Kubernetes调度之Pod亲和性
Kubernetes调度中的Pod亲和性

abstract.png
Pod亲和性
节点亲和性,是基于节点的标签对Pod进行调度。而Pod亲和性则可以实现基于已经在节点上运行Pod的标签来约束新Pod可以调度到的节点。具体地,如果X上已经运行了一个或多个满足规则Y的Pod,则这个新Pod也应该运行在X上。其中,X可以是节点、机架、可用性区域、地理区域等。可通过topologyKey字段定义拓扑域X,其取值是节点标签的键名Key;而Y则是Kubernetes尝试满足的规则。可以通过标签选择器的形式来定义。此外,Pod亲和性使用podAffinity字段,其下支持两种亲和性:
「requiredDuringSchedulingIgnoredDuringExecution」:requiredDuringScheduling表明其是一个强制性的调度,调度器只有在规则被满足的时候才能执行调度;而IgnoredDuringExecution则表明其不会影响已在节点上运行的Pod
「preferredDuringSchedulingIgnoredDuringExecution」:preferredDuringScheduling表明其是一个偏好性的调度,调度器会根据偏好优先选择满足对应规则的节点来调度Pod。但如果找不到满足规则的节点,调度器则会选择其他节点来调度Pod。而IgnoredDuringExecution则表明其不会影响已在节点上运行的Pod
强制性调度
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的前端服务
# 应用的前端服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-frontendspec: # Pod副本数量 replicas: 2 selector: matchLabels: app: frontend # Pod模板 template: metadata: # 标签信息: 应用的前端服务 labels: app: frontend spec: # 容器信息 containers: - name: my-app-frontend image: jocatalin/kubernetes-bootcamp:v1效果如下所示,可以看到前端服务运行了2个Pod。分别在my-k8s-cluster-multi-node-worker2、my-k8s-cluster-multi-node-worker3节点上
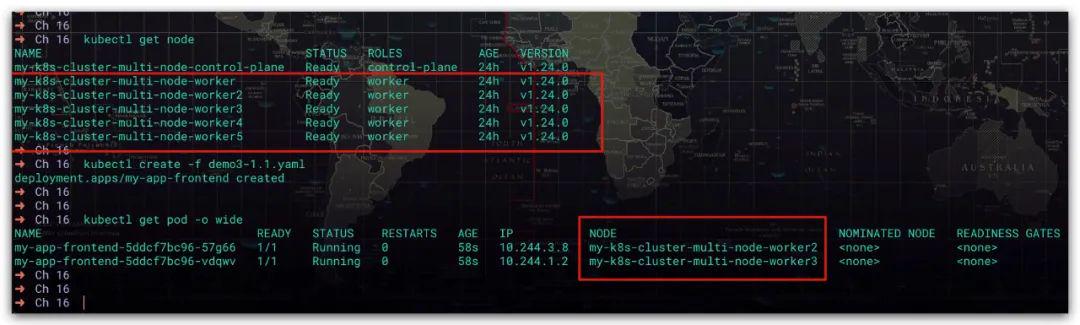
figure 1.jpeg
现在我们来部署应用的后端服务,这里我们期望后端服务的Pod能够运行在前端服务的Pod所在的节点上。这时就可以通过节点亲和性实现。具体地:
首先,使用podAffinity来定义Pod亲和性规则,使用requiredDuringSchedulingIgnoredDuringExecution定义强制性的调度规则
然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是前端服务的Pod
最后,使用topologyKey来定义拓扑域信息,这里我们使用的是节点主机名。对于 此时即将被调度的新Pod 与 标签选择器所确定的Pod 来说,它们各自运行节点的主机名是相同的。即,后端服务的Pod 必须被调度到 与前端服务的Pod所在节点拥有相同主机名 的节点上
这样即可实现后端服务的Pod所在的节点上,一定存在前端服务的Pod
# 应用的后端服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-backendspec: # Pod副本数量 replicas: 4 selector: matchLabels: app: backend # Pod模板 template: metadata: # 标签信息: 应用的后端服务 labels: app: backend spec: # 亲和性 affinity: # Pod亲和性规则 podAffinity: # 强制性的调度规则, 但不会影响已在节点上运行的Pod requiredDuringSchedulingIgnoredDuringExecution: - topologyKey: kubernetes.io/hostname # 标签选择器 labelSelector: matchLabels: app: frontend # 容器信息 containers: - name: my-app-backend image: tutum/dnsutils command: - sleep - infinity效果如下所示。后端服务的5个Pod均运行在my-k8s-cluster-multi-node-worker2、my-k8s-cluster-multi-node-worker3节点上

figure 2.jpeg
