Java分布式解决方案(一)
随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。
如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高
并发大流量的电商业务场景下,微服务更是企业首选的架构模式。随着业务发展壮大,用户量暴
涨,单节点处理能力就会成为瓶颈,如果并发量居高不下,服务器很容易因负载过高而导致崩溃
宕机。出于高并发,高可用的考虑,项目就应该演变到分布式架构了。然而分布式环境下我们又
会面临更多的挑战需要去应对。比如:1、分布式系统中接口繁多,重试机制必不可少,接口幂等性问题?2、如果下单、付款分布在不同的服务上,如何保证跨服务事务?3、高并发场景下资源共享问题?4、分库分表后,引发了ID重复问题?那么,我们需要如何解决分布式呢?
文章目录
- 🔥分布式全局唯一ID
- 🔥分布式全局唯一ID解决方案
- 🔥什么是雪花算法SonwFlake
- 🔥雪花算法SonwFlake落地实现
- 🔥雪花算法SonwFlake落地实现之Mybatis Plus
🔥分布式全局唯一ID

何为 ID
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
为什么需要分布式ID
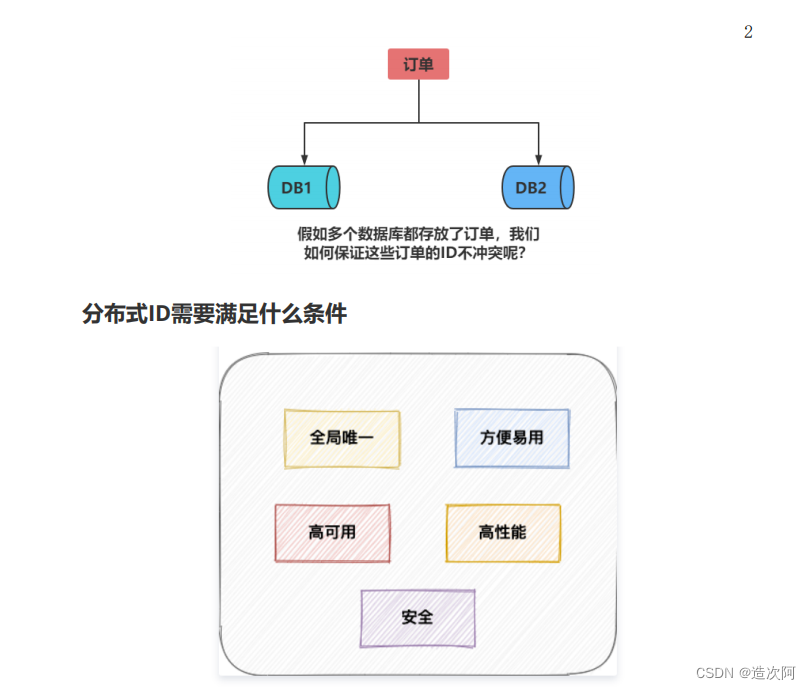
随着系统数据量越来越大,单数据库压力太大无法维持性能,所以可能就需要变成一主多从这样读写分离,随着继续扩大一主多从也无法支撑了。这时就需要分库分表,这样的话就会出现不同库表之间的数据id不能再依赖数据库自增的id,而需要外部一种方式生成全局统一的唯一id。
分布式ID需要满足什么条件
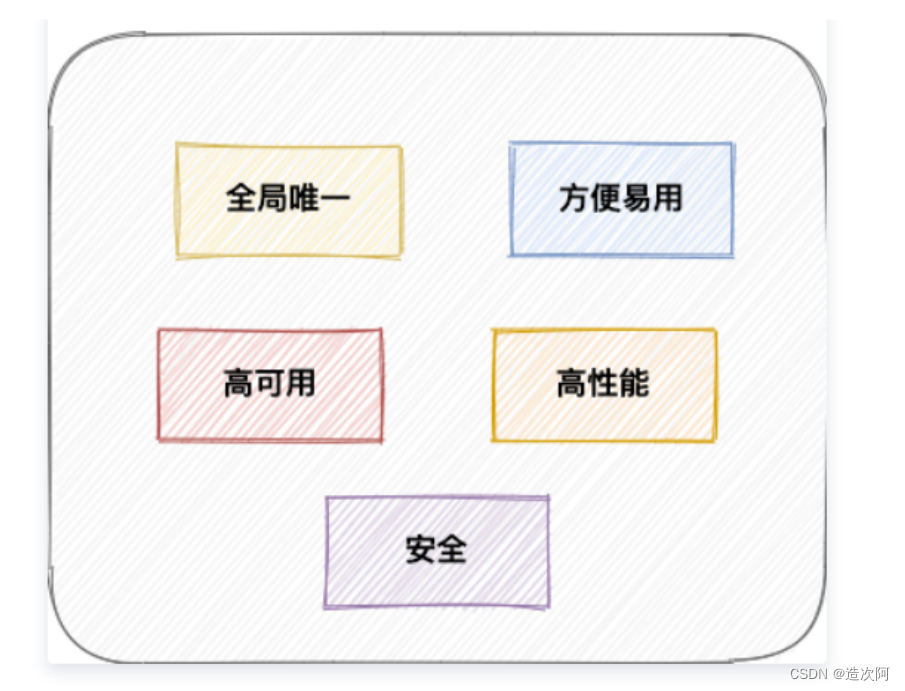
⭐唯一性:全局必须唯一。
⭐高性能:不能在生成id上浪费过多的时间,使其成为功能的性能瓶颈。
⭐高可用:必须保证可用性。
⭐趋势递增:这个不是必须的,但是最好还是满足,因为比如innodb索引就是按照键值排序的,所以有序性可以让维护索引的效率提高。
🔥分布式全局唯一ID解决方案

