LLM大模型基本概念,及其相关问题汇总(1)
什么是涌现?为什么会出现涌现?
"大模型的涌现能力"这个概念可能是指大型神经网络模型在某些任务上表现出的出乎意料的能力,超出了人们的预期。出现的原因从结论上来看,是模型不够好,导致的原因主要是:
- 数据量的增加:随着互联网的发展和数字化信息的爆炸增长,可用于训练模型的数据量大大增加。更多的数据可以提供更丰富、更广泛的语言知识和语境,使得模型能够更好地理解和生成文本。
- 计算能力的提升:随着计算硬件的发展,特别是图形处理器(GPU)和专用的AI芯片(如TPU)的出现,计算能力大幅提升。这使得训练更大、更复杂的模型成为可能,从而提高了模型的性能和涌现能力。
- 模型架构的改进:近年来,一些新的模型架构被引入,如Transformer,它在处理序列数据上表现出色。这些新的架构通过引入自注意力机制等技术,使得模型能够更好地捕捉长距离的依赖关系和语言结构,提高了模型的表达能力和生成能力。
- 预训练和微调的方法:预训练和微调是一种有效的训练策略,可以在大规模无标签数据上进行预训练,然后在特定任务上进行微调。这种方法可以使模型从大规模数据中学习到更丰富的语言知识和语义理解,从而提高模型的涌现能力。
其实导致涌现出现的原因拆解开就是因为技术糅合导致的不可控。大模型的涌现能力是由数据量的增加、计算能力的提升、模型架构的改进以及预训练和微调等因素共同作用的结果。
大模型基本概念
1. 大模型:一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。大语言模型(Large Language Model,LLM)是针对语言的大模型。
2. 175B、60B、540B等:这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
3. 强化学习:(Reinforcement Learning)一种机器学习的方法,通过从外部获得激励来校正学习方向从而获得一种自适应的学习能力。
4. 基于人工反馈的强化学习(RLHF):(Reinforcement Learning from Human Feedback)构建人类反馈数据集,训练一个激励模型,模仿人类偏好对结果打分,这是GPT-3后时代大语言模型越来越像人类对话核心技术。
5. 涌现:(Emergence)或称创发、突现、呈展、演生,是一种现象。许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。研究发现,模型规模达到一定阈值以上后,会在多步算术、大学考试、单词释义等场景的准确性显著提升,称为涌现。
6. 泛化:(Generalization)模型泛化是指一些模型可以应用(泛化)到其他场景,通常为采用迁移学习、微调等手段实现泛化。
7. 微调:(FineTuning)针对大量数据训练出来的预训练模型,后期采用业务相关数据进一步训练原先模型的相关部分,得到准确度更高的模型,或者更好的泛化。
8. 指令微调:(Instruction FineTuning),针对已经存在的预训练模型,给出额外的指令或者标注数据集来提升模型的性能。
9. 思维链:(Chain-of-Thought,CoT)。通过让大语言模型(LLM)将一个问题拆解为多个步骤,一步一步分析,逐步得出正确答案。需指出,针对复杂问题,LLM直接给出错误答案的概率比较高。思维链可以看成是一种指令微调。
Transformer架构以及在大型语言模型中的作用
Transformer架构是一种深度神经网络架构,于2017年由Vaswani等人在他们的论文“Attention is All You Need”中首次提出。自那以后,它已成为大型语言模型(如BERT和GPT)最常用的架构。
Transformer架构使用注意机制来解析输入序列,例如句子或段落,专门用于自然语言处理(NLP)应用。与传统的循环神经网络(RNN)不同,Transformer采用自注意力技术,使其能够同时关注输入序列的多个部分。
在大型语言模型中,Transformer架构用于创建输入文本的深层表示,然后可以用于各种NLP任务,如文本分类、命名实体识别和文本生成。这些模型在大量文本数据上进行了预训练,使它们能够学习数据中的模式和关系,然后可以进行特定的NLP任务的微调。
总的来说,Transformer架构通过提供强大而灵活的架构,彻底改变了NLP领域,特别适用于处理大量文本数据。在大型语言模型中的使用已经在各种NLP任务的性能上实现了显著的改进,并使从业者更容易将最先进的NLP模型集成到他们的项目中。
如何使用预训练模型来执行NLP任务?
