DS:顺序表的实现(超详细!!)

创作不易,友友们给个三连呗!
本文为博主在DS学习阶段的第一篇博客,所以会介绍一下数据结构,并在最后学习对顺序表的实现,在友友们学习数据结构之前,一定要对三个部分的知识——指针、结构体、动态内存管理的内容有一定的了解,如果友友们对这三块知识不熟悉的话,可以去看看博主的文章哦!
深入理解指针(1)
深入理解指针(2)
深入理解指针(3)
深入理解指针(4)
自定义类型-——结构体
动态内存管理
如果了解了这三块的知识,可以更好地学习后面地内容,下面步入正题!
一、数据结构相关概念
什么是数据结构呢?从字面意识理解,就是“数据”与“结构”。
1.1 什么是数据?
比如常⻅的数值1、2、3、4.....、教务系统⾥保存的用户信息(姓名、性别、年龄、学历等 等)、网页里肉眼可以看到的信息(⽂字、图⽚、视频等等),这些都是数据。
1.2 什么是结构?
当我们想要使⽤⼤量使⽤同⼀类型的数据时,通过⼿动定义⼤量的独⽴的变量对于程序来说,可读性⾮常差,我们可以借助类似数组这样的数据结构将⼤量的数据组织在⼀起,结构也可以理解为组织数据的方式。举个例子,假设我们要在一个大草原上找到一只叫“咩咩”的羊很困难,但是在羊圈里找到1号羊就很简单,因为“羊圈”这个结构有效地将羊群组织了起来。
广泛一点说,我们生活中每天都充斥着各种各样的数据,为了能够更方便的管理数据,我们需要有一个将数据有效地组织起来的方法,这时候就需要用到——数据结构。
1.3 什么是数据结构?
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在⼀种或多种特定关系 的数据元素的集合。数据结构反映数据的内部构成,即数据由那部分构成,以什么⽅式构成,以及数据元素之间呈现的结构。
在一个生意火爆的餐馆中,如果不借助排队的⽅式来管理客⼾,会导致客⼾就餐感受差、等餐时间⻓、餐厅营业混乱等 情况。同理,程序中如果不对数据进⾏管理,可能会导致数据丢失、操作数据困难、野指针等情况。 通过数据结构,能够有效将数据组织和管理在⼀起。按照我们的⽅式任意对数据进⾏增删改查等操作。
1.4 数据结构能为我们做什么??
1、能够存储数据(如顺序表、链表等结构)
2、存储的数据方便查找
3、方便我们操作数据(增加、删除、修改)
1.5 最基础的数据结构
最基础的数据结构:数组。

