【计算机网络】IP 协议
网络层IP协议
- 一、认识 IP 地址
- 二、IP 协议报头格式
- 三、网段划分
- 1. 初识子网划分
- 2. 理解子网划分
- 3. 子网掩码
- 4. 特殊的 IP 地址
- 5. IP 地址的数量限制
- 6. 私有 IP 地址和公网 IP 地址
- 7. 理解全球网络
- (1)理解公网
- (2)理解私网
- (3)全球网络
- 四、路由
一、认识 IP 地址
首先我们学的 IP 地址是在网络协议栈中的网络层的,数据包经过 TCP/UDP 传输层封装报头后,传给下层网络层,而网络层主要是在复杂的网络环境中确定一个合适的路径发送给对方。
其实我们以前学的 TCP 协议,给 IP 协议提供的是可靠性,如果发送失败了,TCP 的超时重传策略就可以支持重新发送,继续传给网络层让 IP 协议发送。所以,IP 协议的本质工作就是提供一种能力,将数据跨网络从主机A发送到主机B。
下面我们认识一下 IP 地址,首先在公网中需要给所有的主机进行唯一标识,假设从主机A发送到主机B,就需要源 IP 地址和目的 IP 地址来标识源主机和目的主机。其实 IP 地址在被设计的时候是经过精心设计的,比如 IP 地址是由目标网络+目标主机组合成的,就像我们的学号一样,可以区分出一个学生是哪一个学院哪一个专业的。
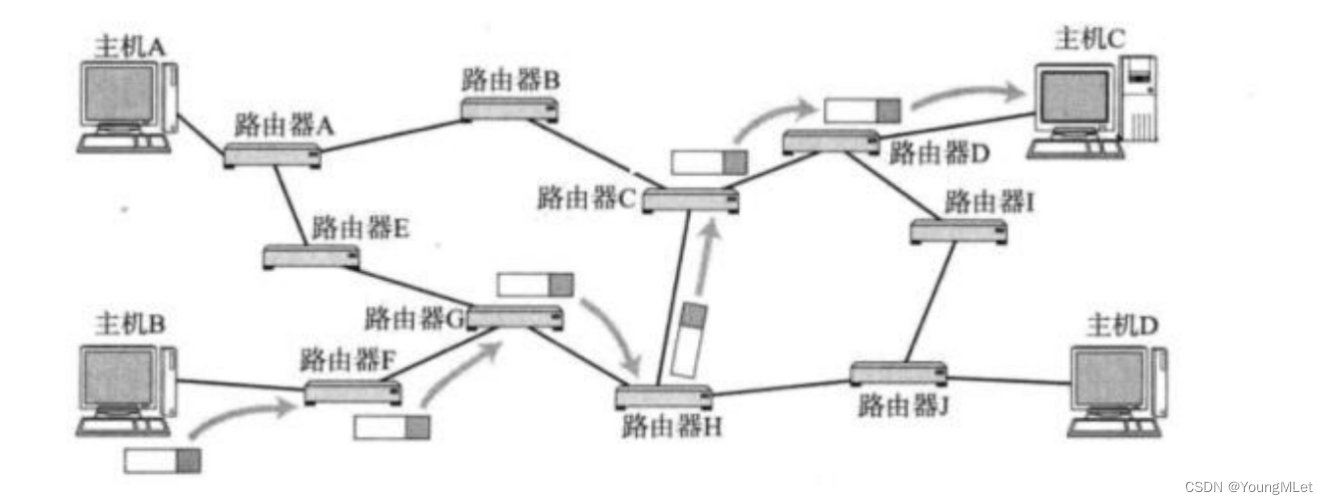
在众多的子网中,子网之间通过路由器连接起来,如果子网1中的主机A需要将数据发送给子网2中的主机B,首先需要通过目标 IP 地址中的目标网络,找到子网2,怎么找到呢?通过路由器的转发!在公网中,路由器是认识并可以通过路径找到某个子网的!那么数据到了子网2后,就可以找到主机B.
所以完整的查找过程如下:
这样的查找过程相对于在公网中一个一个去找就大大提高了效率!这只是在多个局域网中的传输,我们还可以把这多个局域网看做成一个广域网,那么每一个广域网与广域网之间也可以用路由器连接起来!此时就可以进行各种跨网络传输了!
二、IP 协议报头格式
IP 协议的报头格式如下:
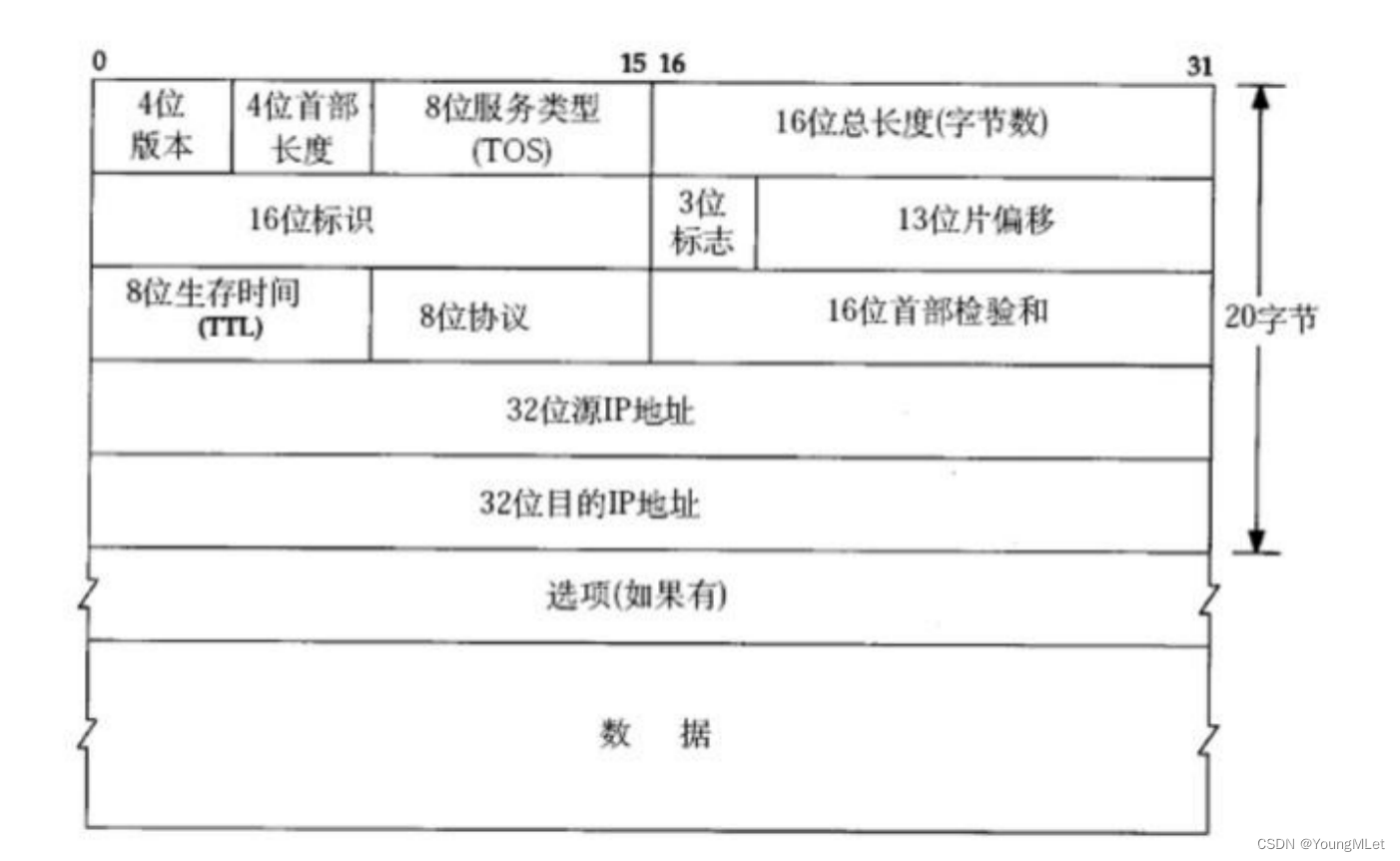
我们可以看到报头的长度是 20 个字节,所以报头和有效载荷可以通过固定长度 + 子描述字段(4位首部长度+16位总长度)进行分离。
- 4 位首部长度
这个 4 位首部长度与 TCP 协议中 4 位首部长度是一样的。也就是整个报头的取值范围在 [20, 60] 字节之间。
- 16 位总长度(total length)
IP 数据报整体占多少个字节。
- 4 位版本
指定 IP 协议的版本,对于 IPv4 来说,就是 4.
- 8位服务类型(Type Of Service)
3位优先权字段(已经弃用),4位 TOS 字段,和1位保留字段(必须置为0).;4位 TOS 分别表示: 最小延时,最大吞吐量,最高可靠性,最小成本,这四者相互冲突,只能选择一个。对于 ssh/telnet 这样的应用程序,最小延时比较重要;对于 ftp 这样的程序,最大吞吐量比较重要。
- 8 位生存时间(Time To Live, TTL)
数据报到达目的地的最大报文跳数,一般是64;每次经过一个路由,TTL -= 1,一直减到 0 还没到达,那么就丢弃了。这个字段主要是用来防止出现路由循环。
- 8 位协议
表示上层协议的类型,即要把 IP 的有效载荷交付给上层的哪一个协议
- 16 位头部校验和
使用CRC进行校验, 来鉴别头部是否损坏。
- 32 位源IP地址和 32 位目标IP地址
表示发送端和接收端,本质上是通过目标 IP 地址来进行路径选择。
- 16 位标识 和 3 位标志 和 13 位片偏移
实际上,在一台主机中,报文并没有通过网络层直接发出去,而是继续交给自己的下一层协议,数据链路层。而数据链路层不能一次发送过大的报文!(原因我们到 Mac帧 的学习再说) 所以要求上层不能交付给数据链路层过大的报文!所以就倒逼 TCP 层就算对方接收缓冲区有很多空间,也不能一次发送太多过来,也就是有了滑动窗口控制发送的数据这么一个说法。
其中数据链路层能发送的最大报文的规定我们可以通过 ifconfig 查看,如下,所能转发的最大报文的字节数称为 mtu:
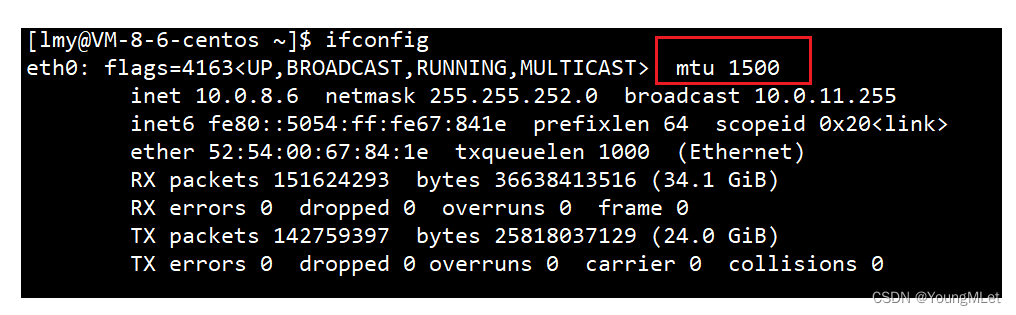
这个 mtu 1500 指的是数据链路层的报头 + 有效载荷,实际上我们能够转发的 IP 报文是要 1500 减去数据链路层的报头大小。
如果 IP 报文就是非常大呢?此时就需要 IP 层进行分片转发,到了目标主机还要在网络层进行组装。所以就要求 IP 报头里涵盖分片和组装的相关信息,所以 16 位标识、3 位标志、13 位片偏移 就是 IP 分片和组装的字段!
下面我们开始介绍这几个字段的含义:
- 16 位标识:IP 报文的编号,不同的 IP 报文,编号是不一样的,分片之后的报文,编号是相同的。也就是唯一标识主机发送的报文,如果 IP 报文在数据链路层被分片了, 那么每一个片里面的这个标识都是相同的。
- 3 位标志:第一位保留(保留的意思是现在不用,但是还没想好说不定以后要用到)。第二位置为 1 表示禁止分片,这时候如果报文长度超过 MTU,IP模块就会丢弃报文。第三位表示 “更多分片”,如果分片了的话,最后一个分片置为 0,其他是 1,类似于一个结束标记。
- 13 位分片偏移:是分片相对于原始 IP 报文开始处的偏移。其实就是在表示当前分片在原报文中处在哪个位置。实际偏移的字节数是这个值 * 8 得到的。因此,除了最后一个报文之外,其他报文的长度必须是 8 的整数倍(否则报文就不连续了)。比如在分片的时候报文被分为了 3 片,那么对于第一片来说它的片偏移就是 0,第二个的片偏移就是前面报文的和,也就是 1500,第三个就是 3000.
那么分片完后如何组装呢?首先需要确保将分片全部聚集在一起,也就是通过相同的 16 位标识 可以将它们聚在一起,随后再根据片偏移进行排序即可进行组装。那对方网络层收到的这个 IP 报文怎么判断该报文是被分片了呢?最简单的就是可以通过收到任意一个分片报文的片偏移不为 0 判断,如果是 0 呢?也就是被分片的第一个分片报文?那就可以通过 3 位标志 中的最后一位结束标记位是否为 1,如果是 1 说明不是最后一个,也就是这是分片的第一个分片报文!
其中要确保所有分片聚集在一起还有一个问题,就是如果其中一个分片报文丢失了呢?首先最简单的就是丢失第一个和最后一个。丢失第一个可以通过组装的时候发现没有一个片偏移是 0 的,就能分辨出第一个丢失。丢失最后一个可以通过组装的时候发现没有一个结束标记为 0,就能分辨出最后一个丢失。如果中间的分片报文丢了呢?丢失的分片报文的后一个分片报文的片偏移量是前面分片报文的和,此时如果中间的报文丢了,就能通过比较丢失报文的后一个片偏移量和前面报文的和不一致判断出来。这就能确保所有分片全部聚在一起了。
要注意的是,每一个分片都要带 IP 协议的报头的,如果没有报头,那么报头中的信息全部都没有了,也就无法进行组装了!所以假设报头是 20 字节的话,实际分片后的数据大小应该要减去 20 字节。
但是实际上并不建议分片,因为如果在组装的时候发现有其中一片丢失了,整体上该报文就被全部丢弃了,这就要求发送方的 TCP 层整体重新发送了,如果是 UDP,该报文也就丢失了。
三、网段划分
1. 初识子网划分
IP地址分为两个部分,网络号和主机号:
- 网络号:保证相互连接的两个网段具有不同的标识;
- 主机号:同一网段内,主机之间具有相同的网络号,但是必须有不同的主机号;
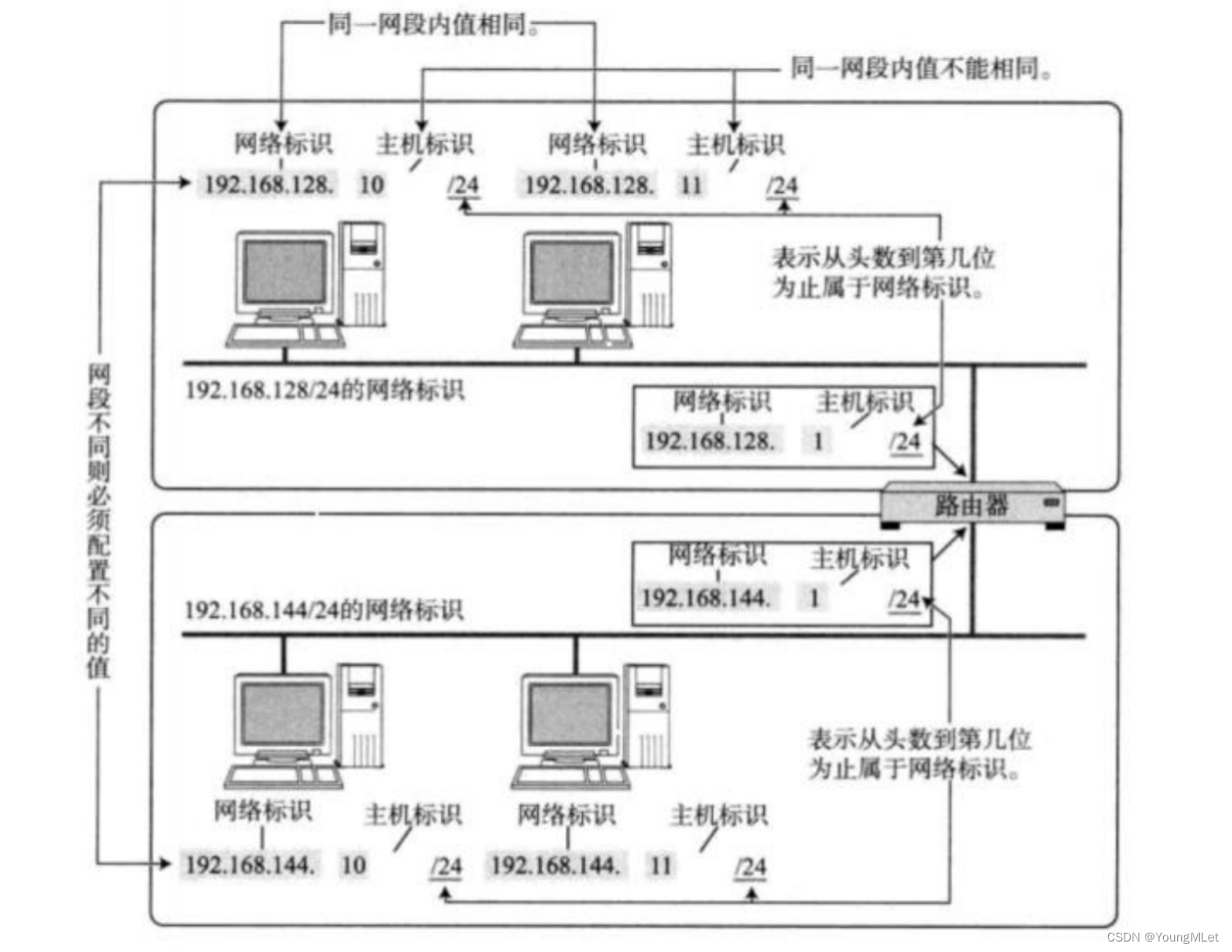
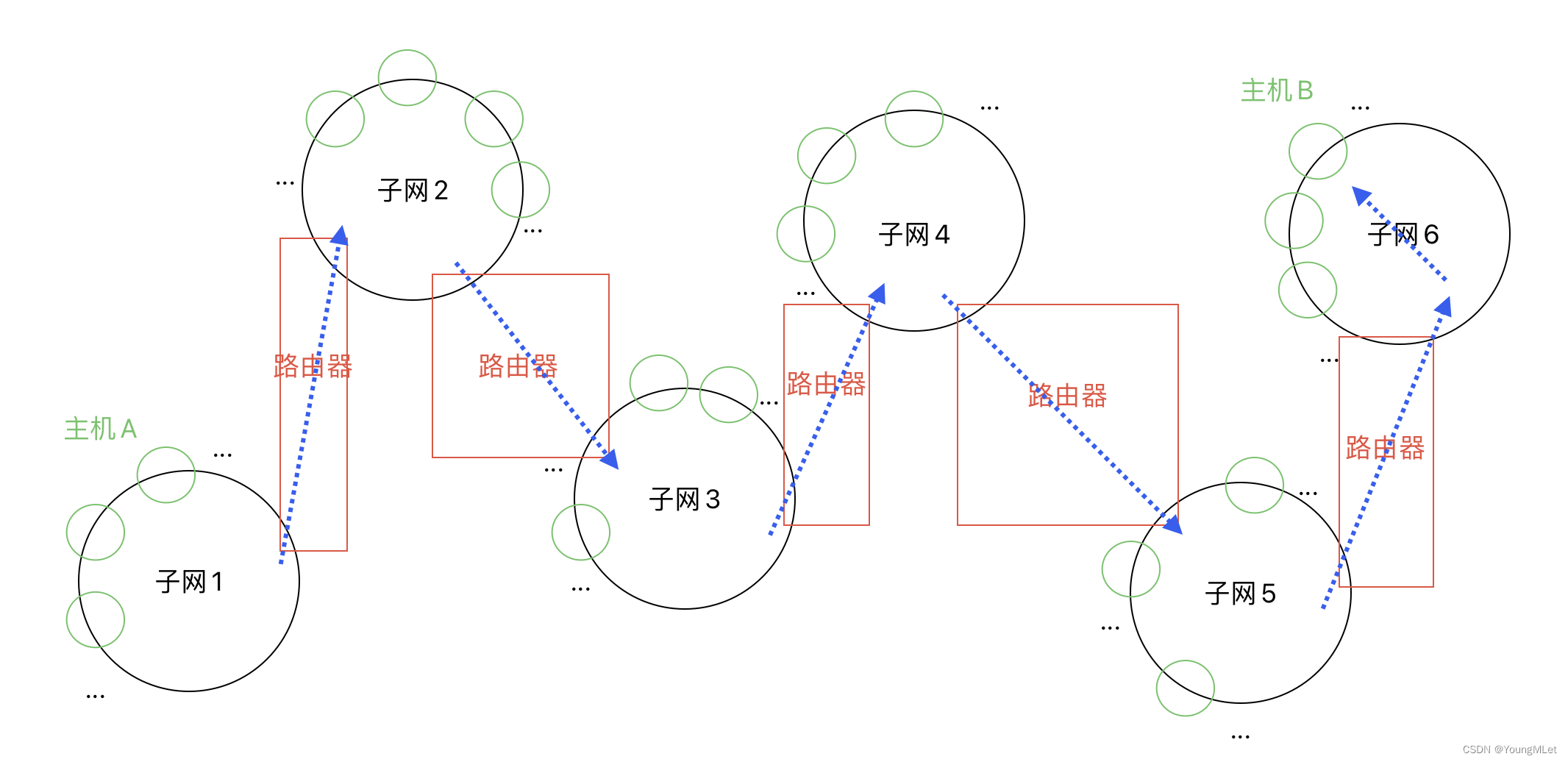
对于上图的理解,我们需要认识下面几点:
- 路由器本质也是特定一个子网的主机,也要配置 IP 地址;
- 路由器一定至少要连接两个子网,路由器也就相当于同时在两个子网,也就是路由器必须要配置多个 IP;我们只需要认为路由器有多张网卡即可;
- 路由器一般是一个子网中的第一台设备,一般它的 IP 地址都是 xxx.xxx.xxx.1,也就是 网络号.1;
- 路由器的功能不仅仅是 IP 报文的转发,路由器还可以构建子网(局域网);
- 不同的子网其实就是把网络号相同的主机放到一起;
- 如果在子网中新增一台主机,则这台主机的网络号和这个子网的网络号一致,但是主机号必须不能和子网中的其他主机重复;
2. 理解子网划分
由于 IP 地址是由 4 个字节组成,也就是 32 位,那么全球中的 IP 地址只有 2^32 个,也就是 IP 地址是一种有限的资源。所以 IP 地址不能乱使用,要有一定的划分方式。
曾经提出过一种划分网络号和主机号的方案,把所有 IP 地址分为五类,如下图所示:

- A类 0.0.0.0 到 127.255.255.255
- B类 128.0.0.0 到 191.255.255.255
- C类 192.0.0.0 到 223.255.255.255
- D类 224.0.0.0 到 239.255.255.255
- E类 240.0.0.0 到 247.255.255.255
随着 Internet 的飞速发展,这种划分方案的局限性很快显现出来,大多数组织都申请B类网络地址,导致B类地址很快就分配完了,而A类却浪费了大量地址。
例如,申请了一个B类地址,理论上一个子网内能允许6万5千多个主机。A类地址的子网内的主机数更多。然而实际网络架设中,不会存在一个子网内有这么多的情况,因此大量的 IP 地址都被浪费掉了。
针对这种情况提出了新的划分方案,称为 CIDR(Classless Interdomain Routing).
3. 子网掩码
- 引入一个额外的子网掩码(subnet mask)来区分网络号和主机号;
- 子网掩码也是一个 32 位的正整数,通常用一串 “0” 来结尾;
- 将 IP 地址和子网掩码进行 “按位与” 操作,得到的结果就是网络号;
- 网络号和主机号的划分与这个 IP 地址是A类、B类还是C类无关;
例如下面两个例子:
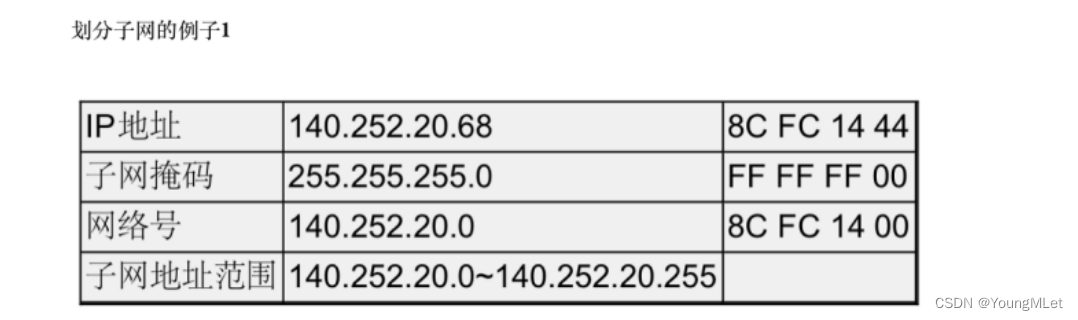

