NLP_词的向量表示Word2Vec 和 Embedding
文章目录
- 词向量
- Word2Vec:CBOW模型和Skip-Gram模型
- 通过nn.Embedding来实现词嵌入
- Word2Vec小结
词向量
下面这张图就形象地呈现了词向量的内涵:把词转化为向量,从而捕捉词与词之间的语义和句法关系,使得具有相似含义或相关性的词语在向量空间中距离较近。

我们把语料库中的词和某些上下文信息,都“嵌入”了向量表示中。
将词映射到向量空间时,会将这个词和它周围的一些词语一起学习,这就使得具有相似语义的词在向量空间中靠得更近。这样,我们就可以通过向量之间的距离来度量词之间的相似性了。
Word2Vec:CBOW模型和Skip-Gram模型
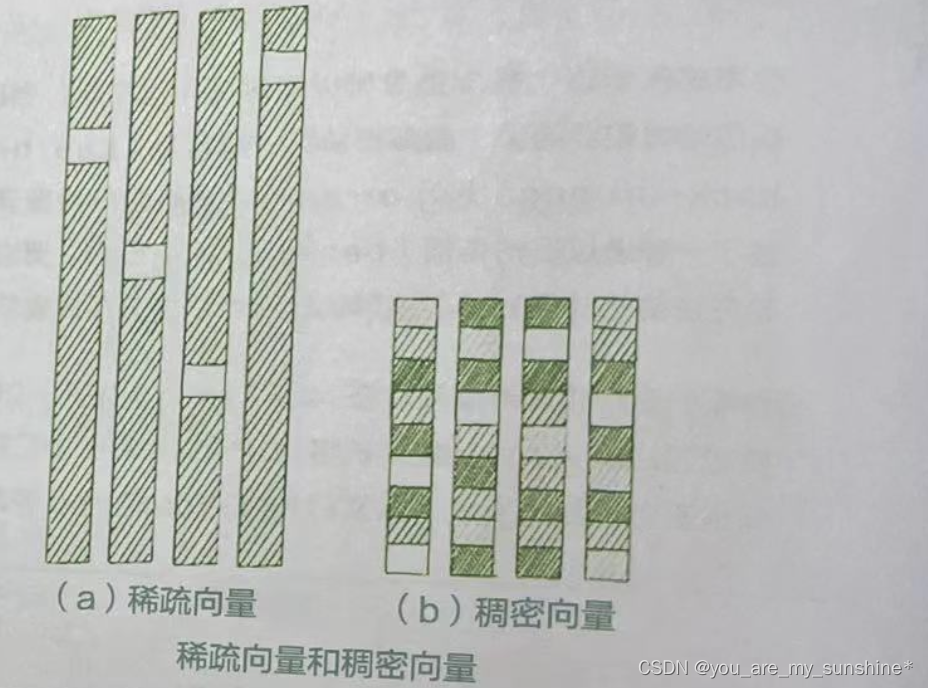
稠密向量中的元素大部分为非零值。稠密向量通常具有较低的维度,同时能够捕捉到更丰富的信息。Word2Vec就是一种典型的稠密向量表示。稠密向量能够捕捉词与词之间的语义和语法关系,使得具有相似含义或相关性的词在向量空间中距离较近。
在自然语言处理中,稠密向量通常更受欢迎,因为它们能够捕捉到更多的信息,同时计算效率更高。下图直观地展示了二者的区别。
通过Word2Vec学习得到的向量可以捕捉到词与词之间的语义和语法关系。而且,这个算法比以前的方法更加高效,能够轻松地处理大规模的文本数据。因此,Word2Vec迅速流行起来。
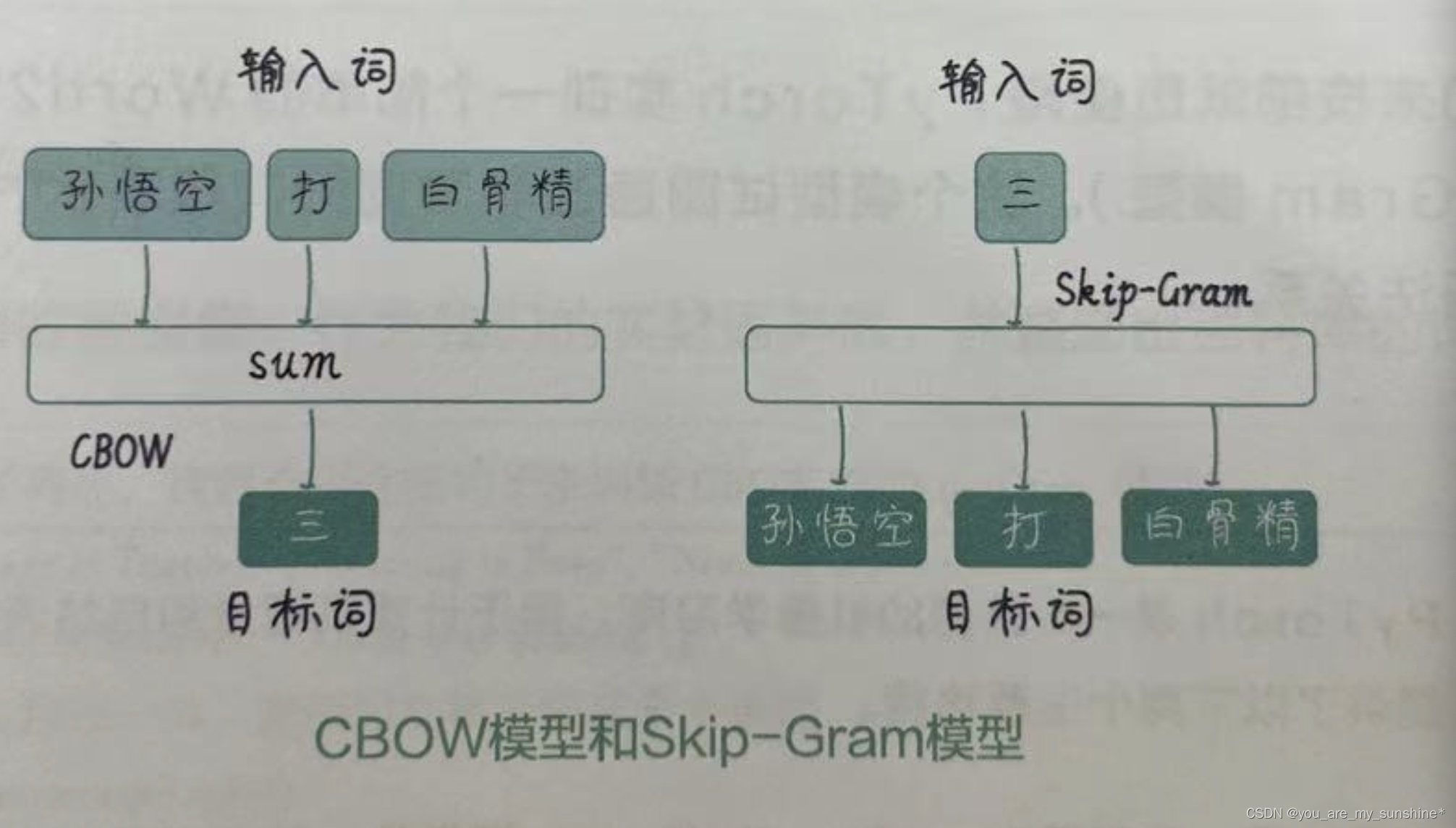
具体来说,Word2Vec有两种主要实现方式:CBOW(Continuous Bag of Words,有时翻译为“连续词袋”)模型和Skip-Gram(有时翻译为“跳字”)模型,如下图所示。CBOW模型通过给定上下文词(也叫“周围词”)来预测目标词(也叫“中心词”);而Skip-Gram模型则相反,通过给定目标词来预测上下文词。这两个模型都是通过训练神经网络来学习词向量的。在训练过程中,我们通过最小化预测词和实际词之间的损失来学习词向量。当训练完成后,词向量可以从神经网络的权重中提取出来。
通过nn.Embedding来实现词嵌入
在PyTorch中,nn.Embedding是nn中的一个模块,它用于将离散的索引(通常是单词在词汇表中的索引)映射到固定大小的向量空间。在自然语言处理任务中,词嵌入是将单词表示为高维向量的一种常见方法。词嵌入可以捕捉单词之间的相似性、语义关系等。在训练过程中,嵌入层会自动更新权重以最小化损失函数,从而学习到有意义的词向量。
嵌入层的构造函数接收以下两个参数。
- num_embeddings :词汇表的大小,即唯一单词的数量。
- embedding_dim:词嵌入向量的维度。
使用嵌入层有以下优点。 - 更简洁的代码:与线性层相比,嵌入层提供了更简洁、更直观的表示词嵌入的方式。这使得代码更容易理解和维护。
- 更高的效率:嵌入层比线性层更高效,因为它不需要进行矩阵乘法操作。它直接从权重矩阵中查找对应的行(嵌入向量),这在计算上更高效。
- 更容易训练:嵌入层不需要将输入转换为One-Hot编码后的向量。我们可以直接将单词索引作为输入,从而减少训练的计算复杂性。
# 定义一个句子列表,后面会用这些句子来训练 CBOW 和 Skip-Gram 模型
sentences = ["Kage is Teacher", "Mazong is Boss", "Niuzong is Boss","Xiaobing is Student", "Xiaoxue is Student",]
