深度学习自然语言处理(NLP)模型BERT:从理论到Pytorch实战
文章目录
- 深度学习自然语言处理(NLP)模型BERT:从理论到Pytorch实战
- 一、引言
- 传统NLP技术概览
- 规则和模式匹配
- 基于统计的方法
- 词嵌入和分布式表示
- 循环神经网络(RNN)与长短时记忆网络(LSTM)
- Transformer架构
- 二、什么是BERT?
- BERT的架构
- 整体理念
- 架构部件
- Encoder层
- 嵌入层(Embedding Layer)
- 部件的组合
- 架构特点
- 三、BERT的核心特点
- Attention机制
- 自注意力(Self-Attention)
- 多头注意力(Multi-Head Attention)
- 预训练和微调
- 预训练(Pre-training)
- 微调(Fine-tuning)
- BERT与其他Transformer架构的不同之处
- 预训练策略
- 双向编码
- 掩码语言模型(Masked Language Model)
- 四、BERT的场景应用
- 文本分类
- 情感分析
- 命名实体识别(Named Entity Recognition, NER)
- 文本摘要
- 五、BERT的Python和PyTorch实现
- 预训练模型的加载
- 安装依赖库
- 加载模型和分词器
- 输入准备
- 模型推理
- 微调BERT模型
- 数据准备
- 微调模型
- 模型评估
- 六、总结
- 架构的价值
- 发展前景
- 发展前景
- 结语
深度学习自然语言处理(NLP)模型BERT:从理论到Pytorch实战
本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。

一、引言
在信息爆炸的时代,自然语言处理(NLP)成为了一门极其重要的学科。它不仅应用于搜索引擎、推荐系统,还广泛应用于语音识别、情感分析等多个领域。然而,理解和生成自然语言一直是机器学习面临的巨大挑战。接下来,我们将深入探讨自然语言处理的一些传统方法,以及它们在处理语言模型时所面临的各种挑战。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于深度学习的自然语言处理(NLP)模型。它是由Google在2018年提出的,采用了Transformer架构,并在大规模语料库上进行了预训练。BERT的特点之一是其双向(Bidirectional)处理能力,它能够同时考虑到句子中所有单词的上下文,而不仅仅是单词之前或之后的部分。这种双向性使得BERT在许多NLP任务中表现出色,例如文本分类、问答和命名实体识别等。
传统NLP技术概览
规则和模式匹配
早期的NLP系统大多基于规则和模式匹配。这些方法具有高度的解释性,但缺乏灵活性。例如,正则表达式和上下文无关文法(CFG)被用于文本匹配和句子结构的解析。
基于统计的方法
随着计算能力的提升,基于统计的方法如隐马尔可夫模型(HMM)和最大熵模型逐渐流行起来。这些模型利用大量的数据进行训练,以识别词性、句法结构等。
词嵌入和分布式表示
Word2Vec、GloVe等词嵌入方法标志着NLP从基于规则到基于学习的向量表示的转变。这些模型通过分布式表示捕捉单词之间的语义关系,但无法很好地处理词序和上下文信息。
循环神经网络(RNN)与长短时记忆网络(LSTM)
RNN和LSTM模型为序列数据提供了更强大的建模能力。特别是LSTM,通过其内部门机制解决了梯度消失和梯度爆炸的问题,使模型能够捕获更长的依赖关系。
Transformer架构
Transformer模型改变了序列建模的格局,通过自注意力(Self-Attention)机制有效地处理了长距离依赖,并实现了高度并行化。但即使有了这些进展,仍然存在许多挑战和不足。
在这一背景下,BERT(Bidirectional Encoder Representations from Transformers)模型应运而生,它综合了多种先进技术,并在多个NLP任务上取得了显著的成绩。
二、什么是BERT?
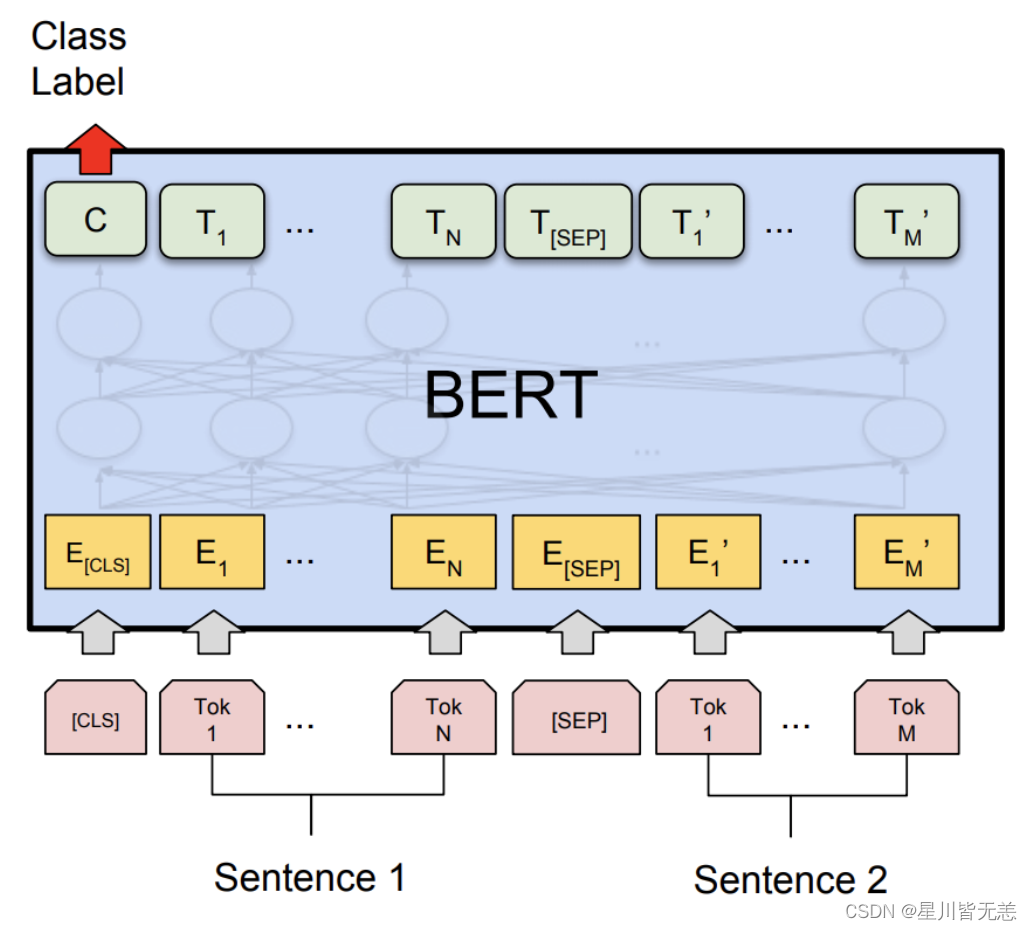
BERT的架构
BERT(Bidirectional Encoder Representations from Transformers)模型基于Transformer架构,并通过预训练与微调的方式,对自然语言进行深度表示。在介绍BERT架构的各个维度和细节之前,我们先理解其整体理念。
整体理念
BERT的设计理念主要基于以下几点:
- 双向性(Bidirectional): 与传统的单向语言模型不同,BERT能同时考虑到词语的前后文。
- 通用性(Generality): 通过预训练和微调的方式,BERT能适用于多种自然语言处理任务。
- 深度(Depth): BERT通常具有多层(通常为12层或更多),这使得模型能够捕捉复杂的语义和语法信息。
架构部件
Encoder层
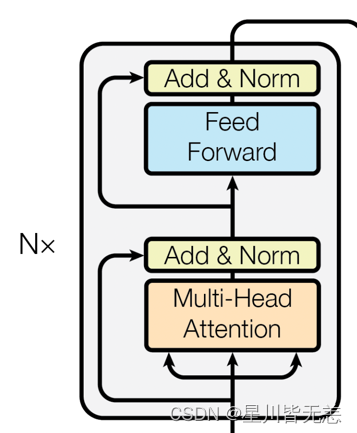
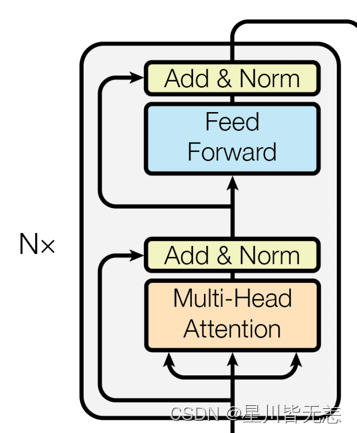
BERT完全基于Transformer的Encoder层。每个Encoder层都包含两个主要的部分:
- 自注意力机制(Self-Attention): 这一机制允许模型考虑到输入序列中所有单词对当前单词的影响。
- 前馈神经网络(Feed-Forward Neural Networks): 在自注意力的基础上,前馈神经网络进一步对特征进行非线性变换。