子网掩码通常是由二进制的一串连续的 “1” 和一串连续的 “0” 组成,其中如果 “1” 越多,对应的 IP 地址与子网掩码按位与后,得到的网络号的主机数就变得越少;如果子网掩码中 “0” 越多,也就是得到的网络号中主机变得越多,网络也就越大。所以子网掩码就可以通过调整 “1” 的个数进而调整一个子网中的主机号的增多或者减少!
子网掩码是在路由器中配置的,所以当我们的报文每经过一个路由器,路由器就会拿到我们报文中的目的 IP 地址,和自己内部的子网掩码按位与,就得到了网络号,然后路由器就可以经过目的网络将我们的数据进行转发。
通常子网掩码的书写方式为:xxx.xxx.xxx.xxx/n,其中 /n 表示该地址的前 n 位全部为 “1”,后面的就为全 “0”.
4. 特殊的 IP 地址
- 将 IP 地址中的主机地址全部设为 0,就成为了网络号,代表这个局域网;
- 将 IP 地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包;
- 127.* 的 IP 地址用于本机环回(loop back)测试,通常是127.0.0.1;
5. IP 地址的数量限制
我们知道,IP 地址**(IPv4)**是一个 4字节32位 的正整数,那么一共只有 2^32 个 IP 地址,大概是 43亿左右,而 TCP/IP 协议规定,每个主机都需要有一个 IP 地址。这意味着,一共只有 43 亿台主机能接入网络吗?实际上,由于一些特殊的 IP 地址的存在,数量远不足 43 亿。另外 IP 地址并非是按照主机台数来配置的,而是每一个网卡都需要配置一个或多个 IP 地址。
CIDR 在一定程度上缓解了 IP 地址不够用的问题(提高了利用率,减少了浪费,但是 IP 地址的绝对上限并没有增加),仍然不是很够用,这时候有三种方式来解决:
- 动态分配 IP 地址:只给接入网络的设备分配IP地址。因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的;
- NAT 技术:后面介绍;
- IPv6:IPv6并不是IPv4的简单升级版。这是互不相干的两个协议,彼此并不兼容;IPv6用16字节128位来表示一个IP地址;但是目前IPv6还没有普及;
6. 私有 IP 地址和公网 IP 地址
如果一个组织内部组建局域网,IP 地址只用于局域网内的通信,而不直接连到 Internet 上,理论上使用任意的 IP 地址都可以,但是RFC 1918(网络标准文档)规定了用于组建局域网的私有 IP 地址:
10.*,前8位是网络号,共 16,777,216 个地址;172.16.到172.31.,前 12 位是网络号,共 1,048,576 个地址;192.168.*,前16位是网络号,共 65,536 个地址 ;
包含在这个范围中的,都称为私有IP,其余的则称为公网IP。所以 IP 地址被硬性的划分为公网IP和私有IP。
7. 理解全球网络
(1)理解公网
我们知道,在 IPv4 下,IP 地址是有限的资源,所以在全球中是通过各种综合指标给每个国家进行分配 IP 地址。
全球大概有两百个国家,所以在 32 位的公网 IP 地址中,假设需要前 8 位来划分每一个国家,按照国家的不同有不同的编号,假设中国的前 8 位为 0000 0001,其它国家就类似这样划分就可以了。所以我们国家的前八位 IP 地址为 1.XXX.XXX.XXX.
在全球中,每个国家都有自己的国际路由器,它们之间是互相连接起来的。假设对于我们国家来说,我们的子网掩码是 1.XXX.XXX.XXX/8. 假设我们国家有 30 多个省,所以我们还需要该公网 IP 的 6 个比特位来给每个省进行划分,以广东为例,此时对于国内路由器来说,子网掩码就应该是 1.8.xxx.xxx/14.
那么在广东下,也有非常多的市级,那么还需要一些比特位对这些市级进行 IP 的地址划分,假设还需要 4 个比特位,那么假设以广州为例,对应的子网掩码就应该是 1.8.128.xxx/18;所以如果在广州下的某一台主机,假设该主机序号为 6,那么该主机的公网 IP 地址为 1.8.128.6.
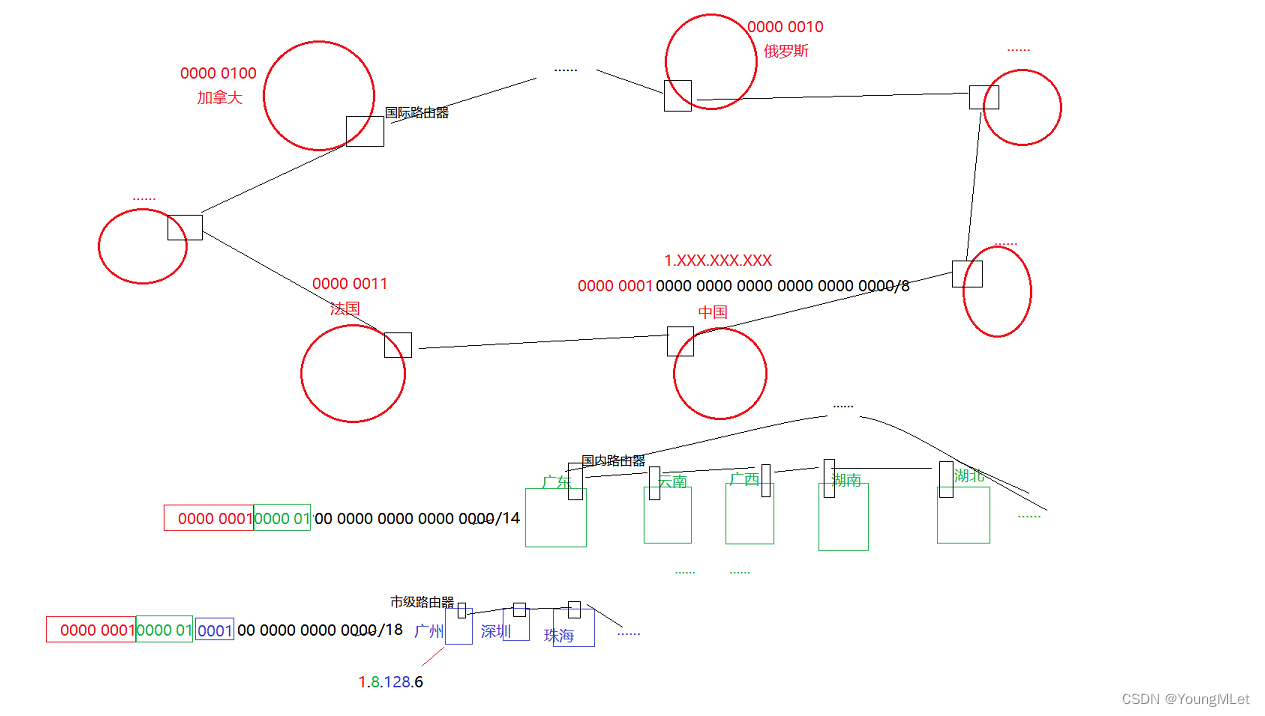
假设现在某个国家需要访问这个 IP 地址,就需要对这个公网 IP 地址的前 8 位进行判断,如果判断到不是本国的,就将这个 IP 地址放到国际广域网中,当中国的国际路由器将该 IP 地址与自己的子网掩码按位与后,如果匹配就说明该 IP 地址的目标网络就是中国国内的网络。到了国内网络后,该 IP 地址进入到各省的广域网中,当广东的国内路由器的子网掩码和该 IP 地址按位与后匹配,该 IP 地址就进入到广州市内的网络,就可以找到对应的主机。
(2)理解私网
我们平时家里的路由器,是能够构建子网(局域网)的,其中构建子网内的每一台设备,都有自己的 IP 地址,该地址就是私网 IP 地址。那么该 IP 为什么不能是公网 IP 呢?因为公网 IP 地址划分到市级之后,剩下的位数已经严重不足了!
当一个子网中的设备发起服务器请求时,首先是将数据包交给家用路由器,然后家用路由器再将数据包交给运营商路由器,然后再进入公网,再访问服务器。
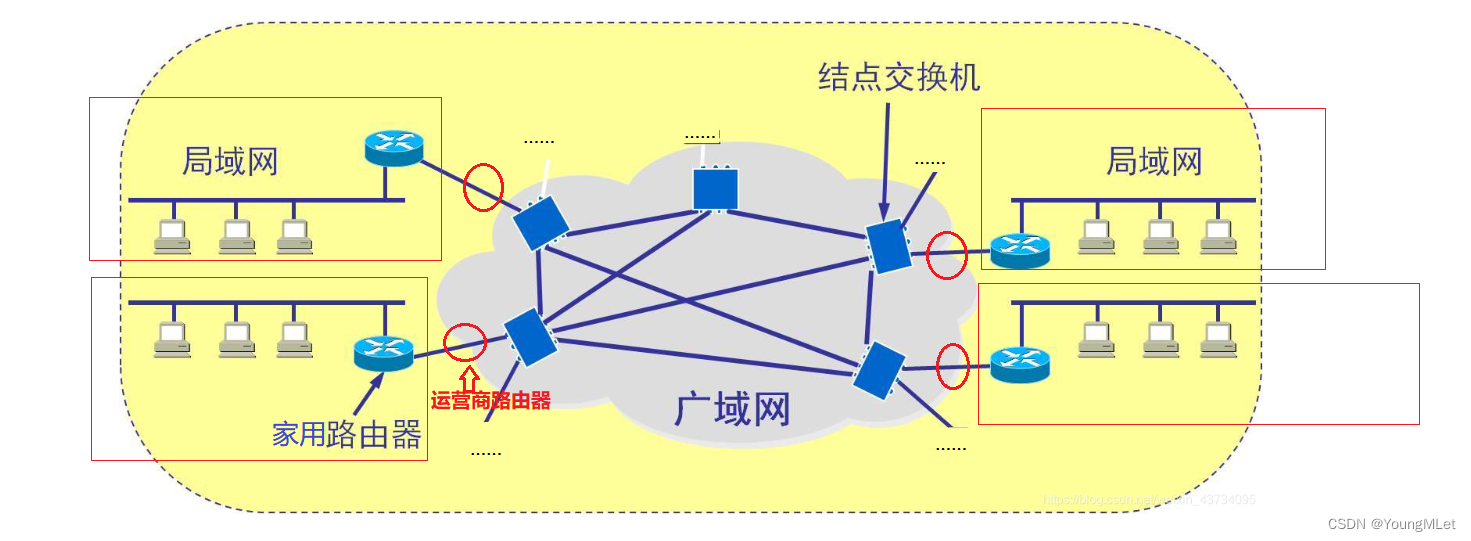
这个过程具体点就是,该数据包中的源 IP 地址就是对应设备的私网 IP 地址,目标 IP 地址就是访问的服务器对应的 IP 地址。那么当数据包经过上面的流程到了服务器之后,如果服务器需要将数据响应回来,那么此时它的源 IP 地址就是服务器的 IP 地址,目标 IP 地址就是发送设备的私网 IP 地址。但是,这个目标 IP 地址是个私网 IP,私网 IP 是不能出现在公网中的!同一个私网 IP,在不同的局域网中可能多次出现过!所以这个数据响应就在公网中回不来了!
怎么解决这个问题呢?由于在路由器中至少要有两个 IP 地址,其中有一个叫做 子网IP,也就是 LAN口IP,就是当前子网的 IP 地址;还有一个叫做 WAN口IP,就是相对于当前子网来说对外的 IP;如果这是一个家用路由器,那么它的 WAN口IP 就是运营商路由器的 IP;如果这是一个运营商路由器,那么它的 WAN口IP 就是公网 IP!
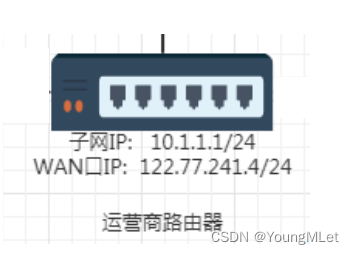
所以在数据包转发的过程中,会做一种策略,每转发一次,会将源 IP 地址替换成每一个路由器的 WAN口IP 地址!所以数据包的源 IP 地址首先是该设备的内网 IP 地址,当数据包交给了家用路由器后,源 IP 地址就变成了家用路由器的 WAN口IP 地址,也就是运营商路由器的 IP 地址;当数据包又经过家用路由器转发给运营商路由器后,该数据包的源 IP 地址就变成了运营商的 WAN口IP 地址,也就是该运营商路由器的入口公网 IP 地址!到了公网之后该数据包的源 IP 地址就变成了公网 IP 地址,所以在服务器进行响应的时候,第一个目标 IP 地址就是发送过来的运营商的公网入口 IP 地址,然后就可以找到该运营商的路由器进而一步一步返回到私网的设备中!至于该数据包怎么回来,我们后面再谈。
那么上面这种私有 IP 地址不断被替换的过程我们称为 NAT技术!
(3)全球网络
那么真实的全球网络情况就是,使用公网 IP 构建全球网络,以及国内网络,到了市级之后,就不能继续使用公网 IP 进行划分了,所以就接入到私网中!所以现在整个主流的互联网世界,采用的方案是:公网+私网 共同构成互联网!如下图:
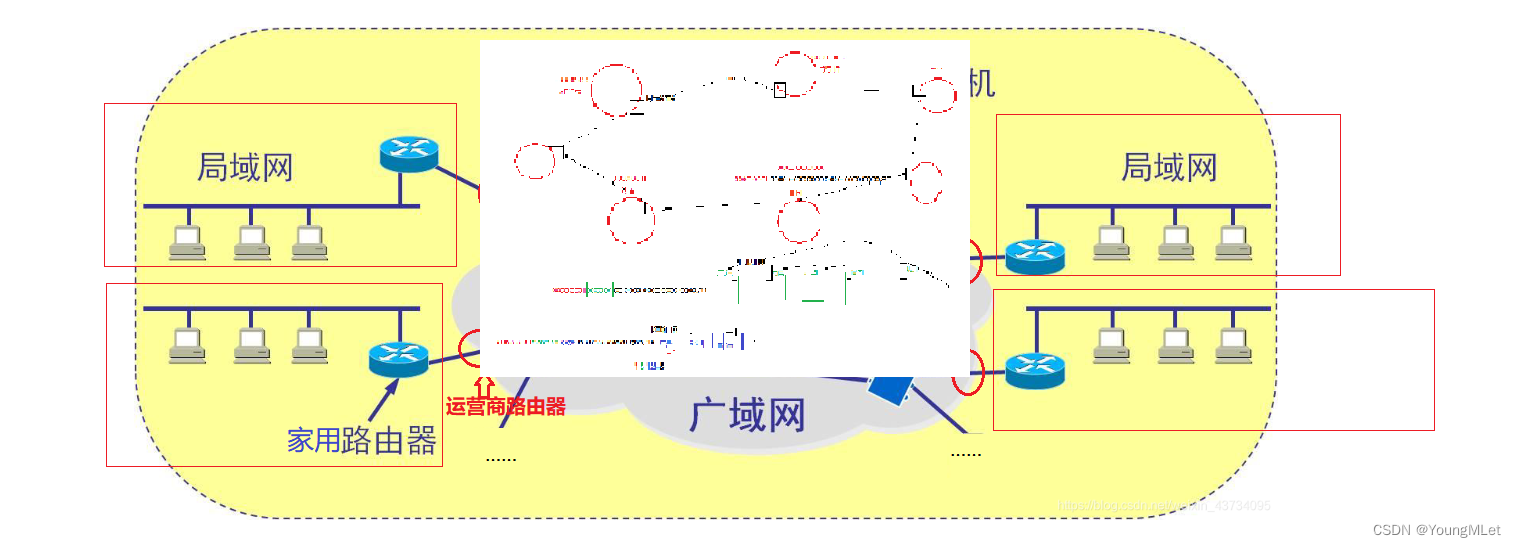
所以在这套全球网络中,大量的私网中出现同样的 IP 地址也不影响,因为 NAT 主要是为了解决 IP 地址不足的问题的。
四、路由
路由就是在复杂的网络结构中,找出一条通往终点的路线。路由的过程,就像下图这样一跳一跳(Hop by Hop) “问路” 的过程:
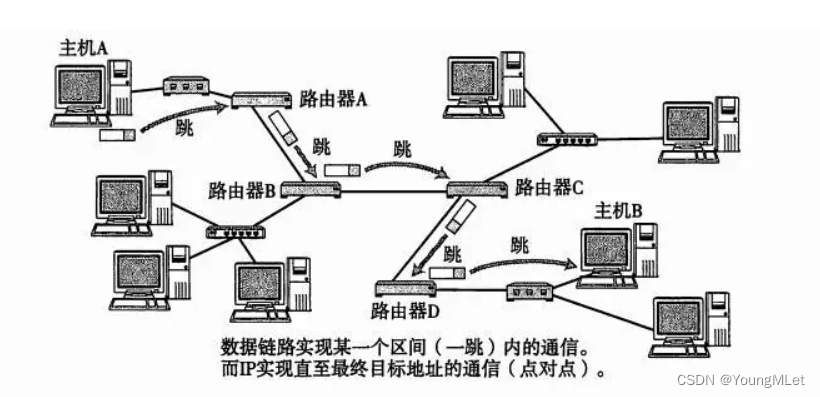
IP 数据包的传输过程也和问路一样
- 当 IP 数据包,到达路由器时,路由器会先查看目的IP;
- 路由器决定这个数据包是能直接发送给目标主机,还是需要发送给下一个路由器;
- 依次反复,一直到达目标IP地址;
当一台主机向服务端发送数据时,在 IP 层会有源 IP 地址和目的 IP 地址,但是发送的主机,它也是工作在应用层的,只要有应用层,那么就肯定就有网络层,因为应用层是在网络层之上的。也就是说,我们的本地主机也是可以工作在网络层的,所以在主机把报文下发的时候,实际上是要在本机内进行路由!所以每一台主机都有自己的路由表,路由表可以使用 route 命令查看,如下:

其中每一列的含义,Destination 表示目标网络地址,也就是该路由器连接的网络;Gateway 表示下一跳的路由器;Genmask 表示子网掩码,每一个目标网络都要配上子网掩码;Flags 中,U 表示正在使用,G 表示该条目所对应的是路由器;Iface 表示通往该网段的出口,最终报文在进行转发时,想把它发出去,就通过这个接口发。
所以查路由表的过程是,用目标主机的 IP 的地址按位与上 Genmask,用结果与每一行的 Destination 做对比,如果对比成功,就通过 Iface 的接口发出去;如果对比不成功,也就是不相同,直接对比下一个。
那么查路由表的结果有几种:
- 没有结果
- 给具体的下一跳
- 路由器不清楚,但是会帮我们转入默认路由
- 到达入口路由器
其中如果是第一种情况,纯属就是路由器设置出的 bug,所以我们不考虑。那么对于第三种情况,默认路由一般指的是同网段的另一台路由器,也就是出口路由器,因为出口路由器一定还会级联其它不同的网络。
相关文章:
【计算机网络】IP 协议
网络层IP协议 一、认识 IP 地址二、IP 协议报头格式三、网段划分1. 初识子网划分2. 理解子网划分3. 子网掩码4. 特殊的 IP 地址5. IP 地址的数量限制6. 私有 IP 地址和公网 IP 地址7. 理解全球网络(1)理解公网(2)理解私网…...

