MySQL数据库 各种指令操作大杂烩(DML增删改、DQL查询、SQL...)
文章目录
- 前言
- 一、DML 增删改
- 添加数据
- 修改数据
- 删除数据
- 二、DQL 查询
- 基本查询
- 条件查询
- 聚合函数(count、max、min、avg、sum)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
- DQL 语句练习
- 三、SQL
- DCL 权限控制
- 约束案例
- 多表查询
- 事务
- 存储引擎
- 字符串函数
- 数值函数
- 日期函数
- 流程函数
前言
本篇选自本人前段时间对MySQL的皮毛学习,在这里进行一个简单的汇总,希望能对读者有或多或少的帮助,若有什么不懂的知识盲区,可在评论区交流讨论。
一、DML 增删改
添加数据
-
- 给指定字段添加数据 insert into 表名(字段1,字段2…) values (值1,值2…);
insert into employee(id, workno, name, gender, age, idcard, entrydate) values (1,'1','Itcase','男',10,'012345678998765432','2022-9-19');
-
- 查看表中的值
select * from employee;
-
- 给全部字段添加数据 insert into 表名 values (值1,值2…);
insert into employee values(2,'2','张无忌','男',18,'012345678901234567','2022-9-19');
-
- 批量添加数据 inset into 表名 (字段1,字段2…) values (值1,值2…),(值1,值2…),(值1,值2…);
#insert into 表名 values (值1,值2...),(值1,值2...),(值1,值2...);
insert into employee values(3,'3','韦一笑','男',28,'012345678901234567','2022-9-19'),(4,'4','张三丰','男',38,'012345678901234567','2022-9-19');
修改数据
update 表名 set 字段1=值1,字段2=值2,… [where 条件];
-
- 修改id为1的数据,将name修改为itheima
update employee set name = 'itheima' where id=1;
-
- 修改id为1的数据,将name修改为小昭,gender修改为女
update employee set name='小昭',gender='女' where id=1;
-
- 将所有的员工入职日期修改为2008-01-01
update employee set entrydate='2008-01-01';
删除数据
delete from 表名 [where 条件]
-
- 删除 gender为女的员工
delete from employee where gender='女';
-
- 删除所有员工
delete from employee;
-
- 删除employee表
drop table employee;
二、DQL 查询
数据准备
create table emp(id int comment '编号',workno varchar(10) comment '工号',name varchar(10) comment '姓名',gender char(1) comment '性别',age tinyint unsigned comment '年龄',idcard char(18) comment '身份证号',workaddress varchar(50) comment '工作地点',entrydate date comment '入职时间'
) comment '员工表';
插入数据
insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate)
values (1,'1','柳岩','女',20,'123654879654123658','北京','2000-01-01'),(2,'2','张无忌','男',18,'123654879654123611','北京','2005-09-01'),(3,'3','韦一笑','男',38,'123654879654123650','上海','2005-08-01'),(4,'4','赵敏','女',18,'123654879654123658','北京','2009-12-01'),(5,'5','小昭','女',16,'123654879654120008','上海','2007-07-01'),(6,'6','杨逍','男',28,'123654879654120058','北京','2006-01-01'),(7,'7','范瑶','男',40,'123654879650023658','北京','2005-05-01'),(8,'8','黛绮丝','女',38,'123654870054123658','天津','2015-05-01'),(9,'9','范凉凉','女',45,'123654879654123658','北京','2010-04-01'),(10,'10','陈友谅','男',53,'123054879654123658','上海','2011-01-01'),(11,'11','张士诚','男',55,'103654879654123658','江苏','2015-05-01'),(12,'12','常遇春','男',32,'120654879654123658','北京','2004-02-01'),(13,'13','张三丰','男',88,'123654879654123658','江苏','2020-11-01'),(14,'14','灭绝','女',65,'123650000654123658','西安','2019-05-01'),(15,'15','胡青牛','男',70,'123654879654120000','西安','2018-04-01'),(16,'16','周芷若','女',18,null,'北京','2012-06-01');
基本查询
select 字段列表 from 表名列表
-
- 查询多个字段 select 字段1,字段2… from 表名;
select * from 表名;
-
- 设置别名
select 字段1 [as 别名1],字段2 [as 别名2]... from 表名;
-
- 去除重复记录
select distinct 字段列表 from 表名;
- (1) 查询指定字段 name,workno,age 返回
select name,workno,age from emp;
- (2)查询所有字段返回
select id,workno, name, gender, age, idcard, workaddress, entrydate from emp;
