对话模型Demo解读(使用代码解读原理)
文章目录
- 前言
- 一、数据加工
- 二、模型搭建
- 三、模型训练
- 1、构建模型
- 2、优化器与损失函数定义
- 3、模型训练
- 四、模型推理
- 五、所有Demo源码
前言
对话模型是一种人工智能技术,旨在使计算机能够像人类一样进行对话和交流。这种模型通常基于深度学习和自然语言处理技术,能够理解自然语言并做出相应的回应。然而现有博客很少介绍对话模型内容,也很少用一个简单代码带领大家理解其原理。因此,我创建一个简单的对话模型,在不适用Hugging Face或LSTM结构,旨在使用一个简单的全连接神经网络来实现这个模型,且代码基于PyTorch框架搭建,意在帮助读者构建对话模型知识。当然,模型仅是一个简单模型,旨在帮助理解原理,不具备很好效果能力。
一、数据加工
文本数据最终都是转为对应字典索引代表其文本内容,输入模型加工,实现nlp任务,对话模型也不列外。因此,我们需要构建一个字典映射(可参考:点击这里)与文本数据,并按照字典映射转换为对应索引id,其代码如下:
# 定义一个简单的对话数据集
data = [("hi", "hello"),("how are you?", "I'm fine, thank you."),("what's your name?", "I'm a chatbot.")
]# 构建词汇表
vocab = list(set(" ".join([x[0] + " " + x[1] for x in data])))
vocab.append("<SOS>")
vocab.append("<EOS>")word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}# 将对话数据集转换为索引序列
def to_idx_seq(sentence):return [word_to_idx[word] for word in sentence]data_x = [to_idx_seq(x[0]) for x in data]
data_y = [to_idx_seq(x[1]) for x in data]data_y =[[word_to_idx["<SOS>"]]+list(x)+[word_to_idx["<EOS>"]] for x in data_y]其字典内容如下:
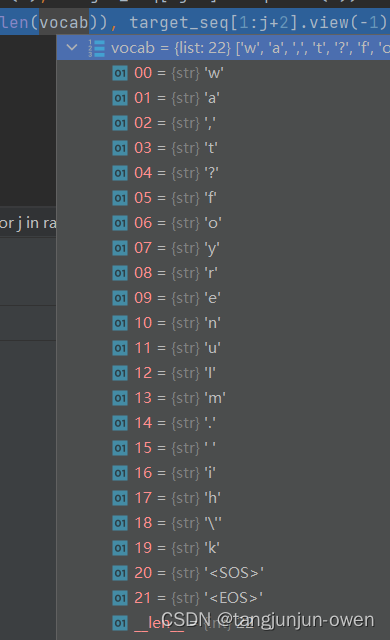
二、模型搭建
这里,也是最重要内容,如何搭建对话模型,我是使用transformer结构搭建(之前模型使用LSTM模型搭建),创建一个简单的对话生成模型,也使用一个基于全连接层的神经网络来实现这个模型,其代码如下:
# 定义一个简单的Transformer生成式对话模型
class ChatbotTransformer(nn.Module):def __init__(self, input_dim, output_dim, nhead, num_encoder_layers, num_decoder_layers):super(ChatbotTransformer, self).__init__()self.input_dim = input_dimself.output_dim = output_dimself.embedding = nn.Embedding(len(vocab), input_dim)self.transformer = nn.Transformer(d_model=input_dim, nhead=nhead, num_encoder_layers=num_encoder_layers, num_decoder_layers=num_decoder_layers)self.fc = nn.Linear(input_dim, output_dim)def forward(self, src, tgt):src = self.embedding(src).permute(1, 0, 2) # 调整输入张量维度tgt = self.embedding(tgt).permute(1, 0, 2) # 调整输入张量维度output = self.transformer(src, tgt)output = self.fc(output)return output从代码上看,我们需要输入src为前面提问数据,而答案生成输入,是每个tgt字输入,按照顺序输出预测。
三、模型训练
1、构建模型
我大概试了一下,使用更多层对于简单数据反而效果不佳,我的数据又比较简单,我构建了较少的层来预测模型。其模型构建代码如下:
# 创建模型实例
# model = ChatbotTransformer(input_dim=256, output_dim=len(vocab), nhead=8, num_encoder_layers=6, num_decoder_layers=6)
model = ChatbotTransformer(input_dim=16, output_dim=len(vocab), nhead=8, num_encoder_layers=1, num_decoder_layers=1)
2、优化器与损失函数定义
优化器定义我将不考虑介绍,只说下文本预测是交叉熵方式,实际文本基本都采用该方法作为loss计算。其代码如下:
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
3、模型训练
接下来,我们解读如何训练对话模型,我们获得对应输入数据与生成预测数据,我们开始训练模型,其代码如下:
