torch.matmul和torch.bmm区别
torch.matmul可用于4维数组的相乘,而torch.bmm只能用户3维数组的相乘,以/home/tiger/.local/lib/python3.9/site-packages/transformers/models/vit/modeling_vit.py中的ViTSelfAttention实现为例,在transpose_for_scores之前的shape是(batch_size, seq_len, all_head_size),然后在transpose_for_scores被转成了(batch_size, num_attention_heads, seq_len, attention_head_size)。这个4维数组只在最后2维上乘:
class ViTSelfAttention(nn.Module):def __init__(self, config: ViTConfig) -> None:super().__init__()if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):raise ValueError(f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "f"heads {config.num_attention_heads}.")self.num_attention_heads = config.num_attention_headsself.attention_head_size = int(config.hidden_size / config.num_attention_heads)self.all_head_size = self.num_attention_heads * self.attention_head_sizeself.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)self.dropout = nn.Dropout(config.attention_probs_dropout_prob)def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)x = x.view(new_x_shape)return x.permute(0, 2, 1, 3)def forward(self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:mixed_query_layer = self.query(hidden_states)# 在transpose_for_scores之前的shape是(batch_size, seq_len, all_head_size),然后在transpose_for_scores被转成了(batch_size, num_attention_heads, seq_len, attention_head_size)。这个4维数组只在最后2维上乘key_layer = self.transpose_for_scores(self.key(hidden_states))value_layer = self.transpose_for_scores(self.value(hidden_states))query_layer = self.transpose_for_scores(mixed_query_layer)import pdb; pdb.set_trace();# Take the dot product between "query" and "key" to get the raw attention scores.attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))attention_scores = attention_scores / math.sqrt(self.attention_head_size)# Normalize the attention scores to probabilities.attention_probs = nn.functional.softmax(attention_scores, dim=-1)# This is actually dropping out entire tokens to attend to, which might# seem a bit unusual, but is taken from the original Transformer paper.attention_probs = self.dropout(attention_probs)# Mask heads if we want toif head_mask is not None:attention_probs = attention_probs * head_maskcontext_layer = torch.matmul(attention_probs, value_layer)context_layer = context_layer.permute(0, 2, 1, 3).contiguous()new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)context_layer = context_layer.view(new_context_layer_shape)outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)return outputs
用torch.bmm也可以实现self_attention,参考 Bert Transformer细节总结
相关文章:

torch.matmul和torch.bmm区别
torch.matmul可用于4维数组的相乘,而torch.bmm只能用户3维数组的相乘,以/home/tiger/.local/lib/python3.9/site-packages/transformers/models/vit/modeling_vit.py中的ViTSelfAttention实现为例,在transpose_for_scores之前的shape是(batch…...

k8s学习(RKE+k8s+rancher2.x)成长系列之概念介绍(一)
一、前言 本文使用国内大多数中小型企业使用的RKE搭建K8s并拉起高可用Rancher2.x的搭建方式,以相关技术概念为起点,实际环境搭建,程序部署为终点,从0到1的实操演示的学习方式,一步一步,保姆级的方式学习k8…...

PHP - Yii2 异步队列
1. 前言使用场景 在 PHP Yii2 中,队列是一种特殊的数据结构,用于处理和管理后台任务。队列允许我们将耗时的任务(如发送电子邮件、push通知等)放入队列中,然后在后台异步执行。这样可以避免在处理大量请求时阻塞主应用…...

leetcode560和为k的子数组
class Solution { public:int subarraySum(vector<int>& nums, int k) {unordered_map<int,int>mp;mp[0]1;int count0,pre0;for(auto& x:nums){prex;if(mp.find(pre-k)!mp.end()){countmp[pre-k];}mp[pre];}return count;} }; 一个超级好的思路࿰…...
【ProtoBuf】使用指南
一.什么是ProtoBuf 特点:ProtoBuf是用于序列化和反序列化的一种方法,类似xml和json,但是效率更高,体积更小。ProtoBuf具有语⾔⽆关、平台⽆关,扩展性、兼容性好等特点。 ProtoBuf是需要依赖通过编译生成的头文件和源…...

Buffer Pool
Buffer Pool 概念free链表flush链表LRU链表chunk 概念 MySQL在启动时向操作系统申请的一片连续的内存,默认128M。然后将这块内存分为一个一个缓冲页(16KB,因为页就是16KB的)。再为每个缓冲页创建对应的控制块用于管理。比如第一次查询数据之后ÿ…...

jetson-inference----docker内运行分类任务
系列文章目录 jetson-inference入门 jetson-inference----docker内运行分类任务 文章目录 系列文章目录前言一、进入jetson-inference的docker二、分类任务总结 前言 继jetson-inference入门 一、进入jetson-inference的docker 官方运行命令 进入jetson-inference的docker d…...