select * from emp;
- (3)查询所有员工的工作地址,起别名
select workaddress as '工作地址' from emp;
select workaddress '工作地址' from emp; #as可省略
- (4)查询公司员工的上班地址(不要重复)
select distinct workaddress '工作地址' from emp;
条件查询
select 字段列表 from 表名 where 条件列表;
-
- 查询年龄等于88的员工
select * from emp where age=88;
select id,workno, name, gender, age, idcard, workaddress, entrydate from emp where age=88;
-
- 查询年龄小于20的员工信息
select * from emp where age<20;
-
- 查询小于等于20的员工信息
select * from emp where age<=20;
-
- 查询没有身份证号的员工信息
select * from emp where idcard is null;
-
- 查询有身份证号的员工信息
select * from emp where idcard is not null;
-
- 查询年龄不等于88的员工信息
select * from emp where age!=88;
select * from emp where age<>88;
-
- 查询年龄在15岁(包含)到20岁(包含)之间的员工信息
select * from emp where age>=15 && age <=20;
select * from emp where age>=15 and age <=20;
select * from emp where age between 15 and 20;
-
- 查询性别为女且年龄小于25岁的员工信息
select * from emp where gender='女' and age<25;
-
- 查询年龄等于18或20或40的员工信息
select * from emp where age=18 || age =20 || age=40;
select * from emp where age=18 or age =20 or age=40;
select * from emp where age in(18,20,40);
-
- 查询名字为俩个字的员工信息 一个’_‘代表一个字符
select * from emp where name like '__';
- 11.查询身份证号最后一位是0的员工信息 一个’%‘代表任意字符
select * from emp where idcard like '%0';
select * from emp where idcard like '_________________0';
聚合函数(count、max、min、avg、sum)
select 聚合函数(字段列表) from 表名;
-
- 统计该企业员工数量
select count(*) from emp;
-
- 统计该企业员工的平均年龄
select avg(age) from emp;
-
- 统计该企业员工的最大年龄
select max(age) from emp;
-
- 统计该企业员工的最小年龄
select min(age) from emp;
-
- 统计西安地区员工的年龄之和
select sum(age) from emp where workaddress='西安';
分组查询(group by)
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
-
- 根据性别分组,统计男性员工和女性员工
select gender,count(*) from emp group by gender;
-
- 根据性别分组,统计男性员工和女性员工的平均年龄
select gender,avg(age) from emp group by gender;
-
- 查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress, count(*) from emp where age<45 group by workaddress having count(*)>=3;
排序查询(order by)
select 字段列表 from 表名 order by 字段1 排序方式1,字段2 排序方式2;
-
- 根据年龄对公司的员工进行升序排序
select * from emp order by age asc;
select * from emp order by age; #默认会升序
select * from emp order by age desc; #降序
-
- 根据入职时间,对员工进行降序排序
select * from emp order by entrydate desc;
-
- 根据年龄对公司的员工进行升序排序,年龄相同,再按照入职时间进行降序排序
select * from emp order by age asc,entrydate desc;
分页查询(limit)
select 字段列表 from 表名 limit 起始索引,查询记录数;
-
- 查询第一页员工数据,每页展示10条记录
select * from emp limit 0,10;
select * from emp limit 10; #可以省略起始索引0
-
- 查询第二页员工数据,每页展示10条记录 起始索引=(查询页码-1)*每页显示记录数
select * from emp limit 10,10;
DQL 语句练习
DQL 语句执行顺序: from->where->group by->select->order by->limit
-
- 查询年龄为20,21,22,23岁的女性员工信息。
select * from emp where age in(20,21,22,23) and gender='女';
-
- 查询性别为男,并且年龄在20-40岁(含)以内的姓名为三个字的员工。
select * from emp where gender='男'and age>20 and age<=40 and name like '___';
-
- 统计员工表中,年龄小于60岁的,男性员工和女性员工的人数。
select gender, count(*) from emp where age<60 group by gender;
-
- 查询所有年龄小于等于35岁员工的姓名和年龄,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序
select name,age from emp where age<=35 order by age asc,entrydate desc ;
-
- 查询性别为男,且年龄在20-40岁(含)以内的前3个员工信息,对查询的结果按年龄升序排序,年龄相同按入职时间升序排序.