嵌入层(Embedding Layer)
BERT使用了Token Embeddings, Segment Embeddings和Position Embeddings三种嵌入方式,将输入的单词和附加信息编码为固定维度的向量。
部件的组合
- 每个Encoder层都依次进行自注意力和前馈神经网络计算,并附加Layer Normalization进行稳定。
- 所有Encoder层都是堆叠(Stacked)起来的,这样能够逐层捕捉更抽象和更复杂的特征。
- 嵌入层的输出会作为第一个Encoder层的输入,然后逐层传递。
架构特点
- 参数共享: 在预训练和微调过程中,所有Encoder层的参数都是共享的。
- 灵活性: 由于BERT的通用性和深度,你可以根据任务的不同在其基础上添加不同类型的头部(Head),例如分类头或者序列标记头。
- 高计算需求: BERT模型通常具有大量的参数(几亿甚至更多),因此需要大量的计算资源进行训练。
通过这样的架构设计,BERT模型能够在多种自然语言处理任务上取得出色的表现,同时也保证了模型的灵活性和可扩展性。
三、BERT的核心特点
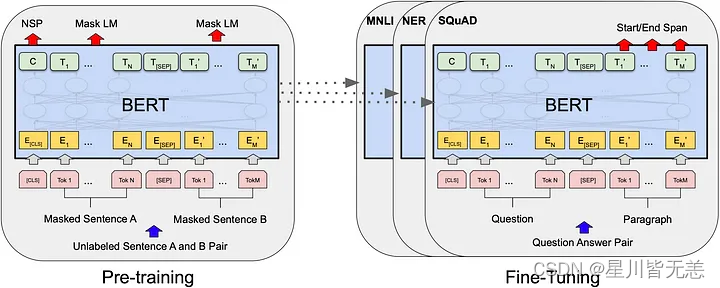
BERT模型不仅在多项NLP任务上取得了显著的性能提升,更重要的是,它引入了一系列在自然语言处理中具有革新性的设计和机制。接下来,我们将详细探讨BERT的几个核心特点。
Attention机制
自注意力(Self-Attention)
自注意力是BERT模型中一个非常重要的概念。不同于传统模型在处理序列数据时,只能考虑局部或前序的上下文信息,自注意力机制允许模型观察输入序列中的所有词元,并为每个词元生成一个上下文感知的表示。
# 自注意力机制的简单PyTorch代码示例
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embedding size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, queries, mask):N = queries.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]# Split the embedding into self.head different piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = queries.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)# Scaled dot-product attentionattention = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:attention = attention.masked_fill(mask == 0, float("-1e20"))attention = torch.nn.functional.softmax(attention, dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return out
多头注意力(Multi-Head Attention)
BERT进一步引入了多头注意力(Multi-Head Attention),将自注意力分成多个“头”,每个“头”学习序列中不同部分的上下文信息,最后将这些信息合并起来。
预训练和微调
BERT模型的成功很大程度上归功于其两阶段的训练策略:预训练(Pre-training)和微调(Fine-tuning)。下面我们会详细地探讨这两个过程的特点、技术点和需要注意的事项。
预训练(Pre-training)
预训练阶段是BERT模型训练过程中非常关键的一步。在这个阶段,模型在大规模的无标签文本数据上进行训练,主要通过以下两种任务来进行:
- 掩码语言模型(Masked Language Model, MLM): 在这个任务中,输入句子的某个比例的词会被随机地替换成特殊的
[MASK]标记,模型需要预测这些被掩码的词。 - 下一个句子预测(Next Sentence Prediction, NSP): 模型需要预测给定的两个句子是否是连续的。
技术点:
- 动态掩码: 在每个训练周期(epoch)中,模型看到的每一个句子的掩码都是随机的,这样可以增加模型的鲁棒性。
- 分词器: BERT使用了WordPiece分词器,能有效处理未登录词(OOV)。
注意点:
- 数据规模需要非常大,以充分训练庞大的模型参数。
- 训练过程通常需要大量的计算资源,例如高性能的GPU或TPU。
微调(Fine-tuning)
在预训练模型好之后,接下来就是微调阶段。微调通常在具有标签的小规模数据集上进行,以使模型更好地适应特定的任务。
技术点:
- 学习率调整: 由于模型已经在大量数据上进行了预训练,因此微调阶段的学习率通常会设置得相对较低。
- 任务特定头: 根据任务的不同,通常会在BERT模型的顶部添加不同的网络层(例如,用于分类任务的全连接层、用于序列标记的CRF层等)。
注意点:
- 避免过拟合:由于微调数据集通常比较小,因此需要仔细选择合适的正则化策略,如Dropout或权重衰减(weight decay)。
通过这两个阶段的训练,BERT不仅能够捕捉到丰富的语义和语法信息,还能针对特定任务进行优化,从而在各种NLP任务中都表现得非常出色。
