前端整理 —— javascript 2
1. generator(生成器)
详细介绍
generator 介绍
-
generator 是 ES6 提供的一种异步编程解决方案,在语法上,可以把它理解为一个状态机,内部封装了多种状态。执行generator,会生成返回一个遍历器对象。返回的遍历器对象,可以依次遍历generator函数的每一个状态。同时 ES6 规定这个遍历器是Generator函数的实例,也继承了 Genarator函数的 prototype 对象上的方法
-
最简单的generator函数,其实它就是一个普通的函数,但是它有两个特征:
- 第一就是function关键字与函数名之间有一个*号
- 其二就是函数体内使用yield表达式来遍历状态
function* newGenerator() {yield 'hello';yield 'world';return 'ending'; } -
执行 generator 函数之后,该函数并不会立即执行,返回的也不是函数运行结果,而是一个指向内部状态的指针对象。通常使用遍历器对象的 next 方法。使得指针移向下一个状态。每一次调用 next() 方法,内部指针就从函数头部或上一次停下来的地方开始执行,直到遇到下一个 yield 表达式位置,由此可以看出,generator 是分段执行的,yield 表达式是暂停执行的标记,而next方法可以恢复执行
【注:generator函数可以随心所欲的交出和恢复函数的执行权,yield 交出执行权,next() 恢复执行权】
yield
- yield 表达式在 generator 中是作为一个暂停标志,当碰到 yield 时,函数暂停执行。等到下一次 next() 执行时,函数才从当前 yield 位置开始执行。并且,yield表达式只能用在 Generator 函数里边。同时,yield 如果后边带一个 *,则就是相当于一个 for…of 的简写形式,如果 yield 后边不带 *,则返回的是 generator 的值
function* gen() {yield 'hello';yield* 'hello'; } let f = gen(); console.log(f.next().value); // hello console.log(f.next().value); // h console.log(f.next().value); // e console.log(f.next().value); // l console.log(f.next().value); // l console.log(f.next().value); // o - 无论是触发了 yield 还是 return,next() 函数总会返回一个带有 value 和 done 属性的对象,value 为返回值,done 则是一个Boolean 对象,用来标识 Generator 是否还能继续提供返回值
function * oddGenerator () {yield 1yield 3return 5 } let iterator = oddGenerator() let first = iterator.next() // { value: 1, done: false } let second = iterator.next() // { value: 3, done: false } let third = iterator.next() // { value: 5, done: true }
next,throw,return
-
以上的三个方法在本质上其实是一样的,就是让 generator 恢复执行,并且使用不同的语句来替代 yield 语句
- next() 是将 yield 表达式替换成一个值
- throw() 是将 yield 表达式替换成一个 throw 语句
- return() 是将 yield 表达式替换成一个 return 语句
例:
function* dataConsumer() {console.log('Started');console.log(`1. ${yield}`);console.log(`2. ${yield}`);return 'result'; } let genObj = dataConsumer(); genObj.next(); // Started genObj.next('a'); // 1. a genObj.next('b'); // 2. b -
yield test() 时,值是还没有确定的,什么时候会确定呢,就是执行下一次 next 方法时,通过传参数 next(val) 的方式来确定值,什么意思呢,看下面这段代码
const test = () => new Promise((resolve,reject) =>setTimeout(() => {resolve('test')},1000) )function* func(){const ans = yield test();console.log(ans);const ans2 = yield test();console.log(ans2); }const it = func(); const p = it.next(); // 返回 {value: Promise,done: false },这是 ans 并没有获取到 resolve 的值 p.value.then(res => {console.log(res);const p2 = it.next(res); // 这一步时上面代码中的 ans 才会被确定值为 res;p2.value.then(res => {console.log(res);}) })如果 next() 中不带参数,则 yield 每次运行之后的返回值都是为 undefined,即 yield 1 运行之后返回值为 undefined
function * oddGenerator () {yield 1 // 值为 undefined } let iterator = oddGenerator() let first = iterator.next()
应用场景
- 协程
- 协程可以理解成多线程间的协作,比如说 A,B 两个线程根据实际逻辑控制共同完成某个任务,A 运行一段时间后,暂缓执行,交由 B 运行,B 运行一段时间后,再交回 A 运行,直到运行任务完成。对于 JavaScript 单线程来说,我们可以理解为函数间的协作,由多个函数间相互配合完成某个任务
- Generator 函数是 ES6 对协程的实现,但属于不完全实现。Generator 函数被称为“半协程”,意思是只有 Generator 函数的调用者,才能将程序的执行权还给 Generator 函数。如果是完全执行的协程,任何函数都可以让暂停的协程继续执行
- 如果将 Generator 函数当做协程,完全可以将多个需要互相协作的任务写成 Generator 函数,他们之间使用 yield 标识交换控制权
- Generator 函数执行产生的上下文环境,一旦遇到 yield 命令,就会暂时退出堆栈,但是并不消失,里面的所有变量和对象会冻结在当前状态。等到对它执行 next 命令时,这个上下文环境又会重新加入调用栈,冻结的变量和对象恢复执行。
- 异步编程
解决回调地狱,异步流控(按顺序控制异步操作),例:- 普通方法实现肚包鸡的制作过程:
setTimeout(function() {console.log("prepare chicken");setTimeout(function() {console.log("fired chicken");setTimeout(function() {console.log("stewed chicken");....},500)},500) },500); - 用 Generator 函数来实现肚包鸡的制作过程:
(重点在流程控制部分,很妙的思路)// 准备 function prepare(sucess) {setTimeout(function() {console.log("prepare chicken");sucess();},500) }// 炒鸡 function fired(sucess) {setTimeout(function() {console.log("fired chicken");sucess();},500) }// 炖鸡 function stewed(sucess) {setTimeout(function() {console.log("stewed chicken");sucess();},500) }// 上料 function sdd(sucess) {setTimeout(function() {console.log("sdd chicken");sucess();},500) }// 上菜 function serve(sucess) {setTimeout(function() {console.log("serve chicken");sucess();},500) }// 流程控制 function run(fn) {const gen = fn();function next() {// 返回工序函数的句柄给 resultconst result = gen.next();if (result.done) return; // 结束// result.value 就是yield返回的值,是各个工序的函数result.value(next); // value 就是制作过程中不同阶段的函数,next 作为入参,即本工序成功后,执行下一工序}next(); };//工序 function* task(){yield prepare;yield fired;yield stewed;yield sdd;yield serve; }//开始执行 run(task);
- 普通方法实现肚包鸡的制作过程:
使用举例
- 实现自增 id
function* next_id() {for (id = 1; ; id++) {yield id;} } - 实现 async 和 await 功能
- await 实现
const test = (data) => new Promise((resolve, reject) => {setTimeout(() => {resolve(data);}, 1000) })async function func(){const aaa = await test(1)const bbb = await test(2)return 3; } - Generator 实现
const test = (data) => new Promise((resolve, reject) => {setTimeout(()=>{resolve(data);}, 1000) })// 重点在这 function autoStart(generator) {const gen = generator();return new Promise((resolve, reject) => { // 最终应该返回一个 Promise 对象function _next(val) {const p = gen.next(val);if(p.done) { // 递归结束条件console.log(p.value);resolve(p.value);return; //递归结束}// p.value 即 test() 返回的 Promise,在 1000 毫秒后改变状态// 避免 p.value 为基本类型的情况,不然应该是 p.value.then()Promise.resolve(p.value).then(res => {// 在 Promise 改变状态的时候,也就是 1000 毫秒后运行_next(res); // 本质就是递归})}_next();}) }function* generator(){const aaa = yield test(1);console.log(aaa);const bbb = yield test(2);console.log(bbb)return 3; }let res = autoStart(generator);console.log(res); setTimeout(() => {console.log(res); }, 5000);
- await 实现
2. js 垃圾回收机制
为啥需要回收
在 js 中,数据类型分为简单类型和引用类型,简单类型,内存是保存在栈空间中,复杂数据类型,内存是保存在堆空间中
- 基本类型:这些类型在内存中分别占有固定大小的空间,他们的值保存在栈空间,通过按值来访问的
- 引用类型:引用类型,值大小不固定,栈内存中存放地址指向堆内存中的对象,是按引用访问的
对于栈的内存空间,只保存简单数据类型的内存,由操作系统自动分配和自动释放
而堆空间中的内存,由于大小不固定,系统无法无法进行自动释放,这个时候就需要JS引擎来手动的释放这些内存
js 两种 GC 机制
-
“引用计数”:
- 早期的浏览器最常使用的垃圾回收方法
- 语言引擎有一张"引用表",保存了内存里面所有的资源(通常是各种值)的引用次数。即数据存在堆内存中,如果一个值的引用次数是 0,就表示没有任何变量或数据指向它,因此可以将这块内存释放,被回收
- 但这种方法对于 obj1.a = obj2,obj2.a = obj1 这种互相指向的情况没有办法,obj1 和 obj2 通过各自的属性相互引用,所有它们的引用计数都不为零,这样就不会被垃圾回收机制回收,造成内存浪费,所以现在已经废弃不用了
- 引用计数算法其实还有一个比较大的缺点,就是我们需要单独拿出一片空间去维护每个变量的引用计数,这对于比较大的程序,空间开销还是比较大的
-
“标记清除”:
-
现在的浏览器最常使用的垃圾回收方法
-
核心思想:分标记和清除两个阶段完成
- 遍历所有对象找标记活动对象
- 遍历所有对象清除没有标记对象
- 回收相应的空间
-
标记阶段:
- 标记阶段就是找到可访问对象的一个过程;对象的可达性,垃圾回收是从一组对象的指针(objects pointers)开始的,我们将其称之为根集(root set),这其中包括了执行栈和全局对象;然后垃圾回收器会跟踪每一个指向 JavaScript 对象的指针,并将对象标记为可访问的,同时跟踪对象中每一个属性的指针并标记为可访问的,这个过程会递归的进行,直至所有节点没有可遍历的路径