select * from emp where gender='男' and age<=40 and age>=20 order by age asc ,entrydate desc limit 3;
三、SQL
查询用户
user mysql;
select * from user;
直接选中左框中的mysql,找到user表,双击即可查看用户
创建用户
create user '用户名'@'主机名' identified by '密码';
修改用户密码
alter user '用户名'@'主机名' identified with mysql_native_password by '新密码';
删除用户
drop user '用户名'@'主机名';
-
- 创建用户itcast,只能够在当前主机localhost访问,密码123456;
create user 'itcase'@'localhost' identified by '123456';
-
- 创建用户heima,可以在任意主机访间该数据库,密码123456;
create user ' heima' @'%' identified by '123456';
-
- 修改用户heima的访问密码为1234;
alter user ' heima'@'%' identified with mysql_native_password by '1234';
-
- 删除itcast@localhost用户;
drop user 'itcase'@'localhost';
DCL 权限控制
-
- 查询权限
show grants for '用户名'@'主机名';
-
- 授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
-
- 撤销权限
remove 权限列表 on 数据库名.表名 from '用户名'@'主机名';
约束案例
约束名称 描述 关键字
非空约束 保证列中所有数据不能有null值 NOT NULL
唯一约束 保证列中所有数据各不相同 UNIQUE
主键约束 主键是一行数据的唯一标识,要求非空且唯一 PRIMARY KEY
检查约束 保证列中的值满足某一条件 CHECK
默认约束 保存数据时,未指定值则采用默认值 DEFAULT
外键约束 外键用来让两个表的数据之间建立链接,保证数据的一致性和完整性 FOREIGN KEY
- 员工表 在创建表时添加约束
create table emp1 (id int primary key auto_increment , -- 员工id,主键且自增长ename varchar(50) not null unique , -- 员工姓名,非空并且唯一joindate date not null , -- 入职日期,非空salary double(7,2) not null , -- 工资,非空bonus double(7,2) default 0 -- 奖金,如果没有奖金默认为0
);
– 例:建完表后添加约束 alter table 表名 modify 字段名 数据类型 not null;
– 删除约束: alter table 表名 modify 字段名 数据类型;
show databases ;
use itcase;
show tables ;
select * from emp1;
drop table dept;
insert into emp1(id, ename, joindate, salary, bonus) values (1,'张三','1999-11-11',8800,5000);
-
- 添加约束
(1) 创建表时添加外键约束
CREATE TABLE表名(列名 数据类型,...[CONSTRAINT] [外键名称] FOREIGN KEY(外键列名)REFERENCES 主表(主表列名)
);
(2) 建完表后添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键字段名称)REFERENCES 主表名称(主表列名称);
例:alter table emp add constraint fk_emp_dept foreign key(dep_id) references dept(id);
-
- 删除约束
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
例:alter table emp drop foreign key fk_emp_dept;
-
- 练习
-- 部门表
create table dept (id int primary key auto_increment , -- 部门id,主键且自增长dep_name varchar(20) , -- 部门名addr varchar(20) -- 部门地址
);
-- 员工表
create table emp (id int primary key auto_increment , -- 员工id,主键且自增长name varchar(20) , -- 员工姓名age int,dep_id int, -- 所属部门id-- 添加外键 dep_id,关联dept表的id主键constraint fk_emp_dept foreign key(dep_id) references dept(id)
);
-- 添加俩个部门
insert into dept(dep_name, addr) values ('研发部','广州'),('销售部','深圳');-- 添加员工 dep_id 表示员工所在的部门
insert into emp(name,age,dep_id) values ('张三',20,1),('李四',20,1),('王五',20,1),('赵六',20,2),('孙七',20,2),('周八',20,2);
select * from emp;多表查询
-
- 隐式内连接
select 字段列表 from 表1,表2… where 条件;
- 隐式内连接
select emp.id,emp.name,emp.age,dept.dep_name from emp,dept where emp.dep_id=dept.id;
select t1.id,t1.name,t1.age,t2.dep_name from emp t1,dept t2 where t1.dep_id=t2.id;
-
- 显示内连接
select 字段列表 from 表1 [inner] join 表2 on 条件;
- 显示内连接
select * from emp inner join dept on emp.dep_id=dept.id;
select * from emp join dept on emp.dep_id=dept.id; #inner可省略
-
- 左外连接
select 字段列表 from 表1 left [outer] join 表2 on 条件;
- 左外连接
左外连接:相当于查询A表所有数据和交集部分数据
select * from emp left join dept on emp.dep_id=dept.id;
