细数语音识别中的几个former
随着Transformer在人工智能领域掀起了一轮技术革命,越来越多的领域开始使用基于Transformer的网络结构。目前在语音识别领域中,Tranformer已经取代了传统ASR建模方式。近几年关于ASR的研究工作很多都是基于Transformer的改进,本文将介绍其中应用较为广泛的几个former架构。
1. Conformer

💡 Motivation & Method
Transformer模型擅长获取基于内容的全局信息但是对高细粒度的局部特征效果不佳,而CNN擅长获取局部特征信息对于全局信息则需要更多的层。他们希望将CNN和Transformer优势结合起来对音频序列的局部和全局依赖关系进行建模。
🌌 Model architecture
Conformer也是编码器-解码器结构,其中encoder由两个类似夹心饼干的前馈层组成,多头自注意力模块和卷积模块夹在两个前馈神经网络中间,紧接着Layernorm层。在本篇论文中,仅使用1层LSTM作为decoder。

卷积模块(CNN)
conformer的卷积模块包含点向卷积,GLU激活层,1-D深度卷积,Batchnorm,然后是swish激活层,其结构如下所示:

前馈模块(FFM)
前馈模块,第一个线性层使用4的扩展因子,第二个线性层将其投影回模型维度。使用了swish激活和pre-norm残差单元。

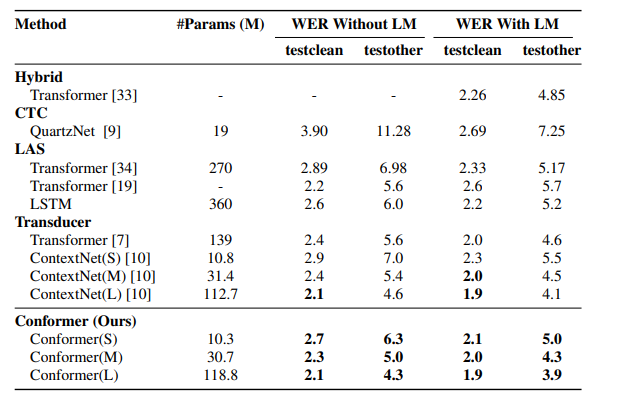
📊 Experiment results
在参数量相当的情况下Confomer可以达到比ContextNet更低的WER。当Conformer参数量为30.7M时,其WER甚至优于参数量为139M的Transformer结构。
🧮 Ablation Studies
本文一系列的消融实验验证了如下的几个结构和参数的最优配置
-
马卡龙风格的FFN优于残差结构的FFN
-
深度卷积优于轻量卷积
-
多头注意力头heads数目为4最好
-
CNN卷积核大小32最佳
模型最终在LibriSpeech test clean/test other测试集上分别获得了1.9%和3.9%的WER。

2. Branchformer

💡 Motivation & Method
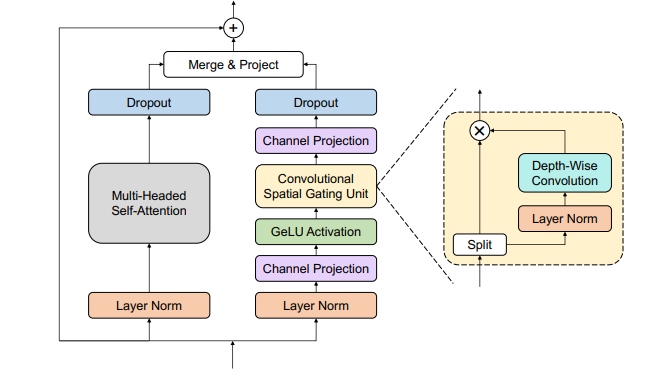
受Conformer启发,他们想提出了一种更灵活、可解释和可定制的encoder替代方案。Branchformer具有并行分支,可用于对端到端语音处理中的各种范围依赖关系进行建模。在每个encoder层中,一支使用self-attention来挖掘全局依赖关系,另一支使用带有卷积门控(cgMLP)的MLP模块来提取局部关系。
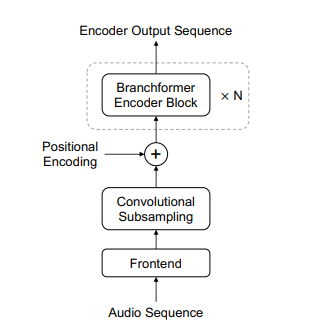
🌌 Model architecture
如下图所示,左边为encoder的总体结构。右边为Branchformer的结构。它由两个平行的分支组成。一个分支利用注意力捕获全局信息,而另一个分支利用带有卷积门控的MLP提取局部信息。
|
|
|
📊 Experiment results

