提升图像分割精度:学习UNet++算法

文章目录
- 一、UNet++ 算法简介
- 1.1 什么是 UNet++ 算法
- 1.2 UNet++ 的优缺点
- 1.3 UNet++ 在图像分割领域的应用
- 二、准备工作
- 2.1 Python 环境配置
- 2.2 相关库的安装
- 三、数据处理
- 3.1 数据的获取与预处理
- 3.2 数据的可视化与分析
- 四、网络结构
- 4.1 UNet++ 的网络结构
- 4.2 UNet++ 各层的作用
- 五、训练模型
- 5.1 模型训练流程
- 5.2 模型评估指标
- 5.3 模型优化方法
- 六、基于 UNet++ 的医学图像分割实战案例
- 七、与其他算法的对比
- 7.1 UNet++ 与 UNet 的对比
- 7.2 UNet++ 与 DeepLabv3+ 的对比
- 八、总结与展望
- 8.1 UNet++ 的未来发展
- 8.2 学习建议
由于工作需要对
UNet++算法进行调参,对规则做较大的修改,初次涉及,有误的地方,请各位大佬指教哈。
一、UNet++ 算法简介
1.1 什么是 UNet++ 算法
UNet++ 算法是基于 UNet 算法的改进版本,旨在提高图像分割的性能和效果。它由 Zhou et al. 在论文 “UNet++: A Nested U-Net Architecture for Medical Image Segmentation” 中提出。
与 UNet 不同,UNet++ 引入了一种“嵌套结构”,通过逐层向上和向下的卷积特征融合,从而增强了模型的表达能力和上下文感知能力。
具体来说,UNet++ 将原始的 UNet 模型中的编码器和解码器部分拆分为多个子模块,每个子模块都包含一个编码器和一个解码器。
- 在编码器中,每个子模块将输入图像连续下采样两次,并利用卷积层提取特征;
- 在解码器中,每个子模块将上一级的输出和对应的编码器特征进行上采样和融合,然后再进行下一级的解码操作。
- 最终,UNet++ 的输出由所有子模块的输出组合而成。
UNet++ 的嵌套结构有助于提高模型的表示能力和上下文感知能力,从而提高图像分割的性能和效果。实验证明,UNet++ 在医学图像分割等任务中具有显著的性能优势。
1.2 UNet++ 的优缺点
UNet++ 是一种基于原始 UNet 模型的改进版本,旨在提高语义分割任务的性能。
UNet++ 的一些优点和缺点:
优点:
- 更好的特征表达:UNet++ 通过引入一系列嵌套和跳跃连接,能够更好地捕捉图像中的多尺度特征信息。这有助于提高模型对目标的理解和区分能力。
- 更精确的分割:UNet++ 提供了更多的上下文信息和细节信息,可以更准确地进行语义分割。它能够更好地处理目标边界、细小结构和遮挡等复杂情况。
- 减少特征丢失:传统 UNet 模型存在特征丢失的问题,即由于多次下采样和上采样操作,导致模型在不同尺度上丢失了一部分特征信息。UNet++ 通过增加跳跃连接和嵌套结构,可以减轻特征丢失问题,提高模型的感知能力。
- 可扩展性:UNet++ 模型结构相对简单,易于理解和实现。同时,它具有良好的可扩展性,可以根据任务的需求进行灵活的修改和调整。
缺点:
- 计算和内存需求较高:UNet++ 引入了更多的嵌套结构和跳跃连接,这会增加模型的参数量和计算复杂度。在资源受限的情况下,可能需要较高的计算和内存资源。
- 需要大量的标注数据:像其他深度学习模型一样,UNet++ 需要大量的标注数据来进行训练。获取和标注足够数量的高质量数据可能是一个挑战。
- 对于小目标的分割效果有限:由于 UNet++ 是基于原始 UNet 进行改进的,对于小目标的分割效果可能仍然有限。对于一些具有小目标的任务,可能需要进一步优化模型或采用其他方法。
综上所述,UNet++ 在语义分割任务中具有良好的性能,能够提供更好的特征表达和更精确的分割结果。然而,它也存在计算和内存需求较高、对标注数据的依赖性强等一些限制。在实际应用中,需要根据具体情况权衡其优缺点,并选择合适的模型和参数配置。
1.3 UNet++ 在图像分割领域的应用
UNet++ 在图像分割领域被广泛应用,特别是在医学影像分割、自然图像分割和遥感图像分割等领域。
典型的应用:
- 医学影像分割:在医学影像领域,UNet++ 被广泛应用于各种临床任务,例如肺结节分割、肝脏分割、心脏分割和视网膜分割等。由于 UNet++ 能够处理多尺度和复杂的形状,它在医学影像分割中具有很高的准确性和稳定性。
- 自然图像分割:在自然图像领域,UNet++ 被用于各种场景下的图像分割任务,例如人物分割、道路分割和建筑物分割等。相比传统的卷积神经网络,UNet++ 能够更好地捕捉不同尺度和分辨率的图像特征,从而提高分割的准确性和鲁棒性。
- 遥感图像分割:在遥感图像领域,UNet++ 被广泛用于地物分类、农业作物分类和城市土地利用分析等任务。由于遥感图像具有多尺度、高分辨率和复杂的空间结构,UNet++ 能够更好地处理这些问题,提高图像分割的准确性和效率。
总之,UNet++ 在图像分割领域具有广泛的应用前景,在不同领域和场景下都表现出了很高的性能和鲁棒性。
二、准备工作
2.1 Python 环境配置
使用 UNet++ 进行图像分割,需要先配置 Python 环境和相关的深度学习框架。
基本的环境配置建议:
- 安装 Anaconda:Anaconda 是一个流行的 Python 发行版,包含了许多常用的科学计算工具和库,可以方便地管理 Python 环境和依赖项。建议从官网下载并安装最新版本的 Anaconda。
- 创建虚拟环境:使用 Anaconda 创建一个虚拟环境,可以避免不同项目之间的依赖冲突。具体操作可参考 Anaconda 的文档,例如通过命令
conda create --name myenv python=3.8创建一个名为 myenv 的 Python 3.8 环境。 - 安装 PyTorch:PyTorch 是一个流行的深度学习框架,支持动态图和静态图两种模式。UNet++ 基于 PyTorch 实现,因此需要先安装 PyTorch。可以通过命令
conda install pytorch torchvision torchaudio -c pytorch安装最新版本的 PyTorch。 - 安装其他依赖项:除了 PyTorch 外,还需要安装一些其他的 Python 库和依赖项,例如
Numpy、Pandas、Matplotlib、Scikit-learn、OpenCV等。可以通过命令conda install numpy pandas matplotlib scikit-learn opencv等来安装这些库。
总之,使用 UNet++ 进行图像分割需要先配置好 Python 环境和相关的库和框架,以确保能够顺利地运行和调试代码。
2.2 相关库的安装
使用 UNet++ 进行图像分割需要安装以下相关库:
- PyTorch:作为 UNet++ 的实现框架,需要先安装 PyTorch,可以通过官方网站下载或者使用 pip 命令安装。
- NumPy:是 Python 中一个数值计算的基础库,用来处理多维数组和矩阵运算,常用于科学计算和数据分析。可以使用 pip 命令安装。
- Matplotlib:是 Python 的一个绘图库,用于绘制各种静态、交互式的图表和可视化界面。可以使用 pip 命令安装。
- OpenCV:是一个跨平台的计算机视觉库,提供了许多图像处理和计算机视觉算法的实现,常用于图像和视频分析。可以使用 pip 命令安装。
- Scikit-learn:是一个机器学习的开源库,提供了许多常见的机器学习算法和工具,例如分类、聚类、回归等。可以使用 pip 命令安装。
除了以上库外,还可以根据具体需要安装其他的库和依赖项,例如 Pandas、SciPy、TensorFlow 等。
可以使用 pip 命令来安装这些库,例如:
pip install torch
pip install numpy
pip install matplotlib