-
- 右外连接
select 字段列表 from 表1 right [outer] join 表2 on 条件
- 右外连接
右外连接:相当于查询B表所有数据和交集部分数据
select * from emp right join dept on emp.dep_id=dept.id;
-
- 子查询:
单行单列:作为条件值,使用=、!=、>、<等进行条件判断
select 字段列表 from 表 where 字段名=(子查询);
- 子查询:
(1) 查询‘财务部’所有的员工信息 emp是员工表 dept是部门表
select id from dept where dname='财务部'; 获取财务部的部门id号
select * from emp where dep_id=(select id from dept where dname='财务部');
-
- 多行单列:作为条件值,使用in等关键字进行条件判断
select 字段列表 from 表 where 字段名 in (子查询);
- 多行单列:作为条件值,使用in等关键字进行条件判断
(2) 查询‘财务部’和‘市场部’所有的员工信息 emp是员工表 dept是部门表
select id from dept where dname='财务部' or dname='市场部'; 获取财务部和市场部的部门id号
select * from emp where dep_i in (select id from dept where dname='财务部' or dname='市场部');
-
- 多行多列:作为虚拟表
select 字段列表 from (子查询) where 条件;
- 多行多列:作为虚拟表
(3) 查询入职日期是’2011-11-11’之后的员工信息和部门信息
select * from emp where join_data>'2011-11-11'; 获取入职日期是'2011-11-11’之后的员工信息
select * from (select * from emp where join_data>'2011-11-11') t1,dept where t1.dep_id=dept.id;
事务
- 1. 开启事务
start transaction;或者begin - 2. 提交事务
commit; - 3. 回滚事务
rollback;
-- 创建账户表
drop table if exists account;
create table account(id int primary key auto_increment,name varchar(10),money double(10,2)
);
select * from account;
-- 添加数据
insert into account(name,money) values('张三',1000),('李四',1000);update account set money=1000; #设置 张三李四 余额变为1000-
- 转账操作
(1)开启事务
begin ;
(2)查询李四的余额
select money from account where name='李四';
(3)李四金额 -500
update account set money=money-500 where name='李四';
(4)张三金额 +500
update account set money=money+500 where name='张三';
-
- 提交事务
commit ;
-
- 回滚事务
rollback ;
事务四大特征:
-
原子性(Atomicity):事务是不可分割的最小操作单位,要么同时成功,要么同时失败
-
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态
-
隔离性(lsolation) :多个事务之间,操作的可见性
-
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
-
- 查询事务的默认提交方式
select @@autocommit;#1为自动 0为手动 mysql数据库默认为自动
- 查询事务的默认提交方式
-
- 修改事务的提交方式
set @@autocommit=0;# 0 为手动方式 即需要手动调用 commit;
- 修改事务的提交方式
并发事务问题:
- 脏读:一个事务读到另外一个事务还没有提交的数据。
- 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复
- 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了"幻影”。
事务隔离级别:
脏读 不可重复读 幻读
read uncommitted 有 有 有
read committed 0 1 1
repeatable read 0 0 1
serializable 0 0 0
- 查看事务隔离级别
select @@transaction_isolation;
- 设置事务隔离级别
set [session | global] transaction isolation level {read uncommitted | read committed | repeatable read | serializable }
set session transaction isolation level read uncommitted ;
set session transaction isolation level repeatable read ;
存储引擎
-
- 查询建表语句 —默认存储引擎:InnoDB
show create table account;
-
- 查询当前数据库支持的存储引擎
show engines ;
-
- 创建表my_myisam,并指定MyISAM存储引擎
create table my_myisam(id int,name varchar(10)
)engine =MyISAM;
字符串函数
-
- concat 字符串连接
select concat('hello','MySQL');
-
- lower 都转为小写
select lower('Hello');
-
- upper 都转为大写
select upper('Hello');
-
- lpad 向左填充
select lpad('01',5,'hadia'); # 将字符串’hadia‘给字符串’01‘ 左边填充至5个字符
-
- rpad 向右填充
select rpad('01',5,'hadia');
-
- trim 去除首尾的空格
select trim(' hello to me ');
-
- substring 截取字符
select substring('hello mysql',1,5); #截取字符串的 第一个位置开始的5个字符
(1)案例:由于业务需求变更,企业员工的工号统一为5位数,目前不足5位数的全部在前面补0,如1号员工的工号应该为00001