UUID
Java本身提供了UUID,这是一个唯一的字符串,它可以不依赖其他工具在本地生成。
优点
⭐代码实现简单
⭐本地生成,没有性能问题
⭐全球唯一的,数据迁移容易
缺点
⭐每次生成的ID是无序的,不满足趋势递增
⭐UUID是字符串,而且比较长,占用空间大,查询效率低
⭐ID没有含义,可读性差
依靠数据库自增字段生成
一个数据库压力大就搞多个数据库,之后搞一个Step步长的概念,每个数据库的自增起始值不同,但是他们的增长Step相同。如下图所示。
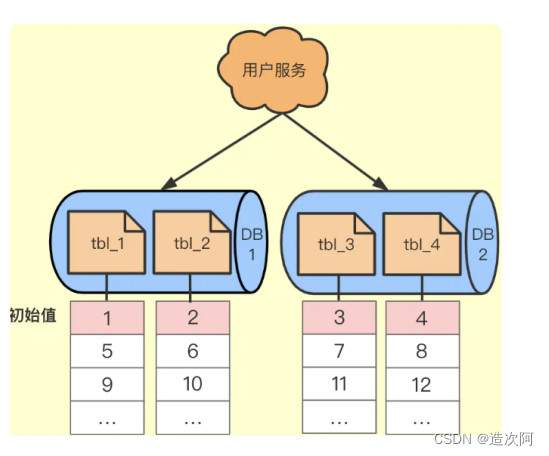
优点
⭐返回的分布式ID是趋势递增的id唯一。解决了单点问题,即使一个宕机其他的还可以提供服务。
缺点
⭐单点压力还是很大,因为DB本身写操作就耗时间。最主要的问题还是扩容困难,比如要加一台DB3是很难加进来的,除非停机,将所有DB的id进行修改,同时修改步长。
号段模式
它没有采用新插入记录返回id的方案,而是一个业务类型就是一行数据,用一行数据来维护这个业务的自增id。服务来修改这行数据的max_id,比如当前max_id值是0,那么来给max_id加上1000,如果返回成功,就代表这个服务获得了1-1000这段分布式id,之后将这段缓存在服务内部,用完之后再来表中取。
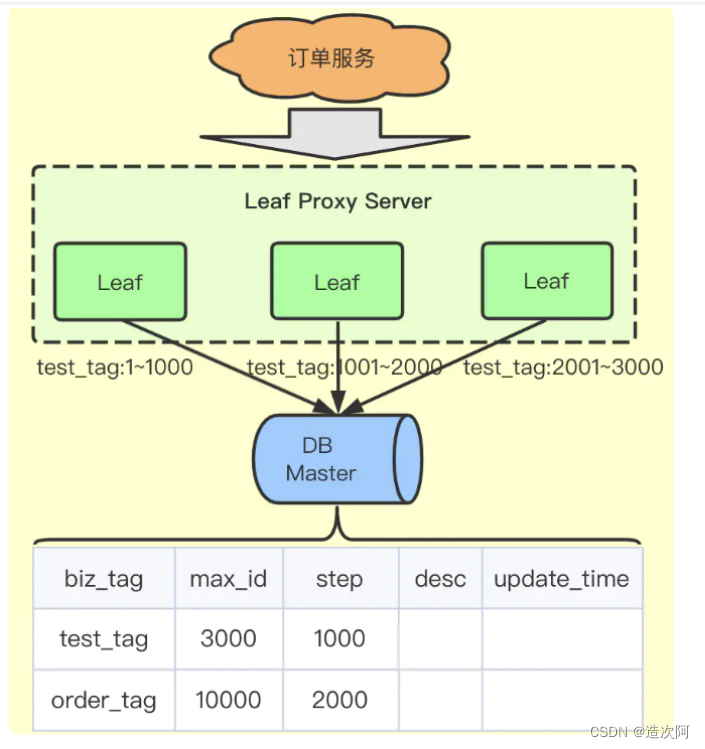
优点
⭐效率很高,db的压力减小,而且一张表可以维护很多业务的分布式id。
缺点
⭐复杂性提高,需要系统为了这个生成方案对号段进行缓存。
Redis自增key方案
通过incr命令让一个key自增,自增后的值作为分布式id。