# 将所有句子连接在一起,然后用空格分隔成多个单词
words = ' '.join(sentences).split()
# 构建词汇表,去除重复的词
word_list = list(set(words))
# 创建一个字典,将每个词映射到一个唯一的索引
word_to_idx = {word: idx for idx, word in enumerate(word_list)}
# 创建一个字典,将每个索引映射到对应的词
idx_to_word = {idx: word for idx, word in enumerate(word_list)}
voc_size = len(word_list) # 计算词汇表的大小
print(" 词汇表:", word_list) # 输出词汇表
print(" 词汇到索引的字典:", word_to_idx) # 输出词汇到索引的字典
print(" 索引到词汇的字典:", idx_to_word) # 输出索引到词汇的字典
print(" 词汇表大小:", voc_size) # 输出词汇表大小

# 生成 Skip-Gram 训练数据
def create_skipgram_dataset(sentences, window_size=2):data = [] # 初始化数据for sentence in sentences: # 遍历句子sentence = sentence.split() # 将句子分割成单词列表for idx, word in enumerate(sentence): # 遍历单词及其索引# 获取相邻的单词,将当前单词前后各 N 个单词作为相邻单词for neighbor in sentence[max(idx - window_size, 0): min(idx + window_size + 1, len(sentence))]:if neighbor != word: # 排除当前单词本身# 将相邻单词与当前单词作为一组训练数据data.append((neighbor, word))return data
# 使用函数创建 Skip-Gram 训练数据
skipgram_data = create_skipgram_dataset(sentences)
# 打印未编码的 Skip-Gram 数据样例(前 3 个)
print("Skip-Gram 数据样例(未编码):", skipgram_data[:3])

# 定义 One-Hot 编码函数
import torch # 导入 torch 库
def one_hot_encoding(word, word_to_idx): tensor = torch.zeros(len(word_to_idx)) # 创建一个长度与词汇表相同的全 0 张量 tensor[word_to_idx[word]] = 1 # 将对应词的索引设为 1return tensor # 返回生成的 One-Hot 向量
# 展示 One-Hot 编码前后的数据
word_example = "Teacher"
print("One-Hot 编码前的单词:", word_example)
