数据挖掘实战-基于机器学习的电商文本分类模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验步骤
4.1数据探索
4.2数据预处理
4.3文本归一化
4.4特征工程
4.5训练模型
1.项目背景
随着电子商务的蓬勃发展,电商平台上产生了海量的文本数据,包括商品描述、用户评价、客服对话等。这些文本数据包含了丰富的信息,对于电商企业而言,能够充分挖掘这些信息将有助于提升用户体验、优化产品推荐、改进客户服务等方面。然而,由于文本数据的复杂性和庞大数量,传统的人工处理方式已经难以满足需求,因此利用机器学习技术对电商文本进行自动分类成为一项具有重要意义的研究任务。
电商文本分类模型的研究对于实现自动化、智能化的电商运营管理具有重要意义。通过将文本数据划分到不同的类别,可以实现对商品的自动分类、用户评价的情感分析、客户问题的自动解答等应用,为电商企业提供更高效、精准的运营决策支持。
在实际应用中,电商文本数据的特点包括语言风格多样、信息噪声较大、时效性强等,传统的基于规则的文本处理方法难以应对这些挑战。因此,利用机器学习技术,特别是深度学习方法,对电商文本进行自动分类成为一种更为有效的解决方案。通过构建和训练电商文本分类模型,可以更好地处理大规模、高维度的文本数据,从而提高分类的准确性和效率。
2.数据集介绍
数据集来源于Kaggle,原始数据集共有50425条,2个变量,变量解释如下:
label:文本的标签类型。
text:文本内容。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验步骤
4.1数据探索
## 导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
import spacy
nlp = spacy.load("en_core_web_lg")
# 加载数据
data = pd.read_csv('ecommerceDataset.csv',header=None)
data.columns =['label','text']
data.head()
统计缺失值
data.isnull().sum()
统计重复值
data.duplicated().sum()
数据描述性统计
data.describe()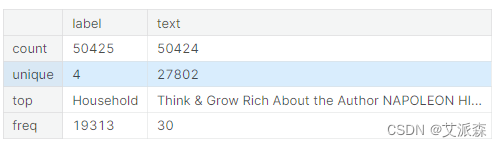
4.2数据预处理
# 删除缺失值
data.dropna(inplace=True)
# 删除重复值
data.drop_duplicates(inplace=True)## 标签在数据集中的分布
sns.countplot(x='label',data=data,palette='Blues')
plt.xlabel(' ')
plt.ylabel('Count')
plt.title('Target Distribution')
