人工智能|深度学习——使用多层级注意力机制和keras实现问题分类
代码下载
使用多层级注意力机制和keras实现问题分类资源-CSDN文库
1 准备工作
1.1 什么是词向量?
”词向量”(词嵌入)是将一类将词的语义映射到向量空间中去的自然语言处理技术。即将一个词用特定的向量来表示,向量之间的距离(例如,任意两个向量之间的L2范式距离或更常用的余弦距离)一定程度上表征了的词之间的语义关系。由这些向量形成的几何空间被称为一个嵌入空间。
传统的独热表示( one-hot representation)仅仅将词符号化,不包含任何语义信息。必须考虑将语义融入到词表示中。
解决办法将原来稀疏的巨大维度压缩嵌入到一个更小维度的空间进行分布式表示。这也是词向量又名词嵌入的缘由了。
例如,“椰子”和“北极熊”是语义上完全不同的词,所以它们的词向量在一个合理的嵌入空间的距离将会非常遥远。但“厨房”和“晚餐”是相关的话,所以它们的词向量之间的距离会相对小。
理想的情况下,在一个良好的嵌入空间里,从“厨房”向量到“晚餐”向量的“路径”向量会精确地捕捉这两个概念之间的语义关系。在这种情况下,“路径”向量表示的是“发生的地点”,所以你会期望“厨房”向量 - “晚餐"向量(两个词向量的差异)捕捉到“发生的地点”这样的语义关系。基本上,我们应该有向量等式:晚餐 + 发生的地点 = 厨房(至少接近)。如果真的是这样的话,那么我们可以使用这样的关系向量来回答某些问题。例如,应用这种语义关系到一个新的向量,比如“工作”,我们应该得到一个有意义的等式,工作+ 发生的地点 = 办公室,来回答“工作发生在哪里?”。
词向量通过降维技术表征文本数据集中的词的共现信息。方法包括神经网络(“Word2vec”技术),或矩阵分解。
1.2 获取词向量
词向量 对与中文自然语言处理任务 是基石,一般情况下 有两种获取方式:
- 别人训练好的百科数据。优势:包含词语多,符合日常用语的语义;劣势:专有名词不足,占用空间大;
- 自己训练。优势:专有名词,针对具体任务语义更准确; 劣势:泛化性差。
步骤:
graph LR
文本-->分词
分词-->训练词向量
训练词向量-->保存词向量
具体代码:
import gensim## 训练自己的词向量,并保存。
def trainWord2Vec(filePath):sentences = gensim.models.word2vec.LineSentence(filePath) # 读取分词后的 文本model = gensim.models.Word2Vec(sentences, size=100, window=5, min_count=1, workers=4) # 训练模型model.save('./CarComment_vord2vec_100')def testMyWord2Vec():# 读取自己的词向量,并简单测试一下 效果。inp = './CarComment_vord2vec_100' # 读取词向量model = gensim.models.Word2Vec.load(inp)print('空间的词向量(100维):',model['空间'])print('打印与空间最相近的5个词语:',model.most_similar('空间', topn=5))if __name__ == '__main__':#trainWord2Vec('./CarCommentAll_cut.csv')testMyWord2Vec()pass这样我们就 拥有了 预训练的 词向量文件
CarComment_vord2vec_100。下一单元 继续讲解如何在keras中使用它。
2 转化词向量为keras所需格式
上一步拿到了所有词语的词向量,但还需转化词向量为keras所需格式。众所周知,keras中使用预训练的词向量的层是
Embedding层,而Embedding层中所需要的格式为 一个巨大的“矩阵”:第i列表示词索引为i的词的词向量所以,本单元的总体思路就是给 Embedding 层提供一个
[ word : word_vector]的词典来初始化Embedding层中所需要的大矩阵 ,并且标记为不可训练。
2.1 获取所有词语word和词向量
首先要导入 预训练的词向量。
## 1 导入 预训练的词向量
myPath = './CarComment_vord2vec_100' # 本地词向量的地址
Word2VecModel = gensim.models.Word2Vec.load(myPath) # 读取词向量vector = Word2VecModel.wv['空间'] # 词语的向量,是numpy格式
gensim的word2vec模型 把所有的单词和 词向量 都存储在了Word2VecModel.wv里面,讲道理直接使用这个.wv即可。 但是我们打印这个东西的 类型print(type(Word2VecModel.wv)) # 结果为:Word2VecKeyedVectorsfor i,j in Word2VecModel.wv.vocab.items():print(i) # 此时 i 代表每个单词print(j) # j 代表封装了 词频 等信息的 gensim“Vocab”对象,例子:Vocab(count:1481, index:38, sample_int:3701260191)break发现它是 gensim自己封装的一种数据类型:
Word2VecKeyedVectors,
<class 'gensim.models.keyedvectors.Word2VecKeyedVectors'>
不能使用
for循环迭代取单词。
2.2 构造“词语-词向量”字典
第二步 构造数据:
- 构造 一个list存储所有单词:vocab_list 存储所有词语。
- 构造一个字典word_index :
{word : index},key是每个词语,value是单词在字典中的序号。 在后期 tokenize(序号化) 训练集的时候就是用该词典。 构造包含- 构造一个 大向量矩阵embeddings_matrix (按照embedding层的要求):行数 为 所有单词数,比如 10000;列数为 词向量维度,比如100。
代码:
## 2 构造包含所有词语的 list,以及初始化 “词语-序号”字典 和 “词向量”矩阵
vocab_list = [word for word, Vocab in Word2VecModel.wv.vocab.items()]# 存储 所有的 词语word_index = {" ": 0}# 初始化 `[word : token]` ,后期 tokenize 语料库就是用该词典。
word_vector = {} # 初始化`[word : vector]`字典# 初始化存储所有向量的大矩阵,留意其中多一位(首行),词向量全为 0,用于 padding补零。
# 行数 为 所有单词数+1 比如 10000+1 ; 列数为 词向量“维度”比如100。
embeddings_matrix = np.zeros((len(vocab_list) + 1, Word2VecModel.vector_size))2.3 填充字典和矩阵
第三步:填充 上述步骤中 的字典 和 大矩阵
## 3 填充 上述 的字典 和 大矩阵
for i in range(len(vocab_list)):# print(i)word = vocab_list[i] # 每个词语word_index[word] = i + 1 # 词语:序号word_vector[word] = Word2VecModel.wv[word] # 词语:词向量embeddings_matrix[i + 1] = Word2VecModel.wv[word] # 词向量矩阵2.4 在 keras的Embedding层中使用 预训练词向量
from keras.layers import EmbeddingEMBEDDING_DIM = 100 #词向量维度embedding_layer = Embedding(input_dim = len(embeddings_matrix), # 字典长度EMBEDDING_DIM, # 词向量 长度(100)weights=[embeddings_matrix], # 重点:预训练的词向量系数input_length=MAX_SEQUENCE_LENGTH, # 每句话的 最大长度(必须padding) trainable=False # 是否在 训练的过程中 更新词向量)- Embedding层的输入shape
此时 输入Embedding层的数据的维度是 形如
(samples,sequence_length)的2D张量,注意,此时句子中的词语word已经被转化为 index(依靠word_index,所以在embedding层之前 往往结合input层, 用于将 文本 分词 转化为数字形式)
- Embedding层的输出shape
Embedding层把 所有输入的序列中的整数,替换为对应的词向量矩阵中对应的向量(也就是它的词向量),比如一句话[1,2,8]将被序列[词向量第[1]行,词向量第[2]行,词向量第[8]行]代替。
这样,输入一个2D张量后,我们可以得到一个3D张量:
(samples, sequence_length, embeddings_matrix)
*2.5 不使用“预训练”而直接生成词向量
我们也可以直接使用Keras自带的Embedding层训练词向量,而不用预训练的word2vec词向量。代码如下所示:
embedding_layer = Embedding(len(word_index) + 1, # 由于 没有预训练,设置+1 EMBEDDING_DIM, # 设置词向量的维度input_length=MAX_SEQUENCE_LENGTH) #设置句子的最大长度可以看出在使用 Keras的中Embedding层时候,不指定参数
weights=[embeddings_matrix]即可自动生成词向量。
先是随机初始化,然后,在训练数据的过程中训练。
在参考文献1中 做的对比实验,对于新闻文本分类任务:直接使用Keras自带的Embedding层训练词向量而不用预训练的word2vec词向量,得到0.9的准确率。
使用预训练的word2vec词向量,同样的模型最后可以达到0.95的分类准确率。
所以使用预训练的词向量作为特征是非常有效的。一般来说,在自然语言处理任务中,当样本数量非常少时,使用预训练的词向量是可行的(实际上,预训练的词向量引入了外部语义信息,往往对模型很有帮助)。
3 整体代码:在Keras模型中使用预训练的词向量
文本数据预处理,将每个文本样本转换为一个数字矩阵,矩阵的每一行表示一个词向量。下图梳理了处理文本数据的一般步骤。
3.1 读取数据

