GPT-1原理-Improving Language Understanding by Generative Pre-Training
文章目录
- 前言
- 提出动机
- 模型猜想
- 模型提出
- 模型结构
- 模型参数
- 模型预训练
- 训练的目标
- 训练方式
- 训练参数
- 预训练数据集
- 预训练疑问点
- 模型微调
- 模型输入范式
- 模型训练
- 微调建议
- 微调疑问点
- 实验结果分析
- GPT-1缺陷
前言
首先想感慨一波
- 这是当下最流行的大模型的的开篇之作,由OpenAI提出。
- 虽然【预训练+微调】的训练范式最初不是由GPT-1提出,但是基于transformer的【预训练+微调】的范式是由GPT-1提出的,这也是现在大模型所用的范式。
- 这篇论文出自18年,比google公司出的bert要早几个月,我前面详细分析过一次bert的论文[BERT原理-Pre-training of Deep Bidirectional Transformers for Language Understanding],其实bert的思路有大部分是来自GPT-1的。
细品一下,虽然当时这篇论文平平无奇,但是历史见证它的后劲很强大。下面会逐一的记录一下我看了这篇论文后的理解。
提出动机
首先我们来回顾一下在自然语言任务中,尤其是自然语言理解任务中,大概有以下的几种任务包括:文本蕴含、问题回答、语义相似度评估和文档分类等。
那如何通过AI算法的手段去解决和完成这些NLI任务呢?
在传统的AI算法开发的过程中,一般是利用标注好的数据去训练一个模型,然后再将训练好的模型应用于具体的业务领域,下面就以NLP中的情感分类来举例子:
- 数据集构建: 构建情感分类数据集,
| 数据(feature) | 标签(label) |
|---|---|
| 你真的狗阿 | 负面 |
| 小明的表现还是很不错的 | 负面 |
| 。。。 | 。。。 |
- 模型构建: 构建一个深度学习或者机器学习的二分类模型,用来实现情感分类
- 模型训练:训练好后的模型就可以完成情感分类任务了。
但是以上的这种传统的做法还是存在着一些局限,如:
- 训练的数据集需要人为的标注,且数据集要足够大,这样就要求原始预料足够多,同时标注的人力也要足够大。
- 训练好后的模型只能完成单一的任务,且在这个单一任务上,未来要预测的数据的分布情况要和训练数据集的分布情况大致保持一致,这也就是大家所说的数据的独立同分布的概念的本质意思。如果不一致,模型效果就会变差,这很好理解,也就是说你训练的数据集是一种分布形式,那么模型学到的就是这种分布形式的规律,所以未来要预测的数据同样要符合这个规律,如果规律不一样,那么效果就不会太好。这就是风控领域的PSI技术原理。
- 训练好后的模型只能完成单一任务。如果这个模型是基于情感分类数据集来训练的,那么训练好后的模型就只能完成情感分类任务。
总结一下就是,在传统的AI任务中,你需要标注一堆的数据,然后去训练一个模型,训练好后的模型去上线预测的时候,只能完成单一任务,且单一任务中进来的数据也要和原始训练数据呈现独立同分布的规则,这种模型或者训练的范式,我们称之为狭窄专家。
其实这就为现实的发展增加了不少的阻碍,最明显的地方在于有些领域的原始数据语料本身就特别少,那这种有监督式的训练就不能够sota了。所以探索一种能够在少样本下sota的模型,变得有现实意义。
模型猜想
以上已经描述了监督学习在NLI任务上可能存在的阻碍,那到底该如何改善呢?该怎么做呢?作者最先想到的点子就是:
- 能不能在一些未标注且不缺分领域的海量数据上去训练得到一个模型,学习得到一些通用知识。这个模型具有一些基础的能力,诸如词的embedding表示能力等(预训练)。
- 然后在这个基础模型的基础上再利用少量的特有领域的标注数据对模型进行二次训练,这样就可以完成在特定领域的工作(微调)。
我们写过论文的都知道,既然你在论文中提出来了这个假设,自然肯定是能实现了哈哈,同样的作者提出的这种思想,在很多地方也找到了佐证。最典型的就是词向量的表示。
还记得以前的word2vec是如何工作的吗?先训练好word2vec,然后单词通过模型之后,就会得到词向量,有了词向量就可以做很多的事情,通常情况下,不会直接来使用这个词向量来完成具体的NLI任务,当然了它也完不成,一般情况是将词经过word2vec向量化表示,然后接着利用向量化后的特征来训练其他的模型(如rnn或lstm等)来完成具体的NLI任务。这是不是有点验证了作者提出的猜想呢?
