【文本到上下文 #6】Word2Vec、GloVe 和 FastText
一、说明
欢迎来到“文本到上下文”博客的第 6 个系列。到目前为止,我们已经探索了自然语言处理的基础知识、应用和挑战。我们深入研究了标记化、文本清理、停用词、词干提取、词形还原、词性标记和命名实体识别。我们的探索包括文本表示技术,如词袋、TF-IDF 和词嵌入的介绍。然后,我们将 NLP 与机器学习联系起来,涵盖监督和无监督学习、情感分析以及分类和回归的基础知识。最近,我们涉足深度学习,讨论了神经网络、RNN 和 LSTM。现在,我们将更深入地研究深度学习领域的单词嵌入。
以下是第 6 篇博文中的预期内容:
- Word2Vec:深入研究 Word2Vec 的世界,探索其架构、工作原理以及它如何彻底改变对文本中语义关系的理解。我们将研究它的两种主要训练算法:连续词袋 (CBOW) 和 Skip-gram,以了解它们在捕获上下文词义中的作用。
- GloVe(单词表示的全局向量):解开 GloVe 模型的复杂性。我们将通过利用全局词-词共现统计来探索它与 Word2Vec 的不同之处,提供一种独特的方法,根据词库中的集体上下文嵌入词。
- 快速文本:研究 FastText 的功能,重点关注其处理词汇外单词的创新方法。了解 FastText 如何将单词分解为更小的单元 (n-gram) 以及此方法如何增强单词的表示,尤其是在具有丰富形态的语言中。
- 正确的嵌入模型:深入了解为您的 NLP 项目选择嵌入模型时要考虑的关键因素。我们将讨论每个模型的细微差别,帮助您确定哪一个模型在语言丰富性、计算效率和应用范围方面最符合您的特定需求。
- 比较 Word Embeddings 代码示例:通过动手实践代码示例将理论付诸实践。本节将提供一个实际演示,比较 Word2Vec、GloVe 和 FastText 在常见 NLP 任务中的性能,让您切实了解它们在实际应用中的优势和劣势。
这篇博文不仅旨在向您介绍这些高级嵌入技术,还旨在为您提供在 NLP 项目中实施这些技术时做出明智决策的知识。
二、Word2Vec
Word2Vec 是一种流行的词嵌入技术,旨在将词表示为高维空间中的连续向量。它引入了两个模型:连续词袋 (CBOW) 和 Skip-gram,每个模型都有助于学习向量表示。
1. 模型架构:
- 连续词袋 (CBOW):在 CBOW 中,模型根据目标词的上下文预测目标词。上下文词用作输入,目标词是输出。该模型经过训练,以最小化预测目标词和实际目标词之间的差异。
- 跳过克: 相反,Skip-gram 模型预测给定目标词的上下文词。目标词用作输入,该模型旨在预测可能出现在其上下文中的词。与 CBOW 一样,目标是最小化预测词和实际上下文词之间的差异。
2. 神经网络训练:
CBOW 和 Skip-gram 模型都利用神经网络来学习向量表示。神经网络在大型文本语料库上进行训练,调整连接的权重以最小化预测误差。此过程将相似的单词在生成的向量空间中更紧密地放在一起。
3. 矢量表示:
训练后,Word2Vec 会在高维空间中为每个单词分配一个唯一的向量。这些向量捕获单词之间的语义关系。具有相似含义的单词或经常出现在类似上下文中的单词具有彼此接近的向量,表明它们的语义相似性。
4.优点和缺点:
优势:
-
有效地捕获语义关系。
-
适用于大型数据集。
-
提供有意义的单词表示形式。
缺点: -
可能会与生僻词作斗争。
-
忽略词序。
5. 玩具数据集代码示例:
提供的代码示例演示了如何使用 Gensim 库在玩具数据集上训练 Word2Vec 模型。展示了句子的标记化、模型训练和对单词嵌入的访问。
# Code Example with Toy Dataset
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize# Toy dataset
sentences = ["I love natural language processing.", "Word embeddings are powerful."]# Tokenize sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]# Train Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, workers=4)# Access embeddings
word_embeddings = model.wv
print(word_embeddings['natural'])
总之,Word2Vec 的机制涉及训练神经网络模型(CBOW 和 Skip-gram)来学习有效捕获单词之间语义关系的向量表示。生成的向量在向量空间中提供了有意义且有效的词表示。
三、GloVe(用于单词表示的全局向量)
全局词表示向量 (GloVe) 是一种强大的词嵌入技术,它通过考虑词在语料库中的共现概率来捕获词之间的语义关系。GloVe有效性的关键在于词语矩阵的构建和后续的因式分解过程。
1. 词语矩阵形成:
GloVe机制的第一步是创建一个词-上下文矩阵。该矩阵旨在表示给定单词在整个语料库中出现在另一个单词附近的可能性。矩阵中的每个单元格都包含单词在特定上下文窗口中一起出现的频率的共现计数。
让我们考虑一个简化的例子。假设我们的语料库中有以下句子:
- “词嵌入捕捉语义含义。”
- “GloVe是一个有影响力的词嵌入模型。”
单词上下文矩阵可能如下所示:
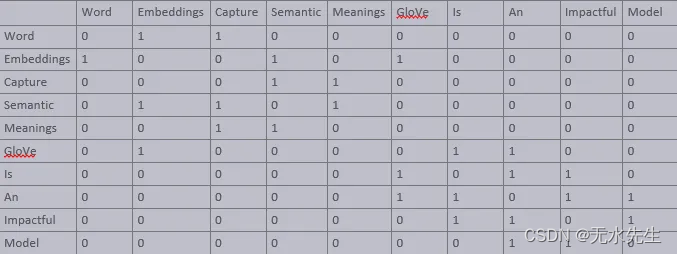
在这里,每一行和每一列对应于语料库中的一个唯一单词,单元格中的值表示这些单词在特定上下文窗口中一起出现的频率。