优点
⭐有序递增,可读性强
⭐性能较高
缺点
⭐占用带宽,依赖Redis
雪花算法(SnowFlake)
SnowFlake生成的是一个Long类型的值,Long类型的数据占用8个字节,也就是64位。SnowFlake将64进行拆分,每个部分具有不同的含义,当然机器码、序列号的位数可以自定义也可以。

优点
⭐本地生成,不依赖中间件。
⭐生成的分布式id足够小,只有8个字节,而且是递增的。
缺点
⭐时钟回拨问题,强烈依赖于服务器的时间,如果时间出现时间回拨就可能出现重复的id。
🔥什么是雪花算法SonwFlake

Snowflake常称为雪花算法,是Twitter开源的分布式ID生成算法,生成后是一个64bit的long型数值,组成部分引入了时间戳,基本保持了自增。
雪花算法作用
⭐生成的所有的id都是随着时间递增
⭐分布式系统内不会产生重复的id
SnowFlake算法优点
⭐高性能高可用:生成时不依赖于数据库,完全在内存中生成
⭐高吞吐:每秒钟能生成数百个的自增ID
⭐ ID自增:存入数据库中,索引效率高
SnowFlake算法的缺点
依赖系统时间,如果系统时间被回调,或者改变,可能会造成ID冲突或者重复
雪花算法组成

注意:
⭕1位,不用,二进制中的最高位是符号位,1表示负数,0表示正数,由于我们生成的雪花算法都是正整数,所以这里是0 。
⭕41位,这里的时间戳是表示的是从起始时间算起,到生成id时间所经历的时间戳,也就是(当前时间戳-起始时间戳(固定)) 这里一共是41位,范围就是(0~ 2^41-1),这么大的毫秒数转化成时间就是大约69年 。
⭕10位,这里的10位代表工作机器id,一共可以部署在(2^10=1024)台机器上面,10位又可以分为前面五位是数据中心id(0~31),后面五位是机器id(0-31) 。
⭕共12位,序列位,一共可用(0 ~ 2^12-1)共4096个数字。
🔥雪花算法SonwFlake落地实现

