YOLOV5训练自己的数据集教程(万字整理,实现0-1)
文章目录
一、YOLOV5下载地址
二、版本及配置说明
三、初步测试
四、制作自己的数据集及转txt格式
1、数据集要求
2、下载labelme
3、安装依赖库
4、labelme操作
五、.json转txt、.xml转txt
六、修改配置文件
1、coco128.yaml->ddjc_parameter.yaml
2、yolov5x.yaml->ddjc_model.yaml
八、调train和detect的参数并开始训练
1、在train.py,寻找函数def parse_opt(known=False),更改参数
2、train运行结果
3、在detect.py,寻找函数def parse_opt(),更改参数
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。YOLOv5是Glenn Jocher等人研发,它是Ultralytics公司的开源项目。YOLOv5根据参数量分为了
n、s、m、l、x五种类型,其参数量依次上升,当然了其效果也是越来越好。从2020年6月发布至2022年11月已经更新了7个大版本,在v7版本中还添加了语义分割的功能。
一、YOLOV5下载地址
GitHub官方下载(推荐):https://github.com/ultralytics/yolov5
二、版本及配置说明
- 我是用cpu训练的,如果有条件的可以使用gpu进行训练,训练速度会相差10倍。
- 当然,用gpu下载pytorch的时候要下载cuda版本。
- 我采用的是Anaconda+Pycharm的配置,大家要了解一些关于pip和conda的指令,方便管理包和环境。
- 当我们下好yolov5后,可以发现有一个requirements.txt文件,使用Anaconda Prompt,切换到Yolov5的位置,pip install -r requirements.txt即可一步到位全部下完。下面是requirements.txt文件的内容。
# YOLOv5 requirements # Usage: pip install -r requirements.txt# Base ---------------------------------------- matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.1 Pillow>=7.1.2 PyYAML>=5.3.1 requests>=2.23.0 scipy>=1.4.1 # Google Colab version torch>=1.7.0 torchvision>=0.8.1 tqdm>=4.41.0 protobuf<4.21.3 # https://github.com/ultralytics/yolov5/issues/8012# Logging ------------------------------------- tensorboard>=2.4.1 # wandb# Plotting ------------------------------------ pandas>=1.1.4 seaborn>=0.11.0# Export -------------------------------------- # coremltools>=4.1 # CoreML export # onnx>=1.9.0 # ONNX export # onnx-simplifier>=0.3.6 # ONNX simplifier # scikit-learn==0.19.2 # CoreML quantization # tensorflow>=2.4.1 # TFLite export # tensorflowjs>=3.9.0 # TF.js export # openvino-dev # OpenVINO export# Extras -------------------------------------- ipython # interactive notebook psutil # system utilization thop # FLOPs computation # albumentations>=1.0.3 # pycocotools>=2.0 # COCO mAP # roboflows
三、初步测试
配置完成后,运行detect.py,如果一切正常,那么可以在runs/detect/exp中能发现被处理过的标签,就成功了,如果没有显示下图,那么可能是有的库的版本不对应,可以根据报错提示用pip uninstall 包后下载相应版本,要多试,因为有的库与库之间是相互联系的。

四、制作自己的数据集及转txt格式
1、数据集要求
我的数据集为跌倒检测方面的,有1000张,上千张时处理后效果较好。
在yolov5中新建一个ddjc的文件夹,包含以下文件夹:
2、下载labelme
这个是对图片进行标注的工具
下载地址:GitHub - labelmeai/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation). - labelmeai/labelme![]() https://github.com/wkentaro/labelme
https://github.com/wkentaro/labelme
下载压缩包后解压即可。
3、安装依赖库
在Anaconda Prompt里安装pyqt5和labelme,pyqt5是labelme的依赖项。
pip install pyqt5
pip install labelme4、labelme操作
然后在Anaconda Prompt里输入labelme,打开界面如下,右击,点击rectangle,即画矩形框,框选你要识别训练的东西。