print("One-Hot 编码后的向量:", one_hot_encoding(word_example, word_to_idx))
# 展示编码后的 Skip-Gram 训练数据样例
print("Skip-Gram 数据样例(已编码):", [(one_hot_encoding(context, word_to_idx), word_to_idx[target]) for context, target in skipgram_data[:3]])

# 定义 Skip-Gram 模型
import torch.nn as nn # 导入 neural network
class SkipGram(nn.Module):def __init__(self, voc_size, embedding_size):super(SkipGram, self).__init__()# 从词汇表大小到嵌入大小的嵌入层(权重矩阵)self.input_to_hidden = nn.Embedding(voc_size, embedding_size) # 从嵌入大小到词汇表大小的线性层(权重矩阵)self.hidden_to_output = nn.Linear(embedding_size, voc_size, bias=False) def forward(self, X):hidden_layer = self.input_to_hidden(X) # 生成隐藏层:[batch_size, embedding_size]output_layer = self.hidden_to_output(hidden_layer) # 生成输出层:[batch_size, voc_size]return output_layer
embedding_size = 2 # 设定嵌入层的大小,这里选择 2 是为了方便展示
skipgram_model = SkipGram(voc_size, embedding_size) # 实例化 Skip-Gram 模型
print("Skip-Gram 模型:", skipgram_model)

# 训练 Skip-Gram 类
learning_rate = 0.001 # 设置学习速率
epochs = 1000 # 设置训练轮次
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
import torch.optim as optim # 导入随机梯度下降优化器
optimizer = optim.SGD(skipgram_model.parameters(), lr=learning_rate)
# 开始训练循环
loss_values = [] # 用于存储每轮的平均损失值
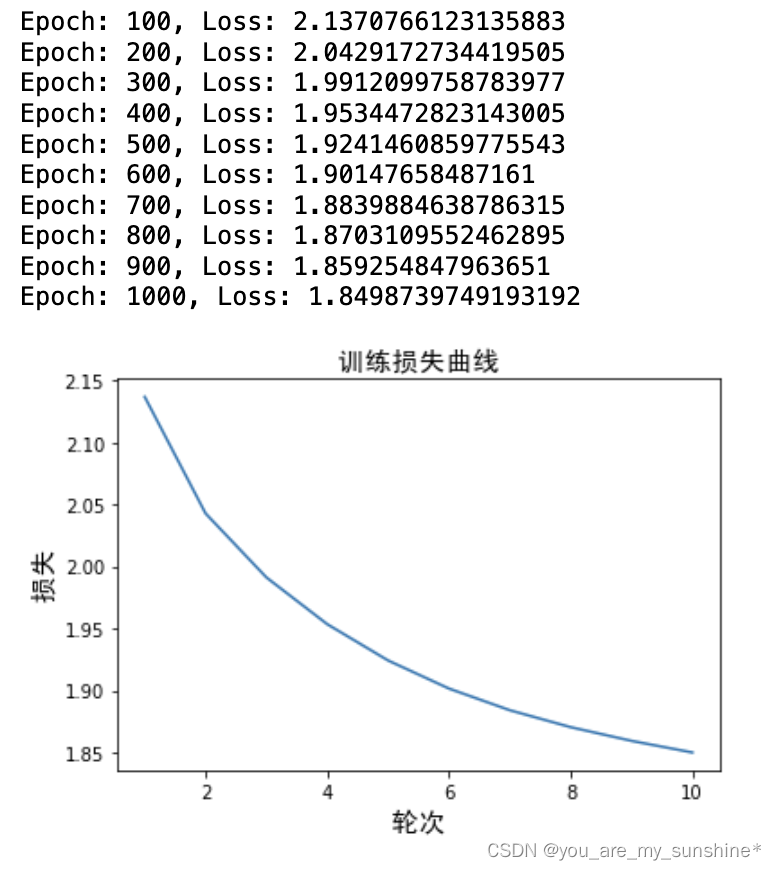
for epoch in range(epochs):loss_sum = 0 # 初始化损失值for context, target in skipgram_data: X = torch.tensor([word_to_idx[target]], dtype=torch.long) # # 输入是中心词y_true = torch.tensor([word_to_idx[context]], dtype=torch.long) # 目标词是周围词y_pred = skipgram_model(X) # 