大语言模型---强化学习
本文章参考,原文链接:https://blog.csdn.net/qq_35812205/article/details/133563158
SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量
RLHF(分为奖励模型训练、近端策略优化两个步骤)则是将output作为一个整体考虑,优化目标是使模型生成高质量回复
引发思考:
使用排序数据集和DPO(Direct Preference Learning)直接偏好学习或其他替代方法(如RAILF、ReST等)来训练模型。这可以帮助模型生成更高质量的回复,而不是直接使用RLHF。
为了减少幻觉(如拒绝回答),可以构造排序数据集(如good response为拒绝话术,bad response是没拒绝的胡乱回答)进行RLHF。这种方法可以帮助模型学习在拒绝回答时如何更好地处理情况。
奖励模型训练:奖励模型通常也采用基于 Transformer 架构的预训练语言模型。在奖励模型中,移除最后一个
非嵌入层,并在最终的 Transformer 层上叠加了一个额外的线性层。无论输入的是何种文本,奖励
模型都能为文本序列中的最后一个标记分配一个标量奖励值,样本质量越高,奖励值越大。
在RLHF中(比如MOSS-RLHF)是使用奖励模型来初始化评论家模型(critic model)和奖励模型(reward model),评论家模型也使用奖励模型初始化,便于在早期提供较准确的状态值估计;但是注意PPO会对策略模型、评论家模型训练并更新;奖励模型、参考模型不参与训练。
异策略:固定一个演员和环境交互(不需要更新),将交互得到的轨迹交给另一个负责学习的演员训练。PPO就是策略梯度的异策略版本。通过重要性采样(这里使用KL散度)进行策略梯度的更新。PPO解决了传统策略梯度方法的缺点:高方差、低数据效率、易发散等问题。
PPO-clip算法通过引入裁剪机制来限制策略更新的幅度,使得策略更新更加稳定
强化学习基础知识
1、强化学习框架的六要素
强化学习(RL)是研究agent智能体和环境交互的问题,目标是使agent在复杂而不确定的环境中最大化奖励值。
智能体(Agent):强化学习的主体也就是作出决定的“大脑”;
环境(Environment):智能体所在的环境,智能体交互的对象;
行动(Action):由智能体做出的行动;
奖励(Reward):智能体作出行动后,该行动带来的奖励;
状态(State):智能体自身当前所处的状态;
