【机器学习算法】KNN鸢尾花种类预测案例和特征预处理。全md文档笔记(已分享,附代码)

本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用,结合场景解决实际问题。包括K-近邻算法,线性回归,逻辑回归,决策树算法,集成学习,聚类算法。K-近邻算法的距离公式,应用LinearRegression或SGDRegressor实现回归预测,应用LogisticRegression实现逻辑回归预测,应用DecisionTreeClassifier实现决策树分类,应用RandomForestClassifie实现随机森林算法,应用Kmeans实现聚类任务。
全套笔记和代码自取移步gitee仓库: gitee仓库获取完整文档和代码
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
共 7 章,44 子模块
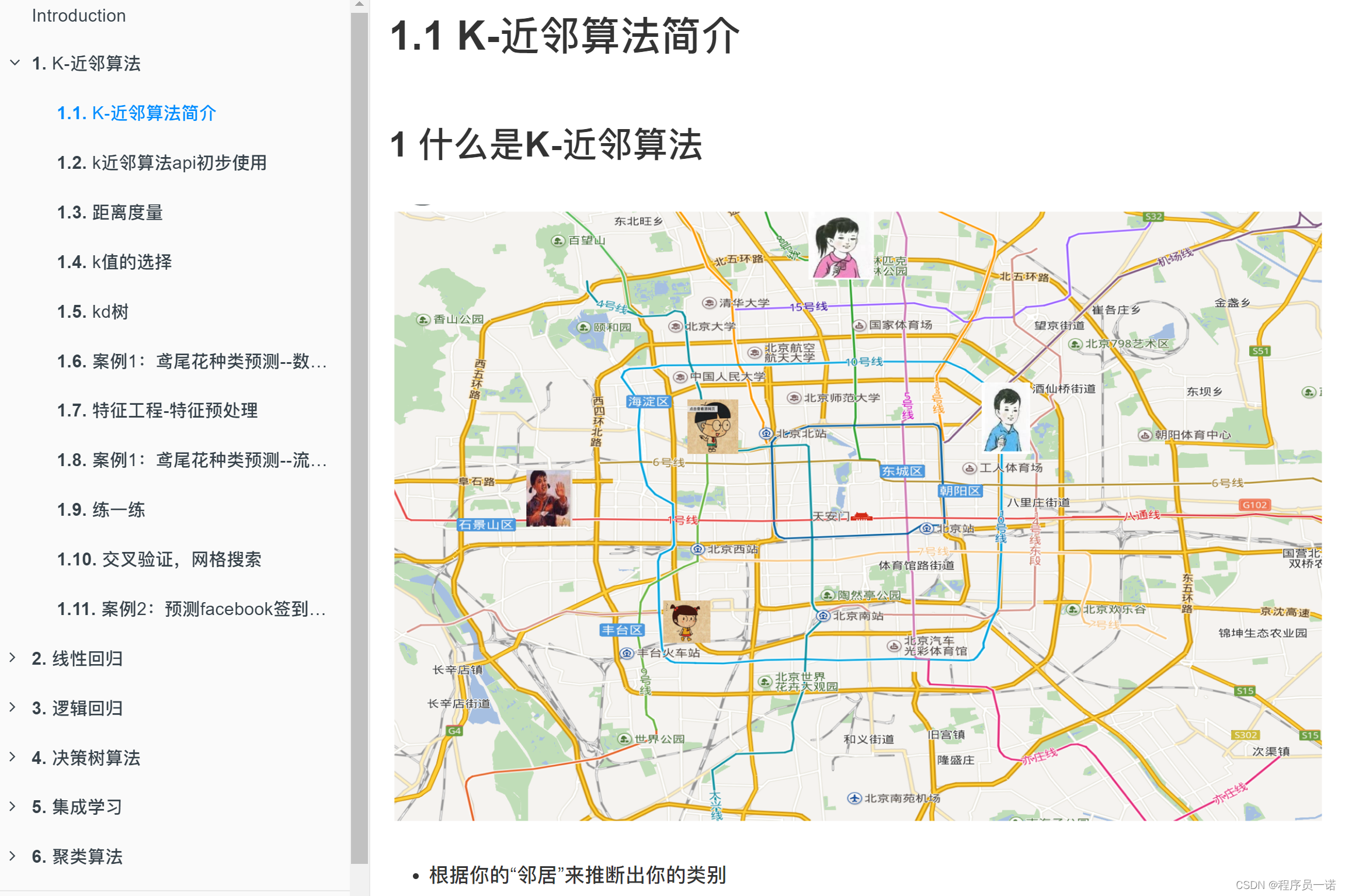
K-近邻算法
学习目标
- 掌握K-近邻算法实现过程
- 知道K-近邻算法的距离公式
- 知道K-近邻算法的超参数K值以及取值问题
- 知道kd树实现搜索的过程
- 应用KNeighborsClassifier实现分类
- 知道K-近邻算法的优缺点
- 知道交叉验证实现过程
- 知道超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
1.8 案例:鸢尾花种类预测—流程实现
1 再识K-近邻算法API
-
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
-
n_neighbors:
- int,可选(默认= 5),k_neighbors查询默认使用的邻居数
-
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}
-
快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,
- brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。
- kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
- ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
-
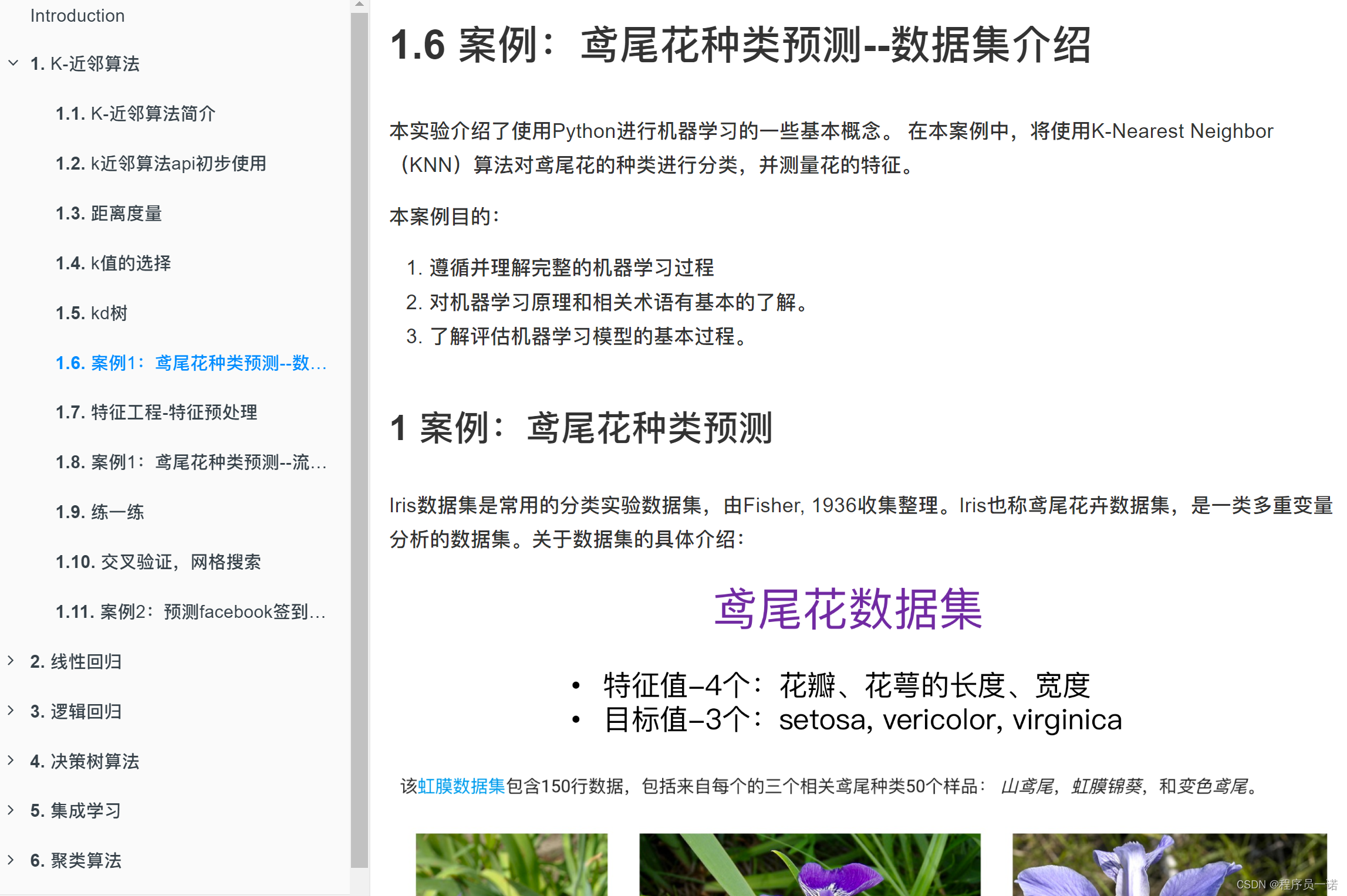
2 案例:鸢尾花种类预测
2.1 数据集介绍
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:

2.2 步骤分析
- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
- 5.模型评估
2.3 代码过程
- 导入模块
python from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier
- 先从sklearn当中获取数据集,然后进行数据集的分割
```python
1.获取数据集
iris = load_iris()
2.数据基本处理
x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22) ```
-
进行数据标准化
-
特征值的标准化
```python
3、特征工程:标准化
transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) ```
- 模型进行训练预测
```python
4、机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=9) estimator.fit(x_train, y_train)
5、模型评估
