深度学习 Day27——J6ResNeXt-50实战解析
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
文章目录
- 前言
- 1 我的环境
- 2 pytorch实现DenseNet算法
- 2.1 前期准备
- 2.1.1 引入库
- 2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
- 2.1.3 导入数据
- 2.1.4 可视化数据
- 2.1.4 图像数据变换
- 2.1.4 划分数据集
- 2.1.4 加载数据
- 2.1.4 查看数据
- 2.2 搭建ResNeXt50模型
- 2.3 训练模型
- 2.3.1 设置超参数
- 2.3.2 编写训练函数
- 2.3.3 编写测试函数
- 2.3.4 正式训练
- 2.4 结果可视化
- 2.4 指定图片进行预测
- 2.6 模型评估
- 3 tensorflow实现DenseNet算法
- 3.1.引入库
- 3.2.设置GPU(如果使用的是CPU可以忽略这步)
- 3.3.导入数据
- 3.4.查看数据
- 3.5.加载数据
- 3.6.再次检查数据
- 3.7.配置数据集
- 3.8.可视化数据
- 3.9.构建ResNeXt50网络
- 3.10.编译模型
- 3.11.训练模型
- 3.12.模型评估
- 3.13.图像预测
- 4 知识点详解
- 4.1ResNeXt50详解
- 4.2 ResNeXt50对比ResNet50V2、DenseNet
- 4.2.1 网络结构
- 4.2.2 精度和计算量
- 4.2.3 适用范围
- 4 总结
前言
关键字: pytorch实现ResNeXt50详解算法,tensorflow实现ResNeXt50详解算法,ResNeXt50详解
1 我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:
torch == 1.9.1+cu111
torchvision == 0.10.1+cu111
TensorFlow 2.10.1 - 显卡:NVIDIA GeForce RTX 4070
2 pytorch实现DenseNet算法
2.1 前期准备
2.1.1 引入库
import torch
import torch.nn as nn
import time
import copy
from torchvision import transforms, datasets
from pathlib import Path
from PIL import Image
import torchsummary as summary
import torch.nn.functional as F
from collections import OrderedDict
import re
import torch.utils.model_zoo as model_zoo
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
"""前期准备-设置GPU"""
# 如果设备上支持GPU就使用GPU,否则使用CPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print("Using {} device".format(device))
输出
Using cuda device
2.1.3 导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\monkeypox_recognition"
data_dir = Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[-1] for path in data_paths]
print(classeNames)
输出
['Monkeypox', 'Others']2.1.4 可视化数据
'''前期工作-可视化数据'''
subfolder = Path(data_dir) / "Monkeypox"
image_files = list(p.resolve() for p in subfolder.glob('*') if p.suffix in [".jpg", ".png", ".jpeg"])
plt.figure(figsize=(10, 6))
for i in range(len(image_files[:12])):image_file = image_files[i]ax = plt.subplot(3, 4, i + 1)img = Image.open(str(image_file))plt.imshow(img)plt.axis("off")
# 显示图片
plt.tight_layout()
plt.show()
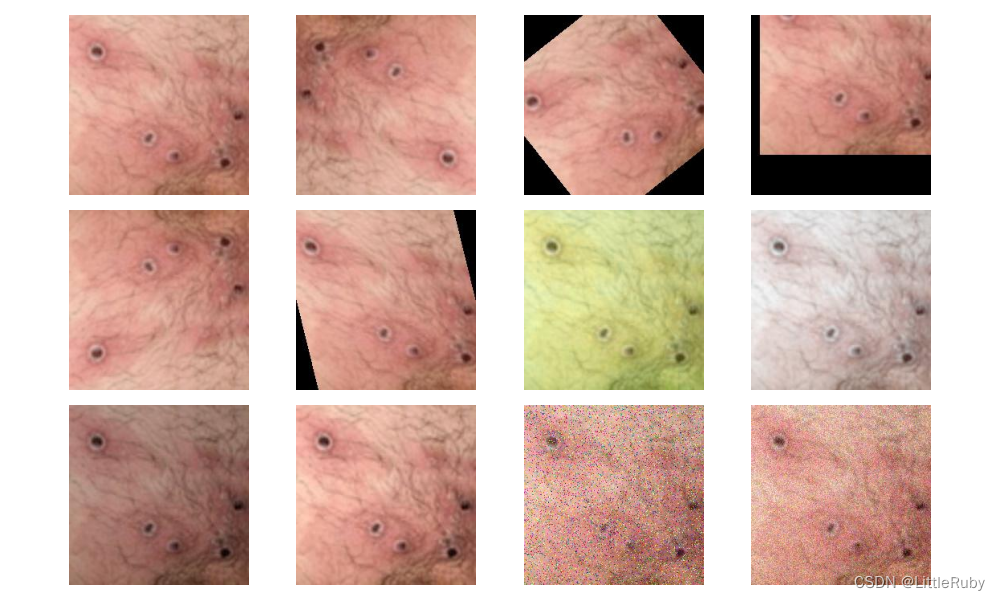
2.1.4 图像数据变换
'''前期工作-图像数据变换'''
total_datadir = data_dir# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
输出
Dataset ImageFolderNumber of datapoints: 2142Root location: D:\DeepLearning\data\monkeypox_recognitionStandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
{'Monkeypox': 0, 'Others': 1}2.1.4 划分数据集
'''前期工作-划分数据集'''
train_size = int(0.8 * len(total_data)) # train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;
test_size = len(total_data) - train_size # test_size表示测试集大小,是总体数据长度减去训练集大小。
# 使用torch.utils.data.random_split()方法进行数据集划分。该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,
# 并将划分结果分别赋值给train_dataset和test_dataset两个变量。
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print("train_dataset={}\ntest_dataset={}".format(train_dataset, test_dataset))
print("train_size={}\ntest_size={}".format(train_size, test_size))
输出
train_dataset=<torch.utils.data.dataset.Subset object at 0x000002A96E08E0D0>
test_dataset=<torch.utils.data.dataset.Subset object at 0x000002A96E04E640>
train_size=1713
test_size=429
2.1.4 加载数据
'''前期工作-加载数据'''
batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
2.1.4 查看数据
'''前期工作-查看数据'''
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
输出
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
2.2 搭建ResNeXt50模型
"""构建ResNeXt50网络"""class BN_Conv2d(nn.Module):"""BN_CONV_RELU"""def __init__(self, in_channels, out_channels, kernel_size, stride, padding, dilation=1, groups=1, bias=False):super(BN_Conv2d, self).__init__()self.seq = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=bias),nn.BatchNorm2d(out_channels))def forward(self, x):return F.relu(self.seq(x))class ResNeXt_Block(nn.Module):"""ResNeXt block with group convolutions"""def __init__(self, in_chnls, cardinality, group_depth, stride):super(ResNeXt_Block, self).__init__()self.group_chnls = cardinality * group_depthself.conv1 = BN_Conv2d(in_chnls, self.group_chnls, 1, stride=1, padding=0)self.conv2 = BN_Conv2d(self.group_chnls, self.group_chnls, 3, stride=stride, padding=1, groups=cardinality)self.conv3 = nn.Conv2d(self.group_chnls, self.group_chnls * 2, 1, stride=1, padding=0)self.bn = nn.BatchNorm2d(self.group_chnls * 2)self.short_cut = nn.Sequential(nn.Conv2d(in_chnls, self.group_chnls * 2, 1, stride, 0, bias=False),nn.BatchNorm2d(self.group_chnls * 2))def forward(self, x):out = self.conv1(x)out = self.conv2(out)out = self.bn(self.conv3(out))out += self.short_cut(x)return F.relu(out)class ResNeXt(nn.Module):"""ResNeXt builder"""def __init__(self, layers: object, cardinality, group_depth, num_classes) -> object:super(ResNeXt, self).__init__()self.cardinality = cardinalityself.channels = 64self.conv1 = BN_Conv2d(3, self.channels, 7, stride=2, padding=3)d1 = group_depthself.conv2 = self.___make_layers(d1, layers[0], stride=1)d2 = d1 * 2self.conv3 = self.___make_layers(d2, layers[1], stride=2)d3 = d2 * 2self.conv4 = self.___make_layers(d3, layers[2], stride=2)d4 = d3 * 2self.conv5 = self.___make_layers(d4, layers[3], stride=2)self.fc = nn.Linear(self.channels, num_classes) # 224x224 input sizedef ___make_layers(self, d, blocks, stride):strides = [stride] + [1] * (blocks - 1)layers = []for stride in strides:layers.append(ResNeXt_Block(self.channels, self.cardinality, d, stride))self.channels = self.cardinality * d * 2return nn.Sequential(*layers)def forward(self, x):out = self.conv1(x)out = F.max_pool2d(out, 3, 2, 1)out = self.conv2(out)out = self.conv3(out)out = self.conv4(out)out = self.conv5(out)out = F.avg_pool2d(out, 7)out = out.view(out.size(0), -1)out = F.softmax(self.fc(out), dim=1)return out该模型相比DenseNet的区别是,在最后一个denseblock后增加SE_layer。
# SE_layer
self.features.add_module('SE-module', Squeeze_excitation_layer(num_features))
输出
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,408BatchNorm2d-2 [-1, 64, 112, 112] 128BN_Conv2d-3 [-1, 64, 112, 112] 0Conv2d-4 [-1, 128, 56, 56] 8,192BatchNorm2d-5 [-1, 128, 56, 56] 256BN_Conv2d-6 [-1, 128, 56, 56] 0Conv2d-7 [-1, 128, 56, 56] 4,608BatchNorm2d-8 [-1, 128, 56, 56] 256BN_Conv2d-9 [-1, 128, 56, 56] 0Conv2d-10 [-1, 256, 56, 56] 33,024BatchNorm2d-11 [-1, 256, 56, 56] 512Conv2d-12 [-1, 256, 56, 56] 16,384BatchNorm2d-13 [-1, 256, 56, 56] 512ResNeXt_Block-14 [-1, 256, 56, 56] 0Conv2d-15 [-1, 128, 56, 56] 32,768BatchNorm2d-16 [-1, 128, 56, 56] 256BN_Conv2d-17 [-1, 128, 56, 56] 0Conv2d-18 [-1, 128, 56, 56] 4,608BatchNorm2d-19 [-1, 128, 56, 56] 256BN_Conv2d-20 [-1, 128, 56, 56] 0Conv2d-21 [-1, 256, 56, 56] 33,024BatchNorm2d-22 [-1, 256, 56, 56] 512Conv2d-23 [-1, 256, 56, 56] 65,536BatchNorm2d-24 [-1, 256, 56, 56] 512ResNeXt_Block-25 [-1, 256, 56, 56] 0Conv2d-26 [-1, 128, 56, 56] 32,768BatchNorm2d-27 [-1, 128, 56, 56] 256BN_Conv2d-28 [-1, 128, 56, 56] 0Conv2d-29 [-1, 128, 56, 56] 4,608BatchNorm2d-30 [-1, 128, 56, 56] 256BN_Conv2d-31 [-1, 128, 56, 56] 0Conv2d-32 [-1, 256, 56, 56] 33,024BatchNorm2d-33 [-1, 256, 56, 56] 512Conv2d-34 [-1, 256, 56, 56] 65,536BatchNorm2d-35 [-1, 256, 56, 56] 512ResNeXt_Block-36 [-1, 256, 56, 56] 0Conv2d-37 [-1, 256, 56, 56] 65,536BatchNorm2d-38 [-1, 256, 56, 56] 512BN_Conv2d-39 [-1, 256, 56, 56] 0Conv2d-40 [-1, 256, 28, 28] 18,432BatchNorm2d-41 [-1, 256, 28, 28] 512BN_Conv2d-42 [-1, 256, 28, 28] 0Conv2d-43 [-1, 512, 28, 28] 131,584BatchNorm2d-44 [-1, 512, 28, 28] 1,024Conv2d-45 [-1, 512, 28, 28] 131,072BatchNorm2d-46 [-1, 512, 28, 28] 1,024ResNeXt_Block-47 [-1, 512, 28, 28] 0Conv2d-48 [-1, 256, 28, 28] 131,072BatchNorm2d-49 [-1, 256, 28, 28] 512BN_Conv2d-50 [-1, 256, 28, 28] 0Conv2d-51 [-1, 256, 28, 28] 18,432BatchNorm2d-52 [-1, 256, 28, 28] 512BN_Conv2d-53 [-1, 256, 28, 28] 0Conv2d-54 [-1, 512, 28, 28] 131,584BatchNorm2d-55 [-1, 512, 28, 28] 1,024Conv2d-56 [-1, 512, 28, 28] 262,144BatchNorm2d-57 [-1, 512, 28, 28] 1,024ResNeXt_Block-58 [-1, 512, 28, 28] 0Conv2d-59 [-1, 256, 28, 28] 131,072BatchNorm2d-60 [-1, 256, 28, 28] 512BN_Conv2d-61 [-1, 256, 28, 28] 0Conv2d-62 [-1, 256, 28, 28] 18,432BatchNorm2d-63 [-1, 256, 28, 28] 512BN_Conv2d-64 [-1, 256, 28, 28] 0Conv2d-65 [-1, 512, 28, 28] 131,584BatchNorm2d-66 [-1, 512, 28, 28] 1,024Conv2d-67 [-1, 512, 28, 28] 262,144BatchNorm2d-68 [-1, 512, 28, 28] 1,024ResNeXt_Block-69 [-1, 512, 28, 28] 0Conv2d-70 [-1, 256, 28, 28] 131,072BatchNorm2d-71 [-1, 256, 28, 28] 512BN_Conv2d-72 [-1, 256, 28, 28] 0Conv2d-73 [-1, 256, 28, 28] 18,432BatchNorm2d-74 [-1, 256, 28, 28] 512BN_Conv2d-75 [-1, 256, 28, 28] 0Conv2d-76 [-1, 512, 28, 28] 131,584BatchNorm2d-77 [-1, 512, 28, 28] 1,024Conv2d-78 [-1, 512, 28, 28] 262,144BatchNorm2d-79 [-1, 512, 28, 28] 1,024ResNeXt_Block-80 [-1, 512, 28, 28] 0Conv2d-81 [-1, 512, 28, 28] 262,144BatchNorm2d-82 [-1, 512, 28, 28] 1,024BN_Conv2d-83 [-1, 512, 28, 28] 0Conv2d-84 [-1, 512, 14, 14] 73,728BatchNorm2d-85 [-1, 512, 14, 14] 1,024BN_Conv2d-86 [-1, 512, 14, 14] 0Conv2d-87 [-1, 1024, 14, 14] 525,312BatchNorm2d-88 [-1, 1024, 14, 14] 2,048Conv2d-89 [-1, 1024, 14, 14] 524,288BatchNorm2d-90 [-1, 1024, 14, 14] 2,048ResNeXt_Block-91 [-1, 1024, 14, 14] 0Conv2d-92 [-1, 512, 14, 14] 524,288BatchNorm2d-93 [-1, 512, 14, 14] 1,024BN_Conv2d-94 [-1, 512, 14, 14] 0Conv2d-95 [-1, 512, 14, 14] 73,728BatchNorm2d-96 [-1, 512, 14, 14] 1,024BN_Conv2d-97 [-1, 512, 14, 14] 0Conv2d-98 [-1, 1024, 14, 14] 525,312BatchNorm2d-99 [-1, 1024, 14, 14] 2,048Conv2d-100 [-1, 1024, 14, 14] 1,048,576BatchNorm2d-101 [-1, 1024, 