交大论文下载器
原作者地址:
https://github.com/olixu/SJTU_Thesis_Crawler
问题:
http://thesis.lib.sjtu.edu.cn/的学位论文下载系统,该版权保护系统用起来很不方便,加载起来非常慢,所以该下载器实现将网页上的每一页的图片合并成一个PDF。
解决方案
:
使用PyMuPDF对图片进行合并
修改
在使用过程中发现我的mac python3执行有错,需要修改代码。
修改如下
修改fitz没有convertToPDF方法的问题
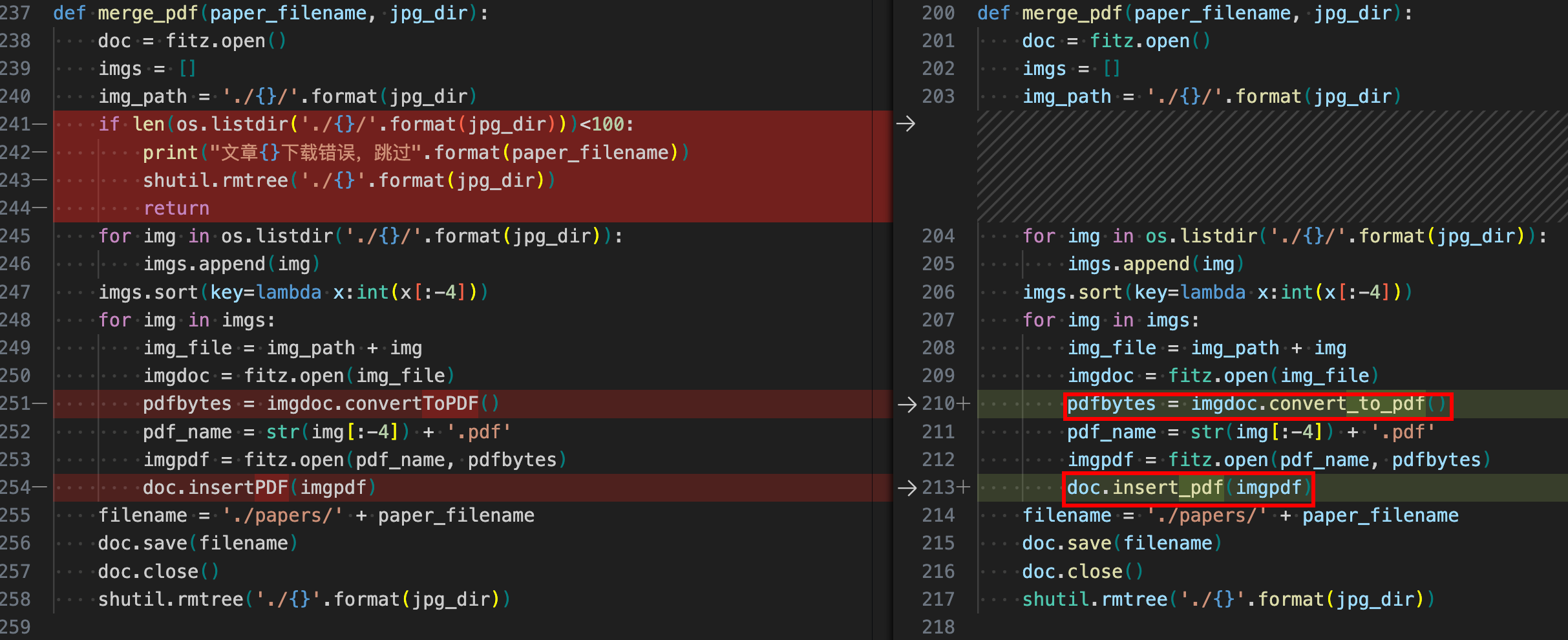
设置超时时间10s,如果超时则break
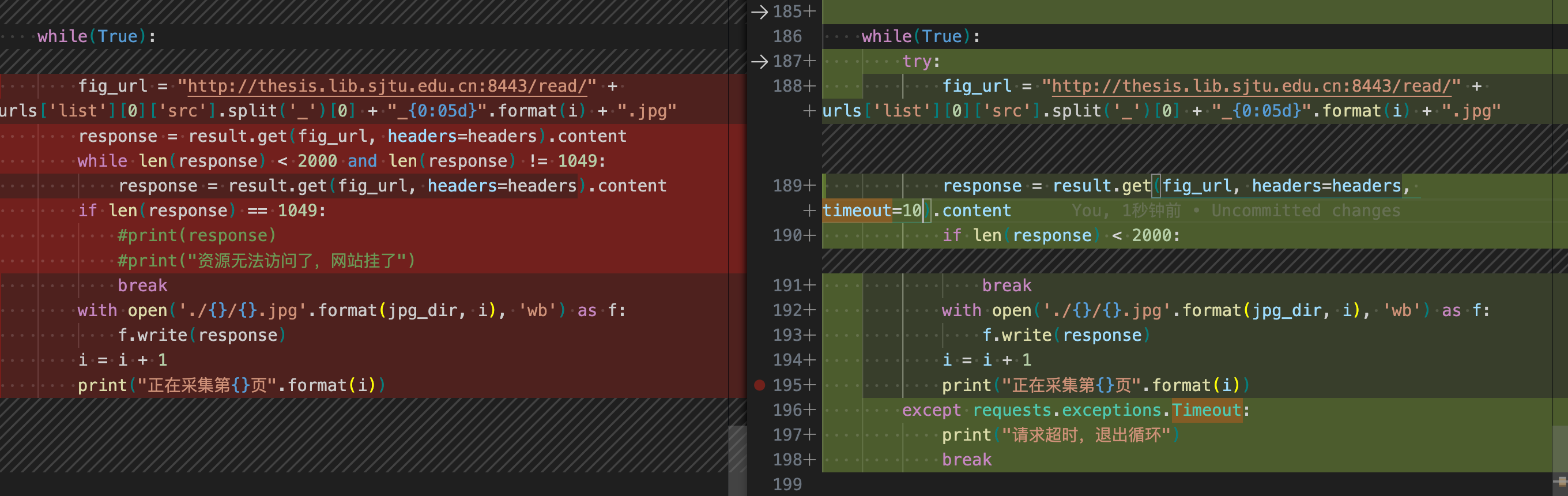
只下载电院的论文
根据题名来查询

完整代码
# -*- encoding: utf-8 -*-
'''
@File : downloader.py
@Time : 2021/06/27 10:24:10
@Author : olixu
@Version : 1.0
@Contact : 273601727@qq.com
@WebSite : https://blog.oliverxu.cn
'''# here put the import lib
from __future__ import print_function, unicode_literals
import os
import sys
import time
import random
import json
import shutil
from collections import defaultdict
from urllib.parse import quote
import requests
from lxml import etree
import fitz
from PyInquirer import style_from_dict, Token, promptdef main():"""下载学位论文入口程序:调用方式:python downloader.py --pages '1-2' --major '计算机'"""answers = search_arguments()info_url, pages = arguments_extract(answers)papers = download_main_info(info_url, pages)will_download = confirmation(papers)['confirmation']if will_download:paper_download(papers)else:print('Bye!')def paper_download(papers):jpg_dir = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + "".join(random.sample('zyxwvutsrqponmlkjihgfedcba23429837498234',5))for paper in papers:print(100*'@')paper_filename = paper['year'] + '_' + paper['filename'] + '_' + paper['author'] + '_' + paper['mentor'] + '.pdf'if verify_name(paper_filename):print("论文{}已经存在".format(paper_filename))continueprint("正在下载论文:", paper['filename'])init(jpg_dir=jpg_dir)try:download_jpg(paper['link'], jpg_dir=jpg_dir)merge_pdf(paper_filename, jpg_dir=jpg_dir)except Exception as e:print(e)def search_arguments():style = style_from_dict({Token.Separator: '#cc5454',Token.QuestionMark: '#673ab7 bold',Token.Selected: '#cc5454', # defaultToken.Pointer: '#673ab7 bold',Token.Instruction: '', # defaultToken.Answer: '#f44336 bold',Token.Question: '',})questions = [{'type': 'input','name': 'content','message': '请输入你的检索词'}]answers = prompt(questions, style=style)return answersdef arguments_extract(answers):choose_key = {'主题':'topic', '题名':'title', '关键词':'keyword', '作者':'author', '院系':'department', '专业':'subject', '导师':'teacher', '年份':'year'}xuewei = {'硕士及博士':'0', '博士':'1', '硕士':'2'}px = {'按题名字顺序排序':'1', '按学位年度倒排序':'2'}info_url = "http://thesis.lib.sjtu.edu.cn/sub.asp?content={}&choose_key={}&xuewei={}&px={}&page=".format(quote(answers['content']), \'title', \'2', \'1')print(info_url)pages = [1, 1]return info_url, pagesdef confirmation(papers):print("\033[\033[1;32m 检索到了以下{}篇文章\033[0m".format(len(papers)))for i in papers:print('\033[1;31m 题目\033[0m', i['filename'], '\033[1;34m 作者\033[0m', i['author'], '\033[1;36m 导师\033[0m', i['mentor'], '\033[1;35m 年份\033[0m', i['year'])# 这里需要格式化输出对其一下questions = [{'type': 'confirm','message': "确认下载{}篇文章吗?".format(len(papers)),'name': 'confirmation','default': 'True'}]answers = prompt(questions)return answersdef verify_name(paper_filename):if not os.path.exists('./papers'):os.mkdir('./papers')if paper_filename in os.listdir('./papers'):return Truereturn Falsedef init(jpg_dir):"""初始化文件夹路径"""try:shutil.rmtree('./{}/'.format(jpg_dir))print("删除本地{}文件夹".format(jpg_dir))except Exception as e:print(e)try:os.mkdir('./{}/'.format(jpg_dir))print("新建本地{}文件夹".format(jpg_dir))except Exception as e:print(e)def download_main_info(info_url: str, pages: list):papers = []info_url = info_urlheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'}result = requests.Session()for page in range(pages[0], pages[1]+1):print("正在抓取第{}页的info".format(page))info_url_construction = info_url + str(page)response = result.get(info_url_construction, headers=headers, allow_redirects=False)html = etree.HTML(response.content, etree.HTMLParser())for i in range(2, 22):# 有些是论文保密,所以link需要错误处理info_dict = defaultdict(str)try:# deparment = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[4]/text()'.format(i))[0]# if deparment != '(030)电子信息与电气工程学院':# continuefilename = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]//td[2]/text()'.format(i))[0]author = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[3]/div/text()'.format(i))[0]mentor = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[6]/div/text()'.format(i))[0]year = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[8]/div/text()'.format(i))[0]link = "http://thesis.lib.sjtu.edu.cn/" + html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[9]/div/a[2]/@href'.format(i))[0]info_dict['filename'] = filenameinfo_dict['author'] = authorinfo_dict['mentor'] = mentorinfo_dict['year'] = yearinfo_dict['link'] = linkpapers.append(info_dict)except Exception as e:# print(e)passprint("总共抓取到{}个元数据信息".format(len(papers)))return papersdef download_jpg(url: str, jpg_dir: str):"""下载论文链接为jpg:param url: 阅读全文链接"""url = urlheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'}result = requests.Session()print("开始获取图片地址")response = result.get(url, headers=headers, allow_redirects=False)url = response.headers['Location']response = result.get(url, headers=headers, allow_redirects=False)url = response.headers['Location']response = result.get(url, headers=headers, allow_redirects=False)url_bix = response.headers['Location'].split('?')[1]url = "http://thesis.lib.sjtu.edu.cn:8443/read/jumpServlet?page=1&" + url_bixresponse = result.get(url, headers=headers, allow_redirects=False)urls = json.loads(response.content.decode())print("已经获取到图片地址")i = 1while(True):try:fig_url = "http://thesis.lib.sjtu.edu.cn:8443/read/" + urls['list'][0]['src'].split('_')[0] + "_{0:05d}".format(i) + ".jpg"response = result.get(fig_url, headers=headers, timeout=10).contentif len(response) < 2000:breakwith open('./{}/{}.jpg'.format(jpg_dir, i), 'wb') as f:f.write(response)i = i + 1print("正在采集第{}页".format(i))except requests.exceptions.Timeout:print("请求超时,退出循环")breakdef merge_pdf(paper_filename, jpg_dir):doc = fitz.open()imgs = []img_path = './{}/'.format(jpg_dir)for img in os.listdir('./{}/'.format(jpg_dir)):imgs.append(img)imgs.sort(key=lambda x:int(x[:-4]))for img in imgs:img_file = img_path + imgimgdoc = fitz.open(img_file)pdfbytes = imgdoc.convert_to_pdf()pdf_name = str(img[:-4]) + '.pdf'imgpdf = fitz.open(pdf_name, pdfbytes)doc.insert_pdf(imgpdf)filename = './papers/' + paper_filenamedoc.save(filename)doc.close()shutil.rmtree('./{}'.format(jpg_dir))if __name__=='__main__':main()相关文章:
交大论文下载器
原作者地址: https://github.com/olixu/SJTU_Thesis_Crawler 问题: http://thesis.lib.sjtu.edu.cn/的学位论文下载系统,该版权保护系统用起来很不方便,加载起来非常慢,所以该下载器实现将网页上的每一页的图片合并…...