plt.show()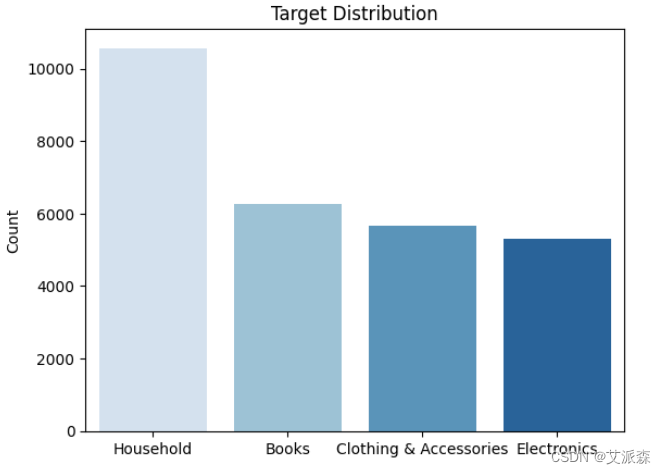
4.3文本归一化
文本归一化:它是为了在各种NLP任务中使用而对文本进行清理和预处理的过程。
过程包括几种技术,它们是:
- 情况下归一化
- 标点符号删除
- 停止词删除
- 阻止/词元化
- 标记
- 将缩写和同义词转换为其完整形式
每种技术都有其优点(降低维数,加快过程)和缺点(即信息丢失)。
## 删除标点符号
import stringdef remove_punct(text):punctuations =string.punctuationmytokens = ''.join(word for word in text if word not in punctuations)return mytokens## 删除停用词
from spacy.lang.en.stop_words import STOP_WORDSdef remove_stopwords(text):stop_words = spacy.lang.en.stop_words.STOP_WORDSmytokens = [word for word in text if word not in stop_words]return mytokens## 标记化+词形化
nlp.max_length = 19461259def tokenization(text):token = nlp(text)## lemma token = [word.lemma_ for word in token]## convert tokens into lower casetoken = [ word.lower() for word in token]return tokendef text_norm(text): punct_text = remove_punct(text) tokens = tokenization(punct_text) final_tokens = remove_stopwords(tokens)return final_tokens4.4特征工程
在NLP中,特征工程涉及将文本数据转换为数字特征,以便将它们提供给ML模型。
技术:
- N-grams[有助于捕获上下文并有助于提高对模型的文本理解]
- 词类
- 命名实体识别
- 词袋[计数矢量器]
- TF-IDF
- 高级模型的词嵌入
每个技术都是基于任务需求使用的
- 词性标注、NER、解析——用于了解语言的结构
- CV,TF-IDF——有一个很大的语料库,想把它们简化成更少的单词
- 单词嵌入——了解语言的语义
## CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
bow_vectorizer = CountVectorizer(tokenizer=text_norm,max_df=0.9,min_df=2,ngram_range=(1,1))## TF-IDF Vectorizer
