ORM模型类
模型
创建两个表
创建模型类
from django.db import models# Create your models here.
class BookInfo(models.Model):name = models.CharField(max_length=10, unique=True) # 书名pub_date = models.DateField(null=True) # 发布时间read_count = models.IntegerField(default=0) # 阅读量comment_count = models.IntegerField(default=0) # 点击量is_delete = models.BooleanField(default=False) # 软删除class Meta:db_table = "bookinfo" # 修改表的名字verbose_name = "书籍管理" # admin站点使用的def __str__(self):return self.nameclass PeopleInfo(models.Model):# 定义一个有序字典GENDER_CHOICE = {(1, "male"),(2, "female"),}name = models.CharField(max_length=10) # 人物名字gender = models.SmallIntegerField(choices=GENDER_CHOICE, default=1) # 人物性别description = models.CharField(max_length=100, null=True) # 人物描述is_delete = models.BooleanField(default=False) # 软删除book = models.ForeignKey(BookInfo, on_delete=models.CASCADE) # 外键class Meta:db_table = "peopleinfo"def __str__(self):return self.name生成迁移文件
python .\manage.py makemigrations
执行迁移文件
python .\manage.py migrate 数据库表名
模型类如果未指明表名,django默认以小写app应用名_小写模型名为数据库表名
可通过db_table指明数据库表名,在模型类里面进行定义
class Meta:db_table = "bookinfo" # 修改表的名字verbose_name = "书籍管理" # admin站点使用的关于主键
django会为表创建自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后django不会再创建自动增长的主键列
属性名命名限制
- 不能是python的保留关键字
- 不允许使用连续的下划线,这是由django的查询方式决定的
- 定义属性时需要指定字段类型,通过 字段类型的参数指定选项
属性名=models.字段类型(选项)字段类型
| 类型 | 说明 |
| AutoField | 自增整数,不指定是django会自动创建,属性名为id |
| BooleanField | 布尔字段,值为True或False |
| NullBooleanField | 支持Null、True、False三种值 |
| CharField | 字符串,参数max_length表示最大字符个数 |
| TextField | 大文本字段,一般超过4000个字符时使用 |
| IntegerField | 整数 |
| DecimaIField | 十进制浮点数,参数max_digits表示总位数,参数decimal_places表示小数位数 |
| FloatField | 浮点数 |
| DateField | 日期,参数auto_now每次保存时设置为当前时间,参数auto_now_add第一次被创建时设置为当前时间,默认都为False,不可组合 |
| TimeFoeld | 时间,参数同DateField |
| DateTimeField | 日期时间,参数同DateField |
| FileField | 上传文件字段 |
| ImageFiled | 继承于FileField,对上传的内容进行校验,确保是有效的图片 |
选项
null是数据库范畴的概念,blank是表单验证的范畴
| 选项 | 说明 |
| null | 如果为True,表示允许为空,默认False |
| blank | 如果为True,表示允许为空白,默认False |
| db_column | 字段名称,若未指定,使用属性的名称 |
| db_index | 若值为True,则会为表中的字段创建索引,默认False |
| default | 指定默认值 |
| primary_key | 若为True,字段成为模型主键,默认False |
| unique | 如果为True,字段中的值不可重复,默认False |
外键
on_delete=
指外键被删除后被关联字段的数据要做什么操作
可选参数
- CASCADE级联:删除主表数据时,连同外键表字段中的数据一起删除
- PROTECT保护:通过抛出ProtecteError异常,无法删除主表中的数据
- SET_NULL设置为NULL,仅在该字段null=True允许为空时,将关联字段数据置为空
- SET_DEFAULT设置默认值:仅在该字段设置了默认值时可用
- SET()设置为特定值或调用特定方法
- DO_NOTHING:不做任何操作,如果数据库前置指明级联性,会抛出IntegrityError异常
返回一个对象=models.ForeignKey(外键类名,on_delete=[])shell
作用
快速验证增删改查的结果,最终的代码还是要写在视图中
进入shell命令
python manage.py shell增加数据
方式一,创建对象,一个对象就是一条数据
需要调用save()方法,保存
导入模型类
from bookmanager.book.models import BookInfobook=BookInfo(name="django",pub_date="2000-1-1",read_count="10")
book.save()"""
mysql> select * from bookinfo-> ;
+----+--------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+--------+---------------+-----------+------------+------------+
| 1 | django | 0 | 0 | 2000-01-01 | 10 |
+----+--------+---------------+-----------+------------+------------+
1 row in set (0.00 sec)
"""方式二,使用objects
不需要save()
# objects相当于一个代理,直接跟数据库打交道
BookInfo.objects.create(name="flask",pub_date="2020-1-1",read_count="100")"""
mysql> select * from bookinfo ;
+----+--------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+--------+---------------+-----------+------------+------------+