框选之后输入标签的名字,注意,可以框选多个作为标签。框选完一张图后保存,然后接着下一张图。保存的文件格式是.json
五、.json转txt、.xml转txt
yolov5只识别txt,所以要将标注后的数据集转化为txt。
转换的时候可能会有问题,可以移步我的这篇博客统计XML文件内标签的种类和其数量及将xml格式转换为yolov5所需的txt格式-CSDN博客
我用的是公开的数据集,格式为.xml,转换时也遇到了目录和无法统计标签的过程,但都得以解决。
在你设置好的绝对路径下新建转换py文件,代码为:
.xml-txt
import xml.etree.ElementTree as ETimport pickle
import os
from os import listdir, getcwd
from os.path import join
import globclasses = ['fall', 'no fall', 'no fall', 'nofall']def convert(size, box):dw = 1.0 / size[0]dh = 1.0 / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_name):in_file = open('./labels/train1/' + image_name[:-3] + 'xml') # xml文件路径out_file = open('./labels/train/' + image_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径f = open('./labels/train1/' + image_name[:-3] + 'xml')xml_text = f.read()root = ET.fromstring(xml_text)f.close()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:print(cls)continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()if __name__ == '__main__':for image_path in glob.glob("./images/train/*.jpg"): # 每一张图片都对应一个xml文件这里写xml对应的图片的路径image_name = image_path.split('\\')[-1]convert_annotation(image_name).json-txt
import json
import osname2id = {'hero':0,'sodier':1,'tower':2}#标签名称def convert(img_size, box):dw = 1. / (img_size[0])dh = 1. / (img_size[1])x = (box[0] + box[2]) / 2.0 - 1y = (box[1] + box[3]) / 2.0 - 1w = box[2] - box[0]h = box[3] - box[1]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def decode_json(json_floder_path, json_name):txt_name = 'C:\\Users\\86189\\Desktop\\' + json_name[0:-5] + '.txt'#存放txt的绝对路径txt_file = open(txt_name, 'w')json_path = os.path.join(json_floder_path, json_name)data = json.load(open(json_path, 'r', encoding='gb2312',errors='ignore'))img_w = data['imageWidth']img_h = data['imageHeight']for i in data['shapes']:label_name = i['label']if (i['shape_type'] == 'rectangle'):x1 = int(i['points'][0][0])y1 = int(i['points'][0][1])x2 = int(i['points'][1][0])y2 = int(i['points'][1][1])bb = (x1, y1, x2, y2)bbox = convert((img_w, img_h), bb)txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')if __name__ == "__main__":json_floder_path = ''#存放json的文件夹的绝对路径json_names = os.listdir(json_floder_path)for json_name in json_names:decode_json(json_floder_path, json_name)转换完成后的txt文件:

第一个数字是数据集中第0个种类,其余均是与坐标相关的值。有几个标签就有几个种类。
六、修改配置文件
1、coco128.yaml->ddjc_parameter.yaml
在yolov5/data/coco128.yaml中先复制一份,粘贴到ddjc中,改名为ddjc_parameter.yaml(意义为ddjc的参数配置)
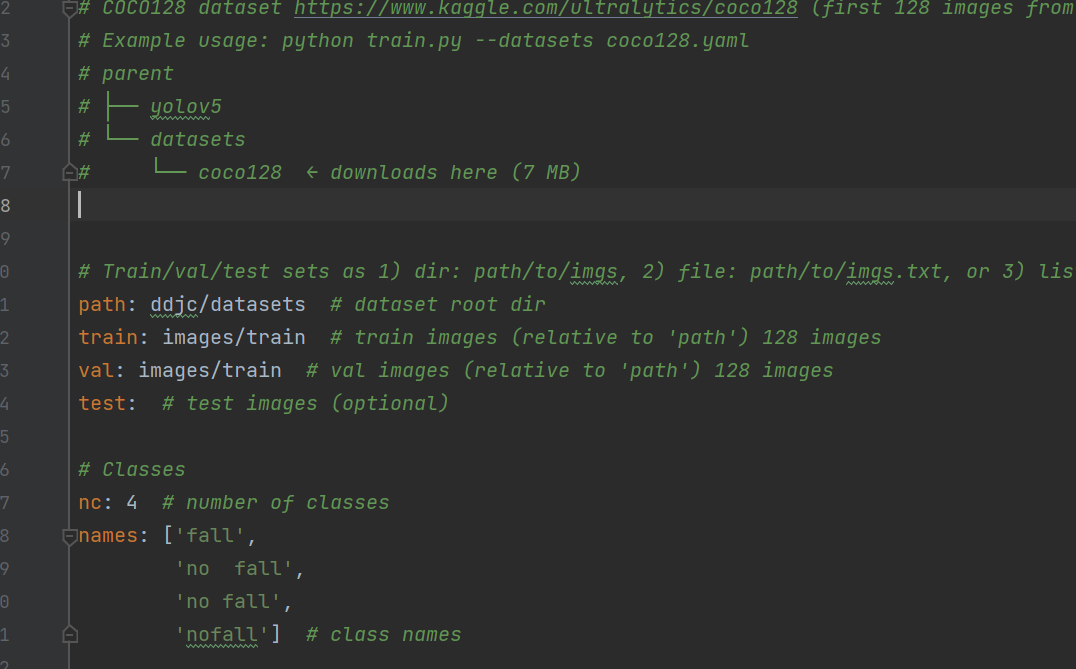
ddjc_parameter.yaml文件需要修改的参数是nc与names。nc是标签名个数,names就是标签的名字,跌倒检测有4个标签,标签名字都如下:['fall', 'no fall', 'no fall', 'nofall']
路径解释:如何正确使用机器学习中的训练集、验证集和测试集?-CSDN博客
2、yolov5x.yaml->ddjc_model.yaml
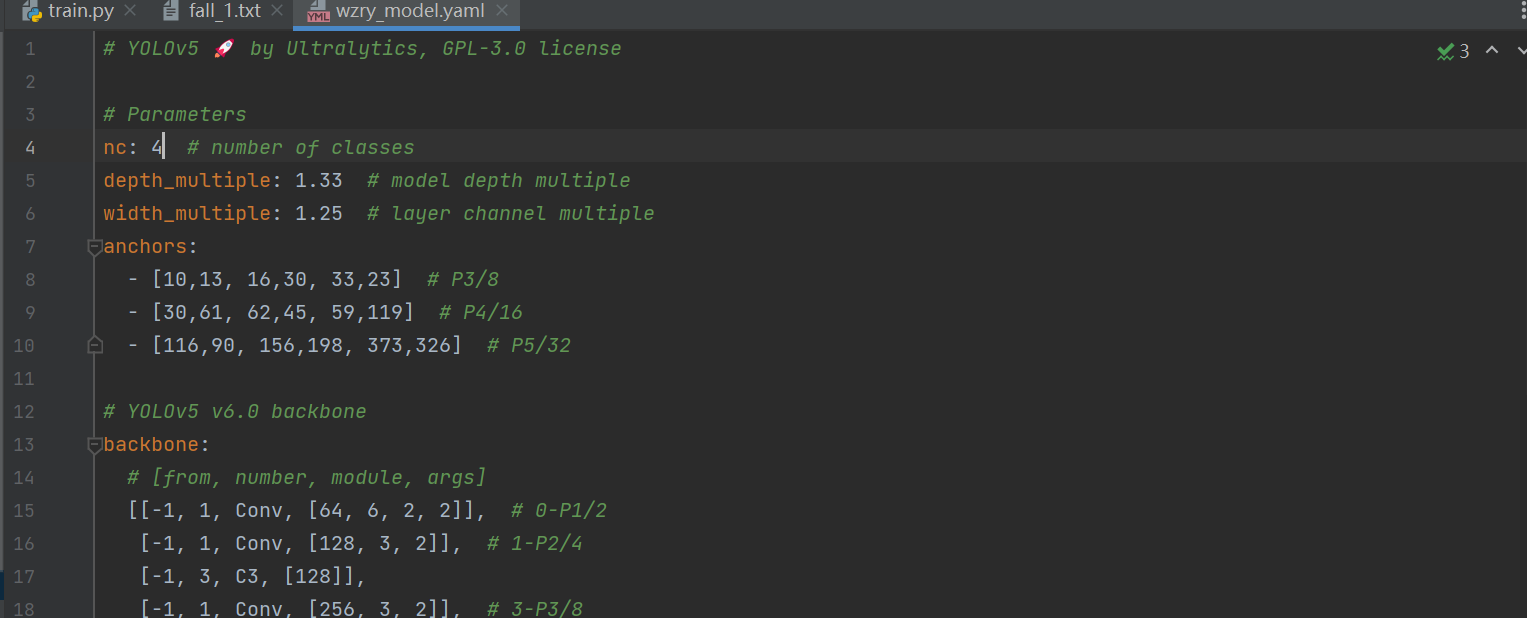
yolov5有4种配置,不同配置的特性如下,我选择yolov5x,效果较好,但是训练时间会很长。