3. EfficientConformer

💡 Motivation & Method
受Conformer启发,他们想在有限的计算预算下降低Conformer体系结构的复杂性。为了降低Conformer的复杂度,EfficientConformer进行了如下的优化:
-
使用渐进式下采样引入到Conformer编码器中
-
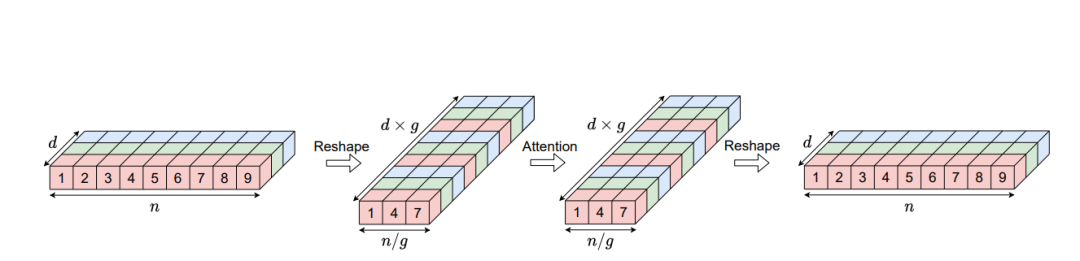
提出了一种名为分组注意力的新型注意力机制。增加grouped操作将自注意力模块的计算复杂度从O(n2d)降低为O(n2d/g),n为时间维度,d为隐层维度,g为group_size
🌌 Model architecture
EfficientConformer结构如下所示,它将原始的Conformer blocks分解为三步,前两个步在N个Conformer Block之后叠加Downsampling Block,沿着时间维度进行下采样;最后一步叠加N个Conformer Block,不再叠加Downsampling Block。

卷积模块(CNN)
上面是Conformer的CNN模块,下面是EfficientConformer的CNN模块。序列下采样是使用跨行深度卷积执行的。将DepthwiseConv的stride设置为大于1的值,从而实现时间维度下采样。因为下采样后输出的shape比输入的shape小,因此残差模块需要增加Pointwise Projection模块将输入和输出映射到相同的维度。

多头注意力模块(GMHA)
首先将Q、K、V的维度变换为(n/g, d*g),其中g为group_size,再进行attention计算,最后将维度变换为原始的(n, d)。变换后,注意力模块的计算复杂度可降低为O(n2d/g)
📊 Experiment results
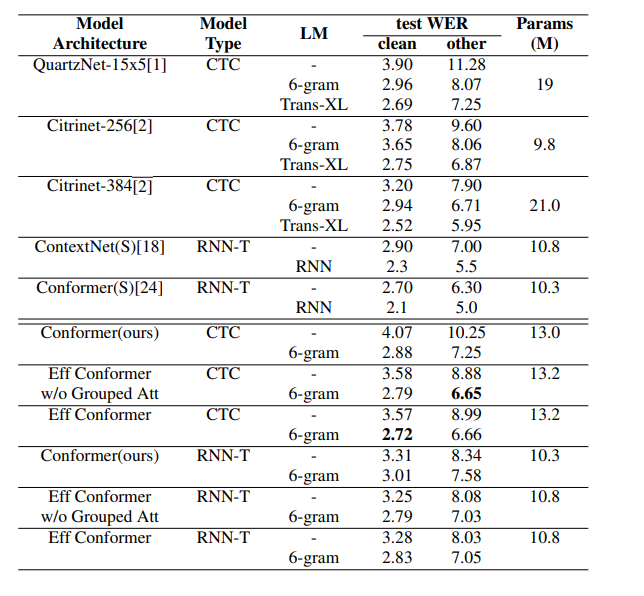
4. Squeezeformer