| 1 | django | 0 | 0 | 2000-01-01 | 10 |
| 2 | flask | 0 | 0 | 2020-01-01 | 100 |
+----+--------+---------------+-----------+------------+------------+
2 rows in set (0.00 sec)
"""更新数据
方式一get,需要调用save()方法
get查询,查询后返回一个对象,通过对象属性赋值来更改数据
from bookmanager.book.models import BookInfo# get查询,查询后返回一个对象,通过对象属性赋值来更改数据
book=BookInfo.objects.get(id=1)
book.name="新版Django"
book.save()"""
mysql> select * from bookinfo ;
+----+------------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+------------+---------------+-----------+------------+------------+
| 1 | 新版Django | 0 | 0 | 2000-01-01 | 10 |
| 2 | flask | 0 | 0 | 2020-01-01 | 100 |
+----+------------+---------------+-----------+------------+------------+
2 rows in set (0.00 sec)"""
方式二filter,不需要调用save()方法
BookInfo.objects.filter(id=2).update(name="升级flask",pub_date="2024-2-2")"""
>>> BookInfo.objects.filter(id=2).update(name="升级flask",pub_date="2024-2-2")
1mysql> select * from bookinfo ;
+----+------------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+------------+---------------+-----------+------------+------------+
| 1 | 新版Django | 0 | 0 | 2000-01-01 | 10 |
| 2 | 升级flask | 0 | 0 | 2024-02-02 | 100 |
+----+------------+---------------+-----------+------------+------------+
2 rows in set (0.00 sec)
"""删除数据
删除分为两种
物理删除:从硬盘上彻底删除
逻辑删除:修改标志位,给数据打上标签
方式一get
先使用get查询数据,然后调用对象的呃delete方法,不用调用save()方法
book=BookInfo.objects.get(id=1)
book.delete"""
>>> book=BookInfo.objects.get(id=1)
>>> book.delete()
(1, {'book.PeopleInfo': 0, 'book.BookInfo': 1})mysql> select * from bookinfo ;
+----+-----------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+-----------+---------------+-----------+------------+------------+
| 2 | 升级flask | 0 | 0 | 2024-02-02 | 100 |
+----+-----------+---------------+-----------+------------+------------+
1 row in set (0.00 sec)
"""方式二filter
BookInfo.objects.filter(id=2).delete()"""
>>> BookInfo.objects.filter(id=2).delete()
(1, {'book.PeopleInfo': 0, 'book.BookInfo': 1})mysql> select * from bookinfo ;
Empty set (0.00 sec)
"""运算符
| 运算符 | 说明 |
| exact等于 | id__exact=1,查询id=1 |
| contains包含 | name__contains="刘",查询名字中包含刘的 |
| endswith结尾 | name__endswith="刚",查询名字结尾包含刚的 |
| isnull=True为空 | name__isnull=True,查询名字为空的 |
| in=[]值是否在列表里面 | id__in=[1,3,5],查询id为1,3,5的数据 |
| gt大于 | id__gt=3,查询id大于3的数据 |
| gte大于等于 | id__gte=3,查询id大于等于3的数据 |
| lt小于 | id__lt=3,查询id小于3的数据 |
| lte小于等于 | id__lte=3,查询id小于等于3的数据 |
| year年份 | date__year=2024,查询日期年是2024年的数据 |
查询
基础查询
- get:只能查到一条数据,通常用于精确查询,如果不存在会抛出异常
- all:查询多个结果,返回的一个数组
- count:统计查询结果的数量
get查询
book=BookInfo.objects.get(id=3)"""
>>> book=BookInfo.objects.get(id=3)
>>> book
<BookInfo: 内测flask>mysql> select * from bookinfo ;
+----+-----------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+-----------+---------------+-----------+------------+------------+
| 3 | 内测flask | 0 | 0 | 2020-01-01 | 100 |
| 4 | django | 0 | 0 | 2000-01-01 | 10 |
+----+-----------+---------------+-----------+------------+------------+
2 rows in set (0.00 sec)
"""all查询
books=BookInfo.object.all()
books"""
>>> books=BookInfo.objects.all()
>>> books
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>]>mysql> select * from bookinfo ;
+----+-----------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+-----------+---------------+-----------+------------+------------+
| 3 | 内测flask | 0 | 0 | 2020-01-01 | 100 |
