rabbitmq知识梳理
一.WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
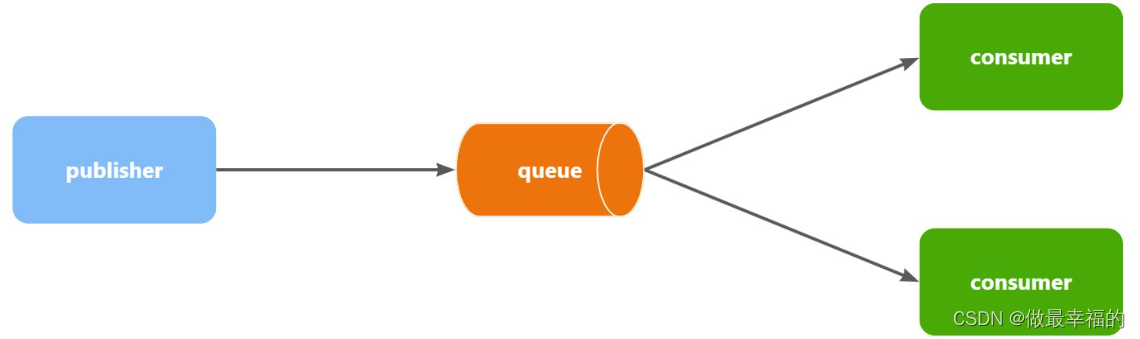
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
接下来,我们就来模拟这样的场景。
首先,我们在控制台创建一个新的队列,命名为work.queue:
1.消息发送
这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
/*** workQueue* 向队列中不停发送消息,模拟消息堆积。*/@Testpublic void testWorkQueue() throws InterruptedException {// 队列名称String queueName = "work.queue";// 消息String message = "hello, message_";for (int i = 0; i < 50; i++) {// 发送消息,每20毫秒发送一次,相当于每秒发送50条消息rabbitTemplate.convertAndSend(queueName, message + i);Thread.sleep(20);}}
2.消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(20);
}@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());Thread.sleep(200);
}
注意到这两消费者,都设置了`Thead.sleep`,模拟任务耗时:
- 消费者1 sleep了20毫秒,相当于每秒钟处理50个消息
- 消费者2 sleep了200毫秒,相当于每秒处理5个消息
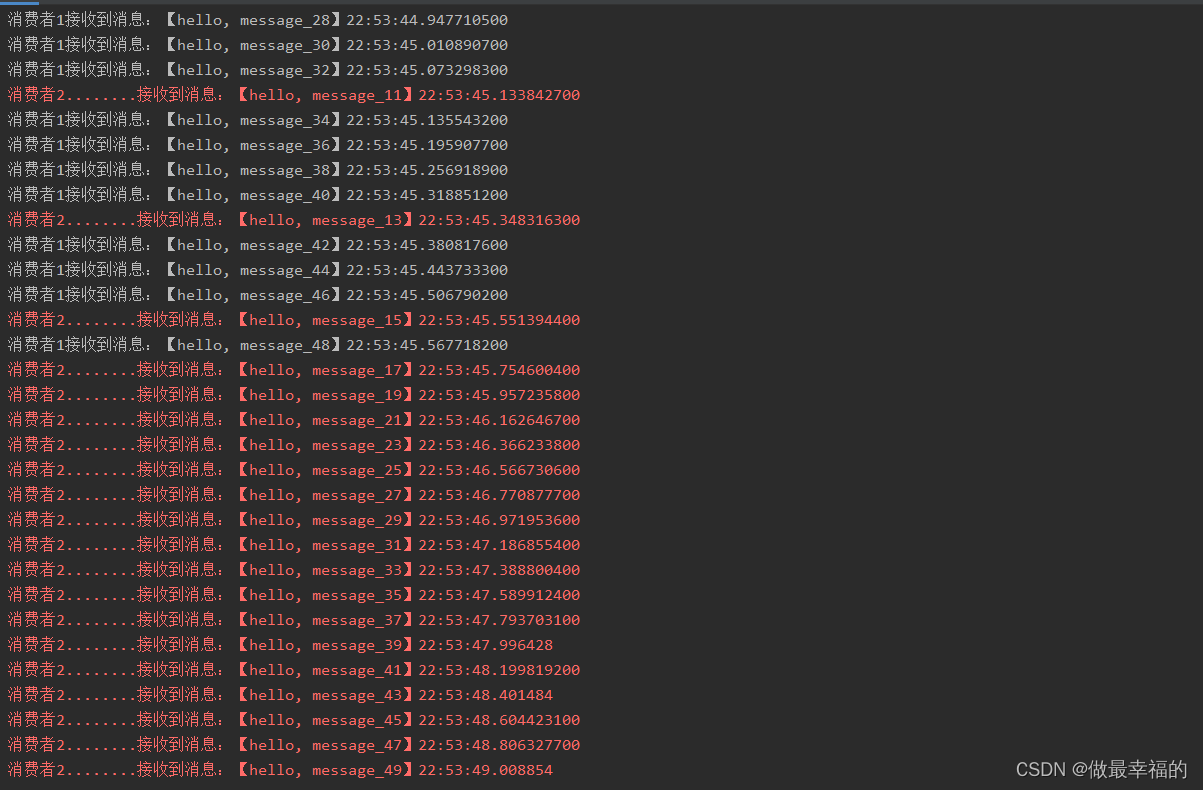
可以看到消费者1和消费者2竟然每人消费了25条消息:
- 消费者1很快完成了自己的25条消息
- 消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力,最终消息处理的耗时远远超过了1秒。这样显然是有问题的。
3.能者多劳
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
spring:rabbitmq:listener:simple:prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
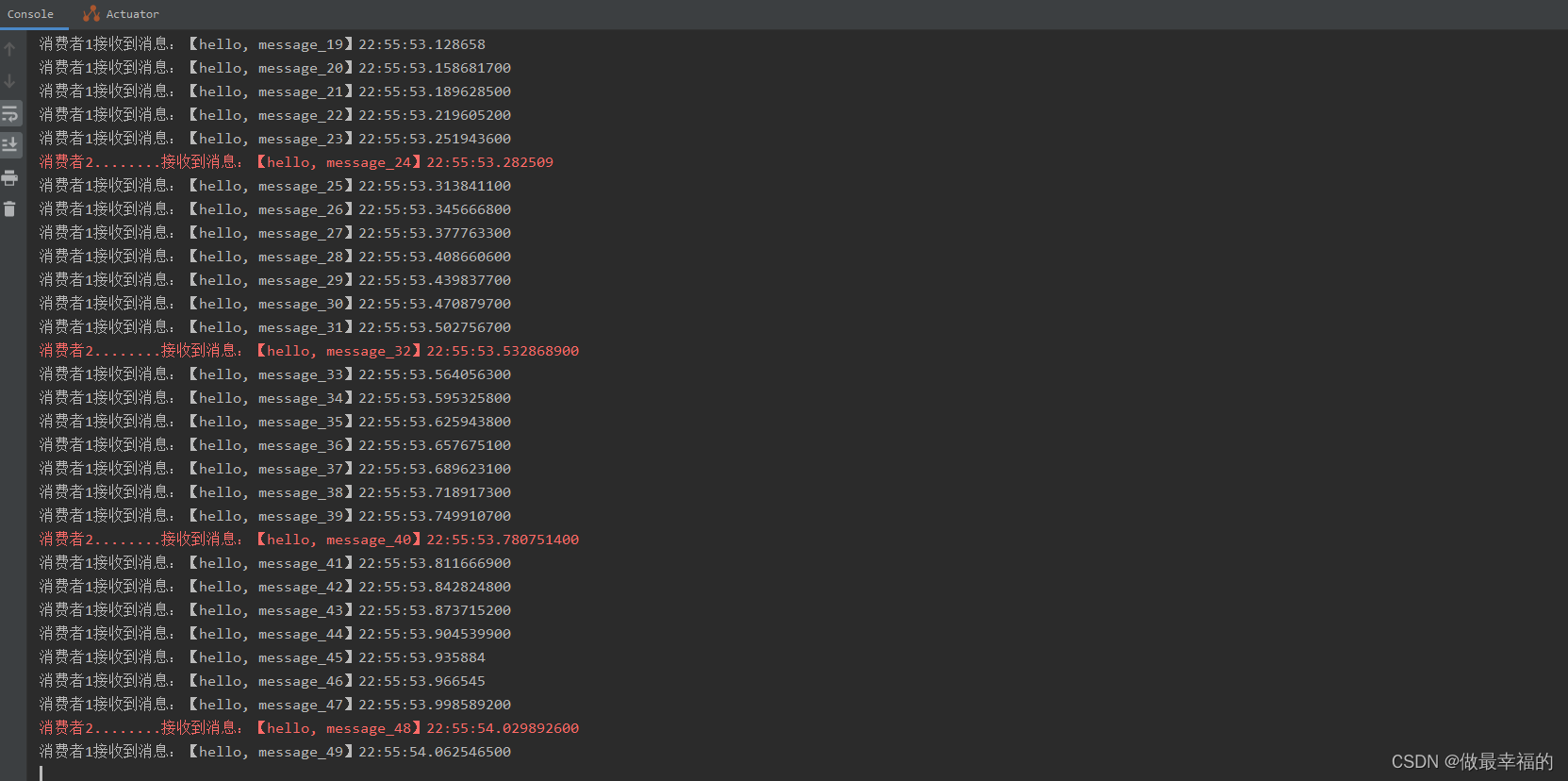
可以发现,由于消费者1处理速度较快,所以处理了更多的消息;消费者2处理速度较慢,只处理了6条消息。而最终总的执行耗时也在1秒左右,大大提升。正所谓能者多劳,这样充分利用了每一个消费者的处理能力,可以有效避免消息积压问题。
4.总结
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量
二.交换机类型
在之前的两个测试案例中,都没有交换机,生产者直接发送消息到队列。而一旦引入交换机,消息发送的模式会有很大变化:
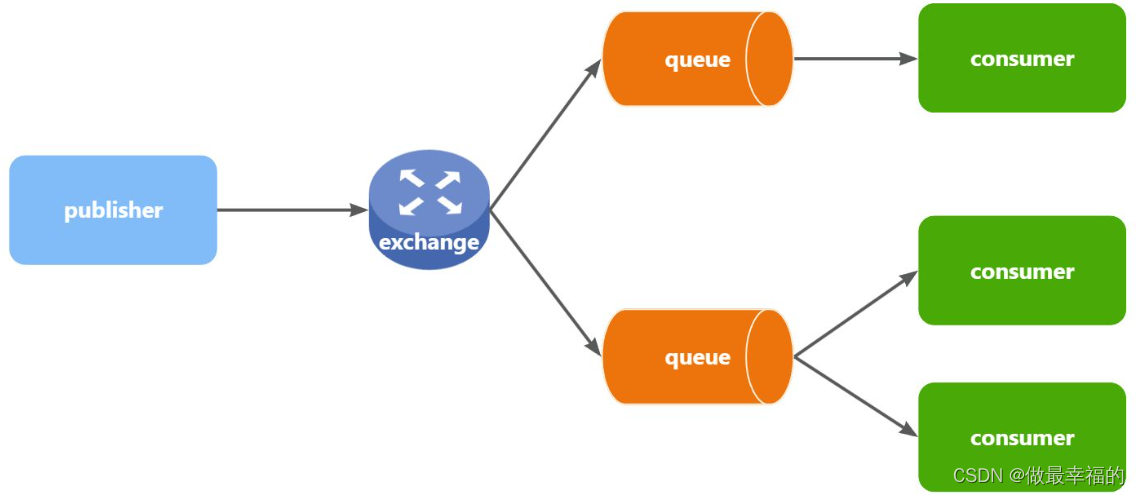
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,不再发送消息到队列中,而是发给交换机
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
- Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
- Consumer:消费者,与以前一样,订阅队列,没有变化
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
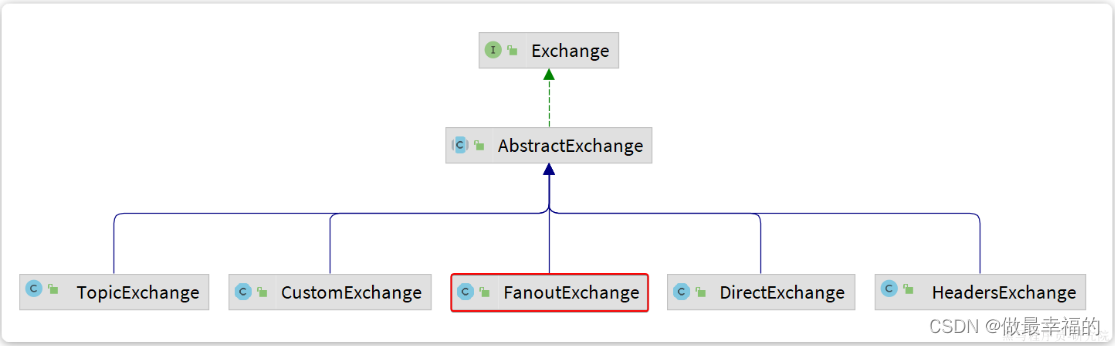
交换机的类型有四种:
- Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
- Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
- Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
- Headers:头匹配,基于MQ的消息头匹配,用的较少。
本次记录前面的三种交换机模式。
1.Fanout交换机
说明
Fanout,英文翻译是扇出,我觉得在MQ中叫广播更合适。
在广播模式下,消息发送流程是这样的:
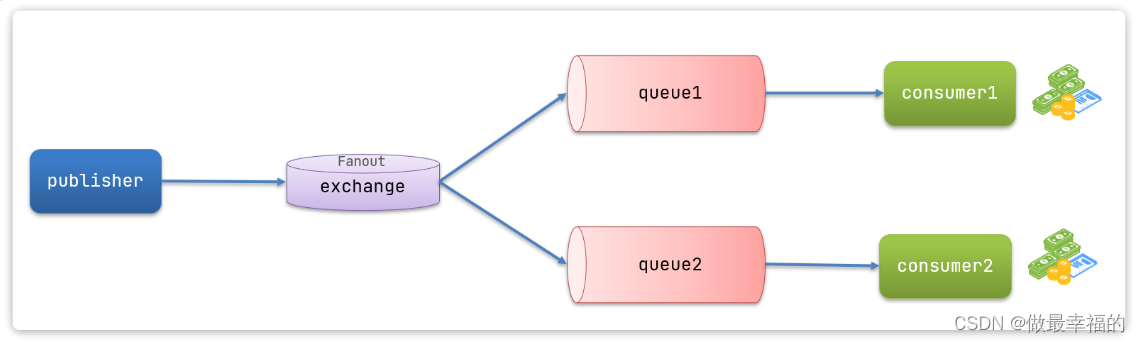
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
我们的计划是这样的:
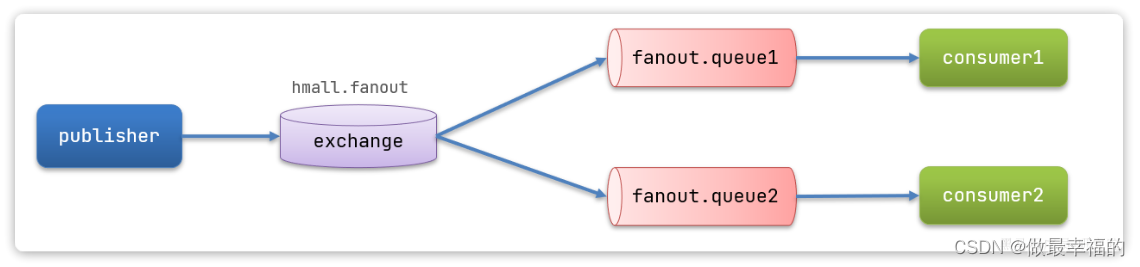
- 创建一个名为
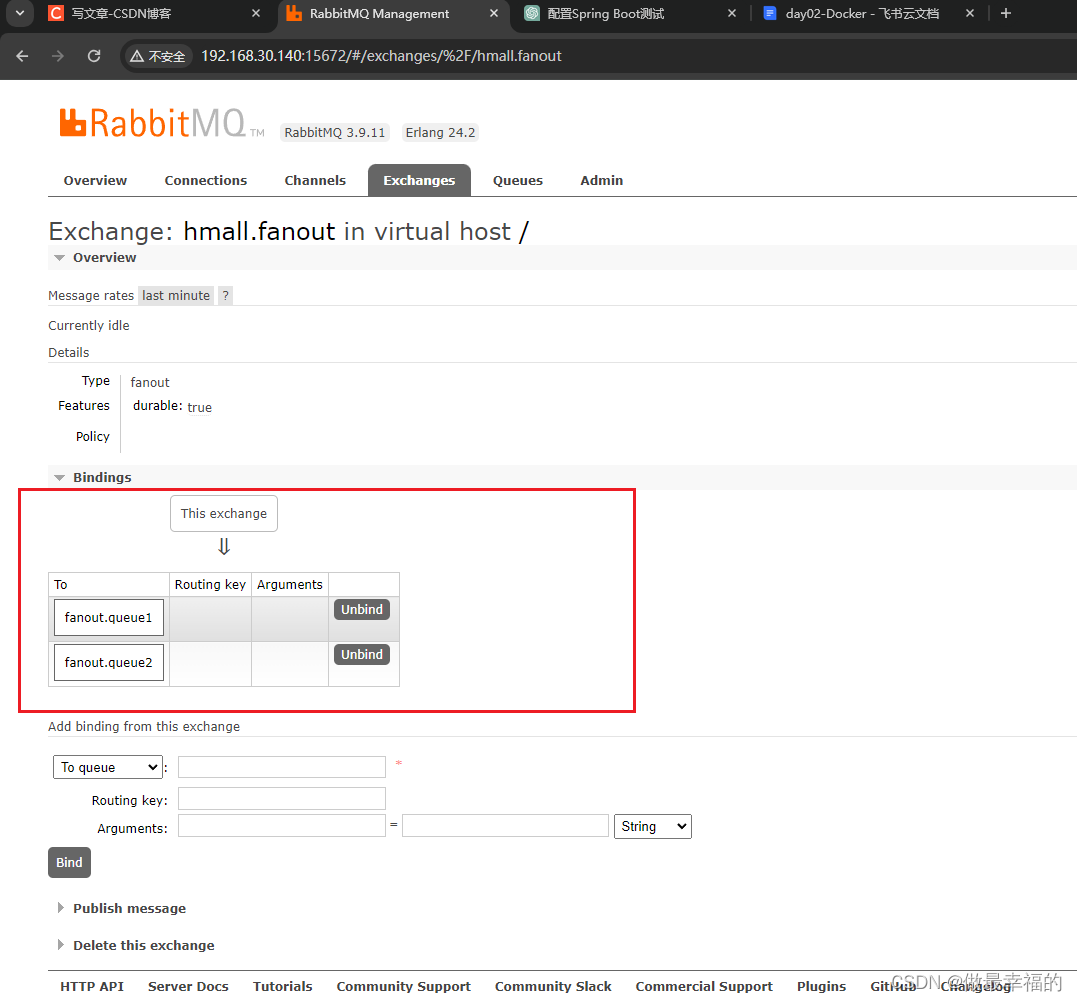
hmall.fanout的交换机,类型是Fanout - 创建两个队列
fanout.queue1和fanout.queue2,绑定到交换机hmall.fanout
