sql数据库常用操作指令
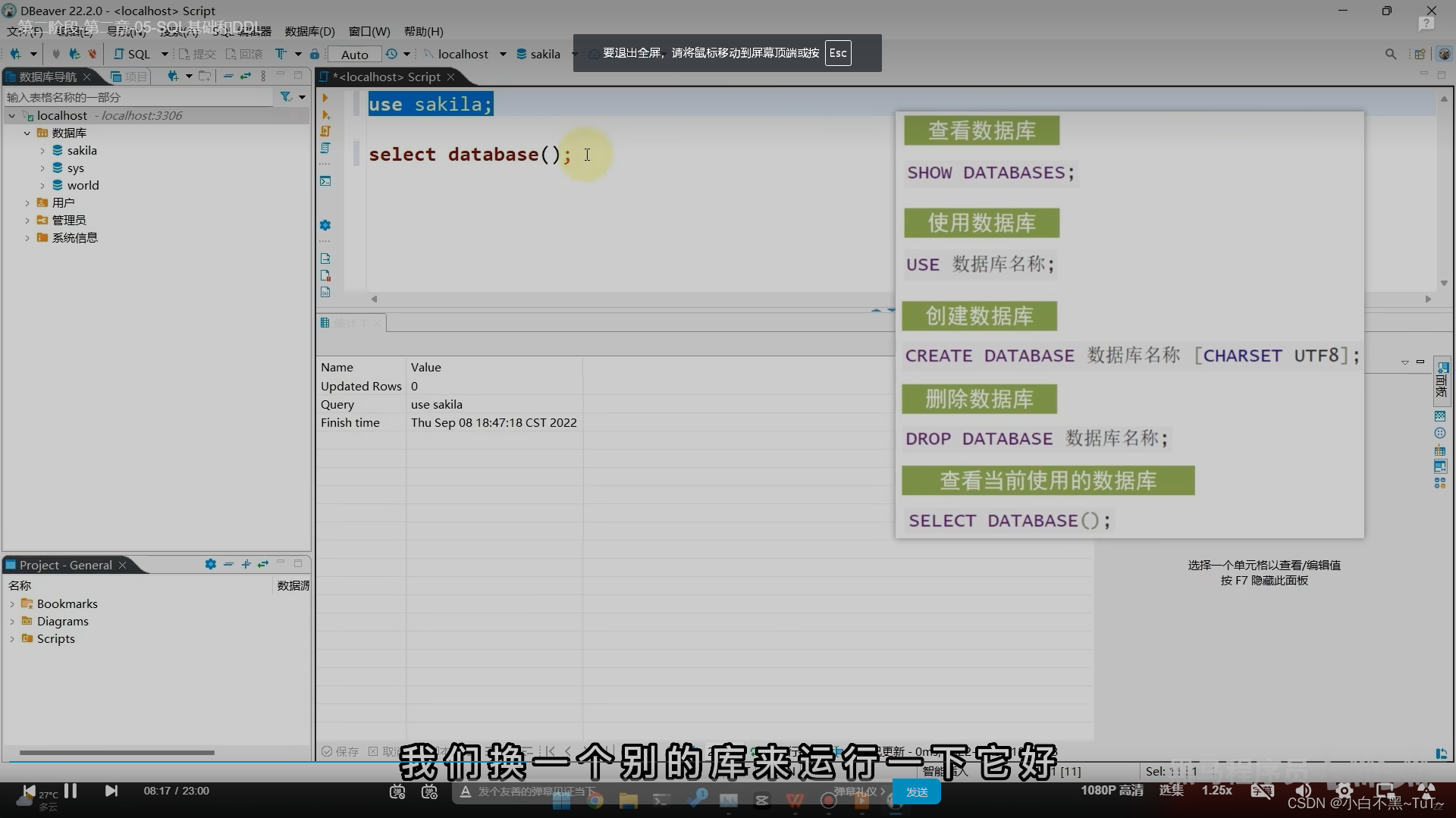
一、操作库
-- 创建库
create database db1;
-- 创建库是否存在,不存在则创建
create database if not exists db1;
-- 查看所有数据库
show databases;
-- 查看某个数据库的定义信息
show create database db1;
-- 修改数据库字符信息
alter database db1 character set utf8;
-- 删除数据库
drop database db1;
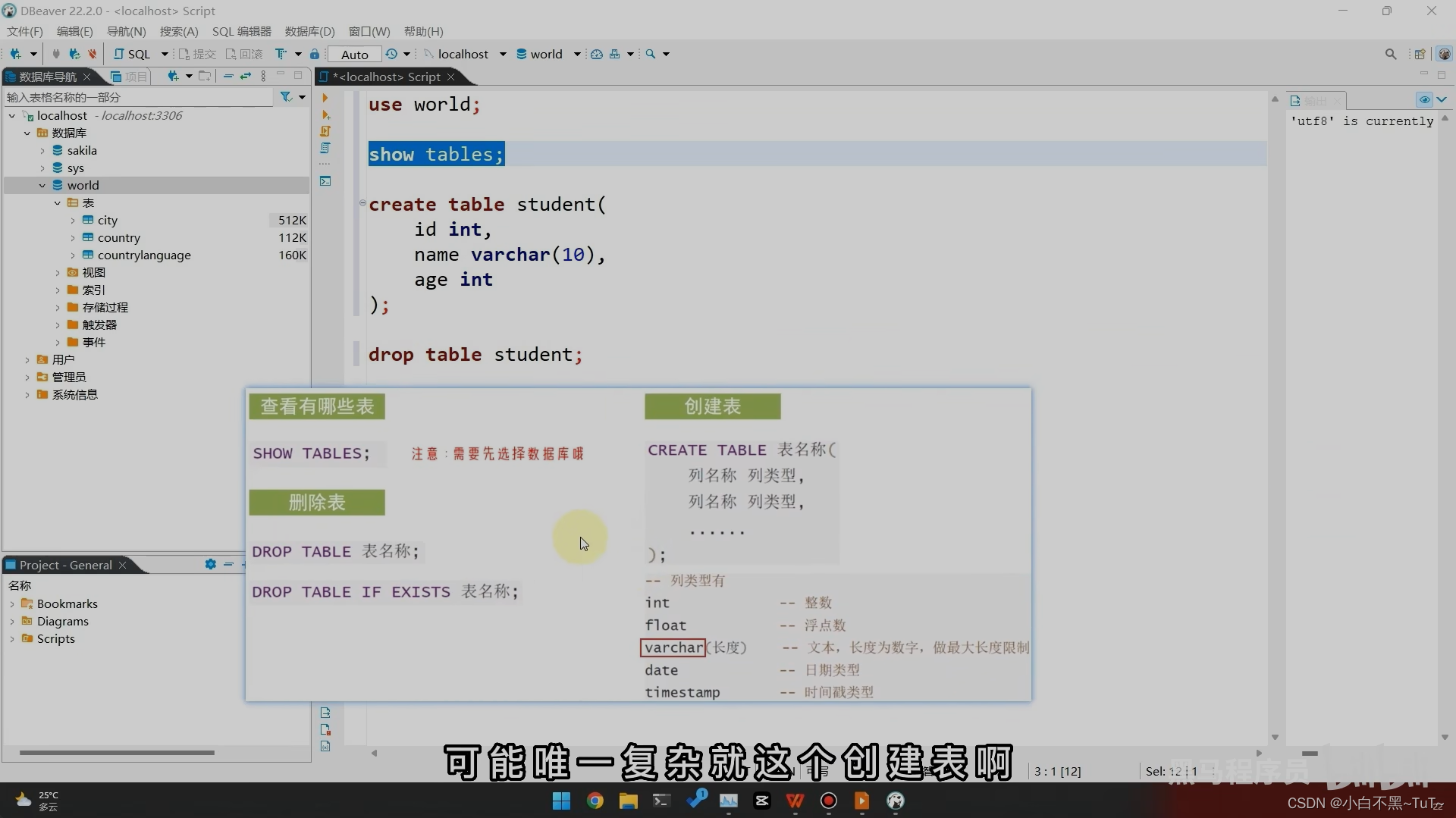
二、操作表
--创建表
create table student(
id int,
name varchar(32),
age int ,
score double(4,1),
birthday date,
insert_time timestamp
);
-- 查看表结构
desc 表名;
-- 查看创建表的SQL语句
show create table 表名;
-- 修改表名
alter table 表名 rename to 新的表名;
-- 添加一列
alter table 表名 add 列名 数据类型;
-- 删除列
alter table 表名 drop 列名;
-- 删除表
drop table 表名;
drop table if exists 表名 ;
