深度学习中数据的转换
原始(文本、音频、图像、视频、传感器等)数据被转化成结构化且适合机器学习算法或深度学习模型使用的格式。

原始数据转化为结构化且适合机器学习和深度学习模型使用的格式,通常需要经历以下类型的预处理和转换:
-
文本数据:
- 文本清洗:去除特殊字符、标点符号、数字等,并进行大小写统一、去停用词。
- 分词或Tokenization:将文本分割成单词、词语或其他单位。
- 词汇编码:构建词汇表并为每个词分配一个整数ID;或者直接应用预训练的词嵌入(如Word2Vec、GloVe)。
- 序列填充或截断:使所有序列具有相同长度以适应模型输入要求。
-
音频数据:
- 数据加载:读取音频文件并转换为数字信号,如PCM样本。
- 预处理:标准化音频信号幅度、降噪、分帧、提取MFCCs(梅尔频率倒谱系数)或其他特征表示。
- 转换为张量:组织特征矩阵为适合模型输入的张量形式。
-
图像数据:
- 图像读取:使用库如PIL、OpenCV等加载图片文件。
- 大小调整:根据模型需求对图像尺寸进行缩放或裁剪。
- 归一化:将像素值从0-255范围归一化到0-1之间。
- 转换为张量:将图像数据转化为numpy数组后通过
torch.tensor()或tf.convert_to_tensor()将其转换为张量。
-
视频数据:
- 视频解码:读取视频文件并逐帧提取图像。
- 单帧图像处理:对每一帧执行与图像数据相同的预处理步骤。
- 特征提取:可能包括运动特征、光流等高级特征的计算。
- 将连续帧堆叠或串联起来形成三维张量(帧数×高度×宽度×通道数)。
-
传感器数据:
- 读取与解析:获取传感器输出的原始数据,可能是CSV、JSON或其他格式。
- 异常值处理:识别并处理异常或错误的测量值。
- 特征工程:构造有助于描述系统状态的时间序列特征,如移动平均、差分、滑动窗口统计量等。
- 转换为张量:将处理后的数据整理为一维或多维张量,用于时序模型的输入。
经过以上预处理和转换,原始数据可以被有效整合进机器学习或深度学习算法中,作为模型训练和预测的基础。
1.常见的数据类型
-
文本数据(Text Data):
- 文本数据是由字符或单词组成的非结构化数据,可以是电子邮件、文章、社交媒体帖子、书籍、文档等。
- 文本挖掘和自然语言处理技术用于从这种数据中提取信息和洞察。
-
音频数据(Audio Data):
- 音频数据包含声音信号,可以是语音、音乐或其他声波形式,通常以数字音频文件的形式存储,表示为时间序列信号。
- 在语音识别、语音合成、音乐信息检索等领域广泛应用。
-
视频数据(Video Data):
- 视频数据是一种复杂的数据类型,它结合了图像帧序列与音频流,包含了时间和空间两个维度的信息。
- 用于视频分析、行为识别、动作捕捉、实时监控等多个领域。
-
网络/图数据(Network/Graph Data):
- 图数据由节点(顶点)和边组成,描述实体之间的关系。例如社交网络中的用户关系、网页间的链接结构等。
- 社交网络分析、推荐系统、知识图谱构建等工作都会用到图数据。
-
传感器数据(Sensor Data):
- 来自各种物理设备(如温度计、运动传感器、GPS等)连续测量并记录的数据,通常表现为时间序列。
- 应用于物联网(IoT)、工业自动化、健康监测等多种场景。
-
地理位置数据(Geospatial Data):
包括经纬度坐标、地理编码、地图数据等,用于地理信息系统(GIS)、导航、位置服务等方面。 -
多模态数据(Multimodal Data):
同时包含两种或多种不同类型的数据,例如文本+图像(带有说明的图片)、视频+音频(电影片段)等。 -
元数据(Metadata):
描述其他数据的数据,例如文件创建日期、作者信息、文件大小等,有助于管理和理解底层数据。
每种数据类型都有其特定的处理方法和技术,根据应用场景选择合适的分析工具和算法进行处理和分析。
2.常见的序列数据类型
序列数据是指由一个或多个元素按照特定顺序排列的数据结构,每个元素在序列中都有其唯一的位置(索引)。在不同的编程语言和应用领域中,序列数据广泛存在,并且有多种具体表现形式。以下是几种常见的序列数据类型:
-
列表 (List):