from sklearn.feature_extraction.text import TfidfVectorizertf_idf = TfidfVectorizer(min_df=2,max_df=0.90,tokenizer=text_norm,ngram_range=(1,1))4.5训练模型
拆分数据集
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,ConfusionMatrixDisplay,confusion_matrix# train:test = 70:30
X = data['text']
y = data['label']X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=7)print("Count Vectorizer + Logistic Regression \n\n ")
## 使用Count Vectorizer创建管道
pipe_bow = Pipeline([('vectorizer', bow_vectorizer),('classifier', LogisticRegression())])## 拟合数据
pipe_bow.fit(X_train,y_train)
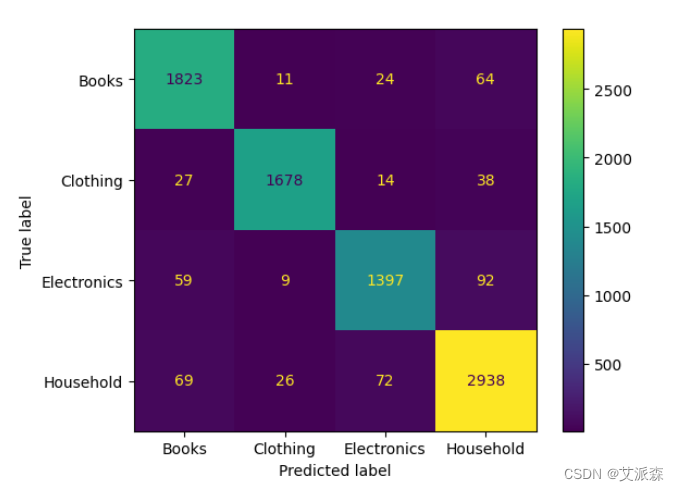
y_pred_bow = pipe_bow.predict(X_test)print(classification_report(y_test,y_pred_bow))
ConfusionMatrixDisplay(confusion_matrix(y_test,y_pred_bow),display_labels=['Books','Clothing','Electronics','Household']).plot()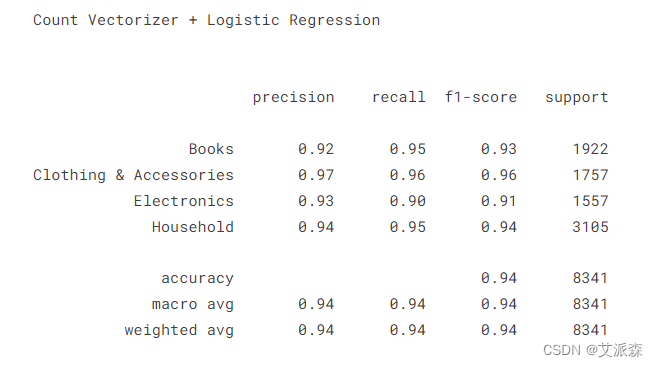
print("TF_IDF + Logistic Regression \n\n ")
## 使用TF-IDF创建一个管道
pipe_tf = Pipeline([('vectorizer', tf_idf),('classifier', LogisticRegression())])## 拟合数据
pipe_tf.fit(X_train,y_train)
y_pred_tf = pipe_tf.predict(X_test)print(classification_report(y_test,y_pred_tf))
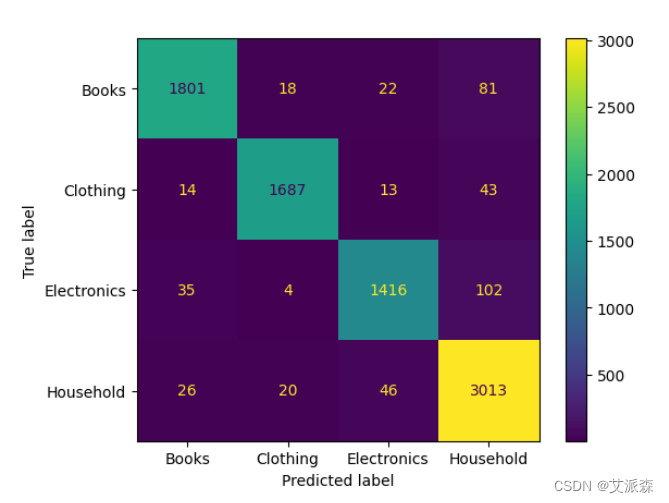
ConfusionMatrixDisplay(confusion_matrix(y_test,y_pred_tf),display_labels=['Books','Clothing','Electronics','Household']).plot()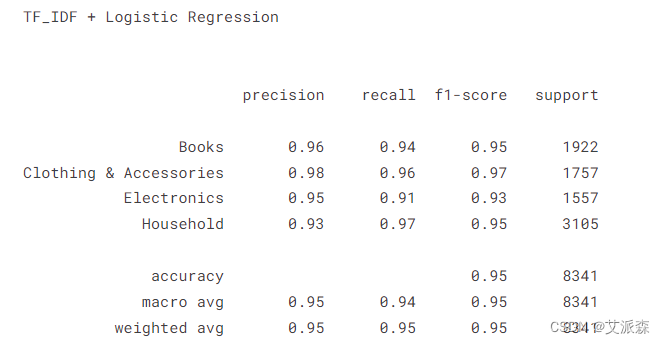
