前端经典面试题(有答案)
代码输出结果
var a = 10var obj = {
a: 20,
say: () => {
console.log(this.a)
}
}
obj.say()
var anotherObj = { a: 30 }
obj.say.apply(anotherObj)
输出结果:10 10
我么知道,箭头函数时不绑定this的,它的this来自原其父级所处的上下文,所以首先会打印全局中的 a 的值10。后面虽然让say方法指向了另外一个对象,但是仍不能改变箭头函数的特性,它的this仍然是指向全局的,所以依旧会输出10。
但是,如果是普通函数,那么就会有完全不一样的结果:
var a = 10var obj = {
a: 20,
say(){
console.log(this.a)
}
}
obj.say()
var anotherObj={a:30}
obj.say.apply(anotherObj)
输出结果:20 30
这时,say方法中的this就会指向他所在的对象,输出其中的a的值。
Compositon api
Composition API也叫组合式API,是Vue3.x的新特性。
通过创建 Vue 组件,我们可以将接口的可重复部分及其功能提取到可重用的代码段中。仅此一项就可以使我们的应用程序在可维护性和灵活性方面走得更远。然而,我们的经验已经证明,光靠这一点可能是不够的,尤其是当你的应用程序变得非常大的时候——想想几百个组件。在处理如此大的应用程序时,共享和重用代码变得尤为重要
Vue2.0中,随着功能的增加,组件变得越来越复杂,越来越难维护,而难以维护的根本原因是Vue的API设计迫使开发者使用watch,computed,methods选项组织代码,而不是实际的业务逻辑。
另外Vue2.0缺少一种较为简洁的低成本的机制来完成逻辑复用,虽然可以minxis完成逻辑复用,但是当mixin变多的时候,会使得难以找到对应的data、computed或者method来源于哪个mixin,使得类型推断难以进行。
所以Composition API的出现,主要是也是为了解决Option API带来的问题,第一个是代码组织问题,Compostion API可以让开发者根据业务逻辑组织自己的代码,让代码具备更好的可读性和可扩展性,也就是说当下一个开发者接触这一段不是他自己写的代码时,他可以更好的利用代码的组织反推出实际的业务逻辑,或者根据业务逻辑更好的理解代码。
第二个是实现代码的逻辑提取与复用,当然mixin也可以实现逻辑提取与复用,但是像前面所说的,多个mixin作用在同一个组件时,很难看出property是来源于哪个mixin,来源不清楚,另外,多个mixin的property存在变量命名冲突的风险。而Composition API刚好解决了这两个问题。
通俗的讲:
没有Composition API之前vue相关业务的代码需要配置到option的特定的区域,中小型项目是没有问题的,但是在大型项目中会导致后期的维护性比较复杂,同时代码可复用性不高。Vue3.x中的composition-api就是为了解决这个问题而生的
compositon api提供了以下几个函数:
setup
ref
reactive
watchEffect
watch
computed
toRefs
生命周期的hooks
都说Composition API与React Hook很像,说说区别
从React Hook的实现角度看,React Hook是根据useState调用的顺序来确定下一次重渲染时的state是来源于哪个useState,所以出现了以下限制
不能在循环、条件、嵌套函数中调用Hook
必须确保总是在你的React函数的顶层调用Hook
useEffect、useMemo等函数必须手动确定依赖关系
而Composition API是基于Vue的响应式系统实现的,与React Hook的相比
声明在setup函数内,一次组件实例化只调用一次setup,而React Hook每次重渲染都需要调用Hook,使得React的GC比Vue更有压力,性能也相对于Vue来说也较慢
Compositon API的调用不需要顾虑调用顺序,也可以在循环、条件、嵌套函数中使用
响应式系统自动实现了依赖收集,进而组件的部分的性能优化由Vue内部自己完成,而React Hook需要手动传入依赖,而且必须必须保证依赖的顺序,让useEffect、useMemo等函数正确的捕获依赖变量,否则会由于依赖不正确使得组件性能下降。
虽然Compositon API看起来比React Hook好用,但是其设计思想也是借鉴React Hook的。
垃圾回收
对于在JavaScript中的字符串,对象,数组是没有固定大小的,只有当对他们进行动态分配存储时,解释器就会分配内存来存储这些数据,当JavaScript的解释器消耗完系统中所有可用的内存时,就会造成系统崩溃。
内存泄漏,在某些情况下,不再使用到的变量所占用内存没有及时释放,导致程序运行中,内存越占越大,极端情况下可以导致系统崩溃,服务器宕机。
JavaScript有自己的一套垃圾回收机制,JavaScript的解释器可以检测到什么时候程序不再使用这个对象了(数据),就会把它所占用的内存释放掉。
针对JavaScript的来及回收机制有以下两种方法(常用):标记清除,引用计数
标记清除
v8 的垃圾回收机制基于分代回收机制,这个机制又基于世代假说,这个假说有两个特点,一是新生的对象容易早死,另一个是不死的对象会活得更久。基于这个假说,v8 引擎将内存分为了新生代和老生代。
新创建的对象或者只经历过一次的垃圾回收的对象被称为新生代。经历过多次垃圾回收的对象被称为老生代。
新生代被分为 From 和 To 两个空间,To 一般是闲置的。当 From 空间满了的时候会执行 Scavenge 算法进行垃圾回收。当我们执行垃圾回收算法的时候应用逻辑将会停止,等垃圾回收结束后再继续执行。
这个算法分为三步:
首先检查 From 空间的存活对象,如果对象存活则判断对象是否满足晋升到老生代的条件,如果满足条件则晋升到老生代。如果不满足条件则移动 To 空间。
如果对象不存活,则释放对象的空间。
最后将 From 空间和 To 空间角色进行交换。
新生代对象晋升到老生代有两个条件:
第一个是判断是对象否已经经过一次 Scavenge 回收。若经历过,则将对象从 From 空间复制到老生代中;若没有经历,则复制到 To 空间。
第二个是 To 空间的内存使用占比是否超过限制。当对象从 From 空间复制到 To 空间时,若 To 空间使用超过 25%,则对象直接晋升到老生代中。设置 25% 的原因主要是因为算法结束后,两个空间结束后会交换位置,如果 To 空间的内存太小,会影响后续的内存分配。
老生代采用了标记清除法和标记压缩法。标记清除法首先会对内存中存活的对象进行标记,标记结束后清除掉那些没有标记的对象。由于标记清除后会造成很多的内存碎片,不便于后面的内存分配。所以了解决内存碎片的问题引入了标记压缩法。
由于在进行垃圾回收的时候会暂停应用的逻辑,对于新生代方法由于内存小,每次停顿的时间不会太长,但对于老生代来说每次垃圾回收的时间长,停顿会造成很大的影响。 为了解决这个问题 V8 引入了增量标记的方法,将一次停顿进行的过程分为了多步,每次执行完一小步就让运行逻辑执行一会,就这样交替运行
Proxy代理
proxy在目标对象的外层搭建了一层拦截,外界对目标对象的某些操作,必须通过这层拦截
var proxy = newProxy(target, handler);
new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为
var target = {
name: 'poetries'
};
var logHandler = {
get: function(target, key) {
console.log(`${key} 被读取`);
return target[key];
},
set: function(target, key, value) {
console.log(`${key} 被设置为 ${value}`);
target[key] = value;
}
}
var targetWithLog = newProxy(target, logHandler);
targetWithLog.name; // 控制台输出:name 被读取
targetWithLog.name = 'others'; // 控制台输出:name 被设置为 othersconsole.log(target.name); // 控制台输出: others
targetWithLog 读取属性的值时,实际上执行的是 logHandler.get :在控制台输出信息,并且读取被代理对象 target 的属性。
在 targetWithLog 设置属性值时,实际上执行的是 logHandler.set :在控制台输出信息,并且设置被代理对象 target 的属性的值
// 由于拦截函数总是返回35,所以访问任何属性都得到35var proxy = newProxy({}, {
get: function(target, property) {
return35;
}
});
proxy.time// 35
proxy.name// 35
proxy.title// 35
Proxy 实例也可以作为其他对象的原型对象
var proxy = newProxy({}, {
get: function(target, property) {
return35;
}
});
let obj = Object.create(proxy);
obj.time// 35
proxy对象是obj对象的原型,obj对象本身并没有time属性,所以根据原型链,会在proxy对象上读取该属性,导致被拦截
Proxy的作用
对于代理模式 Proxy 的作用主要体现在三个方面
拦截和监视外部对对象的访问
降低函数或类的复杂度
在复杂操作前对操作进行校验或对所需资源进行管理
Proxy所能代理的范围--handler
实际上 handler 本身就是ES6所新设计的一个对象.它的作用就是用来 自定义代理对象的各种可代理操作 。它本身一共有13中方法,每种方法都可以代理一种操作.其13种方法如下
// 在读取代理对象的原型时触发该操作,比如在执行 Object.getPrototypeOf(proxy) 时。
handler.getPrototypeOf()
// 在设置代理对象的原型时触发该操作,比如在执行 Object.setPrototypeOf(proxy, null) 时。
handler.setPrototypeOf()
// 在判断一个代理对象是否是可扩展时触发该操作,比如在执行 Object.isExtensible(proxy) 时。
handler.isExtensible()
// 在让一个代理对象不可扩展时触发该操作,比如在执行 Object.preventExtensions(proxy) 时。
handler.preventExtensions()
// 在获取代理对象某个属性的属性描述时触发该操作,比如在执行 Object.getOwnPropertyDescriptor(proxy, "foo") 时。
handler.getOwnPropertyDescriptor()
// 在定义代理对象某个属性时的属性描述时触发该操作,比如在执行 Object.defineProperty(proxy, "foo", {}) 时。
andler.defineProperty()
// 在判断代理对象是否拥有某个属性时触发该操作,比如在执行 "foo" in proxy 时。
handler.has()