在Python中,列表是可变的有序集合,可以包含任意类型的元素,并通过索引访问。 -
元组 (Tuple):
同样在Python中,元组也是有序的,但它是不可变的,一旦创建就不能修改。 -
数组:
许多编程语言如C、Java、JavaScript等提供数组数据类型,它是一个固定大小的、相同数据类型元素的集合,可以通过索引进行访问。 -
字符串 (String):
字符串本质上是一种字符序列,在大多数编程语言中被视为一种特殊的有序序列。 -
时间序列数据:
在数据分析领域,时间序列是一系列按时间排序的数据点,通常用于表示某种度量随时间的变化情况,例如股票价格、气温记录、网页点击流等。 -
向量和矩阵:
在数学和机器学习中,向量和矩阵是数值型数据的有序集合,它们具有线性和空间维度的概念。 -
队列 (Queue) 和 栈 (Stack):
这两种数据结构也是一种特殊类型的序列,队列遵循先进先出(FIFO)原则,而栈遵循后进先出(LIFO)原则。 -
序列化数据:
在数据存储和传输过程中,将对象转换成一连串的比特或字节序列的过程也产生序列数据。 -
音频信号 和 视频帧:
在多媒体处理领域,音频信号是由一系列采样点构成的,视频则是由连续的图像帧组成的序列。
这些序列数据结构和概念在算法设计、数据处理、机器学习模型训练等诸多方面都扮演着重要角色。
3.将不同类型的原始数据结构化处理
将不同类型的原始数据转化为适合深度学习模型使用的结构化格式,会因数据类型的不同而采取不同的处理方式。以下是一些常见数据类型的转化方法:
-
文本数据:
- 预处理:如前所述,包括清洗、分词、去除停用词等。
- 编码:构建词汇表并进行词索引编码,或者直接应用预训练的词嵌入模型。
- 序列填充或截断以适应固定长度。
-
数值数据:
- 标准化/归一化:对连续数值特征进行标准化(Z-score标准化)或归一化(Min-Max归一化),使得所有特征在同一尺度上,并消除量纲影响。
- 处理缺失值:可以使用平均值、中位数或众数填充缺失数值,或者采用插值、多重插补等更复杂的方法。
-
分类数据:
- 独热编码(One-hot Encoding):对于类别变量,将其转换为一组二进制向量,其中只有一个元素为1,代表当前类别。
- 整数编码(Label Encoding):对于有序类别或离散类别,也可以直接映射为整数。
-
图像数据:
- 数据加载:读取图像文件并转换为数组形式,常用的是三维张量(宽度、高度、通道数)。
- 预处理:包括尺寸调整(统一输入大小)、色彩空间转换(RGB到灰度或RGB到BGR等)、归一化(通常将像素值缩放到0-1之间)。
-
时间序列数据:
- 重采样与填充:处理不规则的时间间隔,可能需要通过插值等方式转换为均匀时间步长的序列。
- 特征提取:根据时序特性构造滑动窗口、统计特征(如移动平均、方差等)。
-
多模态数据:
- 各模态数据单独预处理后,再进行融合,例如联合文本和图像特征进行处理。
最终的目标是将所有这些预处理后的数据整合成深度学习模型所需的输入格式,通常是张量(Tensor)形式,以便在神经网络中进行高效计算。
4.原始文本数据的结构化处理(具体步骤)
将原始文本数据转化成适合深度学习模型使用的结构化格式通常涉及以下几个关键步骤:
-
预处理:
- 文本清洗:去除无关字符(如特殊符号、标点符号等),转换为统一的大小写,以及删除停用词(在自然语言处理中常见但不携带过多语义信息的词汇)。
- 分词/Tokenization:将文本分割成单词或子词单位。对于一些语言可能还需要进行分词。
-
编码:
- 将词语映射到整数索引:构建一个词汇表,并为每个唯一的词分配一个整数ID。这样文本就变成了整数序列。
- 词嵌入(Word Embedding):进一步将这些整数索引转化为固定维度的稠密向量表示,例如可以使用预先训练好的词向量模型(如Word2Vec、GloVe)或在训练过程中自动生成(如通过神经网络模型训练得到)。
-
填充与截断:
对于深度学习中的序列模型(如RNN、LSTM或Transformer),需要确保所有输入序列具有相同的长度。对于过长的序列,可以选择截断;对于过短的序列,则可以通过添加特殊填充token(如<pad>标记)来填充至相同长度。 -
构建批次:
将预处理并编码后的文本数据组织成批量样本,用于后续模型训练和预测。 -
