漫谈数据库表设计及索引设计
一.数据库表设计
在数据库表设计上有个很重要的设计准则,称为范式设计。
什么是范式设计?
范式来自英文Normal Form,简称NF。MySQL是关系型数据库,但是要想设计—个好的关系,必须使关系满足一定的约束条件,此约束已经形成了规范,分成几个等级,一级比一级要求得严格。满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般来说,数据库只需满足第三范式(3NF)就行了。
1.1 第一范式
所有属性都不可再分,即数据项不可分,强调数据表的原子性,是其他范式的基础。
比如一个表中需要记录一个人的姓名和年龄,那么只能将name和名称拆分成两列,id,name,age,而不能设计为id,name-age。
如果仅仅使用第一范式来规范表格是远远不够的,依然会出现问题,此时需要引入规范化概念,将其转换为更标准的表格,减少数据依赖。第一范式是关系型数据库最基本的要求,如果数据库表的设计不符合这个最基本的要求,那么操作一定是不能成功的。
1.2 第二范式
第二范式是在第一范式的基础上建立起来的,要求数据库表中的每个实例或行必须可以被唯一地区分。即需要为表加上一个列,以实现各个实例的唯一标识,这个唯一属性列被称为主关键字或主码。还要求实体的属性完全依赖于主关键字。所谓完全依赖指不能存在仅仅依赖主关键字一部分的属性。如两张表
| 订单表ID | 订单时间 | 产品ID |
|---|---|---|
| 1 | 2023-02-26 | 1| |
| 产品表ID | 产品名称 |
|---|---|
| 1 | java |
| 2 | C |
一个订单有多个产品,所以订单的主键为 订单ID和产品ID组成的联合主键,不符合第二范式,而且产品ID和订单ID没有强关联,所以把订单表进行拆分为订单表与订单与商品的中间表
| 订单表ID | 订单时间 |
|---|---|
| 1 | 2023-02-26 |
中间表:
| 表ID | 订单表ID | 产品ID |
|---|---|---|
| 1 | 1 | 2 |
| 产品表ID | 产品名称 |
|---|---|
| 1 | java |
| 2 | C |
1.3 第三范式
指每一个非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主键对主键的传递依赖。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门介绍等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余
| 部门表ID | 部门编号 | 部门名称 | 部门介绍 |
|---|---|---|---|
| 1 | dep01 | 部门一 | 业务 |
| 2 | dep02 | 部门二 | 销售 |
| 员工表ID | 员工编号 | 员工所在部门ID | 部门名称 |
|---|---|---|---|
| 1 | dem01 | 1 | 部门一 |
| 2 | dem02 | 2 | 部门二 |
如果员工表中部门表的id发生变化,那么部门名称也会发生变化,这不符合第三范式,应该把部门名称这一列从员工表中删除。
1.4 反范式设计
如果完全符合三范式,也是有问题的,在实际的业务查询中会大量存在着表的关联查询,而大量的表关联很多的时候非常影响查询的性能。所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进行违反。允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间。
例如:商品信息表:
| 商品名称 | 出版社名称 | 图书价格 | 作者 |
|---|---|---|---|
| java | 人民出版社 | 10 | xxx |
分类表:
| 分类ID | 分类名称 |
|---|---|
| 1 | 计算机 |
商品和分类对应表
| 商品ID | 分类ID |
|---|---|
| 1 | 1 |
商品信息和分类信息经常一起查询,所以把分类信息也放到商品表里面,冗余存放。
| 商品名称 | 出版社名称 | 图书价格 | 作者 | 分类名称 |
|---|---|---|---|---|
| java | 人民出版社 | 10 | xxx | 计算机 |
范式化设计优缺点
- 范式化的更新操作通常比反范式化要快。
- 当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要修改更少的数据。
- 范式化的表通常更小,可以更好地放在内存里,所以执行操作会更快。
- 很少有多余的数据意味着检索列表数据时更少需要DISTINCT或者GROUP BY语句。在非范式化的结构中必须使用DISTINCT或者GROUPBY才能获得一份唯一的列表,但是如果是一张单独的表,很可能则只需要简单的查询这张表就行了。
范式化设计的缺点是通常需要关联。稍微复杂一些的查询语句在符合范式的表上都可能需要至少一次关联,也许更多。这不但代价昂贵,也可能使一些索引策略无效。例如,范式化可能将列存放在不同的表中,而这些列如果在一个表中本可以属于同一个索引。
反范式化设计优缺点
- 反范式设计可以减少表的关联
- 可以更好的进行索引优化。
反范式设计缺点也很明显,1、存在数据冗余及数据维护异常,2、对数据的修改需要更多的成本。
1.5 实际工作中的反范式实现
范式化和反范式化的各有优劣,怎么选择最佳的设计?