Hutool简介
Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。
引入相关依赖
hutool工具包已经提供雪花算法ID生成的工具类。
<!--
https://mvnrepository.com/artifact/cn.hutool/hu
tool-all -->
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.13</version>
</dependency>
Snowflake
分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。Twitter的Snowflake 算法就是这种生成器。
//参数1为机器标识
//参数2为数据标识
Snowflake snowflake = IdUtil.getSnowflake(1,
1);
long id = snowflake.nextId();
//简单使用
long id = IdUtil.getSnowflakeNextId();
String id = snowflake.getSnowflakeNextIdStr();
雪花算法SpringBoot引用
config文件
package com.example.demo.config;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
import lombok.extern.slf4j.Slf4j;
import
org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Slf4j
@Component
public class IdGeneratorSnowflake {private long workerId = 0; //第几号机房private long datacenterId = 1; //第几号机器private Snowflake snowflake =
IdUtil.getSnowflake(workerId, datacenterId);@PostConstruct //构造后开始执行,加载初始化工作public void init(){try{//获取本机的ip地址编码workerId =
NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());log.info("当前机器的workerId: " +
workerId);}catch (Exception e){e.printStackTrace();log.warn("当前机器的workerId获取失败 -
---> " + e);workerId =
NetUtil.getLocalhostStr().hashCode();}}/**
分布式全局唯一ID实现_雪花算法SonwFlake落地实现之
Mybatis Plus
初始化工程* 生成id* @return*/public synchronized long snowflakeId(){return snowflake.nextId();}
}
🔥雪花算法SonwFlake落地实现之Mybatis Plus

初始化工程
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-bootstarter</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-bootstarter</artifactId><version>3.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connectorjava</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-startertest</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintageengine</artifactId></exclusion></exclusions></dependency></dependencies>
编写相关配置
在 application.yml 配置文件中添加 MySQL 数据库的相关配置:
spring.datasource.driver-classname=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.66.1
00:3306/test?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
开启MapperScan扫描
在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:
@SpringBootApplication
@MapperScan("com.itbaizhan.sonwflake.mapper")
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class,
args);}
}
编码
编写实体类 User.java
@Data
public class User {@TableId(type = IdType.ASSIGN_ID)// 雪花算法private Long id;private String name;private Integer age;private String email;
}
编写Mapper
public interface UserMapper extends
BaseMapper<User> {
}
添加测试类
@Testvoid createUser() {User user = new User();user.setName("张三");user.setAge(18);user.setEmail("23472@qq.com");userMapper.insert(user);}
相关文章:
Java分布式解决方案(一)
随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。 如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高 并发大流量的电商业务场景下,微服务…...
设备树的节点和属性)
设备树系统学习(二)设备树的节点和属性
一、节点 1.节点命名格式 格式:<name>[@<unit-address>] name:是一个简单的 ASCII 字符串,长度最多为 31 个字符,节节点是根据它所代表的设备类型来命名的,比如 “gpu” 就表示这个节点是 gpu外设。 unit-address:一般表示设备的地址或寄存器首地址,可以为…...

