Hadoop集群搭建,基于3.3.4hadoop和centos8【图文教程-从零开始搭建Hadoop集群】,常见问题解决
Hadoop集群搭建,基于3.3.4hadoop和centos8【小白图文教程-从零开始搭建Hadoop集群】,常见问题解决
- Hadoop集群搭建,基于3.3.4hadoop
- 1.虚拟机的创建
- 1.1 第一台虚拟机的创建
- 1.2 第一台虚拟机的安装
- 1.3 第一台虚拟机的网络配置
- 1.3.1 主机名和IP映射配置
- 1.3.2 网络参数配置
- 1.4 第一台虚拟机的Java,Hadoop环境搭建
- 1.4.1 Java环境搭建
- 1.4.2 Hadoop环境搭建
- 1、修改core-site.xml
- 2、修改hdfs-site.xml,添加以下内容
- 3、修改mapred-site.xml
- 4、修改yarn-site.xml,添加以下内容
- 5、修改 slaves文件
- 2、克隆另外两台虚拟机及网络配置
- 2.1 克隆虚拟机
- 2.2 克隆虚拟机网络配置
- 3、设置node-01到其余两台虚拟机的SSH免密登录
- 3、格式化NameNode
- 5、启动hadoop
- 6、启动和关闭Hadoop集群
- 6、通过UI查看Hadoop运行状态
- 遇到的问题
Hadoop集群搭建,基于3.3.4hadoop
Hadoop集群搭建,我这里采用的是Hadoop3.3.4,Jdk1.8,centos8,vmware16版本的。
1.虚拟机的创建
首先我们需要创建三台虚拟机,先创建第一台虚拟机,然后对第一台虚拟机进行配置(网络配置,免密配置,jdk,hadoop环境的安装),然后进行克隆,将第一台虚拟机克隆两个虚拟机出来,最后开始搭建集群。
一些目录说明 :
/export/data/ :存放数据类的文件
/export/servers/ :存放服务类软件
/export/software/ :存放安装包文件
1.1 第一台虚拟机的创建
打开VMware进行第一台虚拟机的创建,点击新建虚拟机
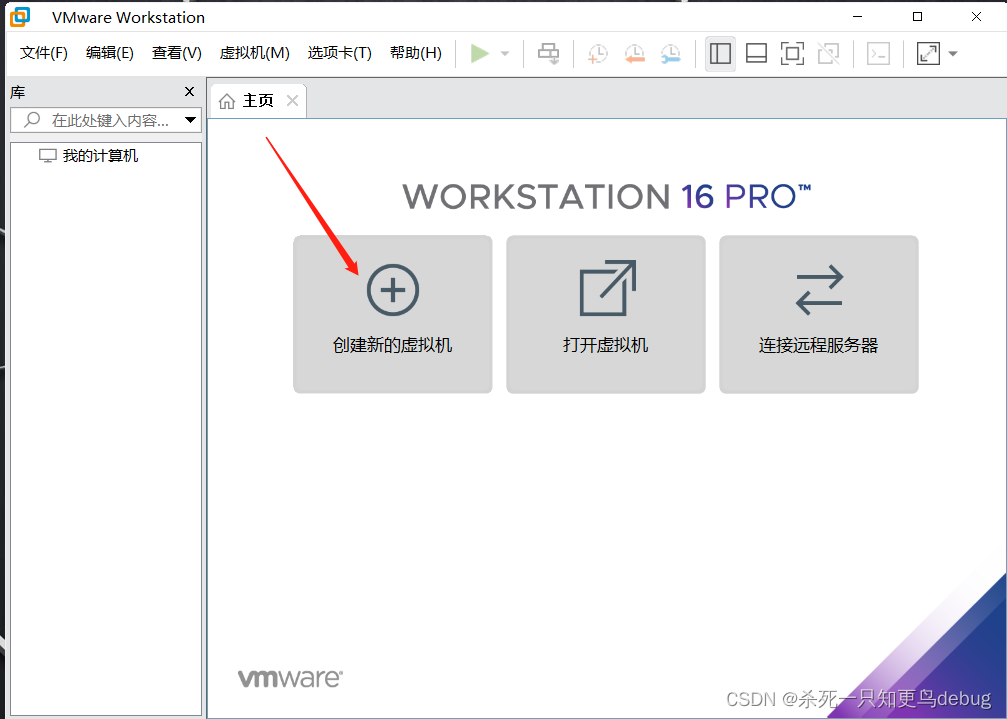
选择典型,下一步
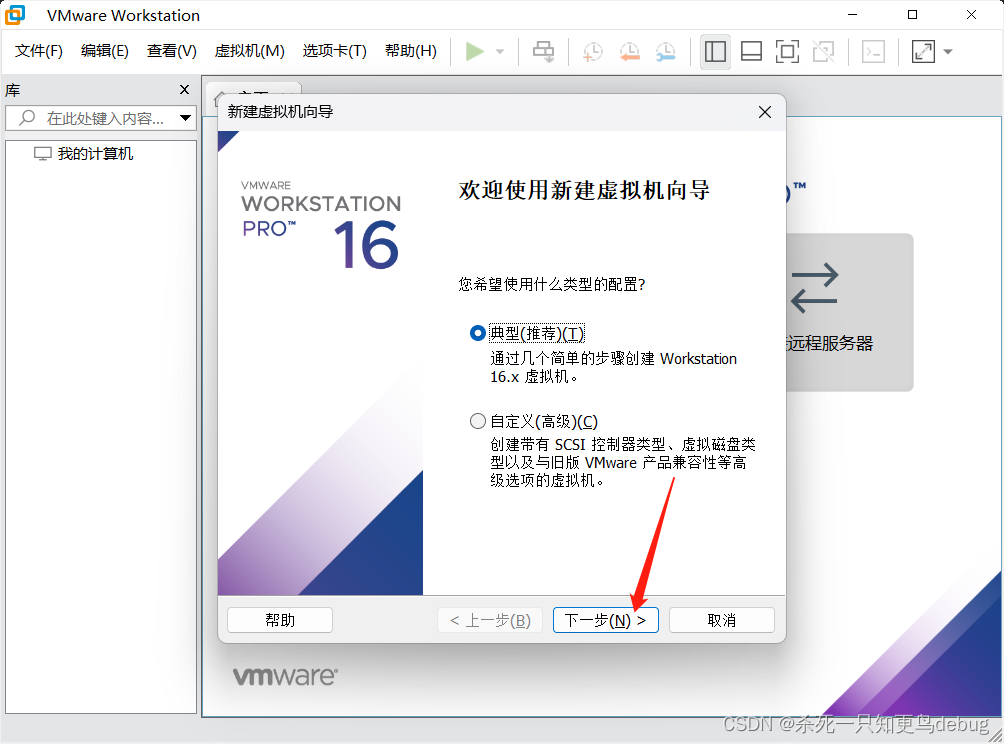
我这里因为提前已经准备好了centos8的镜像资源,所以直接将光盘驱动文件选择了,然后点击下一步
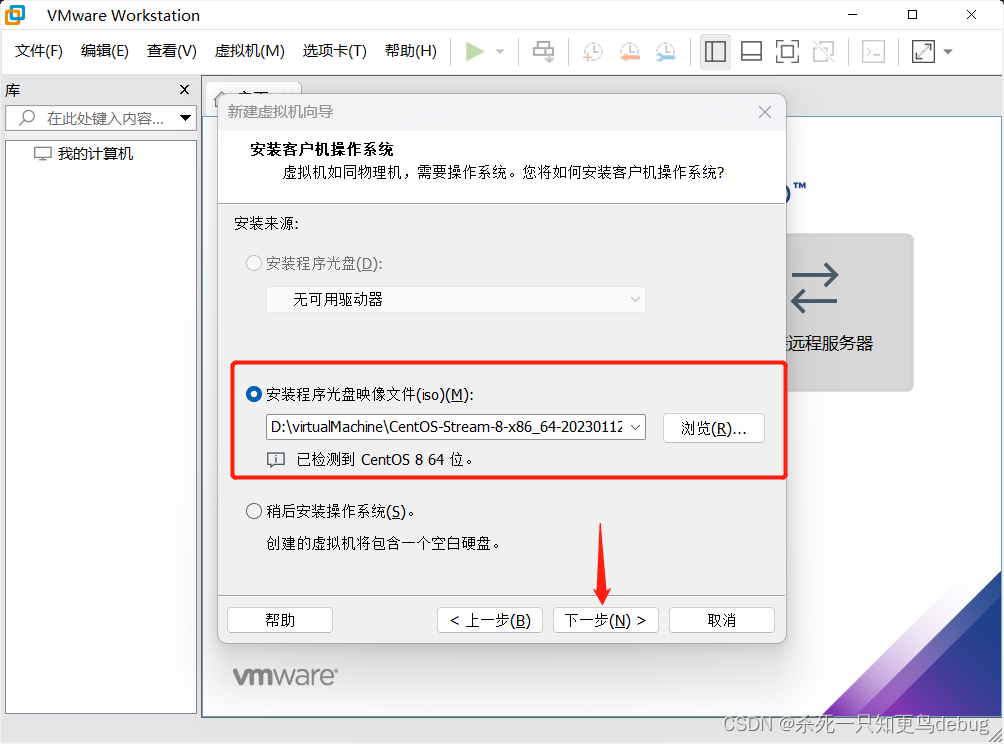
然后自定义虚拟机名称,已经安装的位置,我这里使用node-01(主虚拟机)作为第一台虚拟机的名称,然后点击下一步
磁盘空间默认20GB即可,下一步
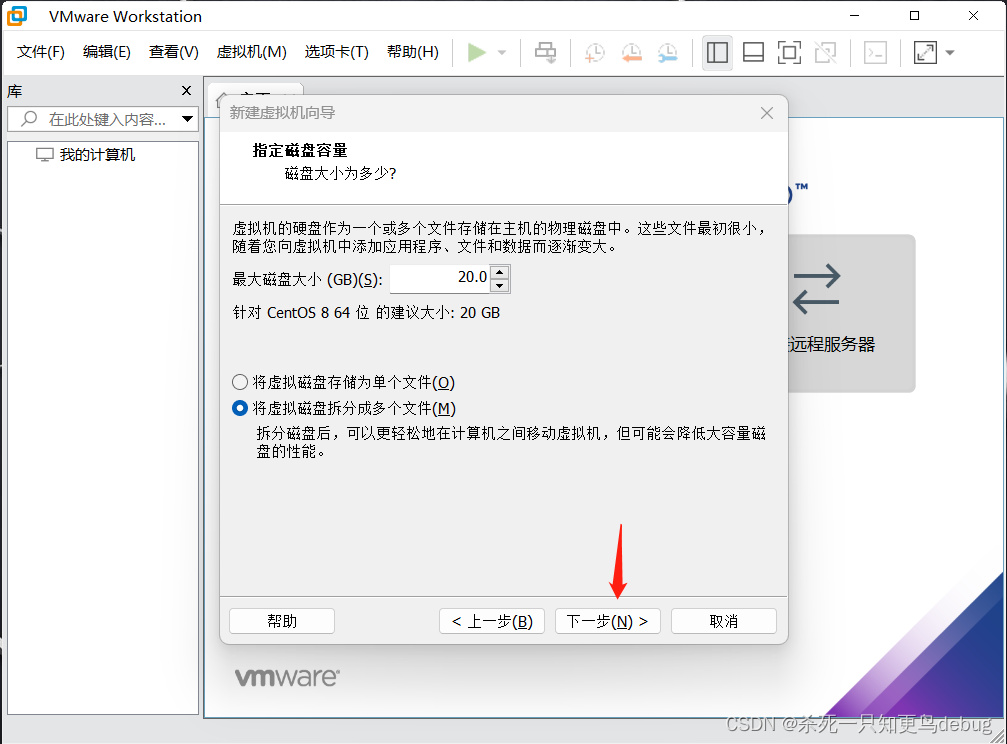
点击自定义硬件,对虚拟机的内存和cpu进行一定的配置
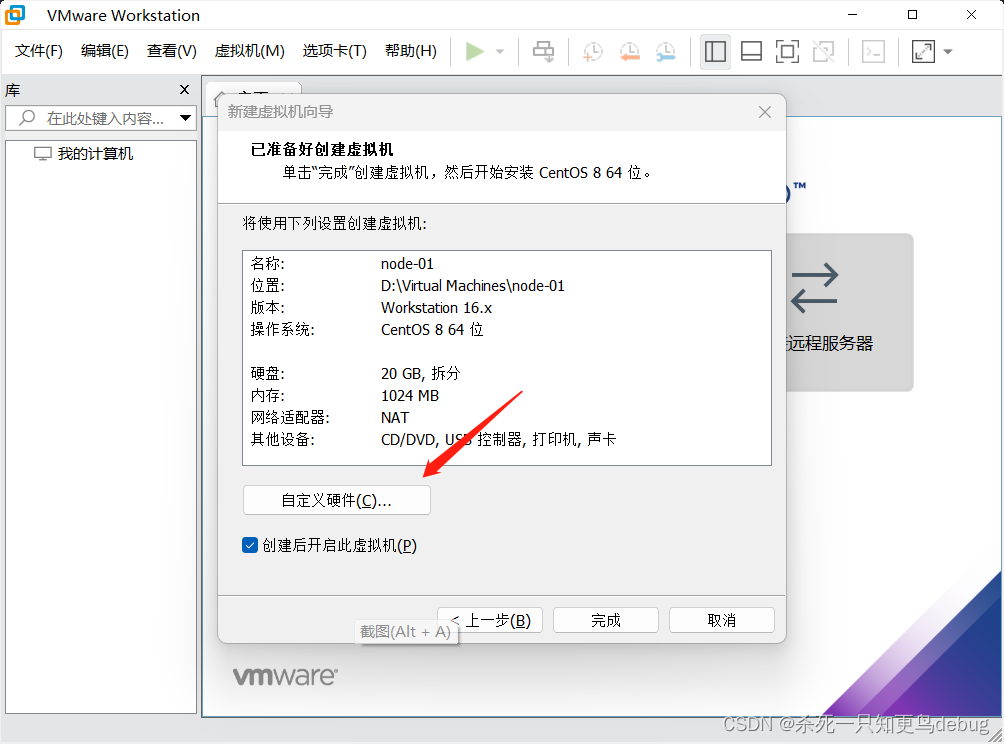
这里我只将虚拟机的内存进行了更改,由默认的1GB改到了2GB,然后点击关闭
点击完成
1.2 第一台虚拟机的安装
然后进入到虚拟机安装的环节,通过上下键切换,选择Install Centos stream 8-stream
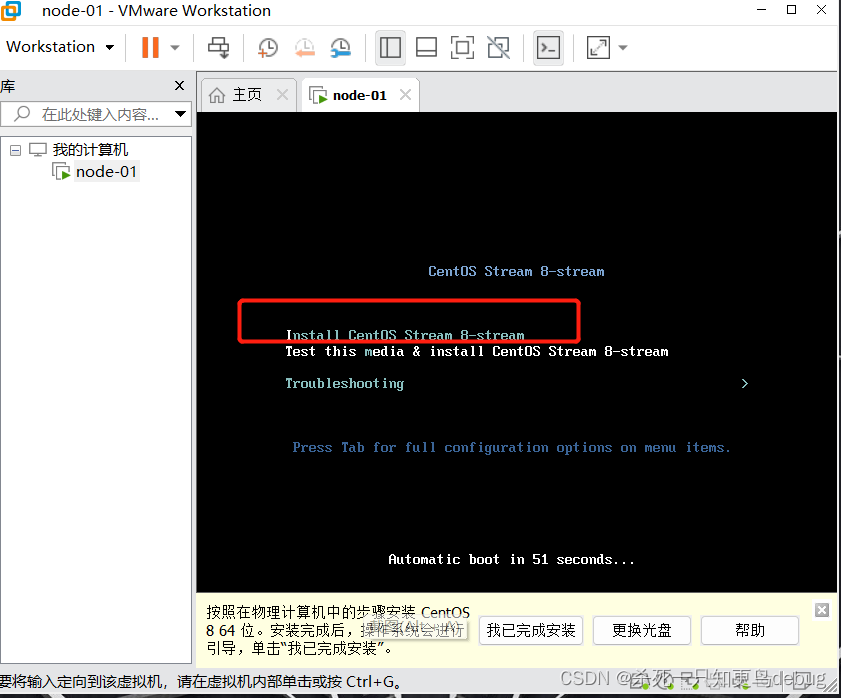
选择语言,中文,然后点击继续
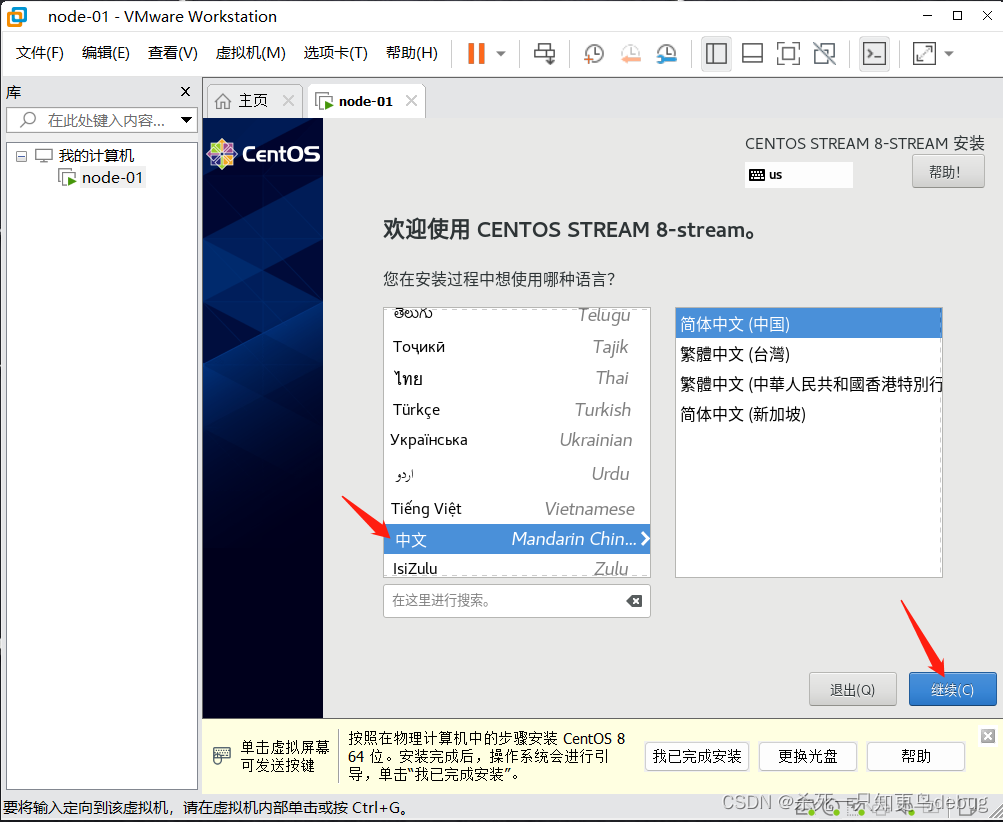
选择root密码,对root账户的密码进行初始化设定
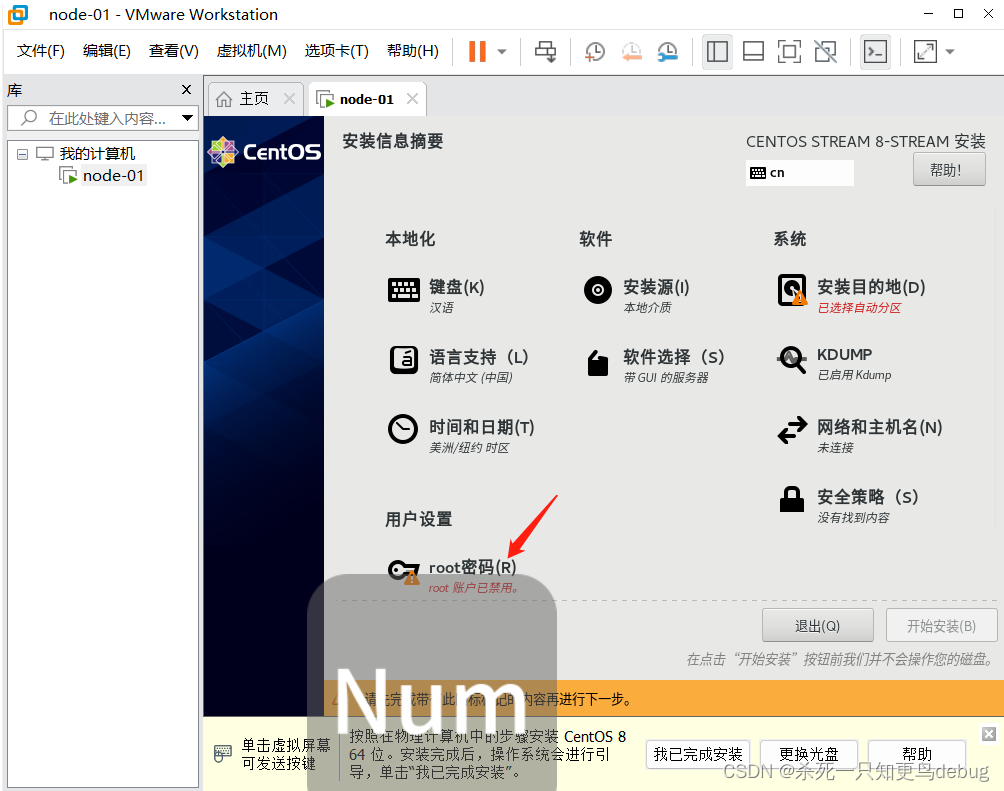
点击完成

