【Spark分布式内存计算框架——Structured Streaming】1. Structured Streaming 概述
前言
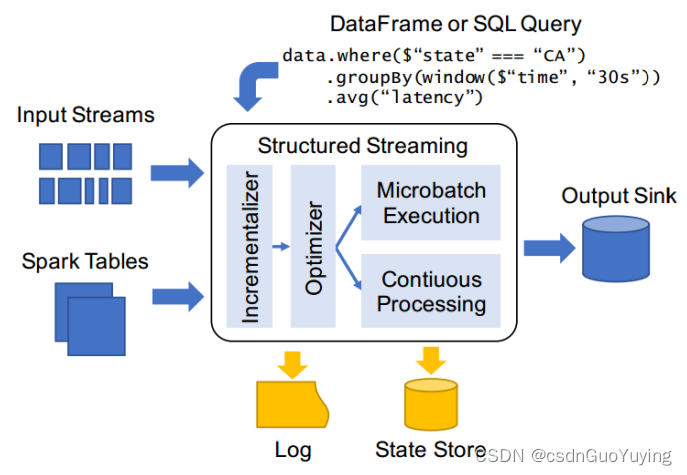
Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。
Structured Streaming并不是对Spark Streaming的简单改进,而是吸取了在开发Spark SQL和Spark Streaming过程中的经验教训,以及Spark社区和Databricks众多客户的反馈,重新开发的全新流式引擎,致力于为批处理和流处理提供统一的高性能API。同时,在这个新的引擎中,也很容易实现之前在Spark Streaming中很难实现的一些功能,比如Event Time(事件时间)的支持,Stream-Stream Join(2.3.0 新增的功能),毫秒级延迟(2.3.0 即将加入的 Continuous Processing)。
第一章 Structured Streaming
Spark Streaming是Apache Spark早期基于RDD开发的流式系统,用户使用DStream API来编写代码,支持高吞吐和良好的容错。其背后的主要模型是Micro Batch(微批处理),也就是将数据流切成等时间间隔(BatchInterval)的小批量任务来执行。
Structured Streaming则是在Spark 2.0加入的,经过重新设计的全新流式引擎。它的模型十分简洁,易于理解。一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾,用户可以使用Dataset/DataFrame 或者 SQL 来对这个动态数据源进行实时查询。
文档:http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html
1.1 Spark Streaming 不足
Spark Streaming 会接收实时数据源的数据,并切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。

本质上,这是一种micro-batch(微批处理)的方式处理,用批的思想去处理流数据。这种设计让Spark Streaming面对复杂的流式处理场景时捉襟见肘。
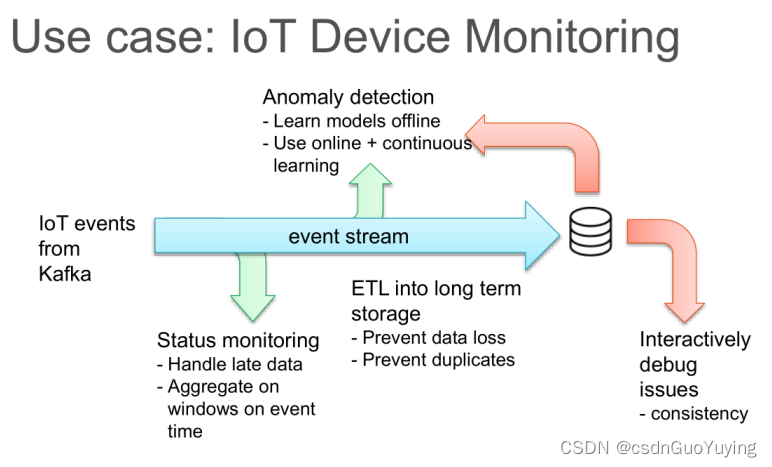
Spark Streaming 存在哪些不足,总结一下主要有下面几点:
第一点:使用 Processing Time 而不是 Event Time
- Processing Time 是数据到达 Spark 被处理的时间,而 Event Time 是数据自带的属性,一般表示数据产生于数据源的时间。
- 比如 IoT 中,传感器在 12:00:00 产生一条数据,然后在 12:00:05 数据传送到 Spark,那么 Event Time 就是 12:00:00,而 Processing Time 就是 12:00:05。
- Spark Streaming是基于DStream模型的micro-batch模式,简单来说就是将一个微小时间段(比如说 1s)的流数据当前批数据来处理。如果要统计某个时间段的一些数据统计,毫无疑问应该使用 Event Time,但是因为 Spark Streaming 的数据切割是基于Processing Time,这样就导致使用 Event Time 特别的困难。
