即席查询框架怎么选?
怎么理解即席查询
即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
即席查询与批处理的区别
批处理
在数据仓库系统中,根据应用程序的需求,需要对源数据进行加工,这些加工过程往往是固定的处理原则,这种情况下,可以把数据的增删改查SQL语句写成一个批处理脚本,由调度程序定时执行。
特点:由于批处理脚本中的SQL语句是固定的,所以可以提前完成SQL语句的调优工作,使得批处理脚本的运行效率达到最佳。
即席查询
通常的方式是,将数据仓库中的维度表和事实表映射到语义层,用户可以通过语义层选择表,建立表间的关联,最终生成SQL语句。即席查询是用户在使用时临时生产的,系统无法预先优化这些查询,所以即席查询也是评估数据仓库的一个重要指标。在一个数据仓库系统中,即席查询使用的越多,对数据仓库的要求就越高,对数据模型的对称性的要求也越高。
现在市场上运用更多的是:Kylin、Druid、Presto、Impala等等这些框架去诠释大数据即席查询的功能。
此篇就来介绍四种框架的优缺点,用途与场景选择。
Kylin
Kylin特点
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
- 标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
- 支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
- 亚秒级响应:Kylin拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
- 可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
- BI工具集成
- ODBC:与Tableau、Excel、PowerBI等工具集成
- JDBC:与Saiku、BIRT等Java工具集成
- RestAPI:与JavaScript、Web网页集成
- Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
Kylin工作原理
Apache Kylin的工作原理本质上是MOLAP(Multidimension On-Line Analysis Processing)Cube,也就是多维立方体分析。在这里需要分清楚两个概念:
维度和度量
维度:即观察数据的角度。比如员工数据,可以从性别角度来分析,也可以更加细化,从入职时间或者地区的维度来观察。维度是一组离散的值,比如说性别中的男和女,或者时间维度上的每一个独立的日期。因此在统计时可以将维度值相同的记录聚合在一起,然后应用聚合函数做累加、平均、最大和最小值等聚合计算。
度量:即被聚合(观察)的统计值,也就是聚合运算的结果。比如说员工数据中不同性别员工的人数,又或者说在同一年入职的员工有多少。
Cube和Cuboid
有了维度跟度量,一个数据表或者数据模型上的所有字段就可以分类了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和度量做预计算的Cube理论。
给定一个数据模型,我们可以对其上的所有维度进行聚合,对于N个维度来说,组合的所有可能性共有2n种。对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,称为Cube
下面举一个简单的例子说明,假设有一个电商的销售数据集,其中维度包括
时间[time]、商品[item]、地区[location]和供应商[supplier]
度量为销售额。那么所有维度的组合就有16种,如下图所示:
一维度(1D)的组合有4种:[time]、[item]、[location]和[supplier]4种;
二维度(2D)的组合有6种:[time, item]、[time, location]、[time, supplier]、[item, location]、[item, supplier]、[location, supplier]
三维度(3D)的组合也有4种
最后还有零维度(0D)和四维度(4D)各有一种,总共16种
核心算法
Kylin的工作原理就是对数据模型做Cube预计算,并利用计算的结果加速查询:
- 指定数据模型,定义维度和度量;
- 预计算Cube,计算所有Cuboid并保存为物化视图;
预计算过程是Kylin从Hive中读取原始数据,按照我们选定的维度进行计算,并将结果集保存到Hbase中,默认的计算引擎为MapReduce,可以选择Spark作为计算引擎。一次build的结果,我们称为一个Segment。构建过程中会涉及多个Cuboid的创建,具体创建过程由kylin.cube.algorithm参数决定,参数值可选 auto,layer 和 inmem, 默认值为 auto,即 Kylin 会通过采集数据动态地选择一个算法 (layer or inmem),如果用户很了解 Kylin 和自身的数据、集群,可以直接设置喜欢的算法。 - 执行查询,读取Cuboid,运行,产生查询结果
逐层构建算法(layer)
一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
算法优点:
- 此算法充分利用了MapReduce的能力,处理了中间复杂的排序和洗牌工作,故而算法代码清晰简单,易于维护;
- 受益于Hadoop的日趋成熟,此算法对集群要求低,运行稳定;在内部维护Kylin的过程中,很少遇到在这几步出错的情况;即便是在Hadoop集群比较繁忙的时候,任务也能完成。
算法缺点: - 当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
- 由于Mapper不做预聚合,此算法会对Hadoop MapReduce输出较多数据; 虽然已经使用了Combiner来减少从Mapper端到Reducer端的数据传输,所有数据依然需要通过Hadoop MapReduce来排序和组合才能被聚合,无形之中增加了集群的压力;
- 对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
快速构建算法(inmem)