在yolov5/models先复制一份yolov5x.yaml到ddjc,更名为ddjc_model.yaml(意为模型),只将如下的nc修改为标签的个数。
八、调train和detect的参数并开始训练
1、在train.py,寻找函数def parse_opt(known=False),更改参数
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5x', help='initial weights path') # 修改处 初始权重
parser.add_argument('--cfg', type=str, default=ROOT /'ddjc/ddjc_model.yaml', help='model.yaml path') # 修改处 训练模型文件
parser.add_argument('--data', type=str, default=ROOT /'ddjc/ddjc_parameter.yaml', help='dataset.yaml path') # 修改处 数据集参数文件
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path') # 超参数设置
parser.add_argument('--epochs', type=int, default=50) # 修改处 训练轮数
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch') # 修改处 batch size
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=384, help='train, val image size (pixels)')# 修改处 图片大小
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')#修改处,选择
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=10, help='max dataloader workers (per RANK in DDP mode)')#修改处修改处的解释:
- 我们训练的初始权重的位置,是以.pt结尾的文件
- 训练模型文件,在本项目中对应ddjc_model.yaml;
- 数据集参数文件,在本项目中对于ddjc_parameter.yaml;
- 超参数设置,是人为设定的参数。包括学习率,不用改;
- 训练轮数,决定了训练时间与训练效果。如果选择训练模型是yolov5x.yaml,那么大约200轮数值就稳定下来了(收敛),我设置的50轮,因为这大概已经需要25h的时间了;
- 批量处理文件数,这个要设置地小一些,否则会out of memory。这个决定了我们训练的速度
- 图片大小,虽然我们训练集的图片是已经固定下来了,但是传入神经网络时可以resize大小,太大了训练时间会很长,且有可能报错,这个根据自己情况调小一些;
- 断续训练,如果说在训练过程中意外地中断,那么下一次可以在这里填True,会接着上一次runs/exp继续训练
- GPU加速,填0是电脑默认的CUDA,前提是电脑已经安装了CUDA才能GPU加速训练,安装过程可查博客,填cpu就是用gpu进行训练。
- 多线程设置,越大读取数据越快,但是太大了也会报错,因此也要根据自己状况填小。
2、train运行结果
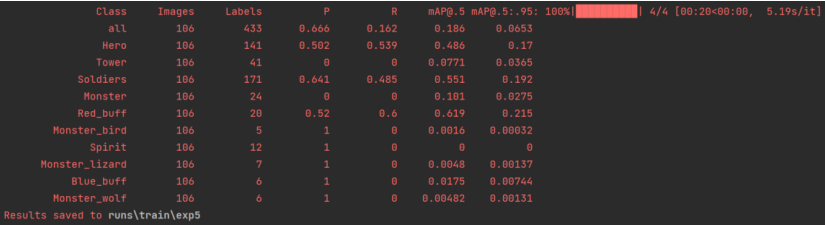
结果保存在runs/train/exp中,多次训练就会有exp1、exp2,我这里训练到第五轮了。

best.pt和last.pt是我们训练出来的权重文件,用于detect.py。last是最后一次的训练结果,best是效果最好的训练结果(只是看起来,但是泛化性不一定强)。
3、在detect.py,寻找函数def parse_opt(),更改参数
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT /'runs/train/exp7/weights/last.pt', help='model path(s)') # 修改处 权重文件
parser.add_argument('--source', type=str, default=ROOT /'wzry/datasets/images/test/SVID_20210726_111258_1.mp4', help='file/dir/URL/glob, 0 for webcam')# 修改处 图像、视频或摄像头
parser.add_argument('--data', type=str, default=ROOT / 'ddjc/ddjc_parameter.yaml', help='(optional) dataset.yaml path') # 修改处 参数文件
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w') # 修改处 高 宽
parser.add_argument('--conf-thres', type=float, default=0.50, help='confidence threshold') # 置信度
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')# 非极大抑制
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # 修改处运行结果在runs/detect/exp中。
九、我训练过程中存在并调试好的一些问题
请移步:YOLOv5训练过程中的各种报错-CSDN博客
希望能帮到大家,若需要数据集和训练好的模型,请留言。