接着我们再对网络进行配置,选择网络和主机名
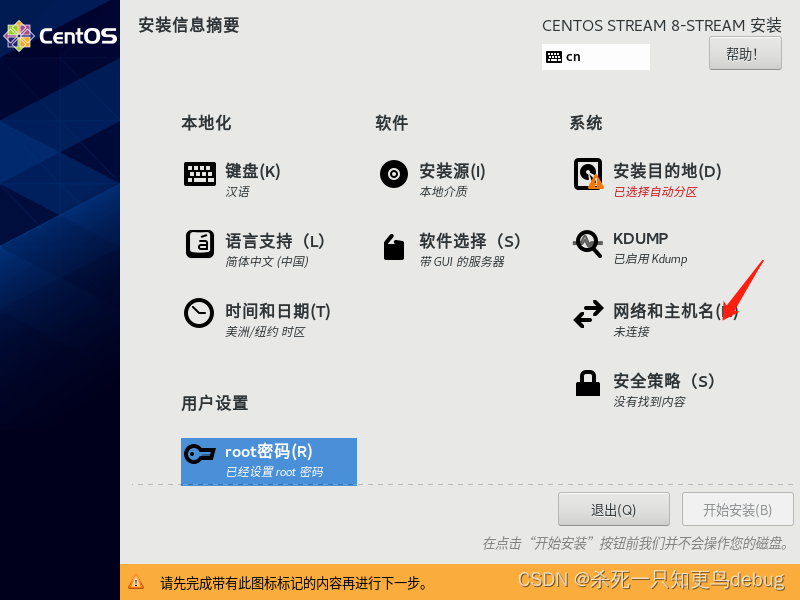
将网络开启,然后设定主机名,并且应用,然后点击完成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SCi6iw8q-1678112318718)(C:\Users\robin\AppData\Roaming\Typora\typora-user-images\image-20230306143654062.png)]](https://img-blog.csdnimg.cn/b304acc0c15c4fc8a9a339ff9cfd16a5.png)
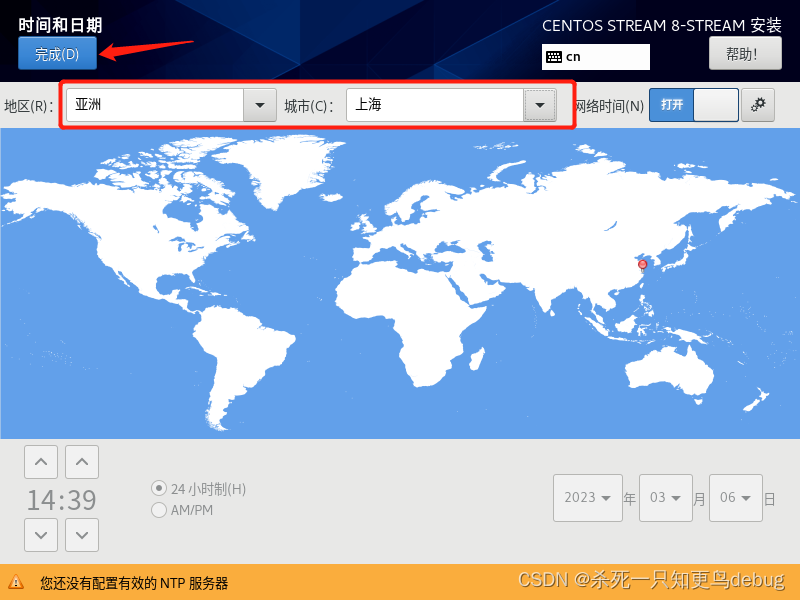
然后选择时区,将时区设为ASia/Shanghai
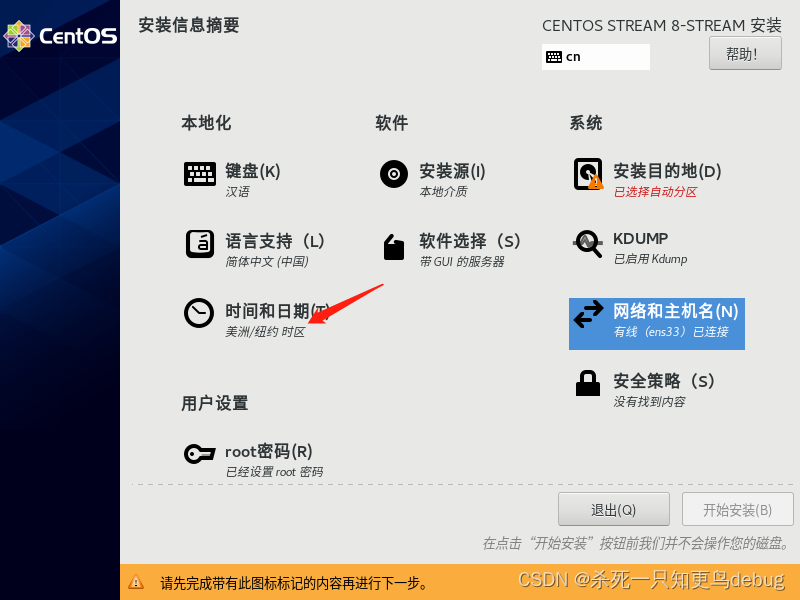
点击完成
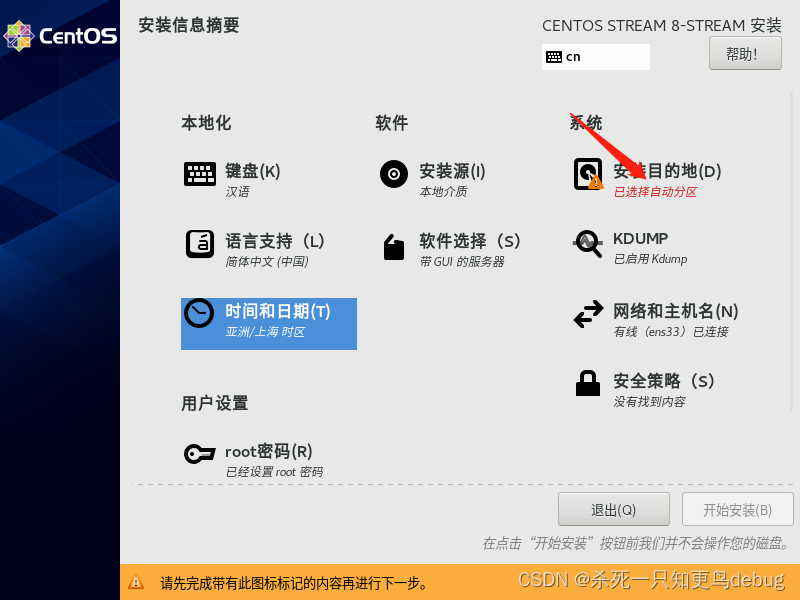
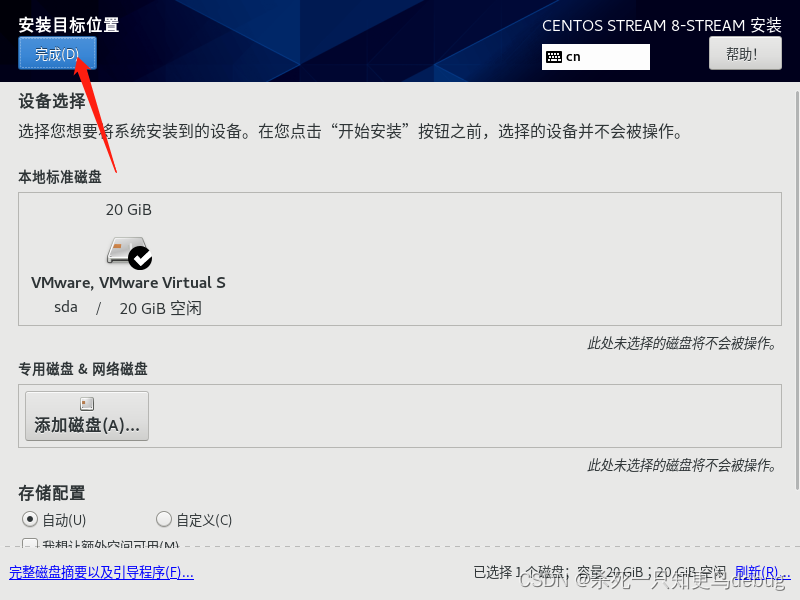
然后选择分区,默认分区也可以
然后进行软件的选择
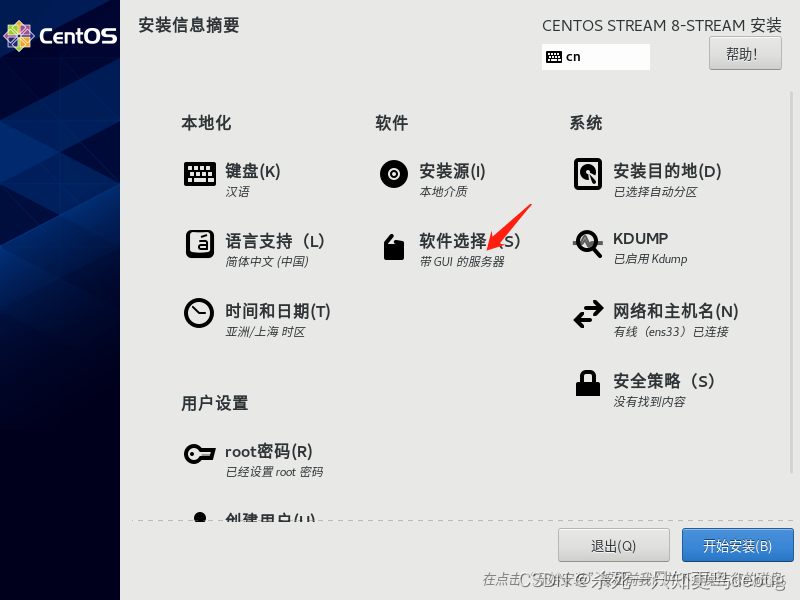
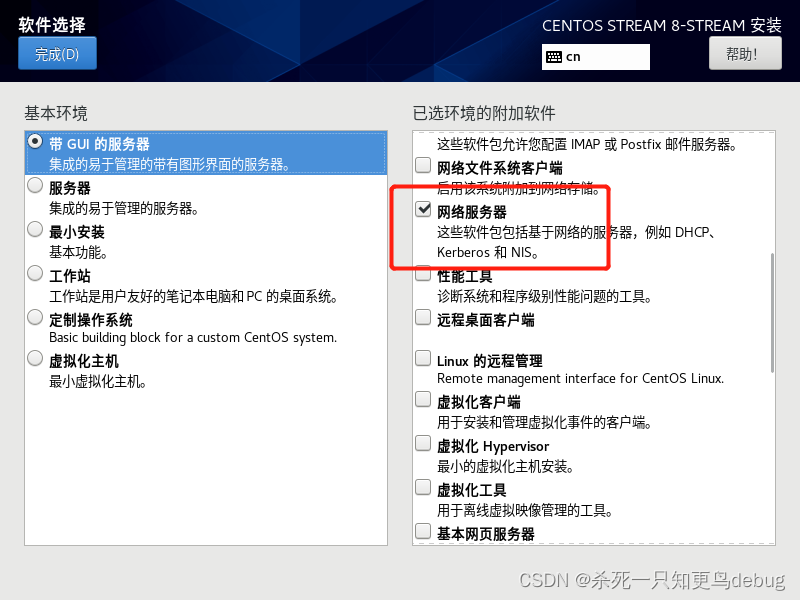
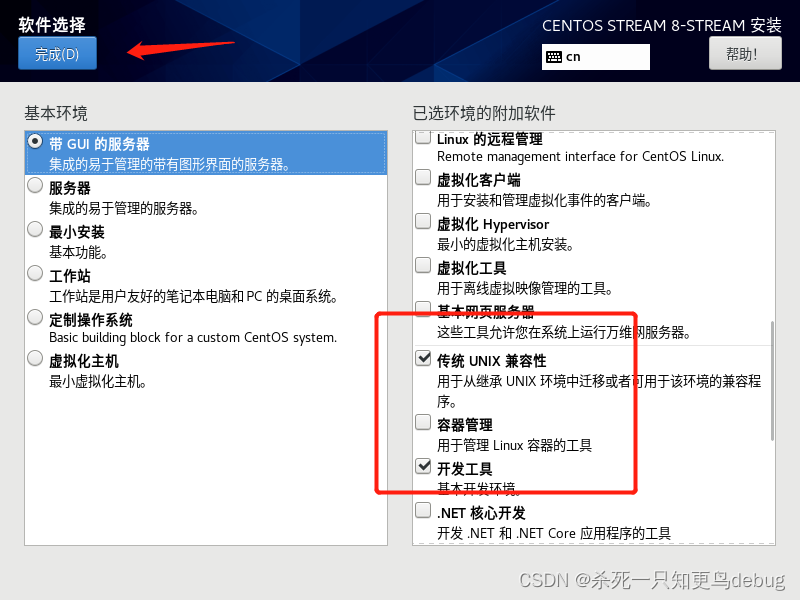
因为我是小白,所以还是选择了带GUI图形界面的,然后选择网络服务器,传统的UNIX兼容性和基本的开发工具即可
然后开始安装即可,大概几分钟左右
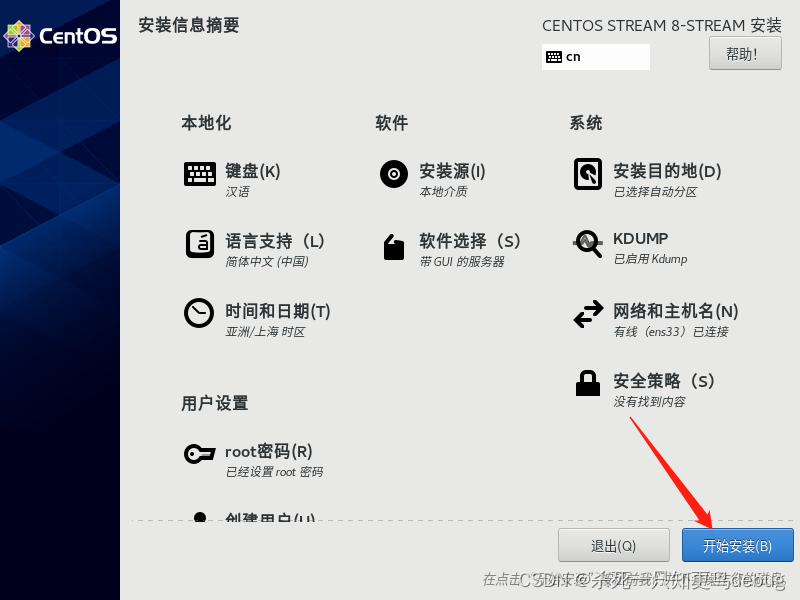
点击重启系统即可