目标(Objective):指智能体希望达成的目标。
串起6要素:一个在不断变化的【环境】中的【智能体】,为了达成某个【目标】,需要不断【行动】,行动给予反馈即【奖励】,智能体对这些奖励进行学习,改变自己所处的【状态】,再进行下一步行动,即持续这个【行动-奖励-更新状态】的过程,直到达到目标。
策略与价值:
- agent在尝试各种行为时,就是在学习一个策略policy(一套指导agent在特定状态下行动的规则)
- agent会估计价值value,即预测未来采取某个行为后所能带来的奖励
任何一个有智力的个体,它的学习过程都遵循强化学习所描述的原理。比如说,婴儿学走路就是通过与环境交互,不断从失败中学习,来改进自己的下一步的动作才最终成功的。再比如说,在机器人领域,一个智能机器人控制机械臂来完成一个指定的任务,或者协调全身的动作来学习跑步,本质上都符合强化学习的过程。
奖励模型(Reward Model)和评论模型(Critic Model)
奖励模型(Reward Model):奖励模型是强化学习中一个基本元素,它定义了智能体执行特定动作后将得到的奖励。换句话说,奖励模型为智能体在其环境中执行的每个动作提供奖励(正面)或惩罚(负面)。这个模型帮助智能体理解哪些动作是有利的,哪些不是,因此,智能体尝试通过最大化获得的总奖励来找到最优策略。
评论模型(Critic Model):评论模型是一种基于值迭代的方法,它在每个状态或动作上评估(或者"评论")期望的未来奖励。评论者用来估计一个动作或状态的长期价值,通常在演员-评论者模型(Actor-Critic Models)中使用,演员选择动作,评论者评估动作。
两者的主要区别在于,奖励模型直接反映了每个动作的即时反馈,而评论模型是对未来奖励的一个预测或估计,关注的是长期价值,通常基于数学期望来进行评估。
RLHF对齐
1. 训练奖励模型和RL
用奖励模型训练SFT模型,生成模型使用奖励或惩罚来更新策略,以便生成更高质量、符合人类偏好的文本。
| 奖励模型 | RL强化学习 | |
| 作用 | (1)学习人类兴趣偏好,训练奖励模型。由于需要学习到偏好答案,训练语料中含有response_rejected不符合问题的答案。 (2)奖励模型能够在RL强化学习阶段对多个答案进行打分排序。 | 根据奖励模型,训练之前的sft微调模型,RL强化学习阶段可以复用sft的数据集 |
