SqlAlchemy使用教程(六) -- ORM 表间关系的定义与CRUD操作

- SqlAlchemy使用教程(一) 原理与环境搭建
- SqlAlchemy使用教程(二) 入门示例及编程步骤
- SqlAlchemy使用教程(三) CoreAPI访问与操作数据库详解
- SqlAlchemy使用教程(四) MetaData 与 SQL Express Language 的使用
- SqlAlchemy使用教程(五) ORM API 编程入门
本章内容,稍微有些复杂,建议腾出2小时空闲时间,冲杯咖啡或泡杯茶 😃 , 慢慢看,在电脑上跑下代码,可以加深理解.
六、表间关系的定义与CRUD操作
表间关系主要包括:一对多,一对一,多对多。其中一对多关系中也隐含了多对一关系。
表间关系是数据库操作中的重要技术点,非常有必要理解与掌握。
1、 一对多表间关系的定义
一对多表间关系实现语法
以一对多关系为例,
- 子表侧,与父表是一对多关系,
- 父表侧,可以反向查询子表数据,与子表是多对一关系。
class Parent(Base):__tablename__ = "parent_table"id: Mapped[int] = mapped_column(primary_key=True)children: Mapped[List["Child"]] = relationship(back_populates="parent")class Child(Base):__tablename__ = "child_table"id: Mapped[int] = mapped_column(primary_key=True)parent_id: Mapped[int] = mapped_column(ForeignKey("parent_table.id"))parent: Mapped["Parent"] = relationship(back_populates="children")
说明:
1)在子表中添加外键字段,以及relationship()引用,
2)在父表中添加relationship()引用,用于反向查询。
示例代码
父表:company, 子表 person, 表结构类定义如下。
from sqlalchemy.orm import DeclarativeBase, Session
from sqlalchemy.orm import Mapped, mapped_column
from sqlalchemy.orm import relationship
from sqlalchemy import ForeignKey
from sqlalchemy import String, Integer
from typing import Listclass Base(DeclarativeBase):pass
class Company(Base):__tablename__ = "company"id: Mapped[int] = mapped_column(Integer, primary_key=True)company_name: Mapped[str] = mapped_column(String(30), index=True)persons: Mapped[List['Person']] = relationship(back_populates="company", cascade="all, delete-orphan")def __repr__(self) -> str:return f"Company(id={self.id}, company_name={self.company_name})"class Person(Base):__tablename__ = "person"id: Mapped[int] = mapped_column(Integer, primary_key=True)name: Mapped[str] = mapped_column(String(30))age: Mapped[int] = mapped_column(Integer)company_id: Mapped[int] = mapped_column(ForeignKey("company.id"))company: Mapped['Company'] = relationship(back_populates="persons")def __repr__(self) -> str:return f"Person(id={self.id}, name={self.name})"
说明:
1)从子表视角看,1个人只属于1个Company; 但1个Company 对应多个人,因此在父表则,relationship() 左侧的类型注解为 List[‘Person’], 也可以用Set[‘Person’]
2)父表中添加删除依赖,cascade=“all, delete-orphan”,即子表中不存在对父表记录的引用时,才能删除,以保证数据的完整性。
3)当前版本可能存在bug, 官方文档中的示例中有的字段使用简化写法(右侧未给出mapped_column()),sqlite3运行是没有问题的,但mysql, postgresql创建表时会丢弃简化写法的字段,导致后续insert等操作失败。 因此请严格请勿采有简化写法。
多对一关系的实现语法
当不需要反向查询时,则父表与子表形成Many to One 多对一关系, 在父表则添加子表的外键与relationship()引用,子表无须做额外配置
class Parent(Base):__tablename__ = "parent_table"id: Mapped[int] = mapped_column(primary_key=True)child_id: Mapped[int] = mapped_column(ForeignKey("child_table.id"))child: Mapped["Child"] = relationship()class Child(Base):__tablename__ = "child_table"id: Mapped[int] = mapped_column(primary_key=True)
如果允许 child_id空值,则将改字段的类型注解修改为
from typing import Optional
......
child_id: Mapped[Optional[int]] = mapped_column(ForeignKey("child_table.id"))
对于3.10+版本,类型注解支持 | 操作符
child_id: Mapped[int | None] = mapped_column(ForeignKey("child_table.id"))
child: Mapped[Child | None] = relationship(back_populates="parents")
2、 插入数据与多表联合查询
1)在数据库创建表
# 创建数据库连接引擎对象
engine = create_engine("mysql+mysqlconnector://root:Admin&123@localhost:3306/testdb")
# 将DDL语句映射到数据库表,如果数据库表不存在,则创建该表
Base.metadata.create_all(engine)
# 打印创建创建的表
Print(Base.metadata.tables)
2)插入数据
基本步骤包括:
(1)为测试方便,先写1个get_or_create()函数,如果插入对象在数据库中已存在则不插入,以方便连续测试。
(2)创建session对象
(3)先创建父表对象并插入
(4)创建子表对象并插入
(5)用多表查询方法检查结果
Step-1: 自定义create_or_create()函数
官方提供的upsert方法不通用。下面函数是通用的,
def get_or_create(session, model, defaults=None, **kwargs):"""如果不存在则创建,如果存在则返回输入参数:session: sqlalchemy sessionmodel: 自定义的ORM类defaults: 有默认值的字段kwargs: 其他字段(必须包含主要字段)返回值:instance: 返回的实例"""instance = session.query(model).filter_by(**kwargs).first()if instance:print("instance already exists", instance)return instanceelse:params = dict((k, v) for k, v in kwargs.items()if not isinstance(v, ClauseElement))if defaults:params.update(defaults)instance = model(**params)session.add(instance)session.commit()print("instance inserted", instance)return instance
Step-2: 向两个关联表插入数据
用with 语句创建session对象,插入操作顺序,先父表再子表