- word2vec的训练类似于作者提出的第一阶段的训练
- 二次训练其他的模型(诸如lstm),类似于作者提出的二次训练
以上的工作模式被证明有一定的效果。
基于以上的种种,作者提出(或者说是普及了)的这种基于transformer的两段式训练范式:预训练+微调。打开了未来的大门。
模型提出
接着,作者在论文中分析了,基于LSTM这种两段式的训练有一个问题:LSTM很难处理一些长文本信息,这是循环神经网络不可避免的问题,所以作者提出了一种新的模型,就是基于transformer的decoder模型架构。以这种架构来完成模型的预训练和微调。
模型结构
transformer结构
作者提出的GPT-1的结构其实就是基于transformer的解码器的简单的堆叠,那么我们先来看看transformer是怎么样的。
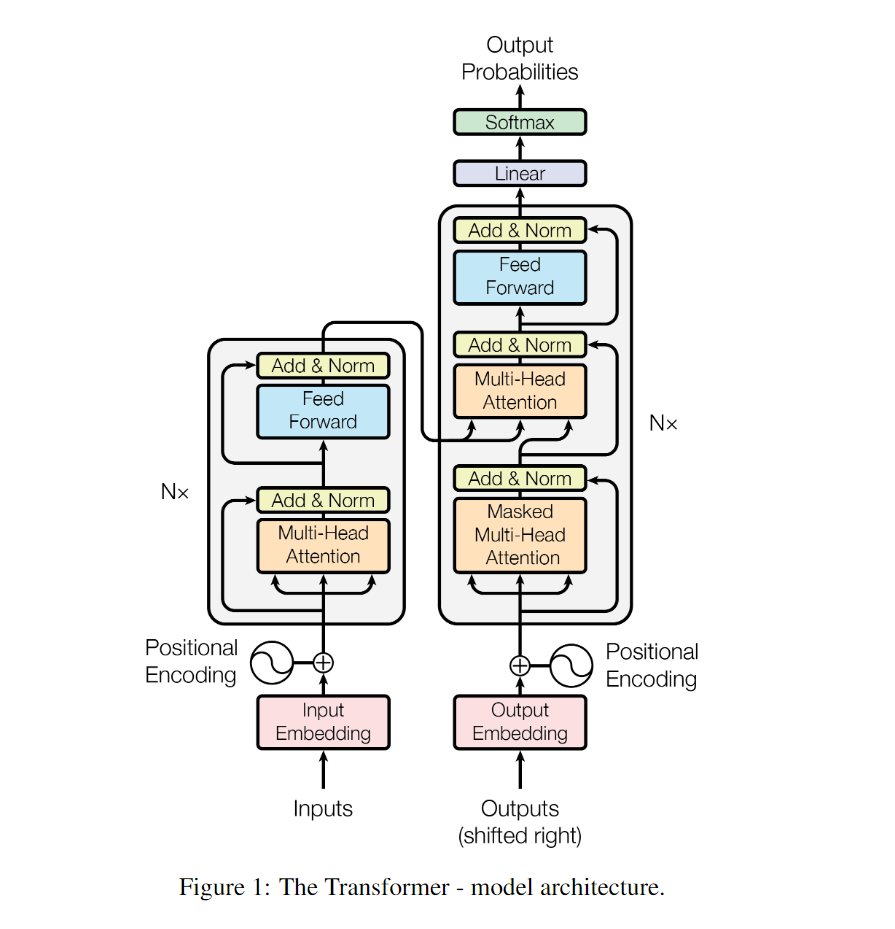
以上就是transformer的结构,左边是编码器encoder,右边是解码器decoder,解码器块和编码器块的差别其实就在于解码器块多了一个掩码机制(Masked Multi-Head Attention)。这个掩码机制会将要预测的token的未来token进行掩码。避免信息穿越。
举一个例子,比如在将“你发工资了嘛”这句话输入到模型进行模型训练时,在预测“发”时,输入的时“你”,预测“工”时,输入的时“你发”。它是不能看到句子未来的词的,这时和bert是完全不一样的。
具体关于transformer的内容,会在transformer论文中分享,这里只做最简单的介绍。
GPT-1结构
GPT-1的模型结构非常简单,其实就是基于transformer的decoder部分做了一个12层的堆叠,下面我先绘制一个GPT-1的结构图
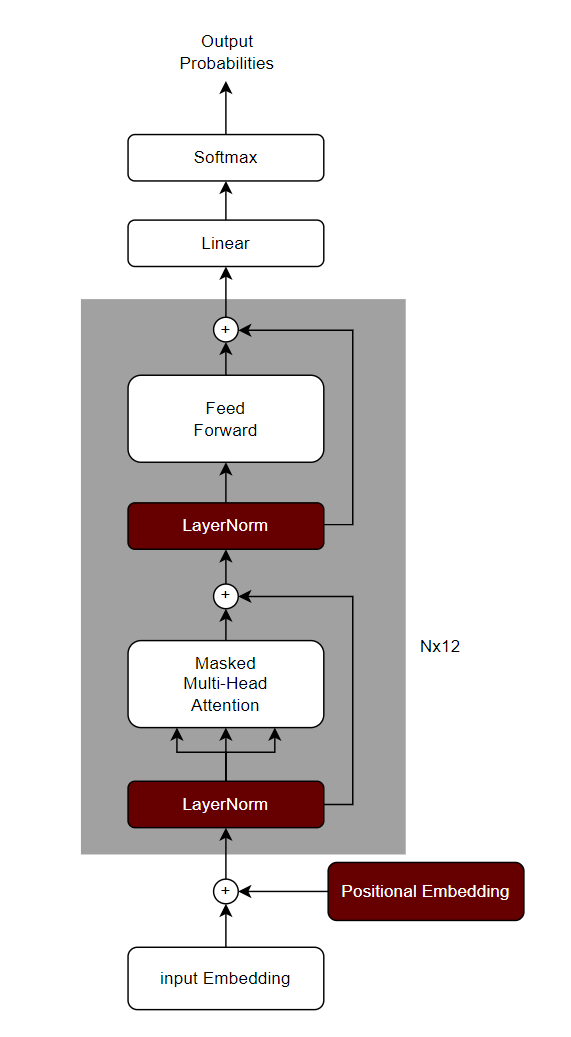
可以看出这就是基于transformer的decoder部分来设计的,但是还是有了一些简单的修改,具体一些在架构上显著的修改,我用红色的标注出来了。下面我大概描述一下。
- 位置编码(Positional Embedding)部分采用了和input Embeddingg一样的可学习的embedding模块,而不是transformer的正余弦计算原理。这个改进让positional Embedding也变得可学习了,而不是固定的。
- LayerNorm部分被提前了,原始的transformer部分,是先进行多头注意力计算,然后进行layerNorm,而在GPT-1这里则被提前了。
- 少了一个Mutil-Head Attention模块,只保留了Masked Mutil-Head Attention。
- 第三部分则是激活函数的变化,原始的transformer用的是relu,而GPT-1用的是GELU。
