为什么神经网络做不了2次函数拟合,网上的都是骗人的吗?
环境:tensorflow2 kaggle
这几天突发奇想,用深度学习训练2次函数。先在网上找找相同的资料这方面资料太少了。大多数如下:
 。
。
给我的感觉就是,用深度学习来做,真的很容易。
网上写出代码分析的比较少。但是也找到了一篇,写的言简意赅,不过我自已训练时,却发现对训练之外的数据,预测的不好。下面分两部分来阐明这一现像与我的思考。
一、代码复现:
(204条消息) tensorflow2.0实现简单曲线拟合_一只双鱼儿的博客-CSDN博客_tensorflow2 曲线拟合
网络结构如下:
model = tf.keras.Sequential([tf.keras.layers.Dense(10,input_shape=(1,),activation="elu"),tf.keras.layers.Dense(1)
])
该文章效果如下:
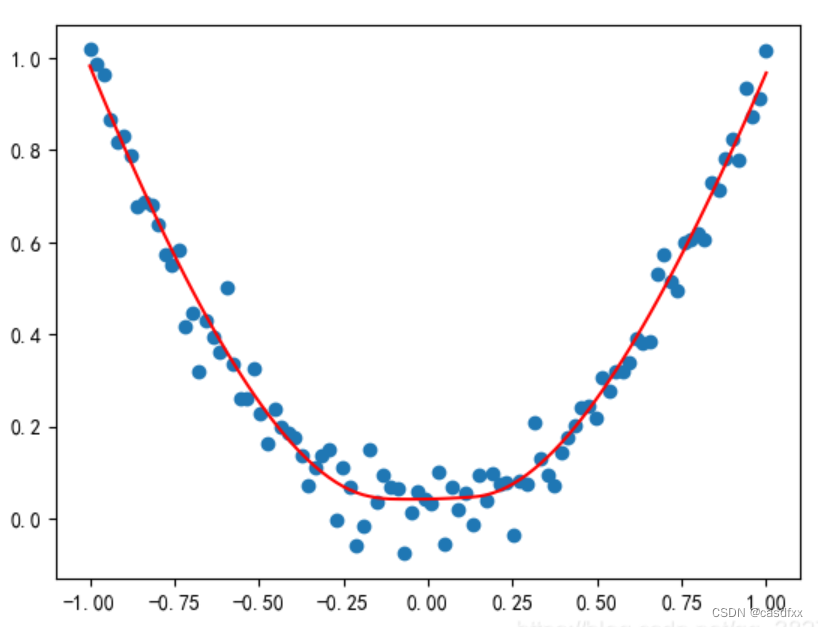
可以看出,在训练集内效果是很好的,但是博主没有使用训练集外的数据。于是我扩展了预测集,效果如下:
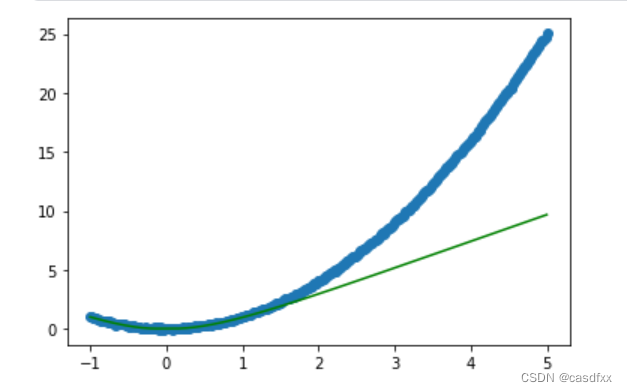
可以发现 ,在[1,5]定义域内,基本就是直线了。
这就很奇怪了,在训练集内是曲线,之外是直线。看网络结构,确实引入了非线性的环节如:activation="elu"。那这个非线性环节究竟有多大用呢?这就引出了第一个问题。
我试着将网络结构改为如下(也就是只保留线性环节):
"""
model = tf.keras.Sequential([tf.keras.layers.Dense(10,input_shape=(1,),activation="elu"),tf.keras.layers.Dense(1)
])
"""
model = tf.keras.Sequential([tf.keras.layers.Dense(1,input_shape=(1,)),tf.keras.layers.Dense(1)
])效果如下:
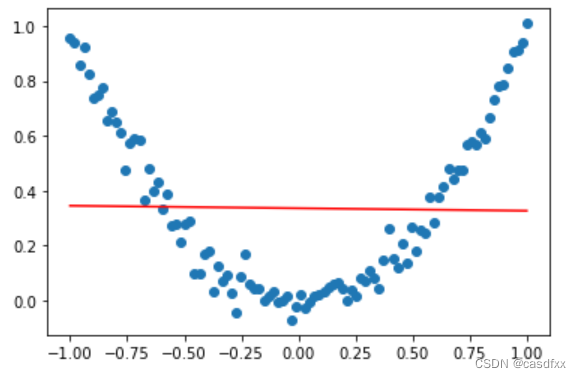
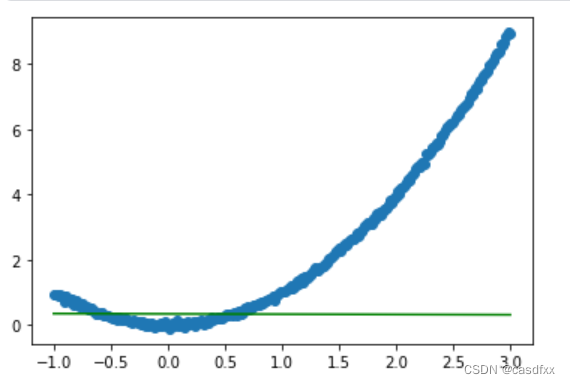
好吧,那第一个问题是解决了。activation="elu"效果是很明显的。
二、为什么在训练集之外,生成了直线?
是过拟合吗?将训练集变成了查表法?
我做了如下实验,这其实是我的第二步(y=ax^2+bx+c+[noise],第一步没保存),用来满足y=x^2已经足够了:
ds_x = []
ds_y = []# 生成数据集
ds_x = np.linspace(-1,1,100)
ds_y = 5*ds_x**2 + 9*ds_x + 300 + np.random.randn(100)*0.05class model_x2(tf.keras.Model):def __init__(self):super(model_x2,self).