第二点:Complex, low-level api
- DStream(Spark Streaming 的数据模型)提供的API类似RDD的API,非常的low level;
- 当编写Spark Streaming程序的时候,本质上就是要去构造RDD的DAG执行图,然后通过Spark Engine运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导致执行效率上的天壤之别;
第三点:reason about end-to-end application
- end-to-end指的是直接input到out,如Kafka接入Spark Streaming然后再导出到HDFS中;
- DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证;
第四点:批流代码不统一
- 尽管批流本是两套系统,但是这两套系统统一起来确实很有必要,有时候确实需要将的流处理逻辑运行到批数据上面;
- Streaming尽管是对RDD的封装,但是要将DStream代码完全转换成RDD还是有一点工作量的,更何况现在Spark的批处理都用DataSet/DataFrameAPI;
流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年Google发表了The Dataflow Model的论文( https://yq.aliyun.com/articles/73255 )。Google开源Apache Beam项目,基本上就是对Dataflow模型的实现,目前已经成为Apache的顶级项目,但是在国内使用不多。
国内使用的更多的是Apache Flink,因为阿里大力推广Flink,甚至把花7亿元把Flink母公司收购。
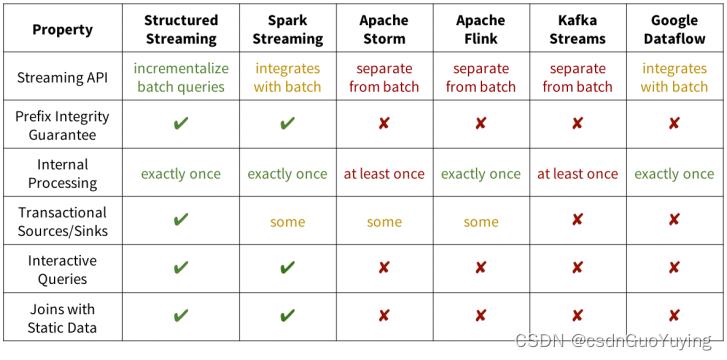
使用Yahoo的流基准平台,要求系统读取广告点击事件,并按照活动ID加入到一个广告活动的静态表中,并在10秒的event-time窗口中输出活动计数。比较了Kafka Streams 0.10.2、Apache Flink 1.2.1和Spark 2.3.0,在一个拥有5个c3.2*2大型Amazon EC2 工作节点和一个master节点的集群上(硬件条件为8个虚拟核心和15GB的内存)。
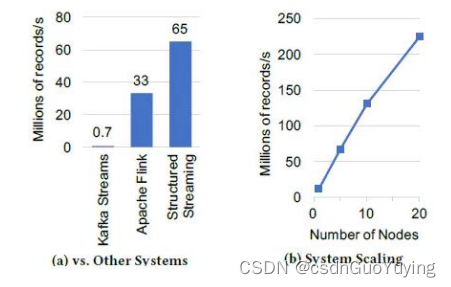
上图(a)展示了每个系统最大稳定吞吐量(积压前的吞吐量),Flink可以达到3300万,而Structured Streaming可以达到6500万,近乎两倍于Flink。这个性能完全来自于Spark SQL的内置执行优化,包括将数据存储在紧凑的二进制文件格式以及代码生成。
1.2 Structured Streaming 概述
或许是对Dataflow模型的借鉴,也许是英雄所见略同,Spark在2.0版本中发布了新的流计算的API:Structured Streaming结构化流。Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,可以使用静态数据批处理一样的方式来编写流式计算操作,并且支持基于event_time的时间窗口的处理逻辑。随着数据不断地到达,Spark 引擎会以一种增量的方式来执行这些操作,并且持续更新结算结果。

模块介绍