方法1:比对真实值和预测值
y_predict = estimator.predict(x_test) print("预测结果为:\n", y_predict) print("比对真实值和预测值:\n", y_predict == y_test)
方法2:直接计算准确率
score = estimator.score(x_test, y_test) print("准确率为:\n", score) ```
1.9 练一练
同学之间讨论刚才完成的机器学习代码,并且确保在自己的电脑是哪个运行成功
总结
-
在本案例中,具体完成内容有:
-
使用可视化加载和探索数据,以确定特征是否能将不同类别分开。
- 通过标准化数字特征并随机抽样到训练集和测试集来准备数据。
-
通过统计学,精确度度量进行构建和评估机器学习模型。
-
k近邻算法总结
-
优点:
- 简单有效
- 重新训练的代价低
-
适合类域交叉样本
- KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
-
适合大样本自动分类
- 该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
-
缺点:
-
惰性学习
- KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
-
类别评分不是规格化
- 不像一些通过概率评分的分类
-
输出可解释性不强
- 例如决策树的输出可解释性就较强
-
对不均衡的样本不擅长
- 当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
-
计算量较大
- 目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
-
1.10 交叉验证,网格搜索
1 什么是交叉验证(cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
1.1 分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
- 训练集:训练集+验证集
- 测试集:测试集

1.2 为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
2 什么是网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3 交叉验证,网格搜索(模型选择与调优)API:
-
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
-
对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
-
结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
4 鸢尾花案例增加K值调优
- 使用GridSearchCV构建估计器
```python
1、获取数据集
iris = load_iris()
2、数据基本处理 -- 划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
3、特征工程:标准化
实例化一个转换器类
transfer = StandardScaler()
调用fit_transform
x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test)
4、KNN预估器流程
4.1 实例化预估器类
estimator = KNeighborsClassifier()
4.2 模型选择与调优——网格搜索和交叉验证
准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
4.3 fit数据进行训练
estimator.fit(x_train, y_train)
5、评估模型效果
