Java自带的线程池及调用、ThreadPoolExecutor类(线程池的7大参数)、任务队列及底层原理
day32
线程池
引入
一个线程完成一项任务所需时间为:
- 创建线程时间 - Time1
- 线程中执行任务的时间 - Time2
- 销毁线程时间 - Time3
注意:优化在Time1,Time3(创建销毁线程费时间)
为什么需要线程池
- 线程池技术正是关注如何缩短或调整Time1和Time3的时间,从而提高程序的性能。项目中可以把Time1,T3分别安排在项目的启动和结束的时间段或者一些空闲的时间段
- 线程池不仅调整Time1,Time3产生的时间段,而且它还显著减少了创建线程的数目,提高线程的复用率
- 系统启动一个新线程的成本是比较高的,因为涉及与操作系统的交互,在这种情形下,使用线程池可以很好地提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,优先考虑使用线程池
为什么使用线程池?
1.优化并调成创建线程和销毁线程的事件
2.提高线程的复用率
3.有效控制项目中的线程目数
Java提供的线程池
ExecutorService:线程池的接口
Executors:创建各种线程池的工具类
理解:实现了ExcutorService接口;底层:死循环,监视有没有提交任务,所以pool.shutdown关闭
分类
1.单个线程的线程池
2.指定线程的线程池
3.可缓存线程的线程池
理解:先没有线程,等有任务就添加一定数量的线程,去分批次执行,等有线程空闲了就干掉
缺点:线程目数不可控
4.延迟任务的线程池
多少时间运行一次(TimeUnit提供了很多时间单位)
public class Test {public static void main(String[] args) {//创建单个线程的线程池//ExecutorService pool = Executors.newSingleThreadExecutor();//创建指定线程的线程池//ExecutorService pool = Executors.newFixedThreadPool(3);//创建可缓存线程的线程池,自动回收60s闲置线程ExecutorService pool = Executors.newCachedThreadPool();//循环创建任务对象,并提交给线程池for (int i = 1; i <= 100; i++) {pool.execute(new Task(i));//提交任务,i为任务编号(方便理解)}pool.shutdown();//关闭线程池}
}
class Task implements Runnable{private int i;public Task(int i) {this.i = i;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + "-->" + i);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}
}
public class Test01 {public static void main(String[] args) throws InterruptedException {//获取延迟任务的线程池ScheduledExecutorService pool = Executors.newSingleThreadScheduledExecutor();//设置延迟时间(时间,时间单位)pool.awaitTermination(6, TimeUnit.SECONDS);//循环创建任务对象,并提交给线程池for (int i = 1; i <= 100; i++) {//创建任务对象Task task = new Task(i);//提交任务pool.execute(task);}//关闭线程池pool.shutdown(); }
}
public class Task implements Runnable{private int num;public Task(int num) {this.num = num;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + "处理了第" + num + "个任务");}}
深入源码
ExecutorService pool = Executors.newSingleThreadExecutor();
ExecutorService pool = Executors.newFixedThreadPool(3);
ExecutorService pool = Executors.newCachedThreadPool();
三种线程池底层都是ThreadPoolExecutor类的对象
-- 分析ThreadPoolExecutor类的构造方法源码--------------------------------
public ThreadPoolExecutor(int corePoolSize, ------------- 核心线程数量 int maximumPoolSize, ------------- 最大线程数量 long keepAliveTime, ------------- 闲置时间,作用于核心线程数与最大线程数之间的线程TimeUnit unit, ------------- keepAliveTime的时间单位(可以是毫秒、秒....)BlockingQueue<Runnable> workQueue, -- 任务队列ThreadFactory threadFactory, -------- 线程工厂RejectedExecutionHandler handler ---- 达到了线程界限和队列容量时的处理方案(拒绝策略)
) {}