偏好性调度
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的前端服务
# 应用的后端服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-backendspec: # Pod副本数量 replicas: 2 selector: matchLabels: app: backend # Pod模板 template: metadata: # 标签信息: 应用的后端服务 labels: app: backend spec: # 容器信息 containers: - name: my-app-backend image: tutum/dnsutils command: - sleep - infinity效果如下所示,可以看到后端服务运行了2个Pod。分别在my-k8s-cluster-multi-node-worker、my-k8s-cluster-multi-node-worker3节点上。而通过标签信息可知,这两个节点都位于上海

figure 3.jpeg
现在我们来部署应用的缓存服务,这里我们期望 缓存服务Pod所在的节点 能够尽可能与 前端服务Pod所在的节点 在通过一个地理区域,以减少网络通讯的延迟。
首先,使用podAffinity来定义Pod亲和性规则,使用preferredDuringSchedulingIgnoredDuringExecution定义偏好性的调度规则。可通过权重值来定义对节点偏好,权重值越大优先级越高。其中,权重范围: 1~100
然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是前端服务的Pod
最后,使用topologyKey来定义拓扑域信息,这里我们使用的是节点的Region标签地理位置。此时即将被调度的新Pod 将会更倾向于调度到 与标签选择器所确定的Pod的所在节点 具有相同Region标签值的节点当中。即,缓存服务的Pod的所在节点 与 后端服务的Pod的所在节点 将会尽可能得位于同一个地理区域(具有相同Region标签值)
# 应用的缓存服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-redisspec: # Pod副本数量 replicas: 4 selector: matchLabels: app: redis # Pod模板 template: metadata: # 标签信息: 应用的后端服务 labels: app: redis spec: # 亲和性 affinity: # Pod亲和性规则 podAffinity: # 偏好性的调度规则, 但不会影响已在节点上运行的Pod preferredDuringSchedulingIgnoredDuringExecution: - weight: 70 # 权重范围: 1~100, 权重值越大, 优先级越高 podAffinityTerm: topologyKey: Region # 标签选择器 labelSelector: matchLabels: app: backend # 容器信息 containers: - name: my-app-redis image: redis:3.2-alpine效果如下所示。缓存服务的4个Pod均运行同样位于上海的节点上。需要注意的是,由于这里是偏好性调度。故如果当上海的节点由于某种原因导致无法调度Pod到其上运行,调度器选择其他地域的节点进行调度也是合法的、允许的。比如这里位于广州的节点

figure 4.jpeg
Pod反亲和性
而Pod反亲和性,同样也是基于已经在节点上运行Pod的标签来约束新Pod可以调度到的节点。只不过其与Pod亲和性恰恰相反。即,如果X上已经运行了一个或多个满足规则Y的Pod,则这个新Pod不应该运行在X上。此外,Pod反亲和性使用podAntiAffinity字段,其下同样支持两种反亲和性:requiredDuringSchedulingIgnoredDuringExecution 强制性调度、preferredDuringSchedulingIgnoredDuringExecution 偏好性调度
强制性调度