标签处理:
如果是分类任务,需要对类别标签进行编码,如独热编码(one-hot encoding)或者整数编码;如果是序列标注任务,则需将标签序列也进行同样的预处理和编码。
完成以上步骤后,原始文本数据就转化成了深度学习模型能够直接接受和处理的结构化数值形式。
5.深度学习中原始数据转换成张量数据(代码操作示例)
在深度学习中,原始数据通常需要经过预处理并转换为张量(Tensor)格式,以便于在诸如PyTorch或TensorFlow等框架中进行训练和推断。以下是几种常见类型原始数据转换成张量的步骤:
图像数据
- 读取图像:使用
PIL、OpenCV等库加载图片文件。 - 转换颜色空间(如果必要):将图像从RGB或其他颜色模式转换为模型期望的颜色空间,例如灰度或RGB。
- 尺寸调整:根据模型要求对图像进行缩放或裁剪到合适的大小。
- 归一化:将像素值标准化至0-1之间(除以255),或者按需应用其他类型的归一化方法。
- 转换为张量:使用如
torchvision.transforms中的ToTensor()函数将numpy数组形式的图像数据转换为PyTorch张量。
Python
1import torch
2from torchvision import transforms
3
4# 转换器
5transform = transforms.Compose([
6 transforms.Resize((224, 224)),
7 transforms.ToTensor(),
8 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 对于ImageNet数据集常见的均值和标准差归一化
9])
10
11# 加载图像并转换为张量
12image = Image.open('path_to_image.jpg')
13image_tensor = transform(image)数值型数据(如CSV)
- 读取数据:使用
pandas读取CSV文件,并可能进行缺失值填充、离群值处理等操作。 - 特征提取与编码:将分类变量进行独热编码或其他形式的数值化处理。
- 数据归一化:对数值特征进行标准化或归一化。
- 转换为张量:将处理后的numpy数组通过
torch.from_numpy()或直接构造torch.tensor()来创建张量。
Python
1import pandas as pd
2import torch
3
4# 读取数据
5data = pd.read_csv('dataset.csv')
6
7# 数据预处理...
8# 假设 data_processed 是已经预处理好的数值型数据
9numpy_data = data_processed.values
10
11# 创建张量
12tensor_data = torch.from_numpy(numpy_data)
13
14# 或者对于多维数据,比如序列数据
15# 可能需要添加维度,例如时间步长维度
16tensor_sequence_data = torch.tensor(numpy_data).unsqueeze(1) # 添加一个维度表示序列序列数据(如文本)
- 分词或编码:将文本转换为单词索引或嵌入向量(如使用
Tokenizer类,如Hugging Face Transformers库中的BertTokenizer)。 - 填充或截断:确保所有序列长度相同,对于过短的序列进行填充(padding),过长的序列进行截断(truncation)。
- 构建张量:将编码后的序列作为张量的一维或多维元素。
Python
1from transformers import BertTokenizer
2
3tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
4
5# 分词并转换为ID列表
6inputs = tokenizer("This is a text sequence", return_tensors='pt')
7
8# 输入已经是张量形式了
9input_ids = inputs['input_ids']