假设您是一家金融科技初创公司的有经验的软件工程师:
在我之前的一个项目中,我利用预训练模型来提高我们的客户支持聊天机器人的准确性。该聊天机器人最初是在一小组客户咨询的小型数据集上训练的,但由于训练数据量有限,它在某些问题上表现不佳。
为了解决这个问题,我在公司更大的客户咨询数据集上对一个预训练的BERT模型进行了微调。这使模型能够学习数据中的特定模式和关系,从而显著提高了聊天机器人在测试集上的准确性。
除了提高聊天机器人的性能外,使用预训练模型还节省了大量时间和资源,与从零开始训练模型相比。这使我们能够迅速部署更新后的聊天机器人,提供更好的客户体验。
总的来说,预训练模型已经证明在我的NLP项目中是一个有价值的工具,提供高性能和资源节省,并我期待在将来的项目中继续使用它们。
解释微调以及它如何用于定制预训练模型以适应特定任务
微调是一种将预训练模型适应特定任务的过程。它涉及在特定任务的较小数据集上训练预训练模型,使模型能够学习任务特定的特征并适应任务的数据分布。
例如,像BERT或GPT-2这样的预训练语言模型可以针对特定的NLP任务,如情感分析或命名实体识别,进行微调。在这种情况下,微调过程涉及使用特定任务的标记示例的小型数据集来训练模型,通过更新模型参数来改善模型在任务上的性能。
微调过程可以通过使用反向传播和梯度下降等训练算法来更新模型的参数来完成,就像在任何其他机器学习任务中一样。然而,由于模型已经在大量文本数据上进行了预训练,它已经对语言有很强的理解,可以更快地学习任务特定的特征,而不需要从零开始训练模型。
微调具有几个优点。它允许将预训练模型适应特定任务和领域,提高模型在特定任务上的性能。与从头开始训练模型相比,它还节省时间和计算资源,因为预训练模型提供了性能的强大基线。
总的来说,微调是一种用于定制预训练模型以适应特定任务的强大技术,并已成为NLP项目中的常见实践。
将大型语言模型集成到生产系统的过程:
将大型语言模型集成到生产系统通常涉及多个步骤,包括对输入数据进行预处理、定义模型架构、训练模型以及在生产环境中部署模型。以下是该过程的高层概述:
1. 预处理输入数据:首先,需要对输入数据进行预处理,以确保可以输入模型。这可能包括数据清洗、将文本转换为数值表示以及将数据分为训练和测试集。
2. 定义模型架构:接下来,需要定义模型架构。这涉及选择一个预训练语言模型,如BERT或GPT-2,并对其进行微调以适应特定任务。模型架构可能还包括其他层和组件,如分类器,以执行所需的任务。
3. 训练模型:一旦模型架构被定义,下一步是在经过预处理的数据上训练模型。这涉及使用训练算法,如随机梯度下降,来更新模型参数,并提高模型在任务上的性能。
4. 评估模型:在模型经过训练后,评估模型在测试集上的性能非常重要。这可能包括计算指标,如准确度或F1分数,以评估模型的性能并确定需要改进的方面。
5. 部署模型:最后一步是在生产环境中部署模型。这可能涉及将经过训练的模型转换为可以部署在生产环境中的格式,如TensorFlow Serving或Flask,并将其集成到生产系统中。
6. 监控和维护:一旦模型被部署,监控其性能并根据需要进行更新非常重要。这可能涉及重新训练模型以适应新数据、更新模型架构以及解决在生产环境中出现的任何问题。
如何优化模型性能?
以下是一位金融科技初创公司有经验的软件工程师的虚构答案:
一个例子是针对用于识别欺诈交易的模型。该模型最初是在大量历史交易数据上进行训练的,但由于数据不平衡,其性能不佳。为了解决这个问题,我使用了过采样技术来平衡数据并提高模型的性能。
除了过采样,我还通过微调超参数来优化模型性能。这包括调整学习速率、批量大小和训练周期数等参数,以找到能够实现最佳性能的值的组合。
最后,我还尝试了不同的模型架构,包括决策树和随机森林,以确定最适合该任务的模型。通过比较不同模型的性能,我能够选择表现最佳的模型并将其集成到生产环境中。
总的来说,优化模型性能涉及数据预处理、调整超参数和模型选择的组合。在我的以前的项目中,我通过利用这些技术改进了欺诈检测模型的性能,为我们的客户提供了更准确的解决方案。
大型语言模型中的注意机制?以及是如何工作的?
注意机制是许多最先进的NLP模型的重要组成部分,包括基于Transformer的模型,如BERT和GPT。
注意机制的工作原理是允许模型在进行预测时有选择地关注输入序列的不同部分。这是通过计算每个输入序列元素的一组注意分数来实现的,这些分数表示每个元素对于给定任务的重要性。然后,这些注意分数用于加权输入元素,并生成加权和,作为模型下一层的输入。
在高层次上,注意机制允许模型根据手头的任务动态地调整其关注点。例如,在机器翻译任务中,注意机制可能在不同时间关注源句子中的不同单词,使模型能够有选择地关注生成翻译时的重要信息。
在实践中,注意机制是通过一组参数来实现的,称为注意权重,这些参数在训练过程中学习。这些注意权重用于计算注意分数并生成输入元素的加权和。注意权重可以看作是模型用于存储有关输入序列信息的一种记忆。
总的来说,注意机制在提高大型语言模型性能方面发挥了至关重要的作用,因为它允许模型有选择地关注输入序列的不同部分,并更好地捕捉元素之间的关系。
如何处理大型语言模型的计算需求?
处理大型语言模型的计算需求可能是一个挑战,尤其是在模型必须集成到生产环境中的实际应用中。以下是在项目中管理计算需求的一些策略:
- 硬件优化:大型语言模型需要大量的计算资源,如高端GPU或TPU。为了满足模型的需求,重要的是使用适当的硬
以下是将上述文本翻译成中文:
你如何处理大型语言模型的计算需求?