def load_file():dataFrame_2016 = pd.read_csv('data\\nlpcc2016_kbqa_traindata_zong_right.csv',encoding='utf-8')print(dataFrame_2016.columns) # 打印列的名称texts = [] # 存储读取的 xlabels = [] # 存储读取的y# 遍历 获取数据for i in range(len(dataFrame_2016)):texts.append(dataFrame_2016.iloc[i].q_text) # 每个元素为一句话“《机械设计基础》这本书的作者是谁?”labels.append(dataFrame_2016.iloc[i].q_type) # 每个元素为一个int 代表类别 # [2, 6, ... 3] 的形式## 把类别从int 3 转换为(0,0,0,1,0,0)的形式labels = to_categorical(np.asarray(labels)) # keras的处理方法,一定要学会# 此时为[[0. 0. 1. 0. 0. 0. 0.]....] 的形式return texts, labels # 总文本,总标签3.2 句子分词
## 2. cut_sentence2word 句子分词
def cut_sentence2word(texts):texts = [jieba.lcut(Sentence.replace('\n', '')) for Sentence in texts] # 句子分词return texts3.3 *构造词向量字典
## 3.获取word2vec模型, 并构造,词语index字典,词向量字典
def get_word2vec_dictionaries(texts):def get_word2vec_model(texts=None): # 获取 预训练的词向量 模型,如果没有就重新训练一个。if os.path.exists('data_word2vec/Word2vec_model_embedding_25'): # 如果训练好了 就加载一下不用反复训练model = Word2Vec.load('data_word2vec/Word2vec_model_embedding_25')# print(model['作者'])return modelelse:model = Word2Vec(texts, size = EMBEDDING_LEN, window=7, min_count=10, workers=4)model.save('data_word2vec/Word2vec_model_embedding_25') # 保存模型return modelWord2VecModel = get_word2vec_model(texts) # 获取 预训练的词向量 模型,如果没有就重新训练一个。vocab_list = [word for word, Vocab in Word2VecModel.wv.vocab.items()] # 存储 所有的 词语word_index = {" ": 0}# 初始化 `[word : token]` ,后期 tokenize 语料库就是用该词典。word_vector = {} # 初始化`[word : vector]`字典# 初始化存储所有向量的大矩阵,留意其中多一位(首行),词向量全为 0,用于 padding补零。# 行数 为 所有单词数+1 比如 10000+1 ; 列数为 词向量“维度”比如100。embeddings_matrix = np.zeros((len(vocab_list) + 1, Word2VecModel.vector_size))## 填充 上述 的字典 和 大矩阵for i in range(len(vocab_list)):word = vocab_list[i] # 每个词语word_index[word] = i + 1 # 词语:序号word_vector[word] = Word2VecModel.wv[word] # 词语:词向量embeddings_matrix[i + 1] = Word2VecModel.wv[word] # 词向量矩阵return word_index, word_vector, embeddings_matrix3.4 文本序号化Tokenizer
在上文中已经得到了每条文本的文字了,但是text-CNN等深度学习模型的输入应该是数字矩阵。可以使用Keras的Tokenizer模块实现转换。
简单讲解Tokenizer如何实现转换。当我们创建了一个Tokenizer对象后,使用该对象的fit_on_texts()函数,可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小。可能这时会有疑问:Tokenizer是如何判断文本的一个词呢?其实它是以空格去识别每个词。因为英文的词与词之间是以空格分隔,所以我们可以直接将文本作为函数的参数,但是当我们处理中文文本时,我们需要使用分词工具将词与词分开,并且词间使用空格分开。具体实现如下:

当然 ,也可以使用之前构建的
word_index字典,手动 构建文本tokenizer句子:(推荐这种方法,这样序号下标与预训练词向量一致。)
# 序号化 文本,tokenizer句子,并返回每个句子所对应的词语索引
def tokenizer(texts, word_index):data = []for sentence in texts:new_txt = []for word in sentence:try:new_txt.append(word_index[word]) # 把句子中的 词语转化为indexexcept:new_txt.append(0)data.append(new_txt)texts = sequence.pad_sequences(data, maxlen = MAX_SEQUENCE_LENGTH) # 使用kears的内置函数padding对齐句子,好处是输出numpy数组,不用自己转化了return texts3.5 切分数据
## 5.切分数据
def split_data(texts, labels):x_train, x_test, y_train, y_test = train_test_split(texts, labels, test_size=0.2)return x_train, x_test, y_train, y_test3.6 使用Embedding层将每个词编码转换为词向量
通过以上操作,已经将每个句子变成一个向量,但上文已经提及text-CNN的输入是一个数字矩阵,即每个影评样本应该是以一个矩阵,每一行代表一个词,因此,需要将词编码转换成词向量。使用Keras的Embedding层可以实现转换。
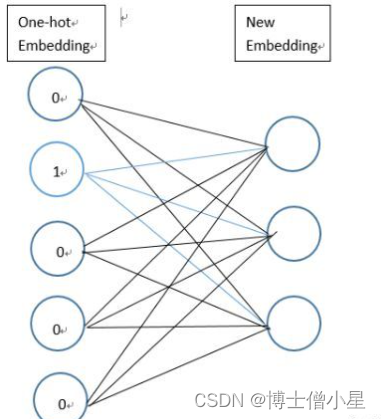
需要声明一点的是Embedding层是作为模型的第一层,在训练模型的同时,得到该语料库的词向量。当然,也可以使用已经预训练好的词向量表示现有语料库中的词。
embedding_layer = Embedding(input_dim=len(embeddings_matrix), # 字典长度output_dim = EMBEDDING_LEN, # 词向量 长度(25)weights=[embeddings_matrix], # 重点:预训练的词向量系数input_length=MAX_SEQUENCE_LENGTH, # 每句话的 最大长度(必须padding) 10trainable=False, # 是否在 训练的过程中 更新词向量name= 'embedding_layer')然后利用 keras的建模能力,把Embedding层嵌入到 模型中去即可。后面可以接CNN或者LSTM
参考文献
参考《Keras的中Embedding层 官方文档》: 嵌入层 Embedding - Keras中文文档
参考1 官方文档《在Keras模型中使用预训练的词向量》:在Keras模型中使用预训练的词向量 - Keras中文文档
参考2 :《Keras 模型中使用预训练的 gensim 词向量(word2vec) 和可视化》 Keras 模型中使用预训练的 gensim 词向量和可视化 | Eliyar's Blog
参考3《Embedding原理和Tensorflow-tf.nn.embedding_lookup()》:Embedding原理和Tensorflow-tf.nn.embedding_lookup()_embedding必须通过nn.lookup-CSDN博客
相关文章:
人工智能|深度学习——使用多层级注意力机制和keras实现问题分类
代码下载 使用多层级注意力机制和keras实现问题分类资源-CSDN文库 1 准备工作 1.1 什么是词向量? ”词向量”(词嵌入)是将一类将词的语义映射到向量空间中去的自然语言处理技术。即将一个词用特定的向量来表示,向量之间的距离(例…...