重新启动后,它会让你确认是否接受服务,选择接受即可,然后创建用户这项根据个人需求我就暂时不创建了。

初始界面,如下,第一台虚拟机搭建完毕
1.3 第一台虚拟机的网络配置
我们可以使用XShell来进行远程登录,使用Xftp来进行文件的传输和下载,我这里就不过多赘述,在我的另外一篇文章中都有详细的介绍。
(1条消息) Xshell和Xftp的下载和在linux虚拟机中的使用_xshell和xftp下载_杀死一只知更鸟debug的博客-CSDN博客
1.3.1 主机名和IP映射配置
配置主机名
vi /etc/sysconfig/network
将虚拟机主机名称设为 node-01,node-02,node-03

配置IP映射
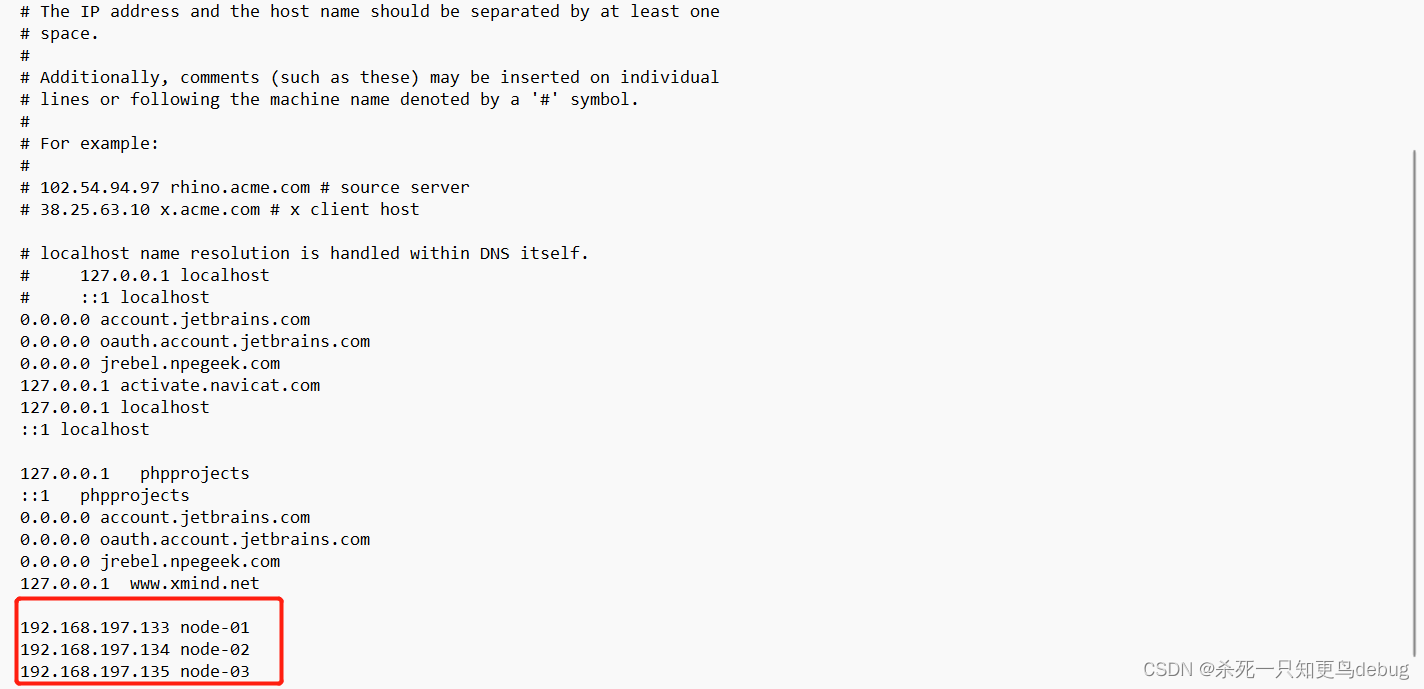
vi /etc/hosts
将IP地址与主机名,进行关联,对/etc/hosts文件进行下面的添加
192.168.197.133 node-01
192.168.197.134 node-02
192.168.197.135 node-03

1.3.2 网络参数配置
修改IP地址
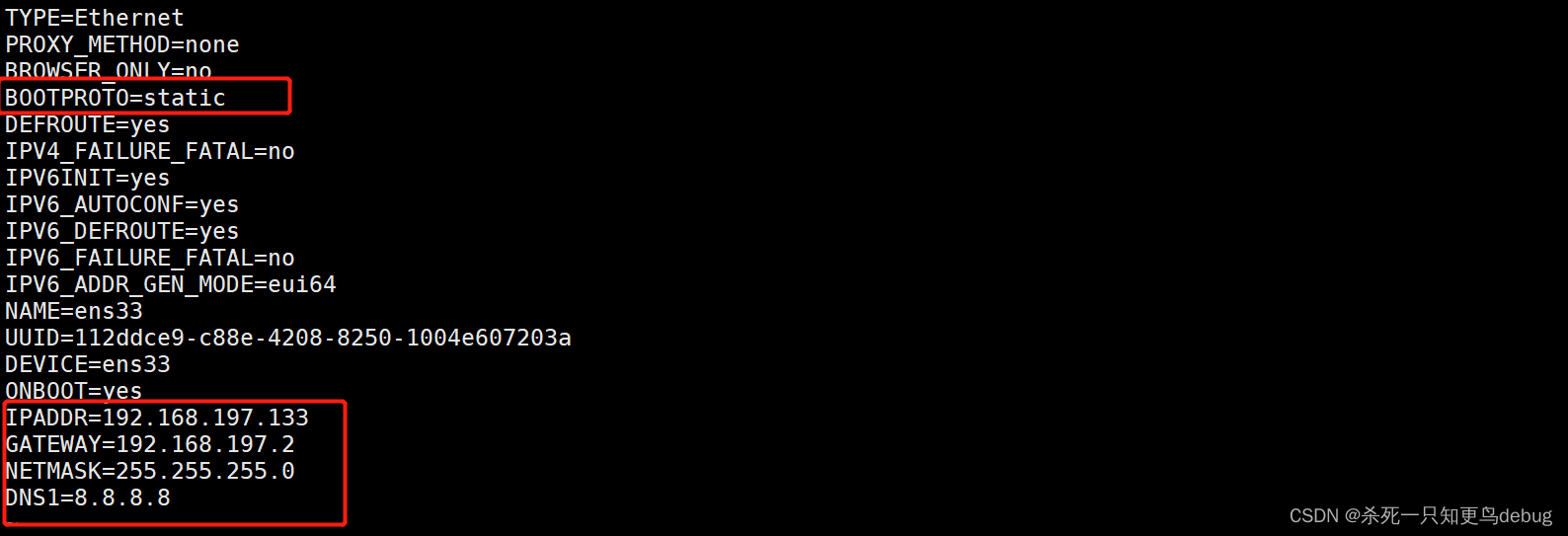
vi /etc/sysconfig/network-scripts/ifcfg-ens33
默认配置如下图