执行步骤:1.创建线程池后2.任务提交后,查看是否有核心线程:3.1 没有 -> 就创建核心线程 -> 执行任务 -> 执行完毕后又回到线程池中3.2 有 -> 查看是否有闲置核心线程:4.1 有 -> 执行任务 -> 执行完毕后又回到线程池4.2 没有 -> 查看当前核心线程数是否核心线程数量:5.1 否 -> 就创建核心线程 -> 执行任务 -> 执行完毕后又回到线程池中5.2 是 -> 查看任务列表是否装载满:6.1 没有 -> 就放入列表中,等待出现闲置线程6.2 装满 -> 查看是否有普通线程(核心线程数到最大线程数量之间的线程)7.1 没有 -> 就创建普通线程 -> 执行任务 -> 执行完毕后又回到线程池中7.2 有 -> 查看是否有闲置普通线程7.1.1 有 -> 执行任务 -> 执行完毕后又回到线程池中7.1.2 没有 -> 查看现在所有线程数量是否为最大线程数:8.1 是 -> 执行处理方案(默认处理抛出异常)8.2 否 ->就创建普通线程-> 执行任务 -> 执行完毕后又回到线程池中
注:1.为了更好的理解,在这里区分核心线程和普通线程,实际上区分的这么清楚,都是线程2.默认的处理方案就是抛出RejectedExecutionException
总结:核心线程满载 -> 任务队列 -> 普通线程 -> 拒绝策略-- 分析单个线程的线程池的源码 --------------------------------
ExecutorService pool = Executors.newSingleThreadExecutor();
new ThreadPoolExecutor(1, -- 核心线程数量 1, -- 最大线程数量 0L, -- 闲置时间TimeUnit.MILLISECONDS, -- 时间单位(毫秒)new LinkedBlockingQueue<Runnable>() -- 无界任务队列,可以无限添加任务
)
-- 分析指定线程的线程池的源码 --------------------------------
ExecutorService pool = Executors.newFixedThreadPool(3);
new ThreadPoolExecutor(nThreads, -- 核心线程数量 nThreads, -- 最大线程数量 0L, -- 闲置时间TimeUnit.MILLISECONDS, -- 时间单位(毫秒)new LinkedBlockingQueue<Runnable>()-- 无界任务队列,可以无限添加任务
)
-- 创建可缓存线程的线程池 -----------------------------------
new ThreadPoolExecutor(0, -- 核心线程数量 Integer.MAX_VALUE,-- 最大线程数量 60L, -- 闲置时间TimeUnit.SECONDS, -- 时间单位(秒)new SynchronousQueue<Runnable>() -- 直接提交队列(同步队列):没有容量队列
任务队列详解
| 队列名称 | 详解 |
|---|---|
| LinkedBlockingQueue无界任务队列 | 使用无界任务队列,线程池的任务队列可以无限制的添加新的任务,而线程池创建的最大线程数量就是你corePoolSize设置的数量,也就是说在这种情况下maximumPoolSize这个参数是无效的,哪怕你的任务队列中缓存了很多未执行的任务,当线程池的线程数达到corePoolSize后,就不会再增加了;若后续有新的任务加入,则直接进入队列等待,当使用这种任务队列模式时,一定要注意你任务提交与处理之间的协调与控制,不然会出现队列中的任务由于无法及时处理导致一直增长,直到最后资源耗尽的问题 |
| SynchronousQueue 同步任务队列 直接提交任务队列 | 使用直接提交任务队列,队列没有容量,每执行一个插入操作就会阻塞,需要再执行一个删除操作才会被唤醒,反之每一个删除操作也都要等待对应的插入操作。 任务队列为SynchronousQueue,创建的线程数大于maximumPoolSize时,直接执行了拒绝策略抛出异常。 使用SynchronousQueue队列,提交的任务不会被保存,总是会马上提交执行。如果用于执行任务的线程数量小于maximumPoolSize,则尝试创建新的线程,如果达到maximumPoolSize设置的最大值,则根据你设置的handler执行拒绝策略。因此这种方式你提交的任务不会被缓存起来,而是会被马上执行,在这种情况下,你需要对你程序的并发量有个准确的评估,才能设置合适的maximumPoolSize数量,否则很容易就会执行拒绝策略; |
| ArrayBlockingQueue有界任务队列 | 使用有界任务队列,若有新的任务需要执行时,线程池会创建新的线程,直到创建的线程数量达到corePoolSize时,则会将新的任务加入到等待队列中。若等待队列已满,即超过ArrayBlockingQueue初始化的容量,则继续创建线程,直到线程数量达到maximumPoolSize设置的最大线程数量,若大于maximumPoolSize,则执行拒绝策略。在这种情况下,线程数量的上限与有界任务队列的状态有直接关系,如果有界队列初始容量较大或者没有达到超负荷的状态,线程数将一直维持在corePoolSize以下,反之当任务队列已满时,则会以maximumPoolSize为最大线程数上限。 |
| PriorityBlockingQueue优先任务队列 | 使用优先任务队列,它其实是一个特殊的无界队列,它其中无论添加了多少个任务,线程池创建的线程数也不会超过corePoolSize的数量,只不过其他队列一般是按照先进先出的规则处理任务,而PriorityBlockingQueue队列可以自定义规则根据任务的优先级顺序先后执行。 |
对优先队列的使用说明:
public class Test {public static void main(String[] args) {ThreadPoolExecutor pool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS, new PriorityBlockingQueue<>(), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());for (int i = 1; i <= 10; i++) {pool.execute(new Task(i));}pool.shutdown();}
}
