ClickHouse 与 Amazon S3 结合?一起来探索其中奥秘
目录
ClickHouse 简介
ClickHouse 与对象存储
ClickHouse 与 S3 结合的三种方法
示例参考架构
小结
参考资料
ClickHouse 简介
ClickHouse 是一种快速的、开源的、用于联机分析(OLAP)的列式数据库管理系统(DBMS),由俄罗斯的Yandex公司开发,于2016年开源。ClickHouse 作为交互式分析领域的后起之秀,发展速度非常快,目前在 GitHub 上已收获 14K Star。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |

ClickHouse 主打顶尖的极致性能,每台服务器每秒钟可以处理数亿至数十亿多行或者是数十GB的数据。ClickHouse 基于列式存储,通过 SQL 查询海量数据并实时生成分析报告。ClickHouse 充分利用了所有可用的硬件优化技术,以尽可能快地处理每个查询。向量化的查询执行引入了 SIMD 处理器指令和运行时代码生成技术。列式存储的数据会提高CPU缓存的命中率。ClickHouse 概览文档中的图片清晰地展示了行式存储与列式存储在 OLAP 领域中的速度差距。
行式存储
在分布式集群中,副本之间的数据读取会自动保持平衡,以避免增加延迟。同时,ClickHouse 支持多主异步复制模式,这种情况下所有节点角色都是相等的,可以避免出现单点故障,单个节点或整个可用区的停机时间并不会影响系统的读写可用性。
在网络和应用分析,广告网络和实时出价,电信,电子商务和金融以及商业智能等领域,ClickHouse 都有很好的支持与应用,更多信息请参考 ClickHouse 官网。
01 ClickHouse与对象存储
ClickHouse 针对数据量和查询场景提供了不同的数据库和数据表引擎,此外它也可以使用多种多样的专用引擎或表函数(例如 HDFS,Kafka,S3 等)与许多外部系统进行通讯。在现代化的云架构中,对象存储是最重要的存储组成部分。2006年,亚马逊云科技正式推出的第一个云服务也是 Amazon S3(Simple Storage Service),目前 Amazon S3 已经成为事实上的云对象存储标准。
使用对象存储可以给数据分析系统带来诸多优势。首先,它可以使用数据湖架构中的原始数据。其次,对象存储可以为数据表数据提供高性价比且高可靠性的存储。针对 S3 目前 ClickHouse 已经上述对象存储的这两种用途。
02 ClickHouse 与 S3 结合的三种方法
1)通过 MergeTree 表引擎集成 S3
前面提到 ClickHouse 提供了众多数据库和数据表引擎,这其中最强大的表引擎当属 MergeTree (合并树)引擎及合并树系列(*MergeTree)中的其他引擎。MergeTree 系列的引擎被设计用于插入海量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
MergeTree 系列表引擎可以将数据存储在多块设备上。这对某些可以潜在被划分为“冷”“热”的表来说是很有用的。近期数据被定期的查询但只需要比较小的磁盘存储空间。相反,大量的、详尽的历史数据被用到的频率相对较少。ClickHouse 可以将 S3 对象存储用于 MergeTree 表数据,这样针对“热”的数据,可以放置在快速的磁盘上(比如 NVMe 固态硬盘或内存中),“冷”的数据可以存放在S3对象存储中。在MergeTree 系列表引擎中使用S3的参考架构如下图所示:
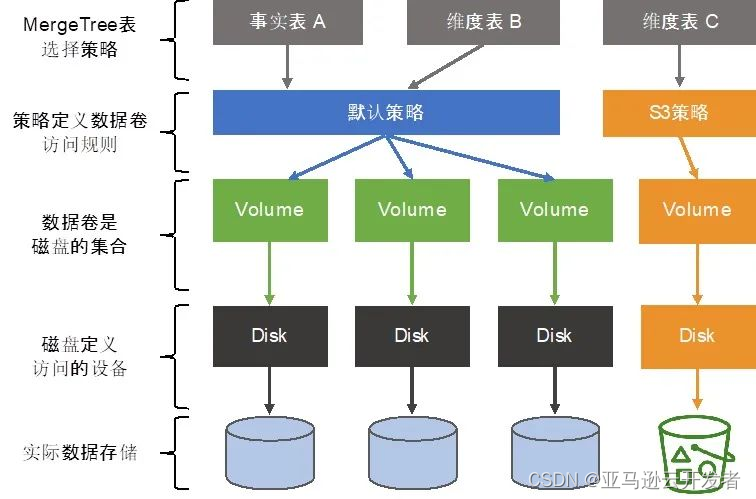