2. 词向量的因式分解:
有了词语上下文矩阵后,GloVe 转向矩阵分解。这里的目标是将这个高维矩阵分解为两个较小的矩阵——一个代表单词,另一个代表上下文。让我们将它们表示为 W 表示单词,将 C 表示为上下文。理想的情况是当 W 和 CT 的点积(C 的转置)近似于原始矩阵时:
X≈W⋅CT扫描
通过迭代优化,GloVe 调整 W 和 C,以最小化 X 和 W⋅CT 之间的差异。此过程为每个单词生成精细的向量表示,捕获其共现模式的细微差别。
3. 矢量表示:
经过训练后,GloVe为每个单词提供了一个密集的向量,不仅可以捕获本地上下文,还可以捕获全局单词使用模式。这些向量对语义和句法信息进行编码,根据单词在语料库中的整体用法揭示单词之间的相似性和差异性。
4. 优点和缺点:
优势:
-
高效捕获语料库的全局统计数据。
-
善于表示语义和句法关系。
-
有效捕捉词语类比。
缺点: -
需要更多内存来存储共现矩阵。
-
对非常小的语料库效果较差。
5. 玩具数据集代码示例:
以下代码片段演示了在玩具数据集上使用 GloVe Python 包的 GloVe 模型的基本用法。该示例涵盖了共现矩阵的创建、GloVe 模型的训练以及词嵌入的检索。
from glove import Corpus, Glove
from nltk.tokenize import word_tokenize# Toy dataset
sentences = ["Word embeddings capture semantic meanings.","GloVe is an impactful word embedding model."]# Tokenize sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]# Creating a corpus object
corpus = Corpus() # Training the corpus to generate the co-occurrence matrix
corpus.fit(tokenized_sentences, window=10)# Training the GloVe model
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)
glove.add_dictionary(corpus.dictionary)# Retrieve and display word embeddings
word = "glove"
embedding = glove.word_vectors[glove.dictionary[word]]
print(f"Embedding for '{word}': {embedding}")
总之,GloVe的词嵌入方法侧重于在语料库中捕获全局词共现模式,提供丰富而有意义的向量表示。这种方法有效地编码了语义和句法关系,根据其广泛的使用模式提供了对词义的全面视图。上面的代码示例说明了如何在基本数据集上实现 GloVe 嵌入。
四、快速文本
FastText 是由 Facebook AI Research (FAIR) 开发的一种高级单词嵌入技术,它扩展了 Word2Vec 模型。与 Word2Vec 不同,FastText 不仅考虑整个单词,还包含子单词信息——单词的一部分,如 n-gram。这种方法可以处理形态丰富的语言,并更有效地捕获有关单词结构的信息。
1. 子词信息:
FastText 将每个单词表示为除了整个单词本身之外的字符 n-gram 包。这意味着“apple”一词由单词本身及其组成 n 元语法(如“ap”、“pp”、“pl”、“le”等)表示。这种方法有助于捕捉较短单词的含义,并更好地理解后缀和前缀。
2. 模型训练:
与 Word2Vec 类似,FastText 可以使用 CBOW 或 Skip-gram 体系结构。但是,它在训练期间包含子词信息。FastText 中的神经网络经过训练,不仅基于目标单词,还基于这些 n-gram 来预测单词(在 CBOW 中)或上下文(在 Skip-gram 中)。
3. 处理生僻和未知词:
FastText 的一个显着优势是它能够为生僻词甚至在训练期间未看到的单词生成更好的单词表示。通过将单词分解为 n-gram,FastText 可以根据这些单词的子词单元为这些单词构造有意义的表示形式。
4. 优点和缺点:
优势:
-
更好地表示生僻词。
-
能够处理词汇表外的单词。
-
由于子词信息,单词表示更丰富。
缺点: -
由于 n-gram 信息而增加模型大小。
-
与 Word2Vec 相比,训练时间更长。
5. 玩具数据集代码示例:
以下代码演示了如何在玩具数据集上将 FastText 与 Gensim 库一起使用。它突出显示了模型训练和访问词嵌入。
from gensim.models import FastText
from nltk.tokenize import word_tokenize# Toy dataset
sentences = ["FastText embeddings handle subword information.","It is effective for various languages."]
# Tokenize sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]# Train FastText model
model = FastText(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, workers=4)# Access embeddings