class Task implements Runnable,Comparable<Task>{private int priority;public Task(int priority) {this.priority = priority;}@Overridepublic void run() {try {Thread.sleep(1000);System.out.println(Thread.currentThread().getName() + " priority:" + this.priority);} catch (InterruptedException e) {e.printStackTrace();}}//当前对象和其他对象做比较,当前优先级大就返回-1,优先级小就返回1,值越小优先级越高@Overridepublic int compareTo(Task o) {return (this.priority>o.priority)?-1:1;}
}
总结:除了第一个任务直接创建线程执行外,其他的任务都被放入了优先任务队列,按优先级进行了重新排列执行,且线程池的线程数一直为corePoolSize,也就是只有一个。
代码实现
无界队列
理解:这个队列没有上限
继承关系:LinkedBlockingQueue -> AbstractQueue -> AbstractCollection
小结:
1.LinkedBlockingQueue是Collection集合家族的一员
2.Collection集合家族(List、Set、Queue)
3.LinkedBlockingQueue数据结构单向链表
缺点:LinkedBlockingQueue可能造成内存溢出
有界队列
继承关系:ArrayBlockingQueue -> AbstractQueue -> AbstractCollection
小结:
1.ArrayBlockingQueue是Collection集合家族的一员
2.Collection集合家族(List、Set、Queue)
3.ArrayBlockingQueue数据结构一维数组
public class Test01 {public static void main(String[] args) throws InterruptedException {//创建无界队列LinkedBlockingQueue<String> queue = new LinkedBlockingQueue<>();//创建有界队列//ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<>(6);//添加元素queue.put("aaa");queue.put("bbb");queue.put("ccc");queue.put("ddd");queue.put("eee");queue.put("fff");//删除元素queue.remove("ccc");//遍历队列Iterator<String> it = queue.iterator();while (it.hasNext()) {String string = it.next();System.out.println(string);} }
}
优先队列
继承关系:ArrayBlockingQueue -> AbstractQueue -> AbstractCollection
小结:
1.ArrayBlockingQueue是Collection集合家族的一员
2.Collection集合家族(List、Set、Queue)
3.ArrayBlockingQueue数据结构一维数组
public class Test03 {public static void main(String[] args) throws InterruptedException {//创建优先队列PriorityBlockingQueue<Task> queue = new PriorityBlockingQueue<>();//无参构造底层使用的是元素的内置比较器//添加元素queue.add(new Task(3));queue.add(new Task(1));queue.add(new Task(4));queue.add(new Task(2));//遍历取出队列while(!queue.isEmpty()){//删除第一元素Task poll = queue.poll();System.out.println(poll.getPriority());}}
}
Task类
public class Task implements Runnable,Comparable<Task>{private int priority;//优先级别public Task(int priority) {this.priority = priority;}@Overridepublic void run() {System.out.println("任务被处理了");}//当前对象和其他对象做比较,当前优先级大就返回-1,优先级小就返回1,值越小优先级越高@Overridepublic int compareTo(Task o) {return Integer.compare(this.priority, o.priority);}public int getPriority() {return priority;}
}总结
1.Java自带的线程池
单个线程的线程池
指定线程个数的线程池
可缓存的线程池
延迟任务的线程池2.线程池的7大参数
核心线程数
最大线程数
任务队列(有界、无界、同步、优先队列)
拒绝策略
闲置时间
时间单位
线程工厂3.线程池的调用步骤(核心线程、任务队列、普通线程、拒绝策略)
4.任务队列及底层原理(有界、无界、同步、优先队列)
相关文章:
、任务队列及底层原理)
Java自带的线程池及调用、ThreadPoolExecutor类(线程池的7大参数)、任务队列及底层原理
day32 线程池 引入 一个线程完成一项任务所需时间为: 创建线程时间 - Time1线程中执行任务的时间 - Time2销毁线程时间 - Time3 注意:优化在Time1,Time3(创建销毁线程费时间) 为什么需要线程池 线程池技术正是关注如何缩短或调整Time1和Tim…...