完全的范式化和完全的反范式化设计都是实验室里才有的东西,在真实世界中很少会这么极端地使用。在实际应用中经常需要混用。
性能提升-缓存和汇总
最常见的反范式化数据的方法是复制或者缓存,在不同的表中存储相同的特定列。
比如从父表冗余一些数据到子表的。前面我们看到的分类信息放到商品表里面进行冗余存放就是典型的例子。
缓存衍生值也是有用的。如果需要显示每个用户发了多少消息,可以每次执行一个对用户发送消息进行count的子查询来计算并显示它,也可以在user表用户中建一个消息发送数目的专门列,每当用户发新消息时更新这个值。
有需要时创建一张完全独立的汇总表或缓存表也是提升性能的好办法。“缓存表”来表示存储那些可以比较简单地从其他表获取(但是每次获取的速度比较慢)数据的表(例如,逻辑上冗余的数据)。而“汇总表”时,则保存的是使用GROUP BY语句聚合数据的表。
在使用缓存表和汇总表时,有个关键点是如何维护缓存表和汇总表中的数据,常用的有两种方式,实时维护数据和定期重建,这个取决于应用程序,不过一般来说,缓存表用实时维护数据更多点,往往在一个事务中同时更新数据本表和缓存表,汇总表则用定期重建更多,使用定时任务对汇总表进行更新。
性能提升-计数器表
计数器表在Web应用中很常见。比如网站点击数、用户的朋友数、文件下载次数等。对于高并发下的处理,首先可以创建一张独立的表存储计数器,这样可使计数器表小且快,并且可以使用一些更高级的技巧。
比如假设有一个计数器表,只有一行数据,记录网站的点击次数,网站的每次点击都会导致对计数器进行更新,问题在于,对于任何想要更新这一行的事务来说,这条记录上都有一个全局的互斥锁(mutex)。这会使得这些事务只能串行执行,会严重限制系统的并发能力。
怎么改进呢?可以将计数器保存在多行中,每次随机选择一行进行更新。在具体实现上,可以增加一个槽(slot)字段,然后预先在这张表增加100行或者更多数据,当对计数器更新时,选择一个随机的槽(slot)进行更新即可。
这种解决思路其实就是写热点的分散,在JDK的JDK1.8中新的原子类LongAdder也是这种处理方式,而我们在实际的缓冲中间件Redis等的使用、架构设计中,可以采用这种写热点的分散的方式,当然架构设计中对于写热点还有削峰填谷的处理方式,这种在MySQL的实现中也有体现。
反范式设计在分库分表中的查询
例如,用户购买了商品,需要将交易记录保存下来,那么如果按照买家的纬度分表,则每个买家的交易记录都被保存在同一表中, 我们可以很快、 很方便地査到某个买家的购买情况, 但是某个商品被购买的交易数据很有可能分布在多张表中, 査找起来比较麻烦 。 反之, 按照商品维度分表, 则可以很方便地査找到该商品的购买情况, 但若要査找到买家的交易记录, 则会比较麻烦 。
所以常见的解决方式如下。
( 1 ) 在多个分片表查询后合并数据集, 这种方式的效率很低。
( 2 ) 记录两份数据, 一份按照买家纬度分表, 一份按照商品维度分表,
( 3 ) 通过搜索引擎解决, 但如果实时性要求很高, 就需要实现实时搜索
在某电商交易平台下, 可能有买家査询自己在某一时间段的订单, 也可能有卖家査询自已在某一时间段的订单, 如果使用了分库分表方案, 则这两个需求是难以满足的, 因此, 通用的解决方案是, 在交易生成时生成一份按照买家分片的数据副本和一份按照卖家分片的数据副本,查询时分别满足之前的两个需求,因此,查询的数据和交易的数据可能是分别存储的,并从不同的系统提供接口。
二. 索引
2.1 聚集索引/聚簇索引
InnoDB中使用了聚集索引,就是将表的主键用来构造一棵B+树,并且将整张表的行记录数据存放在该B+树的叶子节点中。也就是所谓的索引即数据,数据即索引。由于聚集索引是利用表的主键构建的,所以每张表只能拥有一个聚集索引。
聚集索引的叶子节点就是数据页。换句话说,数据页上存放的是完整的每行记录。因此聚集索引的一个优点就是:通过聚集索引能获取完整的整行数据。另一个优点是:对于主键的排序查找和范围查找速度非常快。
如果我们没有定义主键呢?MySQL会使用唯一性索引,没有唯一性索引,MySQL也会创建一个隐含列RowID来做主键,然后用这个主键来建立聚集索引。

2.2 辅助索引/二级索引