word_embeddings = model.wv
print(word_embeddings['subword'])
总之,FastText 通过整合子词信息来丰富单词嵌入景观,使其在捕捉语言中的复杂细节和处理罕见或看不见的单词方面非常有效。
五、选择正确的嵌入模型
Word2Vec:当语义关系至关重要并且您拥有大型数据集时使用。
GloVe:适用于不同的数据集,并且捕获全球上下文很重要。
FastText:选择形态丰富的语言或处理词汇表外的单词至关重要。
六、比较 Word Embeddings 代码示例
# Import necessary libraries
from gensim.models import Word2Vec
from gensim.models import FastText
from glove import Corpus, Glove
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt# Toy dataset
toy_data = ["word embeddings are fascinating","word2vec captures semantic relationships","GloVe considers global context","FastText extends Word2Vec with subword information"
]# Function to train Word2Vec model
def train_word2vec(data):model = Word2Vec([sentence.split() for sentence in data], vector_size=100, window=5, min_count=1, workers=4)return model# Function to train GloVe model
def train_glove(data):corpus = Corpus()corpus.fit(data, window=5)glove = Glove(no_components=100, learning_rate=0.05)glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)return glove# Function to train FastText model
def train_fasttext(data):model = FastText(sentences=[sentence.split() for sentence in data], vector_size=100, window=5, min_count=1, workers=4)return model# Function to plot embeddings
def plot_embeddings(model, title):labels = model.wv.index_to_keyvectors = [model.wv[word] for word in labels]tsne_model = TSNE(perplexity=40, n_components=2, init='pca', n_iter=2500, random_state=23)new_values = tsne_model.fit_transform(vectors)x, y = [], []for value in new_values:x.append(value[0])y.append(value[1])plt.figure(figsize=(10, 8)) for i in range(len(x)):plt.scatter(x[i],y[i])plt.annotate(labels[i],xy=(x[i], y[i]),xytext=(5, 2),textcoords='offset points',ha='right',va='bottom')plt.title(title)plt.show()# Train models
word2vec_model = train_word2vec(toy_data)
glove_model = train_glove(toy_data)
fasttext_model = train_fasttext(toy_data)# Plot embeddings
plot_embeddings(word2vec_model, 'Word2Vec Embeddings')
plot_embeddings(glove_model, 'GloVe Embeddings')
plot_embeddings(fasttext_model, 'FastText Embeddings')
七、 结论
当我们结束对高级词嵌入的探索时,我们 NLP 之旅的下一站将是序列到序列模型、注意力机制和编码器-解码器架构。这些先进的技术在机器翻译和摘要等任务中发挥了重要作用,使模型能够专注于输入序列的特定部分。
请继续关注下一期,我们将揭开序列到序列模型的复杂性,揭示注意力机制和编码器-解码器架构的力量。
相关文章:
【文本到上下文 #6】Word2Vec、GloVe 和 FastText
一、说明 欢迎来到“文本到上下文”博客的第 6 个系列。到目前为止,我们已经探索了自然语言处理的基础知识、应用和挑战。我们深入研究了标记化、文本清理、停用词、词干提取、词形还原、词性标记和命名实体识别。我们的探索包括文本表示技术,如词袋、TF…...