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的后端服务。这里为了便于后续演示,我们规定后端服务的Pod只允许运行在上海的节点上
# 应用的后端服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-backendspec: # Pod副本数量 replicas: 5 selector: matchLabels: app: backend # Pod模板 template: metadata: # 标签信息: 应用的后端服务 labels: app: backend spec: # 配置节点选择器, 要求K8s只将该Pod部署到包含标签Region=ShangHai的节点上 nodeSelector: Region: ShangHai # 容器信息 containers: - name: my-app-backend image: tutum/dnsutils command: - sleep - infinity效果如下所示,可以看到后端服务运行了5个Pod。分别运行在位于上海的my-k8s-cluster-multi-node-worker、my-k8s-cluster-multi-node-worker3、my-k8s-cluster-multi-node-worker5节点上

figure 5.jpeg
现在我们来部署应用的前端服务,同时基于某种特殊原因的考量,我们期望该应用的前、后端服务的Pod分别运行在不同区域。即前端服务的Pod的运行在位于上海的节点,则我们希望后端服务的Pod运行在除上海之外的节点当中。这时就可以通过节点反亲和性实现。具体地:
首先,使用podAntiAffinity来定义Pod反亲和性规则,使用requiredDuringSchedulingIgnoredDuringExecution定义强制性的调度规则
然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是后端服务的Pod
最后,使用topologyKey来定义拓扑域信息,这里我们使用的是节点的Region标签地理位置。对于 此时即将被调度的新Pod 与 标签选择器所确定的Pod 来说,它们各自运行节点的地理位置是不同的。即,后端服务的Pod 必须被调度到 与前端服务的Pod所在节点拥有不同地理位置 的节点上
# 应用的前端服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-frontendspec: # Pod副本数量 replicas: 5 selector: matchLabels: app: frontend # Pod模板 template: metadata: # 标签信息: 应用的前端服务 labels: app: frontend spec: # 亲和性 affinity: # Pod反亲和性规则 podAntiAffinity: # 强制性的调度规则, 但不会影响已在节点上运行的Pod requiredDuringSchedulingIgnoredDuringExecution: - topologyKey: Region # 标签选择器 labelSelector: matchLabels: app: backend # 容器信息 containers: - name: my-app-frontend image: jocatalin/kubernetes-bootcamp:v1效果如下所示。前端服务的5个Pod均运行在位于广州的my-k8s-cluster-multi-node-worker2、my-k8s-cluster-multi-node-worker4节点上

figure 6.jpeg
偏好性调度
这里提供了一个存在5个工作节点的K8s集群,然后我们使用Deployment部署了应用的后端服务
# 应用的后端服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-backendspec: # Pod副本数量 replicas: 2 selector: matchLabels: app: backend # Pod模板 template: metadata: # 标签信息: 应用的后端服务 labels: app: backend spec: # 容器信息 containers: - name: my-app-backend image: tutum/dnsutils command: - sleep - infinity效果如下所示,可以看到前端服务运行了2个Pod。分别在my-k8s-cluster-multi-node-worker、my-k8s-cluster-multi-node-worker4节点上
figure 7.jpeg