💡 Motivation & Method
他们发现Conformer架构的设计选择并不是最优的,它存在如下的一些问题:
-
Conformer学习到的网络深层相邻语音帧的特征表示具有很高的时间冗余性。
-
马卡龙结构以及背靠背多头注意力(MHA)和卷积模块过于复杂。这种复杂性使得很难在专用硬件平台上有效地部署模型进行推理而且对ASR效果是没必要的。
-
微观层面上的一些组件不够简洁且对ASR效果没帮助
在重新研究了Conformer的宏观和微观结构(宏观是指整体结构、微观指一些小的组件)的设计选择后,提出了Squeezeformer:
-
Temporal U-Net 结构: 结合Temporal U-Net,下采样层将网络中间的采样率减半,上采样层在最后恢复采样率以保持训练稳定性。
-
MFCF block 结构: 作者推荐采用self-attention + ffn + conv module + ffn (MFCF)的组合替代标准Conformer中ffn + self-attention + conv module + ffn(这里的1/2也被取消)。
-
微观架构改动: GLU被替换为Swish;同时作者推荐adaptive scale + PostLN的方式,代替单纯的PreLN或PostLN;subsampling中部分conv被替换为depthwise conv
🌌 Model architecture
Conformer结构(左)和Squeezeformer(右)结构包括用于采样率下采样和上采样的Temporal U-Net结构,仅使用层后归一化的标准transformer风格块结构,以及深度可分离的子采样层。

📊 Experiment results
条形图和线形图分别表示librisspeech test-other数据集上的WER和FLOPs。对于每次改进,都保持FLOPs差不多情况下对比Squeezeformer比Conformer模型降低1.40%的WER。

在LibriSpeech-960hr上进行实验。最后三列中包括了单个NVIDIA Tesla A100 GPU上的参数数量、FLOPs和吞吐量(Thp)

5. Zipformer

💡 Motivation & Method
受Conformer、Squeezeformer启发,他们想提出一种更快,更高效的内存,性能更好的Transformer。
-
类似u-net的编码器结构,其中中间层以较低的帧速率运行,不同层选择不同分辨率;
-
用更多的模块重组块结构,在块结构中重用注意力权重以提高效率;
-
将LayerNorm改进为BiasNorm用以保留一些长度信息;
-
使用功能比Swish更好的SwooshR和SwooshL激活函数。还提出了一个新的优化器,称为ScaledAdam,它按每个张量的当前规模缩放更新以保持相对变化大致相同,并且还显式学习参数规模。
🌌 Model architecture
前面两个blocks用的是50Hz(20ms)这个比Squeezeformer要高,后面的才变低。就是说有更多的采样率种类。

MHSA通过两步学习全局信息:使用点积运算计算注意力权重,并使用这些注意力权重聚合不同的帧信息。这两步复杂度较高。因此,作者将MHSA分解为两个独立的模块:多头注意力权重(MHAW)和自我注意力(SA)。通过使用一个MHAW模块和两个SA模块,更有效地执行两次注意力计算。此外,还提出了一个新的模块非线性注意力(NLA),以充分利用已计算的注意力权重来学习全局信息。
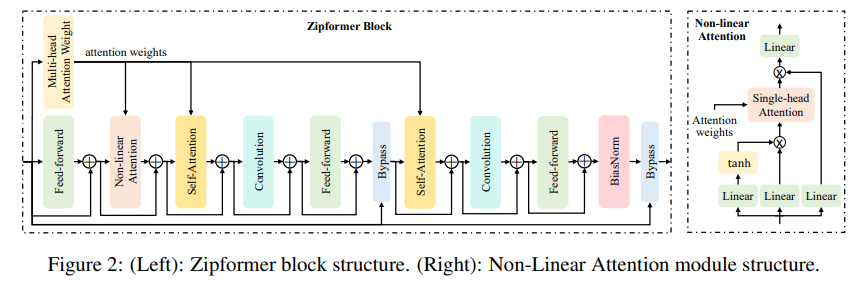
📊 Experiment results