-
清除阶段:
- 标志阶段结束后,未被打上标志的对象,说明从根节点无法访问它,垃圾回收器就会回收该内存
-
“标记清除算” 对比 “引用计数算法”,标记清除法最大的优点是能够回收循环引用的对象,它也是 v8 引擎使用最多的算法
-
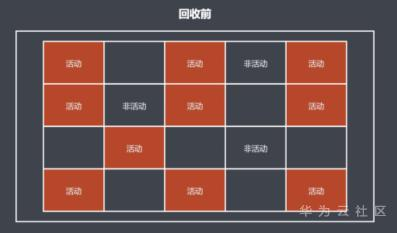
但还是存在缺点,空间碎片化:
红色区域是一个根对象,就是一个全局变量,会被标记;而蓝色区域就是没有被标记的对象,会被回收机制回收。这时就会出现一个问题,表面上蓝色区域被回收了三个空间,但是这三个空间是不连续的,当我们有一个需要三个空间的对象,那么我们刚刚被回收的空间是不能被分配的,这就是 “空间碎片化”
-
GC(垃圾回收)的收集方法
-
标记清除
- 上面说的,将未标记到的统一回收,但会造成空间碎片化
-
标记整理
- 为了解决 “空间碎片化” 的问题,提高对内存的利用
- 标记整理可以看做是标记清除的增强,标记阶段的操作和标记清除一致
- 清除阶段会先执行整理,移动对象位置,将存活的对象移动到一边,然后再清理端边界外的内存
- 但也还是存在缺点,回收前需要移动对象位置,不会立即回收对象,回收的效率比较慢
- 适合老年代进行垃圾收集