有了数组,为什么还要学习其他的数据结构?
假定数组有10个空间,已经使⽤了5个,向数组中插⼊数据步骤: 求数组的⻓度,求数组的有效数据个数,向下标为数据有效个数的位置插⼊数据(注意:这⾥是 否要判断数组是否满了,满了还能继续插⼊吗)..... 假设数据量⾮常庞⼤,频繁的获取数组有效数据个数会影响程序执⾏效率。
结论:最基础的数据结构能够提供的操作已经不能完全满⾜复杂算法实现。
二、顺序表相关概念
2.1 线性表
线性表(linear list)是n个具有相同特性的数据元素的有限序列,也可以理解成具有部分相同特性的一类数据结构的集合。
线性表是⼀种在实际中⼴泛使⽤的数据结构,常⻅的线性表:顺序表、链表、栈、队列、字符串... 线性表在逻辑上是线性结构,也就说是连续的⼀条直线。但是在物理结构上并不⼀定是连续的, 线性表在物理上存储时,通常以数组和链式结构的形式存储。
案例:蔬菜分为绿叶类、⽠类、菌菇类。
2.2 如何理解数据结构中逻辑结构和物理结构?
逻辑结构:对数据之间关系的描述
物理结构:数据存储在磁盘中的方式
2.3 顺序表的分类
对于咖喱饭来说,他的底层是米饭,通过增加了咖喱升级成了咖喱饭。
对于顺序表来说,顺序表的底层结构是数组,即通过对数组的封装,实现了常用的增删改查等接口,将数组升级为了所谓的顺序表。
ps:接口就是规定程序做什么,但是又不在其中实现。友友们暂时理解成功能就行。
顺序表由于底层数组的不同(定长数组和动态数组),又区分了静态顺序表和动态顺序表
注:顺序表的物理结构也是线性的,因为底层是数组,有连续存放的特点!
2.3.1 静态顺序表
概念:使用定长数组存储元素
#define N 1000 //定义一个宏,方便根据需要修改定长数组的大小,这样就不用改动后面的内容
typedef int SLDataType;
//因为顺序表根据需要可能需要存储不同的数据类型,所以将其进行重命名
//如果想改成char和float,可以直接在这里修改,不需要去改动后面的内容
typedef struct Seqlist
{SLDataType a[N];//定长数组,可以通过修改#define定义的N来改变数组大小int size;
//定长数组开辟了N个空间,但不代表里面有N个有效数个数,所以需要size来记录有效数个数。
}SL;//将名字修改得简短一点1、为什么不直接用a[1000],还要定义一个宏来表示?
为了方便代码的修改,如果在代码写一半的时候,我们发现开辟的数组大小需要进行调整,那么只需要修改#define定义的N就行了,如果是直接写1000,一旦需要修改,所有程序中出现的a[1000]就得一个个修改!
2、为什么需要给int重命名为SLDataType?
因为我们希望我们的顺序表是灵活的,在当前数据表我们需要存储的是int类型的数据,但如果在后期,我们希望能够有存储char、float、double的顺序表,只需要将typedef int SLDataType中的int进行修改就行,如果没有这条重命名,那么当我希望用这个顺序表存储其他类型元素时,就休要修改大量的代码!!
3、为什么需要size(有效数个数)
因为我们虽然开辟了这么多空间,但是并不代表这么多空间都存储着有效的数据,所以我们需要用一个size来记录该数组存储的有效数据个数。
2.3.2 静态顺序表的劣势
如果使用静态顺序表存储数据,那么在准备该项目的一开始就得将数组长度定下来,但是很多时候我们需要存储数据的多少是在程序运行的时候才能得知的(比如我开发了一个app,但是一开始并不知道会有多少人来使用),就可能造成以下问题:
1、给定的数组长度如果不够,那么会导致后续的数据保存失败,造成数据丢失。
假如我们开发了一个app,我们需要一开始就预估数组的大小,假设我们预估100,但是有200个人来注册,那么当前100人注册完成后,从101个人开始由于数组容量不够,数据不能有效保存,这就会造成数据丢失!!这在企业中会是一个非常严重的事故!并且会让别人知道你是一个容易出事故的员工。
2、给定的数组长度如果太大,就会造成空间浪费
我们考虑到我们的app可能会很火爆,所以我们预先设置了10000的大小,但一运行发现不到100个人注册,如果你团队的其他人也不注重这个,那么就会造成一个小业务却占用巨大内存空间的问题,这不仅会造成硬件上的浪费,还会让别人知道你是一个对内存的管理能力极差的员工。
2.3.3 动态顺序表
通过分析静态顺序表的劣势,我们发现该方法特别容易出问题,所以我们就需要动态顺序表,因为动态顺序表的底层是动态数组,他和定长数组的区别就是长度并不是在一开始就确定的!!这使得程序员可以在程序运行过程中更灵活地去管理内存,根据需求去开辟空间,尽可能减少了空间浪费。
typedef int SLDataType;
//因为顺序表根据需要可能需要存储不同的数据类型,所以将其进行重命名
//如果想改成char和float,可以直接在这里修改,不需要去改动后面的内容
typedef struct Seqlist
{SLDataType*a;//动态数组,一开始不确定大小,程序员可以根据过程中的需求去合理开辟int capacity;//空间容量,假设我们扩容了,用其记录扩容后动态数组的大小。int size;//开辟了相应的空间,但需要size来记录有效数个数。
}SL;//将名字修改得简短一点跟静态顺序表相比,除了底层的数组不同,我们还需要一个capacity,因为动态数组的创建并不像定长数组一样可以一开始就知道数组的容量,所以当我们为该动态数组动态开辟内存时,就需要使用capacity去记录该动态数组的容量。
三、顺序表的实现
我们知道了静态顺序表可能存在的问题,所以我们一般使用的是动态顺序表,下面介绍的也是动态顺序表的实现。
3.1 初始化和销毁
1、初始化
void SLInit(SL* ps)
//为什么要传址?
//1.如果是传值,形参是实参的临时‘值’拷贝,如果我们创建
// 的ps未初始化,那么是没有办法进行值传递的!!
//2.即使我们初始化了,将值传过去了,由于形参是实参的
// 临时拷贝,因此并不会改变实际ps的值!!
{ps->a = NULL;ps->size = ps->capacity = 0;
}为什么这里的参数要用指针形式?
(1)如果是传值,形参是实参的临时‘值’拷贝,如果我们创建的ps未初始化,那么是没有办法进行值传递的!!
(2)即使我们初始化了,将值传过去了,由于形参是实参的临时拷贝,因此并不会改变实际ps的值!
综上,由于我们需要去改变ps的实际内容,就必须传地址,所以需要用指针类型去接收,在后续的其他函数中也是如此!!
2、销毁
//必须要确保有动态内存的开辟,才能将其释放!所以释放前一定要判断是否为空
void SLDestory(SL* ps)
{assert(ps);if (ps->a)free(ps->a);//释放不代表不存在ps->a = NULL;ps->size = 0;ps->capacity = 0;
}(1)为什么销毁前还需要判断ps是否为空?
如果传入的是NULL,就没有必要销毁,也就是说,free其实跟realloc是配对的,如果没有对顺序表的动态数组开辟过空间,那么自然也没有必要free。
(2)ps->a已经被释放了,为什么还要赋给NULL,有必要吗?
非常有必要!!因为这段空间被释放,并不代表不存在,只不过是失去了这段空间的使用权限,指针的值并没有改变,我们无法直接通过指针自身来进行判断空间是否已经被释放,将指针置空有助于判断一个指针所指向的空间已经被释放,因为写大量代码之后可能会忘记掉ps->a已经被释放,一旦误用造成程序崩溃,而如果ps->a是一个空指针,那么编译器会通过报错来提醒你。
3.2 扩容的原则
(1)一次扩一个元素大小的空间
插入一个元素不会造成空间的浪费,但是这样就需要不断地进行扩容,我们知道realloc本质也是个函数,每次调用都需要开辟函数栈帧,不断地调用会导致程序运行的效率低下。
(2)一次扩容固定大小的空间(比如10、100、1000)
这个扩容的固定大小我们难以合理的把握,如果小了会造成频繁扩容产生的效率底下,如果大了就会造成空间浪费。
(3)成倍数的扩容(1.5倍、2倍)
这是一种定式:1.5倍或者2倍数的增长相比其他方法更能节省空间,至于为什么,这个博主暂时还没有办法深入解释,但如果问为什么是1.5倍或2倍,而不是3倍或4倍,可以说就是因为倍数过大会导致数据插入越来越多,扩容大小就越来越大。总之一定要记住这个定式!!所以我们后面的数据结构扩容基本都是扩大1.5或者2倍。
3.3 扩容的方式
因为使用动态开辟扩容,由于数组是开辟的是连续的内存,当我们直接扩大时,如果后面的空间尚未被分配,那么就可以直接扩大,但是如果该空间已经被分配了,那么如果强行占用,就会造成别的数据丢失,所以有以下两者情况:

情况1:要扩展内存就直接原有内存之后直接追加空间,原来空间的数据不发⽣变化。
情况2:原有空间之后没有⾜够多的空间时,扩展的⽅法是:在堆空间上另找⼀个合适大小的连续空间,然后将旧空间里原有数据拷贝在新空间上,然后释放旧空间,最好返回新空间的地址。
3.4 扩容和打印
1、扩容
因为在后续的操作中,比如尾插、头插、指定位置插入,每加入一个数据有可能会导致空间不足,所以我们先来实现这样的一个扩容函数。
void SLCheckCapacity(SL* ps)
{if (ps->capacity == ps->size)//判断是否需要扩容{int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;//如果capacity为0,则赋给他4的初始值,如果不为零,就乘两倍SLDataType* temp = (SLDataType*)realloc(ps->a, newcapacity * sizeof(SLDataType));//注意第二个参数的单位是字节,所以newcapacity要乘以sizeof(SLDataType)。//realloc可以调整动态开辟内存的大小,比calloc和malloc更灵活一点if (temp == NULL)//relloc可能开辟失败 失败则退出程序{perror("realloc");exit(1);//退出程序}//if不成立则开辟成功ps->a = temp;//记录开辟空间的首地址ps->capacity = newcapacity;//记录新的容量大小}
}(1)int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity的含义是什么?
因为我们在对顺序表初始化的时候,给capacity赋给的是0,如果是0无论乘以多少倍容量都不会变,所以我们这边应用了一个三目表达式,用newcapacity来接收结果,如果capacity为0,那我就先赋给他一个初始值4,如果他不为0,则按照原计划乘2倍,最后再将newcapacity的值赋给ps->capacity。
(2)为什么使用realloc?
malloc和calloc的作用是申请一段连续的空间,然后calloc还多了一个初始化的功能,但是realloc可以调整动态开辟空间的大小,因为我们未来很可能需要多次扩容,显然realloc更加灵活,但是也有两个易错点:1、realloc的第二个参数传递的是调整后的空间大小,他的单位是字节!!所以newcapacity要乘以sizeof(SLDataType)才行。2、realloc也有可能会开辟失败,所以一定不要直接用我们顺序表里的动态数组去接收返回的地址,因为原来的数组中可能已经存在一些数据了,如果动态开辟空间失败,还会造成原来数据的丢失!!所以一定要先用一个相同类型的指针去接收开辟空间的地址,并进行判断,确保不为NULL了,才能安全地传给我们顺序表里地动态数组。
(3)exit(1)和return1的区别是什么?
使用场景:
return 用于从函数返回。在 main 函数中,return 也会结束程序。
exit() 是一个标准库函数,可以在程序中的任何地方被调用来终止程序。
结束方式:
return 只会结束当前的函数,且如果是在子函数中使用,程序其余部分还会继续执行。
exit() 则会立即结束整个程序的执行,且不会返回到调用者。
清理操作:
当在 main 函数中使用return结束程序时,这与调用 exit() 是相等的,因为他们都会执行一些清理操作。这包括执行所有 atexit 设置的终止函数,刷新所有的buffered I/O,关闭所有打开的文件等。
但是在子程序(非main函数)中,return 不会执行这些操作,而 exit() 仍会执行。
终止状态传递
return 在 main 函数中的用法和 exit() 都可以向操作系统传递终止状态。在 main 中 return 0; 或者 exit(0); 表示程序正常结束。
在其他函数中,return 我们可以返回一个值来表示函数结果,而 exit() 不仅会结束程序,而且不返回任何
总的来说就是return 1温柔一点,exit(1)会暴力一点,在这里用哪个都是可以的,平时还是要结合实际情况来使用。
2、打印
该函数没有太大的意义,单纯就是为了让我们在实现顺序表的过程中对每一个封装的函数进行验证,这样我们可以及时找到错误并改正,如果等到全部代码写完了再去判断对错,此时调试的难度就很大了!所以写这个函数目的就是为了验证!!
void SLPrint(SL* ps)
{for (int i = 0; i < ps->size; i++){printf("%d ", ps->a[i]);}需要注意的是:其实对于打印函数来说,我们并不需要对里面的数据有任何操作,只是单纯的展示,所以这里使用值传递也是可以的,但是为了保证接口一致性,这样就是方便用户和我们在使用该顺序表时不需要去考虑什么时候是值传递,什么时候是地址传递。
3.5 尾插和头插
1、尾插
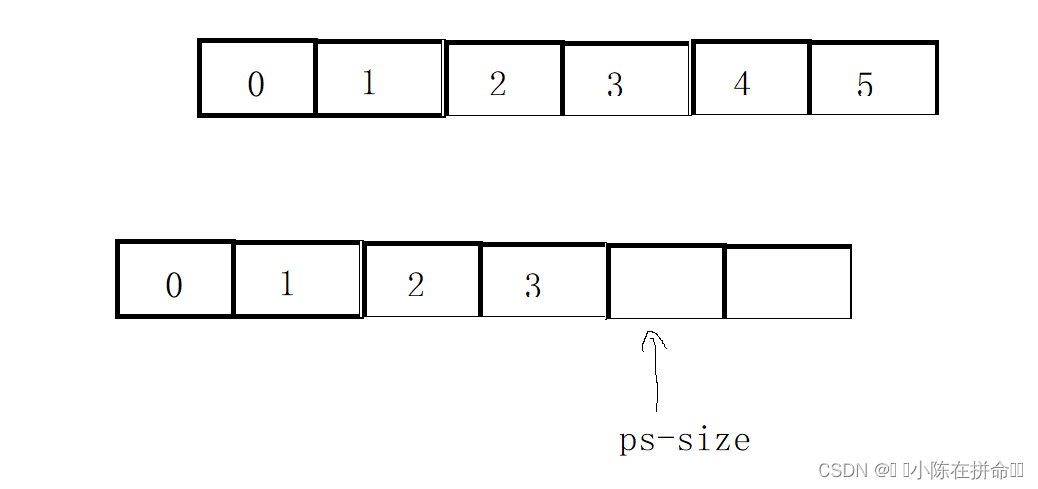
有两者情况,一种时空间足够,直接插入,一种是空间不够,需要扩容后才能插入。
void SLPushBack(SL* ps, SLDataType x)
{//assert粗暴的判断方式assert(ps);//温柔的判断方式//if (ps)//return 1;SLCheckCapacity(ps);//判断是否需要扩容//空间足够直接插入ps->a[ps->size] = x;ps->size++;//插入数据后,有效个数加1
}
为什么需要判断ps是否为空??
因为我们封装这个函数是为了实现顺序表的尾插,如果传入的是一个空指针,那么后续操作就会出问题,其实这也是为了避免该函数被滥用!不能是你想传什么就传什么,后面的很多函数接口都要考虑这个情况!!
注:只要是插入数据,一定不要忘记最后要size++
2、头插