1.在控制台增加两个新的队列
然后再创建一个交换机:

然后绑定两个队列到交换机:
测试
1.消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
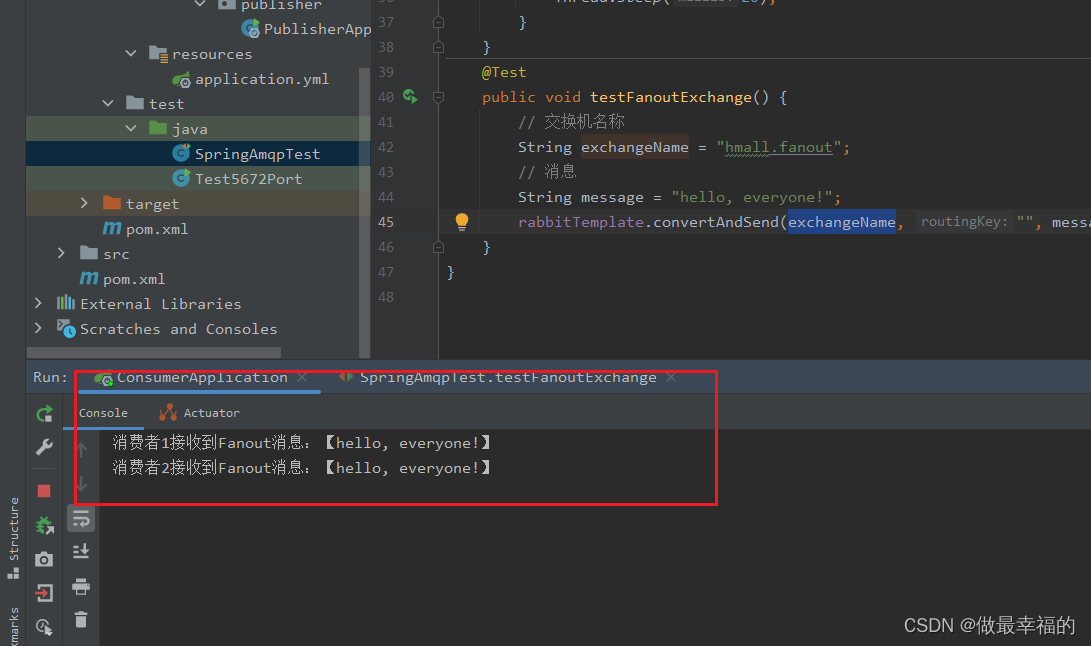
public void testFanoutExchange() {// 交换机名称String exchangeName = "hmall.fanout";// 消息String message = "hello, everyone!";rabbitTemplate.convertAndSend(exchangeName, "", message);
}
2.消息接收
在consumer服务的SpringRabbitListener中添加两个方法,作为消费者:
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) {System.out.println("消费者1接收到Fanout消息:【" + msg + "】");
}@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) {System.out.println("消费者2接收到Fanout消息:【" + msg + "】");
}
3.总结
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
2.Direct交换机
说明
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
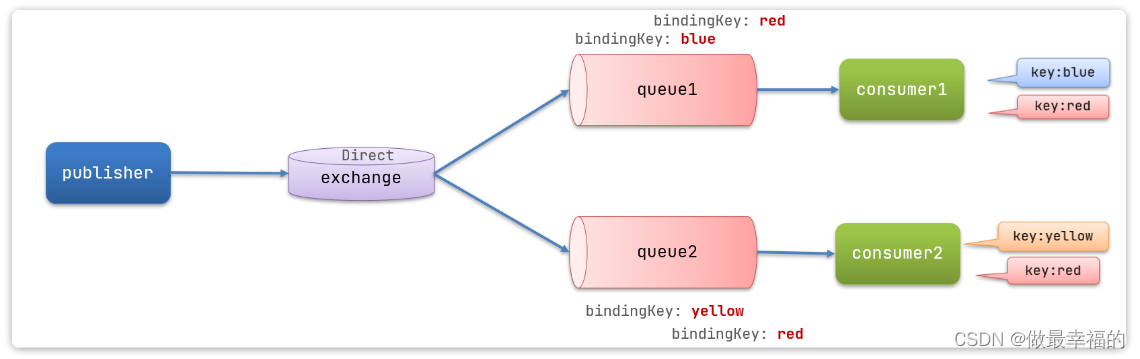
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
案例需求如图:
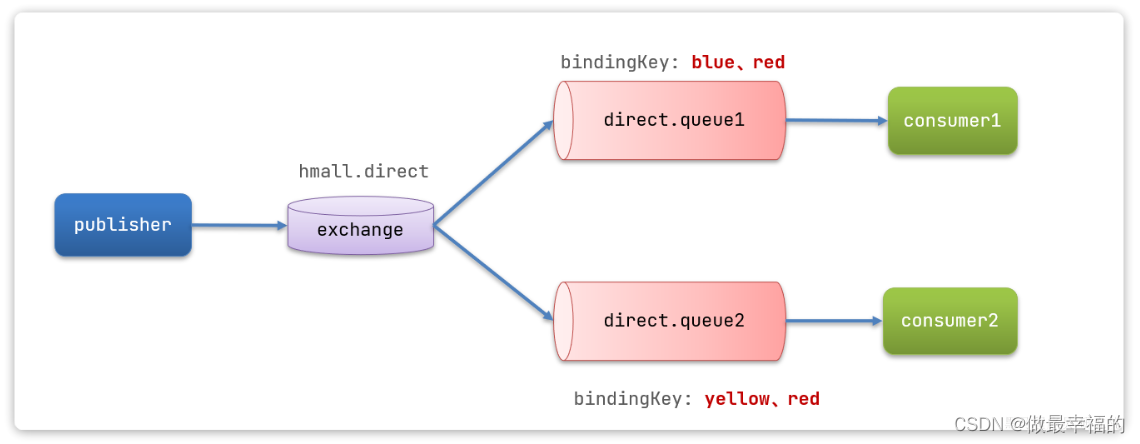
- 声明一个名为
hmall.direct的交换机 - 声明队列
direct.queue1,绑定hmall.direct,bindingKey为blud和red - 声明队列
direct.queue2,绑定hmall.direct,bindingKey为yellow和red - 在
consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2 - 在publisher中编写测试方法,向
hmall.direct发送消息
声明队列和交换机
首先在控制台声明两个队列direct.queue1和direct.queue2
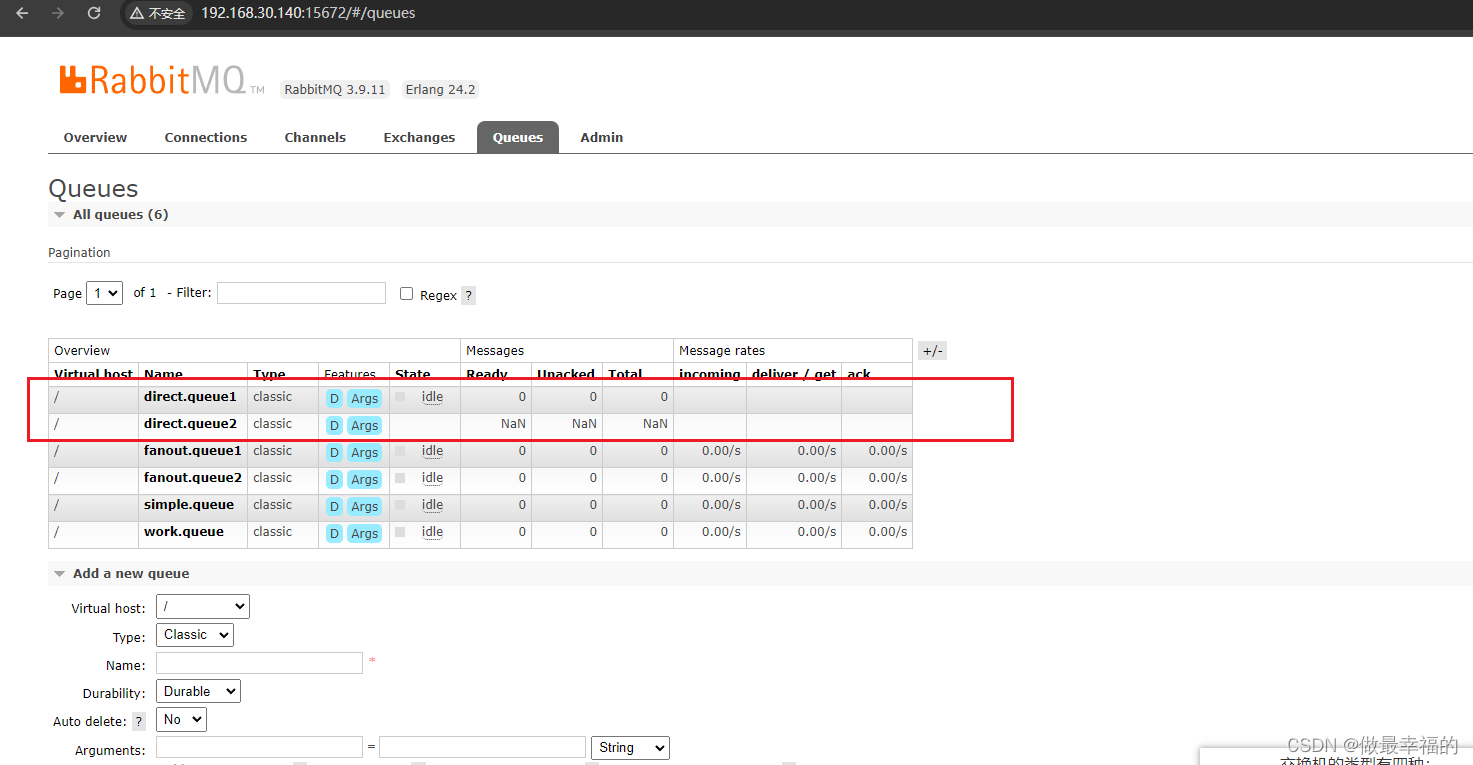
然后声明一个direct类型的交换机,命名为hmall.direct:
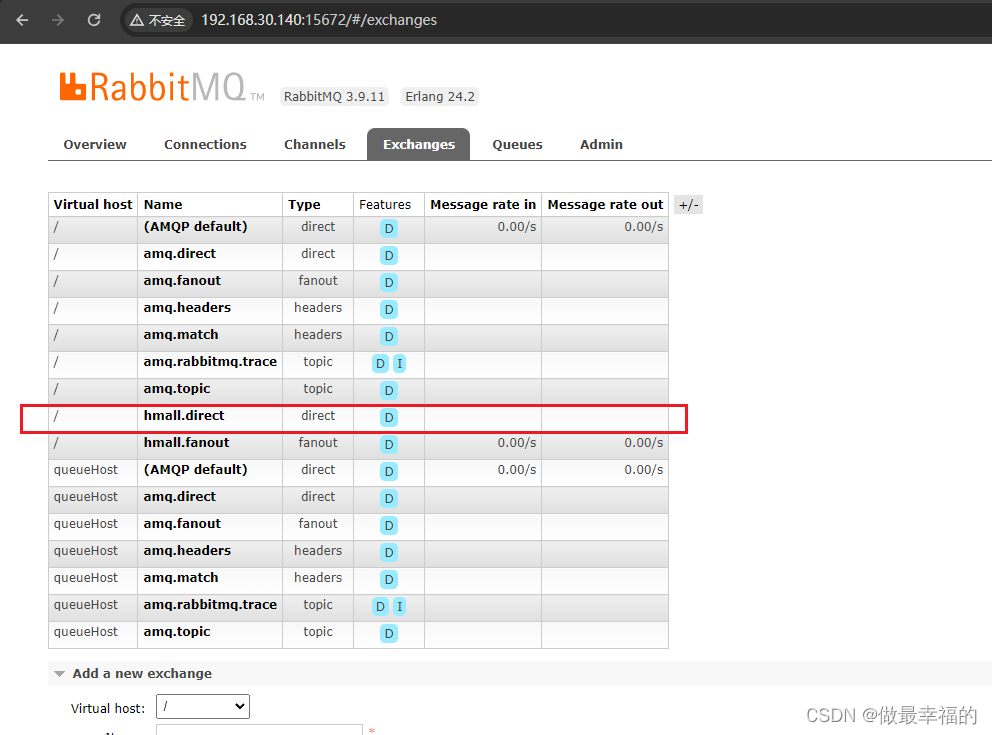
然后使用red和blue作为key,绑定direct.queue1到hmall.direct:
同理,使用red和yellow作为key,绑定direct.queue2到hmall.direct,步骤略,最终结果:
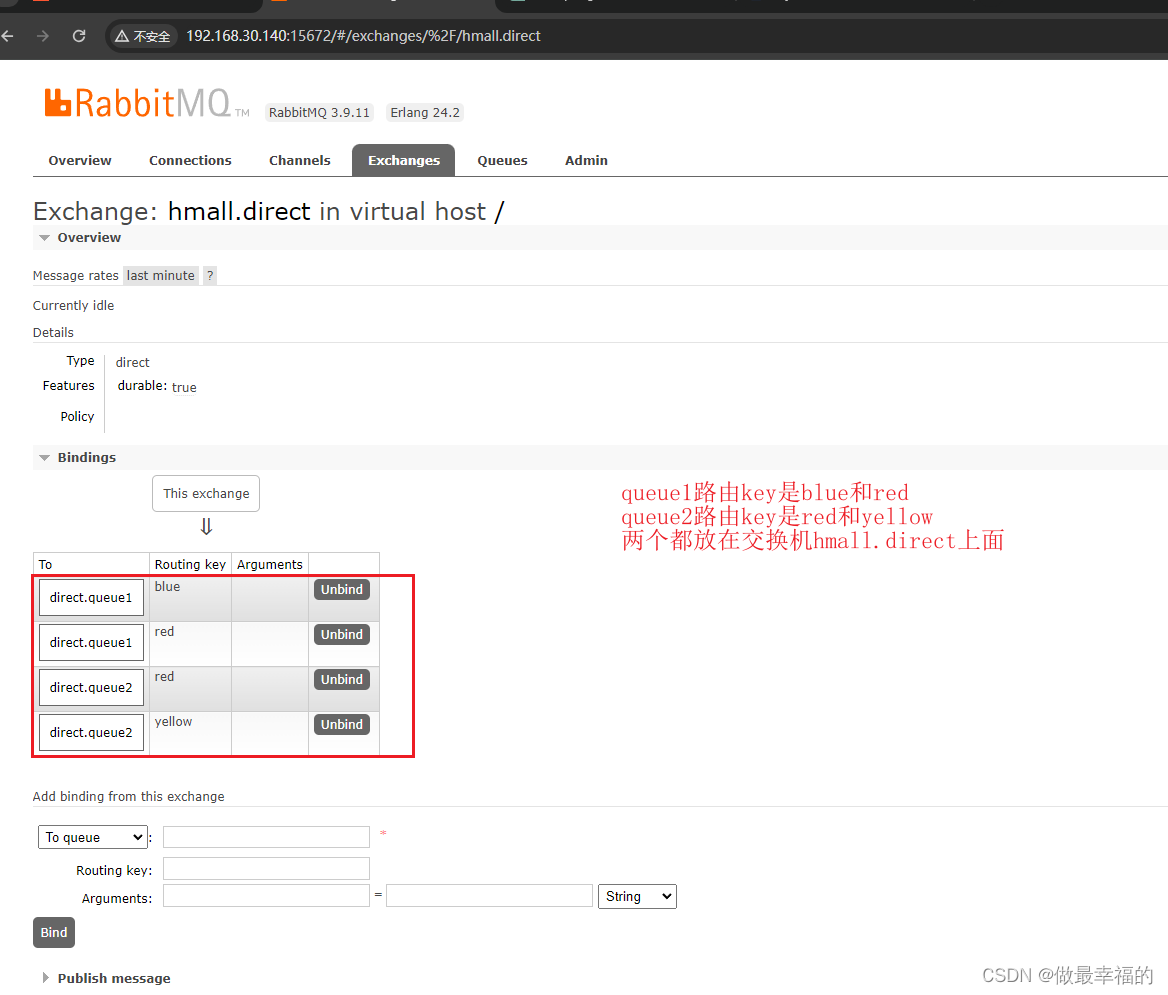
测试
1.消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
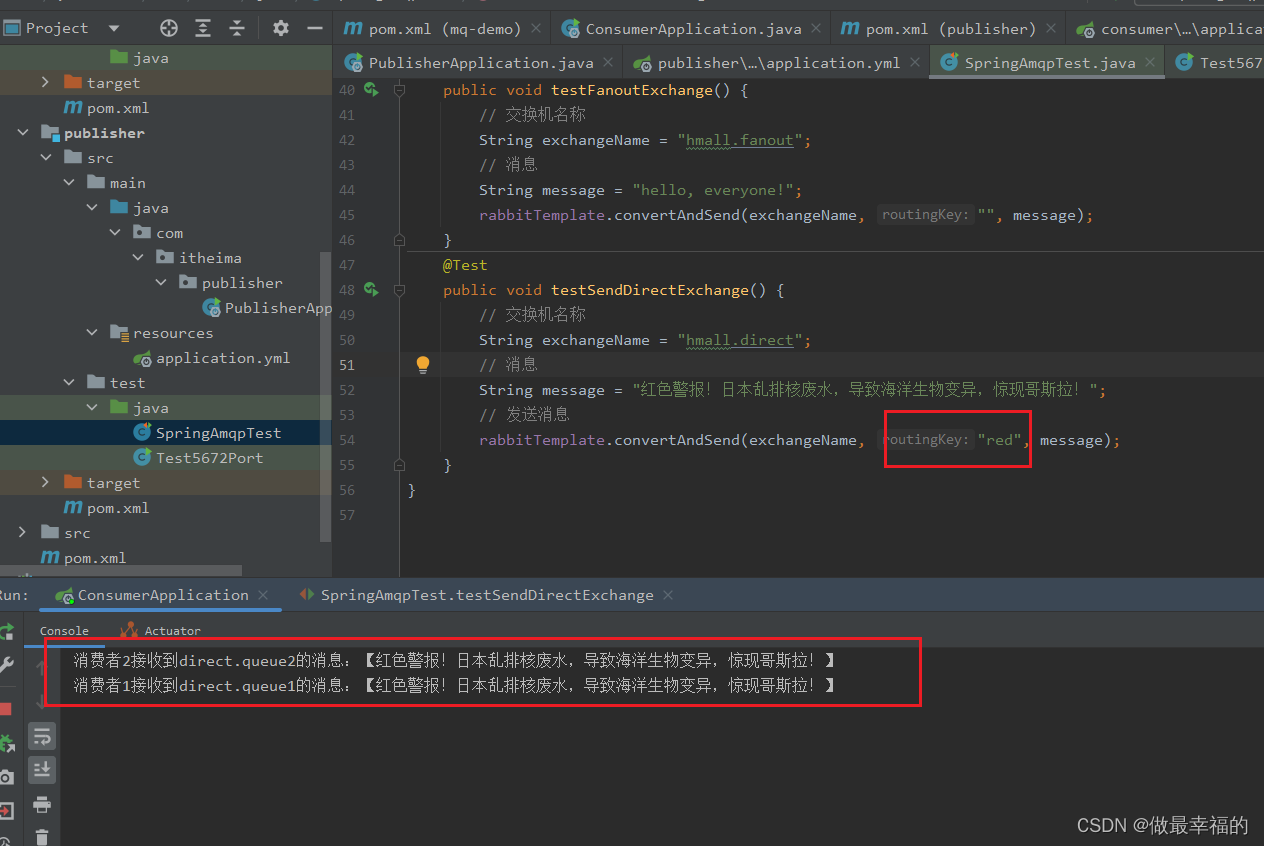
public void testSendDirectExchange() {// 交换机名称String exchangeName = "hmall.direct";// 消息String message = "红色警报!日本乱排核废水,导致海洋生物变异,惊现哥斯拉!";// 发送消息rabbitTemplate.convertAndSend(exchangeName, "red", message);
}
2.消息接收
在consumer服务的SpringRabbitListener中添加方法:
@RabbitListener(queues = "direct.queue1")
public void listenDirectQueue1(String msg) {System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");
}@RabbitListener(queues = "direct.queue2")
public void listenDirectQueue2(String msg) {System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】");
}
由于使用的red这个key,所以两个消费者都收到了消息:
我们再切换为blue这个key:
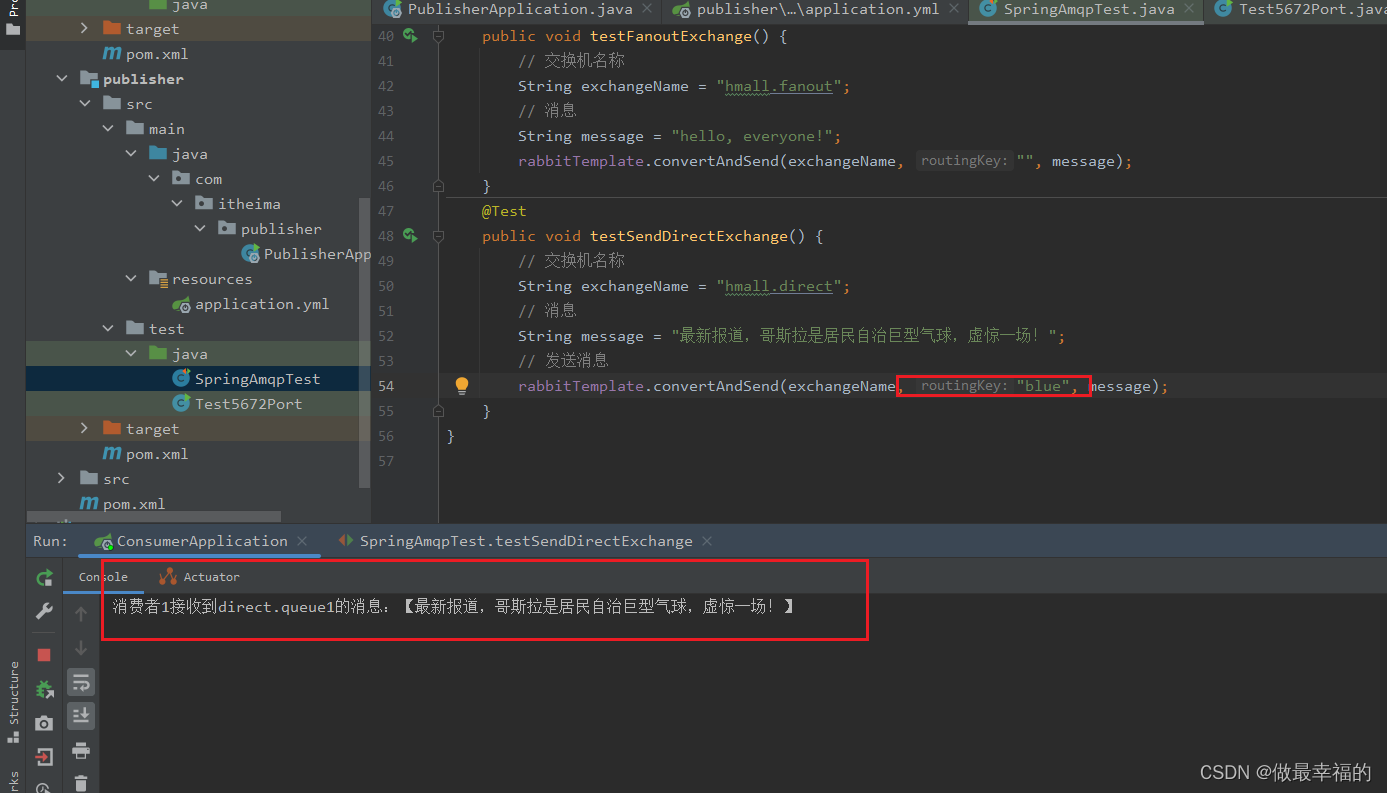
3.总结
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
3.Topic交换机
说明
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。
只不过Topic类型Exchange可以让队列在绑定RoutingKey 的时候使用通配符!
