【搭建个人知识库-3】
搭建个人知识库-3
- 1 大模型开发范式
- 1.1 RAG原理
- 1.2 LangChain框架
- 1.3 构建向量数据库
- 1.4 构建知识库助手
- 1.5 Web Demo部署
- 2 动手实践
- 2.1 环境配置
- 2.2 知识库搭建
- 2.2.1 数据收集
- 2.2.2 加载数据
- 2.2.3 构建向量数据库
- 2.3 InternLM接入LangChain
- 2.4 构建检索问答链
- 1 加载向量数据库
- 2 实例化自定义LLM与Prompt Template
- 3 构建检索问答链
- 2.5 Web Demo
- 3 作业
基于InternLM和LangChain搭建专属个人的大模型知识库;
- 大模型开发范式
- LangChain简介
- 构建
1 大模型开发范式
大模型具有简单的广度回答,但是在垂直领域的知识受限;
- 如何让LLM及时获得最新的知识
- 如何打造垂直领域大模型
- 如何打造个人专属的LLM应用
两种常用开发范式:RAG VS Finetune
即:检索增强生成 VS 算法微调;
RAG:
- 成本低
- 可实时更新
- 受基座影响大
- 单次回答知识有限
Finetune:
- 可个性化微调
- 知识覆盖面广
- 成本高昂
- 无法实时更新
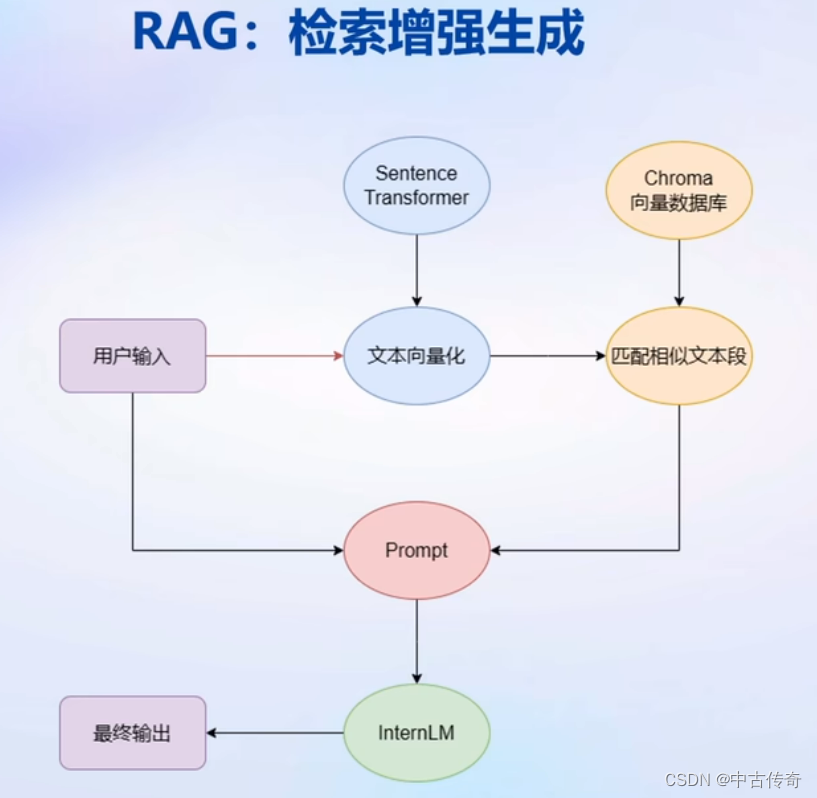
1.1 RAG原理
1.2 LangChain框架
LangChain框架:是一个开源工具,为各种LLM提供通用接口来简化应用程序的开发流程,帮助开发者自由构建LLM应用;
LangChain的核心组成模块:
- 链:将组件实现端到端应用,通过一个对象封装实现一系列LLM操作;
- Eg:检索问答链,覆盖实现了RAG的全部流程;
1.3 构建向量数据库
加载源文件–>文档分块–>文档向量化;