| 4 | django | 0 | 0 | 2000-01-01 | 10 |
+----+-----------+---------------+-----------+------------+------------+
2 rows in set (0.00 sec)
"""count统计查询
books_count=BookInfo.objects.all().count()
books_countcounts=BookInfo.objects.count()
counts
"""
>>> books_count=BookInfo.objects.all().count()
>>> books_count
2>>> counts=BookInfo.objects.count()
>>> counts
2mysql> select count(*) from bookinfo;
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.00 sec
"""
过滤查询
- filter过滤出多个结果,返回的是一个列表
- exclude排除掉符合条件剩下的结果,返回的也是一个列表
- get过滤第单一结果,只返回一个结果
filter查询
模型名.objects.filter(属性名__运算符=值)
BookInfo.objects.filter(id=4)
BookInfo.objects.filter(id__exact=4)"""
>>> BookInfo.objects.filter(id=4)
<QuerySet [<BookInfo: django>]>
>>> BookInfo.objects.filter(id__exact=4)
<QuerySet [<BookInfo: django>]>"""exclude查询
模型名.objects.exclude(属性名__运算符=值)
BookInfo.objects.exclude(id=4)
BookInfo.objects.exclude(id__exact=4)"""
>>> BookInfo.objects.exclude(id=4)
<QuerySet [<BookInfo: 内测flask>, <BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>
>>> BookInfo.objects.exclude(id__exact=4)
<QuerySet [<BookInfo: 内测flask>, <BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>"""get查询
模型名.objects.get(属性名__运算符=值)
BookInfo.objects.get(id=4)
BookInfo.objects.get(id__excat=4)
"""
>>> BookInfo.objects.get(id__exact=4)
<BookInfo: django>
>>> BookInfo.objects.get(id=4)
<BookInfo: django>"""F对象
对查询对象的属性进行比较,需要导入模块
from django.db.models import F模型类名.objects.filter(属性名__运算符=F(“第二个属性名”))
from django.db.models import FBookInfo.objects.filter(read_count__gt=F("comment_count"))"""
>>> from django.db.models import F
>>> BookInfo.objects.filter(read_count__gt=F("comment_count"))
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>]>mysql> select * from bookinfo ;
+----+-----------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+-----------+---------------+-----------+------------+------------+
| 3 | 内测flask | 0 | 0 | 2020-01-01 | 100 |
| 4 | django | 0 | 0 | 2000-01-01 | 10 |
| 5 | python | 10 | 0 | 2024-01-01 | 0 |
| 6 | java | 200 | 0 | 2022-01-01 | 0 |
| 7 | html | 50 | 0 | 2020-01-01 | 0 |
+----+-----------+---------------+-----------+------------+------------+
5 rows in set (0.00 sec)
"""Q对象
可用实现逻辑与和逻辑或的查询
需要导入模块
from django.db.models import Q并且查询
BookInfo.objects.filter(id=5).filter(read_count__lt=10)
BookInfo.objects.filter(id=5,read_count__lt=10)"""
>>> BookInfo.objects.filter(id=5).filter(read_count__lt=10)
<QuerySet [<BookInfo: python>]>
>>> BookInfo.objects.filter(id=5,read_count__lt=10)
<QuerySet [<BookInfo: python>]>mysql> select * from bookinfo ;
+----+-----------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+-----------+---------------+-----------+------------+------------+
| 3 | 内测flask | 0 | 0 | 2020-01-01 | 100 |
| 4 | django | 0 | 0 | 2000-01-01 | 10 |
| 5 | python | 10 | 0 | 2024-01-01 | 0 |
| 6 | java | 200 | 0 | 2022-01-01 | 0 |
| 7 | html | 50 | 0 | 2020-01-01 | 0 |
+----+-----------+---------------+-----------+------------+------------+
5 rows in set (0.00 sec)
""Q查询
或查询:模型类名.objects.filter(Q(属性名__运算符=值)|Q(属性名__运算符=值)|....)
from django.db.models import QBookInfo.objects.filter(Q(id=5)|Q(read_count__lt=10))"""
>>> BookInfo.objects.filter(Q(id=5)|Q(read_count__lt=10))
<QuerySet [<BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>"""并且查询:模型类名.objects.filter(Q(属性名__运算符=值)&Q(属性名__运算符=值)&.....)