ThreadPool-线程池使用及原理
1. 线程池使用方式 示例代码: // 一池N线程 Executors.newFixedThreadPool(int) // 一个任务一个任务执行,一池一线程 Executors.newSingleThreadExecutorO // 线程池根据需求创建线程,可扩容,遇强则强 Executors.newCachedThre…...

高性能服务系列【十一】主题匹配
主题匹配核心算法就是字符串匹配,在字符串匹配基础上,会加入分段匹配需求,类似URL的点分式字符串。这个算法在几个场景中十分普遍。 1、应用层的路由寻址。比如反向代理中,根据请求中的URL,转发到对应的后台服务。 2…...
Vue 2 组件发布到 npm 的常见问题解决
按照 Vue 2 组件打包并发布到 npm 的方法配置项目后,项目在实际开发过程中,随着代码写法的多样性增加而遇到的各种打包问题,本文将予以逐一解决: 本文目录 同时导出多个组件 样式表 import 问题解决 Json 文件 import 问题解决…...

p2p原理
p2p原理 P2P (Peer-to-Peer) 是一种分布式计算和网络架构模型,它允许对等节点之间直接通信和共享资源,而无需通过集中的服务器。P2P 原理的核心概念是平等性(peer equality),即所有节点在网络中都具有相同的功能和能力…...

从供方协议管理到外部供方管理
从GJB 5000A的供方协议管理到GJB 5000B的外部供方管理,军用软件的研制对承接单位有了更高的标准和要求,也对外部供方管理有了更改的要求,让我们看看具体的变化吧! 供方协议管理的目的: 管理供方产品的获取工作。 外部…...

微服务demo(四)nacosfeigngateway
一、gateway使用: 1、集成方法 1.1、pom依赖: 建议:gateway模块的pom不要去继承父工程的pom,父工程的pom依赖太多,极大可能会导致运行报错,新建gateway子工程后,pom父类就采用默认的spring-b…...

2D与动画
2D转换 1.移动 translate 1. 语法 transform: translate(x,y); 或者分开写 transform: translateX(n); transform: translateY(n); 2.重点 定义 2D 转换中的移动,沿着 X 和 Y 轴移动元素 translate最大的优点:不会影响到其他元素的位置 translat…...

Maven:构建现代化软件项目的强大工具
在软件开发的世界中,Maven 是一个备受欢迎的构建工具。它提供了一种标准化、自动化的方式来管理项目的依赖、构建过程和部署。本文将深入探讨 Maven 的各个方面,帮助您更好地理解和使用这一强大的工具。 一、Maven 的简介 Maven 是一个基于项目…...
)
脏牛提权(靶机复现)
目录 一、脏牛漏洞概述 二、漏洞复现 1.nmap信息收集 1.1.查看当前IP地址 1.2.扫描当前网段,找出目标机器 1.3.快速扫描目标机全端口 三、访问收集到的资产 192.168.40.134:80 192.168.40.134:1898 四、msf攻击 1.查找对应exp 2.选择对应exp并配置相关设置 五、内…...
用html写一个贪吃蛇游戏
<!DOCTYPE html> <html> <head><title>贪吃蛇</title><meta charset"UTF-8"><meta name"keywords" content"贪吃蛇"><meta name"Description" content"这是一个初学者用来学习的小…...

Topaz Gigapixel AI for Mac 图像放大软件
Topaz Gigapixel AI for Mac是一款专为Mac用户设计的智能图像放大软件。它采用了人工智能技术,特别是深度学习算法,以提高图像的分辨率和质量,使得图像在放大后仍能保持清晰的细节。这款软件的特点在于其能够将低分辨率的图片放大至高分辨率&…...

uniapp先显示提示消息再返回上一页
一、描述 在有些业务场景中,需要先弹出提示后,再返回上一页。 二、思路 使用定时器,先弹出提示消息,然后开个定时器俩秒后再执行,返回上一页的操作,并且清除定时器。 三、实现 uni.showToast({title: …...
【爬虫开发】爬虫从0到1全知识md笔记第2篇:requests模块,知识点:【附代码文档】
爬虫开发从0到1全知识教程完整教程(附代码资料)主要内容讲述:爬虫课程概要,爬虫基础爬虫概述,,http协议复习。requests模块,requests模块1. requests模块介绍,2. response响应对象,3. requests模块发送请求,4. request…...

【算法刷题day11】Leetcode: 20. 有效的括号、 1047. 删除字符串中的所有相邻重复项、150. 逆波兰表达式求值
20. 有效的括号 文档链接:[代码随想录] 题目链接:20. 有效的括号 状态:ok 题目: 给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符…...