| 训练语料 | {‘question’: ‘土源性线虫感染的多发地区是哪里?’, ‘response_chosen’: ‘苏北地区;贵州省剑河县;西南贫困地区;桂东;江西省鄱阳湖区;江西省’, ‘response_rejected’: ‘在热带和亚热带地区的农村。’}, | 根据奖励模型,训练之前的sft微调模型,RL强化学习阶段可以复用sft的数据集 |
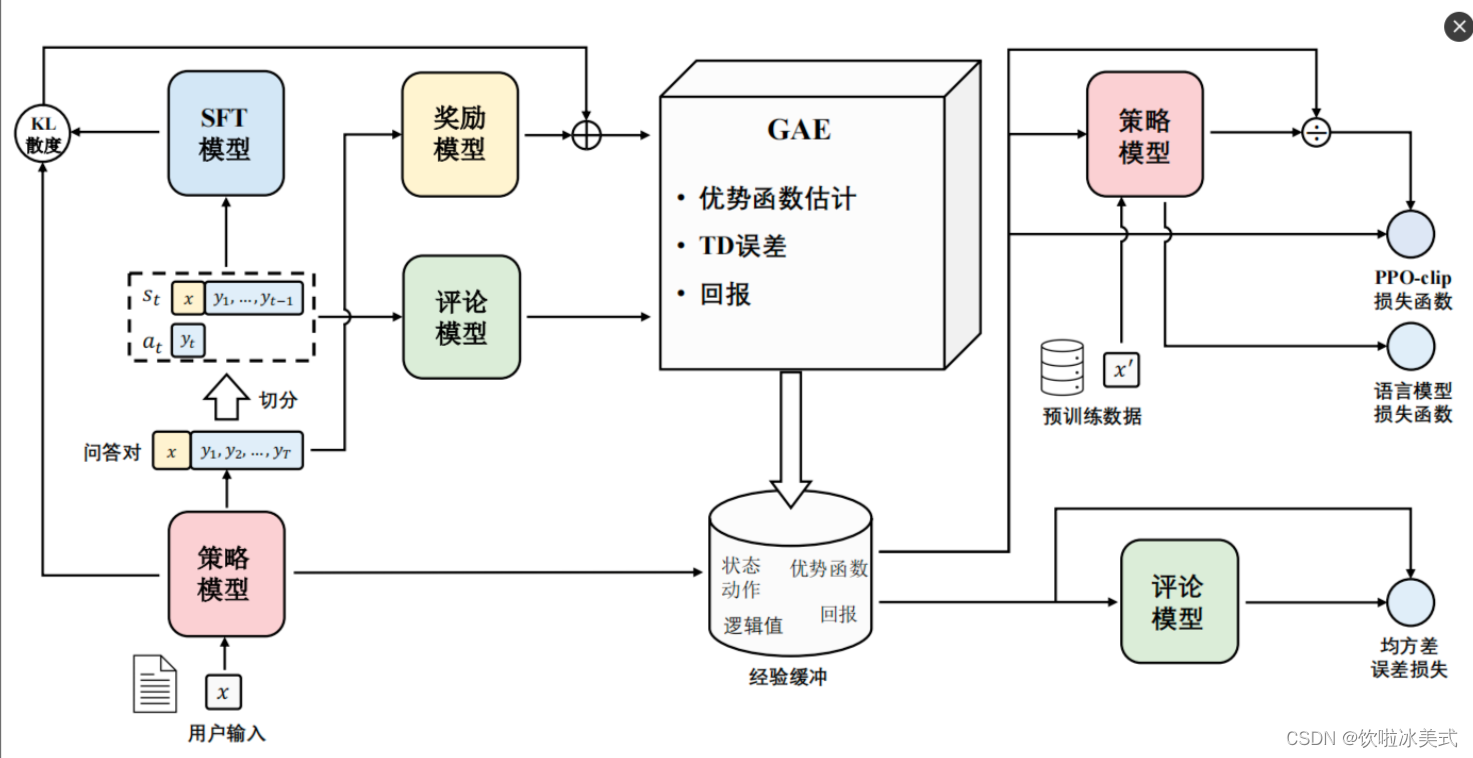
RLHF(reinforcement learning from human feedback)
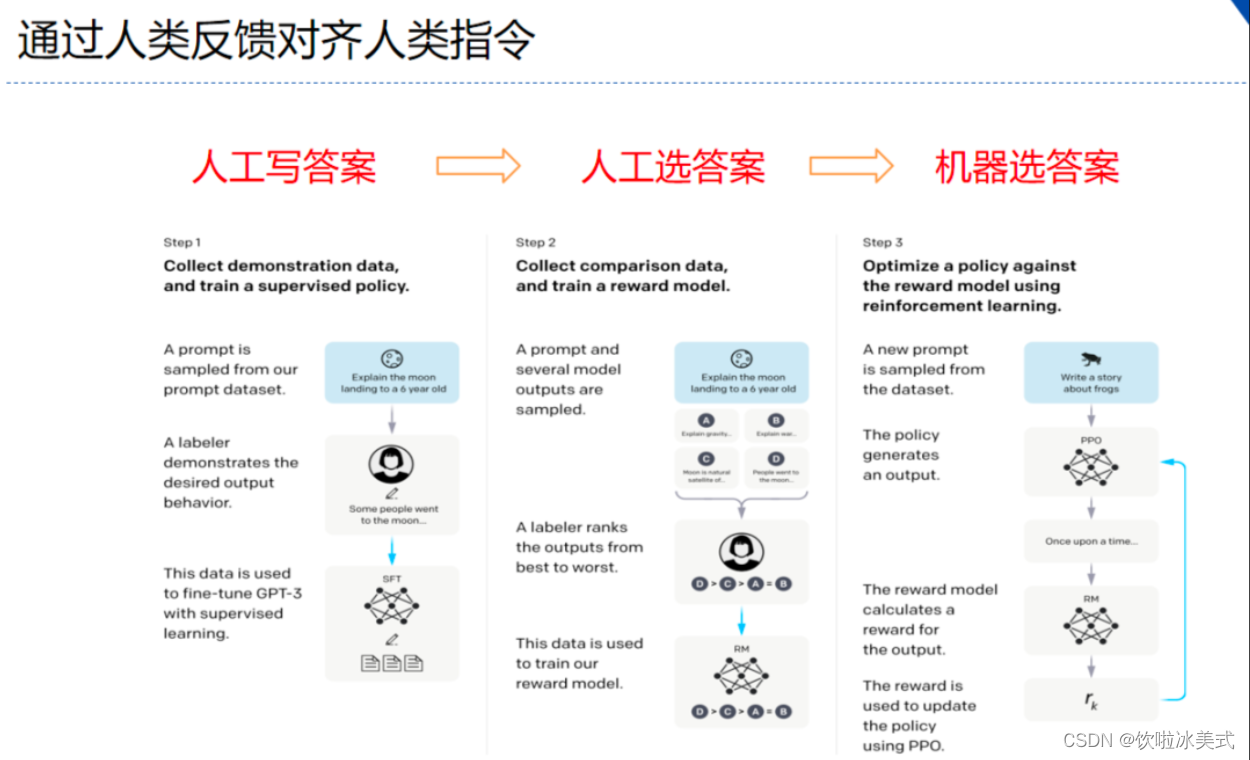
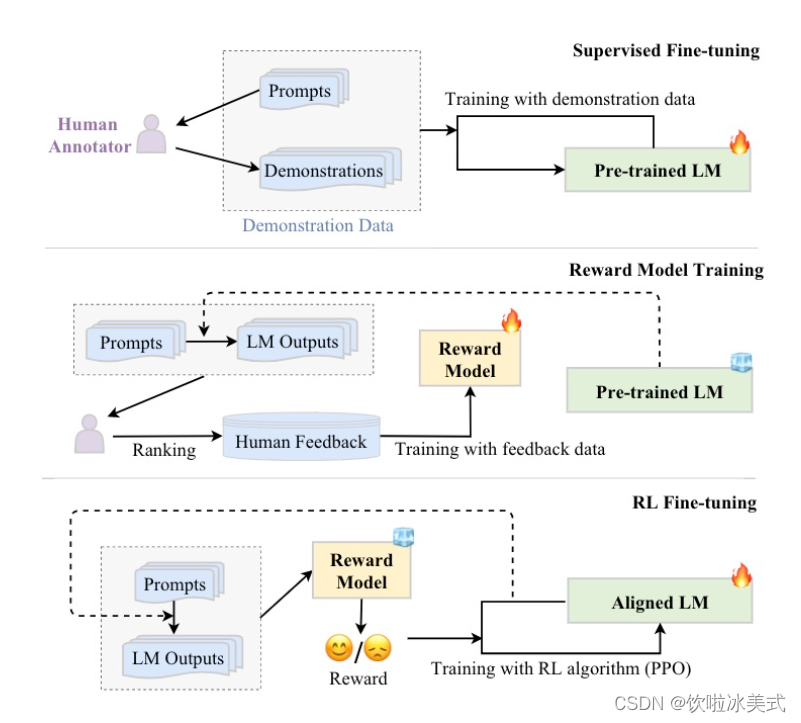
分为三个步骤:
- step1 我做你看:有监督学习,从训练集中挑出一批prompt,人工对prompt写答案。其实就是构造sft数据集进行微调。
- step2 你做我看:奖励模型训练,这次不人工写答案了,而是让GPT或其他大模型给出几个候选答案,人工对其质量排序,Reward model学习一个打分器;这个让机器学习人类偏好的过程就是【对齐】,但可能会导致胡说八道,可以通过KL Divergence等方法解决。

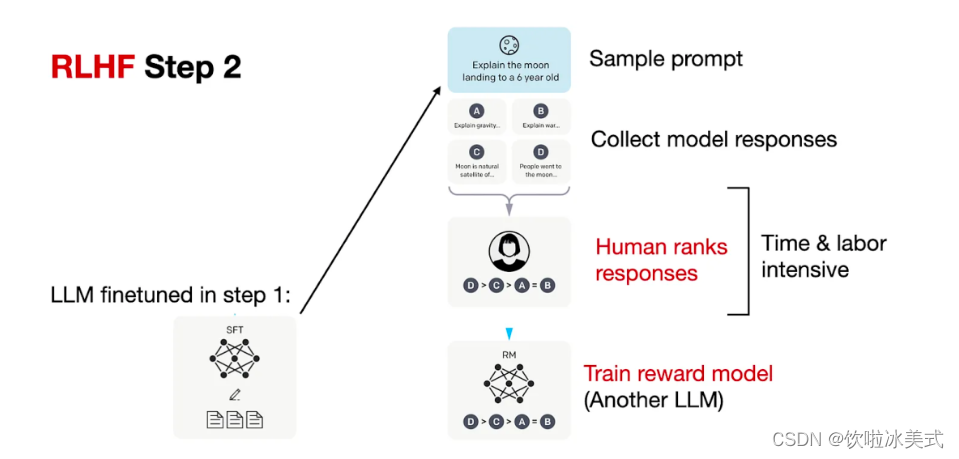
- step3 自学成才:PPO训练,利用第二阶段的奖励模型RM计算奖励分数,同时使用PPO(近端策略优化)更新第一步训练得到的sft模型,最大优化该目标函数:

常见的公开偏好数据集
源自《Llama 2: Open Foundation and Fine-Tuned Chat Models》Table 6:
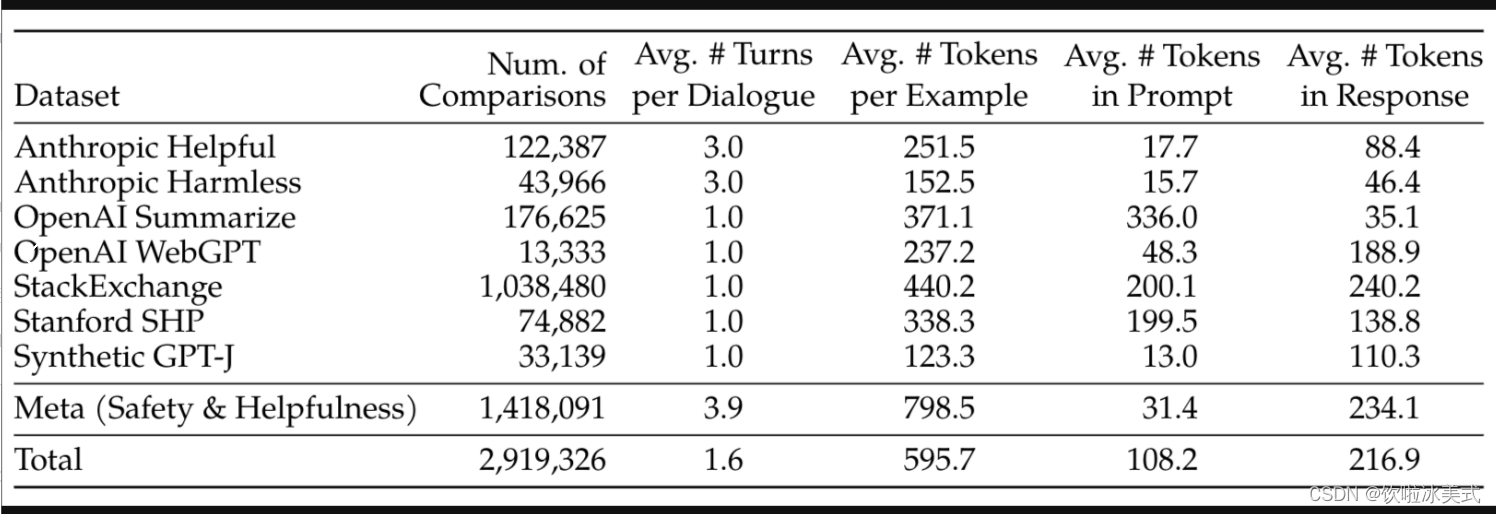
如:https://huggingface.co/datasets/lvwerra/stack-exchange-paired
PPO近端策略优化
PPO思想:保证策略改进同时,通过一些约束来控制策略更新的幅度;在每次迭代中,通过采样多个轨迹数据来更新策略:
- 使用当前策略对环境交互,收集多个轨迹数据
- 利用第一步的轨迹数据计算当前策略和旧策略之间的KL散度,通过控制KL散度大小来限制策略更新的幅度
- 使用优化器对策略进行更新,使其更加接近当前的样本策略
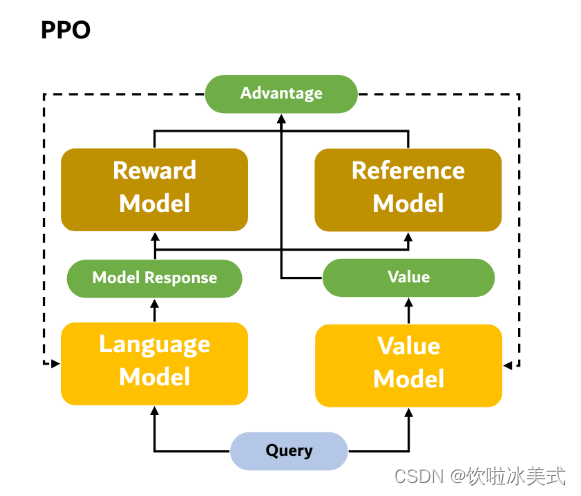
近端策略优化PPO涉及到四个模型:
(1)策略模型(Policy Model),生成模型回复。
(2)奖励模型(Reward Model),输出奖励分数来评估回复质量的好坏。