上边介绍的聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的,那如果我们想以别的列作为搜索条件怎么办?我们一般会建立多个索引,这些索引被称为辅助索引/二级索引。
对于辅助索引(Secondary Index,也称二级索引、非聚集索引),叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了相应行数据的聚集索引键。
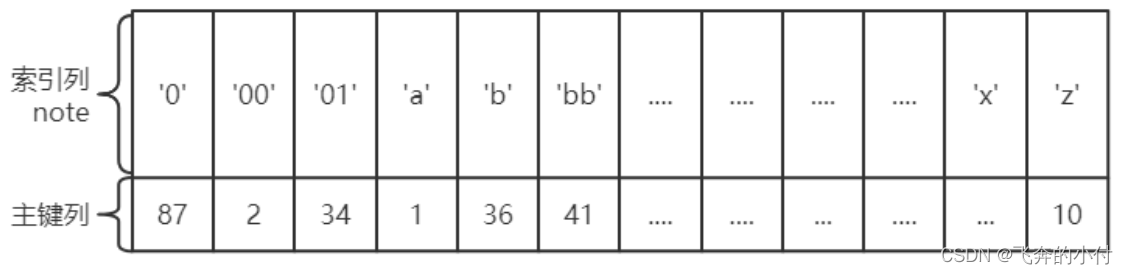
比如辅助索引index(node),那么叶子节点中包含的数据就包括了(主键、note)。
回表
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后再通过主键索引(聚集索引)来找到一个完整的行记录。这个过程也被称为回表。也就是根据辅助索引的值查询一条完整的用户记录需要使用到2棵B+树----一次辅助索引,一次聚集索引。
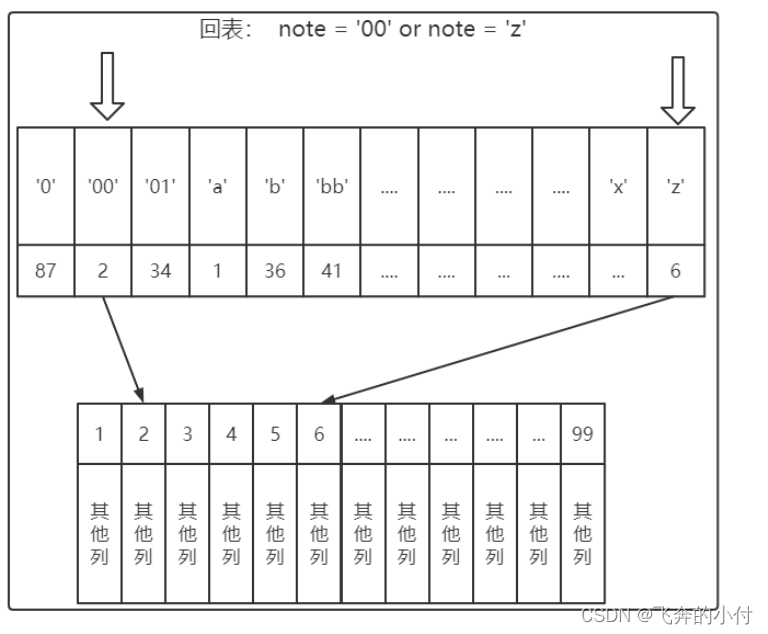
为什么我们还需要一次回表操作呢?直接把完整的用户记录放到辅助索引的叶子节点不就好了么?如果把完整的用户记录放到叶子节点是可以不用回表,但是太占地方了,相当于每建立一棵B+树都需要把所有的用户记录再都拷贝一遍,这就有点太浪费存储空间了。而且每次对数据的变化要在所有包含数据的索引中全部都修改一次,性能也非常低下。
很明显,回表的记录越少,性能提升就越高,需要回表的记录越多,使用二级索引的性能就越低,甚至让某些查询宁愿使用全表扫描也不使用二级索引。
那什么时候采用全表扫描的方式,什么时候使用采用二级索引 + 回表的方式去执行查询呢?这个就是查询优化器做的工作,查询优化器会事先对表中的记录计算一些统计数据,然后再利用这些统计数据根据查询的条件来计算一下需要回表的记录数,需要回表的记录数越多,就越倾向于使用全表扫描,反之倾向于使用二级索引 + 回表的方式。
MRR
从上文可以看出,每次从二级索引中读取到一条记录后,就会根据该记录的主键值执行回表操作。而在某个扫描区间中的二级索引记录的主键值是无序的,也就是说这些二级索引记录对应的聚簇索引记录所在的页面的页号是无序的。
每次执行回表操作时都相当于要随机读取一个聚簇索引页面,而这些随机IO带来的性能开销比较大。MySQL中提出了一个名为Disk-Sweep Multi-Range Read (MRR,多范围读取)的优化措施,即先读取一部分二级索引记录,将它们的主键值排好序之后再统一执行回表操作。
相对于每读取一条二级索引记录就立即执行回表操作,这样会节省一些IO开销。使用这个 MRR优化措施的条件比较苛刻,所以我们直接认为每读取一条二级索引记录就立即执行回表操作。
2.3 联合索引/复合索引
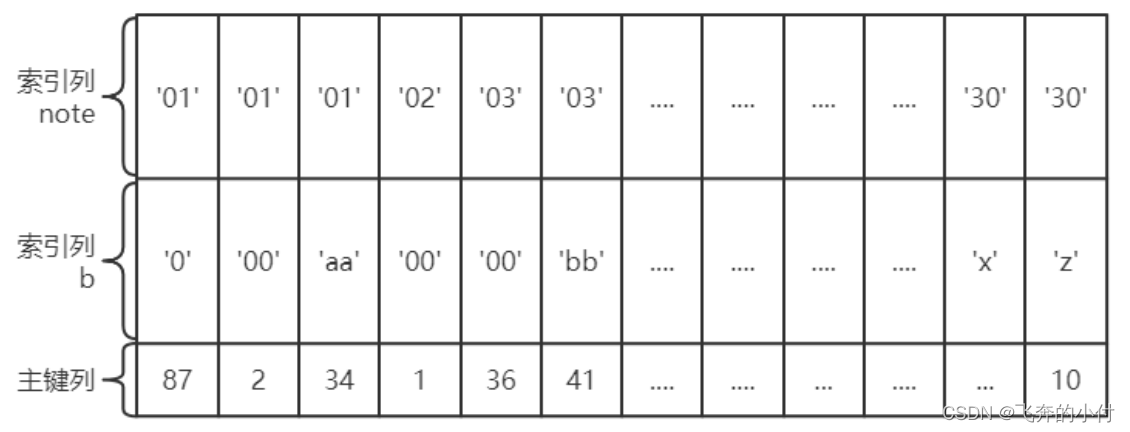
前面我们对索引的描述,隐含了一个条件,那就是构建索引的字段只有一个,但实践工作中构建索引的完全可以是多个字段。所以,将表上的多个列组合起来进行索引我们称之为联合索引或者复合索引,比如index(a,b)就是将a,b两个列组合起来构成一个索引。
千万要注意一点,建立联合索引只会建立1棵B+树,多个列分别建立索引会分别以每个列则建立B+树,有几个列就有几个B+树,比如,index(note)、index(b),就分别对note,b两个列各构建了一个索引。
index(note,b)在索引构建上,包含了两个意思:
1、先把各个记录按照note列进行排序。
2、在记录的note列相同的情况下,采用b列进行排序
2.4 自适应哈希索引
InnoDB存储引擎除了我们前面所说的各种索引,还有一种自适应哈希索引,我们知道B+树的查找次数,取决于B+树的高度,在生产环境中,B+树的高度一般为3~4层,故需3~4次的IO查询。
所以在InnoDB存储引擎内部自己去监控索引表,如果监控到某个索引经常用,那么就认为是热数据,然后内部自己创建一个hash索引,称之为自适应哈希索引( Adaptive Hash Index,AHI),创建以后,如果下次又查询到这个索引,那么直接通过hash算法推导出记录的地址,直接一次就能查到数据,比重复去B+tree索引中查询三四次节点的效率高了不少。