Python脚本之操作Redis Cluster【二】
本文为博主原创,未经授权,严禁转载及使用。 本文链接:https://blog.csdn.net/zyooooxie/article/details/112484045 之前写过一篇 使用redis-py来操作redis集群, https://blog.csdn.net/zyooooxie/article/details/123760358 &am…...

认识数学建模
文章目录 1 什么是数学建模2 数学建模的比赛形式3 参加数学建模的好处4 数学建模的流程5 数学建模成员分工6 数学建模常用软件7 数学建模竞赛7.1 美国大学生数学建模竞赛7.2 MathorCup高校数学建模挑战赛7.3 华中杯大学生数学建模挑战赛7.4 认证杯数学建模网络挑战赛7.5 华东杯…...
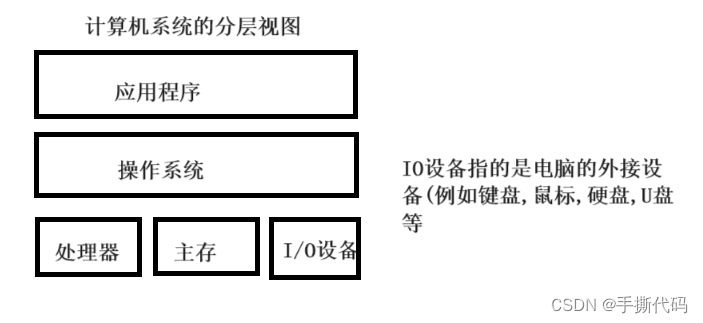
计算机工作原理解析和解剖(基础版)
我们会从软件⼯程师的⻆度解释计算机是如何⼯作的,我们的主要⽬标既不是期待 ⼤家可以造出⾃⼰的计算机,也不是介绍如何编程,⽽是希望让⼤家了解计算机的核⼼⼯作机制后,打破计算机的神秘感,并且有利于理解我们平时编程…...

外网ssh远程连接服务器
文章目录 外网ssh远程连接服务器一、前言二、配置流程1. 在服务器上安装[cpolar](https://www.cpolar.com/)客户端2. 查看版本号,有正常显示版本号即为安装成功3. token认证4. 简单穿透测试5. 向系统添加服务6. 启动cpolar服务7. 查看服务状态8. 登录后台࿰…...

滴滴基于 Ray 的 XGBoost 大规模分布式训练实践
背景介绍 作为机器学习模型的核心代表,XGBoost 在滴滴众多策略算法业务场景中发挥着至关重要的作用。因此,保障并持续提升 XGBoost 模型的离线训练及在线推理稳定性一直是机器学习平台的重点工作。同时,面对多样化的业务场景定制需求和数据规…...