-
复制算法
- 也可以解决 “空间碎片化” 的问题,提高对内存的利用
- 它先将可用的内存按容量划分为大小相同的两块,每次只是用其中的一块。当这块内存用完了,就将还存活着的对象复制到另一块上面,然后把已经使用过的内存空间一次清理掉
- 牺牲空间换取时间,所以缺点是将内存缩小位原来的一半
- 适合新生代进行垃圾回收
- 改进思路:
由于新生代都是朝生夕死的,所以不需要1:1划分内存空间,可以将内存划分为一块较大的Eden和两块较小的Suvivor空间。每次使用Eden和其中一块Survivor。当回收的时候,将Eden和Survivor中还活着的对象一次性地复制到另一块Survivor空间上,最后清理掉Eden和刚才使用过的Suevivor空间。其中Eden和Suevivor的大小比例是8:1。缺点是需要老年代进行分配担保,如果第二块的Survovor空间不够的时候,需要对老年代进行垃圾回收,然后存储新生代的对象,这些新生代当然会直接进入来老年代

-
优化收集方法的思路(分代收集算法):
- 根据对象存活的周期的不同将内存划分为几块,然后再选择合适的收集算法
- 一般是分成新生代和老年代,这样就可以根据各个年待的特点采用最适合的收集算法。在新生代中,每次垃圾收集都会有大量的对象死去,只有少量存活,所以选用复制算法,老年代因为对象存活率高,没有额外空间对他进行分配担保,所以一般采用标记整理或者标记清除算法进行回收
V8引擎的内存回收策略
-
分代内存
在V8引擎的内存结构中,堆内存分为两类进行处理,新生代内存和老生代内存
- 新生代内存:是指临时分配内存,存活时间短
【 新生代内存可分为两个区域 From-space,To-space 】
【 其中 from 区域还可细分为 nursery 子代和 intermediate 子代 】 - 老生代内存:是常驻内存,存活时间长
【 新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了 】

- 新生代内存:是指临时分配内存,存活时间短
-
垃圾回收器
对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收- 副垃圾回收器 - Scavenge(复制算法):主要负责新生代的垃圾回收
- 主垃圾回收器 - Mark-Sweep & Mark-Compact(标记清除,标记整理):主要负责老生代的垃圾回收
-
晋升
- 如果新生代中的一个变量经过多次垃圾回收后,依旧存活。该对象就会被认为是一个声明周期较长的对象,被放入老生代内存中,对象从新生代转移到老生代的过程,称为晋升
- 对象晋升的条件有两个:
- 已经经历过一次 Scavenge(即在Form空间中的 intermediate 子代区域中的对象)
- To(当前闲置)空间内存占用超过25%
- 即在新生代中,分为 nursery 子代和 intermediate 子代两个区域,一个对象第一次分配内存时会被分配到新生代中的nursery子代,如果进过下一次垃圾回收这个对象还存在新生代中,这时候我们移动到 intermediate 子代,再经过下一次垃圾回收,如果这个对象还在新生代中,副垃圾回收器会将该对象移动到老生代中,这个移动的过程被称为晋升
-
采用分代收集算法
新生代采用 复制算法,老生代采用 标记整理 或 标记清楚 算法
新生代中,大部分对象在内存中存活的周期很短,所以需要一个效率非常高的算法
老生代中,对象都已经至少经历过一次或者多次的回收所以它们的存活概率会更大,支持的容量交大,会出现空间资源浪费问题
v8 解决全停顿问题
-
什么是全停顿:
- 由于垃圾回收是在JS引擎中进行的,而当活动对象较多的时候,它的执行速度不可能很快,为了避免JavaScript应用逻辑和垃圾回收器的内存资源竞争导致的不一致性问题,垃圾回收器会将 JavaScript 应用暂停,这个过程,被称为全停顿
- 在新生代中,由于空间小,存活对象较少,Scavenge算法执行效率较快,所以全停顿的影响并不大。而老生代中就不一样,如果老生代中的活动对象较多,垃圾回收器就会暂停主线程较长的时间,使得页面变得卡顿
- orinoco(V8的垃圾回收器) 为了提升用户体验,解决全停顿问题,它利用了增量标记、懒性清理、并发、并行来降低主线程挂起的时间
-
增量标记:(优化标记过程)
- 为了减少全停顿的时间,V8 对标记进行了优化,将一次停顿进行的标记过程,分成了很多小步。每执行完一小步就让应用逻辑执行一会儿,这样交替多次后完成标记
- 长时间的 “全停顿” 垃圾回收,用户体验感变得非常糟糕,同时会严重影响性能
- 从 2011 年起,v8 就将「全暂停」标记换成了增量标记。改进后的标记方式,最大停顿时间减少到原来的 1/6
- 由于每个小的增量标价之间执行了 JavaScript 代码,堆中的对象指针可能发生了变化,需要使用写屏障技术来记录这些引用关系的变化,所以也暴露出来增量标记的,缺点:
- 并没有减少主线程的总暂停的时间,甚至会略微增加
- 由于写屏障(Write-barrier)机制的成本,增量标记可能会降低应用程序的吞吐量

-
懒性清理:(优化清理过程)
- 当增量标记完成后,假如当前的可用内存足以让我们快速的执行代码,其实我们是没必要立即清理内存的,可以将清理的过程延迟一下,让 JavaScript 逻辑代码先执行,也无需一次性清理完所有非活动对象内存,垃圾回收器会按需逐一进行清理,直到所有的页都清理完毕
-
并发式GC:
- 并发式GC允许在在垃圾回收的同时不需要将主线程挂起,两者可以同时进行,只有在个别时候需要短暂停下来让垃圾回收器做一些特殊的操作。但是这种方式也要面对增量回收的问题,就是在垃圾回收过程中,由于JavaScript代码在执行,堆中的对象的引用关系随时可能会变化,所以也要进行写屏障操作