计算预测值loss = criterion(y_pred, y_true) # 计算损失loss_sum += loss.item() # 累积损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数if (epoch+1) % 100 == 0: # 输出每 100 轮的损失,并记录损失print(f"Epoch: {epoch+1}, Loss: {loss_sum/len(skipgram_data)}") loss_values.append(loss_sum / len(skipgram_data))
# 绘制训练损失曲线
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.font_manager import FontProperties
font = FontProperties(fname='SimHei.ttf', size = 15)
# 绘制二维词向量图
#plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
#plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
#plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.plot(range(1, epochs//100 + 1), loss_values) # 绘图
plt.title(' 训练损失曲线 ', FontProperties = font) # 图题
plt.xlabel(' 轮次 ', FontProperties = font) # X 轴 Label
plt.ylabel(' 损失 ', FontProperties = font) # Y 轴 Label
plt.show() # 显示图
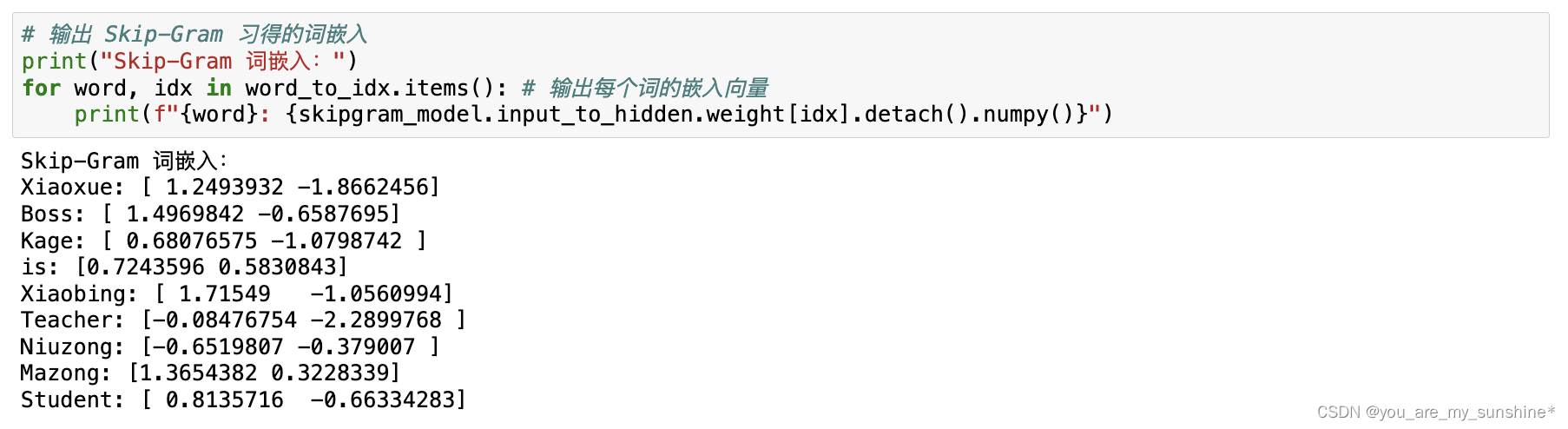
# 输出 Skip-Gram 习得的词嵌入
print("Skip-Gram 词嵌入:")
for word, idx in word_to_idx.items(): # 输出每个词的嵌入向量print(f"{word}: {skipgram_model.input_to_hidden.weight[idx].detach().numpy()}")
# 绘制二维词向量图
#plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
#plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
#plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
fig, ax = plt.subplots()
for word, idx in word_to_idx.items():# 获取每个单词的嵌入向量vec = skipgram_model.input_to_hidden.weight[idx].detach().numpy() ax.scatter(vec[0], vec[1]) # 在图中绘制嵌入向量的点ax.annotate(word, (vec[0], vec[1]), fontsize=12) # 点旁添加单词标签
