【Spark分布式内存计算框架——Spark Core】7. RDD Checkpoint、外部数据源
第五章 RDD Checkpoint
RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
在Spark Core中对RDD做checkpoint,可以切断做checkpoint RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;

演示范例代码如下:
import org.apache.spark.{SparkConf, SparkContext}
/**
* RDD数据Checkpoint设置,案例演示
*/
object SparkCkptTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// TODO: 设置检查点目录,将RDD数据保存到那个目录
sc.setCheckpointDir("datas/spark/ckpt/")
// 读取文件数据
val datasRDD = sc.textFile("datas/wordcount/wordcount.data")
// TODO: 调用checkpoint函数,将RDD进行备份,需要RDD中Action函数触发
datasRDD.checkpoint()
datasRDD.count()
// TODO: 再次执行count函数, 此时从checkpoint读取数据
datasRDD.count()
// 应用程序运行结束,关闭资源
Thread.sleep(100000)
sc.stop()
}
}
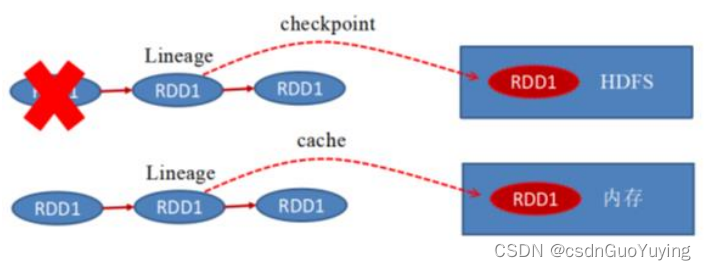
持久化和Checkpoint的区别:
1)、存储位置
- Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存);
- Checkpoint 可以保存数据到 HDFS 这类可靠的存储上;
2)、生命周期 - Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法;
- Checkpoint的RDD在程序结束后依然存在,不会被删除;
3)、Lineage(血统、依赖链、依赖关系) - Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来;
- Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链;
第六章 外部数据源
Spark可以从外部存储系统读取数据,比如RDBMs表中或者HBase表中读写数据,这也是企业中常常使用,如下两个场景:
1)、要分析的数据存储在HBase表中,需要从其中读取数据数据分析
- 日志数据:电商网站的商家操作日志
- 订单数据:保险行业订单数据
2)、使用Spark进行离线分析以后,往往将报表结果保存到MySQL表中 - 网站基本分析(pv、uv。。。。。)
6.1 HBase 数据源
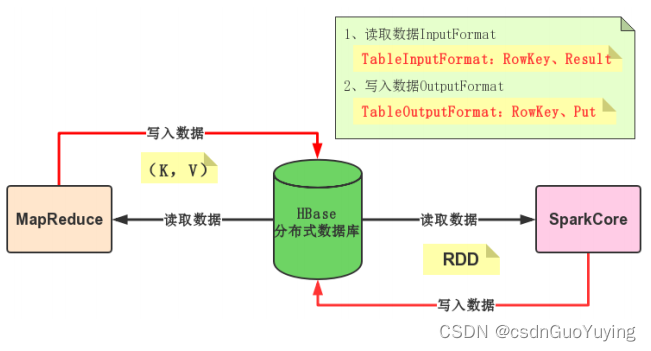
Spark可以从HBase表中读写(Read/Write)数据,底层采用TableInputFormat和TableOutputFormat方式,与MapReduce与HBase集成完全一样,使用输入格式InputFormat和输出格式OutputFoamt。
HBase Sink
回 顾 MapReduce 向 HBase 表 中 写 入 数 据 , 使 用 TableReducer , 其 中 OutputFormat 为TableOutputFormat,读取数据Key:ImmutableBytesWritable,Value:Put。
写 入 数 据 时 , 需 要 将 RDD 转换为 RDD[(ImmutableBytesWritable, Put)] 类 型 , 调 用saveAsNewAPIHadoopFile方法数据保存至HBase表中。
HBase Client连接时,需要设置依赖Zookeeper地址相关信息及表的名称,通过Configuration设置属性值进行传递。