with Session(engine) as session:# 插入数据get_or_create(session, Company, company_name="蜀汉")get_or_create(session, Company, company_name="曹魏")get_or_create(session, Company, company_name="东吴")stmt = select(Company)results = session.scalars(stmt)print(results.all())# insert data in person tablecompany_shu = session.scalars(select(Company).where(Company.company_name == "蜀汉")).first()get_or_create(session, Person, name="刘备",age=42, company=company_shu)get_or_create(session, Person, name="关羽",age=40, company=company_shu)get_or_create(session, Person, name="张飞", age=38, company=company_shu)company_wei = session.scalars(select(Company).where(Company.company_name == "曹魏")).first()get_or_create(session, Person, name="张辽", age=40, company=company_wei)get_or_create(session, Person, name="曹操", age=38, company=company_wei)company_wu = session.scalars(select(Company).where(Company.company_name == "东吴")).first()get_or_create(session, Person, name="周瑜", age=30, company=company_wu)
3) 多表联合查询
# select with Join 多表查询stmt = select(Person).join(Person.company).where(Company.company_name == "蜀汉").order_by(Person.age)results = session.scalars(stmt)# 遍历结果for r in results:print(r.name, r.age, r.company.company_name)
Output:
instance inserted Company(id=1, company_name=蜀汉)
instance inserted Company(id=2, company_name=曹魏)
instance inserted Company(id=3, company_name=东吴)
[Company(id=1, company_name=蜀汉), Company(id=2, company_name=曹魏), Company(id=3, company_name=东吴)]
instance inserted Person(id=1, name=刘备)
instance inserted Person(id=2, name=关羽)
instance inserted Person(id=3, name=张飞)
instance inserted Person(id=4, name=张辽)
instance inserted Person(id=5, name=曹操)
instance inserted Person(id=6, name=周瑜)
张飞 38 蜀汉
关羽 40 蜀汉
刘备 42 蜀汉
删除数据
当删除父表记录时,子表中应无对此数据的引用,否则无法删除。
3、 一对一关系
从外键角度看,一对一关系也是一对多关系。实现时,
- 在父表中收集子表数据时,类型注解不使用集合类型即可。
- 子表中relationship()方法中添加single_parent=True.
class Parent(Base):__tablename__ = "parent_table"id: Mapped[int] = mapped_column(primary_key=True)
child: Mapped["Child"] = relationship(back_populates="parent") # 一对多时,使用child: Mapped[List["Child"]] class Child(Base):__tablename__ = "child_table"id: Mapped[int] = mapped_column(primary_key=True)parent_id: Mapped[int] = mapped_column(ForeignKey("parent_table.id"))parent: Mapped["Parent"] = relationship(back_populates="child",single_parent=True)
4、 多对多关系
多对多关系特点:
1)父表与子表,子表与父表之间均为多对多关系。
2)通常使用1张中间表, 与父表、子表均实现1对多关系。
(当然有的ORM模型将中间表的创建隐藏起来,但在数据库中还是可以看到)
多对多关系定义示例
from __future__ import annotationsfrom sqlalchemy import Column
from sqlalchemy import Table
from sqlalchemy import ForeignKey
from sqlalchemy import Integer
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import mapped_column
from sqlalchemy.orm import DeclarativeBase
from sqlalchemy.orm import relationshipclass Base(DeclarativeBase):pass# note for a Core table, we use the sqlalchemy.Column construct,
# not sqlalchemy.orm.mapped_column
association_table = Table("association_table",Base.metadata,Column("left_id", ForeignKey("left_table.id")),Column("right_id", ForeignKey("right_table.id")),
)class Parent(Base):__tablename__ = "left_table"id: Mapped[int] = mapped_column(primary_key=True)children: Mapped[List[Child]] = relationship(secondary=association_table, back_populates="parents")class Child(Base):__tablename__ = "right_table"id: Mapped[int] = mapped_column(primary_key=True)parents: Mapped[List[Parent]] = relationship(secondary=association_table, back_populates="children")
多对多关系的查询、插入操作与一对多查询相似。 需要注意的是删除操作。
从多对多关系中删除数据
用SQL来实现时,需要先从父表与子表删除数据,再从中间表删除。ORM API 可以自动完成这个过程。 如要删除子表的某条记录。
myparent.children.remove(somechild)
注:通过session.delete(somechild)时,MySql可能会报错,我遇到的原因有多种,不建议使用。
同样,如果要删除父表中的1条记录:
mychild.parent.remove(someparent)
相关文章:
SqlAlchemy使用教程(六) -- ORM 表间关系的定义与CRUD操作
SqlAlchemy使用教程(一) 原理与环境搭建SqlAlchemy使用教程(二) 入门示例及编程步骤SqlAlchemy使用教程(三) CoreAPI访问与操作数据库详解SqlAlchemy使用教程(四) MetaData 与 SQL Express Language 的使用SqlAlchemy使用教程(五) ORM API 编程入门 本章内容,稍微有…...
-Linux ARM平台编程第五天-kernel配置(物联技术666))
嵌入式培训机构四个月实训课程笔记(完整版)-Linux ARM平台编程第五天-kernel配置(物联技术666)
链接:https://pan.baidu.com/s/1eb94AaDM-cIZsbr929Isbw?pwd1688 提取码:1688 上午:linux内核介绍 徐登伟老师 下午:linux的配置 教学内容: 一、基本kernel的制作: 1、去开源社区下载原…...