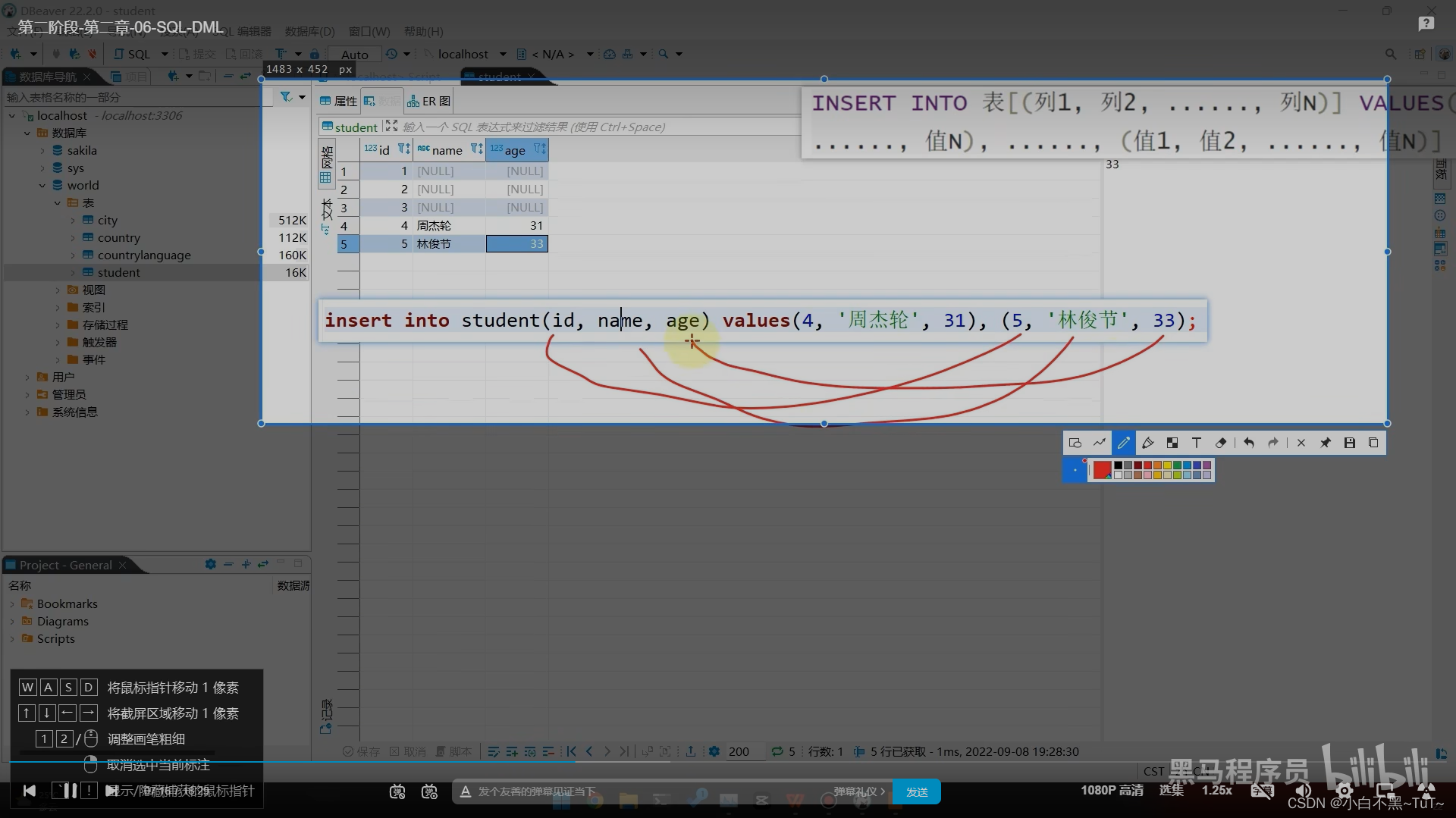
一、增加 insert into
-- 写全所有列名
insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
-- 不写列名(所有列全部添加)
insert into 表名 values(值1,值2,...值n);
-- 插入部分数据
insert into 表名(列名1,列名2) values(值1,值2);
二、删除 delete
-- 删除表中数据
deletefrom 表名 where 列名 = 值;
-- 删除表中所有数据
deletefrom 表名;
-- 删除表中所有数据(高效 先删除表,然后再创建一张一样的表。)
truncatetable 表名;
三、修改 update
-- 不带条件的修改(会修改所有行)
update 表名 set 列名 = 值;
-- 带条件的修改
update 表名 set 列名 = 值 where 列名=值;
一、基础关键字
BETWEEN...AND (在什么之间)和 IN( 集合)
-- 查询年龄大于等于20 小于等于30
SELECT * FROM student WHERE age >= 20 && age <=30;
SELECT * FROM student WHERE age >= 20 AND age <=30;
SELECT * FROM student WHERE age BETWEEN 20 AND 30;
-- 查询年龄22岁,18岁,25岁的信息
SELECT * FROM student WHERE age = 22 OR age = 18 OR age = 25
SELECT * FROM student WHERE age IN (22,18,25);
is null(不为null值) 与 like(模糊查询)、distinct(去除重复值)
-- 查询英语成绩不为null
SELECT * FROM student WHERE english IS NOT NULL;
_:单个任意字符
%:多个任意字符
-- 查询姓马的有哪些? like
SELECT * FROM student WHERE NAME LIKE '马%';
-- 查询姓名第二个字是化的人
SELECT * FROM student WHERE NAME LIKE "_化%";
-- 查询姓名是3个字的人
SELECT * FROM student WHERE NAME LIKE '___';
-- 查询姓名中包含德的人
SELECT * FROM student WHERE NAME LIKE '%德%';
-- 关键词 DISTINCT 用于返回唯一不同的值。
-- 语法:SELECT DISTINCT 列名称 FROM 表名称
SELECT DISTINCT NAME FROM student ;
二、排序查询 order by
语法:order by 子句
order by 排序字段1 排序方式1 , 排序字段2 排序方式2...