InnoDB存储引擎使用的哈希函数采用除法散列方式,其冲突机制采用链表方式。注意,对于自适应哈希索引仅是数据库自身创建并使用的,我们并不能对其进行干预。通过命令show engine innodb status\G可以看到当前自适应哈希索引的使用状况。
哈希索引只能用来搜索等值的查询,如 SELECT* FROM table WHERE index co=xxx。而对于其他查找类型,如范围查找,是不能使用哈希索引的,
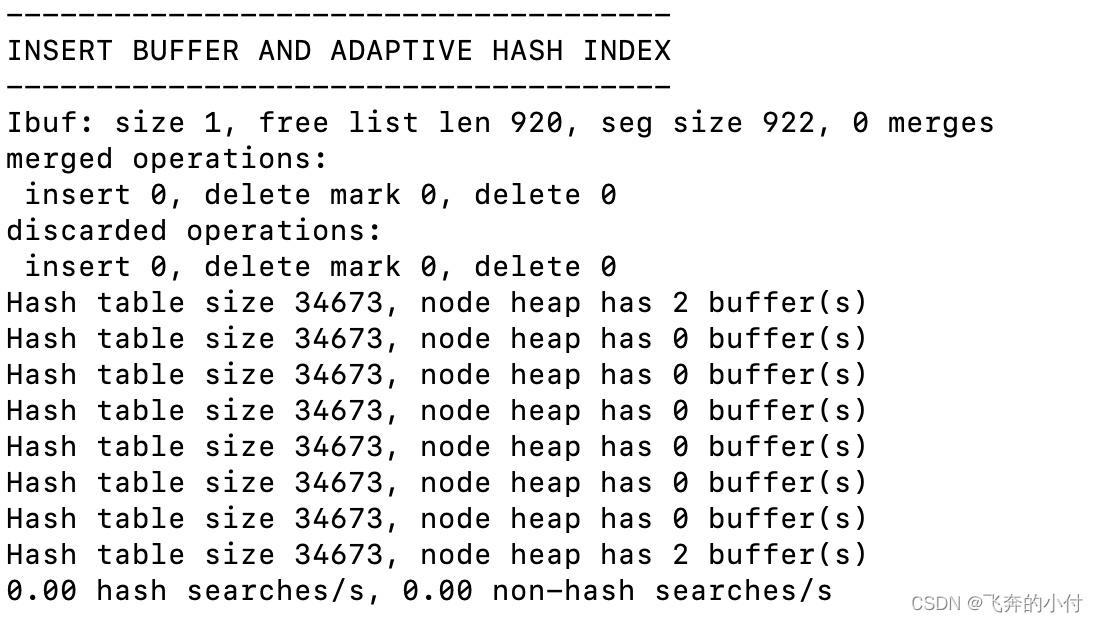
由于AHI是由 InnoDB存储引擎控制的,因此这里的信息只供我们参考。不过我们可以通过观察 SHOW ENGINE INNODB STATUS的结果及参数 innodb_adaptive_hash_index来考虑是禁用或启动此特性,默认AHI为开启状态。
什么时候需要禁用呢?如果发现监视索引查找和维护哈希索引结构的额外开销远远超过了自适应哈希索引带来的性能提升就需要关闭这个功能。
同时在MySQL 5.7中,自适应哈希索引搜索系统被分区。每个索引都绑定到一个特定的分区,每个分区都由一个单独的 latch 锁保护。分区由 innodb_adaptive_hash_index_parts 配置选项控制 。在早期版本中,自适应哈希索引搜索系统受到单个 latch 锁的保护,这可能成为繁重工作负载下的争用点。innodb_adaptive_hash_index_parts 默认情况下,该选项设置为8。最大设置为512。当然禁用或启动此特性和调整分区个数这个应该是DBA的工作,我们了解即可。
InnoDB三大特性:自适应hash,双写缓冲区,bufferpool
2.5 全文检索之倒排索引
倒排索引就是,将文档中包含的关键字全部提取处理,然后再将关键字和文档之间的对应关系保存起来,最后再对关键字本身做索引排序。用户在检索某一个关键字时,先对关键字的索引进行查找,再通过关键字与文档的对应关系找到所在文档。
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引。从InnoDB 1.2.x版本开始,InnoDB存储引擎开始支持全文检索,对应的MySQL版本是5.6.x系列,官方文档https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html。
注意,不管什么引擎,只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
不过MySQL从设计之初就是关系型数据库,存储引擎虽然支持全文检索,整体架构上对全文检索支持并不好而且限制很多,比如每张表只能有一个全文检索的索引,不支持没有单词界定符( delimiter)的语言,如中文、日语、韩语等。
所以如果有大批量或者专门的全文检索需求,还是应该选择专门的全文检索引擎。
创建
创建表时创建全文索引
create table fulltext_test (id int(11) NOT NULL AUTO_INCREMENT,content text NOT NULL,tag varchar(255),PRIMARY KEY (id),FULLTEXT KEY content_tag_fulltext(content,tag)
) DEFAULT CHARSET=utf8;
在已存在的表上创建全文索引
create fulltext index content_tag_fulltext on fulltext_test(content,tag);
通过 SQL 语句 ALTER TABLE 创建全文索引
alter table fulltext_test add fulltext index content_tag_fulltext(content,tag);
和常用的模糊匹配使用 like + % 不同,全文索引有自己的语法格式,使用 match 和 against 关键字,比如
select * from fulltext_test where match(content,tag) against('xxx xxx');
总结:MySQL有哪些索引类型
- 从数据结构角度可分为B+树索引、哈希索引、以及FULLTEXT索引(现在MyISAM和InnoDB引擎都支持了)和R-Tree索引(用于对GIS数据类型创建SPATIAL索引);