现在我们来部署应用的缓存服务,这里由于后端服务、缓存服务都非常占用资源。故我们提出下述调度要求
缓存服务Pod所在的节点 能够尽可能与 前端服务Pod所在的节点 不是同一个节点
缓存服务Pod所在的节点 能够尽可能与 前端服务Pod所在的节点 不在同一个地理区域
上诉2点均为偏好性要求,且第1点优先级是最高的
首先,使用podAntiAffinity来定义Pod反亲和性规则,使用preferredDuringSchedulingIgnoredDuringExecution定义偏好性的调度规则。可通过权重值来定义偏好,权重值越大优先级越高。其中,权重范围: 1~100
然后,使用标签选择器来确定Pod的范围,这里我们显然选择的是前端服务的Pod
最后,使用topologyKey来定义拓扑域信息。这里我们分别使用了节点主机名、地理位置。以此实现即将被调度的新Pod 将会更倾向于调度到 与标签选择器所确定的Pod的所在节点 具有不同节点 或 不同地理区域的节点上
# 应用的缓存服务apiVersion: apps/v1kind: Deploymentmetadata: name: my-app-redisspec: # Pod副本数量 replicas: 4 selector: matchLabels: app: redis # Pod模板 template: metadata: # 标签信息: 应用的后端服务 labels: app: redis spec: # 亲和性 affinity: # Pod反亲和性规则 podAntiAffinity: # 偏好性的调度规则, 但不会影响已在节点上运行的Pod preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 # 权重范围: 1~100, 权重值越大, 优先级越高 podAffinityTerm: topologyKey: kubernetes.io/hostname # 标签选择器 labelSelector: matchLabels: app: backend - weight: 1 # 权重范围: 1~100, 权重值越大, 优先级越高 podAffinityTerm: topologyKey: Region # 标签选择器 labelSelector: matchLabels: app: backend # 容器信息 containers: - name: my-app-redis image: redis:3.2-alpine效果如下所示。缓存服务的4个Pod均运行在与后端服务Pod所在节点不同的节点上。但这里由于是偏好性调度,当最终结果未满足两个服务运行在不同的地理位置时,即调度器选择相同地理位置的节点进行调度也是合法的、允许的
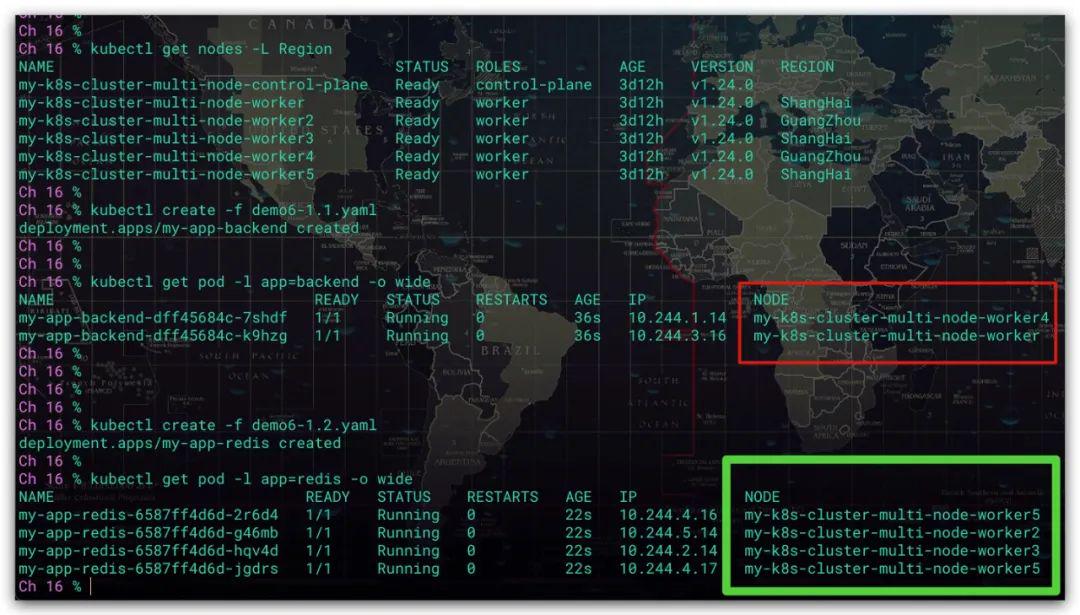
figure 8.jpeg
相关文章:
Kubernetes调度之Pod亲和性
Kubernetes调度中的Pod亲和性abstract.pngPod亲和性节点亲和性,是基于节点的标签对Pod进行调度。而Pod亲和性则可以实现基于已经在节点上运行Pod的标签来约束新Pod可以调度到的节点。具体地,如果X上已经运行了一个或多个满足规则Y的Pod,则这个…...

建立相关在线社群的3个简单步骤
在线社群管理和社交媒体营销通常被视为一回事。虽然社群管理确实是社交媒体营销的一个关键部分,但它的意义超越了社交媒体的内容发布。因此,在线社群对于企业的数字营销十分重要。创建、维护和发展社群不是一件容易的工作,也不是一个快速的过…...

安全运营的新模式
安全运营的新模式是传统安全运维的扩展和升级,其实现落地需要管理和技术两斱面同时支撑、相互衎接和配合,缺夰仸何一个都是行不通的。管理斱面,在顶层设计时,网络安全运营要根据国家信息安全等级保护 2.0 的相关要求,参…...

Day10-网页布局实战CSS3
一 补充 1 画三角形 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthdevi…...
)
代码规范(C/C++规范)
文章目录前言个人编写的代码规范链接请求合作大体章节END前言 什么是代码规范 一套用于统一代码开发的准则 为什么需要代码规范 提升代码可读性,提升团队效率 个人编写的代码规范 近期本人编写了一份以C/C为主的代码规范。 其他语言开发者也可以阅读参考。 本…...