yolov5 opencv dnn部署自己的模型
yolov5 opencv dnn部署自己的模型 github开源代码地址使用github源码结合自己导出的onnx模型推理自己的视频推理条件c部署c 推理结果 github开源代码地址 yolov5官网还提供的dnn、tensorrt推理链接本人使用的opencv c github代码,代码作者非本人,也是上面作者推荐的…...

Cortex-M4处理器 电源管理
Cortex-M4处理器的休眠模式可以降低功耗。 模式可以是以下一种或两种: 休眠模式停止处理器时钟深度睡眠模式停止系统时钟,关闭锁相环和闪存。 如果设备实现了两种提供不同级别省电的睡眠模式,那么SCR的SLEEPDEEP位将选择使用哪种睡眠模式。…...

Linux 驱动开发基础知识——编写LED驱动程序(三)
个人名片: 🦁作者简介:一名喜欢分享和记录学习的在校大学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:V…...

YOLOv8 视频识别
YOLOv8 是一种目标检测算法,用于识别视频中的物体。要控制视频识别中的帧,可以通过以下方式来实现: 设置帧率:可以通过设置视频的帧率来控制视频的播放速度,从而影响视频识别的速度。 跳帧处理:可以通过跳…...
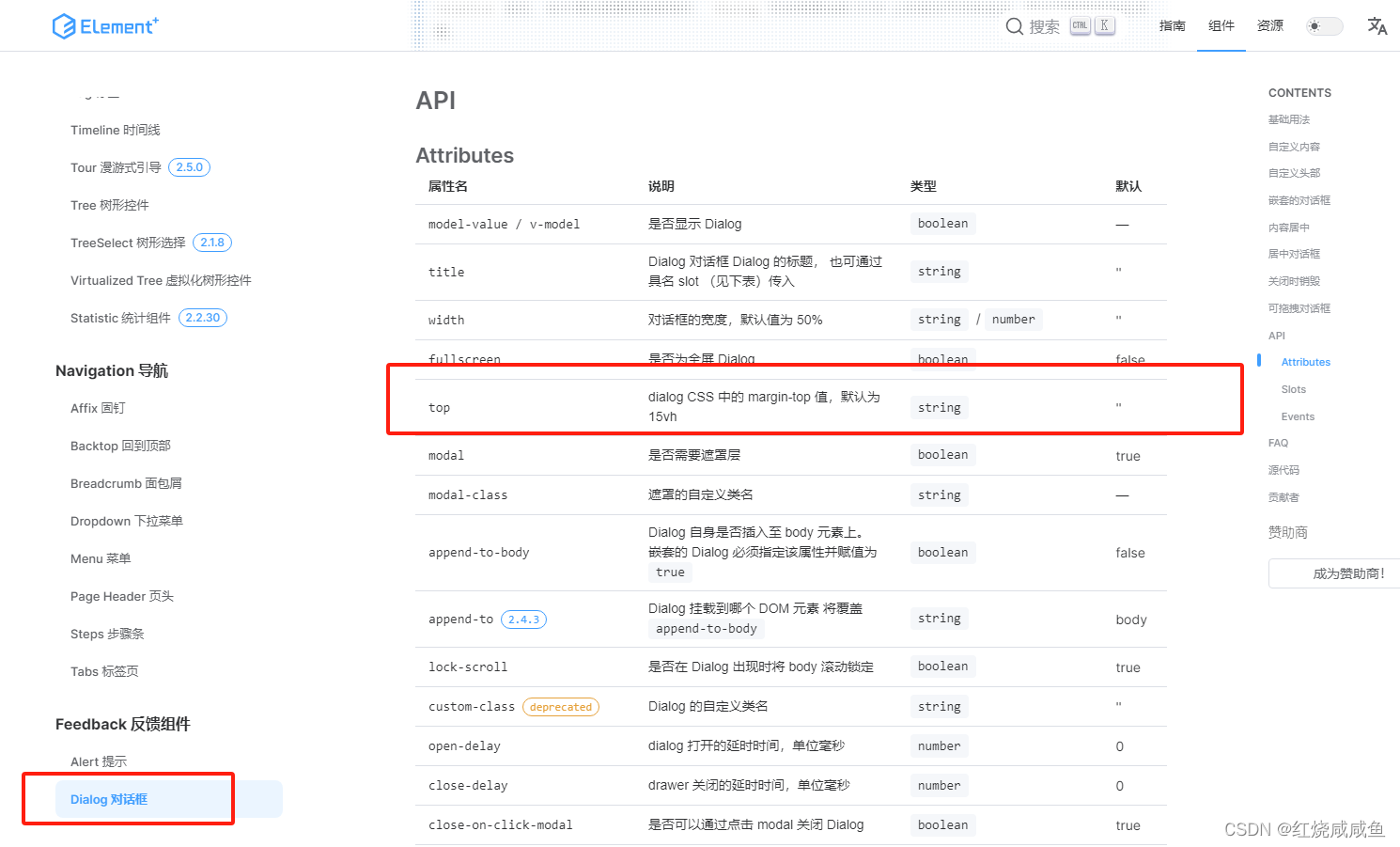
elementplus Dialog 对话框设置距离页面顶部的距离
默认为 15vh,当弹窗过于高的时候,这个距离其实是不合适的 <el-dialogv-model"dialogVisible"title"Tips"width"30%":before-close"handleClose"top"6vh"><span>This is a message</s…...
便捷接口调测:API 开发工具大比拼 | 开源专题 No.62
