每日一博 - 关于日志记录的最佳实践
文章目录
- 概述
- 选择合适的日志等级
- 打印函数的入参、出参
- 打印日志对象要做判空处理,避免阻断流程
- 推荐使用 Slf4j
- 不用e.printStackTrace()打印日志
- 低级别的日志输出,必须进行日志级别开关判断
- 不打印重复日志
- 打印全部的异常信息,方便定位问题
- 核心业务逻辑,在每个分支首行都打印日志
- 不打印无意义的日志(不携带上下文、日志链路 id)
- 日志尽量使用英文

概述
记录日志是任何应用程序中至关重要的一部分,它可以帮助开发人员了解应用程序的行为、调试问题以及监控系统的健康状态。
-
使用日志框架:
- 选择一个成熟、广泛使用且功能丰富的日志框架,如Log4j2、Logback或java.util.logging (JUL)。
- Log4j2和Logback是目前较为流行的选择,它们提供了丰富的功能和灵活的配置选项。
-
使用SLF4J进行日志抽象:
- SLF4J (Simple Logging Facade for Java) 提供了一种日志框架的抽象,可以在运行时绑定到不同的日志框架。
- 这样可以使得你的应用程序代码与具体的日志框架解耦,方便后期切换日志框架。
-
选择合适的日志级别:
- 根据日志信息的重要性选择合适的日志级别,常见的级别包括DEBUG、INFO、WARN、ERROR和FATAL。
- DEBUG用于调试信息,INFO用于一般的信息记录,WARN用于警告,ERROR用于错误信息,FATAL用于严重的致命错误。
-
记录有意义的信息:
- 确保记录的日志信息具有可读性和实用性,包括时间戳、线程信息、异常信息等。
- 避免记录过于冗长或无用的信息,以免日志文件变得过大。
-
避免直接打印日志:
- 避免在代码中直接使用System.out.println()或System.err.println()等方式打印日志,而是应该使用日志框架提供的API来记录日志。
- 这样可以更好地控制日志的输出格式、级别和目的地。
-
使用合适的日志格式:
- 配置日志格式以适应你的应用程序需求,包括时间戳格式、日志级别、线程信息等。
- 可以考虑使用JSON格式或者结构化日志格式,以便后续的日志分析和处理。
-
配置日志输出:
- 配置日志输出目的地,可以输出到控制台、文件、数据库等不同的地方。
- 针对不同的环境(如开发、测试、生产),可以配置不同的日志输出策略和目的地。
-
定期维护日志:
- 定期清理和归档日志文件,以防止日志文件过大影响系统性能和存储空间。
-
记录异常信息:
- 在捕获和处理异常时,确保记录足够的信息以便于后续排查问题。
- 可以记录异常的堆栈跟踪、异常类型、异常发生的位置等信息。
-
开启日志异步记录:
- 对于高并发的应用程序,可以考虑开启日志的异步记录,以减少对系统性能的影响。