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,利用Mapper端计算先完成大部分聚合,再将聚合后的结果交给Reducer,从而降低对网络瓶颈的压力。该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube
与之前算法相比,快速算法主要有两点不同:
- Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
- 一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
Kylin总结
Kylin的优点
- 写SQL查询,结果预聚合.
- 有可视化页面
什么场景用Kylin
- 查询数据后想要立马可视化的
Kylin的缺点
- 集群依赖较多,如HBase和Hive等,属于重量级方案,因此运维成本也较高。
- 查询的维度组合数量需要提前确定好,不适合即席查询分析
- 预计算量大,资源消耗多
什么时候不可以用Kylin
- 查询维度过多
Impala
什么是Impala
Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。
是CDH平台首选的PB级大数据实时查询分析引擎。
Impala为什么快?
查询引擎都会分为Frontend和Backend两部分,Frontend主要用于进行SQL的语法分析、词法分析、逻辑优化等,Backend则偏向底层做物理优化。
Frontend
Frontend主要负责解析编译SQL生成后端可以执行的查询计划。
SQL的查询编译器是个标准的流程:SQL解析,语法分析,查询计划/优化。impala的查询分析器,会把标准的SQL解析成一个解析树,里面包含所有的查询信息,比如表、字段、表达式等等。一个可执行的执行计划通常包含两部分:单点的查询计划Single Node Planning 和 分布式并发查询计划 parallelization \ fragmentation。
在第一个阶段,语法解析树会被翻译成一个单点的不可以直接执行的树形结构,一般会包含:HDFS\HBase scan, hash join, cross join, union, hash agg, sort, top-n, analytic eval等。这一步主要负责基于最下层的查询节点、谓词下推、限制查询数量、join优化等优化查询性能。主要是依赖于表或者分区的统计信息进行代价评估。
第二个阶段就是基于第一个阶段优化后的单点执行计划,生成分布式的执行计划,并尽量满足最小化数据移动以及最大化数据本地性。分布式执行主要通过在节点间增加数据交换节点或者直接移动少量的数据在本地进行聚合。目前支持的join策略有broadcast和partition两种。前者是把join的整个表广播到各个节点;后者是基于hash重新分区,使得两部分数据到同一个节点。Impala通过衡量哪一种网络传输压力小,耗费的资源少,就选哪种.
所有的聚合操作都是在本地进行预聚合,然后再通过网络传输做最终的聚合。对于分组聚合,会先基于分区表达式进行的预聚合,然后通过并行的网络传输在各个节点进行每一部分的聚合。对于非分组的聚合最后一步是在单独的节点上进行。排序和TOPN的模式差不多:都是现在单独的节点进行排序/topN,然后汇总到一个节点做最后的汇总。最后根据是否需要数据交换为边界,切分整个执行计划树,相同节点的执行计划组成一个fragment。
Backend
impala的backend接收到fragment后在本地执行,它的设计采取了很多硬件上的特点,backend底层是用C++编写,使用了很多运行时代码生成的技术,对比java来说减轻内存的压力。
impala的查询设计思路也是按照volcano风格设计,处理的时候是getNext一批一批处理的。大部分的命令都是管道形式处理的,因此会消耗大量的数据存储中间数据。当执行的时候如果内存超出使用的范围,也可以把结果缓存到磁盘,经常有溢出可能的有如hash join, agg, sorting等操作。
运行时代码生成:impala内部使用了LLVM的机制,性能提升5倍。LLVM是一套与编译器相关的库,与传统的编译器不同,它更注重模块化与重用性。允许impala应用在运行时进行即时编译以及代码生成。运行时代码生成通常用于内部处理,比如用于解析文件格式的代码,对于扫描一些大表,这点尤为重要
总结几点就是:
- 真正的MPP(大规模并行处理)查询引擎。
- 使用C++开发而不是Java,降低运行负荷。
- 运行时代码生成(LLVM IR),提高效率。
- 全新的执行引擎(不是Mapreduce)。
- 在执行SQL语句的时候,Impala不会把中间数据写入到磁盘,而是在内存中完成了所有的处理。
- 使用Impala的时候,查询任务会马上执行而不是生产Mapreduce任务,这会节约大量的初始化时间。
- Impala查询计划解析器使用更智能的算法在多节点上分布式执行各个查询步骤,同时避免了sorting和shuffle这两个非常耗时的阶段,这两个阶段往往是不需要的。
- Impala拥有HDFS上面各个data block的信息,当它处理查询的时候能够在各个datanode上面更均衡的分发查询。
Impala总结:
Impala优点
- 基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。
- 无需转换为Mapreduce,直接访问存储在HDFS,HBase中的数据进行作业调度,速度快。
- 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
- 支持各种文件格式,如TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
- 可以访问hive的metastore,对hive数据直接做数据分析。
Impala缺点
- 对内存的依赖大,且完全依赖于hive。
- 实践中,分区超过1万,性能严重下降。
- 只能读取文本文件,而不能直接读取自定义二进制文件。
每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新
Presto
什么是Presto