刷题DAY38 | LeetCode 509-斐波那契数 70-爬楼梯 746-使用最小花费爬楼梯
509 斐波那契数(easy) 斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n - 1)…...
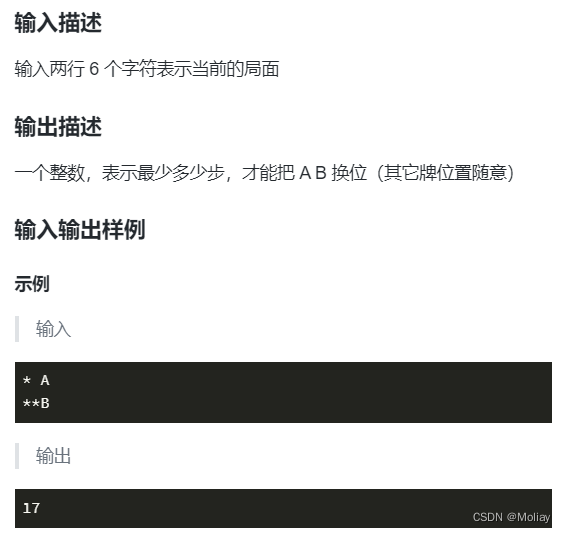
蓝桥杯-卡片换位
solution 有一个测试点没有空格,要特别处理,否则会有一个测试点运行错误! 还有输入数据的规模在变,小心顺手敲错了边界条件 #include<iostream> #include<string> #include<queue> #include<map> #incl…...
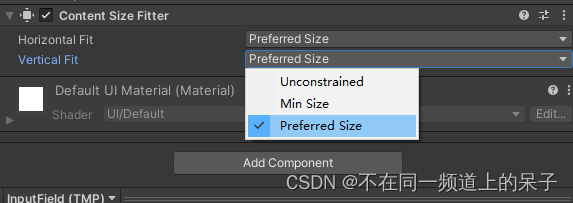
Unity 布局控制器Content Size Fitter
Content Size Fitter是Unity中的一种布局控制器组件,用于根据其内容的大小来调整包含它的UI元素的大小。换句话来说就是,Content Size Fitter可以根据UI元素内部内容的大小,自动调整UI元素的大小,以确保内容能够正确显示。 如下图…...