BERT与其他Transformer架构的不同之处
预训练策略
虽然Transformer架构通常也会进行某种形式的预训练,但BERT特意设计了两个阶段:预训练和微调。这使得BERT可以首先在大规模无标签数据上进行预训练,然后针对特定任务进行微调,从而实现了更广泛的应用。
双向编码
大多数基于Transformer的模型(例如GPT)通常只使用单向或者条件编码。与之不同,BERT使用双向编码,可以更全面地捕捉到文本中词元的上下文信息。
掩码语言模型(Masked Language Model)
BERT在预训练阶段使用了一种名为“掩码语言模型”(Masked Language Model, MLM)的特殊训练策略。在这个过程中,模型需要预测输入序列中被随机掩码(mask)的词元,这迫使模型更好地理解句子结构和语义信息。
四、BERT的场景应用
BERT模型由于其强大的表征能力和灵活性,在各种自然语言处理(NLP)任务中都有广泛的应用。下面,我们将探讨几个常见的应用场景,并提供相关的代码示例。
文本分类
文本分类是NLP中最基础的任务之一。使用BERT,你可以轻松地将文本分类到预定义的类别中。
from transformers import BertTokenizer, BertForSequenceClassification
import torch# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')# 准备输入数据
inputs = tokenizer("Hello, how are you?", return_tensors="pt")# 前向传播
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1, label set as 1
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
情感分析
情感分析是文本分类的一个子任务,用于判断一段文本的情感倾向(正面、负面或中性)。
# 继续使用上面的模型和分词器
inputs = tokenizer("I love programming.", return_tensors="pt")# 判断情感
outputs = model(**inputs)
logits = outputs.logits
predictions = torch.softmax(logits, dim=-1)
命名实体识别(Named Entity Recognition, NER)
命名实体识别是识别文本中特定类型实体(如人名、地名、组织名等)的任务。
from transformers import BertForTokenClassification# 加载用于Token分类的BERT模型
model = BertForTokenClassification.from_pretrained('dbmdz/bert-large-cased-finetuned-conll03-english')# 输入数据
inputs = tokenizer("My name is John.", return_tensors="pt")# 前向传播
outputs = model(**inputs)
logits = outputs.logits
文本摘要
BERT也可以用于生成文本摘要,即从一个长文本中提取出最重要的信息。
from transformers import BertForConditionalGeneration# 加载用于条件生成的BERT模型(这是一个假设的例子,实际BERT原生不支持条件生成)
model = BertForConditionalGeneration.from_pretrained('some-conditional-bert-model')# 输入数据
inputs = tokenizer("The quick brown fox jumps over the lazy dog.", return_tensors="pt")# 生成摘要
summary_ids = model.generate(inputs.input_ids, num_beams=4, min_length=5, max_length=20)
print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))
这只是使用BERT进行实战应用的冰山一角。其灵活和强大的特性使它能够广泛应用于各种复杂的NLP任务。通过合理的预处理、模型选择和微调,你几乎可以用BERT解决任何自然语言处理问题。
五、BERT的Python和PyTorch实现

预训练模型的加载
加载预训练的BERT模型是使用BERT进行自然语言处理任务的第一步。由于BERT模型通常非常大,手动实现整个架构并加载预训练权重是不现实的。幸运的是,有几个库简化了这一过程,其中包括transformers库,该库提供了丰富的预训练模型和相应的工具。
安装依赖库
首先,你需要安装transformers和torch库。你可以使用下面的pip命令进行安装:
pip install transformers
pip install torch
加载模型和分词器
使用transformers库,加载BERT模型和相应的分词器变得非常简单。下面是一个简单的示例:
from transformers import BertTokenizer, BertModel# 初始化分词器和模型
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")# 查看模型架构
print(model)
这段代码会下载BERT的基础版本(uncased)和相关的分词器。你还可以选择其他版本,如bert-large-uncased。
输入准备
加载了模型和分词器后,下一步是准备输入数据。假设我们有一个句子:“Hello, BERT!”。
# 分词
inputs = tokenizer("Hello, BERT!", padding=True, truncation=True, return_tensors="pt")print(inputs)
tokenizer会自动将文本转换为模型所需的所有类型的输入张量,包括input_ids、attention_mask等。
模型推理
准备好输入后,下一步是进行模型推理,以获取各种输出:
with torch.no_grad():outputs = model(**inputs)# 输出的是一个元组
# outputs[0] 是所有隐藏状态的最后一层的输出
# outputs[1] 是句子的CLS标签的隐藏状态
last_hidden_states = outputs[0]
pooler_output = outputs[1]print(last_hidden_states.shape)
print(pooler_output.shape)
输出的last_hidden_states张量的形状为 [batch_size, sequence_length, hidden_dim],而pooler_output的形状为 [batch_size, hidden_dim]。
以上就是加载预训练BERT模型和进行基本推理的全过程。在理解了这些基础知识后,你可以轻松地将BERT用于各种NLP任务,包括但不限于文本分类、命名实体识别或问答系统。
微调BERT模型
微调(Fine-tuning)是将预训练的BERT模型应用于特定NLP任务的关键步骤。在此过程中,我们在特定任务的数据集上进一步训练模型,以便更准确地进行预测或分类。以下是使用PyTorch和transformers库进行微调的详细步骤。
数据准备
假设我们有一个简单的文本分类任务,其中有两个类别:正面和负面。我们将使用PyTorch的DataLoader和Dataset进行数据加载和预处理。
from torch.utils.data import DataLoader, Dataset
import torchclass TextClassificationDataset(Dataset):def __init__(self, texts, labels, tokenizer):self.texts = textsself.labels = labelsself.tokenizer = tokenizerdef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]inputs = self.tokenizer(text, padding='max_length', truncation=True, max_length=512, return_tensors="pt")return {'input_ids': inputs['input_ids'].flatten(),'attention_mask': inputs['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 假设texts和labels分别是文本和标签的列表
texts = ["I love programming", "I hate bugs"]
labels = [1, 0]
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')dataset = TextClassificationDataset(texts, labels, tokenizer)
dataloader = DataLoader(dataset, batch_size=2)
微调模型
在这里,我们将BERT模型与一个简单的分类层组合。然后,在微调过程中,同时更新BERT模型和分类层的权重。
from transformers import BertForSequenceClassification
from torch.optim import AdamW# 初始化模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 使用AdamW优化器
optimizer = AdamW(model.parameters(), lr=1e-5)# 训练模型
for epoch in range(3):for batch in dataloader:input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['labels']outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossloss.backward()optimizer.step()optimizer.zero_grad()print(f'Epoch {epoch + 1} completed')