相关文章:
YOLOV5训练自己的数据集教程(万字整理,实现0-1)
文章目录 一、YOLOV5下载地址 二、版本及配置说明 三、初步测试 四、制作自己的数据集及转txt格式 1、数据集要求 2、下载labelme 3、安装依赖库 4、labelme操作 五、.json转txt、.xml转txt 六、修改配置文件 1、coco128.yaml->ddjc_parameter.yaml 2、yolov5x.…...
精通Go语言文件上传:深入探讨r.FormFile函数的应用与优化
1. 介绍 1.1 概述 在 Web 开发中,文件上传是一项常见的功能需求,用于允许用户向服务器提交文件,如图像、文档、视频等。Go 语言作为一门强大的服务器端编程语言,提供了方便且高效的方式来处理文件上传操作。其中,r.F…...

【C语言】字符串
C语言用字符数组存放字符串,字符数组中的各元素依次存放字符串的各字符 一维字符数组:存放一个字符串(每个数组元素存放一个字符)二维字符数组:存放多个一维数组(字符串);二维数组的…...

云计算探索-DAS、NAS与SAN存储技术演进及其应用比较
1,介绍 随着信息技术的飞速发展,数据存储的需求日益增长,各种存储技术也应运而生。在众多的存储解决方案中,直接附加存储(Direct Attached Storage,简称DAS)、网络附加存储(Network …...
手机有线投屏到直播姬pc端教程
1 打开哔哩哔哩直播姬客户端并登录(按下图进行操作) 2 手机用usb数据线连接电脑(若跳出安装驱动的弹窗点击确定或允许),usb的连接方式为仅充电(手机差异要求为仅充电),不同品牌手机要求可能不一样,根据实际的来 3 在投屏过程中不要更改usb的连接方式(不然电脑会死机需要重启) …...

SOA、分布式、微服务之间的关系?
分布式它本身就是一种系统部署的架构理念,意思就是将一个系统拆分为各个部分,然后分别部署到不同的机器上去,SOA和微服务项目的部署方式都可以是分布式架构。 而SOA和微服务它们都是面向服务的架构,但是微服务相比于SOA在服务粒度…...
)
Java多线程学习(概念笔记)
面试题:并行和并发有什么区别? 现在都是多核CPU,在多核CPU下 并发是同一时间应对多件事情的能力,多个线程轮流使用一个或多个CPU 并行是同一时间动手做多件事情的能力,4核CPU同时执行4个线程 面试题:创建线…...
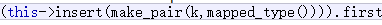
【C++】set和map
set和map就是我们上篇博客说的key模型和keyvalue模型。它们属于是关联式容器,我们之前说过普通容器和容器适配器,这里的关联式容器就是元素之间是有关联的,通过上篇博客的讲解我们也对它们直接的关系有了一定的了解,那么下面我们先…...
yolov5 v7.0打包exe文件,使用C++调用
cd到yolo5文件夹下 pyinstaller -p 当前路径 -i logo图标 detect.py问题汇总 运行detect.exe找不到default.yaml 这个是yolov8里的文件 1 复制权重文件到exe所在目录。 2 根据报错提示的配置文件路径,把default.yaml复制放到相应的路径下。(缺少相应…...

保研线性代数机器学习基础复习2
1.什么是群(Group)? 对于一个集合 G 以及集合上的操作 ,如果G G-> G,那么称(G,)为一个群,并且满足如下性质: 封闭性:结合性:中性…...
vultr ubuntu 服务器远程桌面安装及连接
一. 概述 vultr 上开启一个linux服务器,都是以终端形式给出的,默认不带 ui 桌面的,那其实对于想使用服务器上浏览器时的情形不是很好。那有没有方法在远程服务器安装桌面,然后原程使用呢?至少ubuntu的服务器是有的&am…...
前端学习<二>CSS基础——12-CSS3属性详解:动画详解
前言 本文主要内容: 过渡:transition 2D 转换 transform 3D 转换 transform 动画:animation 过渡:transition transition的中文含义是过渡。过渡是CSS3中具有颠覆性的一个特征,可以实现元素不同状态间的平滑过渡…...
Sqoop 的安装与配置
目录 1 下载并解压2 修改配置文件3 添加环境变量4 拷贝 JDBC 驱动5 测试Sqoop是否能够成功连接数据库 下载地址 1 下载并解压 (1)上传安装包 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz 到 hadoop101 的 /opt/software 路径中 (2…...