10attention_mask = inputs['attention_mask'] # 对于BERT模型,还需要注意mask总的来说,无论是哪种类型的数据,最终的目标都是将其组织成适合神经网络输入的形式——即具有正确维度、数据类型和结构的张量。
附:具有正确维度、数据类型和结构的张量:
在深度学习和机器学习中,张量(Tensor)是表示多维数据的数据结构。为了使原始数据能够被机器学习或深度学习算法有效地处理,需要将数据转换为具有正确维度、数据类型和结构的张量。
-
正确维度:张量的维度反映了数据的结构,例如:
- 一维张量可以代表一个序列,如文本中的单词索引序列。
- 二维张量通常用于表示图像数据,其中第一维对应高度,第二维对应宽度,第三维(如果存在)则可能表示颜色通道(对于RGB图像有3个通道)。
- 高维张量可用于表示更复杂的数据结构,如视频数据(时间步长×高度×宽度×通道数),或者多个样本组成的批量数据(样本数×特征数)。
-
数据类型:张量中的元素应具有适合模型训练和预测的数据类型,常见的包括:
- 浮点型(float32或float64):用于存储数值型特征或权重等。
- 整型(int32或int64):常用于表示类别标签或词索引等离散值。
- 布尔型(bool):在某些情况下用于标记位或二元分类结果。
-
结构:张量的结构必须与所使用的模型架构相匹配。例如,在使用卷积神经网络处理图像时,输入张量的形状应该是
(batch_size, channels, height, width);而在处理文本任务时,输入通常是经过编码的词嵌入张量,其形状可能是(batch_size, sequence_length, embedding_size)。
通过上述步骤对原始数据进行预处理,并将其转化为正确的张量形式后,这些数据就能直接作为深度学习模型的输入,进行后续的学习和推理过程。
相关文章:
深度学习中数据的转换
原始(文本、音频、图像、视频、传感器等)数据被转化成结构化且适合机器学习算法或深度学习模型使用的格式。 原始数据转化为结构化且适合机器学习和深度学习模型使用的格式,通常需要经历以下类型的预处理和转换: 文本数据…...

如何系统地自学 Python?
目录 Python 数据类型 控制结构 函数和模块 文件操作 异常处理 类和对象 列表推导式和生成器 匿名函数和高阶函数 面向对象编程 总结 Python Python是一种面向对象、解释型计算机程序设计语言,由Guido van Rossum于1989年发明,第一个公开发行…...

【软考】传输层协议之UDP
目录 一、说明二、特点 一、说明 1.用户数据报协议(User Datagram Protocol)是一种不可靠的、无连接的协议,可以保证应用程序进程间的通信 2.与TCP相比,UDP是一种无连接的协议,它的错误检测功能要弱很多 3.TCP有助于提…...
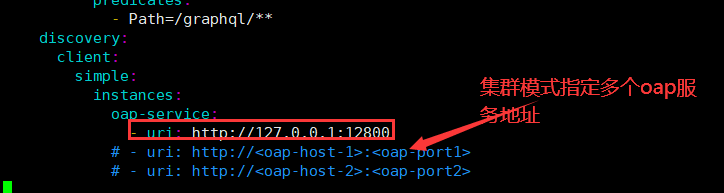
微服务-微服务链路追踪组件Skywalking实战
自动化监控系统Prometheus&Grafana实战: https://vip.tulingxueyuan.cn/detail/v_60f96e69e4b0e6c3a312c726/3?fromp_6006cac4e4b00ff4ed156218&type8&parent_pro_idp_6006d8c8e4b00ff4ed1569b2 APM-性能监控项目班: https://vip.tuling…...

Stream、Collections、Collectors用法
当涉及Java编程中的集合处理时,Stream、Collections和Collectors是三个常用的工具。以下是它们各自的主要功能和使用的一些方法的概要: Stream: 概要:Stream 是 Java 8 引入的一个强大工具,用于处理集合数据的流式操作…...

Jetson Xavier NX 与笔记本网线连接 ,网络共享,ssh连接到vscode
Jetson Xavier NX 与笔记本网线连接 ,网络共享,ssh连接到vscode Jetson Xavier NX桌面版需要连接显示屏、鼠标和键盘,操作起来并不方便,因此常常需要ssh远程连接到本地笔记本电脑,这里介绍一种连接方式,通过…...