hoppscotch/hoppscotch Stars: 56.1k License: MIT Hoppscotch 是一个开源的 API 开发生态系统,主要功能包括发送请求和获取实时响应。该项目具有以下核心优势: 轻量级:采用简约的 UI 设计。快速:实时发送请求并获得响应。支持多…...

openssl3.2/test/certs - 008 - root-nonca trust variants: +serverAuth +anyEKU
文章目录 openssl3.2/test/certs - 008 - root-nonca trust variants: serverAuth anyEKU概述笔记END openssl3.2/test/certs - 008 - root-nonca trust variants: serverAuth anyEKU 概述 openssl3.2 - 官方demo学习 - test - certs 笔记 // \file my_openssl_win_log_doc…...
cg插画设计行业怎么样,如何学习插画设计
插画设计行业是一个充满创意和艺术性的行业,随着数字化时代的不断发展,cg插画的应用范围越来越广泛,市场需求也在逐年增长。以下是一些关于acg插画设计行业的现状和发展趋势: 市场需求不断增长:随着广告、媒体、影视、…...

1.25学习总结
今天学习了二叉树,了解了二叉树的创建和遍历的过程 今天所了解的遍历过程主要分为三种,前序中序和后序,都是DFS的想法 前序遍历:先输出在遍历左节点和右节点(输出->左->右) 中序遍历:先…...
C语言每日一题(48)回文链表
力扣 234 回文链表 题目描述 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 示例 1: 输入:head [1,2,2,1] 输出:true示例 2࿱…...

提高代码效率的5个Python内存优化技巧
大家好,当项目变得越来越大时,有效地管理计算资源是一个不可避免的需求。Python与C或c等低级语言相比,似乎不够节省内存。 但是其实有许多方法可以显著优化Python程序的内存使用,这些方法可能在实际应用中并没有人注意࿰…...
