A Survey on Multimodal Large Language Models
目录
- 1. Introduction
- 2. 概述
- 方法
- 多模态指令调优
- 3.1.1 简介
- 3.1.2 预备知识
- 3.1.3 模态对齐
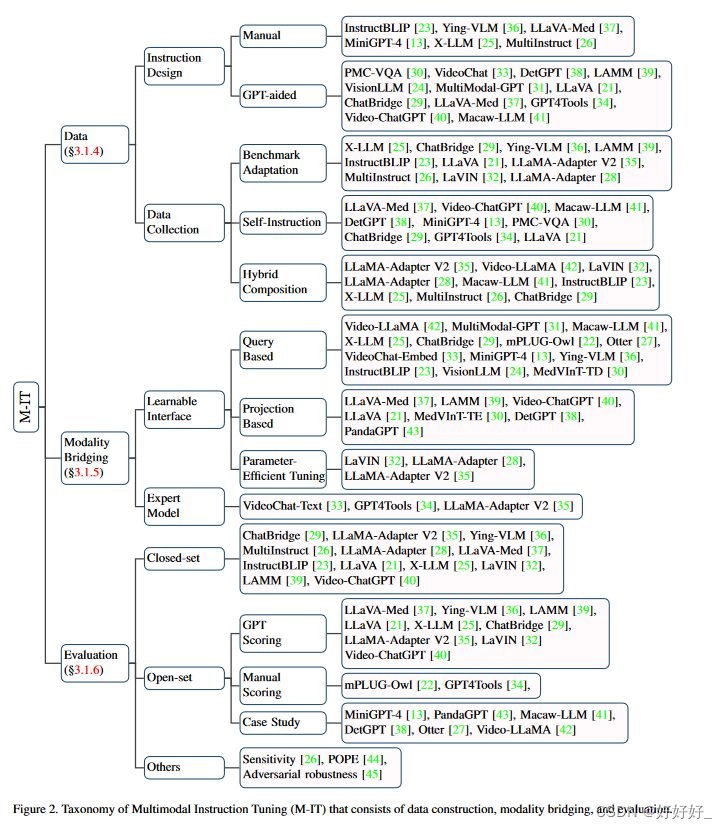
- 3.1.4 数据
- 3.1.5 模态桥接
- 3.1.6 评估
- 3.2.多模态情境学习
- 3.3.多模态思维链
- 3.3.1 模态桥接
- 3.3.2 学习范式
- 3.3.3 链配置
- 3.3.4 生成模式
- 3.4.LLMs辅助视觉推理
- 3.4.1 简介
- 3.4.2 训练范式
- 3.4.3 功能
- 3.4.4 评估
- 4. 挑战和未来方向
- 5.结论
多模态大语言模型(MLLM)最近成为一个新的研究热点,它使用强大的大语言模型(LLM)作为大脑来执行多模态任务。 MLLM 令人惊讶的新兴功能,例如基于图像编写故事和无 OCR 的数学推理,在传统方法中很少见,这表明了通向通用人工智能的潜在途径。本文旨在追溯和总结MLLM的最新进展。首先,论文明确了MLLM的定义并描述了其相关概念。然后,论文讨论关键技术和应用,包括多模态指令调优(M-IT)、多模态上下文学习(M-ICL)、多模态思维链(M-CoT)和LLM辅助视觉推理(LAVR) 。最后,论文讨论了现有的挑战并指出了有前途的研究方向。收集最新论文的相关 GitHub 链接位于 [https://github.com/BradyFU/AwesomeMultimodal-Large-Language-Models]
1. Introduction
1.引言近年来,大型语言模型取得了显着的进展[1-4]。通过扩大数据规模和模型规模,LLMs展现了惊人的能力,包括情境学习 (ICL) [5]、指令遵循 [4, 6] 和思想链 (CoT) [7]。尽管法LLMs在大多数自然语言处理(NLP)任务中表现出了令人惊讶的零/少样本推理性能,但他们本质上对视觉“视而不见”,因为他们只能理解离散文本。同时,大视野基础模型在感知方面进展迅速[8-10],而传统与文本的结合更注重模态对齐[11]和任务统一[12],在推理方面发展缓慢。
鉴于这种互补性,单模态LLM和视觉模型同时走向彼此,最终导致了MLLM这个新领域。从形式上来说,它指的是基于LLM的模型,具有接收和推理多模态信息的能力。从发展通用人工智能(AGI)的角度来看,MLLM可能比LLM更进一步,原因如下:(1)MLLM更符合人类感知世界的方式。人类接收多感官输入,这些输入通常是互补和合作的。因此,多模态信息有望使 MLLM 更加智能。 (2)MLLM提供了更加用户友好的界面。得益于多模态输入的支持,用户可以以更加灵活的方式与智能助手进行交互和沟通。 (3) MLLM 是一个更全面的任务解决者。虽然 LLM 通常可以执行 NLP 任务,但 MLLM 通常可以支持更广泛的任务。
GPT-4 [2] 因其展示的令人惊叹的示例而引发了对 MLLM 的研究狂潮,但并未开放多模态接口,目前尚未公开该模型的信息。尽管如此,研究界还是做出了许多努力来开发功能强大且开源的 MLLM,并展示了一些令人惊讶的实用能力,例如基于图像编写网站代码 [13]、理解图像的深层含义等。 meme [14],以及无 OCR 的数学推理 [15]。这篇综述的目的是为了让研究者了解MLLMs的基本思想、主要方法和当前进展。论文主要关注视觉和语言形式,但也包括涉及其他形式的作品。具体来说,论文将现有的 MLLM 分为四种类型并进行相应的总结,同时维护一个实时更新的 GitHub 页面。
2. 概述
本文将最近具有代表性的 MLLM 分为四种主要类型:
- 多模态指令调优 (M-IT)
- 多模态上下文学习 (M-ICL)