可以通过图发现:头插,需要将所有数据往后挪一位!!挪动的时候要注意挪动的顺序,如果是从前往后挪,那么0一旦覆盖原来1的位置,1的数据就丢失了,所以必须从后往前挪!!
void SLPushFront(SL* ps, SLDataType x)
{assert(ps);//判断传入的是否是空指针SLCheckCapacity(ps);//判断是否需要扩容//空间足够 从后往前挪for (int i = ps->size; i > 0; i--){ps->a[i] = ps->a[i - 1];//边界判断:ps->a[1]=ps->a[0]}ps->a[0] = x;ps->size++;
}for循环边界的判断:找循环的最后一次去验证就行,比如说int i = ps->size; i > 0;我们通过观察最后一次循环ps->a[1]=ps->a[0]恰好是我们想要的结果,所有数据都后挪完成了,说明此时for循环的边界没有问题,如果不是我们想要的结果,再及时去调整for循环的边界条件。
3.6 尾删和头删
1、尾删

有两者情况,有数据的情况就删除最后一个元素,如果没有数据,就不执行!
void SLPopBack(SL* ps)
{assert(ps);//判断传入的是否是空指针assert(ps->size);//确保里面有元素,否则不执行//ps->a[ps->size - 1] = 0;没必要ps->size--;
}为什么ps->a[ps->size - 1] = 0没必要,因为无论这里是否有值,只要size--了,那么他就不是有效的元素了,即使后面又插入了新元素,插入的新元素都是直接覆盖掉原数据,所以没必要特意地去赋值0!!
2、头删