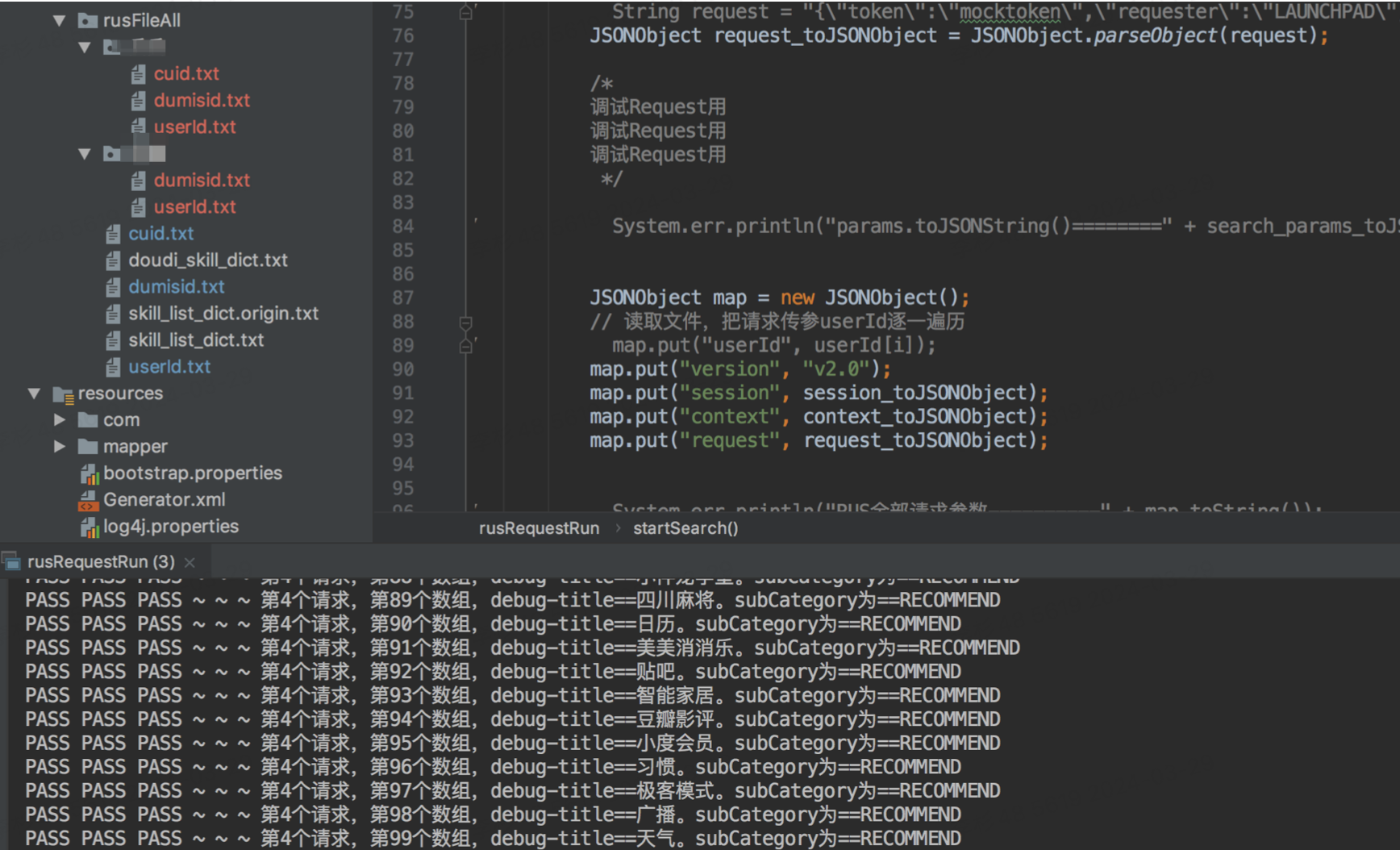
推荐算法策略需求-rank model优化
1.pred_oobe (base) [rusxx]$ pwd /home/disk2/data/xx/icode/baidu/oxygen/rus-pipeline/pipeline-migrate/UserBaseActiveStatPipeline/his_session (base) [rusxx]$ sh test.sh 2. user_skill_history_dict_expt2包含userid [workxx]$ vim /home/work/xx/du-rus/du_rus_o…...