🧮 Ablation Studies

6. Paraformer

💡 Motivation & Method
自回归解码效率很低。为加快推理速度,设计了非自回归(NAR)方法,以实现并行生成。目前NAR存在以下问题:
-
由于输出令牌的独立性假设,单步NAR的性能不如AR模型,特别是在大规模语料库中。
-
改进单步NAR存在两个挑战:一是准确预测输出令牌的数量并提取隐藏变量; 其次,增强对输出令牌之间相互依赖关系的建模。
-
旨在改进单步NAR模型,使其在大规模语料库上获得与AR模型相当的识别性能
为了解决上述问题,Paraformer的作者提出了如下的解决方案:
-
采用一个预测器(Predictor)来预测文字个数并通过Continuous integrate-and-fire (CIF)机制来抽取文字对应的声学隐变量。
-
受Glancing language model(GLM)启发,设计了一个基于GLM的 Sampler模块来增强模型对上下文语义的建模。
-
设计了一种生成负样本的策略来进行最小词错误率训练,以进一步提高性能。
自回归与非自回归结构如下所示,Transformer模型属于自回归模型,也就是说后面的token的推断是基于前面的token的。不能并行,如果使用非自回归模型的话可以极大提升其速度。

🌌 Model architecture
Paraformer可以分为5个部分,包括Encoder, Predictor, Sampler, Decoder 和Loss function。
-
Encoder 与自回归模型保持一致,可以为 Self-attention、SAN-M 或者 Conformer 结构
-
Predictor 为2层 DNN 模型,预测目标文字个数以及抽取目标文字对应的声学向量指导解码
-
Sampler 依据输入的声学向量和目标向量,生产含有语义的特征向量。(推理时不用)
-
Decoder 结构与自回归模型类似,为双向建模(自回归为单向建模)
-
Loss function 部分,除了交叉熵(CE)与 MWER 区分性优化目标,还包括了 Predictor 优化目标 MAE
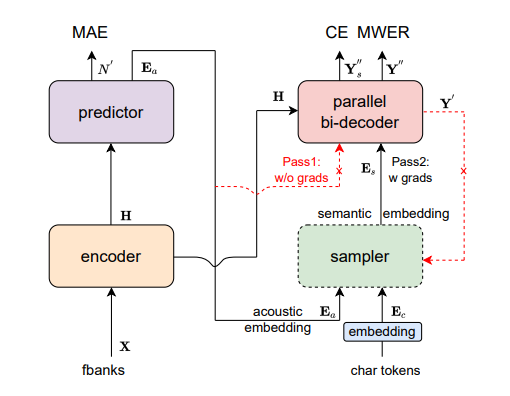
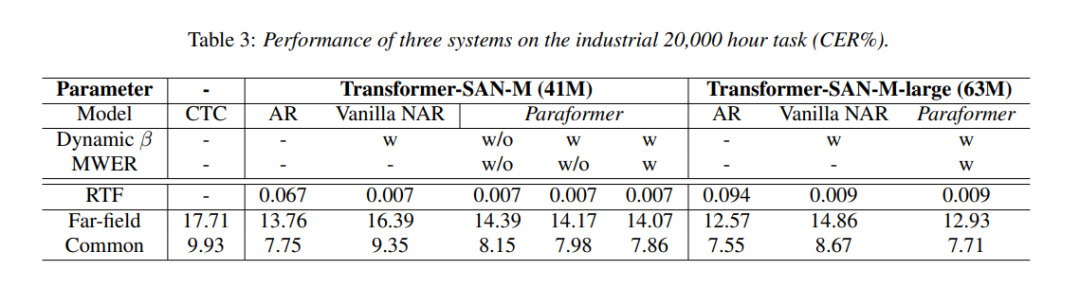
📊 Experiment results
在Aishell-1上的实验结果表明Paraformer以牺牲一点点精度为代价的情况下,将RTF提升了近10倍。