2)通过 S3 表引擎集成
除了 MergeTree 表引擎,ClickHouse 还直接提供了专用的 S3 表引擎,进一步加强了 Amazon S3 生态系统的集成,可以充分利用数据湖中已有的各种开放数据格式例如Parquet。通过以下语句就可以进行 S3 表引擎的创建:
ENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])3)通过 S3 表函数集成
ClickHouse 提供表接口的方式对 S3 中的文件进行 SELECT/INSERT 操作,这种方式使用起来更加方便,可以快速与 ClickHouse 中已有的数据进行连接等操作。通过以下语句就可以使用S3表函数:
3)通过 S3 表函数集成
ClickHouse 提供表接口的方式对 S3 中的文件进行 SELECT/INSERT 操作,这种方式使用起来更加方便,可以快速与 ClickHouse 中已有的数据进行连接等操作。通过以下语句就可以使用S3表函数:
s3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])上述方式分别适用于不同的应用场景,可以根据具体情况进行单独或者结合使用。
此外,可以看到这里面还涉及到 S3 访问权限的安全问题。在 ClickHouse 20.13之前的版本中,必须要在 SQL 或 ClickHouse 存储配置中提供 Amazon Web Services 的访问密钥(Access Key 和 Secret Access Key)才能访问,这是既不安全也不方便的模式。但是在20.13版本中,ClickHouse 提供了实用 IAM Role 访问方式,解决了访问 S3 的安全性问题。
03 示例参考架构
接下来,我们将演示如何实现上述介绍的 ClickHouse 与 S3 结合的三种方法。演示的参考架构如下图所示,我们将 ClickHouse 环境部署在一个 VPC 私有子网中,然后通过 VPC Enpoints 内网的方式来访问 S3 中的数据。
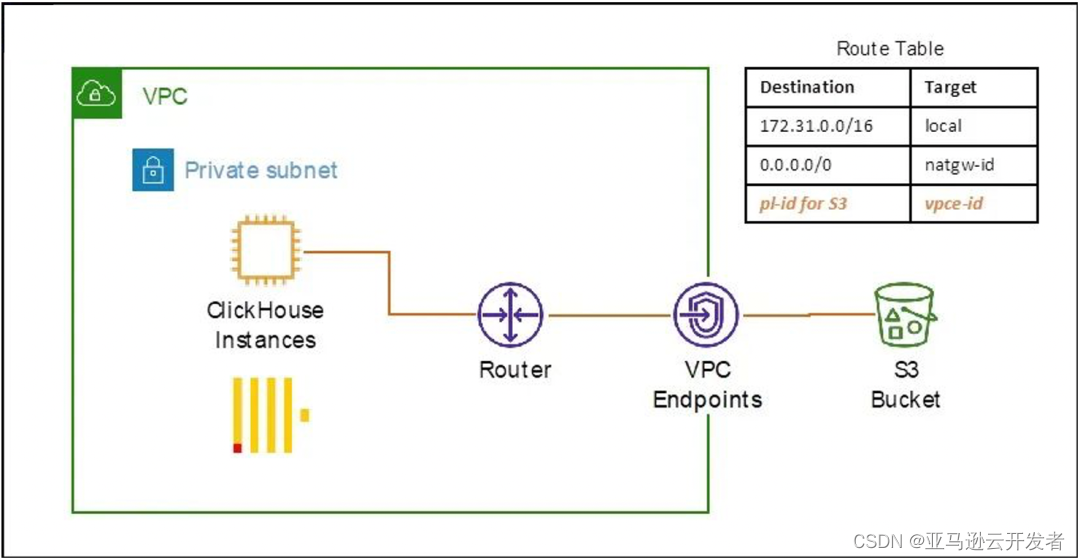
在示例中,我们将使用纽约出租车数据,该数据分析是 Kaggle 竞赛的著名赛题之一,也是学习数据分析的经典练习案例,项目数据可以从 NYC 网站上进行下载,这里选取了2020年6月的 Yellow Taxi Trip Records 数据。
以下示例的操作环境为亚马逊云科技中国(北京)区域。
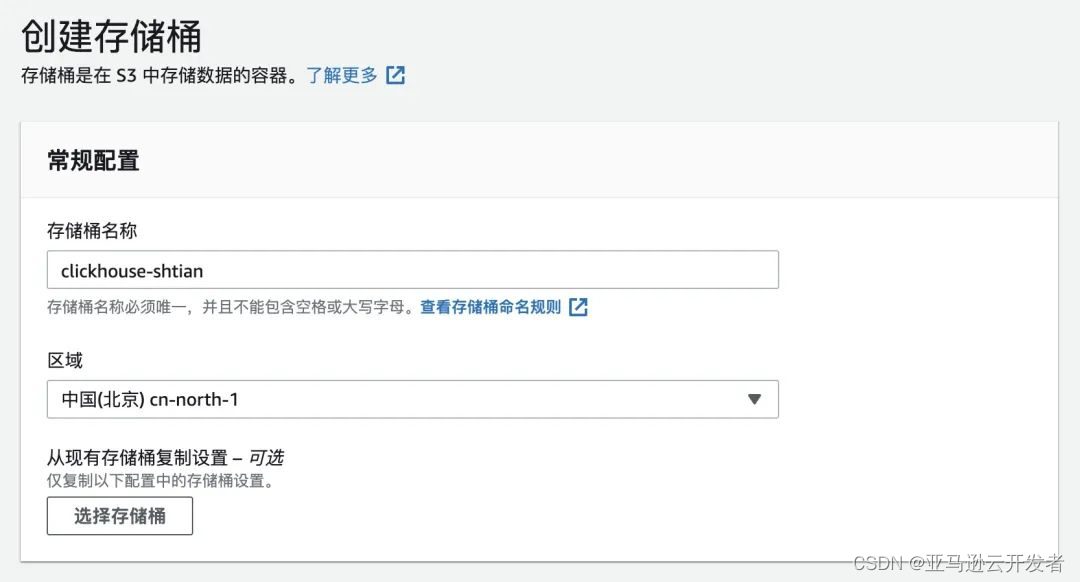
1)创建 S3 存储桶
首先,在亚马逊云科技中国(北京)区域创建存储数据的S3存储桶,例如 clickhouse-shtian。
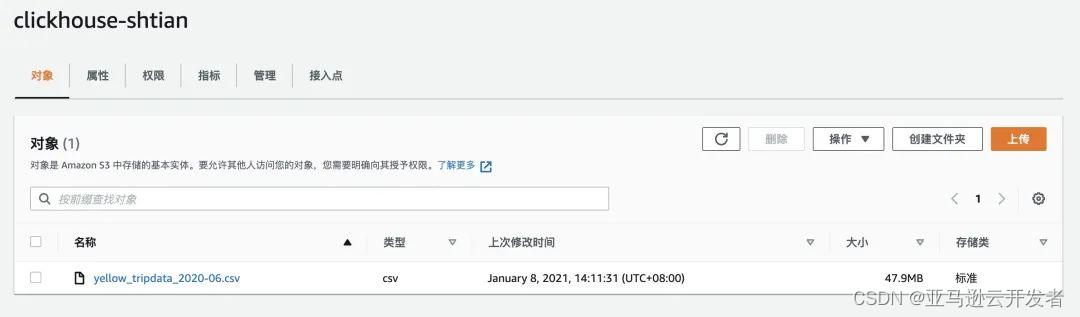
2)下载数据并上传到 S3 存储桶中
首先,在 NYC 网站上将2020年6月 Yellow Taxi Trip Records 数据下载下来,然后上传到刚刚创建的 S3 桶中。
3)创建并配置 S3 的 VPC Enpoint
VPC Enpoint 的创建和配置请参考 VPC 文档,确保子网路由表中包含下图中第二条路有条目。

4)部署 ClickHouse
示例操作系统为 Amazon Linux 2,ClickHouse 版本为20.13.1.5591,演示使用单点部署模式,实际使用环境建议部署集群模式,提升高可用的同时也增加性能。需要注意的是在创建 EC2 实例过程中需要配置 IAM 角色,可以参考文档适用于 Amazon EC2 的 IAM 角色进行设置,并确保这个角色具有 S3 桶的读写权限。