处理大型语言模型的计算需求可能是一个挑战,尤其是在模型必须集成到生产环境中的实际应用中。以下是在项目中管理计算需求的一些建议:
- 硬件优化:大型语言模型需要大量的计算资源,包括高端GPU或TPU。为了满足模型的需求,使用适当的硬件非常重要,无论是使用云端GPU还是投资于本地硬件。
- 模型修剪:模型修剪涉及移除模型的多余或不重要的组件,可以显著减少模型的计算需求而不损害性能。这可以通过权重修剪、结构修剪和激活修剪等技术来实现。
- 模型量化:量化涉及减少模型权重和激活的精度,可以显著减少模型的内存需求和计算需求。这可以通过量化感知训练或后训练量化等技术来实现。
- 模型蒸馏:模型蒸馏涉及训练一个较小的模型来模仿较大模型的行为。这可以显著减少模型的计算需求而不损害性能,因为较小的模型可以更高效地训练,并且可以在资源有限的环境中部署。
- 并行处理:并行处理涉及将模型的工作负载分布到多个GPU或处理器上,可以显著减少运行模型所需的时间。这可以通过数据并行处理、模型并行处理或管道并行处理等技术来实现。
通过使用这些策略的组合,可以有效地管理大型语言模型的计算需求,确保模型能够在实际应用中得以有效部署。
使用大型语言模型时遇到的挑战或限制
在NLP项目中使用大型语言模型可能会面临一些挑战和限制。一些常见的挑战包括:
- 计算需求:大型语言模型需要大量的计算资源,如高端GPU或TPU,这可能会在资源有限或需要实时应用的环境中造成部署困难。
- 内存需求:存储大型语言模型的参数需要大量内存,这使得在内存受限的环境中部署或对较小数据集进行微调变得具有挑战性。
- 解释性不足:大型语言模型通常被视为黑盒,难以理解其推理和决策,而这在某些应用中很重要。
- 过拟合:在小数据集上微调大型语言模型可能会导致过拟合,降低对新数据的准确性。
- 偏见:大型语言模型是在大量数据上训练的,这可能会引入模型的偏见。这可能在要求结果中保持中立和公平的应用中构成挑战。
- 道德关切:使用大型语言模型可能会对社会产生重大影响,因此必须考虑伦理问题。例如,通过语言模型生成假新闻或带有偏见的决策可能会带来负面后果。
NLP中生成模型和判别模型的区别
在NLP中,生成模型和判别模型是用于执行不同NLP任务的两个广泛类别的模型。
生成模型关注学习底层数据分布并从中生成新样本。它们建模输入和输出的联合概率分布,旨在最大化生成观察数据的可能性。在NLP中的一个生成模型示例是语言模型,其目标是基于先前的单词来预测序列中的下一个单词。
判别模型则关注学习输入-输出空间中正负示例之间的边界。它们建模给定输入情况下输出的条件概率分布,旨在最大化对新示例的分类准确性。在NLP中的一个判别模型示例是情感分析模型,其目标是根据文本内容将文本分类为积极、消极或中性。
总之,生成模型的目标是生成数据,而判别模型的目标是对数据进行分类。
一、基础篇
1. 目前 主流的开源模型体系 有哪些?
2. prefix LM 和 causal LM 区别是什么?
3. 涌现能力是啥原因?
4. 大模型LLM的架构介绍?
5. 你比较关注那些主流的开源大模型?
6. 目前大模型模型结构都有那些?
7. prefix LM 和 causal LM、encoder-decoder 区别及各自有什么优缺点?
8. 模型幻觉是什么?业内解决方案是什么?
9. 大模型的 Tokenizer 的实现方法及原理?
10. ChatGLM3 的词表实现方法?
11. GPT3、LLAMA、Chatglm 的Layer Normalization 的区别是什么?各自的优缺点是什么?
12. 大模型常用的激活函数有那些?
14. Multi-query Attention 与 Grouped-query Attention 是否了解?区别是什么?
15. 多模态大模型是否有接触?落地案例?
二、大模型(LLMs)进阶面
1. llama 输入句子长度理论上可以无限长吗?
2. 什么是 LLMs 复读机问题?
3. 为什么会出现 LLMs 复读机问题?
4. 如何缓解 LLMs 复读机问题?
5. LLMs 复读机问题
6. llama 系列问题
7. 什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?
8. 各个专业领域是否需要各自的大模型来服务?
9. 如何让大模型处理更长的文本?
10. 大模型参数微调、训练、推理
11. 如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
12. 为什么SFT之后感觉LLM傻了?
13. SFT 指令微调数据 如何构建?
14. 领域模型Continue PreTrain 数据选取?
15. 领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
16. 领域模型Continue PreTrain ,如何 让模型在预训练过程中就学习到更多的知识?
17. 进行SFT操作的时候,基座模型选用Chat还是Base?
18.领域模型微调 指令&数据输入格式 要求?
19. 领域模型微调 领域评测集 构建?
20. 领域模型词表扩增是不是有必要的?
21. 如何训练自己的大模型?
22. 训练中文大模型有啥经验?
23. 指令微调的好处?
24. 预训练和微调哪个阶段注入知识的?
25. 想让模型学习某个领域或行业的知识,是应该预训练还是应该微调?
26. 多轮对话任务如何微调模型?
27. 微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
28. 微调模型需要多大显存?
29. 大模型LLM进行SFT操作的时候在学习什么?