-
并行式GC
- 并行式GC允许主线程和辅助线程同时执行同样的GC工作,这样可以让辅助线程来分担主线程的GC工作,使得垃圾回收所耗费的时间等于总时间除以参与的线程数量(加上一些同步开销)

- 并行式GC允许主线程和辅助线程同时执行同样的GC工作,这样可以让辅助线程来分担主线程的GC工作,使得垃圾回收所耗费的时间等于总时间除以参与的线程数量(加上一些同步开销)
-
副垃圾回收器
- V8在新生代垃圾回收中,使用并行(parallel)机制,在整理排序阶段,也就是将活动对象从from-to复制到space-to的时候,启用多个辅助线程,并行的进行整理。由于多个线程竞争一个新生代的堆的内存资源,可能出现有某个活动对象被多个线程进行复制操作的问题,为了解决这个问题,V8在第一个线程对活动对象进行复制并且复制完成后,都必须去维护复制这个活动对象后的指针转发地址,以便于其他协助线程可以找到该活动对象后可以判断该活动对象是否已被复制

-
主垃圾回收器
- V8在老生代垃圾回收中,如果堆中的内存大小超过某个阈值之后,会启用并发(Concurrent)标记任务。每个辅助线程都会去追踪每个标记到的对象的指针以及对这个对象的引用,而在JavaScript代码执行时候,并发标记也在后台的辅助进程中进行,当堆中的某个对象指针被JavaScript代码修改的时候,写入屏障(write barriers)技术会在辅助线程在进行并发标记的时候进行追踪
- 当并发标记完成或者动态分配的内存到达极限的时候,主线程会执行最终的快速标记步骤,这个时候主线程会挂起,主线程会再一次的扫描根集以确保所有的对象都完成了标记,由于辅助线程已经标记过活动对象,主线程的本次扫描只是进行check操作,确认完成之后,某些辅助线程会进行清理内存操作,某些辅助进程会进行内存整理操作,由于都是并发的,并不会影响主线程JavaScript代码的执行

-
V8 当前解决全停顿问题的方案
2011 年,V8应用了增量标记机制。直至 2018 年,Chrome64 和 Node.js V10 启动并发标记,同时在并发的基础上添加并行技术,使得垃圾回收时间大幅度缩短
3. 内存泄漏与优化
内存泄漏
-
内存泄漏,指在 JS 中已经分配内存地址的对象由于长时间未进行内存释放或无法清除,造成了长期占用内存,使得内存资源浪费,最终导致运行的应用响应速度变慢以及最终崩溃的情况
-
作用域分为全局作用域和局部作用域,局部作用域分为函数作用域和块级作用域,全局作用域的变量就是全局变量,全局变量只有关闭页面才会回收,局部变量在使用完毕后就会被回收,比如一个函数里定义了一个变量,在这个函数运行完毕后这个变量就会被回收
-
在代码中创建对象和变量时会占据内存,但是 JS 基于自己的内存回收机制是可以确定哪些变量不再需要,并将其进行清除。但是,当你的代码中存在逻辑缺陷时,你以为你已经不需要,但是程序中还存在这引用,这就导致程序运行完后并没有进行合适的回收所占有的内存空间。运行时间越长占用内存越多,随之出现的问题就是:性能不佳、高延迟、频繁崩溃
造成内存泄漏的常见原因,及解决办法
- 原因:过多的缓存
解决办法:及时清理过多的缓存 - 原因:滥用闭包
解决办法:尽量避免使用大量的闭包,注意闭包,对闭包进行限制,不能无限制的增长(例如:当闭包里的数组进行 push 数据,超过一定长度,删除一些,再继续push) - 原因:定时器或回调太多
解决办法:与节点或数据相关联的计时器不再需要时,DOM节点对象可以清除,整个回调函数也不再需要。可是,计时器回调函数仍然没有被回收(计时器停止才会被回收) - 原因:当不需要setTimeout或setInterval时,定时器没有被清除,定时器的回调函数以及其内部依赖的变量都不能被回收,会造成内存泄漏
解决办法:在定时器完成工作时,需要手动清除定时器。 - 太多无效的DOM引用。DOM删除了,但是节点的引用还在,导致GC无法实现对其所占内存的回收
解决办法:给删除的DOM节点引用设置为null。 - 滥用全局变量。全局变量是根据定义无法被垃圾回收机制进行收集的,因此需要特别注意临时存储和处理大量信息的全局变量。如果必须使用全局变量来存储数据,请确保将其指定为null或在完成后重新分配它
解决办法:尽量不要定义全局变量,定义了也要及时手动回收(如:让这个变量的值等于 undefined、null 或重定义),使用严格模式 - 从外到内执行appendChild。此时即使调用removeChild也无法进行释放内存
解决办法:从内到外appendChild。 - 反复重写同一个数据会造成内存大量占用,但是IE浏览器关闭后会被释放
- 注意程序逻辑,避免编写『死循环』之类的代码
- 避免 DOM对象和 JS 对象相互引用
关于内存泄漏,如果想要更好地排查以及提前避免问题的发生,最好的解决方法是通过熟练使用 Chrome 的内存剖析工具,多分析多定位 Chrome 帮你分析保留的内存快照,来查看持续占用大量内存的对象
4. AST(抽象语法树)
AST 是什么
- AST是源代码语法结构的一种抽象表示,以树状的形式表现编程语言的语法结构,树上每个节点都表示源代码中的一种结构
常见用途
- 编辑器的错误提示,代码格式化,代码高亮,代码自动补全
- elint、pretiier 对代码错误或风格的检查
- webpack 通过 babel 转译 javascript 语法
AST 生成
- 代码执行的第一步是读取代码文件中的 字符流,然后通过 词法分析 生成 token,之后再通过 语法分析 生成 AST,最后 生成 机器码执行。整个解析过程主要分为以下两个步骤:
- 词法分析(或叫分词):将整个代码字符串分割成最小语法单元数组
- 语法分析:在分词基础上建立分析语法单元之间的关系
词法分析
- 词法分析,也称之为 扫描 或者 令牌化(Token),这一步主要是将字符流(char stream)转换为令牌流(token stream),就是在源代码的基础上进行分词,简单来说就是调用 next() 方法,一个一个字母的来读取字符,然后与定义好的 JavaScript 关键字符做比较,生成对应的 token,token 是一个不可分割的最小单元
- 词法分析器里,每个关键字是一个 token ,每个标识符是一个 token,每个操作符是一个 token,每个标点符号也都是一个 token。除此之外,还会过滤掉源程序中的注释和空白字符(换行符、空格、制表符等),最终,整个代码将被分割进一个 tokens 列表(或者说一维数组)
- 例如,词法分析器 从左往右逐个字符扫描分析 整个程序的字符串,当遇到不同的字符时,会驱使它迁移到不同的状态。在扫描字符的时候,遇到 c 字母,如果后面还有字符,将继续扫描,直到遇到空格,识别出 const,发现是一个关键字,将其生成词法单元 { type: ‘Keyword’, value: ‘const’ },然后接着扫描,以此类推,生成 Token List
语法分析
- 语法分析会将词法分析出来的 token 转化成有语法含义的抽象语法树结构(AST),同时验证语法,语法如果有错,会抛出语法错误
- 词法分析和语法分析不是完全独立的,而是交错进行的,也就是说,词法分析器不会在读取所有的词法记号后再使用语法分析器来处理。通常情况下,每取得一个词法记号,就将其送入语法分析器进行分析
举例
(使用的工具 AST explorer,详情)
function square(n) {return n * n;
}
经过转化,输出 AST 结构如下:

AST 的每一层都拥有相同的结构(为了简化,移除了某些属性):
{type: "FunctionDeclaration",id: {...},params: [...],body: {...}
}
{type: "Identifier",name: ...
}
{type: "BinaryExpression",operator: ...,left: {...},right: {...}
}
这样的每一层结构,被称为 节点(Node),每一个节点都包含 type 属性,用于表示节点类型,比如:FunctionDeclaration、Identifier、BinaryExpression 等等。除此之外,Babel 还为每个节点额外生成了一些属性,用于描述该节点在原始代码中的位置,比如: start、end、loc
还有一些例子,可以看出大概 AST 转换后的结构:
while b != 0
{if a > ba = a-belseb = b-a
}
return a

sum=0
for i in range(0,100)sum=sum+i
end

<letter><address><city>ShiChuang</city></address><people><id>12478</id><name>Nosic</name></people>
</letter>

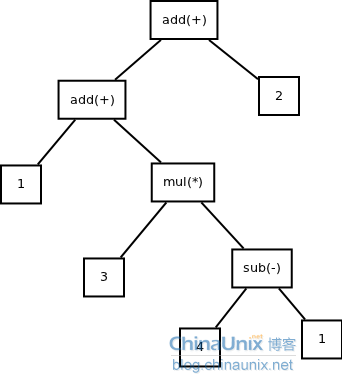
1 + 3 * ( 4 - 1 ) + 2
5. babel 工作原理(AST 的使用)
具体的看这,详情
节点类型(babel)
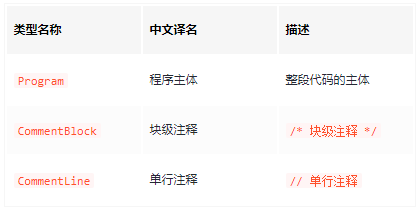
AST 节点类型,主要分为以下几个大类:字面量、标志符、语句、声明、表达式、注释 等等
- 字面量(Literal):

- 标志符(Identifier):
程序中所有的 变量名、函数名、对象键(key) 以及函数中的参数名,都属于标志符(Identifier) - 语句(Statement):
语句是能够独立执行的基本单位,常见的语句类型有