plt.title(' 二维词嵌入 ', FontProperties = font) # 图题
plt.xlabel(' 向量维度 1', FontProperties = font) # X 轴 Label
plt.ylabel(' 向量维度 2', FontProperties = font) # Y 轴 Label
plt.show() # 显示图

此外,因为nn.Embedding 是一个简单的查找表,所以input_to_hidden. weight的维度为[voc_size,embedding_size]。因此,当打印和可视化权重时,需要使用weight[idx] 来获取权重。
这个向量蕴含在 PyTorch的嵌入层中,可以通过embedding_size参数来调整它的维度。此处嵌入层的维度是2,但刚才说过,处理真实语料库时,嵌入层的维度一般来说有几百个,这样才可以习得更多的语义知识。其实,几百维的词向量,对于动辄拥有上万,甚至十万、百万个词的词汇表(《辞海》的词条数,总条目数近13万)来说,已经算是很“低”维、很稠密了。
所以,词向量或者说词嵌入的学习过程就是,通过神经网络来习得包含词的语义信息的向量,这个向量通常是几维到几百维不等,然后可以降维进行展示,以显示词和词之间的相似程度。如图所示。
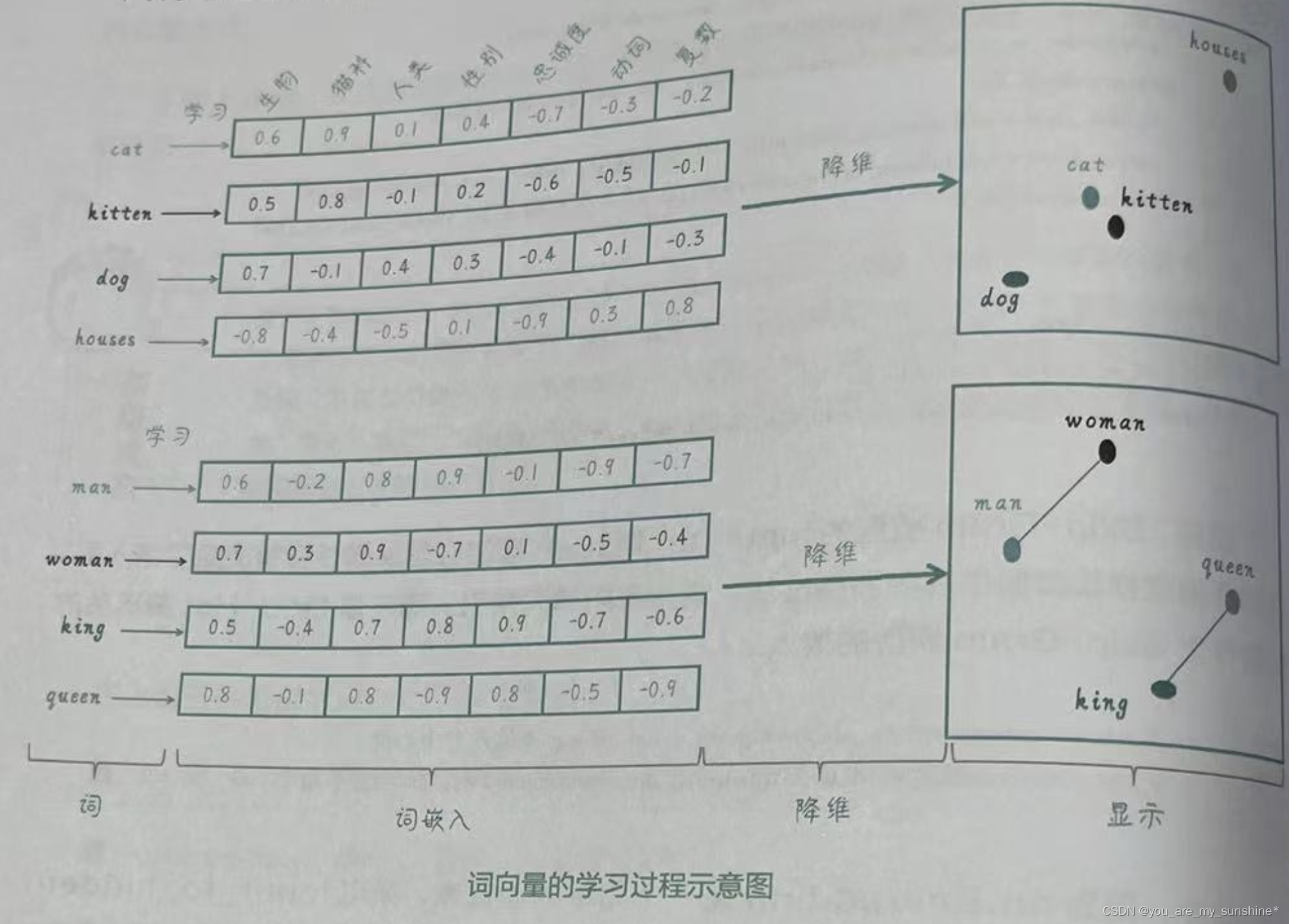
这些词向量捕捉了词与词之间的关系之后,具有相似含义或用法的词在向量空间中会靠得更近。我们可以使用这些词向量作为其他自然语言处理任务(如文本分类、文本相似度比较、命名实体识别等)的输入特征。
Word2Vec之后的许多词嵌入方法,如G1oVe (Global Vectors for Word Representation)和fastText,也都是这样使用的。我们可以拿到别人已经训练好的词向量(G1oVe和fastText都提供现成的词向量供我们下载)作为输入,来完成我们的下游NLP任务;也可以利用PyTorch 的nn.Embedding,来针对特定语料库从头开始词嵌入的学习,然后再把学到的词向量(也就是经过nn.Embedding的参数处理后的序列信息)作为输入,完成下游NLP任务。
Word2Vec小结
Word2Vec对整个自然语言处理领域产生了巨大的影响。后来的许多词嵌入方法,如GloVe 和 fastText 这两种被广泛应用的词向量,都受到了Word2Vec的启发。如今,Word2Vec已经成为词嵌入领域的基石。它的出现使得更复杂的NLP任务,如文本分类、情感分析、命名实体识别、机器翻译等,处理起来更轻松。这主要是因为 Word2Vec 生成的词向量能够捕捉到单词之间的语义和语法关系。
然而,Word2Vec仍然存在一些局限性。
- (1)词向量的大小是固定的。Word2Vec这种“在全部语料上一次习得,然后反复使用”的词向量被称为静态词向量。它为每个单词生成一个固定大小的向量,这限制了模型捕捉词义多样性的能力。在自然语言中,许多单词具有多种含义,但 Word2Vec无法为这些不同的含义生成多个向量表示。
- (2)无法处理未知词汇。Word2Vec只能为训练过程中出现过的单词生成词向量。对于未知或低频词汇,Word2Vec无法生成合适的向量表示。虽然可以通过拼接词根等方法来解决这个问题,但这并非Word2Vec 本身的功能。