C语言常见面试题:C语言中如何进行网页开发编程?
在C语言中进行网页开发通常不是一个直接的过程,因为C语言主要用于系统级编程,而不是Web开发。传统的Web开发主要使用高级语言如JavaScript、Python、Ruby、PHP等,以及与Web相关的技术,如HTML、CSS和数据库。 然而,如果…...
DevOps落地笔记-20|软件质量:决定系统成功的关键
上一课时介绍通过提高工程效率来提高价值交付效率,从而提高企业对市场的响应速度。在提高响应速度的同时,也不能降低软件的质量,这就是所谓的“保质保量”。具备高质量软件,高效率的企业走得更快更远。相反,低劣的软件…...
政安晨:梯度与导数~示例演绎《机器学习·神经网络》的高阶理解
这篇文章确实需要一定的数学基础,第一次接触的小伙伴可以先看一下我示例演绎这个主题的前两篇文章: 示例演绎机器学习中(深度学习)神经网络的数学基础——快速理解核心概念(一): 政安晨&#…...

CTFSHOW命令执行web入门29-54
description: >- 这里就记录一下ctfshow的刷题记录是web入门的命令执行专题里面的题目,他是有分类,并且覆盖也很广泛,所以就通过刷这个来,不过里面有一些脚本的题目发现我自己根本不会笑死。 如果还不怎么知道写题的话,可以去看我的gitbook,当然csdn我也转载了我自己的…...

探索ChatGPT4:新一代人工智能语言模型的突破
ChatGPT4,作为最新一代的语言处理模型,代表了人工智能在自然语言理解和生成方面的最新突破。本文将深入介绍ChatGPT4的新特性,探讨其在各个领域的潜在应用。 ChatGPT4概述 在继承了前一代模型的强大基础之上,ChatGPT4引入了多项…...

PVST详解
PVST(Per-VLAN Spanning Tree)是Cisco公司的一种扩展的Spanning Tree协议,允许在每个VLAN中独立运行一个Spanning Tree实例,从而提高网络的可靠性和性能。 PVST协议在每个交换机中维护多个Spanning Tree实例,每个实例…...

c++ 子进程交互 逻辑
目录 一、主进程逻辑 1、创建子进程时候,写入自己的HWND 2、响应子进程消息...
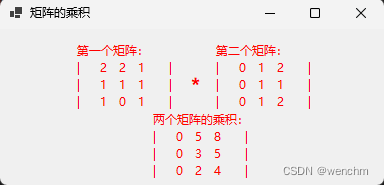
C#实现矩阵乘法
目录 一、使用的方法 1.矩阵 2.矩阵的乘法原理 二、实例 1.源码 2.生成效果 一、使用的方法 矩阵相当于一个数组,主要用来存储一系列数,例如,mn矩阵是排列在m行和n列中的一系列数,mn矩阵可与一个np矩阵相乘,结果…...

Objective-C 中的SEL
在 Objective-C 中,SEL(Selector)是一种用来表示方法的类型。 它实际上是一个指向方法的指针,用于在运行时动态调用方法。 下面是一个使用 SEL 的代码示例: #import <Foundation/Foundation.h>interface MyCl…...

使用 Docker 镜像预热提升容器启动效率详解
概要 在容器化部署中,Docker 镜像的加载速度直接影响到服务的启动时间和扩展效率。本文将深入探讨 Docker 镜像预热的概念、必要性以及实现方法。通过详细的操作示例和实践建议,读者将了解如何有效地实现镜像预热,以加快容器启动速度,提高服务的响应能力。 Docker 镜像预热…...
锁(二)队列同步器AQS
一、队列同步器AQS 1、定义 用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。是实现锁的关键。 2、实现 同步器的设计是基于模板方法模式的,也就是说&#…...

