUDA对应的pytorch版本?
参考:此链接...
分布式锁3: zk实现分布式锁5 使用中间件curator
一 curator的说明 1.1 curator的说明 curator是netflix公司开源的一个zk客户端。对Zookeeper提供的原生客户端进行封装,简化了Zookeeper客户端的开发量。Curator解决了很多zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册wathcer和Node…...
扩展边界opencv
扩展图像的边缘(如上边增加50像素)通常是通过添加额外的像素行来实现的 使用cv2.copyMakeBorder函数 valueborder_color指定了边框的颜色 import cv2 import numpy as np# 读取图像 image cv2.imread(th.jpg)# 设置边框宽度 top_border_width 50 # …...

开源C语言库Melon:Cron格式解析
本文介绍开源C语言库Melon的cron格式解析。 关于 Melon 库,这是一个开源的 C 语言库,它具有:开箱即用、无第三方依赖、安装部署简单、中英文文档齐全等优势。 Github repo 简介 cron也就是我们常说的Crontab中的时间格式,格式如…...

vue的学习方法
学习Vue.js的方法如下: 先了解基本概念和语法:学习Vue.js的第一步是了解它的基本概念,例如组件、指令、数据绑定等。你可以开始阅读Vue官方文档并参考教程和示例来掌握这些基本概念和语法。 实践项目:在理解了Vue.js的基本概念和…...

Hive之set参数大全-2
C 指定是否启用表达式缓存的评估 hive.cache.expr.evaluation 是 Hive 中的一个配置属性,用于指定是否启用表达式缓存的评估。表达式缓存是一项优化技术,它可以在执行查询时缓存表达式的评估结果,以减少计算开销。 在 Hive 配置中…...

C++面试宝典第17题:找规律填数
题目 仔细观察下面的数字序列,找到规律,并填写空白处的数字。 (1)1, 2, 4, 7, 11, 16, __ (2)-1, 2, 7, 28, __, 126 (3)6, 10, 18, 32, 57, __ (4)19, 6, 1, 2, 11, __ (5)2, 3, 5, 7, 11, __ (6)1, 8, 9, 4, __, 1/6 (7)1, 2, 3, 7, 16, __, 321 (8)1, 2, …...

ubuntu查看内存使用情况
在Ubuntu中,你可以使用一些命令来查看内存使用情况。这些命令可以帮助你了解系统的内存使用情况,包括已用内存、空闲内存、缓存和缓冲区的内存等。 1、使用free命令 free命令是一个非常有用的命令,可以快速查看系统的内存使用情况。在终端中…...

ES6 新增 Set、Map 两种数据结构的理解
ES6 新增 Set、Map 两种数据结构的理解 Set 是一种叫做集合的数据结构, 集合是由一堆无序的、相关联的 , 且不重复的内存结构【 数学中称为元素 】组成的组合; Map 是一种叫做字典的数据结构 字典是一些元素的集合 。每个元素有一个称作 key 的域 , 不同…...
影视视频知识付费行业万能通用网站系统源码,三网合一,附带完整的安装部署教程
在数字化时代,知识付费行业逐渐成为主流。人们对高质量内容的需求日益增长,越来越多的人愿意为有价值的知识和信息服务付费。为了满足这一市场需求,罗峰给大家分享一款全新的影视视频知识付费网站系统源码,为用户提供一站式的知识…...

Java字符串拼接常用方法总结
使用场景:用某个分隔符拼接字符串 下边是我使用过的几种方式废话不多说,直接上代码初始数据 1.使用流2.StringBuilder3.[StringJoiner](https://blog.csdn.net/qq_43417581/article/details/126076152?ops_request_misc%257B%2522request%255Fid%2522%2…...

【2023 CSIG垂直领域大模型】大模型时代,如何完成IDP智能文档处理领域的OCR大一统?
目录 一、像素级OCR统一模型:UPOCR1.1、为什么提出UPOCR?1.2、UPOCR是什么?1.2.1、Unified Paradigm 统一范式1.2.2、Unified Architecture统一架构1.2.3、Unified Training Strategy 统一训练策略 1.3、UPOCR效果如何? 二、OCR大一统模型前…...
Phi-2小语言模型QLoRA微调教程
前言 就在不久前,微软正式发布了一个 27 亿参数的语言模型——Phi-2。这是一种文本到文本的人工智能程序,具有出色的推理和语言理解能力。同时,微软研究院也在官方 X 平台上声称:“Phi-2 的性能优于其他现有的小型语言模型&#…...

hadoop自动获取时间
1、自动获取前15分钟 substr(from_unixtime(unix_timestamp(concat(substr(20240107100000,1,4),-,substr(20240107100000,5,2),-,substr(20240107100000,7,2), ,substr(20240107100000,9,2),:,substr(20240107100000,11,2),:,00))-15*60,yyyyMMddHHmmss),1) unix_timestam…...

【面试高频算法解析】算法练习8 单调队列
前言 本专栏旨在通过分类学习算法,使您能够牢固掌握不同算法的理论要点。通过策略性地练习精选的经典题目,帮助您深度理解每种算法,避免出现刷了很多算法题,还是一知半解的状态 专栏导航 二分查找回溯(Backtracking&…...

ATTCK视角下的信息收集:Sysmon检测
目录 1、简介 2、使用Sysmon 3、检测Sysmon是否安装运行 4、检测Sysmon是否被卸载 5、使Sysmon在终端隐匿运行的技术 1、简介 Sysmon(系统监视器)是由windows sysinternals 出品的Sysinternals 系列工具中的一个 它是windows系统服务和设备驱动程…...

02、Kafka ------ 配置 Kafka 集群
目录 配置 Kafka 集群配置步骤启动各Kafka节点 配置 Kafka 集群 启动命令: 1、启动 zookeeper 服务器端 小黑窗输入命令: zkServer 2、启动 zookeeper 的命令行客户端工具 (这个只是用来看连接的节点信息,不启动也没关系&#…...

2024年全球网络安全预测报告
1.Gartner Gartners Top Strategic Predictions for 2024 and Beyond《Gartner顶级战略预测:2024年及未来》 https://www.gartner.com/en/articles/gartner-s-top-strategic-predictions-for-2024-and-beyond 2.IDC Top 10 Worldwide IT Industry 2024 Predict…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...