(3)评论模型(Critic Model/value model),来预测回复的好坏,可以在训练过程中实时调整模型,选择对未来累积收益最大的行为。
(4)参考模型(Reference Model)提供了一个 SFT 模型的备份,帮助模型不会出现过于极端的变化。
近端策略优化PPO的实施流程如下:
环境采样:策略模型基于给定输入生成一系列的回复,奖励模型则对这些回复进行打分获得奖励。
优势估计:利用评论模型预测生成回复的未来累积奖励,并借助广义优势估计(Generalized Advantage Estimation,GAE)算法来估计优势函数,能够有助于更准确地评估每次行动的好处。
GAE:基于优势函数加权估计的GAE可以减少策略梯度估计方差
优化调整:使用优势函数来优化和调整策略模型,同时利用参考模型确保更新的策略不会有太大的变化,从而维持模型的稳定性。
相关强化学习概念对应:
- Policy:现有LLM接受输入,进行输出的过程。
- State:当前生成的文本序列。
- Action Space:即vocab,也就是从vocab中选取一个作为本次生成的token。
KL散度(Kullback-Leibler Divergence),可以衡量两个概率分布之间的差异程度。在 PPO 算法中,KL 散度(Kullback-Leibler Divergence)的计算公式如下:
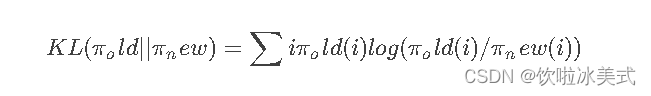
其中,π_old 表示旧的策略,π_new 表示当前的样本策略。KL 散度的含义是用 π_old 的分布对 π_new 的分布进行加权,然后计算两个分布之间的差异程度。
具体来说,KL 散度的计算方法是首先计算 π_old(i) / π_new(i) 的比值,然后对其取对数并乘以 π_old(i) 来进行加权。最后将所有加权后的结果相加,即可得到 KL 散度的值。这里的KL散度值是一个【惩罚项】,即经过RL训练后模型和SFT后模型的KL散度(繁殖两个模型偏差太多,导致模型效果下降,RLHF的主要目的是alignment)。
注意:KL 散度是一个非对称的度量,即 KL(π_old || π_new) 与 KL(π_new || π_old) 的值可能不相等。在 PPO 算法中,我们通常使用 KL(π_old || π_new) 来控制策略更新的幅度,因为 KL(π_old || π_new) 的值通常比 KL(π_new || π_old) 更容易控制,并且更能够反映出策略改变的方向。