# 模型训练
epochs = 800
for epoch in range(epochs):total_loss = 0for i in range(len(data_x)):optimizer.zero_grad()input_seq = torch.tensor(data_x[i])target_seq = torch.tensor(data_y[i])for j in range(len(target_seq)-1):if random.random() < 0.5:j = random.randint(0, len(target_seq)-2)output = model(input_seq.unsqueeze(0), target_seq[:j+1].unsqueeze(0)) # 使用目标序列的前n-1个词预测后n-1个词loss = criterion(output.view(-1, len(vocab)), target_seq[1:j+2].view(-1)) # 计算损失,需要将输出形状转换成二维loss.backward()optimizer.step()total_loss += loss.item()if (epoch+1) % 10 == 0:print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, epochs, total_loss / len(data_x)))假设input_seq =tensor([17, 6, 0, 15, 1, 8, 9, 15, 7, 6, 11, 4]),target_seq=tensor([20, 12, 18, 13, 15, 5, 16, 10, 9, 2, 15, 3, 17, 1, 10, 19, 15, 7, 6, 11, 14, 21]),vocab为字典映射,共22个映射。我将试图模型连续2轮解释一下,训练时候相关变化。
第二轮输出结果:
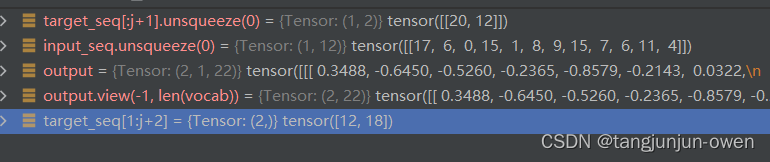
第三轮输出结果:
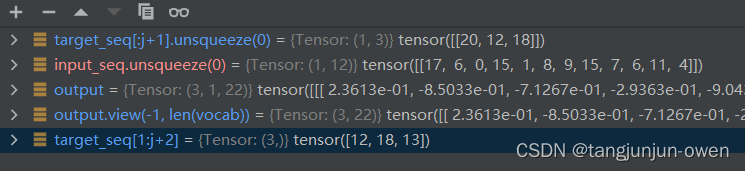
后面以此类推迭代。
很明显,提问每次都是全部输入,而输出则是第一个20开始与输入共同进模型,分别是模型src与tgt,不断重复与预测完成训练。而loss计算都是往后取一个target文本,也发现并不会计算20索引""文本。
四、模型推理
最后,让我们使用训练好的模型进行推理,实际和上面训练讲到方法类似,我们开始""文本开始,不断给出生成对应文本,也就是对话内容。
# 进行推理
def generate_response(input_sentence):model.eval()input_seq = torch.tensor(to_idx_seq(input_sentence))target_seq = torch.tensor([word_to_idx["<SOS>"]]) # 在开始时使用特殊的起始标记with torch.no_grad():for i in range(20): # 限制生成的句子长度为20个词output = model(input_seq.unsqueeze(0), target_seq.unsqueeze(0))output_token = output.argmax(2)[-1].item()print(idx_to_word[output_token], end=" ")target_seq = torch.cat((target_seq, torch.tensor([output_token])), dim=0)res = [idx_to_word[int(k)] for k in target_seq]print(res[1:-1])return res[1:-1]# 进行对话生成
generate_response("hi")其结果如下:
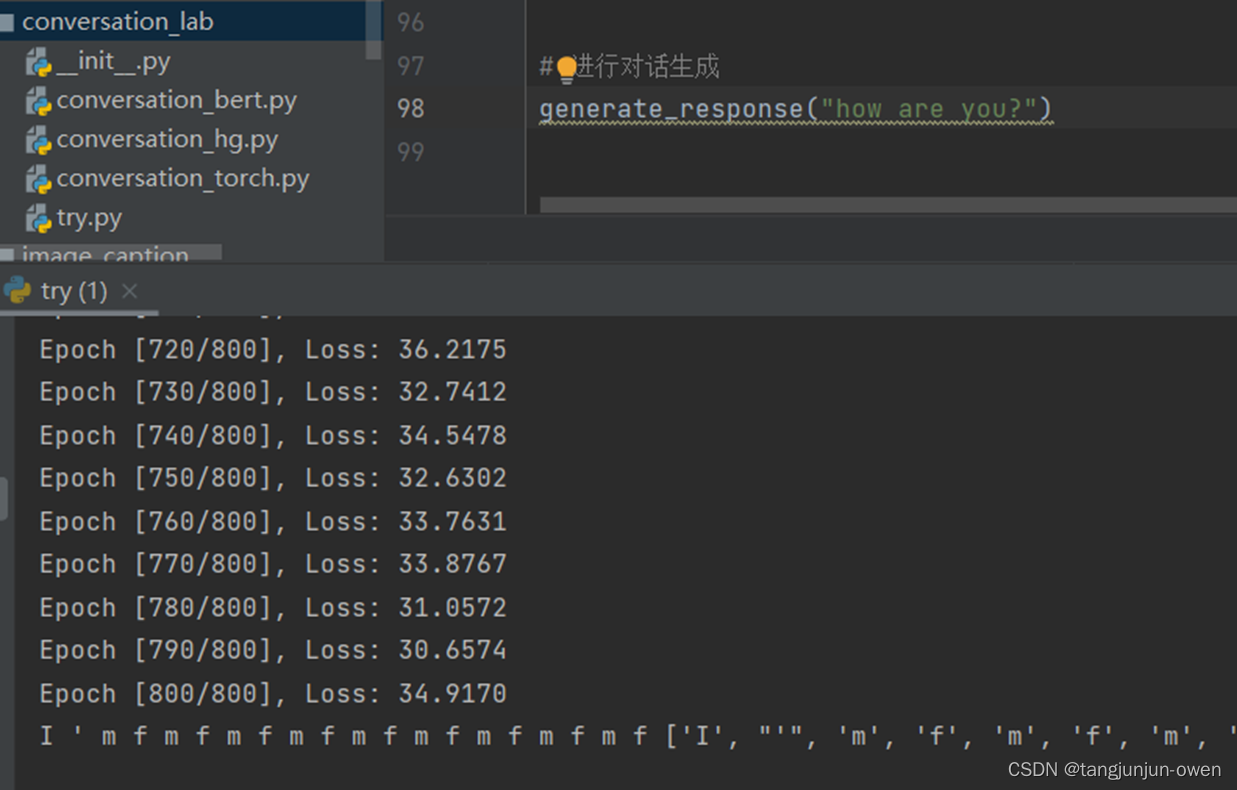
五、所有Demo源码
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
# 定义一个简单的对话数据集
data = [# ("hi", "hello"),("how are you?", "I'm fine, thank you."),# ("what's your name?", "I'm a chatbot.")
]# 构建词汇表
vocab = list(set(" ".join([x[0] + " " + x[1] for x in data])))
vocab.append("<SOS>")
vocab.append("<EOS>")word_to_idx = {word: i for i, word in enumerate(vocab)}
idx_to_word = {i: word for i, word in enumerate(vocab)}# 将对话数据集转换为索引序列
def to_idx_seq(sentence):return [word_to_idx[word] for word in sentence]data_x = [to_idx_seq(x[0]) for x in data]
data_y = [to_idx_seq(x[1]) for x in data]data_y =[[word_to_idx["<SOS>"]]+list(x)+[word_to_idx["<EOS>"]] for x in data_y]# 定义一个简单的Transformer生成式对话模型