// 在读取代理对象的某个属性时触发该操作,比如在执行 proxy.foo 时。
handler.get()
// 在给代理对象的某个属性赋值时触发该操作,比如在执行 proxy.foo = 1 时。
handler.set()
// 在删除代理对象的某个属性时触发该操作,比如在执行 delete proxy.foo 时。
handler.deleteProperty()
// 在获取代理对象的所有属性键时触发该操作,比如在执行 Object.getOwnPropertyNames(proxy) 时。
handler.ownKeys()
// 在调用一个目标对象为函数的代理对象时触发该操作,比如在执行 proxy() 时。
handler.apply()
// 在给一个目标对象为构造函数的代理对象构造实例时触发该操作,比如在执行new proxy() 时。
handler.construct()
为何Proxy不能被Polyfill
如class可以用function模拟;promise可以用callback模拟
但是proxy不能用Object.defineProperty模拟
目前谷歌的polyfill只能实现部分的功能,如get、set https://github.com/GoogleChro...
// commonJS requireconst proxyPolyfill = require('proxy-polyfill/src/proxy')();
// Your environment may also support transparent rewriting of commonJS to ES6:importProxyPolyfillBuilderfrom'proxy-polyfill/src/proxy';
const proxyPolyfill = ProxyPolyfillBuilder();
// Then use...const myProxy = newproxyPolyfill(...);
列举几个css中可继承和不可继承的元素
不可继承的:display、margin、border、padding、background、height、min-height、max-height、width、min-width、max-width、overflow、position、left、right、top、bottom、z-index、float、clear、table-layout、vertical-align
所有元素可继承:visibility和cursor。
内联元素可继承:letter-spacing、word-spacing、white-space、line-height、color、font、font-family、font-size、font-style、font-variant、font-weight、text-decoration、text-transform、direction。
终端块状元素可继承:text-indent和text-align。
列表元素可继承:list-style、list-style-type、list-style-position、list-style-image`。
transition和animation的区别
Animation和transition大部分属性是相同的,他们都是随时间改变元素的属性值,他们的主要区别是transition需要触发一个事件才能改变属性,而animation不需要触发任何事件的情况下才会随时间改变属性值,并且transition为2帧,从from .... to,而animation可以一帧一帧的
OSI七层模型
ISO为了更好的使网络应用更为普及,推出了OSI参考模型。
(1)应用层
OSI参考模型中最靠近用户的一层,是为计算机用户提供应用接口,也为用户直接提供各种网络服务。我们常见应用层的网络服务协议有:HTTP,HTTPS,FTP,POP3、SMTP等。
在客户端与服务器中经常会有数据的请求,这个时候就是会用到http(hyper text transfer protocol)(超文本传输协议)或者https.在后端设计数据接口时,我们常常使用到这个协议。
FTP是文件传输协议,在开发过程中,个人并没有涉及到,但是我想,在一些资源网站,比如百度网盘`迅雷`应该是基于此协议的。
SMTP是simple mail transfer protocol(简单邮件传输协议)。在一个项目中,在用户邮箱验证码登录的功能时,使用到了这个协议。
(2)表示层
表示层提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别。如果必要,该层可提供一种标准表示形式,用于将计算机内部的多种数据格式转换成通信中采用的标准表示形式。数据压缩和加密也是表示层可提供的转换功能之一。
在项目开发中,为了方便数据传输,可以使用base64对数据进行编解码。如果按功能来划分,base64应该是工作在表示层。
(3)会话层
会话层就是负责建立、管理和终止表示层实体之间的通信会话。该层的通信由不同设备中的应用程序之间的服务请求和响应组成。
(4)传输层
传输层建立了主机端到端的链接,传输层的作用是为上层协议提供端到端的可靠和透明的数据传输服务,包括处理差错控制和流量控制等问题。该层向高层屏蔽了下层数据通信的细节,使高层用户看到的只是在两个传输实体间的一条主机到主机的、可由用户控制和设定的、可靠的数据通路。我们通常说的,TCP UDP就是在这一层。端口号既是这里的“端”。
(5)网络层
本层通过IP寻址来建立两个节点之间的连接,为源端的运输层送来的分组,选择合适的路由和交换节点,正确无误地按照地址传送给目的端的运输层。就是通常说的IP层。这一层就是我们经常说的IP协议层。IP协议是Internet的基础。我们可以这样理解,网络层规定了数据包的传输路线,而传输层则规定了数据包的传输方式。
(6)数据链路层
将比特组合成字节,再将字节组合成帧,使用链路层地址 (以太网使用MAC地址)来访问介质,并进行差错检测。
网络层与数据链路层的对比,通过上面的描述,我们或许可以这样理解,网络层是规划了数据包的传输路线,而数据链路层就是传输路线。不过,在数据链路层上还增加了差错控制的功能。
(7)物理层
实际最终信号的传输是通过物理层实现的。通过物理介质传输比特流。规定了电平、速度和电缆针脚。常用设备有(各种物理设备)集线器、中继器、调制解调器、网线、双绞线、同轴电缆。这些都是物理层的传输介质。
OSI七层模型通信特点:对等通信 对等通信,为了使数据分组从源传送到目的地,源端OSI模型的每一层都必须与目的端的对等层进行通信,这种通信方式称为对等层通信。在每一层通信过程中,使用本层自己协议进行通信。
参考 前端进阶面试题详细解答
定时器与requestAnimationFrame、requestIdleCallback
1. setTimeout
setTimeout的运行机制:执行该语句时,是立即把当前定时器代码推入事件队列,当定时器在事件列表中满足设置的时间值时将传入的函数加入任务队列,之后的执行就交给任务队列负责。但是如果此时任务队列不为空,则需等待,所以执行定时器内代码的时间可能会大于设置的时间
setTimeout(() => {
console.log(1);
}, 0)
console.log(2);
输出 2, 1;
setTimeout的第二个参数表示在执行代码前等待的毫秒数。上面代码中,设置为0,表面意思为 执行代码前等待的毫秒数为0,即立即执行。但实际上的运行结果我们也看到了,并不是表面上看起来的样子,千万不要被欺骗了。
实际上,上面的代码并不是立即执行的,这是因为setTimeout有一个最小执行时间,HTML5标准规定了setTimeout()的第二个参数的最小值(最短间隔)不得低于4毫秒。 当指定的时间低于该时间时,浏览器会用最小允许的时间作为setTimeout的时间间隔,也就是说即使我们把setTimeout的延迟时间设置为0,实际上可能为 4毫秒后才事件推入任务队列。
定时器代码在被推送到任务队列前,会先被推入到事件列表中,当定时器在事件列表中满足设置的时间值时会被推到任务队列,但是如果此时任务队列不为空,则需等待,所以执行定时器内代码的时间可能会大于设置的时间
setTimeout(() => {
console.log(111);
}, 100);
上面代码表示100ms后执行console.log(111),但实际上实行的时间肯定是大于100ms后的, 100ms 只是表示 100ms 后将任务加入到"任务队列"中,必须等到当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码耗时很长,有可能要等很久,所以并没有办法保证,回调函数一定会在setTimeout()指定的时间执行。
2. setTimeout 和 setInterval区别
setTimeout: 指定延期后调用函数,每次setTimeout计时到后就会去执行,然后执行一段时间后才继续setTimeout,中间就多了误差,(误差多少与代码的执行时间有关)。
setInterval:以指定周期调用函数,而setInterval则是每次都精确的隔一段时间推入一个事件(但是,事件的执行时间不一定就不准确,还有可能是这个事件还没执行完毕,下一个事件就来了).
btn.onclick = function(){
setTimeout(function(){
console.log(1);
},250);
}
击该按钮后,首先将onclick事件处理程序加入队列。该程序执行后才设置定时器,再有250ms后,指定的代码才被添加到队列中等待执行。 如果上面代码中的onclick事件处理程序执行了300ms,那么定时器的代码至少要在定时器设置之后的300ms后才会被执行。队列中所有的代码都要等到javascript进程空闲之后才能执行,而不管它们是如何添加到队列中的。
如图所示,尽管在255ms处添加了定时器代码,但这时候还不能执行,因为onclick事件处理程序仍在运行。定时器代码最早能执行的时机是在300ms处,即onclick事件处理程序结束之后。
3. setInterval存在的一些问题:
JavaScript中使用 setInterval 开启轮询。定时器代码可能在代码再次被添加到队列之前还没有完成执行,结果导致定时器代码连续运行好几次,而之间没有任何停顿。而javascript引擎对这个问题的解决是:当使用setInterval()时,仅当没有该定时器的任何其他代码实例时,才将定时器代码添加到队列中。这确保了定时器代码加入到队列中的最小时间间隔为指定间隔。
但是,这样会导致两个问题:
某些间隔被跳过;
多个定时器的代码执行之间的间隔可能比预期的小
假设,某个onclick事件处理程序使用setInterval()设置了200ms间隔的定时器。如果事件处理程序花了300ms多一点时间完成,同时定时器代码也花了差不多的时间,就会同时出现跳过某间隔的情况
例子中的第一个定时器是在205ms处添加到队列中的,但是直到过了300ms处才能执行。当执行这个定时器代码时,在405ms处又给队列添加了另一个副本。在下一个间隔,即605ms处,第一个定时器代码仍在运行,同时在队列中已经有了一个定时器代码的实例。结果是,在这个时间点上的定时器代码不会被添加到队列中
使用setTimeout构造轮询能保证每次轮询的间隔。
setTimeout(function () {
console.log('我被调用了');
setTimeout(arguments.callee, 100);
}, 100);