BookInfo.objects.filter(Q(id=5)&Q(read_count__lt=10))"""
>>> BookInfo.objects.filter(Q(id=5)&Q(read_count__lt=10))
<QuerySet [<BookInfo: python>]>"""非not查询:模型类名.objects.filter(~Q(属性名__运算符=值))
BookInfo.objects.filter(~Q(id=5)&Q(read_count__lt=10))
BookInfo.objects.filter(~Q(id=5)&~Q(read_count__lt=10)) BookInfo.objects.filter(~Q(id=5)|Q(read_count__lt=10))
BookInfo.objects.filter(~Q(id=5)|~Q(read_count__lt=10))
"""
>>> BookInfo.objects.filter(~Q(id=5)&Q(read_count__lt=10))
<QuerySet [<BookInfo: java>, <BookInfo: html>]>
>>> BookInfo.objects.filter(~Q(id=5)&~Q(read_count__lt=10))
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>]>>>> BookInfo.objects.filter(~Q(id=5)|Q(read_count__lt=10))
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>, <BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>
>>> BookInfo.objects.filter(~Q(id=5)|~Q(read_count__lt=10))
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>, <BookInfo: java>, <BookInfo: html>]>"""聚合函数
Sum、Max、Min、Avg、Count
模块名.objects.aggregate(聚合函数("字段名"))
需要导入模块
from django.db.models import Sum,Max,Min,Avg,Countfrom django.db.models import Sum,Max,Min,Count,AvgBookInfo.objects.aggregate(Sum("read_count"))
BookInfo.objects.aggregate(Avg("read_count"))
BookInfo.objects.aggregate(Max("read_count"))
BookInfo.objects.aggregate(Min("read_count"))
BookInfo.objects.aggregate(Count("read_count"))"""
>>> from django.db.models import Sum,Max,Min,Count,Avg
>>> BookInfo.objects.aggregate(Sum("read_count"))
{'read_count__sum': 110}>>> BookInfo.objects.aggregate(Avg("read_count"))
{'read_count__avg': 22.0}>>> BookInfo.objects.aggregate(Max("read_count"))
{'read_count__max': 100}>>> BookInfo.objects.aggregate(Min("read_count"))
{'read_count__min': 0}>>> BookInfo.objects.aggregate(Count("read_count"))
{'read_count__count': 5}
"""排序
升序
BookInfo.object.all().order_by("read_count")"""
>>> BookInfo.objects.all().order_by("read_count")
<QuerySet [<BookInfo: python>, <BookInfo: java>, <BookInfo: html>, <BookInfo: django>, <BookInfo: 内测flask>]>"""降序
BookInfo.objects.all().order_by("-read_count")
"""
>>> BookInfo.objects.all().order_by("-read_count")
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>, <BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>"""关联查询
关联查询往往是查询通过外键关联两个表的数据
系统会自动在主表中添加小写外键类名_set的方法
一对多模型类对象.多对应的模型类名小写_set
# 需要拿到主表数据的一个对象
# 然后去调用关联表的模型类_set
book=BookInfo.objects.get(id=6)
book.peopleinfo_set.all()
"""
>>> book=BookInfo.objects.get(id=6)
>>> book.peopleinfo_set.all()
<QuerySet [<PeopleInfo: 詹姆斯·高斯林>, <PeopleInfo: 余麻子>]>mysql> select * from peopleinfo ;
+----+----------------+--------+---------+-------------+-----------+
| id | name | gender | book_id | description | is_delete |
+----+----------------+--------+---------+-------------+-----------+
| 1 | 吉多·范罗苏姆 | 1 | 3 | python之夫 | 0 |
| 4 | 吉多·范罗苏姆 | 1 | 5 | python之夫 | 0 |
| 5 | 詹姆斯·高斯林 | 1 | 6 | java之夫 | 0 |
| 6 | 余麻子 | 1 | 6 | java继夫 | 0 |
+----+----------------+--------+---------+-------------+-----------+
4 rows in set (0.00 sec)mysql> select * from bookinfo ;