14, 14] 2,048ResNeXt_Block-102 [-1, 1024, 14, 14] 0Conv2d-103 [-1, 512, 14, 14] 524,288BatchNorm2d-104 [-1, 512, 14, 14] 1,024BN_Conv2d-105 [-1, 512, 14, 14] 0Conv2d-106 [-1, 512, 14, 14] 73,728BatchNorm2d-107 [-1, 512, 14, 14] 1,024BN_Conv2d-108 [-1, 512, 14, 14] 0Conv2d-109 [-1, 1024, 14, 14] 525,312BatchNorm2d-110 [-1, 1024, 14, 14] 2,048Conv2d-111 [-1, 1024, 14, 14] 1,048,576BatchNorm2d-112 [-1, 1024, 14, 14] 2,048ResNeXt_Block-113 [-1, 1024, 14, 14] 0Conv2d-114 [-1, 512, 14, 14] 524,288BatchNorm2d-115 [-1, 512, 14, 14] 1,024BN_Conv2d-116 [-1, 512, 14, 14] 0Conv2d-117 [-1, 512, 14, 14] 73,728BatchNorm2d-118 [-1, 512, 14, 14] 1,024BN_Conv2d-119 [-1, 512, 14, 14] 0Conv2d-120 [-1, 1024, 14, 14] 525,312BatchNorm2d-121 [-1, 1024, 14, 14] 2,048Conv2d-122 [-1, 1024, 14, 14] 1,048,576BatchNorm2d-123 [-1, 1024, 14, 14] 2,048ResNeXt_Block-124 [-1, 1024, 14, 14] 0Conv2d-125 [-1, 512, 14, 14] 524,288BatchNorm2d-126 [-1, 512, 14, 14] 1,024BN_Conv2d-127 [-1, 512, 14, 14] 0Conv2d-128 [-1, 512, 14, 14] 73,728BatchNorm2d-129 [-1, 512, 14, 14] 1,024BN_Conv2d-130 [-1, 512, 14, 14] 0Conv2d-131 [-1, 1024, 14, 14] 525,312BatchNorm2d-132 [-1, 1024, 14, 14] 2,048Conv2d-133 [-1, 1024, 14, 14] 1,048,576BatchNorm2d-134 [-1, 1024, 14, 14] 2,048ResNeXt_Block-135 [-1, 1024, 14, 14] 0Conv2d-136 [-1, 512, 14, 14] 524,288BatchNorm2d-137 [-1, 512, 14, 14] 1,024BN_Conv2d-138 [-1, 512, 14, 14] 0Conv2d-139 [-1, 512, 14, 14] 73,728BatchNorm2d-140 [-1, 512, 14, 14] 1,024BN_Conv2d-141 [-1, 512, 14, 14] 0Conv2d-142 [-1, 1024, 14, 14] 525,312BatchNorm2d-143 [-1, 1024, 14, 14] 2,048Conv2d-144 [-1, 1024, 14, 14] 1,048,576BatchNorm2d-145 [-1, 1024, 14, 14] 2,048ResNeXt_Block-146 [-1, 1024, 14, 14] 0Conv2d-147 [-1, 1024, 14, 14] 1,048,576BatchNorm2d-148 [-1, 1024, 14, 14] 2,048BN_Conv2d-149 [-1, 1024, 14, 14] 0Conv2d-150 [-1, 1024, 7, 7] 294,912BatchNorm2d-151 [-1, 1024, 7, 7] 2,048BN_Conv2d-152 [-1, 1024, 7, 7] 0Conv2d-153 [-1, 2048, 7, 7] 2,099,200BatchNorm2d-154 [-1, 2048, 7, 7] 4,096Conv2d-155 [-1, 2048, 7, 7] 2,097,152BatchNorm2d-156 [-1, 2048, 7, 7] 4,096ResNeXt_Block-157 [-1, 2048, 7, 7] 0Conv2d-158 [-1, 1024, 7, 7] 2,097,152BatchNorm2d-159 [-1, 1024, 7, 7] 2,048BN_Conv2d-160 [-1, 1024, 7, 7] 0Conv2d-161 [-1, 1024, 7, 7] 294,912BatchNorm2d-162 [-1, 1024, 7, 7] 2,048BN_Conv2d-163 [-1, 1024, 7, 7] 0Conv2d-164 [-1, 2048, 7, 7] 2,099,200BatchNorm2d-165 [-1, 2048, 7, 7] 4,096Conv2d-166 [-1, 2048, 7, 7] 4,194,304BatchNorm2d-167 [-1, 2048, 7, 7] 4,096ResNeXt_Block-168 [-1, 2048, 7, 7] 0Conv2d-169 [-1, 1024, 7, 7] 2,097,152BatchNorm2d-170 [-1, 1024, 7, 7] 2,048BN_Conv2d-171 [-1, 1024, 7, 7] 0Conv2d-172 [-1, 1024, 7, 7] 294,912BatchNorm2d-173 [-1, 1024, 7, 7] 2,048BN_Conv2d-174 [-1, 1024, 7, 7] 0Conv2d-175 [-1, 2048, 7, 7] 2,099,200BatchNorm2d-176 [-1, 2048, 7, 7] 4,096Conv2d-177 [-1, 2048, 7, 7] 4,194,304BatchNorm2d-178 [-1, 2048, 7, 7] 4,096ResNeXt_Block-179 [-1, 2048, 7, 7] 0Linear-180 [-1, 4] 8,196
================================================================
Total params: 37,574,724
Trainable params: 37,574,724
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 379.37
Params size (MB): 143.34
Estimated Total Size (MB): 523.28
----------------------------------------------------------------
None2.3 训练模型
2.3.1 设置超参数
"""训练模型--设置超参数"""
loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数
learn_rate = 1e-4 # 学习率
optimizer1 = torch.optim.SGD(model.parameters(), lr=learn_rate)# 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大
optimizer2 = torch.optim.Adam(model.parameters(), lr=learn_rate)
lr_opt = optimizer2
model_opt = optimizer2
# 调用官方动态学习率接口时使用2
lambda1 = lambda epoch : 0.92 ** (epoch // 4)
# optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(lr_opt, lr_lambda=lambda1) #选定调整方法2.3.2 编写训练函数
"""训练模型--编写训练函数"""
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)X, y = X.to(device), y.to(device) # 用于将数据存到显卡# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # 清空过往梯度loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新网络参数# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
2.3.3 编写测试函数
"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()#统计预测正确的个数test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss2.3.4 正式训练
"""训练模型--正式训练"""
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_test_acc=0for epoch in range(epochs):milliseconds_t1 = int(time.time() * 1000)# 更新学习率(使用自定义学习率时使用)# adjust_learning_rate(lr_opt, epoch, learn_rate)model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, model_opt)scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = lr_opt.state_dict()['param_groups'][0]['lr']milliseconds_t2 = int(time.time() * 1000)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E}')if best_test_acc < epoch_test_acc:best_test_acc = epoch_test_acc#备份最好的模型best_model = copy.deepcopy(model)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E},Update the best model')print(template.format(epoch + 1, milliseconds_t2-milliseconds_t1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
Epoch: 1, duration:15650ms, Train_acc:54.8%, Train_loss:1.187, Test_acc:59.9%,Test_loss:1.147, Lr:1.00E-04,Update the best model
Epoch: 2, duration:15311ms, Train_acc:62.2%, Train_loss:1.112, Test_acc:58.7%,Test_loss:1.150, Lr:1.00E-04
Epoch: 3, duration:15336ms, Train_acc:67.3%, Train_loss:1.067, Test_acc:62.9%,Test_loss:1.117, Lr:1.00E-04,Update the best model
Epoch: 4, duration:14853ms, Train_acc:68.0%, Train_loss:1.061, Test_acc:65.0%,Test_loss:1.093, Lr:1.00E-04,Update the best model
Epoch: 5, duration:14930ms, Train_acc:68.0%, Train_loss:1.059, Test_acc:64.6%,Test_loss:1.087, Lr:1.00E-04
Epoch: 6, duration:15118ms, Train_acc:67.2%, Train_loss:1.067, Test_acc:60.1%,Test_loss:1.126, Lr:1.00E-04
Epoch: 7, duration:15024ms, Train_acc:67.8%, Train_loss:1.059, Test_acc:68.5%,Test_loss:1.050, Lr:1.00E-04,Update the best model
Epoch: 8, duration:14973ms, Train_acc:66.9%, Train_loss:1.065, Test_acc:67.6%,Test_loss:1.074, Lr:1.00E-04
Epoch: 9, duration:14902ms, Train_acc:69.3%, Train_loss:1.049, Test_acc:64.1%,Test_loss:1.099, Lr:1.00E-04
Epoch:10, duration:15237ms, Train_acc:70.2%, Train_loss:1.035, Test_acc:71.6%,Test_loss:1.024, Lr:1.00E-04,Update the best model
Epoch:11, duration:14890ms, Train_acc:71.0%, Train_loss:1.029, Test_acc:73.4%,Test_loss:1.010, Lr:1.00E-04,Update the best model
Epoch:12, duration:14951ms, Train_acc:70.5%, Train_loss:1.034, Test_acc:70.2%,Test_loss:1.043, Lr:1.00E-04
Epoch:13, duration:14967ms, Train_acc:72.3%, Train_loss:1.020, Test_acc:71.8%,Test_loss:1.022, Lr:1.00E-04
Epoch:14, duration:14966ms, Train_acc:73.8%, Train_loss:1.004, Test_acc:72.5%,Test_loss:1.017, Lr:1.00E-04
Epoch:15, duration:14886ms, Train_acc:75.5%, Train_loss:0.987, Test_acc:72.3%,Test_loss:1.015, Lr:1.00E-04
Epoch:16, duration:14895ms, Train_acc:72.6%, Train_loss:1.012, Test_acc:72.5%,Test_loss:1.025, Lr:1.00E-04
Epoch:17, duration:15037ms, Train_acc:74.3%, Train_loss:0.994, Test_acc:73.2%,Test_loss:1.016, Lr:1.00E-04
Epoch:18, duration:14797ms, Train_acc:76.5%, Train_loss:0.976, Test_acc:70.6%,Test_loss:1.026, Lr:1.00E-04
Epoch:19, duration:15157ms, Train_acc:72.6%, Train_loss:1.018, Test_acc:72.0%,Test_loss:1.018, Lr:1.00E-04
Epoch:20, duration:14767ms, Train_acc:73.1%, Train_loss:1.009, Test_acc:74.4%,Test_loss:1.003, Lr:1.00E-04,Update the best model2.4 结果可视化
"""训练模型--结果可视化"""
epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

2.4 指定图片进行预测
def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片plt.show()test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))"""指定图片进行预测"""
classes = list(total_data.class_to_idx)
# 预测训练集中的某张照片
predict_one_image(image_path=str(Path(data_dir) / "Monkeypox/M01_01_01.jpg"),model=model,transform=train_transforms,classes=classes)
输出
预测结果是:Monkeypox2.6 模型评估
"""模型评估"""
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
# 查看是否与我们记录的最高准确率一致
print(epoch_test_acc, epoch_test_loss)输出
0.7435897435897436 0.99769913298743113 tensorflow实现DenseNet算法
3.1.引入库
from PIL import Image
import numpy as np
from pathlib import Path
import matplotlib.pyplot as plt# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import tensorflow as tf
from keras import layers, models, Input
from keras.layers import Input, Activation, BatchNormalization, Flatten
from keras.layers import Dense, Conv2D, MaxPooling2D, ZeroPadding2D, GlobalMaxPooling2D, AveragePooling2D, Flatten, \Dropout, BatchNormalization, GlobalAveragePooling2D
from keras.models import Model
from keras import regularizers
from tensorflow import keras
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
3.2.设置GPU(如果使用的是CPU可以忽略这步)
'''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
# 检查GPU是否可用
print(tf.test.is_built_with_cuda())
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0], "GPU")
执行结果
True
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
3.3.导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\monkeypox_recognition"
data_dir = Path(data_dir)
3.4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
image_list = list(data_dir.glob('Monkeypox/*.jpg'))
image = Image.open(str(image_list[1]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.axis("off")
plt.show()
执行结果:
图片总数为: 2142
JPEG (224, 224) RGB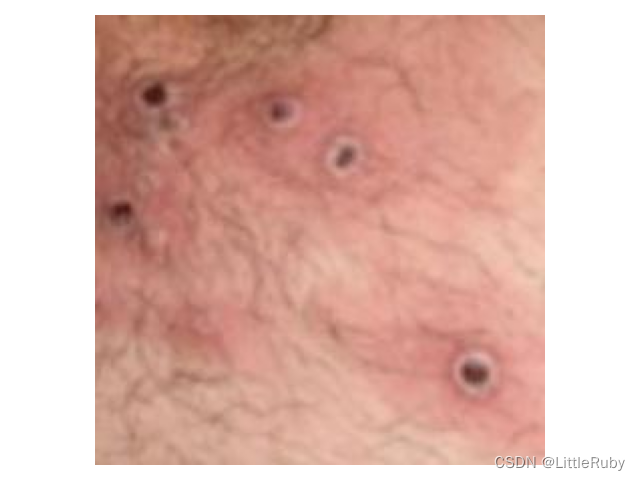
3.5.加载数据
'''数据预处理-加载数据'''
batch_size = 32
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 2142 files belonging to 2 classes.
Using 1714 files for training.
Found 2142 files belonging to 2 classes.
Using 428 files for validation.