callee 是 arguments 对象的一个属性。它可以用于引用该函数的函数体内当前正在执行的函数。在严格模式下,第5版 ECMAScript (ES5) 禁止使用arguments.callee()。当一个函数必须调用自身的时候, 避免使用 arguments.callee(), 通过要么给函数表达式一个名字,要么使用一个函数声明.
setTimeout(functionfn(){
console.log('我被调用了');
setTimeout(fn, 100);
},100);
这个模式链式调用了setTimeout(),每次函数执行的时候都会创建一个新的定时器。第二个setTimeout()调用当前执行的函数,并为其设置另外一个定时器。这样做的好处是,在前一个定时器代码执行完之前,不会向队列插入新的定时器代码,确保不会有任何缺失的间隔。而且,它可以保证在下一次定时器代码执行之前,至少要等待指定的间隔,避免了连续的运行。
4. requestAnimationFrame
4.1 60fps与设备刷新率
目前大多数设备的屏幕刷新率为60次/秒,如果在页面中有一个动画或者渐变效果,或者用户正在滚动页面,那么浏览器渲染动画或页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致。
卡顿:其中每个帧的预算时间仅比16毫秒多一点(1秒/ 60 = 16.6毫秒)。但实际上,浏览器有整理工作要做,因此您的所有工作是需要在10毫秒内完成。如果无法符合此预算,帧率将下降,并且内容会在屏幕上抖动。此现象通常称为卡顿,会对用户体验产生负面影响。
跳帧: 假如动画切换在 16ms, 32ms, 48ms时分别切换,跳帧就是假如到了32ms,其他任务还未执行完成,没有去执行动画切帧,等到开始进行动画的切帧,已经到了该执行48ms的切帧。就好比你玩游戏的时候卡了,过了一会,你再看画面,它不会停留你卡的地方,或者这时你的角色已经挂掉了。必须在下一帧开始之前就已经绘制完毕;
Chrome devtool 查看实时 FPS, 打开 More tools => Rendering, 勾选 FPS meter
4.2 requestAnimationFrame实现动画
requestAnimationFrame是浏览器用于定时循环操作的一个接口,类似于setTimeout,主要用途是按帧对网页进行重绘。
在 requestAnimationFrame 之前,主要借助 setTimeout/ setInterval 来编写 JS 动画,而动画的关键在于动画帧之间的时间间隔设置,这个时间间隔的设置有讲究,一方面要足够小,这样动画帧之间才有连贯性,动画效果才显得平滑流畅;另一方面要足够大,确保浏览器有足够的时间及时完成渲染。
显示器有固定的刷新频率(60Hz或75Hz),也就是说,每秒最多只能重绘60次或75次,requestAnimationFrame的基本思想就是与这个刷新频率保持同步,利用这个刷新频率进行页面重绘。此外,使用这个API,一旦页面不处于浏览器的当前标签,就会自动停止刷新。这就节省了CPU、GPU和电力。
requestAnimationFrame 是在主线程上完成。这意味着,如果主线程非常繁忙,requestAnimationFrame的动画效果会大打折扣。
requestAnimationFrame 使用一个回调函数作为参数。这个回调函数会在浏览器重绘之前调用。
requestID = window.requestAnimationFrame(callback);
window.requestAnimFrame = (function(){
returnwindow.requestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.oRequestAnimationFrame ||
window.msRequestAnimationFrame ||
function( callback ){
window.setTimeout(callback, 1000 / 60);
};
})();
上面的代码按照1秒钟60次(大约每16.7毫秒一次),来模拟requestAnimationFrame。
5. requestIdleCallback()
MDN上的解释:requestIdleCallback()方法将在浏览器的空闲时段内调用的函数排队。这使开发者能够在主事件循环上执行后台和低优先级工作,而不会影响延迟关键事件,如动画和输入响应。函数一般会按先进先调用的顺序执行,然而,如果回调函数指定了执行超时时间timeout,则有可能为了在超时前执行函数而打乱执行顺序。
requestAnimationFrame会在每次屏幕刷新的时候被调用,而requestIdleCallback则会在每次屏幕刷新时,判断当前帧是否还有多余的时间,如果有,则会调用requestAnimationFrame的回调函数,
图片中是两个连续的执行帧,大致可以理解为两个帧的持续时间大概为16.67,图中黄色部分就是空闲时间。所以,requestIdleCallback 中的回调函数仅会在每次屏幕刷新并且有空闲时间时才会被调用.
利用这个特性,我们可以在动画执行的期间,利用每帧的空闲时间来进行数据发送的操作,或者一些优先级比较低的操作,此时不会使影响到动画的性能,或者和requestAnimationFrame搭配,可以实现一些页面性能方面的的优化,
react 的 fiber 架构也是基于 requestIdleCallback 实现的, 并且在不支持的浏览器中提供了 polyfill
总结
从单线程模型和任务队列出发理解 setTimeout(fn, 0),并不是立即执行。
JS 动画, 用requestAnimationFrame 会比 setInterval 效果更好
requestIdleCallback()常用来切割长任务,利用空闲时间执行,避免主线程长时间阻塞
ES6模块与CommonJS模块有什么异同?
ES6 Module和CommonJS模块的区别:
CommonJS是对模块的浅拷⻉,ES6 Module是对模块的引⽤,即ES6 Module只存只读,不能改变其值,也就是指针指向不能变,类似const;
import的接⼝是read-only(只读状态),不能修改其变量值。 即不能修改其变量的指针指向,但可以改变变量内部指针指向,可以对commonJS对重新赋值(改变指针指向),但是对ES6 Module赋值会编译报错。
ES6 Module和CommonJS模块的共同点:
CommonJS和ES6 Module都可以对引⼊的对象进⾏赋值,即对对象内部属性的值进⾏改变。
选择器权重计算方式
!important > 内联样式 = 外联样式 > ID选择器 > 类选择器 = 伪类选择器 = 属性选择器 > 元素选择器 = 伪元素选择器 > 通配选择器 = 后代选择器 = 兄弟选择器
属性后面加!import会覆盖页面内任何位置定义的元素样式
作为style属性写在元素内的样式
id选择器
类选择器
标签选择器
通配符选择器(*)
浏览器自定义或继承
同一级别:后写的会覆盖先写的
css选择器的解析原则:选择器定位DOM元素是从右往左的方向,这样可以尽早的过滤掉一些不必要的样式规则和元素
类型及检测方式
1. JS内置类型
JavaScript 的数据类型有下图所示
其中,前 7 种类型为基础类型,最后 1 种(Object)为引用类型,也是你需要重点关注的,因为它在日常工作中是使用得最频繁,也是需要关注最多技术细节的数据类型
JavaScript一共有8种数据类型,其中有7种基本数据类型:Undefined、Null、Boolean、Number、String、Symbol(es6新增,表示独一无二的值)和BigInt(es10新增);
1种引用数据类型——Object(Object本质上是由一组无序的名值对组成的)。里面包含 function、Array、Date等。JavaScript不支持任何创建自定义类型的机制,而所有值最终都将是上述 8 种数据类型之一。
引用数据类型: 对象Object(包含普通对象-Object,数组对象-Array,正则对象-RegExp,日期对象-Date,数学函数-Math,函数对象-Function)
在这里,我想先请你重点了解下面两点,因为各种 JavaScript 的数据类型最后都会在初始化之后放在不同的内存中,因此上面的数据类型大致可以分成两类来进行存储:
原始数据类型 :基础类型存储在栈内存,被引用或拷贝时,会创建一个完全相等的变量;占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储。
引用数据类型 :引用类型存储在堆内存,存储的是地址,多个引用指向同一个地址,这里会涉及一个“共享”的概念;占据空间大、大小不固定。引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
JavaScript 中的数据是如何存储在内存中的?
在 JavaScript 中,原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址。
在 JavaScript 的执行过程中, 主要有三种类型内存空间,分别是代码空间、栈空间、堆空间。其中的代码空间主要是存储可执行代码的,原始类型(Number、String、Null、Undefined、Boolean、Symbol、BigInt)的数据值都是直接保存在“栈”中的,引用类型(Object)的值是存放在“堆”中的。因此在栈空间中(执行上下文),原始类型存储的是变量的值,而引用类型存储的是其在"堆空间"中的地址,当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手流程。
在编译过程中,如果 JavaScript 引擎判断到一个闭包,也会在堆空间创建换一个“closure(fn)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存闭包中的变量。所以闭包中的变量是存储在“堆空间”中的。
JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。通常情况下,栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间。因此需要“栈”和“堆”两种空间。
题目一:初出茅庐
let a = {
name: 'lee',
age: 18
}
let b = a;
console.log(a.name); //第一个console
b.name = 'son';
console.log(a.name); //第二个consoleconsole.log(b.name); //第三个console
这道题比较简单,我们可以看到第一个 console 打出来 name 是 'lee',这应该没什么疑问;但是在执行了 b.name='son' 之后,结果你会发现 a 和 b 的属性 name 都是 'son',第二个和第三个打印结果是一样的,这里就体现了引用类型的“共享”的特性,即这两个值都存在同一块内存中共享,一个发生了改变,另外一个也随之跟着变化。
你可以直接在 Chrome 控制台敲一遍,深入理解一下这部分概念。下面我们再看一段代码,它是比题目一稍复杂一些的对象属性变化问题。
题目二:渐入佳境
let a = {
name: 'Julia',
age: 20
}
functionchange(o) {
o.age = 24;
o = {
name: 'Kath',
age: 30
}
return o;
}
let b = change(a); // 注意这里没有new,后面new相关会有专门文章讲解console.log(b.age); // 第一个consoleconsole.log(a.age); // 第二个console