+----+-----------+---------------+-----------+------------+------------+
| id | name | comment_count | is_delete | pub_date | read_count |
+----+-----------+---------------+-----------+------------+------------+
| 3 | 内测flask | 0 | 0 | 2020-01-01 | 100 |
| 4 | django | 0 | 0 | 2000-01-01 | 10 |
| 5 | python | 10 | 0 | 2024-01-01 | 0 |
| 6 | java | 200 | 0 | 2022-01-01 | 0 |
| 7 | html | 50 | 0 | 2020-01-01 | 0 |
+----+-----------+---------------+-----------+------------+------------+
5 rows in set (0.00 sec)
"""
多对一的模型类对象.多对应的模型类中的关系类属性名
因为从表的外键已经指向了一个主表对象,所以可以直接获取从表对象来调用主表模型类,可以获得主表模型类的对象,也可以获取主表模型类对象的属性
people=PeopleInfo.objects.get(id=1)
people.book.all()"""
>>> people=PeopleInfo.objects.get(id=1)
# 获取主表模型类对象
>>> people.book
<BookInfo: 内测flask>
# 获取主表模型类对象的属性
>>> people.book.name
'内测flask'"""关联过滤查询
语法格式:模型类名.objects.(关联模型类名小写__字段名__运算符=值)
从一的数据表中查询符合条件的从表的值(左一右多)
BookInfo.objects.filter(peopleinfo__name__exact="余麻子")
BookInfo.objects.filter(peopleinfo__name__contains="余")"""
>>> BookInfo.objects.filter(peopleinfo__name__exact="余麻子")
<QuerySet [<BookInfo: java>]>
>>> BookInfo.objects.filter(peopleinfo__name__contains="余")
<QuerySet [<BookInfo: java>]>"""根据从表的数据查询主表数据(使用外键)
PeopleInfo.objects.filter(book.name__exact="python")""""
>>> PeopleInfo.objects.filter(book__name__exact="python")
<QuerySet [<PeopleInfo: 吉多·范罗苏姆>]>"""查询结果集QuerySet
什么是结果集,必须是结果集才有两大特性
返回的查询结果不是单一的数据,而是一个集合QuerySet
两大特性(影响效率,在views视图中不执行就不不会消耗资源)
- 惰性执行:只有用的时候才会去执行,例如
# 在数据库中之句话并没有执行
book=BookInfo.objects.all()
# 当需要用到book时,才会请求数据库返回数据
book"""
>>> book=BookInfo.objects.all()
>>> book # 这是才会去看book是什么数据
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>, <BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>"""- 缓存:使用同一个查询集(QuerySet),第一次使用会直接查询,然后把结果缓存下来,再次使用结果集时候就会用到这个缓存数据,减少数据库查询的次数
# 这句话返回的是一个结果集QuerySet,它可以被缓存到内存中
books=BookInfo.objects.all() """
>>> books=BookInfo.objects.all()
>>> books
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>, <BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>
>>> [book.id for book in books]
[3, 4, 5, 6, 7]
"""限制查询集(切片操作)
不支持复数索引
# 返回了一个结果集合,可以操作下标索引
books=BookInfo.objects.all()"""
>>> books=BookInfo.objects.all()
>>> books
<QuerySet [<BookInfo: 内测flask>, <BookInfo: django>, <BookInfo: python>, <BookInfo: java>, <BookInfo: html>]>
>>> books[1]
<BookInfo: django>
>>> books[0:1]
<QuerySet [<BookInfo: 内测flask>]>
""""分页(查询文档学习)
相关文章:
ORM模型类
模型 创建两个表 创建模型类 from django.db import models# Create your models here. class BookInfo(models.Model):name models.CharField(max_length10, uniqueTrue) # 书名pub_date models.DateField(nullTrue) # 发布时间read_count models.IntegerField(default…...
Java强训day14(选择题编程题)
选择题 编程题 题目1 import java.util.Scanner;public class Main {public static void main(String[] args) {//读入年月日(字符串形式读入)Scanner sc new Scanner(System.in);String s sc.nextLine();String[] ss s.split(" ");i…...
Redis核心技术与实战【学习笔记】 - 31.番外篇:Redis客户端如何与服务器端交换命令和数据
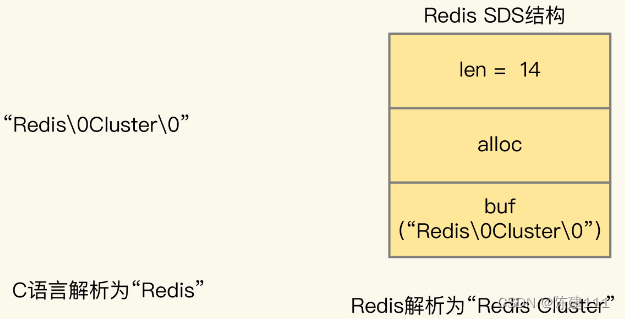
简述 Redis 使用 RESP 协议(Redis Serialzation Protocol)协议定义了客户端和服务器端交互的命令、数据的编码格式。在 Redis 2.0 版本中,RESP 协议正式称为客户端和服务器端的标准通信协议。从 Redis 2.0 到 Redis 5.0 ,RESP 协…...