- 声明(Declaration):
声明语句是一种特殊的语句,它执行的逻辑是在作用域内声明一个 变量、函数、class、import、export 等

- 表达式(Expression):
表达式的特点是执行完以后有返回值,这是和语句 (statement) 的区别

- Comment & Program:
babel 编译流程
babel 的编译过程和大多数其他语言的编译器大致相同,可以分为 3 个阶段:解析 → 转换 → 生成
- 解析(Parser)
- 将代码字符串解析成抽象语法树(AST),每个 JavaScript 引擎(比如Chrome浏览器中的 V8 引擎)都有自己的 AST 解析器,而Babel是通过 @babel/parser 实现的。解析过程有两个阶段:词法分析 和 语法分析,词法分析阶段把字符串形式的代码转换为令牌(tokens)流,令牌类似于 AST 中节点;而语法分析阶段则会把一个令牌流转换成 AST 的形式,同时这个阶段会把令牌中的信息转换成 AST 的表述结构
- 转换(Transform)
- 对抽象语法树进行转换操作,转换步骤接收 AST 并对其进行遍历,在此过程中对节点进行添加、更新及移除等操作。 Babel 通过 @babel/traverse 对其进行深度优先遍历,维护 AST 树的整体状态,并且可完成对其的替换,删除或者增加节点,这个方法的参数为原始 AST 和自定义的转换规则,返回结果为转换后的 AST
- 生成(Generator)
- 根据变换后的抽象语法树再生成代码字符串,同时还会创建 源码映射(source maps)
- 代码生成其实很简单:深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串
- Babel 通过 @babel/generator 将 AST 转换成 js 代码,过程就是深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串
babel apis
我们知道 Babel 的编译流程分为三步:Parse → Transform → Generate,每一步都暴露了一些 Api 出来:
- 解析阶段:通过 @babel/parser 将源码转成 AST;
- 转换阶段:通过 @babel/traverse 遍历AST,并调用 visitor 函数修改 AST,期间涉及到 AST 的判断、创建、修改等,这时候就需要 @babel/types 了,当需要批量创建 AST 的时候可以使用 @babel/template 来简化 AST 创建逻辑
- 生成阶段:通过 @babel/generate 将 AST 输出为目标代码字符串,同时生成 sourcemap
- 中途遇到错误想打印代码位置的时候,使用 @babel/code-frame 包
- Babel 的整体功能通过 @babel/core 提供,基于上面的包完成 Babel 整体的编译流程,并实现插件功能
AST 实战(babel)
AST 实战
相关文章:
前端整理 —— javascript 2
1. generator(生成器) 详细介绍 generator 介绍 generator 是 ES6 提供的一种异步编程解决方案,在语法上,可以把它理解为一个状态机,内部封装了多种状态。执行generator,会生成返回一个遍历器对象。返回的…...
Spring-注解注入
一、回顾XML注解 bean 配置 创建 bean public class Student { } 配置 xml bean <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/beans"xmlns:xsi"http://www.w3.org/2001/XMLSche…...
)
华为校招机试 - 攻城战(Java JS Python)
目录 题目描述 输入描述 输出描述 用例 题目解析 JavaScript算法源码 Java算法源码...

Docker入门
Docker一、何为DockerDocker是一个开源的应用容器引擎,基于GO语言并遵循从Apache2.0协议开源。Docker可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后在发布到任何流行的Linux机器上,也可以实现虚拟化。容器是完全使…...

时间序列分析 | CNN-LSTM卷积长短期记忆神经网络时间序列预测(Matlab完整程序)
时间序列分析 | CNN-LSTM卷积长短期记忆神经网络时间序列预测(Matlab完整程序) 目录 时间序列分析 | CNN-LSTM卷积长短期记忆神经网络时间序列预测(Matlab完整程序)预测结果模型输出基本介绍完整程序参考资料预测结果 模型输出 layers = 具有以下层的 151 Layer 数组:...
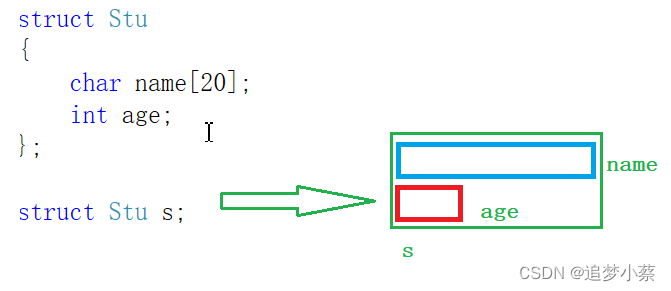
【蒸滴C】C语言结构体入门?看这一篇就够了
目录 一、结构体的定义 二、结构的声明 例子 三、 结构成员的类型 结构体变量的定义和初始化 1.声明类型的同时定义变量p1 2.直接定义结构体变量p2 3.初始化:定义变量的同时赋初值。 4.结构体变量的定义放在结构体的声明之后 5.结构体嵌套初始化 6.结构体…...

第十三届蓝桥杯
这里写目录标题一、刷题统计(ceil函数返回的是等值于某最小整数的浮点值,不强制转换回int就wa,没错就连和int整数相加都wa二、修剪灌木(主要应看清楚会调转方向三、统计子矩阵(前缀和滑动窗口⭐)四、[积木画…...