pip install opencv-python
pip install scikit-learn
注意,不同库的安装可能需要在不同操作系统和环境下进行,具体步骤和命令可能会有所不同。建议查看相应库的官方文档和指南,以确保正确安装和使用。
三、数据处理
3.1 数据的获取与预处理
获取和预处理 UNet++ 的数据通常遵循以下步骤:
- 数据收集:收集用于训练和测试的图像和对应的标签。标签可以是人工标注的图像分割掩码,表示图像中的目标区域。
- 数据清洗与预处理:对收集到的图像进行清洗和预处理操作,以提高数据质量和适应模型要求。可能的预处理操作包括图像缩放、裁剪、旋转、翻转等。
- 数据增强:通过应用各种变换和扩增技术来增加数据集的多样性和数量,以提升模型的泛化能力。常见的数据增强方法包括随机翻转、旋转、缩放、平移、亮度调整等。
- 数据划分:将数据集划分为训练集、验证集和测试集。训练集用于模型参数的学习,验证集用于调整模型的超参数和监控训练过程,测试集用于评估模型的性能。
- 数据加载:编写数据加载器代码,将图像和对应的标签加载到内存中,并进行必要的预处理操作,例如归一化、转换为张量等。可以使用 PyTorch 的数据加载工具,如
torchvision.datasets和torch.utils.data.DataLoader。 - 数据可视化:可选地,可以对加载和预处理后的数据进行可视化,以确保数据处理的正确性。可以使用 Matplotlib 或其他绘图库来展示图像和标签。
需要根据具体的数据集和任务来确定数据获取和预处理的具体步骤。UNet++ 模型通常用于语义分割任务,因此需要准备带有相应标签的图像数据集,并对数据进行适当的预处理和增强,以提供足够的多样性和质量。
3.2 数据的可视化与分析
对 UNet++ 模型的数据进行可视化和分析可以帮助了解数据的特征和分布,以及评估数据质量和模型的性能。
常见的数据可视化和分析方法:
- 图像可视化:使用图像库(如
Matplotlib、OpenCV等)加载并显示原始图像和其对应的标签,可以直观地查看图像和目标区域的形状、颜色等特征。 - 分割掩码可视化:将图像中的分割掩码转换为彩色图像或叠加在原始图像上进行显示,可以清楚地观察到模型的预测效果,以及目标区域与背景的区分情况。
- 数据统计分析:计算数据集中的样本数量、类别分布等统计信息,可以帮助了解数据集的平衡性和不平衡性,以及各个类别的样本数量是否合理。
- 数据增强效果分析:将数据增强后的图像与原始图像进行对比,观察增强操作对图像的影响,确保增强操作不会引入不可预期的错误。
- 可视化模型预测结果:使用训练好的 UNet++ 模型对测试集图像进行预测,并将预测结果与真实标签进行对比,可视化显示预测的分割效果,以评估模型的性能。
- 损失曲线分析:绘制训练过程中的损失函数曲线,可以观察模型的训练进展和收敛情况,判断是否需要调整学习率或其他超参数。
以上方法可以通过使用 Python 的数据处理和可视化库来实现,例如 Matplotlib、NumPy、Pandas 等。可以根据具体需求选择合适的方法和工具进行数据可视化和分析。
四、网络结构
4.1 UNet++ 的网络结构
UNet++ 是一种用于图像分割任务的改进型 U-Net 网络结构,它通过引入多级跨层连接来提高网络性能。
UNet++ 的网络结构由编码器(Contracting Path)和解码器(Expanding Path)组成。
- 编码器负责逐渐降低输入图像的空间分辨率,提取特征信息;
- 在编码器中,每个级别都由多个卷积块(Conv Block)和下采样操作(Downsampling)组成,用于逐渐减小特征图的尺寸。
- 解码器则逐渐恢复特征图的空间分辨率,并结合跨层连接进行特征融合,最终生成输出的分割掩码。
- 在解码器中,每个级别都由上采样操作(Upsampling)、跨层连接和多个卷积块组成。跨层连接允许浅层特征与深层特征进行融合,以提高分割性能。
最后,通过在解码器的最高级别上应用卷积操作,生成最终的分割掩码。
4.2 UNet++ 各层的作用
UNet++ 网络结构由编码器和解码器组成,每个级别都有不同的作用。
各层的作用说明:
- 编码器(Contracting Path):
- Level 0:接收输入图像并进行初始特征提取。
- Level 1、Level 2、Level 3:逐渐降低特征图的空间分辨率,提取更高级别的特征信息。
- 解码器(Expanding Path):
- Level 0:通过上采样操作将低分辨率特征图恢复到输入图像的大小,并进行跨层连接。
- Level 1、Level 2、Level 3:逐渐增加特征图的空间分辨率,同时与相应级别的编码器特征进行跨层连接和特征融合。
- 跨层连接:
- 跨层连接用于将编码器和解码器中相同级别的特征图进行融合。
- 每个级别的解码器通过上采样操作将特征图的空间分辨率扩大,然后与相应级别的编码器特征图进行连接。
- 跨层连接使得浅层特征与深层特征进行融合,有助于网络学习更全局和局部的特征。
- 卷积块(Conv Block):
- 卷积块通常由多个卷积层和激活函数组成。
- 卷积层用于提取特征,激活函数引入非线性变换。
- 在编码器和解码器的每个级别上都有卷积块,用于处理特征图。
通过编码器和解码器的结构以及跨层连接,在 UNet++ 中实现了逐渐降低分辨率、提取特征、逐渐恢复分辨率和特征融合的过程。这种设计使得 UNet++ 能够有效地进行图像分割任务,并在各个级别上获取丰富的特征信息。
五、训练模型
5.1 模型训练流程
UNet++ 模型的训练流程:
- 数据准备:
- 准备标注好的图像数据和对应的分割掩码。
- 对图像进行预处理,如缩放、裁剪、归一化等。
- 构建模型:
- 根据 UNet++ 的网络结构,在深度学习框架中构建模型。
- 定义损失函数,如交叉熵损失函数、Dice Loss 等。
- 划分数据集:
- 将数据集划分为训练集、验证集和测试集。
- 训练集用于训练模型,验证集用于调节超参数和监控模型性能,测试集用于最终评估模型性能。
- 训练模型:
- 将准备好的数据输入到模型中进行训练。
- 在每个迭代周期(epoch)结束时,使用验证集进行模型性能评估。
- 通过调节超参数、修改模型结构等方式不断优化模型。
- 模型评估:
- 使用测试集对训练好的模型进行评估,计算出模型在测试集上的精度、召回率、F1 值等指标。
- 模型应用:
- 将训练好的模型用于实际应用中,如对新的图像进行分割。
在训练过程中,需要注意的是,为了防止模型过拟合,可以采取一些策略,如数据增强、使用正则化方法、提前停止等。此外,为了加速模型的训练,可以使用 GPU 等硬件加速设备。
5.2 模型评估指标
对于 UNet++ 模型的评估,一般可以使用以下指标来衡量其性能:
- 准确率(Accuracy):准确率度量模型在整个测试集上
正确分类的样本比例,计算公式为:准确率 = (真阳性 + 真阴性) / (真阳性 + 真阴性 + 假阳性 + 假阴性)。准确率越高,表示模型分类的准确性越好。 - 精确率(Precision):精确率表示模型预测为正样本的样本中,
真正为正样本的比例,计算公式为:精确率 = 真阳性 / (真阳性 + 假阳性)。精确率高表示模型将负样本误判为正样本的能力较低。 - 召回率(Recall):召回率表示
真实正样本中被模型预测正确的比例,计算公式为:召回率 = 真阳性 / (真阳性 + 假阴性)。召回率高表示模型能够较好地捕捉到正样本。 - F1 值(F1 Score):F1 值是
精确率和召回率的综合评价指标,计算公式为:F1 值 = 2 * (精确率 * 召回率) / (精确率 + 召回率)。F1 值综合考虑了分类的准确性和召回能力,是常用的评价指标之一。
除了上述指标,还可以根据具体任务需要,考虑其他评价指标,如交并比(Intersection over Union,IoU)、Dice 系数等。这些指标可以帮助评估模型在图像分割任务中的性能表现,选择适合的指标进行模型评估和比较。
5.3 模型优化方法