['Monkeypox', 'Others']
3.6.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(16, 336, 336, 3)。这是一批形状336x336x3的16张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(16,)的张量,这些标签对应16张图片
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
运行结果
(32, 224, 224, 3)
(32,)
3.7.配置数据集
'''数据预处理-配置数据集'''
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)3.8.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(10, 5))
for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]], fontsize=10)plt.axis("off")
# 显示图片
plt.show()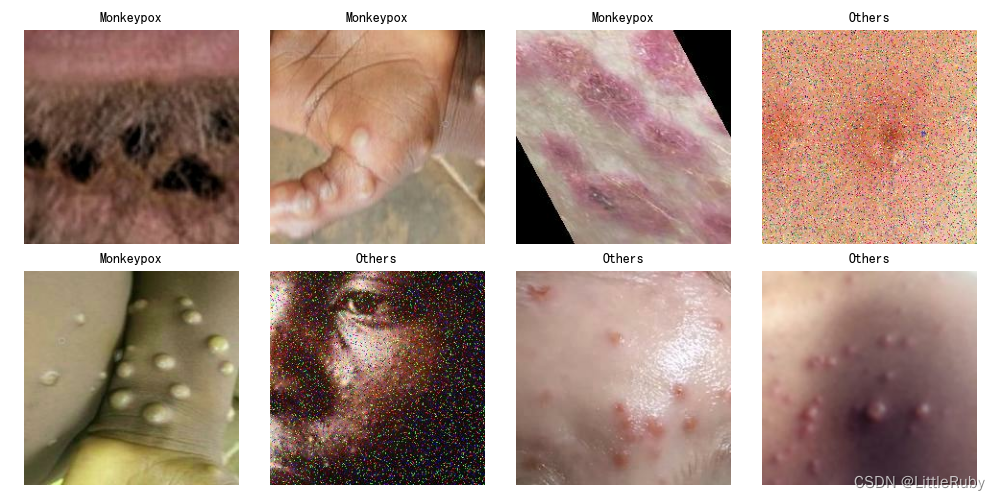
3.9.构建ResNeXt50网络
"""构建ResNeXt50网络"""# ----------------------- #
# groups代表多少组
# g_channels代表每组的特征图数量
# ----------------------- #
def group_conv2_block(x_0, strides, groups, g_channels):g_list = []for i in range(groups):x = Lambda(lambda x: x[:, :, :, i * g_channels: (i + 1) * g_channels])(x_0)x = Conv2D(filters=g_channels, kernel_size=3, strides=strides, padding='same', use_bias=False)(x)g_list.append(x)x = concatenate(g_list, axis=3)x = BatchNormalization(epsilon=1.001e-5)(x)x = Activation('relu')(x)return x# 结构快
def block(x, filters, strides=1, groups=32, conv_short=True):if conv_short:short_cut = Conv2D(filters=filters * 2, kernel_size=1, strides=strides, padding='same')(x)short_cut = BatchNormalization(epsilon=1.001e-5)(short_cut)else:short_cut = x# 三层卷积x = Conv2D(filters=filters, kernel_size=1, strides=1, padding='same')(x)x = BatchNormalization(epsilon=1.001e-5)(x)x = Activation('relu')(x)g_channels = int(filters / groups)x = group_conv2_block(x, strides=strides, groups=groups, g_channels=g_channels)x = Conv2D(filters=filters * 2, kernel_size=1, strides=1, padding='same')(x)x = BatchNormalization(epsilon=1.001e-5)(x)x = Add()([x, short_cut])x = Activation('relu')(x)return xdef Resnext(inputs, classes):x_input = keras.layers.Input(shape=inputs)x = ZeroPadding2D((3, 3))(x_input)x = Conv2D(filters=64, kernel_size=7, strides=2, padding='valid')(x)x = BatchNormalization(epsilon=1.001e-5)(x)x = Activation('relu')(x)x = ZeroPadding2D((1, 1))(x)x = MaxPool2D(pool_size=3, strides=2, padding='valid')(x)x = block(x, filters=128, strides=1, conv_short=True)x = block(x, filters=128, conv_short=False)x = block(x, filters=128, conv_short=False)x = block(x, filters=256, strides=2, conv_short=True)x = block(x, filters=256, conv_short=False)x = block(x, filters=256, conv_short=False)x = block(x, filters=256, conv_short=False)x = block(x, filters=512, strides=2, conv_short=True)x = block(x, filters=512, conv_short=False)x = block(x, filters=512, conv_short=False)x = block(x, filters=512, conv_short=False)x = block(x, filters=512, conv_short=False)x = block(x, filters=512, conv_short=False)x = block(x, filters=1024, strides=2, conv_short=True)x = block(x, filters=1024, conv_short=False)x = block(x, filters=1024, conv_short=False)x = GlobalAvgPool2D()(x)x = Dense(classes, activation='softmax')(x)model = keras.models.Model(inputs=[x_input], outputs=[x])return modelmodel = Resnext(inputs= (img_width, img_height, 3),classes=4)
model.summary()网络结构结果如下:
Model: "model"
__________________________________________________________________________________________________Layer (type) Output Shape Param # Connected to
==================================================================================================input_1 (InputLayer) [(None, 224, 224, 3 0 [] )] conv2d (Conv2D) (None, 112, 112, 64 9408 ['input_1[0][0]'] ) batch_normalization (BatchNorm (None, 112, 112, 64 256 ['conv2d[0][0]'] alization) ) max_pooling2d (MaxPooling2D) (None, 56, 56, 64) 0 ['batch_normalization[0][0]'] batch_normalization_1 (BatchNo (None, 56, 56, 64) 256 ['max_pooling2d[0][0]'] rmalization) activation (Activation) (None, 56, 56, 64) 0 ['batch_normalization_1[0][0]'] conv2d_1 (Conv2D) (None, 56, 56, 128) 8192 ['activation[0][0]'] batch_normalization_2 (BatchNo (None, 56, 56, 128) 512 ['conv2d_1[0][0]'] rmalization) activation_1 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_2[0][0]'] conv2d_2 (Conv2D) (None, 56, 56, 32) 36864 ['activation_1[0][0]'] concatenate (Concatenate) (None, 56, 56, 96) 0 ['max_pooling2d[0][0]', 'conv2d_2[0][0]'] batch_normalization_3 (BatchNo (None, 56, 56, 96) 384 ['concatenate[0][0]'] rmalization) activation_2 (Activation) (None, 56, 56, 96) 0 ['batch_normalization_3[0][0]'] conv2d_3 (Conv2D) (None, 56, 56, 128) 12288 ['activation_2[0][0]'] batch_normalization_4 (BatchNo (None, 56, 56, 128) 512 ['conv2d_3[0][0]'] rmalization) activation_3 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_4[0][0]'] conv2d_4 (Conv2D) (None, 56, 56, 32) 36864 ['activation_3[0][0]'] concatenate_1 (Concatenate) (None, 56, 56, 128) 0 ['concatenate[0][0]', 'conv2d_4[0][0]'] batch_normalization_5 (BatchNo (None, 56, 56, 128) 512 ['concatenate_1[0][0]'] rmalization) activation_4 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_5[0][0]'] conv2d_5 (Conv2D) (None, 56, 56, 128) 16384 ['activation_4[0][0]'] batch_normalization_6 (BatchNo (None, 56, 56, 128) 512 ['conv2d_5[0][0]'] rmalization) activation_5 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_6[0][0]'] conv2d_6 (Conv2D) (None, 56, 56, 32) 36864 ['activation_5[0][0]'] concatenate_2 (Concatenate) (None, 56, 56, 160) 0 ['concatenate_1[0][0]', 'conv2d_6[0][0]'] batch_normalization_7 (BatchNo (None, 56, 56, 160) 640 ['concatenate_2[0][0]'] rmalization) activation_6 (Activation) (None, 56, 56, 160) 0 ['batch_normalization_7[0][0]'] conv2d_7 (Conv2D) (None, 56, 56, 128) 20480 ['activation_6[0][0]'] batch_normalization_8 (BatchNo (None, 56, 56, 128) 512 ['conv2d_7[0][0]'] rmalization) activation_7 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_8[0][0]'] conv2d_8 (Conv2D) (None, 56, 56, 32) 36864 ['activation_7[0][0]'] concatenate_3 (Concatenate) (None, 56, 56, 192) 0 ['concatenate_2[0][0]', 'conv2d_8[0][0]'] batch_normalization_9 (BatchNo (None, 56, 56, 192) 768 ['concatenate_3[0][0]'] rmalization) activation_8 (Activation) (None, 56, 56, 192) 0 ['batch_normalization_9[0][0]'] conv2d_9 (Conv2D) (None, 56, 56, 128) 24576 ['activation_8[0][0]'] batch_normalization_10 (BatchN (None, 56, 56, 128) 512 ['conv2d_9[0][0]'] ormalization) activation_9 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_10[0][0]'] conv2d_10 (Conv2D) (None, 56, 56, 32) 36864 ['activation_9[0][0]'] concatenate_4 (Concatenate) (None, 56, 56, 224) 0 ['concatenate_3[0][0]', 'conv2d_10[0][0]'] batch_normalization_11 (BatchN (None, 56, 56, 224) 896 ['concatenate_4[0][0]'] ormalization) activation_10 (Activation) (None, 56, 56, 224) 0 ['batch_normalization_11[0][0]'] conv2d_11 (Conv2D) (None, 56, 56, 128) 28672 ['activation_10[0][0]'] batch_normalization_12 (BatchN (None, 56, 56, 128) 512 ['conv2d_11[0][0]'] ormalization) activation_11 (Activation) (None, 56, 56, 128) 0 ['batch_normalization_12[0][0]'] conv2d_12 (Conv2D) (None, 56, 56, 32) 36864 ['activation_11[0][0]'] concatenate_5 (Concatenate) (None, 56, 56, 256) 0 ['concatenate_4[0][0]', 'conv2d_12[0][0]'] batch_normalization_13 (BatchN (None, 56, 56, 256) 1024 ['concatenate_5[0][0]'] ormalization) activation_12 (Activation) (None, 56, 56, 256) 0 ['batch_normalization_13[0][0]'] conv2d_13 (Conv2D) (None, 56, 56, 128) 32768 ['activation_12[0][0]'] average_pooling2d (AveragePool (None, 28, 28, 128) 0 ['conv2d_13[0][0]'] ing2D) batch_normalization_14 (BatchN (None, 28, 28, 128) 512 ['average_pooling2d[0][0]'] ormalization) activation_13 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_14[0][0]'] conv2d_14 (Conv2D) (None, 28, 28, 128) 16384 ['activation_13[0][0]'] batch_normalization_15 (BatchN (None, 28, 28, 128) 512 ['conv2d_14[0][0]'] ormalization) activation_14 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_15[0][0]'] conv2d_15 (Conv2D) (None, 28, 28, 32) 36864 ['activation_14[0][0]'] concatenate_6 (Concatenate) (None, 28, 28, 160) 0 ['average_pooling2d[0][0]', 'conv2d_15[0][0]'] batch_normalization_16 (BatchN (None, 28, 28, 160) 640 ['concatenate_6[0][0]'] ormalization) activation_15 (Activation) (None, 28, 28, 160) 0 ['batch_normalization_16[0][0]'] conv2d_16 (Conv2D) (None, 28, 28, 128) 20480 ['activation_15[0][0]'] batch_normalization_17 (BatchN (None, 28, 28, 128) 512 ['conv2d_16[0][0]'] ormalization) activation_16 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_17[0][0]'] conv2d_17 (Conv2D) (None, 28, 28, 32) 36864 ['activation_16[0][0]'] concatenate_7 (Concatenate) (None, 28, 28, 192) 0 ['concatenate_6[0][0]', 'conv2d_17[0][0]'] batch_normalization_18 (BatchN (None, 28, 28, 192) 768 ['concatenate_7[0][0]'] ormalization) activation_17 (Activation) (None, 28, 28, 192) 0 ['batch_normalization_18[0][0]'] conv2d_18 (Conv2D) (None, 28, 28, 128) 24576 ['activation_17[0][0]'] batch_normalization_19 (BatchN (None, 28, 28, 128) 512 ['conv2d_18[0][0]'] ormalization) activation_18 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_19[0][0]'] conv2d_19 (Conv2D) (None, 28, 28, 32) 36864 ['activation_18[0][0]'] concatenate_8 (Concatenate) (None, 28, 28, 224) 0 ['concatenate_7[0][0]', 'conv2d_19[0][0]'] batch_normalization_20 (BatchN (None, 28, 28, 224) 896 ['concatenate_8[0][0]'] ormalization) activation_19 (Activation) (None, 28, 28, 224) 0 ['batch_normalization_20[0][0]'] conv2d_20 (Conv2D) (None, 28, 28, 128) 28672 ['activation_19[0][0]'] batch_normalization_21 (BatchN (None, 28, 28, 128) 512 ['conv2d_20[0][0]'] ormalization) activation_20 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_21[0][0]'] conv2d_21 (Conv2D) (None, 28, 28, 32) 36864 ['activation_20[0][0]'] concatenate_9 (Concatenate) (None, 28, 28, 256) 0 ['concatenate_8[0][0]', 'conv2d_21[0][0]'] batch_normalization_22 (BatchN (None, 28, 28, 256) 1024 ['concatenate_9[0][0]'] ormalization) activation_21 (Activation) (None, 28, 28, 256) 0 ['batch_normalization_22[0][0]'] conv2d_22 (Conv2D) (None, 28, 28, 128) 32768 ['activation_21[0][0]'] batch_normalization_23 (BatchN (None, 28, 28, 128) 512 ['conv2d_22[0][0]'] ormalization) activation_22 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_23[0][0]'] conv2d_23 (Conv2D) (None, 28, 28, 32) 36864 ['activation_22[0][0]'] concatenate_10 (Concatenate) (None, 28, 28, 288) 0 ['concatenate_9[0][0]', 'conv2d_23[0][0]'] batch_normalization_24 (BatchN (None, 28, 28, 288) 1152 ['concatenate_10[0][0]'] ormalization) activation_23 (Activation) (None, 28, 28, 288) 0 ['batch_normalization_24[0][0]'] conv2d_24 (Conv2D) (None, 28, 28, 128) 36864 ['activation_23[0][0]'] batch_normalization_25 (BatchN (None, 28, 28, 128) 512 ['conv2d_24[0][0]'] ormalization) activation_24 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_25[0][0]'] conv2d_25 (Conv2D) (None, 28, 28, 32) 36864 ['activation_24[0][0]'] concatenate_11 (Concatenate) (None, 28, 28, 320) 0 ['concatenate_10[0][0]', 'conv2d_25[0][0]'] batch_normalization_26 (BatchN (None, 28, 28, 320) 1280 ['concatenate_11[0][0]'] ormalization) activation_25 (Activation) (None, 28, 28, 320) 0 ['batch_normalization_26[0][0]'] conv2d_26 (Conv2D) (None, 28, 28, 128) 40960 ['activation_25[0][0]'] batch_normalization_27 (BatchN (None, 28, 28, 128) 512 ['conv2d_26[0][0]'] ormalization) activation_26 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_27[0][0]'] conv2d_27 (Conv2D) (None, 28, 28, 32) 36864 ['activation_26[0][0]'] concatenate_12 (Concatenate) (None, 28, 28, 352) 0 ['concatenate_11[0][0]', 'conv2d_27[0][0]'] batch_normalization_28 (BatchN (None, 28, 28, 352) 1408 ['concatenate_12[0][0]'] ormalization) activation_27 (Activation) (None, 28, 28, 352) 0 ['batch_normalization_28[0][0]'] conv2d_28 (Conv2D) (None, 28, 28, 128) 45056 ['activation_27[0][0]'] batch_normalization_29 (BatchN (None, 28, 28, 128) 512 ['conv2d_28[0][0]'] ormalization) activation_28 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_29[0][0]'] conv2d_29 (Conv2D) (None, 28, 28, 32) 36864 ['activation_28[0][0]'] concatenate_13 (Concatenate) (None, 28, 28, 384) 0 ['concatenate_12[0][0]', 'conv2d_29[0][0]'] batch_normalization_30 (BatchN (None, 28, 28, 384) 1536 ['concatenate_13[0][0]'] ormalization) activation_29 (Activation) (None, 28, 28, 384) 0 ['batch_normalization_30[0][0]'] conv2d_30 (Conv2D) (None, 28, 28, 128) 49152 ['activation_29[0][0]'] batch_normalization_31 (BatchN (None, 28, 28, 128) 512 ['conv2d_30[0][0]'] ormalization) activation_30 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_31[0][0]'] conv2d_31 (Conv2D) (None, 28, 28, 32) 36864 ['activation_30[0][0]'] concatenate_14 (Concatenate) (None, 28, 28, 416) 0 ['concatenate_13[0][0]', 'conv2d_31[0][0]'] batch_normalization_32 (BatchN (None, 28, 28, 416) 1664 ['concatenate_14[0][0]'] ormalization) activation_31 (Activation) (None, 28, 28, 416) 0 ['batch_normalization_32[0][0]'] conv2d_32 (Conv2D) (None, 28, 28, 128) 53248 ['activation_31[0][0]'] batch_normalization_33 (BatchN (None, 28, 28, 128) 512 ['conv2d_32[0][0]'] ormalization) activation_32 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_33[0][0]'] conv2d_33 (Conv2D) (None, 28, 28, 32) 36864 ['activation_32[0][0]'] concatenate_15 (Concatenate) (None, 28, 28, 448) 0 ['concatenate_14[0][0]', 'conv2d_33[0][0]'] batch_normalization_34 (BatchN (None, 28, 28, 448) 1792 ['concatenate_15[0][0]'] ormalization) activation_33 (Activation) (None, 28, 28, 448) 0 ['batch_normalization_34[0][0]'] conv2d_34 (Conv2D) (None, 28, 28, 128) 57344 ['activation_33[0][0]'] batch_normalization_35 (BatchN (None, 28, 28, 128) 512 ['conv2d_34[0][0]'] ormalization) activation_34 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_35[0][0]'] conv2d_35 (Conv2D) (None, 28, 28, 32) 36864 ['activation_34[0][0]'] concatenate_16 (Concatenate) (None, 28, 28, 480) 0 ['concatenate_15[0][0]', 'conv2d_35[0][0]'] batch_normalization_36 (BatchN (None, 28, 28, 480) 1920 ['concatenate_16[0][0]'] ormalization) activation_35 (Activation) (None, 28, 28, 480) 0 ['batch_normalization_36[0][0]'] conv2d_36 (Conv2D) (None, 28, 28, 128) 61440 ['activation_35[0][0]'] batch_normalization_37 (BatchN (None, 28, 28, 128) 512 ['conv2d_36[0][0]'] ormalization) activation_36 (Activation) (None, 28, 28, 128) 0 ['batch_normalization_37[0][0]'] conv2d_37 (Conv2D) (None, 28, 28, 32) 36864 ['activation_36[0][0]'] concatenate_17 (Concatenate) (None, 28, 28, 512) 0 ['concatenate_16[0][0]', 'conv2d_37[0][0]'] batch_normalization_38 (BatchN (None, 28, 28, 512) 2048 ['concatenate_17[0][0]'] ormalization) activation_37 (Activation) (None, 28, 28, 512) 0 ['batch_normalization_38[0][0]'] conv2d_38 (Conv2D) (None, 28, 28, 256) 131072 ['activation_37[0][0]'] average_pooling2d_1 (AveragePo (None, 14, 14, 256) 0 ['conv2d_38[0][0]'] oling2D) batch_normalization_39 (BatchN (None, 14, 14, 256) 1024 ['average_pooling2d_1[0][0]'] ormalization) activation_38 (Activation) (None, 14, 14, 256) 0 ['batch_normalization_39[0][0]'] conv2d_39 (Conv2D) (None, 14, 14, 128) 32768 ['activation_38[0][0]'] batch_normalization_40 (BatchN (None, 14, 14, 128) 512 ['conv2d_39[0][0]'] ormalization) activation_39 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_40[0][0]'] conv2d_40 (Conv2D) (None, 14, 14, 32) 36864 ['activation_39[0][0]'] concatenate_18 (Concatenate) (None, 14, 14, 288) 0 ['average_pooling2d_1[0][0]', 'conv2d_40[0][0]'] batch_normalization_41 (BatchN (None, 14, 14, 288) 1152 ['concatenate_18[0][0]'] ormalization) activation_40 (Activation) (None, 14, 14, 288) 0 ['batch_normalization_41[0][0]'] conv2d_41 (Conv2D) (None, 14, 14, 128) 36864 ['activation_40[0][0]'] batch_normalization_42 (BatchN (None, 14, 14, 128) 512 ['conv2d_41[0][0]'] ormalization) activation_41 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_42[0][0]'] conv2d_42 (Conv2D) (None, 14, 14, 32) 36864 ['activation_41[0][0]'] concatenate_19 (Concatenate) (None, 14, 14, 320) 0 ['concatenate_18[0][0]', 'conv2d_42[0][0]'] batch_normalization_43 (BatchN (None, 14, 14, 320) 1280 ['concatenate_19[0][0]'] ormalization) activation_42 (Activation) (None, 14, 14, 320) 0 ['batch_normalization_43[0][0]'] conv2d_43 (Conv2D) (None, 14, 14, 128) 40960 ['activation_42[0][0]'] batch_normalization_44 (BatchN (None, 14, 14, 128) 512 ['conv2d_43[0][0]'] ormalization) activation_43 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_44[0][0]'] conv2d_44 (Conv2D) (None, 14, 14, 32) 36864 ['activation_43[0][0]'] concatenate_20 (Concatenate) (None, 14, 14, 352) 0 ['concatenate_19[0][0]', 'conv2d_44[0][0]'] batch_normalization_45 (BatchN (None, 14, 14, 352) 1408 ['concatenate_20[0][0]'] ormalization) activation_44 (Activation) (None, 14, 14, 352) 0 ['batch_normalization_45[0][0]'] conv2d_45 (Conv2D) (None, 14, 14, 128) 45056 ['activation_44[0][0]'] batch_normalization_46 (BatchN (None, 14, 14, 128) 512 ['conv2d_45[0][0]'] ormalization) activation_45 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_46[0][0]'] conv2d_46 (Conv2D) (None, 14, 14, 32) 36864 ['activation_45[0][0]'] concatenate_21 (Concatenate) (None, 14, 14, 384) 0 ['concatenate_20[0][0]', 'conv2d_46[0][0]'] batch_normalization_47 (BatchN (None, 14, 14, 384) 1536 ['concatenate_21[0][0]'] ormalization) activation_46 (Activation) (None, 14, 14, 384) 0 ['batch_normalization_47[0][0]'] conv2d_47 (Conv2D) (None, 14, 14, 128) 49152 ['activation_46[0][0]'] batch_normalization_48 (BatchN (None, 14, 14, 128) 512 ['conv2d_47[0][0]'] ormalization) activation_47 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_48[0][0]'] conv2d_48 (Conv2D) (None, 14, 14, 32) 36864 ['activation_47[0][0]'] concatenate_22 (Concatenate) (None, 14, 14, 416) 0 ['concatenate_21[0][0]', 'conv2d_48[0][0]'] batch_normalization_49 (BatchN (None, 14, 14, 416) 1664 ['concatenate_22[0][0]'] ormalization) activation_48 (Activation) (None, 14, 14, 416) 0 ['batch_normalization_49[0][0]'] conv2d_49 (Conv2D) (None, 14, 14, 128) 53248 ['activation_48[0][0]'] batch_normalization_50 (BatchN (None, 14, 14, 128) 512 ['conv2d_49[0][0]'] ormalization) activation_49 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_50[0][0]'] conv2d_50 (Conv2D) (None, 14, 14, 32) 36864 ['activation_49[0][0]'] concatenate_23 (Concatenate) (None, 14, 14, 448) 0 ['concatenate_22[0][0]', 'conv2d_50[0][0]'] batch_normalization_51 (BatchN (None, 14, 14, 448) 1792 ['concatenate_23[0][0]'] ormalization) activation_50 (Activation) (None, 14, 14, 448) 0 ['batch_normalization_51[0][0]'] conv2d_51 (Conv2D) (None, 14, 14, 128) 57344 ['activation_50[0][0]'] batch_normalization_52 (BatchN (None, 14, 14, 128) 512 ['conv2d_51[0][0]'] ormalization) activation_51 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_52[0][0]'] conv2d_52 (Conv2D) (None, 14, 14, 32) 36864 ['activation_51[0][0]'] concatenate_24 (Concatenate) (None, 14, 14, 480) 0 ['concatenate_23[0][0]', 'conv2d_52[0][0]'] batch_normalization_53 (BatchN (None, 14, 14, 480) 1920 ['concatenate_24[0][0]'] ormalization) activation_52 (Activation) (None, 14, 14, 480) 0 ['batch_normalization_53[0][0]'] conv2d_53 (Conv2D) (None, 14, 14, 128) 61440 ['activation_52[0][0]'] batch_normalization_54 (BatchN (None, 14, 14, 128) 512 ['conv2d_53[0][0]'] ormalization) activation_53 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_54[0][0]'] conv2d_54 (Conv2D) (None, 14, 14, 32) 36864 ['activation_53[0][0]'] concatenate_25 (Concatenate) (None, 14, 14, 512) 0 ['concatenate_24[0][0]', 'conv2d_54[0][0]'] batch_normalization_55 (BatchN (None, 14, 14, 512) 2048 ['concatenate_25[0][0]'] ormalization) activation_54 (Activation) (None, 14, 14, 512) 0 ['batch_normalization_55[0][0]'] conv2d_55 (Conv2D) (None, 14, 14, 128) 65536 ['activation_54[0][0]'] batch_normalization_56 (BatchN (None, 14, 14, 128) 512 ['conv2d_55[0][0]'] ormalization) activation_55 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_56[0][0]'] conv2d_56 (Conv2D) (None, 14, 14, 32) 36864 ['activation_55[0][0]'] concatenate_26 (Concatenate) (None, 14, 14, 544) 0 ['concatenate_25[0][0]', 'conv2d_56[0][0]'] batch_normalization_57 (BatchN (None, 14, 14, 544) 2176 ['concatenate_26[0][0]'] ormalization) activation_56 (Activation) (None, 14, 14, 544) 0 ['batch_normalization_57[0][0]'] conv2d_57 (Conv2D) (None, 14, 14, 128) 69632 ['activation_56[0][0]'] batch_normalization_58 (BatchN (None, 14, 14, 128) 512 ['conv2d_57[0][0]'] ormalization) activation_57 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_58[0][0]'] conv2d_58 (Conv2D) (None, 14, 14, 32) 36864 ['activation_57[0][0]'] concatenate_27 (Concatenate) (None, 14, 14, 576) 0 ['concatenate_26[0][0]', 'conv2d_58[0][0]'] batch_normalization_59 (BatchN (None, 14, 14, 576) 2304 ['concatenate_27[0][0]'] ormalization) activation_58 (Activation) (None, 14, 14, 576) 0 ['batch_normalization_59[0][0]'] conv2d_59 (Conv2D) (None, 14, 14, 128) 73728 ['activation_58[0][0]'] batch_normalization_60 (BatchN (None, 14, 14, 128) 512 ['conv2d_59[0][0]'] ormalization) activation_59 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_60[0][0]'] conv2d_60 (Conv2D) (None, 14, 14, 32) 36864 ['activation_59[0][0]'] concatenate_28 (Concatenate) (None, 14, 14, 608) 0 ['concatenate_27[0][0]', 'conv2d_60[0][0]'] batch_normalization_61 (BatchN (None, 14, 14, 608) 2432 ['concatenate_28[0][0]'] ormalization) activation_60 (Activation) (None, 14, 14, 608) 0 ['batch_normalization_61[0][0]'] conv2d_61 (Conv2D) (None, 14, 14, 128) 77824 ['activation_60[0][0]'] batch_normalization_62 (BatchN (None, 14, 14, 128) 512 ['conv2d_61[0][0]'] ormalization) activation_61 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_62[0][0]'] conv2d_62 (Conv2D) (None, 14, 14, 32) 36864 ['activation_61[0][0]'] concatenate_29 (Concatenate) (None, 14, 14, 640) 0 ['concatenate_28[0][0]', 'conv2d_62[0][0]'] batch_normalization_63 (BatchN (None, 14, 14, 640) 2560 ['concatenate_29[0][0]'] ormalization) activation_62 (Activation) (None, 14, 14, 640) 0 ['batch_normalization_63[0][0]'] conv2d_63 (Conv2D) (None, 14, 14, 128) 81920 ['activation_62[0][0]'] batch_normalization_64 (BatchN (None, 14, 14, 128) 512 ['conv2d_63[0][0]'] ormalization) activation_63 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_64[0][0]'] conv2d_64 (Conv2D) (None, 14, 14, 32) 36864 ['activation_63[0][0]'] concatenate_30 (Concatenate) (None, 14, 14, 672) 0 ['concatenate_29[0][0]', 'conv2d_64[0][0]'] batch_normalization_65 (BatchN (None, 14, 14, 672) 2688 ['concatenate_30[0][0]'] ormalization) activation_64 (Activation) (None, 14, 14, 672) 0 ['batch_normalization_65[0][0]'] conv2d_65 (Conv2D) (None, 14, 14, 128) 86016 ['activation_64[0][0]'] batch_normalization_66 (BatchN (None, 14, 14, 128) 512 ['conv2d_65[0][0]'] ormalization) activation_65 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_66[0][0]'] conv2d_66 (Conv2D) (None, 14, 14, 32) 36864 ['activation_65[0][0]'] concatenate_31 (Concatenate) (None, 14, 14, 704) 0 ['concatenate_30[0][0]', 'conv2d_66[0][0]'] batch_normalization_67 (BatchN (None, 14, 14, 704) 2816 ['concatenate_31[0][0]'] ormalization) activation_66 (Activation) (None, 14, 14, 704) 0 ['batch_normalization_67[0][0]'] conv2d_67 (Conv2D) (None, 14, 14, 128) 90112 ['activation_66[0][0]'] batch_normalization_68 (BatchN (None, 14, 14, 128) 512 ['conv2d_67[0][0]'] ormalization) activation_67 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_68[0][0]'] conv2d_68 (Conv2D) (None, 14, 14, 32) 36864 ['activation_67[0][0]'] concatenate_32 (Concatenate) (None, 14, 14, 736) 0 ['concatenate_31[0][0]', 'conv2d_68[0][0]'] batch_normalization_69 (BatchN (None, 14, 14, 736) 2944 ['concatenate_32[0][0]'] ormalization) activation_68 (Activation) (None, 14, 14, 736) 0 ['batch_normalization_69[0][0]'] conv2d_69 (Conv2D) (None, 14, 14, 128) 94208 ['activation_68[0][0]'] batch_normalization_70 (BatchN (None, 14, 14, 128) 512 ['conv2d_69[0][0]'] ormalization) activation_69 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_70[0][0]'] conv2d_70 (Conv2D) (None, 14, 14, 32) 36864 ['activation_69[0][0]'] concatenate_33 (Concatenate) (None, 14, 14, 768) 0 ['concatenate_32[0][0]', 'conv2d_70[0][0]'] batch_normalization_71 (BatchN (None, 14, 14, 768) 3072 ['concatenate_33[0][0]'] ormalization) activation_70 (Activation) (None, 14, 14, 768) 0 ['batch_normalization_71[0][0]'] conv2d_71 (Conv2D) (None, 14, 14, 128) 98304 ['activation_70[0][0]'] batch_normalization_72 (BatchN (None, 14, 14, 128) 512 ['conv2d_71[0][0]'] ormalization) activation_71 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_72[0][0]'] conv2d_72 (Conv2D) (None, 14, 14, 32) 36864 ['activation_71[0][0]'] concatenate_34 (Concatenate) (None, 14, 14, 800) 0 ['concatenate_33[0][0]', 'conv2d_72[0][0]'] batch_normalization_73 (BatchN (None, 14, 14, 800) 3200 ['concatenate_34[0][0]'] ormalization) activation_72 (Activation) (None, 14, 14, 800) 0 ['batch_normalization_73[0][0]'] conv2d_73 (Conv2D) (None, 14, 14, 128) 102400 ['activation_72[0][0]'] batch_normalization_74 (BatchN (None, 14, 14, 128) 512 ['conv2d_73[0][0]'] ormalization) activation_73 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_74[0][0]'] conv2d_74 (Conv2D) (None, 14, 14, 32) 36864 ['activation_73[0][0]'] concatenate_35 (Concatenate) (None, 14, 14, 832) 0 ['concatenate_34[0][0]', 'conv2d_74[0][0]'] batch_normalization_75 (BatchN (None, 14, 14, 832) 3328 ['concatenate_35[0][0]'] ormalization) activation_74 (Activation) (None, 14, 14, 832) 0 ['batch_normalization_75[0][0]'] conv2d_75 (Conv2D) (None, 14, 14, 128) 106496 ['activation_74[0][0]'] batch_normalization_76 (BatchN (None, 14, 14, 128) 512 ['conv2d_75[0][0]'] ormalization) activation_75 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_76[0][0]'] conv2d_76 (Conv2D) (None, 14, 14, 32) 36864 ['activation_75[0][0]'] concatenate_36 (Concatenate) (None, 14, 14, 864) 0 ['concatenate_35[0][0]', 'conv2d_76[0][0]'] batch_normalization_77 (BatchN (None, 14, 14, 864) 3456 ['concatenate_36[0][0]'] ormalization) activation_76 (Activation) (None, 14, 14, 864) 0 ['batch_normalization_77[0][0]'] conv2d_77 (Conv2D) (None, 14, 14, 128) 110592 ['activation_76[0][0]'] batch_normalization_78 (BatchN (None, 14, 14, 128) 512 ['conv2d_77[0][0]'] ormalization) activation_77 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_78[0][0]'] conv2d_78 (Conv2D) (None, 14, 14, 32) 36864 ['activation_77[0][0]'] concatenate_37 (Concatenate) (None, 14, 14, 896) 0 ['concatenate_36[0][0]', 'conv2d_78[0][0]'] batch_normalization_79 (BatchN (None, 14, 14, 896) 3584 ['concatenate_37[0][0]'] ormalization) activation_78 (Activation) (None, 14, 14, 896) 0 ['batch_normalization_79[0][0]'] conv2d_79 (Conv2D) (None, 14, 14, 128) 114688 ['activation_78[0][0]'] batch_normalization_80 (BatchN (None, 14, 14, 128) 512 ['conv2d_79[0][0]'] ormalization) activation_79 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_80[0][0]'] conv2d_80 (Conv2D) (None, 14, 14, 32) 36864 ['activation_79[0][0]'] concatenate_38 (Concatenate) (None, 14, 14, 928) 0 ['concatenate_37[0][0]', 'conv2d_80[0][0]'] batch_normalization_81 (BatchN (None, 14, 14, 928) 3712 ['concatenate_38[0][0]'] ormalization) activation_80 (Activation) (None, 14, 14, 928) 0 ['batch_normalization_81[0][0]'] conv2d_81 (Conv2D) (None, 14, 14, 128) 118784 ['activation_80[0][0]'] batch_normalization_82 (BatchN (None, 14, 14, 128) 512 ['conv2d_81[0][0]'] ormalization) activation_81 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_82[0][0]'] conv2d_82 (Conv2D) (None, 14, 14, 32) 36864 ['activation_81[0][0]'] concatenate_39 (Concatenate) (None, 14, 14, 960) 0 ['concatenate_38[0][0]', 'conv2d_82[0][0]'] batch_normalization_83 (BatchN (None, 14, 14, 960) 3840 ['concatenate_39[0][0]'] ormalization) activation_82 (Activation) (None, 14, 14, 960) 0 ['batch_normalization_83[0][0]'] conv2d_83 (Conv2D) (None, 14, 14, 128) 122880 ['activation_82[0][0]'] batch_normalization_84 (BatchN (None, 14, 14, 128) 512 ['conv2d_83[0][0]'] ormalization) activation_83 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_84[0][0]'] conv2d_84 (Conv2D) (None, 14, 14, 32) 36864 ['activation_83[0][0]'] concatenate_40 (Concatenate) (None, 14, 14, 992) 0 ['concatenate_39[0][0]', 'conv2d_84[0][0]'] batch_normalization_85 (BatchN (None, 14, 14, 992) 3968 ['concatenate_40[0][0]'] ormalization) activation_84 (Activation) (None, 14, 14, 992) 0 ['batch_normalization_85[0][0]'] conv2d_85 (Conv2D) (None, 14, 14, 128) 126976 ['activation_84[0][0]'] batch_normalization_86 (BatchN (None, 14, 14, 128) 512 ['conv2d_85[0][0]'] ormalization) activation_85 (Activation) (None, 14, 14, 128) 0 ['batch_normalization_86[0][0]'] conv2d_86 (Conv2D) (None, 14, 14, 32) 36864 ['activation_85[0][0]'] concatenate_41 (Concatenate) (None, 14, 14, 1024 0 ['concatenate_40[0][0]', ) 'conv2d_86[0][0]'] batch_normalization_87 (BatchN (None, 14, 14, 1024 4096 ['concatenate_41[0][0]'] ormalization) ) activation_86 (Activation) (None, 14, 14, 1024 0 ['batch_normalization_87[0][0]'] ) conv2d_87 (Conv2D) (None, 14, 14, 512) 524288 ['activation_86[0][0]'] average_pooling2d_2 (AveragePo (None, 7, 7, 512) 0 ['conv2d_87[0][0]'] oling2D) batch_normalization_88 (BatchN (None, 7, 7, 512) 2048 ['average_pooling2d_2[0][0]'] ormalization) activation_87 (Activation) (None, 7, 7, 512) 0 ['batch_normalization_88[0][0]'] conv2d_88 (Conv2D) (None, 7, 7, 128) 65536 ['activation_87[0][0]'] batch_normalization_89 (BatchN (None, 7, 7, 128) 512 ['conv2d_88[0][0]'] ormalization) activation_88 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_89[0][0]'] conv2d_89 (Conv2D) (None, 7, 7, 32) 36864 ['activation_88[0][0]'] concatenate_42 (Concatenate) (None, 7, 7, 544) 0 ['average_pooling2d_2[0][0]', 'conv2d_89[0][0]'] batch_normalization_90 (BatchN (None, 7, 7, 544) 2176 ['concatenate_42[0][0]'] ormalization) activation_89 (Activation) (None, 7, 7, 544) 0 ['batch_normalization_90[0][0]'] conv2d_90 (Conv2D) (None, 7, 7, 128) 69632 ['activation_89[0][0]'] batch_normalization_91 (BatchN (None, 7, 7, 128) 512 ['conv2d_90[0][0]'] ormalization) activation_90 