这道题涉及了 function,你通过上述代码可以看到第一个 console 的结果是 30,b 最后打印结果是 {name: "Kath", age: 30};第二个 console 的返回结果是 24,而 a 最后的打印结果是 {name: "Julia", age: 24}。
是不是和你预想的有些区别?你要注意的是,这里的 function 和 return 带来了不一样的东西。
原因在于:函数传参进来的 o,传递的是对象在堆中的内存地址值,通过调用 o.age = 24(第 7 行代码)确实改变了 a 对象的 age 属性;但是第 12 行代码的 return 却又把 o 变成了另一个内存地址,将 {name: "Kath", age: 30} 存入其中,最后返回 b 的值就变成了 {name: "Kath", age: 30}。而如果把第 12 行去掉,那么 b 就会返回 undefined
2. 数据类型检测
(1)typeof
typeof 对于原始类型来说,除了 null 都可以显示正确的类型
console.log(typeof2); // numberconsole.log(typeoftrue); // booleanconsole.log(typeof'str'); // stringconsole.log(typeof []); // object []数组的数据类型在 typeof 中被解释为 objectconsole.log(typeoffunction(){}); // functionconsole.log(typeof {}); // objectconsole.log(typeofundefined); // undefinedconsole.log(typeofnull); // object null 的数据类型被 typeof 解释为 object
typeof 对于对象来说,除了函数都会显示 object,所以说 typeof 并不能准确判断变量到底是什么类型,所以想判断一个对象的正确类型,这时候可以考虑使用 instanceof
(2)instanceof
instanceof 可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链中是不是能找到类型的 prototype
console.log(2instanceofNumber); // falseconsole.log(trueinstanceofBoolean); // false console.log('str'instanceofString); // false console.log([] instanceofArray); // trueconsole.log(function(){} instanceofFunction); // trueconsole.log({} instanceofObject); // true // console.log(undefined instanceof Undefined);// console.log(null instanceof Null);
instanceof 可以准确地判断复杂引用数据类型,但是不能正确判断基础数据类型;
而 typeof 也存在弊端,它虽然可以判断基础数据类型(null 除外),但是引用数据类型中,除了 function 类型以外,其他的也无法判断
// 我们也可以试着实现一下 instanceoffunction_instanceof(left, right) {
// 由于instance要检测的是某对象,需要有一个前置判断条件//基本数据类型直接返回falseif(typeof left !== 'object' || left === null) returnfalse;
// 获得类型的原型let prototype = right.prototype// 获得对象的原型
left = left.__proto__// 判断对象的类型是否等于类型的原型while (true) {
if (left === null)
returnfalseif (prototype === left)
returntrue
left = left.__proto__
}
}
console.log('test', _instanceof(null, Array)) // falseconsole.log('test', _instanceof([], Array)) // trueconsole.log('test', _instanceof('', Array)) // falseconsole.log('test', _instanceof({}, Object)) // true
(3)constructor
console.log((2).constructor === Number); // trueconsole.log((true).constructor === Boolean); // trueconsole.log(('str').constructor === String); // trueconsole.log(([]).constructor === Array); // trueconsole.log((function() {}).constructor === Function); // trueconsole.log(({}).constructor === Object); // true
这里有一个坑,如果我创建一个对象,更改它的原型,constructor就会变得不可靠了
functionFn(){};
Fn.prototype=newArray();
var f=newFn();
console.log(f.constructor===Fn); // falseconsole.log(f.constructor===Array); // true
(4)Object.prototype.toString.call()
toString() 是 Object 的原型方法,调用该方法,可以统一返回格式为 “[object Xxx]” 的字符串,其中 Xxx 就是对象的类型。对于 Object 对象,直接调用 toString() 就能返回 [object Object];而对于其他对象,则需要通过 call 来调用,才能返回正确的类型信息。我们来看一下代码。
Object.prototype.toString({}) // "[object Object]"Object.prototype.toString.call({}) // 同上结果,加上call也okObject.prototype.toString.call(1) // "[object Number]"Object.prototype.toString.call('1') // "[object String]"Object.prototype.toString.call(true) // "[object Boolean]"Object.prototype.toString.call(function(){}) // "[object Function]"Object.prototype.toString.call(null) //"[object Null]"Object.prototype.toString.call(undefined) //"[object Undefined]"Object.prototype.toString.call(/123/g) //"[object RegExp]"Object.prototype.toString.call(newDate()) //"[object Date]"Object.prototype.toString.call([]) //"[object Array]"Object.prototype.toString.call(document) //"[object HTMLDocument]"Object.prototype.toString.call(window) //"[object Window]"// 从上面这段代码可以看出,Object.prototype.toString.call() 可以很好地判断引用类型,甚至可以把 document 和 window 都区分开来。
实现一个全局通用的数据类型判断方法,来加深你的理解,代码如下
functiongetType(obj){
let type = typeof obj;
if (type !== "object") { // 先进行typeof判断,如果是基础数据类型,直接返回return type;
}
// 对于typeof返回结果是object的,再进行如下的判断,正则返回结果returnObject.prototype.toString.call(obj).replace(/^\[object (\S+)\]$/, '$1'); // 注意正则中间有个空格
}
/* 代码验证,需要注意大小写,哪些是typeof判断,哪些是toString判断?思考下 */getType([]) // "Array" typeof []是object,因此toString返回getType('123') // "string" typeof 直接返回getType(window) // "Window" toString返回getType(null) // "Null"首字母大写,typeof null是object,需toString来判断getType(undefined) // "undefined" typeof 直接返回getType() // "undefined" typeof 直接返回getType(function(){}) // "function" typeof能判断,因此首字母小写getType(/123/g) //"RegExp" toString返回
小结
typeof
直接在计算机底层基于数据类型的值(二进制)进行检测
typeof null为object 原因是对象存在在计算机中,都是以000开始的二进制存储,所以检测出来的结果是对象
typeof 普通对象/数组对象/正则对象/日期对象 都是object
typeof NaN === 'number'
instanceof
检测当前实例是否属于这个类的
底层机制:只要当前类出现在实例的原型上,结果都是true
不能检测基本数据类型
constructor
支持基本类型
constructor可以随便改,也不准
Object.prototype.toString.call([val])
返回当前实例所属类信息
判断 Target 的类型,单单用 typeof 并无法完全满足,这其实并不是 bug,本质原因是 JS 的万物皆对象的理论。因此要真正完美判断时,我们需要区分对待:
基本类型(null): 使用 String(null)
基本类型(string / number / boolean / undefined) + function: - 直接使用 typeof即可
其余引用类型(Array / Date / RegExp Error): 调用toString后根据[object XXX]进行判断
3. 数据类型转换
我们先看一段代码,了解下大致的情况。
'123' == 123// false or true?'' == null// false or true?'' == 0// false or true?
[] == 0// false or true?
[] == ''// false or true?