对于 UNet++ 模型的优化,可以考虑以下方法:
- 数据增强(Data Augmentation):通过对训练数据进行旋转、缩放、翻转等操作,增加数据的多样性,扩充数据集,提升模型的泛化能力。
- 学习率调整(Learning Rate Schedule):采用动态学习率调整策略,如学习率衰减(learning rate decay)、余弦退火(cosine annealing)等,有助于更好地收敛和找到全局最优解。
- 正则化(Regularization):使用
L1/L2正则化项,限制模型参数的大小,防止过拟合。可以通过添加权重衰减项(weight decay)或Dropout 层来实现。 - 批归一化(Batch Normalization):在每个
mini-batch的数据上做归一化处理,加速模型收敛,提高模型的稳定性和泛化能力。 - 梯度裁剪(Gradient Clipping):限制梯度的范围,避免梯度爆炸或消失问题。
- 模型结构优化:可以尝试调整网络的深度、宽度,增加或减少特征图的数量,甚至使用其他的分割网络结构进行对比。
- 集成学习(Ensemble Learning):将多个训练好的模型进行集成,如投票、平均等方式,提升模型的表现。
- 硬件加速:使用 GPU 或其他专用硬件进行模型训练,加速计算过程,缩短训练时间。
- 模型剪枝(Model Pruning):通过剪枝技术去除冗余参数、稀疏连接等,减小模型的计算量和内存占用,提高推理速度。
- 权重初始化:选择合适的权重初始化方法,如
Xavier 初始化、He 初始化等,避免模型陷入局部最优解。
以上是一些常见的 UNet++ 模型优化方法,可以根据具体情况选择合适的方法进行尝试和调整。
六、基于 UNet++ 的医学图像分割实战案例
基于 UNet++ 的医学图像分割实战案例是肺部图像分割的简单实例流程:
- 数据收集:收集带有标注的肺部 CT 扫描图像数据集,包括肺组织和病变区域的标注。
- 数据预处理:对收集到的图像进行预处理,如调整大小、裁剪、灰度化等,确保输入数据的一致性和标准化。
- 数据增强:使用数据增强技术,如旋转、平移、缩放、翻转等,生成更多多样化的训练数据,增加模型的泛化能力。
- 划分数据集:将数据集划分为训练集、验证集和测试集,通常采用
70-15-15或80-10-10的比例。 - 构建 UNet++ 模型:根据 UNet++ 结构,构建医学图像分割模型。可以选择使用预训练的权重作为初始化,并根据具体任务进行微调。
- 模型训练:使用训练集对 UNet++ 模型进行训练,通过优化算法(如
Adam、SGD)和损失函数(如交叉熵损失函数)来最小化模型的预测结果与真实标签的差异。 - 模型验证:使用验证集对训练过程中的模型进行验证,评估模型的性能和泛化能力。
- 模型调优:根据验证结果,调整模型超参数,如学习率、批大小、网络深度等,进一步提升模型性能。
- 模型测试:使用测试集对最终调优的模型进行测试,评估模型在未见过的数据上的分割性能。
- 结果评估:根据测试结果,计算评价指标,如准确率、精确率、召回率、F1 值等,评估模型的性能。
- 可视化结果:将模型预测的肺部分割结果与真实标签进行可视化比较,观察模型的分割效果,可以使用图像处理库如 Matplotlib 进行可视化操作。
- 模型部署:根据具体需求,将训练好的模型部署到实际应用中,进行肺部图像分割任务。
基于 UNet++ 的医学图像分割实战代码案例的主要步骤:
Step 1: 导入所需的库和模块
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, Concatenate
from tensorflow.keras.optimizers import Adam
Step 2: 构建 UNet++ 模型
def unet_plusplus(input_shape):inputs = Input(input_shape)# 编码器部分conv1_1 = Conv2D(64, 3, activation='relu', padding='same')(inputs)conv1_2 = Conv2D(64, 3, activation='relu', padding='same')(conv1_1)pool1 = MaxPooling2D(pool_size=(2, 2))(conv1_2)conv2_1 = Conv2D(128, 3, activation='relu', padding='same')(pool1)conv2_2 = Conv2D(128, 3, activation='relu', padding='same')(conv2_1)pool2 = MaxPooling2D(pool_size=(2, 2))(conv2_2)# ... 添加更多编码器层次 ...# 解码器部分# ... 添加更多解码器层次 ...model = Model(inputs=inputs, outputs=output)return model
Step 3: 定义损失函数和评价指标
def dice_coef(y_true, y_pred, smooth=1):intersection = tf.reduce_sum(y_true * y_pred)union = tf.reduce_sum(y_true) + tf.reduce_sum(y_pred)dice = (2. * intersection + smooth) / (union + smooth)return dicedef dice_loss(y_true, y_pred):loss = 1 - dice_coef(y_true, y_pred)return loss
Step 4: 编写训练代码
def train_unet_plusplus(train_images, train_masks, val_images, val_masks, input_shape, batch_size, epochs):model = unet_plusplus(input_shape)model.compile(optimizer=Adam(learning_rate=1e-4), loss=dice_loss, metrics=[dice_coef])# 数据增强和预处理train_data_gen = tf.keras.preprocessing.image.ImageDataGenerator(rotation_range=10,width_shift_range=0.1,height_shift_range=0.1,zoom_range=0.1,horizontal_flip=True,vertical_flip=True,rescale=1.0/255.0)val_data_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255.0)train_generator = train_data_gen.flow(train_images, train_masks, batch_size=batch_size)val_generator = val_data_gen.flow(val_images, val_masks, batch_size=batch_size)model.fit(train_generator,steps_per_epoch=len(train_images) // batch_size,validation_data=val_generator,validation_steps=len(val_images) // batch_size,epochs=epochs)return model
Step 5: 调用训练函数进行模型训练
# 设置训练参数
input_shape = (256, 256, 3)
batch_size = 16
epochs = 10# 准备训练数据和验证数据
train_images = ...