Presto是一个facebook开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。presto的架构由关系型数据库的架构演化而来。presto之所以能在各个内存计算型数据库中脱颖而出,在于以下几点:
- 清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。例如调度,presto自身提供了对集群的监控,可以根据监控信息完成调度。
- 简单的数据结构,列式存储,逻辑行,大部分数据都可以轻易的转化成presto所需要的这种数据结构。
- 丰富的插件接口,完美对接外部存储系统,或者添加自定义的函数。
Presto的执行过程
Presto包含三类角色,coordinator,discovery,worker。coordinator负责query的解析和调度。discovery负责集群的心跳和角色管理。worker负责执行计算。
presto-cli提交的查询,实际上是一个http POST请求。查询请求发送到coordinator后,经过词法解析和语法解析,生成抽象语法树,描述查询的执行。
执行计划编译器,会根据抽象语法树,层层展开,把语法树所表示的结构,转化成由单个操作所组成的树状的执行结构,称为逻辑执行计划。
原始的逻辑执行计划,直接表示用户所期望的操作,未必是性能最优的,在经过一系列性能优化和转写,以及分布式处理后,形成最终的逻辑执行计划。这时的逻辑执行计划,已经包含了map-reduce操作,以及跨机器传输中间计算结果操作。
scheduler从数据的meta上获取数据的分布,构造split,配合逻辑执行计划,把对应的执行计划调度到对应的worker上。
在worker上,逻辑执行计划生成物理执行计划,根据逻辑执行计划,会生成执行的字节码,以及operator列表。operator交由执行驱动来完成计算。
Presto总结
优点
- Presto与Hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。
- 能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
- 部署也比Hive简单,因为Hive是基于HDFS的,需要先部署HDFS。
缺点
- 虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
- 为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
Druid
Druid是什么
Druid是一个专为大型数据集上的高性能切片和OLAP分析而设计的数据存储,druid提供低延时的数据插入,实时的数据查询。Druid最常用作为GUI分析应用程序提供动力的数据存储,或者用作需要快速聚合的高度并发API的后端。
Druid的主要特点
- 列式存储格式 Druid使用面向列的存储,这意味着它只需要加载特定查询所需的精确列。这为仅查看几列的查询提供了巨大的速度提升。此外,每列都针对其特定数据类型进行了优化,支持快速扫描和聚合。
- 高可用性与高可拓展性 Druid采用分布式、SN(share-nothing)架构,管理类节点可配置HA,工作节点功能单一,不相互依赖,这些特性都使得Druid集群在管理、容错、灾备、扩容等方面变得十分简单。Druid通常部署在数十到数百台服务器的集群中,并且可以提供数百万条记录/秒的摄取率,保留数万亿条记录,以及亚秒级到几秒钟的查询延迟。
- 实时或批量摄取 实时流数据分析。区别于传统分析型数据库采用的批量导入数据进行分析的方式,Druid提供了实时流数据分析,采用LSM(Long structure-merge)-Tree结构使Druid拥有极高的实时写入性能;同时实现了实时数据在亚秒级内的可视化。
- 容错,恢复极好的架构,不会丢失数据 一旦Druid摄取了您的数据,副本就会安全地存储在深层存储(通常是云存储,HDFS或共享文件系统)中。即使每个Druid服务器都出现故障,您的数据也可以从深层存储中恢复。对于仅影响少数Druid服务器的更有限的故障,复制可确保在系统恢复时仍可进行查询。
- 亚秒级的OLAP查询分析 Druid采用了列式存储、倒排索引、位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作。
- Druid的核心是时间序列,把数据按照时间序列分批存储,十分适合用于对按时间进行统计分析的场景
- Druid支持水平扩展,查询节点越多、所支持的查询数据量越大、响应越快
- Druid支持低延时的数据插入,数据实时可查,不支持行级别的数据更新
Druid为什么快
我们知道Druid能够同时提供对大数据集的实时摄入和高效复杂查询的性能,主要原因就是它独到的架构设计和基于Datasource与Segment的数据存储结构。
- Druid在数据插入时按照时间序列将数据分为若干segment,支持低延时地按照时间序列上卷,所以按时间做聚合效率很高
- Druid数据按列存储,每个维度列都建立索引,所以按列过滤取值效率很高
- Druid用以查询的Broker和Historical支持多级缓存,每个segment启动一个线程并发执行查询,查询支持多Historical内部的线程级并发及Historical之间的进程间并发,Broker将各Historical的查询结果做合并
Druid总结:什么选择使用
- 需要交互式聚合和快速探究大量数据时;
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
- 对数据尤其是大数据进行实时分析时;
- 需要一个高可用、高容错、高性能数据库时。
即席查询总结
- Kylin:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
- Impala:基于内存计算,速度快,支持的数据源没有Presto多。
- Presto:它没有使用Mapreduce,大部分场景下比HIVE块一个数量级,其中的关键是所有的处理都在内存中完成。
- Druid:是一个实时处理时序数据的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
相关文章:

即席查询框架怎么选?
怎么理解即席查询 即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查…...

【C语言】实现双向链表
目录 (一)头文件 (二) 功能实现 (1)初始化 (2)打印链表 (3) 头插与头删 (4)尾插与尾删 (5)指定位置之后…...
Python操作MySQL基础
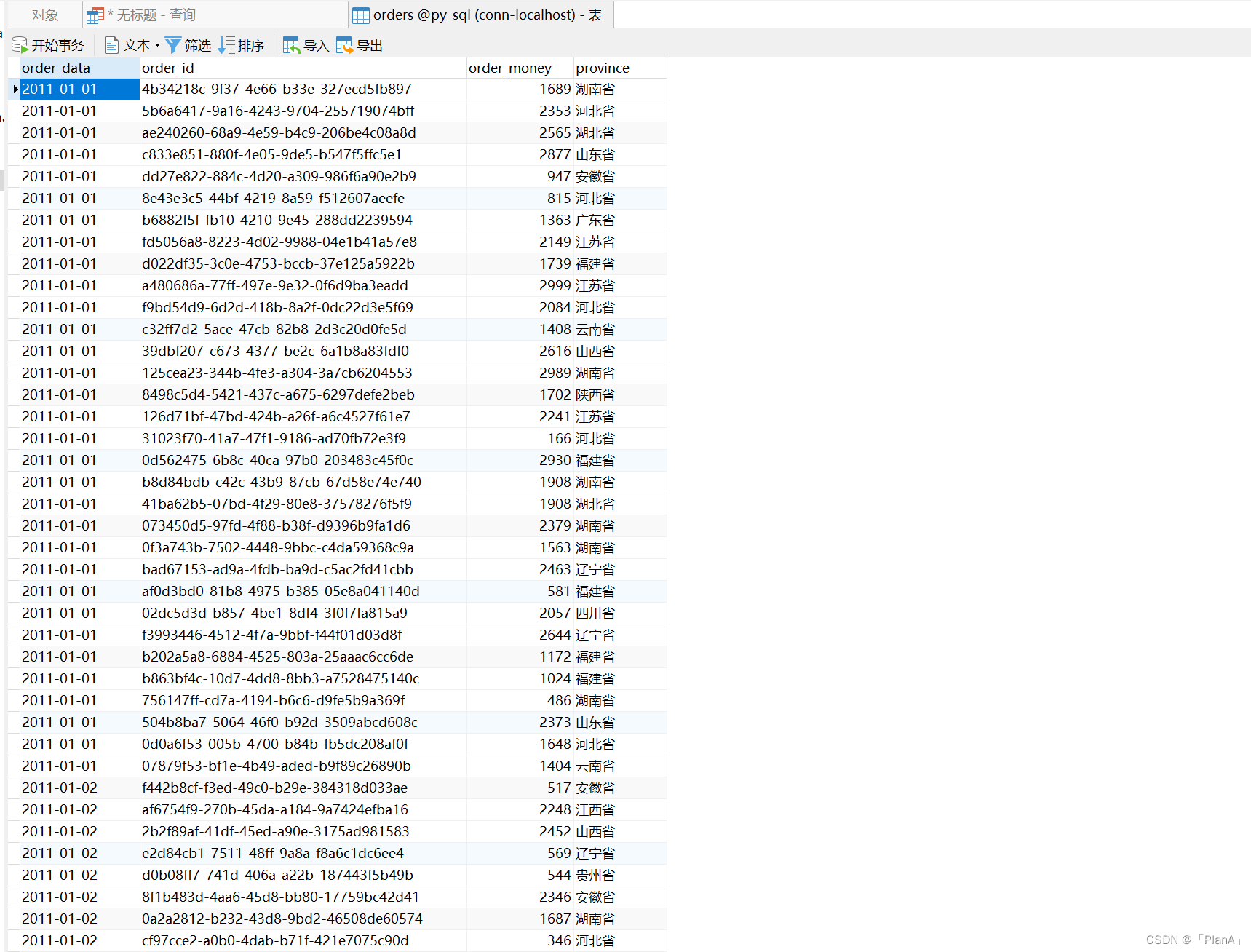
除了使用图形化工具以外,我们也可以使用编程语言来执行SQL从而操作数据库。在Python中,使用第三方库: pymysql来完成对MySQL数据库的操作。 安装第三方库pymysql 使用命令行,进入cmd,输入命令pip install pymysql. 创建到MySQL的数据库连接…...