SSH 登录到 EC2 实例上,然后下载对应版本的安装包,然后解压并安装。
wget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-client-20.13.1.5591.tgzwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-common-static-20.13.1.5591.tgzwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-common-static-dbg-20.13.1.5591.tgzwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-server-20.13.1.5591.tgztar -xzvf clickhouse-common-static-20.13.1.5591.tgz
sudo clickhouse-common-static-20.13.1.5591/install/doinst.shtar -xzvf clickhouse-common-static-dbg-20.13.1.5591.tgz
sudo clickhouse-common-static-dbg-20.13.1.5591/install/doinst.shtar -xzvf clickhouse-client-20.13.1.5591.tgz
sudo clickhouse-client-20.13.1.5591/install/doinst.shtar -xzvf clickhouse-server-20.13.1.5591.tgz
sudo clickhouse-server-20.13.1.5591/install/doinst.sh安装成功后,后看到如下提示:
…ClickHouse has been successfully installed.Start clickhouse-server with:sudo clickhouse startStart clickhouse-client with:clickhouse-client根据提示使用以下命令启动 clickhouse-server 服务:
sudo clickhouse start执行命令 clickhouse-client 启动客户端,可以看到连接到服务器并
$ clickhouse-client ClickHouse client version 20.13.1.5591 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 20.13.1 revision 54443.5)配置 ClickHouse 实现通过 MergeTree 表引擎集成 S3
创建并编辑 ClickHouse 配置文件,ClickHouse 的主配置文件通常在/etc/clickhouse-server/config.xml,其他附加配置我们可以通过在/etc/clickhouse-server/config.d/添加 xml 文件来设置,也方便配置的扩展。
sudo vim /etc/clickhouse-server/config.d/merge-s3.xml复制一下内容到文件中,其中 use_environment_credentials 表示通过 IAM 的角色、环境变量或者.Amazon Web Services 中的安全配置来访问 S3。注意替换 endpoint 部分对应的 S3 存储桶和路径:
<yandex><storage_configuration><disks><s3><type>s3</type><endpoint>https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/mergetree/</endpoint><use_environment_credentials>true</use_environment_credentials></s3></disks><policies><s3><volumes><main><disk>s3</disk></main></volumes></s3></policies></storage_configuration>
</yandex>编辑 /etc/clickhouse-server/config.xml.修改 openSSL 中的client配置,添加一行/etc/pki/tls/certs/ca-bundle.crt,设定SSL/TLS访问的CA证书。如果想使用S3的http端点,则无需配置此选项,但是会存在数据传输安全风险,因此建议使用上面的https的端点并进行如下配置。
<client> <!-- Used for connecting to https dictionary source and secured Zookeeper communication --><loadDefaultCAFile>true</loadDefaultCAFile><caConfig>/etc/pki/tls/certs/ca-bundle.crt</caConfig><cacheSessions>true</cacheSessions><disableProtocols>sslv2,sslv3</disableProtocols><preferServerCiphers>true</preferServerCiphers><!-- Use for self-signed: <verificationMode>none</verificationMode> --><invalidCertificateHandler><!-- Use for self-signed: <name>AcceptCertificateHandler</name> --><name>RejectCertificateHandler</name></invalidCertificateHandler></client></openSSL>此外,根据操作系统不同,caConfig 选项可能不需要单独添加。实际测试在使用 Ubuntu 18.04 的时候,ClickHouse 会自动找到 CA 证书的位置,无需额外配置。但是,在使用 Amazon Linux 2 操作系统时需要配置上述选项,否则 ClickHouse 找不到 CA 证书的位置,并且会报如下证书错误:
Error message: Poco::Exception. Code: 1000, e.code() = 0, e.displayText() = SSL Exception: error:1000007d:SSL routines:OPENSSL_internal:CERTIFICATE_VERIFY_FAILED (version 20.13.1.5591 (official build))重启 clickhouse-server 使配置文件生效:
sudo clickhouse restart启动客户端 clickhouse-client,创建 MergeTree 引擎的数据表,并选择定义好的 S3 存储策略:
CREATE TABLE default.s3mergetree
(`VendorID` UInt8,`VendorName` String
)
ENGINE = MergeTree
PARTITION BY VendorName
ORDER BY VendorID
SETTINGS storage_policy = 's3'插入2行测试数据:
INSERT INTO default.s3mergetree VALUES (1, 'Vendor1') (2, 'Vendor2')然后查询这个数据表:
SELECT *
FROM default.s3mergetree返回结果如下,查询成功:
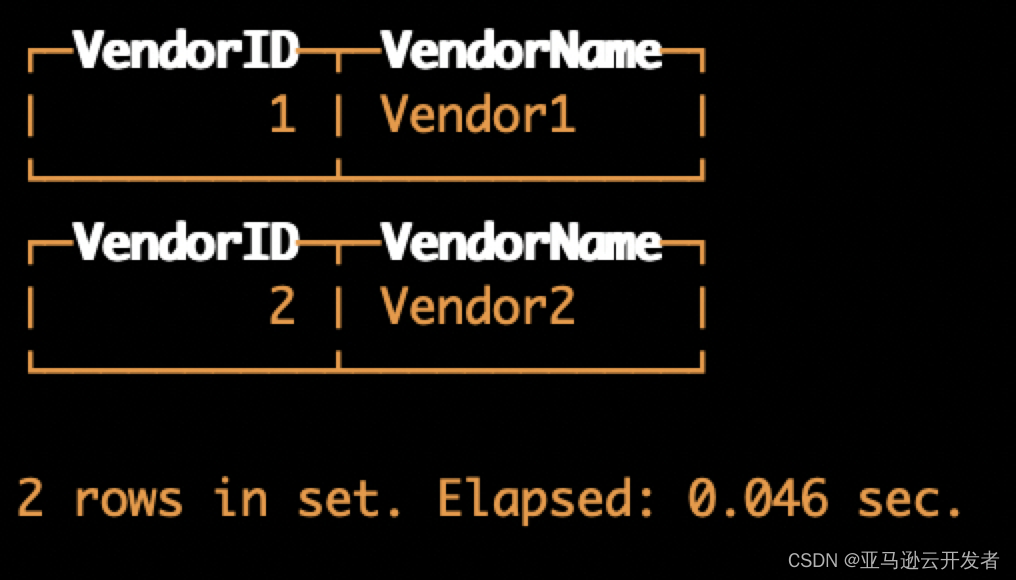
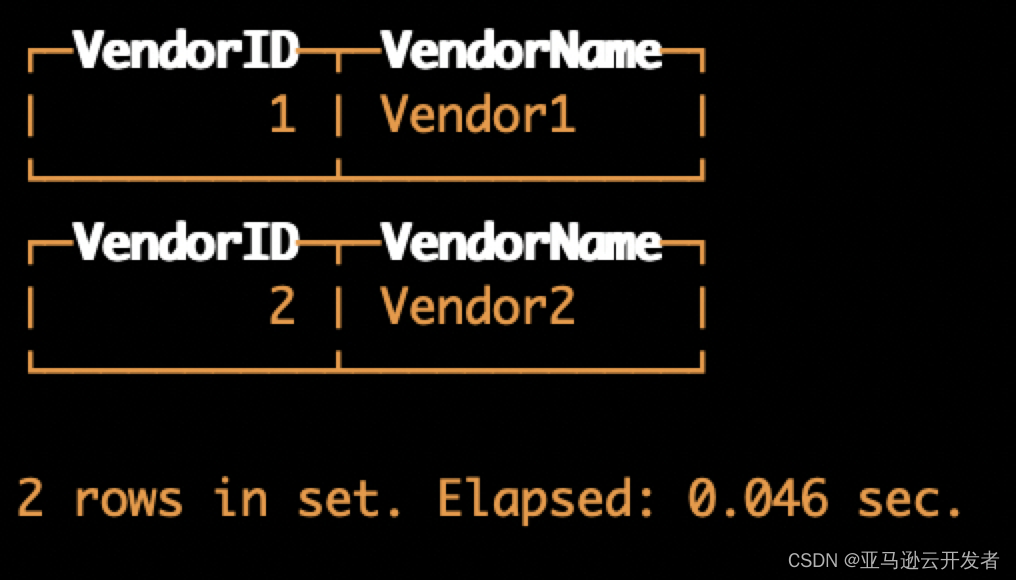
但是实际上数据文件中并没有保存真实的数据,而是存储了 S3 数据的链接。

