大数据技术原理与应用期末复习(林子雨)
大数据技术原理与应用期末复习(林子雨)
- Hadoop的特性
- HBase编程实践
- NoSQL的四大类型
- 键值数据库
- 优点:
- 缺点:
- 列族数据库
- 优点:
- 缺点:
- 文档数据库
- 优点:
- 缺点:
- 图数据库
- 优点:
- 缺点:
- NoSQL的三大基石
- CAP:
- BASE
- BASE的基本含义
- 最终一致性
- MapReduce的各个执行阶段
- 关系的自然连接运算
- Hadoop的局限性与不足
- Hadoop的改进与提升
- Hadoop1.0和Hadoop2.0比较
- 不断完善的Hadoop生态系统
- Spark生态系统
- Spark的应用场景
- 流计算
- 对于一个流计算来说,需要达到哪些需求
- Flink的优势
Hadoop的特性
1.高可靠性:
采用冗余数据存储方式,即一个副本发生故障,其他副本可保证正常对外提供服务
2.高效性:
hadoop采用分布式存储和分布式处理,能够高效的处理PB级数据
3.高可扩展性:
可以高效稳定地运行在廉价的计算机集群上,可扩展到数以千计的计算机节点上
4.高容错性:
自动保存数据的多个副本,能将失败的任务重新分配
5.低成本:
采用廉价的计算机集群,成本低
6.运行在linux平台上
HBase编程实践
1.create:创建表
(1)create ‘t1’, {name => ‘f1’, versions => 5}
创建一个t1的表,列族为f1,列族版本号为5
(2)create ‘t1’, {name => ‘f1’},{name=>‘f2’},{name=>‘f3’}
创建t1,列族为f1,f2,f3
或者可以这样写:
create ‘t1’,‘f1’,‘f2’,‘f3’
(3)创建表t1,将表依据分割算法HexStringSplit分布在15个Region里:
create ‘t1’,‘f1’,{unmregions => 15,splitalgo => ‘HexStringSplit’}
(4)创建表,指定切分点:
create ‘t1’,‘f1’,{splits =>[‘10’,‘20’,‘30’,‘40’]}
2.向表t1中行row1和列f1:c1所对应的单元格添加数据value1,时间戳为123455:
put ‘t1’, ‘row1’,‘f1:c1’,‘value1’,123455
3.获得表r1行,c1列,时间范围为[ts1,ts2],版本号为4:
get ‘t1’,‘r1’,{columns => ‘c1’,timerange => [ts1,ts2],versions => 4}
4.流览表信息
(1)流览表“.META.”、列info:regioninfo的数据:
scan ‘.META.’ ,{columns => ‘info:regioninfo’}
(2)流览表 c1列,时间范围是[1234,4321]的数据:
scan ‘t1’ ,{columns => ‘c1’,timerange=>[1234,4321]}
5.修改表的列族模式
(1)向表t1添加列族f1:
alter ‘t1’,name => ‘f1’
(2)删除t1中的f1列:
alter ‘t1’ , name=>‘f1’,method=>‘delete’
(3)设定表t1中列族f1最大为128MB:
alter ‘t1’ ,method=>‘table_att’,max_filessize => ‘134217728’