class ChatbotTransformer(nn.Module):def __init__(self, input_dim, output_dim, nhead, num_encoder_layers, num_decoder_layers):super(ChatbotTransformer, self).__init__()self.input_dim = input_dimself.output_dim = output_dimself.embedding = nn.Embedding(len(vocab), input_dim)self.transformer = nn.Transformer(d_model=input_dim, nhead=nhead, num_encoder_layers=num_encoder_layers, num_decoder_layers=num_decoder_layers)self.fc = nn.Linear(input_dim, output_dim)def forward(self, src, tgt):src = self.embedding(src).permute(1, 0, 2) # 调整输入张量维度tgt = self.embedding(tgt).permute(1, 0, 2) # 调整输入张量维度output = self.transformer(src, tgt)output = self.fc(output)return output# 创建模型实例
# model = ChatbotTransformer(input_dim=256, output_dim=len(vocab), nhead=8, num_encoder_layers=6, num_decoder_layers=6)
model = ChatbotTransformer(input_dim=16, output_dim=len(vocab), nhead=8, num_encoder_layers=1, num_decoder_layers=1)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)# 模型训练
epochs = 800
for epoch in range(epochs):total_loss = 0for i in range(len(data_x)):optimizer.zero_grad()input_seq = torch.tensor(data_x[i])target_seq = torch.tensor(data_y[i])for j in range(len(target_seq)-1):if random.random() < 0.5:j = random.randint(0, len(target_seq)-2)output = model(input_seq.unsqueeze(0), target_seq[:j+1].unsqueeze(0)) # 使用目标序列的前n-1个词预测后n-1个词loss = criterion(output.view(-1, len(vocab)), target_seq[1:j+2].view(-1)) # 计算损失,需要将输出形状转换成二维loss.backward()optimizer.step()total_loss += loss.item()if (epoch+1) % 10 == 0:print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, epochs, total_loss / len(data_x)))# 进行推理
def generate_response(input_sentence):model.eval()input_seq = torch.tensor(to_idx_seq(input_sentence))target_seq = torch.tensor([word_to_idx["<SOS>"]]) # 在开始时使用特殊的起始标记with torch.no_grad():for i in range(20): # 限制生成的句子长度为20个词output = model(input_seq.unsqueeze(0), target_seq.unsqueeze(0))output_token = output.argmax(2)[-1].item()print(idx_to_word[output_token], end=" ")target_seq = torch.cat((target_seq, torch.tensor([output_token])), dim=0)res = [idx_to_word[int(k)] for k in target_seq]print(res[1:-1])return res[1:-1]# 进行对话生成
generate_response("how are you?")相关文章:
对话模型Demo解读(使用代码解读原理)
文章目录 前言一、数据加工二、模型搭建三、模型训练1、构建模型2、优化器与损失函数定义3、模型训练 四、模型推理五、所有Demo源码 前言 对话模型是一种人工智能技术,旨在使计算机能够像人类一样进行对话和交流。这种模型通常基于深度学习和自然语言处理技术&…...