选择合适的日志等级
-
Error:
- 严重的问题,可能导致系统崩溃或者业务受到重大影响。
- 应该关注系统的稳定性和安全性,运维团队需要重点监控并及时处理。
- 例如:数据库连接失败、关键服务无法启动、未处理的异常等。
-
Warn:
- 不会导致系统崩溃,但可能会影响系统的正常运行。
- 开发人员需要关注,可能需要进一步调查和处理,以防问题进一步恶化。
- 例如:潜在的性能问题、不符合预期的业务流程、资源使用超出预期等。
-
Info:
- 关键的系统运行信息,用于保留系统运行的关键指标。
- 记录重要的业务流程、函数的入参和出参、关键操作的执行情况等。
- 这些信息可以帮助开发人员了解系统的运行情况,以及后续的故障排查和性能优化。
- 例如:用户登录、订单创建、支付成功等重要操作的记录。
-
Debug:
- 用于开发和调试阶段,记录开发人员在关键处理步骤中的变化情况,便于快速定位问题。
- 包含详细的调试信息,如对象数据的变化、条件语句的执行结果等。
- 在生产环境中应该关闭或者限制输出,避免影响系统性能和日志文件大小。
- 例如:方法的参数值、中间变量的取值、特定条件下的执行路径等。
根据具体情况选择合适的日志级别,以确保日志既能够提供足够的信息用于故障排查和性能分析,又不会造成过多的日志噪音。
打印函数的入参、出参
在日志记录过程中,关键是确保只记录关键有效的信息,而不是把所有信息都记录下来。过多的无效日志会导致日志文件变得庞大,增加了存储和维护的成本,也会增加后续日志分析的难度。
因此,有效日志应该是日志记录中的杀手锏,它们提供了足够的信息用于故障排查、性能分析和业务监控,而不会造成不必要的负担。
举个例子:
public String doBiz(Request req, Integer id){// 记录函数入参log.debug("Entering GetName method. Request: {}", req);// 在打印日志时避免直接打印敏感信息如 uid、traceId,可以考虑在日志配置中做处理,或者在代码中做脱敏处理// 执行业务逻辑String name = "artisan";// 记录函数出参及执行时间log.debug("Exiting GetName method. Result: {}, Execution time: {}ms", name, System.currentTimeMillis());return name;
}
有效日志-------》比如函数的入口处,打印入参,还包括用户唯一标识 (uid)、链路标识 (traceId) 等。函数出口打印返回值及时间等
-
函数入参记录:
- 使用
log.debug()记录函数的入参时,将整个请求对象req作为参数传入,确保了记录了函数的所有入参信息。
- 使用
-
函数出参及执行时间记录:
- 使用
log.debug()记录函数的出参时,打印了方法的返回值name和执行时间。 - 打印了方法的执行时间,以便于后续性能分析。
- 使用
这样做的好处是保留了关键有效的日志信息,同时避免了记录过多的日志导致日志文件过大。
打印日志对象要做判空处理,避免阻断流程
通过在日志记录之前进行null检查,可以避免空指针异常的发生,同时在日志中记录了警告信息,表明接收到了空的book对象。这样既确保了程序的健壮性,又不会因为一行简单的日志记录而引发异常。
为了避免这种情况,可以先检查对象是否为null,然后再进行日志记录。
public void doSome(Book book){if (book != null) {log.info("do do and print log: {}", book.getName());} else {log.warn("Received null book object.");}// do something......
}
推荐使用 Slf4j
Slf4j是一种使用门面模式的日志框架,它提供了统一的API接口,可以在不修改代码的情况下,灵活地切换底层的日志实现。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;private static final Logger logger = LoggerFactory.getLogger(Artisan.class);
LoggerFactory.getLogger(JavaPub.class)会返回一个与Artisan类相关联的Logger对象,通过这个Logger对象,我们可以记录日志。
通过这种方式,我们可以利用Slf4j的门面模式来记录日志,而无需关心具体的日志实现,从而实现了日志框架的解耦。
不用e.printStackTrace()打印日志
在日志记录中,应避免使用e.printStackTrace()来打印异常信息。这种方式打印的日志包含了完整的堆栈信息,使得日志不够规整,增加了定位问题的难度。同时,如果使用ELK等日志分析工具,处理这种格式的日志也会非常困难。
看个错误的例子
public void doBiz(){try{// 业务代码...} catch (Exception e){e.printStackTrace();}
}
另外,e.printStackTrace()产生的字符串记录的是堆栈信息,如果信息过长过多,会导致字符串常量池所在的内存块溢出,从而使系统请求被阻塞。
推荐做法:
public void doBiz(){try{// 业务逻辑...} catch (Exception e){log.error("程序异常 failed", e);}
}
建议使用日志框架提供的相应方法来记录异常信息,如log.error("程序异常 failed", e)。这样可以将异常信息记录在日志中,方便查看和分析,同时保持日志的规整性和可读性。

低级别的日志输出,必须进行日志级别开关判断
在低级别的日志输出(如trace、debug)中,必须进行日志级别开关的判断,以避免不必要的资源浪费。这样的开关判断逻辑通常放在日志工具类中。
示例代码:
public void doSomething(){User user = new User(1, "aritsan", "log practice");if (logger.isDebugEnabled()) {logger.debug("print debug log. name is {}", user.getName());}
}
我们通过判断日志级别是否为DEBUG,来决定是否记录DEBUG级别的日志。这样做可以避免在日志级别不符合条件时,执行字符串拼接操作或者执行对象的toString()方法,从而避免不必要的资源浪费。
public void doSth(){String name = "artisan";logger.trace("print debug log" + name);logger.debug("print debug log" + name);logger.info("print info log" + name);// 业务逻辑...
}
这个栗子中没有进行日志级别开关的判断,即使日志级别为WARN时,仍然会执行字符串拼接操作,可能会浪费系统资源。因此,建议在低级别的日志输出中加上日志级别开关判断,以提高系统的性能和效率。