方法a:比对预测结果和真实值
y_predict = estimator.predict(x_test) print("比对预测结果和真实值:\n", y_predict == y_test)
方法b:直接计算准确率
score = estimator.score(x_test, y_test) print("直接计算准确率:\n", score) ```
- 然后进行评估查看最终选择的结果和交叉验证的结果
python print("在交叉验证中验证的最好结果:\n", estimator.best_score_) print("最好的参数模型:\n", estimator.best_estimator_) print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
- 最终结果
python 比对预测结果和真实值: [ True True True True True True True False True True True True True True True True True True False True True True True True True True True True True True True True True True True True True True] 直接计算准确率: 0.947368421053 在交叉验证中验证的最好结果: 0.973214285714 最好的参数模型: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform') 每次交叉验证后的准确率结果: {'mean_fit_time': array([ 0.00114751, 0.00027037, 0.00024462]), 'std_fit_time': array([ 1.13901511e-03, 1.25300249e-05, 1.11011951e-05]), 'mean_score_time': array([ 0.00085751, 0.00048693, 0.00045625]), 'std_score_time': array([ 3.52785082e-04, 2.87650037e-05, 5.29673344e-06]), 'param_n_neighbors': masked_array(data = [1 3 5], mask = [False False False], fill_value = ?) , 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([ 0.97368421, 0.97368421, 0.97368421]), 'split1_test_score': array([ 0.97297297, 0.97297297, 0.97297297]), 'split2_test_score': array([ 0.94594595, 0.89189189, 0.97297297]), 'mean_test_score': array([ 0.96428571, 0.94642857, 0.97321429]), 'std_test_score': array([ 0.01288472, 0.03830641, 0.00033675]), 'rank_test_score': array([2, 3, 1], dtype=int32), 'split0_train_score': array([ 1. , 0.95945946, 0.97297297]), 'split1_train_score': array([ 1. , 0.96 , 0.97333333]), 'split2_train_score': array([ 1. , 0.96, 0.96]), 'mean_train_score': array([ 1. , 0.95981982, 0.96876877]), 'std_train_score': array([ 0. , 0.00025481, 0.0062022 ])}