Android 自定义BaseFragment
直接上代码: BaseFragment代码: package com.example.custom.fragment;import android.content.Context; import android.os.Bundle; import android.view.LayoutInflater; import android.view.View; import android.view.ViewGroup; import androidx…...

[C#] 如何对列表,字典等进行排序?
对列表进行排序 下面是一个基于C#的列表排序的案例: using System; using System.Collections.Generic;class Program {static void Main(string[] args){// 创建一个列表List<int> numbers new List<int>() { 5, 2, 8, 1, 10 };// 使用Sort方法对列…...

Mac 下载安装Java、maven并配置环境变量
下载Java8 下载地址:https://www.oracle.com/java/technologies/downloads/ 根据操作系统选择版本 没有oracle账号需要注册、激活登录 mac直接选择.dmg文件进行下载,下载后安装。 默认安装路径:/Library/Java/JavaVirtualMachines/jdk-1…...

【多模态】27、Vary | 通过扩充图像词汇来提升多模态模型在细粒度感知任务(OCR等)上的效果
文章目录 一、背景二、方法2.1 生成 new vision vocabulary2.1.1 new vocabulary network2.1.2 Data engine in the generating phrase2.1.3 输入的格式 2.2 扩大 vision vocabulary2.2.1 Vary-base 的结构2.2.2 Data engine2.2.3 对话格式 三、效果3.1 数据集3.2 图像细粒度感…...
【包括石头剪刀布判断程序(模拟版)】)
|Python新手小白低级教程|第二十章:函数(2)【包括石头剪刀布判断程序(模拟版)】
文章目录 前言一、复习一、函数实战之——if语句特殊系统1.判断等第分数(函数名为mark(参数num))2.石头剪刀布判断程序 二、练习总结 前言 Hello,大家好,我是你们的BoBo仔,感谢你们来阅读我的文…...

vue3 之 商城项目—home
home—整体结构搭建 根据上面五个模块建目录图如下: home/index.vue <script setup> import HomeCategory from ./components/HomeCategory.vue import HomeBanner from ./components/HomeBanner.vue import HomeNew from ./components/HomeNew.vue import…...