)
全栈笔记_浏览器扩展篇(manifest.json文件介绍)
manifest.json介绍 是web扩展技术必不可少的插件配置文件,放在根目录作用: 指定插件的基本信息 name:名称manifest_version:manifest.json文件的版本号,可以写2或3version:版本description:描述定义插件的行为: browser_action:添加一个操作按钮到浏览器工具栏,点击按…...
)
蓝桥杯每日一题(python)
##斐波那契数列的应用 --- 题目斐波那契 题目: 如果数组 A (a0, a1, , an−1) 满足以下条件,就说它是一个斐波那契数组: 1. n ≥ 2; 2. a0 a1; 3. 对于所有的 i(i ≥ 2),都满足 ai ai−1 ai−2…...

【Vue】工程化开发脚手架Vue CLI
📝个人主页:五敷有你 🔥系列专栏:Vue⛺️稳重求进,晒太阳 工程化开发&脚手架Vue CLI 基本介绍 Vue Cli是Vue官方提供的一个全局命令工具 可以帮助我们快速创建一个开发Vue项目的标准化基础架子【集成了we…...

嵌入式培训机构四个月实训课程笔记(完整版)-Linux ARM驱动编程第三天-ARM Linux ADC和触摸屏开发 (物联技术666)
链接:https://pan.baidu.com/s/1V0E9IHSoLbpiWJsncmFgdA?pwd1688 提取码:1688 教学内容: 1、ADC S3C2440的A/D转换器包含一个8通道的模拟输入转换器,可以将模拟输入信号转换成10位数字编码。 在A/D转换时钟频率为2.5MHz时&…...
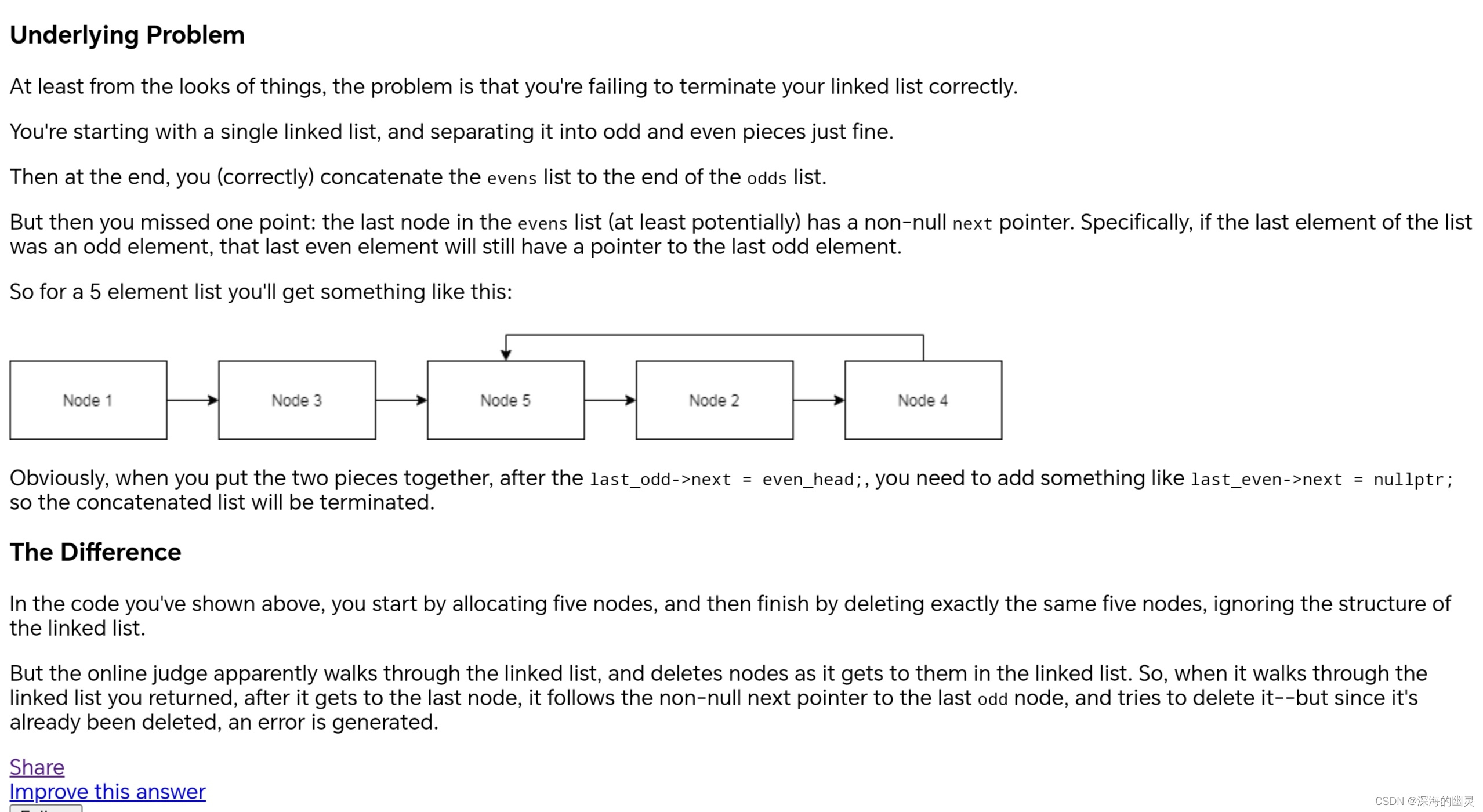
LeetCode “AddressSanitizer:heat-use-after-free on address“问题解决方法
heat-use-after-free : 访问堆上已经被释放的内存地址 现象:同样代码在LeetCode上报错,但是自己在IDE手动打印并不会报错 个人猜测,这个bug可能来源于LeetCode后台输出打印链表的代码逻辑问题。 问题描述 题目来自LeetCode的8…...