7. 总结
-
Conformer: 解决语音全局和局部信息的建模。提出的方案是CNN学习局部信息,Transformer学习全局信息,使用夹心饼干的方式结合两者。结果确实比transformer更好了。
-
Branchformer:提出了另一个CNN和Transformer结合的结构,Conformer是串行夹心饼干,它则是并行结合。
-
EfficientConformer:Conformer在深层的时间尺度上下采样提升效率。
-
Squeezeformer:从数据角度证实了时间维度上的冗余,使用U-Net对中间层降采样,从实验角度证明夹心饼干结构是次优。
-
Zipformer:使用了更多种采样率对transformer进行降采样。
-
Paraformer:使用非自回归方式建模。用实验证实了Transformer中的全局信息用token数量和token之间的关系就可以代替。
根据学术界和工业界的研究现状,目前大家主要解决的两个问题:
-
提升ASR推理效率;
-
ASR-Encoder如何更好地学习语音中全局和局部信息
最后,谈一下个人对ASR任务一些可能的工作方向:
1、如何ASR中的去冗余
去冗余的操作有利于语音识别中的效果和推理效率。语音信号包含信息冗余(除语义信息外其他信息,生理、心理)。另一方面,包含时间冗余(短时不变性)。从信号中摒除冗余有助于关注到需要的语义相关信息。就目前来说FBANK+CNN简单有效地提取到语义局部信息,降采样(从粗到细)可以降低时间维度上的冗余。结合语言学知识或许有更简单有效的表征方式等待探索。
2、ASR研究范式
可以从ASR研究范式中学到什么。早期ASR研究范式是专家知识驱动的。语言学规律指导建模。现在的ASR研究范式是数据驱动的,使用大模型大数据以任务为导向学习。前者依赖人的经验总结,而人的经验必然有很多遗漏是粗糙的。后者依赖数据,仍未达到最优。那应该如何逼近最优呢?数据->原理->模型,利用大数据大模型中间结果分析重新细化和更正语言学理论,再利用规律重设计和精简网络。
参考文献:
[1]. Gulati, A., Qin, J., Chiu, C.-C., et al. Conformer: Convolution-augmented Transformer for Speech Recognition[C]// Interspeech 2020, 5036-5040.
[2]. Peng Y, Dalmia S, Lane I, et al. Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding[C]//International Conference on Machine Learning. PMLR, 2022: 17627-17643.
[3]. Burchi M, Vielzeuf V. Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition[C]//2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021: 8-15.
[4]. Kim S, Gholami A, Shaw A, et al. Squeezeformer: An efficient transformer for automatic speech recognition[J]. Advances in Neural Information Processing Systems, 2022, 35: 9361-9373.
[5]. Yao Z, Guo L, Yang X, et al. Zipformer: A faster and better encoder for automatic speech recognition[J]. arXiv preprint arXiv:2310.11230, 2023.
[6]. Gao, Z., Zhang, S., McLoughlin, I., Yan, Z. (2022) Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition. Proc. Interspeech 2022, 2063-2067.
[7]. EfficientConformer https://zhuanlan.zhihu.com/p/573133117
[8]. Squeezeformer https://zhuanlan.zhihu.com/p/581923274
相关文章:
细数语音识别中的几个former
随着Transformer在人工智能领域掀起了一轮技术革命,越来越多的领域开始使用基于Transformer的网络结构。目前在语音识别领域中,Tranformer已经取代了传统ASR建模方式。近几年关于ASR的研究工作很多都是基于Transformer的改进,本文将介绍其中应…...
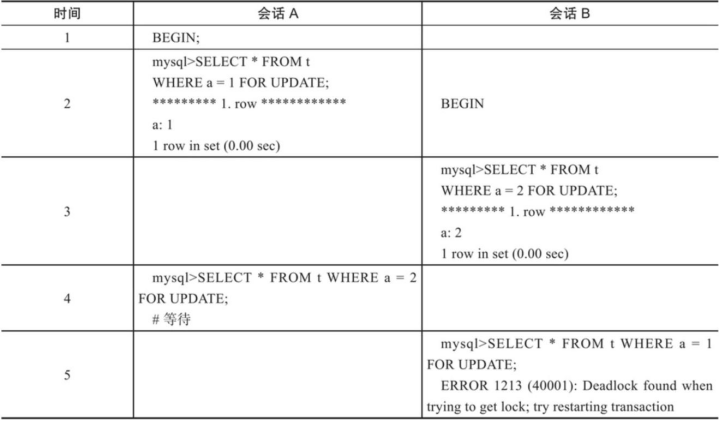
【MySQL进阶】锁
文章目录 锁概述全局锁语法特点 表级锁表锁意向锁 行级锁行锁间隙锁&临键锁 面试了解数据库的锁吗?介绍一下间隙锁InnoDB中行级锁是怎么实现的?数据库在什么情况下会发生死锁?说说数据库死锁的解决办法 锁 概述 锁机制:数据库…...