__init__()self.layer1 = tf.keras.layers.Dense(1)self.layer1_2 = tf.keras.layers.Dense(1)self.layer2 = tf.keras.layers.Dense(1)def call(self,in1):in2 = tf.keras.layers.Multiply()((in1,in1,in1)) #in1 * in1x = self.layer1(in2)x1_2 = self.layer1_2(in1)x2 = tf.keras.layers.concatenate((x,x1_2))out = self.layer2(x2)return outmodel = model_x2()
model.build(input_shape=(None,1))
model.summary()opt = tf.keras.optimizers.Adam(learning_rate=0.01)
los = tf.keras.losses.MeanSquaredError()
acc = tf.keras.metrics.MeanSquaredError()
model.compile(optimizer=opt,loss=los,metrics=acc)model.fit(ds_x,ds_y,epochs=500)#以下就是画图了,将数据集里【-1,1】添加到【-1,3】,多出来的【1,3】示为预测
x = np.linspace(-1,3,20000) #np.array(range(1,100,1))
#y = x**xy_predict = model.predict(x)ds_x = np.linspace(-1,3,100)
ds_y = 5*ds_x**2 + 9*ds_x + 300 + np.random.randn(100)*0.05plt.scatter(ds_x,ds_y)
plt.plot(x,y_predict,'r')
plt.show()#以下就是画图了,将数据集里【-1,1】添加到【-1,3】,多出来的【1,3】示为预测
效果如下:
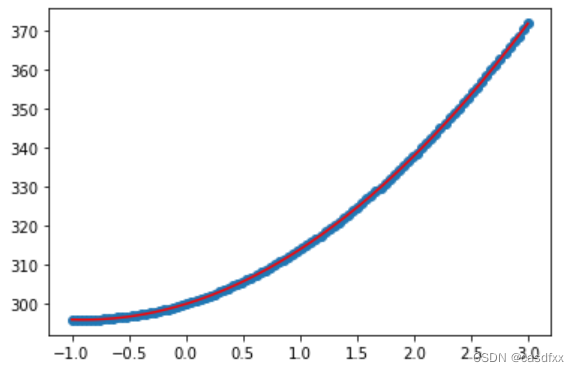
三、结论:
用深度学习的多层结构,拟合非线性数据???
NO,NO,NO
应该手动引用非线性因子。
这不禁让我想起了曾经的日子,我们都知道3极管可以线性放大,但是有没有一种方式可以产生x^2项。当然是可以的,这就涉及到2极管还是3极管。。。的物理公式如下。。。
知道的小伙伴可以在评论区留言。
相关文章:
为什么神经网络做不了2次函数拟合,网上的都是骗人的吗?
环境:tensorflow2 kaggle 这几天突发奇想,用深度学习训练2次函数。先在网上找找相同的资料这方面资料太少了。大多数如下: 。 给我的感觉就是,用深度学习来做,真的很容易。 网上写出代码分析的比较少。但是也找到了…...
【Java】Help notes about JAVA
JAVA语言帮助笔记Java的安装与JDKJava命名规范JAVA的数据类型自动类型转换强制类型转换JAVA的运算符取余运算结果的符号逻辑运算的短路运算三元运算符运算符优先级JAVA的流程控制分支结构JAVA类Scanner类Java的安装与JDK JDK安装网站:https://www.oracle.com/java/…...