注意:
如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
-- 例子
SELECT * FROM person ORDER BY math; --默认升序
SELECT * FROM person ORDER BY math desc; --降序
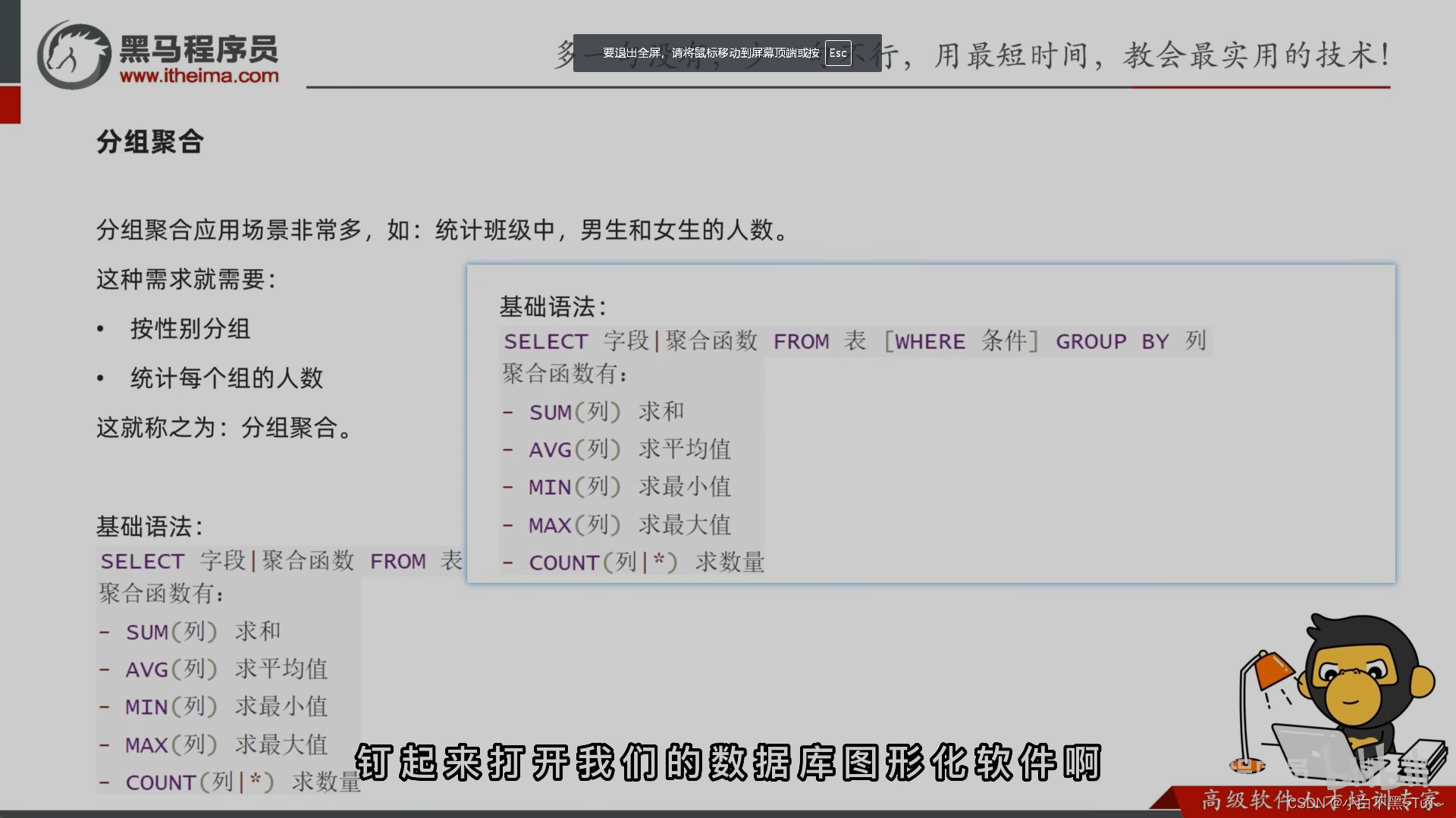
三、 聚合函数:将一列数据作为一个整体,进行纵向的计算。
1.count:计算个数
2.max:计算最大值
3.min:计算最小值
4.sum:计算和
5.avg:计算平均数
四、 分组查询 grout by
语法:group by 分组字段;
注意:分组之后查询的字段:分组字段、聚合函数
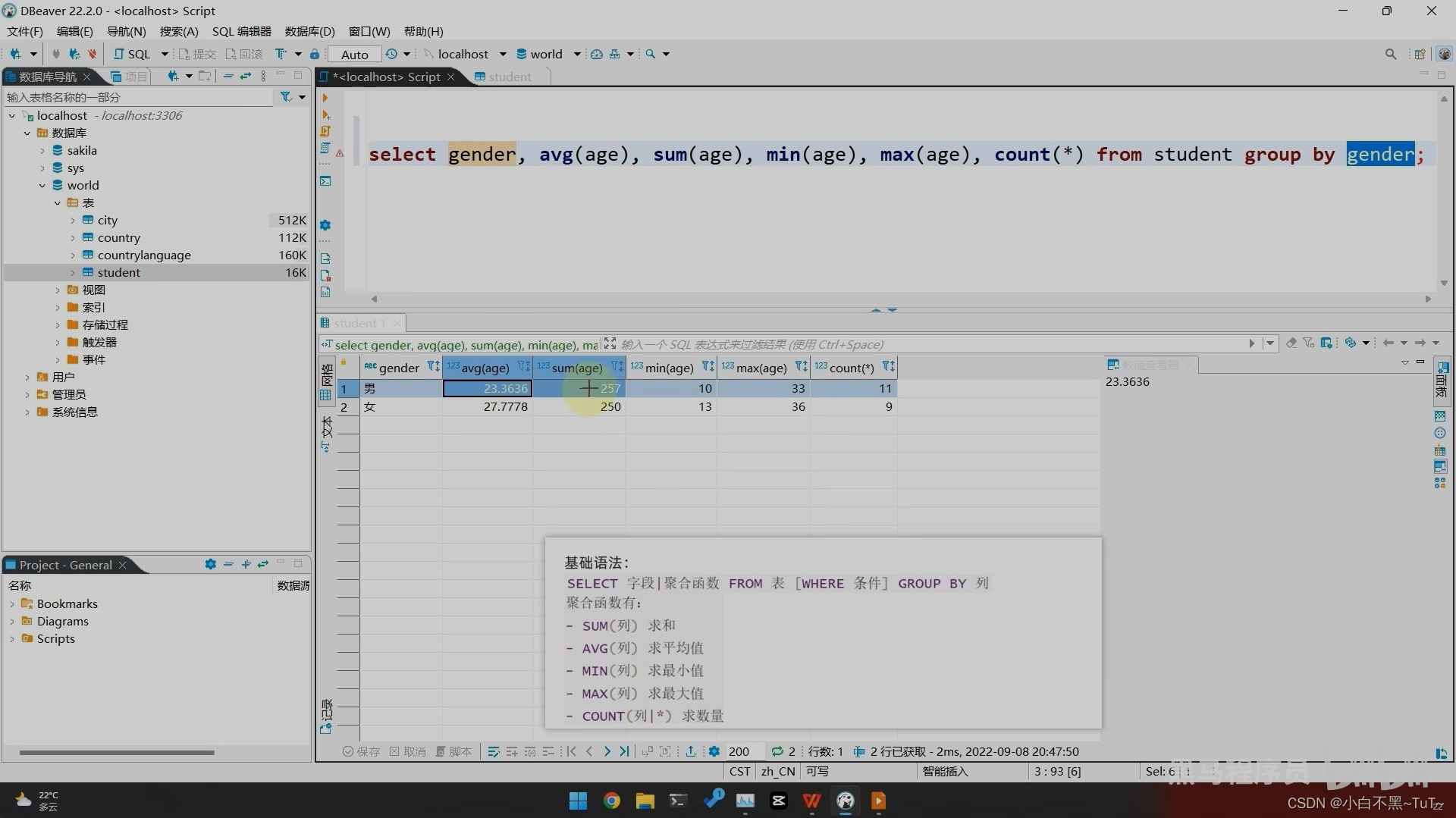
-- 按照性别分组。分别查询男、女同学的平均分
SELECT sex , AVG(math) FROM student GROUP BY sex;
-- 按照性别分组。分别查询男、女同学的平均分,人数
SELECT sex , AVG(math),COUNT(id) FROM student GROUP BY sex;
-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex;
-- 按照性别分组。分别查询男、女同学的平均分,人数 要求:分数低于70分的人,不参与分组,分组之后。人数要大于2个人
SELECT sex , AVG(math),COUNT(id) FROM student WHERE math > 70 GROUP BY sex HAVING COUNT(id) > 2;
SELECT sex , AVG(math),COUNT(id) 人数 FROM student WHERE math > 70 GROUP BY sex HAVING 人数 > 2;
五、 分页查询
语法:limit 开始的索引,每页查询的条数;
2. 公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数
3. limit 是一个MySQL"方言"
-- 每页显示3条记录
SELECT * FROM student LIMIT 0,3; -- 第1页
SELECT * FROM student LIMIT 3,3; -- 第2页
SELECT * FROM student LIMIT 6,3; -- 第3页
六、内连接查询:
1. 从哪些表中查询数据
2.条件是什么
3. 查询哪些字段
1.隐式内连接:使用where条件消除无用数据
-- 查询员工表的名称,性别。部门表的名称