update user set name=lpad(name,5,'0'); # 因为id为int型需要string型,所以这里用name代替
数值函数
-
- ceil() 向上取整
select ceil(1.1);
-
- floor(x) 向下取整
select floor(1.9);
-
- mod(x,y) 返回x/y的模
select mod(3,4);
-
- rand() 返回0~1内的随机数
select rand();
-
- round(x,y) 求参数x的四舍五入的值,保留y位小数
select round(2.345,2);
(2)案例:通过数据库的函数,生成一个六位数的随机验证码
select lpad(round(rand()*1000000,0),6,'0');
日期函数
-
- curdate() 返回当前日期
select curdate();
-
- curtime() 返回当前时间
select curtime();
-
- now() 返回当前日期和时间
select now();
-
- year(date) 获取指定date的年份
select year(now());
-
- month(data) 获取指定date的月份
select month(now());
-
- day(date) 获取指定date的日期
select day(now());
-
- date_add(date,interval expr type) 返回一个日期/时间值加上一个时间间隔expr后的时间值
select date_add(now(),interval 70 day ); #从现在日期往后推70天 interval是固定值,70是变值,day是可变的时间单位 month、year
-
- datediff(date1,date2) 返回起始时间date1和结束时间date2之间的天数
select datediff('2022-10-1','2022-9-26');
(3)案例:查询所有员工的入职天数,并根据入职天数倒序排序
select name,datediff(curdate(),entrydate) as 'days' from emp order by days desc; # entrydate为员工表中的入职天数(这里没创建)
流程函数
-
- if(value,t,f) 如果value为true,则返回t,否则返回f
select if(true,'ok','error');
select if(false,1,0);
-
- ifnull(value1,value2) 如果value1不为空,返回value1,否则返回value2
select ifnull('ok','default');
select ifnull(' ','default');
select ifnull(null,0);
-
- case where[val1] then [res1]… else [default] end 如果val1为true,返回res1,否则返回default默认值
(1)需求:查询emp表的员工姓名和工作地址(北京/上海—> 一线城市,其他----> 二线城市)
select name,(case workaddress when '北京' then '一线城市' when '上海' then '一线城市' else '二线城市' end) as '工作地址' from emp; # workaddress为表中的工作地址,emp为表名
-
- case [expr] when [val1] then [res1]… else [default] end 如果exper的值等于val1,返回res1,… 否则返回default默认值
(1)案例:统计班级各个学员的成绩,展示的规则如下: >=85,展示优秀 >=60,展示及格 否则展示不及格
create table score(
id int comment 'ID', # comment后面加注释
name varchar(20) comment '姓名',
math int comment '数学',
english int comment '英语',
chinese int comment '语文'
) comment '学员成绩表';
insert into score(id,name, math,english,chinese) values (1,'Tom',67,88,95 ),(2,'Rose',23,66,90),(3,'Jack',56,98,76);select id,name,(case when math>=85 then '优秀' when math>=60 then '及格' else '不及格' end) as '数学',(case when english>=85 then '优秀' when english>=60 then '及格' else '不及格' end) as '英语',(case when chinese>=85 then '优秀' when chinese>=60 then '及格' else '不及格' end) as '语文'from score;
相关文章:
)
MySQL数据库 各种指令操作大杂烩(DML增删改、DQL查询、SQL...)
文章目录前言一、DML 增删改添加数据修改数据删除数据二、DQL 查询基本查询条件查询聚合函数(count、max、min、avg、sum)分组查询(group by)排序查询(order by)分页查询(limit)DQL 语句练习三、SQLDCL 权限控制约束案例多表查询事务存储引擎字符串函数数值函数日期函数流程函数…...

Java分布式全局ID(一)
随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。 如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高 并发大流量的电商业务场景下,微服务…...
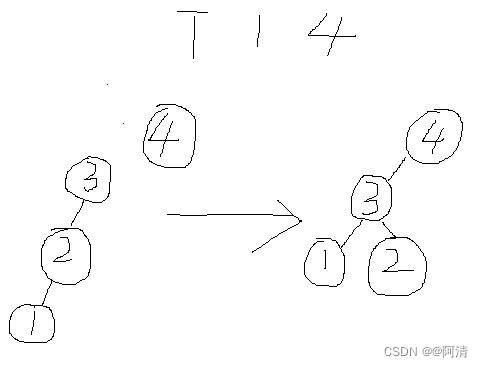
算法分析与设计之并查集详解
算法分析与设计之并查集1.前言2.并查集的基础2.1.关于动态连通性2.2.动态连通性的应用场景:2.3.对问题建模:2.4.建模思路:2.5.API2.7.Quick-Find算法:2.8.Quick-Union算法:3. 并查集的应用1.前言 本文主要介绍解决动态…...

Linux - 内存性能评估
文章目录概述free 命令指定的时间段内不间断地监控内存的使用情况通过watch与free相结合动态监控内存状况vmstat命令监控内存“sar –r”命令组合小结概述 内存的管理和优化是系统性能优化的一个重要部分,内存资源的充足与否直接影响应用系统的使用性能。在进行内存…...

00后初中辍学,转行程序员后,终于找到了女朋友
大家好,这里是程序员晚枫,今天继续分享我们的读者投稿,如需投稿赚稿费的朋友,请在后台私信我:投稿。下面我们进入正文吧~ 我是一位 00 后,从初一辍学,到目前为止已有 8 年的时间了,在…...