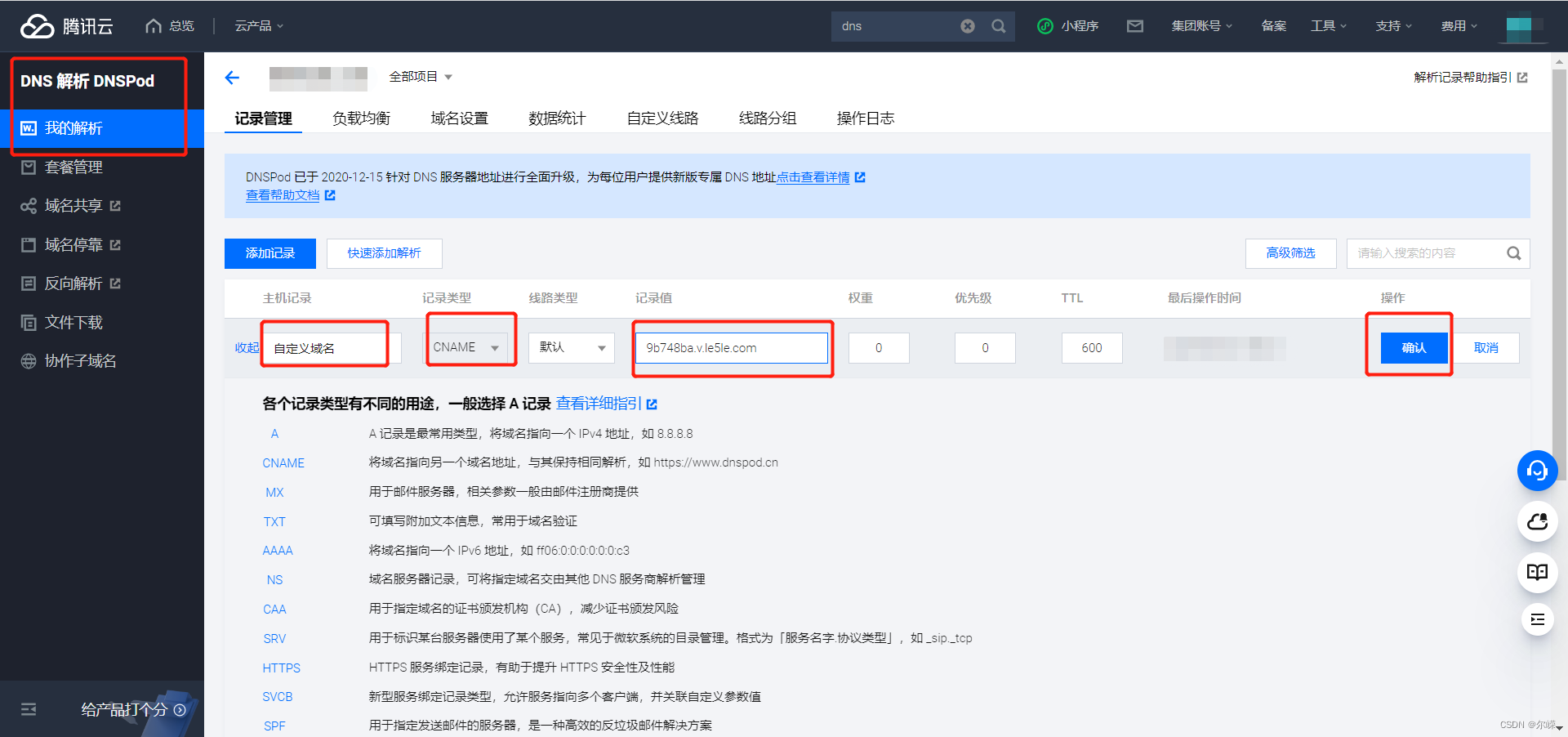
基于一款热门大屏可视化设计器使用教程
乐吾乐大屏可视化设计器是一个用于创建和定制大屏幕数据可视化展示的工具,支持零代码实现物联网、工业智能制造等领域的可视化大屏、触摸屏端UI以及工控可视化的解决方案。同时也是一个Web组态工具,支持2D、3D等多种形式,用于构建具有实时数据…...
梯度下降法、模拟训练、拟合二次曲线、最小二乘法、MSELoss、拟合:f(x)=ax^2+bx+c
本文目标: 以这个公式为例,设计一个算法,用梯度下降法来模拟训练过程,最终得出参数a,b,c 原理介绍 目标函数: 损失函数:,就是mse 损失函数展开: 损失函数对a,b,c求导数: 导数就是梯度…...