1.11 案例2:预测facebook签到位置
1 数据集介绍

数据介绍:将根据用户的位置,准确性和时间戳预测用户正在查看的业务。
python train.csv,test.csv row_id:登记事件的ID xy:坐标 准确性:定位准确性 时间:时间戳 place_id:业务的ID,这是您预测的目标
官网:https://www.kaggle.com/navoshta/grid-knn/data
2 步骤分析
-
对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
-
1 缩小数据集范围 DataFrame.query()
-
2 选取有用的时间特征
-
3 将签到位置少于n个用户的删除
-
分割数据集
-
标准化处理
-
k-近邻预测
3 代码过程
- 1.获取数据集
```python
1、获取数据集
facebook = pd.read_csv("./data/FBlocation/train.csv") ```
- 2.基本数据处理
```python
2.基本数据处理
2.1 缩小数据范围
facebook_data = facebook.query("x>2.0 & x<2.5 & y>2.0 & y<2.5")
2.2 选择时间特征
time = pd.to_datetime(facebook_data["time"], unit="s") time = pd.DatetimeIndex(time) facebook_data["day"] = time.day facebook_data["hour"] = time.hour facebook_data["weekday"] = time.weekday
2.3 去掉签到较少的地方
place_count = facebook_data.groupby("place_id").count() place_count = place_count[place_count["row_id"]>3] facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
2.4 确定特征值和目标值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]] y = facebook_data["place_id"]
2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22) ```
- 特征工程--特征预处理(标准化)
```python
3.特征工程--特征预处理(标准化)
3.1 实例化一个转换器
transfer = StandardScaler()
3.2 调用fit_transform
x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test) ```
- 机器学习--knn+cv
```python
4.机器学习--knn+cv
4.1 实例化一个估计器
estimator = KNeighborsClassifier()
4.2 调用gridsearchCV
param_grid = {"n_neighbors": [1, 3, 5, 7, 9]} estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5)
4.3 模型训练
estimator.fit(x_train, y_train) ```
- 模型评估
```python
5.模型评估
5.1 基本评估方式
score = estimator.score(x_test, y_test) print("最后预测的准确率为:\n", score)