将BOOTPROTO的值改为static,静态路由协议,保持IP的固定
BOOTPROTO=staticIPADDR=192.168.197.133
GATEWAY=192.168.197.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
重启网络配置使其生效
service network restart
然后可以使用 ifconfig指令查看网络是否配置成功。
1.4 第一台虚拟机的Java,Hadoop环境搭建
1.4.1 Java环境搭建
去到Java的官网,然后下载对应的Linux版本的Jdk

创建一个目录,用于存放java的环境,上面已经说过了,要将软件包存放到/export/software文件夹中
mkdir -p /export/data/ # 存放数据类的文件
mkdir -p /export/servers/ # 存放服务类软件
mkdir -p /export/software/ #存放安装包文件

将Jdk通过Xftp传入到Linux虚拟机上刚刚创建的目录下,然后进行解压安装及环境配置
接着切换到java目录下,对压缩包进行解压
cd /export/software # 切换目录
tar -zxvf jdk-8u141-linux-x64.tar.gz -C/export/servers # 解压
配置Java的环境变量,用vi 打开/etc/profile 文件进行配置
vi /etc/profile
将下面的配置信息,写入到 /etc/profile目录中(注意你安装的Java版本及解压的名称)。
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
然后保存退出 Esc : wq
接着重新加载配置文件:
source /etc/profile
然后输入
java -version
此时就可以看到Java环境安装好啦

1.4.2 Hadoop环境搭建
同样,安装Linux中的Hadoop环境,先需要去其官网下载对应的Hadoop版本 Apache Hadoop
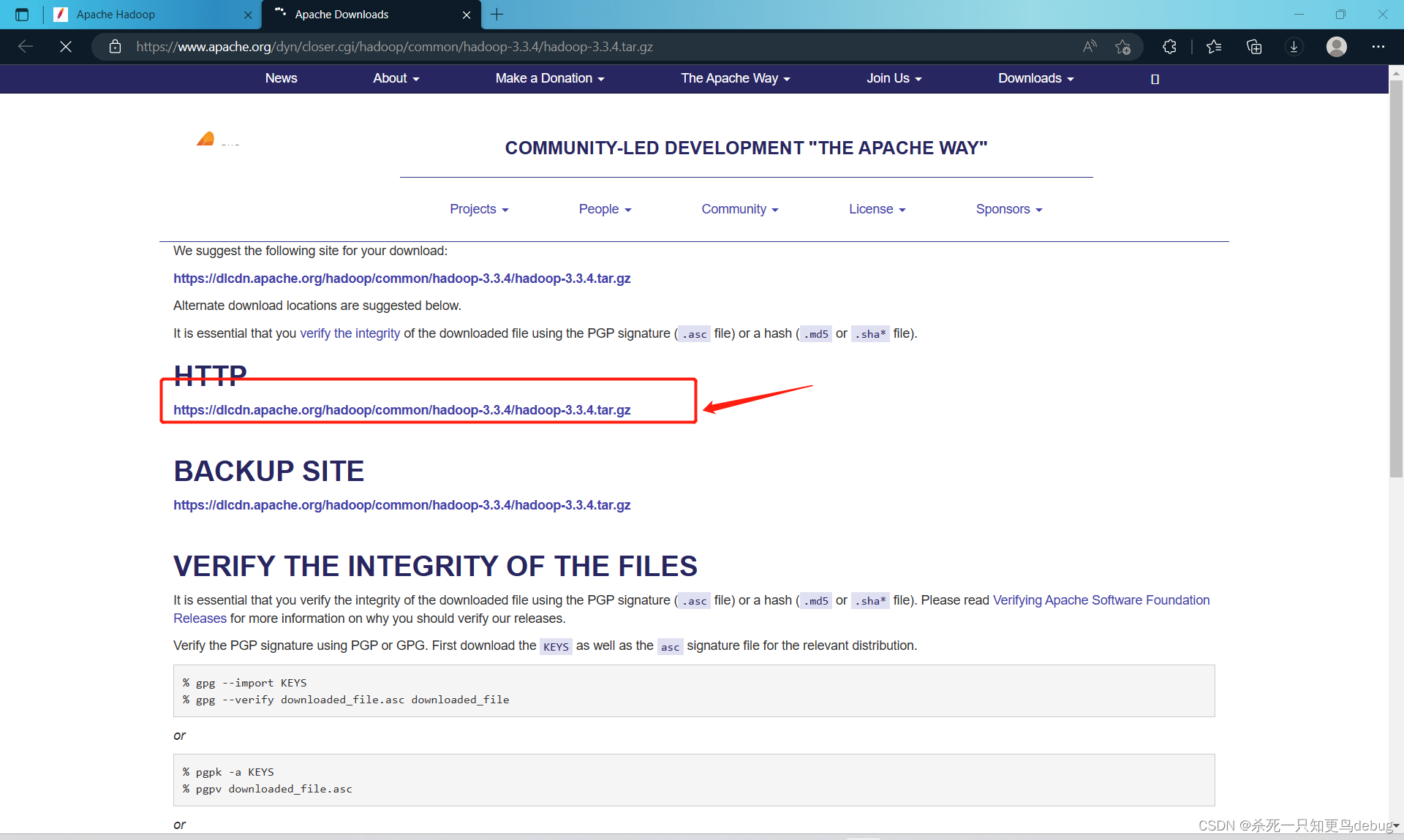
找到压缩包后,将其传输到Linux虚拟机中的 /export/software 目录下,我这里使用的是最新的hadoop3.3.4
Apache Downloads
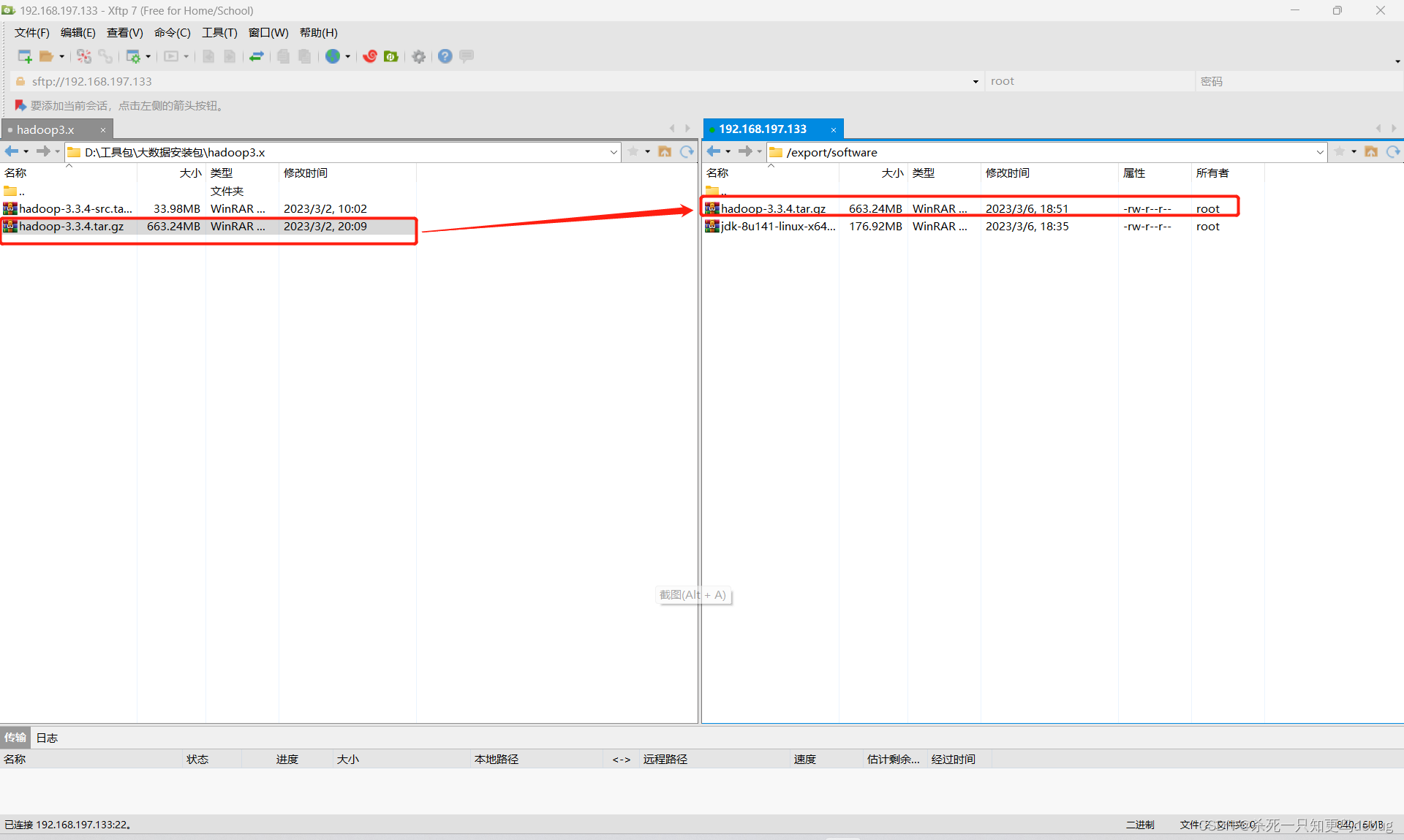
然后解压该压缩包到 /export/servers 目录下
cd /export/software
#如果不存在 modules目录则进行创建 mkdir modules
tar -zxvf hadoop-3.3.4.tar.gz -C /export/servers
接着开始对 /etc/profile 开始配置hadoop系统环境
vi /etc/profile
将下面的内容插入到 /etc/profile 的底部
export HADOOP_HOME=/export/servers/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

然后保存退出 Esc : wq
同样需要重新加载一下配置文件使其生效
source /etc/profile
输入hadoop -version,查看其输出,可见此时hadoop已经安装完毕

配置环境变量:
hadoop所有配置文件都存在安装目录下的/etc/hadoop目录中(我这里是**/export/servers/hadoop-3.3.4/etc/hadoop**),在该目录下的hadoop-env.sh、mapred-env.sh、yarn-env.sh中添加JAVA_HOME环境变量:
export JAVA_HOME=/export/servers/jdk1.8.0_141
如下图:
进入到其安装目录下的/etc/hadoop的目录中,然后对hadoop-env.sh、mapred-env.sh、yarn-env.sh中添加JAVA_HOME环境变量
1. 修改hadoop-env.sh
vi hadoop-env.sh
找到 export JAVA_HOME 然后添加/export/servers/javajdk1.8.0_141(jdk目录位置)