k8s从入门到实践
k8s从入门到实践 介绍 Kubernetes(简称k8s)和Docker Swarm是两个流行的容器编排工具,它们都可以帮助用户管理和部署分布式应用,尤其是基于容器的应用。以下是两者的主要特点和对比: Kubernetes (k8s): 开…...
Qt5.12.0 与 VS2017 在 .pro文件转.vcxproj文件
一、参考资料 stackoverflow qt - How to generate .sln/.vcproj using qmake - Stack Overflowhttps://stackoverflow.com/questions/2339832/how-to-generate-sln-vcproj-using-qmake?answertabtrending#tab-topqt - 如何使用 qmake 生成 .sln/.vcproj - IT工具网 (coder.wo…...
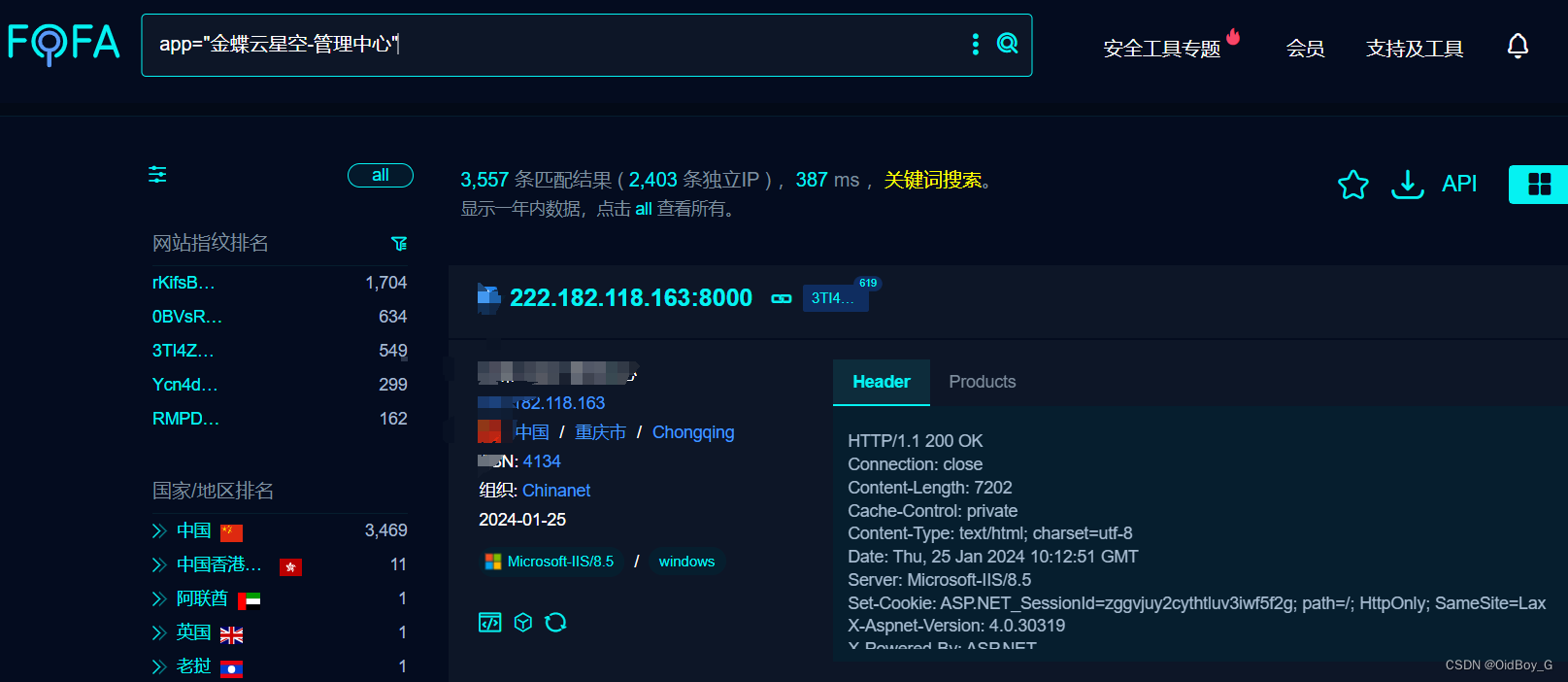
金蝶云星空 ServiceGateway RCE漏洞复现
0x01 产品简介 金蝶云星空是一款云端企业资源管理(ERP)软件,为企业提供财务管理、供应链管理以及业务流程管理等一体化解决方案。金蝶云星空聚焦多组织,多利润中心的大中型企业,以 “开放、标准、社交”三大特性为数字经济时代的企业提供开放的 ERP 云平台。服务涵盖:财…...
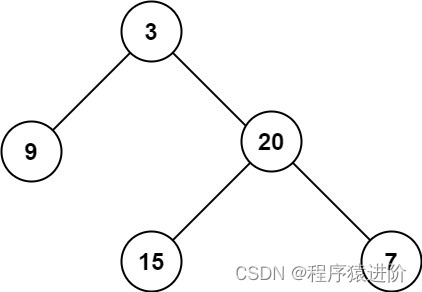
二叉树的最大深度[简单]
优质博文:IT-BLOG-CN 一、题目 给定一个二叉树root,返回其最大深度。 二叉树的最大深度是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3 示例 2:…...

