YOLO算法改进Backbone系列之:EfficientViT
EfficientViT: Memory Effificient Vision Transformer with Cascaded Group Attention
摘要:视觉transformer由于其高模型能力而取得了巨大的成功。然而,它们卓越的性能伴随着沉重的计算成本,这使得它们不适合实时应用。在这篇论文中,本文提出了一个高速视觉transformer家族,名为EfficientViT。本文发现现有的transformer模型的速度通常受到内存低效操作的限制,特别是在MHSA中的张量重塑和单元函数。因此,本文设计了一种具有三明治布局的新构建块,即在高效FFN层之间使用单个内存绑定的MHSA,从而提高了内存效率,同时增强了信道通信。此外,本文发现注意图在头部之间具有很高的相似性,从而导致计算冗余。为了解决这个问题,本文提出了一个级联的群体注意模块,以不同的完整特征分割来馈送注意头,不仅节省了计算成本,而且提高了注意多样性。综合实验表明,高效vit优于现有的高效模型,在速度和精度之间取得了良好的平衡。例如,本文的EfficientViT-M5在准确率上比MobileNetV3-Large高出1.9%,而在Nvidia V100 GPU和Intel Xeon CPU上的吞吐量分别高出40.4%和45.2%。与最近的高效型号MobileViT-XXS相比,efficientvitt - m2的精度提高了1.8%,同时在GPU/CPU上运行速度提高了5.8 ×/3.7 ×,转换为ONNX格式时速度提高了7.4×
本文通过分析DeiT和Swin两个Transformer架构得出如下结论:
- 适当降低MHSA层利用率可以在提高模型性能的同时提高访存效率
- 在不同的头部使用不同的通道划分特征,而不是像MHSA那样对所有头部使用相同的全特征,可以有效地减少注意力计算冗余
- 典型的通道配置,即在每个阶段之后将通道数加倍或对所有块使用等效通道,可能在最后几个块中产生大量冗余
- 在维度相同的情况下,Q、K的冗余度比V大得多 a new building block with a sandwich
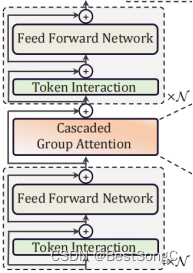
layout(减少self-attention的次数):之前是一个block self-attention->fc->self-attention->fc->self-attention->fc->…N次数;现在是一个blockfc->self-attention->fc;不仅能够提升内存效率而且能够增强通道间的计算
cascaded group attention:让多头串联学习特征:第一个头学习完特征后,第二个头利用第一个头学习到的特征的基础上再去学习(原来的transformer是第二个头跟第一个头同时独立地去学习),同理第三个头学习时也得利用上第二个头学习的结果再去学习
Efficientvit模型结构如下图所示:
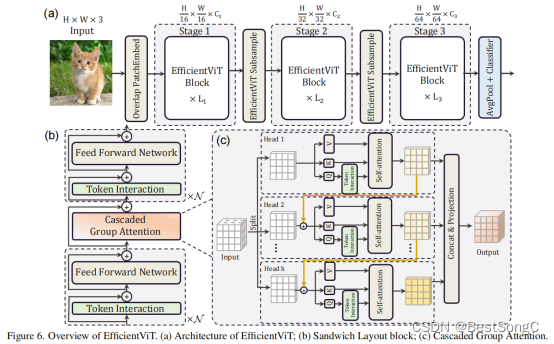
a memory-efficient sandwich layout
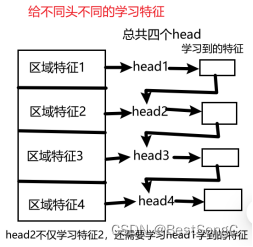
Cascaded Group Attention:解决了原来模型中多头重复学习(学习到的特征很多都是相似的)的问题,这里每个头学到的特征都不同,而且越往下面的头学到的特征越丰富。
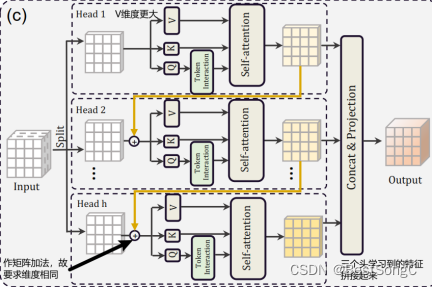
Q是主动查询的行为,特征比K更加丰富,所以额外做了个Token Interation
Q进行self-attention之前先通过多次分组卷积再一次学习
Parameter Reallocation
self-attention主要在进行QK,而且还需要对Q/K进行reshape,所以为了运算效率更快,Q与K的维度小一点
而V只在后面被QK得到的结果进行权重分配,没那么费劲,为了学习更多的特征,所以V维度更大一些
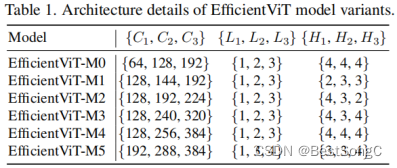
Efficientvit变体模型结构如下表所示:
在YOLOv5项目中添加EfficientViT模型作为Backbone使用的教程:
(1)将YOLOv5项目的models/yolo.py修改parse_model函数以及BaseModel的_forward_once函数
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)# ---------------------------------------------------------------------------------------------------is_backbone = Falselayers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argstry:t = mm = eval(m) if isinstance(m, str) else m # eval stringsexcept:passfor j, a in enumerate(args):with contextlib.suppress(NameError):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept:args[j] = an = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2# -------------------------------------------------------------------------------------elif m in {}:m = m(*args)c2 = m.channel# -------------------------------------------------------------------------------------else:c2 = ch[f]# -------------------------------------------------------------------------------------if isinstance(c2, list):is_backbone = Truem_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module type# -------------------------------------------------------------------------------------np = sum(x.numel() for x in m_.parameters()) # number params# -------------------------------------------------------------------------------------# m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number params# -------------------------------------------------------------------------------------LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist# save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []# -------------------------------------------------------------------------------------if isinstance(c2, list):ch.extend(c2)for _ in range(5 - len(ch)):ch.insert(0, 0)else:ch.append(c2)# -------------------------------------------------------------------------------------return nn.Sequential(*layers), sorted(save)def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)for _ in range(5 - len(x)):x.insert(0, None)for i_idx, i in enumerate(x):if i_idx in self.save:y.append(i)else:y.append(None)x = x[-1]else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x