y_predict = estimator.predict(x_test) print("最后的预测值为:\n", y_predict) print("预测值和真实值的对比情况:\n", y_predict == y_test)
5.2 使用交叉验证后的评估方式
print("在交叉验证中验证的最好结果:\n", estimator.best_score_) print("最好的参数模型:\n", estimator.best_estimator_) print("每次交叉验证后的验证集准确率结果和训练集准确率结果:\n",estimator.cv_results_) ```
未完待续, 同学们请等待下一期
全套笔记和代码自取移步gitee仓库: gitee仓库获取完整文档和代码
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
相关文章:
【机器学习算法】KNN鸢尾花种类预测案例和特征预处理。全md文档笔记(已分享,附代码)
本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用࿰…...
Windows 自带的 Linux 子系统(WSL)安装与使用
WSL官网安装教程: https://learn.microsoft.com/zh-cn/windows/wsl/install Windows 自带的Linux子系统,比用VM什么的香太多了。可以自己看官方教程,也可以以下步骤完成。 如果中间遇到我没遇到的问题百度,可以在评论区评论&#…...

C语言--贪吃蛇
目录 1. 实现目标2. 需掌握的技术3. Win32 API介绍控制台程序控制台屏幕上的坐标COORDGetStdHandleGetConsoleCursorinfoCONSOLE_CURSOR_INFOSetConsoleCursorInfoSetConsoleCursorPositionGetAsyncKeyState 4. 贪吃蛇游戏设计与分析地图<locale.h>本地化类项setlocale函…...
原型设计工具Axure RP
Axure RP是一款专业的快速原型设计工具。Axure(发音:Ack-sure),代表美国Axure公司;RP则是Rapid Prototyping(快速原型)的缩写。 下载链接:https://www.axure.com/ 下载 可以免费试用…...

HeadFirst读书笔记
一、设计模式入门 1、使用模式最好的方式“把模式装进脑子里,然后在你的设计和已有的应用中,寻找何处可以使用它们”。以往是代码复用,现在是经验复用。 2、软件开发的一个不变的真理就是变化。 二、设计原则 1、找出应用中可能需要变化之…...

【C++】---内存管理new和delete详解
一、C/C内存分布 C/C内存被分为6个区域: (1) 内核空间:存放内核代码和环境变量。 (2)栈区:向下增长(存放非静态局部变量,函数参数,返回值等等) …...

go-zero微服务入门教程
go-zero微服务入门教程 本教程主要模拟实现用户注册和用户信息查询两个接口。 准备工作 安装基础环境 安装etcd, mysql,redis,建议采用docker安装。 MySQL安装好之后,新建数据库dsms_admin,并新建表sys_user&#…...

蓝桥杯刷题--python-12
3768. 字符串删减 - AcWing题库 nint(input()) sinput() res0 i0 while(i<n): if s[i]x: ji1 while(j<n and s[j]x): j1 resmax(j-i-2,0) ij else: i1 print(res) 3777. 砖块 - AcWing题库 # https://www.a…...

LeetCode LCR 085.括号生成
正整数 n 代表生成括号的对数,请设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”] 示例 2: 输入&#x…...