模型评估
完成微调后,我们可以在测试数据集上评估模型的性能。
# 在测试数据集上进行评估...
通过这样的微调过程,BERT模型不仅能够从预训练中获得的通用知识,而且能针对特定任务进行优化。
六、总结
经过对BERT(Bidirectional Encoder Representations from Transformers)的深入探讨,我们有机会一窥这一先进架构的内在复杂性和功能丰富性。从其强大的双向注意力机制,到预训练和微调的多样性应用,BERT已经在自然语言处理(NLP)领域中设置了新的标准。
架构的价值
- 预训练和微调: BERT的预训练-微调范式几乎是一种“一刀切”的解决方案,可以轻松地适应各种NLP任务,从而减少了从头开始训练模型的复杂性和计算成本。
- 通用性与专门化: BERT的另一个优点是它的灵活性。虽然原始的BERT模型是一个通用的语言模型,但通过微调,它可以轻松地适应多种任务和行业特定的需求。
- 高度解释性: 虽然深度学习模型通常被认为是“黑盒”,但BERT和其他基于注意力的模型提供了一定程度的解释性。例如,通过分析注意力权重,我们可以了解模型在做决策时到底关注了哪些部分的输入。
发展前景
- 可扩展性: 虽然BERT模型本身已经非常大,但它的架构是可扩展的。这为未来更大和更复杂的模型铺平了道路,这些模型有可能捕获更复杂的语言结构和语义。
- 多模态学习与联合训练: 随着研究的进展,将BERT与其他类型的数据(如图像和音频)结合的趋势正在增加。这种多模态学习方法将进一步提高模型的泛化能力和应用范围。
- 优化与压缩: 虽然BERT的性能出色,但其计算成本也很高。因此,模型优化和压缩将是未来研究的重要方向,以便在资源受限的环境中部署这些高性能模型。
通用性与专门化*: BERT的另一个优点是它的灵活性。虽然原始的BERT模型是一个通用的语言模型,但通过微调,它可以轻松地适应多种任务和行业特定的需求。
3. 高度解释性: 虽然深度学习模型通常被认为是“黑盒”,但BERT和其他基于注意力的模型提供了一定程度的解释性。例如,通过分析注意力权重,我们可以了解模型在做决策时到底关注了哪些部分的输入。
发展前景
- 可扩展性: 虽然BERT模型本身已经非常大,但它的架构是可扩展的。这为未来更大和更复杂的模型铺平了道路,这些模型有可能捕获更复杂的语言结构和语义。
- 多模态学习与联合训练: 随着研究的进展,将BERT与其他类型的数据(如图像和音频)结合的趋势正在增加。这种多模态学习方法将进一步提高模型的泛化能力和应用范围。
- 优化与压缩: 虽然BERT的性能出色,但其计算成本也很高。因此,模型优化和压缩将是未来研究的重要方向,以便在资源受限的环境中部署这些高性能模型。
结语
BERT不仅是自然语言处理中的一个里程碑,也为未来的研究和应用提供了丰富的土壤。正如我们在本文中所探讨的,通过理解其内部机制和学习如何进行有效的微调,我们可以更好地利用这一强大工具来解决各种各样的问题。毫无疑问,BERT和类似的模型将继续引领NLP和AI的未来发展。
今天是大年三十除夕夜,又是新的一年,也是新的开始。外面都是炮声,久违的过年氛围终于回来了。回想这一路走来,闭上眼,都是风景。自己还存在很多不足,我也会坚持自我反思总结,不断进步坚持,新的一年我也会变得更强!
在这里祝大家新年快乐!幸福安康!
新的一年祝愿我们发财、平安、上岸。
相关文章:
深度学习自然语言处理(NLP)模型BERT:从理论到Pytorch实战
文章目录 深度学习自然语言处理(NLP)模型BERT:从理论到Pytorch实战一、引言传统NLP技术概览规则和模式匹配基于统计的方法词嵌入和分布式表示循环神经网络(RNN)与长短时记忆网络(LSTM)Transform…...
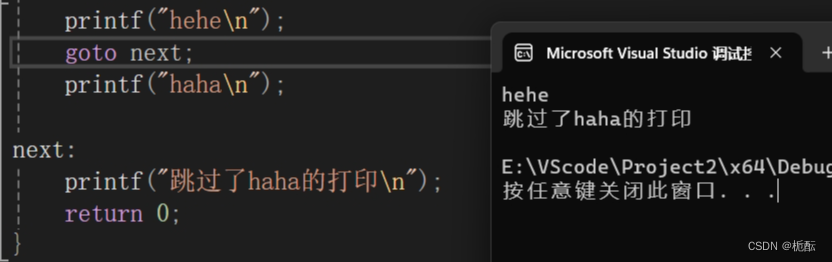
C语言的循环结构
目录 前言 1.三种循环语句 1.while循环 2.for循环 2.1缺少表达式的情况 3.do while循环 2.break语句和continue语句 2.1在while循环中 2.2在for循环中 2.3在do while 循环中 3.循环的嵌套 4.go to语句 前言 C语⾔是结构化的程序设计语⾔,这⾥的结构指的是…...
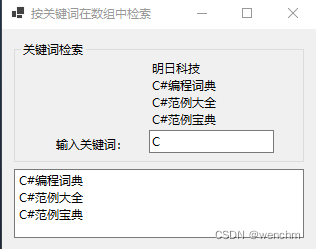
C#用Array类的FindAll方法和List<T>类的Add方法按关键词在数组中检索元素并输出
目录 一、使用的方法 1. Array.FindAll(T[], Predicate) 方法 (1)定义 (2)示例 2.List类的常用方法 (1)List.Add(T) 方法 (2)List.RemoveAt(Int32) 方法 (3&…...
附完整源码】)
【前后端接口AES+RSA混合加解密详解(vue+SpringBoot)附完整源码】
前后端接口AES+RSA混合加解密详解(vue+SpringBoot) 前后端接口AES+RSA混合加解密一、AES加密原理和为什么不使用AES加密二、RSA加密原理和为什么不使用rsa加密三、AES和RSA混合加密的原理四、代码样例前端1. 请求增加加密标识2. 前端加密工具类3.前端axios请求统一封装,和返…...