train_masks = ...
val_images = ...
val_masks = ...# 开始训练
model = train_unet_plusplus(train_images, train_masks, val_images, val_masks, input_shape, batch_size, epochs)
这是一个基于 UNet++ 的医学图像分割实战代码案例的简单示例。具体实现过程中,还需要根据具体数据集和任务需求进行适当调整和优化,如数据预处理、模型参数设置等。
七、与其他算法的对比
7.1 UNet++ 与 UNet 的对比
UNet++ 是对 UNet 模型的改进和扩展,主要在网络结构上进行了优化。
UNet++ 与 UNet 的一些对比:
- 网络结构:UNet 是由对称的编码器(下采样路径)和解码器(上采样路径)组成的 U 形结构,而 UNet++ 在此基础上增加了更深层次的连接,形成了更加复杂的网络结构。
- 特征融合机制:UNet 使用简单的特征拼接方式进行编码器和解码器之间的特征融合,而 UNet++ 引入了多尺度特征融合模块,通过跳跃连接和密集连接的方式,将不同层次的特征进行有效地融合,提升了特征的表达能力。
- 参数数量:UNet++ 相比 UNet 具有更多的参数,因为增加了更多的连接和分支路径,这在一定程度上增加了模型的复杂度和计算量。
- 分割性能:由于引入了更多的连接和层次,UNet++ 在医学图像分割任务中通常具有更好的性能,能够捕捉更多的细节和边缘信息,提高分割的准确性和鲁棒性。
- 训练效率:UNet++ 的训练过程可能会比 UNet 更复杂和耗时,因为具有更多的参数和更深层次的连接。但可以通过一些优化策略(如批归一化、学习率调整等)来提高训练效率。
需要注意的是,UNet++ 并不是在所有情况下都会比 UNet 更好,具体应用中还需要根据任务需求和数据特点进行选择。在资源有限的情况下,UNet 可能更适合,而在需要更高性能和更复杂任务的情况下,可以考虑使用 UNet++。
7.2 UNet++ 与 DeepLabv3+ 的对比
UNet++ 和 DeepLabv3+ 都是用于医学图像分割的先进模型,但在网络结构和特点上有一些区别。
- 网络结构:
- UNet++:UNet++ 是基于 UNet 的改进版本,通过增加
skip connections和nested skip connections来提高分割性能。它包含编码器和解码器部分,编码器通过卷积和池化操作逐渐提取图像特征,解码器通过上采样和跳跃连接将特征进行恢复和整合。 - DeepLabv3+:DeepLabv3+ 是一种深度卷积神经网络,采用了
空洞卷积(dilated convolution)和多尺度特征融合策略,以更好地捕获图像中的细节信息。它由骨干网络和解码器组成,其中骨干网络通常使用预训练的 ResNet 或者 Xception 等网络,而解码器使用空洞卷积和金字塔池化等操作来提取分割结果。
- UNet++:UNet++ 是基于 UNet 的改进版本,通过增加
- 特点和性能:
- UNet++:UNet++ 在分割性能上表现出色,特别适用于小目标和细节分割任务。它通过
skip connections 和 nested skip connections可以更好地利用不同层次的特征信息,提高了分割准确性和边缘细节的保留。 - DeepLabv3+:DeepLabv3+ 在分割性能上也非常强大,特别擅长于大目标和语义分割任务。它通过空洞卷积和多尺度特征融合策略,可以更好地捕获图像中的细节信息和上下文关系,提高了分割准确性和感知范围。
- UNet++:UNet++ 在分割性能上表现出色,特别适用于小目标和细节分割任务。它通过
总的来说,UNet++ 和 DeepLabv3+ 都是优秀的医学图像分割模型,选择哪个模型取决于具体的任务需求和数据特点。如果任务需要更好地保留细节信息和处理小目标,可以考虑使用 UNet++;如果任务需要更好地处理大目标和语义分割,可以考虑使用 DeepLabv3+。此外,还可以根据实际情况进行模型的调整和改进,以获得更好的性能和效果。
八、总结与展望
8.1 UNet++ 的未来发展
UNet++ 模型在医学图像分割领域的应用已经取得了很好的效果,但仍然有一些可以改进和发展的方向。
- 更深的网络结构
- UNet++ 的网络结构相对浅层,在处理一些更复杂的任务时可能存在性能瓶颈。
- 可以考虑增加网络深度或引入更多的模块,提高模型的表达能力和分割性能。
- 更好的跨层信息传递机制
- UNet++ 通过
skip connections和nested skip connections来进行跨层信息传递,但这种方式可能会导致梯度消失或梯度爆炸等问题。 - 可以考虑采用其他更有效的跨层信息传递机制,如
SHG(Selective Hierarchical Guidance)等。
- UNet++ 通过
- 多任务学习和迁移学习
- UNet++ 在单一任务上表现出色,但在多任务和跨领域场景下需要更好的泛化能力和可迁移性。
- 可以考虑将 UNet++ 应用于多个相关任务中,或者使用迁移学习技术将已训练好的模型迁移到其他任务或领域中。
- 高效的模型优化和推理方法
- UNet++ 的模型参数较多,因此需要高效的模型优化和推理方法来提高模型的训练和推理速度。
- 可以考虑使用剪枝、量化、蒸馏等技术进行模型优化,或者使用
GPU、TPU等加速器进行模型推理。
总之,UNet++ 模型在医学图像分割领域具有很大的潜力和前景,在未来的发展中可以通过更深的网络结构、更好的跨层信息传递机制、多任务学习和迁移学习、高效的模型优化和推理方法等方面进行改进和创新,以应对更加复杂和广泛的任务需求。
8.2 学习建议
UNet++ 学习的建议:
- 掌握基础知识
- 在学习 UNet++ 前,需要掌握深度学习、卷积神经网络、图像处理等相关领域的基础知识。
- 学习 UNet 模型
- UNet++ 是基于 UNet 的改进版本,因此需要先了解 UNet 模型的原理和实现方法,可以通过阅读论文、查看代码或者参加课程等方式进行学习。
- 学习 UNet++ 模型
- 掌握 UNet++ 模型的原理和实现方法,了解其编码器、解码器、跨层信息传递等关键技术,并了解其在医学图像分割中的应用。
- 掌握相关工具和框架
- 学习使用相关的深度学习框架和工具,如
TensorFlow、PyTorch等,可以通过官方文档、教程、实战项目等方式进行学习。
- 学习使用相关的深度学习框架和工具,如
- 实践和调试
- 在掌握基础理论和工具的基础上,进行实践和调试,可以通过开源数据集或者自己收集的数据集来进行模型训练和测试,并不断调整参数和模型结构以获得更好的性能和效果。
- 参考资料
- 推荐一些 UNet++ 相关的论文和教程。
- 如 “
UNet++: A Nested U-Net Architecture for Medical Image Segmentation” - “
UnetPlusPlus: A Nested U-Net Architecture for Medical Image Segmentation” - “
A Review on Deep Learning Techniques for Medical Image Segmentation Using Multimodal MRI”
总之,学习 UNet++ 需要掌握深度学习、卷积神经网络、图像处理等相关领域的基础知识,并且需要学习 UNet 和 UNet++ 模型的原理和实现方法,掌握相关的工具和框架,进行实践和调试,最终达到熟练掌握和应用的目的。
抱怨身处黑暗,不如提灯前行
相关文章:
提升图像分割精度:学习UNet++算法
文章目录 一、UNet 算法简介1.1 什么是 UNet 算法1.2 UNet 的优缺点1.3 UNet 在图像分割领域的应用 二、准备工作2.1 Python 环境配置2.2 相关库的安装 三、数据处理3.1 数据的获取与预处理3.2 数据的可视化与分析 四、网络结构4.1 UNet 的网络结构4.2 UNet 各层的作用 五、训练…...