DPO、PPO 和 BPO 都是用于训练强化学习代理的算法,但它们在算法原理和实现上有一些不同之处。
-
DPO(Direct Policy Optimization):DPO 是一种直接策略优化方法,它通过直接优化策略函数来提高代理的性能。与值函数(价值函数)相比,DPO 不需要估计状态值或状态动作值,而是直接优化策略函数来最大化长期累积奖励。DPO 可能包括各种方法,如 REINFORCE 算法、TRPO(Trust Region Policy Optimization)等。
-
PPO(Proximal Policy Optimization):PPO 也是一种策略优化方法,它专注于近端策略优化。PPO 通过限制每次策略更新的大小来确保稳定性和收敛性,这通常通过一种叫做“近端策略裁剪”的方法来实现。PPO 在训练过程中不需要使用价值函数,而是直接优化策略函数。PPO 的设计目标是简化和提高算法的稳定性。
-
BPO(Batch Policy Optimization):BPO 是一种批量策略优化方法,它使用离线收集的数据批次进行策略更新。与在线方法不同,BPO 不需要与环境交互来收集数据,而是使用事先收集的大量数据进行策略更新。BPO 可以更有效地利用离线数据,但也面临着样本效率和数据偏差等挑战。
相关文章:
大语言模型---强化学习
本文章参考,原文链接:https://blog.csdn.net/qq_35812205/article/details/133563158 SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量 RLHF(分为奖励模型训练、近端策略优化…...

前端三剑客 —— CSS (第二节)
目录 内容回顾: CSS选择器*** 属性选择器 伪类选择器 1):link 超链接点击之前 2):visited 超链接点击之后 3):hover 鼠标悬停在某个标签上时 4):active 鼠标点击某个标签时,但没有松开 5):fo…...

牛客NC31 第一个只出现一次的字符【simple map Java,Go,PHP】
题目 题目链接: https://www.nowcoder.com/practice/1c82e8cf713b4bbeb2a5b31cf5b0417c 核心 Map参考答案Java import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*…...