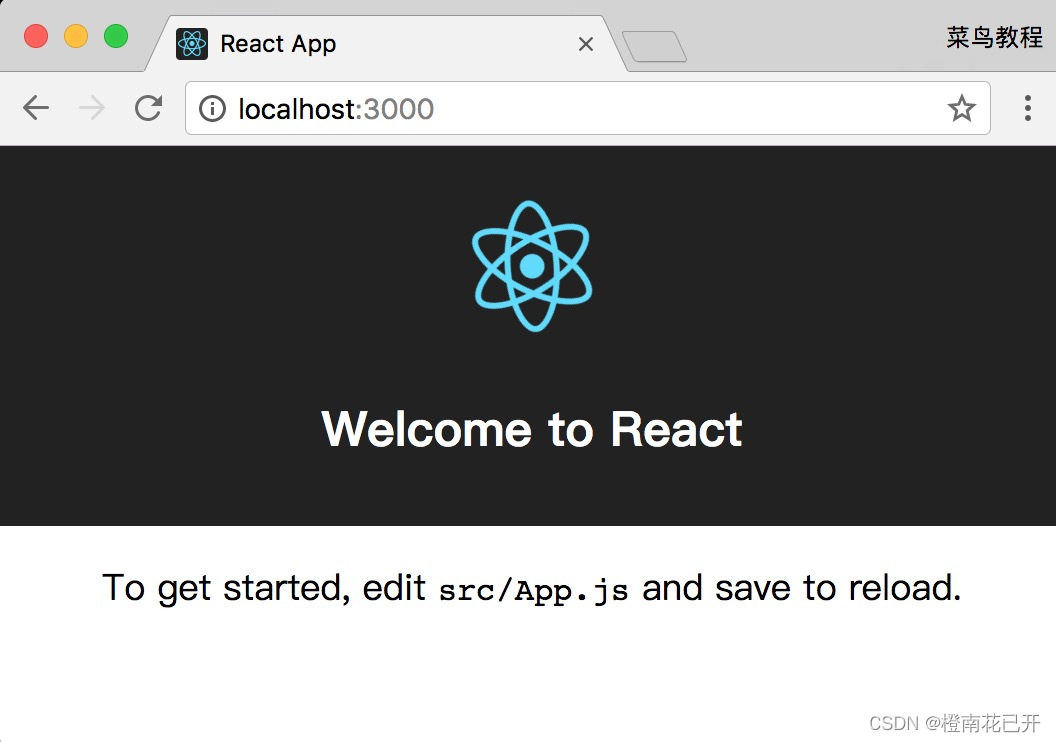
React环境配置
1.安装Node.js Node.js官网:https://nodejs.org/en/ 下载之后按默认选项安装好 重启电脑即可自动完成配置 2.安装React 国内使用 npm 速度很慢,可以使用淘宝定制的 cnpm (gzip 压缩支持) 命令行工具代替默认的 npm。 ①使用 winR 输入 cmd 打开终端 ②依…...

Pandas 数据处理-排序与排名的深度探索【第69篇—python:文本数据处理】
文章目录 Pandas 数据处理-排序与排名的深度探索1. sort_index方法2. sort_values方法3. rank方法4. 多列排序5. 排名方法的参数详解6. 处理重复值7. 对索引进行排名8. 多级索引排序与排名9. 更高级的排序自定义10. 性能优化技巧10.1 使用nsmallest和nlargest10.2 使用sort_val…...

第8节、双电机多段直线运动【51单片机+L298N步进电机系列教程】
↑↑↑点击上方【目录】,查看本系列全部文章 摘要:前面章节主要介绍了bresenham直线插值运动,本节内容介绍让两个电机完成连续的直线运动,目标是画一个正五角星 一、五角星图介绍 五角星总共10条直线,10个顶点。设定左下角为原点…...
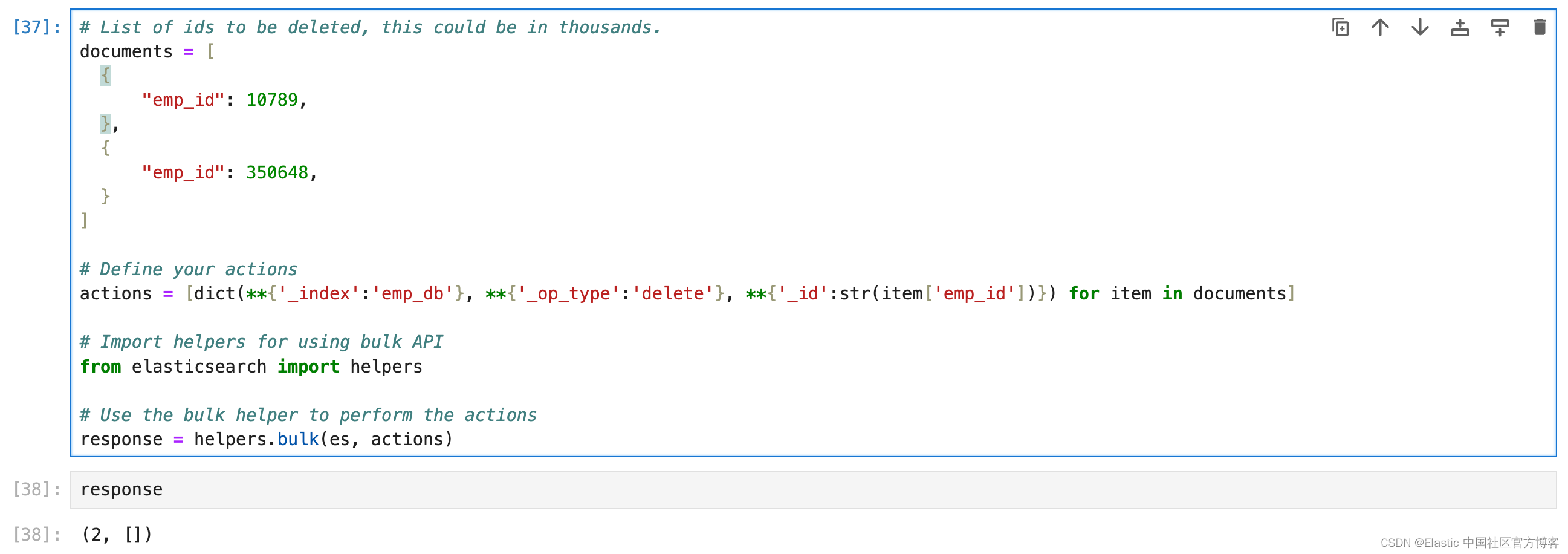
Elasticsearch:基本 CRUD 操作 - Python
在我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”,我详细讲述了如何建立 Elasticsearch 的客户端连接。我们也详述了如何对数据的写入及一些基本操作。在今天的文章中,我们针对数据的 CRUD (cre…...