1.4 构建知识库助手
- LangChain支持自定义LLM,可以直接接入到框架中;
- 只需将InternLM部署到本地,并封装一个自定义LLM类,调用本地的InternLM即可。
RAG方案优化建议:

1.5 Web Demo部署
支持简易Web 部署的框架:Gradio、Streamlit等;
2 动手实践
2.1 环境配置
1.安装环境,激活环境,并安装依赖
2.模型下载
- 直接从服务器copy;–不可取;
- modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='/root/data/model', revision='v1.0.3')
3.LangChain相关环境部署
4.下载NLTK相关资源
在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。
2.2 知识库搭建
2.2.1 数据收集
- OpenCompass:面向大模型评测的一站式平台
- IMDeploy:涵盖了 LLM 任务的全套轻量化、部署和服务解决方案的高效推理工具箱)
- XTuner:轻量级微调大语言模型的工具库
- InternLM-XComposer:浦语·灵笔,基于书生·浦语大语言模型研发的视觉-语言大模型
- Lagent:一个轻量级、开源的基于大语言模型的智能体(agent)框架
- InternLM:一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖
开源使用方式
# clone 上述开源仓库
git clone https://gitee.com/open-compass/opencompass.git
git clone https://gitee.com/InternLM/lmdeploy.git
git clone https://gitee.com/InternLM/xtuner.git
git clone https://gitee.com/InternLM/InternLM-XComposer.git
git clone https://gitee.com/InternLM/lagent.git
git clone https://gitee.com/InternLM/InternLM.git
为语料处理方案,在这里只选用仓库中的MD、TXT文件作为示例语料库。
当然也可以选用其中的代码文件放入到知识库中,但是需要针对代码文件格式进行专门的额外处理。(代码文件对逻辑联系要求较高,且规范性较强,在分割时最好基于代码模块进行分割再加入向量数据库)。
创建函数:将仓库里所以满足条件的.md或.txt文件 的路径找出来,定义一个函数:将该函数递归指定文件路径,返回其中所有满足条件的文件路径;
import os
def get_files(dir_path):# args:dir_path,目标文件夹路径file_list = []for filepath, dirnames, filenames in os.walk(dir_path):# os.walk 函数将递归遍历指定文件夹for filename in filenames:# 通过后缀名判断文件类型是否满足要求if filename.endswith(".md"):# 如果满足要求,将其绝对路径加入到结果列表file_list.append(os.path.join(filepath, filename))elif filename.endswith(".txt"):file_list.append(os.path.join(filepath, filename))return file_list
2.2.2 加载数据
在上一步将所有目标文件的路径找出来之后,使用LangChain提供的FileLoader对象来加载目标文件,得到由目标文件解析出的纯文本内容。
不同类型文件对应不同的FileLoader:首先判断目标文件类型,并针对性调用对应类型的FileLoader,即调用FileLoader对象的load方法来得到加载之后的纯文本对象。
Python 真是好东西,实现简洁且可读性超级强
from tqdm import tqdm
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoaderdef get_text(dir_path):# args:dir_path,目标文件夹路径# 首先调用上文定义的函数得到目标文件路径列表file_lst = get_files(dir_path)# docs 存放加载之后的纯文本对象docs = [] # 得到一个纯文本对象对应的列表# 遍历所有目标文件for one_file in tqdm(file_lst):file_type = one_file.split('.')[-1]if file_type == 'md':loader = UnstructuredMarkdownLoader(one_file)elif file_type == 'txt':loader = UnstructuredFileLoader(one_file)else:# 如果是不符合条件的文件,直接跳过continuedocs.extend(loader.load())return docs2.2.3 构建向量数据库
在上一步得到纯文本对象的列表之后,将它引入到LangChain框架中构建向量数据库。由纯文本对象构建向量数据库,先对文本进行分块,接着对文本进行向量化。
1.#LangChain有多种文本分块工具,在这里使用字符串递归分割器
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)2.选用开源词向量模型进行文本向量化
from langchain.embeddings.huggingface import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