不打印重复日志
在嵌套逻辑代码中重复打印日志会增加系统资源消耗,因此应避免这种情况的发生。
对于重复的日志,可以直接删除或者将其级别设置为debug,这样就不会在生产环境中打印出这些冗余的信息。
举个例子:
public void doSomething(String s){log.info("do something and print log: {}", s);doSubSomething(s);
}private void doSubSomething(String s){log.debug("do sub something and print log: {}", s);// 写点业务逻辑...
}
这样做可以减少不必要的日志输出,提高系统的性能和效率。
打印全部的异常信息,方便定位问题
在异常处理中,应该打印完整的异常信息,以便更好地定位问题。
看个错误的示例:
public void doBiz(){try{// 业务逻辑...} catch (Exception e){log.error("发生了一个异常");}
}
反例中的代码没有打印具体的异常信息e,这样就无法准确地了解到底发生了什么类型的异常。
建议修改为:
public void doSth(){try{// 业务逻辑...} catch (Exception e){log.error("发生了一个异常", e);}
}
这样做可以打印出完整的异常信息,包括异常类型、异常消息和堆栈信息,有助于更快地定位和解决问题。
核心业务逻辑,在每个分支首行都打印日志
在编写核心业务逻辑代码时,在行首打印日志可以帮助快速排查和定位异常。
public void doBiz(User user){if(user.isVip()){log.info("User is a JavaPub member. Id: {}. Starting processing for member logic.", user.getUserId());// TODO: Member logic}else{log.info("User is not a member. Id: {}. Starting processing for non-member logic.", user.getUserId());// TODO: Non-member logic}
}
通过这样的日志记录方式,可以清晰地了解到程序的执行流程,便于后续的排查和定位异常。
不打印无意义的日志(不携带上下文、日志链路 id)
在编写日志时,确保日志携带有意义的业务信息,这样可以帮助快速定位问题原因。
看个反例: 日志并没有携带任何业务信息,因此对故障排查没有太大的帮助。
public void doBiz(Request req, User user){log.info("do something and print log. ");// TODO 业务逻辑...
}
正例中的日志携带了业务相关的信息,如用户ID和日志链路ID,这样可以在出现异常时更容易地定位到具体的业务场景,有利于快速解决问题。
public void doBiz(Request req, User user){log.info("do something and print log, id={}, trace_id={}", user.getId(), req.getTraceId());// TODO 业务逻辑...
}
通过在日志中打印关键信息,可以让程序运行过程更加透明,有利于快速定位问题,提高系统的可维护性和可靠性。
日志尽量使用英文
建议在打印日志时尽量使用英文,以避免中文编码与终端不一致导致打印出现乱码,从而影响排查故障的效率。
比如:
log.info("Start processing...");
log.debug("Processing data: {}", data);
log.error("An error occurred while processing data: {}", error);
通过使用英文打印日志,可以确保日志在不同环境中都能正常显示,有利于排查和解决问题。

相关文章:
每日一博 - 关于日志记录的最佳实践
文章目录 概述选择合适的日志等级打印函数的入参、出参打印日志对象要做判空处理,避免阻断流程推荐使用 Slf4j不用e.printStackTrace()打印日志低级别的日志输出,必须进行日志级别开关判断不打印重复日志打印全部的异常信息,方便定位问题核心…...

针对pycharm打开新项目需要重新下载tensorflow的问题解决
目录 一、前提 二、原因 三、解决办法 一、前提 下载包之前,已经打开了,某个项目。 比如:我先打开了下面这个项目: 然后在terminal使用pip命令下载: 如果是这种情况,你下载的这个包一般都只能用在这一个…...