(2)在models/backbone(新建)文件下新建EfficientViT.py,添加如下的代码:
# --------------------------------------------------------
# EfficientViT Model Architecture for Downstream Tasks
# Copyright (c) 2022 Microsoft
# Written by: Xinyu Liu
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import itertoolsfrom timm.models.layers import SqueezeExciteimport numpy as np
import itertools__all__ = ['EfficientViT_M0', 'EfficientViT_M1', 'EfficientViT_M2', 'EfficientViT_M3', 'EfficientViT_M4', 'EfficientViT_M5']class Conv2d_BN(torch.nn.Sequential):def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,groups=1, bn_weight_init=1, resolution=-10000):super().__init__()self.add_module('c', torch.nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=False))self.add_module('bn', torch.nn.BatchNorm2d(b))torch.nn.init.constant_(self.bn.weight, bn_weight_init)torch.nn.init.constant_(self.bn.bias, 0)@torch.no_grad()def fuse(self):c, bn = self._modules.values()w = bn.weight / (bn.running_var + bn.eps)**0.5w = c.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / \(bn.running_var + bn.eps)**0.5m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)m.weight.data.copy_(w)m.bias.data.copy_(b)return mdef replace_batchnorm(net):for child_name, child in net.named_children():if hasattr(child, 'fuse'):setattr(net, child_name, child.fuse())elif isinstance(child, torch.nn.BatchNorm2d):setattr(net, child_name, torch.nn.Identity())else:replace_batchnorm(child)class PatchMerging(torch.nn.Module):def __init__(self, dim, out_dim, input_resolution):super().__init__()hid_dim = int(dim * 4)self.conv1 = Conv2d_BN(dim, hid_dim, 1, 1, 0, resolution=input_resolution)self.act = torch.nn.ReLU()self.conv2 = Conv2d_BN(hid_dim, hid_dim, 3, 2, 1, groups=hid_dim, resolution=input_resolution)self.se = SqueezeExcite(hid_dim, .25)self.conv3 = Conv2d_BN(hid_dim, out_dim, 1, 1, 0, resolution=input_resolution // 2)def forward(self, x):x = self.conv3(self.se(self.act(self.conv2(self.act(self.conv1(x))))))return xclass Residual(torch.nn.Module):def __init__(self, m, drop=0.):super().__init__()self.m = mself.drop = dropdef forward(self, x):if self.training and self.drop > 0:return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,device=x.device).ge_(self.drop).div(1 - self.drop).detach()else:return x + self.m(x)class FFN(torch.nn.Module):def __init__(self, ed, h, resolution):super().__init__()self.pw1 = Conv2d_BN(ed, h, resolution=resolution)self.act = torch.nn.ReLU()self.pw2 = Conv2d_BN(h, ed, bn_weight_init=0, resolution=resolution)def forward(self, x):x = self.pw2(self.act(self.pw1(x)))return xclass CascadedGroupAttention(torch.nn.Module):r""" Cascaded Group Attention.Args:dim (int): Number of input channels.key_dim (int): The dimension for query and key.num_heads (int): Number of attention heads.attn_ratio (int): Multiplier for the query dim for value dimension.resolution (int): Input resolution, correspond to the window size.kernels (List[int]): The kernel size of the dw conv on query."""def __init__(self, dim, key_dim, num_heads=8,attn_ratio=4,resolution=14,kernels=[5, 5, 5, 5],):super().