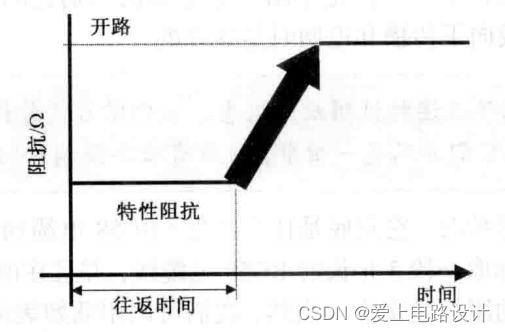
电缆线的阻抗50Ω,真正含义是什么?
当我们提到电缆线的阻抗时,它到底是什么意思?RG58电缆通常指的是50Ω的电缆线。它的真正含义是什么?假如取一段3英尺(0.9144米)长的RG58电缆线,并且在前端测量信号路径与返回路径之间的阻抗。那么测得的阻抗是多少?当然…...

校园团餐SAAS系统源码
## 项目介绍 校园团餐SAAS系统,是全新推出的一款轻量级、高性能、前后端分离的团餐系统,支持微信小程序 。 技术特点 > * 前后端完全分离 (互不依赖 开发效率高) > * 采用PHP8 (强类型严格模式) > * ThinkPHP8.0(轻量级PHP开发框…...

图数据库neo4j入门
neo4j 一、安装二、简单操作<一>、创建<二>、查询<三>、关系<四>、修改<五>、删除 三、常见报错<一>、默认的数据库密码是neo4j,打开浏览器http://localhost:7474登录不上,报错: Neo.ClientError.Security.Unauthorized: The client is un…...
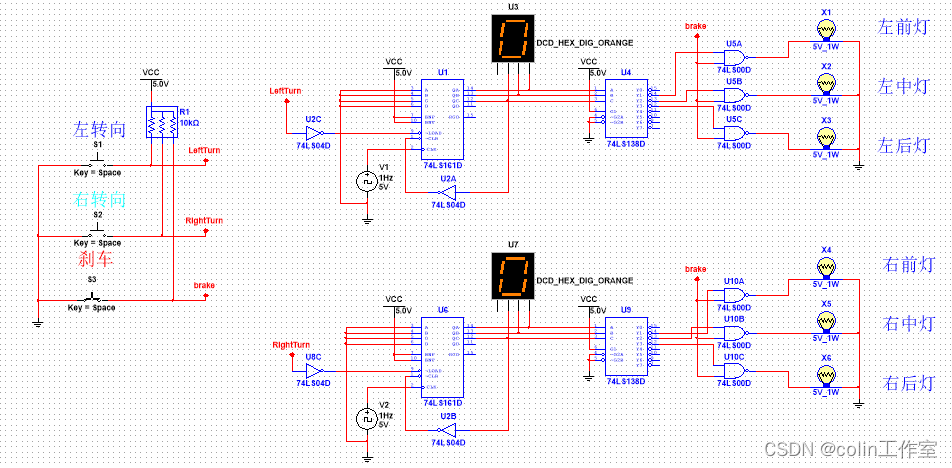
Multisim14.0仿真(五十五)汽车转向灯设计
一、功能描述: 左转向:左侧指示灯循环依次闪亮; 右转向:右侧指示灯循环依次闪亮; 刹车: 所有灯常亮; 正常: 所有灯熄灭。 二、主要芯片: 74LS161D 74LS04D 74…...

2402C++,C++的反向代理
原文 cinatra支持反向代理很简单,5行代码就可以了.先看一个简单的示例: #include "cinatra/coro_http_reverse_proxy.hpp" using namespace cinatra; int main() {reverse_proxy proxy_rr(10, 8091);proxy_rr.add_dest_host("127.0.0.1:9001");proxy_rr.a…...