<商务世界>《第29课 外贸展会上应注意的事项》
1 参展前需要知道的问题 1)在开展前,是否发邀请给外商,告诉他们你的展位号,你的企业及产品的优势? 2)你的展位布置是否能够吸引外商? 3)你参展的产品是否具有个性,特色&…...

sklearn主成分分析PCA
文章目录 基本原理PCA类图像降维与恢复 基本原理 PCA,即主成分分析(Principal components analysis),顾名思义就是把矩阵分解成简单的组分进行研究,而拆解矩阵的主要工具是线性变换,具体形式则是奇异值分解。 设有 m m m个 n n …...
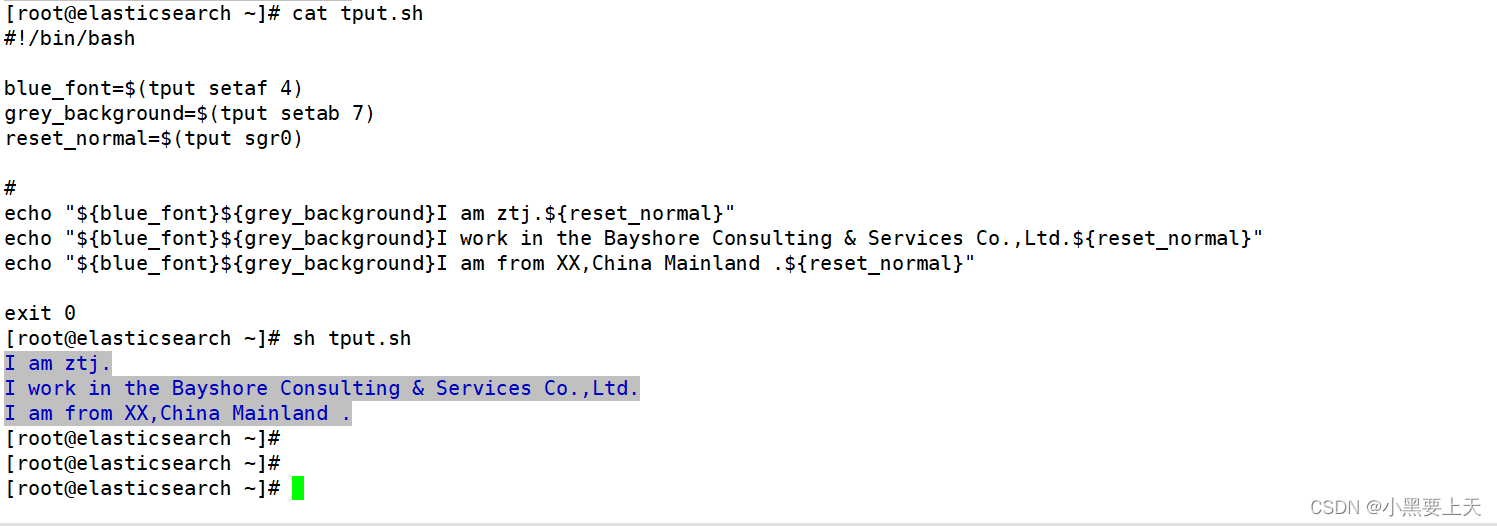
linux命令之tput
1.tput介绍 linux命令tput是可以在终端中进行文本和颜色的控制和格式化,其是一个非常有用的命令 2.tput用法 命令: man tput 3.样例 3.1.清除屏幕 命令: tput clear [rootelasticsearch ~]# tput clear [rootelasticsearch ~]# 3.2.…...
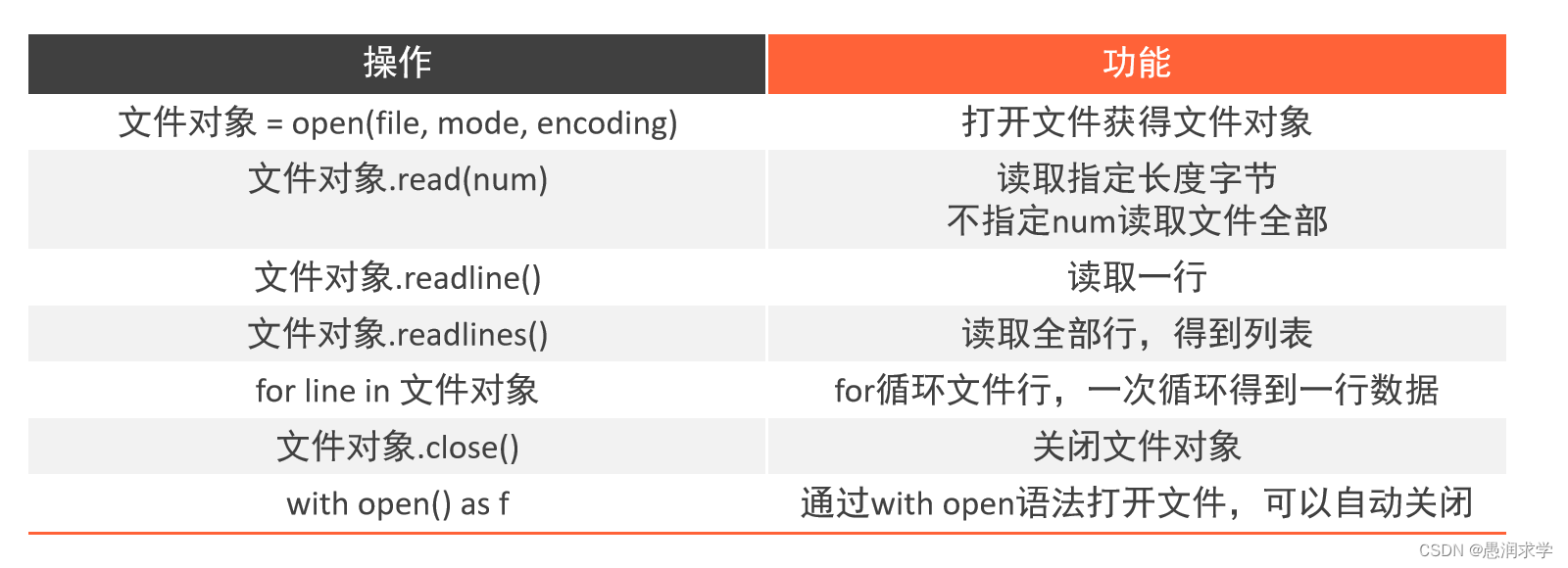
python基础——文件操作【文件编码、文件的打开与关闭操作、文件读写操作】
📝前言: 这篇文章主要讲解一下python中对于文件的基础操作: 1,文件编码 2,文件的打开与关闭操作 3,文件读写操作 🎬个人简介:努力学习ing 📋个人专栏:C语言入…...