__init__()self.num_heads = num_headsself.scale = key_dim ** -0.5self.key_dim = key_dimself.d = int(attn_ratio * key_dim)self.attn_ratio = attn_ratioqkvs = []dws = []for i in range(num_heads):qkvs.append(Conv2d_BN(dim // (num_heads), self.key_dim * 2 + self.d, resolution=resolution))dws.append(Conv2d_BN(self.key_dim, self.key_dim, kernels[i], 1, kernels[i]//2, groups=self.key_dim, resolution=resolution))self.qkvs = torch.nn.ModuleList(qkvs)self.dws = torch.nn.ModuleList(dws)self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(self.d * num_heads, dim, bn_weight_init=0, resolution=resolution))points = list(itertools.product(range(resolution), range(resolution)))N = len(points)attention_offsets = {}idxs = []for p1 in points:for p2 in points:offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))if offset not in attention_offsets:attention_offsets[offset] = len(attention_offsets)idxs.append(attention_offsets[offset])self.attention_biases = torch.nn.Parameter(torch.zeros(num_heads, len(attention_offsets)))self.register_buffer('attention_bias_idxs',torch.LongTensor(idxs).view(N, N))@torch.no_grad()def train(self, mode=True):super().train(mode)if mode and hasattr(self, 'ab'):del self.abelse:self.ab = self.attention_biases[:, self.attention_bias_idxs]def forward(self, x): # x (B,C,H,W)B, C, H, W = x.shapetrainingab = self.attention_biases[:, self.attention_bias_idxs]feats_in = x.chunk(len(self.qkvs), dim=1)feats_out = []feat = feats_in[0]for i, qkv in enumerate(self.qkvs):if i > 0: # add the previous output to the inputfeat = feat + feats_in[i]feat = qkv(feat)q, k, v = feat.view(B, -1, H, W).split([self.key_dim, self.key_dim, self.d], dim=1) # B, C/h, H, Wq = self.dws[i](q)q, k, v = q.flatten(2), k.flatten(2), v.flatten(2) # B, C/h, Nattn = ((q.transpose(-2, -1) @ k) * self.scale+(trainingab[i] if self.training else self.ab[i]))attn = attn.softmax(dim=-1) # BNNfeat = (v @ attn.transpose(-2, -1)).view(B, self.d, H, W) # BCHWfeats_out.append(feat)x = self.proj(torch.cat(feats_out, 1))return xclass LocalWindowAttention(torch.nn.Module):r""" Local Window Attention.Args:dim (int): Number of input channels.key_dim (int): The dimension for query and key.num_heads (int): Number of attention heads.attn_ratio (int): Multiplier for the query dim for value dimension.resolution (int): Input resolution.window_resolution (int): Local window resolution.kernels (List[int]): The kernel size of the dw conv on query."""def __init__(self, dim, key_dim, num_heads=8,attn_ratio=4,resolution=14,window_resolution=7,kernels=[5, 5, 5, 5],):super().__init__()self.dim = dimself.num_heads = num_headsself.resolution = resolutionassert window_resolution > 0, 'window_size must be greater than 0'self.window_resolution = window_resolutionself.attn = CascadedGroupAttention(dim, key_dim, num_heads,attn_ratio=attn_ratio, resolution=window_resolution,kernels=kernels,)def forward(self, x):B, C, H, W = x.shapeif H <= self.window_resolution and W <= self.window_resolution:x = self.attn(x)else:x = x.permute(0, 2, 3, 1)pad_b = (self.window_resolution - H %self.window_resolution) % self.window_resolutionpad_r = (self.window_resolution - W %self.window_resolution) % self.window_resolutionpadding = pad_b > 0 or pad_r > 0if padding:x = torch.nn.functional.pad(x, (0, 0, 0, pad_r, 0, pad_b))pH, pW = H + pad_b, W + pad_rnH = pH // self.window_resolutionnW = pW // self.window_resolution# window partition, BHWC -> B(nHh)(nWw)C -> BnHnWhwC -> (BnHnW)hwC -> (BnHnW)Chwx = x.view(B, nH, self.window_resolution, nW, self.window_resolution, C).transpose(2, 3).reshape(B * nH * nW, self.window_resolution, self.window_resolution, C).permute(0, 3, 1, 2)x = self.attn(x)# window reverse, (BnHnW)Chw -> (BnHnW)hwC -> BnHnWhwC -> B(nHh)(nWw)C -> BHWCx = x.permute(0, 2, 3, 1).view(B, nH, nW, self.window_resolution, self.window_resolution,C).transpose(2, 3).reshape(B, pH, pW, C)if padding:x = x[:, :H, :W].contiguous()x = x.permute(0, 3, 1, 2)return xclass EfficientViTBlock(torch.nn.Module):""" A basic EfficientViT building block.Args:type (str): Type for token mixer. Default: 's' for self-attention.ed (int): Number of input channels.kd (int): Dimension for query and key in the token mixer.nh (int): Number of attention heads.ar (int): Multiplier for the query dim for value dimension.resolution (int): Input resolution.window_resolution (int): Local window resolution.kernels (List[int]): The kernel size of the dw conv on query."""def __init__(self, type,ed, kd, nh=8,ar=4,resolution=14,window_resolution=7,kernels=[5, 5, 5, 5],):super().