RoutingKey 一般都是有一个或多个单词组成,多个单词之间以.分割,例如: item.insert
通配符规则:
#:匹配一个或多个词*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert或者item.spuitem.*:只能匹配item.spu
测试
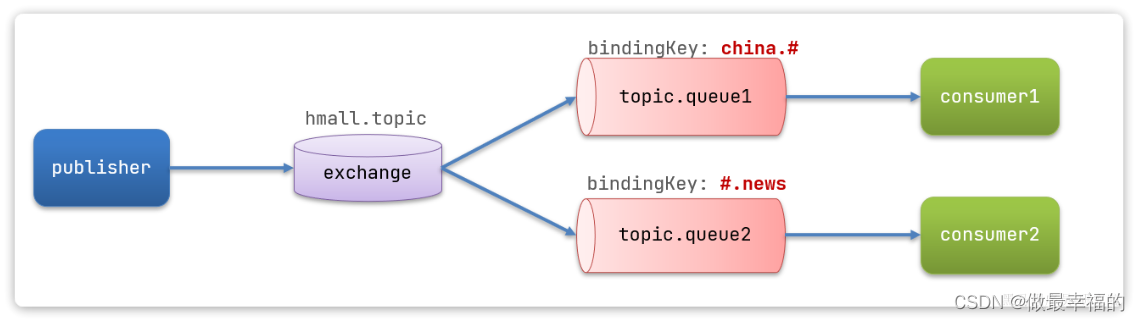
假如此时publisher发送的消息使用的RoutingKey共有四种:
china.news代表有中国的新闻消息;china.weather代表中国的天气消息;japan.news则代表日本新闻japan.weather代表日本的天气消息;
解释:
topic.queue1:绑定的是china.#,凡是以china.开头的routing key都会被匹配到,包括:china.newschina.weather
topic.queue2:绑定的是#.news,凡是以.news结尾的routing key都会被匹配。包括:china.newsjapan.news
接下来,我们就按照上图所示,来演示一下Topic交换机的用法。
首先,在控制台按照图示例子创建队列、交换机,并利用通配符绑定队列和交换机。此处步骤略。最终结果如下:
1.消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
/*** topicExchange*/
@Test
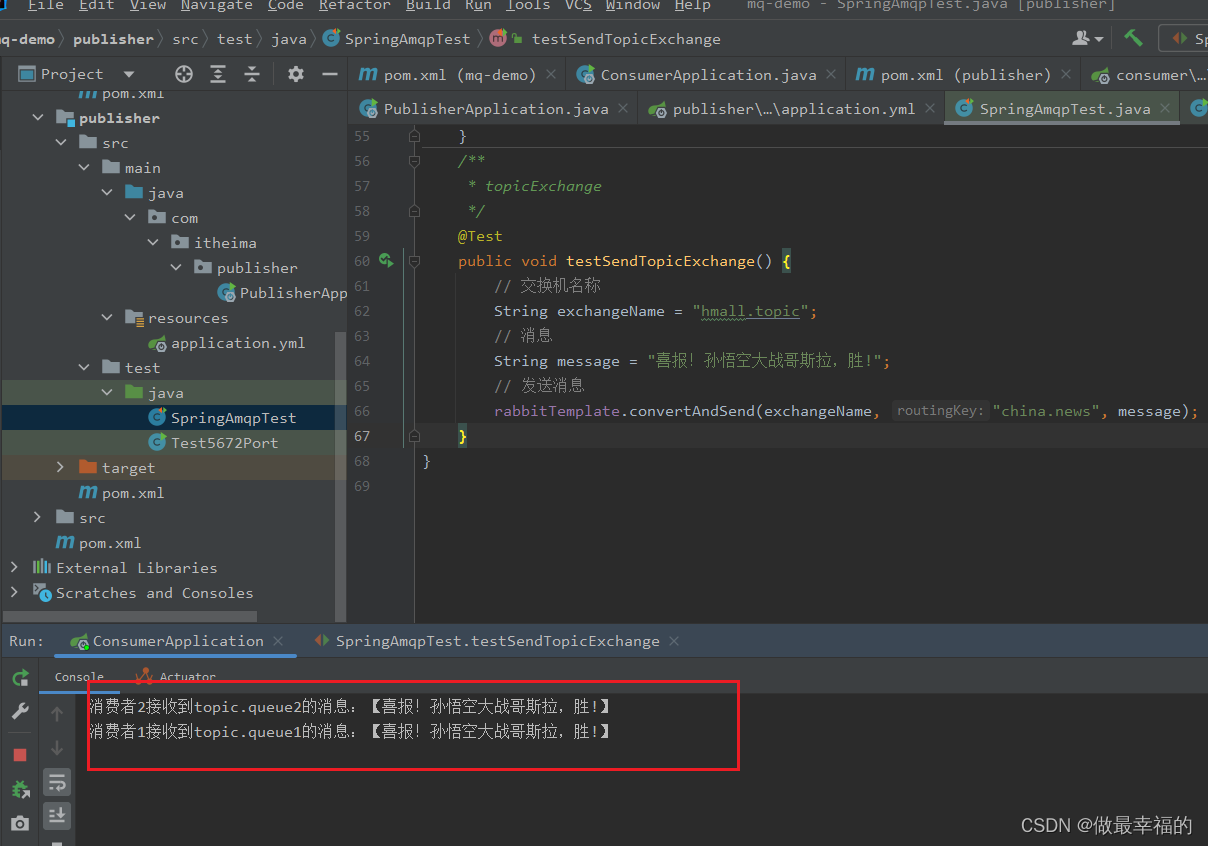
public void testSendTopicExchange() {// 交换机名称String exchangeName = "hmall.topic";// 消息String message = "喜报!孙悟空大战哥斯拉,胜!";// 发送消息rabbitTemplate.convertAndSend(exchangeName, "china.news", message);
}
2.消息接收
@RabbitListener(queues = "topic.queue1")
public void listenTopicQueue1(String msg){System.out.println("消费者1接收到topic.queue1的消息:【" + msg + "】");
}@RabbitListener(queues = "topic.queue2")
public void listenTopicQueue2(String msg){System.out.println("消费者2接收到topic.queue2的消息:【" + msg + "】");
}
3.总结
描述下Direct交换机与Topic交换机的差异?
- Topic交换机接收的消息RoutingKey必须是多个单词,以
**.**分割 - Topic交换机与队列绑定时的bindingKey可以指定通配符
#:代表0个或多个词*:代表1个词
4.声明队列和交换机
在之前我们都是基于RabbitMQ控制台来创建队列、交换机。但是在实际开发时,队列和交换机是程序员定义的,将来项目上线,又要交给运维去创建。那么程序员就需要把程序中运行的所有队列和交换机都写下来,交给运维。在这个过程中是很容易出现错误的。
因此推荐的做法是由程序启动时检查队列和交换机是否存在,如果不存在自动创建。
1.基本API
SpringAMQP提供了一个Queue类,用来创建队列
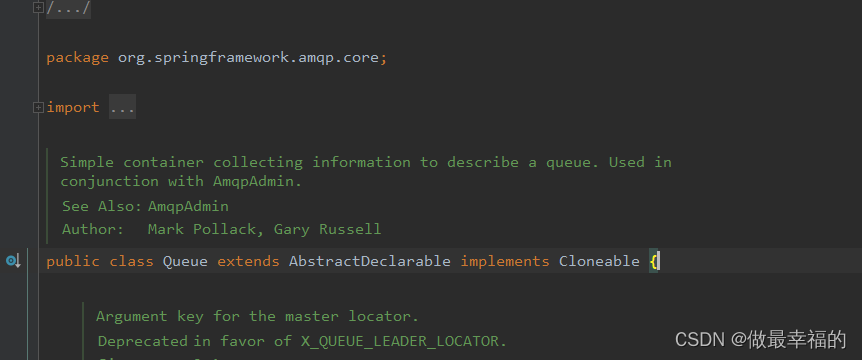
SpringAMQP还提供了一个Exchange接口,来表示所有不同类型的交换机:
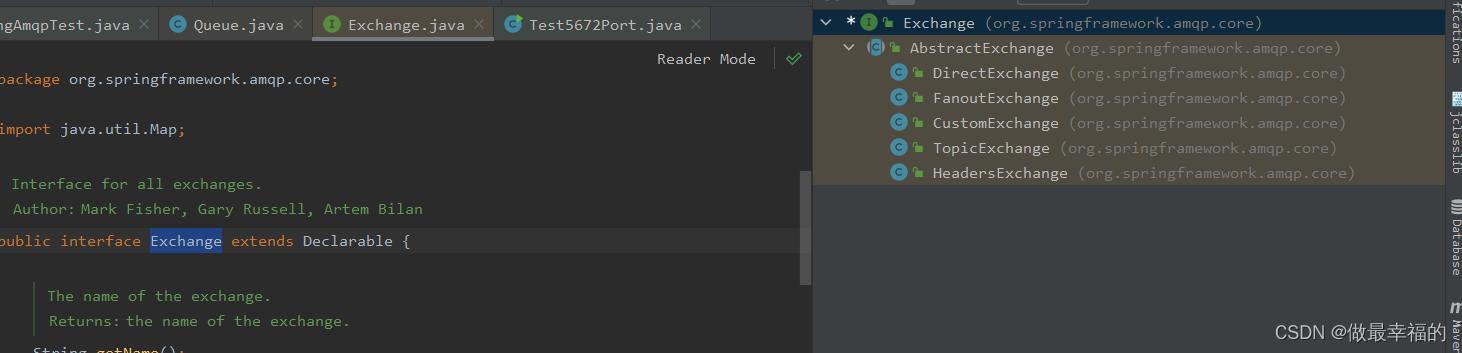
我们可以自己创建队列和交换机,不过SpringAMQP还提供了ExchangeBuilder来简化这个过程:
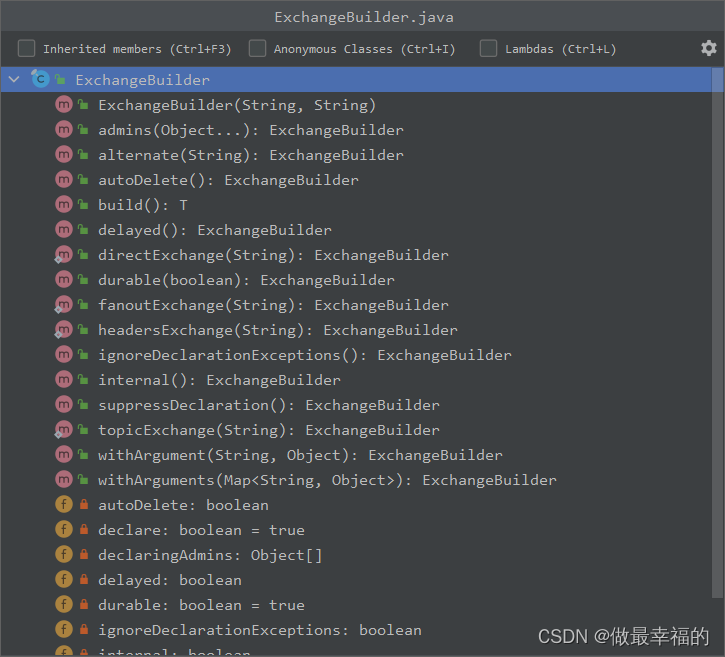
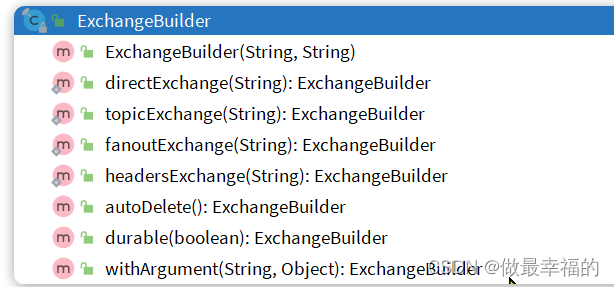
而在绑定队列和交换机时,则需要使用BindingBuilder来创建Binding对象: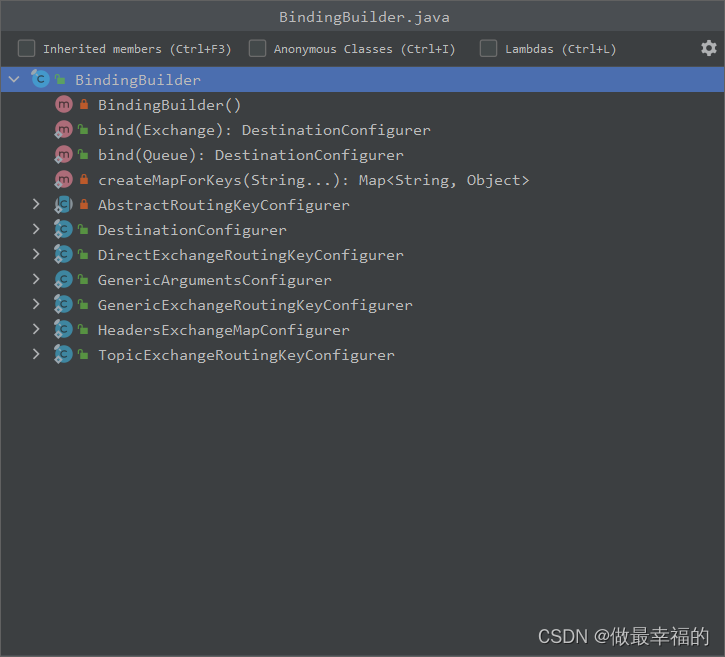
1.fanout示例
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.FanoutExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class FanoutConfig {/*** 声明交换机* @return Fanout类型交换机*/@Beanpublic FanoutExchange fanoutExchange(){return new FanoutExchange("hmall.fanout");}/*** 第1个队列*/@Beanpublic Queue fanoutQueue1(){return new Queue("fanout.queue1");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);}/*** 第2个队列*/@Beanpublic Queue fanoutQueue2(){return new Queue("fanout.queue2");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);}
}
2.direct示例
direct模式由于要绑定多个KEY,会非常麻烦,每一个Key都要编写一个binding:
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class DirectConfig {/*** 声明交换机* @return Direct类型交换机*/@Beanpublic DirectExchange directExchange(){return ExchangeBuilder.directExchange("hmall.direct").build();}/*** 第1个队列*/@Beanpublic Queue directQueue1(){return new Queue("direct.queue1");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue1WithRed(Queue directQueue1, DirectExchange directExchange){return BindingBuilder.bind(directQueue1).to(directExchange).with("red");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue1WithBlue(Queue directQueue1, DirectExchange directExchange){return BindingBuilder.bind(directQueue1).to(directExchange).with("blue");}/*** 第2个队列*/@Beanpublic Queue directQueue2(){return new Queue("direct.queue2");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue2WithRed(Queue directQueue2, DirectExchange directExchange){return BindingBuilder.bind(directQueue2).to(directExchange).with("red");}/*** 绑定队列和交换机*/@Beanpublic Binding bindingQueue2WithYellow(Queue directQueue2, DirectExchange directExchange){return BindingBuilder.bind(directQueue2).to(directExchange).with("yellow");}