【知识整理】招人理念、组织结构、招聘
1、个人思考 几个方面: 新人:选、育、用、留 老人:如何甄别? 团队怎么演进? 有没有什么注意事项 怎么做招聘? 2、 他人考虑 重点: 1、从零开始,讲一个搭建团队的流程 2、标…...
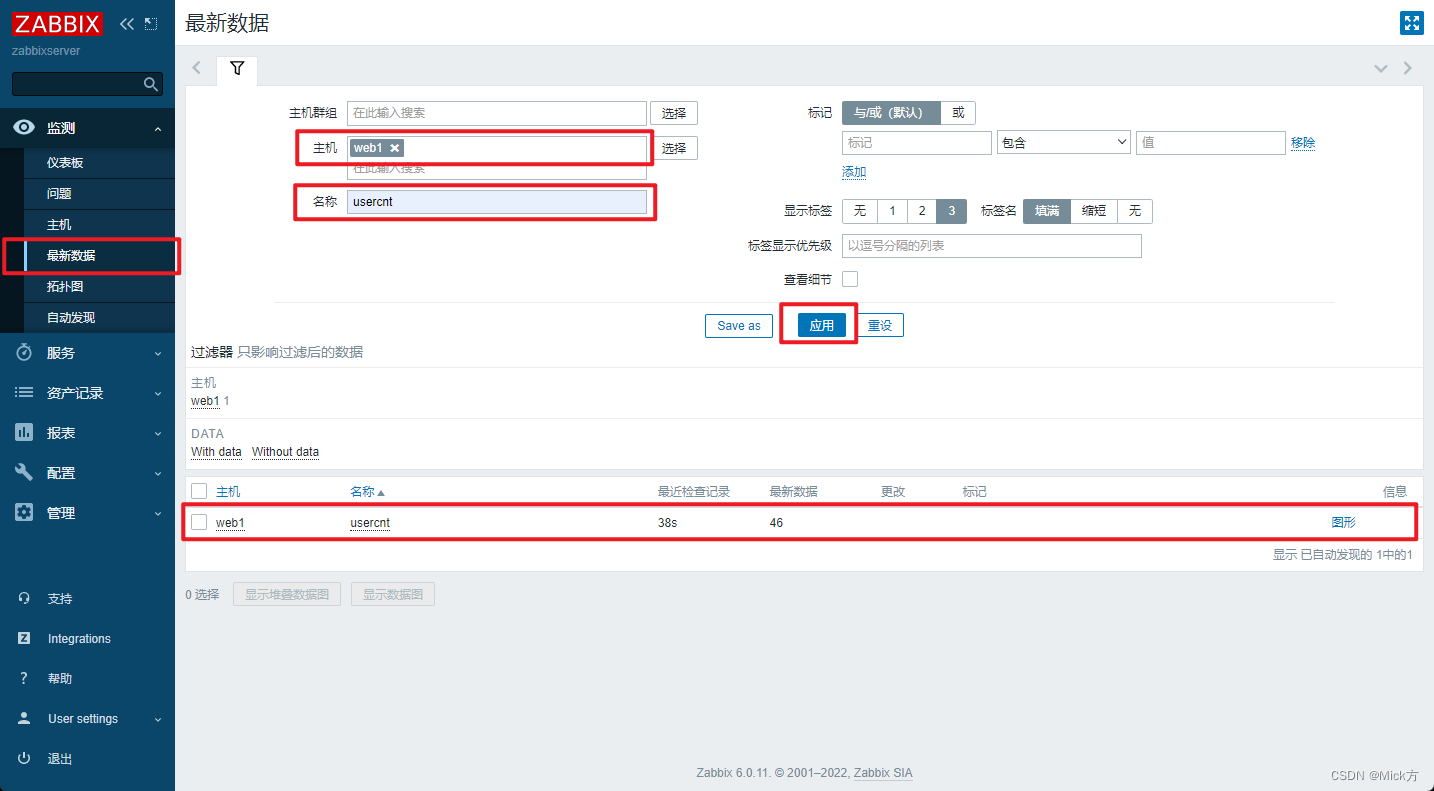
监控概述、安装zabbix、配置zabbixagent、添加被控端主机、常用监控指标、自定义监控项
目录 监控概述 监控命令 zabbix 安装zabbix 6.0 配置zabbix监控web1服务器 在web1上安装agent 在web页面中添加对web1的监控 常用监控指标 自定义监控项 实现监控web1用户数量的监控项 在被控端创建key 创建模板 应用模板到主机 查看结果 监控概述 对服务的管理&am…...