30. 预训练和SFT操作有什么不同
31. 样本量规模增大,训练出现OOM错
32. 大模型LLM进行SFT 如何对样本进行优化?
33. 模型参数迭代实验
34.为什么需要进行参选微调?参数微调的有点有那些?
35.模型参数微调的方式有那些?你最常用那些方法?
36.prompt tuning 和 prefix tuning 在微调上的区别是什么?
37. LLaMA-adapter 如何实现稳定训练?
38. LoRA 原理与使用技巧有那些?
39. LoRA 微调优点是什么?
40. AdaLoRA 的思路是怎么样的?
41. LoRA 权重合入chatglm模型的方法?
42. P-tuning 讲一下?与 P-tuning v2 区别在哪里?优点与缺点?
43. 为什么SFT之后感觉LLM傻了?
44. 垂直领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
45. 进行SFT操作的时候,基座模型选用Chat还是Base?
46. 领域模型词表扩增是不是有必要的?
47. 训练中文大模型的经验和方法
48. 模型微调用的什么模型?模型参数是多少?微调模型需要多大显存?
49. 预训练和SFT操作有什么不同?
50. 训练一个通用大模型的流程有那些
51.DDO 与 DPO 的区别是什么?
52. 是否接触过 embeding 模型的微调方法
53.有哪些省内存的大语言模型训练/微调/推理方法?
54. 大模型(LLMs)评测有那些方法?如何衡量大模型的效果?
55.如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?
56. 模型训练的数据集问题:一般数据集哪里找?
57.为什么需要进行模型量化及原理?
58.大模型词表扩充的方法及工具?
59.大模型应用框架
60.搭建大模型应用遇到过那些问题?如何解决的?
61.如何提升大模型的检索效果
62.是否了解上下文压缩方法?
63.如何实现窗口上下文检索?
64.开源的 RAG 框架有哪些,你比较了解?
65. 大模型应用框架 LangChain 和 LlamaIndex 各种的优势有那些?
66. 你使用的向量库有那些?各自有点与区别?
67. 使用外部知识数据库时需要对文档进行分块,如何科学的设置文档块的大小?
68. LLMs 受到上下文长度的限制,如果检索到的文档带有太多噪声,该如何解决这样的问题?
69. RAG(检索增强生成)对于大模型来说,有什么好处?
三、大模型(LLMs)langchain面
什么是 LangChain?
LangChain 包含哪些 核心概念?
什么是 LangChain Agent?
如何使用 LangChain ?
LangChain 支持哪些功能?
什么是 LangChain model?
LangChain 包含哪些特点?
LangChain 如何使用?
LangChain 存在哪些问题及方法方案?
LangChain 替代方案?
LangChain 中 Components and Chains 是什么?
LangChain 中 Prompt Templates and Values 是什么?
LangChain 中 Example Selectors 是什么?
LangChain 中 Output Parsers 是什么?
LangChain 中 Indexes and Retrievers 是什么?
LangChain 中 Chat Message History 是什么?
LangChain 中 Agents and Toolkits 是什么?
LangChain 如何调用 LLMs 生成回复?
LangChain 如何修改 提示模板?
LangChain 如何链接多个组件处理一个特定的下游任务?
LangChain 如何Embedding & vector store?
LangChain 低效的令牌使用问题
LangChain 文档的问题
LangChain 太多概念容易混淆,过多的“辅助”函数问题
LangChain 行为不一致并且隐藏细节问题
LangChain 缺乏标准的可互操作数据类型问题
四、大模型分布式训练
大模型进行训练,你用的是什么框架?
业内常用的分布式AI框架,你什么了解?
数据并行、张量并行、流水线并行的原理及区别?
推理优化技术 Flash Attention 的作用是什么?
推理优化技术 Paged Attention 的作用是什么?
CPU-offload,ZeRO-offload 了解?
ZeRO,零冗余优化器 的三个阶段?
混合精度训练的优点是什么?可能带来什么问题?
Megatron-DeepSpeed 方法?
Megatron-LM 方法
五、大模型(LLMs)推理
为什么大模型推理时显存涨的那么多还一直占着?
大模型在gpu和cpu上推理速度如何?
推理速度上,int8和fp16比起来怎么样?
大模型有推理能力吗?
大模型生成时的参数怎么设置?
有哪些省内存的大语言模型训练/微调/推理方法?
如何让大模型输出合规化
应用模式变更
相关文章:
)
LLM大模型基本概念,及其相关问题汇总(1)
什么是涌现?为什么会出现涌现? "大模型的涌现能力"这个概念可能是指大型神经网络模型在某些任务上表现出的出乎意料的能力,超出了人们的预期。出现的原因从结论上来看,是模型不够好,导致的原因主要是&#…...

【已解决】pt文件转onnx后再转rknn时得到推理图片出现大量锚框变花屏
前言 环境介绍: 1.编译环境 Ubuntu 18.04.5 LTS 2.RKNN版本 py3.8-rknn2-1.4.0 3.单板 迅为itop-3568开发板 一、现象 采用yolov5训练并将pt转换为onnx,再将onnx采用py3.8-rknn2-1.4.0推理转换为rknn,rknn模型能正常转换,…...