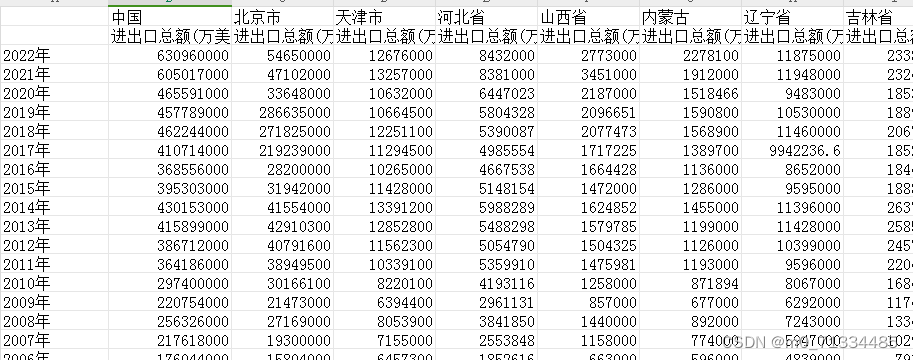
1992-2022年全国及31省对外开放度测算数据(含原始数据+计算结果)(无缺失)
1992-2022年全国及31省对外开放度测算数据(含原始数据计算结果)(无缺失) 1、时间:1992-2022年 2、来源:各省年鉴、国家统计局、统计公报、 3、指标:进出口总额(万美元)…...

JVM之GC垃圾回收
GC垃圾回收 如何判断对象可以回收 引用计数法 如果有对象引用计数加一,没有对象引用,计数减一,如果计数为零,则回收 但是如果存在循环引用,即A对象引用B对象,B对象引用A对象,会造成内存泄漏 可…...

自然语言学习nlp 六
https://www.bilibili.com/video/BV1UG411p7zv?p118 Delta Tuning,尤其是在自然语言处理(NLP)和机器学习领域中,通常指的是对预训练模型进行微调的一种策略。这种策略不是直接更新整个预训练模型的权重,而是仅针对模型…...

fpga 需要掌握哪些基础知识?
个人根据自己的一些心得总结一下fpga 需要掌握的基础知识,希望对你有帮助。 1、数电(必须掌握的基础),然后进阶学模电, 2、掌握HDL(verilog或VHDL)一般建议先学verilog,然后可以学…...

Qt未来市场洞察
跨平台开发:Qt作为一种跨平台的开发框架,具有良好的适应性和灵活性,未来将继续受到广泛应用。随着多设备和多平台应用的增加,Qt的前景在跨平台开发领域将更加广阔。 物联网应用:由于Qt对嵌入式系统和物联网应用的良好支…...

GPT-4模型中的token和Tokenization概念介绍
Token从字面意思上看是游戏代币,用在深度学习中的自然语言处理领域中时,代表着输入文字序列的“代币化”。那么海量语料中的文字序列,就可以转化为海量的代币,用来训练我们的模型。这样我们就能够理解“用于GPT-4训练的token数量大…...

宽字节注入漏洞原理以及修复方法
漏洞名称:宽字节注入 漏洞描述: 宽字节注入是相对于单字节注入而言的,该注入跟HTML页面编码无关,宽字节注入常见于mysql中,GB2312、GBK、GB18030、BIG5、Shift_JIS等这些都是常说的宽字节,实际上只有两字节。宽字节带来的安全问…...

【Linux】SystemV IPC
进程间通信 一、SystemV 共享内存1. 共享内存原理2. 系统调用接口(1)创建共享内存(2)形成 key(3)测试接口(4)关联进程(5)取消关联(6)释…...

iview 页面中判断溢出才使用Tooltip组件
使用方法 <TextTooltip :content"contentValue"></TextTooltip> 给Tooltip再包装一下 <template><Tooltip transfer :content"content" :theme"theme" :disabled"!showTooltip" :max-width"300" :p…...
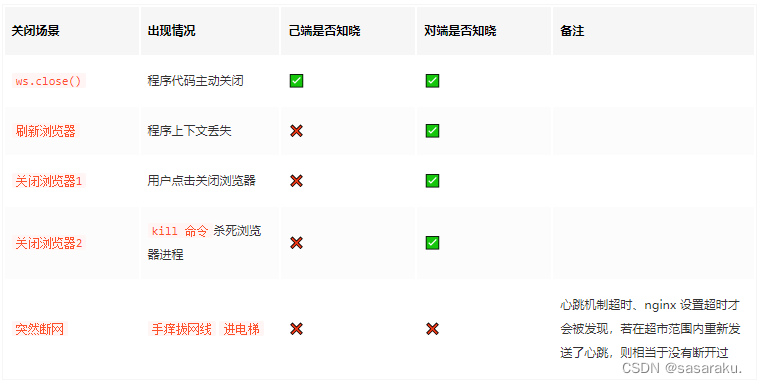
如何使用websocket
如何使用websocket 之前看到过一个面试题:吃饭点餐的小程序里,同一桌的用户点餐菜单如何做到的实时同步? 答案就是:使用websocket使数据变动时服务端实时推送消息给其他用户。 最近在我们自己的项目中我也遇到了类似问题…...