__init__()self.dw0 = Residual(Conv2d_BN(ed, ed, 3, 1, 1, groups=ed, bn_weight_init=0., resolution=resolution))self.ffn0 = Residual(FFN(ed, int(ed * 2), resolution))if type == 's':self.mixer = Residual(LocalWindowAttention(ed, kd, nh, attn_ratio=ar, \resolution=resolution, window_resolution=window_resolution, kernels=kernels))self.dw1 = Residual(Conv2d_BN(ed, ed, 3, 1, 1, groups=ed, bn_weight_init=0., resolution=resolution))self.ffn1 = Residual(FFN(ed, int(ed * 2), resolution))def forward(self, x):return self.ffn1(self.dw1(self.mixer(self.ffn0(self.dw0(x)))))class EfficientViT(torch.nn.Module):def __init__(self, img_size=400,patch_size=16,frozen_stages=0,in_chans=3,stages=['s', 's', 's'],embed_dim=[64, 128, 192],key_dim=[16, 16, 16],depth=[1, 2, 3],num_heads=[4, 4, 4],window_size=[7, 7, 7],kernels=[5, 5, 5, 5],down_ops=[['subsample', 2], ['subsample', 2], ['']],pretrained=None,distillation=False,):super().__init__()resolution = img_sizeself.patch_embed = torch.nn.Sequential(Conv2d_BN(in_chans, embed_dim[0] // 8, 3, 2, 1, resolution=resolution), torch.nn.ReLU(),Conv2d_BN(embed_dim[0] // 8, embed_dim[0] // 4, 3, 2, 1, resolution=resolution // 2), torch.nn.ReLU(),Conv2d_BN(embed_dim[0] // 4, embed_dim[0] // 2, 3, 2, 1, resolution=resolution // 4), torch.nn.ReLU(),Conv2d_BN(embed_dim[0] // 2, embed_dim[0], 3, 1, 1, resolution=resolution // 8))resolution = img_size // patch_sizeattn_ratio = [embed_dim[i] / (key_dim[i] * num_heads[i]) for i in range(len(embed_dim))]self.blocks1 = []self.blocks2 = []self.blocks3 = []for i, (stg, ed, kd, dpth, nh, ar, wd, do) in enumerate(zip(stages, embed_dim, key_dim, depth, num_heads, attn_ratio, window_size, down_ops)):for d in range(dpth):eval('self.blocks' + str(i+1)).append(EfficientViTBlock(stg, ed, kd, nh, ar, resolution, wd, kernels))if do[0] == 'subsample':#('Subsample' stride)blk = eval('self.blocks' + str(i+2))resolution_ = (resolution - 1) // do[1] + 1blk.append(torch.nn.Sequential(Residual(Conv2d_BN(embed_dim[i], embed_dim[i], 3, 1, 1, groups=embed_dim[i], resolution=resolution)),Residual(FFN(embed_dim[i], int(embed_dim[i] * 2), resolution)),))blk.append(PatchMerging(*embed_dim[i:i + 2], resolution))resolution = resolution_blk.append(torch.nn.Sequential(Residual(Conv2d_BN(embed_dim[i + 1], embed_dim[i + 1], 3, 1, 1, groups=embed_dim[i + 1], resolution=resolution)),Residual(FFN(embed_dim[i + 1], int(embed_dim[i + 1] * 2), resolution)),))self.blocks1 = torch.nn.Sequential(*self.blocks1)self.blocks2 = torch.nn.Sequential(*self.blocks2)self.blocks3 = torch.nn.Sequential(*self.blocks3)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):outs = []x = self.patch_embed(x)x = self.blocks1(x)outs.append(x)x = self.blocks2(x)outs.append(x)x = self.blocks3(x)outs.append(x)return outsEfficientViT_m0 = {'img_size': 224,'patch_size': 16,'embed_dim': [64, 128, 192],'depth': [1, 2, 3],'num_heads': [4, 4, 4],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],}EfficientViT_m1 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 144, 192],'depth': [1, 2, 3],'num_heads': [2, 3, 3],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],}EfficientViT_m2 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 192, 224],'depth': [1, 2, 3],'num_heads': [4, 3, 2],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],}EfficientViT_m3 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 240, 320],'depth': [1, 2, 3],'num_heads': [4, 3, 4],'window_size': [7, 7, 7],'kernels': [5, 5, 5, 5],}EfficientViT_m4 