SELECT emp.name,emp.gender,dept.name FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
SELECT
t1.name, -- 员工表的姓名
t1.gender,-- 员工表的性别
t2.name -- 部门表的名称
FROM
emp t1,
dept t2
WHERE
t1.`dept_id` = t2.`id`;
2.显式内连接
-- 语法:
select 字段列表 from 表名1 [inner] join 表名2 on 条件
-- 例如:
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id`;
SELECT * FROM emp JOIN dept ON emp.`dept_id` = dept.`id`;
七、外连接查询
1.左外连接 -- 查询的是左表所有数据以及其交集部分。
-- 语法:select 字段列表 from 表1 left [outer] join 表2 on 条件;
-- 例子:
-- 查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECT t1.*,t2.`name` FROM emp t1 LEFT JOIN dept t2 ON t1.`dept_id` = t2.`id`;
2.右外连接 -- 查询的是右表所有数据以及其交集部分。
-- 语法:
select 字段列表 from 表1 right [outer] join 表2 on 条件;
-- 例子:
SELECT * FROM dept t2 RIGHT JOIN emp t1 ON t1.`dept_id` = t2.`id`;
八、子查询:查询中嵌套查询
-- 查询工资最高的员工信息
-- 1 查询最高的工资是多少 9000
SELECT MAX(salary) FROM emp;
-- 2 查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp.`salary` = 9000;
-- 一条sql就完成这个操作。这就是子查询
SELECT * FROM emp WHERE emp.`salary` = (SELECT MAX(salary) FROM emp);
1.子查询的结果是单行单列的
子查询可以作为条件,使用运算符去判断。 运算符: > >= < <= =
-- 查询员工工资小于平均工资的人
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);
2. 子查询的结果是多行单列的:
子查询可以作为条件,使用运算符in来判断