【数学建模】【2024年】【第40届】【MCM/ICM】【E题 财产保险的可持续性】【解题思路】
一、题目 (一) 赛题原文 2024 ICM Problem E: Sustainability of Property Insurance Extreme-weather events are becoming a crisis for property owners and insurers. The world has endured “more than $1 trillion in damages from more than …...
SpringCloud--Eureka注册中心服务搭建注册以及服务发现
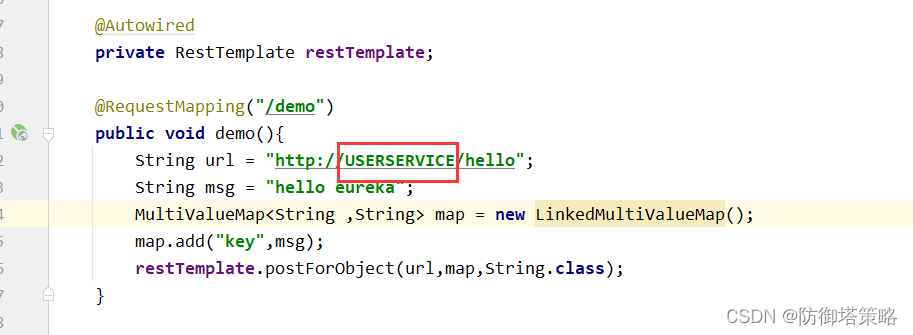
注意springboot以及springcloud版本,可能有莫名其妙的错误,这里使用的是springboot-2.6.13,springcloud-2021.0.5 一,Eureka-Server搭建: 1.创建项目:引入依赖 <dependency><groupId>org.sp…...
ansible shell模块 可以用来使用shell 命令 支持管道符 shell 模块和 command 模块的区别
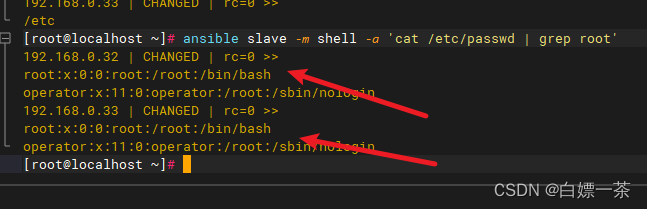
这里写目录标题 说明shell模块用法shell 模块和 command 模块的区别 说明 shell模块可以在远程主机上调用shell解释器运行命令,支持shell的各种功能,例如管道等 shell模块用法 ansible slave -m shell -a cat /etc/passwd | grep root # 可以使用管道…...