通过上图我们可以发现,删除了首元素之后,要将后面的元素依次往前挪,如果是从后往前挪,那么3一旦覆盖2,就找不到2了,所以必须从前往后挪!!
void SLPopFront(SL* ps)
{assert(ps);//判断传入的是否是空指针assert(ps->size);//确保里面有元素,否则不执行
//从前往后挪for (int i = 0; i < ps->size - 1; i++){ps->a[i] = ps->a[i + 1];//边界判断ps->a[size-2] = ps->a[size-1]}ps->size--;
}3.7 指定位置之前插入和指定位置删除
指定位置的插入以及删除,我们都需要传入一个指定的位置pos。
1、指定位置之前插入
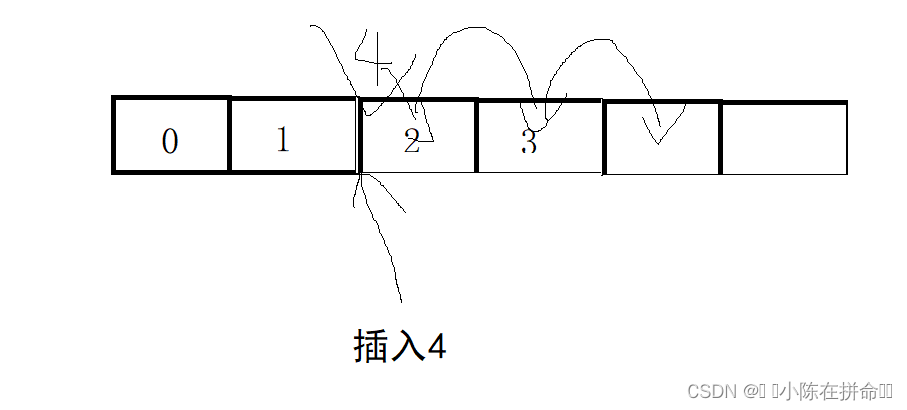
由图可知,插入之前要先将插入位置后面的元素往后挪一位,然后再插入!!如果从前往后挪,2会覆盖3,就找不到3了,所以要从后往前挪!!
void SLInsert(SL* ps, int pos, SLDataType x)
{assert(ps);//判断传入的是否是空指针assert(pos >= 0 && pos <= ps->size);//确保不要瞎传一个pos的值进来!!SLCheckCapacity(ps);//判断是否需要扩容//pos之后的元素从后往前挪for (int i = ps->size; i > pos; i--){ps->a[i] = ps->a[i - 1];//边界判断ps->a[pos+1] = ps->a[pos]}ps->a[pos] = x;ps->size++;
}为什么要有assert(pos >= 0 && pos <= ps->size)??
因为我们封装这个函数,是希望在指定的位置去插入一个数据,但是如果你传入的这个位置,并不是目前数组的有效位置,那么即使你插入进去了,该数据也不会被访问到,所以这个操作也是为了避免函数被滥用。
2、指定位置删除
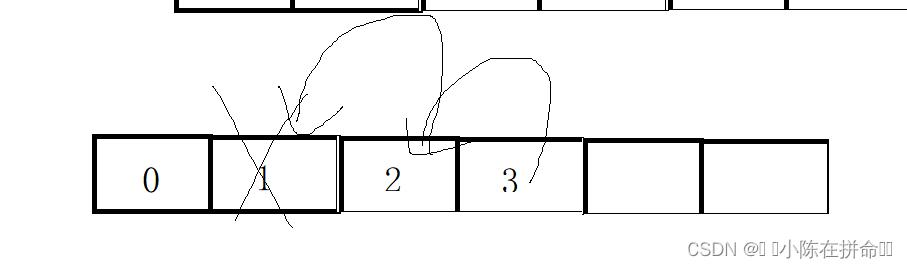
由图可知,指定位置删除之后,要把后面的元素往前挪!!要从前往后挪!!
void SLErase(SL* ps, int pos)
{assert(ps);//判断传入的是否是空指针assert(pos >= 0 && pos <= ps->size);//确保不要瞎传一个pos的值进来!!assert(ps->size);//确保里面有元素,否则不执行for (int i = pos; i < ps->size-1; i++){ps->a[i] = ps->a[i+1];//边界判断:ps->a[i-2] = ps->a[i-1];}ps->size--;
}
3.8 查找
指定位置之前和指定位置删除,都需要传入一个pos(指定的位置),那么如果我们是想要在下标为几的位置操作,那么直接传该下标就好了,但是如果我们是想要根据该下标的内容去找到该下标,比如说我希望删除该顺序表中的3,那么就需要我们去遍历数组找到这个3的下标,再传给指定位置删除的接口来实现!
int SLFind(SL* ps, SLDataType x)
{
//加上断言对代码的健壮性更好
assert(ps);
for (int i = 0; i < ps->size; i++)
{if (ps->a[i] == x) {return i;//找到了,返回下标
}return -1;//找不到,返回一个无效的下标
}3.9 总结
1、我们多次用到assert的意义是什么??
我们利用assert,本质上是为了避免函数被滥用,比如说涉及到对顺序表内部的数据进行增删等操作,我们需要通过assert(ps)来确保传入的不是一个NULL指针,涉及到对数据进行删除,我们需要用assert(ps->size)来确保顺序表内部有元素可以被删除的,避免了对空顺序表的操作。在对指定位置进行操作时,我们需要通过assert(pos >= 0 && pos <= ps->size)来避免传入的是无效位置,因为这样插入的数据是不会被访问到的。综上我们发现,assert能够及时发现我们代码中可能存在的误操作!!其实我们思考的基点,是从传入的参数开始的,也就是说,作为一个程序员,我们思考封装该函数需要什么参数的时候,也要思考这个参数有没有可能会传入一个导致程序崩溃的参数,所以我们必须思考这个问题,然后用assert来预防这些问题,不论是误用还是被他人滥用,会立即停止程序并指出错误,而不会出现程序崩溃的问题!!!
2、for循环的边界判断
当我们使用for循环的时候,无法判断边界的时候,一定不要慌张,可以先预估一个大概的值,然后通过推测最后一次循环带来的结果是否和我们想要的结果一样,如果不一样,及时地进行调整,一定可以找到正确的边界值。
3、数据结构的一些思考
无论是顺序表还是链表,我们在操作写代码的时候,其实可以通过画图去理解,不要光凭想象,好记性不如烂笔头,画图可以很好地帮助理解我们应该怎么去对数据结构进行操作,以及前期学习的指针也是如此,遇到任何的指针运算题,一定要画图!!!
4、顺序表的通用性
这次我们是利用顺序表存储int类型的数据,那如果下次我们想要存储char类型、float类型、double类型也是可以的,这也是为什么我们前期需要对int重命名的原因,想修改存放的类型直接在那里改一下就可以了,同时我们应该思考,我们设置的上述所有接口是否都可以无缝衔接??其实都是可以的(可以仔细看看上面所有接口,比如将int换成float是否通用),打印函数是不可以的,因为这个函数本身的存在意义就是为了方便我们当每次封装完一个接口的时候,可以通过main函数去调用,并使用打印函数打印出来,本身就是一个展示的作用,目的是为了我们测试我们的代码是否正确。查找函数也是不可以的,因为查找函数我们实现的是通过下标对应int类型元素去找到下标,但以后我们可能还会根据不同的情况去寻找下标,比如在通讯录中,可能就是根据名字去找下标!
综上,希望友友们可以利用这个打印函数,每写完一个功能的函数就自己去调用检测一下,如果有问题就自己去调试,相比直接抄,会有很大收获的!!下面我会把所有代码都写出来方便友友们复制!!同时要注意,代码虽然是对的,但是并不意味着一定要这样写!!只是参考,如果可以优化的话友友们可以进行发挥!!
四、顺序表实现的所有代码
seqlist.h
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>typedef int SLDataType;
//因为顺序表根据需要可能需要存储不同的数据类型,所以将其进行重命名
//如果想改成char和float,可以直接在这里修改,不需要去改动后面的内容
typedef struct Seqlist
{SLDataType*a;//动态数组,一开始不确定大小,程序员可以根据过程中的需求去合理开辟int capacity;//空间容量,假设我们扩容了,用其记录扩容后动态数组的大小。int size;//开辟了相应的空间,但需要size来记录有效数个数。
}SL;//将名字修改得简短一点void SLInit(SL* ps);//初始化
void SLDestory(SL* ps);//销毁
void SLPrint(SL* ps);//打印
void SLCheckCapacity(SL* ps);//扩容
void SLPushBack(SL* ps, SLDataType x);//尾插
void SLPushFront(SL* ps, SLDataType x);//头插
void SLPopBack(SL* ps);//尾删
void SLPopFront(SL* ps);//头删
void SLInsert(SL* ps, int pos, SLDataType x);//指定位置之前插入
void SLErase(SL* ps, int pos);//指定位置删除
int SLFind(SL* ps, SLDataType x);//查找指定数据的位置seqlist.c
#include"seqlist.h"
void SLInit(SL* ps)
{//为什么要传址?
//1.如果是传值,形参是实参的临时‘值’拷贝,如果我们创建
// 的ps未初始化,那么是没有办法进行值传递的!!
//2.即使我们初始化了,将值传过去了,由于形参是实参的
// 临时拷贝,因此并不会改变实际ps的值!!ps->a = NULL;ps->size = ps->capacity = 0;
}//必须要确保有动态内存的开辟,才能将其释放!所以释放前一定要判断是否为空
void SLDestory(SL* ps)
{if (ps->a)free(ps->a);//释放不代表不存在ps->a = NULL;ps->size = 0;ps->capacity = 0;
}void SLCheckCapacity(SL* ps)
{if (ps->capacity == ps->size)//判断是否需要扩容{int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;//如果capacity为0,则赋给他4的初始值,如果不为零,就乘两倍SLDataType* temp = (SLDataType*)realloc(ps->a, newcapacity * sizeof(SLDataType));//注意第二个参数的单位是字节,所以newcapacity要乘以sizeof(SLDataType)。//realloc可以调整动态开辟内存的大小,比calloc和malloc更灵活一点if (temp == NULL)//relloc可能开辟失败 失败则退出程序{perror("realloc fail");exit(1);//退出程序}//if不成立则开辟成功ps->a = temp;//记录开辟空间的首地址ps->capacity = newcapacity;//记录新的容量大小}
}void SLPrint(SL* ps)
{for (int i = 0; i < ps->size; i++){printf("%d ", ps->a[i]);}
}void SLPushBack(SL* ps, SLDataType x)
{//assert粗暴的判断方式assert(ps);//温柔的判断方式//if (ps)//return 1;SLCheckCapacity(ps);//判断是否需要扩容//空间足够直接插入ps->a[ps->size] = x;ps->size++;//插入数据后,有效个数加1
}void SLPushFront(SL* ps, SLDataType x)
{assert(ps);//判断传入的是否是空指针SLCheckCapacity(ps);//判断是否需要扩容//空间足够 数据往后挪一位for (int i = ps->size; i > 0; i--){ps->a[i] = ps->a[i - 1];//边界判断:ps->a[1]=ps->a[0]}ps->a[0] = x;ps->size++;
}void SLPopBack(SL* ps)
{assert(ps);assert(ps->size);//确保里面有元素,否则不执行//ps->a[ps->size - 1] = 0;没必要ps->size--;
}void SLPopFront(SL* ps)
{assert(ps);//判断传入的是否是空指针assert(ps->size);//确保里面有元素,否则不执行for (int i = 0; i < ps->size - 1; i++){ps->a[i] = ps->a[i + 1];//边界判断ps->a[size-2] = ps->a[size-1]}ps->size--;
}void SLInsert(SL* ps, int pos, SLDataType x)
{assert(ps);//判断传入的是否是空指针assert(pos >= 0 && pos <= ps->size);//确保不要瞎传一个pos的值进来!!SLCheckCapacity(ps);//判断是否需要扩容//pos之后的元素从后往前挪for (int i = ps->size; i > pos; i--){ps->a[i] = ps->a[i - 1];//边界判断ps->a[pos+1] = ps->a[pos]}ps->a[pos] = x;ps->size++;
}void SLErase(SL* ps, int pos)
{assert(ps);//判断传入的是否是空指针assert(pos >= 0 && pos <= ps->size);//确保不要瞎传一个pos的值进来!!assert(ps->size);//确保里面有元素,否则不执行for (int i = pos; i < ps->size-1; i++){ps->a[i] = ps->a[i+1];//边界判断:ps->a[i-2] = ps->a[i-1];}ps->size--;
}int SLFind(SL* ps, SLDataType x)
{
//加上断言对代码的健壮性更好
assert(ps);
for (int i = 0; i < ps->size; i++)
{if (ps->a[i] == x) {return i;//找到了,返回下标
}return -1;//找不到,返回一个无效的下标
}注意:除了查找函数和打印函数需要根据内容的不同修改,其他函数基本上都可以通用!!
相关文章:
DS:顺序表的实现(超详细!!)
创作不易,友友们给个三连呗! 本文为博主在DS学习阶段的第一篇博客,所以会介绍一下数据结构,并在最后学习对顺序表的实现,在友友们学习数据结构之前,一定要对三个部分的知识——指针、结构体、动态内存管理的…...