Structured Streaming 在 Spark 2.0 版本于 2016 年引入,设计思想参考很多其他系统的思想,比如区分 processing time 和 event time,使用 relational 执行引擎提高性能等。同时也考虑了和 Spark 其他组件更好的集成。
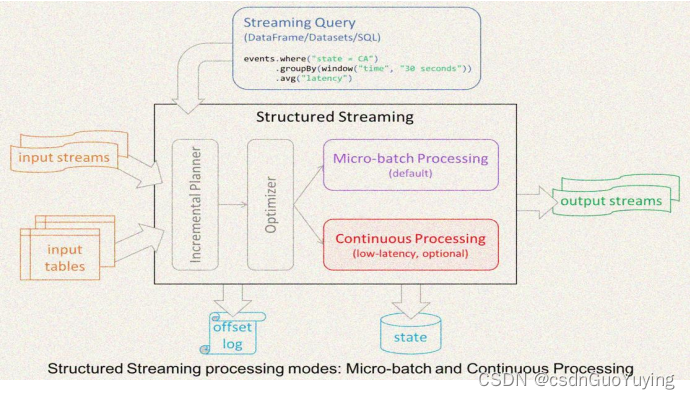
Structured Streaming 和其他系统的显著区别主要如下:
第一点:Incremental query model(增量查询模型)
- Structured Streaming 将会在新增的流式数据上不断执行增量查询,同时代码的写法和批处理 API(基于Dataframe和Dataset API)完全一样,而且这些API非常的简单。
第二点:Support for end-to-end application(支持端到端应用)
- Structured Streaming 和内置的 connector 使的 end-to-end 程序写起来非常的简单,而且 “correct by default”。数据源和sink满足 “exactly-once” 语义,这样我们就可以在此基础上更好地和外部系统集成。
第三点:复用 Spark SQL 执行引擎
- Spark SQL 执行引擎做了非常多的优化工作,比如执行计划优化、codegen、内存管理等。这也是Structured Streaming取得高性能和高吞吐的一个原因。
相关文章:
【Spark分布式内存计算框架——Structured Streaming】1. Structured Streaming 概述
前言 Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。 Structured Streaming并不是对Spark Streaming的简单改进…...
【Windows】【Linux】---- Java证书导入
问题: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target 无法找到请求目标的有效证书路径 一、Windows—java证书导入 1、下载证书到本地(以下…...

【Linux学习】菜鸟入门——gcc与g++简要使用
一、gcc/g gcc/g是编译器,gcc是GCC(GUN Compiler Collection,GUN编译器集合)中的C编译器;g是GCC中的C编译器。使用g编译文件时会自动链接STL标准库,而gcc不会自动链接STL标准库。下面简单介绍一下Linux环境下(Windows差…...

Cadence Allegro 导出Bill of Material Report详解
⏪《上一篇》 🏡《总目录》 ⏩《下一篇》 目录 1,概述2,Assigned Functions Report作用3,Assigned Functions Report示例4,Assigned Functions Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
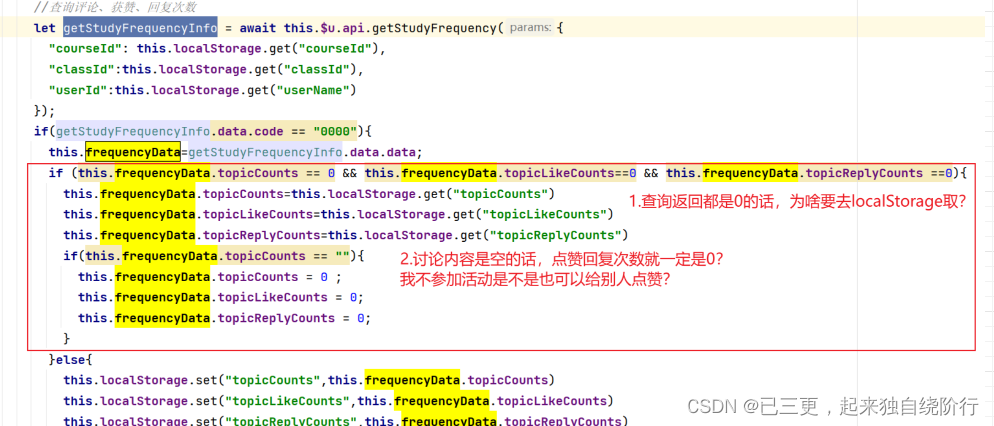
localStorage线上问题的思考
一、背景: localStorage作为HTML5 Web Storage的API之一,使用标准的键值对(Key-Value,简称KV)数据类型主要作用是本地存储。本地存储是指将数据按照键值对的方式保存在客户端计算机中,直到用户或者脚本主动清除数据&a…...