Java笔记(死锁、线程通信、单例模式)
一、死锁 1.概述 死锁 : 死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法往下执行。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进…...
DAY11_(简易版)VUEElement综合案例
目录 1 VUE1.1 概述1.1.1 Vue js文件下载 1.2 快速入门1.3 Vue 指令1.3.1 v-bind & v-model 指令1.3.2 v-on 指令1.3.3 条件判断指令1.3.4 v-for 指令 1.4 生命周期1.5 案例1.5.1 需求1.5.2 查询所有功能1.5.3 添加功能 2 Element2.0 element-ui js和css和字体图标下载2.1 …...
【Kafka】开发实战和Springboot集成kafka
目录 消息的发送与接收生产者消费者 SpringBoot 集成kafka服务端参数配置 消息的发送与接收 生产者 生产者主要的对象有: KafkaProducer , ProducerRecord 。 其中 KafkaProducer 是用于发送消息的类, ProducerRecord 类用于封装Kafka的消息…...
初识C语言)
【C语言】(1)初识C语言
什么是C语言 C语言是一种广泛应用的计算机编程语言,它具有强大的功能和灵活性,使其成为系统编程和底层开发的首选语言。C语言的设计简洁、高效,且不依赖于特定的硬件或系统,因此在各种计算平台上都能稳定运行。 C语言的特点 高…...
)
SpringCloudStream整合MQ(待完善)
概念 Spring Cloud Stream 的主要目标是各种各样MQ的学习成本,提供一致性的编程模型,使得开发者能够更容易地集成消息组件(如 Apache Kafka、RabbitMQ、RocketMQ) 官网地址:Spring Cloud Stream 组件 1. Binder 2…...
【Java 数据结构】包装类简单认识泛型
包装类&简单认识泛型 1 包装类1.1 基本数据类型和对应的包装类1.2 装箱和拆箱1.3 自动装箱和自动拆箱 2 什么是泛型3 引出泛型3.1 语法 4 泛型类的使用4.1 语法4.2 示例4.3 类型推导(Type Inference) 5 泛型如何编译的5.1 擦除机制5.2 为什么不能实例化泛型类型数组 6 泛型…...
第139期 做大还是做小-Oracle名称哪些事(20240125)
数据库管理139期 2024-01-25 第139期 做大还是做小-Oracle名称哪些事(20240125)1 问题2 排查3 扩展总结 第139期 做大还是做小-Oracle名称哪些事(20240125) 作者:胖头鱼的鱼缸(尹海文) Oracle A…...