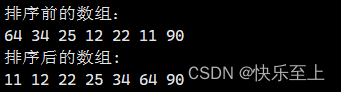
排序算法---冒泡排序
原创不易,转载请注明出处。欢迎点赞收藏~ 冒泡排序是一种简单的排序算法,其原理是重复地比较相邻的两个元素,并将顺序不正确的元素进行交换,使得每次遍历都能将一个最大(或最小)的元素放到末尾。通过多次遍…...

基于数据挖掘的微博事件分析与可视化大屏分析系统
设计原理,是指一个系统的设计由来,其将需求合理拆解成功能,抽象的描述系统的模块,以模块下的功能。功能模块化后,变成可组合、可拆解的单元,在设计时,会将所有信息分解存储在各个表中࿰…...
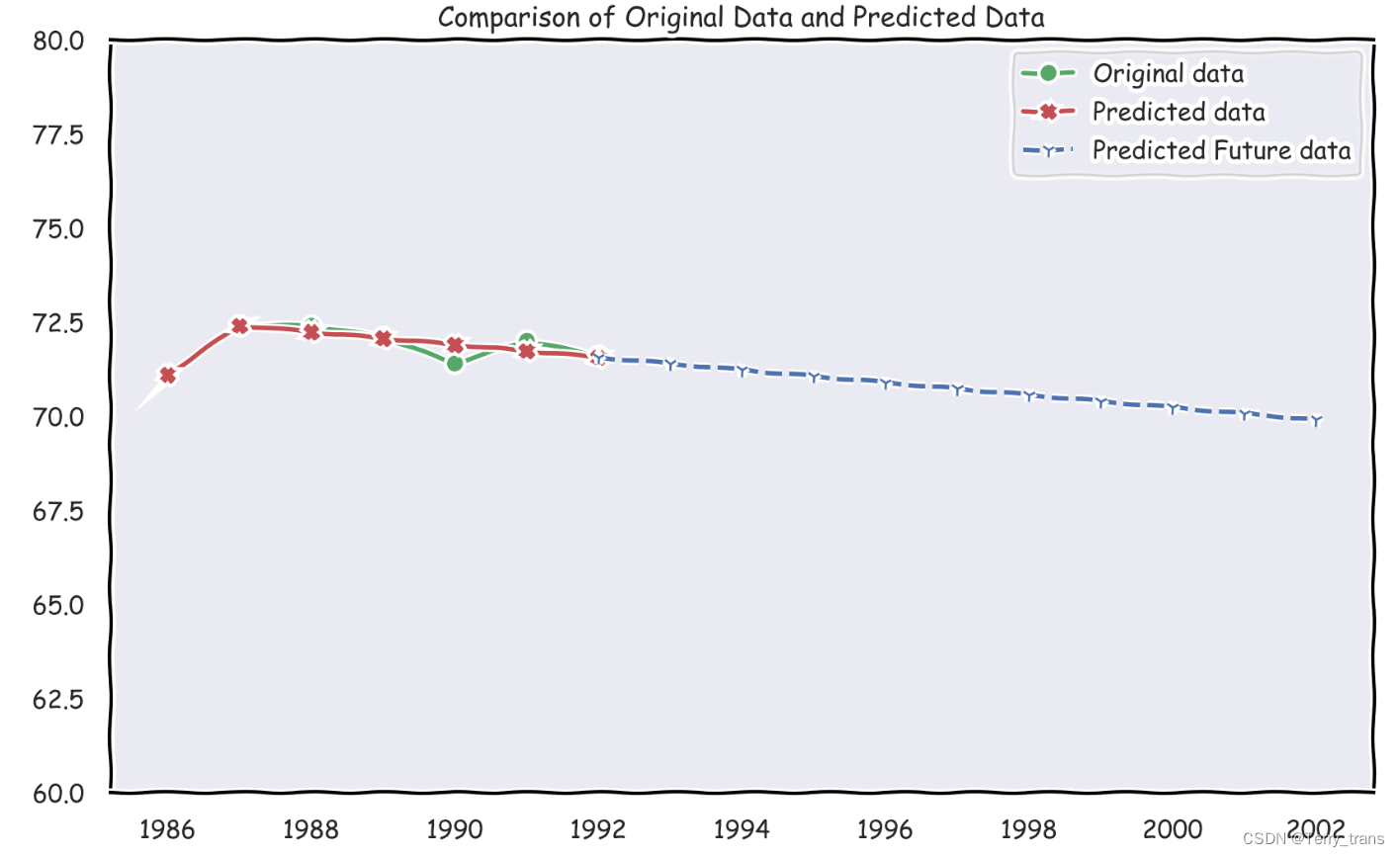
数学建模-灰色预测最强讲义 GM(1,1)原理及Python实现
目录 一、GM(1,1)模型预测原理 二、GM(1,1)模型预测步骤 2.1 数据的检验与处理 2.2 建立模型 2.3 检验预测值 三、案例 灰色预测应用场景:时间序列预测 灰色预测的主要特点是模型使用的…...