- 多模态思维链 (M-CoT) 和
- LLM 辅助视觉推理 (LAVR) )。
前三者构成了MLLM的基础,而最后一个则是以LLM为核心的多模式体系。需要注意的是,这三种技术是相对独立的,并且可以组合使用。因此,论文对一个概念的阐释也可能涉及到其他概念。论文首先详细介绍 M-IT(第 3.1 节),从架构和数据两个方面揭示LLMs如何适应多模态。然后论文介绍 M-ICL(第 3.2 节),这是一种在推理阶段常用来提高小样本性能的有效技术。另一种重要的技术是 M-CoT(第 3.3 节),它通常用于复杂的推理任务。之后,论文进一步总结了LLMs在 LAVR 中主要扮演的几个角色(第 3.4 节),其中经常涉及到这三种技术。最后,论文总结了潜在的研究方向。
方法
多模态指令调优
3.1.1 简介
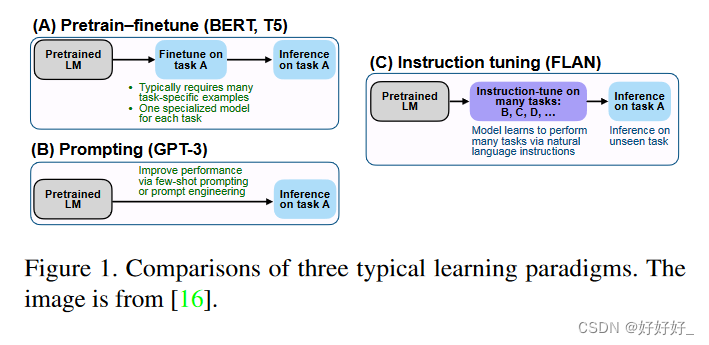
指令是指任务的描述。指令调优是一种涉及在指令格式数据集集合上微调预训练的 LLM 的技术 [16]。通过这种方式进行调整,LLM 可以通过遵循新指令泛化到未见过的任务,从而提高零样本性能。这个简单而有效的想法引发了 NLP 领域后续工作的成功,例如 ChatGPT [1]、InstructGPT [17]、FLAN [16, 18] 和 OPT-IML [19]。
指令调优和相关典型学习范式之间的比较如图1所示。监督微调方法通常需要许多特定于任务的数据来训练特定于任务的模型。提示方法减少了对大规模数据的依赖,并且可以通过提示工程完成专门的任务。在这种情况下,尽管少样本性能有所提高,但零样本性能仍然相当平均[5]。不同的是,指令调优学习如何泛化到未见过的任务,而不是像两个对应任务那样适应特定的任务。此外,指令调整与多任务提示高度相关[20]。
相比之下,传统的多模态模型仍然局限于前两种调优范式,缺乏零样本能力。因此,最近的许多著作 [13,21,22] 都在探索将LLMs指令调整的成功扩展到多模态。为了从单模态扩展到多模态,数据和模型都需要进行相应的调整。对于数据,研究人员通常通过调整现有基准数据集[23-28]或通过自我指导来获取M-IT数据集[13,21,29]。关于模型,常见的做法是将跨模态的信息注入LLM中,并将其视为强推理者。相关工作要么直接将外来嵌入与LLMs[21,23-25,27,28,30-32]对齐,要么诉诸专家模型将跨模态翻译成LLMs可以吸收的自然语言[33,34]。以这种方式表述,这些作品通过多模态指令调整将 LLM 转变为多模态聊天机器人 [13,21,22,33,35] 和多模态通用任务求解器 [23,24,26]。在本节的以下部分中,论文首先提供基础知识(第 3.1.2 节),接下来论文介绍了 M-IT 之前的对齐预训练(第 3.1.3 节)。然后论文构建如图 2 所示的剩余内容:首先介绍如何收集 M-IT 数据(第 3.1.4 节),然后详细讨论 MLLM 的模型自适应,即桥接 M-IT 数据的各种方法。不同模式之间的差距(§3.1.5)。最后,论文介绍了评估指令调整 MLLM 的评估方法(第 3.1.6 节)。
3.1.2 预备知识
本节简要说明多模态指令示例的一般结构和M-IT 的通用过程。多模式指令样本通常包括指令和输入输出对。该指令通常是描述任务的自然语言句子,例如“详细描述图像”。输入可以是图像-文本对,如视觉问答(VQA)任务[46],或仅图像,如图像字幕任务[47]。输出是对以输入为条件的指令的答案。指令模板是灵活的,并且可以进行手动设计[21,31,33],如表1所示。请注意,指令样本也可以推广到多轮指令,其中多模态输入是共享的[21,30, 31、43]。形式上,多模态指令样本可以用三元组形式表示,即(I,M,R),其中I,M,R分别表示指令,多模态输入和真实响应。 MLLM 在给定指令和多模态输入的情况下预测答案:

这里,A 表示预测答案,θ 是模型的参数。训练目标通常是用于训练 LLM [21,30,32,43] 的原始自回归目标,基于该目标,MLLM 被迫预测响应的下一个标记。目标可以表示为:
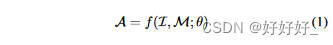
其中 N 是真实响应的长度。
3.1.3 模态对齐
通常对配对数据进行大规模(与指令调整相比)预训练,以鼓励不同模态之间的对齐[25,29,35,38]。对齐数据集通常是图像文本对[48-56]或自动语音识别(ASR)[57-59]数据集,它们都包含文本。更具体地说,图像-文本对以自然语言句子的形式描述图像,而 ASR 数据集包含语音转录。对齐预训练的常见方法是保持预训练模块(例如视觉编码器和 LLM)冻结并训练可学习的界面 [21,37,38],这将在下一节中进行说明。
3.1.4 数据
多模式指令跟随数据的收集是M-IT 的关键。收集方法可大致分为基准适应、自我指导[60]和混合组合。

3.1.5 模态桥接
由于LLMs只能感知文本,因此有必要弥合自然语言和其他模态之间的差距。然而,以端到端的方式训练大型多模态模型成本高昂。此外,这样做会面临灾难性遗忘的风险[61]。因此,更实用的方法是在预训练的视觉编码器和LLM之间引入可学习的接口。另一种方法是借助专家模型将图像翻译成语言,然后将语言发送给LLM。
可学习接口:可学习接口负责在冻结预训练模型的参数时连接不同的模式。挑战在于如何有效地将视觉内容翻译成LLMs可以理解的文本。一种常见且可行的解决方案是利用一组可学习的查询标记以基于查询的方式提取信息[62],该解决方案首先在 Flamingo [63] 和 BLIP-2 [64] 中实现,随后由各种工作[23,25,42]。此外,一些方法使用基于投影的接口来缩小模态差距[21,30,38,43]。例如,LLavA [21]采用简单的线性层来嵌入图像特征,MedVInTTE [30]使用两层多层感知器作为桥梁。还有一些作品探索了参数高效的调整方式。 LLaMA-Adapter [28, 35] 在训练过程中在 Transformer 中引入了一个轻量级适配器模块。 LaVIN [32] 设计了一种混合模态适配器来动态决定多模态嵌入的权重。
专家模型:除了可学习的接口之外,使用专家模型(例如图像字幕模型)也是弥合模态差距的可行方法[35]。不同的是,专家模型背后的想法是将多模态输入转换为语言而无需训练。通过这种方式,LLMs可以通过转换后的语言间接理解多模态。例如,VideoChat-Text [33] 使用预先训练的视觉模型来提取动作等视觉信息,并使用语音识别模型丰富描述。尽管使用专家模型很简单,但它可能不如采用可学习界面那么灵活。将外来形式转换为文本通常会导致信息丢失。正如 VideoChat-Text [33] 指出的那样,将视频转换为文本描述会扭曲时空关系。
3.1.6 评估
M-IT 后的模型性能评估有多种指标,根据问题类型大致可分为两类,包括封闭集和开放集。闭集问题是指一种问题类型,其可能的答案选项是预先定义的并限制在有限的集合内。评估通常在适应基准的数据集上进行。在这种情况下,可以自然地通过基准指标来判断响应[21,23,25,26,28,29,32,35]。例如,Instruct-BLIP [23] 报告了 ScienceQA [65] 的准确性,以及 NoCaps [67] 和 Flickr30K [68] 上的 CIDEr 评分 [66]。评估设置通常是零样本[23,26,29,36]或微调[21,23,25,28,32,35–37]。第一个设置通常选择涵盖不同一般任务的广泛数据集,并将它们分为保留数据集和保留数据集。在对前者进行调整后,使用未见过的数据集甚至未见过的任务对后者进行零样本性能评估。相反,第二种设置经常出现在特定领域下游任务的评估中。例如,LLaVA [21] 和 LLaMA-Adapter [28] 报告了 ScienceQA [65] 上的微调性能。 LLaVA-Med [37] 报告了生物医学 VQA 的结果 [69–71]。
上述评估方法通常仅限于选定的小范围任务或数据集,缺乏全面的定量比较。为此,一些人努力开发专门为 MLLM 设计的新基准 [39,40,72]。例如,Fu 等人。 [73]构建了综合评估基准MME,共包括14个感知认知任务。 MME中的所有指令-答案对都是手动设计的,以避免数据泄漏。通过详细的排行榜和分析来评估 10 个高级 MLLM。 LAMM-Benchmark [39] 被提议在各种 2D/3D 视觉任务上定量评估 MLLM。 Video-ChatGPT [40]提出了一种基于视频的会话模型的定量评估框架,其中包含两种类型的评估,即基于视频的生成性能评估和零样本问答。
与封闭集问题相比,开放集问题的回答可以更加灵活,其中 MLLM 通常扮演聊天机器人的角色。由于聊天的内容可以是任意的,因此比封闭式输出更难以判断。标准可分为手工评分、GPT评分和案例研究。手动评分需要人类评估生成的响应。这种方法通常涉及旨在评估特定维度的手工问题。例如,mPLUGOwl [22]收集了视觉相关的评估集来判断自然图像理解、图表和流程图理解等能力。类似地,GPT4Tools [34] 分别为微调和零样本性能构建了两个集合,并从思想、行动、论证和整体方面评估响应。由于人工评估是劳动密集型的,一些研究人员探索了用GPT进行评级,即GPT评分。这种方法通常用于评估多模式对话的表现。 LLaVA [21] 建议通过 GPT-4 在不同方面对响应进行评分,例如有用性和准确性。具体来说,从 COCO [48] 验证集中采样了 30 个图像,每个图像通过 GPT-4 上的自我指导与一个简短问题、一个详细问题和一个复杂推理问题相关联。 MLLM 和 GPT-4 生成的答案都会发送到 GPT4 进行比较。后续工作遵循这一想法,并提示 ChatGPT [22] 或 GPT-4 [25,29,32,36,37] 对结果进行评分 [22,25,29,32,37] 或判断哪个更好 [35]。基于 GPT-4 的评分的一个主要问题是,目前其多模式界面尚未公开。因此,GPT-4 只能根据图像相关的文本内容(例如标题或边界框坐标)生成响应,而无需访问图像 [37]。因此,在这种情况下将 GPT-4 设置为性能上限可能是有问题的。另一种方法是通过案例研究来比较 MLLM 的不同能力。例如,mPLUG-Owl 使用视觉相关的笑话理解案例与 GPT-4 [2] 和 MM-REACT [14] 进行比较。同样,Video-LLaMA [42]提供了一些案例来展示多种能力,例如视听共同感知和常识概念识别。其他一些其他方法侧重于 MLLM 的特定方面。例如,MultiInstruct [26] 提出了一种称为灵敏度的指标,用于评估模型对各种指令的鲁棒性。李等人。 [44]深入研究了物体幻觉问题,并提出了一种查询方法POPE来评估这方面的性能。赵等人。 [45]考虑安全问题并建议评估 MLLM 对对抗性攻击的鲁棒性。
3.2.多模态情境学习
ICL 是LLMs重要的新兴能力之一。 ICL 有两个优点:(1)与从大量数据中学习隐式模式的传统监督学习范式不同,ICL 的关键是从类比中学习[74]。具体来说,在 ICL 设置中,LLMs从一些示例以及可选指令中学习,并推断出新问题,从而以几次方式解决复杂和看不见的任务 [14,75,76]。 (2)ICL通常以免训练的方式实现[74],因此可以在推理阶段灵活地集成到不同的框架中。与 ICL 密切相关的技术是指令调整(参见第 3.1 节),经验表明它可以增强 ICL 能力 [16]。在 MLLM 的背景下,ICL 已扩展到更多模式,形成多模式 ICL (M-ICL)。基于(§3.1.2)中的设置,在推理时,可以通过向原始样本添加演示集(即一组上下文样本)来实现 M-ICL。在这种情况下,可以如表3所示扩展模板。请注意,论文列出了两个上下文中的示例进行说明,但示例的数量和顺序可以灵活调整。事实上,模型通常对演示的安排很敏感 [74, 77]。