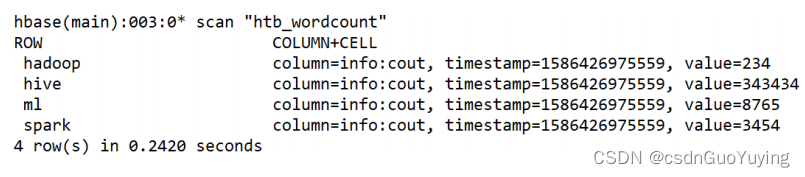
范例演示:将词频统计结果保存HBase表,表的设计

代码如下:
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将RDD数据保存至HBase表中
*/
object SparkWriteHBase {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// TODO: 1、构建RDD
val list = List(("hadoop", 234), ("spark", 3454), ("hive", 343434), ("ml", 8765))
val outputRDD: RDD[(String, Int)] = sc.parallelize(list, numSlices = 2)
// TODO: 2、将数据写入到HBase表中, 使用saveAsNewAPIHadoopFile函数,要求RDD是(key, Value)
// TODO: 组装RDD[(ImmutableBytesWritable, Put)]
/**
* HBase表的设计:
* 表的名称:htb_wordcount
* Rowkey: word
* 列簇: info
* 字段名称: count
*/
val putsRDD: RDD[(ImmutableBytesWritable, Put)] = outputRDD.mapPartitions{ iter =>
iter.map { case (word, count) =>
// 创建Put实例对象
val put = new Put(Bytes.toBytes(word))
// 添加列
put.addColumn(
// 实际项目中使用HBase时,插入数据,先将所有字段的值转为String,再使用Bytes转换为字节数组
Bytes.toBytes("info"), Bytes.toBytes("cout"), Bytes.toBytes(count.toString)
)
// 返回二元组
(new ImmutableBytesWritable(put.getRow), put)
}
}
// 构建HBase Client配置信息
val conf: Configuration = HBaseConfiguration.create()
// 设置连接Zookeeper属性
conf.set("hbase.zookeeper.quorum", "node1.itcast.cn")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// 设置将数据保存的HBase表的名称
conf.set(TableOutputFormat.OUTPUT_TABLE, "htb_wordcount")
/*
def saveAsNewAPIHadoopFile(
path: String,// 保存的路径
keyClass: Class[_], // Key类型
valueClass: Class[_], // Value类型
outputFormatClass: Class[_ <: NewOutputFormat[_, _]], // 输出格式OutputFormat实现
conf: Configuration = self.context.hadoopConfiguration // 配置信息
): Unit
*/
putsRDD.saveAsNewAPIHadoopFile(
"datas/spark/htb-output-" + System.nanoTime(), //
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf
)
// 应用程序运行结束,关闭资源
sc.stop()
}
}
运行完成以后,使用hbase shell查看数据:
HBase Source
回 顾 MapReduce 从 读 HBase 表 中 的 数 据 , 使 用 TableMapper , 其 中 InputFormat 为TableInputFormat,读取数据Key:ImmutableBytesWritable,Value:Result。
从HBase表读取数据时,同样需要设置依赖Zookeeper地址信息和表的名称,使用Configuration设置属性,形式如下:

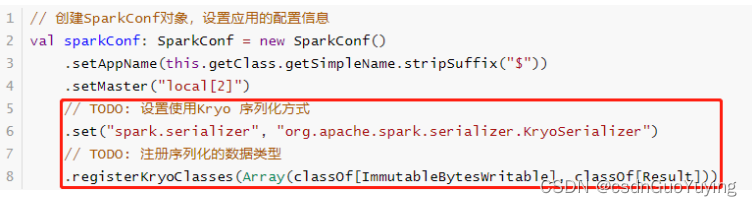
此外,读取的数据封装到RDD中,Key和Value类型分别为:ImmutableBytesWritable和Result,不支持Java Serializable导致处理数据时报序列化异常。设置Spark Application使用Kryo序列化,性能要比Java 序列化要好,创建SparkConf对象设置相关属性,如下所示:
范例演示:从HBase表读取词频统计结果,代码如下
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 从HBase 表中读取数据,封装到RDD数据集
*/
object SparkReadHBase {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// TODO: 设置使用Kryo 序列化方式
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// TODO: 注册序列化的数据类型
.registerKryoClasses(Array(classOf[ImmutableBytesWritable], classOf[Result]))
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// TODO: a. 读取HBase Client 配置信息
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "node1.itcast.cn")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// TODO: b. 设置读取的表的名称
conf.set(TableInputFormat.INPUT_TABLE, "htb_wordcount")
/*
def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](
conf: Configuration = hadoopConfiguration,
fClass: Class[F],
kClass: Class[K],
vClass: Class[V]
): RDD[(K, V)]
*/
val resultRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
conf, //
classOf[TableInputFormat], //
classOf[ImmutableBytesWritable], //
classOf[Result] //
)
println(s"Count = ${resultRDD.count()}")
resultRDD
.take(5)
.foreach { case (rowKey, result) =>
println(s"RowKey = ${Bytes.toString(rowKey.get())}")
// HBase表中的每条数据封装在result对象中,解析获取每列的值
result.rawCells().foreach { cell =>
val cf = Bytes.toString(CellUtil.cloneFamily(cell))
val column = Bytes.toString(CellUtil.cloneQualifier(cell))
val value = Bytes.toString(CellUtil.cloneValue(cell))
val version = cell.getTimestamp
println(s"\t $cf:$column = $value, version = $version")
}
}
// 应用程序运行结束,关闭资源
sc.stop()
}
}
运行结果:

6.2 MySQL 数据源
实际开发中常常将分析结果RDD保存至MySQL表中,使用foreachPartition函数;此外Spark中提供JdbcRDD用于从MySQL表中读取数据。
调用RDD#foreachPartition函数将每个分区数据保存至MySQL表中,保存时考虑降低RDD分区数目和批量插入,提升程序性能。
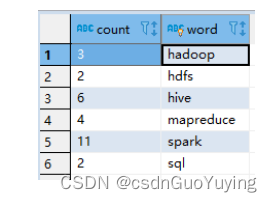
范例演示:将词频统计WordCount结果保存MySQL表tb_wordcount。
- 建表语句
USE db_test ;
CREATE TABLE `tb_wordcount` (
`count` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`word` varchar(100) NOT NULL,
PRIMARY KEY (`word`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ;
- 演示代码
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将词频统计结果保存到MySQL表中
*/
object SparkWriteMySQL {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 1. 从HDFS读取文本数据,封装集合RDD
val inputRDD: RDD[String] = sc.textFile("datas/wordcount/wordcount.data")
// 2. 处理数据,调用RDD中函数
val resultRDD: RDD[(String, Int)] = inputRDD
// 3.a 每行数据分割为单词
.flatMap(line => line.split("\\s+"))
// 3.b 转换为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 3.c 按照Key分组聚合
.reduceByKey((tmp, item) => tmp + item)
// 3. 输出结果RDD保存到MySQL数据库
resultRDD
// 对结果RDD保存到外部存储系统时,考虑降低RDD分区数目
.coalesce(1)
// 对分区数据操作
.foreachPartition{iter => saveToMySQL(iter)}
// 应用程序运行结束,关闭资源
sc.stop()
}
/**
* 将每个分区中的数据保存到MySQL表中
* @param datas 迭代器,封装RDD中每个分区的数据
*/
def saveToMySQL(datas: Iterator[(String, Int)]): Unit = {
// a. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// b. 获取连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnic
ode=true",
"root", "123456"
)
// c. 获取PreparedStatement对象
val insertSql = "INSERT INTO db_test.tb_wordcount (word, count) VALUES(?, ?)"
pstmt = conn.prepareStatement(insertSql)
conn.setAutoCommit(false)
// d. 将分区中数据插入到表中,批量插入
datas.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setLong(2, count.toLong)
// 加入批次
pstmt.addBatch()
}
// TODO: 批量插入
pstmt.executeBatch()
conn.commit()
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
- 运行程序,查看数据库表的数据
相关文章:
【Spark分布式内存计算框架——Spark Core】7. RDD Checkpoint、外部数据源
第五章 RDD Checkpoint RDD 数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。 Checkpoint的产生就是…...

Connext DDSQoS参考
1 QoS策略列表 ConnextDDS 6.1.1版中所有QoS策略的高级视图。 1. QoS策略描述...
【正则表达式】获取html代码文本内所有<script>标签内容
文章目录一. 背景二. 思路与过程1. 正则表达式中需要限定<script>开头与结尾2. 增加标签格式的限定3. 不限制<script>首尾的内部内容4. 中间的内容不能出现闭合的情况三. 结果与代码四. 正则辅助工具一. 背景 之前要对学生提交的html代码进行检查,在获…...

有 9 种springMVC常用注解高频使用,来了解下?
文章目录1、Controller2、RequestMapping2.1 RequestMapping注解有六个属性2.1.1 value2.1.2 method2.1.3 consumes2.1.4 produces2.1.5 params2.1.6 headers2.2 Request Mapping("/helloword/?/aa")的Ant路径,匹配符2.3 Request …...

【ES6】掌握Promise和利用Promise封装ajax
💻 【ES6】掌握Promise和利用Promise封装ajax 🏠专栏:JavaScript 👀个人主页:繁星学编程🍁 🧑个人简介:一个不断提高自我的平凡人🚀 🔊分享方向:目…...
REDIS-持久化方案
我们知道redis是内存数据库,它的数据是存储在内存中的,我们知道内存的一个特点是断电数据就丢失,所以redis提供了持久化功能,可以将内存中的数据状态存储到磁盘里面,避免数据丢失。 Redis持久化有三种方案,…...
五、Java框架之Maven进阶
黑马课程 文章目录1. 分模块开发1.1 分模块开发入门案例示例:抽取domain层示例:抽取dao层1.2 依赖管理2. 聚合和继承2.1 聚合概述聚合实现步骤2.2 继承 dependencyManagement3. 属性管理3.1 依赖版本属性管理3.2 配置文件属性管理(了解&#…...