rustup update 升级rust时异常 directory does not exist: ‘share/doc/rust/html‘ 解决方法
最近把原来的老版本rust升级为最新版本, 转悠了半天给我报一个 目录不存在异常而升级失败。 异常信息: info: rolling back changes error: failure removing component rust-docs-x86_64-apple-darwin, directory does not exist: share/doc/rust/ht…...
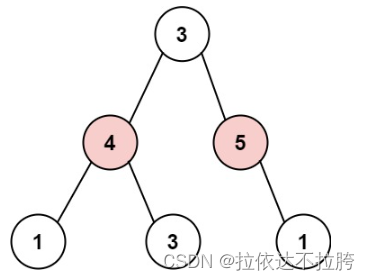
算法学习——LeetCode力扣动态规划篇5
算法学习——LeetCode力扣动态规划篇5 198. 打家劫舍 198. 打家劫舍 - 力扣(LeetCode) 描述 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统…...

C语言-文件
目录 1.什么是文件?1.1 程序文件1.2 数据文件 2.二进制文件和文本文件?3.文件的打开和关闭4.文件的顺序读写5.文件的随机读写5.1 fseek5.2 ftell5.3 rewind 6.文件读取结束的判定7.文件缓冲区 1.什么是文件? 磁盘上的文件就是文件 一般包含两…...