}
3.基于注解声明
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
例如,我们同样声明Direct模式的交换机和队列:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue1"),exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");
}@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "direct.queue2"),exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】");
}
再试试Topic模式:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "topic.queue1"),exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),key = "china.#"
))
public void listenTopicQueue1(String msg){System.out.println("消费者1接收到topic.queue1的消息:【" + msg + "】");
}@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "topic.queue2"),exchange = @Exchange(name = "hmall.topic", type = ExchangeTypes.TOPIC),key = "#.news"
))
public void listenTopicQueue2(String msg){System.out.println("消费者2接收到topic.queue2的消息:【" + msg + "】");
}
4.消息转换器
Spring的消息发送代码接收的消息体是一个Object:
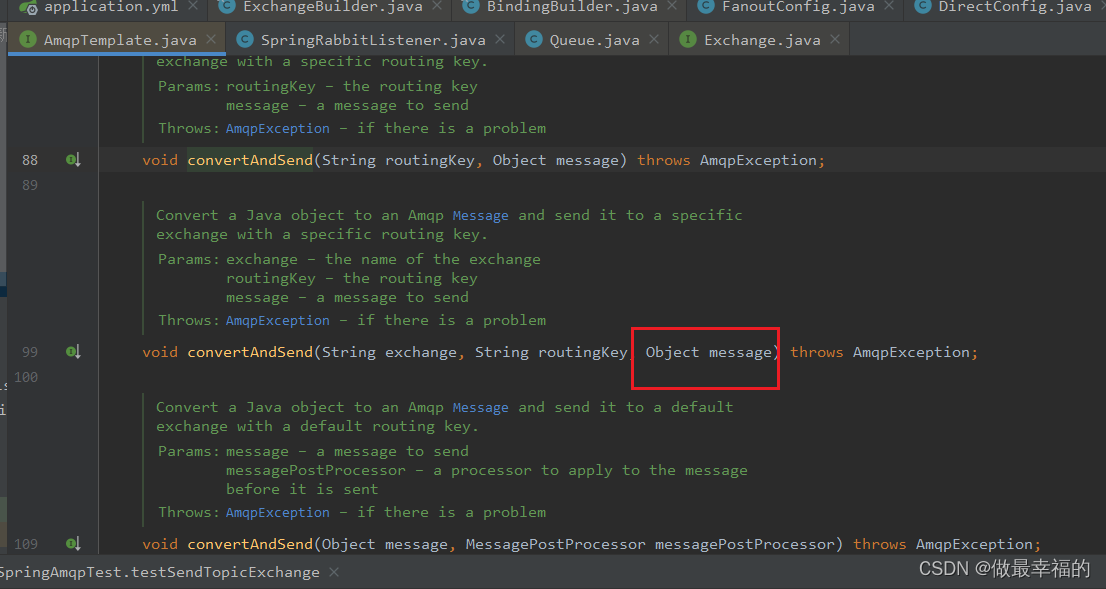
而在数据传输时,它会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
我们来测试一下。
1)创建测试队列
首先,我们在consumer服务中声明一个新的配置类:
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MessageConfig {@Beanpublic Queue objectQueue() {return new Queue("object.queue");}
}
注意,这里我们先不要给这个队列添加消费者,我们要查看消息体的格式。
重启consumer服务以后,该队列就会被自动创建出来了:
2)发送消息
我们在publisher模块的SpringAmqpTest中新增一个消息发送的代码,发送一个Map对象:
@Test
public void testSendMap() throws InterruptedException {// 准备消息Map<String,Object> msg = new HashMap<>();msg.put("name", "柳岩");msg.put("age", 21);// 发送消息rabbitTemplate.convertAndSend("object.queue", msg);
}
发送消息后查看控制台:
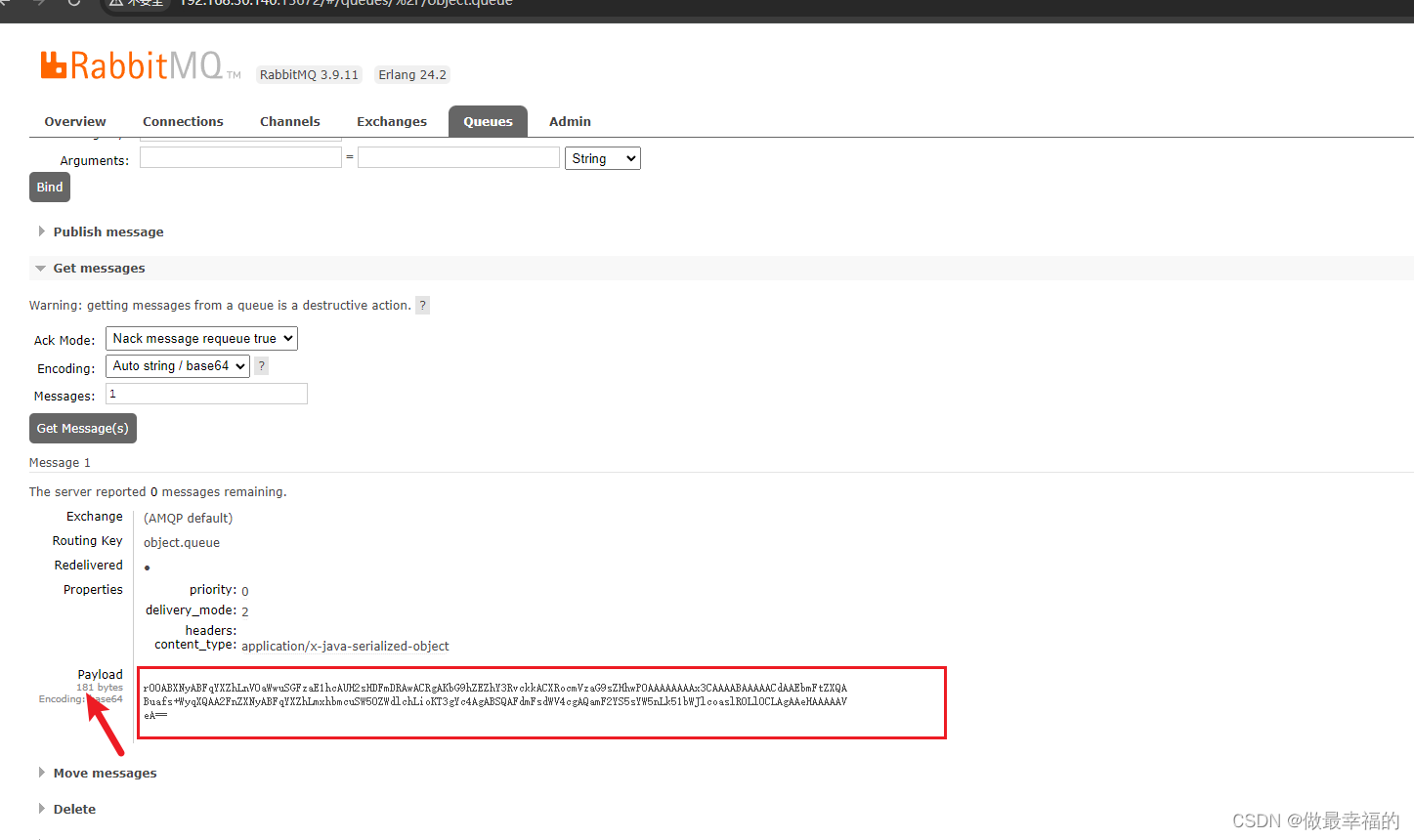
可以看到消息格式非常不友好。
1.配置JSON转换器
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><version>2.9.10</version>
</dependency>
注意,如果项目中引入了spring-boot-starter-web依赖,则无需再次引入Jackson依赖。
配置消息转换器,在publisher和consumer两个服务的启动类中添加一个Bean即可:
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jackson2JsonMessageConverter.setCreate MessageIds(true);return jackson2JsonMessageConverter;
}
消息转换器中添加的messageId可以便于我们将来做幂等性判断。
此时,我们到MQ控制台删除object.queue中的旧的消息。然后再次执行刚才的消息发送的代码,到MQ的控制台查看消息结构:
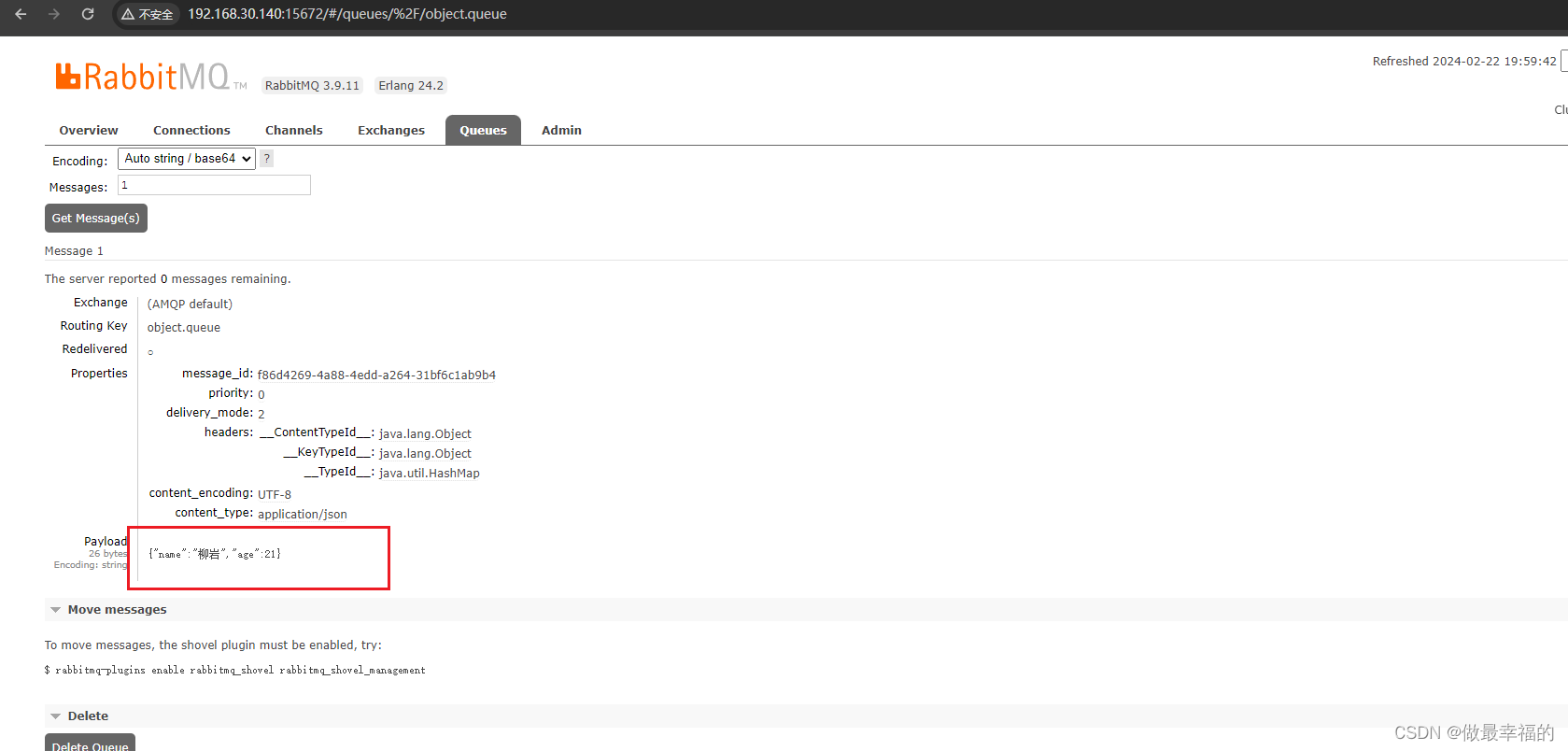
2.消费者接收Object
@RabbitListener(queues = "object.queue")
public void listenSimpleQueueMessage(Map<String, Object> msg) throws InterruptedException {System.out.println("消费者接收到object.queue消息:【" + msg + "】");
}
三.发送者的可靠性
首先,我们一起分析一下消息丢失的可能性有哪些。
消息从发送者发送消息,到消费者处理消息,需要经过的流程是这样的:
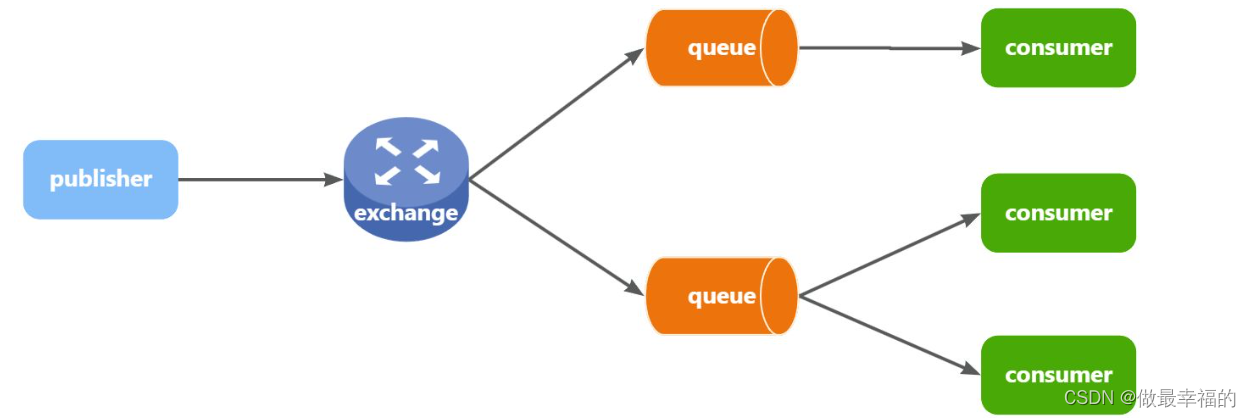
消息从生产者到消费者的每一步都可能导致消息丢失:
- 发送消息时丢失:
- 生产者发送消息时连接MQ失败
- 生产者发送消息到达MQ后未找到
Exchange - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue - 消息到达MQ后,处理消息的进程发生异常
- MQ导致消息丢失:
- 消息到达MQ,保存到队列后,尚未消费就突然宕机
- 消费者处理消息时:
- 消息接收后尚未处理突然宕机
- 消息接收后处理过程中抛出异常
综上,我们要解决消息丢失问题,保证MQ的可靠性,就必须从3个方面入手:
- 确保生产者一定把消息发送到MQ
- 确保MQ不会将消息弄丢
- 确保消费者一定要处理消息
我们先来看如何确保生产者一定能把消息发送到MQ。
1.生产者重试机制(生产者发送消息时连接MQ失败)
首先第一种情况,就是生产者发送消息时,出现了网络故障,导致与MQ的连接中断。
为了解决这个问题,SpringAMQP提供的消息发送时的重试机制。即:当RabbitTemplate与MQ连接超时后,多次重试。
修改publisher模块的application.yaml文件,添加下面的内容:
spring:rabbitmq:connection-timeout: 1s # 设置MQ的连接超时时间template:retry:enabled: true # 开启超时重试机制initial-interval: 1000ms # 失败后的初始等待时间multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multipliermax-attempts: 3 # 最大重试次数
我们利用命令停掉RabbitMQ服务:
docker stop mq
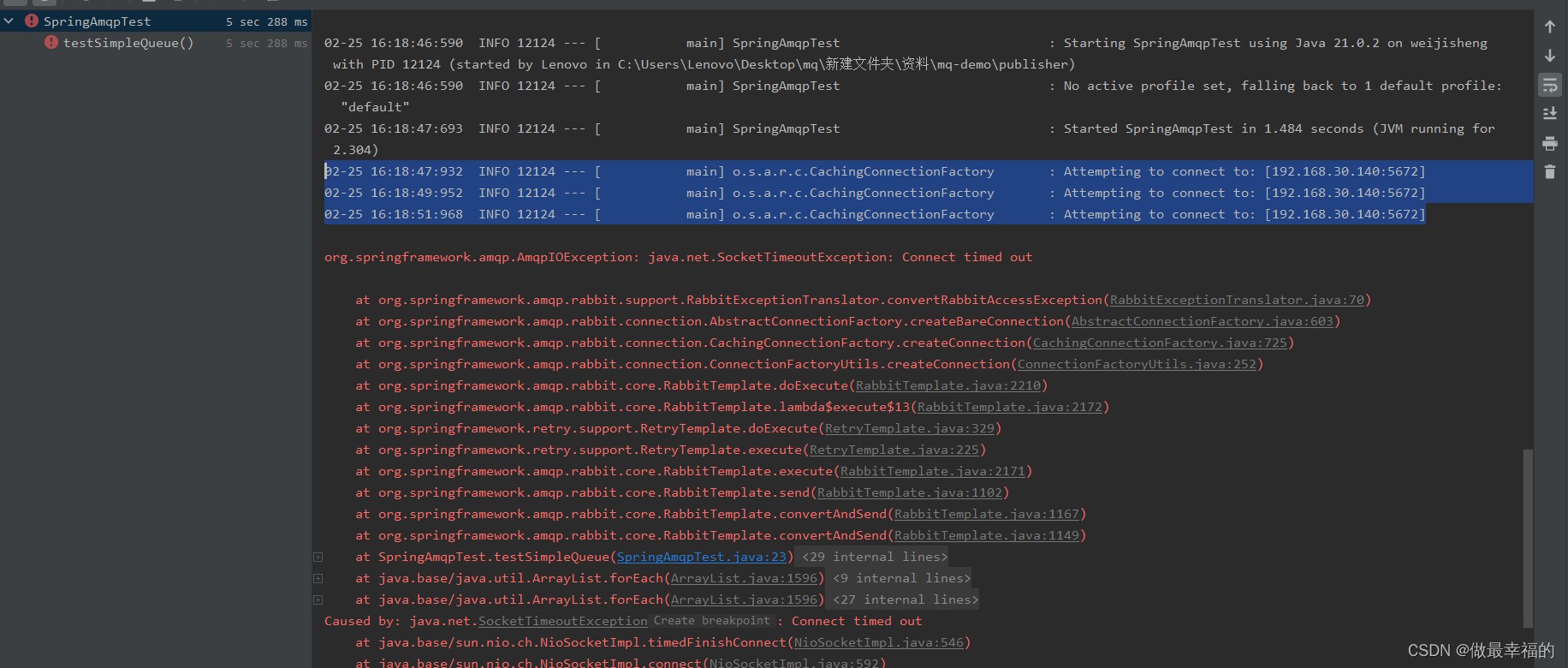
然后测试发送一条消息,会发现会每隔1秒重试1次,总共重试了3次。消息发送的超时重试机制配置成功了!