01)
软考系统架构设计师(摘抄)01
架构师承担的责任 系统架构师设计师是承担系统架构设计的核心角色,他不仅是连接用户需求和系统进一步设计与实现的桥梁,也是系统开发早期阶段质量保证的关键角色。系统架构师就是项目的总设计师,他是一个既需要掌控整体又需要洞悉局部瓶颈&a…...
5G无线接入网和接口协议
**部分笔记** 4.3无线协议架构 NR无线协议分为两个平面:用户面和控制面。 用户面(UP):协议栈及用户数据采用的协议 控制面(Control Plane,CP)协议栈即系统的控制信令传输采用的协议簇。 虚线标注的是信令数据的流向。一个UE在…...

【力扣刷题日记】1173.即时食物配送I
前言 练习sql语句,所有题目来自于力扣(https://leetcode.cn/problemset/database/)的免费数据库练习题。 今日题目: 1173.即时食物配送I 表:Delivery 列名类型delivery_idintcustomer_idintorder_datedatecustomer…...

2024年github之node排行榜top50
如果有帮助到您还请动动手帮忙点赞,关注,评论转发,感谢啦!💕💕💕😘😘😘 本文由Butterfly一键发布工具发布 2024年github之node排行榜top50 语言star项目名称…...

当我们在地址栏输入URL的时候浏览器发生了什么
URL 解析 是否合法 首先判断你输入的是一个合法的 URL 还是一个待搜索的关键词,并且根据你输入的内容进行自动完成、字符编码等操作。检查http缓存 DNS 查询 浏览器缓存 -> 操作系统缓存 -> 路由器缓存 -> DNS缓存 -> 根域名服务器查询 TCP 连接 …...
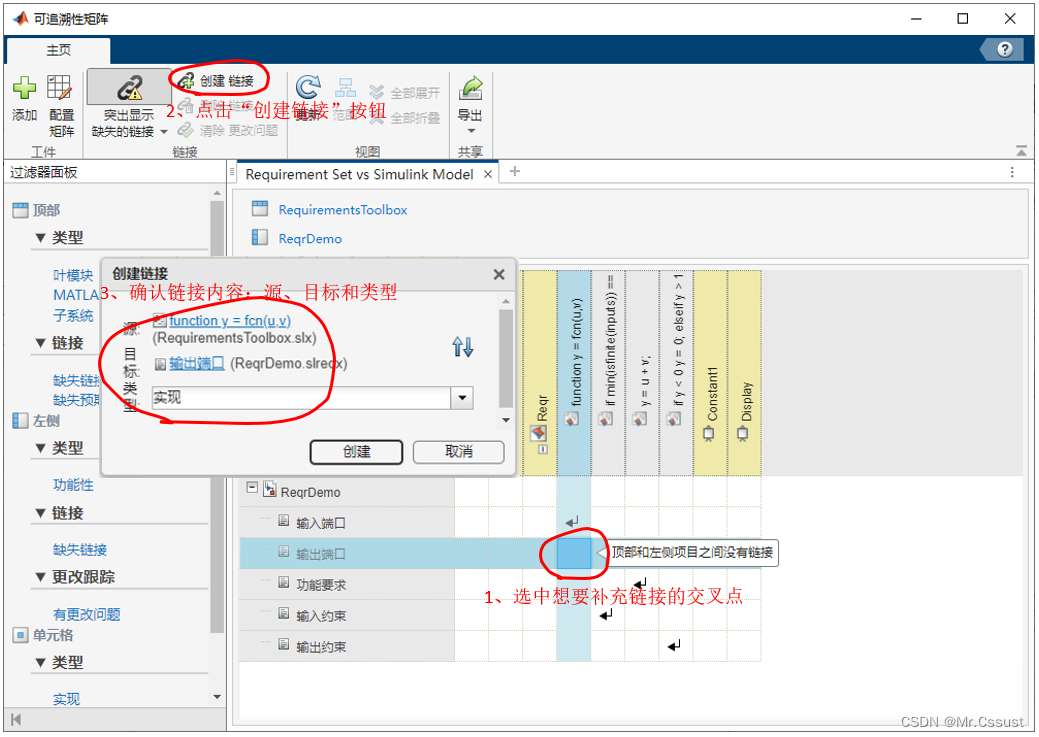
【研发日记】Matlab/Simulink开箱报告(十一)——Requirements Toolbox
目录 前言 Requirements Toolbox 编写需求 需求联接设计 需求跟踪开发进度 追溯性矩阵 分析和应用 总结 前言 见《开箱报告,Simulink Toolbox库模块使用指南(六)——S-Fuction模块(TLC)》 见《开箱报告&#x…...

Elastic 8.13:Elastic AI 助手中 Amazon Bedrock 的正式发布 (GA) 用于可观测性
作者:来自 Elastic Brian Bergholm 今天,我们很高兴地宣布 Elastic 8.13 的正式发布。 有什么新特性? 8.13 版本的三个最重要的组件包括 Elastic AI 助手中 Amazon Bedrock 支持的正式发布 (general availability - GA),新的向量…...