牛客NC30 缺失的第一个正整数【simple map Java,Go,PHP】
题目 题目链接: https://www.nowcoder.com/practice/50ec6a5b0e4e45348544348278cdcee5 核心 Map参考答案Java import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可…...
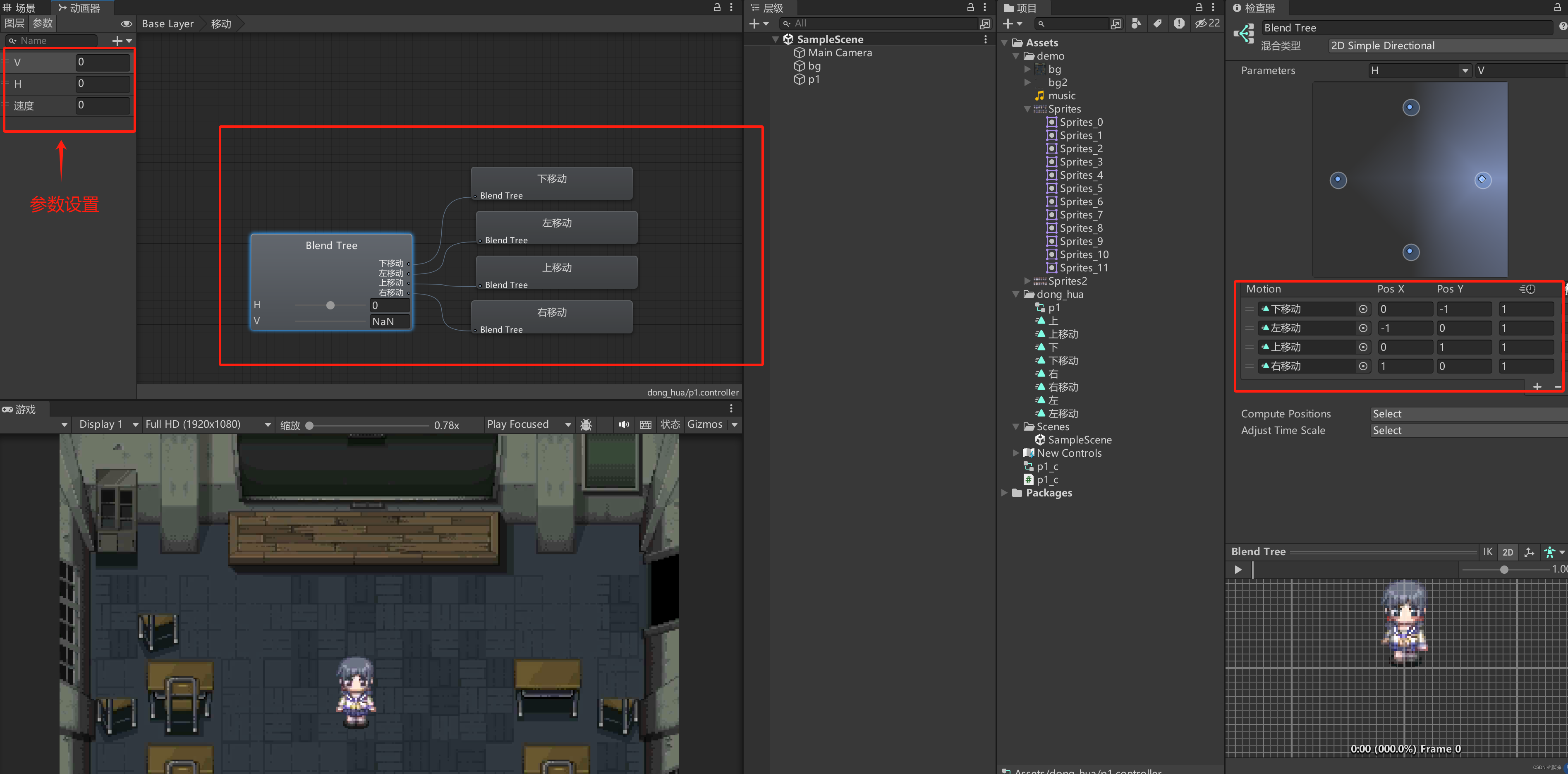
Unity 基于Rigidbody2D模块的角色移动
制作好站立和移动的动画后 控制器设计 站立 移动 角色移动代码如下: using System.Collections; using System.Collections.Generic; using Unity.VisualScripting; using UnityEngine;public class p1_c : MonoBehaviour {// 获取动画组件private Animator …...
Stata 15 for Mac:数据统计分析新标杆,让研究更高效!
Stata 是一种统计分析软件,适用于数据管理、数据分析和绘图。Stata 15 for Mac 具有以下功能: 数据管理:Stata 提供强大的数据管理功能,用户可以轻松导入、清洗、整理和管理数据集。 统计分析:Stata 提供了广泛的统计…...

vue配置代理proxy
如何配置代理 在 vue devServer服务器配置文件 vue.config.js 的 devServer 选项中配置 proxy module.exports {// publicPath:process.env.NODE_ENV production ? /vue_workspac/aihuhuproject/ : /,//基本路径publicPath: ./,//默认的/是绝对路径,如果不确定在…...