git flow与分支管理
git flow与分支管理 一、git flow是什么二、分支管理1、主分支Master2、开发分支Develop3、临时性分支功能分支预发布分支修补bug分支 三、分支管理最佳实践1、分支名义规划2、环境与分支3、分支图 四、git flow缺点 一、git flow是什么 Git 作为一个源码管理系统,…...
【Linux】学习-进程信号
进程信号 信号入门 生活角度的信号 你在网上买了很多件商品,再等待不同商品快递的到来。但即便快递没有到来,你也知道快递来临时,你该怎么处理快递。也就是你能“识别快递”,也就是你意识里是知道如果这时候快递员送来了你的包裹,你知道该如何处理这些包裹当快递员到了你…...
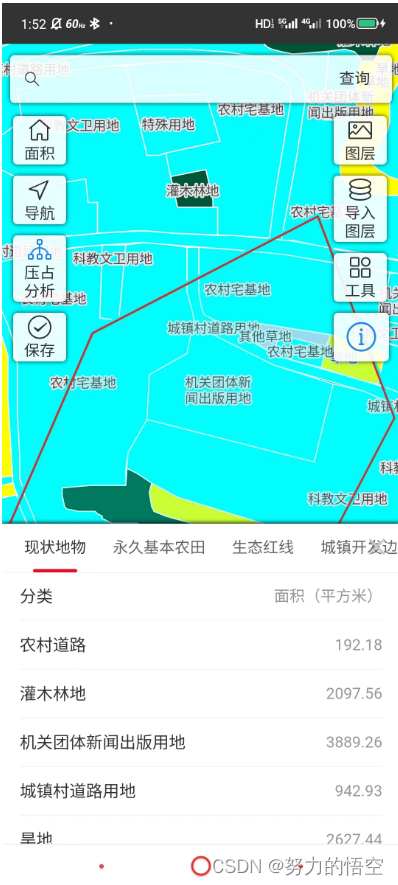
webgis后端安卓系统部署攻略
目录 前言 一、将后端项目编译ARM64 二、安卓手机安装termux 1.更换为国内源 2.安装ssh远程访问 3.安装文件远程访问 三、安装postgis数据库 1.安装数据库 2.数据库配置 3.数据导入 四、后端项目部署 五、自启动设置 总结 前言 因为之前一直做的H5APP开发…...

【数据分享】1929-2023年全球站点的逐日平均风速数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、能见度等指标,说到气象数据,最详细的气象数据是具体到气象监测站点的数据! 有关气象指标的监测站点数据,之前我们分享过1929-2023年全球气象站…...

【多模态大模型】视觉大模型SAM:如何使模型能够处理任意图像的分割任务?
SAM:如何使模型能够处理任意图像的分割任务? 核心思想起始问题: 如何使模型能够处理任意图像的分割任务?5why分析5so分析 总结子问题1: 如何编码输入图像以适应分割任务?子问题2: 如何处理各种形式的分割提示?子问题3:…...

Shell之sed
sed是什么 Linux sed 命令是利用脚本来处理文本文件。 可依照脚本的指令来处理、编辑文本文件。主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。 sed命令详解 语法 sed [-hnV][-e <script>][-f<script文件>][文本文件] sed [-nefr] [动作…...

AJAX——认识URL
1 什么是URL? 统一资源定位符(英语:Uniform Resource Locator,缩写:URL,或称统一资源定位器、定位地址、URL地址)俗称网页地址,简称网址,是因特网上标准的资源的地址&…...

《Docker极简教程》--Docker环境的搭建--在Linux上搭建Docker环境
更新系统:首先确保所有的包管理器都是最新的。对于基于Debian的系统(如Ubuntu),可以使用以下命令:sudo apt-get update sudo apt-get upgrade安装必要的依赖项:安装一些必要的工具,比如ca-certi…...

开源微服务平台框架的特点是什么?
借助什么平台的力量,可以让企业实现高效率的流程化办公?低代码技术平台是近些年来较为流行的平台产品,可以帮助很多行业进入流程化办公新时代,做好数据管理工作,从而提升企业市场竞争力。流辰信息专业研发低代码技术平…...
)
C#系列-C#操作UDP发送接收数据(10)
在C#中,发送UDP数据并接收响应通常涉及创建两个UdpClient实例:一个用于发送数据,另一个用于接收响应。以下是发送UDP数据并接收响应的示例代码: 首先,我们需要定义一个方法来发送UDP数据,并等待接收服务器…...
))
突破编程_C++_面试(基础知识(10))
面试题29:什么是嵌套类,它有什么作用 嵌套类指的是在一个类的内部定义的另一个类。嵌套类可以作为外部类的一个成员,但它与其声明类型紧密关联,不应被用作通用类型。嵌套类可以访问外部类的所有成员,包括私有成员&…...