redis复制和分区:主从复制、哨兵模式和集群模式
概述 在 Redis 中,复制和分区是用于数据冗余和性能扩展的关键特性。以下是主从复制、哨兵模式和集群模式的工作原理的简要概述: 主从复制 (Replication) 基本概念:Redis 的主从复制功能允许多个 Redis 服务器具有相同的数据副本。这在读取操…...
个人实现的QT拼图游戏(开源),QT拖拽事件详解
文章目录 效果图引言玩法 拖拽概念基本概念如何在Qt中使用拖放注意事项 游戏关键问题总结 效果图 
gin渲染篇
1. 各种数据格式的响应 json、结构体、XML、YAML类似于java的properties、ProtoBuf package mainimport ("github.com/gin-gonic/gin""github.com/gin-gonic/gin/testdata/protoexample" )// 多种响应方式 func main() {// 1.创建路由// 默认使用了2个中…...

第三方控价服务商怎么选
用对了方法,事半功倍,品牌控价也是如此,品牌方在治理工作中,如果选择自建团队进行处理,需要包含对数据技术的抓取团队,还要有对治理规则熟悉的操作团队,涉及人员和系统,费用成本相应…...
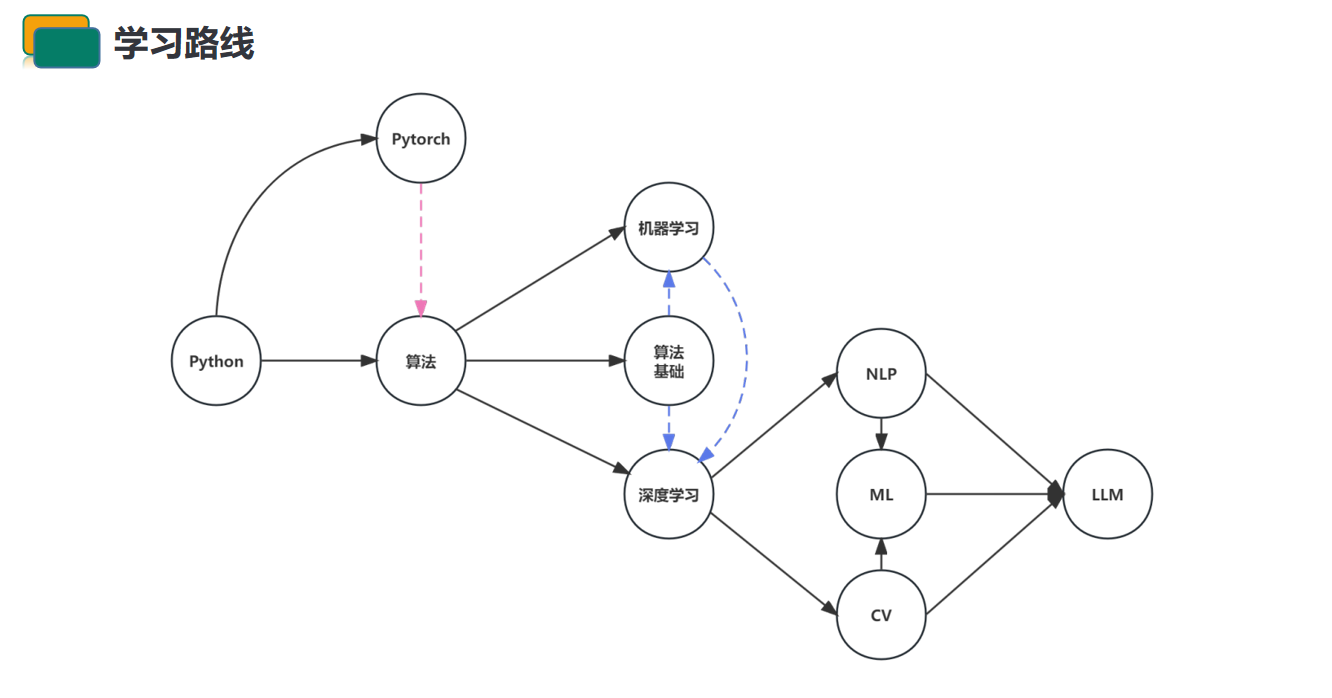
大模型的学习路线图推荐—多维度深度分析【云驻共创】
🐲本文背景 近年来,随着深度学习技术的迅猛发展,大模型已经成为学术界和工业界的热门话题。大模型具有数亿到数十亿的参数,这使得它们在处理复杂任务时表现得更为出色,但同时也对计算资源和数据量提出了更高的要求。 …...