hadoop 常用命令
hadoop 常用命令 hadoop fs -mkdir /test hadoop fs -put /opt/frank/tb_test03.txt /test/ hadoop fs -ls /test/ hadoop fs -cat /test/tb_test03.txt hadoop fs -rm /test/tb_test03.txt hadoop dfs 也能使用、但不推荐,执行会提示: DEPRECATED: Us…...
pdf在浏览器上无法正常加载的问题
一、背景 觉得很有意思给大家分享一下。事情是这样的,开发给我反馈说,线上环境接口请求展示pdf异常,此时碰巧我前不久正好在ingress前加了一层nginx,恰逢此时内心五谷杂陈,思路第一时间便放在了改动项。捣鼓了好久无果…...
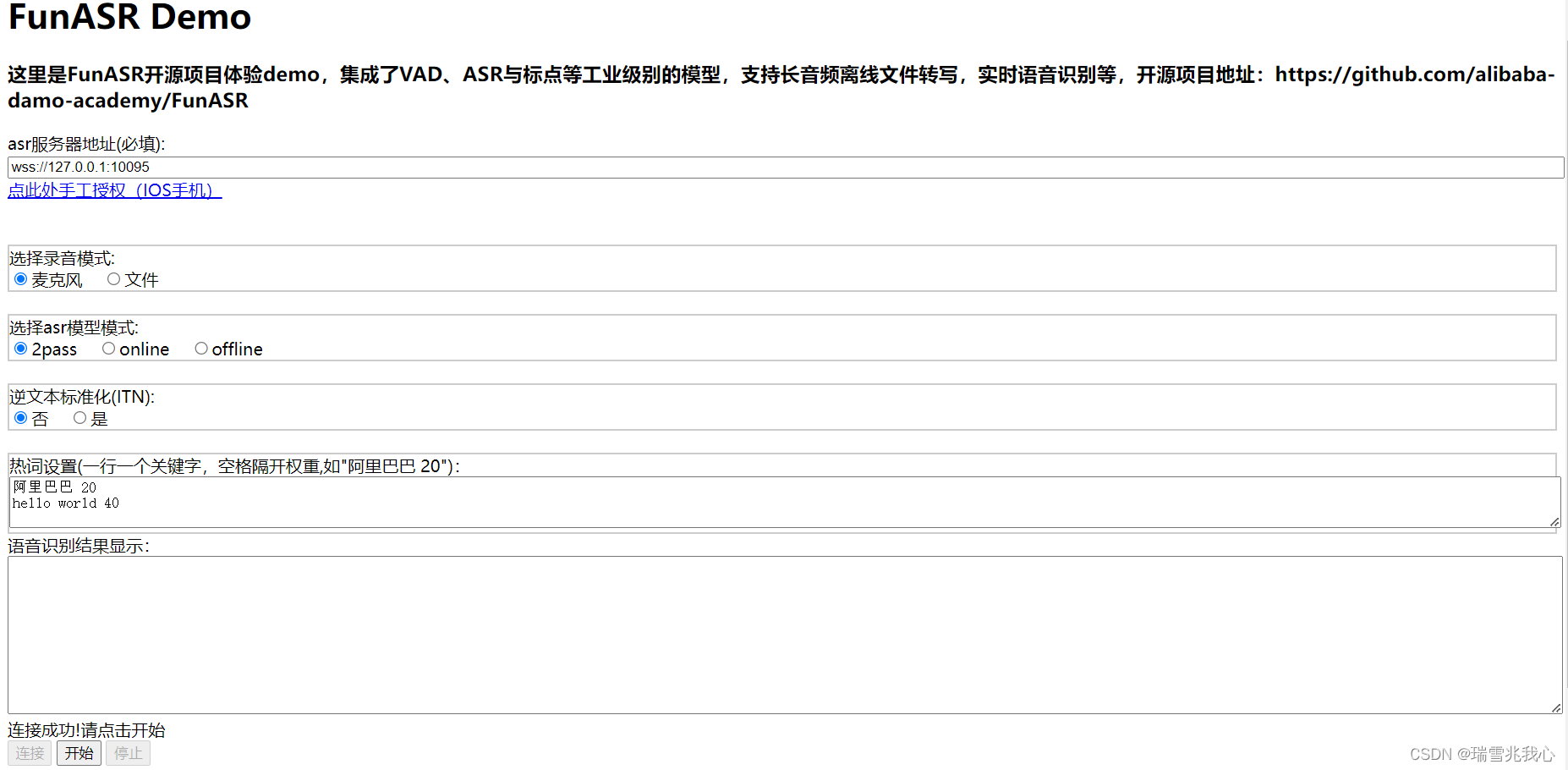
实时语音识别(Python+HTML实战)
项目下载地址:FunASR 1 安装库文件 项目提示所需要下载的库文件:pip install -U funasr 和 pip install modelscope 运行过程中,我发现还需要下载以下库文件才能正常运行: 下载:pip install websockets,pi…...