查看 S3 中的数据信息,数据文件是长这个样子的:
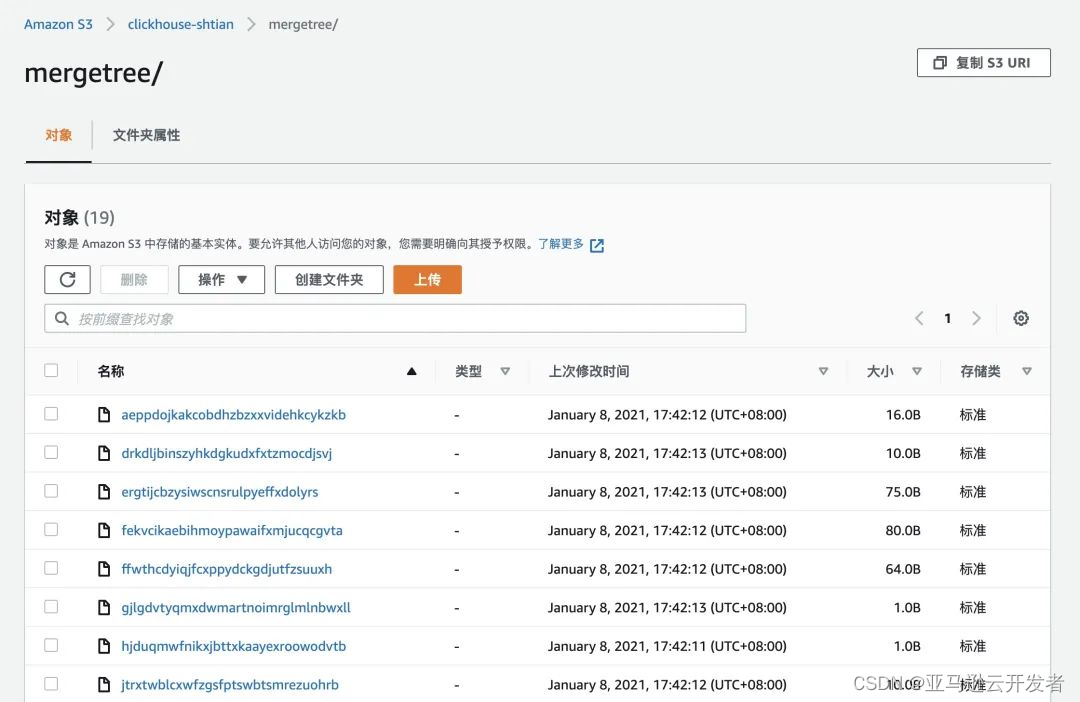
尽管原来在块存储中需要硬链接的合并、变异和重命名操作现在是在引用上操作的,S3 数据完全没有被触及,但是通过查看上述文件结构发现这会导致另一个问题,就是针对这些数据并没有办法通过其他数据分析工具进行处理,因为 ClickHouse 本身也是采用的专有数据存储格式,这也是该方案的一个弊端,借助了 MergeTree 的好处但仅仅是使用 S3 做为存储。
6)配置 ClickHouse 实现通过专用表引擎集成 S3
创建并编辑 ClickHouse 配置文件:
sudo vim /etc/clickhouse-server/config.d/table-s3.xml复制一下内容到文件中:
<yandex><s3><endpoint><endpoint>https://s3.cn-north-1.amazonaws.com.cn</endpoint><use_environment_credentials>true</use_environment_credentials></endpoint></s3>
</yandex>重启 clickhouse-server 使配置文件生效:
sudo clickhouse restart启动客户端 clickhouse-client,创建 S3 引擎的数据表:
CREATE TABLE default.s3table
(`VendorID` UInt8,`tpep_pickup_datetime` DateTime,`tpep_dropoff_datetime` DateTime,`passenger_count` UInt8,`trip_distance` Float32,`RatecodeID` UInt8,`store_and_fwd_flag` String,`PULocationID` UInt8,`DOLocationID` UInt8,`payment_type` UInt8,`fare_amount` Float32,`extra` Float32,`mta_tax` Float32,`tip_amount` Float32,`tolls_amount` Float32,`improvement_surcharge` Float32,`total_amount` Float32,`congestion_surcharge` Float32
)
ENGINE = S3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames)然后进行基本的查询:
SELECTVendorID,tpep_pickup_datetime,tpep_pickup_datetime,passenger_count,tolls_amount,total_amount,congestion_surcharge
FROM default.s3table
LIMIT 10返回结果如下,查询成功:
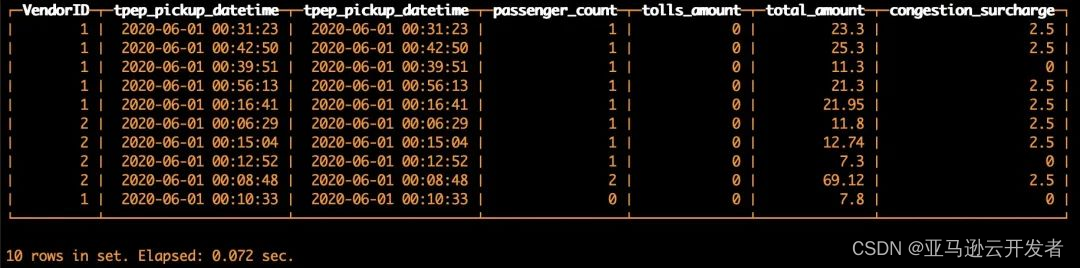
需要注意的是,插入数据在这种情况下也是支持的,但是如果表是使用单文件定义的(如本示例),那么插入会覆盖当前文件的内容。如果是使用通配符的方式进行定义(如*.CSV),在插入数据的时候会写到*.CSV,目前已经将问题反馈提交到 ClickHouse 开源社区。因此,建议目前使用这种方法时,只去查询 S3 中的数据。
该方案的优势在于对于已有的数据湖中的数据,比如各种开放数据格式 CSV、Parquet 等,都可以通过 ClickHouse 进行查询,无需作出额外的改动,趋于 LakeHouse 这样的新架构。
7)配置 ClickHouse 实现通过专用表函数集成 S3
在步骤6中的配置 etc/clickhouse-server/config.d/table-s3.xml对 S3 专用表函数也是生效的,所以直接在客户端 clickhouse-client 继续进行查询即可:
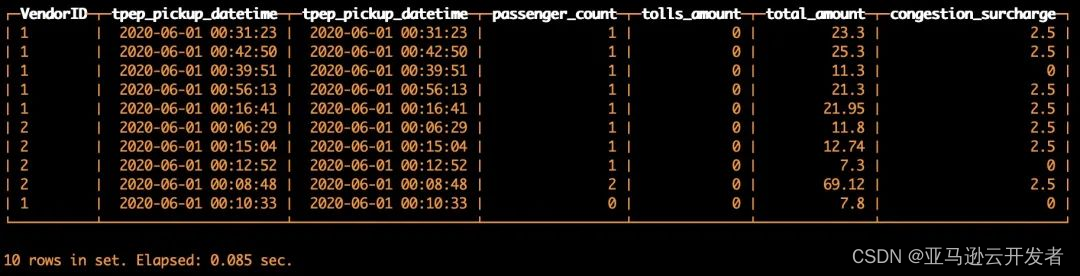
SELECTVendorID,tpep_pickup_datetime,tpep_pickup_datetime,passenger_count,tolls_amount,total_amount,congestion_surcharge
FROM s3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames, 'VendorID UInt8,tpep_pickup_datetime DateTime,tpep_dropoff_datetime DateTime,passenger_count UInt8,trip_distance Float32,RatecodeID UInt8,store_and_fwd_flag String,PULocationID UInt8,DOLocationID UInt8,payment_type UInt8,fare_amount Float32,extra Float32,mta_tax Float32,tip_amount Float32,tolls_amount Float32,improvement_surcharge Float32,total_amount Float32,congestion_surcharge Float32')
LIMIT 10
复制代码返回结果如下,数据查询成功:
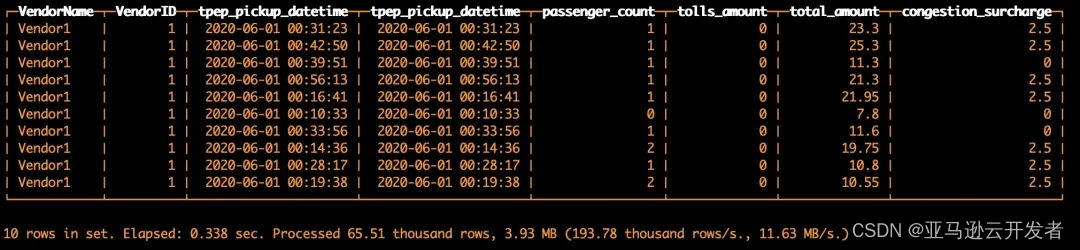
除了单独使用 S3 表函数,还可以和其他 MergeTree 表进行连接,例如我们可以使用以下 SQL 将 S3 表函数和步骤5中创建的表进行 JOIN 查询。
SELECTVendorName,VendorID,tpep_pickup_datetime,tpep_pickup_datetime,passenger_count,tolls_amount,total_amount,congestion_surcharge
FROM s3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames, 'VendorID UInt8,tpep_pickup_datetime DateTime,tpep_dropoff_datetime DateTime,passenger_count UInt8,trip_distance Float32,RatecodeID UInt8,store_and_fwd_flag String,PULocationID UInt8,DOLocationID UInt8,payment_type UInt8,fare_amount Float32,extra Float32,mta_tax Float32,tip_amount Float32,tolls_amount Float32,improvement_surcharge Float32,total_amount Float32,congestion_surcharge Float32') AS s3
INNER JOIN default.s3mergetree ON s3.VendorID = s3mergetree.VendorID
WHERE s3mergetree.VendorID = 1
LIMIT 10复制代码返回结果如下,数据查询成功:
该方案同样发挥了数据湖的价值,可以和已有的各种开放数据格式 CSV、Parquet 等数据进行连接,扩展了数据仓库的使用范围。
通过上述演示,可以基本实现不同应用场景下的 ClickHouse 和 S3 结合。由于 ClickHouse 是开源项目,所以和 S3 的集成和更丰富的特性还在逐步完善中。
04 小结
本文首先简单介绍了 ClickHouse 及其特性和使用场景,然后介绍了通过与 Amazon S3 存储的结合,可以为数据分析系统带来的优势:成本优化以及数据湖的应用。接下来,我们又介绍了 ClickHouse 和 S3 集成的三种方案,并通过具体示例来展示了各方案的具体实现方法和优劣势。
参考资料:
https://altinity.com/blog/clickhouse-and-s3-compatible-object-storage?trk=cndc-detail
https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-multiple-volumes?trk=cndc-detail
https://clickhouse.tech/docs/en/engines/table-engines/integrations/s3/?trk=cndc-detail
https://clickhouse.tech/docs/en/sql-reference/table-functions/s3/?trk=cndc-detail
本篇作者