初步探索Pyglet库:打造轻量级多媒体与游戏开发利器
目录 pyglet库 功能特点 安装和导入 安装 导入 基本代码框架 导入模块 创建窗口 创建控件 定义事件 运行应用 程序界面 运行结果 完整代码 标签控件 常用事件 窗口事件 鼠标事件 键盘事件 文本事件 其它场景 网页标签 音乐播放 图片显示 祝大家新…...

【npm】安装全局包,使用时提示:不是内部或外部命令,也不是可运行的程序或批处理文件
问题 如图,明明安装Vue是全局包,但是使用时却提示: 解决办法 使用以下命令任意一种命令查看全局包的配置路径 npm root -g 然后将此路径(不包括node_modules)添加到环境变量中去,这里注意,原…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...
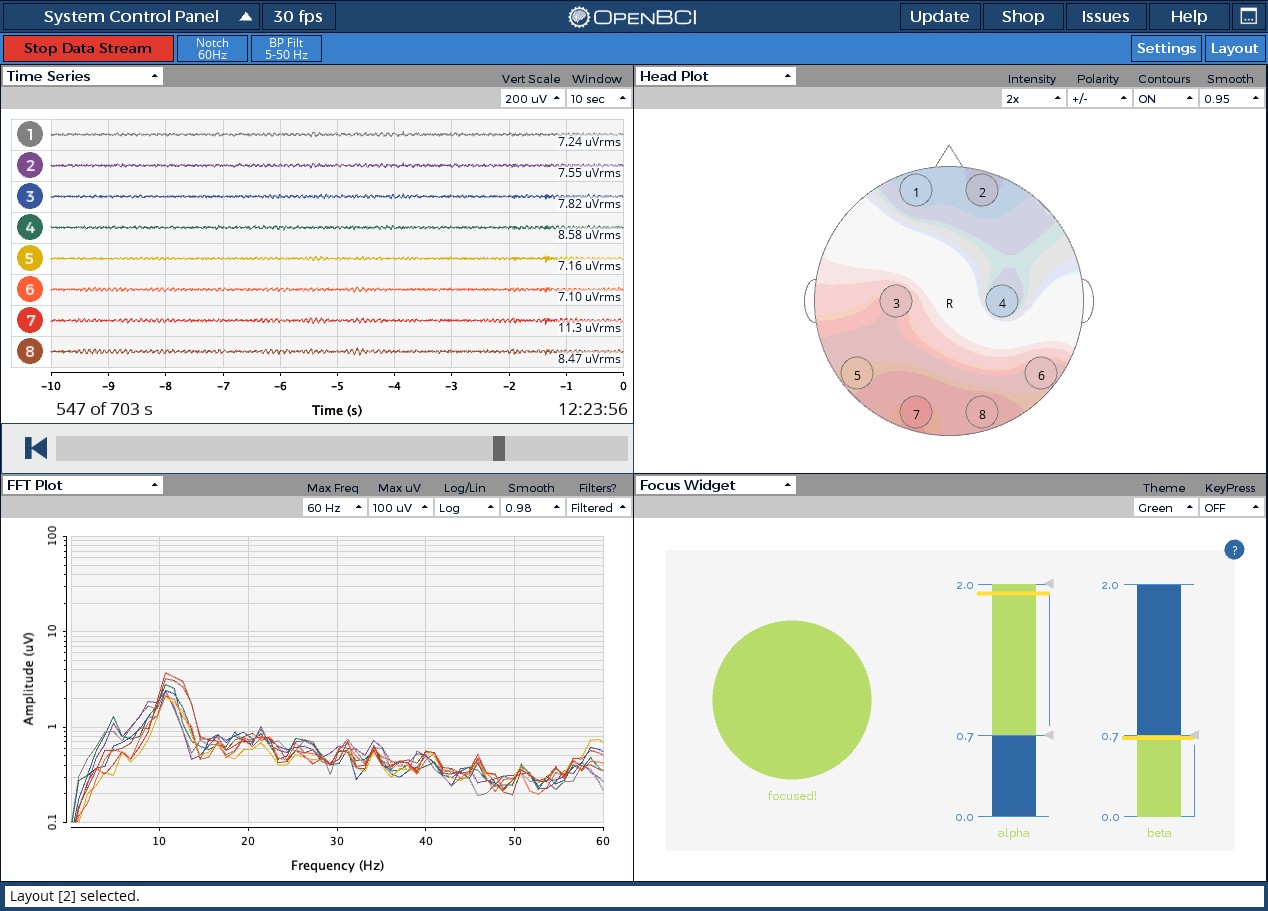
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...