6.统计表行数:
count ‘t1’
7.显示表的相关信息:
describe ‘t1’
8.使表有效、无效:
enable ‘t1’
disable ‘t1’
9.删除指定表格的数据:
删除表t1、行r1、列c1、时间戳ts1的数据:
delete ‘t1’,‘r1’,‘c1’,ts1
10.删除表:
drop ‘t1’
NoSQL的四大类型
键值数据库
使用一个哈希表
优点:
扩展性好、灵活性好、大量写操作时性能高
缺点:
条件查询效率低,无法存储结构化信息
列族数据库
数据库由多行构成,每行数据库包含多个列族
优点:
查询速度快、可扩展性好、易进行分布式扩展、复杂性低
缺点:
功能较少、不支持强事务一致性
文档数据库
文档是文档数据库的最小单位
优点:
性能好、灵活性高、复杂性低、数据结构灵活
缺点:
缺乏统一的查询语法
图数据库
优点:
灵活性高、支持复杂的图算法、可用于构建复杂的关系图谱
缺点:
复杂性高,只能支持一定的数据规模
NoSQL的三大基石
CAP:
C:一致性(Consistency),任何一个读操作总是能读到之前完成的写操作的结果,多点数据是一致的
A:可用性(Availability),指快速获取数据,在确定时间内返回操作结果
P:分区容忍性,指一部分节点不能与其他节点通信时,分离的系统也能正常运行
注意:三者只能满足其二
BASE
一个数据库事务具有ACID四个性质
A(Atomicity):原子性,事务必须是原子工作单元,对于数据修改,要么全执行,要么全不执行
C(Consistency):一致性,事务在完成时,必须所有的数据状态保持一致
I(Isolation):隔离性,并发事务所做的修改必须与任何其他并发事务所做的修改隔离
D(Durability):持久性,事务完成之后对系统的影响是永久的
BASE的基本含义
1.基本可用性:
一部分发生问题不可用时,其他部分还可继续正常使用
2.软状态:
指状态可以有一段时间不同步,具有一定滞后性
3.最终一致性
数据保持一致(最新)
最终一致性
从服务端来看:
更新如何复制分布到整个系统,以保持数据最终一致性
从客户端来看:
在高并发的数据访问下,后续操作能否获取最新数据
MapReduce的各个执行阶段
1.MapReduce框架使用InputFormat模块做Map前的处理,验证是否符合输入定义,将文件分为多个InputSplit,InputSplit是MapReduce对文件中信息进行处理和运算的输入单位,并没有对文件进行实际切分,只是记录了数据的位置和长度,是逻辑切分
2.因为是逻辑切分不是物理切分,所以还需要通过RecordReader根据InputSplit中的信息来处理具体记录,加载数据并将其转换为适合Map任务读取的键值对,输入给Map
3.Map任务根据用户自定义的映射规则,输出一系列<key,value>作为中间结果
4.对map输出进行一定的分区、排序、合并、归并、等,得到<key,value-list>形式的中间结果,交给reduce处理,这个过程称为shuffle
5.reduce以<key,value-list>作为输入,执行用户定义的逻辑,输出结果交给OutputFormat模块
6.OutputFormat模块验证输出目录是否存在,以及文件类型,都满足就输出到分布式文件系统
关系的自然连接运算
可以使用Map过程把来自R的每个元组<a,b>装换成<b,<R,a>>,其中键就是b,值就是<R,a>
例如:

Hadoop的局限性与不足
1.抽象层次低。功能实现需要手工编写代码来完成,一个简单的功能需要写大量的代码
2.表达能力有限。MapReduce把复杂分布式编程工作高度抽象为Map和Reduce两个函数,降低了开发人员开发复杂度,也带来了表达能力有限的问题,实际生产环境中一些是无法用简单的Map和Reduce来完成的
3.开发者需要自己管理作业之间的依赖关系。一个作业只包含Map和Reduce两个阶段,通常的实际应用问题需要大量的作业进行协作才能完成,存在复杂的依赖关系,MapReduce并没有提供依赖关系的管理机制
4.难以看到程序的整体逻辑。没有更高层次的抽象机制对程序整体逻辑进行设计
5.执行迭代操作效率低。每次迭代都要执行Map、Reduce任务,这个过程的数据来自HDFS,每次数据又存到HDFS,反复的读写降低了迭代操作的效率
6.资源浪费。Reduce任务需要等到Map执行完才能开始,这样让费资源
7.实时性差。只适用于离线批处理数据,无法支持交互式数据、实时数据处理
Hadoop的改进与提升
Hadoop1.0和Hadoop2.0比较
| 组件 | Hdoop1.0的问题 | Hadoop2.0的改进 |
|---|---|---|
| HDFS | 单一名称节点,存在单点失效问题 | 设计了HDFS HA,有名称节点热备份机制 |
| HDFS | 单一命名空间,无法实现资源隔离 | 设计了HDFS联邦,管理多个命名空间 |
| Mapreduce | 资源管理效率低 | 新的资源管理框架YARN |
不断完善的Hadoop生态系统
| 组件 | 功能 | 解决Hadoop中存在的问题 |
|---|---|---|
| Pig | 处理大规模数据的脚本语言,用户只需写几条简单的语句,系统会自动转换为MapReduce作业 | 解决了抽象层次低,需手工写大量代码问题 |
| Oozie | 工作流和协作服务引擎,协调Hadoop上运行的不同任务 | 解决了无依赖管理机制 |
| Tez | 支持DAG作业,对作业操作进行重新分解和组合,形成一个大的DAG作业,减少不必要的操作 | 提高了效率 |
| Kafka | 分布式发布订阅消息系统,不同类型的分布式系统可以接入Kafka,实现hadoop各个组件之间的不同类型数据的实时高效交换 | 解决了hadoop各组件间没有数据交换中介这个问题 |
Spark生态系统
spark专注于数据的处理分析,数据存储还是要借助于Hadoop分布式文件系统HDFS
1.Spark Core
包含了spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等,主要面向批量数据处理,spark建立在RDD(统一的抽象弹性分布式数据集)之上,使其可以以一致的方式应对不同的大数据处理场景
2.Spark SQL
允许开发人员直接处理RDD,同时可查询Hive、HBase等外部资源,能统一处理关系表和RDD,使得开发人员不需要自己编写Spark应用程序,可使用SQL语句查询
3.Spark Streaming
支持高吞吐量、可容错处理的实时数据流处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短作业都可以使用Spark Core进行快速处理,支持多种数据流,如Kafka、Flume、TCP套接字等
4.Structured Streaming
基于Spark SQL引擎构建的、可扩展且容错的流处理引擎,可编写流处理程序,简化了使用者的难度
5.MLlib(机器学习)
提供了常用的机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛
6.GraphX(图计算)
是Spark常用于图计算的API,可认为是Pregel在Spark上的重写及优化了,有丰富的功能和运算符,可用在海量数据上
Spark的应用场景
| 应用场景 | 时间跨度 | 其他框架 | Spark生态中的组件 |
|---|---|---|---|
| 复杂的批量数据处理 | 小时级 | MapReduce、Hive | Spark Core |
| 基于历史数据的交互式查询 | 分钟级、秒级 | Impala、Dremel、Drill | Spark SQL |
| 基于实时数据流的数据处理 | 毫秒级、秒级 | Storm 、S4 | Spark Streaming、Structured Streaming |
| 基于历史数据的数据挖掘 | – | Mahout | MLlib |
| 图结构数据的处理 | – | Pregel、Hama | GraphX |
流计算
对于一个流计算来说,需要达到哪些需求
1.高性能
每秒处理几十万条
2.海量式
支持TB级别,甚至是PB级别的数据规模
3.实时性
必须保证一个较低的时延,达到秒级别,甚至是毫秒级别
4.分布式
支持大数据的基本架构,必须能够平滑扩展
5.易用性
能够快速进行开发和部署
6.可靠性
能可靠地处理流数据
Flink的优势
1.同时支持高吞吐、高延迟、高性能
2.同时支持流处理和批处理
对于Flink而言,批量数据是流数据的一个子集,批处理被视作一种特殊的流处理,因此可用同一套引擎来处理流数据和批量数据
3.高度灵活的流式窗口
窗口是若干元素的集合,窗口可以是时间驱动的,也可以是数据驱动的,窗口可以分为翻滚窗口、滚动窗口、会话窗口
4.支持有状态计算
5.具有良好的容错性
6.具有独立的内存管理
7.支持迭代和增量迭代
对于某些迭代而言,并不是单次迭代产生的下一次工作集中的每个元素都需要重新参与下一轮迭代,有时只需要重新计算部分数据同时选择性地更新解集,这种称为增量迭代
相关文章:
大数据技术原理与应用期末复习(林子雨)
大数据技术原理与应用期末复习(林子雨) Hadoop的特性HBase编程实践NoSQL的四大类型键值数据库优点:缺点: 列族数据库优点:缺点: 文档数据库优点:缺点: 图数据库优点:缺点…...