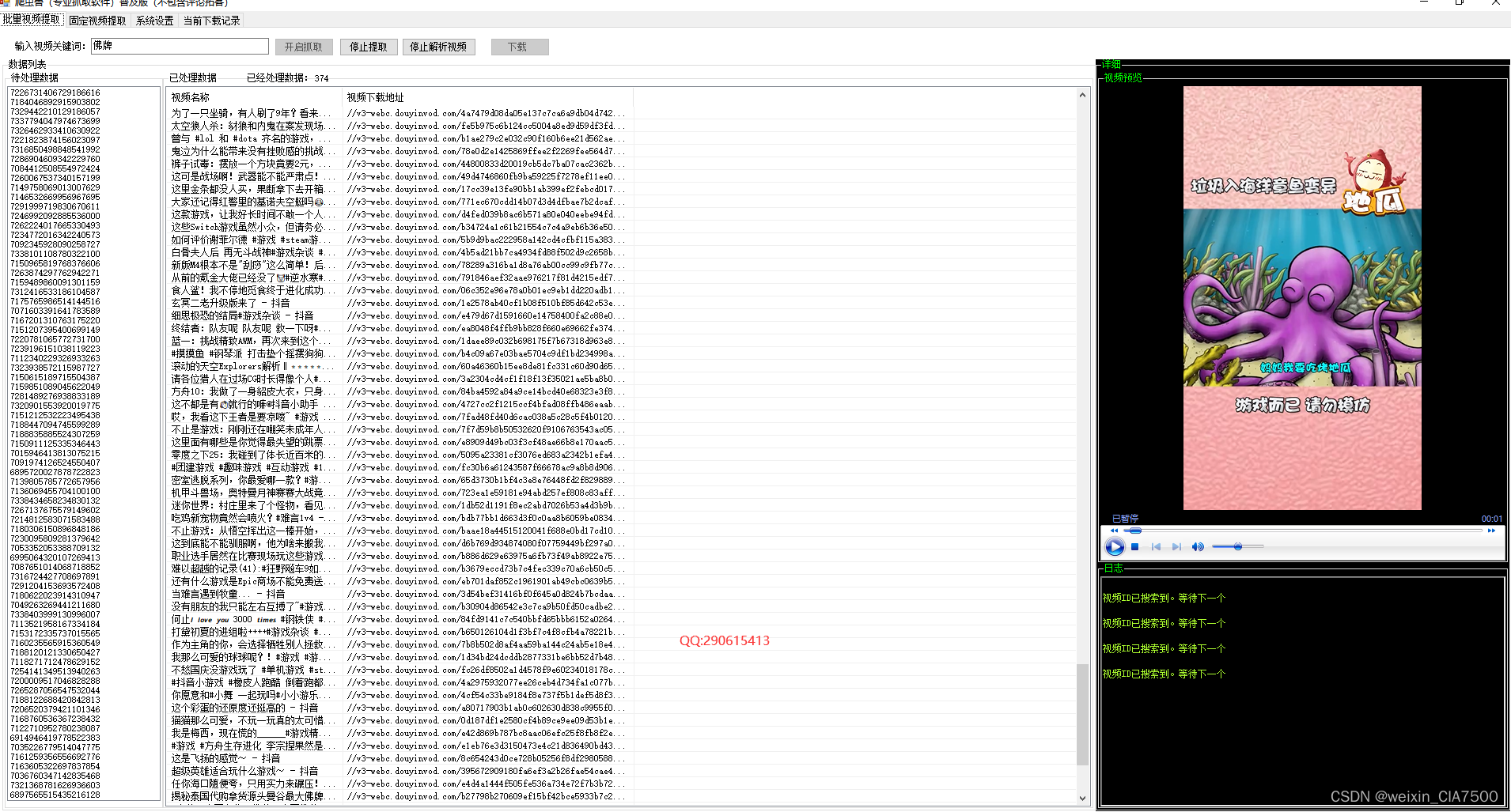
抖音视频评论数据提取软件|抖音数据抓取工具
一、开发背景: 在业务需求中,我们经常需要下载抖音视频。然而,在网上找到的视频通常只能通过逐个复制链接的方式进行抓取和下载,这种操作非常耗时。我们希望能够通过关键词自动批量抓取并选择性地下载抖音视频。因此,为…...