在多模态应用方面,M-ICL主要用于两种场景:(1)解决各种视觉推理任务[14,27,63,78,79]和(2)教授LLMs使用外部工具[75,76,80]。前者通常涉及从一些特定于任务的示例中学习并归纳到一个新的但类似的问题。从说明和演示中提供的信息中,LLMs可以了解任务正在做什么以及输出模板是什么,并最终生成预期的答案。相比之下,工具使用的示例通常是纯文本且更细粒度。它们通常包含一系列可以顺序执行以完成任务的步骤。因此,第二种情况与 CoT 密切相关(参见§3.3)。
3.3.多模态思维链
正如开创性工作[7]所指出的,CoT是“一系列中间推理步骤”,已被证明在复杂推理任务中是有效的[7,87,88]。 CoT的主要思想是促使LLM不仅输出最终答案,而且输出导致答案的推理过程,类似于人类的认知过程。受 NLP 成功的启发,多项工作 [81,82,85,86] 被提出将单模态 CoT 扩展到多模态 CoT (M-CoT)。论文总结了这些工作,如图 3 所示。首先,与 M-IT 中的情况类似(参见第 3.1 节),需要填补模态缺口(第 3.3.1 节)。然后,论文介绍了获取 M-CoT 能力的不同范例(§3.3.2)。最后,论文描述了 M-CoT 的更具体方面,包括配置(第 3.3.3 节)和链的公式(第 3.3.4 节)。
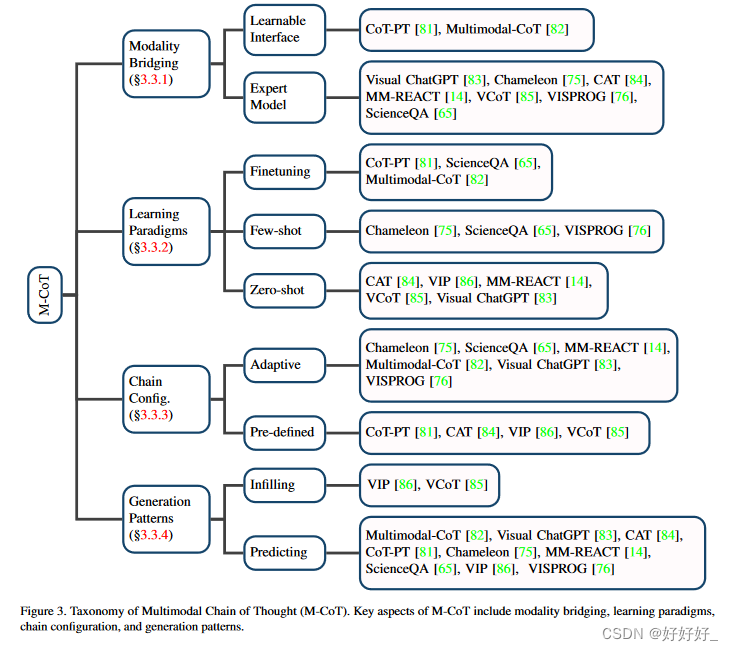
3.3.1 模态桥接
为了将 NLP 的成功转移到多模态,模态桥接是首先要解决的问题。大致有两种方法可以实现这一目标:通过特征融合或通过将视觉输入转换为文本描述。与§3.1.5中的情况类似,论文将它们分别归类为可学习接口和专家模型,并按顺序进行讨论。可学习的界面这种方法涉及采用可学习的界面将视觉嵌入映射到单词嵌入空间。然后,映射的嵌入可以作为提示,发送给其他语言的LLMs以引发 M-CoT 推理。例如,CoT-PT [81]链接多个元网络进行提示调整以模拟推理链,其中每个元网络将视觉特征嵌入到提示的特定步骤偏差中。 Multimodal-CoT [82] 采用具有共享 Transformer 结构的两阶段框架 [89],其中视觉和文本特征通过交叉注意力进行交互。专家模型引入专家模型将视觉输入转换为文本描述是另一种模态桥接方式。例如,ScienceQA [65] 采用图像字幕模型,并将图像字幕和原始语言输入的串联提供给LLMs。虽然简单明了,但这种方法可能会在字幕过程中丢失信息 [33, 82]。
3.3.2 学习范式
学习范式也是一个值得研究的方面。获取 M-CoT 能力的方法大致有三种,即通过微调和免训练的少样本/零样本学习。三种方式的样本量要求按降序排列。
3.3.3 链配置
链配置是推理的一个重要方面,可以分为自适应和预定义的形式。前一种配置要求 LLM 自行决定何时停止推理链 [14, 65, 75, 76, 82, 83],而后一种设置则以预定义的长度停止推理链 [81, 84–86] 。
3.3.4 生成模式
论文将当前的工作总结为(1)基于填充的模式和(2)基于预测的模式。具体来说,基于填充的模式需要在周围上下文(之前和之后的步骤)之间推导步骤来填补逻辑间隙 [85, 86]。相反,基于预测的模式需要在给定条件(例如指令和先前的推理历史)的情况下扩展推理链[14,65,75,76,82,83]。两种类型的模式都要求生成的步骤一致且正确。
3.4.LLMs辅助视觉推理
3.4.1 简介
受到工具增强LLMs[95-98]成功的启发,一些研究探索了调用外部工具[14,34,75,76]或视觉基础模型[14, 83,84,91,92,99]用于视觉推理任务。这些作品以LLMs为不同角色的帮助者,构建了特定任务[84,90,93]或通用[14,75,76,80,83]视觉推理系统。与传统的视觉推理模型[100-102]相比,这些作品表现出几个良好的特点:(1)泛化能力强。这些系统配备了从大规模预训练中学到的丰富的开放世界知识,可以轻松泛化到看不见的物体或概念,并具有出色的零/少样本性能[75,76,90,91,93,94]。 (2)涌现能力。借助强大的推理能力和丰富的LLMs知识,这些系统能够执行复杂的任务。例如,给定一个图像,MM-REACT [14] 可以解释表面之下的含义,例如解释为什么一个模因很有趣。 (3)更好的交互性和控制性。传统模型通常允许一组有限的控制机制,并且通常需要昂贵的精选数据集[103,104]。相比之下,基于 LLM 的系统能够在用户友好的界面中进行精细控制(例如点击和自然语言查询)[84]。本节的以下部分的组织如图 4 所示:论文首先介绍用于构建 LLM 辅助视觉推理系统的不同训练范例(第 3.4.2 节)。随后,论文深入研究LLMs在这些系统中发挥的主要作用(§3.4.3)。最后,论文评估了各种类型的绩效
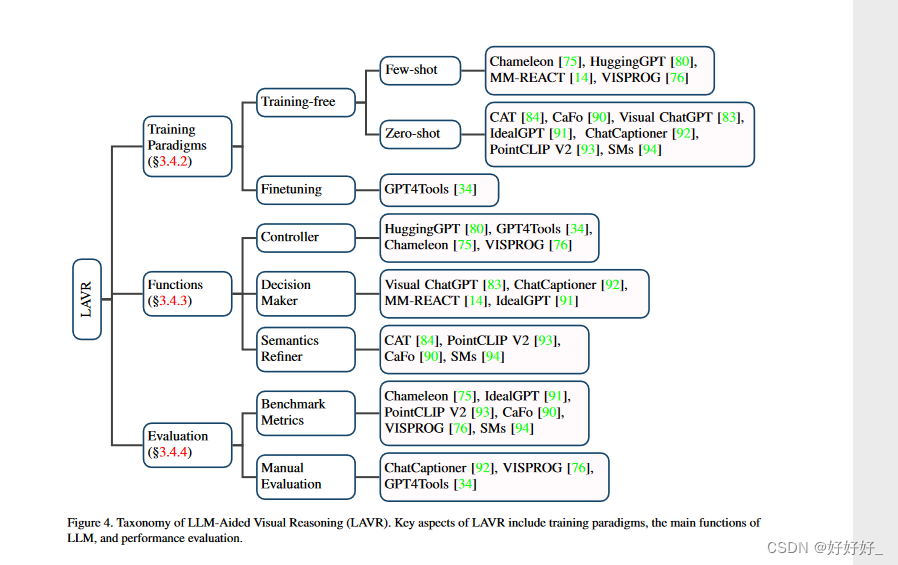
3.4.2 训练范式
根据训练范式,LLM辅助视觉推理系统可以分为两种类型,即trainingfree和finetuning。
3.4.3 功能