Python的面向对象、封装、继承、多态相关的定义,用法,意义
面向对象编程(OOP)是一种编程范式,它使用对象的概念来模拟现实世界的实体,并通过类(Class)来创建这些实体的蓝图。OOP的核心概念包括封装、继承和多态。 Python中的面向对象编程 在Python中,一…...
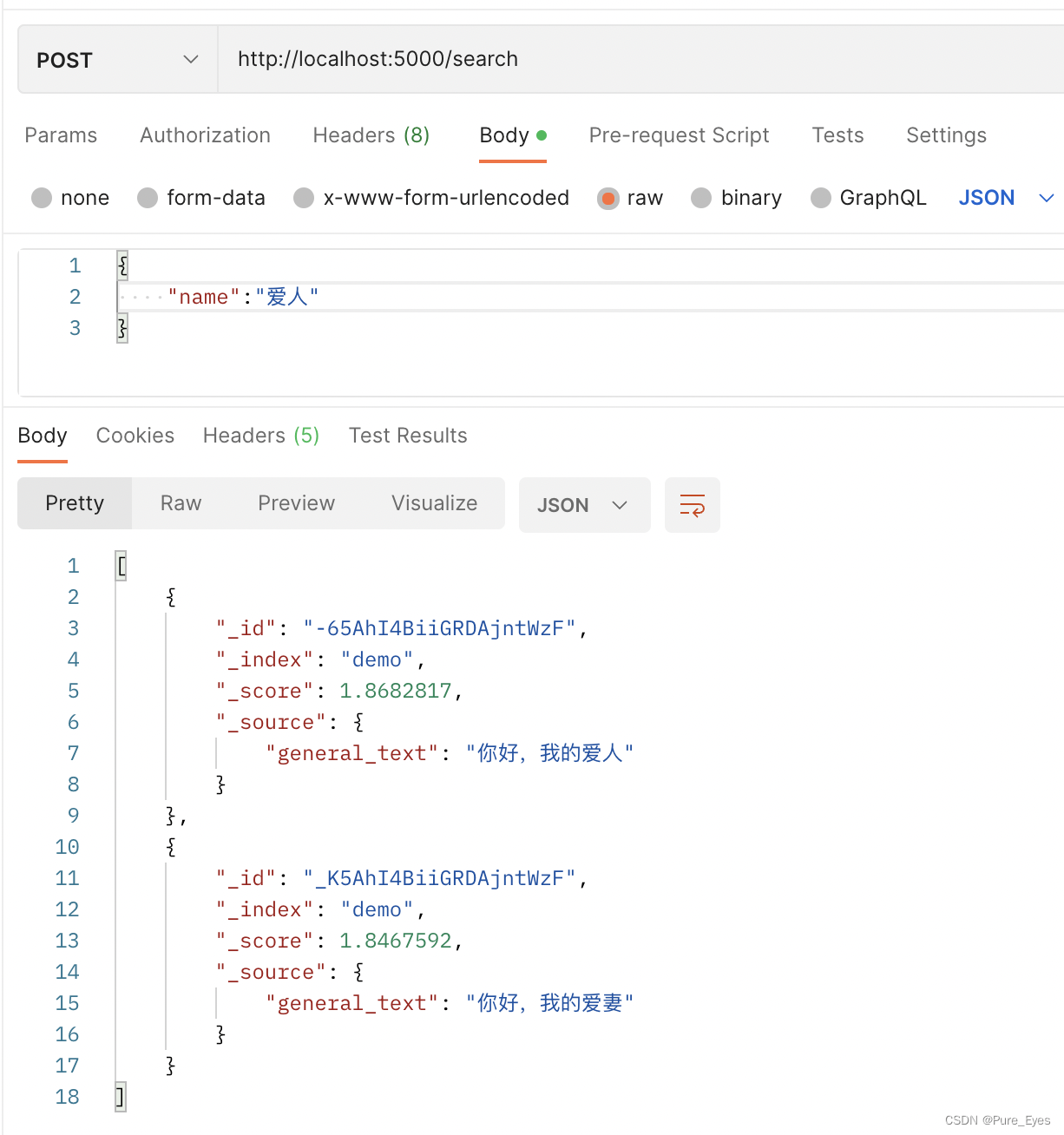
Elasticsearch 向量搜索
目标记录 ["你好,我的爱人","你好,我的爱妻","你好,我的病人","世界真美丽"] 搜索词 爱人 预期返回 ["你好,我的爱人","你好,我的爱妻"] 示例代码…...
)
2024蓝桥杯每日一题(背包)
备战2024年蓝桥杯 -- 每日一题 Python大学A组 试题一:货币系统 试题二:01背包问题 试题三:完全背包问题 试题一:货币系统 【题目描述】 给定 V 种货币(单位:元),每…...
Redis桌面客户端
3.4.Redis桌面客户端 安装完成Redis,我们就可以操作Redis,实现数据的CRUD了。这需要用到Redis客户端,包括: 命令行客户端图形化桌面客户端编程客户端 3.4.1.Redis命令行客户端 Redis安装完成后就自带了命令行客户端࿱…...