x86_64 ubuntu22.04编译MetaRTC
metaRTC5.0 API https://github.com/metartc/metaRTC/wiki/metaRTC5.0-API Sample https://github.com/metartc/metaRTC/wiki/metaRTC5.0-API-Sample MetaRTC7.0编译 https://github.com/metartc/metaRTC/wiki/Here-we-come,-write-a-C-version-of-webRTC-that-runs-everywhere…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...
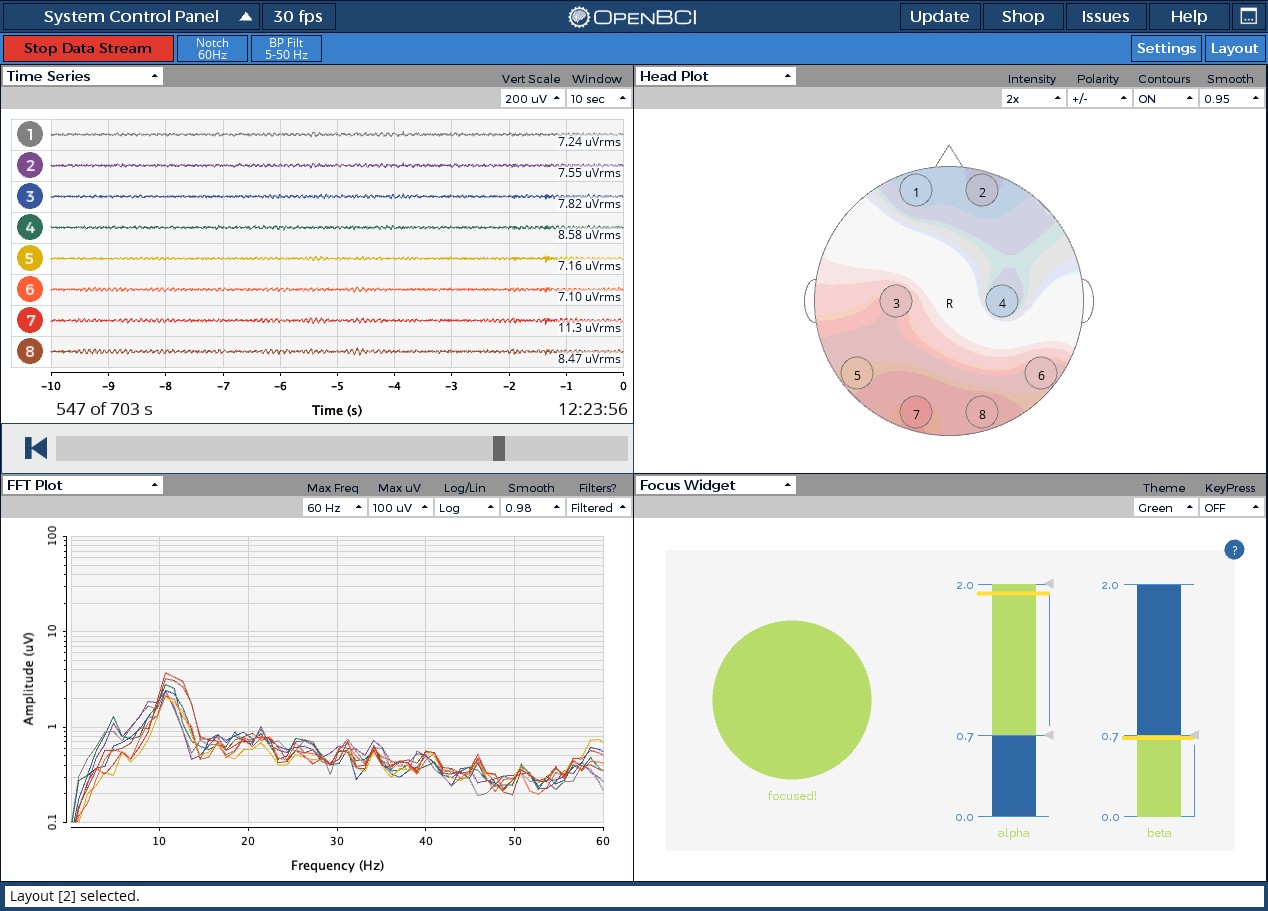
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...