3.将Chroma作为向量数据库,基于上文分块后的文档以及加载的开源向量化模型,将语料加载到指定路径下的向量数据库:
from langchain.vectorstores import Chroma
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings,persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
2.3 InternLM接入LangChain
为方便构建LLM应用,基于本地进行部署InternLM,继承LangChain的LLM类自定义一个InternLM LLM子类,从而实现将InternLM接入到LangChain框架中。
完成 LangChain 的自定义 LLM 子类之后,可以以完全一致的方式调用 LangChain 的接口,而无需考虑底层模型调用的不一致。
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchclass InternLM_LLM(LLM):# 基于本地 InternLM 自定义 LLM 类tokenizer : AutoTokenizer = Nonemodel: AutoModelForCausalLM = Nonedef __init__(self, model_path :str):# model_path: InternLM 模型路径# 从本地初始化模型super().__init__()print("正在从本地加载模型...")self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()self.model = self.model.eval()print("完成本地模型的加载")def _call(self, prompt : str, stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any):# 重写调用函数system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文."""messages = [(system_prompt, '')]response, history = self.model.chat(self.tokenizer, prompt , history=messages)return response@propertydef _llm_type(self) -> str:return "InternLM"
在上述类定义中,我们分别重写了构造函数和 _call 函数:对于构造函数,我们在对象实例化的一开始加载本地部署的 InternLM 模型,从而避免每一次调用都需要重新加载模型带来的时间过长;_call 函数是 LLM 类的核心函数,LangChain 会调用该函数来调用 LLM,在该函数中,我们调用已实例化模型的 chat 方法,从而实现对模型的调用并返回调用结果。
在Python中看到了类似C++中的用法
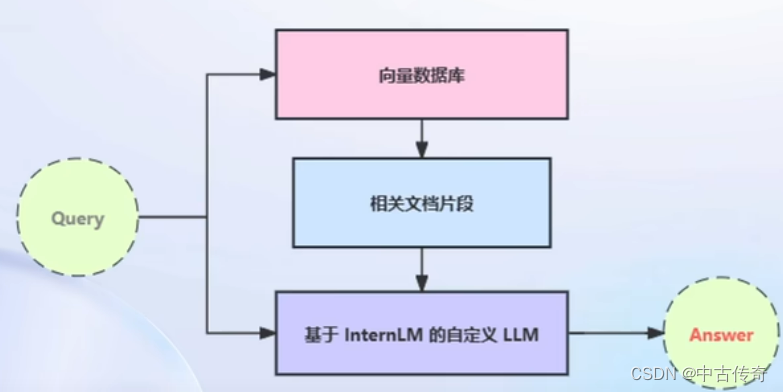
2.4 构建检索问答链
LangChain 通过提供检索问答链对象来实现对于 RAG 全流程的封装。所谓检索问答链,即通过一个对象完成检索增强问答(即RAG)的全流程。
原理:调用一个 LangChain 提供的 RetrievalQA 对象,通过初始化时填入已构建的数据库和自定义 LLM 作为参数,来简便地完成检索增强问答的全流程,LangChain 会自动完成基于用户提问进行检索、获取相关文档、拼接为合适的 Prompt 并交给 LLM 问答的全部流程。
1 加载向量数据库
将上文构建的向量数据库导入进来,直接通过Chroma以及上文定义的词向量模型来加载已构建的数据库:
vedtordb对象即为已经构建好的向量数据库对象,它可以针对用户的query进行语义向量检索,得到与用户提问相关的知识;
2 实例化自定义LLM与Prompt Template
实例化一个基于InternLM自定义的LLM对象:
3 构建检索问答链
调用 LangChain 提供的检索问答链构造函数,基于我们的自定义 LLM、Prompt Template 和向量知识库来构建一个基于 InternLM 的检索问答链:
2.5 Web Demo
上面两个小节分别完成之后,搭建基于Gradio框架部署到网页,搭建一个小型的Demo,这样便于测试和调试;
-
将上面的代码封装成一个函数:用于返回 构建的检索问答链对象的函数。在启动Gradio的initial时调用函数得到检索问答链对象,后续直接使用该对象进行问答对话,避免重复加载模型;
-
定义一个类:负责加载并存储检索问答链,响应Web界面里调用该检索问答链进行回答的动作;
-
按照Gradio框架使用方法,实例化一个Web界面并将点击动作绑定到上述类的回答方法即可。
-
启动上面封装的脚本,默认会在7860端口运行,因此做好服务器端口与本地端口映射。
ssh -L 7860:127.0.0.1:7860 root@ssh.intern-ai.org.cn -p 34825
3 作业
相关文章:
【搭建个人知识库-3】
搭建个人知识库-3 1 大模型开发范式1.1 RAG原理1.2 LangChain框架1.3 构建向量数据库1.4 构建知识库助手1.5 Web Demo部署 2 动手实践2.1 环境配置2.2 知识库搭建2.2.1 数据收集2.2.2 加载数据2.2.3 构建向量数据库 2.3 InternLM接入LangChain2.4 构建检索问答链1 加载向量数据…...
如何看待 Linux 内核邮件列表重启将内核中的 C 代码转换为 C++
如何看待 Linux 内核邮件列表重启将内核中的 C 代码转换为 C 的讨论? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「Linux的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿…...