-- 查询'财务部'和'市场部'所有的员工信息
SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部';
SELECT * FROM emp WHERE dept_id = 3 OR dept_id = 2;
-- 子查询
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部');
子查询的结果是多行多列的:
子查询可以作为一张虚拟表参与查询
-- 查询员工入职日期是2011-11-11日之后的员工信息和部门信息
-- 子查询
SELECT * FROM dept t1 ,(SELECT * FROM emp WHERE emp.`join_date` > '2011-11-11') t2 WHERE t1.id = t2.dept_id;
-- 普通内连接
SELECT * FROM emp t1,dept t2 WHERE t1.`dept_id` = t2.`id` AND t1.`join_date` > '2011-11-11'
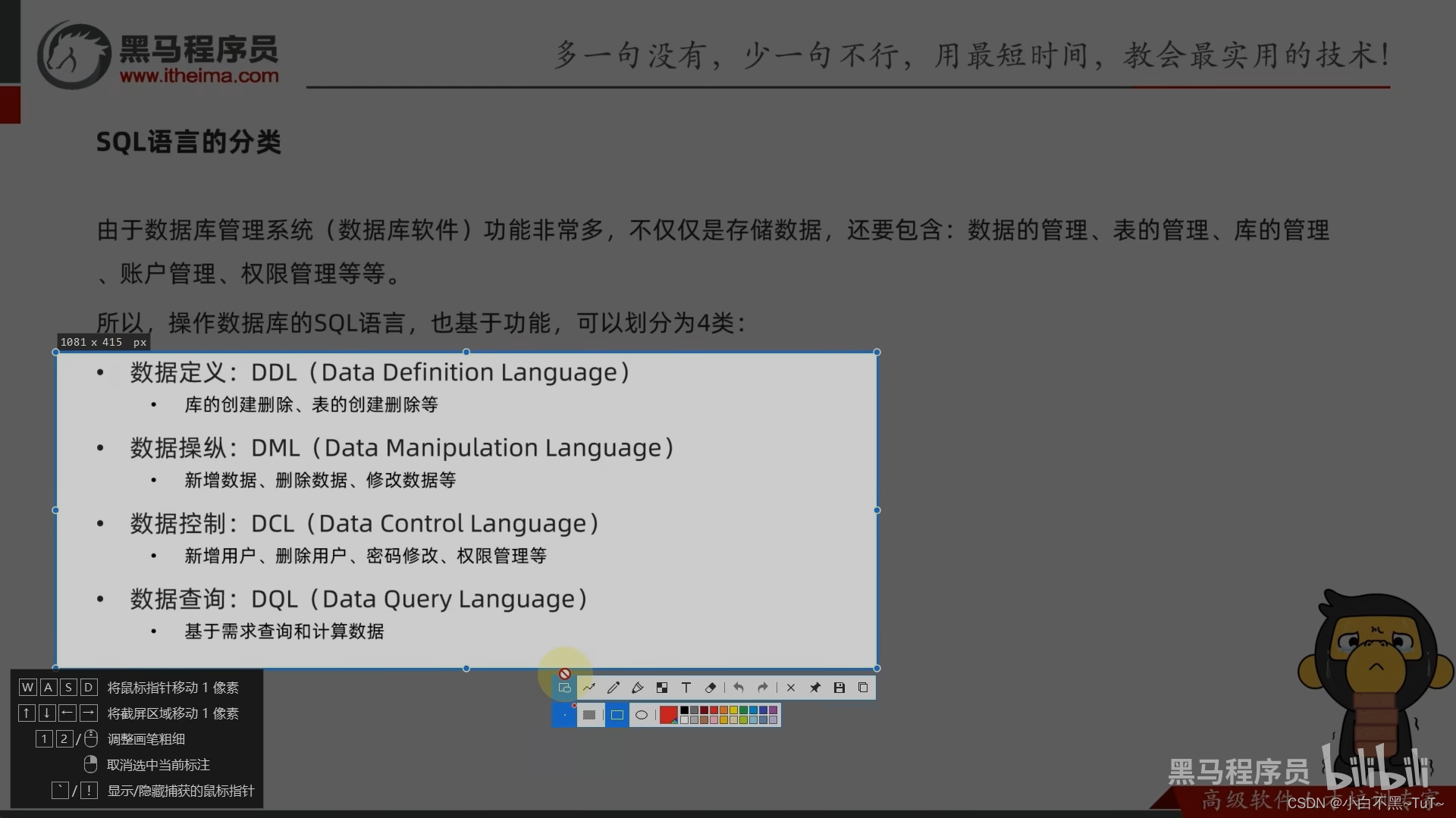
DCL(Data Control Language)数据控制语言
管理用户
添加用户
语法:CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
删除用户
语法:DROP USER '用户名'@'主机名';
权限管理
查询权限
-- 查询权限
SHOW GRANTS FOR '用户名'@'主机名';
SHOW GRANTS FOR 'lisi'@'%';
授予权限
-- 授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
-- 给张三用户授予所有权限,在任意数据库任意表上
GRANT ALL ON *.* TO 'zhangsan'@'localhost';
撤销权限
-- 撤销权限:
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
REVOKE UPDATE ON db3.`account` FROM 'lisi'@'%';
相关文章:
sql数据库常用操作指令
一、操作库-- 创建库create database db1;-- 创建库是否存在,不存在则创建create database if not exists db1;-- 查看所有数据库show databases;-- 查看某个数据库的定义信息 show create database db1; -- 修改数据库字符信息alter database db1 character set ut…...