驱动开发--多路复用-信号
一、多路复用 每个进程都有一个描述符数组,这个数组的下标为描述符, 描述符的分类: 文件描述符:设备文件、管道文件 socket描述符 1.1 应用层:三套接口select、poll、epoll select:位运算实现 监控的描…...

LeetCode 2859. 计算 K 置位下标对应元素的和【位操作】1000
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
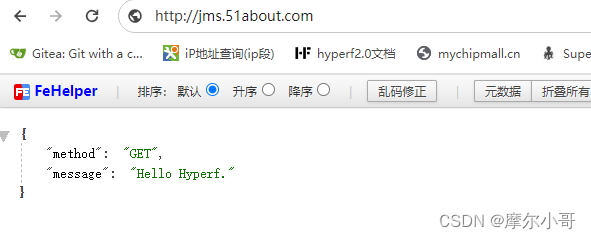
composer安装hyperf后,nginx配置hyperf
背景 引入hyperf项目用作微服务,使用composer 安装hyperf后,对hyperf进行nginx配置。 配置步骤 因为hyperf监听的是端口,不像其他laravel、lumen直接指向文件即可。所有要监听端口号。 1 配置nginx server {listen 80;//http:…...

Flink对接Kafka的topic数据消费offset设置参数
scan.startup.mode 是 Flink 中用于设置消费 Kafka topic 数据的起始 offset 的配置参数之一。 scan.startup.mode 可以设置为以下几种模式: earliest-offset:从最早的 offset 开始消费数据。latest-offset:从最新的 offset 开始消费数据。…...
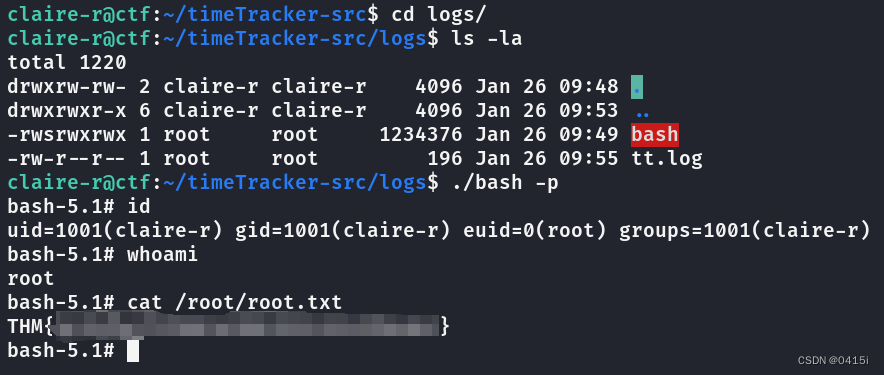
TryHackMe-Umbrella
靶场介绍 Breach Umbrella Corp’s time-tracking server by exploiting misconfigurations around containerisation. 利用集装箱化的错误配置,破坏Umbrella公司的时间跟踪服务器。 Task 1 What is the DB password? 数据库的密码是多少? 端口扫描&am…...

Excel导出警告:文件格式和拓展名不匹配
原因描述: Content-Type 原因:Content-Type,即内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定文件接收方将以什么形式、什么编码读取这个文件,这就是经常…...
kafka集群和Filebeat+Kafka+ELK
一、Kafka 概述 1.1 为什么需要消息队列(MQ) 主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从…...

golang map真有那么随机吗?——map遍历研究
在随机选取map中元素时,本想用map遍历的方式来返回,但是却并没有通过测试。 那么难道map的遍历并不是那么的随机吗? 以下代码参考go1.18 hiter是map遍历的结构,主要记录了当前遍历的元素、开始位置等来完成整个遍历过程 // A ha…...