Mysql设置访问权限(docker配置)
1.运行命令:docker exec -it 数据库名 bash,我这里是bot_test, docker exec -it bot_test bash 2.运行命令mysql -uroot -p --default-character-setutf8,输入密码连接数据库 3.运行命令show databases,查看当前的表 4.进入my…...
【Linux】详解软硬链接
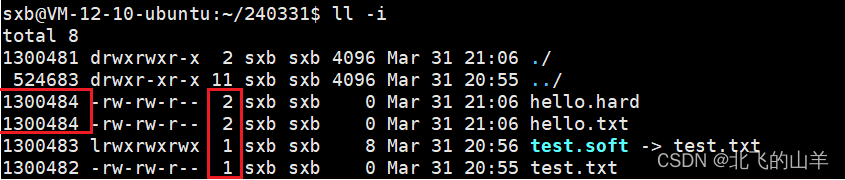
一、软硬链接的建立方法 1.1软链接的建立 假设在当前目录下有一个test.txt文件,要对其建立软链接,做法如下: ln就是link的意思,-s表示软链接,test.txt要建立软链接的文件名,后面跟上要建立的软链接文件名…...

维修贝加莱4PP420.1043-B5触摸屏Power Panel 400工业电脑液晶
深圳捷达工控维修为贝加莱、HMI 显示电源面板 400 4PP420.1043-B5 提供专业电子维修。在 深圳捷达工控维修,我们拥有及时且经济高效地维修 B&R 、HMI Display Power Panel 400 4PP420.1043-B5 的经验。我们为发送给我们工厂维修的贝加莱 HMI 显示面板 400 4PP42…...
Java_21 完成一半题目
完成一半题目 有 N 位扣友参加了微软与力扣举办了「以扣会友」线下活动。主办方提供了 2*N 道题目,整型数组 questions 中每个数字对应了每道题目所涉及的知识点类型。 若每位扣友选择不同的一题,请返回被选的 N 道题目至少包含多少种知识点类型。 示例…...

【WPF应用21】WPF 中的 TextBox 控件详解与示例
在 Windows Presentation Foundation (WPF) 中,TextBox 控件是一个强大的输入控件,允许用户输入、编辑和选择文本。TextBox 控件在各种应用程序中都非常常见,例如表单、对话框和编辑器。本文将详细介绍 TextBox 控件的功能、使用方法、属性、…...

小程序页面传参?
小程序页面之间传递参数通常可以通过以下几种方式实现: 通过 URL 参数传递:可以在跳转目标页面时,在 URL 中添加参数,目标页面可以通过 options 参数获取传递过来的数据。 // 页面 A wx.navigateTo({url: targetPage?param1value…...
C++list的模拟实现
为了实现list,我们需要实现三个类 一、List的节点类 template<class T> struct ListNode {ListNode(const T& val T()):_pPre(nullptr),_pNext(nullptr),_val(val){}ListNode<T>* _pPre;ListNode<T>* _pNext;T _val; }; 二、List的迭代器…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...
AI语音助手的Python实现
引言 语音助手(如小爱同学、Siri)通过语音识别、自然语言处理(NLP)和语音合成技术,为用户提供直观、高效的交互体验。随着人工智能的普及,Python开发者可以利用开源库和AI模型,快速构建自定义语音助手。本文由浅入深,详细介绍如何使用Python开发AI语音助手,涵盖基础功…...
基础)
6个月Python学习计划 Day 16 - 面向对象编程(OOP)基础
第三周 Day 3 🎯 今日目标 理解类(class)和对象(object)的关系学会定义类的属性、方法和构造函数(init)掌握对象的创建与使用初识封装、继承和多态的基本概念(预告) &a…...