【数据结构】二叉树的基本操作中的一些易错点
文章目录前言一、求二叉树节点个数二、求树的叶子结点个数三、求树的高度四、二叉树查找值为x的结点总结前言 笔者整理出了一些关于萌新在入门二叉树时容易犯的一些错误,你也来试试自己会不会掉到这些坑里把~ 一、求二叉树节点个数 错误示例: int Tre…...
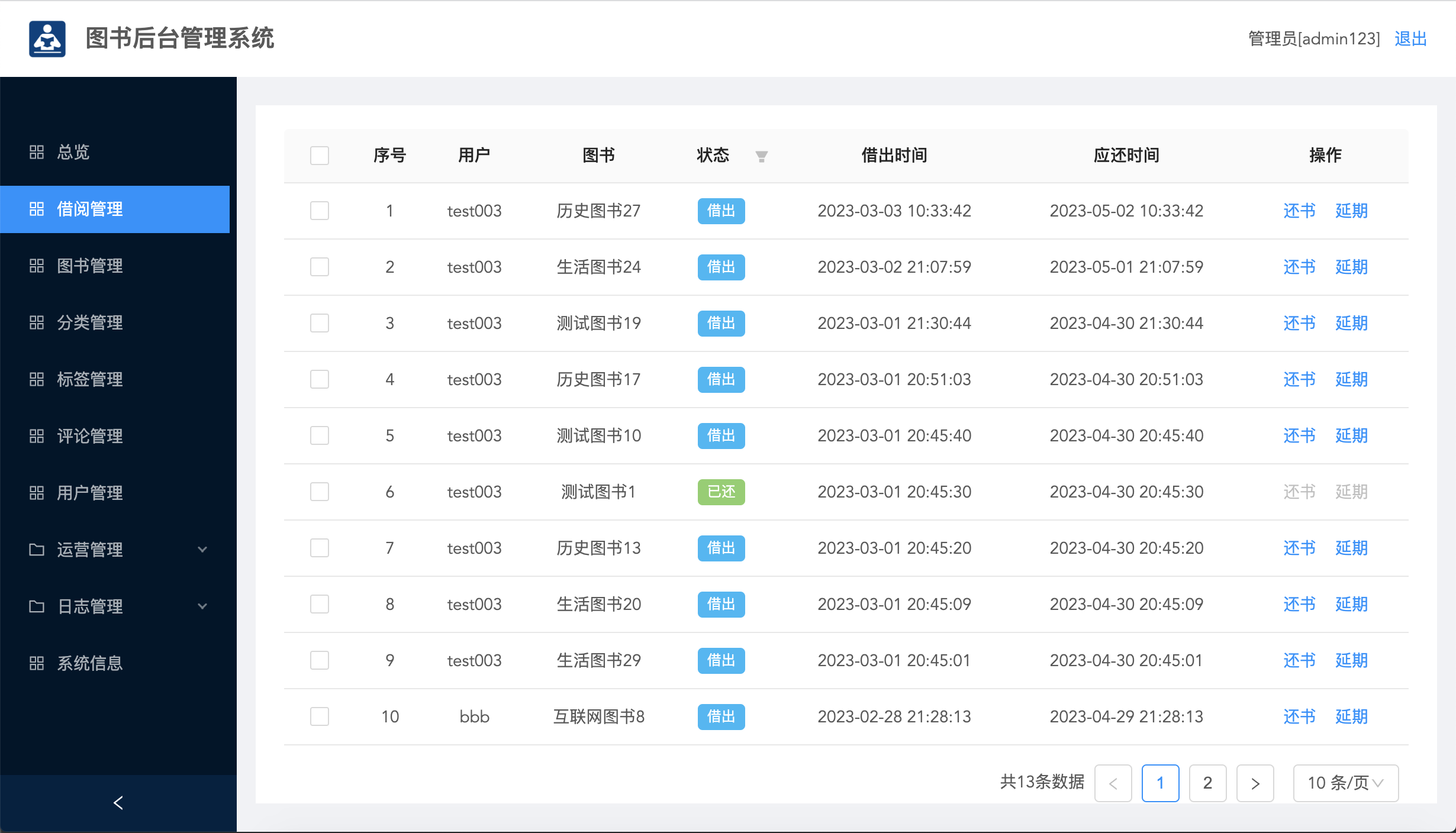
在线图书借阅网站( Python +Vue 实现)
功能介绍 平台采用B/S结构,后端采用主流的Python语言进行开发,前端采用主流的Vue.js进行开发。 整个平台包括前台和后台两个部分。 前台功能包括:首页、图书详情页、用户中心模块。后台功能包括:总览、借阅管理、图书管理、分类…...
不平衡数据集的建模的技巧和策略
不平衡数据集是指一个类中的示例数量与另一类中的示例数量显著不同的情况。 例如在一个二元分类问题中,一个类只占总样本的一小部分,这被称为不平衡数据集。类不平衡会在构建机器学习模型时导致很多问题。不平衡数据集的主要问题之一是模型可能会偏向多数…...