DevOps文章之 操作手册用户使用说明书
前言 最近主导了几个项目操作手册的编写。有新开发的项目,要重新编写操作手册;有中途接手别的项目,后来功能迭代,需要更新原操作手册;有客户对操作手册有意见,需要调整;零零散散写了数万字的手…...

【RT-DETR进阶实战】利用RT-DETR进行视频划定区域目标统计计数
👑欢迎大家订阅本专栏,一起学习RT-DETR👑 一、本文介绍 Hello,各位读者,最近会给大家发一些进阶实战的讲解,如何利用RT-DETR现有的一些功能进行一些实战, 让我们不仅会改进RT-DETR,也能够利用RT-DETR去做一些简单的小工作,后面我也会将这些功能利用PyQt或者是…...

2.11学习总结
有效点对https://www.acwing.com/problem/content/description/5472/ 给定一个 n� 个节点的无向树,节点编号 1∼n1∼�。 树上有两个不同的特殊点 x,y�,�,对于树中的每一个点对 (u,v)(u≠v)(�,…...
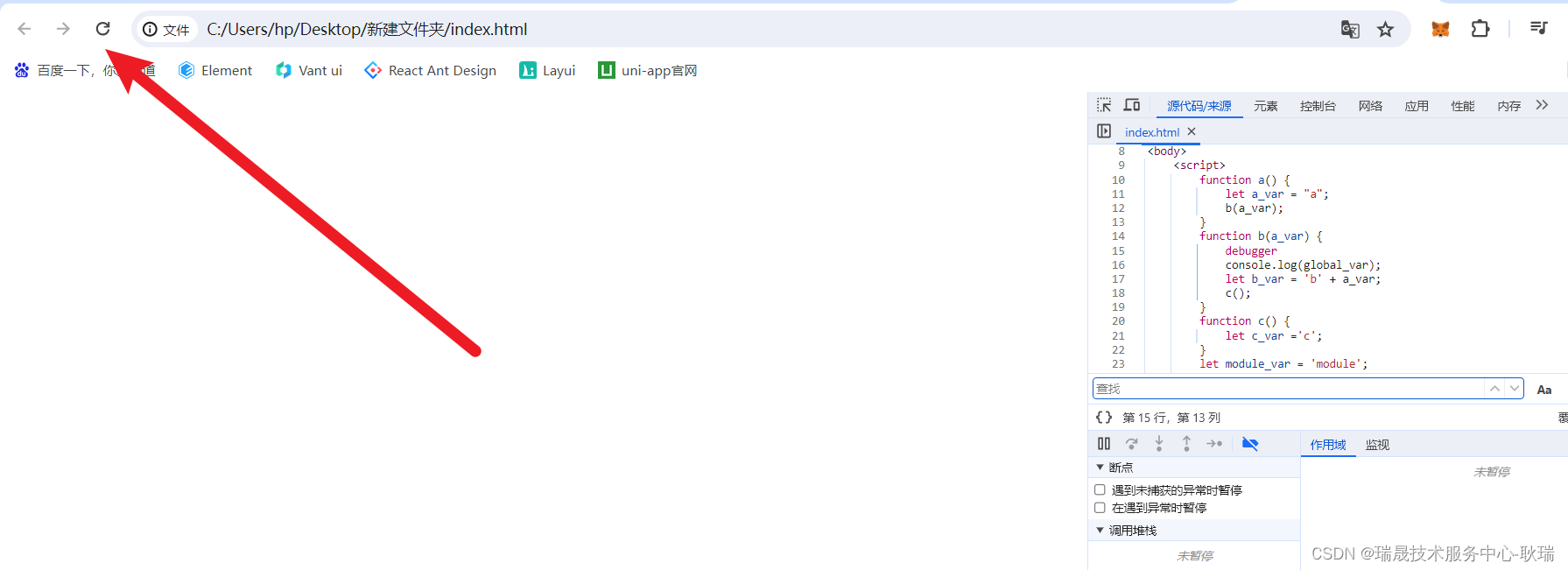
以谷歌浏览器为例 讲述 JavaScript 断点调试操作用法
今天来说个比较实用的东西 用浏览器开发者工具 对 javaScript代码进行调试 我们先创建一个index.html 编写代码如下 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content&…...

Vue前端框架--Vue工程项目问题总结{脚手架 Vue-cli}
Vue脚手架部署问题总结 我所遇到的一共两大问题 只有先执行npm install之后 才能run serve 否则会报错 vue-cli-serve不是内部或者外部的命令,也不是可运行的程序或者批处理文件的错误 1. 运行npm install会报错 2. 运行npm run serve报错 nodejs官网为 https://no…...