:::warning
注意:当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
:::
2生产者确认机制
一般情况下,只要生产者与MQ之间的网路连接顺畅,基本不会出现发送消息丢失的情况,因此大多数情况下我们无需考虑这种问题。
不过,在少数情况下,也会出现消息发送到MQ之后丢失的现象,比如:
- MQ内部处理消息的进程发生了异常
- 生产者发送消息到达MQ后未找到
Exchange - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue,因此无法路由
针对上述情况,RabbitMQ提供了生产者消息确认机制,包括Publisher Confirm和Publisher Return两种。在开启确认机制的情况下,当生产者发送消息给MQ后,MQ会根据消息处理的情况返回不同的回执。
具体如图所示:
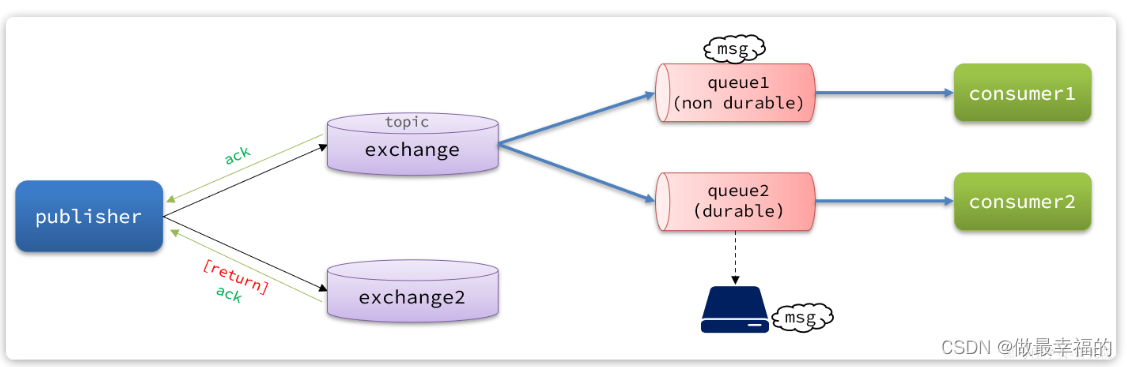
总结如下:
- 当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功
- 临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
- 持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
- 其它情况都会返回NACK,告知投递失败
其中ack和nack属于Publisher Confirm机制,ack是投递成功;nack是投递失败。而return则属于Publisher Return机制。
默认两种机制都是关闭状态,需要通过配置文件来开启。
1.实现生产者确认机制
在publisher模块的application.yaml中添加配置:
spring:rabbitmq:publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型publisher-returns: true # 开启publisher return机制
none:关闭confirm机制simple:同步阻塞等待MQ的回执correlated:MQ异步回调返回回执
一般我们推荐使用correlated,回调机制。
logging:pattern:dateformat: MM-dd HH:mm:ss:SSSlevel:com.weijisheng: debug
spring:rabbitmq:host: 192.168.30.140port: 5672virtual-host: /username: guestpassword: guest
# connection-timeout: 1s
# template:
# retry:
# enabled: true
# multiplier: 2publisher-confirm-type: correlatedpublisher-returns: true2.定义ReturnCallback
每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置。我们在publisher模块定义一个配置类:
@Slf4j
@AllArgsConstructor
@Configurationpublic class MqConfig {private final RabbitTemplate rabbitTemplate;@PostConstructpublic void init(){rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {@Overridepublic void returnedMessage(ReturnedMessage returned) {log.error("触发return callback,");log.debug("exchange: {}", returned.getExchange());log.debug("routingKey: {}", returned.getRoutingKey());log.debug("message: {}", returned.getMessage());log.debug("replyCode: {}", returned.getReplyCode());log.debug("replyText: {}", returned.getReplyText());}});}
}
3.定义ConfirmCallback
由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发消息时定义。具体来说,是在调用RabbitTemplate中的convertAndSend方法时,多传递一个参数:
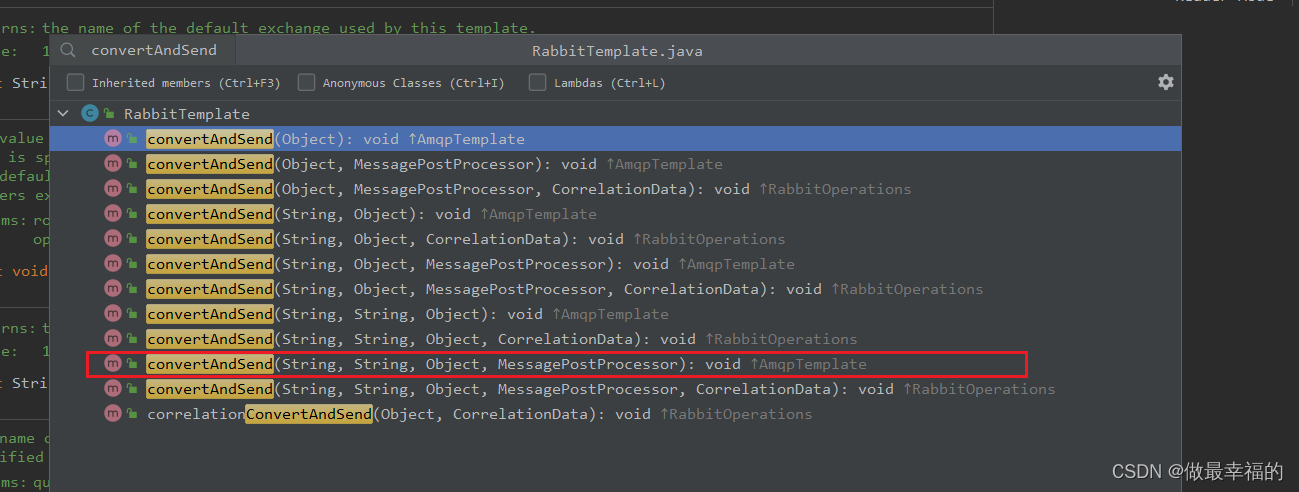
这里的CorrelationData中包含两个核心的东西:
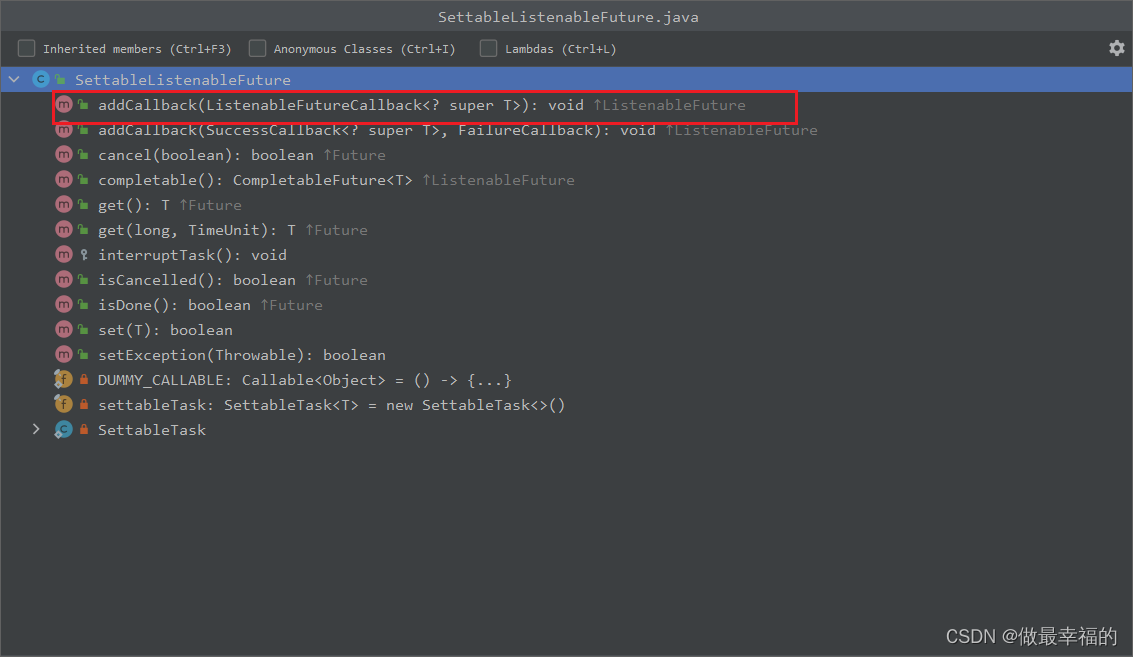
id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆SettableListenableFuture:回执结果的Future对象
将来MQ的回执就会通过这个Future来返回,我们可以提前给CorrelationData中的Future添加回调函数来处理消息回执:
我们新建一个测试,向系统自带的交换机发送消息,并且添加ConfirmCallback:
@Testvoid testConfirmCallback() throws InterruptedException {// 1.创建cdCorrelationData cd = new CorrelationData(UUID.randomUUID().toString());// 2.添加ConfirmCallbackcd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {@Overridepublic void onFailure(Throwable ex) {log.error("消息回调失败", ex);}@Overridepublic void onSuccess(CorrelationData.Confirm result) {log.debug("收到confirm callback回执");if(result.isAck()){// 消息发送成功log.debug("消息发送成功,收到ack");}else{// 消息发送失败log.error("消息发送失败,收到nack, 原因:{}", result.getReason());}}});rabbitTemplate.convertAndSend("hmall.direct", "weijisheng", "hello", cd);Thread.sleep(2000);}
}
在这里记录一个小插曲
我的idea突然出现问题,不能运行了报如下这个错误

然后我看了一下我的jdk版本是21我在网上找了一下发现网上jdk21的lombok版本要1.18.30,但是我的是1.18.26,我重新更改了一下maven配置就可以了。
上面执行过程执行结果如下:
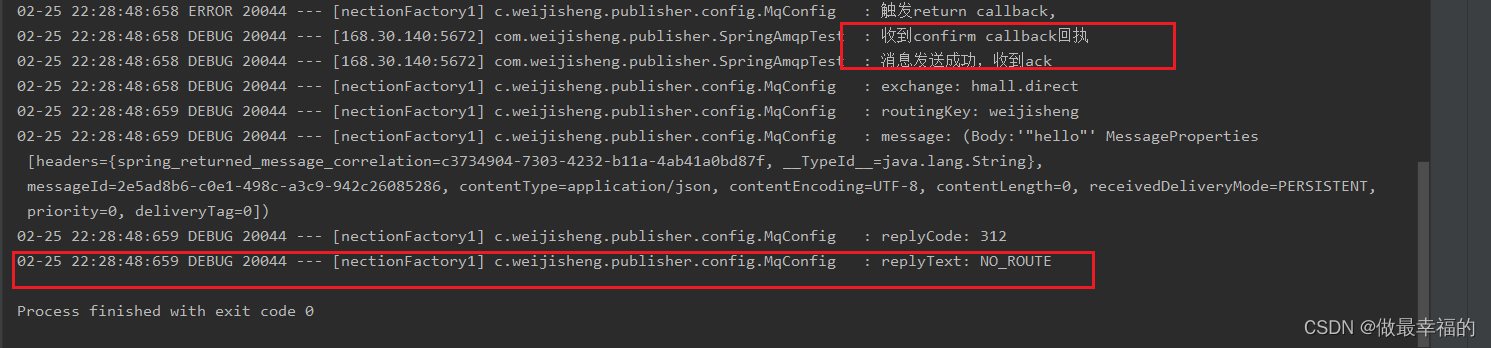
可以看到,由于传递的RoutingKey是错误的,路由失败后,触发了return callback,同时也收到了ack。
当我们修改为正确的RoutingKey以后,就不会触发return callback了,只收到ack。
而如果连交换机都是错误的,则只会收到nack。
:::warning
注意:
开启生产者确认比较消耗MQ性能,一般不建议开启。而且大家思考一下触发确认的几种情况:
- 路由失败:一般是因为RoutingKey错误导致,往往是编程导致