[职场] 服务行业个人简历 #笔记#笔记
服务行业个人简历 服务员个人简历范文1 姓名: XXX国籍:中国 目前所在地:天河区民族:汉族 户口所在地:阳江身材: 160cm43kg 婚姻状况:未婚年龄: 21岁 培训认证:诚信徽章: 求职意向及工作经历 人才类型:普通求职 应聘职位: 工作年限:职称:初级 求职类型:全职可到职日期:随时 月薪…...

代码随想录算法训练营|day30
第七章 回溯算法 332.重新安排行程51.N皇后37.解数独代码随想录文章详解 332.重新安排行程 (1)参考 创建map存储src,[]dest映射关系,并对[]dest排序 每次取map中第一个dest访问,将其作为新的src,每访问一条src->destÿ…...

PHPExcel导出excel
PHPExcel下载地址 https://gitee.com/mirrors/phpexcelhttps://github.com/PHPOffice/PHPExcel 下载后目录结构 需要的文件如下图所示 将上面的PHPExcel文件夹和PHPExcel.php复制到你需要的地方 这是一个简单的示例代码 <?php$dir dirname(__FILE__); //require_once …...
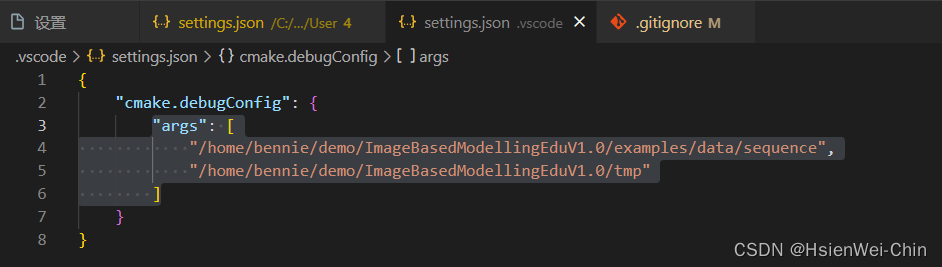
ubuntu系统下c++ cmakelist vscode debug(带传参的debug)的详细示例
c和cmake的debug,网上很多都需要配置launch.json,cpp.json啥的,记不住也太复杂了,我这里使用cmake插件带有的设置,各位可以看一看啊✌(不知不觉,竟然了解了vscode中配置文件的生效逻辑🤣) 克隆…...

聊聊JIT优化技术
🎬作者简介:大家好,我是小徐🥇☁️博客首页:CSDN主页小徐的博客🌄每日一句:好学而不勤非真好学者 📜 欢迎大家关注! ❤️ 我们知道,想要把高级语言转变成计算…...
LabVIEW动平衡测试与振动分析系统
LabVIEW动平衡测试与振动分析系统 介绍了利用LabVIEW软件和虚拟仪器技术开发一个动平衡测试与振动分析系统。该系统旨在提高旋转机械设备的测试精度和可靠性,通过精确测量和分析设备的振动数据,以识别和校正不平衡问题,从而保证机械设备的高…...

《低功耗方法学》翻译——附录B:UPF命令语法
附录B:UPF命令语法 本章介绍了文本中引用的所选UPF命令的语法。 节选自“统一电源格式(UPF)标准,1.0版”,经该Accellera许可复制。版权所有:(c)2006-2007。Accellera不声明或代表摘录材料的准确性或内容&…...

Leetcode 3027. Find the Number of Ways to Place People II
Leetcode 3027. Find the Number of Ways to Place People II 1. 解题思路2. 代码实现 题目链接:3027. Find the Number of Ways to Place People II 1. 解题思路 这一题的话我也没想到啥特别好的思路,采用的纯粹是遍历剪枝的思路。 遍历的话好理解&…...
android inset 管理
目录 简介 Insets管理架构 Insets相关类图 app侧的类 WMS侧的类 inset show的流程 接口 流程 WMS侧确定InsetsSourceControl的流程 两个问题 窗口显示时不改变现有的inset状态 全屏窗口上的dialog 不显示statusbar问题 View 和 DecorView 设置insets信息 输入法显…...