然后保存退出 Esc :wq
yarn-env.sh
vi yarn-env.sh

保存退出
1、修改core-site.xml
Hadoop的核心配置文件,其目的是配置HdFS地址,端口号,以及临时文件目录
vi core-site.xml # 使用vi对其xml进行配置
添加以下内容
<property><!-- 配置Hadoop 的临时目录 --><name>hadoop.tmp.dir</name><value>file:/export/servers/hadoop-3.3.4/tmp</value>
</property>
<property><!-- 配置Hadoop的文件系统,由URI指定 --><name>fs.defaultFS</name><!-- 这里我之前配置过主机名和IP映射所以写成主机名即可,没配置过的话,写完整的IP地址即可 192.168.197.133--><value>hdfs://node-01:9000</value>
</property>
参数说明:
- fs.defaultFS:默认文件系统,HDFS的客户端访问HDFS需要此参数
- hadoop.tmp.dir:指定Hadoop数据存储的临时目录,其它目录会基于此路径, 建议设置到一个足够空间的地方,而不是默认的/tmp下
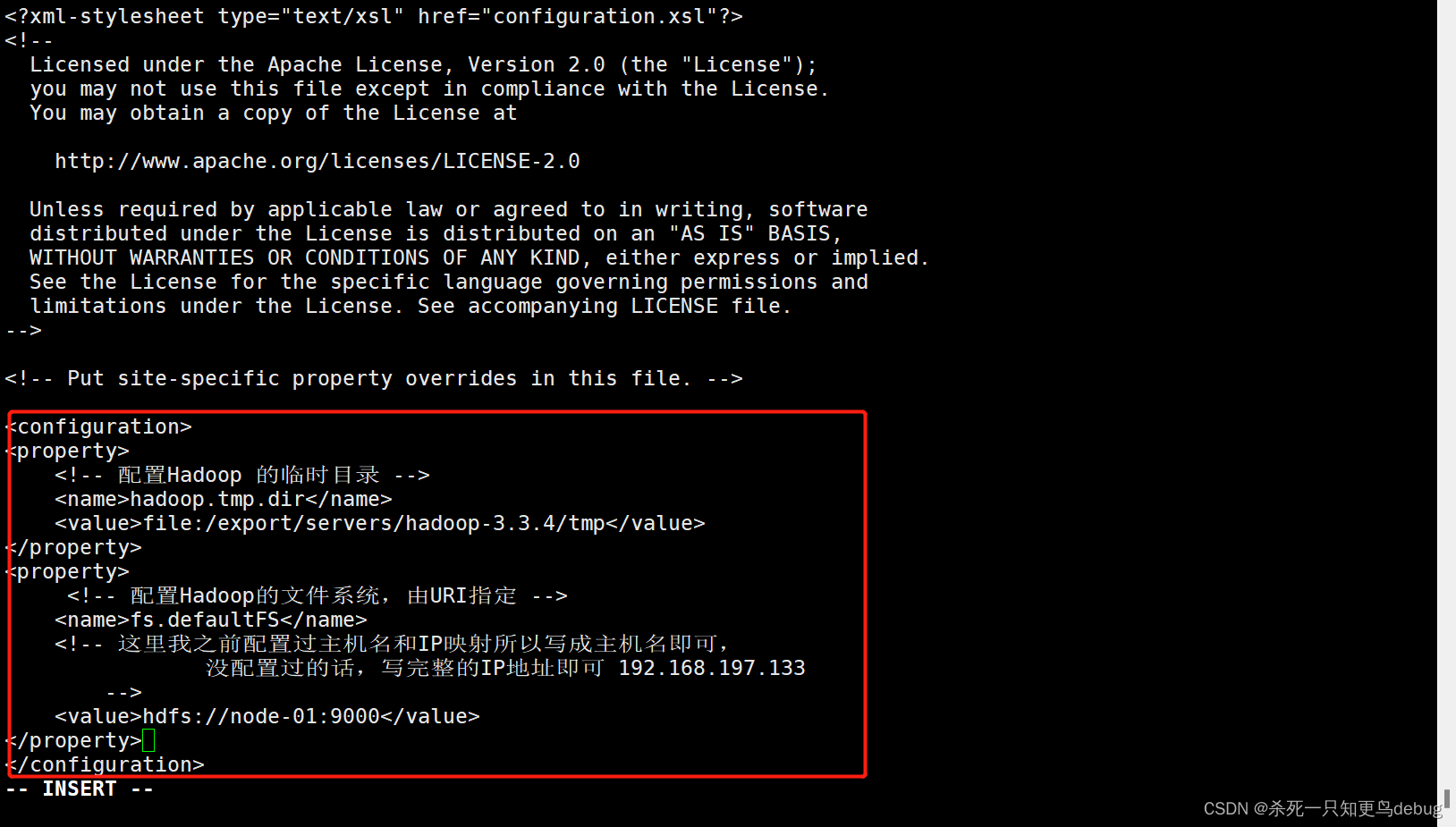
2、修改hdfs-site.xml,添加以下内容
vi hdfs-site.xml
hdfs-site.xml 用于设置HDFS的NameNode和DataNode两大进程
<!-- 指定hdfs副本的数量 -->
<property><name>dfs.replication</name><value>2</value>
</property>
<!-- secondary 所在的主机IP和端口号 -->
<property><name>dfs.namenode.secondary.http-address</name><value>node-02:50090</value>
</property>
参数说明:
- dfs.replication:数据块副本数 - dfs.name.dir:指定namenode节点的文件存储目录
- dfs.data.dir:指定datanode节点的文件存储目录
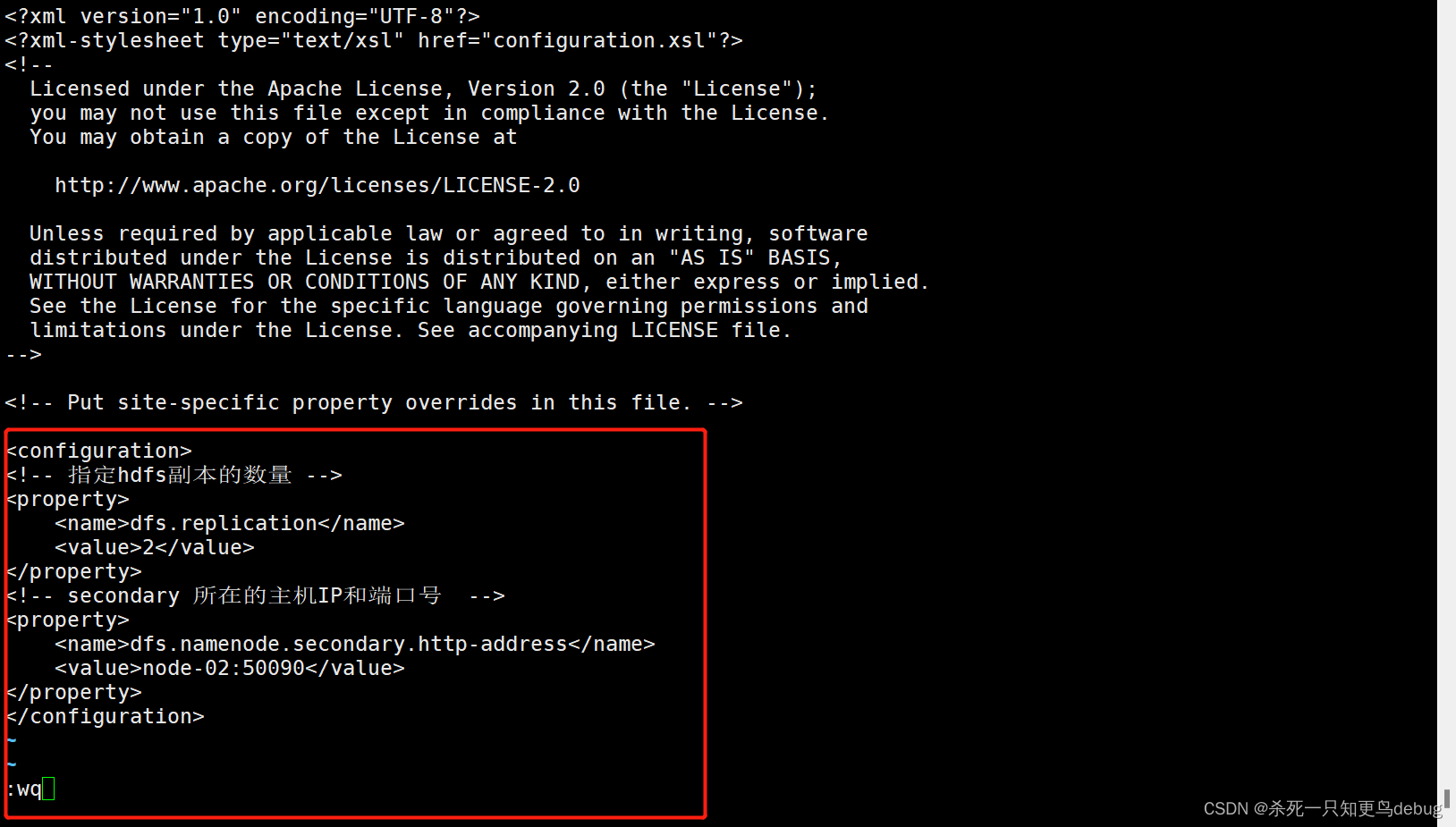
3、修改mapred-site.xml
mapred-site.xml是MapReduce的核心配置文件,用于指定MapReduce运行时框架。
vi marped-site.xml
添加以下内容
<property><!-- 指定MapReduce运行时框架,指定yarn,默认是local --><name>mapreduce.framework.name</name><value>yarn</value>
</property>
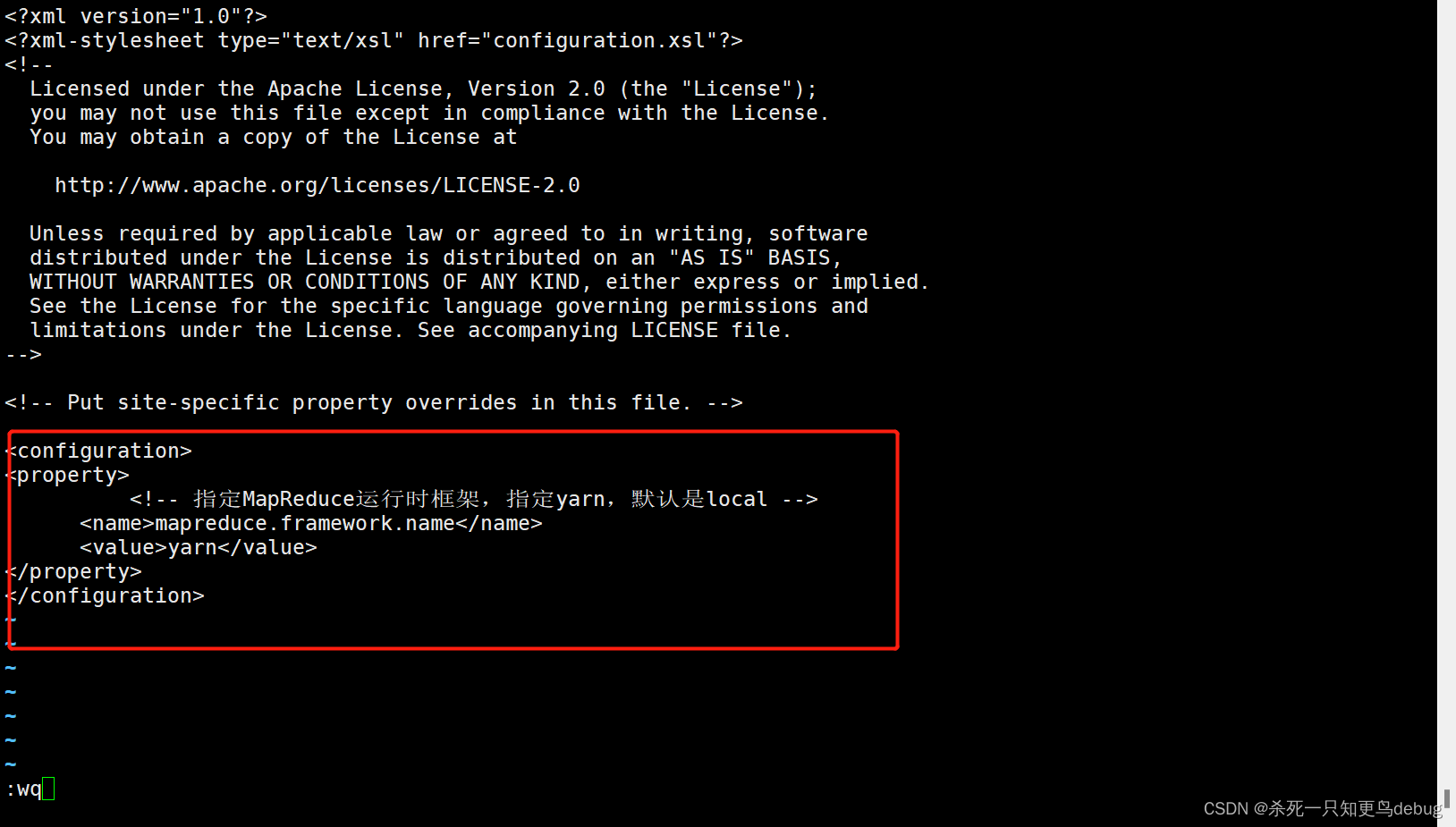
4、修改yarn-site.xml,添加以下内容
yarn-site.xml是YARN框架的核心配置文件,需要指定YARN集群的管理者。
vi yarn-site.xml
添加如下配置:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN集群的管理者Resoucemanage的地址--><property><name>yarn.resourcemanager.hostname</name><value>node-01</value></property>
参数说明:
- yarn.nodemanager.aux-services:NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可以运行Mapreduce程序。yarn提供了该配置用于在nodemanager上扩展自定已服务,MapReduce的Shuffle功能正式一种扩展服务。
5、修改 slaves文件
slaves文件用于记录Hadoop集群的所有从节点(HDFSde DataNode 和 YARN 的 NodeManager所在主机)的主机名,用来配合一键启动脚本集群从节点(保证配置了SSH免密登录)。打开该配置文件,先删除里面的默认内容(localhost),然后配置如下内容
vi slaves# 添加如下内容
node-01
node-02
node-03
2、克隆另外两台虚拟机及网络配置
2.1 克隆虚拟机
右键,选择管理,然后点击克隆
流程如下:
选择完整克隆,点击下一步
虚拟机名称和位置,自定义
此时第二台虚拟机已经克隆完毕,接着我们再以相同的方式克隆第三台虚拟机node-03
2.2 克隆虚拟机网络配置
配置主机名
vi /etc/sysconfig/network
# 或者使用
hostnamectl set-hostname 主机名
主机名配置后,使用reboot指令进行重启才会生效
将新克隆的虚拟机主机名称分别设为 node-02,node-03
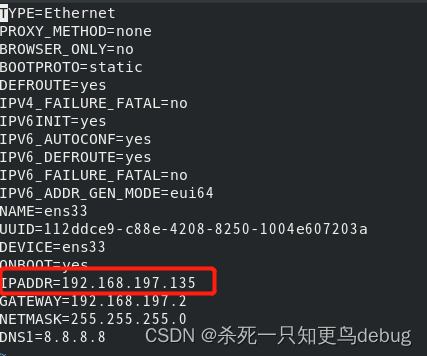
修改IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改IPADDR即可
node-02 对应 192.168.197.134
node-03 对应 192.168.197.135
3、设置node-01到其余两台虚拟机的SSH免密登录
1、在各个节点中生成密钥文件
$ cd ~/.ssh/ # 若没有该目录,执行ssh localhsot
$ ssh-keygen -t rsa # 生成密钥文件,提示输出加密信息,一直回车即可
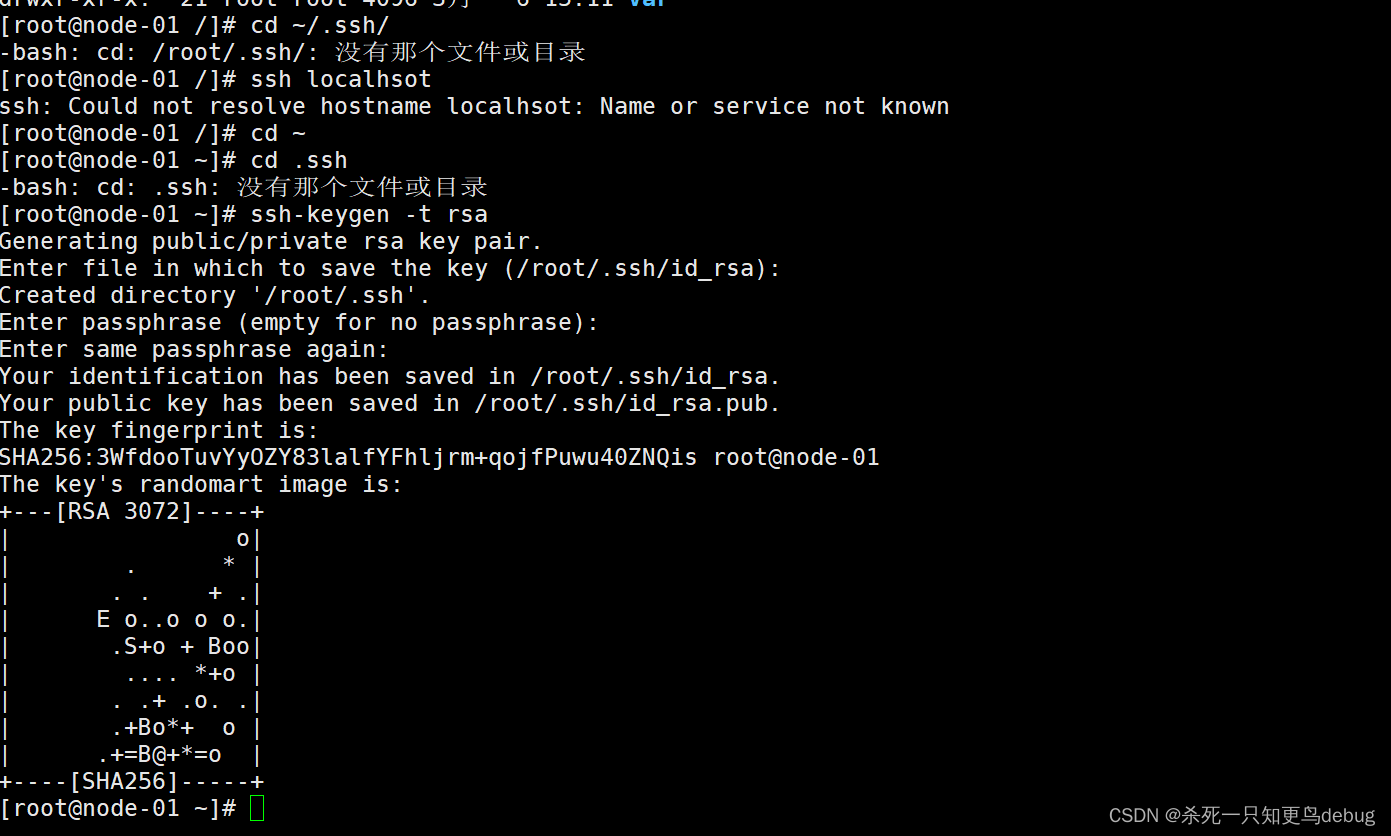
tip:如果提示说不存在ssh目录,直接执行 ssh-keygen -t rsa 即可
2、分别在三个节点中心以下命令,将公钥信息复制并追加到对方节点的授权文件authorized.key中
$ ssh-copy-id node-01
$ ssh-copy-id node-02
$ ssh-copy-id node-03
这里记得将每个虚拟机开启,然后在远程登录软件中进行免密配置
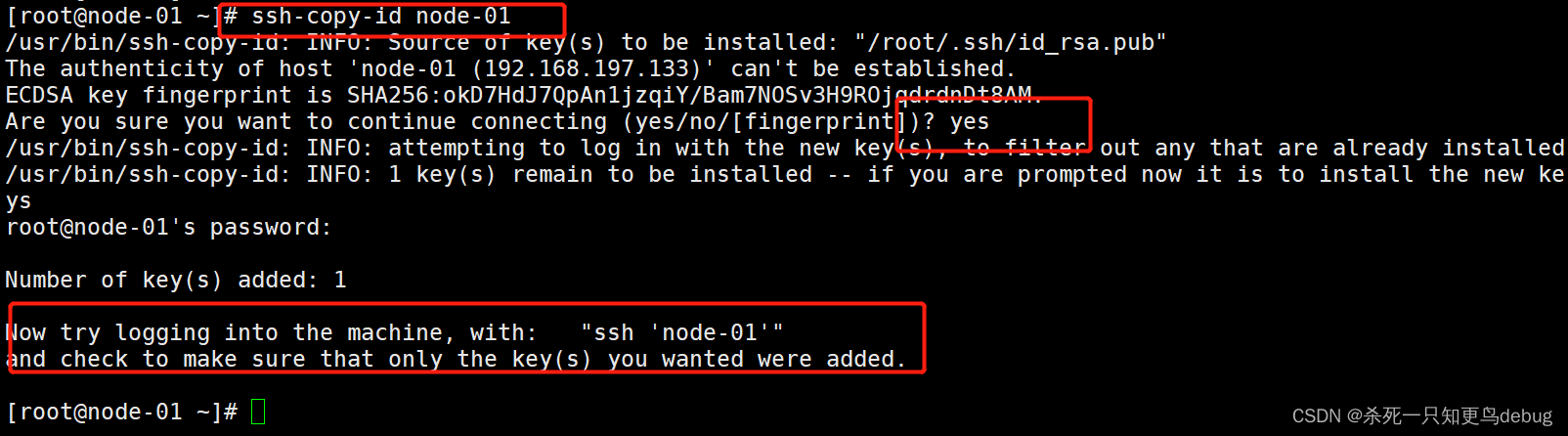
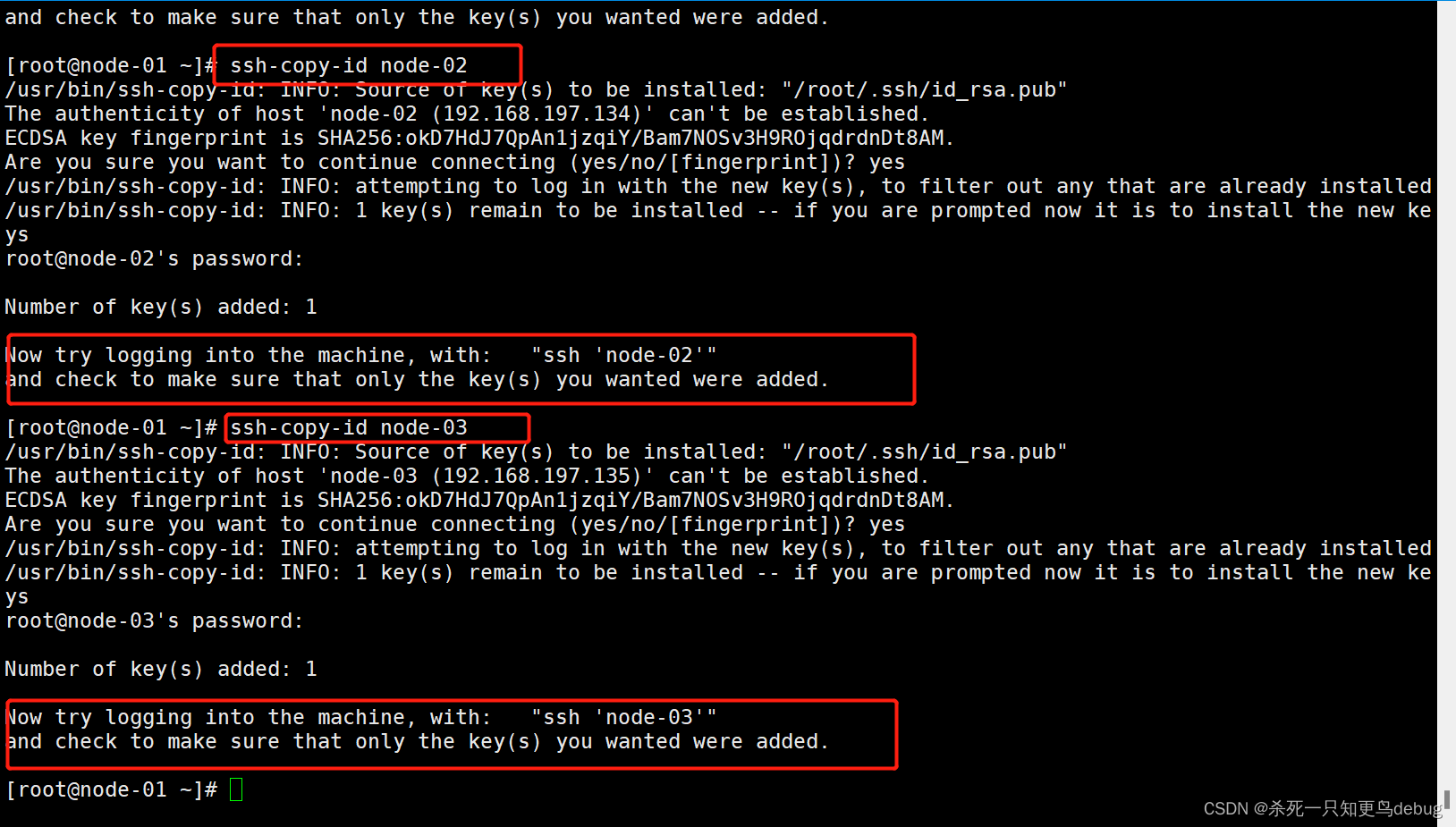
3、修改授权文件权限
$ chmod 700 ~/.ssh
$ chmod 600 ~/.ssh/authorized_keys
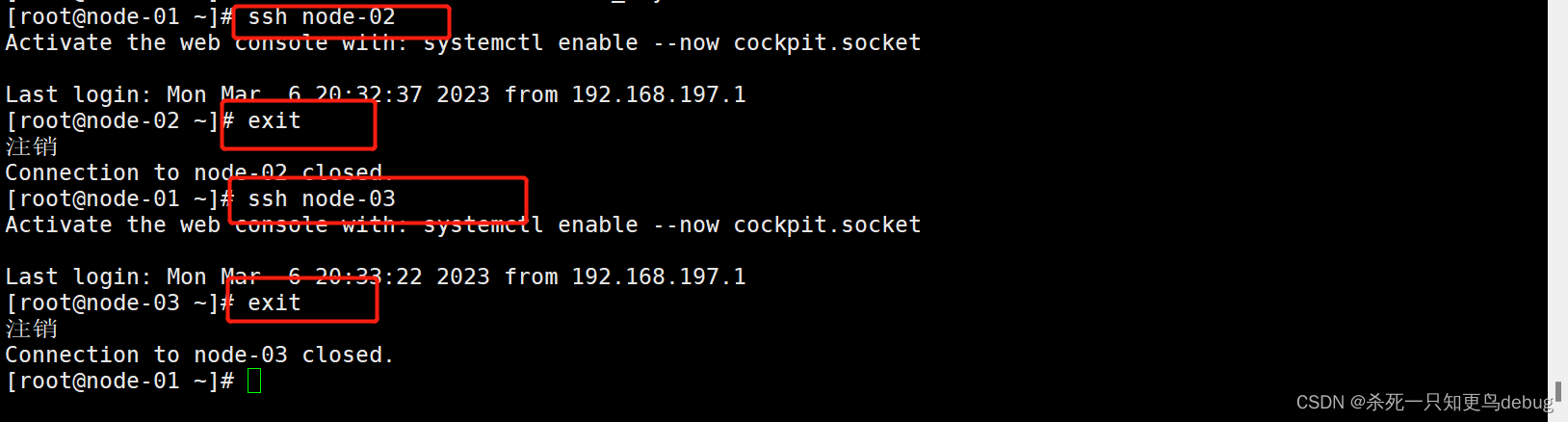
4、测试无密钥登陆
ssh node-02
exit
ssh node-03
exit
3、格式化NameNode
在主节点进行格式化即可(node-01),启动Hadoop之前需要格式化NameNode,格式化NameNode可以初始化HDFS文件系统的一些目录和文件,在node-01上执行:
# 必须在NameNode节点上进行format操作
$ hadoop namenode -format
5、启动hadoop
# 启动hadoop
$ start-all.sh # 停止hadoop
$ stop-all.sh # 查看节点角色
$ jps
启动 Hadoop 服务时权限异常,strat-all .sh
Starting namenodes on [node-01]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [node-02]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
如果出现没有定义HDFS_NAMENODE_USER
则在环境变量中在添加:
1.进入环境变量
vi ~/.bash_profile
2.添加:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