.NET DES加密算法实现
简介: DES(Data Encryption Standard)加密算法作为一种历史悠久的对称加密算法,自1972年由美国国家标准局(NBS)发布以来,广泛应用于各种数据安全场景。本文将从算法原理、优缺点及替代方案等方…...

构建操作可靠的数据流系统
文章目录 前言数据流动遇到的困难先从简单开始可靠性延迟丢失 性能性能损失性能——分层重试 可扩展性总结 前言 在流式架构中,任何对非功能性需求的漏洞都可能导致严重后果。如果数据工程师没有将可伸缩性、可靠性和可操作性等非功能性需求作为首要考虑因素来构建…...

awesome-cheatsheets:超级速查表 - 编程语言、框架和开发工具的速查表
awesome-cheatsheets:超级速查表 - 编程语言、框架和开发工具的速查表,单个文件包含一切你需要知道的东西 官网:GitHub - skywind3000/awesome-cheatsheets: 超级速查表 - 编程语言、框架和开发工具的速查表,单个文件包含一切你需…...

GFW不起作用
闲着折腾,刷openwrt到一个小米3G路由器后,GFW不起作用。后面发现是自己电脑设置了DNS,解析完IP后,在经过代代,IP不在GFW的清单里,所以转发控制就没有起作用。 结论 在经过代代前的所有节点,都…...
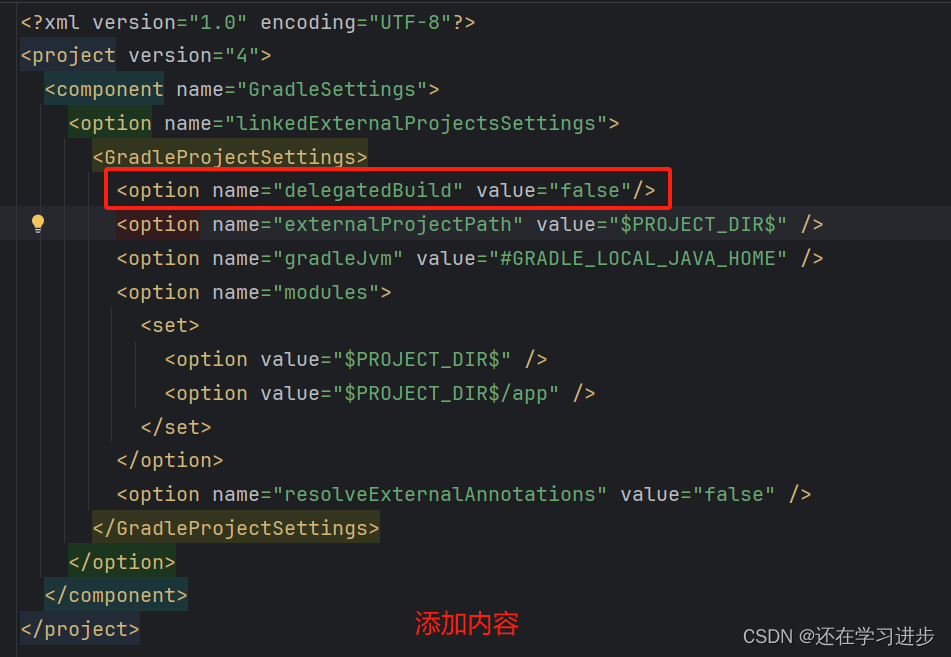
AndroidStudio出现类似 Could not create task ‘:app:ToolOperatorDemo.main()‘. 错误
先看我们的报错 翻译过来大概意思是:无法创建任务:app:ToolOperatorDemo.main()。 没有找到名称为“main”的源集。 解决方法: 在.idea文件夹下的gradle.xml文件中 <GradleProjectSettings>标签下添加<option name"delegatedBuild" value"f…...