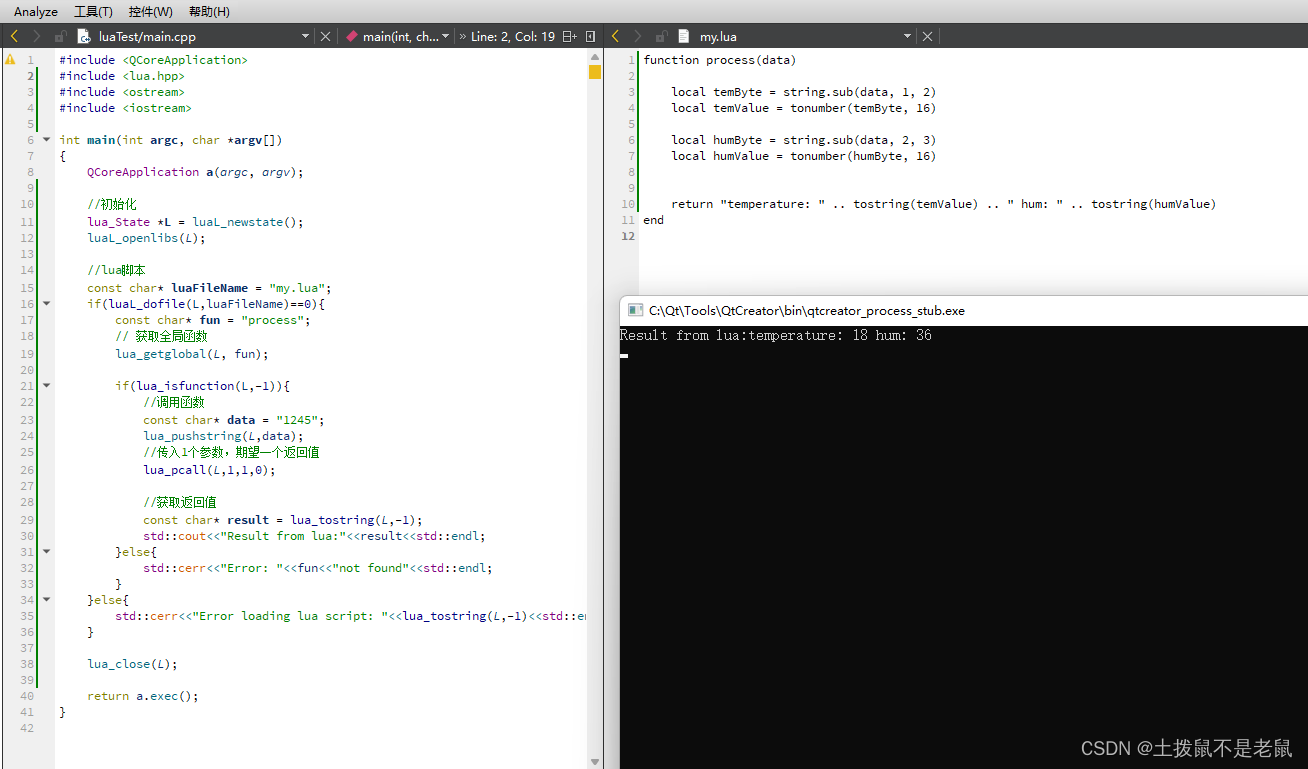
C++ 调用lua 脚本
需求: 使用Qt/C 调用 lua 脚本 扩展原有功能。 步骤: 1,工程中引入 头文件,库文件。lua二进制下载地址(Lua Binaries) 2, 调用脚本内函数。 这里调用lua 脚本中的process函数,并…...
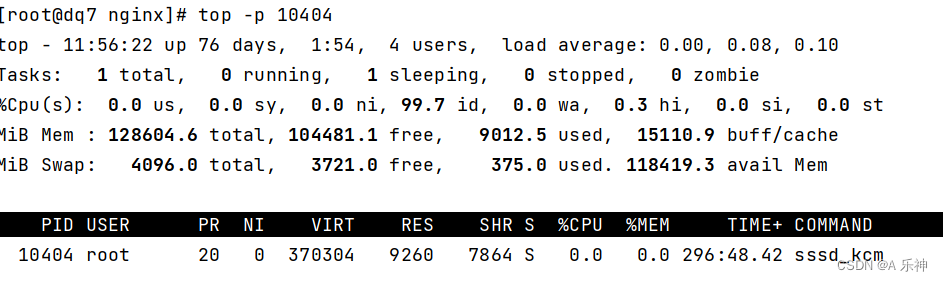
Centos 内存和硬盘占用情况以及top作用
目录 只查看内存使用情况: 内存使用排序取前5个: 硬盘占用情况 定位占用空间最大目录 top查看cpu及内存使用信息 前言-与正文无关 生活远不止眼前的苦劳与奔波,它还充满了无数值得我们去体验和珍惜的美好事物。在这个快节奏的世界中&…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...