用flinkcdc debezium来捕获数据库的删除内容
我在用flinkcdc把数据从sqlserver写到doris 正常情况下sqlserver有删除数据,doris是能捕获到并很快同步删除的。 但是我现在情况是doris做为数仓,数据写到ods,ods的数据还会通过flink计算后写入dwd层,所以此时ods的数据是删除了…...

mariadb数据库从入门到精通
mariadb数据库的安装以及安全初始化 mariadb数据库的安装以及安全初始化 mariadb数据库的安装以及安全初始化一、实验前提二、mariadb数据库的安装三、mariadb数据库安全初始化3.1 设定数据库基本的安全初始化3.2关闭对外开放端口 系列文章目录一、查看数据库二、进入库并且查看…...
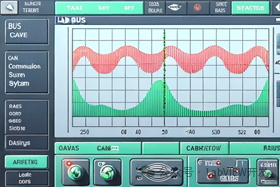
LabVIEW探测器CAN总线系统
介绍了一个基于FPGA和LabVIEW的CAN总线通信系统,该系统专为与各单机进行系统联调测试而设计。通过设计FPGA的CAN总线功能模块和USB功能模块,以及利用LabVIEW开发的上位机程序,系统成功实现了CAN总线信息的收发、存储、解析及显示功能。测试结…...
)
侧输出流(Side Output)
侧输出流(Side Output)是处理函数中的一个重要功能,允许我们将自定义的数据发送到侧输出流中进行处理或输出。通过将数据发送到侧输出流,我们可以将不同的数据流进行分离,以便进行不同的处理和操作。 在处理函数中&…...