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 256, 384],'depth': [1, 2, 3],'num_heads': [4, 4, 4],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],}EfficientViT_m5 = {'img_size': 224,'patch_size': 16,'embed_dim': [192, 288, 384],'depth': [1, 3, 4],'num_heads': [3, 3, 4],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],}def EfficientViT_M0(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None, model_cfg=EfficientViT_m0):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M1(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None, model_cfg=EfficientViT_m1):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M2(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None, model_cfg=EfficientViT_m2):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M3(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None, model_cfg=EfficientViT_m3):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M4(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None, model_cfg=EfficientViT_m4):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M5(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None, model_cfg=EfficientViT_m5):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():# k = k[9:]if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dict
(3)在models/yolo.py导入EfficientViT模型并在parse_model函数中修改如下:
from models.backbone.EfficientViT import *
---------------------------------------------------
elif m in {EfficientViT_M0, EfficientViT_M1, EfficientViT_M2, EfficientViT_M3, EfficientViT_M4, EfficientViT_M5,}:
m = m(*args)
c2 = m.channel
---------------------------------------------------
(4)在model下面新建配置文件:yolov5-efficientvit.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, EfficientViT_M0, []], # 4[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 6[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7[[-1, 3], 1, Concat, [1]], # cat backbone P4 8[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]], # 10[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11[[-1, 2], 1, Concat, [1]], # cat backbone P3 12[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 14[[-1, 10], 1, Concat, [1]], # cat head P4 15[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 17[[-1, 5], 1, Concat, [1]], # cat head P5 18[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
(5)运行验证:在models/yolo.py文件指定–cfg参数为新建的yolov5-efficientvit.yaml
from n params module arguments 0 -1 1 2155680 EfficientViT_M0 [] 1 -1 1 117440 models.common.SPPF [192, 256, 5] 2 -1 1 33024 models.common.Conv [256, 128, 1, 1] 3 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 4 [-1, 3] 1 0 models.common.Concat [1] 5 -1 1 90880 models.common.C3 [256, 128, 1, False] 6 -1 1 8320 models.common.Conv [128, 64, 1, 1] 7 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 8 [-1, 2] 1 0 models.common.Concat [1] 9 -1 1 22912 models.common.C3 [128, 64, 1, False] 10 -1 1 36992 models.common.Conv [64, 64, 3, 2] 11 [-1, 10] 1 0 models.common.Concat [1] 12 -1 1 74496 models.common.C3 [128, 128, 1, False] 13 -1 1 147712 models.common.Conv [128, 128, 3, 2] 14 [-1, 5] 1 0 models.common.Concat [1] 15 -1 1 329216 models.common.C3 [384, 256, 1, False] 16 [13, 16, 19] 1 115005 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 128, 256]]
YOLOv5-efficientvit summary: 582 layers, 3131677 parameters, 3131677 gradients
Fusing layers...
YOLOv5-efficientvit summary: 556 layers, 3129213 parameters, 3129213 gradients
目前整个项目计划更新至少有50+Vision Transformer Backbone,以及一些其他的改进策略,另外后续也会同步更新改进后的模型在MS COCO数据集上从零开始训练得到的模型权重和训练结果。想要了解项目的朋友私信博主或关注gzh:BestSongC 发送yolo改进即可获取项目信息。
相关文章:
YOLO算法改进Backbone系列之:EfficientViT
EfficientViT: Memory Effificient Vision Transformer with Cascaded Group Attention 摘要:视觉transformer由于其高模型能力而取得了巨大的成功。然而,它们卓越的性能伴随着沉重的计算成本,这使得它们不适合实时应用。在这篇论文中&#x…...