“Vue学习注意事项:掌握核心特性,注意性能优化和第三方库的使用“
Vue是一款易学易用的JavaScript框架,它可以帮助开发者构建动态、高性能的用户界面。Vue的核心概念包括数据绑定、指令、计算属性和组件化,学习Vue需要注意以下几个点:1. 理解Vue的基本概念和用法Vue的基本概念包括模板、组件、数据绑定、计算…...
计算机网络协议详解(二)
文章目录🔥HTTP协议介绍🔥HTTP协议特点🔥HTTP协议发展和版本🔥HTTP协议中URI、URL、URN🔥HTTP协议的请求分析🔥HTTP协议的响应分析🔥MIME类型🔥HTTP协议介绍 HTTP协议介绍 什么是超…...
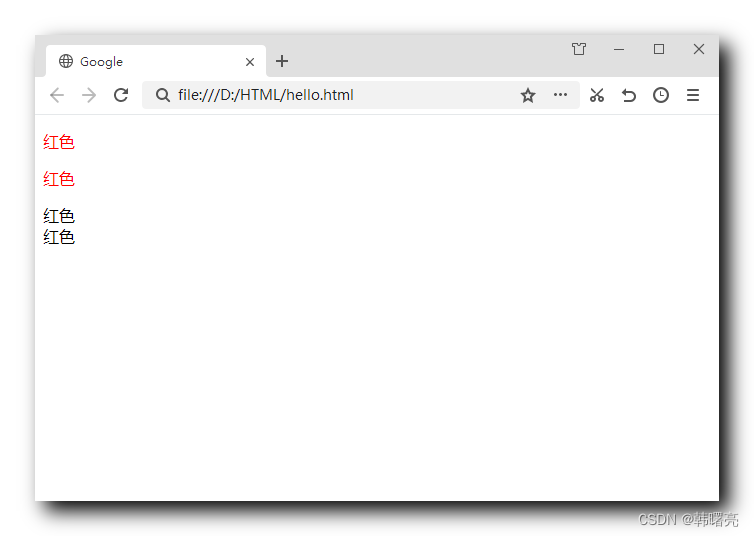
【CSS】CSS 复合选择器 ② ( 子元素选择器 | 交集选择器 )
文章目录一、子元素选择器1、语法说明2、代码分析3、代码示例二、交集选择器1、语法说明2、代码示例一、子元素选择器 1、语法说明 子元素选择器 可以选择 某个基础选择器 选择出的 元素组 的 直接子元素 ( 亲儿子元素 ) 中 使用基础选择器 选择 元素 ; 子元素选择器语法 : 父选…...

Java集合专题
文章目录框架体系CollectionListArrayListLinkedListVectorSetHashSetLinkedHashSetTreeSetMapHashMapHashtableLinkedHashMapTreeMapPropertiesCollections框架体系 1、集合主要分了两组(单列集合,双列集合) 2、Collection接口有两个重要的子…...
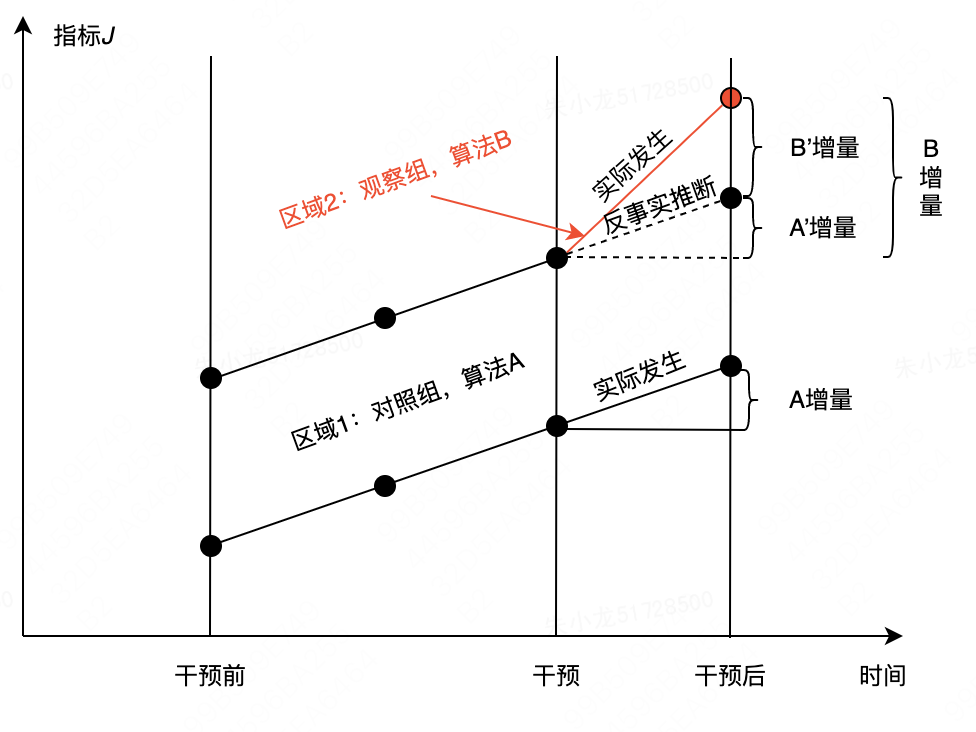
双重差分法(DID):算法策略效果评估的利器
文章目录算法评估DID原理简单实例Python实现算法评估 作为一名算法出身的人,曾长期热衷于算法本身的设计和优化。至于算法的效果评估,通常使用公开数据集做测试,然后对比当前已公开的结果,便可得到结论。 但是在实际落地过程中&…...