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_91[0][0]'] conv2d_91 (Conv2D) (None, 7, 7, 32) 36864 ['activation_90[0][0]'] concatenate_43 (Concatenate) (None, 7, 7, 576) 0 ['concatenate_42[0][0]', 'conv2d_91[0][0]'] batch_normalization_92 (BatchN (None, 7, 7, 576) 2304 ['concatenate_43[0][0]'] ormalization) activation_91 (Activation) (None, 7, 7, 576) 0 ['batch_normalization_92[0][0]'] conv2d_92 (Conv2D) (None, 7, 7, 128) 73728 ['activation_91[0][0]'] batch_normalization_93 (BatchN (None, 7, 7, 128) 512 ['conv2d_92[0][0]'] ormalization) activation_92 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_93[0][0]'] conv2d_93 (Conv2D) (None, 7, 7, 32) 36864 ['activation_92[0][0]'] concatenate_44 (Concatenate) (None, 7, 7, 608) 0 ['concatenate_43[0][0]', 'conv2d_93[0][0]'] batch_normalization_94 (BatchN (None, 7, 7, 608) 2432 ['concatenate_44[0][0]'] ormalization) activation_93 (Activation) (None, 7, 7, 608) 0 ['batch_normalization_94[0][0]'] conv2d_94 (Conv2D) (None, 7, 7, 128) 77824 ['activation_93[0][0]'] batch_normalization_95 (BatchN (None, 7, 7, 128) 512 ['conv2d_94[0][0]'] ormalization) activation_94 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_95[0][0]'] conv2d_95 (Conv2D) (None, 7, 7, 32) 36864 ['activation_94[0][0]'] concatenate_45 (Concatenate) (None, 7, 7, 640) 0 ['concatenate_44[0][0]', 'conv2d_95[0][0]'] batch_normalization_96 (BatchN (None, 7, 7, 640) 2560 ['concatenate_45[0][0]'] ormalization) activation_95 (Activation) (None, 7, 7, 640) 0 ['batch_normalization_96[0][0]'] conv2d_96 (Conv2D) (None, 7, 7, 128) 81920 ['activation_95[0][0]'] batch_normalization_97 (BatchN (None, 7, 7, 128) 512 ['conv2d_96[0][0]'] ormalization) activation_96 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_97[0][0]'] conv2d_97 (Conv2D) (None, 7, 7, 32) 36864 ['activation_96[0][0]'] concatenate_46 (Concatenate) (None, 7, 7, 672) 0 ['concatenate_45[0][0]', 'conv2d_97[0][0]'] batch_normalization_98 (BatchN (None, 7, 7, 672) 2688 ['concatenate_46[0][0]'] ormalization) activation_97 (Activation) (None, 7, 7, 672) 0 ['batch_normalization_98[0][0]'] conv2d_98 (Conv2D) (None, 7, 7, 128) 86016 ['activation_97[0][0]'] batch_normalization_99 (BatchN (None, 7, 7, 128) 512 ['conv2d_98[0][0]'] ormalization) activation_98 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_99[0][0]'] conv2d_99 (Conv2D) (None, 7, 7, 32) 36864 ['activation_98[0][0]'] concatenate_47 (Concatenate) (None, 7, 7, 704) 0 ['concatenate_46[0][0]', 'conv2d_99[0][0]'] batch_normalization_100 (Batch (None, 7, 7, 704) 2816 ['concatenate_47[0][0]'] Normalization) activation_99 (Activation) (None, 7, 7, 704) 0 ['batch_normalization_100[0][0]']conv2d_100 (Conv2D) (None, 7, 7, 128) 90112 ['activation_99[0][0]'] batch_normalization_101 (Batch (None, 7, 7, 128) 512 ['conv2d_100[0][0]'] Normalization) activation_100 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_101[0][0]']conv2d_101 (Conv2D) (None, 7, 7, 32) 36864 ['activation_100[0][0]'] concatenate_48 (Concatenate) (None, 7, 7, 736) 0 ['concatenate_47[0][0]', 'conv2d_101[0][0]'] batch_normalization_102 (Batch (None, 7, 7, 736) 2944 ['concatenate_48[0][0]'] Normalization) activation_101 (Activation) (None, 7, 7, 736) 0 ['batch_normalization_102[0][0]']conv2d_102 (Conv2D) (None, 7, 7, 128) 94208 ['activation_101[0][0]'] batch_normalization_103 (Batch (None, 7, 7, 128) 512 ['conv2d_102[0][0]'] Normalization) activation_102 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_103[0][0]']conv2d_103 (Conv2D) (None, 7, 7, 32) 36864 ['activation_102[0][0]'] concatenate_49 (Concatenate) (None, 7, 7, 768) 0 ['concatenate_48[0][0]', 'conv2d_103[0][0]'] batch_normalization_104 (Batch (None, 7, 7, 768) 3072 ['concatenate_49[0][0]'] Normalization) activation_103 (Activation) (None, 7, 7, 768) 0 ['batch_normalization_104[0][0]']conv2d_104 (Conv2D) (None, 7, 7, 128) 98304 ['activation_103[0][0]'] batch_normalization_105 (Batch (None, 7, 7, 128) 512 ['conv2d_104[0][0]'] Normalization) activation_104 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_105[0][0]']conv2d_105 (Conv2D) (None, 7, 7, 32) 36864 ['activation_104[0][0]'] concatenate_50 (Concatenate) (None, 7, 7, 800) 0 ['concatenate_49[0][0]', 'conv2d_105[0][0]'] batch_normalization_106 (Batch (None, 7, 7, 800) 3200 ['concatenate_50[0][0]'] Normalization) activation_105 (Activation) (None, 7, 7, 800) 0 ['batch_normalization_106[0][0]']conv2d_106 (Conv2D) (None, 7, 7, 128) 102400 ['activation_105[0][0]'] batch_normalization_107 (Batch (None, 7, 7, 128) 512 ['conv2d_106[0][0]'] Normalization) activation_106 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_107[0][0]']conv2d_107 (Conv2D) (None, 7, 7, 32) 36864 ['activation_106[0][0]'] concatenate_51 (Concatenate) (None, 7, 7, 832) 0 ['concatenate_50[0][0]', 'conv2d_107[0][0]'] batch_normalization_108 (Batch (None, 7, 7, 832) 3328 ['concatenate_51[0][0]'] Normalization) activation_107 (Activation) (None, 7, 7, 832) 0 ['batch_normalization_108[0][0]']conv2d_108 (Conv2D) (None, 7, 7, 128) 106496 ['activation_107[0][0]'] batch_normalization_109 (Batch (None, 7, 7, 128) 512 ['conv2d_108[0][0]'] Normalization) activation_108 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_109[0][0]']conv2d_109 (Conv2D) (None, 7, 7, 32) 36864 ['activation_108[0][0]'] concatenate_52 (Concatenate) (None, 7, 7, 864) 0 ['concatenate_51[0][0]', 'conv2d_109[0][0]'] batch_normalization_110 (Batch (None, 7, 7, 864) 3456 ['concatenate_52[0][0]'] Normalization) activation_109 (Activation) (None, 7, 7, 864) 0 ['batch_normalization_110[0][0]']conv2d_110 (Conv2D) (None, 7, 7, 128) 110592 ['activation_109[0][0]'] batch_normalization_111 (Batch (None, 7, 7, 128) 512 ['conv2d_110[0][0]'] Normalization) activation_110 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_111[0][0]']conv2d_111 (Conv2D) (None, 7, 7, 32) 36864 ['activation_110[0][0]'] concatenate_53 (Concatenate) (None, 7, 7, 896) 0 ['concatenate_52[0][0]', 'conv2d_111[0][0]'] batch_normalization_112 (Batch (None, 7, 7, 896) 3584 ['concatenate_53[0][0]'] Normalization) activation_111 (Activation) (None, 7, 7, 896) 0 ['batch_normalization_112[0][0]']conv2d_112 (Conv2D) (None, 7, 7, 128) 114688 ['activation_111[0][0]'] batch_normalization_113 (Batch (None, 7, 7, 128) 512 ['conv2d_112[0][0]'] Normalization) activation_112 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_113[0][0]']conv2d_113 (Conv2D) (None, 7, 7, 32) 36864 ['activation_112[0][0]'] concatenate_54 (Concatenate) (None, 7, 7, 928) 0 ['concatenate_53[0][0]', 'conv2d_113[0][0]'] batch_normalization_114 (Batch (None, 7, 7, 928) 3712 ['concatenate_54[0][0]'] Normalization) activation_113 (Activation) (None, 7, 7, 928) 0 ['batch_normalization_114[0][0]']conv2d_114 (Conv2D) (None, 7, 7, 128) 118784 ['activation_113[0][0]'] batch_normalization_115 (Batch (None, 7, 7, 128) 512 ['conv2d_114[0][0]'] Normalization) activation_114 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_115[0][0]']conv2d_115 (Conv2D) (None, 7, 7, 32) 36864 ['activation_114[0][0]'] concatenate_55 (Concatenate) (None, 7, 7, 960) 0 ['concatenate_54[0][0]', 'conv2d_115[0][0]'] batch_normalization_116 (Batch (None, 7, 7, 960) 3840 ['concatenate_55[0][0]'] Normalization) activation_115 (Activation) (None, 7, 7, 960) 0 ['batch_normalization_116[0][0]']conv2d_116 (Conv2D) (None, 7, 7, 128) 122880 ['activation_115[0][0]'] batch_normalization_117 (Batch (None, 7, 7, 128) 512 ['conv2d_116[0][0]'] Normalization) activation_116 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_117[0][0]']conv2d_117 (Conv2D) (None, 7, 7, 32) 36864 ['activation_116[0][0]'] concatenate_56 (Concatenate) (None, 7, 7, 992) 0 ['concatenate_55[0][0]', 'conv2d_117[0][0]'] batch_normalization_118 (Batch (None, 7, 7, 992) 3968 ['concatenate_56[0][0]'] Normalization) activation_117 (Activation) (None, 7, 7, 992) 0 ['batch_normalization_118[0][0]']conv2d_118 (Conv2D) (None, 7, 7, 128) 126976 ['activation_117[0][0]'] batch_normalization_119 (Batch (None, 7, 7, 128) 512 ['conv2d_118[0][0]'] Normalization) activation_118 (Activation) (None, 7, 7, 128) 0 ['batch_normalization_119[0][0]']conv2d_119 (Conv2D) (None, 7, 7, 32) 36864 ['activation_118[0][0]'] concatenate_57 (Concatenate) (None, 7, 7, 1024) 0 ['concatenate_56[0][0]', 'conv2d_119[0][0]'] global_average_pooling2d (Glob (None, 1024) 0 ['concatenate_57[0][0]'] alAveragePooling2D) dense (Dense) (None, 16) 16400 ['global_average_pooling2d[0][0]'] activation_119 (Activation) (None, 16) 0 ['dense[0][0]'] dense_1 (Dense) (None, 1024) 17408 ['activation_119[0][0]'] activation_120 (Activation) (None, 1024) 0 ['dense_1[0][0]'] reshape (Reshape) (None, 1, 1, 1024) 0 ['activation_120[0][0]'] tf.math.multiply (TFOpLambda) (None, 7, 7, 1024) 0 ['concatenate_57[0][0]', 'reshape[0][0]'] batch_normalization_120 (Batch (None, 7, 7, 1024) 4096 ['tf.math.multiply[0][0]'] Normalization) activation_121 (Activation) (None, 7, 7, 1024) 0 ['batch_normalization_120[0][0]']global_average_pooling2d_1 (Gl (None, 1024) 0 ['activation_121[0][0]'] obalAveragePooling2D) dense_2 (Dense) (None, 1000) 1025000 ['global_average_pooling2d_1[0][0]'] ==================================================================================================
Total params: 8,096,312
Trainable params: 8,012,664
Non-trainable params: 83,648
__________________________________________________________________________________________________
3.10.编译模型
#设置初始学习率
initial_learning_rate = 1e-4
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,loss='sparse_categorical_crossentropy',metrics=['accuracy'])3.11.训练模型
'''训练模型'''
epochs = 20
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
训练记录如下:
Epoch 1/20
54/54 [==============================] - ETA: 0s - loss: 4.1244 - accuracy: 0.5560
Epoch 1: val_accuracy improved from -inf to 0.07818, saving model to best_model.h5
54/54 [==============================] - 25s 236ms/step - loss: 4.1244 - accuracy: 0.5560 - val_loss: 8.7794 - val_accuracy: 0.0782