2023北京老博会,北京养老展,第十届中国国际老年产业博览会
2023第十届(北京)国际老年产业博览会,将于08月28-30日盛大举办; 2023北京老博会:2023第十届中国(北京)国际老年产业博览会The 2023 tenth China (Beijing) International Aged industry Expo&a…...
C++展开模板参数包、函数参数包-(lambda+折叠表达式)
开门见山 以下代码可展开模板参数包和展开函数参数包。 // lambda折叠表达式(需C17) #include <iostream> using namespace std;// 1.展开模板参数包 template<typename ...T> void Func1() {([]() {cout << typeid(T).name() << endl;}(), ...);// …...
【Spark分布式内存计算框架——Spark Core】7. RDD Checkpoint、外部数据源
第五章 RDD Checkpoint RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。 Checkpoint的产生就是…...

Connext DDSQoS参考
1 QoS策略列表 ConnextDDS 6.1.1版中所有QoS策略的高级视图。 1. QoS策略描述...
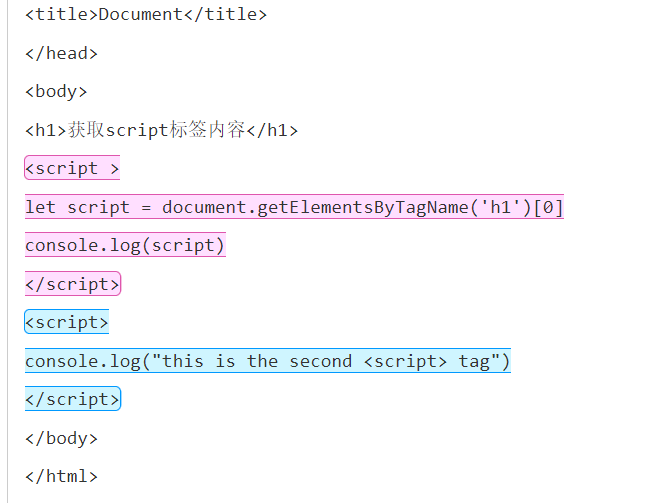
【正则表达式】获取html代码文本内所有<script>标签内容
文章目录一. 背景二. 思路与过程1. 正则表达式中需要限定<script>开头与结尾2. 增加标签格式的限定3. 不限制<script>首尾的内部内容4. 中间的内容不能出现闭合的情况三. 结果与代码四. 正则辅助工具一. 背景 之前要对学生提交的html代码进行检查,在获…...

有 9 种springMVC常用注解高频使用,来了解下?
文章目录1、Controller2、RequestMapping2.1 RequestMapping注解有六个属性2.1.1 value2.1.2 method2.1.3 consumes2.1.4 produces2.1.5 params2.1.6 headers2.2 Request Mapping("/helloword/?/aa")的Ant路径,匹配符2.3 Request …...