什么是DNS域名解析
什么是DNS域名解析?因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,得到该主机名对应的IP地址的过程叫做域名解析。正向解析:…...

Cadence Allegro 导出Assigned Functions Report详解
⏪《上一篇》 🏡《总目录》 ⏩《下一篇》 目录 1,概述2,Assigned Functions Report作用3,Assigned Functions Report示例4,Assigned Functions Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...

Python中Opencv和PIL.Image读取图片的差异对比
近日,在进行深度学习进行推理的时候,发现不管怎么样都得不出正确的结果,再仔细和正确的代码进行对比了后发现原来是Python中不同的库读取的图片数组是有差异的。 image np.array(Image.open(image_file).convert(RGB)) image cv2.imread(…...
win10 WSL2 使用Ubuntu配置与安装教程
Win10 22H2ubuntu 22.04ROS2 文章目录一、什么是WSL2二、Win10 系统配置2.1 更新Windows版本2.2 Win10系统启用两个功能2.3 Win10开启BIOS/CPU开启虚拟化(VT)(很关键)2.4 下载并安装wsl_update_x64.msi2.5 PowerShell安装组件三、PowerShell安装Ubuntu3.…...
)
LeetCode每日一题(28. Find the Index of the First Occurrence in a String)
Given two strings needle and haystack, return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack. Example 1: Input: haystack “sadbutsad”, needle “sad” Output: 0 Explanation: “sad” occurs at index 0 and…...
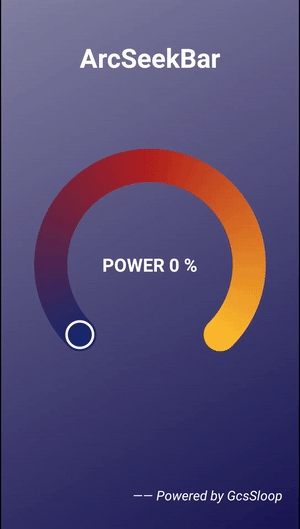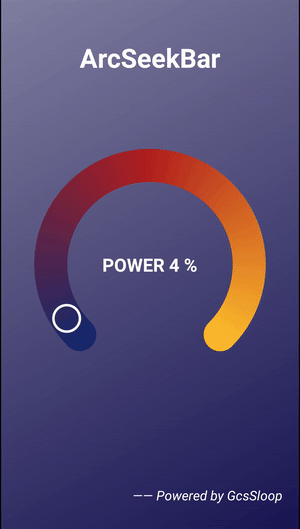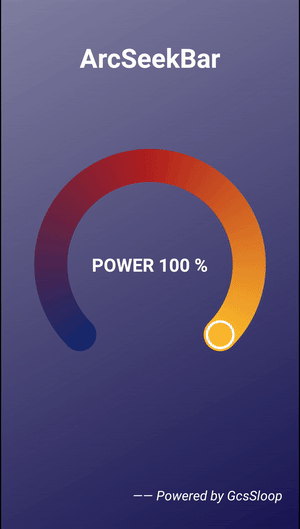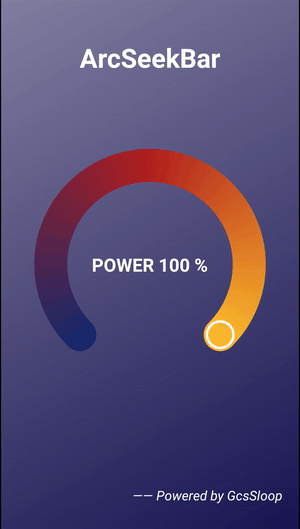
Android 圆弧形 SeekBar
效果预览package com.gcssloop.widget;import android.annotation.SuppressLint;import android.content.Context;import android.content.res.TypedArray;import android.graphics.Canvas;import android.graphics.Color;import android.graphics.Matrix;import android.graph…...