JANGOW: 1.0.1
kali:192.168.223.128 主机发现 nmap -sP 192.168.223.0/24 端口扫描 nmap -p- 192.168.223.154 开启了21 80端口 web看一下,有个busque.php参数是buscar,但是不知道输入什么,尝试文件包含失败 扫描目录 dirsearch -u http://192.168.223.154 dirse…...
Elasticsearch 创建index库 timeout
问题概述 使用 python 客户端 代码进行创建,【之前成功创建,但是现在出现报错,报错代码es_connection.client.indices.create】def create_vector_index(dataset_index_name,vector_query_field,query_field):es_connection = get_collention(dataset_index_name,vector_que…...

2024最新可用免费天气预报API接口
天气API接口数据, 数据字段最全,免费,稳定的实况天气预报接口 5分钟左右更新一次,支持全国3000多个市区县, 包含基本天气信息、24小时逐小时天气、气象预警列表、湿度、能见度、气压、降雨量、紫外线、风力风向风速、日出日落、空气质量、pm2…...
【AIGC】开源声音克隆GPT-SoVITS
GPT-SoVITS 是由 RVC 创始人 RVC-Boss 与 AI 声音转换技术专家 Rcell 共同开发的一款跨语言 TTS 克隆项目,被誉为“最强大中文声音克隆项目” 相比以往的声音克隆项目,GPT-SoVITS 对硬件配置的要求相对较低,一般只需 6GB 显存以上的 GPU 即可…...

YOLOv9图像标注和格式转换