【ES6】掌握Promise和利用Promise封装ajax
💻 【ES6】掌握Promise和利用Promise封装ajax 🏠专栏:JavaScript 👀个人主页:繁星学编程🍁 🧑个人简介:一个不断提高自我的平凡人🚀 🔊分享方向:目…...
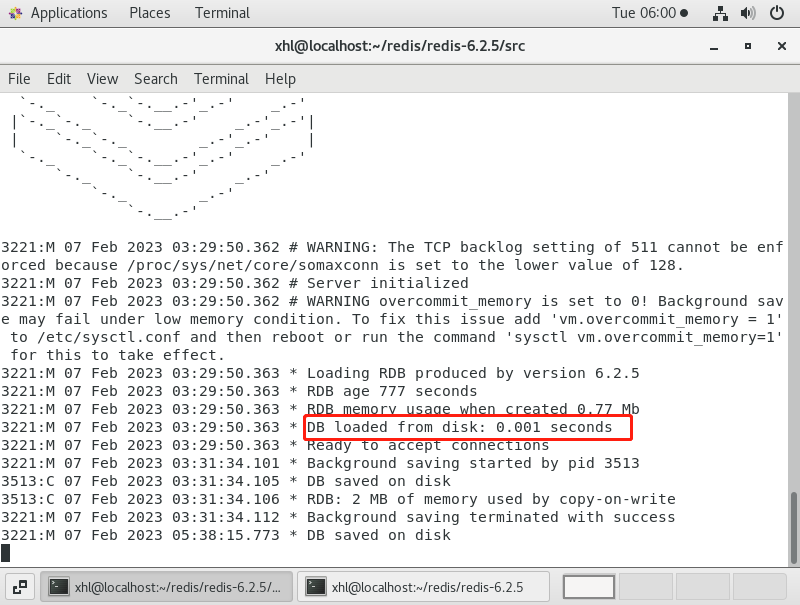
REDIS-持久化方案
我们知道redis是内存数据库,它的数据是存储在内存中的,我们知道内存的一个特点是断电数据就丢失,所以redis提供了持久化功能,可以将内存中的数据状态存储到磁盘里面,避免数据丢失。 Redis持久化有三种方案,…...
五、Java框架之Maven进阶
黑马课程 文章目录1. 分模块开发1.1 分模块开发入门案例示例:抽取domain层示例:抽取dao层1.2 依赖管理2. 聚合和继承2.1 聚合概述聚合实现步骤2.2 继承 dependencyManagement3. 属性管理3.1 依赖版本属性管理3.2 配置文件属性管理(了解&#…...

1.前言【Java面试第三季】
1.前言【Java面试第三季】前言推荐1.前言00_前言闲聊和课程说明本课程介绍目前考核的变化趋势vcr集数和坚持学长谷粉面试题复盘反馈最后前言 2023-2-1 12:30:05 以下内容源自 【尚硅谷Java大厂面试题第3季,跳槽必刷题目必扫技术盲点(周阳主讲࿰…...

06分支限界法
文章目录八数码难题普通BFS算法全局择优算法(A算法,启发式搜索算法)单源最短路径问题装载问题算法思想:队列式分支限界法优先队列式分支限界法布线问题最大团问题批处理作业调度问题分支限界法与回溯法的区别: &#x…...

Docker Compose编排
一、概念1、Docker Compose是什么Docker Compose的前身是Fig,它是一个定义及运行多个Docker容器的工具通过 Compose,不需要使用shell脚本来启动容器,而使用 YAML 文件来配置应用程序需要的所有服务然后使用一个命令,根据 YAML 的文…...

Docker进阶 - 11. Docker Compose 编排服务
注:本文只对一些重要步骤和yml文件进行一些讲解,其他的具体程序没有记录。 目录 1. 原始的微服务工程编排(不使用Compose) 2. 使用Compose编排微服务 2.1 编写 docker-compose.yml 文件 2.2 修改并构建微服务工程镜像 2.3 启动 docker-compose 服务…...
)
福利篇2——嵌入式岗位笔试面试资料汇总(含大厂笔试面试真题)
前言 汇总嵌入式软件岗位笔试面试资料,供参考。 文章目录 前言一、公司嵌入式面经1、小米1)面试时长2)面试问题2、科大讯飞1)面试时长2)面试题目3、其余公司面经二、嵌入式笔试面试资料(全)三、嵌入式岗位薪资报告四、硬件岗位薪资报告一、公司嵌入式面经 1、小米 1)…...

[ubuntu]LVM磁盘管理
LVM是 Logical Volume Manager(逻辑卷管理)的简写,是Linux环境下对磁盘分区进行管理的一种机制,由Heinz Mauelshagen在Linux 2.4内核上实现。LVM可以实现用户在无需停机的情况下动态调整各个分区大小。1.简介 LVM本质上是一个…...

开源流程引擎Camunda
开源流程引擎Camunda 文章作者:智星 1.简介 Camunda是一个轻量级的商业流程开源平台,是一种基于Java的框架,持久层采用Mybatis,可以内嵌集成到Java应用、SpringBooot应用中,也可以独立运行,其支持BPMN&a…...
)
【PTA Advanced】1155 Heap Paths(C++)
目录 题目 Input Specification: Output Specification: Sample Input 1: Sample Output 1: Sample Input 2: Sample Output 2: Sample Input 3: Sample Output 3: 思路 代码 题目 In computer science, a heap is a specialized tree-based data structure that s…...
)
Educational Codeforces Round 129 (Rated for Div. 2)
A. Game with Cards. 题目链接 题目大意: Alice和Bob玩卡牌。Alice有n张,Bob有m张。第一轮选手出一张数字卡牌。第二轮另一个选手要选择一张比他大的,依此类推。谁没有牌可出则输。问Alice和Bob分别先手时,谁赢?输出…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...