[] == ![] // false or true?null == undefined// false or true?Number(null) // 返回什么?Number('') // 返回什么?parseInt(''); // 返回什么?
{}+10// 返回什么?let obj = {
[Symbol.toPrimitive]() {
return200;
},
valueOf() {
return300;
},
toString() {
return'Hello';
}
}
console.log(obj + 200); // 这里打印出来是多少?
首先我们要知道,在 JS 中类型转换只有三种情况,分别是:
转换为布尔值
转换为数字
转换为字符串
转Boolean
在条件判断时,除了 undefined,null, false, NaN, '', 0, -0,其他所有值都转为 true,包括所有对象
Boolean(0) //falseBoolean(null) //falseBoolean(undefined) //falseBoolean(NaN) //falseBoolean(1) //trueBoolean(13) //trueBoolean('12') //true
对象转原始类型
对象在转换类型的时候,会调用内置的 [[ToPrimitive]] 函数,对于该函数来说,算法逻辑一般来说如下
如果已经是原始类型了,那就不需要转换了
调用 x.valueOf(),如果转换为基础类型,就返回转换的值
调用 x.toString(),如果转换为基础类型,就返回转换的值
如果都没有返回原始类型,就会报错
当然你也可以重写 Symbol.toPrimitive,该方法在转原始类型时调用优先级最高。
let a = {
valueOf() {
return0
},
toString() {
return'1'
},
[Symbol.toPrimitive]() {
return2
}
}
1 + a // => 3
四则运算符
它有以下几个特点:
运算中其中一方为字符串,那么就会把另一方也转换为字符串
如果一方不是字符串或者数字,那么会将它转换为数字或者字符串
1 + '1'// '11'true + true// 24 + [1,2,3] // "41,2,3"
对于第一行代码来说,触发特点一,所以将数字 1 转换为字符串,得到结果 '11'
对于第二行代码来说,触发特点二,所以将 true 转为数字 1
对于第三行代码来说,触发特点二,所以将数组通过 toString转为字符串 1,2,3,得到结果 41,2,3
另外对于加法还需要注意这个表达式 'a' + + 'b'
'a' + + 'b'// -> "aNaN"
因为 + 'b' 等于 NaN,所以结果为 "aNaN",你可能也会在一些代码中看到过 + '1'的形式来快速获取 number 类型。
那么对于除了加法的运算符来说,只要其中一方是数字,那么另一方就会被转为数字
4 * '3'// 124 * [] // 04 * [1, 2] // NaN
比较运算符
如果是对象,就通过 toPrimitive 转换对象
如果是字符串,就通过 unicode 字符索引来比较
let a = {
valueOf() {
return0
},
toString() {
return'1'
}
}
a > -1// true
在以上代码中,因为 a 是对象,所以会通过 valueOf 转换为原始类型再比较值。
强制类型转换
强制类型转换方式包括 Number()、parseInt()、parseFloat()、toString()、String()、Boolean(),这几种方法都比较类似
Number() 方法的强制转换规则
如果是布尔值,true 和 false 分别被转换为 1 和 0;
如果是数字,返回自身;
如果是 null,返回 0;
如果是 undefined,返回 NaN;
如果是字符串,遵循以下规则:如果字符串中只包含数字(或者是 0X / 0x 开头的十六进制数字字符串,允许包含正负号),则将其转换为十进制;如果字符串中包含有效的浮点格式,将其转换为浮点数值;如果是空字符串,将其转换为 0;如果不是以上格式的字符串,均返回 NaN;
如果是 Symbol,抛出错误;
如果是对象,并且部署了 [Symbol.toPrimitive] ,那么调用此方法,否则调用对象的 valueOf() 方法,然后依据前面的规则转换返回的值;如果转换的结果是 NaN ,则调用对象的 toString() 方法,再次依照前面的顺序转换返回对应的值。
Number(true); // 1Number(false); // 0Number('0111'); //111Number(null); //0Number(''); //0Number('1a'); //NaNNumber(-0X11); //-17Number('0X11') //17
Object 的转换规则
对象转换的规则,会先调用内置的 [ToPrimitive] 函数,其规则逻辑如下:
如果部署了 Symbol.toPrimitive 方法,优先调用再返回;
调用 valueOf(),如果转换为基础类型,则返回;
调用 toString(),如果转换为基础类型,则返回;
如果都没有返回基础类型,会报错。
var obj = {
value: 1,
valueOf() {
return2;
},
toString() {
return'3'
},
[Symbol.toPrimitive]() {
return4
}
}
console.log(obj + 1); // 输出5// 因为有Symbol.toPrimitive,就优先执行这个;如果Symbol.toPrimitive这段代码删掉,则执行valueOf打印结果为3;如果valueOf也去掉,则调用toString返回'31'(字符串拼接)// 再看两个特殊的case:10 + {}
// "10[object Object]",注意:{}会默认调用valueOf是{},不是基础类型继续转换,调用toString,返回结果"[object Object]",于是和10进行'+'运算,按照字符串拼接规则来,参考'+'的规则C
[1,2,undefined,4,5] + 10// "1,2,,4,510",注意[1,2,undefined,4,5]会默认先调用valueOf结果还是这个数组,不是基础数据类型继续转换,也还是调用toString,返回"1,2,,4,5",然后再和10进行运算,还是按照字符串拼接规则,参考'+'的第3条规则
'==' 的隐式类型转换规则
如果类型相同,无须进行类型转换;
如果其中一个操作值是 null 或者 undefined,那么另一个操作符必须为 null 或者 undefined,才会返回 true,否则都返回 false;
如果其中一个是 Symbol 类型,那么返回 false;
两个操作值如果为 string 和 number 类型,那么就会将字符串转换为 number;
如果一个操作值是 boolean,那么转换成 number;
如果一个操作值为 object 且另一方为 string、number 或者 symbol,就会把 object 转为原始类型再进行判断(调用 object 的 valueOf/toString 方法进行转换)。
null == undefined// true 规则2null == 0// false 规则2'' == null// false 规则2'' == 0// true 规则4 字符串转隐式转换成Number之后再对比'123' == 123// true 规则4 字符串转隐式转换成Number之后再对比0 == false// true e规则 布尔型隐式转换成Number之后再对比1 == true// true e规则 布尔型隐式转换成Number之后再对比var a = {
value: 0,
valueOf: function() {
this.value++;
returnthis.value;
}
};
// 注意这里a又可以等于1、2、3console.log(a == 1 && a == 2 && a ==3); //true f规则 Object隐式转换// 注:但是执行过3遍之后,再重新执行a==3或之前的数字就是false,因为value已经加上去了,这里需要注意一下
'+' 的隐式类型转换规则
'+' 号操作符,不仅可以用作数字相加,还可以用作字符串拼接。仅当 '+' 号两边都是数字时,进行的是加法运算;如果两边都是字符串,则直接拼接,无须进行隐式类型转换。
如果其中有一个是字符串,另外一个是 undefined、null 或布尔型,则调用 toString() 方法进行字符串拼接;如果是纯对象、数组、正则等,则默认调用对象的转换方法会存在优先级,然后再进行拼接。
如果其中有一个是数字,另外一个是 undefined、null、布尔型或数字,则会将其转换成数字进行加法运算,对象的情况还是参考上一条规则。
如果其中一个是字符串、一个是数字,则按照字符串规则进行拼接
1 + 2// 3 常规情况'1' + '2'// '12' 常规情况// 下面看一下特殊情况'1' + undefined// "1undefined" 规则1,undefined转换字符串'1' + null// "1null" 规则1,null转换字符串'1' + true// "1true" 规则1,true转换字符串'1' + 1n// '11' 比较特殊字符串和BigInt相加,BigInt转换为字符串1 + undefined// NaN 规则2,undefined转换数字相加NaN1 + null// 1 规则2,null转换为01 + true// 2 规则2,true转换为1,二者相加为21 + 1n// 错误 不能把BigInt和Number类型直接混合相加'1' + 3// '13' 规则3,字符串拼接
整体来看,如果数据中有字符串,JavaScript 类型转换还是更倾向于转换成字符串,因为第三条规则中可以看到,在字符串和数字相加的过程中最后返回的还是字符串,这里需要关注一下
null 和 undefined 的区别?
首先 Undefined 和 Null 都是基本数据类型,这两个基本数据类型分别都只有一个值,就是 undefined 和 null。
undefined 代表的含义是未定义, null 代表的含义是空对象(其实不是真的对象,请看下面的注意!)。一般变量声明了但还没有定义的时候会返回 undefined,null 主要用于赋值给一些可能会返回对象的变量,作为初始化。
其实 null 不是对象,虽然 typeof null 会输出 object,但是这只是 JS 存在的一个悠久 Bug。在 JS 的最初版本中使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,然而 null 表示为全零,所以将它错误的判断为 object 。虽然现在的内部类型判断代码已经改变了,但是对于这个 Bug 却是一直流传下来。
undefined 在 js 中不是一个保留字,这意味着我们可以使用 undefined 来作为一个变量名,这样的做法是非常危险的,它会影响我们对 undefined 值的判断。但是我们可以通过一些方法获得安全的 undefined 值,比如说 void 0。
当我们对两种类型使用 typeof 进行判断的时候,Null 类型化会返回 “object”,这是一个历史遗留的问题。当我们使用双等号对两种类型的值进行比较时会返回 true,使用三个等号时会返回 false。
TCP/IP五层协议
TCP/IP五层协议和OSI的七层协议对应关系如下:
应用层 (application layer):直接为应用进程提供服务。应用层协议定义的是应用进程间通讯和交互的规则,不同的应用有着不同的应用层协议,如 HTTP协议(万维网服务)、FTP协议(文件传输)、SMTP协议(电子邮件)、DNS(域名查询)等。
传输层 (transport layer):有时也译为运输层,它负责为两台主机中的进程提供通信服务。该层主要有以下两种协议:
传输控制协议 (Transmission Control Protocol,TCP):提供面向连接的、可靠的数据传输服务,数据传输的基本单位是报文段(segment);
用户数据报协议 (User Datagram Protocol,UDP):提供无连接的、尽最大努力的数据传输服务,但不保证数据传输的可靠性,数据传输的基本单位是用户数据报。
网络层 (internet layer):有时也译为网际层,它负责为两台主机提供通信服务,并通过选择合适的路由将数据传递到目标主机。
数据链路层 (data link layer):负责将网络层交下来的 IP 数据报封装成帧,并在链路的两个相邻节点间传送帧,每一帧都包含数据和必要的控制信息(如同步信息、地址信息、差错控制等)。
物理层 (physical Layer):确保数据可以在各种物理媒介上进行传输,为数据的传输提供可靠的环境。
从上图中可以看出,TCP/IP模型比OSI模型更加简洁,它把应用层/表示层/会话层全部整合为了应用层。
在每一层都工作着不同的设备,比如我们常用的交换机就工作在数据链路层的,一般的路由器是工作在网络层的。 在每一层实现的协议也各不同,即每一层的服务也不同,下图列出了每层主要的传输协议:
同样,TCP/IP五层协议的通信方式也是对等通信:
TCP和UDP的使用场景
TCP应用场景: 效率要求相对低,但对准确性要求相对高的场景。因为传输中需要对数据确认、重发、排序等操作,相比之下效率没有UDP高。例如:文件传输(准确高要求高、但是速度可以相对慢)、接受邮件、远程登录。
UDP应用场景: 效率要求相对高,对准确性要求相对低的场景。例如:QQ聊天、在线视频、网络语音电话(即时通讯,速度要求高,但是出现偶尔断续不是太大问题,并且此处完全不可以使用重发机制)、广播通信(广播、多播)。
左右两边定宽,中间自适应
float,float + calc, 圣杯布局(设置BFC,margin负值法),flex
.wrap {
width: 100%;
height: 200px;
}
.wrap > div {
height: 100%;
}
/* 方案1 */.left {
width: 120px;
float: left;
}
.right {
float: right;
width: 120px;
}
.center {
margin: 0120px;
}
/* 方案2 */.left {
width: 120px;
float: left;
}
.right {
float: right;
width: 120px;
}
.center {
width: calc(100% - 240px);
margin-left: 120px;
}
/* 方案3 */.wrap {
display: flex;
}
.left {
width: 120px;
}
.right {
width: 120px;
}
.center {
flex: 1;
}
intanceof 操作符的实现原理及实现
instanceof 运算符用于判断构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。
functionmyInstanceof(left, right) {
// 获取对象的原型let proto = Object.getPrototypeOf(left)
// 获取构造函数的 prototype 对象let prototype = right.prototype;
// 判断构造函数的 prototype 对象是否在对象的原型链上while (true) {
if (!proto) returnfalse;
if (proto === prototype) returntrue;
// 如果没有找到,就继续从其原型上找,Object.getPrototypeOf方法用来获取指定对象的原型
proto = Object.getPrototypeOf(proto);
}
}
UDP协议为什么不可靠?
UDP在传输数据之前不需要先建立连接,远地主机的运输层在接收到UDP报文后,不需要确认,提供不可靠交付。总结就以下四点:
不保证消息交付:不确认,不重传,无超时
不保证交付顺序:不设置包序号,不重排,不会发生队首阻塞
不跟踪连接状态:不必建立连接或重启状态机
不进行拥塞控制:不内置客户端或网络反馈机制
说一下 HTML5 drag API
dragstart:事件主体是被拖放元素,在开始拖放被拖放元素时触发。
darg:事件主体是被拖放元素,在正在拖放被拖放元素时触发。
dragenter:事件主体是目标元素,在被拖放元素进入某元素时触发。
dragover:事件主体是目标元素,在被拖放在某元素内移动时触发。
dragleave:事件主体是目标元素,在被拖放元素移出目标元素是触发。
drop:事件主体是目标元素,在目标元素完全接受被拖放元素时触发。
dragend:事件主体是被拖放元素,在整个拖放操作结束时触发。
实现一个三角形
CSS绘制三角形主要用到的是border属性,也就是边框。
平时在给盒子设置边框时,往往都设置很窄,就可能误以为边框是由矩形组成的。实际上,border属性是右三角形组成的,下面看一个例子:
div {
width: 0;
height: 0;
border: 100px solid;
border-color: orange blue red green;
}
将元素的长宽都设置为0
(1)三角1
div { width: 0; height: 0; border-top: 50px solid red; border-right: 50px solid transparent; border-left: 50px solid transparent;}
(2)三角2
div {
width: 0;
height: 0;
border-bottom: 50px solid red;
border-right: 50px solid transparent;
border-left: 50px solid transparent;
}
(3)三角3
div {
width: 0;
height: 0;
border-left: 50px solid red;
border-top: 50px solid transparent;
border-bottom: 50px solid transparent;
}
(4)三角4
div {
width: 0;
height: 0;
border-right: 50px solid red;
border-top: 50px solid transparent;
border-bottom: 50px solid transparent;
}
(5)三角5
div {
width: 0;
height: 0;
border-top: 100px solid red;
border-right: 100px solid transparent;
}
还有很多,就不一一实现了,总体的原则就是通过上下左右边框来控制三角形的方向,用边框的宽度比来控制三角形的角度。
对this对象的理解
this 是执行上下文中的一个属性,它指向最后一次调用这个方法的对象。在实际开发中,this 的指向可以通过四种调用模式来判断。
第一种是函数调用模式,当一个函数不是一个对象的属性时,直接作为函数来调用时,this 指向全局对象。
第二种是方法调用模式,如果一个函数作为一个对象的方法来调用时,this 指向这个对象。
第三种是构造器调用模式,如果一个函数用 new 调用时,函数执行前会新创建一个对象,this 指向这个新创建的对象。
第四种是 apply 、 call 和 bind 调用模式,这三个方法都可以显示的指定调用函数的 this 指向。其中 apply 方法接收两个参数:一个是 this 绑定的对象,一个是参数数组。call 方法接收的参数,第一个是 this 绑定的对象,后面的其余参数是传入函数执行的参数。也就是说,在使用 call() 方法时,传递给函数的参数必须逐个列举出来。bind 方法通过传入一个对象,返回一个 this 绑定了传入对象的新函数。这个函数的 this 指向除了使用 new 时会被改变,其他情况下都不会改变。
这四种方式,使用构造器调用模式的优先级最高,然后是 apply、call 和 bind 调用模式,然后是方法调用模式,然后是函数调用模式。
new操作符的实现原理
new操作符的执行过程:
(1)首先创建了一个新的空对象
(2)设置原型,将对象的原型设置为函数的 prototype 对象。
(3)让函数的 this 指向这个对象,执行构造函数的代码(为这个新对象添加属性)
(4)判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,就返回这个引用类型的对象。
具体实现:
functionobjectFactory() {
let newObject = null;
let constructor = Array.prototype.shift.call(arguments);
let result = null;
// 判断参数是否是一个函数if (typeof constructor !== "function") {
console.error("type error");
return;
}
// 新建一个空对象,对象的原型为构造函数的 prototype 对象
newObject = Object.create(constructor.prototype);
// 将 this 指向新建对象,并执行函数
result = constructor.apply(newObject, arguments);
// 判断返回对象let flag = result && (typeof result === "object" || typeof result === "function");
// 判断返回结果return flag ? result : newObject;
}
// 使用方法objectFactory(构造函数, 初始化参数);
箭头函数的this指向哪⾥?
箭头函数不同于传统JavaScript中的函数,箭头函数并没有属于⾃⼰的this,它所谓的this是捕获其所在上下⽂的 this 值,作为⾃⼰的 this 值,并且由于没有属于⾃⼰的this,所以是不会被new调⽤的,这个所谓的this也不会被改变。
可以⽤Babel理解⼀下箭头函数:
// ES6 const obj = {
getArrow() {
return() => {
console.log(this === obj);
};
}
}
转化后:
// ES5,由 Babel 转译var obj = {
getArrow: functiongetArrow() {
var _this = this;
returnfunction () {
console.log(_this === obj);
};
}
};
相关文章:
前端经典面试题(有答案)
代码输出结果var a 10var obj {a: 20,say: () > {console.log(this.a)}}obj.say() var anotherObj { a: 30 } obj.say.apply(anotherObj) 输出结果:10 10我么知道,箭头函数时不绑定this的,它的this来自原其父级所处的上下文,…...