【学习】focal loss 损失函数
focal loss用于解决正负样本的不均衡情况 通常我们需要预测的正样本要少于负样本,正负样本分布不均衡会带来什么影响?主要是两个方面。 样本不均衡的话,训练是低效不充分的。因为困难的正样本数量较少,大部分时间都在学习没有用…...

几个好玩好用的AI站点
本文作者系360奇舞团前端开发工程师 ai能力在去年一年飞速增长,各种AI产品如雨后春笋般冒出来,在各种垂直领域上似乎都有AI的身影出现,今天就总结几款好玩的场景,看大家工作生活中是否会用到。 先说一个比较重要的消息是ÿ…...

Java算法 leetcode简单刷题记录5
Java算法 leetcode简单刷题记录5 老人的数目: https://leetcode.cn/problems/number-of-senior-citizens/ substring(a,b) 前闭后开 统计能整除数字的位数: https://leetcode.cn/problems/count-the-digits-that-divide-a-number/ 并不复杂,…...
计算机网络自顶向下Wireshark labs1-Intro
Wireshark labs1 实验文档:http://www-net.cs.umass.edu/wireshark-labs/Wireshark_Intro_v8.0.pdf 介绍 加深对网络协议的理解通常可以通过观察协议的运行和不断调试协议来大大加深,具体而言,就是观察两个协议实体之间交换的报文序列&…...

CSS实现图片放大缩小的几种方法
参考 方法一: 常用使用img标签,制定width或者height的任意一个,图片会自动等比例缩小 <div><img src"https://avatar.csdn.net/8/5/D/1_u012941315.jpg"/> </div> <!-- CSS--> <style> img {widt…...
时间序列预测 — CNN-LSTM-Attention实现多变量负荷预测(Tensorflow):多变量滚动
专栏链接:https://blog.csdn.net/qq_41921826/category_12495091.html 专栏内容 所有文章提供源代码、数据集、效果可视化 文章多次上领域内容榜、每日必看榜单、全站综合热榜 时间序列预测存在的问题 现有的大量方法没有真正的预测未…...

angular-tree-component组件中实现特定节点自动展开
核心API 都在 expandToNode这个函数中 HTML treeData的数据结构大概如下 [{"key": "3293040275","id": "law_category/3293040275","name": "嘿嘿嘿嘿","rank": 0,"parentKey": "0&q…...