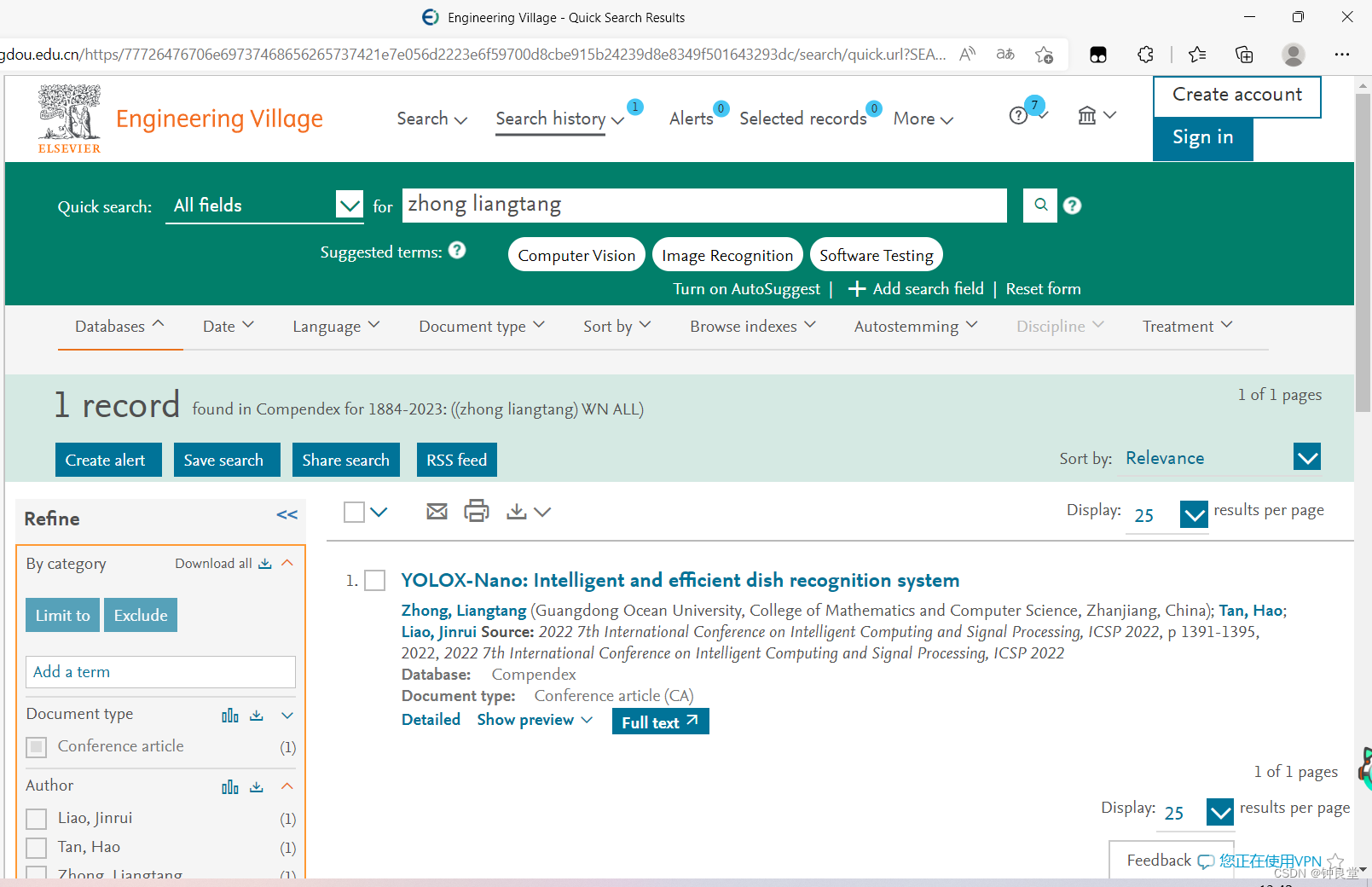
智慧自助餐饮系统(SpringBoot+MP+Vue+微信小程序+JNI+ncnn+YOLOX-Nano)
一、项目简介 本项目是配合智慧自助餐厅下的一套综合系统,该系统分为安卓端、微信小程序用户端以及后台管理系统。安卓端利用图像识别技术进行识别多种不同菜品,识别成功后安卓端显示该订单菜品以及价格并且生成进入小程序的二维码,用户扫描…...
零基础学编程从入门到精通,系统化的编程视频教程上线,中文编程开发语言工具构件之缩放控制面板构件用法
一、前言 零基础学编程从入门到精通,系统化的编程视频教程上线,中文编程开发语言工具构件之缩放控制面板构件用法 编程入门视频教程链接 https://edu.csdn.net/course/detail/39036 编程工具及实例源码文件下载可以点击最下方官网卡片——软件下载—…...
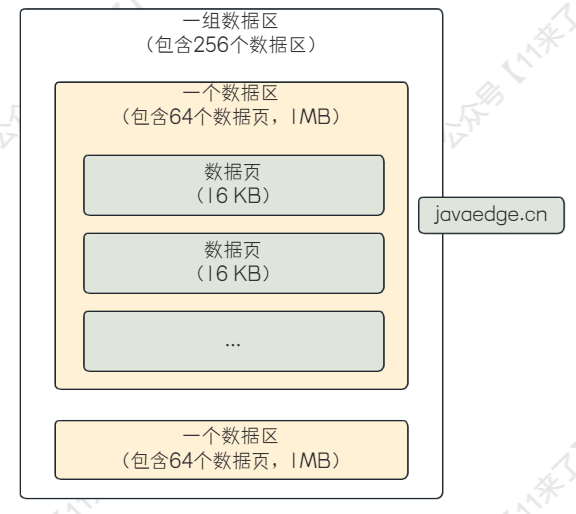
【MySQL进阶之路】MySQL 中表空间和数据区的概念以及预读机制
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送! 在我后台回复 「资料」 可领取编程高频电子书! 在我后台回复「面试」可领取硬核面试笔记! 文章导读地址…...
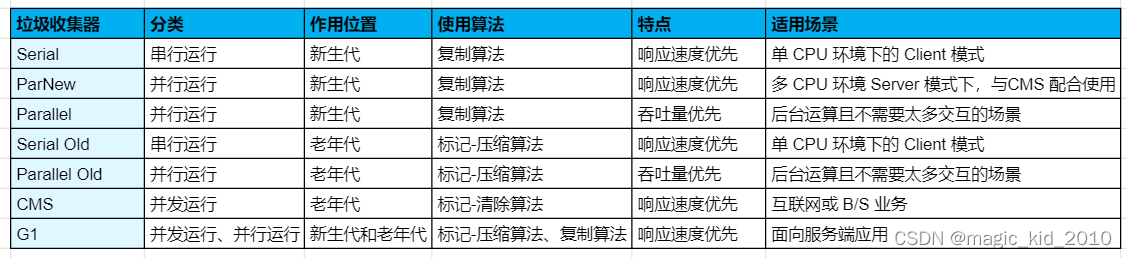
JVM 性能调优 - 常用的垃圾回收器(6)
垃圾收集器 在 JVM(Java虚拟机)中,垃圾收集器(Garbage Collector)是负责自动管理内存的组件。它的主要任务是在程序运行过程中,自动回收不再使用的对象所占用的内存空间,以便为新的对象提供足够的内存。 JVM中的垃圾收集器使用不同的算法和策略来实现垃圾收集过程,以…...

【java】Hibernate访问数据库
一、Hibernate访问数据库案例 Hibernate 是一个在 Java 社区广泛使用的对象关系映射(ORM)工具。它简化了 Java 应用程序中数据库操作的复杂性,并提供了一个框架,用于将对象模型数据映射到传统的关系型数据库。下面是一个简单的使…...
— byte数组传输)
从零开始手写mmo游戏从框架到爆炸(八)— byte数组传输
导航:从零开始手写mmo游戏从框架到爆炸(零)—— 导航-CSDN博客 Netty帧解码器 Netty中,提供了几个重要的可以直接使用的帧解码器。 LineBasedFrameDecoder 行分割帧解码器。适用场景:每个上层数据包,使…...