史天 亚马逊云科技解决方案架构师
拥有丰富的云计算、大数据和机器学习经验,目前致力于数据科学、机器学习、无服务器等领域的研究和实践。译有《机器学习即服务》《基于 Kubernetes 的 DevOps 实践》《Prometheus 监控实战》等。
文章来源:
https://dev.amazoncloud.cn/column/article/62b52536c79fe7390efff055?sc_channel=CSDN
相关文章:
ClickHouse 与 Amazon S3 结合?一起来探索其中奥秘
目录ClickHouse 简介ClickHouse 与对象存储ClickHouse 与 S3 结合的三种方法示例参考架构小结参考资料ClickHouse 简介ClickHouse 是一种快速的、开源的、用于联机分析(OLAP)的列式数据库管理系统(DBMS),由俄罗斯的Yan…...
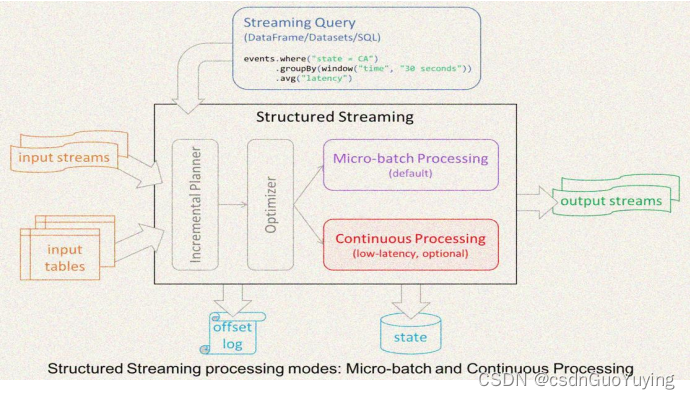
【Spark分布式内存计算框架——Structured Streaming】1. Structured Streaming 概述
前言 Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。 Structured Streaming并不是对Spark Streaming的简单改进…...
【Windows】【Linux】---- Java证书导入
问题: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target 无法找到请求目标的有效证书路径 一、Windows—java证书导入 1、下载证书到本地(以下…...