3.环境变量生效
source ~/.bash_profile
6、启动和关闭Hadoop集群
1.单节点逐个启动和关闭
主节点启动HDFS NameNode节点
hadoop-daemon.sh start namenode
从节点启动HDFS DataNode节点
hadoop-daemon.sh start datanode
主节点启动YARNResourceManager进程
yarn-daemon.sh start resourcemanager
从节点上启动YARN nodemanager进程
yarn-daemon.sh start nodemanager
规划节点node-02启动SecondaryNameNode进程
hadoop-daemon.sh start secondarynamenode
停止则使用stop替换掉start即可
2.脚本一键启动和关闭
start-dfs.sh
start-yarn.sh
这个需要在配置了slaves文件和SSH免密登录(双向的免密登录,即从节点的虚拟机也需要进行SSH免密配置)
6、通过UI查看Hadoop运行状态
在windows下的C:\Windows\System32\drivers\etc中的hosts文件添加集群服务的IP映射
192.168.197.133 node-01
192.168.197.134 node-02
192.168.197.135 node-03
注意先关闭防火墙,然后再进行测试查看运行状态
一下指令需要对主从节点都进行更改:
systemctl stop firewalldsystemctl status firewalldsystemctl disable firewalldsystemctl enable firewalld
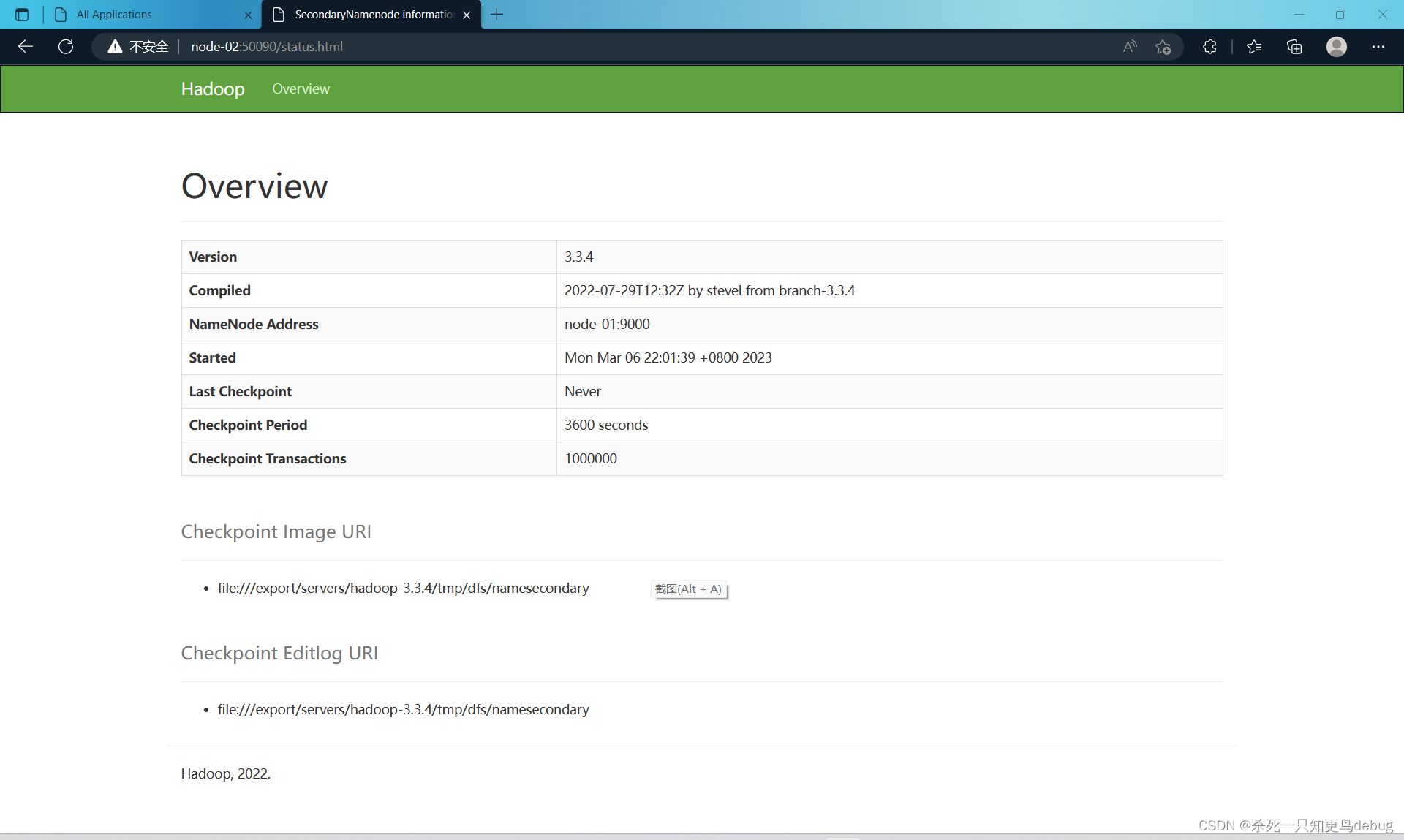
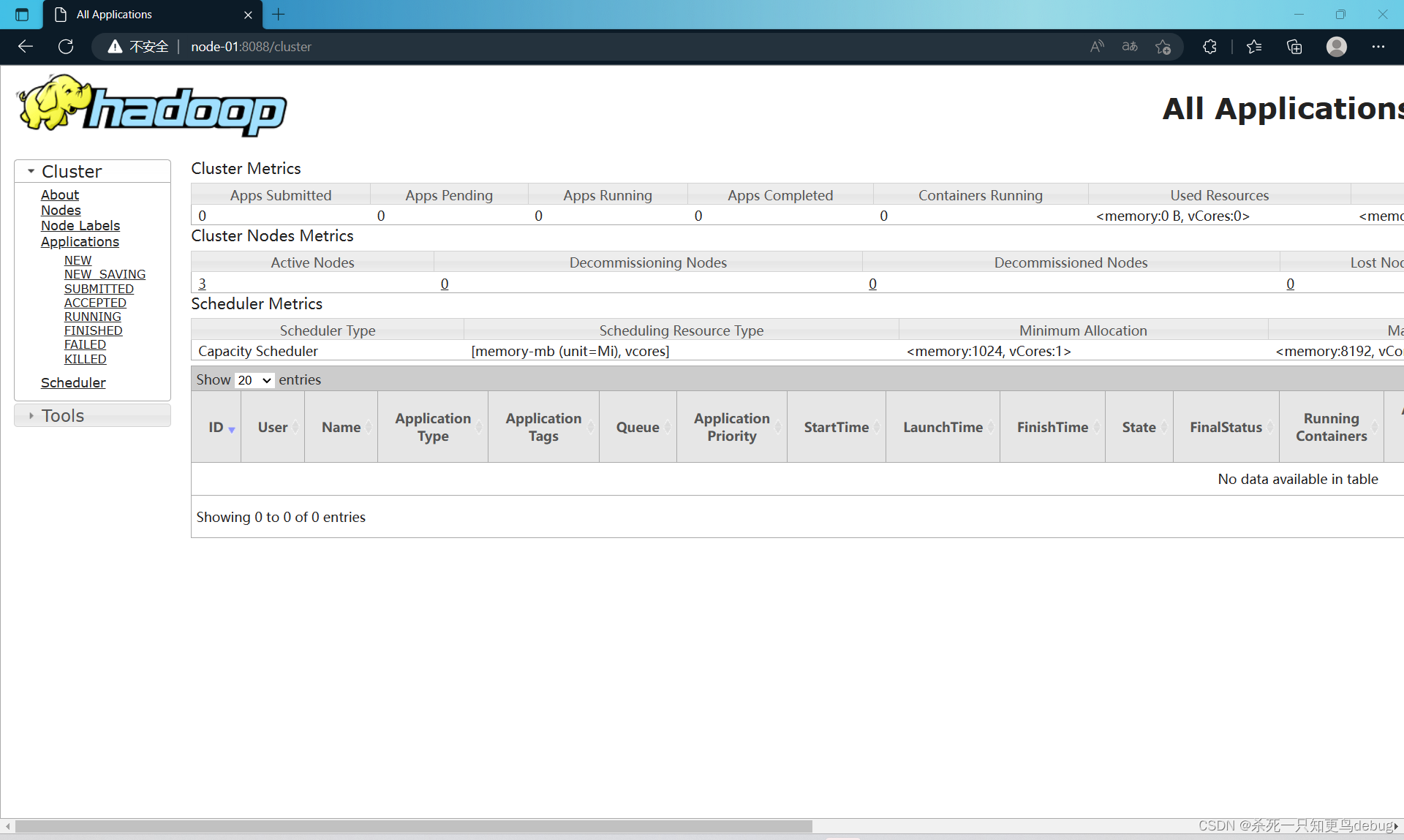
此时我们可以从windows的窗口进行查看了 http://node-01:50090(集群服务IP+端口号)和htpp://node-01:8088 查看YARN和HFDS的集群状态。
遇到的问题
以下纯属个人问题,已在文章中改了正确的配置:
这里我报错了
log4j:WARN No appenders could be found for logger (org.apache.hadoop.conf.Configuration).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "Thread-2" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Unexpected close tag </property>; expected </configuration>.at [row,col,system-id]: [25,10,"file:/export/servers/hadoop-3.3.4/etc/hadoop/mapred-site.xml"]at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3092)at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:3036)at org.apache.hadoop.conf.Configuration.loadProps(Configuration.java:2914)at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2896)at org.apache.hadoop.conf.Configuration.get(Configuration.java:1246)at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1863)at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1840)at org.apache.hadoop.util.ShutdownHookManager.getShutdownTimeout(ShutdownHookManager.java:183)at org.apache.hadoop.util.ShutdownHookManager.shutdownExecutor(ShutdownHookManager.java:145)at org.apache.hadoop.util.ShutdownHookManager.access$300(ShutdownHookManager.java:65)at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:102)
Caused by: com.ctc.wstx.exc.WstxParsingException: Unexpected close tag </property>; expected </configuration>.at [row,col,system-id]: [25,10,"file:/export/servers/hadoop-3.3.4/etc/hadoop/mapred-site.xml"]at com.ctc.wstx.sr.StreamScanner.constructWfcException(StreamScanner.java:634)at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:504)at com.ctc.wstx.sr.StreamScanner.throwParseError(StreamScanner.java:488)at com.ctc.wstx.sr.BasicStreamReader.reportWrongEndElem(BasicStreamReader.java:3352)at com.ctc.wstx.sr.BasicStreamReader.readEndElem(BasicStreamReader.java:3279)at com.ctc.wstx.sr.BasicStreamReader.nextFromTree(BasicStreamReader.java:2900)at com.ctc.wstx.sr.BasicStreamReader.next(BasicStreamReader.java:1121)at org.apache.hadoop.conf.Configuration$Parser.parseNext(Configuration.java:3396)at org.apache.hadoop.conf.Configuration$Parser.parse(Configuration.java:3182)at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3075)... 10 more
提示我说:
/export/servers/hadoop-3.3.4/etc/hadoop/mapred-site.xml 这里配置有问题去看看