qss的使用
参考:qss样式表笔记大全(二):可设置样式的窗口部件列表(上)(持续更新示例)_51CTO博客_qss样式...

archlinux 使用 electron-ssr 代理 socks5
提前下载好 pacman 包 https://github.com/shadowsocksrr/electron-ssr/releases/download/v0.2.7/electron-ssr-0.2.7.pacman 首先要有 yay 和 aur 源,这个可以参考我之前的博客 虚拟机内使用 archinstall 安装 arch linux 2024.01.01 安装依赖 yay 安装的&#…...

macos安装local模式spark
文章目录 配置说明安装hadoop安装Spark测试安装成功 配置说明 Scala - 3.18 Spark - 3.5.0 Hadoop - 3.3.6 安装hadoop 从这里下载相应版本的hadoop下载后解压,配置系统环境变量 > sudo vim /etc/profile添加以下两行 export HADOOP_HOME/Users/collinsliu/…...
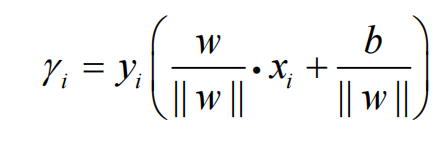
机器学习算法之支持向量机(SVM)
SVM恐怕大家即使不熟悉,也听说过这个大名吧,这一节我们就介绍这相爱相杀一段内容。 前言:在介绍一个新内容之SVM前,我们不觉映入眼帘的问题是为什么要引入SVM?吃的香,睡的着的情况下,肯定不会是…...
线性判别分析(LDA)
一、说明 LDA 是一种监督降维和分类技术。其主要目的是查找最能分隔数据集中两个或多个类的特征的线性组合。LDA 的主要目标是找到一个较低维度的子空间,该子空间可以最大限度地区分不同类别,同时保留与歧视相关的信息。 LDA 是受监督的,这意…...

Vue 前置导航
Vue 前置导航(Vue Front Navigation)是一种在 Vue.js 框架中实现导航功能的常见方式。它通常用于构建单页应用程序(Single Page Application),通过在页面顶部或侧边栏显示导航菜单,使用户能够轻松切换到不同…...

串行通信,并行通信,波特率,全双工,半双工,单工等通信概念
串行通信: 只使用一根线来进行数据发送或者是接收,串行通信传输数据是一位一位进行传输 并行通信: 使用多跟线进行数据的发送和接收,并行通信可以一次传输多个数据位 波特率: 每秒传输数据的位数,决定…...
鸿蒙系统进一步学习(一):学习资料总结,少走弯路
随着鸿蒙Next的计划越来越近,笔者之前的鸿蒙系统扫盲系列中,有很多朋友给我留言,不同的角度的问了一些问题,我明显感觉到一点,那就是许多人参与鸿蒙开发,但是又不知道从哪里下手,因为资料太多&a…...

异步复位同步释放原则
复位信号有一个非常重要的原则,叫作异步复位同步释放原则。异步复位指一个寄存器的复位信号随时可以复位,不必考虑该寄存器的时钟信号正处在哪个相位上。同步释放是指一个寄存器的复位信号从复位态回到释放态的时机,必须与该寄存器的时钟信号…...