3. 算法效率
同一个问题的不同算法在性能上的比较,现在的方法主要是算法时间复杂度。算法效率是算法操作(operate)或处理(treat)数据的重复次数最小。 例题选自《编程珠玑》第8章,算法设计技术。 这个问题是一维模式识别(人工智能)中的一个问题。 输入有n个元素的向量,输出连续子向…...

仪表放大器放大倍数分析-运算放大器
仪表放大器是一种非常特殊的精密差分电压放大器,它的主要特点是采用差分输入、具有很高的输入阻抗和共模抑制比,能够有效放大在共模电压干扰下的信号。本文简单分析一下三运放仪表放大器的放大倍数。 一、放大倍数理论分析 三运放仪表放大器的电路结构…...
laravel8多模块、多应用和多应用路由
1、安装多应用模块 composer require nwidart/laravel-modules2、执行命令,config文件夹下生成一个modules.php配置文件 php artisan vendor:publish --provider"Nwidart\Modules\LaravelModulesServiceProvider"3、修改config文件夹下的modules.php&am…...

【Java学习笔记】6.Java 变量类型
Java 变量类型 在Java语言中,所有的变量在使用前必须声明。声明变量的基本格式如下: type identifier [ value][, identifier [ value] ...] ;格式说明:type为Java数据类型。identifier是变量名。可以使用逗号隔开来声明多个同类型变量。 …...

Promise对象状态属性 工作流程 Promise对象的几个属性
Promise 对象状态属性介绍 实例对象中的一个属性 PromiseState pending 1、pending 变为 resolved / fullfilled 成功 2、pending 变为 rejected 失败 说明:只有这2种,且一个promise对象只能改变一次 无论变为成功还是失败,都会有一个结果…...

webgpu思考obj携带属性
今天在搞dbbh.js的时候,想到一个问题,啥问题呢,先看看情况 画2个材质不相同的box的时候 首先开始createCommandEncoder,然后beginRenderPass,分歧就在这里了 第一个box,他有自己的pipeline,第二个也有,那么…...
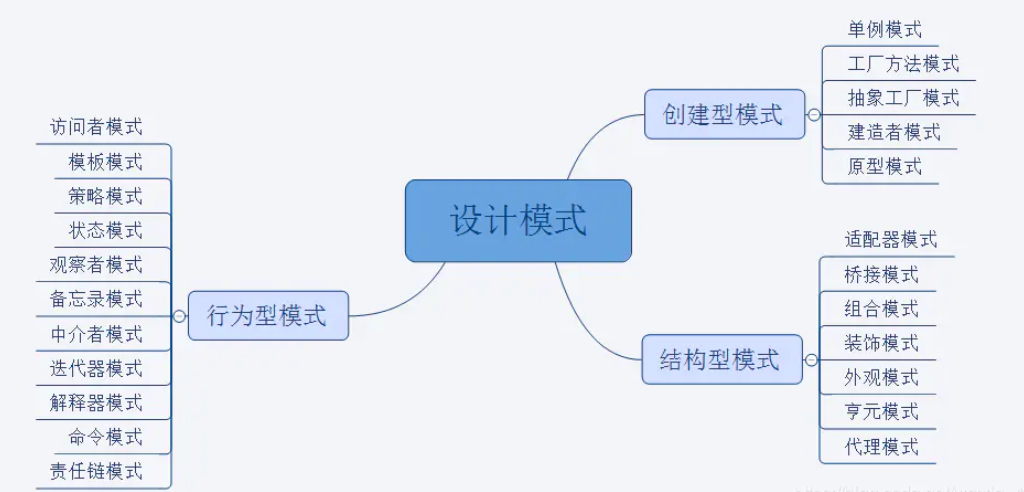
设计模式(只谈理解,没有代码)
1.什么是设计模式设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性、程序的重用性。2.为什么要学习设计模式看懂源代码:如果你不懂设计模式去看Jd…...