C练习——魔术师猜三位数
题目: 有一种室内互动游戏,魔术师要每位观众心里想一个三位数abc(a、b、c分别是百位、十位和个位数字),然后魔术师让观众心中记下acb、bac、bca、cab、cba五个数以及这5个数的和值。只要观众说出这个和是多少…...

three.js 使用 tweenjs绘制相机运动动画
效果: 代码: <template><div><el-container><el-main><div class"box-card-left"><div id"threejs" style"border: 1px solid red"></div><div class"box-right"…...

Oracle VARCHAR和VARCHAR2区别
在Oracle数据库中,VARCHAR和VARCHAR2是两种不同的数据类型,它们的区别如下: 1.存储空间 VARCHAR和VARCHAR2在存储空间上有所不同。在Oracle 7及以下版本中,VARCHAR类型的长度是固定的,如果存储的数据长度小于定义的长…...

HarmonyOS 开发基础(八)Row和Column
HarmonyOS 开发基础(八)Row和Column 一、Column 容器 1、容器说明: 纵向容器主轴方向:从上到下纵向交叉轴方向:从左到右横向 2、容器属性: justifyContent:设置子元素在主轴方向的对齐格式…...

Visual Studio中项目添加链接文件
这个需求在VS里面使用还真不多见,只是最近在做项目的版本编号的时候遇到一个头大的问题,我一个解决方案下面有几十个类库,再发布的时候这几十个类库的版本号必须要统一,之前我们都是在单个的AssemblyInfo.cs里面去改相关的信息&am…...
做一个个人博客第一步该怎么做?
做一个个人博客第一步该怎么做? 好多零基础的同学们不知道怎么迈出第一步。 那么,就找一个现成的模板学一学呗,毕竟我们是高贵的Ctrl c v 工程师。 但是这样也有个问题,那就是,那些模板都,太!…...
vue前端开发自学练习,Props数据传递-类型校验,默认值的设置!
vue前端开发自学练习,Props数据传递-类型校验,默认值的设置! 实际上,vue开发框架的时候,充分考虑到了前端开发人员可能会遇到的各种各样的情况,比如大家经常遇到的,数据类型的校验,再比如,默认…...

Fooocus 使用笔记
目录 换装,换脸,修复畸形 比较和使用教程: 安装教程: github地址: 换装,换脸,修复畸形 🔥迄今最全!Fooocus AI绘图 详细教程 AI换装 AI换脸 AI修复畸形 - 西瓜视频 …...

18. 从零用Rust编写正反向代理, 主动式健康检查源码实现
wmproxy wmproxy是由Rust编写,已实现http/https代理,socks5代理, 反向代理,静态文件服务器,内网穿透,配置热更新等, 后续将实现websocket代理等,同时会将实现过程分享出来ÿ…...
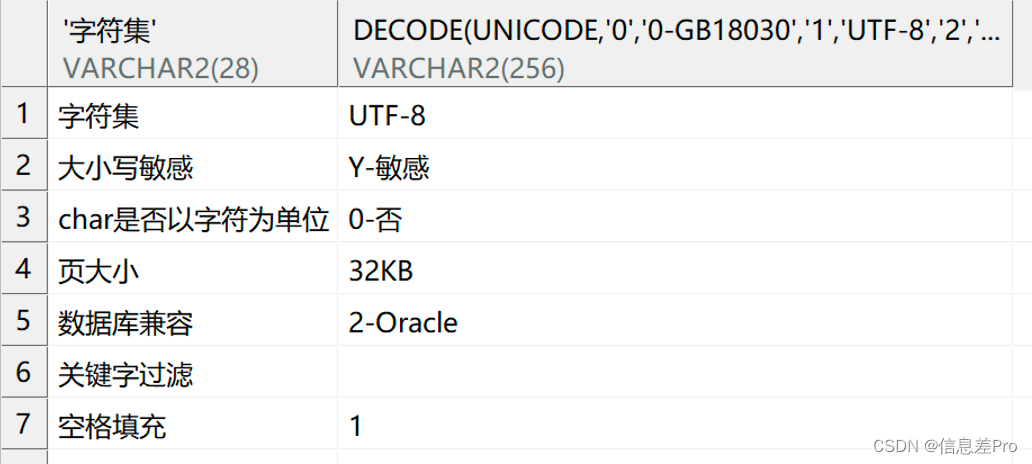
[DM8] 达梦8配置兼容Oracle
查看版本信息 select *,id_code from v$version; 查询解释: DM Database Server 64 V8 1-1-190-21.03.12-136419-ENT 64 版本位数标识,64表示为64位版本,无64则表示为32位版本 V8 大版本号,目前主要是V7、V8 1-1-190…...