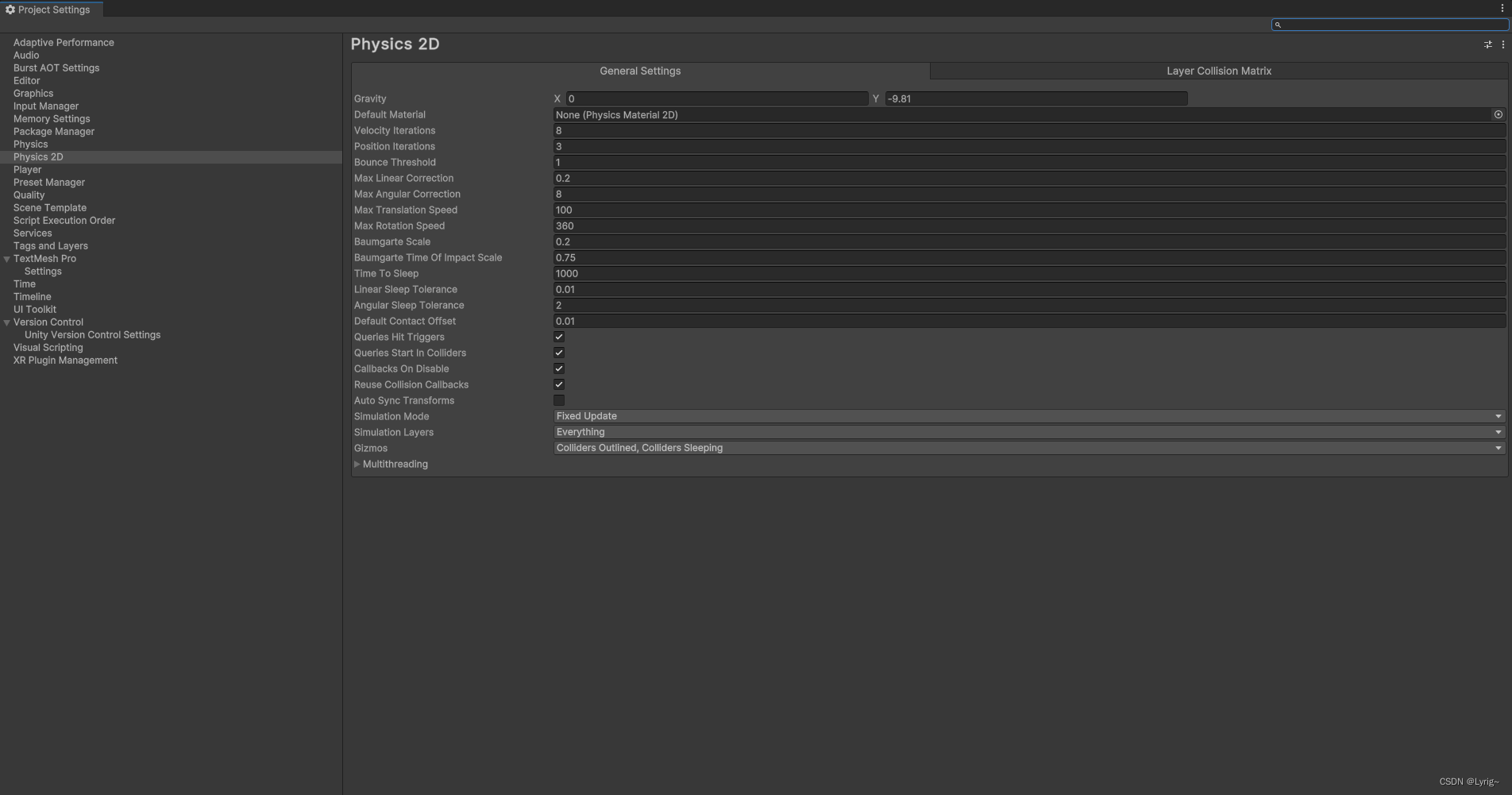
Unity2D 学习笔记 0.Unity需要记住的常用知识
Unity2D 学习笔记 0.Unity需要记住的常用知识 前言调整Project SettingTilemap相关(创建地图块)C#脚本相关程序运行函数private void Awake()void Start()void Update() Collider2D碰撞检测private void OnTriggerStay2D(Collider2D player)private void…...

vue3-应用规模化-单文件组件
单文件组件概念 Vue 的单文件组件 (即 *.vue 文件,英文 Single-File Component,简称 SFC) 是一种特殊的文件格式,使我们能够将一个 Vue 组件的模板、逻辑与样式封装在单个文件中。下面是一个单文件组件的示例: <script setup…...
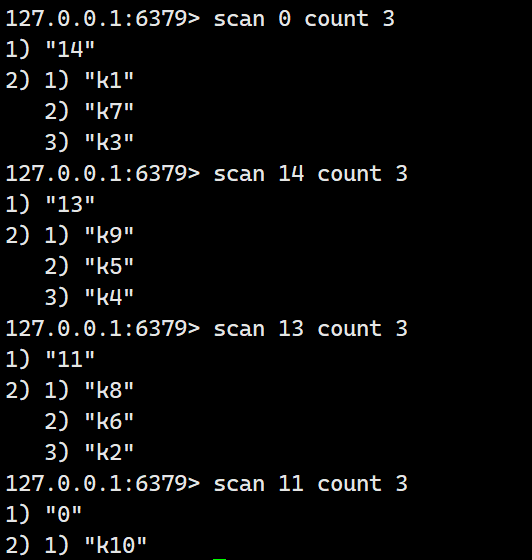
Redis -- 渐进式遍历
家,是心的方向。不论走多远,总有一盏灯为你留着。桌上的碗筷多了几双,笑声也多了几分温暖。家人团聚,是最美的风景线。时间:2024年 2月 8日 12:51:20 目录 前言 语法 示例 前言 试想一个场景,那就是在key非常多的…...