幸运彩票
L1-6 幸运彩票 分数 15 作者 陈越 单位 浙江大学 彩票的号码有 6 位数字,若一张彩票的前 3 位上的数之和等于后 3 位上的数之和,则称这张彩票是幸运的。本题就请你判断…...

搭建yum仓库服务器
安装 1.安装linux 1.1安装依赖 yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel 1.2下载 cd /opt/nginx wget http://nginx.org/download/nginx-1.25.3.tar.gz 1.3解压 tar -xvf nginx-1.25.3.tar.gz 1.4配置 cd nginx-1.25.3 ./configure --pre…...

贪心算法练习day1
练习1--翻硬币 1)题目及要求 2)解题思路 输入的是字符串,要想将两组字符串进行一一对比,需要将字符串转换成字符数组,再使用for循环依次遍历字符数组,进行比对。 输入两行字符串,转换成两个字…...
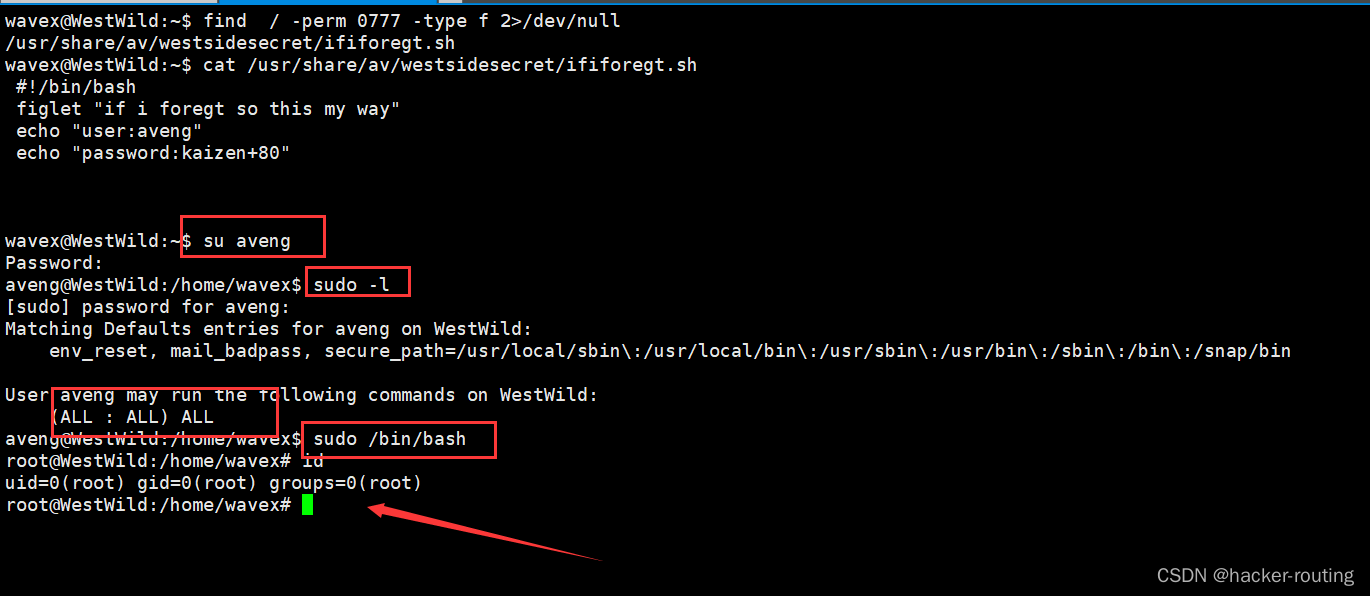
[VulnHub靶机渗透] WestWild 1.1
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【python】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收藏…...