【pytorch】使用mixup技术扩充数据集进行训练
目录1.mixup技术简介2.pytorch实现代码,以图片分类为例1.mixup技术简介 mixup是一种数据增强技术,它可以通过将多组不同数据集的样本进行线性组合,生成新的样本,从而扩充数据集。mixup的核心原理是将两个不同的图片按照一定的比例…...

面向对象设计模式:创建型模式之单例模式
1. 单例模式,Singleton Pattern 1.1 Definition 定义 单例模式是确保类有且仅有一个实例的创建型模式,其提供了获取类唯一实例(全局指针)的方法。 单例模式类提供了一种访问其唯一的对象的方式,可以直接访问…...
IsADirectoryError: [Errno 21] Is a directory: ‘.‘
项目场景: 基于YOLOv5的室内场景识别 工具:colab 问题描述 Traceback (most recent call last): File “train.py”, line 630, in main(opt) File “train.py”, line 494, in main d torch.load(last, map_location‘cpu’)[‘opt’] File “/usr/…...

判断三角面片与空间中球体是否相交
文章目录一、问题描述二、解题思路 在做项目时遇到了一个数学问题,即,如何判断给定一个三角面片与空间中某个球体有相交部分?这个问题看似简单,实际处理起来需要一些方法和手段。一、问题描述 已知空间中球体的球心位置center&a…...

继承下的缺省参数值和访问说明符
前言 本文将介绍 C 继承体系下,函数缺省参数的绑定和函数访问说明符的绑定。这些奇怪的问题实际上不应在我们的代码中出现,但它们能帮助我们理解 C 的动态绑定和静态绑定,也能帮助我们更好的通过面试。 缺省参数值 先来看一段代码…...
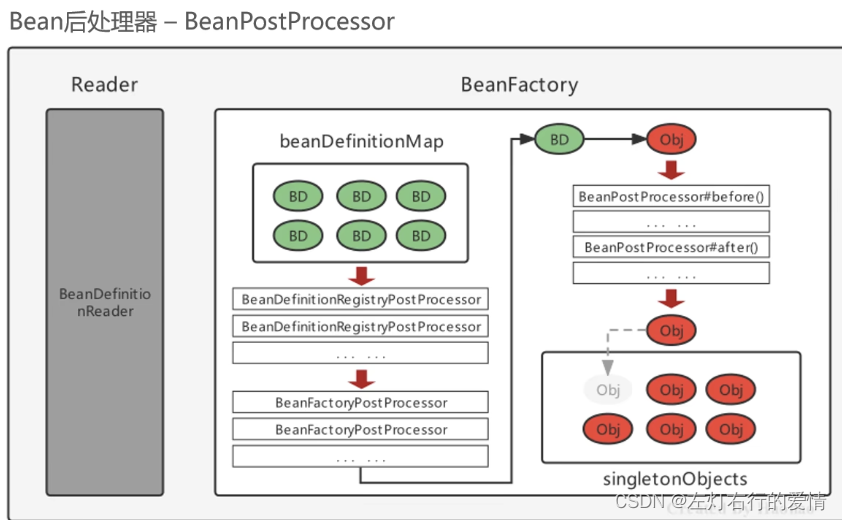
Spring核心模块—— BeanFactoryPostProcessorBeanPostProcessor(后处理器)
后置处理器前言Spring的后处理器BeanFactoryPostProcessor(工厂后处理器)执行节点作用基本信息经典场景子接口——BeanDefinitiRegistryPostProcessor基本介绍用途具体原理例子——注册BeanDefinition使用Spring的BeanFactoryPostProcessor扩展点完成自定…...