【Pytorch简介】1.Introduction 简介
Introduction 简介 大多数机器学习工作流涉及处理数据、创建模型、使用超参数优化模型,以及保存,然后推理已训练的模型。 本模块介绍在 PyTorch(一种常用的 Python ML 框架)中实现的完整机器学习 (ML) 工作流。 我们使用 Fashio…...

什么是Session以及如何在 NestJS 项目中的优雅管理 Session
前言 Web开发中一个常见的问题是用户身份的管理和状态保持。Session 就是处理这个问题的一个传统技术。在这篇文章中,我们将探讨Session是什么,为什么我们需要Session,以及在NestJS项目中如何优雅地管理Session。 什么是Session 众所周知&…...
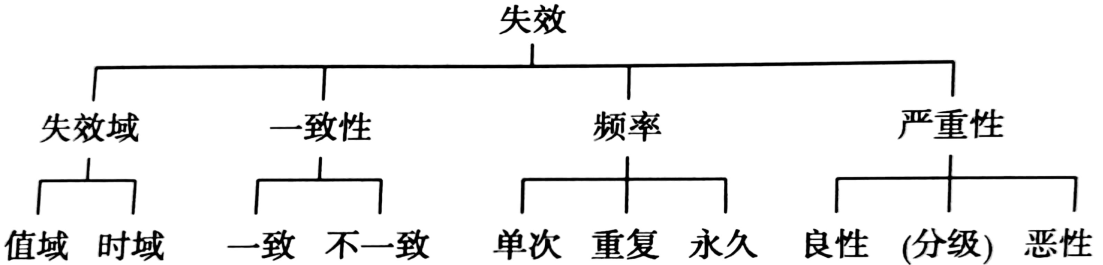
高级分布式系统-第6讲 分布式系统的容错性--故障/错误/失效/异常
分布式系统容错性的概念 分布式系统的容错性: 当发生故障时, 分布式系统应当在进行恢复的同时继续以可接受的方式进行操作, 并且可以从部分失效中自动恢复, 且不会严重影响整体性能。 具体包括以下4个方面的内容: 可…...
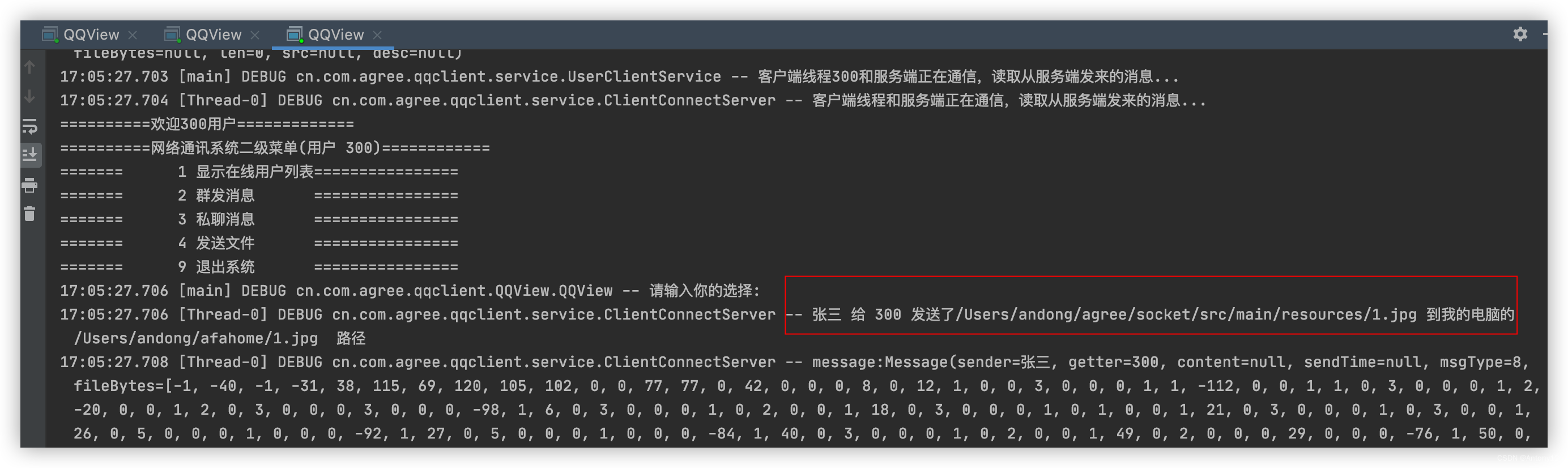
网络多线程开发小项目--QQ登陆聊天功能(服务端推送新闻、离线留言和文件)
9.1.5、QQ登陆聊天功能(服务端推送新闻、离线留言和文件) 9.1.5.1、服务端推送新闻 1、需求分析 2、思路分析 3、代码实现 QQServer: 1)cn.com.agree.qqserver.service.SendNewsToAllClient package cn.com.agree.qqserver.s…...