- 从物理存储角度可分为聚集索引(clustered index)、非聚集索引(non-clustered index);
- 从逻辑角度可分为主键索引、普通索引,或者单列索引、多列索引、唯一索引、非唯一索引等等。
2.6 密集索引和稀疏索引的区别
密集索引的定义:叶子节点保存的不只是键值,还保存了位于同一行记录里的其他列的信息,由于密集索引决定了表的物理排列顺序,一个表只有一个物理排列顺序,所以一个表只能创建一个密集索引。
稀疏索引:叶子节点仅保存了键位信息以及该行数据的地址,有的稀疏索引只保存了键位信息机器主键。
mysam存储引擎,不管是主键索引,唯一键索引还是普通索引都是稀疏索引,innodb存储引擎:有且只有一个密集索引。
所以,密集索引就是innodb存储引擎里的聚簇索引,稀疏索引就是innodb存储引擎里的普通二级索引。
2.7 索引覆盖
即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。所以记住,覆盖索引可以视为索引优化的一种方式,而并不是索引类型的一种。
三. 索引在查询中的使用
1、一个索引就是一个B+树,索引让我们的查询可以快速定位和扫描到我们需要的数据记录上,加快查询的速度。
2、一个select查询语句在执行过程中一般最多能使用一个二级索引来加快查询,即使在where条件中用了多个二级索引。
3.1 索引的代价
1.空间上的代价
这个是显而易见的,每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,一棵很大的B+树由许多数据页组成会占据很多的存储空间。
2.时间上的代价
每次对表中的数据进行增、删、改操作时,都需要去修改各个B+树索引。而且我们讲过,B+树每层节点都是按照索引列的值从小到大的顺序排序而组成了双向链表。不论是叶子节点中的记录,还是非叶子内节点中的记录都是按照索引列的值从小到大的顺序而形成了一个单向链表。
而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收的操作来维护好节点和记录的排序。如果我们建了许多索引,每个索引对应的B+树都要进行相关的维护操作,这必然会对性能造成影响。
既然索引这么有用,我们是不是创建越多越好?既然索引有代价,我们还是别创建了吧?当然不是!按照经验,一般来说,一张表6-7个索引以下都能够取得比较好的性能权衡。
3.2 高性能的索引创建策略
- 索引列的类型尽量小
我们在定义表结构的时候要显式的指定列的类型,以整数类型为例,有TTNYINT、MEDUMNT、INT、BIGTNT这么几种,它们占用的存储空间依次递增,我们这里所说的类型大小指的就是该类型表示的数据范围的大小。能表示的整数范围当然也是依次递增,如果我们想要对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,比如我们能使用INT就不要使用BIGINT,能使用NEDIUMINT就不要使用INT,这是因为:
·数据类型越小,在查询时进行的比较操作越快(CPU层次)
·数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘/0带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。
这个建议对于表的主键来说更加适用,因为不仅是聚簇索引中会存储主键值,其他所有的二级索引的节点处都会存储一份记录的主键值,如果主键适用更小的数据类型,也就意味着节省更多的存储空间和更高效的I/0。
- 创建索引应选择离散性高的列。
索引的选择性/离散性是指,不重复的索引值(也称为基数,cardinality)和数据表的记录总数(N)的比值,范围从1/N到1之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
很差的索引选择性就是列中的数据重复度很高,比如性别字段,不考虑政治正确的情况下,只有两者可能,男或女。那么我们在查询时,即使使用这个索引,从概率的角度来说,依然可能查出一半的数据出来。
- 前缀索引