:计算属性和监视属性总结)
春招冲刺(九):计算属性和监视属性总结
计算属性和监视属性总结 Q1:计算属性 姓:<input type"text" v-model"firstName"><br><br> 名:<input type"text" v-model"lastName"><br><br> 姓名ÿ…...
数据挖掘(作业1)
实验开始前先配置环境 以实验室2023安装的版本为例: 1、安装anaconda:(anaconda自带Python,安装了anaconda就不用再安装Python了) 下载并安装 Anaconda3-2022.10-Windows-x86_64.exe 自己选择安装路径,其他使用默认…...
【UE4 RTS游戏】01-项目准备
步骤新建一个工程,选择俯视角游戏模板我命名工程如下:删除场景内的所有cube再删除Floor和Wall删除TopDownCharacter删除“NavgationMeshBoundVolume”删除“TamplateLabel”和“RecastNavMesh-Default”删除LightmassImportanceVolume、PostProcessVolum…...
)
登录系统账号检测--课后程序(Python程序开发案例教程-黑马程序员编著-第3章-课后作业)
实例8:登录系统账号检测 登录系统一般具有账号密码检测功能,即检测用户输入的账号密码是否正确。若用户输入的账号或密码不正确,提示 “用户名或密码错误”和“您还有*次机会”; 若用户输入的账号和密码正确,提示“登…...

CentOS8基础篇12:使用RPM管理telnet-server软件包
一、RPM包管理工具简介 RedHat软件包管理工具(RedHat Package Manager,RPM) RPM软件包工具常用于软件包的安装、查询、更新升级、校验、卸载以及生成.rpm格式的软件包等操作。 RPM软件包工具只能管理后缀是.rpm的软件包。软件包的命名格式: 软件名称…...

IT女神文章记录之自己