1.前言【Java面试第三季】
1.前言【Java面试第三季】前言推荐1.前言00_前言闲聊和课程说明本课程介绍目前考核的变化趋势vcr集数和坚持学长谷粉面试题复盘反馈最后前言 2023-2-1 12:30:05 以下内容源自 【尚硅谷Java大厂面试题第3季,跳槽必刷题目必扫技术盲点(周阳主讲࿰…...

06分支限界法
文章目录八数码难题普通BFS算法全局择优算法(A算法,启发式搜索算法)单源最短路径问题装载问题算法思想:队列式分支限界法优先队列式分支限界法布线问题最大团问题批处理作业调度问题分支限界法与回溯法的区别: &#x…...

Docker Compose编排
一、概念1、Docker Compose是什么Docker Compose的前身是Fig,它是一个定义及运行多个Docker容器的工具通过 Compose,不需要使用shell脚本来启动容器,而使用 YAML 文件来配置应用程序需要的所有服务然后使用一个命令,根据 YAML 的文…...

Docker进阶 - 11. Docker Compose 编排服务
注:本文只对一些重要步骤和yml文件进行一些讲解,其他的具体程序没有记录。 目录 1. 原始的微服务工程编排(不使用Compose) 2. 使用Compose编排微服务 2.1 编写 docker-compose.yml 文件 2.2 修改并构建微服务工程镜像 2.3 启动 docker-compose 服务…...
)
福利篇2——嵌入式岗位笔试面试资料汇总(含大厂笔试面试真题)
前言 汇总嵌入式软件岗位笔试面试资料,供参考。 文章目录 前言一、公司嵌入式面经1、小米1)面试时长2)面试问题2、科大讯飞1)面试时长2)面试题目3、其余公司面经二、嵌入式笔试面试资料(全)三、嵌入式岗位薪资报告四、硬件岗位薪资报告一、公司嵌入式面经 1、小米 1)…...

[ubuntu]LVM磁盘管理
LVM是 Logical Volume Manager(逻辑卷管理)的简写,是Linux环境下对磁盘分区进行管理的一种机制,由Heinz Mauelshagen在Linux 2.4内核上实现。LVM可以实现用户在无需停机的情况下动态调整各个分区大小。1.简介 LVM本质上是一个…...

开源流程引擎Camunda
开源流程引擎Camunda 文章作者:智星 1.简介 Camunda是一个轻量级的商业流程开源平台,是一种基于Java的框架,持久层采用Mybatis,可以内嵌集成到Java应用、SpringBooot应用中,也可以独立运行,其支持BPMN&a…...
)
【PTA Advanced】1155 Heap Paths(C++)
目录 题目 Input Specification: Output Specification: Sample Input 1: Sample Output 1: Sample Input 2: Sample Output 2: Sample Input 3: Sample Output 3: 思路 代码 题目 In computer science, a heap is a specialized tree-based data structure that s…...
)
Educational Codeforces Round 129 (Rated for Div. 2)
A. Game with Cards. 题目链接 题目大意: Alice和Bob玩卡牌。Alice有n张,Bob有m张。第一轮选手出一张数字卡牌。第二轮另一个选手要选择一张比他大的,依此类推。谁没有牌可出则输。问Alice和Bob分别先手时,谁赢?输出…...

[数据库]表的增删改查
●🧑个人主页:你帅你先说. ●📃欢迎点赞👍关注💡收藏💖 ●📖既选择了远方,便只顾风雨兼程。 ●🤟欢迎大家有问题随时私信我! ●🧐版权:本文由[你帅…...

分享77个JS菜单导航,总有一款适合您
分享77个JS菜单导航,总有一款适合您 77个JS菜单导航下载链接:https://pan.baidu.com/s/1e_384_1KC2oSTDy7AaD3og?pwdzkw6 提取码:zkw6 Python采集代码下载链接:https://wwgn.lanzoul.com/iKGwb0kye3wj class ChinaZJsSeleni…...
kubernetes -- 核心组件介绍以及组件的运行流程
常用组件大白话说 如果想要官方的,详细的信息,请看官方文档。 https://kubernetes.io/zh-cn/docs/concepts/overview/components/ 现在介绍一些核心的概念: etcd:存储所有节点的信息,节点上部署的容器信息等都存在数…...

微信小程序Springboot短视频分享系统
3.1小程序端 用户注册页面,输入用户的个人信息点击注册即可。 注册完成后会返回到登录页面,用户输入自己注册的账号密码即可登录成功 登录成功后我们可以看到有相关的视频还有视频信息,我的信息等。 视频信息推荐是按照点击次数进行推荐的&am…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...