详细分析对比copliot和ChatGPT的差异
Copilot 和 ChatGPT 是两种不同的AI工具,分别在不同领域展现出了强大的功能和潜力: GitHub Copilot 定位与用途:GitHub Copilot 是由GitHub(现为微软子公司)和OpenAI合作开发的一款智能代码辅助工具。它主要集成于Visu…...

TENT:熵最小化的Fully Test-Time Adaption
摘要 在测试期间,模型必须自我调整以适应新的和不同的数据。在这种完全自适应测试时间的设置中,模型只有测试数据和它自己的参数。我们建议通过test entropy minimization (tent[1])来适应:我们通过其预测的熵来优化模型的置信度。我们的方法估计归一化…...
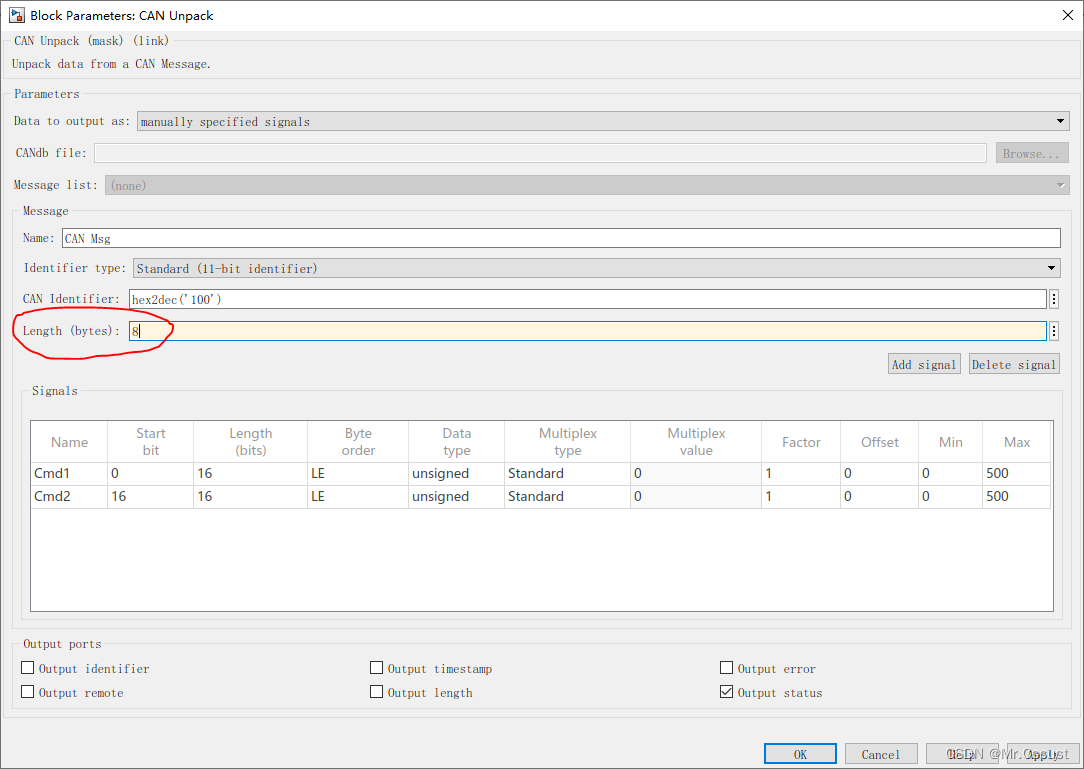
研发日记,Matlab/Simulink避坑指南(五)——CAN解包 DLC Bug
文章目录 前言 背景介绍 问题描述 分析排查 解决方案 总结 前言 见《研发日记,Matlab/Simulink避坑指南(一)——Data Store Memory模块执行时序Bug》 见《研发日记,Matlab/Simulink避坑指南(二)——非对称数据溢出Bug》 见《…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...

基于PIC32单片机实现Android USB音频转SPDIF输出的DIY方案
1. 项目概述:为Android设备打造一个高保真SPDIF音频接口作为一名长期折腾嵌入式音频和家庭影院的玩家,我经常遇到一个痛点:手头那些性能不错的Android手机或平板,其内置的3.5mm耳机孔或者USB-C口的音频输出质量,在连接…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...