让Unity的协程变得简单
作者简介: 高科,先后在 IBM PlatformComputing从事网格计算,淘米网,网易从事游戏服务器开发,拥有丰富的C++,go等语言开发经验,mysql,mongo,redis等数据库,设计模式和网络库开发经验,对战棋类,回合制,moba类页游,手游有丰富的架构设计和开发经验。 (谢谢…...
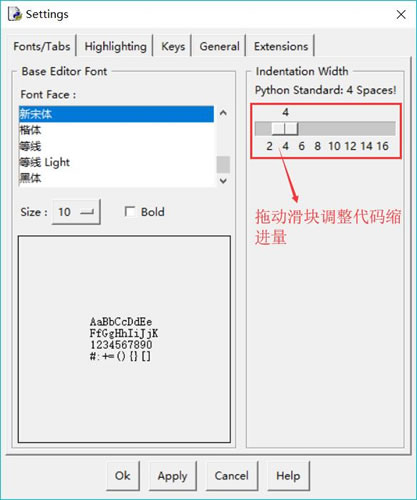
2.9 Python缩进规则(包含快捷键)
Python缩进规则(包含快捷键) 和其它程序设计语言(如 Java、C 语言)采用大括号“{}”分隔代码块不同,Python采用代码缩进和冒号( : )来区分代码块之间的层次。 在 Python 中,对于类…...