06、Eclipse 中使用 SVN
Eclipse 中使用 SVN1 在 Eclipse 中安装 SVN 客户端插件1.1 在线安装1.2 离线安装2 SVN 在 Eclipse 分享3 检出提交更新3.1 检出3.2 提交3.3 更新4 Eclipse 中 SVN 图标及其含义4.1 ?图标4.2 图标4.3 金色圆柱图标4.4 * 图标5 恢复历史版本5.1 恢复步骤5.2 权限控制…...

Zookeeper3.5.7版本——客户端命令行操作(命令行语法)
目录一、命令行语法二、help命令行语法示例一、命令行语法 命令行语法列表 命令基本语法功能描述help显示所有操作命令ls path使用 ls 命令来查看当前 znode 的子节点 [可监听]-w 监听子节点变化-s 附加次级信息create普通创建-s 含有序列-e 临时(重启或者超时消失…...

2023.03.05 学习周报
文章目录摘要文献阅读1.题目2.摘要3.介绍4.SAMPLING THE OUTPUT5.LOSS FUNCTION DESIGN5.1 ranking loss: Top1 & BPR5.2 VANISHING GRADIENTS5.3 ranking-max loss fuction5.4 BPR-max with score regularization6.实验7.结论深度学习1.相关性1.1 什么是相关性1.2 协方差1…...
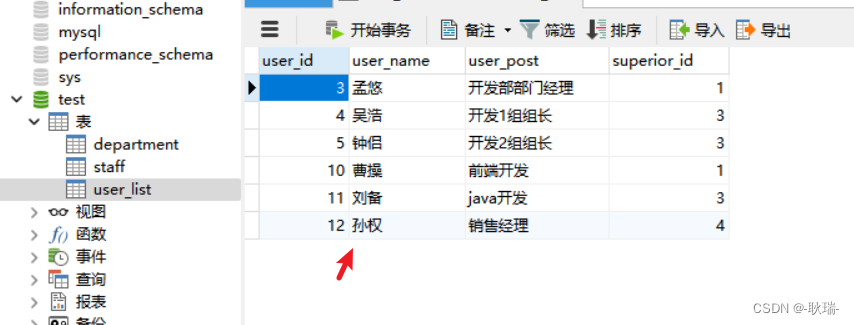
java Spring JdbcTemplate配合mysql实现数据批量修改
其实这个操作和批量添加挺像的 调的同一个方法 首先 我们看数据库结构 这是我本地的 mysql 里面有一个test数据库 里面有一张user_list表 然后创建一个java项目 然后 引入对应的JAR包 在src下创建 dao 目录 在下面创建一个接口 叫 BookDao 参考代码如下 package dao;impo…...
《算法分析与设计》笔记总结
《算法分析与设计》笔记总结第一章 算法引论1.1 算法与程序1.2 表达算法的抽象机制1.3 描述算法1.4 算法复杂性分析第二章 递归与分治策略2.1 递归的概念2.2 分治法的基本思想2.3 二分搜索技术2.4 大整数乘法2.5 Strassen矩阵乘法2.7 合并排序2.8 快速排序2.9 线性时间选择2.10…...