华为云服务器安装mysql连接失败问题
新买了一个华为云服务器,装了一个宝塔linux工具,很好用,很好用。安装软件,管理软件都很方便。具体怎么操作官方文档很详细,不在这里赘述了。 问题:安装好mysql,安全组开放3306端口。修改root连接…...

合作伙伴管理软件VS CRM,企业应该选择哪一个?
当涉及到管理你公司的伙伴关系和与客户的关系时,有两个主要选择:合作伙伴管理软件和CRM(客户关系管理)软件。虽然这两种工具都可以帮助你跟踪商业关系的重要信息,但它们都有各自的优势和不足。 合作伙伴管理软件是专门…...

Matter 系列 #9|乐鑫 Matter 预配置服务加速设备生产
乐鑫 Matter 系列文章 #9 目录 Matter 预配置服务 1. 设备认证 (Device Attestation) 2. 独特性 (Uniqueness) 3. 安全性 (Security) 联系我们 如今,物联网行业蓬勃发展,大量市场参与者正在积极地构建 Matter 智能设备。 乐鑫一直致…...

手把手交叉编译mysql
1.下载mysql(注意下载boost版本,这样会少一步编译) 下载mysql的时候一定要看好交叉编译工具链的版本。因为mysql 8.0需要的工具链版本较高,所以有可能不支持 查看链接如下: MySQL :: MySQL 8.0 Reference Manual :: …...