:指令解析)
使用 C++23 从零实现 RISC-V 模拟器(3):指令解析
指令解析 这章内容进一解析更多的指令,此外将解析指令的过程拆分为一个单独的类,采用表格驱动的方式,将数据和逻辑分离,降低了 if else 嵌套层数过多。 这部分依旧改动不多,只增加了七个指令。此外代码中细碎的变动没…...

CSS Selector—选择方法,和html自动——异步社区的爬取(动态网页)——爬虫(get和post的区别)
这里先说一下GET请求和POST请求: post我们平时是要加data的也就是信息,你会发现我们平时百度之类的 搜索都是post请求 get我们带的是params,是发送我们指定的内容。 要注意是get和post请求!!! 先说一下异…...
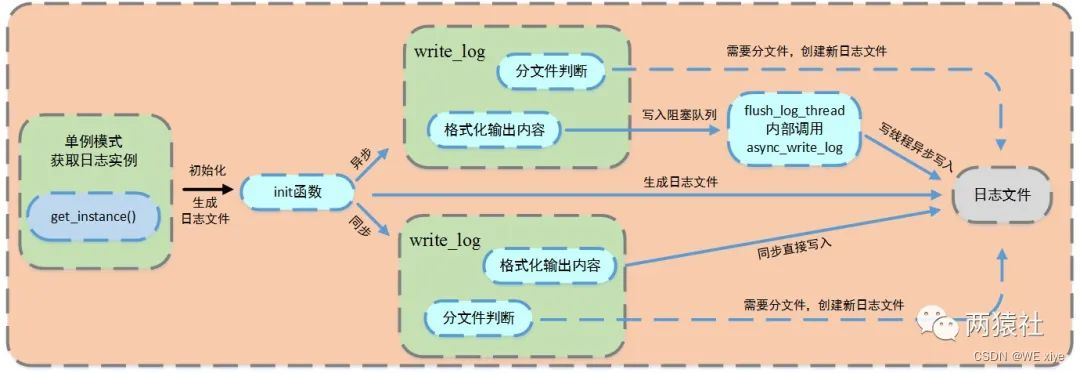
C语言 服务器编程-日志系统
日志系统的实现 引言最简单的日志类 demo按天日志分类和超行日志分类日志信息分级同步和异步两种写入方式 引言 日志系统是通过文件来记录项目的 调试信息,运行状态,访问记录,产生的警告和错误的一个系统,是项目中非常重要的一部…...

HarmonyOS 状态管理装饰器 Observed与ObjectLink 处理嵌套对象/对象数组 结构双向绑定
本文 我们还是来说 两个 harmonyos 状态管理的装饰器 Observed与ObjectLink 他们是用于 嵌套对象 或者 以对象类型为数组元素 的数据结构 做双向同步的 之前 我们说过的 state和link 都无法捕捉到 这两种数据内部结构的变化 这里 我们模拟一个类数据结构 class Person{name:…...

windows中的apache改成手动启动的操作步骤
使用cmd解决安装之后开机自启的问题 services.msc 0. 这个命令是打开本地服务找到apache的服务名称 2 .通过服务名称去查看服务的状态 sc query apacheapache3.附加上关掉和启动的命令(换成是你的服务名称) 关掉命令 sc stop apacheapache启动命令 …...
Intellij Idea的数据库工具 DataGrip
DataGrip DataGrip: IDEA自带,非常好用。智能提示很强大,快捷键跟IDEA自身一致。 如果下载不了 DataGrip,也可以直接用 IDEA 自带的。 常用的快捷键 alt8: 打开数据库Service ctrlshiftF10:打开常用的数…...
精品springboot疫苗发布和接种预约系统
《[含文档PPT源码等]精品基于springboot疫苗发布和接种预约系统[包运行成功]》该项目含有源码、文档、PPT、配套开发软件、软件安装教程、项目发布教程、包运行成功! 软件开发环境及开发工具: Java——涉及技术: 前端使用技术:…...