如何使用 ControlValueAccessor 在 Angular 中创建自定义表单控件
简介 在 Angular 中创建表单时,有时您希望拥有一个不是标准文本输入、选择或复选框的输入。通过实现 ControlValueAccessor 接口并将组件注册为 NG_VALUE_ACCESSOR,您可以将自定义表单控件无缝地集成到模板驱动或响应式表单中,就像它是一个原…...
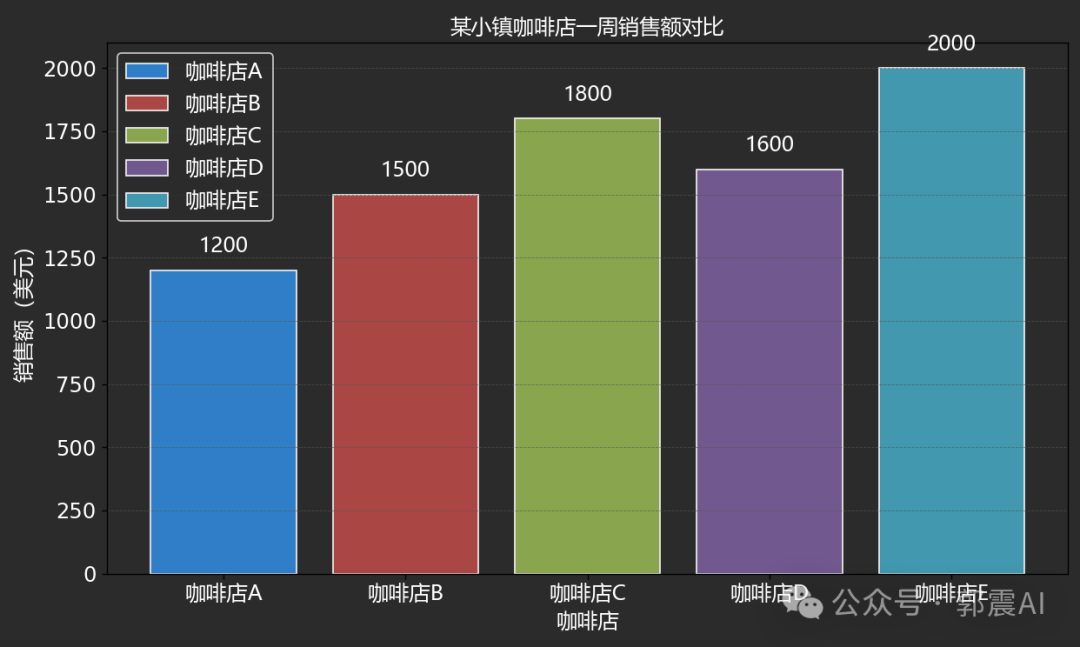
视频讲解:优化柱状图
你好,我是郭震 AI数据可视化 第三集:美化柱状图,完整视频如下所示: 美化后效果前后对比,前: 后: 附完整案例源码: util.py文件 import platformdef get_os():os_name platform.syst…...

OpenAI宣布ChatGPT新增记忆功能;谷歌AI助理Gemini应用登陆多地区
🦉 AI新闻 🚀 OpenAI宣布ChatGPT新增记忆功能,可以自由控制内存,提供个性化聊天和长期追踪服务 摘要:ChatGPT新增的记忆功能可以帮助AI模型记住用户的提问内容,并且可以自由控制其内存。这意味着用户不必…...

Solidworks:平面草图练习
继续练习平面草图,感觉基本入门了。...