- 交换机名称错误:同样是编程错误导致
- MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
:::
四.MQ的可靠性
消息到达MQ以后,如果MQ不能及时保存,也会导致消息丢失,所以MQ的可靠性也非常重要。
1.数据持久化
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:
- 交换机持久化
- 队列持久化
- 消息持久化
我们以控制台界面为例来说明。
1.交换机持久化
在控制台的Exchanges页面,添加交换机时可以配置交换机的Durability参数:
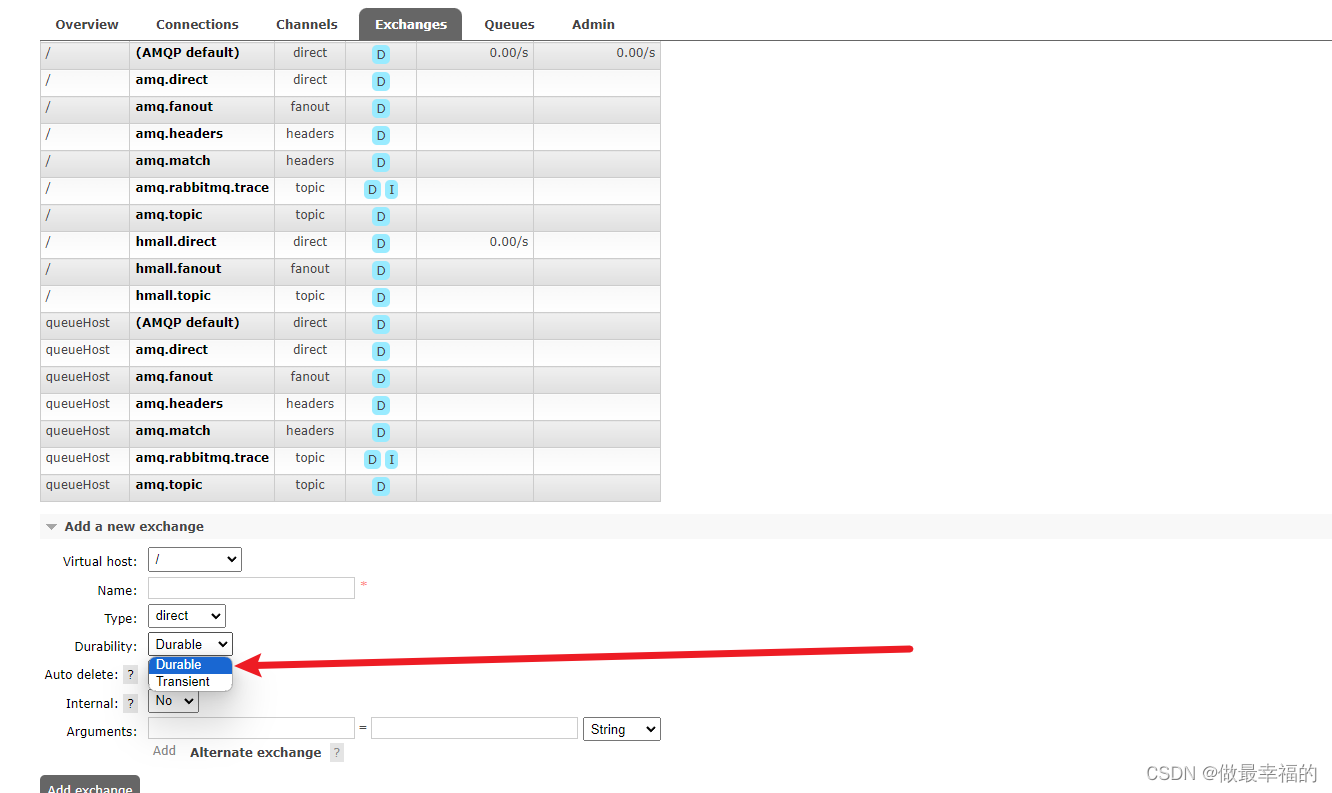
设置为Durable就是持久化模式,Transient就是临时模式。
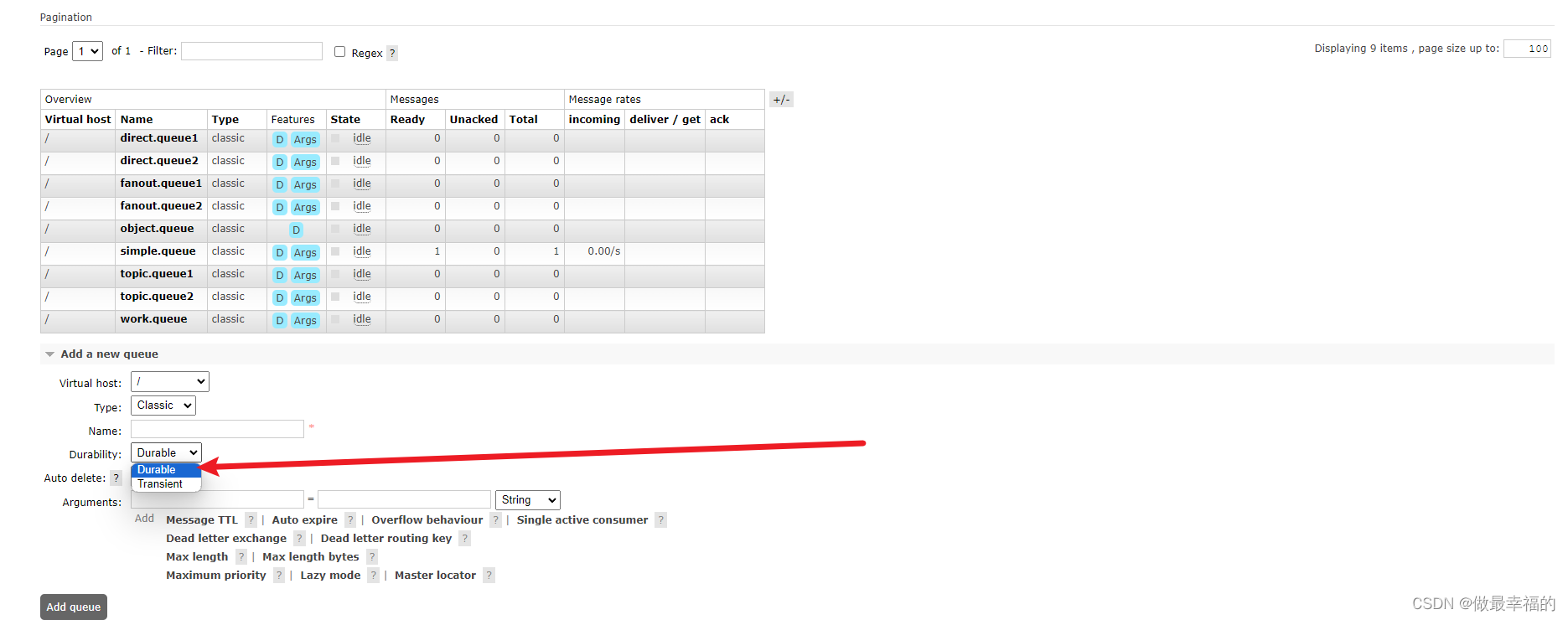
2.队列持久化
在控制台的Queues页面,添加队列时,同样可以配置队列的Durability参数:
3.消息持久化
在控制台发送消息的时候,可以添加很多参数,而消息的持久化是要配置一个properties:
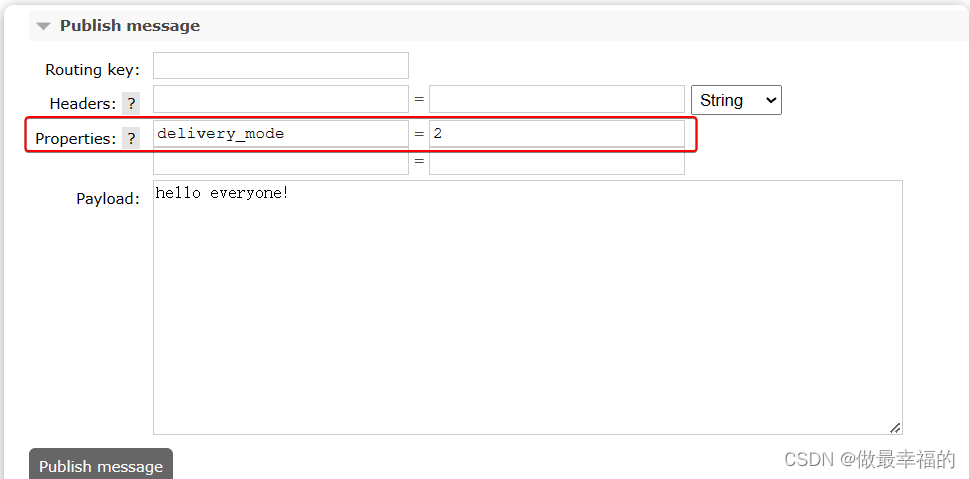
1.注意消息非持久化发送到rabbitmq的时候如果大数据量会出现page out,在page out的时候消息发送速度会降低到零点
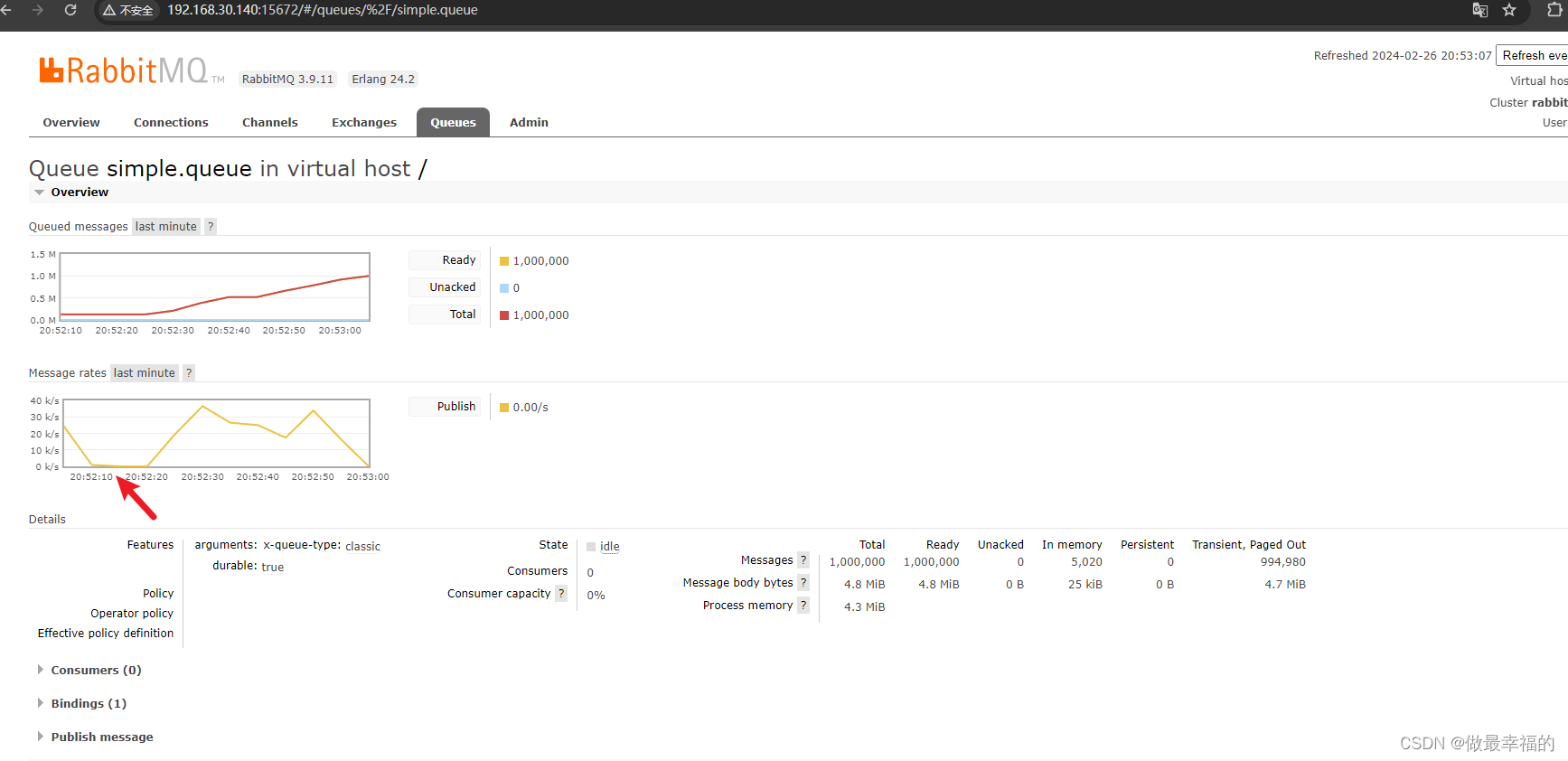
2.当消息持久化到rabbitmq的时候不会出现page out ,速度不会降低到零点一段时间的情况
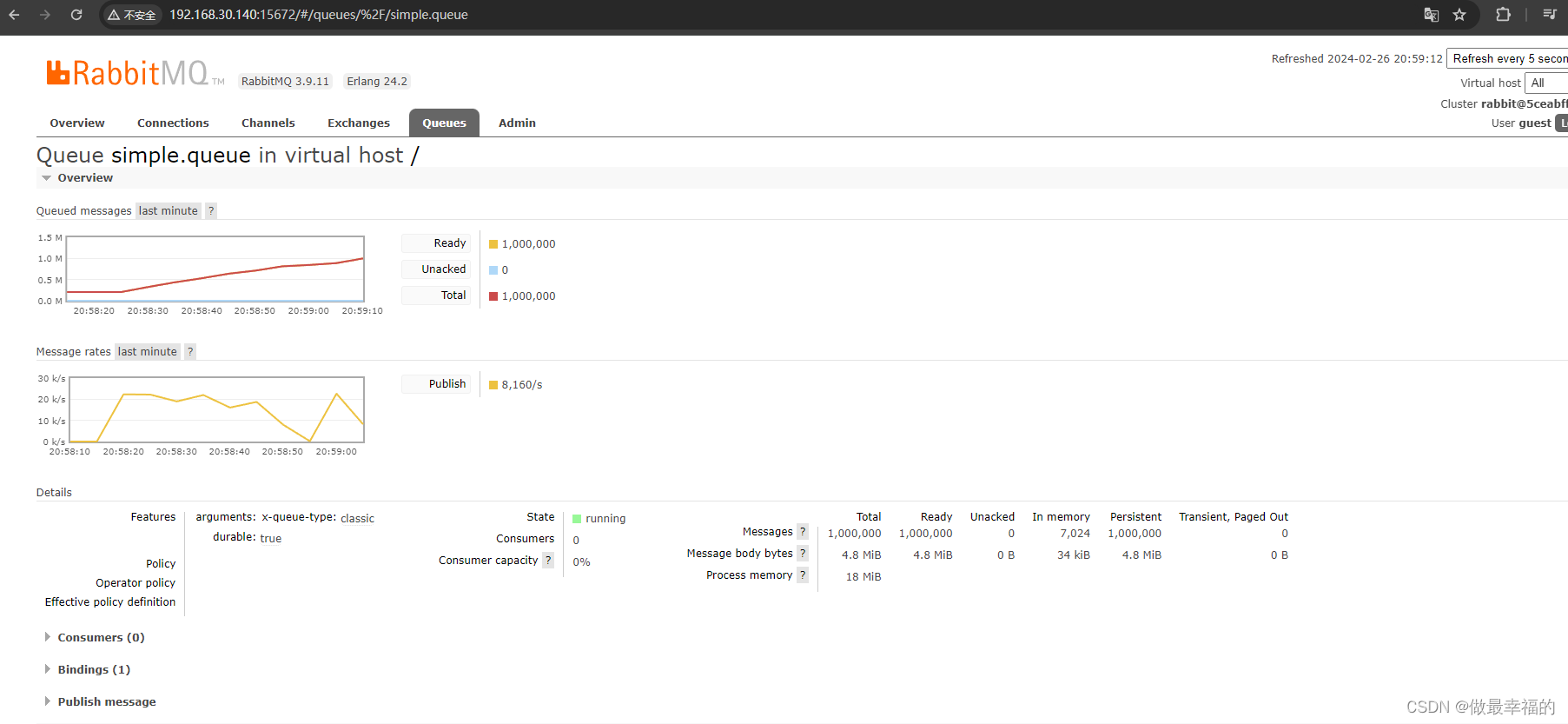
@Testvoid testPageOut() {Message message = MessageBuilder.withBody("hello".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();for (int i = 0; i < 1000000; i++) {rabbitTemplate.convertAndSend("simple.queue", message);}}
:::warning
说明:在开启持久化机制以后,如果同时还开启了生产者确认,那么MQ会在消息持久化以后才发送ACK回执,进一步确保消息的可靠性。
不过出于性能考虑,为了减少IO次数,发送到MQ的消息并不是逐条持久化到数据库的,而是每隔一段时间批量持久化。一般间隔在100毫秒左右,这就会导致ACK有一定的延迟,因此建议生产者确认全部采用异步方式。
:::
2.LazyQueue
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。但在某些特殊情况下,这会导致消息积压,比如:
- 消费者宕机或出现网络故障
- 消息发送量激增,超过了消费者处理速度
- 消费者处理业务发生阻塞
一旦出现消息堆积问题,RabbitMQ的内存占用就会越来越高,直到触发内存预警上限。此时RabbitMQ会将内存消息刷到磁盘上,这个行为成为PageOut. PageOut会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。
为了解决这个问题,从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的模式,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
- 支持数百万条的消息存储
而在3.12版本之后,LazyQueue已经成为所有队列的默认格式。因此官方推荐升级MQ为3.12版本或者所有队列都设置为LazyQueue模式。
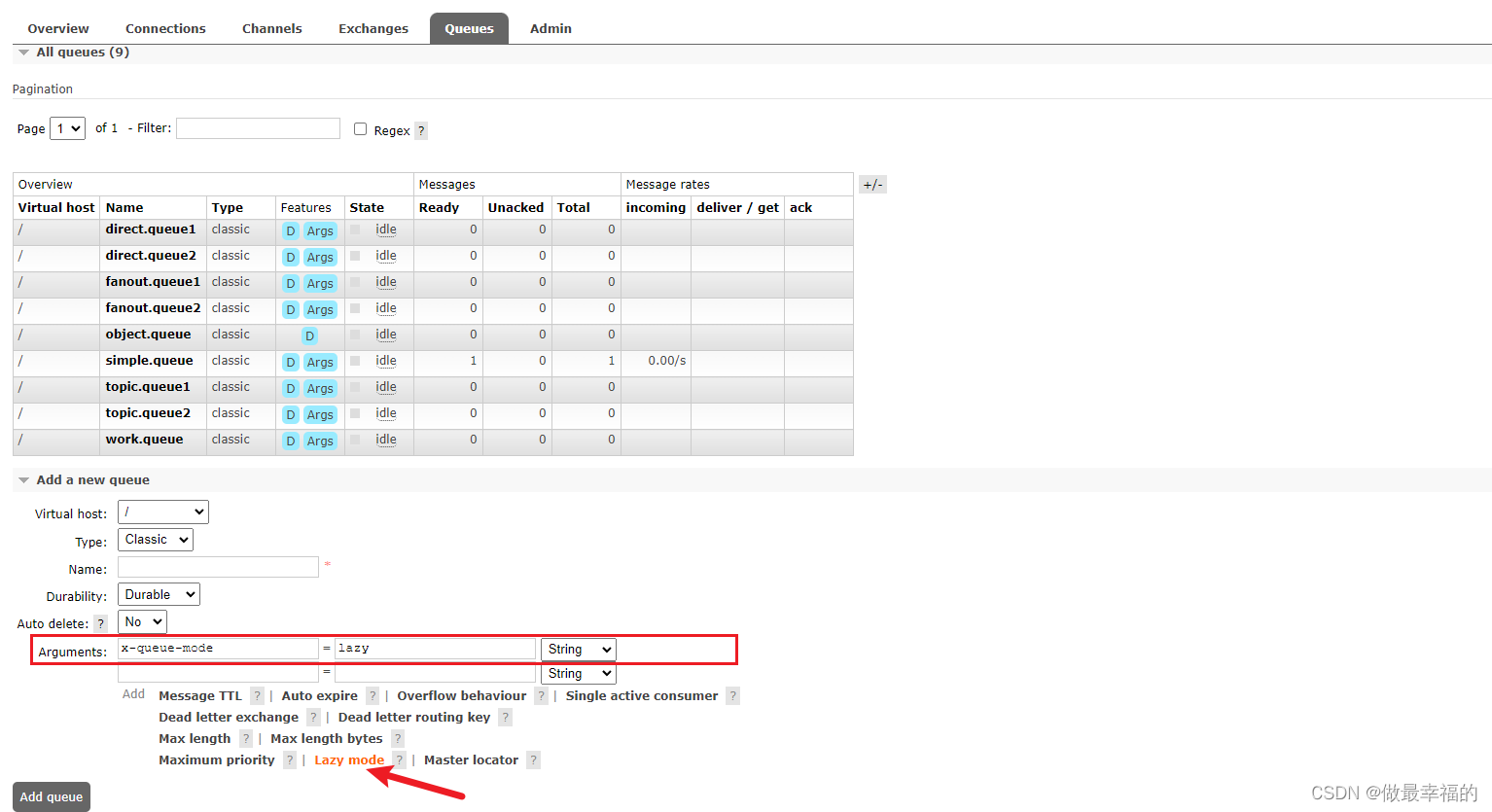
1.控制台配置Lazy模式
在添加队列的时候,添加x-queue-mod=lazy参数即可设置队列为Lazy模式:
2.代码配置Lazy模式
在利用SpringAMQP声明队列的时候,添加x-queue-mod=lazy参数也可设置队列为Lazy模式:
@Bean
public Queue lazyQueue(){return QueueBuilder.durable("lazy.queue").lazy() // 开启Lazy模式.build();
}
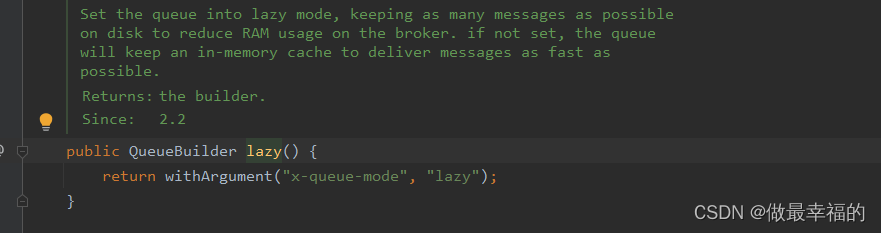
这里是通过QueueBuilder的lazy()函数配置Lazy模式,底层源码如下:
当然,我们也可以基于注解来声明队列并设置为Lazy模式:
@RabbitListener(queuesToDeclare = @Queue(name = "lazy.queue",durable = "true",arguments = @Argument(name = "x-queue-mode", value = "lazy")
))
public void listenLazyQueue(String msg){log.info("接收到 lazy.queue的消息:{}", msg);
}
3.更新已有队列为lazy模式
对于已经存在的队列,也可以配置为lazy模式,但是要通过设置policy实现。
可以基于命令行设置policy:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
命令解读:- `rabbitmqctl` :RabbitMQ的命令行工具
- `set_policy` :添加一个策略
- `Lazy` :策略名称,可以自定义
- `"^lazy-queue$"` :用正则表达式匹配队列的名字
- `'{"queue-mode":"lazy"}'` :设置队列模式为lazy模式
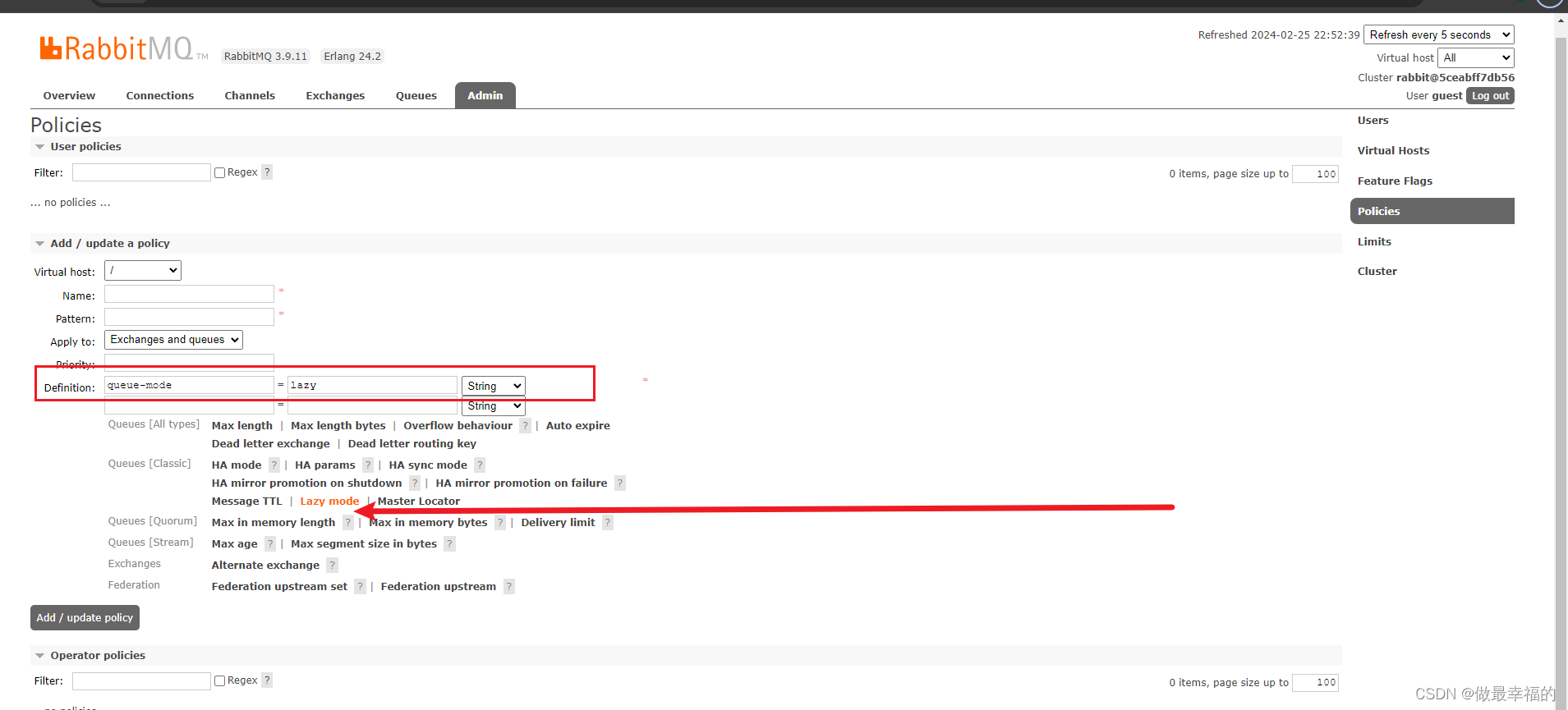
- `--apply-to queues`:策略的作用对象,是所有的队列当然,也可以在控制台配置policy,进入在控制台的`Admin`页面,点击`Policies`,即可添加配置:
lazy队列在100W条件下是最好的性能
总结
RabbitMQ如何保证消息的可靠性
- 首先通过配置可以让交换机、队列、以及发送的消息都持久化。这样队列中的消息会持久化到磁盘,MQ重启消息依然存在。
- RabbitMQ在3.6版本引入了LazzyQueue,并且在3.12版本后会成为队列的默认模式。LazyQueue会将所有消息都持久化。
- 开启持久化和生产者确认时,RabbitMQ只有在消息持久化完成后才会给生产者返回ACK回执。
四.消费者的可靠性
当RabbitMQ向消费者投递消息以后,需要知道消费者的处理状态如何。因为消息投递给消费者并不代表就一定被正确消费了,可能出现的故障有很多,比如:
- 消息投递的过程中出现了网络故障
- 消费者接收到消息后突然宕机
- 消费者接收到消息后,因处理不当导致异常
- …
一旦发生上述情况,消息也会丢失。因此,RabbitMQ必须知道消费者的处理状态,一旦消息处理失败才能重新投递消息。
但问题来了:RabbitMQ如何得知消费者的处理状态呢?
本章我们就一起研究一下消费者处理消息时的可靠性解决方案。
1.消费者确认机制
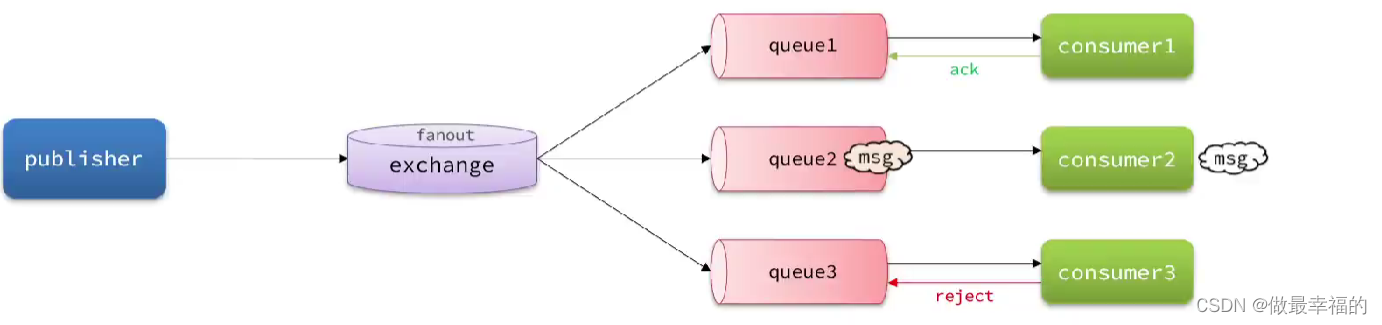
为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制(Consumer Acknowledgement)。即:当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
一般reject方式用的较少,除非是消息格式有问题,那就是开发问题了。因此大多数情况下我们需要将消息处理的代码通过try catch机制捕获,消息处理成功时返回ack,处理失败时返回nack.