Epoch 2/20
54/54 [==============================] - ETA: 0s - loss: 1.3264 - accuracy: 0.6972
Epoch 2: val_accuracy improved from 0.07818 to 0.63477, saving model to best_model.h5
54/54 [==============================] - 12s 214ms/step - loss: 1.3264 - accuracy: 0.6972 - val_loss: 4.7183 - val_accuracy: 0.6348
Epoch 3/20
54/54 [==============================] - ETA: 0s - loss: 0.6500 - accuracy: 0.7515
Epoch 3: val_accuracy did not improve from 0.63477
54/54 [==============================] - 11s 210ms/step - loss: 0.6500 - accuracy: 0.7515 - val_loss: 3.0509 - val_accuracy: 0.5828
Epoch 4/20
54/54 [==============================] - ETA: 0s - loss: 0.4991 - accuracy: 0.8028
Epoch 4: val_accuracy improved from 0.63477 to 0.65811, saving model to best_model.h5
54/54 [==============================] - 12s 217ms/step - loss: 0.4991 - accuracy: 0.8028 - val_loss: 1.5565 - val_accuracy: 0.6581
Epoch 5/20
54/54 [==============================] - ETA: 0s - loss: 0.3937 - accuracy: 0.8448
Epoch 5: val_accuracy did not improve from 0.65811
54/54 [==============================] - 11s 211ms/step - loss: 0.3937 - accuracy: 0.8448 - val_loss: 1.0164 - val_accuracy: 0.6540
Epoch 6/20
54/54 [==============================] - ETA: 0s - loss: 0.3300 - accuracy: 0.8716
Epoch 6: val_accuracy did not improve from 0.65811
54/54 [==============================] - 11s 210ms/step - loss: 0.3300 - accuracy: 0.8716 - val_loss: 0.8846 - val_accuracy: 0.5799
Epoch 7/20
54/54 [==============================] - ETA: 0s - loss: 0.2872 - accuracy: 0.8839
Epoch 7: val_accuracy improved from 0.65811 to 0.66219, saving model to best_model.h5
54/54 [==============================] - 12s 221ms/step - loss: 0.2872 - accuracy: 0.8839 - val_loss: 0.8020 - val_accuracy: 0.6622
Epoch 8/20
54/54 [==============================] - ETA: 0s - loss: 0.2339 - accuracy: 0.9090
Epoch 8: val_accuracy improved from 0.66219 to 0.81855, saving model to best_model.h5
54/54 [==============================] - 12s 220ms/step - loss: 0.2339 - accuracy: 0.9090 - val_loss: 0.4418 - val_accuracy: 0.8186
Epoch 9/20
54/54 [==============================] - ETA: 0s - loss: 0.2030 - accuracy: 0.9247
Epoch 9: val_accuracy improved from 0.81855 to 0.82555, saving model to best_model.h5
54/54 [==============================] - 12s 222ms/step - loss: 0.2030 - accuracy: 0.9247 - val_loss: 0.4440 - val_accuracy: 0.8256
Epoch 10/20
54/54 [==============================] - ETA: 0s - loss: 0.1891 - accuracy: 0.9259
Epoch 10: val_accuracy did not improve from 0.82555
54/54 [==============================] - 12s 215ms/step - loss: 0.1891 - accuracy: 0.9259 - val_loss: 1.0064 - val_accuracy: 0.7421
Epoch 11/20
54/54 [==============================] - ETA: 0s - loss: 0.1565 - accuracy: 0.9440
Epoch 11: val_accuracy did not improve from 0.82555
54/54 [==============================] - 11s 211ms/step - loss: 0.1565 - accuracy: 0.9440 - val_loss: 0.5438 - val_accuracy: 0.8121
Epoch 12/20
54/54 [==============================] - ETA: 0s - loss: 0.1580 - accuracy: 0.9422
Epoch 12: val_accuracy did not improve from 0.82555
54/54 [==============================] - 11s 210ms/step - loss: 0.1580 - accuracy: 0.9422 - val_loss: 1.1685 - val_accuracy: 0.7100
Epoch 13/20
54/54 [==============================] - ETA: 0s - loss: 0.1100 - accuracy: 0.9650
Epoch 13: val_accuracy improved from 0.82555 to 0.89148, saving model to best_model.h5
54/54 [==============================] - 12s 218ms/step - loss: 0.1100 - accuracy: 0.9650 - val_loss: 0.3890 - val_accuracy: 0.8915
Epoch 14/20
54/54 [==============================] - ETA: 0s - loss: 0.0560 - accuracy: 0.9848
Epoch 14: val_accuracy did not improve from 0.89148
54/54 [==============================] - 11s 213ms/step - loss: 0.0560 - accuracy: 0.9848 - val_loss: 0.4445 - val_accuracy: 0.8676
Epoch 15/20
54/54 [==============================] - ETA: 0s - loss: 0.0700 - accuracy: 0.9772
Epoch 15: val_accuracy did not improve from 0.89148
54/54 [==============================] - 11s 212ms/step - loss: 0.0700 - accuracy: 0.9772 - val_loss: 0.4124 - val_accuracy: 0.8839
Epoch 16/20
54/54 [==============================] - ETA: 0s - loss: 0.0994 - accuracy: 0.9638
Epoch 16: val_accuracy did not improve from 0.89148
54/54 [==============================] - 11s 211ms/step - loss: 0.0994 - accuracy: 0.9638 - val_loss: 0.5568 - val_accuracy: 0.8261
Epoch 17/20
54/54 [==============================] - ETA: 0s - loss: 0.0689 - accuracy: 0.9743
Epoch 17: val_accuracy did not improve from 0.89148
54/54 [==============================] - 11s 214ms/step - loss: 0.0689 - accuracy: 0.9743 - val_loss: 0.5721 - val_accuracy: 0.8436
Epoch 18/20
54/54 [==============================] - ETA: 0s - loss: 0.0355 - accuracy: 0.9924
Epoch 18: val_accuracy improved from 0.89148 to 0.91832, saving model to best_model.h5
54/54 [==============================] - 12s 219ms/step - loss: 0.0355 - accuracy: 0.9924 - val_loss: 0.3478 - val_accuracy: 0.9183
Epoch 19/20
54/54 [==============================] - ETA: 0s - loss: 0.0100 - accuracy: 0.9994
Epoch 19: val_accuracy improved from 0.91832 to 0.94516, saving model to best_model.h5
54/54 [==============================] - 12s 217ms/step - loss: 0.0100 - accuracy: 0.9994 - val_loss: 0.1933 - val_accuracy: 0.9452
Epoch 20/20
54/54 [==============================] - ETA: 0s - loss: 0.0208 - accuracy: 0.9947
Epoch 20: val_accuracy did not improve from 0.94516
54/54 [==============================] - 11s 211ms/step - loss: 0.0208 - accuracy: 0.9947 - val_loss: 0.6098 - val_accuracy: 0.84603.12.模型评估
'''模型评估'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
3.13.图像预测
'''指定图片进行预测'''
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5
plt.suptitle("预测结果展示", fontsize=10)
for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1)# 显示图片plt.imshow(images[i].numpy().astype("uint8"))# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0)# 使用模型预测图片中的人物predictions = model.predict(img_array)plt.title(class_names[np.argmax(predictions)], fontsize=10)plt.axis("off")
plt.show()
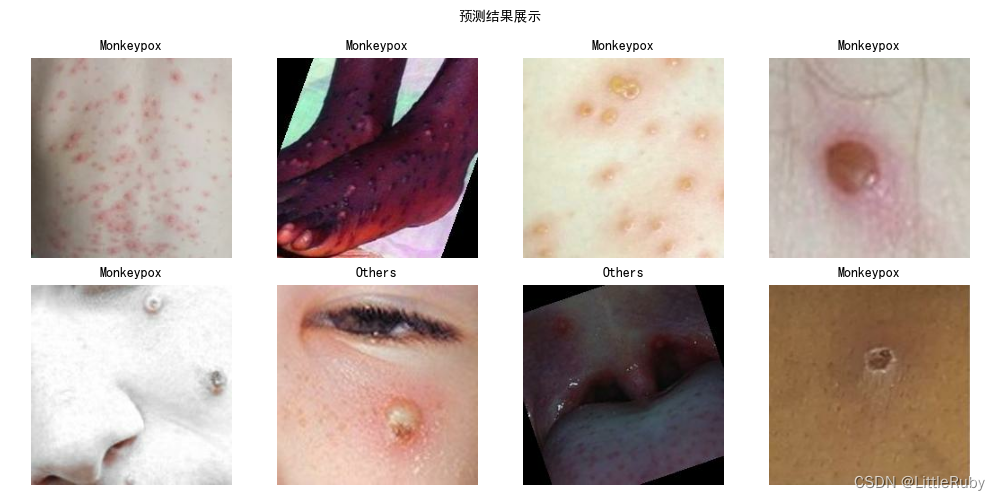
4 知识点详解
4.1ResNeXt50详解
论文:Aggregated Residual Transformations for Deep Neural Networks.pdf
ResNeXt是由何凯明团队在2017年CVPR会议上提出来的新型图像分类网络。ResNeXt是ResNet的升级版,在ResNet的基础上,引入了cardinality的概念,类似于ResNet,ResNeXt也有ResNeXt-50,ResNeXt-101的版本。
这篇文章介绍了一种用于图像分类的简单而有效的网络架构,称为Aggregated Residual Transformations for Deep Neural Networks。该网络采用了VGG/ResNets的策略,通过重复层来增加深度和宽度,并利用分裂-变换-合并策略以易于扩展的方式进行转换。文章还提出了一个新的维度——“基数”,它是指转换集合的大小,可以在保持复杂性不变的情况下提高分类准确性。作者在ImageNet-1K数据集上进行了实证研究,证明了这种方法的有效性。
下图是ResNet(左)与ResNeXt(右)block的差异。在ResNet中,输入的具有256个通道的特征经过1×1卷积压缩4倍到64个通道,之后3×3的卷积核用于处理特征,经1×1卷积扩大通道数与原特征残差连接后输出。
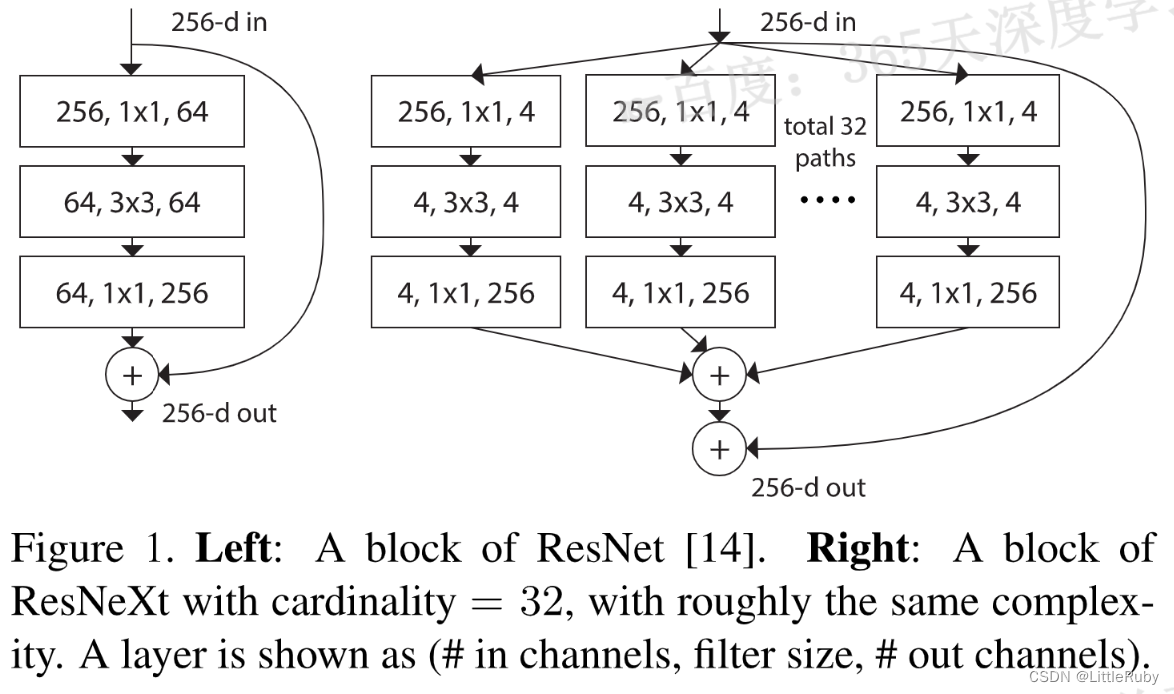
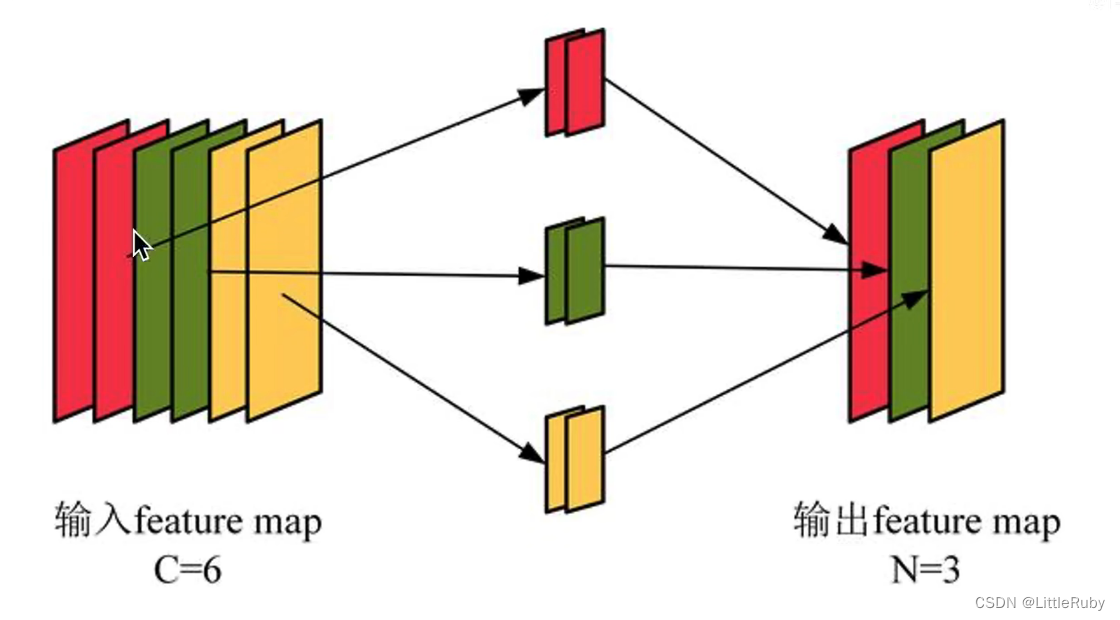
ResNeXt也是相同的处理策略,但在ResNeXt中,输入的具有256个通道的特征被分为32个组,每组被压缩64倍到4个通道后进行处理。32个组相加后与原特征残差连接后输出。这里cardinatity指的是一个block中所具有的相同分支的数目。下图为等效模型。

下图为ResNet50和ResNeXt50(32x4d)的结构对比图。

分组卷积
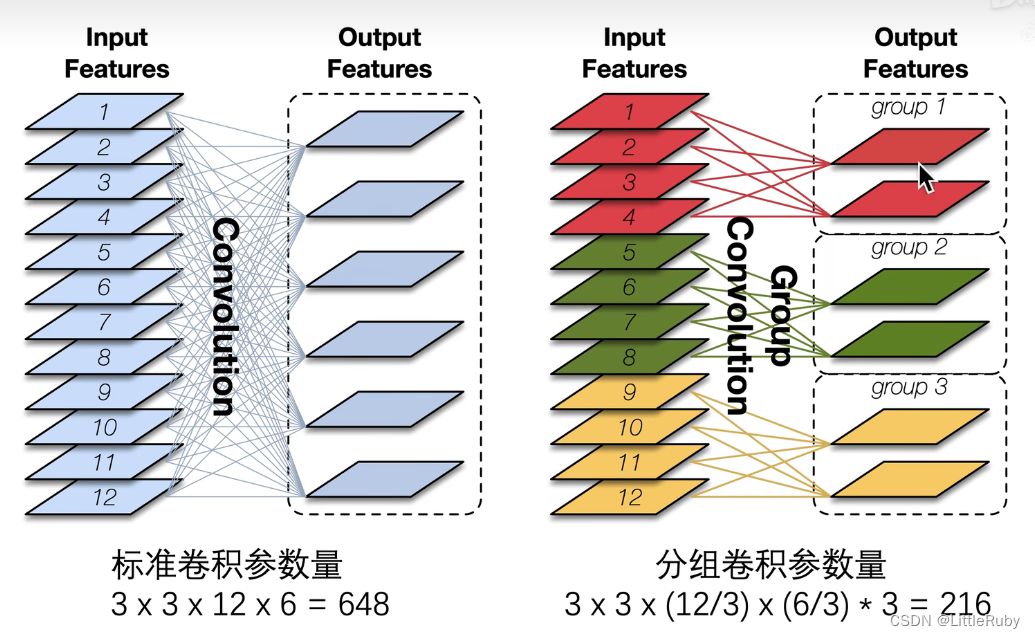
ResNeXt中采用的分组卷机简单来说就是将特征图分为不同的组,再对每组特征图分别进行卷积,这个操作可以有效的降低计算量。
在分组卷积中,每个卷积核只处理部分通道,比如下图中,红色卷积核只处理红色的通道,绿色卷积核只处理绿色通道,黄色卷积核只处理黄色通道。此时每个卷积核有2个通道,每个卷积核生成一张特征图。
4.2 ResNeXt50对比ResNet50V2、DenseNet
4.2.1 网络结构
ResNet-50v2是ResNet系列中的一个经典模型,由50层卷积层、批量归一化、激活函数和池化层构成。它引入了一种全新的残差块结构,即bottleneck结构,使得网络参数量大幅度降低,同时精度也有所提升。
DenseNet是一种全新的网络结构,其特点是不同于传统的网络结构,DenseNet中每一层的输出不仅和前一层的输出有关,还和之前所有层的输出有关,这种密集连接的结构可以有效地缓解梯度消失和参数稀疏问题,提高了模型的泛化能力和精度。
AggResNet(ResNeXt50)则是基于ResNet结构改进而来的新型深度神经网络结构,其特点是采用了聚合残差结构和局部连接结构,同时引入了Random Erasing和Mixup等数据增强和正则化方法,可以进一步提高网络的精度和鲁棒性。
4.2.2 精度和计算量
在ImageNet数据集上,ResNet-50v2和DenseNet在Top-1和Top-5指标上都取得了优异的性能。与之相比,AggResNet在相同的深度下具有更高的精度,并且在参数量和计算量上都显著降低。同时,在较深的网络结构下,AggResNet的优势更加明显,可以达到更高的精度,而ResNet-50v2和DenseNet则难以继续提高精度。
4.2.3 适用范围
ResNet-50v2适用于各种图像分类任务,但在一些特定的视觉任务,如目标检测、语义分割等方面的表现可能不如其他模型。
DenseNet则在各种任务中都具有优异的性能,尤其在目标检测和语义分割等像素级别的任务中表现突出。
AggResNet则不仅适用于图像分类任务,同时也可以应用于目标检测、语义分割和行人重识别等视觉任务中,并且在这些任务中具有优异的性能。
4 总结
ResNet-50v2、DenseNet和AggResNet都是非常优秀的深度神经网络结构,它们在不同的任务和场景中都具有不同的优势和适用性。
相关文章:
深度学习 Day27——J6ResNeXt-50实战解析
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制🚀 文章来源:K同学的学习圈子 文章目录 前言1 我的环境2 pytorch实现DenseNet算法2.1 前期准备2.1.1 引入库2.1.2 设…...
 C++题解(数学+递归+快速幂))
【力扣 50】Pow(x, n) C++题解(数学+递归+快速幂)
实现 pow(x, n) ,即计算 x 的整数 n 次幂函数(即,xn )。 示例 1: 输入:x 2.00000, n 10 输出:1024.00000 示例 2: 输入:x 2.10000, n 3 输出:9.26100 …...

速盾:服务器接入CDN后上传图片失败的解决方案
本文将探讨当服务器接入CDN后,上传图片失败的常见原因,并提供解决方案以解决这些问题。同时,我们还将附上一些相关的问题和解答,让读者更好地理解和应对这些挑战。 随着互联网的持续发展,网站的性能和速度对于用户体验…...
LabVIEW高级CAN通信系统
LabVIEW高级CAN通信系统 在现代卫星通信和数据处理领域,精确的数据管理和控制系统是至关重要的。设计了一个基于LabVIEW的CAN通信系统,它结合了FPGA技术和LabVIEW软件,主要应用于模拟卫星平台的数据交换。这个系统的设计不仅充分体现了FPGA在…...
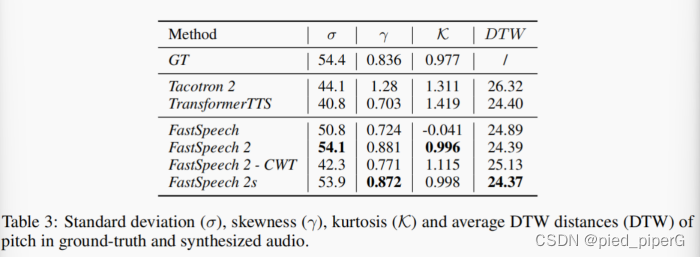
FastSpeech2——TTS论文阅读
笔记地址:https://flowus.cn/share/1683b50b-1469-4d57-bef0-7631d39ac8f0 【FlowUs 息流】FastSpeech2 论文地址:lFastSpeech 2: Fast and High-Quality End-to-End Text to Speechhttps://arxiv.org/abs/2006.04558 Abstract: tacotron→…...
如何才能拥有比特币 - 01 ?
如何才能拥有BTC 在拥有 BTC 之前我们要先搞明白 BTC到底保存在哪里?我的钱是存在银行卡里的,那我的BTC是存在哪里的呢? BTC到底在哪里? 一句话概括,BTC是存储在BTC地址中,而且地址是公开的,…...

Unity | 渡鸦避难所-8 | URP 中利用 Shader 实现角色受击闪白动画
1. 效果预览 当角色受到攻击时,为了增加游戏的视觉效果和反馈,可以添加粒子等动画,也可以使用 Shader 实现受击闪白动画:受到攻击时变为白色,逐渐恢复为正常颜色 本游戏中设定英雄受击时播放粒子效果,怪物…...

K8S--安装metrics-server,解决error: Metrics API not available问题
原文网址:K8S--安装metrics-server,解决error: Metrics API not available问题-CSDN博客 简介 本文介绍K8S通过安装metrics-server来解决error: Metrics API not available问题的方法。 Metrics Server采用了Kubernetes Metrics API的标准,…...

flume自定义拦截器
要自定义 Flume 拦截器,你需要编写一个实现 org.apache.flume.interceptor.Interceptor 接口的自定义拦截器类。以下是一个简单的示例: import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interce…...
安卓Spinner文字看不清
Holo主题安卓13的Spinner文字看不清,明明已经解决了,又忘记了。 spinner.setOnItemSelectedListener(new Spinner.OnItemSelectedListener() {public void onItemSelected(AdapterView<?> arg0, View arg1, int arg2, long arg3) {TextView textV…...