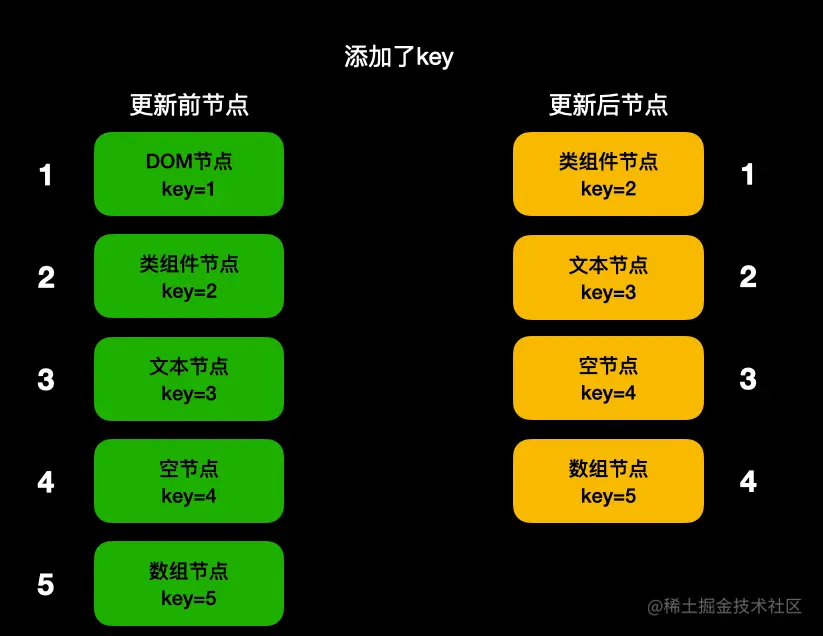
React18原理: 渲染与更新时的重点关注事项
概述 react 在渲染过程中要做很多事情,所以不可能直接通过初始元素直接渲染还需要一个东西,就是虚拟节点,暂不涉及React Fiber的概念,将vDom树和Fiber 树统称为虚拟节点有了初始元素后,React 就会根据初始元素和其他可…...
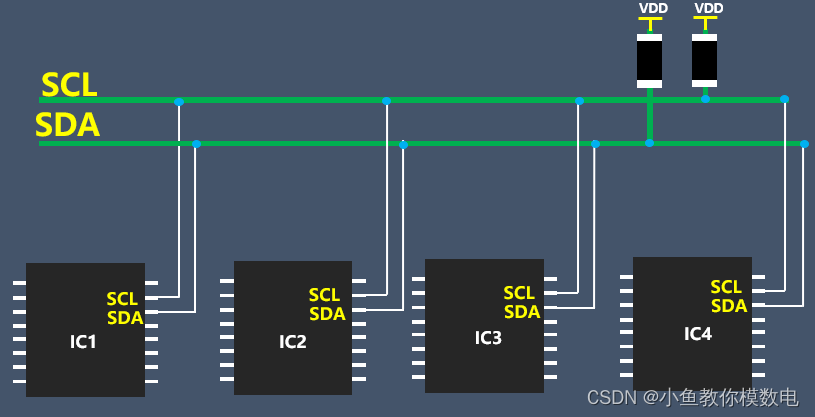
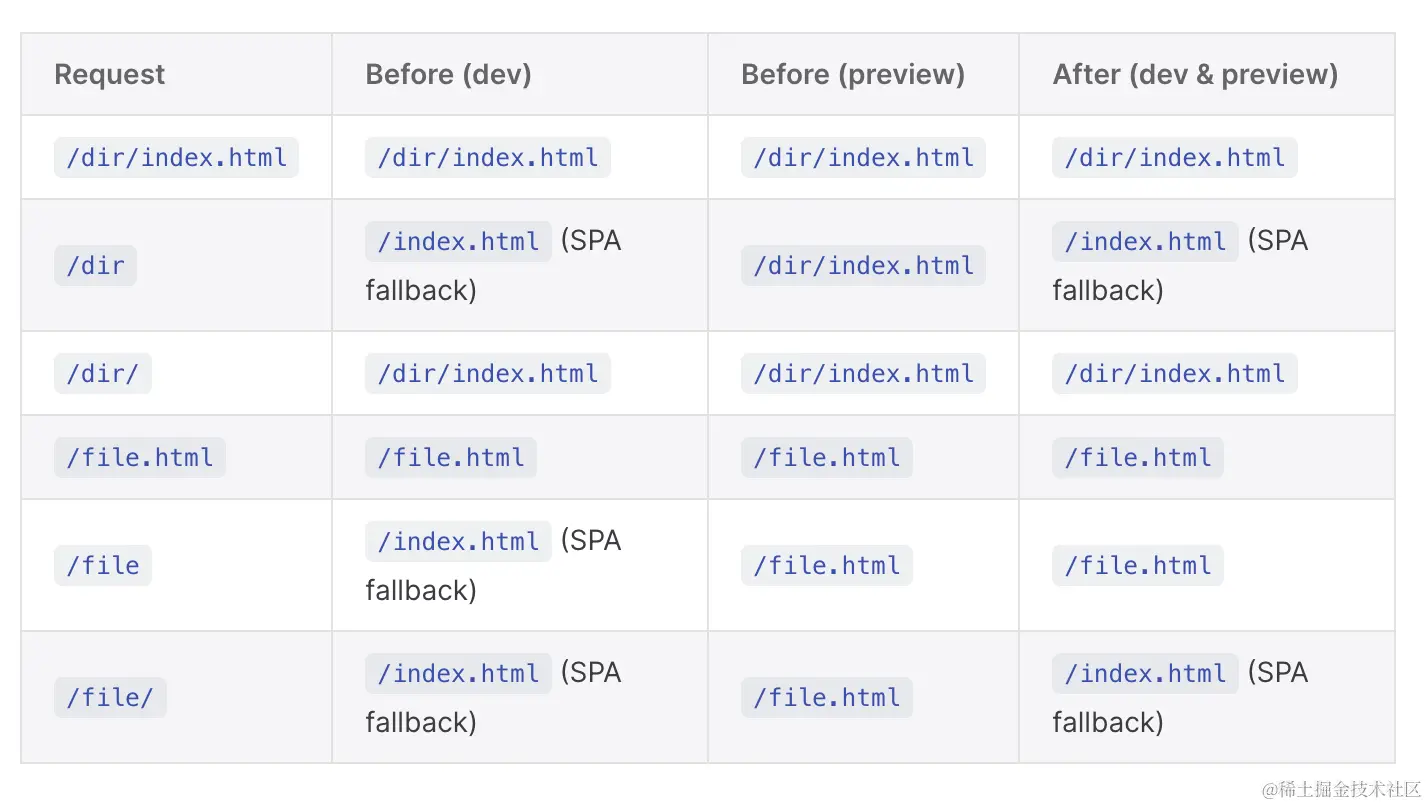
嵌入式I2C 信号线为何加上拉电阻(图文并茂)
IIC 是一个两线串行通信总线,包含一个 SCL 信号和 SDA 信号,SCL 是时钟信号,从主设备发出,SDA 是数据信号,是一个双向的,设备发送数据和接收数据都是通过 SDA 信号。 在设计 IIC 信号电路的时候我们会在 SC…...
Vite 5.0 正式发布
11 月 16 日,Vite 5.0 正式发布,这是 Vite 道路上的又一个重要里程碑!Vite 现在使用 Rollup 4,这已经代表了构建性能的大幅提升。此外,还有一些新的选项可以改善开发服务器性能。 Vite 4 发布于近一年前,它…...