)
MFC 截取对话框生成图片、截取整个屏幕(可取黑白反色或者整体图片取反色)
HWND hwnd ::GetDesktopWindow();//截整个屏幕,用从这往下4句HDC hdc ::GetDC(hwnd);CDC dc;dc.Attach(hdc);CRect rc,rcw;GetWindowRect(&rcw);GetClientRect(&rc);//只截对话框,用这句//rc.SetRect(0, 0, GetSystemMetrics(SM_CXSCREEN), Ge…...

【LeetCode: 331. 验证二叉树的前序序列化 + DFS】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
【Consul】Linux安装Consul保姆级教程
【Consul】Linux安装Consul保姆级教程 大家好 我是寸铁👊 总结了一篇【Consul】Linux安装Consul保姆级教程✨ 喜欢的小伙伴可以点点关注 💝 前言 今天要把编写的go程序放到linux上进行测试Consul服务注册与发现,那怎么样才能实现这一过程&am…...

pytorch常用的模块函数汇总(1)
目录 torch:核心库,包含张量操作、数学函数等基本功能 torch.nn:神经网络模块,包括各种层、损失函数和优化器等 torch.optim:优化算法模块,提供了各种优化器,如随机梯度下降 (SGD)、Adam、RMS…...
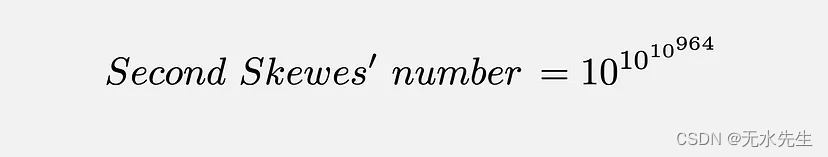
素数的计数律:Π函数、歪斜数
相当多的数字! 一、说明 自从人类开始掌握最起码的算术概念以来,有一类数字一直处于最前沿——素数。素数定义简单,但难以捕捉,众所周知,素数是数学中一些最困难问题的罪魁祸首,让几代最优秀的数学家感到…...

图像识别在农业领域的应用
图像识别技术在农业领域的应用正在逐渐成熟,它通过分析处理拍摄的植物或农田的图像,为农业生产提供决策支持。以下是图像识别在农业中的一些关键应用: 病虫害检测:图像识别技术能够识别作物上的病斑、虫害或异常状况。通过比较高…...
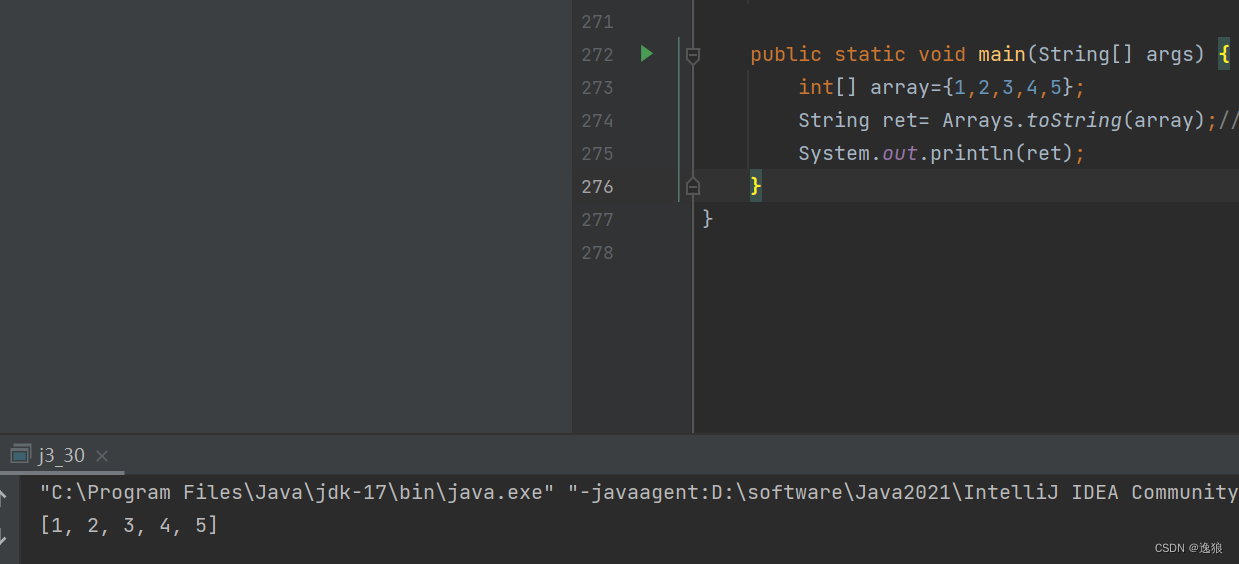
【JavaSE】java刷题--数组练习
前言 本篇讲解了一些数组相关题目(主要以代码的形式呈现),主要目的在于巩固数组相关知识。 上一篇 数组 讲解了一维数组和二维数组的基础知识~ 欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎…...