Jtti:有哪些方法可以提升Tomcat的性能?
提升 Tomcat 性能是确保 Web 应用程序快速响应并能够处理高并发请求的关键任务。以下是一些提升 Tomcat 性能的常见方法: 1. 调整JVM参数: a. 内存分配: 增加 JVM 的堆内存(Heap Memory)以提高应用程序的内存容量。使用 -Xmx 和 -Xms 参数设置…...

LeetCode 2085. 统计出现过一次的公共字符串
目录 一、题目 1、题目描述 2、接口描述 3、原题链接 二、解题报告 1、思路分析 2、复杂度 3、代码详解 C代码 Python3代码 一、题目 1、题目描述 给你两个字符串数组 words1 和 words2 ,请你返回在两个字符串数组中 都恰好出现一次 的字符串的数目。 2…...

130基于MATLAB并结合IBD算法的盲迭代反卷积法进行图像复原
基于MATLAB并结合IBD算法的盲迭代反卷积法进行图像复原 ,输出复原前后图像,PSF频谱结果。程序已调通,可直接运行。 130 matlab盲迭代反卷积IBD (xiaohongshu.com)...

Flying HTML生成PDF添加水印
HTML转PDF并添加水印 <!-- 用于生成PDF --> <dependency><groupId>org.xhtmlrenderer</groupId><artifactId>flying-saucer-pdf</artifactId><version>9.1.20</version> </dependency>import java.io.File; import jav…...