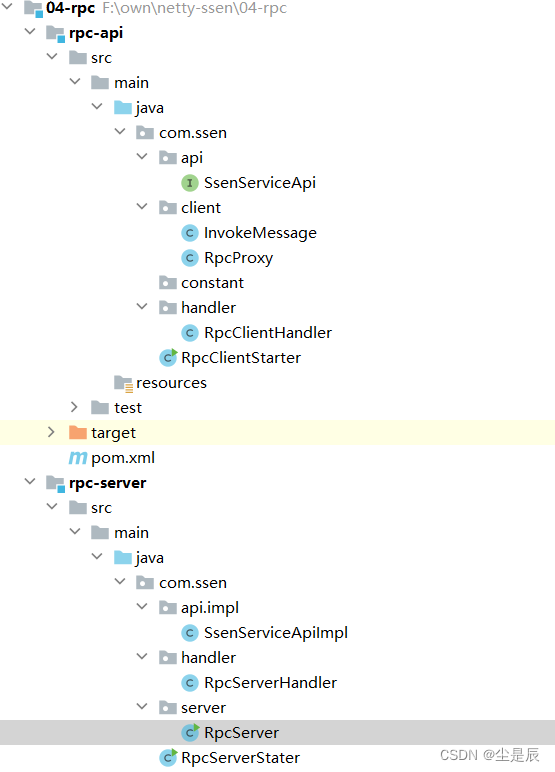
利用netty手写rpc框架
前言:利用netty异步事件驱动的网络通信模型,来实现rpc通信 一、大致目录结构: 二、两个端:服务端(发布),客户端(订阅消费),上代码: 1.服务端&am…...

js+views 压缩上传的图片
安装image-conversion插件,在before-upload方法中对上传的图片文件进行处理 遇到的问题: 1、因为在上传文件之前的钩子中对图片进行了压缩处理,所以组件中上传的data会丢失,需要重新赋值 2、imageConversion 的引入需要使用impor…...
【安卓基础5】中级控件
🏆作者简介:|康有为| ,大四在读,目前在小米安卓实习,毕业入职 🏆本文收录于 安卓学习大全持续更新中,欢迎关注 🏆安卓学习资料推荐: 视频:b站搜动脑学院 视频…...
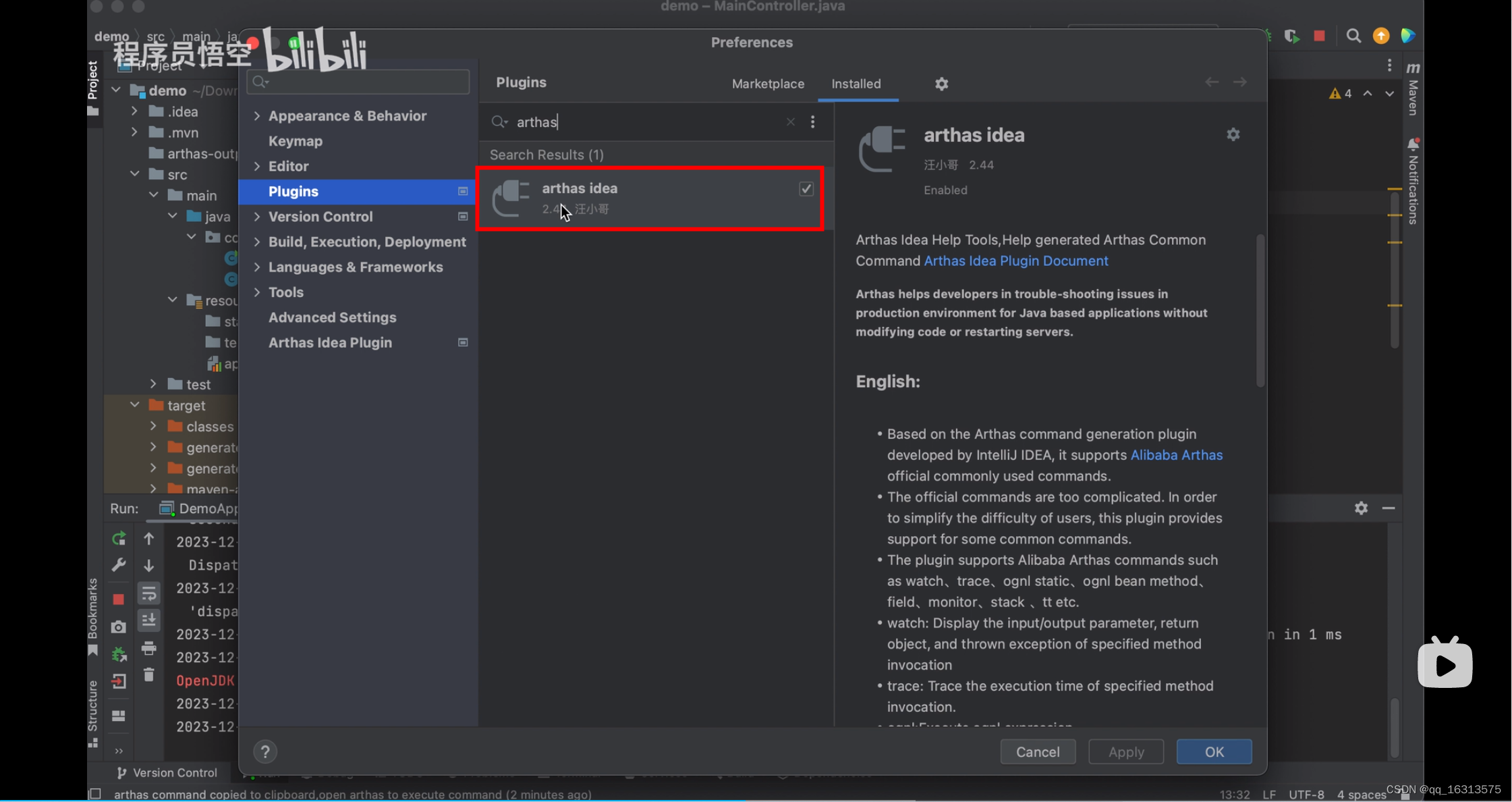
Arthas—【学习篇】
1. Arthas官网 arthas 2. 下载 从 Maven 仓库下载 最新版本,点击下载:编辑在新窗口打开 点击这个 mavrn-central 即可显示下面的图片 #从 Github Releases 页下载 Releases alibaba/arthas GitHub 3. 解压 将压缩包复制到一个位置&…...

css pointer-events 多层鼠标点击事件
threejs 无法滑动视角,菜单界面覆盖threejs操作事件。 pointer-events /* Keyword values */ pointer-events: auto; pointer-events: none; pointer-events: visiblePainted; /* SVG only */ pointer-events: visibleFill; /* SVG only */ pointer-events: visib…...

k8s中基于alpine的pod无法解析域名问题