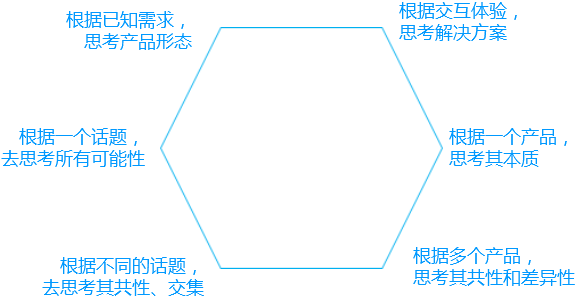
产品新人如何培养产品思维?
什么是产品思维?其实很难定义,不同人有不同的定义。有的人定义为以用户为中心打磨一个完美体验的产品;有的定义为从需求调研到需求上线各个步骤需要思考的点,等等。本文想讨论的产品思维是:怎么去发现问题,…...

「兔了个兔」CSS如此之美,看我如何实现可爱兔兔LOADING页面(万字详解附源码)
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学会计学专业大二本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后…...
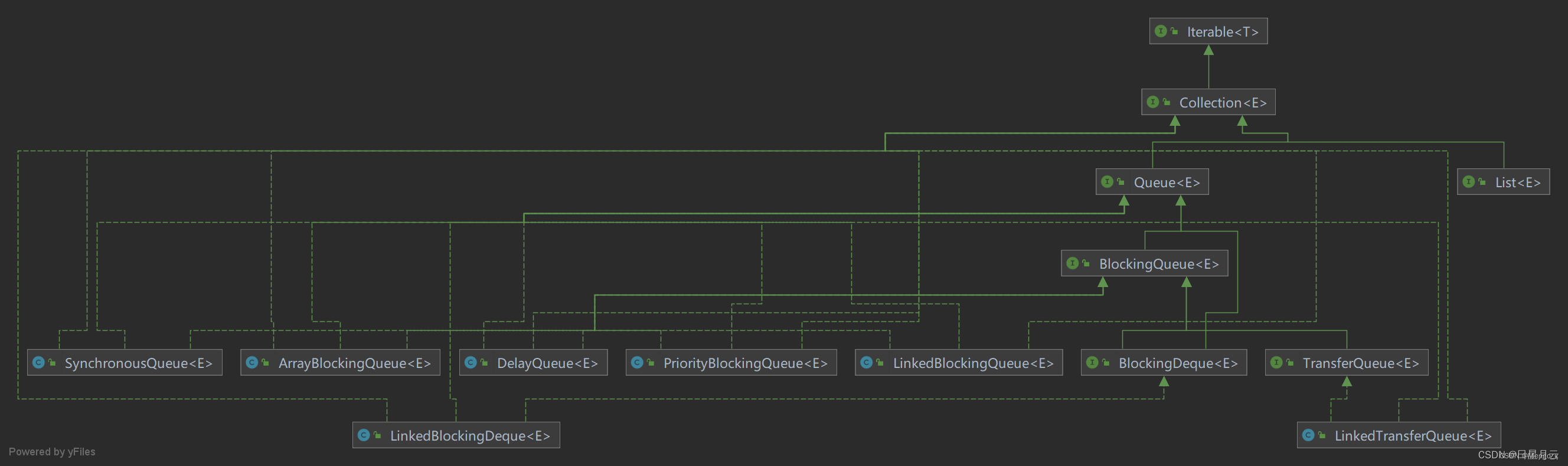
【Java】阻塞队列 BlcokingQueue 原理、与等待唤醒机制condition/await/singal的关系、多线程安全总结
在实习过程中使用阻塞队列对while sleep 轮询机制进行了改造,提升了发送接收的效率,这里做一点点总结。 自从Java 1.5之后,在java.util.concurrent包下提供了若干个阻塞队列,BlcokingQueue继承了Queue接口,是线程安全…...

【水下图像增强】Enhancing Underwater Imagery using Generative Adversarial Networks
原始题目Enhancing Underwater Imagery using Generative Adversarial Networks中文名称使用 GAN 增强水下图像发表时间2018年1月11日平台ICRA 2018来源University of Minnesota, Minneapolis MN文章链接https://arxiv.org/abs/1801.04011开源代码官方:https://gith…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...

CSS 工具对比:UnoCSS vs Tailwind CSS,谁是你的菜?
在现代前端开发中,Utility-First (功能优先) CSS 框架已经成为主流。其中,Tailwind CSS 无疑是市场的领导者和标杆。然而,一个名为 UnoCSS 的新星正以其惊人的性能和极致的灵活性迅速崛起。 这篇文章将深入探讨这两款工具的核心理念、技术差…...