值得注意的是,Word2Vec本身并不是一个完善的语言模型,因为语言模型的目标是根据上下文预测单词,而Word2Vec主要关注生成有意义的词向量。尽管 CBOW和 Skip-Gram 模型在训练过程中学习了单词之间的关系,但它们并未直接对整个句子的概率分布进行建模。而后来的模型,如基于循环神经网络、长短期记忆网络和 Transformer 的模型,则通过对上下文进行建模,更好地捕捉到了语言结构,从而成为更为强大的语言模型。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…
相关文章:
NLP_词的向量表示Word2Vec 和 Embedding
文章目录 词向量Word2Vec:CBOW模型和Skip-Gram模型通过nn.Embedding来实现词嵌入Word2Vec小结 词向量 下面这张图就形象地呈现了词向量的内涵:把词转化为向量,从而捕捉词与词之间的语义和句法关系,使得具有相似含义或相关性的词语在向量空间…...

python:xml.etree 生成思维导图 Freemind文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录 请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad 转换编码。 xml 是 python 标准库,在 D:\Python39\Lib\xml\etree python 用 xm…...
Solidworks:从2D走向3D
Sokidworks 的强大之处在于三维实体建模,这个形状看似复杂,实际上只需要拉伸一次,再做一次减法拉伸就行了。第一次做三维模型,费了不少时间才搞明白。 接下来做一个稍微复杂一点的模型,和上面这个操作差不多࿰…...

【开源】JAVA+Vue.js实现高校学院网站
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 学院院系模块2.2 竞赛报名模块2.3 教育教学模块2.4 招生就业模块2.5 实时信息模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 学院院系表3.2.2 竞赛报名表3.2.3 教育教学表3.2.4 招生就业表3.2.5 实时信息表 四、系…...
题解19-24
48. 旋转图像 - 力扣(LeetCode) 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在** 原地** 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 示例 1࿱…...

基于图像掩膜和深度学习的花生豆分拣(附源码)
目录 项目介绍 图像分类网络构建 处理花生豆图片完成预测 项目介绍 这是一个使用图像掩膜技术和深度学习技术实现的一个花生豆分拣系统 我们有大量的花生豆图片,并以及打好了标签,可以看一下目录结构和几张具体的图片 同时我们也有几张大的图片&…...
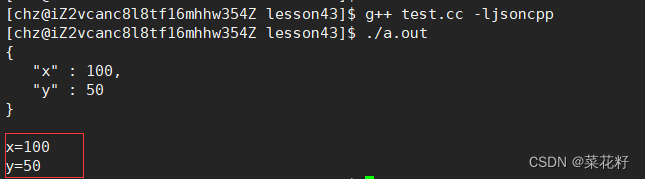
【网络】:序列化和反序列化
序列化和反序列化 一.json库 二.简单使用json库 前面已经讲过TCP和UDP,也写过代码能够进行双方的通信了,那么有没有可能这种通信是不安全的呢?如果直接通信,可能会被底层捕捉;可能由于网络问题,一方只接收到…...