有时候需要索引很长的字符列,这会让索引变得大且慢,我们可以使用前缀索引,这样可以大大节约索引空间,从而提高索引效率。但这样会降低索引的选择性,一般情况下我们需要保证某个列前缀的选择性也是足够高的,以满足查询性能。(尤其对于BLOB、TEXT或者很长的VARCHAR类型的列,应该使用前缀索引,因为MySQL不允许索引这些列的完整长度)。诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长(以便节约空间)。前缀应该足够长,以使得前缀索引的选择性接近于索引整个列。
阿里规范泰山版建议这个前缀长度为20比较合适,可以使用“count(distinct left(列名, 索引长度))/count(*)的区分度来确定”。
前缀索引是一种能使索引更小、更快的有效办法,但另一方面也有其缺点MySQL无法使用前缀索引做ORDER BY和GROUP BY,也无法使用前缀索引做覆盖扫描。
有时候后缀索引 (suffix index)也有用途(例如,找到某个域名的所有电子邮件地址)。MySQL原生并不支持反向索引,但是可以把字符串反转后存储,并基于此建立前缀索引。可以通过触发器或者应用程序自行处理来维护索引。
- 只为用于搜索、排序或分组的列创建索引
只为出现在WHERE 子句中的列、连接子句中的连接列创建索引,而出现在查询列表中的列一般就没必要建立索引了,除非是需要使用覆盖索引。又或者为出现在ORDER BY或GROUP BY子句中的列创建索引。
如果有了索引的话,恰巧这个分组顺序又和我们索引中的索引列的顺序是一致的,而我们的B+树索引又是按照索引列排好序的,这不正好么,所以可以直接使用B+树索引进行分组。和使用B+树索引进行排序是一个道理,分组列的顺序也需要和索引列的顺序一致。
- 合理设计组合索引
在一个多列B-Tree索引中,索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列,等等。所以,索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的ORDER BY、GROUP BY和DISTINCT等子句的查询需求。
所以多列索引的列顺序至关重要。对于如何选择索引的列顺序有一个经验法则:将选择性最高的列放到索引最前列。当不需要考虑排序和分组时,将选择性最高的列放在前面通常是很好的。这时候索引的作用只是用于优化WHERE条件的查找。在这种情况下,这样设计的索引确实能够最快地过滤出需要的行,对于在WHERE子句中只使用了索引部分前缀列的查询来说选择性也更高。
然而,性能不只是依赖于索引列的选择性,也和查询条件的有关。可能需要根据那些运行频率最高的查询来调整索引列的顺序,比如排序和分组,让这种情况下索引的选择性最高。
同时,在优化性能的时候,可能需要使用相同的列但顺序不同的索引来满足不同类型的查询需求。
- 主键尽量是很少改变的列
行是按照聚集索引物理排序的,如果主键频繁改变,物理顺序会变,mysql要不断调整B+树,中间可能会出现页面的分裂和合并等,会导致性能急剧下降。
- 处理冗余和重复索引、未使用的索引
MySQL允许在相同列上创建多个索引,无论是有意的还是无意的。MySQL需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能。重复索引是指在相同的列上按照相同的顺序创建的相同类型的索引。应该避免这样创建重复索引,发现以后也应该立即移除。
- 尽量使用三星索引
如果查询使用三星索引,一次查询通常只需要进行一次磁盘随机读以及一次窄索引片的扫描,因此其相应时间通常比使用一个普通索引的响应时间少几个数量级。
三星索引概念是在《Rrelational Database Index Design and the optimizers》 一书(这本书也是《高性能MySQL》作者强烈推荐的一本书)中提出来的。原文如下:
The index earns one star if it places relevant rows adjacent to each other,
a second star if its rows are sorted in the order the query needs,
and a final star if it contains all the columns needed for the query.