LLM在LLM辅助视觉推理系统中可以分为三种角色:
- LLM作为控制器
- LLM作为决策者
- LLM作为语义精炼器两个角色
控制者和决策者与 CoT 相关(见§3.3)。它被频繁使用,因为复杂的任务需要分解为中间更简单的步骤。
LLM 作为控制器时,LLM 充当中央控制器,(1) 将复杂的任务分解为更简单的子任务/步骤,(2) 将这些任务分配给适当的工具/模块。第一步通常是通过利用LLMs的 CoT 能力来完成的。具体来说,LLM 被明确提示输出任务规划 [80],或者更直接地提示要调用的模块 [34,75,76]。
LLM 作为决策者时,复杂的任务以多轮方式解决,通常以迭代方式[91]。决策者通常履行以下职责:(1)总结当前上下文和历史信息,并决定当前步骤可用的信息是否足以回答问题或完成任务; (2)对答案进行整理和总结,以通俗易懂的方式呈现。
当LLM作为语义精炼时,研究人员主要利用他们丰富的语言学和语义知识。具体来说,LMs经常被要求将信息整合成一致且流畅的自然语言句子[94]或根据不同的特定需求生成文本[84,90,93]。
3.4.4 评估
有两种方法可以评估LLMAided Visual Reasoning系统的性能,即基准指标[75,76,90,91,93,94]和手动评估[34,76,92]。基准指标一种直接的评估方法是在现有基准数据集上测试系统,因为指标可以直接反映模型完成任务的程度。例如,Chameleon [75] 在复杂推理基准上进行评估,包括 ScienceQA [65] 和 TabMWP [106]。 IdealGPT [91] 报告了 VCR [107] 和 SNLI-VE [108] 的准确性。手动评估有些作品采用手动评级来评估模型的特定方面。例如,ChatCaptioner [92] 要求人类注释者判断不同模型生成的标题的丰富性和正确性。 GPT4Tools [34] 计算思想、行动、论证的成功率和总体成功率,以衡量模型分配工具使用的能力。 VISPROG [76] 在评估语言引导图像编辑任务的模型时手动计算准确性。
4. 挑战和未来方向
MLLM 的发展仍处于初级阶段,因此还有很大的改进空间,论文总结如下:
- 目前的 MLLM 感知能力仍然有限,导致视觉信息不完整或错误收购 [13, 73]。这可能是由于信息容量和计算负担之间的折衷。更具体地说,Q-Former [64] 仅使用 32 个可学习标记来表示图像,这可能会导致信息丢失。尽管如此,扩大token长度不可避免地会给LLMs带来更大的计算负担,因为LLMs的输入长度通常是有限的。一种潜在的方法是引入像 SAM [8] 这样的大型视觉基础模型,以更有效地压缩视觉信息 [21, 29]。
- MLLM 的推理链可能很脆弱。例如,Fu 等人。 [73]发现在数学计算案例中,尽管MLLM计算出正确的结果,但由于推理的破坏,它仍然给出了错误的答案。这表明单模态LLMs的推理能力可能不等于接收视觉信息后的LLMs的推理能力。改进多模态推理的主题值得研究。
- MLLM 的指令跟踪能力需要升级。在 M-IT 之后,尽管有明确的指示“请回答是或否”,一些 MLLM 仍无法生成预期的答案(“是”或“否”)[73]。这表明指令调优可能需要涵盖更多任务以提高泛化能力。
- 物体幻觉问题很普遍[13, 44],这在很大程度上影响了MLLM 的可靠性。这可能归因于对齐预训练不足[13]。因此,一个可能的解决方案是在视觉和文本模态之间执行更细粒度的对齐。细粒度是指图像的局部特征,可以通过SAM[21,29]获得,以及相应的局部文本描述。
- 需要参数有效的培训。现有的两种模态桥接方式,即可学习接口和专家模型,都是减轻计算负担的初步探索。更高效的训练方法可以在计算资源有限的情况下释放 MLLM 的更多功能。
5.结论
该论文对现有的 MLLM 文献进行了调查,并对其主要方向进行了广泛的了解,包括三种常见技术(M-IT、M-ICL 和 MCoT)以及构建任务的通用框架 -求解系统(LAVR)。此外,论文强调了当前需要填补的研究空白,并指出了一些有前途的研究方向。论文希望这项调查能让读者清楚地了解 MLLM 当前的进展,并激发更多的工作。
相关文章:
A Survey on Multimodal Large Language Models
目录 1. Introduction2. 概述方法多模态指令调优 3.1.1 简介3.1.2 预备知识3.1.3 模态对齐3.1.4 数据3.1.5 模态桥接3.1.6 评估 3.2.多模态情境学习3.3.多模态思维链3.3.1 模态桥接3.3.2 学习范式3.3.3 链配置3.3.4 生成模式3.4.LLMs辅助视觉推理3.4.1 简介3.4.2 训练范式3.4.3…...
一)
Java面向对象编程(高级)一
在Java中,面向对象编程更是核心设计理念之一,为开发者提供了丰富的工具和特性来创建灵活、可扩展的应用程序。 本博客将深入探讨Java面向对象编程的高级特性,包括但不限于多态、继承、封装、抽象类、接口等方面的内容。我们将从实际案例出发…...