匆匆时光,一转眼自己已经从一个学生转变成一个职场工作者了刚出校园的时候,对职场充满了憧憬,觉得自己可以大展身手然后其实在我毕业后2年内,踏入码农阶段的时候,是一段非常压抑的工作,不知道谁能体会到那种…...
Compose 动画 (四) : AnimatedVisibility 各种入场和出场动画效果
AnimatedVisibility中的EnterTransition 和 ExitTransition ,用来配置入场/出场时候的动画效果。 默认的入场效果是 fadeIn() expandVertically() 默认的出场效果是 fadeOut() shrinkVertically() 1. EnterTransition和ExitTransition支持的动画 enter的参数类…...
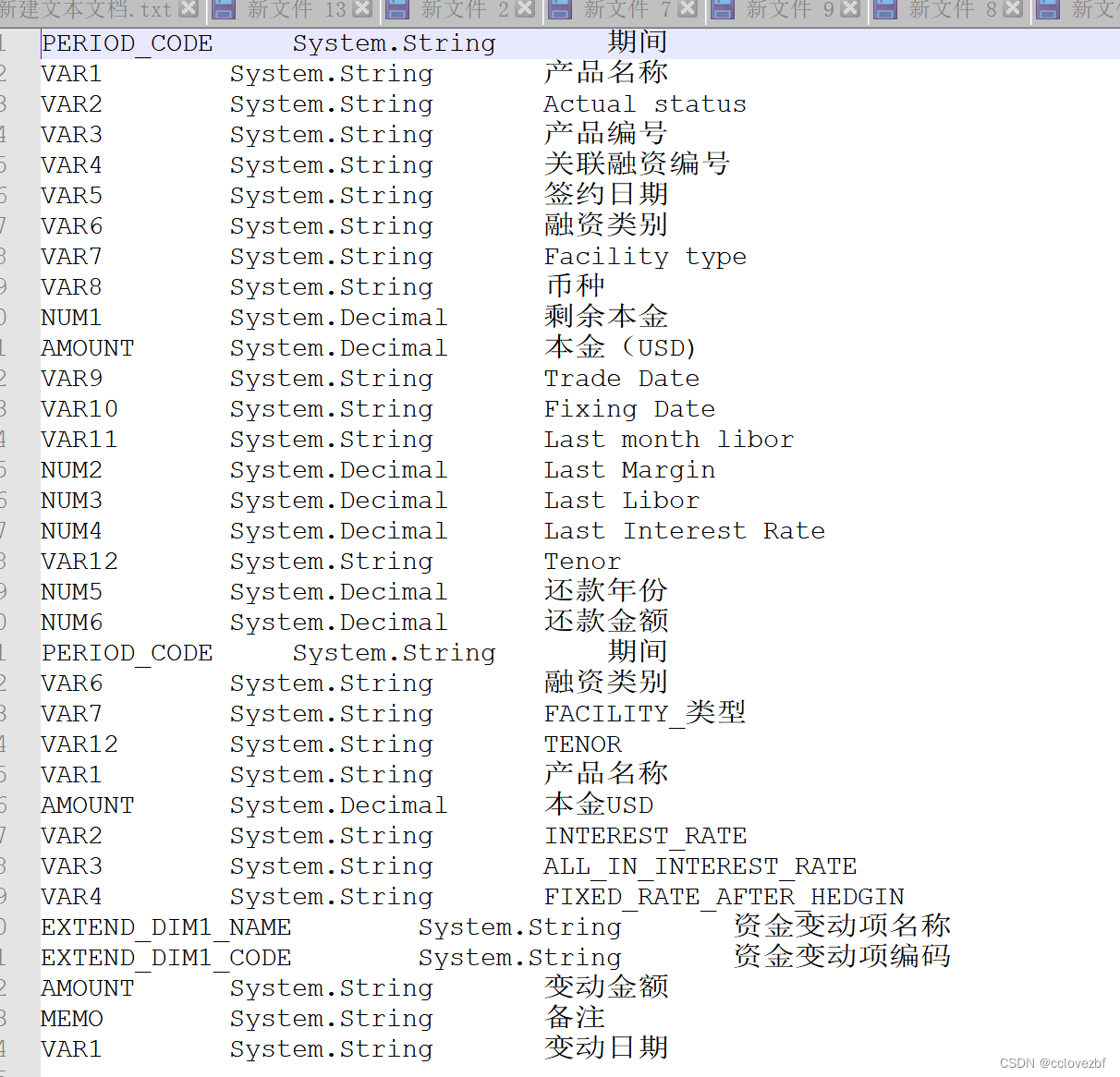
notepad++学习小技巧
不要小瞧了notepadd 这个可是我们的cv好帮手。。。 实战1背景,我找一个同事要表结构 结果他给我了一个xml。顿时一懵,我也不知道为啥好像是从前端扣下来的。 建表我只需要 columnName, displayName当作是comment, dataTypeNamecolumnType借鉴…...

Android supports-screens 屏幕适配
基本概念 supports-screens用于设置屏幕相关,处于Manifest的子标签中。 使您能够指定应用支持的屏幕尺寸,并为比应用支持的最大屏幕还大的屏幕启用屏幕兼容性模式。请务必始终在应用中使用此元素指定应用支持的屏幕尺寸。 注意:建议不要在屏…...
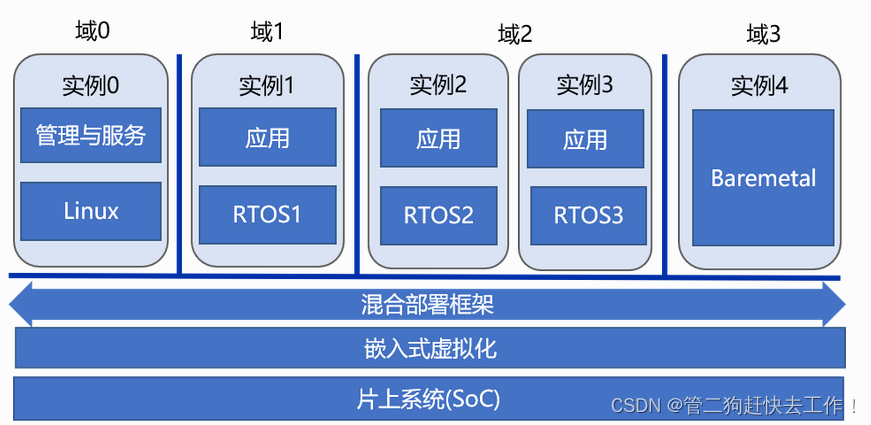
操作系统基础知识介绍之Mixed CriticalitySystems——混合关键系统
一、发展背景 在嵌入式场景中,虽然Linux已经得到了广泛应用,但并不能覆盖所有需求,例如高实时、高可靠、高安全的场合。这些场合往往是实时操作系统 的用武之地。有些应用场景既需要Linux的管理能力、丰富的生态又需要实时操作系统的高实时、…...