预处理、编译、汇编、链接过程
预处理、编译、汇编、链接过程 预处理 引入头文件 #include 展开宏定义 #define 处理条件编译指令 #ifdef 删除注释 添加行号 在Linux下可以使用gcc -E命令把hello.c文件预处理成hello.i文件。windows这些操作都集成在编译器visual studio这些里面了。 编译 进行语法分…...

3、Cocos Creator 节点和组件
目录 1、 节点和组件 2、 节点层级和显示顺序 3、坐标系和节点变换属性 坐标系 锚点 旋转 缩放 尺寸 4、 常用技巧 5、参考 1、 节点和组件 Cocos Creator 的工作流程是以组件式开发为核心的,组件式架构也称作 组件 — 实体系统(或 Entity-C…...
【js刷题:数据结构数组篇之长度最小的子数组】
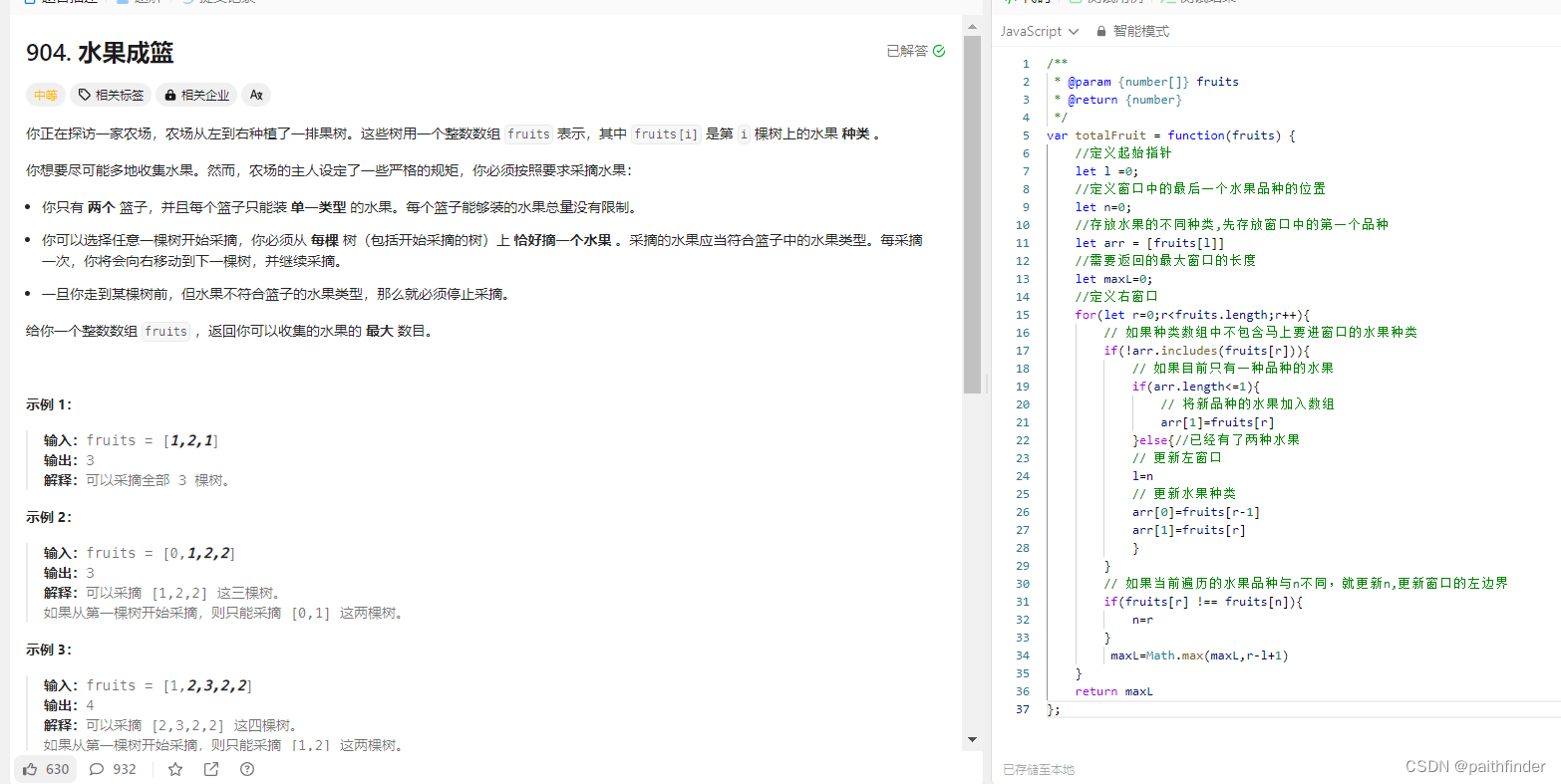
长度最小的子数组 一、题目二、方法1.暴力解法2.滑动窗口是什么滑动窗口的起始位置滑动窗口的结束位置代码展示 3.力扣刷题水果成篮题目思路代码 一、题目 给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组&…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...