4-1 定时任务的示例10个
文章目录前言基本命令与格式示例前言 Linux crontab 是用来定期执行程序的命令。当安装完成操作系统之后,默认都已经安装,并启动此任务调度命令。 crond 命令每分钟会定期检查是否有要执行的工作,如果有要执行的工作便会自动执行该工作。 基…...

外贸建站多少钱才能达到预期效果?
外贸建站多少钱才能达到预期效果?这是每个外贸企业都会问的问题。作为一个做外贸建站多年的人,我有一些个人的操盘感想。 首先,我认为外贸建站的投资是非常必要的。 因为在现代社会,网站已经成为外贸企业开展业务的必要工具之一…...

【Java学习笔记】5.Java 基本数据类型
Java 基本数据类型 变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。 内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。 因此,通过定义不同类型的变量…...

InnoDB 死锁和问题排查
文章目录死锁(dead lock)示例 1问题排查查看连接的线程查看相关的表查看最近一次的死锁信息查看服务器的锁信息查看正在使用的表如何尽可能地避免死锁死锁(dead lock) 两个及以上的事务各自持有对方需要的锁,导致双方…...
——六步法——鸢尾花数据集分类)
tensorflow07——使用tf.keras搭建神经网络(Sequential顺序神经网络)——六步法——鸢尾花数据集分类
使用tf.keras搭建顺序神经网络 六步法——鸢尾花数据集分类 01 导入相关包 02 导入数据集,打乱顺序 03 建立Sequential模型 04 编译——确定优化器,损失函数,评测指标(用哪一种准确率) 05 训练模型——把各项参入填入…...

关于Java连接Hive,Spark等服务的Kerberos工具类封装
关于Java连接Hive,Spark等服务的Kerberos工具类封装 idea连接服务器的hive等相关服务的kerberos认证注意事项 idea 本地配置,连接服务器;进行kerberos认证,连接hive、HDFS、Spark等服务注意事项: 本地idea连接Hadoo…...

大数据框架之Hadoop:MapReduce(五)Yarn资源调度器
Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。 简言之,Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源&…...
uniapp实现地图点聚合功能
前言 在工作中接到的一个任务,在app端实现如下功能: 地图点聚合地图页面支持tab切换(设备、劳务、人员)支持人员搜索显示分布 但是uniapp原有的map标签不支持点聚合功能(最新的版本支持了点聚合功能)&am…...
)
经典分类模型回顾2—GoogleNet实现图像分类(matlab版)
GoogleNet是深度学习领域的一种经典的卷积神经网络,其在ImageNet图像分类任务上的表现十分优秀。下面是使用Matlab实现GoogleNet的图像分类示例。 1. 数据准备 在开始之前,需要准备一些图像数据用来训练和测试模型,可以从ImageNet等数据集中…...

Java经典面试题——谈谈 final、finally、finalize 有什么不同?
典型回答 final 可以用来修饰类、方法、变量,分别有不同的意义,final 修饰的 class 代表不可以继承扩展, final 的变量是不可以修改的,而 final 的方法也是不可以重写的(override)。 finally 则是 Java 保…...

C#的Version类型值与SQL Server中二进制binary类型转换
使用C#语言编写的应用程序可以通过.NET Framework框架提供的Version类来控制每次发布的版本号,以便更好控制每次版本更新迭代。 版本号由两到四个组件组成:主要、次要、内部版本和修订。 版本号的格式如下所示, 可选组件显示在方括号 ([ 和…...