现象 在pod内无法解析指定域名 # 执行ping bash-4.4# ping xx-xx-svc-0.xxx-fcp.svc.cluster.local ping: bad address xx-xx-svc-0.xxx-fcp.svc.cluster.local排查经过 # 执行nslookup bash-4.4# nslookup xx-xx-svc-0.xxx-fcp.svc.cluster.local Server: 172.43.0…...

缩小ppt文件大小的办法
之前用别人模版做了个PPT,100多M,文件存在卡顿问题 解决办法: 1.找到ppt中哪个文件过大,针对解决 2.寻找视频/音频文件,减少体积 3.字体文件是不是过多的问题。 一、文件寻找的内容步骤: 步骤: 1.把p…...
vue3中使用 tui-image-editor进行图片处理,并上传
效果图 下载包 pnpm i tui-image-editor pnpm i tui-color-picker调用组件 //html部分 <el-dialog v-model"imgshow" destroy-on-close width"40%" draggable align-center :show-close"true":close-on-click-modal"false">&l…...

18.贪心算法
排序贪心 区间贪心 删数贪心 统计二进制下有多少1 int Getbit_1(int n){int cnt0;while(n){nn&(n-1);cnt;}return cnt; }暴力加一维前缀和优化 #include <iostream> #include <climits> using namespace std; #define int long long const int N2e510; in…...
[AI]部署安装有道QanyThing
前提条件: 1、win10系统更新到最新的版本,系统版本最好为专业版本 winver 查看系统版本,内部版本要大于19045 2、CPU开启虚拟化 3、开启虚拟化功能,1、2、3每步完成后均需要重启电脑; 注:windows 虚拟…...