springboot网关添加swagger
添加依赖 <dependency><groupId>com.spring4all</groupId><artifactId>swagger-spring-boot-starter</artifactId><version>2.0.2</version></dependency>添加配置类,与服务启动类同一个层级 地址:http…...

代码随想录 Leetcode383. 赎金信
题目: 代码(首刷自解 2024年1月15日): class Solution { public:bool canConstruct(string ransomNote, string magazine) {vector<int> v(26);for(auto letter : magazine) {v[letter - a];}for(auto letter : ransomNote…...

上下左右视频转场模板PR项目工程文件 Vol. 05
pr转场模板,视频画面上下左右转场后带有一点点回弹效果的PR项目工程模板 Vol. 05 项目特点: 回弹效果视频转场; Premiere Pro 2020及以上; 适用于照片和视频转场; 适用于任何FPS和分辨率; 视频教程。 PR转场…...

【正点原子STM32连载】第三十三章 单通道ADC采集实验 摘自【正点原子】APM32E103最小系统板使用指南
1)实验平台:正点原子APM32E103最小系统板 2)平台购买地址:https://detail.tmall.com/item.htm?id609294757420 3)全套实验源码手册视频下载地址: http://www.openedv.com/docs/boards/xiaoxitongban 第三…...
Linux系统使用docker部署Geoserver(简单粗暴,复制即用)
1、拉取镜像 docker pull kartoza/geoserver:2.20.32、创建数据挂载目录 # 统一管理Docker容器的数据文件,geoserver mkdir -p /mydata/geoserver# 创建geoserver的挂载数据目录 mkdir -p /mydata/geoserver/data_dir# 创建geoserver的挂载数据目录,存放shp数据 m…...

libcurl使用默认编译的winssl进行https的双向认证
双向认证: 1.服务器回验证客户端上报的证书 2.客户端回验证服务器的证书 而证书一般分为:1.受信任的根证书,2不受信任的根证书。 但是由于各种限制不想在libcurl中增加openssl,那么使用默认的winssl也可以完成以上两种证书的双…...
 管理数据库(database))
MySQL运维实战(3.3) 管理数据库(database)
作者:俊达 引言 数据库的创建和管理是构建可靠数据的关键,关系到所存储数据的安全与稳定。在 MySQL 这个强大的关系型数据库系统中,数据库的创建与管理需要精准的步骤和妥善的配置。下面,将深入探讨如何使用MySQL 来管理数据库&…...

Web3去中心化存储:重新定义云服务
随着Web3技术的崭露头角,去中心化存储正在成为数字时代云服务的全新范式。传统的云服务依赖于中心化的数据存储架构,而Web3的去中心化存储则为用户带来了更安全、更隐私、更可靠的数据管理方式,重新定义了云服务的未来。 1.摒弃中心化的弊端 …...

纸尿裤行业调研:预计到2024年提高至68.1%
母婴大消费是指围绕孕产妇和0-14岁婴幼童人群,贯穿孕产妇孕产及产后护理周期、婴幼童成长周期的满足其衣、食、住、行、用、玩、教等需求的消费品的总和。 不同产品消费频次各异,纸尿裤是母婴大消费中的最为高频且刚需的易耗品。当前,消费升…...