一些常见的ClickHouse问题和答案
什么是ClickHouse?它与其他数据库系统有什么区别? ClickHouse是一个开源的列式数据库管理系统(DBMS),专门用于高性能、大规模数据分析。与传统的行式数据库相比,ClickHouse具有更高的查询性能、更高的数据…...
第九届蓝桥杯大赛个人赛省赛(软件类)真题C 语言 A 组-分数
solution1 直观上的分数处理 #include <iostream> using namespace std; int main() {printf("1048575/524288");return 0; }#include<stdio.h> #include<math.h> typedef long long ll; struct fraction{ll up, down; }; ll gcd(ll a, ll b){if…...

人工智能应用- 天文学家的助手:03. 观察浩瀚星空
为了获得更清晰的宇宙图像,科学家们将望远镜送入太空,以避开大气层的干扰,避免光污染和大气湍流的影响。哈勃空间望远镜(Hubble Space Telescope,HST)便是其中的代表。它以美国天文学家埃德温哈勃的名字命名…...

从零到一:SuperPoint特征检测算法实战训练与评估全解析
1. 环境准备与依赖安装 第一次接触SuperPoint时,最头疼的就是环境配置。我用的是一台Ubuntu 18.04的机器,显卡是GTX 1080 Ti。建议选择Linux系统,因为后续的编译和GPU加速会更方便。这里分享几个我踩过的坑: 首先是Python版本问题…...

基于PaddleOCR与Flask的PDF文本识别系统搭建指南
1. 为什么选择PaddleOCRFlask处理PDF? 最近帮朋友公司做文档管理系统时,发现他们每天要手动录入上百份PDF合同。这种重复劳动不仅效率低,还容易出错。试过几个方案后,最终用PaddleOCRFlask搭建的解决方案,把识别准确率…...

Ostrakon-VL-8B在单片机系统中的应用前瞻:云端视觉AI赋能边缘设备
Ostrakon-VL-8B在单片机系统中的应用前瞻:云端视觉AI赋能边缘设备 最近和几个做物联网的朋友聊天,大家聊到一个共同的痛点:现在的单片机设备越来越“聪明”,但真要让它“看懂”周围的世界,比如识别个物体、判断个场景…...
)
FPGA玩家必备:SiI9134 HDMI输出寄存器配置全攻略(1080P实战)
FPGA玩家必备:SiI9134 HDMI输出寄存器配置全攻略(1080P实战) 当FPGA开发者需要将处理后的高清视频信号输出到显示器时,SiI9134 HDMI发射芯片是一个经典选择。这款芯片以其稳定的性能和灵活的配置选项,在工业控制、医疗…...

Makani飞行模拟器完全指南:从安装到首次飞行的终极教程
Makani飞行模拟器完全指南:从安装到首次飞行的终极教程 【免费下载链接】makani Makani was a project to develop a commercial-scale airborne wind turbine, culminating in a flight test of the Makani M600 off the coast of Norway. All Makani software has…...

校园管理平台怎么选?功能与成本之间的实用考量
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...
)
嵌入式电源系统实战:基于STM32G4与双RTOS的PFC算法实现与PID参数整定策略(附工程源码)
1. STM32G4硬件选型与双RTOS任务划分 第一次拿到STM32G4芯片规格书时,我被它的性能参数惊艳到了——170MHz主频的Cortex-M4内核搭配5MSPS的ADC,简直就是为数字电源控制量身定制的。在实际项目中,我最终选择了STM32G474RET6这款型号࿰…...

如何安装配置Goland并使用固定公网地址SSH远程连接本地服务器
文章目录 1. 安装配置GoLand2. 服务器开启SSH服务3. GoLand本地服务器远程连接测试4. 安装cpolar内网穿透远程访问服务器端 4.1 服务器端安装cpolar4.2 创建远程连接公网地址 5. 使用固定TCP地址远程开发 本文主要介绍使用GoLand通过SSH远程连接服务器,并结合cpol…...
)
TCP自传:我凭三次握手,成为计网考研必考顶流(附wireshark抓包验证)
大家好!我是TCP。欢迎来探索我哈哈哈。一、我的自述:为什么要讲清我的“三次握手”我是TCP,传输层里最操心、最可靠的协议。从计算机网络课本,到考研真题,再到后端开发面试,我永远是高频考点。很多同学背我…...