任务记录.
播放器端的解码同步问题 miracast的投屏问题,进行修改的问题。 播放器ffplay命令没有声音的修改问题。 任务:如何将断开连接后在连接发送的数据,两秒后再去显示。 猜测: 一直在监听。断开后要求2秒后的数据再显示。那么也就是认为…...

andv vue 实现多张图片上传
1、提示 注意::: 便利出来的数组 点击保存需要 把 双引号去掉 this.formData.image this.imageUrlList.filter((image) > image ! ) 注意::: 回显的时候需要 再把 双引号加上 …...

使用JMeter+Grafana+Influxdb搭建可视化性能测试监控平台
【背景说明】 使用jmeter进行性能测试时,工具自带的查看结果方式往往不够直观和明了,所以我们需要搭建一个可视化监控平台来完成结果监控,这里我们采用三种JMeterGrafanaInfluxdb的方法来完成平台搭建 【实现原理】 通过influxdb数据库存储…...
)
django模板下,vue的使用(前后端不分离)
目录 关于djangovue的结合使用一、在你的templates中引入vue.js二、关于vue与django模板变量的冲突问题三、示例结语 关于djangovue的结合使用 网上的相关教程基本上都是部署node.js,npm安装vue,生成vue项目,然后将vue项目部署至django,这些…...
List(列表))
python笔记(7)List(列表)
目录 创建列表 取列表中的值 更新列表 删除元素 脚本操作符 嵌套列表 Python列表函数&方法 创建列表 创建一个列表(List)用方括号[]括起来就可以,数据项之间用逗号作为分隔符,数据项可以是字符串,数字,甚至…...

java 抠取红色印章(透明背景)
一个亲戚让我帮他把照片里的红色印章抠出来,,,记录下处理过程,代码如下,可直接用: public static void signatureProcess(String sourceImagePath, String targetImagePath) {Graphics2D graphics2D null…...

CSS及javascript
一、CSS简介 css是一门语言,用于控制网页的表现。 cascading style sheet:层叠样式表 二、css的导入方式 css代码与html代码的结合方式 (1)css导入html有三种方式: 1.内联样式:<div style"color:red&quo…...
——4行主要代码(不需要什么前缀和))
LeetCode 1997.访问完所有房间的第一天:动态规划(DP)——4行主要代码(不需要什么前缀和)
【LetMeFly】1997.访问完所有房间的第一天:动态规划(DP)——4行主要代码(不需要什么前缀和) 力扣题目链接:https://leetcode.cn/problems/first-day-where-you-have-been-in-all-the-rooms/ 你需要访问 n 个房间,房间从 0 到 n - 1 编号。同…...

BootsJS上新!一个库解决大部分难题!
不知不觉距离第一次发文章介绍自己写的库BootsJS已经过去一个月了,这个月里收到了许许多多JYM的反馈与建议,自己也再一次对BootsJS进行了改进与完善,又一次增加了很多功能,为此我想应该给JYM们汇报汇报这个月的工作进展。 BootJS仓…...

智慧公厕,让数据和技术更好服务社会生活
智慧公厕,作为智慧城市建设中不可忽视的一部分,正逐渐受到越来越多人的关注。随着科技的不断进步,智能化公厕已经成为一种趋势,通过数据的流转和技术的整合,为社会生活带来了更好的服务。本文以智慧公厕源头实力厂家广…...

大语言模型训练中的显存占用与优化方法简述
在进行大语言模型(LLM)的微调或预训练时,显存(VRAM)不足通常是首要面临的问题。为了在有限的硬件资源下完成训练,了解显存的具体去向以及相应的优化技术是比较基础的工作。 从模型训练的流程来看ÿ…...

每日股票分析自动化:基于Ollama的daily_stock_analysis镜像实战教程
每日股票分析自动化:基于Ollama的daily_stock_analysis镜像实战教程 1. 为什么需要本地化AI股票分析工具 在金融投资领域,及时获取准确的股票分析至关重要。传统方式需要人工收集数据、分析图表、撰写报告,整个过程耗时耗力。而基于大语言模…...

实测有效方案:星图平台一键部署Qwen3-VL:30B,接入飞书提升办公效率
实测有效方案:星图平台一键部署Qwen3-VL:30B,接入飞书提升办公效率 1. 为什么选择Qwen3-VL:30B作为办公助手 1.1 办公场景中的图文处理痛点 在日常办公中,我们经常遇到需要同时处理图片和文字的场景。比如会议结束后,群里堆满了…...

RWKV7-1.5B-g1a惊艳案例:将复杂段落压缩为三条逻辑闭环要点
RWKV7-1.5B-g1a惊艳案例:将复杂段落压缩为三条逻辑闭环要点 1. 模型能力展示:从复杂到简洁的文本处理 RWKV7-1.5B-g1a作为一款轻量级文本生成模型,在信息压缩和提炼方面展现出令人惊喜的能力。我们通过一个实际案例来展示它如何将复杂内容转…...
)
基于springboot美食分享平台设计与开发(源码+精品论文+答辩PPT等资料)
博主介绍:CSDN毕设辅导第一人、靠谱第一人、全网粉丝50W,csdn特邀作者、博客专家、腾讯云社区合作讲师、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交…...

hot100——二分查找
4.寻找两个正序数组的中位数解题思路首先,题目中已经说明,是正序,那么nums1以及nums2中都是从小到大进行排列的;又因为题目中要求时间复杂度为O(log(mn)),一般看到这种时间复杂度是O(log……)形式的,基本上…...

QRazyBox:5分钟解决二维码修复难题的专业工具
QRazyBox:5分钟解决二维码修复难题的专业工具 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 二维码已经成为现代生活中无处不在的数字桥梁,但你是否遇到过这样的情况&…...

大模型进阶必看:Agent Skills如何让AI开发更标准化、可复用?速收藏!
随着AI应用开发成熟,工具调用经历了Function Calling、MCP协议到Agent Skills三个阶段。Agent Skills通过文件系统原生设计,将指令、工作流和资源打包成可复用模块,革新上下文管理,实现代码即工具,摆脱供应商锁定。它使…...

OpenClaw多模型切换指南:Qwen3-32B与本地Llama混合调用
OpenClaw多模型切换指南:Qwen3-32B与本地Llama混合调用 1. 为什么需要多模型切换? 去年冬天,当我第一次尝试用OpenClaw自动处理周报时,发现一个有趣的现象:用同一个模型处理文本润色和代码生成任务,效果差…...

从巨鲸到万物生长:Claude Code如何颠覆AI开发,带你从对话走向Agent平台搭建!
Claude Code凭借其六大核心能力,将AI开发带入全新阶段。通过CLAUDE.md实现项目记忆增强,Skills固化可复用工作流,Sub-Agent处理专业化任务,MCP连接外部服务,Plug-In打包完整解决方案。本文深入解析这些功能,…...