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
**none**:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用**manual**:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活**auto**:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:- 如果是业务异常,会自动返回
nack; - 如果是消息处理或校验异常,自动返回
reject;
- 如果是业务异常,会自动返回
返回Reject的常见异常有:
Starting with version 1.3.2, the default ErrorHandler is now a ConditionalRejectingErrorHandler that rejects (and does not requeue) messages that fail with an irrecoverable error. Specifically, it rejects messages that fail with the following errors:- o.s.amqp…MessageConversionException: Can be thrown when converting the incoming message payload using a MessageConverter.
- o.s.messaging…MessageConversionException: Can be thrown by the conversion service if additional conversion is required when mapping to a @RabbitListener method.
- o.s.messaging…MethodArgumentNotValidException: Can be thrown if validation (for example, @Valid) is used in the listener and the validation fails.
- o.s.messaging…MethodArgumentTypeMismatchException: Can be thrown if the inbound message was converted to a type that is not correct for the target method. For example, the parameter is declared as Message<Foo> but Message<Bar> is received.
- java.lang.NoSuchMethodException: Added in version 1.6.3.
- java.lang.ClassCastException: Added in version 1.6.3.
通过下面的配置可以修改SpringAMQP的ACK处理方式:
consumer
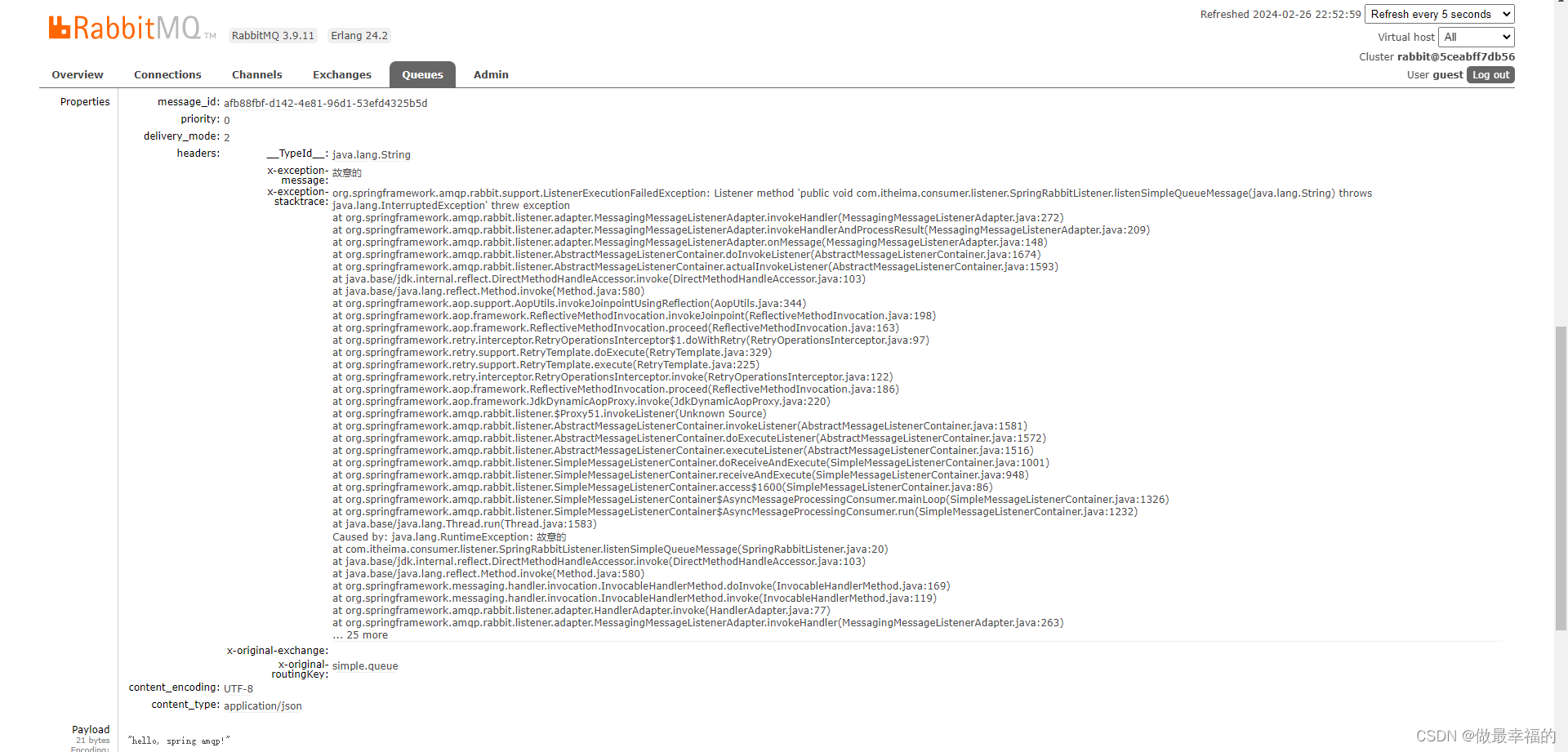
@RabbitListener(queues = "simple.queue")public void listenSimpleQueueMessage(String msg) throws InterruptedException {System.out.println("spring 消费者接收到消息:【" + msg + "】");throw new RuntimeException("故意的");}
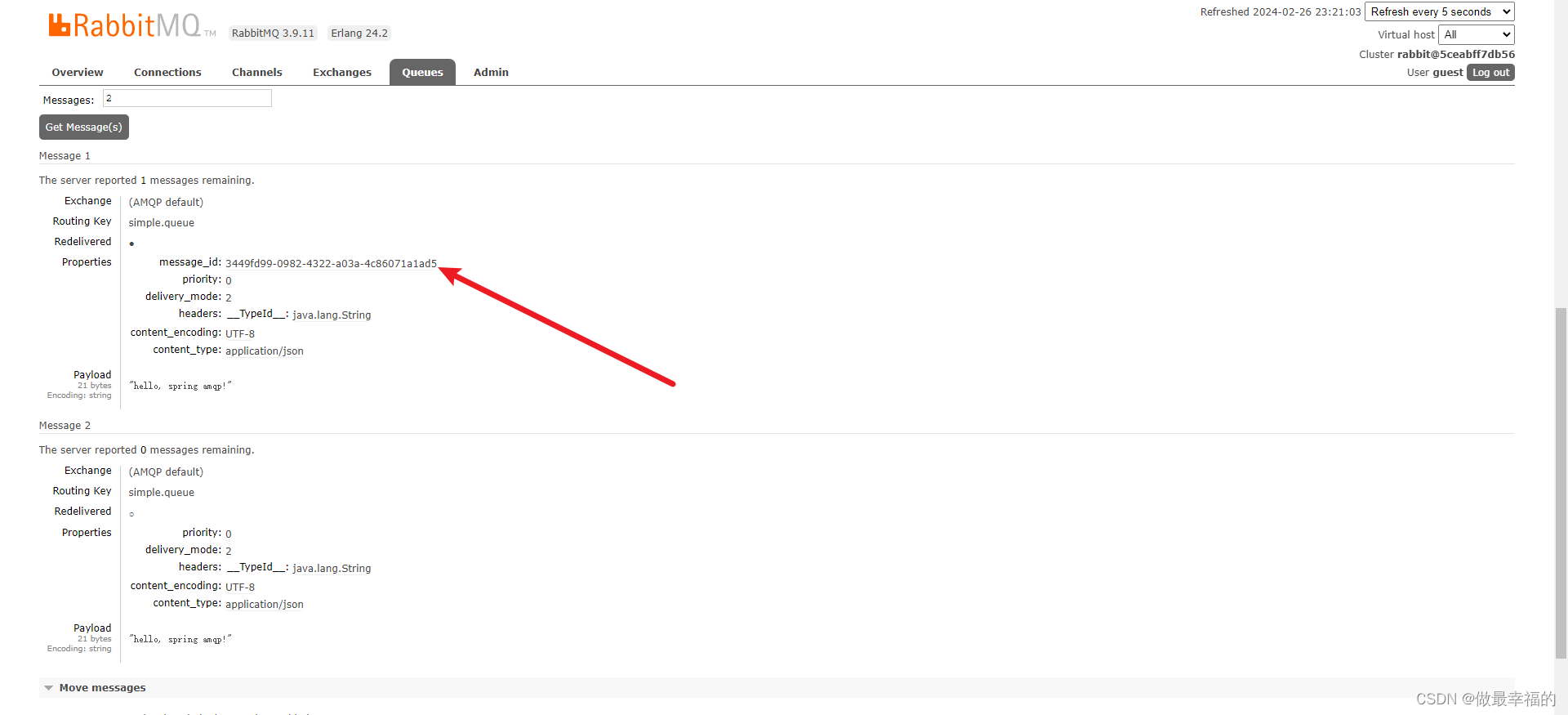
product
@Testpublic void testSimpleQueue() {// 队列名称String queueName = "simple.queue";// 消息String message = "hello, spring amqp!";// 发送消息rabbitTemplate.convertAndSend(queueName, message);}
spring:rabbitmq:listener:simple:acknowledge-mode: none # 不做处理
测试可以发现:当消息处理发生异常时,消息依然被RabbitMQ删除了。
断点还停留在这里,但是消息已经被消费了
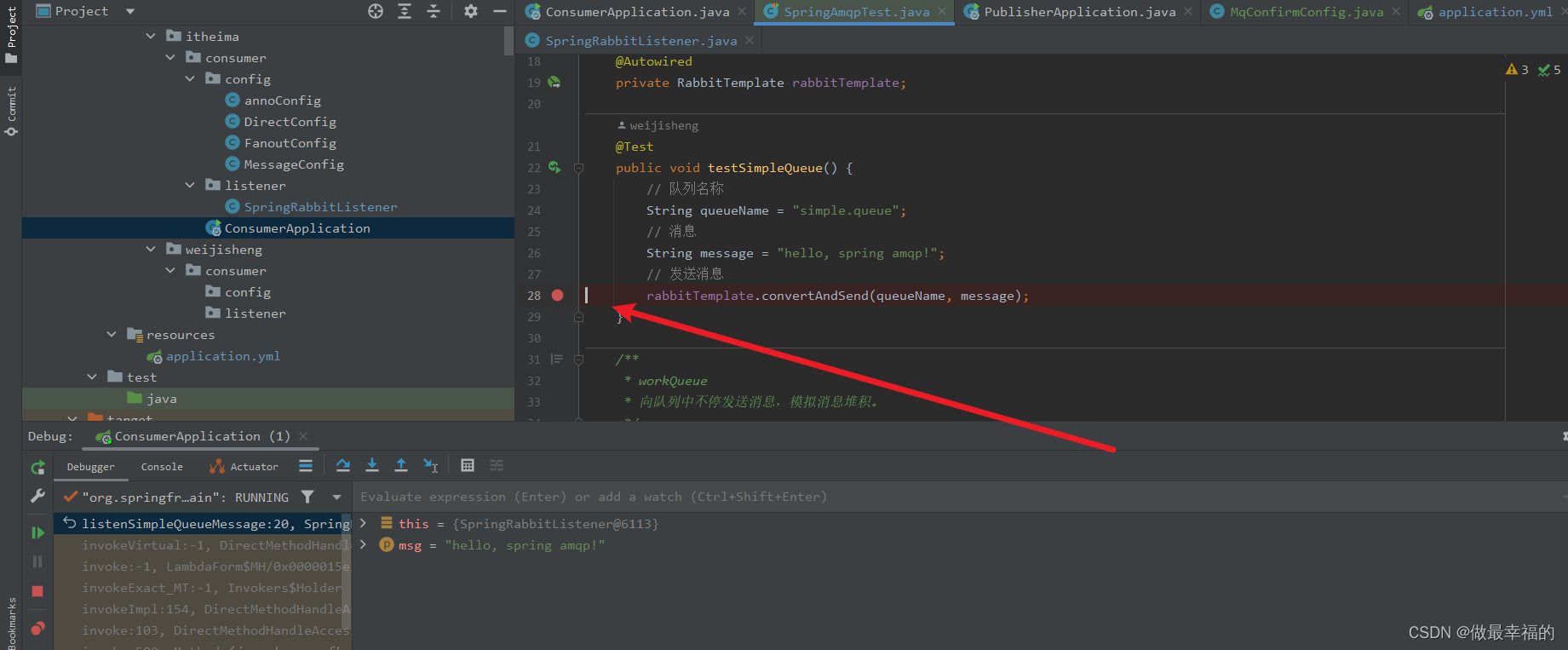
我们再次把确认机制修改为auto:
spring:rabbitmq:listener:simple:acknowledge-mode: auto # 自动ack
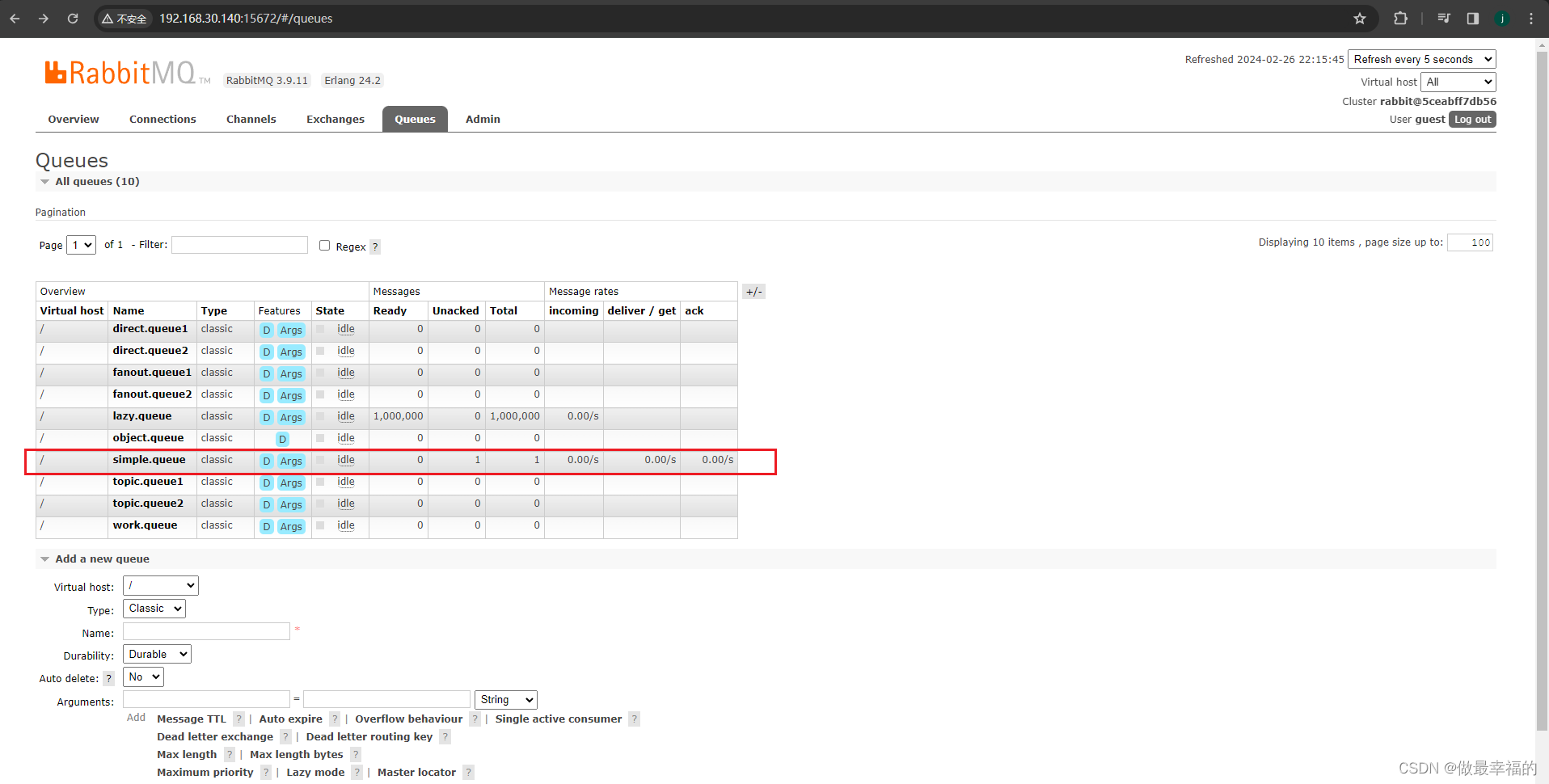
在异常位置打断点,再次发送消息,程序卡在断点时,可以发现此时消息状态为unacked(未确定状态):
放行以后,消息处理失败后,会回到RabbitMQ,并重新投递到消费者。
2.失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
极端情况就是消费者一直无法执行成功,那么消息requeue就会无限循环,导致mq的消息处理飙升,带来不必要的压力:

当然,上述极端情况发生的概率还是非常低的,不过不怕一万就怕万一。为了应对上述情况Spring又提供了消费者失败重试机制:在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
修改consumer服务的application.yml文件,添加内容:
spring:rabbitmq:listener:simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000ms # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
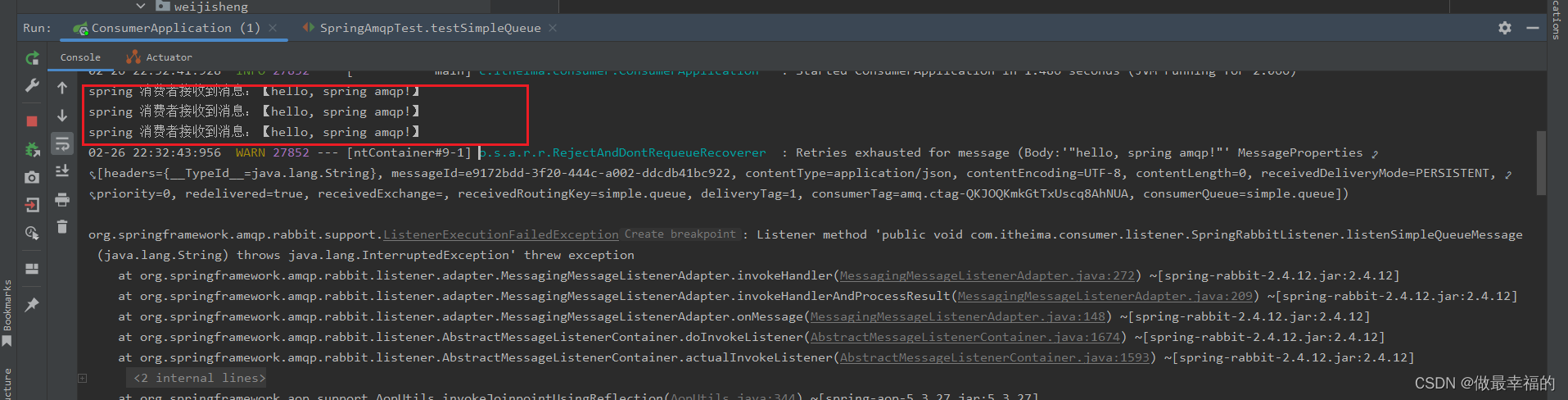
重启consumer服务,重复之前的测试。可以发现:
- 消费者在失败后消息没有重新回到MQ无限重新投递,而是在本地重试了3次
- 本地重试3次以后,抛出了
AmqpRejectAndDontRequeueException异常。查看RabbitMQ控制台,发现消息被删除了,说明最后SpringAMQP返回的是reject
结论:
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回reject,消息会被丢弃
失败处理策略
在之前的测试中,本地测试达到最大重试次数后,消息会被丢弃。这在某些对于消息可靠性要求较高的业务场景下,显然不太合适了。
因此Spring允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义的,它有3个不同实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
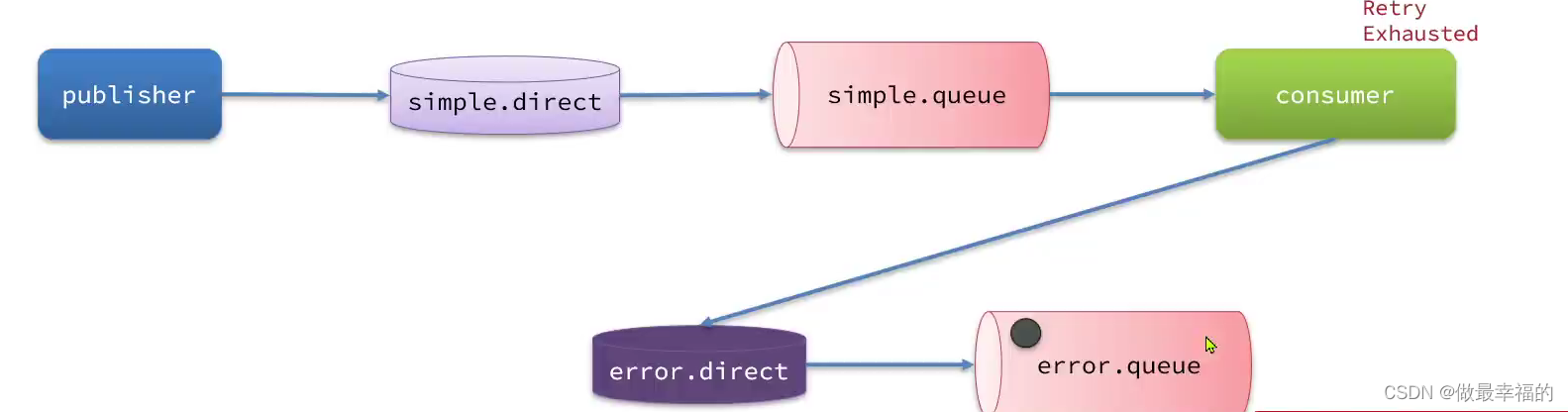
1)在consumer服务中定义处理失败消息的交换机和队列
@Bean
public DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}
2)定义一个RepublishMessageRecoverer,关联队列和交换机
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
完整代码如下:
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.retry.MessageRecoverer;
import org.springframework.amqp.rabbit.retry.RepublishMessageRecoverer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class ErrorConfig {@Beanpublic DirectExchange errorMessageExchange(){return new DirectExchange("error.direct");}@Beanpublic Queue errorQueue(){return new Queue("error.queue");}@Beanpublic Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");}@Beanpublic MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");}
}错误的信息被存储到mq中的错误队列中
总结
消费者如何保证消息一定被消费?