Linux系统下安装Vcpkg,并使用Vcpkg安装、编译OpenSceneGraph
环境:CentOS7 内存:8g(内存过少编译osg时会出现内存不足导致编译失败的情况,内存设置为4G时失败了,我直接加到了8g,所以就以8g为准了) 安装和配置vcpkg cd ~/ git clone https://www.github.com/microsoft/vcpkg cd …...
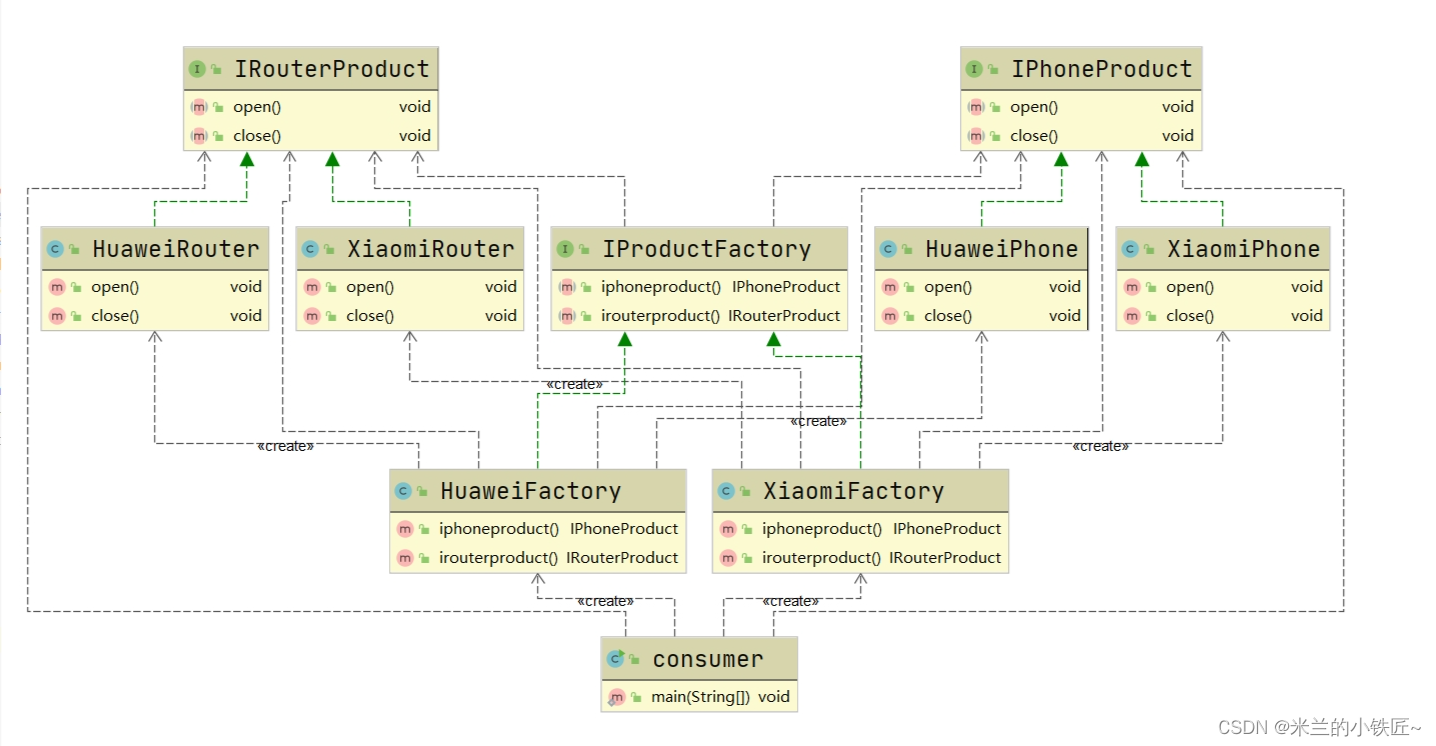
设计模式二(工厂模式)
本质:实例化对象不用new,用工厂代替,实现了创建者和调用者分离 满足: 开闭原则:对拓展开放,对修改关闭 依赖倒置原则:要针对接口编程 迪米特原则:最少了解原则,只与自己直…...

Maven应用手册
没加载出来就reimport,这个时候clean和install没用,那是编译安装项目的。 reimport干了什么? 结合idea的maven教程 父子模块 子模块不需要groupId ruoyi中父模块还添加了子模块的依赖,,, 先安装父再是子…...

笨蛋学设计模式行为型模式-状态模式【20】
行为型模式-状态模式 8.7状态模式8.7.1概念8.7.2场景8.7.3优势 / 劣势8.7.4状态模式可分为8.7.5状态模式8.7.6实战8.7.6.1题目描述8.7.6.2输入描述8.7.6.3输出描述8.7.6.4代码 8.7.7总结 8.7状态模式 8.7.1概念 状态模式是指对象在运行时可以根据内部状态的不同而改变它们…...
)
C++从零开始的打怪升级之路(day18)
这是关于一个普通双非本科大一学生的C的学习记录贴 在此前,我学了一点点C语言还有简单的数据结构,如果有小伙伴想和我一起学习的,可以私信我交流分享学习资料 那么开启正题 今天分享的是关于vector的题目 1.只出现一次的数字1 136. 只出…...

浅谈安科瑞直流电表在新加坡光伏系统中的应用
摘要:本文介绍了安科瑞直流电表在新加坡光伏系统中的应用。主要用于光伏系统中的电流电压电能的计量,配合分流器对发电量进行计量。 Abstract: This article introduces the application of Acrel DC meters in PV system in Indonesia.The device is …...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...