print("TF-IDF + SVM \n\n")
pipe_tf_svm = Pipeline([('vectorizer', tf_idf),('classifier', SVC())])# fit
pipe_tf_svm.fit(X_train,y_train)
y_pred_svm = pipe_tf_svm.predict(X_test)print(classification_report(y_test,y_pred_svm))
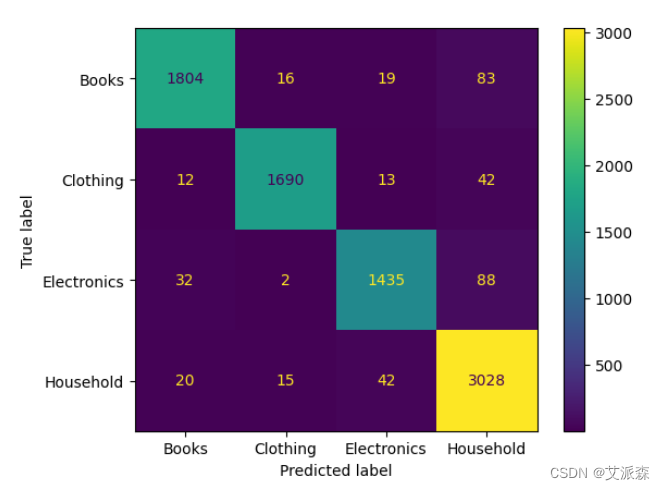
ConfusionMatrixDisplay(confusion_matrix(y_test,y_pred_svm),display_labels=['Books','Clothing','Electronics','Household']).plot()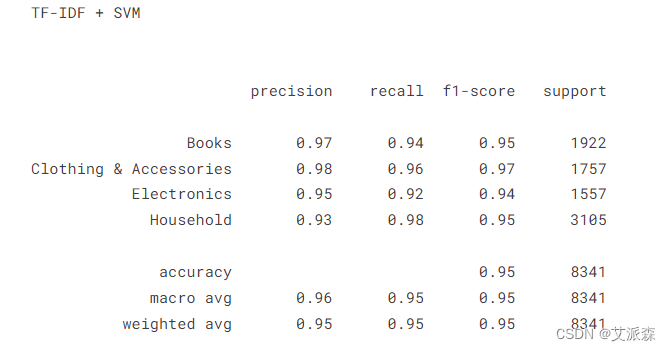
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
资料获取,更多粉丝福利,关注下方公众号获取

相关文章:
数据挖掘实战-基于机器学习的电商文本分类模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
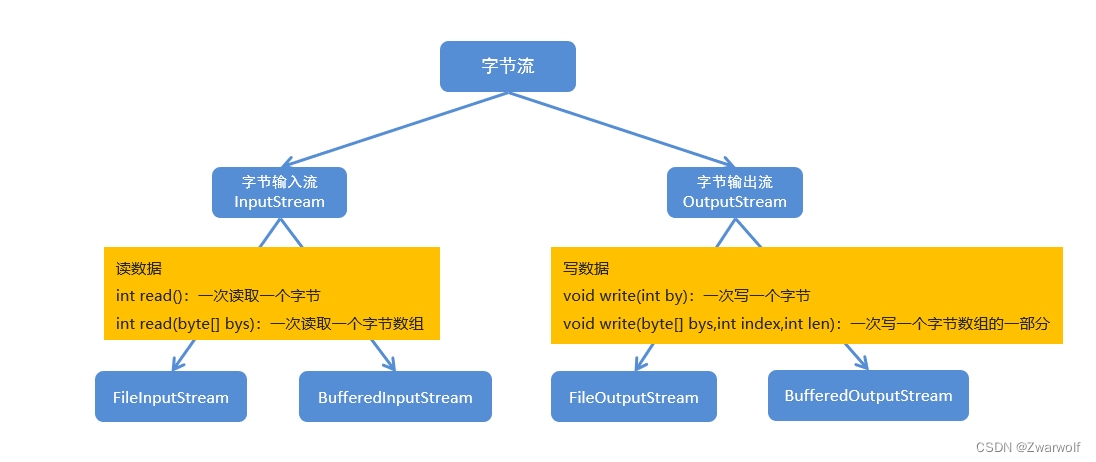
第8章-第4节-Java中字节流的缓冲流
1、缓冲流:属于高级IO流,并不能直接读写数据,需要依赖于基础流。缓冲流的目的是为了提高文件的读写效率?那么是如何提高文件的读写效率的呢? 在内存中设置一个缓冲区,缓冲区的默认大小是8192字节ÿ…...

NULL是什么?
NULL是一个编程术语,通常用于表示一个空值或无效值。在很多编程语言中,NULL用于表示一个变量或指针不引用任何有效的对象或内存位置。 NULL可以看作是一个特殊的值,表示缺少有效的数据或引用。当一个变量被赋予NULL值时,它表示该变…...

FreeRTOS 基础知识
这个基础知识也是非常重要的,那我们要学好 FreeRTOS,这些都是必不可少的。 那么就来看一下本节有哪些内容: 首先呢就是介绍一下什么是任务调度器。接着呢就是任务它拥有哪一些状态了。那这里的内容不多,但是呢都是非常重要的。 …...
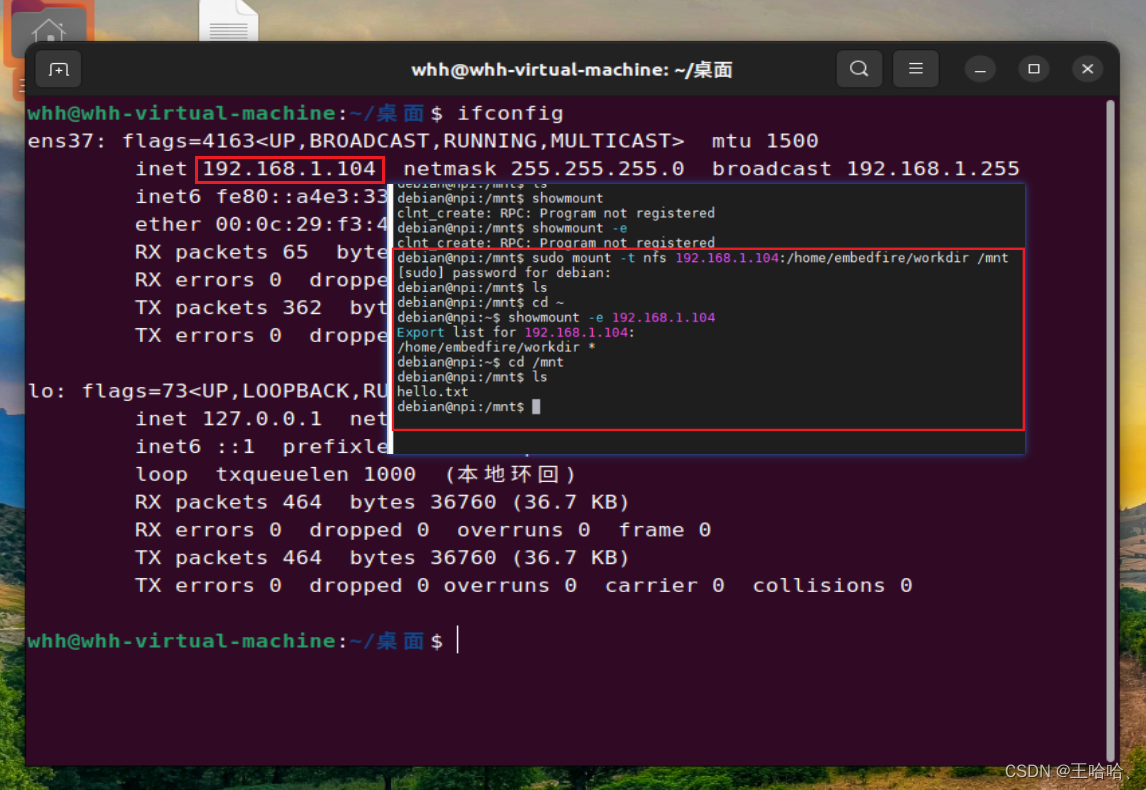
【野火i.MX6NULL开发板】挂载 NFS 网络文件系统
0、前言 参考资料: (误人子弟)《野火 Linux 基础与应用开发实战指南基于 i.MX6ULL 系列》PDF 第22章 参考视频:(成功) https://www.bilibili.com/video/BV1JK4y1t7io?p26&vd_sourcefb8dcae0aee3f1aab…...