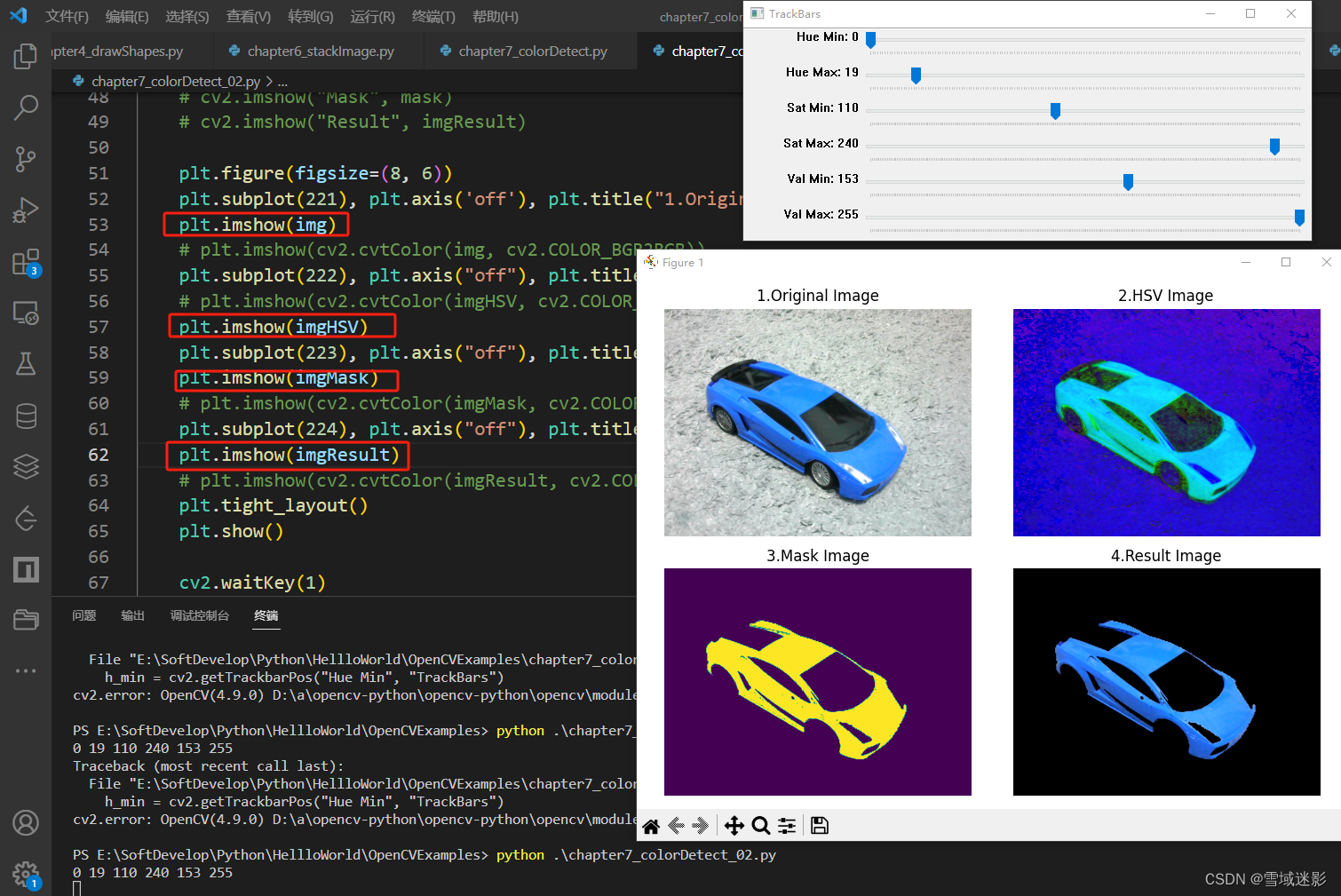
Python中使用opencv-python库进行颜色检测
Python中使用opencv-python库进行颜色检测 之前写过一篇VC中使用OpenCV进行颜色检测的博文,当然使用opencv-python库也可以实现。 在Python中使用opencv-python库进行颜色检测非常简单,首选读取一张彩色图像,并调用函数imgHSV cv2.cvtColor…...

如何修改远程端服务器密钥
前言 一段时间没改密码后,远程就会自动提示CtrlAltEnd键修改密码。但我电脑是笔记本,没有end键。打开屏幕键盘按这三个键也没用。 解决方法 打开远程 1、远程端WINC 输入osk 可以发现打开了屏幕键盘 2、电脑键盘同时按住CtrlAlt(若自身电…...

lnmp指令
LNMP官网:https://lnmp.org 作者: licess adminlnmp.org 问题反馈&技术支持论坛:https://bbs.vpser.net/forum-25-1.html 打赏捐赠:https://lnmp.org/donation.html 自定义参数 lnmp.conf配置文件,可以修改lnmp.conf自定义下…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...