【Linux学习】菜鸟入门——gcc与g++简要使用
一、gcc/g gcc/g是编译器,gcc是GCC(GUN Compiler Collection,GUN编译器集合)中的C编译器;g是GCC中的C编译器。使用g编译文件时会自动链接STL标准库,而gcc不会自动链接STL标准库。下面简单介绍一下Linux环境下(Windows差…...

Cadence Allegro 导出Bill of Material Report详解
⏪《上一篇》 🏡《总目录》 ⏩《下一篇》 目录 1,概述2,Assigned Functions Report作用3,Assigned Functions Report示例4,Assigned Functions Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
localStorage线上问题的思考
一、背景: localStorage作为HTML5 Web Storage的API之一,使用标准的键值对(Key-Value,简称KV)数据类型主要作用是本地存储。本地存储是指将数据按照键值对的方式保存在客户端计算机中,直到用户或者脚本主动清除数据&a…...

什么是DNS域名解析
什么是DNS域名解析?因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,得到该主机名对应的IP地址的过程叫做域名解析。正向解析:…...

Cadence Allegro 导出Assigned Functions Report详解
⏪《上一篇》 🏡《总目录》 ⏩《下一篇》 目录 1,概述2,Assigned Functions Report作用3,Assigned Functions Report示例4,Assigned Functions Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...