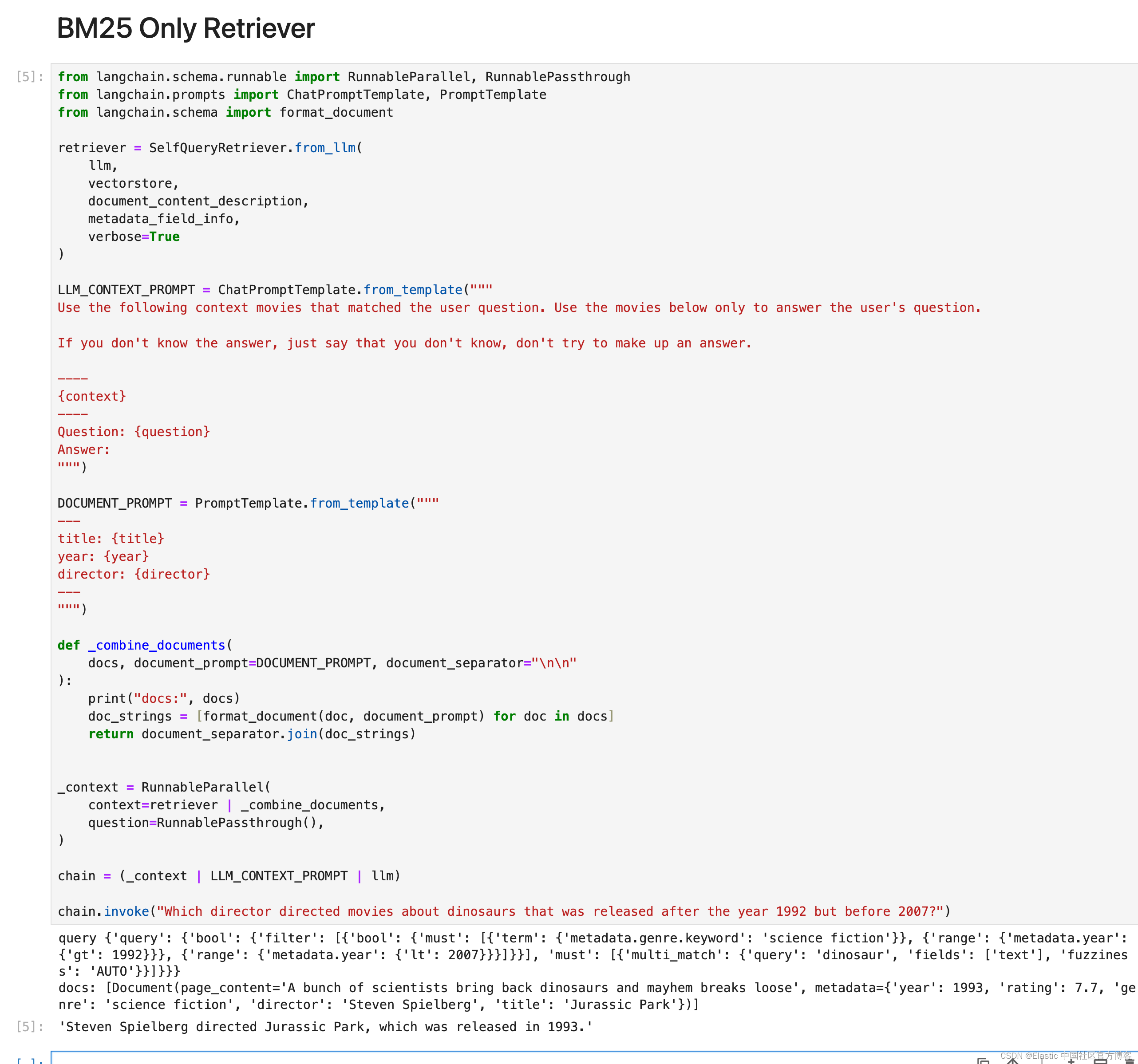
Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器
本工作簿演示了 Elasticsearch 的自查询检索器将非结构化查询转换为结构化查询的示例,我们将其用于 BM25 示例。 在这个例子中: 我们将摄取 LangChain 之外的电影样本数据集自定义 ElasticsearchStore 中的检索策略以仅使用 BM25使用自查询检索将问题转…...

uniapp的api用法大全
页面生命周期API uniApp中的页面生命周期API可以帮助开发者在页面的不同生命周期中执行相应的操作。常用的页面生命周期API包括:onLoad、onShow、onReady、onHide、onUnload等。其中,onLoad在页面加载时触发,onShow在页面显示时触发…...

笔记——asp.net core 中的 REST
REST(reprentational state transfer,表层状态转移) REST原则:提倡按照HTTP的语义使用HTTP。 如果一个系统符合REST原则,我们就说这个系统是Restful风格的。 在RPC风格的Web API系统中,我们把服务端的代码…...

排序算法---堆排序
原创不易,转载请注明出处。欢迎点赞收藏~ 堆排序(Heap Sort)是一种基于二叉堆数据结构的排序算法。它将待排序的元素构建成一个最大堆(或最小堆),然后逐步将堆顶元素与堆的最后一个元素交换位置,…...
通用排序)
Java字符串(包含字母和数字)通用排序
说明:本文章是之前查到的一篇安卓版的,具体原文路径忘记了。稍微改了一点,挺符合业务使用的! 一、看代码 /*** 包含数字的字符串进行比较(按照从小到大排序)*/private static Integer compareString(Stri…...

【Spring】springmvc如何处理接受http请求
目录 编辑 1. 背景 2. web项目和非web项目 3. 环境准备 4. 分析链路 5. 总结 1. 背景 今天开了一篇文章“SpringMVC是如何将不同的Request路由到不同Controller中的?”;看完之后突然想到,在请求走到mvc 之前服务是怎么知道有请求进来…...

2024年安全员-B证证模拟考试题库及安全员-B证理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年安全员-B证证模拟考试题库及安全员-B证理论考试试题是由安全生产模拟考试一点通提供,安全员-B证证模拟考试题库是根据安全员-B证最新版教材,安全员-B证大纲整理而成(含2024年…...

redis过期淘汰策略、数据过期策略与持久化方式
redis的过期淘汰策略 redis过期淘汰策略有很多,默认是no-eviction 不删除任何数据,内存不足存入会直接报错,可以在redis配置文件中进行设置,其中有两个非常重要的概念,LRU与LFU LRU表示最近最少使用,LFU为最少频率使用 又按照volatile已设置过期时间的数据集和allkeys所有数…...