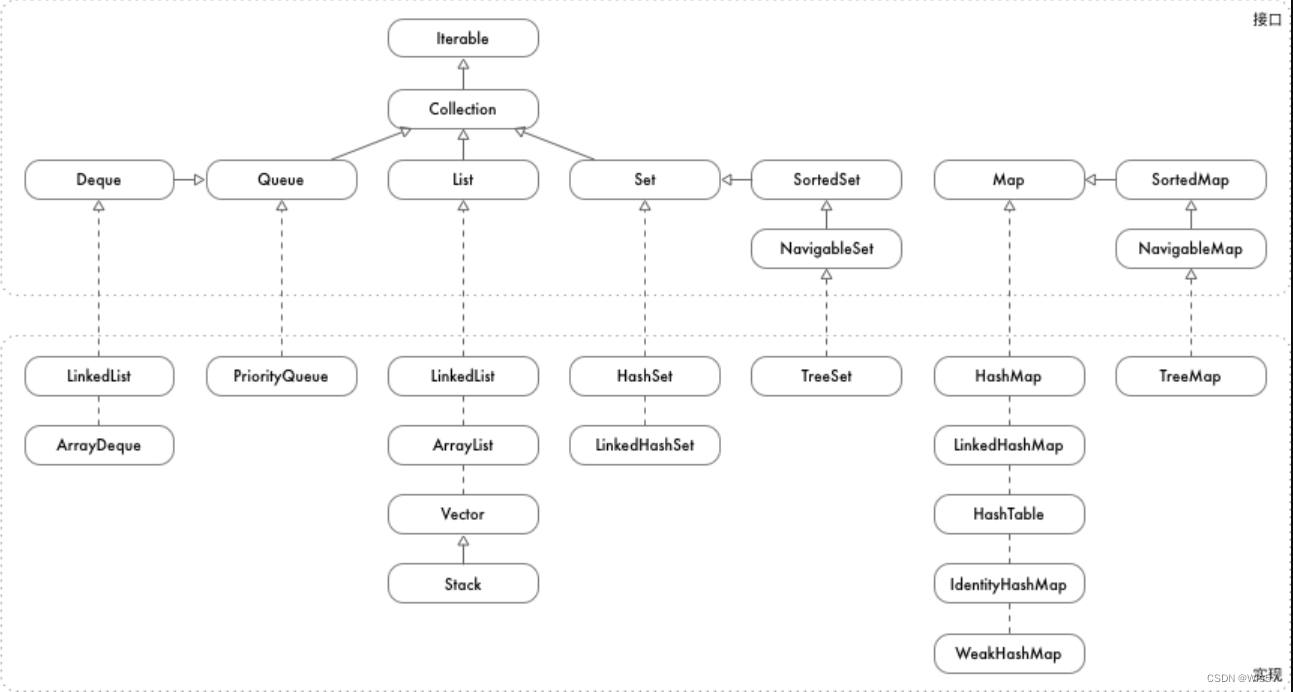
java 字典
java 字典 数据结构总览 Map Map 描述的是一种映射关系,一个 key 对应一个 value,可以添加,删除,修改和获取 key/value,util 提供了多种 Map HashMap: hash 表实现的 map,插入删除查找性能都是 O(1)&…...
【企业服务器LNMP环境搭建】mysql安装
MySQL安装步骤: 1、相关说明 1.1、编译参数的说明 -DCMAKE_INSTALL_PREFIX安装到的软件目录-DMYSQL_DATADIR数据文件存储的路径-DSYSCONFDIR配置文件路径 (my.cnf)-DENABLED_LOCAL_INFILE1使用localmysql客户端的配置-DWITH_PARTITION_STORAGE_ENGINE使mysql支持…...