1056:点和正方形的关系
【题目描述】 有一个正方形,四个角的坐标(x,y)分别是(1,-1),(1,1),(-1,-1),(-1,1),x是横轴,y是纵轴。写一个程序,判断一个给定的点是…...
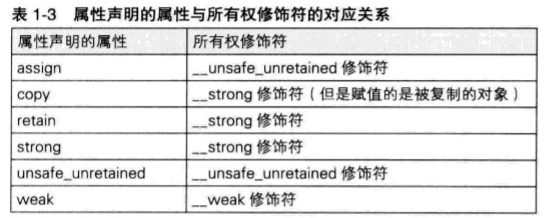
【iOS】ARC学习
文章目录 前言一、autorelease实现二、苹果的实现三、内存管理的思考方式__strong修饰符取得非自己生成并持有的对象__strong 修饰符的变量之间可以相互赋值类的成员变量也可以使用strong修饰 __weak修饰符循环引用 __unsafe_unretained修饰符什么时候使用__unsafe_unretained …...
数据分析 | Matplotlib
Matplotlib 是 Python 中常用的 2D 绘图库,它能轻松地将数据进行可视化,作出精美的图表。 绘制折线图: import matplotlib.pyplot as plt #时间 x[周一,周二,周三,周四,周五,周六,周日] #能量值 y[61,72,66,79,80,88,85] # 用来设置字体样式…...