目标检测数据集 - 行人检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:行人检测数据集,真实场景高质量图片数据,涉及场景丰富,比如校园行人、街景行人、道路行人、遮挡行人、严重遮挡行人数据;适用实际项目应用:公共场所监控场景下行人检测项目,以及作为…...

重磅!巨匠纺品鉴正式签约“体坛冠军程晨”为品牌形象代言人
2024年,巨匠纺品鉴打响品牌营销开年第一战,携手全国啦啦操冠军程晨,强势开启“冠军品牌、冠军优选、冠军品质”中国年,实现品牌战略全面升级,全力传递"冠军品质"的品牌精神,拓展品牌影响力的深度和广度,为品…...
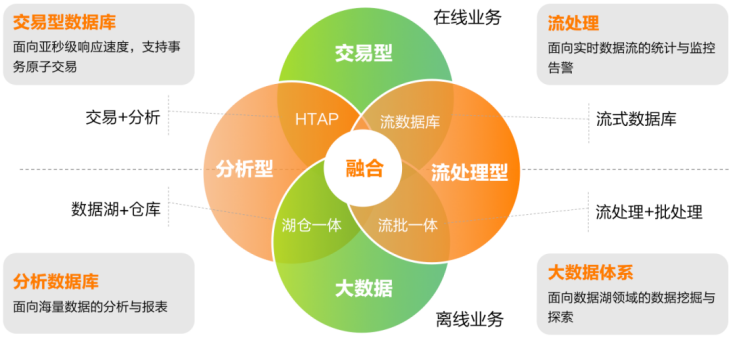
亚信安慧AntDB超融合框架——数智化时代数据库管理的新里程碑
在信息科技飞速发展的时代,亚信科技AntDB团队提出了一项颠覆性的“超融合”理念,旨在满足企业日益增长的复杂混合负载和多样化数据类型的业务需求。这一创新性框架的核心思想在于融合多引擎和多能力,充分发挥分布式数据库引擎的架构优势&…...
设计模式之命令模式【行为型模式】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档> 学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您: 想系统/深入学习某…...

肯尼斯·里科《C和指针》第6章 指针(4)实例
肯尼斯里科《C和指针》第6章 指针(1)-CSDN博客 肯尼斯里科《C和指针》第6章 指针(2)-CSDN博客 肯尼斯里科《C和指针》第6章 指针(3)-CSDN博客 6.12 实例 /* ** 计算一个字符串的长度。 */ #include <…...

diffusers flask streamlit 简洁可视化文生图页面
参考: https://python-bloggers.com/2022/12/stable-diffusion-application-with-streamlit/ https://github.com/LowinLi/stable-diffusion-streamlit 项目结构 本项目很简洁,暂时每次只能返回一张图片;gpu资源T4 16g;测试下来基本也只能支持同时一个人使用 flask:作为…...

ubuntu 使用VNC链接树莓派
ubuntu PC端安装remina sudo apt-add-repository ppa:remmina-ppa-team/remmina-next 然后,运行以下命令来安装 Remmina 软件包: sudo apt update sudo apt install remmina remmina-plugin-rdp remmina-plugin-secret flatpak run -- pkill remmina p…...

水利部:加大北斗、无人机等安全监测新技术的应用推广
水利部:加大北斗、无人机等安全监测新技术的应用推广 近日,水利部召开2023年水库安全管理情况新闻发布会。会上,副部长刘伟平介绍有关情况,并与水利工程建设司、运行管理司、水旱灾害防御司负责人回答记者提问。 为了高质量…...
如何定位和优化程序CPU、内存等性能之巅
摘要 性能优化指在不影响系统运行正确性的前提下,使之运行得更快,完成特定功能所需的时间更短,或拥有更强大的服务能力。本文将介绍性能优化的基本概念以及如何定位和优化程序中的CPU、内存和IO瓶颈。 引言 随着计算机系统的日益复杂和应用…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...