Vue 动态组件与异步组件:深入理解与全面应用
聚沙成塔每天进步一点点 本文内容 ⭐ 专栏简介1. 动态组件实现原理:用法示例: 2. 异步组件实现原理:用法示例: 3. 异步组件的高级应用a. 异步组件的命名:b. 异步组件的加载状态管理: ⭐ 写在最后 ⭐ 专栏简…...
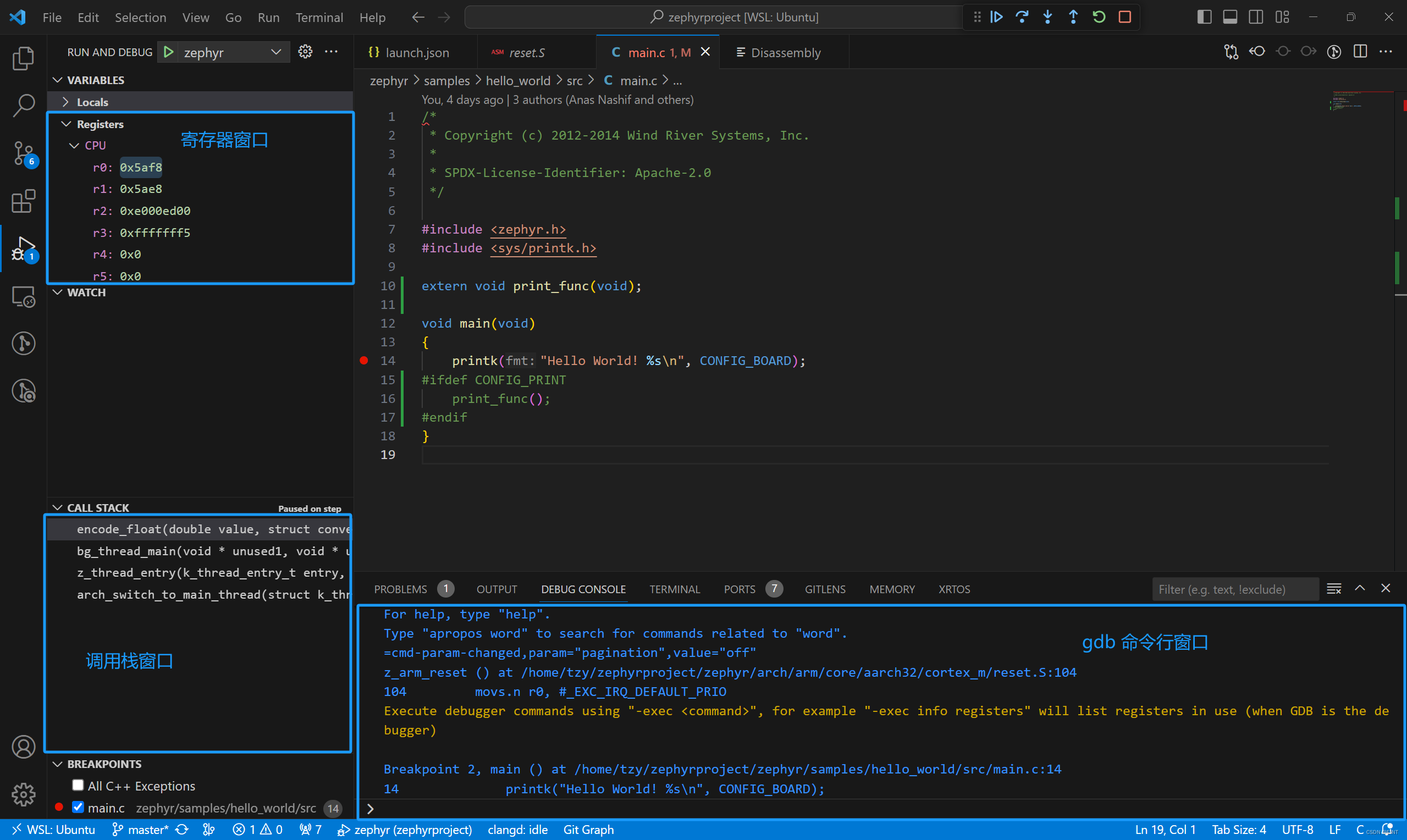
Zephyr 源码调试
背景 调试环境对于学习源码非常重要,但嵌入式系统的调试环境搭建稍微有点复杂,需要的条件略多。本文章介绍如何在 Zephyr 提供的 qemu 上调试 Zephyr 源码,为后续分析 Zephyr OS 相关原理做铺垫。 环境 我的开发环境为 wsl ubuntu…...

数学建模绘图
注意:本文章旨在记录观看B站UP数模加油站之后的笔记文章,无任何商业用途~~ 必备网站 以下网站我都试过,可以正常访问 配色(取色)网站: Color Palettes Generator and Color Gradient Tool Python&#x…...

代码随想录算法训练营第十天 | 239.滑动窗口最大值、347.前K个高频元素
代码随想录算法训练营第十天 | 239.滑动窗口最大值、347.前K个高频元素 文章目录 代码随想录算法训练营第十天 | 239.滑动窗口最大值、347.前K个高频元素1 LeetCode 239.滑动窗口最大值2 LeetCode 347.前K个高频元素 1 LeetCode 239.滑动窗口最大值 题目链接:https…...

【Godot4自学手册】第五节用GDScript语言让主人公动起来
GDScript 是Godot自带的编程语言,用于编写游戏逻辑,它是一种高级面向对象的指令式编程语言,使用渐进类型,专为 Godot 构建。在这一小节里,我将自学用GDScript语言控制主人公的行走和攻击。 一、给Player节点添加GDScr…...