mac npm install 很慢或报错
npm ERR! code CERT_HAS_EXPIRED npm ERR! errno CERT_HAS_EXPIRED npm ERR! request to https://registry.npm.taobao.org/pnpm failed, reason: certificate has expired 1、取消ssl验证: npm config set strict-ssl false 修改后一般就可以了,…...

100天精通Python(实用脚本篇)——第118天:基于selenium和ddddocr库实现反反爬策略之验证码识别
文章目录 专栏导读一、前言二、ddddocr库使用说明1. 介绍2. 算法步骤3. 安装4. 参数说明5. 纯数字验证码识别6. 纯英文验证码识别7. 英文数字验证码识别8. 带干扰的验证码识别 三、验证码识别登录代码实战1. 输入账号密码2. 下载验证码3. 识别验证码并登录 书籍推荐 专栏导读 …...

51单片机与ARM单片机的区别
51的MCU与ARM的MCU的区别 51单片机与ARM单片机区别主要体现在以下几个方面: 指令集架构(ISA): 51单片机:基于Intel 8051架构,采用的是CISC(复杂指令集计算机)设计,其指令…...

Android 10.0 mtk平台系统添加公共so库的配置方法
1.前言 在10.0的系统定制化开发中,由于 Android对应用应用的系统库限制越来越严格,上层应用包括(apk、jar包)不能直接引用系统的一些so库了。如果需要使用,只能使用,系统申明的公共库。 如果使用非系统申明的公共库,apk运行后调用该so库时,app会直接挂掉,或者系统开发…...
simulink平面五杆机构运动学仿真
1、内容简介 略 68-可以交流、咨询、答疑 2、内容说明 simulink平面五杆机构运动学仿真 [ 摘 要 ] 以 MATLAB 程序设计语言为平台 , 以平面可调五杆机构为主要研究对象 , 给定机构的尺寸参数 , 列出所 要分析机构的闭环矢量方程 , 使用 MATLAB 软件中 SIMULINK 仿真工…...

【Docker】APISIX Ingress Controller部署
APISIX Ingress Controller环境标准软件基于Bitnami apisix-ingress-controller:构建。当前版本为1.8.0 你可以通过轻云UC部署工具直接安装部署,也可以手动按如下文档操作,该项目已经全面开源,可以从如下环境获取 配置文件地址: https://git…...

常见的十大网络安全攻击类型
常见的十大网络安全攻击类型 网络攻击是一种针对我们日常使用的计算机或信息系统的行为,其目的是篡改、破坏我们的数据,甚至直接窃取,或者利用我们的网络进行不法行为。你可能已经注意到,随着我们生活中越来越多的业务进行数字化&…...