Python中Opencv和PIL.Image读取图片的差异对比
近日,在进行深度学习进行推理的时候,发现不管怎么样都得不出正确的结果,再仔细和正确的代码进行对比了后发现原来是Python中不同的库读取的图片数组是有差异的。 image np.array(Image.open(image_file).convert(RGB)) image cv2.imread(…...
win10 WSL2 使用Ubuntu配置与安装教程
Win10 22H2ubuntu 22.04ROS2 文章目录一、什么是WSL2二、Win10 系统配置2.1 更新Windows版本2.2 Win10系统启用两个功能2.3 Win10开启BIOS/CPU开启虚拟化(VT)(很关键)2.4 下载并安装wsl_update_x64.msi2.5 PowerShell安装组件三、PowerShell安装Ubuntu3.…...
)
LeetCode每日一题(28. Find the Index of the First Occurrence in a String)
Given two strings needle and haystack, return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack. Example 1: Input: haystack “sadbutsad”, needle “sad” Output: 0 Explanation: “sad” occurs at index 0 and…...
Android 圆弧形 SeekBar
效果预览package com.gcssloop.widget;import android.annotation.SuppressLint;import android.content.Context;import android.content.res.TypedArray;import android.graphics.Canvas;import android.graphics.Color;import android.graphics.Matrix;import android.graph…...
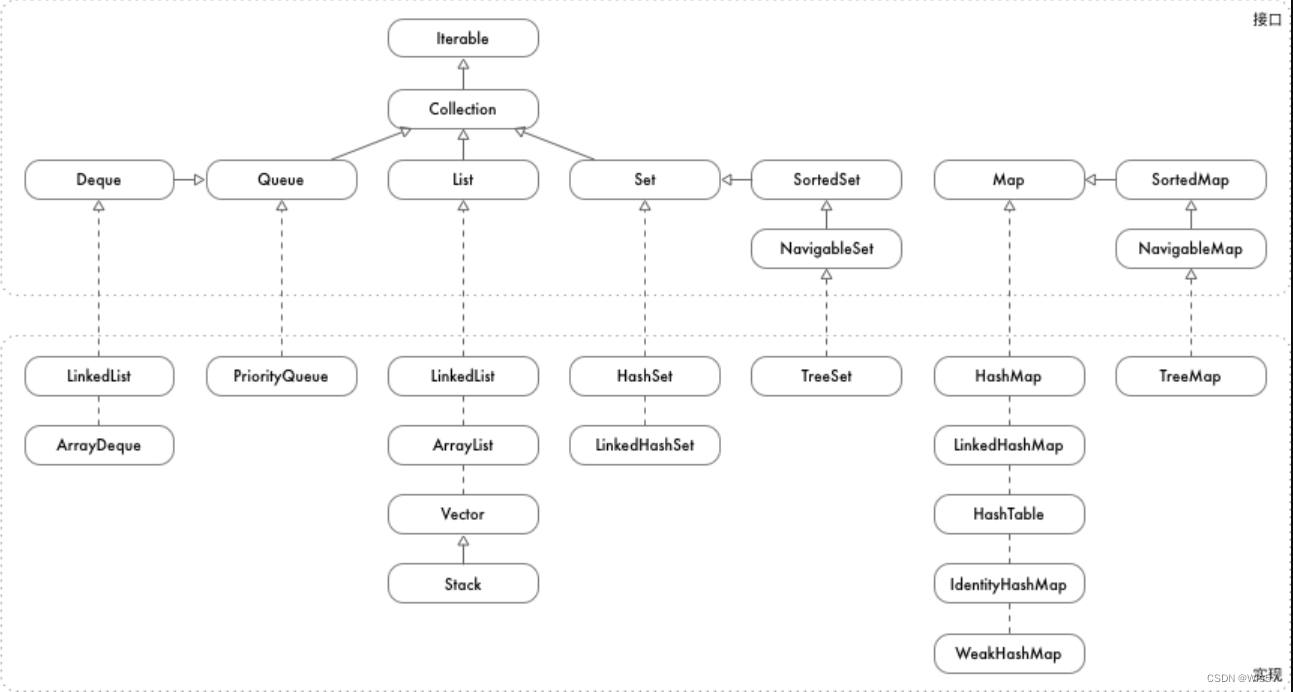
java 字典
java 字典 数据结构总览 Map Map 描述的是一种映射关系,一个 key 对应一个 value,可以添加,删除,修改和获取 key/value,util 提供了多种 Map HashMap: hash 表实现的 map,插入删除查找性能都是 O(1)&…...
【企业服务器LNMP环境搭建】mysql安装
MySQL安装步骤: 1、相关说明 1.1、编译参数的说明 -DCMAKE_INSTALL_PREFIX安装到的软件目录-DMYSQL_DATADIR数据文件存储的路径-DSYSCONFDIR配置文件路径 (my.cnf)-DENABLED_LOCAL_INFILE1使用localmysql客户端的配置-DWITH_PARTITION_STORAGE_ENGINE使mysql支持…...
vue自定义指令以及angular自定义指令(以禁止输入空格为例)
哈喽,小伙伴们,大家好啊,最近要实现一个vue自定义指令,就是让input输入框禁止输入空格建立一个directives的指令文件,里面专门用来建立各个指令的官方文档:自定义指令 | Vue.js (vuejs.org)我们都知道vue中…...

异常 复习
异常复习 异常(广义):泛指程序中一切不正常的情况 错误:例如内存不够用,程序是无法解决的 异常(狭义):程序在运行中出现问题,但是可以通过异常处理机制处理,程序可以继续向后执行 异常体系 Throwable类有两个直接子类:Excepti…...
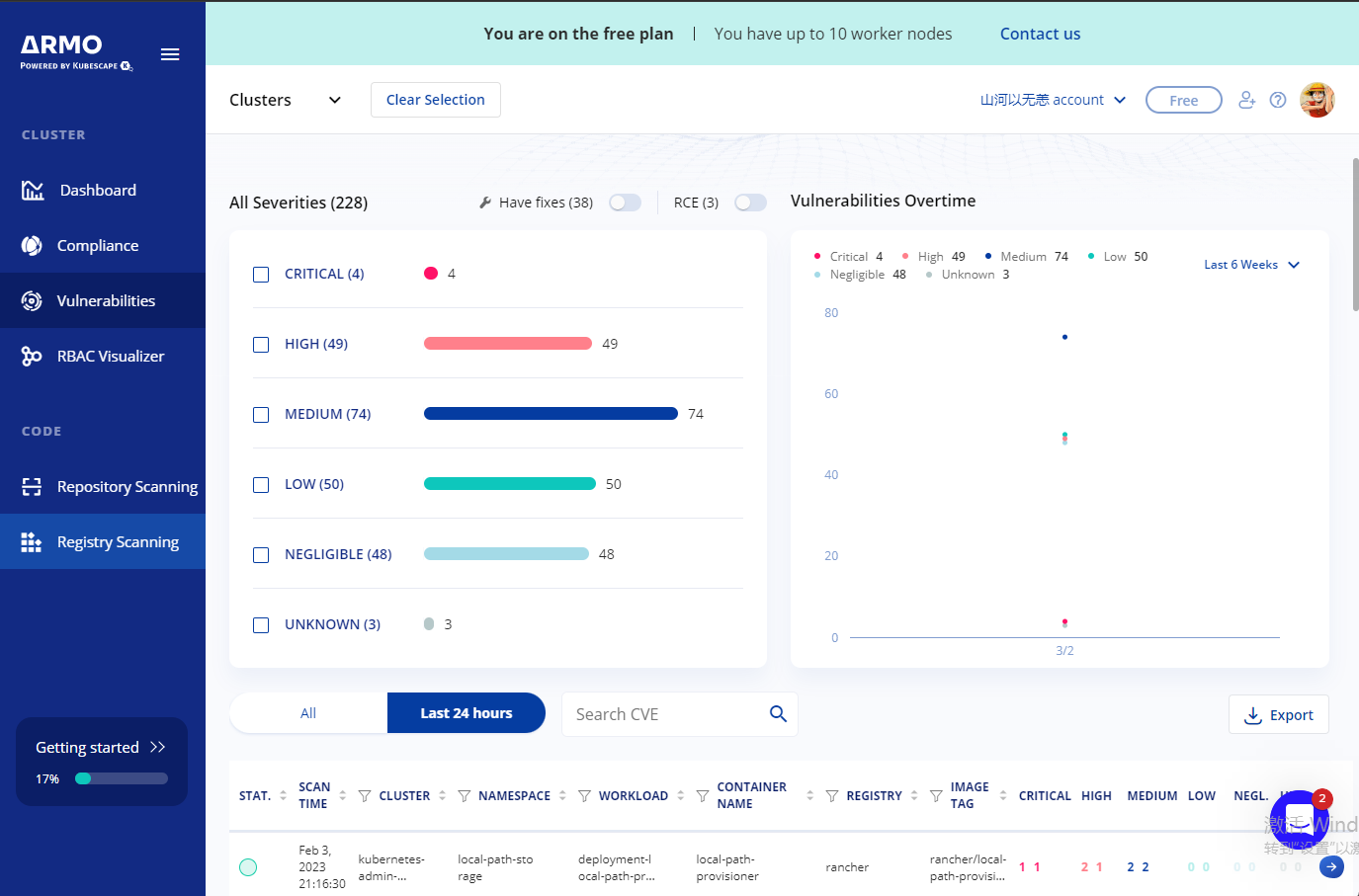
K8s:开源安全平台 kubescape 实现 Pod 的安全合规检查/镜像漏洞扫描
写在前面 生产环境中的 k8s 集群安全不可忽略,即使是内网环境容器化的应用部署虽然本质上没有变化,始终是机器上的一个进程但是提高了安全问题的处理的复杂性分享一个开源的 k8s 集群安全合规检查/漏洞扫描 工具 kubescape博文内容涉及: kube…...