索引将相关的记录放到一起则获得一星;
如果索引中的数据顺序和查找中的排列顺序一致则获得二星;
如果索引中的列包含了查询中需要的全部列则获得三星。
二星(排序星):
在满足一星的情况下,当查询需要排序,group by、 order by,如果查询所需的顺序与索引是一致的(索引本身是有序的),是不是就可以不用再另外排序了,一般来说排序可是影响性能的关键因素。
三星(宽索引星):
在满足了二星的情况下,如果索引中所包含了这个查询所需的所有列(包括 where 子句 和 select 子句中所需的列,也就是覆盖索引),这样一来,查询就不再需要回表了,减少了查询的步骤和IO请求次数,性能几乎可以提升一倍。
一星按照原文稍微有点难以理解,其实它的意思就是:如果一个查询相关的索引行是相邻的或者至少相距足够靠近的话,必须扫描的索引片宽度就会缩至最短,也就是说,让索引片尽量变窄,也就是我们所说的索引的扫描范围越小越好。
这三颗星,哪颗最重要?第三颗星。因为将一个列排除在索引之外可能会导致很多磁盘随机读(回表操作)。第一和第二颗星重要性差不多,可以理解为第三颗星比重是50%,第一颗星为27%,第二颗星为23%,所以在大部分的情况下,会先考虑第一颗星,但会根据业务情况调整这两颗星的优先度。
四.总结
本文主要讲了数据库表设计的规范,三范式,反范式设计,及其各自优缺点,还介绍了索引,包括聚集索引、二级索引、组合索引、倒排索引等,以及对索引创建的优化策略,利用各种手段提高数据库表设计的性能。
相关文章:
漫谈数据库表设计及索引设计
一.数据库表设计 在数据库表设计上有个很重要的设计准则,称为范式设计。 什么是范式设计? 范式来自英文Normal Form,简称NF。MySQL是关系型数据库,但是要想设计—个好的关系,必须使关系满足一定的约束条件,…...

【JavaWeb】CSS基础知识:引入方式 + 选择器
CSS引入 CSS的引入有三种,三种的优缺点各不相同。 行内样式表 <!-- 行内样式表 --><!-- 相当于标签的一个属性 --><!-- 只对当前标签生效 --><!-- 优先级较高,会覆盖其他样式 --><p style"color: blue;">这是…...

02-前端-javaScript
文章目录JavaScript1,JavaScript简介2,JavaScript引入方式2.1 内部脚本2.2 外部脚本3,JavaScript基础语法3.1 书写语法3.2 输出语句3.3 变量3.3.1 全局变量var3.3.2 局部变量let3.3.3 常量const3.4 数据类型3.5 运算符3.5.1 \和区别 ▲3.5.2 …...

对链表学习的总结一
一,单链表结构定义 C/C++ 数组:一组具有相同类型数据的集合。结构体:不同类型数据的集合。 // Definition for singly-linked list. struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next...
还有个高级用法好用)
toSring()还有个高级用法好用
Object.prototype.toString()能够很好的判断数据的类型及内置对象 typeof xxx:能判断出number,string,undefined,boolean,object,function(null是object)Object.prototype.toString.call(xxx):能判断出大部分类型Array.isArray(xxx):判断是否为数组var test= Object.…...
Linux--多线程(3)
目录1. POSIX信号量1.1 概念2. 基于环形队列的生产消费者模型2.1 环形队列的基本原理2.2 基本实现思想3. 多生产多消费1. POSIX信号量 1.1 概念 信号量本质是一个计数器,申请了信号量以后,可以达到预定临界资源的效果。 POSIX信号量和SystemV信号量相同…...

【spring】事务
概述 1、什么事务 事务是数据库操作最基本单元,逻辑上一组操作,要么都成功,如果有一个失败所有操 作都失败 2、事务四个特性(ACID) (1)原子性 (2)一致性 (3…...

博通仍然是美股市场最好的芯片半导体股
来源:猛兽财经 作者:猛兽财经 博通(AVGO)是一家快速增长的半导体公司,并且有很高的股息分红,目前其股息收益率已经高出了平均水平3.2%,而且估值非常合理,仅为预期净利润的14倍。 虽然博通也受到了经济衰退影…...

java开发手册之异常日志
文章目录异常日志异常处理日志规约异常日志 异常处理 1.Java 类库中定义的一类 RuntimeException可以通过预先检查进行规避,而不应该通过 catch 来处理 比如:IndexOutOfBoundsException,NullPointerException 等等。 说明:无法通…...
P6专题:关于P6 EPPM和PPM的区别及选型
目录 引言 什么是 Primavera P6 项目管理? Primavera P6 PPM 关键点 Primavera P6 PPM 是独立工具还是企业工具? 什么是 Primavera P6 企业项目组合管理? 那么EPPM的windows-tool呢? P6 EPPM 适合谁? 更多对比…...