一、软件安装 labelimg安装(anaconda) 方法一、 pip install labelImg 方法二、 pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install lxml -i ht…...

车载系统相关
车载SBL和EC系统介绍 一、概述 车载SBL(Signal Broadcasting Layer)和EC(Electronic Control)系统是现代汽车中不可或缺的组成部分。它们共同协作,确保车辆的稳定、安全和高效运行 二、SBL系统介绍 SBL系统&#x…...

AWS对文本进行语言识别
AWS提供了名为Amazon Comprehend 的服务,它支持对文本进行语言识别。Amazon Comprehend 是一项自然语言处理(NLP)服务,它可以用于分析文本并提取有关文本内容的信息。 我们可以通过使用 Amazon Comprehend API 轻松地集成这些功能…...
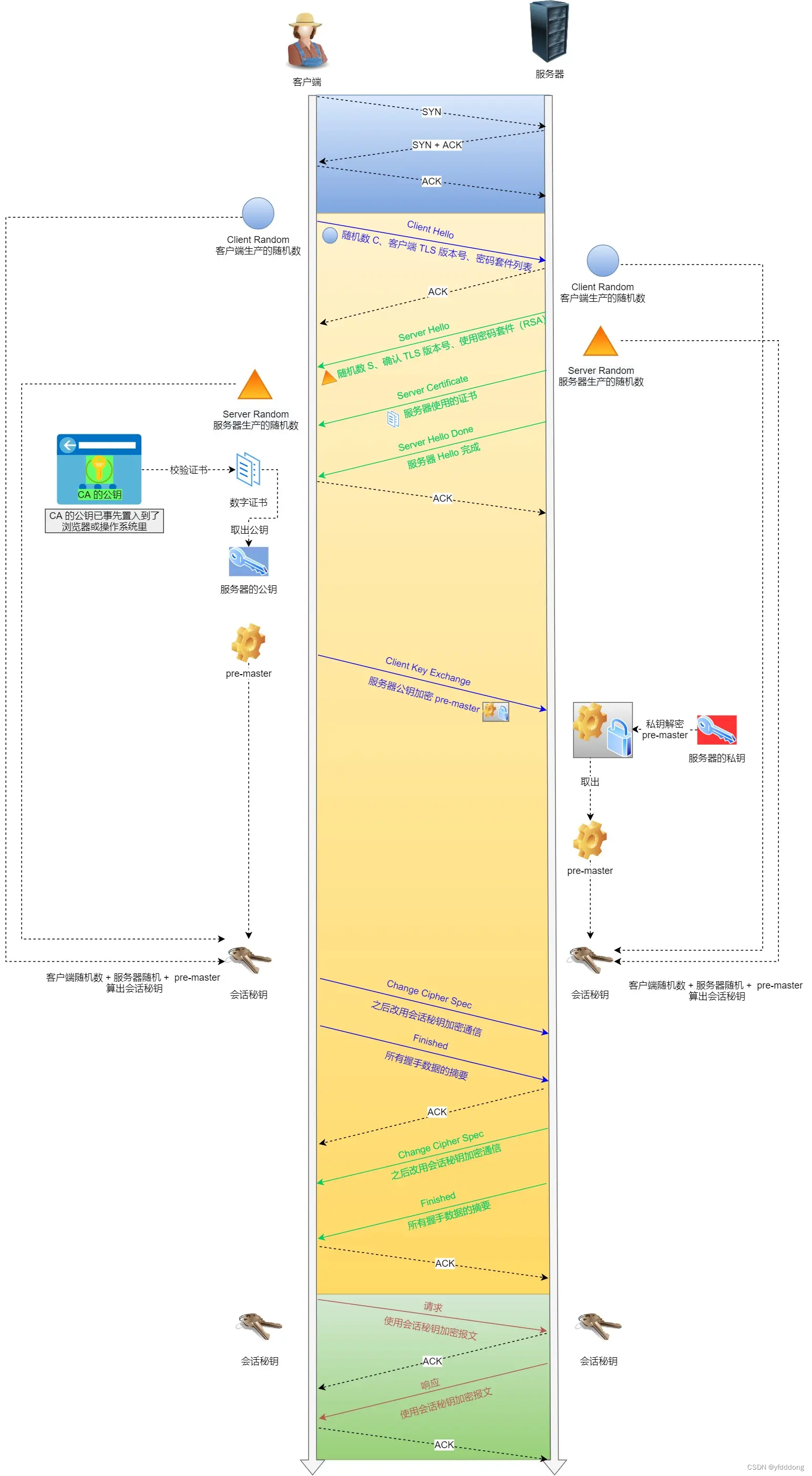
HTTP 与HTTPS笔记
HTTP 80 HTTP是一个在计算机世界里专门在【两点】之间【传输】文字、图片、音频、视频等【超文本】数据的约定和规范。 HTTP状态码 1xx 提示信息,表示目前是协议处理的中间状态,还需要后续的操作;2xx 200 204 026 成功3xx 重定向ÿ…...
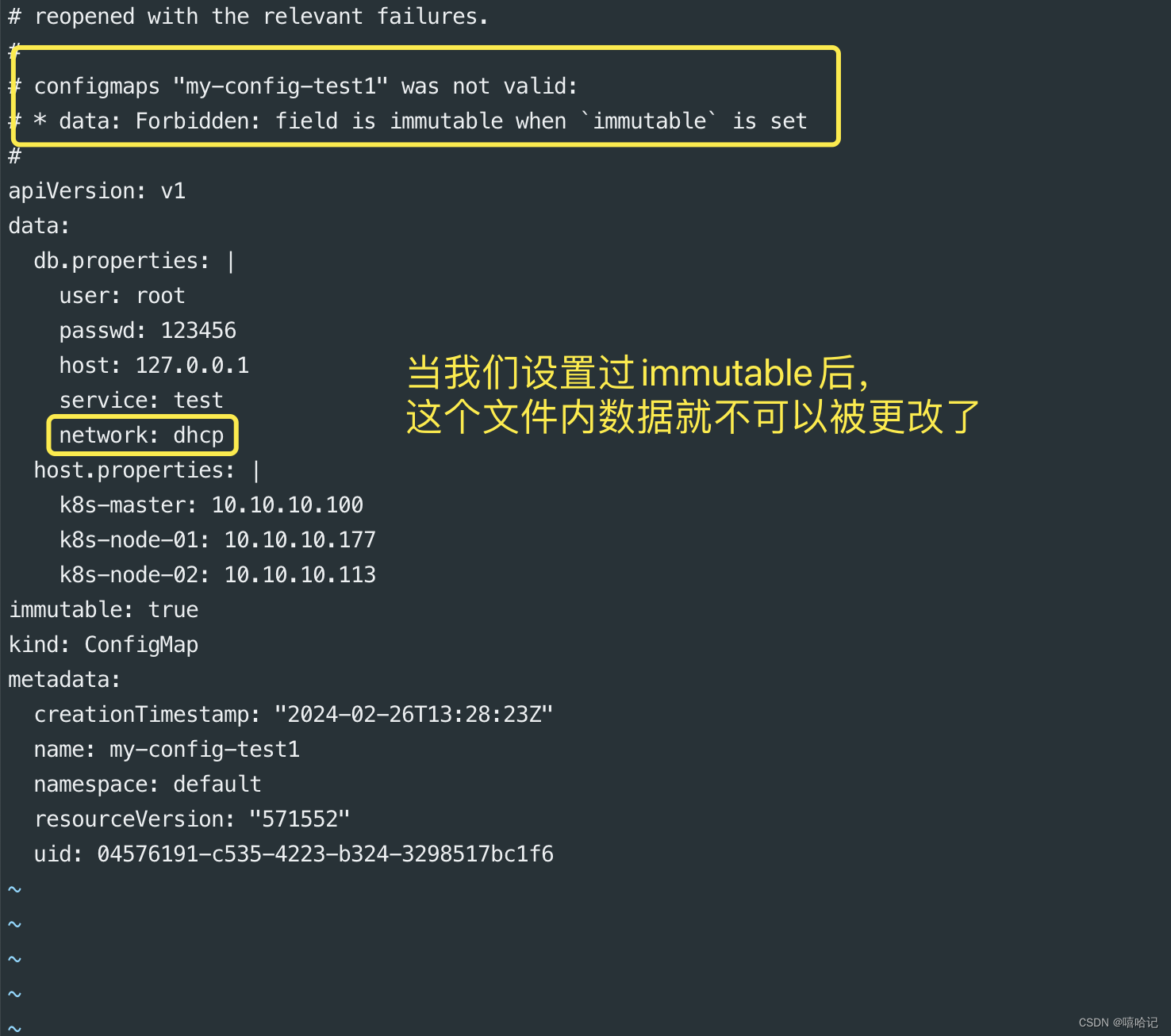
【k8s配置与存储--配置管理】
1、ConfigMap的配置 1.1 ConfigMap介绍 ConfigMap 是一种 API 对象,用来将非机密性的数据保存到键值对中。使用时, Pod 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。 ConfigMap 将你的环境配置信息和容器镜像解耦,便于应用配…...