- 开启消费者确认机制为auto,由spring确认消息处理成功后返回ack,异常时返回nack
- 开启消费者失败重试机制,并设置MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理。
3.业务幂等性
何为幂等性?
幂等是一个数学概念,用函数表达式来描述是这样的:f(x) = f(f(x)),例如求绝对值函数。
在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。例如:
- 根据id删除数据
- 查询数据
但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如:
- 取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况
- 退款业务。重复退款对商家而言会有经济损失。
所以,我们要尽可能避免业务被重复执行。
然而在实际业务场景中,由于意外经常会出现业务被重复执行的情况,例如:
- 页面卡顿时频繁刷新导致表单重复提交
- 服务间调用的重试
- MQ消息的重复投递
我们在用户支付成功后会发送MQ消息到交易服务,修改订单状态为已支付,就可能出现消息重复投递的情况。如果消费者不做判断,很有可能导致消息被消费多次,出现业务故障。
举例:
- 假如用户刚刚支付完成,并且投递消息到交易服务,交易服务更改订单为已支付状态。
- 由于某种原因,例如网络故障导致生产者没有得到确认,隔了一段时间后重新投递给交易服务。
- 但是,在新投递的消息被消费之前,用户选择了退款,将订单状态改为了已退款状态。
- 退款完成后,新投递的消息才被消费,那么订单状态会被再次改为已支付。业务异常。
因此,我们必须想办法保证消息处理的幂等性。这里给出两种方案:
- 唯一消息ID
- 业务状态判断
1.唯一消息ID
这个思路非常简单:
- 每一条消息都生成一个唯一的id,与消息一起投递给消费者。
- 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
- 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。
我们该如何给消息添加唯一ID呢?
其实很简单,SpringAMQP的MessageConverter自带了MessageID的功能,我们只要开启这个功能即可。
以Jackson的消息转换器为例:
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jjmc.setCreateMessageIds(true);return jjmc;
}
2.业务状态判断
业务判断就是基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。
例如我们当前案例中,处理消息的业务逻辑是把订单状态从未支付修改为已支付。因此我们就可以在执行业务时判断订单状态是否是未支付,如果不是则证明订单已经被处理过,无需重复处理。
相比较而言,消息ID的方案需要改造原有的数据库,所以我更推荐使用业务判断的方案。
以支付修改订单的业务为例,我们需要修改OrderServiceImpl中的markOrderPaySuccess方法:
@Overridepublic void markOrderPaySuccess(Long orderId) {// 1.查询订单Order old = getById(orderId);// 2.判断订单状态if (old == null || old.getStatus() != 1) {// 订单不存在或者订单状态不是1,放弃处理return;}// 3.尝试更新订单Order order = new Order();order.setId(orderId);order.setStatus(2);order.setPayTime(LocalDateTime.now());updateById(order);}
上述代码逻辑上符合了幂等判断的需求,但是由于判断和更新是两步动作,因此在极小概率下可能存在线程安全问题。
我们可以合并上述操作为这样:

@Override
public void markOrderPaySuccess(Long orderId) {// UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1lambdaUpdate().set(Order::getStatus, 2).set(Order::getPayTime, LocalDateTime.now()).eq(Order::getId, orderId).eq(Order::getStatus, 1).update();
}
注意看,上述代码等同于这样的SQL语句:
UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1
我们在where条件中除了判断id以外,还加上了status必须为1的条件。如果条件不符(说明订单已支付),则SQL匹配不到数据,根本不会执行。
总结
如何保证支付服务与交易服务之间的订单状态一致性?
- 首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。
- 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递和处理的可靠性。同时也开启了MQ的持久化,避免因服务宕机导致消息丢失。
- 最后,在交易服务更新订单状态时做了业务幂等判断,避免因消息重复消费导致订单状态异常。
如果交易服务消息处理失败,有没有什么兜底方法?
- 可以在交易服务设置定时任务,定期查询订单支付状态。这样即使MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。
相关文章:
rabbitmq知识梳理
一.WorkQueues模型 Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。 当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,…...

【数据结构与算法】动态规划法解题20240227
动态规划法 一、什么是动态规划二、动态规划的解题步骤三、509. 斐波那契数1、动规五部曲: 四、70. 爬楼梯1、动规五部曲: 五、746. 使用最小花费爬楼梯1、动规五部曲: 一、什么是动态规划 动态规划,英文:Dynamic Pro…...
备战蓝桥杯—— 双指针技巧巧答链表2
对于单链表相关的问题,双指针技巧是一种非常广泛且有效的解决方法。以下是一些常见问题以及使用双指针技巧解决: 合并两个有序链表: 使用两个指针分别指向两个链表的头部,逐一比较节点的值,将较小的节点链接到结果链表…...

半监督节点分类-graph learning
半监督节点分类相当于在一个图当中,用一部分节点的类别上已知的,有另外一部分节点的类别是未知的,目标是使用有标签的节点来推断没有标签的节点 注意 半监督节点分类属于直推式学习,直推式学习相当于出现新节点后,需要…...
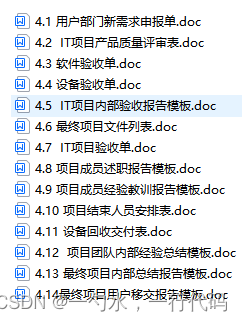
软件文档-运维-开发-管理-资质-评审-招投标-验收
开发文档:这类文档主要用于记录软件的开发过程和细节,包括: 《功能要求》:描述了软件应具备的功能,是软件开发的基础。《投标方案》:向潜在的客户或招标方展示公司的技术和项目实施能力。《需求分析》&…...

猫头虎分享已解决Bug || Vue中的TypeError: Cannot read property ‘name‘ of undefined 错误
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

技术应用:使用Spring Boot、MyBatis Plus和Dynamic DataSource实现多数据源
引言 在现代的软件开发中,许多应用程序需要同时访问多个数据库。例如,一个电子商务平台可能需要访问多个数据库来存储用户信息、产品信息和订单信息等。在这种情况下,使用多数据源是一种常见的解决方案,它允许我们在一个应用程序…...
C# Onnx 使用onnxruntime部署实时视频帧插值
目录 介绍 效果 模型信息 项目 代码 下载 C# Onnx 使用onnxruntime部署实时视频帧插值 介绍 github地址:https://github.com/google-research/frame-interpolation FILM: Frame Interpolation for Large Motion, In ECCV 2022. The official Tensorflow 2…...

编程笔记 Golang基础 016 数据类型:数字类型
编程笔记 Golang基础 016 数据类型:数字类型 1. 整数类型(Integer Types)a) 固定长度整数:b) 变长整数: 2. 浮点数类型(Floating-Point Types)3. 复数类型(Complex Number Types&…...
一周学会Django5 Python Web开发-会话管理(CookiesSession)
锋哥原创的Python Web开发 Django5视频教程: 2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~共计26条视频,包括:2024版 Django5 Python we…...

QT之QString.arg输出固定位数
问题描述 我需要用QString输出一个固定位数的数字字符串。起初我的代码是这样: int img_num 1 auto new_name QString("%1.png").arg((int)img_num, 3, 10, 0); //最后一个参数用u0也是一样的 qDebug() << "new_name:" << new…...

Linux下各种压缩包的压缩与解压
tar 归档,不压缩,常见后缀 .tar # 将文件夹归档成为一个包 tar cf rootfs.tar rootfs # 将归档包还原为文件夹 tar xf rootfs.tar # 将归档包还原到路径 a/b/c tar xf rootfs.tar -C a/b/cgzip压缩, 常见后缀 .tar.gz .tgz # 压缩 tar czf …...
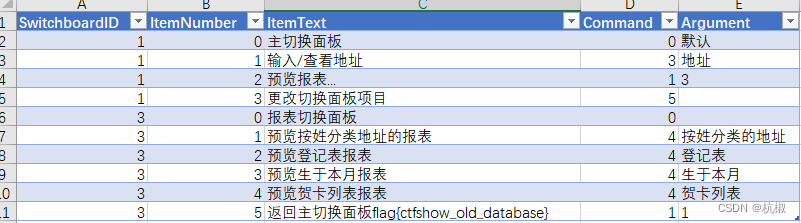
【ctfshow—web】——信息搜集篇1(web1~20详解)
ctfshow—web题解 web1web2web3web4web5web6web7web8web9web10web11web12web13web14web15web16web17web18web19web20 web1 题目提示 开发注释未及时删除 那就找开发注释咯,可以用F12来查看,也可以CtrlU直接查看源代码呢 就拿到flag了 web2 题目提示 j…...
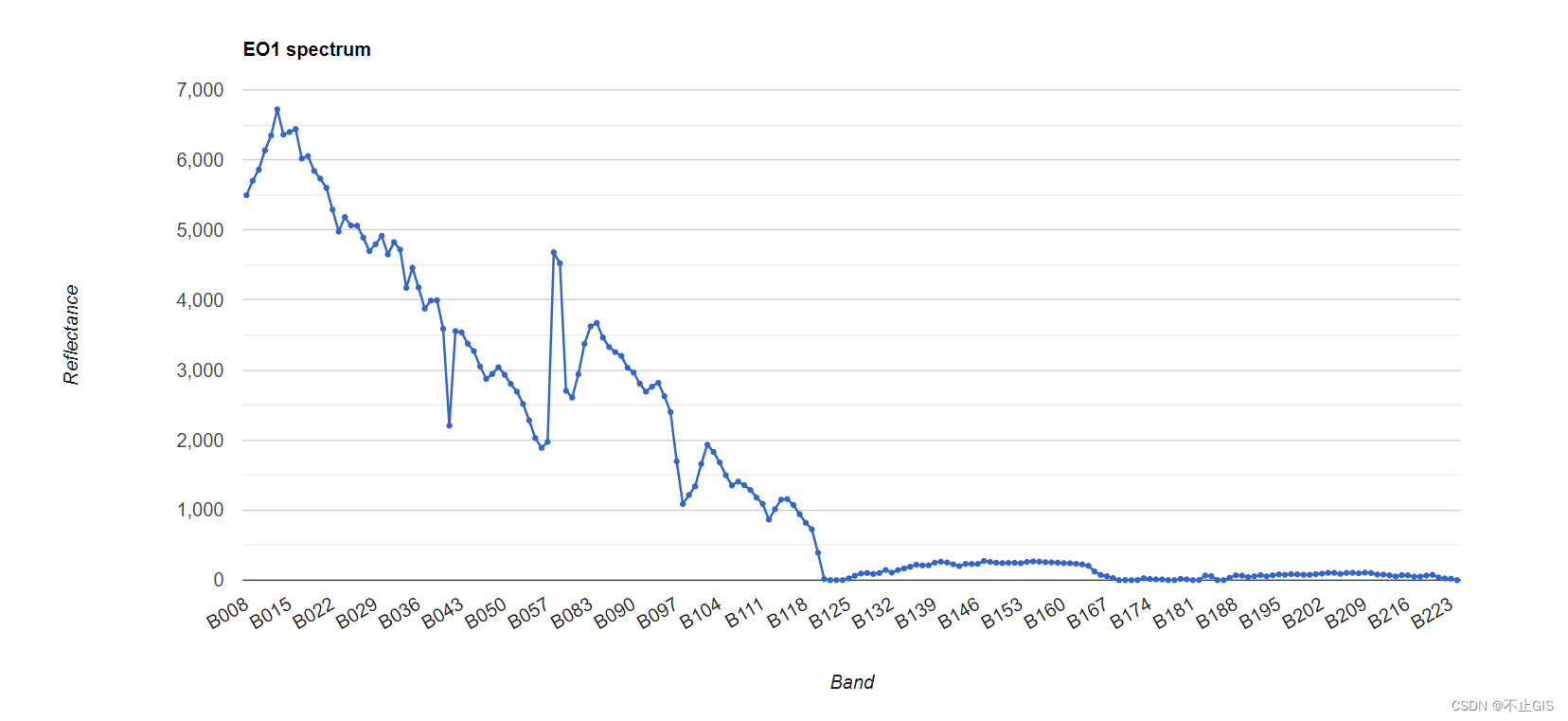
GEE入门篇|遥感专业术语(实践操作4):光谱分辨率(Spectral Resolution)
目录 光谱分辨率(Spectral Resolution) 1.MODIS 2.EO-1 光谱分辨率(Spectral Resolution) 光谱分辨率是指传感器进行测量的光谱带的数量和宽度。 您可以将光谱带的宽度视为每个波段的波长间隔,在多个波段测量辐射亮…...

c++中模板的注意事项
1. 模板定义时,<>中的虚拟类型参数不能为空。(因为我们使用模板就是希望使用模拟类型代替其它的类型,如果我们不定义就没有意义了) 2. 无论是定义函数模板还是类模板,其实template定义与后面使用虚拟类型的类或者函数,是…...
【代码随想录python笔记整理】第十三课 · 链表的基础操作 1
前言:本笔记仅仅只是对内容的整理和自行消化,并不是完整内容,如有侵权,联系立删。 一、链表 在之前的学习中,我们接触到了字符串和数组(列表)这两种结构,它们具有着以下的共同点:1、元素按照一定的顺序来排列。2、可以通过索引来访问数组中的元素和字符串中的字符。由此,…...
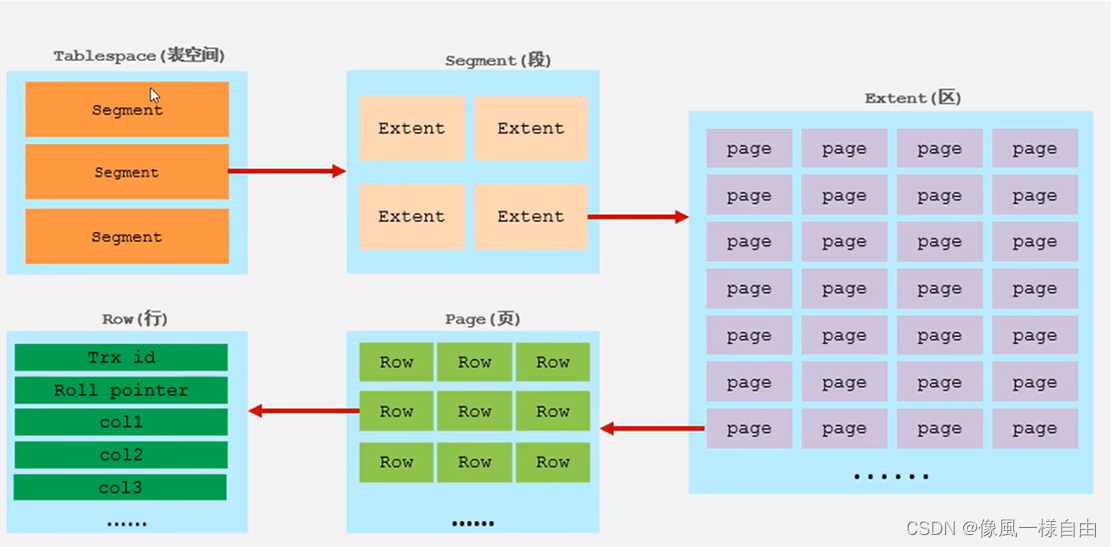
JAVA工程师面试专题-《Mysql》篇
目录 一、基础 1、mysql可以使用多少列创建索引? 2、mysql常用的存储引擎有哪些 3、MySQL 存储引擎,两者区别 4、mysql默认的隔离级别 5、数据库三范式 6、drop、delete 与 truncate 区别? 7、IN与EXISTS的区别 二、索引 1、索引及索…...
|Day22(二叉树))
@ 代码随想录算法训练营第4周(C语言)|Day22(二叉树)
代码随想录算法训练营第4周(C语言)|Day22(二叉树) Day22、二叉树(包含题目 ● 235. 二叉搜索树的最近公共祖先 ● 701.二叉搜索树中的插入操作 ● 450.删除二叉搜索树中的节点 ) 235. 二叉搜索树的最近公…...

福特锐界2021plus 汽车保养手册
福特锐界2021plus汽车保养手册两页,零部件保养要求,电子版放这里方便查询:...

c++进阶路线
学完C后的进阶路线-初学者勿入【程序员Rock】_哔哩哔哩_bilibili 1.系统训练代码阅读能力 代码阅读工具: 1).Source Insight(阅读大型源码) 2).understand(整体代码模块关系构建) 3).SOURCETRAIL 代码阅读能力--千行级 嵌入…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...
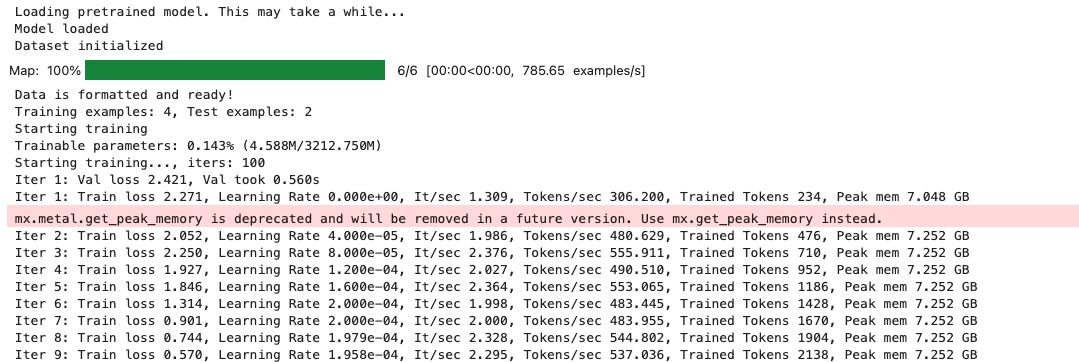
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...