【数据结构初阶】详解链表OJ题
目录一.删除链表中等于给定值的节点二.合并有序链表并返回三.链表的回文结构1.反转单链表2.返回非空链表的中间节点四.输出链表倒数第K个节点五.基于给定值x分割单链表六.返回两个链表的第一个中间节点一.删除链表中等于给定值的节点 我们先来看第一题(题目链接): 因为我们需…...

Java基本数据类型变量自动提升、强制类型转换、String基本类型使用
文章目录基本数据类型变量自动提升特殊情况强制类型转换String基本类型使用基本数据类型变量自动提升 规则: 将取值范围小(或容量小)的类型自动提升为取值范围大(或容量大)的类型 。 byte、short、char-->int-->…...
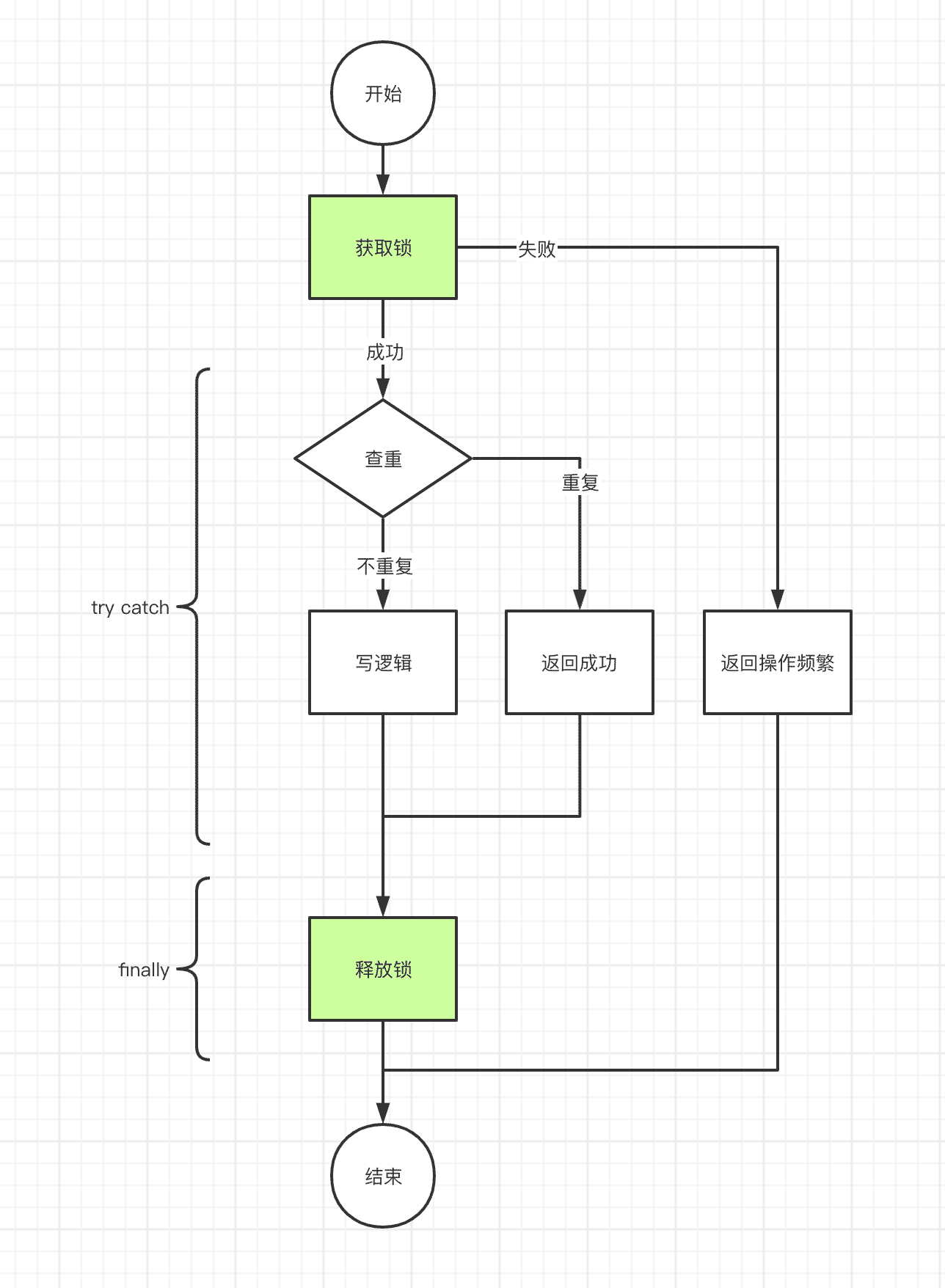
Redis锁与幂等性不得不说的故事
前言: 相信很多小伙伴对缓存锁都不陌生,但是简单的缓存锁想要用好还是需要一些功力。本文总结了笔者多年使用缓存所的一些心得,欢迎交流探讨~ 幂等模型: 幂等场景一般由查重写入两步操作组成,两步操作组成一个最小完…...