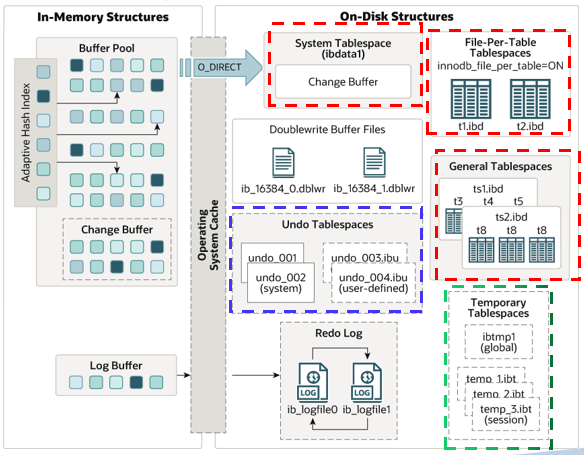
MySQL 8.0 InnoDB Tablespaces之Temporary Tablespaces(临时表空间)
文章目录 MySQL 8.0 InnoDB Tablespaces之Temporary Tablespaces(临时表空间)会话临时表空间会话临时表空间的磁盘分配和回收会话临时表空间的创建创建临时表和查看临时表信息会话临时表空间相关的设置参数innodb_temp_tablespaces_dir 全局临时表空间查…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...
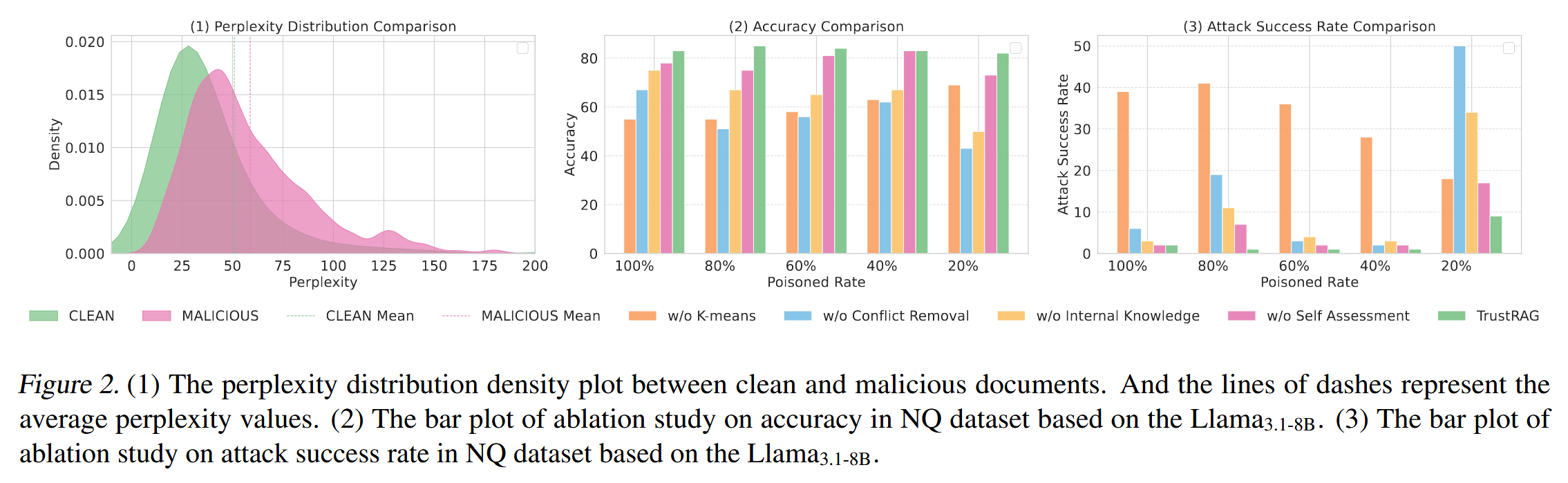
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...
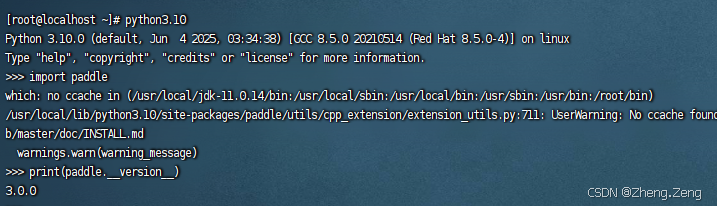
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...

java+webstock
maven依赖 <dependency><groupId>org.java-websocket</groupId><artifactId>Java-WebSocket</artifactId><version>1.3.5</version></dependency><dependency><groupId>org.apache.tomcat.websocket</groupId&…...