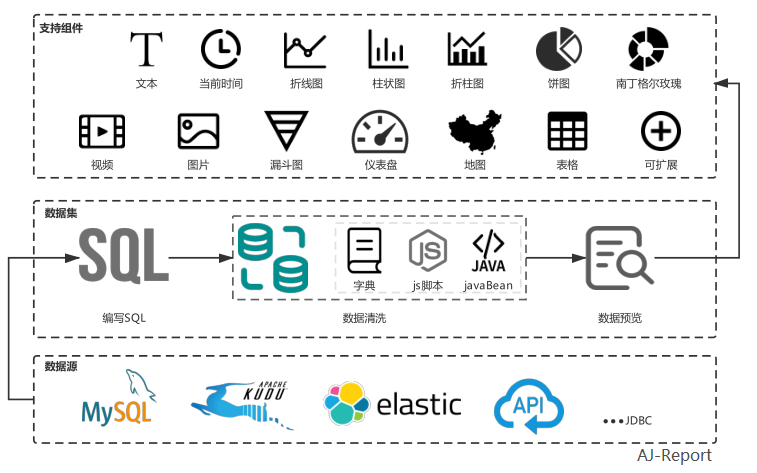
AJ-Report 【开源的一个BI平台】
AJ-Report是全开源的一个BI平台,酷炫大屏展示,能随时随地掌控业务动态,让每个决策都有数据支撑。 多数据源支持,内置mysql、elasticsearch、kudu驱动,支持自定义数据集省去数据接口开发,目前已支持30…...

Matplotlib核心:掌握Figure与Axes
详细介绍Figure和Axes(基于Matplotlib) 🌵文章目录🌵 🌳引言🌳🌳 一、Figure(图形)🌳🍁1. 创建Figure🍁🍁2. 添加Axes&am…...
问题:A注册会计师必须在期中实施实质性程序的情形是()。 #学习方法#其他
问题:A注册会计师必须在期中实施实质性程序的情形是()。 A.甲公司整体控制环境不佳 B.将期中实质性程序所获证据与期末数据进行比较 C.评估的认定层次重大错报风险很高 D.没有把握通过在期中…...
)
C#系列-C#EF框架返回单行记录(24)
在C#中,使用Entity Framework (EF)框架时,如果你想要执行一个查询并返回单行记录,你可以使用SingleOrDefault、FirstOrDefault、Single或First方法。这些方法适用于DbSet<T>对象,它们可以执行查询并返回单个实体或默认值&am…...
的生成)
【PyTorch】张量(Tensor)的生成
PyTorch深度学习总结 第一章 Pytorch中张量(Tensor)的生成 文章目录 PyTorch深度学习总结一、什么是PyTorch?二、张量(Tensor)1、张量的数据类型2、张量生成和信息获取 总结 一、什么是PyTorch? PyTorch是一个开源的深度学习框架,基于Python…...
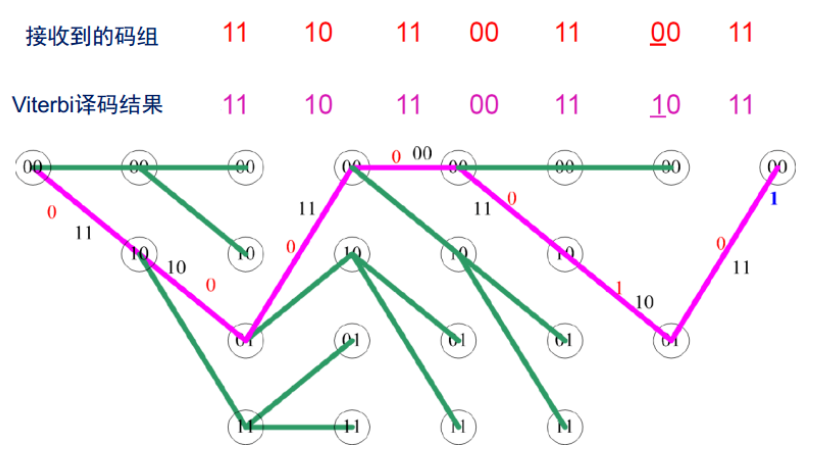
【5G NR】【一文读懂系列】移动通讯中使用的信道编解码技术-Viterbi译码原理
目录 一、引言 二、Viterbi译码的基本原理 2.1 卷积码与网格图 2.2 Viterbi算法的核心思想 2.3 路径度量与状态转移 三、Viterbi译码算法工作原理详解 3.1 算法流程 3.2 关键步骤 3.3 译码算法举例 3.4 性能特点 四、Viterbi译码的应用场景 4.1 移动通信系统 4.2 卫…...

矩阵在计算机图像处理中的应用
矩阵在计算机图像处理中是非常核心的概念,因为它们为表示和操作图像数据提供了一种非常方便和强大的方式。以下是矩阵在计算机图像处理中的一些关键作用: 图像表示:在计算机中,图像通常被表示为像素矩阵,也就是二维数组…...