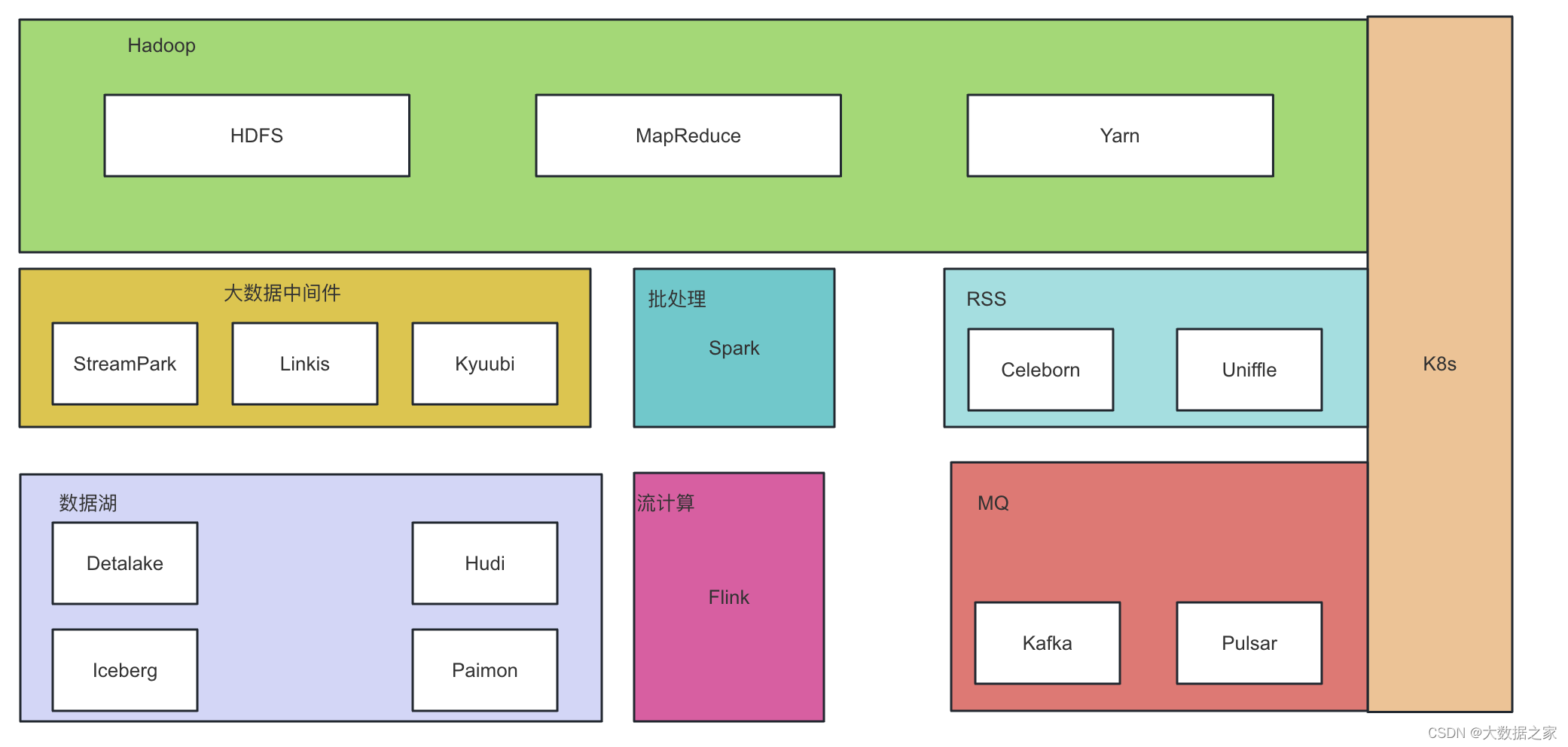
深入浅出hdfs-hadoop基本介绍
一、Hadoop基本介绍 hadoop最开始是起源于Apache Nutch项目,这个是由Doug Cutting开发的开源网络搜索引擎,这个项目刚开始的目标是为了更好的做搜索引擎,后来Google 发表了三篇未来持续影响大数据领域的三架马车论文: Google Fil…...
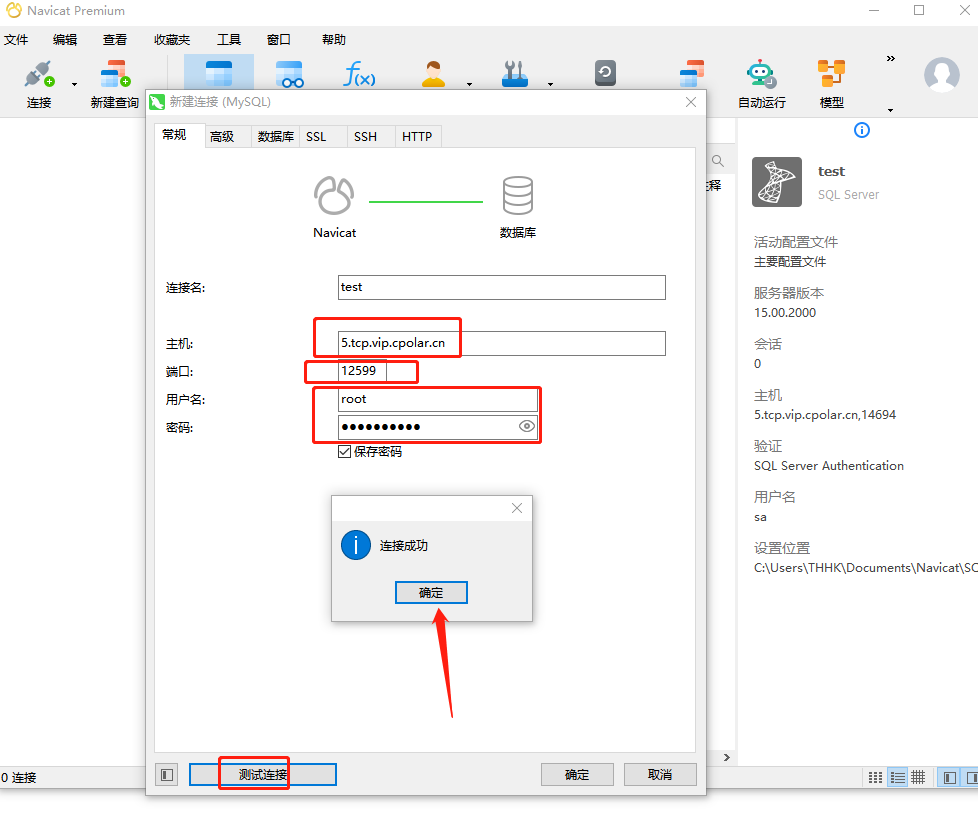
宝塔面板部署MySQL并结合内网穿透实现公网远程访问本地数据库
文章目录 前言1.Mysql服务安装2.创建数据库3.安装cpolar3.2 创建HTTP隧道 4.远程连接5.固定TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 宝塔面板的简易操作性,使得运维难度降低,简化了Linux命令行进行繁琐的配置,下面简单几步,通过宝塔面板cp…...
数据结构<1>——树状数组
树状数组,也叫Fenwick Tree和BIT(Binary Indexed Tree),是一种支持单点修改和区间查询的,代码量小的数据结构。 那神马是单点修改和区间查询?我们来看一道题。 洛谷P3374(模板): 在本题中,单点修改就是将某一个数加上…...
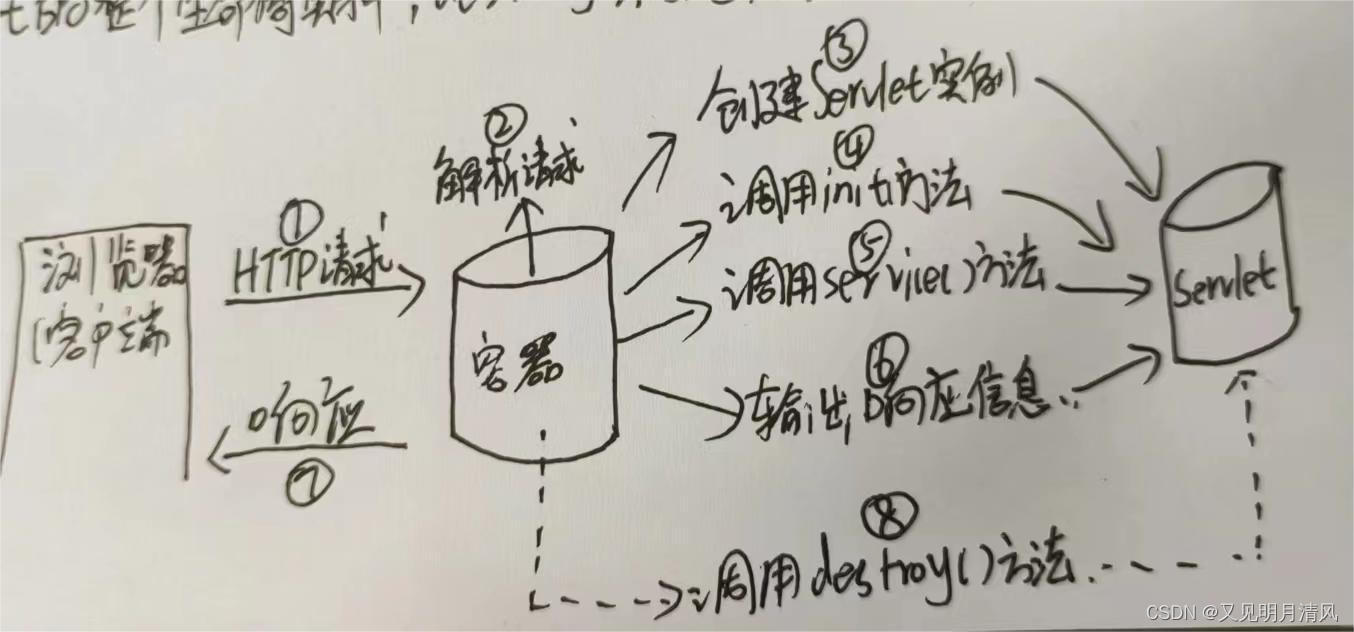
Servlet生命周期
第一阶段: init()初始化阶段 当客户端想Servlet容器(例如Tomcat)发出HTTP请求要求访问Servlet时,Servlet容器首先会解析请求,检查内存中是否已经有了该Servlet对象,如果有ÿ…...
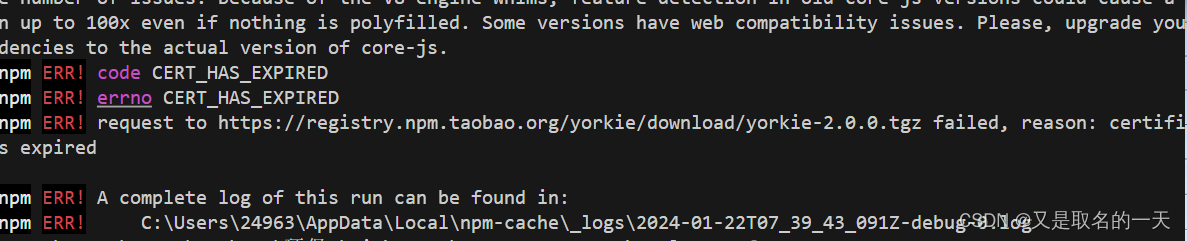
npm i 报一堆版本问题
1,先npm cache clean --force 再下载 插件后缀加上 --legacy-peer-deps 2, npm ERR! code CERT_HAS_EXPIRED npm ERR! errno CERT_HAS_EXPIRED npm ERR! request to https://registry.npm.taobao.org/yorkie/download/yorkie-2.0.0.tgz failed, reason…...

Linux设备管理模型-01:基础数据结构
文章目录 1. 设备管理模型2. 基本数据结构2.1 kobject2.2 kset 1. 设备管理模型 设备模型是内核提供的一个编写驱动的架构。 设备管理是设备-总线-驱动结构。 linux中的设备是由树状模型组织的,从sysfs中可以查看树状结构。 他本身实现了: 电源管理热…...
opencv#32 可分离滤波
滤波的可分离性 就是将一个线性滤波变成多个线性滤波,这里面具体所指的是变成x方向的线性滤波和y方向的线性滤波。无论先做x方向的滤波还是y方向滤波,两者的叠加结果是一致的,这个性质取决于滤波操作是并行的,也就是每一个图像在滤…...

android 导航app 稳定性问题总结
一 重写全局异常处理: 1 是过滤掉一些已知的无法处理的 问题,比如TimeoutException 这种无法根除只能缓解的问题可以直接catch掉 2 是 一些无法继续的问题可以直接杀死重启,一些影响不是很大的,可以局部还原 比如: p…...
第11次修改了可删除可持久保存的前端html备忘录:将样式分离,可以自由秒添加秒删除样式
第11次修改了可删除可持久保存的前端html备忘录:将样式分离,可以自由秒添加秒删除样式 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"…...
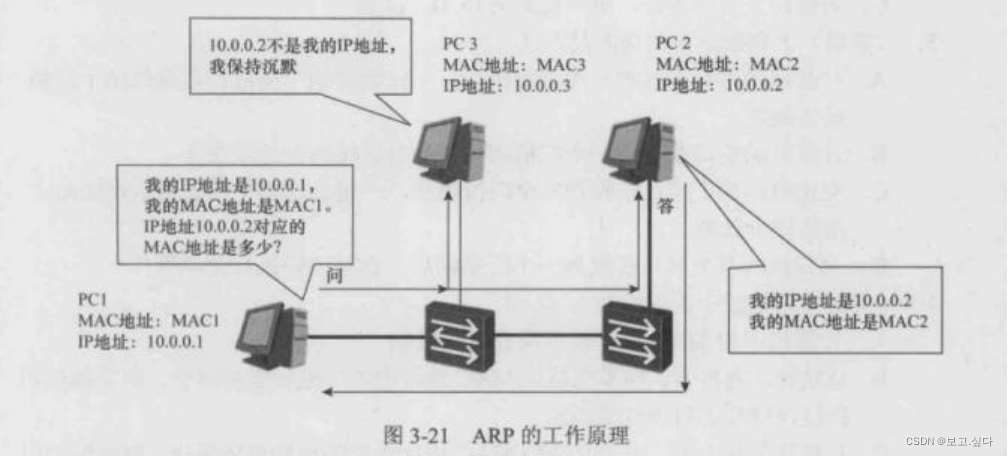
hcip高级网络知识
一:计算机间信息传递原理 抽象语言----编码 编码---二进制 二进制---转换为电流(数字信号) 处理和传递数字信号 二:OSI--七层参考模型 ISO--1979 规定计算机系统互联的组织: OSI/RM ---- 开放式系统互联参考模型 --- 1…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...