Web3.0投票如何做到公平公正且不泄露个人隐私
在当前的数字时代,社交平台举办投票活动已成为了一种普遍现象。然而,随之而来的是一些隐私和安全方面的顾虑,特别是关于个人信息泄露和电话骚扰的问题。期望建立一个既公平公正又能保护个人隐私的投票系统。Web3.0的出现为实现这一目标提供了…...

灰度图像的自动阈值分割
第一种:Otsu (大津法) 一、基于cv2的API调用 1、代码实现 直接给出相关代码: import cv2 import matplotlib.pylab as pltpath r"D:\Desktop\00aa\1.png" img cv2.imread(path, 0)def main2():ret, thresh1 cv2.…...
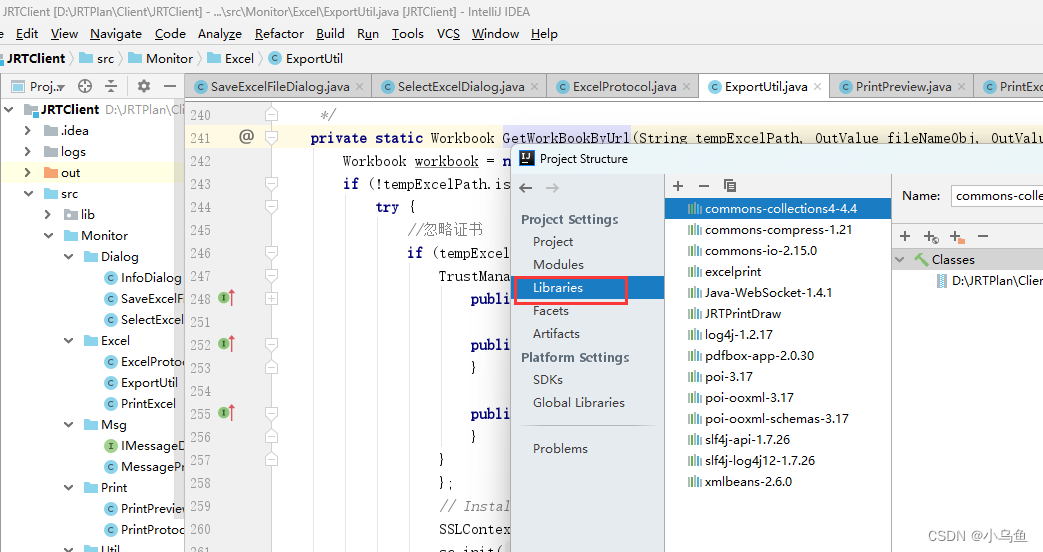
利用Maven获取jar包
我有一个习惯,就是程序不在线依赖网络的任何包。以前用C#时候虽然用Nuget找包,但是添加引用后又马上把Nuget引用删了,再把Nuget下载的dll拷贝到工程再引用dll。 这样做的好处是: 1.别人得到程序代码可以直接编译,不用…...
将vue组件发布成npm包
文章目录 前言一、环境准备1.首先最基本的需要安装nodejs,版本推荐 v10 以上,因为需要安装vue-cli2.安装vue-cli 二、初始化项目1.构建项目2.开发组件/加入组件3. 修改配置文件 三、调试1、执行打包命令2、发布本地连接包3、测试项目 四、发布使用1、注册…...

江科大STM32 中
目录 6、TIM(Timer)定时器基本定时器通用定时器高级定时器示例程序(定时器定时中断&定时器外部时钟)TIM输出比较示例程序(PWM驱动LED呼吸灯&PWM驱动舵机&PWM驱动直流电机)TIM输入捕获示例程序&…...