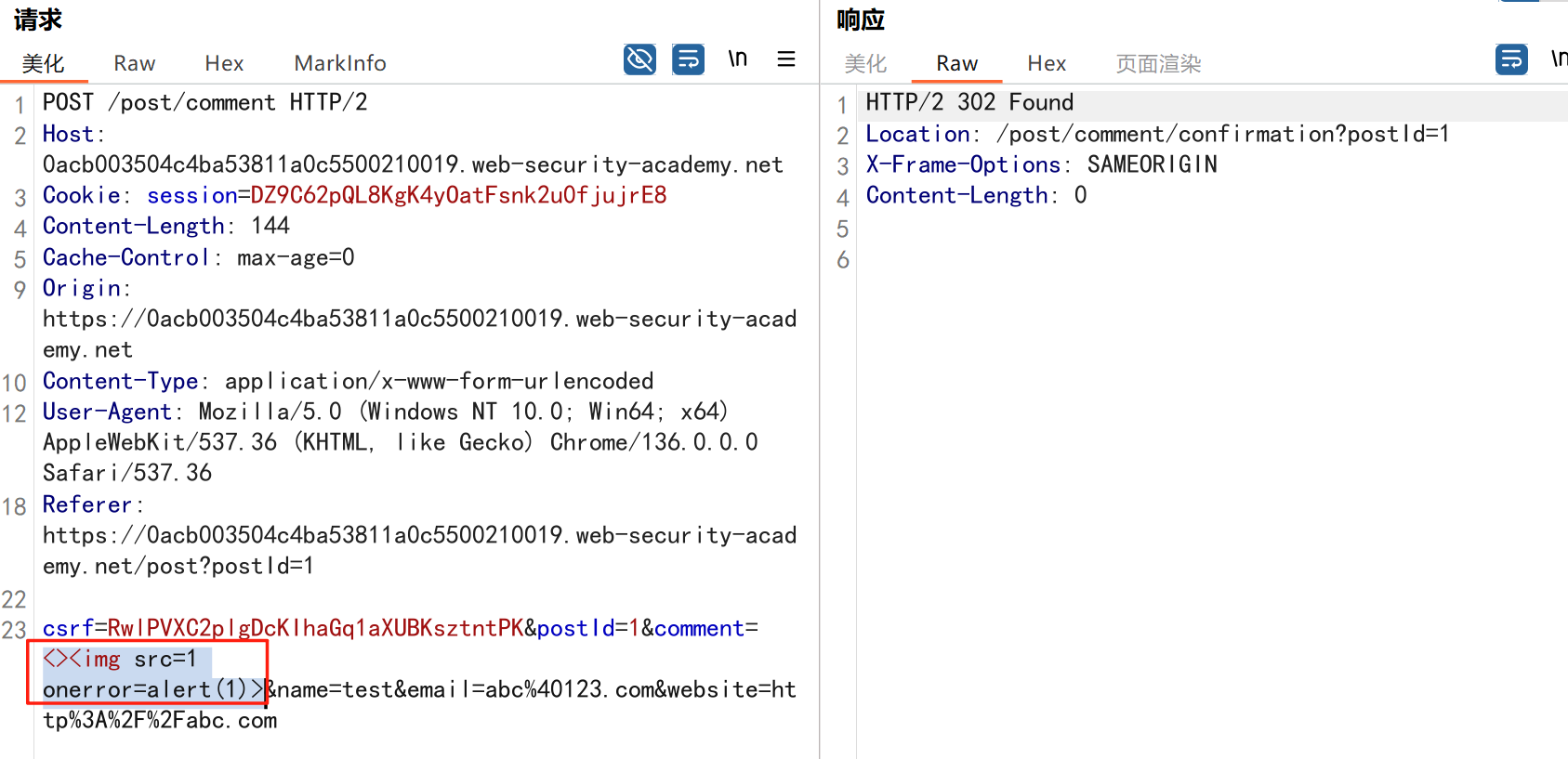
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...

es6+和css3新增的特性有哪些
一:ECMAScript 新特性(ES6) ES6 (2015) - 革命性更新 1,记住的方法,从一个方法里面用到了哪些技术 1,let /const块级作用域声明2,**默认参数**:函数参数可以设置默认值。3&#x…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...