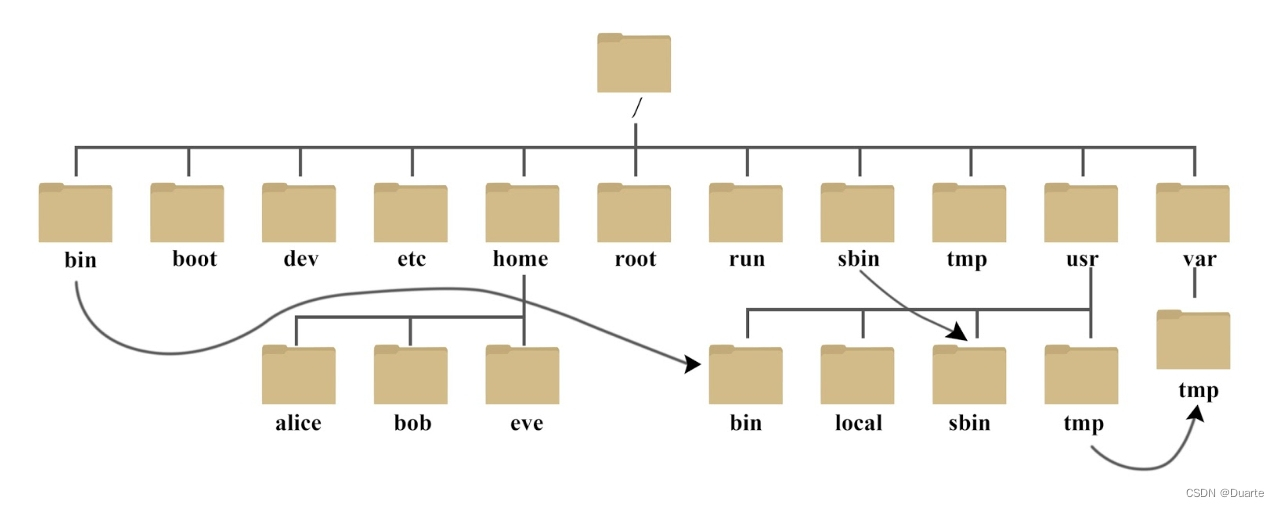
Linux快速入门
一. Linux的结构目录 1.1 Linux的目录结构 Linux为免费开源的系统,拥有众多发行版,为规范诸多的使用者对Linux系统目录的使用,Linux基金会发布了FHS标准(文件系统层次化标准)。多数的Linux发行版都遵循这一规范。 注&…...
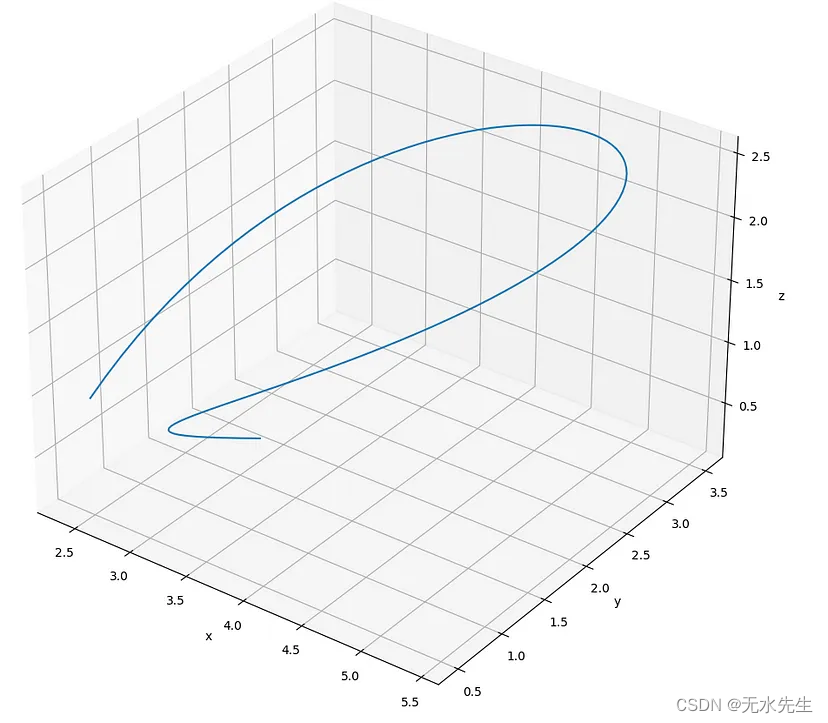
【图形图像的C++ 实现 01/20】 2D 和 3D 贝塞尔曲线
目录 一、说明二、贝塞尔曲线特征三、模拟四、全部代码如下五、资源和下载 一、说明 以下文章介绍了用 C 计算和绘制的贝塞尔曲线(2D 和 3D)。 贝塞尔曲线具有出色的数学能力来计算路径(从起点到目的地点的曲线)。曲线的形…...
python+flask+django医院预约挂号病历分时段管理系统snsj0
技术栈 后端:python 前端:vue.jselementui 框架:django/flask Python版本:python3.7 数据库:mysql5.7 数据库工具:Navicat 开发软件:PyCharm . 第一,研究分析python技术,…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...
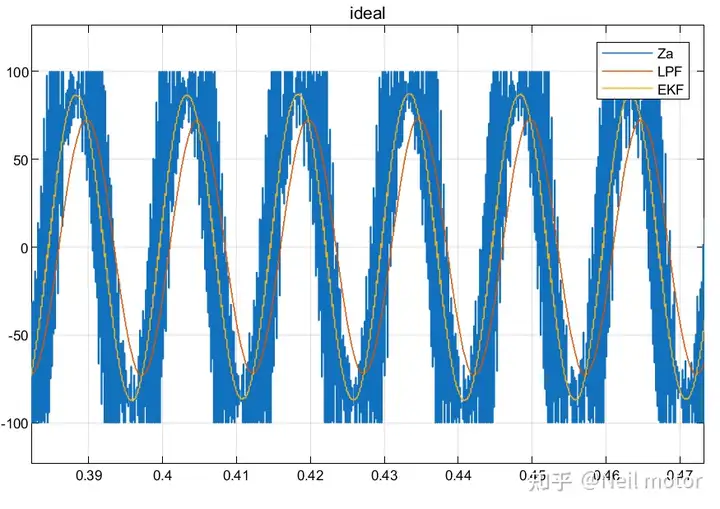
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...