接口幂等性问题和常见解决方案
接口幂等性问题和常见解决方案 1.什么是接口幂等性问题1.1 会产生接口幂等性的问题1.2 解决思路 2.接口幂等性的解决方案2.1 唯一索引解决方案2.2 乐观锁解决方案2.3 分布式锁解决方案2.4 Token解决方案(最优方案) 3 Token解决方案落地3.1 token获取、token校验3.2 自定义注解,…...
网站首页添加JS弹屏公告窗口教程
很多小白站长会遇到想给自己的网站添加一个弹屏公告,用于做活动说明、演示站提示等作用与目的。 下面直接上代码:(直接复制到网页头部、底部php、HTML文件中) <script src"https://www.mohuda.com/site/js/sweetalert.m…...

【Rockchip 安10.1 默认给第三方apk默认开启所有权限】
Rockchip 安10.1 默认给第三方apk默认开启所有权限 问题描述解决方法 郑重声明:本人原创博文,都是实战,均经过实际项目验证出货的 转载请标明出处:攻城狮2015 Platform: Rockchip 3229 OS:Android 10.1 Kernel: 4.19 问题描述 有些第三方或者主界面&…...
python-redis缓存装饰器
目录 redis_decorator安装查看源代码使用 redis_decorators安装查看源代码\_\_init\_\_.pycacheable.py 各种可缓存的类型cache_element.py 缓存的元素caching.py 缓存主要逻辑 使用 总结全部代码参考 redis_decorator 安装 pip install redis_decorator查看源代码 from io …...

每个私域运营者都必须掌握的 5 大关键流量运营核心打法!
很多人觉得私域运营比较简单,只是运营的事情,但事实并非如此,私域运营体系非常大,包含了公私域联动、品牌运营、品类战略,它是一个自上而下,由内到外的系统化工程。 很多人天天在想着如何引流拓客…...

蓝桥杯--平均
在编程竞赛,尤其是参与蓝桥杯的过程中,遇到各种问题需求是家常便饭。最近,我遇到了一个非常有趣且颇具挑战性的算法问题。问题描述如下:对于一个长度为n的数组(n是10的倍数),数组中的每个元素均…...
未来已来:科技驱动的教育变革
我们的基础教育数百年来一成不变。学生们齐聚在一个物理空间,听老师现场授课。每节课时长和节奏几乎一致,严格按照课表进行。老师就像“讲台上的圣人”。这种模式千篇一律,并不适用于所有人。学生遇到不懂的问题,只能自己摸索或者…...

【蓝桥杯每日一题】填充颜色超详细解释!!!
为了让蓝桥杯不变成蓝桥悲,我决定在舒适的周日再来一道题。 例: 输入: 6 0 0 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1 1 1 0 0 0 1 1 0 0 0 0 1 1 1 1 1 1 1 输出: 0 0 0 0 0 0 0 0 1 1 1 1 0 1 1 2 2 1 1 1 2 2 2 1 1 2 2 2 2 1 1…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...
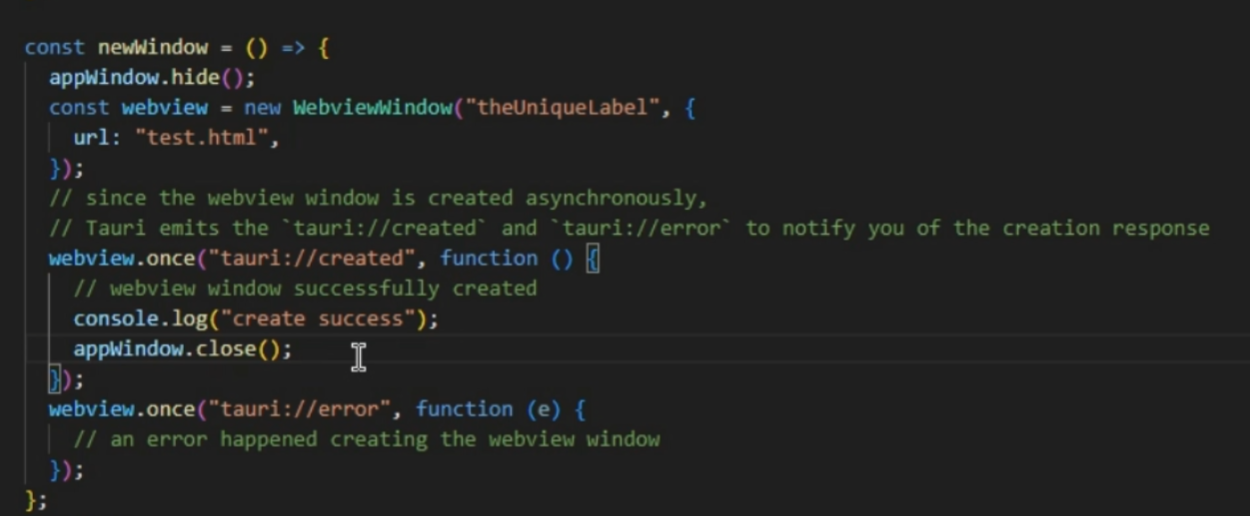
Tauri2学习笔记
教程地址:https://www.bilibili.com/video/BV1Ca411N7mF?spm_id_from333.788.player.switch&vd_source707ec8983cc32e6e065d5496a7f79ee6 官方指引:https://tauri.app/zh-cn/start/ 目前Tauri2的教程视频不多,我按照Tauri1的教程来学习&…...