消息队列mq
应用场景: 1、解耦 2、削峰填谷 3、异步处理 4、消息通讯 工作模式: 一个消息只能被消费一次(订阅模式除外),消费者接受到消息会回调业务逻辑,消费逻辑写在回调函数里面。 1、简单模式:一个生产…...
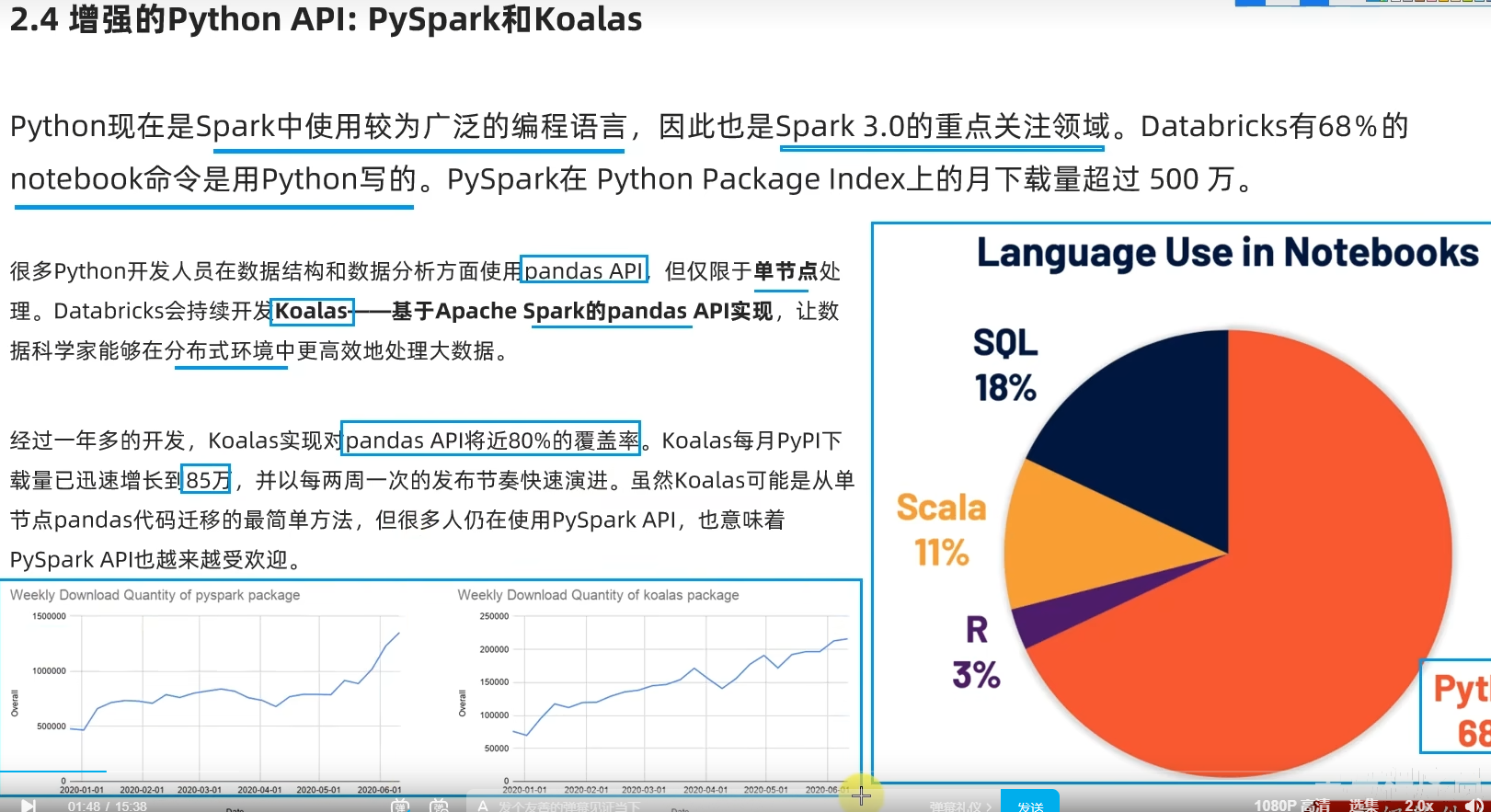
[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
文章目录视频资料:一、Spark基础入门(环境搭建、入门概念)第二章:Spark环境搭建-Local2.1 课程服务器环境2.2 Local模式基本原理2.3 安装包下载2.4 Spark Local模式部署第三章:Spark环境搭建-StandAlone3.1 StandAlone…...

git push和 git pull的使用
git push与git pull是一对推送/拉取分支的git命令。git push 使用本地的对应分支来更新对应的远程分支。$ git push <远程主机名> <本地分支名>:<远程分支名>*注意: 命令中的本地分支是指将要被推送到远端的分支,而远程分支是指推送的目标分支&am…...

首发,pm3包,一个用于多组(3组)倾向评分匹配的R包
目前,本人写的第二个R包pm3包已经正式在CRAN上线,用于3组倾向评分匹配,只能3组不能多也不能少。 可以使用以下代码安装 install.packages("pm3")什么是倾向性评分匹配?倾向评分匹配(Propensity Score Match…...
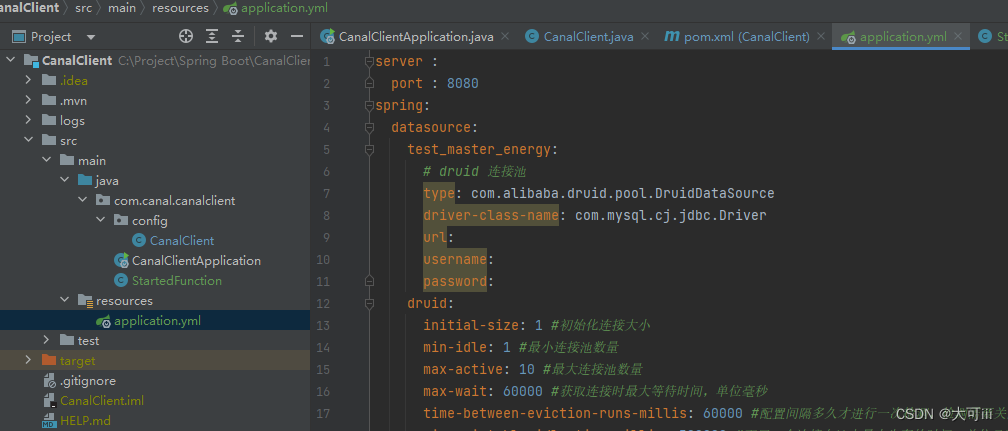
基于Canal的数据同步
基于Canal的数据同步 一、 系统结构 该数据同步系统由Spring Boot和Canal共同组成。 Spring Boot 是一个流行的 Java Web 框架,而 Canal 则是阿里巴巴开源的 MySQL 数据库的数据变更监听框架。结合 Spring Boot 和 Canal,可以实现 MySQL 数据库的实时数…...
vuetify设置页面默认主题色
前言 最近工作中接到一个任务: 项目中分light和dark两种主题色a、b页面默认为dark其他页面默认为light 项目前端环境: vue2jsyarnvuexvuetifyelement ui 解决思路 routerjs中配置路径时进行默认主题设置 在左侧aside点击菜单时,进行主题切…...

【Python入门第二十三天】Python 继承
Python 继承 继承允许我们定义继承另一个类的所有方法和属性的类。 父类是继承的类,也称为基类。 子类是从另一个类继承的类,也称为派生类。 创建父类 任何类都可以是父类,因此语法与创建任何其他类相同: 实例 创建一个名为…...