多了一个poperty结束标记。。。
第二个问题 namenode格式化失败:java.lang.IllegalArgumentException: URI has an authority component:
java.lang.IllegalArgumentException: URI has an authority componentat java.io.File.<init>(File.java:423)at org.apache.hadoop.hdfs.server.namenode.NNStorage.getStorageDirectory(NNStorage.java:353)at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJournals(FSEditLog.java:293)at org.apache.hadoop.hdfs.server.namenode.FSEditLog.initJournalsForWrite(FSEditLog.java:264)at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1257)at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1726)at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1834)
2023-03-06 20:47:32,697 INFO util.ExitUtil: Exiting with status 1: java.lang.IllegalArgumentException: URI has an authority component解决方案,是core-site.xml中的一个配置好像不太一样,3.x和2.x不太一样
cd /export/servers/hadoop-3.3.4/etc/hadoop/
vi core-site.xml
我的配置是:
<configuration>
<property><!-- 配置Hadoop 的临时目录 --><name>hadoop.tmp.dir</name><value>file:/export/servers/hadoop-3.3.4/tmp</value>
</property>
<property><!-- 配置Hadoop的文件系统,由URI指定 --><name>fs.defaultFS</name><!-- 这里我之前配置过主机名和IP映射所以写成主机名即可,没配置过的话,写完整的IP地址即可 192.168.197.133--><value>hdfs://node-01:9000</value>
</property>
</configuration>
正确的配置应为:
<configuration>
<property><!-- 配置Hadoop 的临时目录 --><name>hadoop.tmp.dir</name><value>/export/servers/hadoop-3.3.4/tmp</value>
</property>
<property><!-- 配置Hadoop的文件系统,由URI指定 --><name>fs.defaultFS</name><!-- 这里我之前配置过主机名和IP映射所以写成主机名即可,没配置过的话,写完整的IP地址即可 192.168.197.133--><value>hdfs://node-01:9000</value>
</property>
</configuration>
相关文章:
Hadoop集群搭建,基于3.3.4hadoop和centos8【图文教程-从零开始搭建Hadoop集群】,常见问题解决
Hadoop集群搭建,基于3.3.4hadoop和centos8【小白图文教程-从零开始搭建Hadoop集群】,常见问题解决Hadoop集群搭建,基于3.3.4hadoop1.虚拟机的创建1.1 第一台虚拟机的创建1.2 第一台虚拟机的安装1.3 第一台虚拟机的网络配置1.3.1 主机名和IP映…...
UE4 材质学习 (焚烧材质)
效果步骤随便从网上下载一张图片(地址:链接/链接),导入UE中新建一个材质函数这里命名为“E_Function”双击打开该材质函数,由于需要输出变发光和变透明两种效果,因此这里需要两个输出节点:分别命…...

【c++】STL常用算法2—常用查找算法
文章目录常用查找算法findfind_ifadjacent_findbinary_searchcountcount_if常用查找算法 算法简介: find//查找元素 find_if//按条件查找元素 adjacent_find//查找相邻重复元素 binary_search//二分查找法 count//统计元素个数 count_if//按条件统计元素个数find …...
史上最全最详细的Java架构师成长路径图,程序员必备
从新手码农到高级架构师,要经过几步?要多努力,才能成为为人倚重的技术专家?本文将为你带来一张程序员发展路径图,但你需要知道的是,天下没有普适的道理,具体问题还需具体分析,实践才…...