恒创科技:香港 BGP 服务器网络连通性如何测试?
随着互联网的快速发展,网络连通性测试变得越来越重要。网络连通性测试的目的是确定网络设备之间的连接是否正常,以及数据包是否能够在网络中顺利传输。本文将介绍一种简单易行的香港 BGP 服务器网络连通性的测试方法,利用tracer测试工具。这里…...

《动手学深度学习(PyTorch版)》笔记7.6
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过&…...
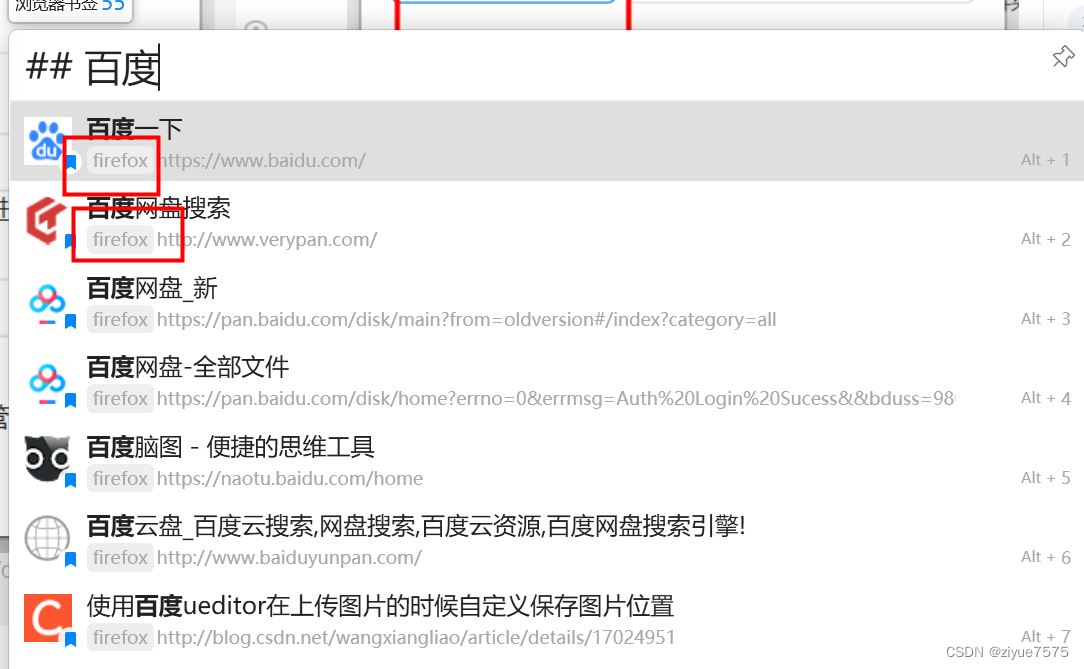
Quicker读取浏览器的书签(包括firefox火狐)
从edge换了火狐,但是quicker不能读取本地的bookmarks文件了,就研究了一下。 方法1:读取本地Bookmarks文件(仅谷歌内核浏览器) 谷歌内核的浏览器本地会有Bookmarks文件,放了所有的书签数据,直接…...

【数学建模】【2024年】【第40届】【MCM/ICM】【B题 搜寻潜水器】【解题思路】
一、题目 (一)赛题原文 2024 MCM Problem A: Resource Availability and Sex Ratios Maritime Cruises Mini-Submarines (MCMS), a company based in Greece, builds submersibles capable of carrying humans to the deepest parts of the ocean. A …...

深入探索Redis:如何有效遍历海量数据集
深入探索Redis:如何有效遍历海量数据集 Redis作为一个高性能的键值存储数据库,广泛应用于各种场景,包括缓存、消息队列、排行榜等。随着数据量的增长,如何高效地遍历Redis中的海量数据成为了一个值得探讨的问题。在本篇博客中&am…...

贪心算法之田忌赛马,多种语言实现
目录 题目描述: 输入: 样例输入: 样例输出: c代码实现: c++代码实现: python代码实现: Java代码实现: 题目描述: 这是中国历史上一个著名的故事。 “那是大约2300年前的事了。田骥将军是齐国的高级官员。他喜欢和国王和其他人一起赛马。 “田和王都有三匹不同等级…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...