C#中,读取一个或多个文件内容的方法
读取一个或多个文件内容的方法 在C#中,可以使用File.ReadAllLines方法一次读取多个文件中的所有行内容。例如,以下代码读取了两个文件中的所有行内容,然后将它们合并在一起: string[] file1Lines File.ReadAllLines("file1…...

1 基于神经辐射场(neural Radiance Fileds, Nerf)的三维重建- 简介
Nerf简介 Nerf(neural Radiance Fileds) 为2020年ICCV上提出的一个基于隐式表达的三维重建方法,使用2D的 Posed Imageds 来生成(表达)复杂的三维场景。现在越来越多的研究人员开始关注这个潜力巨大的领域,也…...
水果FLStudio21.0.0中文版全能数字音乐工作站DAW
FL Studio 21.0.0官方中文版重磅发布纯正简体中文支持,更快捷的音频剪辑及素材管理器,多样主题随心换!Mac版新增对苹果M2/1家族芯片原生支持。编曲、剪辑、录音、混音,20余年的技术积淀和实力研发,FL Studio 已经从电音…...

【GlobalMapper精品教程】055:GM坐标转换器的巧妙使用
GM软件提供了一个简单实用的坐标转换工具,可以实现地理坐标和投影坐标之间的高斯正反算及多种转换计算。 文章目录 一、坐标转换器认识二、坐标转换案例1. 地理坐标←→地理坐标2. 地理坐标←→投影坐标三、在输出坐标上创建新的点四、其他转换工具的使用一、坐标转换器认识 …...
函数是如何实现的)
C语言之中rand()函数是如何实现的
rand()函数是一个C标准库中的随机数生成函数,用于生成一个范围在0到RAND_MAX之间的伪随机数。RAND_MAX是一个常量,它是随机数的最大值,通常被定义为32767。 rand()函数的实现原理可以概括为以下几个步骤: 初始化随机数生成器 在…...
winform控件PropertyGrid的应用(使运行中的程序能像vistual studio那样设置控件属性)
上周在看别人写的上位机demo代码时,发现创建的项目模板是"Windows 窗体控件库"(如下图) 生成的项目结构像自定义控件库,没有程序入口方法Main,但却很神奇能调试,最后发现原来Vistual Studio启动了一个外挂程序UserContr…...
配置DDR3的完整流程与常见错误排查)
FPGA开发避坑指南:Vivado 2023.1下MIG IP核(AXI4接口)配置DDR3的完整流程与常见错误排查
FPGA开发实战:Vivado 2023.1中MIG IP核配置DDR3的深度解析与高效排错 在FPGA开发领域,DDR3内存控制器的实现一直是工程师面临的技术挑战之一。Xilinx Vivado工具链中的Memory Interface Generator(MIG)IP核为这一难题提供了优雅的…...

终极指南:如何用VideoDownloadHelper快速下载网页视频
终极指南:如何用VideoDownloadHelper快速下载网页视频 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网页视频而烦…...

VR-Reversal:突破设备限制的3D视频转换工具
VR-Reversal:突破设备限制的3D视频转换工具 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh_mirrors/vr/V…...

用Neural Renderer和PyTorch搞定3D车辆模型渲染:从.obj文件到Carla数据集实战
3D车辆模型渲染实战:Neural Renderer与Carla数据集深度整合指南 在自动驾驶和计算机视觉领域,逼真的3D车辆模型渲染技术正成为算法开发和测试的关键环节。传统渲染方法往往难以平衡效率与真实感,而基于神经网络的渲染技术为解决这一难题提供了…...

汽车ECU BootLoader开发:基于CAN总线与MPC57XX系列MCU
汽车ECU BootLoader开发基于CAN总线通信MPC57XX系列MCU bootloader开发 文档54页 在汽车电子领域,ECU(Electronic Control Unit)的重要性不言而喻,而BootLoader则是ECU中关键的一环。今天咱们就来聊聊基于CAN总线通信,…...

BiliTools:革新性开源B站资源下载工具,零基础也能轻松掌握的跨平台解决方案
BiliTools:革新性开源B站资源下载工具,零基础也能轻松掌握的跨平台解决方案 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持视频、音乐、番剧、课程下载……持续更新 项目地址: https://gitcode…...

Rivets.js格式化器深度解析:自定义数据转换和业务逻辑处理
Rivets.js格式化器深度解析:自定义数据转换和业务逻辑处理 【免费下载链接】rivets Lightweight and powerful data binding. 项目地址: https://gitcode.com/gh_mirrors/ri/rivets Rivets.js是一个轻量级且功能强大的数据绑定库,它提供了灵活的格…...

Sealos安全架构完全指南:多租户环境下的终极防护策略
Sealos安全架构完全指南:多租户环境下的终极防护策略 【免费下载链接】sealos Sealos is a production-ready Kubernetes distribution that provides a one-stop solution for both public and private cloud. https://sealos.io 项目地址: https://gitcode.com/…...

终极指南:如何用DeepSpeech构建离线语音识别系统
终极指南:如何用DeepSpeech构建离线语音识别系统 【免费下载链接】DeepSpeech DeepSpeech is an open source embedded (offline, on-device) speech-to-text engine which can run in real time on devices ranging from a Raspberry Pi 4 to high power GPU serve…...

5大空间回收功能解决存储焦虑:Czkawka的极速扫描技术革命
5大空间回收功能解决存储焦虑:Czkawka的极速扫描技术革命 【免费下载链接】czkawka 一款跨平台的重复文件查找工具,可用于清理硬盘中的重复文件、相似图片、零字节文件等。它以高效、易用为特点,帮助用户释放存储空间。 项目地址: https://…...