序列化与反序列化概念
序列化是指将对象的状态信息转换为可以存储或传输的形式的过程。 在Java中创建的对象,只要没有被回收就可以被复用,但是,创建的这些对象都是存在于JVM的堆内存中,JVM处于运行状态时候,这些对象可以复用, 但…...
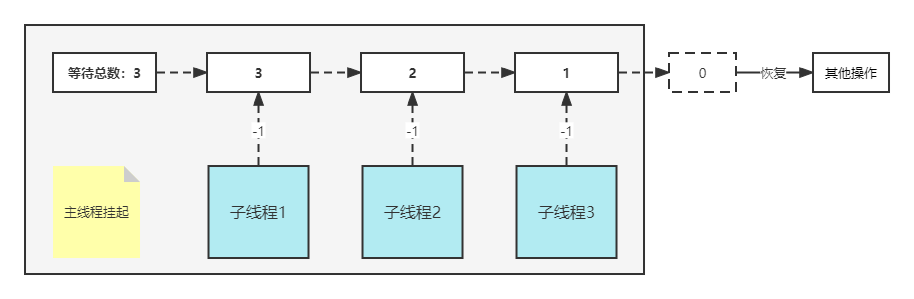
【Java并发编程】CountDownLatch
CountDownLatch是JUC提供的解决方案 CountDownLatch 可以保证一组子线程全部执行完牛后再进行主线程的执行操作。例如,主线程启动前,可能需要启动并执行若干子线程,这时就可以通过 CountDownLatch 来进行控制。 CountDownLatch是通过一个线程…...

【iOS】Blocks
BlockBlocks概要什么是Blocks?Block语法Block类型变量截获自动变量值__block说明符Blocks的实现Block的实质Blocks概要 什么是Blocks? Blocks可简单概括为: 带有自动变量(局部变量)的匿名函数 在使用Blocks时&#x…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...
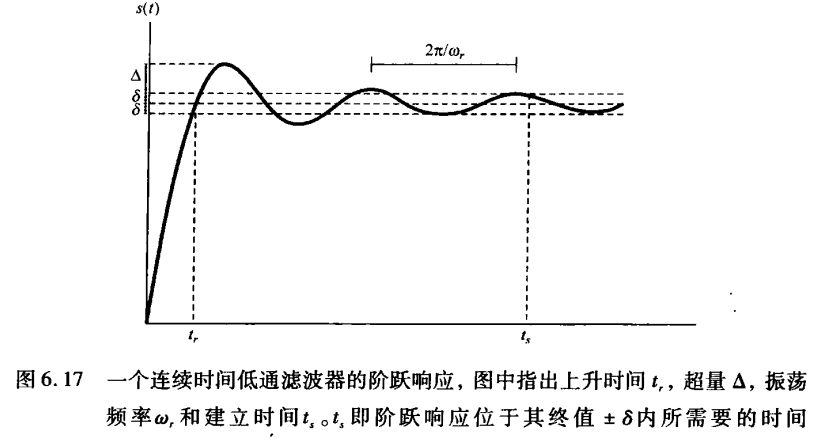
《信号与系统》第 6 章 信号与系统的时域和频域特性
目录 6.0 引言 6.1 傅里叶变换的模和相位表示 6.2 线性时不变系统频率响应的模和相位表示 6.2.1 线性与非线性相位 6.2.2 群时延 6.2.3 对数模和相位图 6.3 理想频率选择性滤波器的时域特性 6.4 非理想滤波器的时域和频域特性讨论 6.5 一阶与二阶连续时间系统 6.5.1 …...
:LeetCode 142. 环形链表 II(Linked List Cycle II)详解)
Java详解LeetCode 热题 100(26):LeetCode 142. 环形链表 II(Linked List Cycle II)详解
文章目录 1. 题目描述1.1 链表节点定义 2. 理解题目2.1 问题可视化2.2 核心挑战 3. 解法一:HashSet 标记访问法3.1 算法思路3.2 Java代码实现3.3 详细执行过程演示3.4 执行结果示例3.5 复杂度分析3.6 优缺点分析 4. 解法二:Floyd 快慢指针法(…...