被问到Tomcat是什么该怎么回答?他还有一个好帮手JDK你知道吗?
目录 Tomcat简介: 使用建议: Tomcat好帮手---JDK Tomcat和JDK的关系 安装JDK 1.打开浏览器输入网址 Oracle | Cloud Applications and Cloud Platform 进入Oracle官网 2、在官网首页菜单栏,点击产品,在硬件和软件中找到Java࿰…...
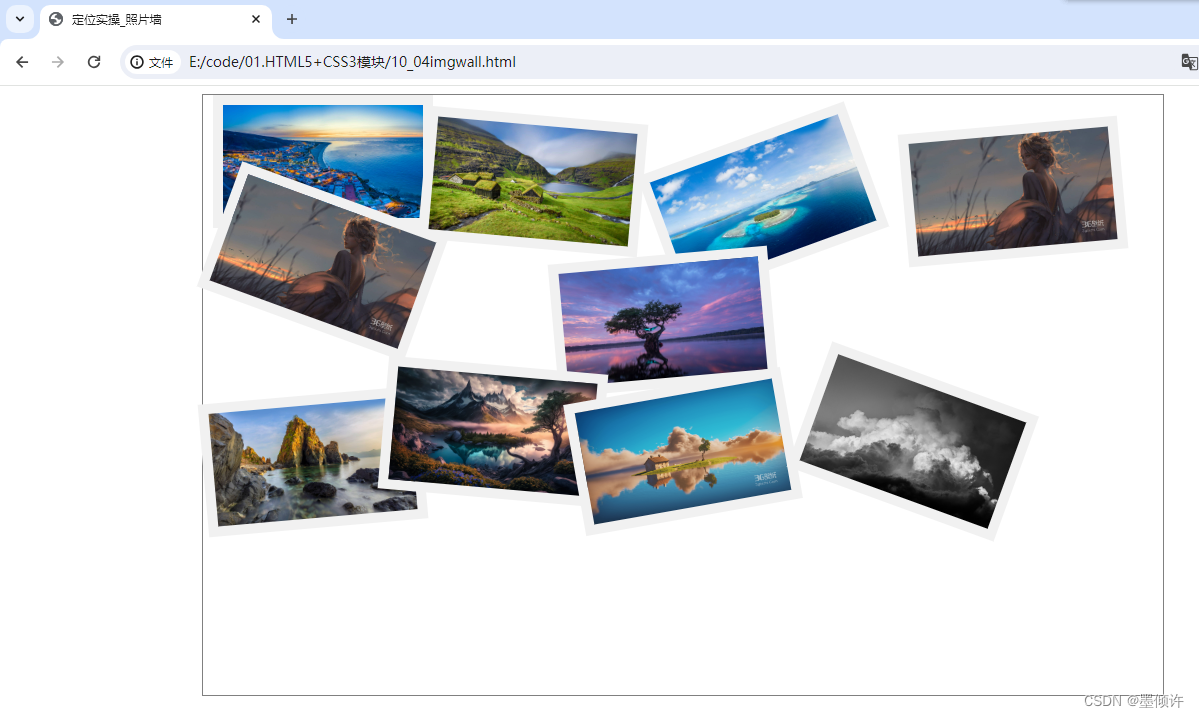
【Web前端实操11】定位实操_照片墙(无序摆放)
设置一个板块,将照片随意无序摆放在墙上,从而形成照片墙。本来效果应该是很唯美好看的,就像这种,但是奈何本人手太笨,只好设置能达到照片墙的效果就可。 代码如下: <!DOCTYPE html> <html lang&…...

图像处理------调整色调
什么是色调? 色调,在画面上表现思想、感情所使用的色彩和色彩的浓淡。分为暖色调和冷色调。 from cv2 import destroyAllWindows, imread, imshow, waitKey#创建棕褐色色调 def make_sepia(img, factor: int):pixel_h, pixel_v img.shape[0], img.shap…...

【操作系统】实验七 显示进程列表
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的很重要&…...
[实战]加密传输数据解密
前言 下面将分享一些实际的渗透测试经验,帮助你应对在测试中遇到的数据包内容加密的情况。我们将以实战为主,技巧为辅,进入逆向的大门。 技巧 开局先讲一下技巧,掌握好了技巧,方便逆向的时候可以更加快速的找到关键函数…...

yarn install 报错 证书过期 Certificate has expired
“Certificate has expired” 的意思是证书已过期。这通常是指数字证书在其有效期限之前已经失效了。数字证书通常用于加密和保护网络通信,以及验证网站的身份。如果证书已经过期,那么使用该证书的网站或服务可能会受到安全威胁。为了保证安全࿰…...
多流转换 (分流,合流,基于时间的合流——双流联结 )
目录 一,分流 1.实现分流 2.使用侧输出流 二,合流 1,联合 2,连接 三,基于时间的合流——双流联结 1,窗口联结 1.1 窗口联结的调用 1.2 窗口联结的处理流程 2,间隔联结 2.1 间隔联…...
Linux破解密码
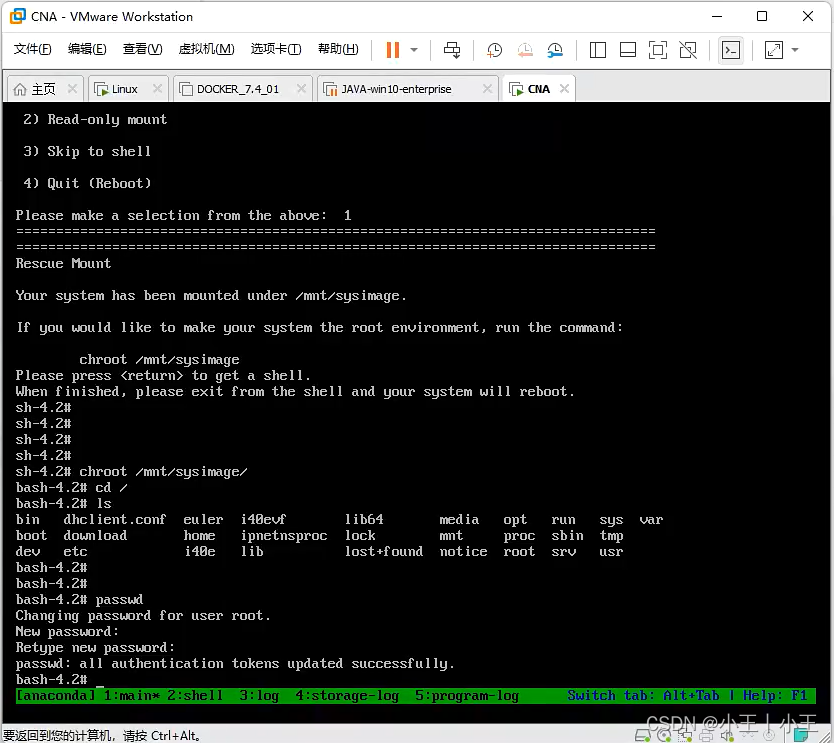
破解root密码(Linux 7) 1、先重启——e 2、Linux 16这一行 末尾加rd.break(不要回车)中断加载内核 3、再ctrlx启动,进入救援模式 4、mount -o remount,rw /sysroot/——(mount挂载 o——opti…...

ABAP 批导demo调用SM30表维护demo
ABAP 批导demo&调用SM30表维护demo &--------------------------------------------------------------------- *& Report ZPP036 &--------------------------------------------------------------------- *& &-----------------------------------…...

Mysql 文件导入与导出
i/o 一、导出(mysqldump)<一>、导出sql文件<二>、导出csv文件 二、导入(load)三、常见报错The Mysql server is running with the --secure-file-priv option so it cannot execute this statement 一、导出(mysqldump) <一>、导出sql文件 1、整库 mysqld…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...