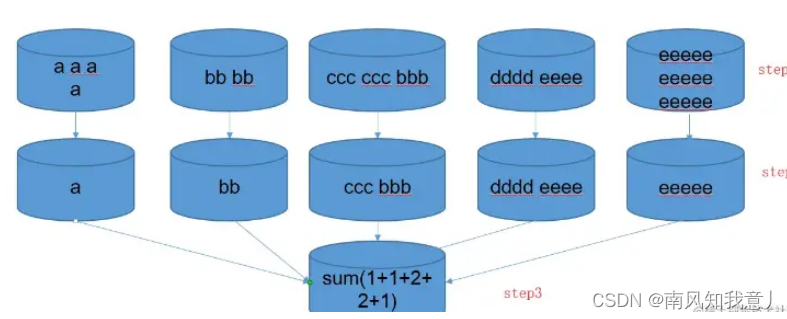
亿万级海量数据去重软方法
文章目录原理案例一需求:方法案例二需求:方法:参考原理 在大数据分布式计算框架生态下,提升计算效率的方法是尽可能的把计算分布式话、并行化,避免单节点计算过载,把计算分摊到各个节点。这样解释小白能够…...

记录--手摸手带你撸一个拖拽效果
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 最近看见一个拖拽效果的视频(抖音:艾恩小灰灰),看好多人评论说跟着敲也没效果,还有就是作者也不回复大家提出的一些疑问,本着知其然必要知其所以然…...
python高德地图+58租房网站平台源码
wx供重浩:创享日记 对话框发送:python地图 免费获取完整源码源文件说明文档配置教程等 在PyCharm中运行《高德地图58租房》即可进入如图1所示的高德地图网页。 具体的操作步骤如下: (1)打开地图网页后,在编…...
ubuntu 将jupyter-lab保存为桌面快捷方式和favourites
ubuntu: 将jupyter-lab保存为桌面快捷方式和favourites desktop shortcut 建立一个新的desktop文件 cd ~/Desktop touch Jupyter-lab.desktop将文件修改成如下: [Desktop Entry] Version1.0 NameJupyterlab CommentBack up your data with one click Exec/home/cjb/…...
Java 类和对象简介
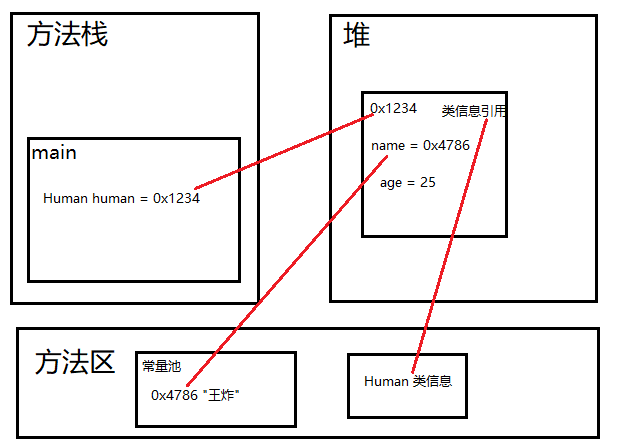
类是对象的抽象,是一组具有相同特性(属性,事物的状态信息)和行为(事物能做什么)的事物的集合,可以看做一类事物的模板。 对象是类的实例化,是具体的事物。 比如:人类和…...

时间复杂度的计算
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【数据结构初阶(C实现)】 文章目录123456789时间复杂度(就是一个函数)的计算,…...
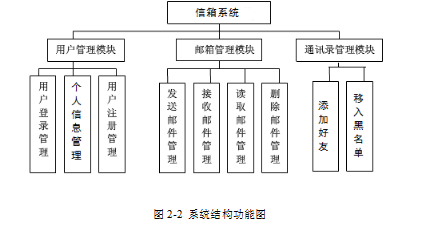
站内信箱系统的设计与实现
技术:Java、JSP等摘要:在经济全球化和信息技术成为发展迅速的今时今日,人们通过电子邮件收发进行信息传递已经成为主流。随着互联网和网络办公的发展,电子邮件正在被广泛应用在人们的日常生活中。跟据调查研究统计,在全…...

systemV共享内存
systemV共享内存 共享内存区是最快的IPC形式。共享内存的大小一般是4KB的整数倍,因为系统分配共享内存是以4KB为单位的(Page)!4KB也是划分内存块的基本单位。 之前学的管道,是通过文件系统来实现让不同的进程看到同一…...

Python基础之if逻辑判断
在学习if语句之前,我们先学习一种数据类型,布尔类型(bool),在if语句中,我们需要通过判断条件是否为真或者假,才进入下面的语句块执行。 一、布尔类型(bool) 布尔类型&a…...
实现pdf文件预览
前言 工作上接到的一个任务,实现pdf的在线预览,其实uniapp中已经有对应的api:uni.openDocument(OBJECT)(新开页面打开文档,支持格式:doc, xls, ppt, pdf, docx, xlsx, pptx。)**实现了相关功能…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...
32单片机——基本定时器
STM32F103有众多的定时器,其中包括2个基本定时器(TIM6和TIM7)、4个通用定时器(TIM2~TIM5)、2个高级控制定时器(TIM1和TIM8),这些定时器彼此完全独立,不共享任何资源 1、定…...