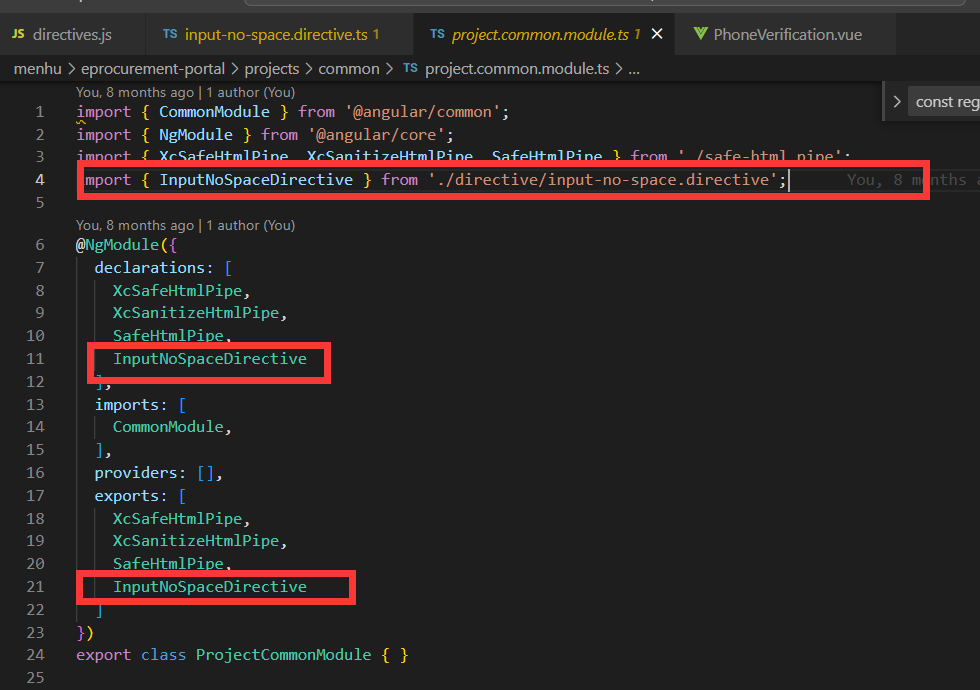
vue自定义指令以及angular自定义指令(以禁止输入空格为例)
哈喽,小伙伴们,大家好啊,最近要实现一个vue自定义指令,就是让input输入框禁止输入空格建立一个directives的指令文件,里面专门用来建立各个指令的官方文档:自定义指令 | Vue.js (vuejs.org)我们都知道vue中…...

异常 复习
异常复习 异常(广义):泛指程序中一切不正常的情况 错误:例如内存不够用,程序是无法解决的 异常(狭义):程序在运行中出现问题,但是可以通过异常处理机制处理,程序可以继续向后执行 异常体系 Throwable类有两个直接子类:Excepti…...
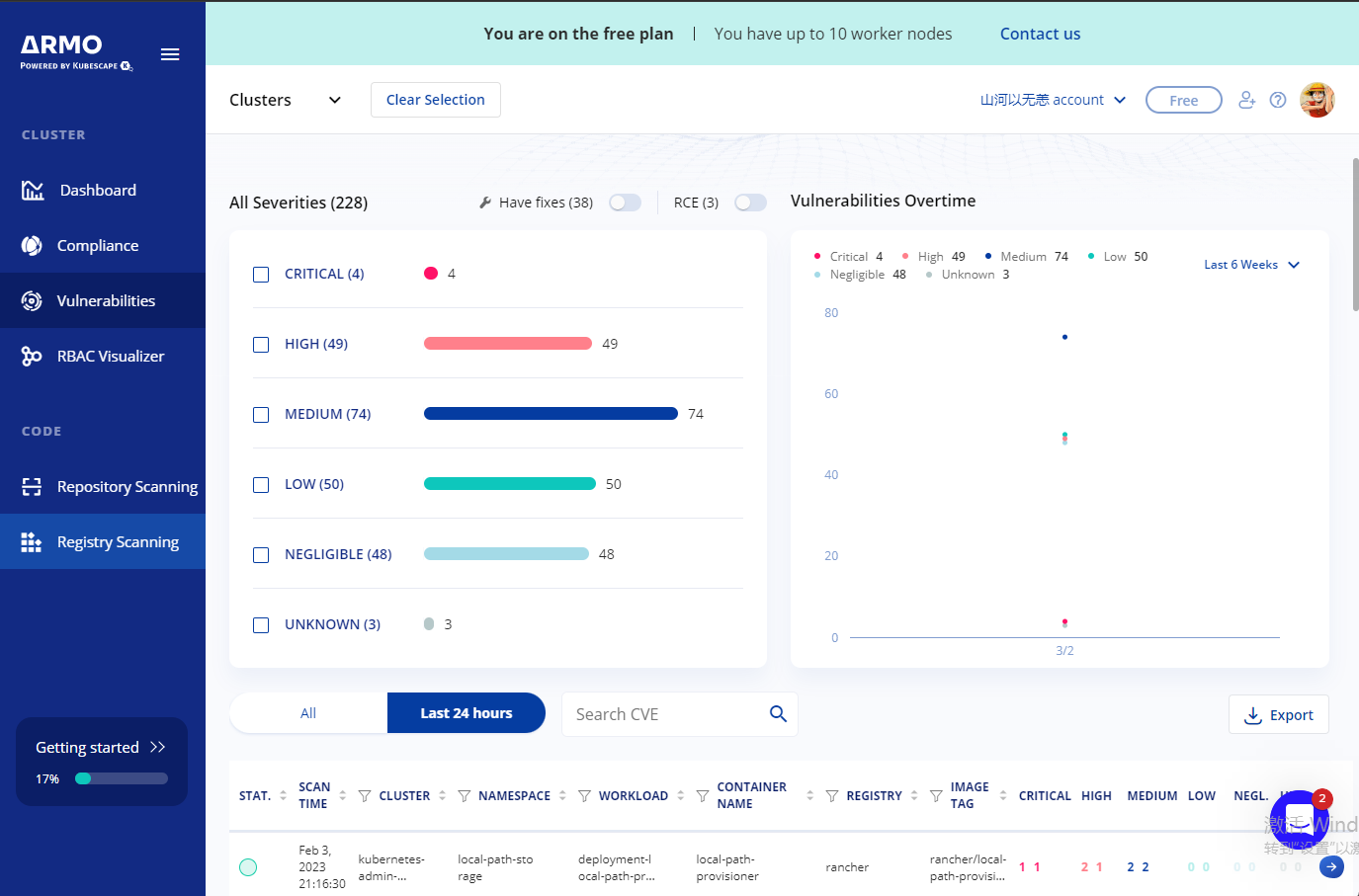
K8s:开源安全平台 kubescape 实现 Pod 的安全合规检查/镜像漏洞扫描
写在前面 生产环境中的 k8s 集群安全不可忽略,即使是内网环境容器化的应用部署虽然本质上没有变化,始终是机器上的一个进程但是提高了安全问题的处理的复杂性分享一个开源的 k8s 集群安全合规检查/漏洞扫描 工具 kubescape博文内容涉及: kube…...

C#中,FTP同步或异步读取大量文件
一次快速读取上万个文件中的内容 在C#中,可以使用FTP客户端类(如FtpWebRequest)来连接FTP服务器并进行文件操作。一次快速读取上万个文件中的内容,可以采用多线程的方式并发读取文件。 以下是一个示例代码,用于读取FT…...
STM32单片机的FLASH和RAM
STM32内置有Flash和RAM(而RAM分为SRAM和DRAM,STM32内为SRAM),硬件上他们是不同的设备存储器、属于两个器件,但这两个存储器的寄存器输入输出端口被组织在同一个虚拟线性地址空间内。 MDK预处理、编译、汇编、链接后编…...

Java 二叉树的遍历
二叉树的遍历(traversing binary tree)是指从根结点出发,按照某种次序依次访问二叉树中所有的结点,使得每个结点被访问依次且仅被访问一次。前序遍历(根 左 右)先访问根结点,然后前序遍历左子树…...

实习日记-C#
数据类型 字符串常量 string a "hello, world"; // hello, world string b "hello, world"; // hello, world string c "hello \t world"; // hello world string d "hello \t wor…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...