【web】云导航项目部署及环境搭建(复杂)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、项目介绍1.1项目环境架构LNMP1.2项目代码说明 二、项目环境搭建2.1 Nginx安装2.2 php安装2.3 nginx配置和php配置2.3.1 修改nginx文件2.3.2 修改vim /etc/p…...

软件测试人员必会的linux命令
文件和目录操作: ● ls:列出目录中的文件和子目录。 ● cd:改变当前工作目录。 ● mkdir:创建新目录。 ● rm:删除文件或目录。 ● cp:复制文件或目录。 ● mv:移动或重命名文件或目录。 文本查看和编辑: ● cat:查看文件内容。 ● more或less:分页查看文件内…...

Mac使用K6工具压测WebSocket
commend空格 打开终端,安装k6 brew install k6验证是否安装成功 k6 version设置日志级别为debug export K6_LOG_LEVELdebug执行脚本(进入脚本所在文件夹下) k6 run --vus 100 --duration 10m --out csvresult.csv script.js 脚本解释&…...
小程序--vscode配置
要在vscode里开发微信小程序,需要安装以下两个插件: 安装后,即可使用vscode开发微信小程序。 注:若要实现鼠标悬浮提示,则需新建jsconfig.json文件,并进行配置,即可实现。 jsconfig.json内容如…...

linux僵尸进程
僵尸进程(Zombie Process)是指在一个进程终止时,其父进程尚未调用wait()或waitpid()函数来获取该进程的终止状态信息,导致进程的资源(如进程表中的记录)仍然保留在系统中的一种状态。 当一个进程结束时&am…...

【web | CTF】攻防世界 Web_php_unserialize
天命:这条反序列化题目也是比较特别,里面的漏洞知识点,在现在的php都被修复了 天命:而且这次反序列化的字符串数量跟其他题目不一样 <?php class Demo { // 初始化给变量内容,也就是当前文件,高亮显示…...
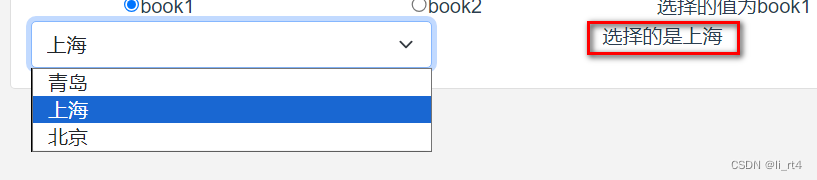
Vue3中的select 的option是多余的?
背景: 通过Vue3中填充一个下拉框,在打开页面时要指定默认选中,并在选项改变时把下拉框的选中值显示出来 问题: 填充通常的作法是设置 <option v-for"option in cities" :value"option.value" >&a…...

考研408深度分析+全年规划
408确实很难,他的难分两方面 一方面是408本身的复习难度,我们都知道,408的考察科目有四科,分别是数据结构,计算机组成原理,操作系统和计算机网络。大家回想一下自己在大学本科时候学习这些专业课的难度&am…...

【算法笔记】ch01_01_0771 宝石与石头
笔记介绍: 本项目是datawhale发布的LeetCode 算法笔记(Leetcode-Notes)课程完成笔记,根据推荐题目循序渐进练习算法题目。主要用python进行书写相关代码,会介绍解题思路及跑通解法。 0771. 宝石与石头 题目大意 描…...

jQuery瀑布流画廊,瀑布流动态加载
jQuery瀑布流画廊,瀑布流动态加载 效果展示 手机布局 jQuery瀑布流动态加载 HTML代码片段 <!-- mediabanner --><div class"mediabanner"><img src"img/mediabanner.jpg" class"bg"/><div class"text&qu…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...