嵌入式STM32 单片机 GPIO 的工作原理详解
STM32的 GPIO 介绍 GPIO 是通用输入/输出端口的简称,是 STM32 可控制的引脚。GPIO 的引脚与外部硬件设备连接,可实现与外部通讯、控制外部硬件或者采集外部硬件数据的功能。 以 STM32F103ZET6 芯片为例子,该芯片共有 144 脚芯片,…...

系统调用的概念
在嵌入式开发、操作系统开发以及一般的系统编程中,系统调用是一个核心概念。它允许用户空间程序请求内核执行某些操作,如打开文件、读写数据、创建进程等。这些操作通常需要特殊的权限或访问硬件资源,因此不能直接在用户模式下执行。 系统调…...
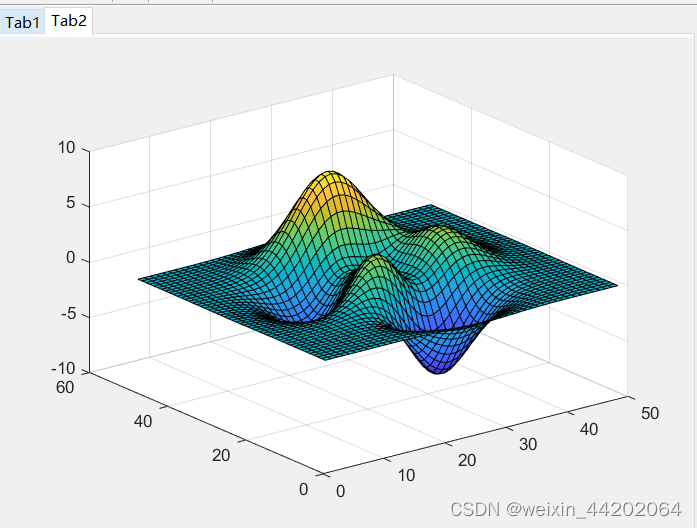
【无标题】Matlab 之axes函数——创建笛卡尔坐标区
**基本用法:**axes 在当前图窗中创建默认的笛卡尔坐标区,并将其设置为当前坐标区。 应用场景1:在图窗中放置两个 Axes 对象,并为每个对象添加一个绘图。 要求1:指定第一个 Axes 对象的位置,使其左下角位于…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...