方法或展开语法(...)来合并对象,Object.freeze()方法来冻结对象,防止对象被修改)
在JavaScript中,Object.assign()方法或展开语法(...)来合并对象,Object.freeze()方法来冻结对象,防止对象被修改
文章目录 一、Object.freeze()方法来冻结对象,防止对象被修改1、基本使用2、冻结数组2.1、浅冻结2.1、深冻结 3、应用场景4、Vue中使用Object.freeze 二、Object.assign()方法或展开语法(...)来合并对象1、Object.assign()1.1、语法1.2、参数…...
池化、线性、激活函数层
一、池化层 池化运算是深度学习中常用的一种操作,它可以对输入的特征图进行降采样,从而减少特征图的尺寸和参数数量。 池化运算的主要目的是通过“收集”和“总结”输入特征图的信息来提取出主要特征,并且减少对细节的敏感性。在池化运算中…...
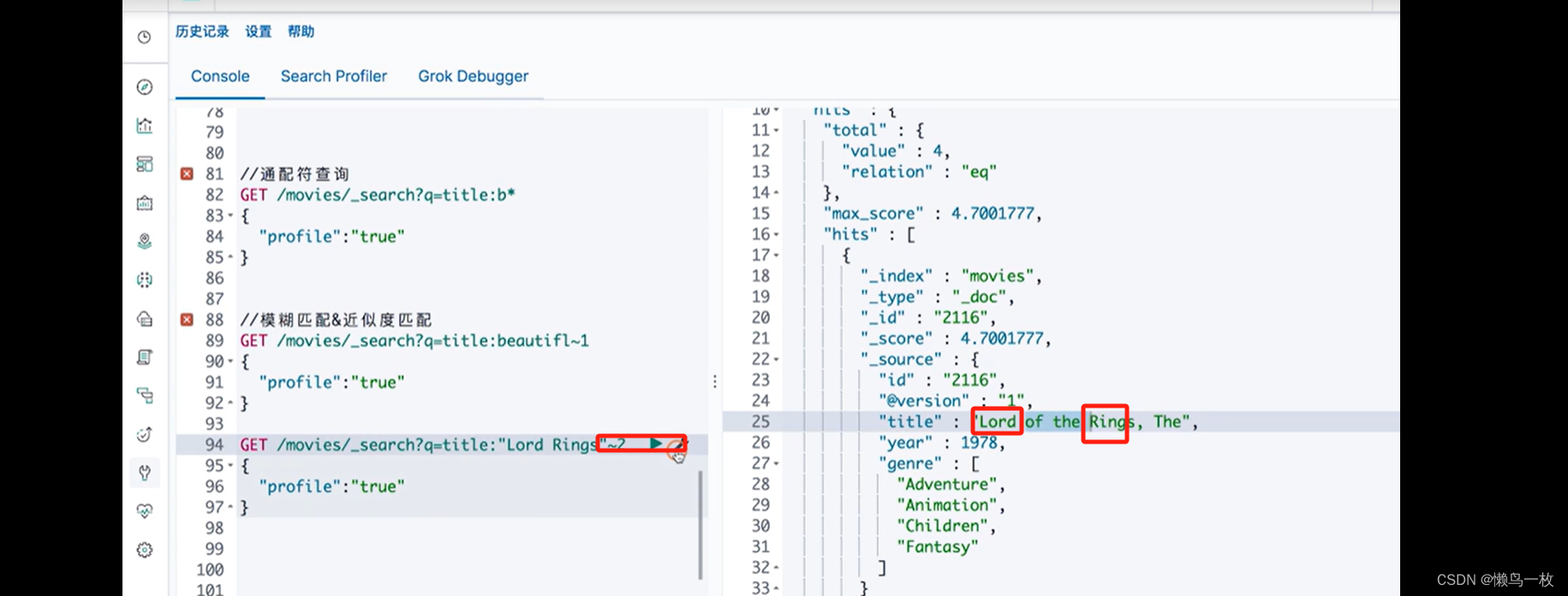
ES-极客学习第二部分ES 入门
基本概念 索引、文档、节点、分片和API json 文档 文档的元数据 需要通过Kibana导入Sample Data的电商数据。具体参考“2.2节-Kibana的安装与界面快速浏览” 索引 kibana 管理ES索引 在系统中找到kibana配置文件(我这里是etc/kibana/kibana.yml) vim /…...