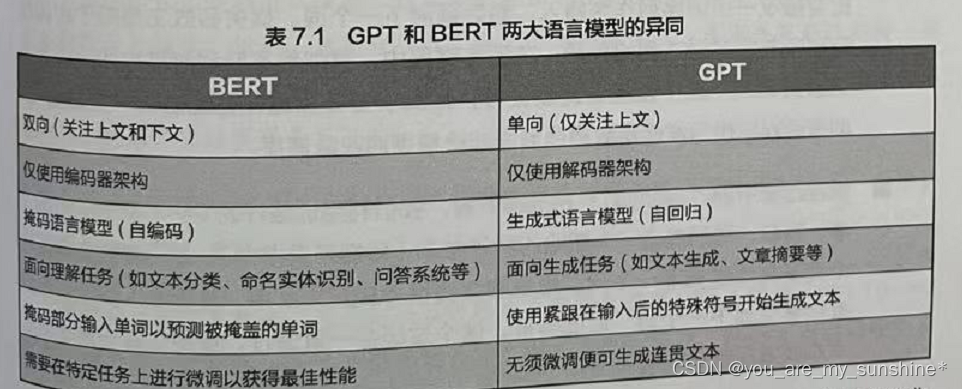
NLP_BERT与GPT争锋
文章目录 介绍小结 介绍 在开始训练GPT之前,我们先比较一下BERT和 GPT 这两种基于 Transformer 的预训练模型结构,找出它们的异同。 Transformer架构被提出后不久,一大批基于这个架构的预训练模型就如雨后春笋般地出现了。其中最重要、影响…...
放一个还看得过去的后台模板设置模块css样式框架
#小李子9479# 如下图 <div class"grid col-3 margin-top-xl"><?php$clist array(cyan, yellow, purple, red, blue, brown);foreach ($clist as $kk > $vv) {?><div style"max-width:400px;width:100%;padding:10px;"><div cl…...

关于信号强度单位dB和dBm区别
dB,dBm 都是功率增益的单位,不同之处如下: 一、dB 是一个相对值,表示两个量的相对大小关系,没有单位。当考虑甲的功率相比于乙功率大或小多少个dB时,按下面的计算公式:10log(甲功率/…...
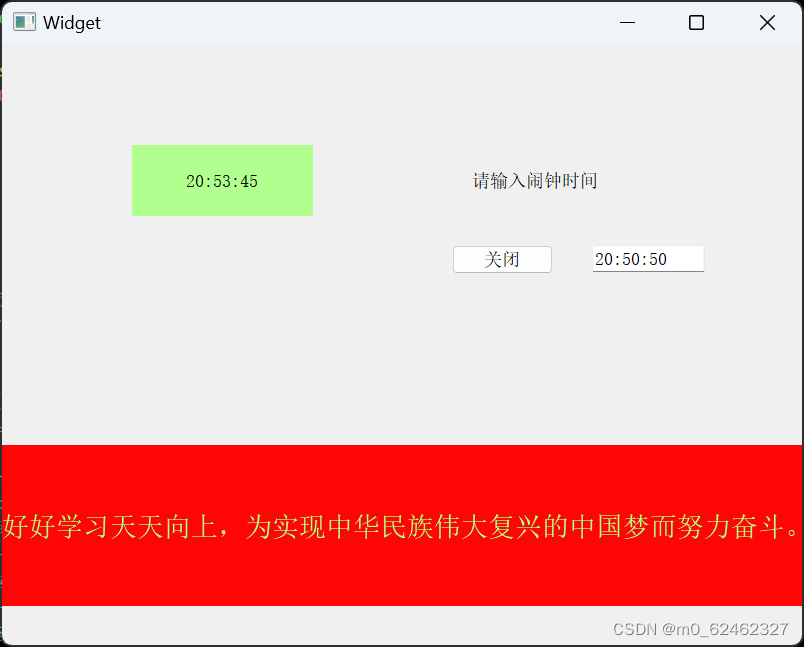
华清远见作业第四十二天——Qt(第四天)
思维导图: 编程: 代码: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include<QTextToSpeech> //语音播报类 QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public Q…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...
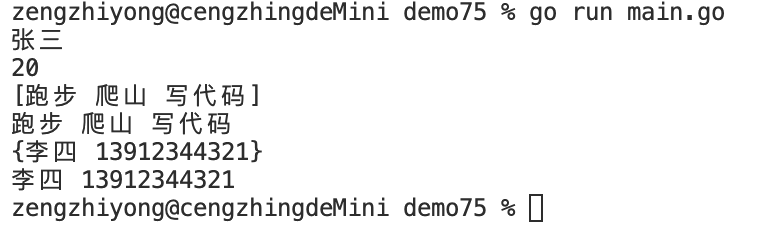
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...