Java实现教学资源共享平台 JAVA+Vue+SpringBoot+MySQL
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 课程档案模块2.3 课程资源模块2.4 课程作业模块2.5 课程评价模块 三、系统设计3.1 用例设计3.2 类图设计3.3 数据库设计3.3.1 课程档案表3.3.2 课程资源表3.3.3 课程作业表3.3.4 课程评价表 四、系统展…...
:使用 ant.jar 执行 SQL 脚本文件)
Spring Boot(六十五):使用 ant.jar 执行 SQL 脚本文件
ant用处,主要用在编译java文件,打包,部署。打包:jar,war,ear包等。ant在项目中有很重要的作用。今天我们讲解它的另一个作用:执行 SQL 脚本文件。 1 引入依赖 <dependency><groupId>org.apache.ant</groupId><artifactId>ant</artifactId&g…...
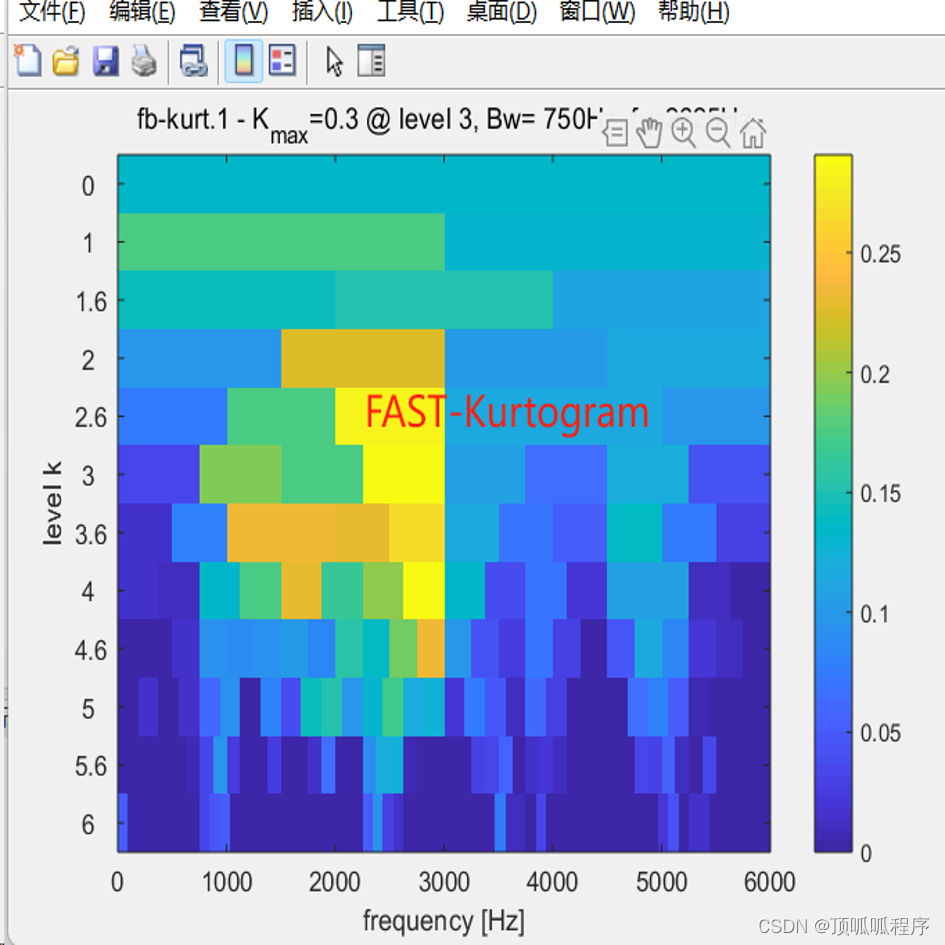
161基于matlab的快速谱峭度方法
基于matlab的快速谱峭度方法,选择信号峭度最大的频段进行滤波,对滤波好信号进行包络谱分析。输出快速谱峭度及包络谱结果。程序已调通,可直接运行。 161 信号处理 快速谱峭度 包络谱分析 (xiaohongshu.com)...
CTFshow-WEB入门-信息搜集
web1(查看注释1) wp 右键查看源代码即可找到flag web2(查看注释2) wp 【CtrlU】快捷键查看源代码即可找到flag web3(抓包与重发包) wp 抓包后重新发包,在响应包中找到flag web4(robo…...
)
django密码管理器(创建项目)
目录 创建项目 安装django 创建项目(django-admin) 创建管理员用户 创建数据库 创建项目 新建一个项目文件夹,如"密码管理器" 安装django 要先安装pip,pip安装地址:pypi.org、pypi.python.org、cheeseshop.python.org pip install django 创建项…...

Centos7之Oracle12c安装与远程连接配置
Centos7之Oracle12c安装与远程连接配置 文章目录 Centos7之Oracle12c安装与远程连接配置1.Oracle官网2. Centos7中安装Oracle12c(12.2.0.1.0)2.1 Introduction (介绍)2.2 Prerequisites(先决条件)2.3 Installation Steps(安装步骤)2.4 Oracle Installer Screens(Oracle安装程序…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...