M1 Mac使用SquareLine-Studio进行LVGL开发
背景 使用Gui-Guider开发遇到一些问题,比如组件不全。使用LVGL官方的设计软件开发 延续上一篇使用的基本环境。 LVGL项目 新建项目 选择Arduino的项目,设定好分辨率及颜色。 设计UI 导出代码 Export -> Create Template Project 导出文件如图…...
web3知识体系汇总
web3.0知识体系 1.行业发展 2. web3的特点: 1、统一身份认证系统 2、数据确权与授权 3、隐私保护与抗审查 4、去中心化运行 Web3.0思维技术思维✖金融思维✖社群思维✖产业思维”,才能从容理解未来Web3.0时代的大趋势。 3.技术栈 Web3.jsSolidit…...

服务器与电脑的区别?
目录 一、什么是服务器 二、什么是电脑 三、服务器和电脑的区别 一、什么是服务器 服务器是指一种专门提供计算和存储资源、运行特定软件服务的物理或虚拟计算机。服务器主要用于接受和处理来自客户端(如个人电脑、手机等)的请求,并向客户…...

结束 代码随想录 链表章节(下一张
环形链表II 首先,先判断有没有环,像物理相对速度一样 只要 相对速度为1 那么快指针绝对会在环里追上慢指针,最后x 和z 的距离其实最后两个index总会相遇,相遇的点就是入口 class Solution { public:ListNode *detectCycle(List…...

re:从0开始的CSS学习之路 6. 字体相关属性
1. 字体相关属性 font-size 字体大小 font-family 字体的系列(字体簇) 可以设置多个字体,每个字体之间以逗号隔开 设置多个字体的目的是为了用户尽可能的支持字体 网页字体的五大类: serif 衬线字体 sans-serif 非衬线字体 monos…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...
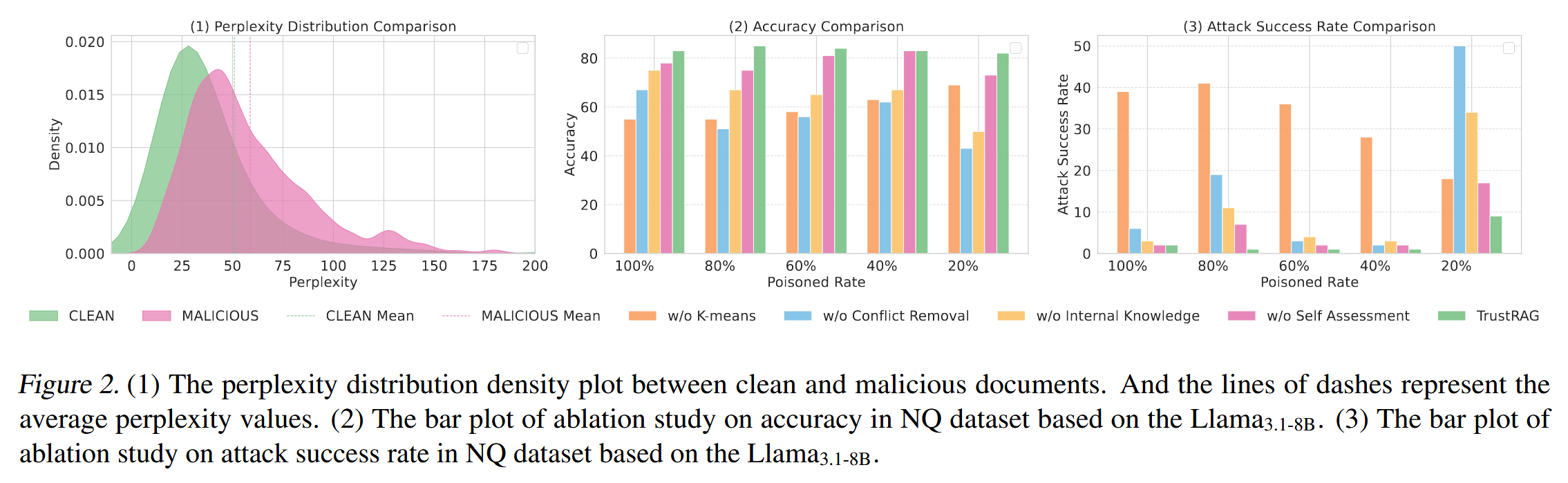
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...