[Redis]不同系统间安装redis服务器
日常服务器端开发,消息队列等需求,免不了用到redis,搭建一个redis服务器,方便开发和测试,我们从以下三类系统来说明下: 安装 Redis 服务器的过程因操作系统而异。以下是在常见的 Linux 发行版(…...
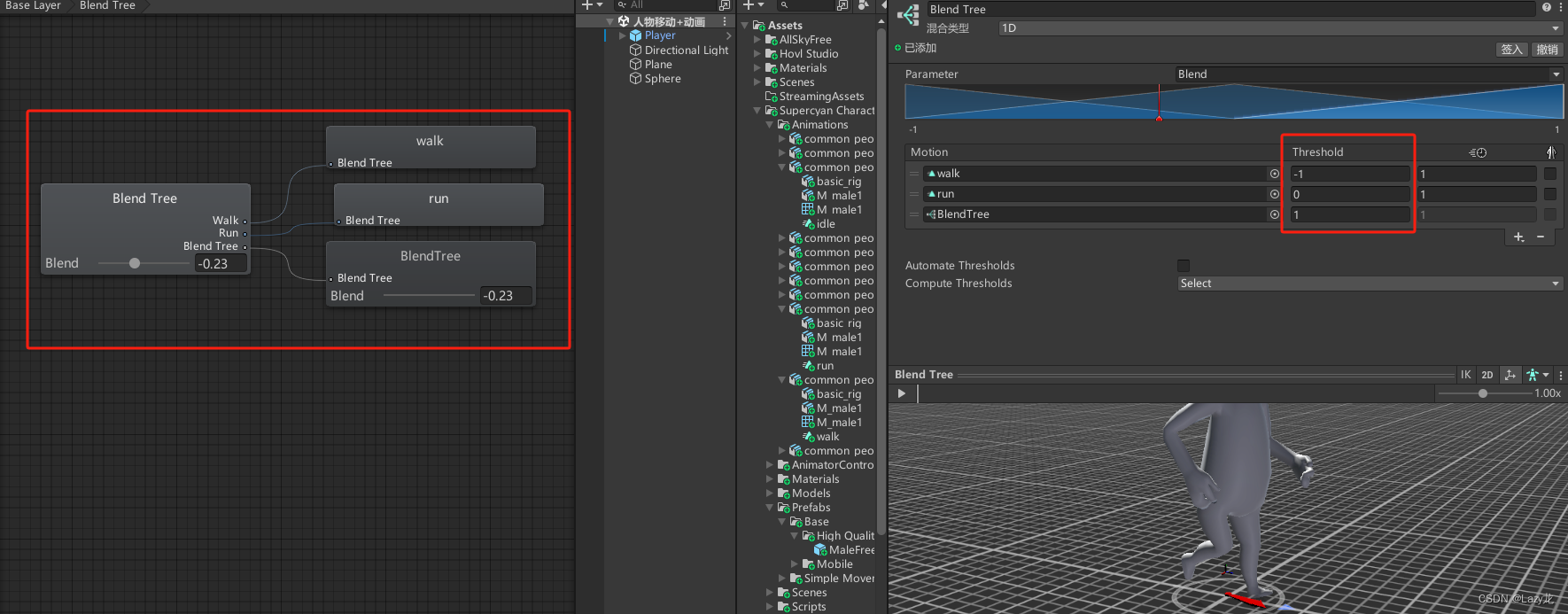
Unity之动画和角色控制
目录 📕 一、动画 1.创建最简单的动画 2.动画控制器 📕二、把动画和角色控制相结合 📕三、实现实例 3.1 鼠标控制角色视角旋转 3.2 拖尾效果 📕四、混合动画 最近学到动画了,顺便把之前创建的地形࿰…...

C语言库函数实现字符串转大小写
目录 引言 代码 引言 处理字符串时,除了将字符串中的所有大写字母转换为小写字母外,我们还可以利用其他相关函数进行更丰富的文本操作。本文将以一段使用isupper()、tolower()函数实现字符串全转小写的C语言程序为例,详细介绍这两个函数以及…...
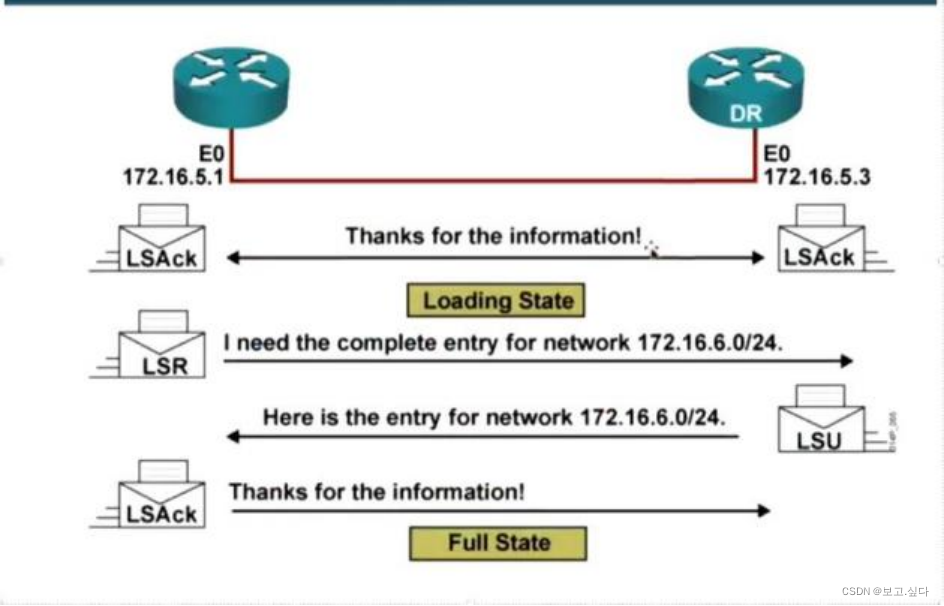
hcip----ospf
一:动态路由协议 IGP 协议---RIP OSPF ISIS EIGRP EGP--EGP ---BGP 三个角度的评判一款动态路由协议的优劣 RIP --request response 1.选路--选路依据不好,可能出现环路 2.收敛速度--计时器 3.占用资源-- RIPV1 RIPV2 RIPNG--ipv6 OSPFV1 OSPFV…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...