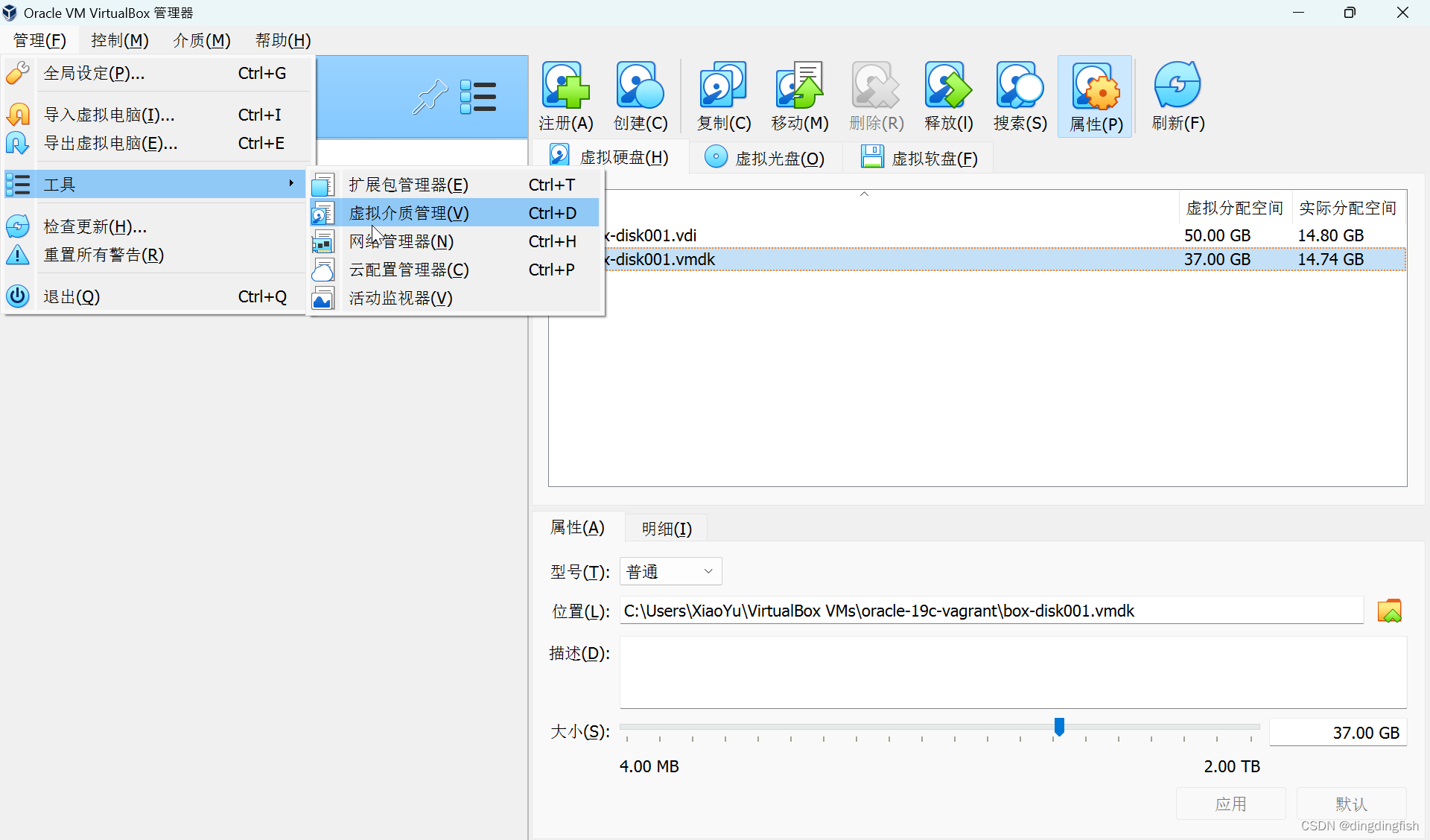
Oracle Vagrant Box 扩展根文件系统
需求 默认的Oracle Database 19c Vagrant Box的磁盘为34GB。 最近在做数据库升级实验,加之导入AWR dump数据,导致空间不够。 因此需要对磁盘进行扩容。 扩容方法1:预先扩容 此方法参考文档Vagrant, how to specify the disk size?。 指…...
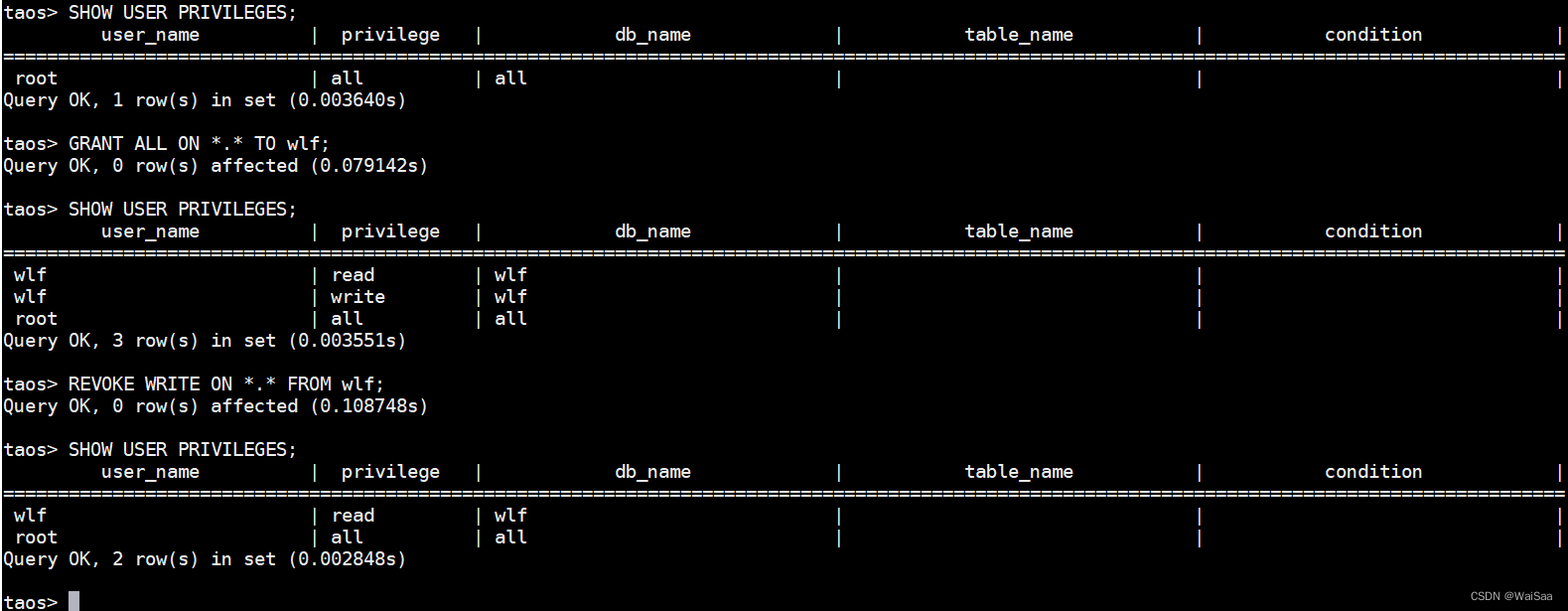
TDengine用户权限管理
Background 官方文档关于用户管理没有很详细的介绍,只有零碎的几条,这里记录下方便后面使用。官方文档:https://docs.taosdata.com/taos-sql/show/#show-users 1、查看用户 show users;super 1,表示超级用户权限 0,表…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...
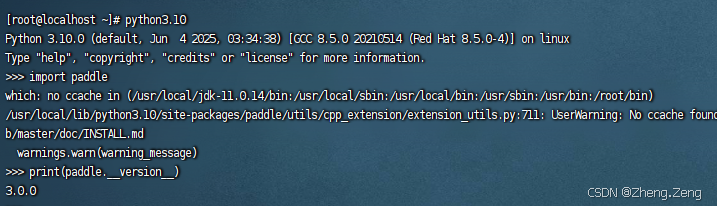
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...