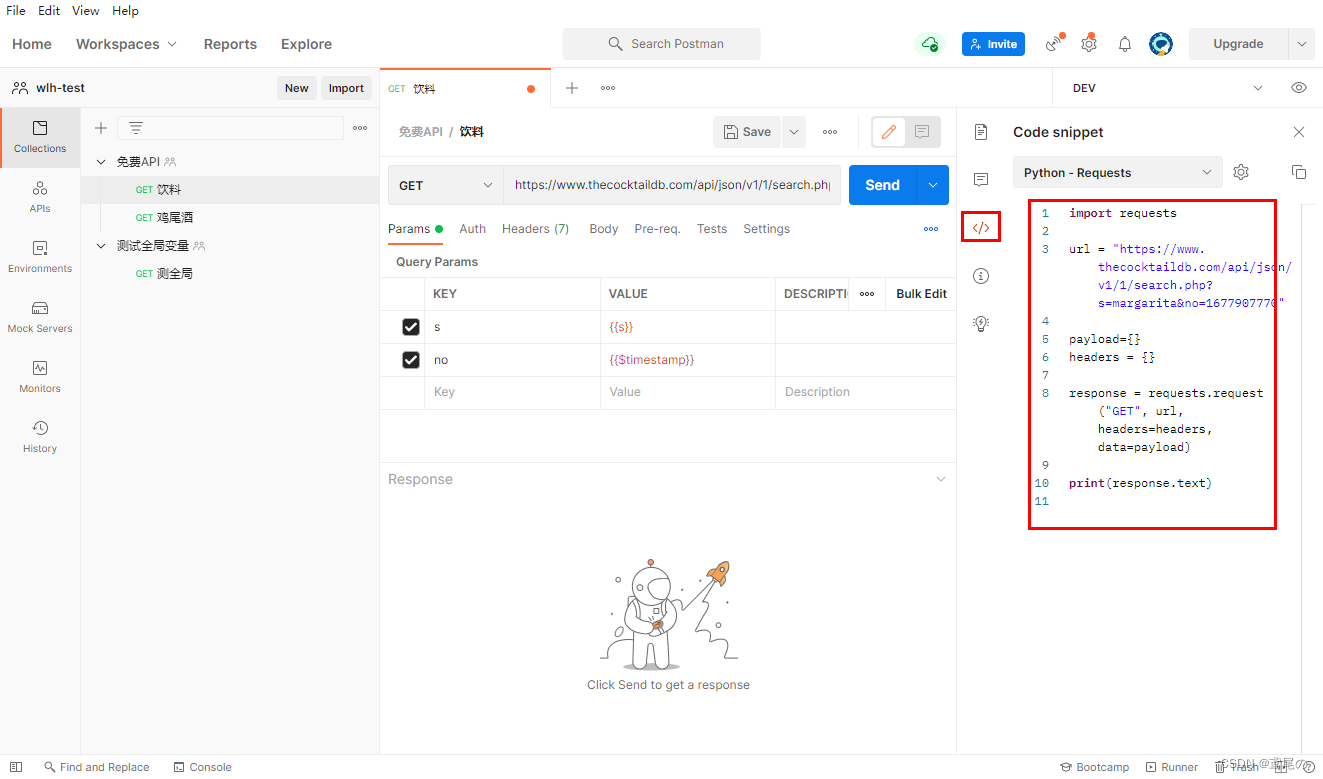
软测入门(五)接口测试Postman
Postman 一款Http接口收工测试工具。如果做自动化测试会使用jemter做。 安装 去官网下载即可。 https://www.postman.com/downloads/?utm_sourcepostman-home 功能介绍 页面上的单词基本上都能了解,不多介绍。 转代码&注释 可将接口的访问转为其他语言的…...
UWB通道选择、信号阻挡和反射对UWB定位范围和定位精度的影响
(一)介绍检查NLOS操作时需要考虑三个方面:(1)由于整体信号衰减,通信范围减小。(2)由于直接路径信号的衰减,导致直接路径检测范围的减小。(3)由于阻…...

linux基本功之列之wget命令实战
文章目录前言一. wget命令介绍二. 语法格式及常用选项三. 参考案例3.1 下载单个文件3.2 使用wget -o 下载文件并改名3.3 -c 参数,下载断开链接时,可以恢复下载3.4 wget后台下载3.5 使用wget下载整个网站四. 补充与汇总常见用法总结前言 大家好ÿ…...

学习ROS时针对gazebo相关的问题(重装与卸载是永远的神)
ResourceNotFound:gazebo_ros 错误解决 参考:https://blog.csdn.net/weixin_42591529/article/details/123869969 当将机器人加载到gazebo时,运行launch文件出现如下错误 这是由于缺少gazebo包所导致的。 解决办法:...

几个C语言容易忽略的问题
1 取模符号自增问题 我们不妨尝试写这样的程序 #include<stdio.h> int main(){int n,t5;printf("%d\n",7%(-3));//1printf("%d\n",(-7)%3);//-1while(--t)printf("%d\n",t);t5;while(t--)printf("%d\n",t);return 0; } 运行…...
CentOS 7.9安装Zabbix 4.4《保姆级教程》
CentOS 7.9安装Zabbix 4.4一、配置一览二、环境准备设置Selinux和firewalld设置软件源1.配置ustc CentOS-Base源2.安装zabbix 4.4官方源3.安装并更换epel源4.清除并生成缓存三、安装并配置Zabbix Server安装zabbix组件安装php安装mariadb并创建数据库修改zabbix_server.conf设置…...

路由器与交换机的区别(基础知识)
文章目录交换机路由器路由器和交换机的区别(1)工作层次不同(2)数据转发所依据的对象不同(3)传统的交换机只能分割冲突域,不能分割广播域;而路由器可以分割广播域(4&#…...

Python基础学习9——函数
基本概念 函数是一种能够完成某项任务的封装工具。在数学中,函数是自变量到因变量的一种映射,通过某种方式能够使自变量的值变成因变量的值。其实本质上也是实现了某种值的转换的任务。 函数的定义 在python中,函数是利用def来进行定义&am…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...