C#中,FTP同步或异步读取大量文件
一次快速读取上万个文件中的内容 在C#中,可以使用FTP客户端类(如FtpWebRequest)来连接FTP服务器并进行文件操作。一次快速读取上万个文件中的内容,可以采用多线程的方式并发读取文件。 以下是一个示例代码,用于读取FT…...
STM32单片机的FLASH和RAM
STM32内置有Flash和RAM(而RAM分为SRAM和DRAM,STM32内为SRAM),硬件上他们是不同的设备存储器、属于两个器件,但这两个存储器的寄存器输入输出端口被组织在同一个虚拟线性地址空间内。 MDK预处理、编译、汇编、链接后编…...

Java 二叉树的遍历
二叉树的遍历(traversing binary tree)是指从根结点出发,按照某种次序依次访问二叉树中所有的结点,使得每个结点被访问依次且仅被访问一次。前序遍历(根 左 右)先访问根结点,然后前序遍历左子树…...

Phi-4-mini-reasoning推理质量评估:GSM8K/MATH数据集本地测试方法
Phi-4-mini-reasoning推理质量评估:GSM8K/MATH数据集本地测试方法 1. 模型简介 Phi-4-mini-reasoning是一个轻量级开源模型,专注于高质量数学推理任务。作为Phi-4模型家族的一员,它通过合成数据训练和微调,特别擅长解决需要密集…...

Next.js API路由的正确使用姿势
在使用Next.js开发应用时,API路由的配置和使用是非常重要的一部分。尤其是当我们从客户端组件中请求API时,如果不正确配置,可能会遇到一些常见的错误,比如404错误。本文将通过实例详细解释如何在Next.js中正确配置和使用API路由。 问题背景 假设你正在使用Next.js 14.2.3…...

MIT-BEVFusion LiDAR Encoder 保姆级拆解:从点云到BEV特征图,手把手带你过一遍代码
MIT-BEVFusion LiDAR Encoder 深度解析:从点云到BEV特征图的完整实现路径 当自动驾驶系统需要理解周围环境时,LiDAR点云数据的高效处理成为关键挑战。MIT-BEVFusion框架中的LiDAR编码器模块,通过创新的稀疏卷积架构,将无序的三维点…...
通义千问Qwen2-VL模型部署避坑指南:如何用transformers库绕过Flash-Attention2安装
通义千问Qwen2-VL模型轻量化部署实战:避开Flash-Attention2的安装陷阱 最近在测试通义千问的多模态模型Qwen2-VL时,发现官方推荐的Flash-Attention2依赖项安装过程异常繁琐,不仅编译耗时数小时,还经常因环境配置问题报错。经过多次…...

OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块
OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块 1. 为什么需要自定义OpenClaw技能 去年夏天,我接手了一个重复性极高的周报生成工作。每周都要从十几个PDF报告中提取关键数据,整理成固定格式的Excel表格,再转成PPT汇报。当…...

OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块
OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块 1. 为什么需要专用技能模块? 上周我在整理技术文档时遇到一个典型场景:需要将十几份混杂着截图和文字说明的会议纪要,自动转换成结构化的Markdown文件。当…...

FastAPI + TinyDB并发陷阱与实战:告别数据错乱的解决方案
核心摘要本文针对在FastAPI框架下使用TinyDB(JSON文件数据库)时遇到的并发写入数据冲突、错乱问题,深入浅出地解释了问题根源,并提供了从“文件锁”到“内存队列”再到“乐观锁”的三种由浅入深的实战解决方案,帮助你根…...

大疆诉影石创新专利侵权,FTO综合分析筑牢研发风控屏障
3月23日,全球无人机巨头大疆对同行影石创新提起专利权属纠纷诉讼,涉案6项专利聚焦无人机飞行控制、结构设计、影像处理等核心技术领域,这场行业龙头间的知识产权纠纷,成为近日行业关注焦点。职务发明权属成为争议关键本次纠纷由大…...

OpenClaw多模态聊天机器人:Qwen2.5-VL-7B实现图片问答与表情包生成
OpenClaw多模态聊天机器人:Qwen2.5-VL-7B实现图片问答与表情包生成 1. 为什么选择OpenClaw构建多模态聊天机器人 去年我在运营一个技术社群时,经常遇到群成员发截图提问的场景。传统聊天机器人要么只能处理文字,要么需要将图片上传到第三方…...

IP-Adapter-FaceID在社交媒体中的应用:内容创作与分享
IP-Adapter-FaceID在社交媒体中的应用:内容创作与分享 【免费下载链接】IP-Adapter-FaceID 项目地址: https://ai.gitcode.com/hf_mirrors/h94/IP-Adapter-FaceID IP-Adapter-FaceID是一款基于Stable Diffusion的AI人脸生成工具,它通过面部识别模…...