第五章 事务管理
1.事务概念 *什么是事务:事务是数据库操作最基本单元,逻辑上是一组操作,要么都成功,要么都失败 *事务的特性(ACID):原子性、隔离性、一致性、持久性 2.搭建事务操作环境 *模拟场景ÿ…...
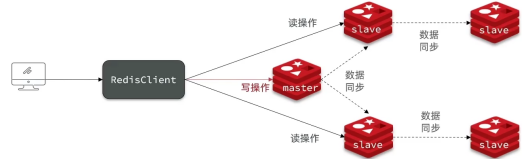
Redis:主从同步
Redis:主从同步一. 概述二. 原理(1) 全量同步(2) 增量同步(3) 优化Redis主从集群三. 总结一. 概述 引入: Redis主从集群采用一个Master负责写,多个Slave负责读的方式(读多写少),那么如何让读取数据时多个从…...
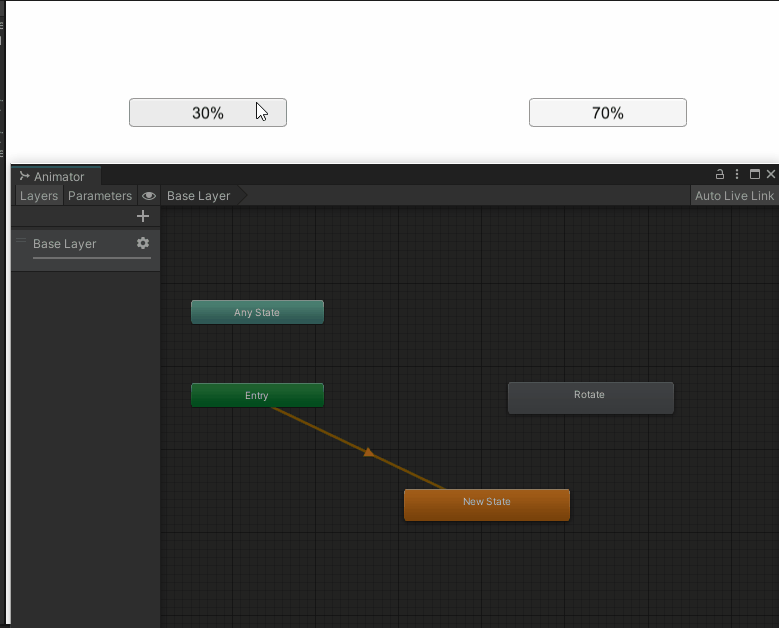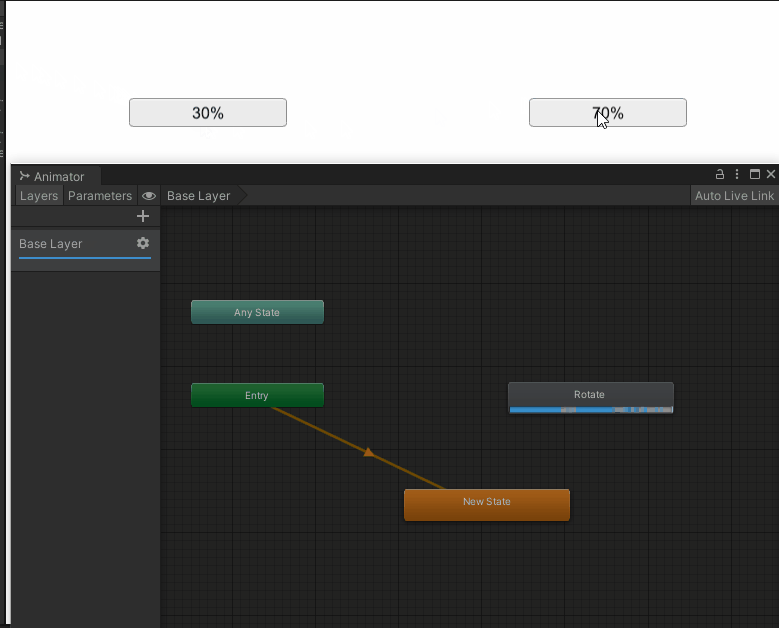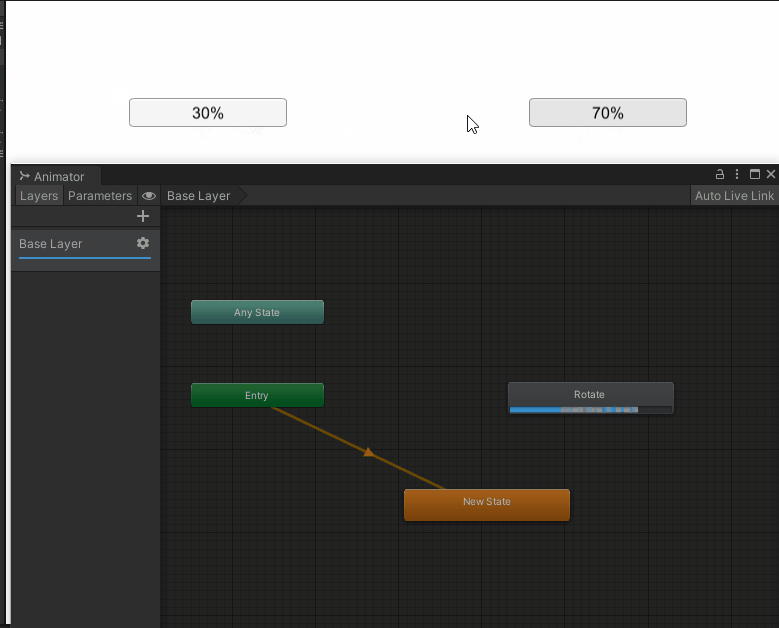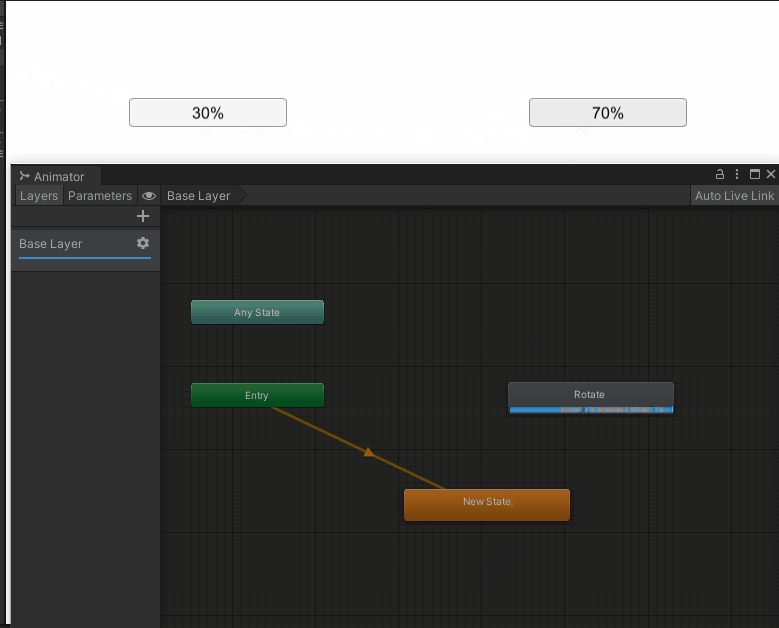
Unity Animator.Play(stateName, layer, normalizedTime) 播放动画函数用法
原理 接口: public void Play(string stateName, int layer -1, float normalizedTime float.NegativeInfinity);参数含义stateName动画状态机的某个状态名字layer第几层的动画状态机,-1 表示播放第一个状态或者第一个哈希到的状态normalizedTime从s…...

python学习——【第三弹】
前言 上一篇文章 python学习——【第二弹】中学习了python中的运算符内容,这篇文章接着学习python中的流程控制语句。 流程控制指的是代码运行逻辑、分支走向、循环控制,是真正体现我们程序执行顺序的操作。流程控制一般分为顺序执行、条件判断和循环控…...

科技云报道:AI大模型背后,竟是惊人的碳排放
科技云报道原创。 自从ChatGPT这样的大型语言模型在全球引起轰动以来,很少有人注意到,训练和运行大型语言模型正在产生惊人的碳排放量。 虽然OpenAI和谷歌都没有说过他们各自产品的计算成本是多少,但据第三方研究人员分析,ChatG…...

如何根据实际需求选择合适的三维实景建模方式?
随着实景三维中国建设的推进,对三维实景建模的数字化需求大幅增加。由于三维实景建模具有采集速度快、计算精度高等建模优势,引起了各个行业的高度关注。三维实景建模是一种应用数码相机或者激光扫描仪对现有场景进行多角度环视拍摄,然后利用…...
CENTO OS上的网络安全工具(十八)ClickHouse及编程环境部署
这篇其实去年就写好了,孰知就在12月31日那一天打进决赛圈,一躺,二过年,三休假,四加班,居然到了三个月以后,才有机会将它发出来…… 一年也就四个季度不是,实在是光阴荏苒,…...
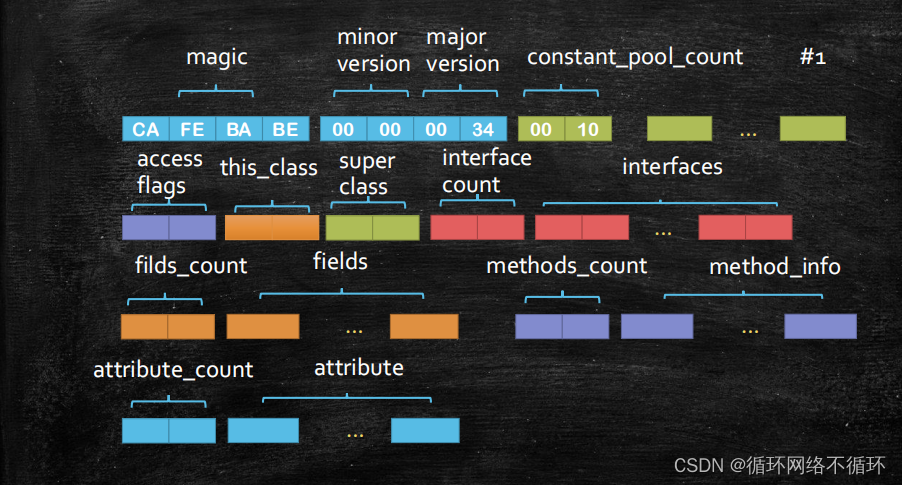
Java中class文件的格式
常见的class文件格式如下图所示,下面我将对一下格式一一作出解释。 一、magic 该部分主要是对语言类型的规范,只有magic这个部分是CAFEBABE时才能被检测为Java语言,否则则不是。 二、minor version和major version minor version主要表示了…...

C++排序算法
排序算法复习 冒泡排序 链接:https://www.runoob.com/w3cnote/bubble-sort.html 每次循环对比【相邻】两个元素,将最大的元素放到数组最后 void bubbleSort(int* arr, int n){//每次确认一个元素的最终位置,循环n-1次即可确认全部元素的最…...

JAVA后端部署项目三步走
1. JAVA部署项目三步走 1.1 查看 运行的端口 lsof -i:8804 (8804 为端口) 发现端口25111被监听 1.2 杀死进程,终止程序 pid 为进程号 kill -9 pid 1.3 后台运行jar包 nohup java -jar -Xms128M -Xmx256M -XX:MetaspaceSize128M -XX:MaxM…...

php使用zookeeper实现分布式锁
介绍 一、zookeeper和redis实现分布式锁的对比 1、redis 分布式场景应用比较广泛,redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能;zk分布式锁,获取不到锁,注册个监听器即可,不需要不…...

力扣-可回收且低脂的产品
大家好,我是空空star,本篇带大家了解一道超级超级超级简单的力扣sql练习题。 文章目录前言一、题目:1757. 可回收且低脂的产品二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交S…...

代码随想录刷题-数组-二分查找
文章目录写在前面原理习题题目1思路和代码题目-2写在前面 这个专栏是记录我刷代码随想录过程中的随想和总结。每一小节都是根据自己的理解撰写的,文章比较短,主要是为了记录和督促自己。刷完一章后,我会再单独整理一篇文章来总结和分享。 本…...

HCIA复习1
HCIA复习 抽象语言---->编码 编码---->二进制 二进制--->电信号 处理电信号 OSI参考模型----OSI/RM 应用层 表示层 会话层 传输层 端口号:0-65535;1-1023是注明端口 网络层 IP地址 数据链路层 物理层 ARP协议 正向ARP---通过IP地址获取目的MAC地…...
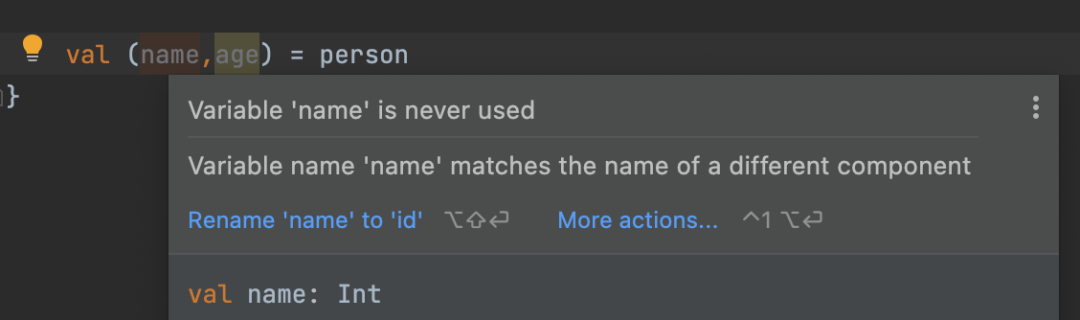
Kotlin中的destructuring解构声明
开发中有时只是想分解一个包含多个字段的对象来初始化几个单独的变量。要实现这一点,可以使用Kotlin的解构声明。本文主要了解:“1、如何使用解构声明这种特性 2、底层是如何实现的 3、如何在你自己的类中实现它1、解构声明的使用解构声明&a…...
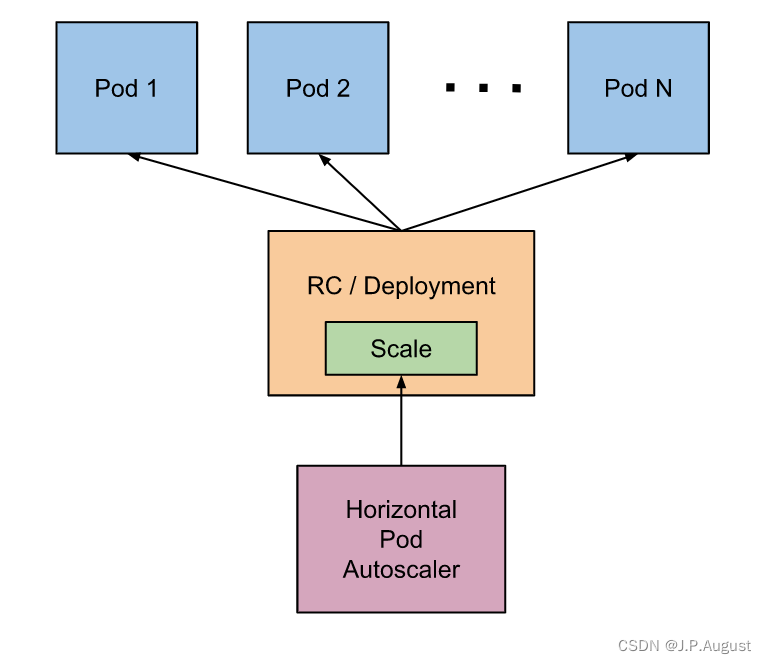
Kubernetes Pod 水平自动伸缩(HPA)
Pod 自动扩缩容 之前提到过通过手工执行kubectl scale命令和在Dashboard上操作可以实现Pod的扩缩容,但是这样毕竟需要每次去手工操作一次,而且指不定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...