升压模块直流隔离低压转高压稳压电源5v12v24v转50V100V110V150V200V250V400V500V600V800V1000V
特点效率高达80%以上1*2英寸标准封装单电压输出价格低稳压输出工作温度: -40℃~85℃阻燃封装,满足UL94-V0 要求温度特性好可直接焊在PCB 上应用HRB W2~40W 系列模块电源是一种DC-DC升压变换器。该模块电源的输入电压分为:4.5~9V、9~18V、及18~36VDC标准&…...

LeetCode:977 有序数组平方
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 示例 1: 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释:平方后,数组变为 […...
)
JAVA环境配置多个环境(全,详细,简单)
下载java包:https://www.oracle.com/java/technologies/downloads (8版本稳定) 直接无脑安装java程序 (包括jdk-开发与jre-运行) 接下来是java环境配置: 创建系统变量 (用户变量也可以&#…...

10 Seata配置Nacos注册中心和配置中心
Seata配置Nacos注册中心和配置中心 Seata支持注册服务到Nacos,以及支持Seata所有配置放到Nacos配置中心,在Nacos中统一维护; 高可用(集群)模式下就需要配合Nacos来完成: 具体配置如下 注册中心 Seata-server端配置注册中心,…...

[数据库]表的增删改查进阶
●🧑个人主页:你帅你先说. ●📃欢迎点赞👍关注💡收藏💖 ●📖既选择了远方,便只顾风雨兼程。 ●🤟欢迎大家有问题随时私信我! ●🧐版权:本文由[你帅…...
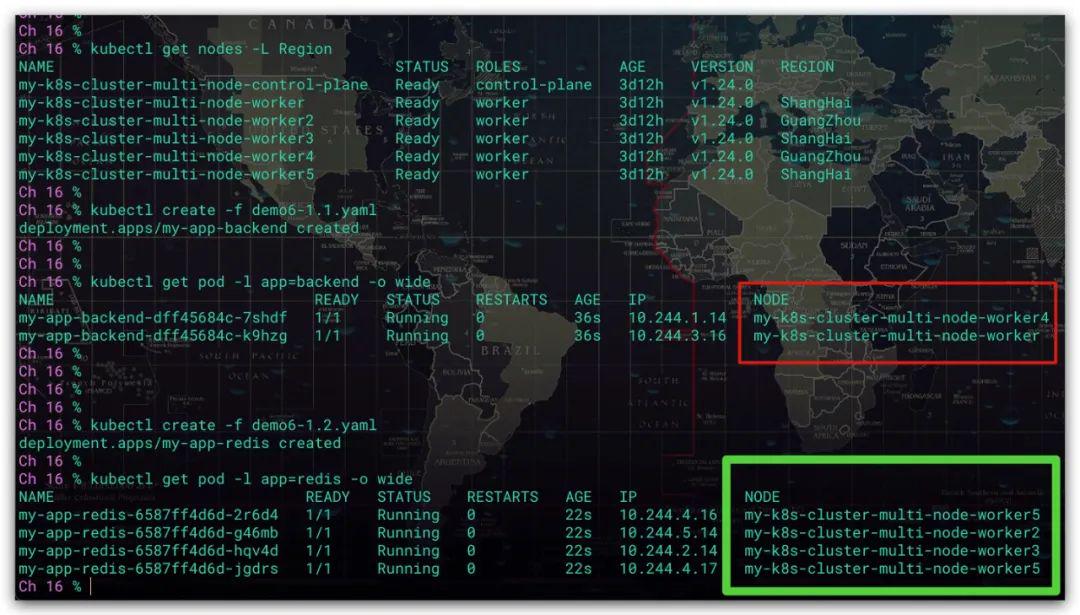
Kubernetes调度之Pod亲和性
Kubernetes调度中的Pod亲和性abstract.pngPod亲和性节点亲和性,是基于节点的标签对Pod进行调度。而Pod亲和性则可以实现基于已经在节点上运行Pod的标签来约束新Pod可以调度到的节点。具体地,如果X上已经运行了一个或多个满足规则Y的Pod,则这个…...

建立相关在线社群的3个简单步骤
在线社群管理和社交媒体营销通常被视为一回事。虽然社群管理确实是社交媒体营销的一个关键部分,但它的意义超越了社交媒体的内容发布。因此,在线社群对于企业的数字营销十分重要。创建、维护和发展社群不是一件容易的工作,也不是一个快速的过…...

安全运营的新模式
安全运营的新模式是传统安全运维的扩展和升级,其实现落地需要管理和技术两斱面同时支撑、相互衎接和配合,缺夰仸何一个都是行不通的。管理斱面,在顶层设计时,网络安全运营要根据国家信息安全等级保护 2.0 的相关要求,参…...

Day10-网页布局实战CSS3
一 补充 1 画三角形 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthdevi…...
)
代码规范(C/C++规范)
文章目录前言个人编写的代码规范链接请求合作大体章节END前言 什么是代码规范 一套用于统一代码开发的准则 为什么需要代码规范 提升代码可读性,提升团队效率 个人编写的代码规范 近期本人编写了一份以C/C为主的代码规范。 其他语言开发者也可以阅读参考。 本…...
:计算属性和监视属性总结)
春招冲刺(九):计算属性和监视属性总结
计算属性和监视属性总结 Q1:计算属性 姓:<input type"text" v-model"firstName"><br><br> 名:<input type"text" v-model"lastName"><br><br> 姓名ÿ…...
数据挖掘(作业1)
实验开始前先配置环境 以实验室2023安装的版本为例: 1、安装anaconda:(anaconda自带Python,安装了anaconda就不用再安装Python了) 下载并安装 Anaconda3-2022.10-Windows-x86_64.exe 自己选择安装路径,其他使用默认…...
【UE4 RTS游戏】01-项目准备
步骤新建一个工程,选择俯视角游戏模板我命名工程如下:删除场景内的所有cube再删除Floor和Wall删除TopDownCharacter删除“NavgationMeshBoundVolume”删除“TamplateLabel”和“RecastNavMesh-Default”删除LightmassImportanceVolume、PostProcessVolum…...
)
登录系统账号检测--课后程序(Python程序开发案例教程-黑马程序员编著-第3章-课后作业)
实例8:登录系统账号检测 登录系统一般具有账号密码检测功能,即检测用户输入的账号密码是否正确。若用户输入的账号或密码不正确,提示 “用户名或密码错误”和“您还有*次机会”; 若用户输入的账号和密码正确,提示“登…...

CentOS8基础篇12:使用RPM管理telnet-server软件包
一、RPM包管理工具简介 RedHat软件包管理工具(RedHat Package Manager,RPM) RPM软件包工具常用于软件包的安装、查询、更新升级、校验、卸载以及生成.rpm格式的软件包等操作。 RPM软件包工具只能管理后缀是.rpm的软件包。软件包的命名格式: 软件名称…...

银河麒麟服务器KY10上快速部署Keepalived高可用集群
1. 为什么需要Keepalived高可用集群? 想象一下你运营着一个电商网站,突然服务器宕机了,所有用户都无法下单。这种情况每年造成的损失可能高达数百万。而Keepalived就像给服务器买了份"意外保险"——当主服务器故障时,备…...

遨博协作机器人ROS实战 - 机械臂URDF模型优化与RViz可视化调试
1. 从“能用”到“好用”:为什么你的机械臂URDF模型需要优化? 大家好,我是老张,在机器人圈子里摸爬滚打了十几年,从最早的工业机械臂编程到现在的协作机器人应用开发,踩过的坑比走过的路还多。今天咱们不聊…...

AutoGen详解:专注多智能体协作,让AI Agent“会分工、能协同”
在AI智能体(Agent)技术向工业级落地迈进的过程中,单一智能体的能力边界逐渐显现——面对复杂的企业级任务(如多步骤数据分析、跨领域项目协作、全流程自动化办公),单个智能体往往难以兼顾“检索、推理、执行…...

法律行业革命:10款开源商用LLM让AI法律助手触手可及
法律行业革命:10款开源商用LLM让AI法律助手触手可及 【免费下载链接】open-llms 📋 A list of open LLMs available for commercial use. 项目地址: https://gitcode.com/gh_mirrors/op/open-llms GitHub 加速计划的 open-llms 项目汇集了一系列可…...

配电网最优潮流与二阶锥:解决配电网规划难题
配电网 最优潮流 二阶锥 最优潮流模型,用于解决配电网规划(DNP)问题。 数学优化模型,旨在找到基于给定参数和约束条件的最优配电网规划解决方案。 SOCPR方法用于处理问题中的非凸性,从而更容易找到大规模配电网的近似…...

WangEditor在Vue2中如何处理Word文档中的特殊格式粘贴?
河南.NET程序员接单记:680元预算搞定CMS编辑器Word/公式导入,开箱即用! 一、项目背景:客户的需求就是我的KPI 最近接了个企业官网CMS外包项目,客户是传统行业,后台新闻发布全靠Word复制粘贴,但…...

2026年专科生必看!千笔·降AI率助手,最受欢迎的降AI率网站
在AI技术迅速发展的今天,越来越多的学生和研究人员开始依赖AI工具辅助论文写作。然而,随着知网、维普、万方等查重系统不断升级算法,以及Turnitin对AIGC(人工智能生成内容)的识别愈发严格,AI率超标问题正成…...
,聊天室系统)
java毕业设计,基于java+原生Sevlet+socket的聊天室系统设计与实现(全套源码+配套论文),聊天室系统
基于java原生Sevletsocket的聊天室系统设计与实现(全套源码配套论文) 大家好,今天给大家介绍基于java原生Sevletsocket的聊天室系统设计与实现,更多精选毕业设计项目实例见文末哦。 文章目录: 基于java原生Sevletsoc…...

ChineseChess-AlphaZero核心架构解析:模型训练与自我对弈机制详解
ChineseChess-AlphaZero核心架构解析:模型训练与自我对弈机制详解 【免费下载链接】ChineseChess-AlphaZero Implement AlphaZero/AlphaGo Zero methods on Chinese chess. 项目地址: https://gitcode.com/gh_mirrors/ch/ChineseChess-AlphaZero ChineseChes…...

零代码搭建文档分析系统:OpenDataLab MinerU完整使用教程
零代码搭建文档分析系统:OpenDataLab MinerU完整使用教程 1. 引言:为什么选择OpenDataLab MinerU? 在日常办公和学术研究中,我们经常需要处理大量PDF文档、扫描件和PPT演示文稿。传统方法要么依赖人工阅读效率低下,要…...