如何在C++中嵌入SQL语句?解释一下什么是ODBC、JDBC以及它们在C++数据库编程中的作用。
如何在C中嵌入SQL语句? 在C中嵌入SQL语句通常涉及使用数据库连接库或ORM(对象关系映射)框架,这些工具提供了与特定数据库管理系统(DBMS)交互的接口。以下是几种在C中嵌入SQL语句的常见方法: 使…...
【Simulink系列】——动态系统仿真 之 混合系统
声明:本系列博客参考有关专业书籍,截图均为自己实操,仅供交流学习! 一、混合系统概述 由不同类型系统共同构成的系统称为混合系统!仿真时必须考虑连续信号和离散信号的采样匹配问题,一般使用变步长连续求…...

PHP中的飞碟运算符、取反运算符、对比非ASCII字符串、对比浮点数操作
对比浮点数 在电脑里存储的浮点数可能会和输入的值有些许差异,比如输入的是10.0,但存储的是10.00001. 在比较两个浮点数是否相等时可以计算下两个数的差值,然后查看下两数之差是否小于可以接受的阈值,如果要求精度在小数点后5位的…...
0.5.0)
unity-unity2d基础操作笔记(二)0.5.0
unity2d基础操作笔记 五十一、canvas中的必须熟悉的属性五十二、如何调整canvas与游戏人物大小近似大小五十三、canvas中的canvas scaler介绍【概念】五十四、ui scale mode介绍【概念】五十五、为什么创建image后,canvas的范围要要远远大于游戏世界?五十六、图片常用操作【技…...

Feign远程调用(学习笔记)
先来看我们以前利用RestTemplate发起远程调用的代码: 存在下面的问题: ●代码可读性差,编程体验不统一 ●参数复杂URL难以维护 Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign 其作用…...

pytorch建模的三种方式
# 可以使用以下3种方式构建模型: # # 1,继承nn.Module基类构建自定义模型。 # # 2,使用nn.Sequential按层顺序构建模型。 # # 3,继承nn.Module基类构建模型并辅助应用模型容器进行封装(nn.Sequential,nn.ModuleList,nn.ModuleDict…...
GO-ICP的使用(一)
一、代码下载以、修改以及使用 下载: 链接:yangjiaolong/Go-ICP: Implementation of the Go-ICP algorithm for globally optimal 3D pointset registration (github.com) 解压之后 : 首先visual studio项目,配置好PCL环境&…...
强制进行垃圾回收)
FPS游戏漫谈System.GC.Collect()强制进行垃圾回收
在Unity中,System.GC.Collect()用于强制进行垃圾回收,但是它是一个相当耗时的操作,可能会导致游戏的帧率下降,甚至出现卡顿。因此,你应该尽量避免在游戏的主循环中频繁调用它。以下是一些关于在Unity中使用System.GC.C…...
第3集《灵峰宗论导读》
《灵峰宗论》导读。诸位法师,诸位同学,阿弥陀佛!(阿弥陀佛!) 请大家打开讲义第5面,悟道。 这一科我们是说明论主略史,在这一科当中,我们根据弘一大师所编的《蕅益大师年…...

java面试设计模式篇
面试专题-设计模式 前言 在平时的开发中,涉及到设计模式的有两块内容,第一个是我们平时使用的框架(比如spring、mybatis等),第二个是我们自己开发业务使用的设计模式。 面试官一般比较关心的是你在开发过程中&#…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...