Nodejs软件安装
Nodejs软件安装 一、简介 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。 官网:http://nodejs.cn/api/ 我们关注于 node.js 的 npm 功能,NPM 是随同 NodeJS 一起安装的包管理工具,JavaScript-NPM,Java-Maven&…...
Photoshop 2024 (PS2024) v25 直装版 支持win/mac版
Photoshop 2024 提供了多种创意工具,如画笔、铅笔、涂鸦和渐变等,用户可以通过这些工具来创建独特和令人印象深刻的设计效果。增强的云同步:通过 Adobe Creative Cloud,用户可以方便地将他们的工作从一个设备无缝同步到另一个设备…...

ChatGPT绘画生成软件MidTool:智能艺术的新纪元
在人工智能的黄金时代,创新技术不断涌现,改变着我们的生活和工作方式。其中,ChatGPT绘画生成软件MidTool无疑是这一变革浪潮中的佼佼者。它不仅是一个软件,更是一位艺术家,一位智能助手,它的出现预示着智能…...

linux安装MySQL5.7(安装、开机自启、定时备份)
一、安装步骤 我喜欢安装在/usr/local/mysql目录下 #切换目录 cd /usr/local/ #下载文件 wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz #解压文件 tar -zxvf mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz -C /usr/local …...

openGauss学习笔记-195 openGauss 数据库运维-常见故障定位案例-分析查询语句运行状态
文章目录 openGauss学习笔记-195 openGauss 数据库运维-常见故障定位案例-分析查询语句运行状态195.1 分析查询语句运行状态195.1.1 问题现象195.1.2 处理办法 openGauss学习笔记-195 openGauss 数据库运维-常见故障定位案例-分析查询语句运行状态 195.1 分析查询语句运行状态…...

Oracle篇—实例中和name相关参数的区别和作用
☘️博主介绍☘️: ✨又是一天没白过,我是奈斯,DBA一名✨ ✌✌️擅长Oracle、MySQL、SQLserver、Linux,也在积极的扩展IT方向的其他知识面✌✌️ ❣️❣️❣️大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注❣…...
python + selenium 初步实现数据驱动
如果在进行自动化测试的时候将测试数据写在代码中,若测试数据有变,不利于数据的修改和维护。但可以尝试通过将测试数据放到excel文档中来实现测试数据的管理。 示例:本次涉及的项目使用的12306 selenium 重构------三层架构 excel文件数据如…...

数字孪生+可视化技术 构建智慧新能源汽车充电站监管平台
前言 充电基础设施为电动汽车提供充换电服务,是重要的交通能源融合类基础设施。近年来,随着新能源汽车产业快速发展,我国充电基础设施持续增长,已建成世界上数量最多、服务范围最广、品种类型最全的充电基础设施体系。着眼未来新…...