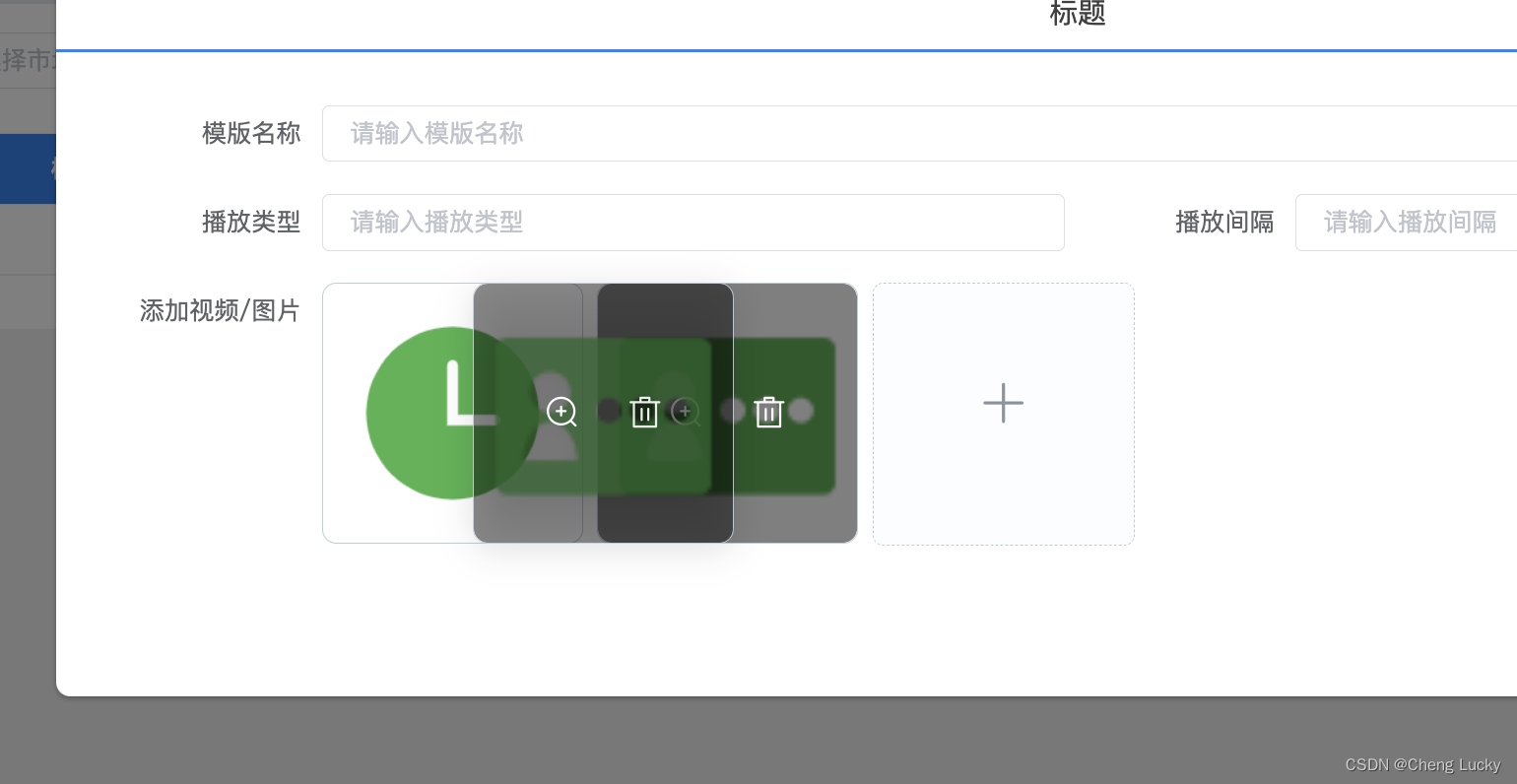
vue+draggable+el-upload上传图片拖拽重排方法
vuedraggableel-upload上传图片拖拽重排方法 1.html <el-row><el-col><el-form-item label"添加视频/图片" prop"device_id"><div class"image-upload"><draggable v-model"fileList" update"dataDr…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...
实现跳一跳小游戏)
鸿蒙(HarmonyOS5)实现跳一跳小游戏
下面我将介绍如何使用鸿蒙的ArkUI框架,实现一个简单的跳一跳小游戏。 1. 项目结构 src/main/ets/ ├── MainAbility │ ├── pages │ │ ├── Index.ets // 主页面 │ │ └── GamePage.ets // 游戏页面 │ └── model │ …...