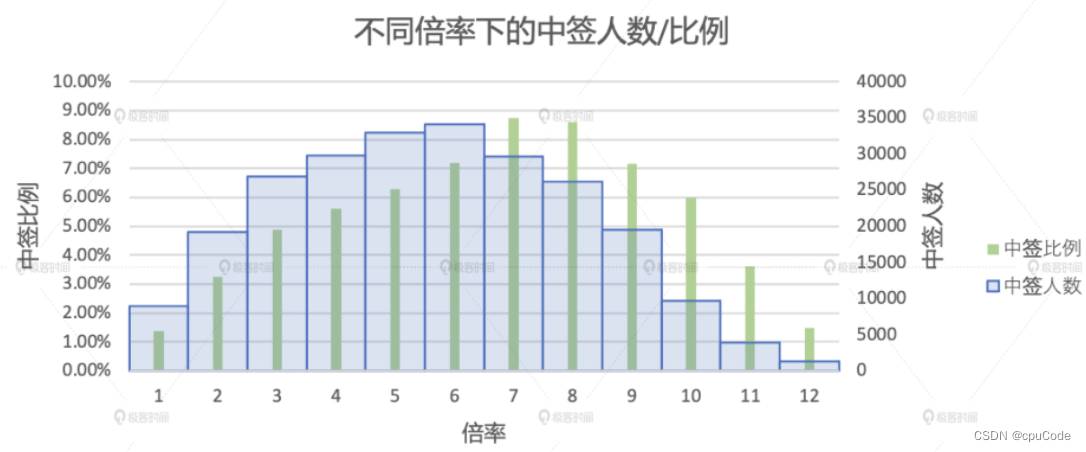
Spark 应用调优
Spark 应用调优人数统计优化摇号次数分布优化Shuffle 常规优化数据分区合并加 Cache优化中签率的变化趋势中签率局部洞察优化倍率分析优化表信息 : apply : 申请者 : 事实表lucky : 中签者表 : 维度表两张表的 Schema ( batchNum,carNum ) : ( 摇号批次,…...
synchronized 与 volatile 关键字
目录1.前言1.synchronized 关键字1. 互斥2.保证内存可见性3.可重入2. volatile 关键字1.保证内存可见性2.无法保证原子性3.synchronized 与 volatile 的区别1.前言 synchronized关键字和volatile是大家在Java多线程学习时接触的两个关键字,很多同学可能学习完就忘记…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...
java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流 前情提要文章介绍一、函数伊始1.1 合格的函数1.2 有形的函数2. 函数对象2.1 函数对象——行为参数化2.2 函数对象——延迟执行 二、 函数编程语法1. 函数对象表现形式1.1 Lambda表达式1.2 方法引用(Math::max) 2 函数接口…...
SQL注入篇-sqlmap的配置和使用
在之前的皮卡丘靶场第五期SQL注入的内容中我们谈到了sqlmap,但是由于很多朋友看不了解命令行格式,所以是纯手动获取数据库信息的 接下来我们就用sqlmap来进行皮卡丘靶场的sql注入学习,链接:https://wwhc.lanzoue.com/ifJY32ybh6vc…...