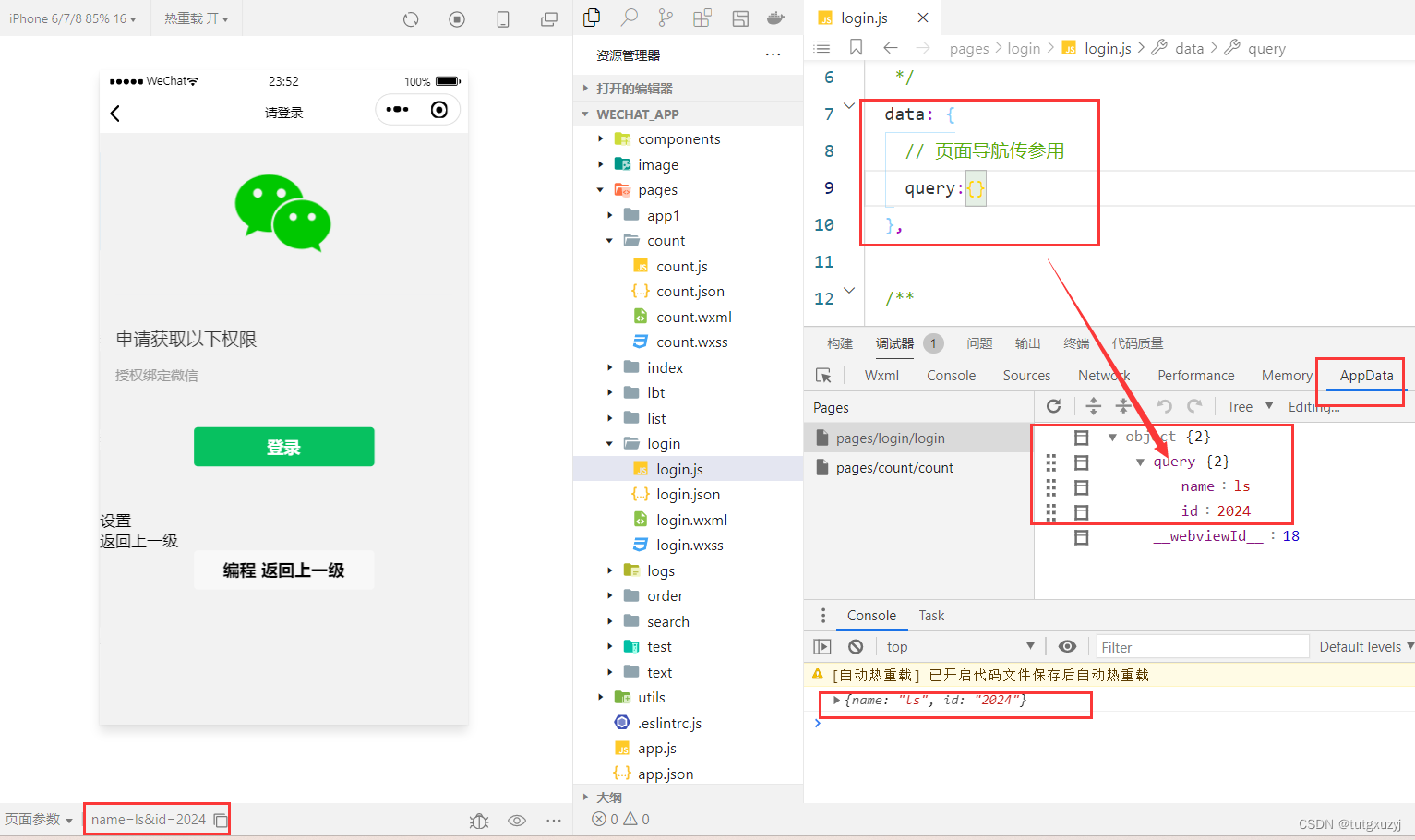
微信小程序开发学习笔记《11》导航传参
微信小程序开发学习笔记《11》导航传参 博主正在学习微信小程序开发,希望记录自己学习过程同时与广大网友共同学习讨论。导航传参 官方文档 一、声明式导航传参 navigator组件的url属性用来指定将要跳转到的页面的路径。同时,路径的后面还可以携带参数…...
BikeDNA(七)外在分析:OSM 与参考数据的比较1
BikeDNA(七)外在分析:OSM 与参考数据的比较1 该笔记本将提供的参考自行车基础设施数据集与同一区域的 OSM 数据进行所谓的外部质量评估进行比较。 为了运行这部分分析,必须有一个参考数据集可用于比较。 该分析基于将参考数据集…...

KY43 全排列
全排列板子 ti #include<bits/stdc.h>using namespace std;string s; map<string, int>mp;void swap(char &a, char &b){char em a;a b;b em; }void dfs(int n){ //将s[n~l]的全排列转化成s[n]s[n1~l]的全排列 if(n s.length()){mp[s] 1;return ;}f…...
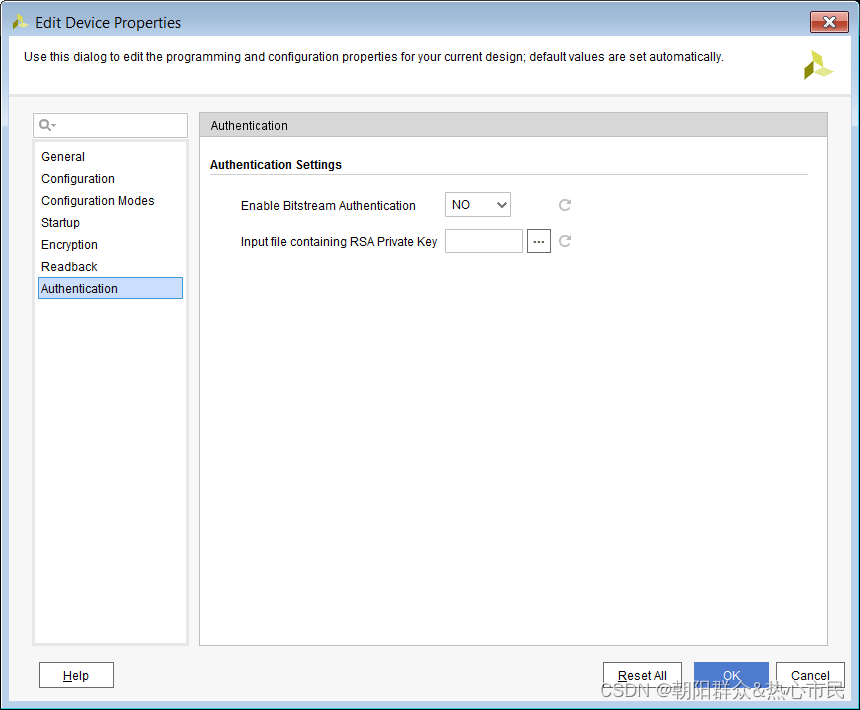
UltraScale 和 UltraScale+ 生成已加密文件和已经过身份验证的文件
注释 :如需了解更多信息,请参阅《使用加密和身份验证确保 UltraScale/UltraScale FPGA 比特流的安全》 (XAPP1267)。 要生成加密比特流,请在 Vivado IDE 中打开已实现的设计。在主工具栏中,依次选择“Flow” → “Bitstream Setti…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...
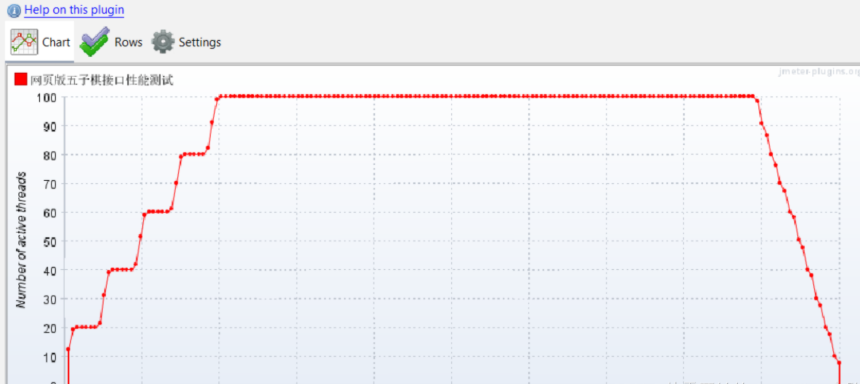
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
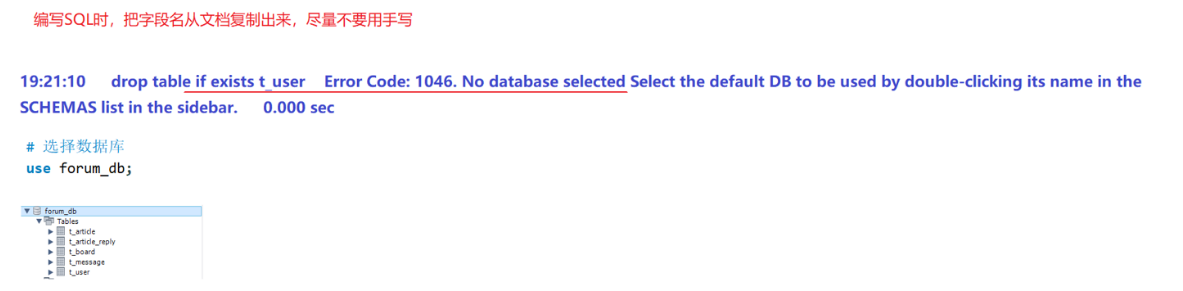
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...