关于GPT-1的结构,以及和transformer的差别就是这么多,这也就可以理解为啥当初论文发出来之后响应没那么大,这放到现在的研究生论文中,高低会质疑创新不足吧哈哈。
模型参数
前面都介绍了模型的具体的结构了,下面就只需要说说结构里面具体的参数设定了
| 模块 | 参数 |
|---|---|
| 解码器块 | 12层 |
| 多头注意力 | 12头 |
| 词embedding | 768维 |
| 前馈神经网络隐藏层维度 | 3072维 |
有这些参数就可以具体确定这个模型了,如果不懂这些参数对应什么,强烈建议看看transformer的原理,后期我也会补一篇关于transformer论文的分析。
虽然我们已经有了模型,但是我们该如何训练呢?而训练很大程度是由训练目标决定的,比如我们的训练目标是二分类,那么我就知道模型其实就是把特征输入进行,做一个sigmoid做二分类预测,最后计算loss反向BP。所以我们接下来就要知道预训练和微调阶段的各自训练目标是啥。
模型预训练
训练的目标
前面已经说了,作者看了很多论文之后,提出了这种预训练+微调的两段式训练范式。而在预训练阶段是通过在未标注数据上进行大量训练。而这里就有一个疑问了:
- 在未标记的语料上训练模型,到底该选择什么样的训练目标呢?到底是以情感分类为目标呢?还是以实体识别问分类目标呢?还是其他的NLI任务?
前面都说了,如果是以具体的任务为目标,首先这就不符合作者的初衷了,作者是希望训练一个通才来,这个模型虽然不一定能完成多种任务,但是要具备完成多种任务的基础能力,而如果以某一个具体任务为目标,就变成了前面所提到了狭隘的专家模型了;其次是数据上,这个数据是要人去标注的,根据作者的假设这显然是第二阶段要做的,那这个阶段该如何做呢?首先从数据上看,这个阶段有的都是一些未标注的大量文本数据;其次从之前所得到的启发来看,以往的这种两段式训练范式,在第一段中都是通过学习词的embedding表示,来捕获词或者短语级别的信息。诸如word2vec。所以作者受到启发,就是利用预训练来获得词的通用embedding表示,既然是学习词的通用embedding表示,那训练时候数据该如何组织呢?这些都是一些未标注的数据阿?作者这里采用的训练思想就是:预测下一个词的出现概率。利用出现的词来预测出现未出现的词,这就是训练的目标。
训练方式
这样所有的都解决了阿,所有的未标注的数据都可以用起来啦。我还是举一个例子吧,以:“你是一个打不死的码农”为例
| 特征(feature) | 标签(label) |
|---|---|
| 你 | 是 |
| 你是 | 一 |
| 你是一 | 个 |
| 你是一个 | 打 |
| 你是一个打 | 不 |
| 你是一个打不 | 死 |
| 。。。 | 。。。 |
将特征输入到模型,来预测标签,当然表格中的特征长度虽然是不一样的,但是实际情况下,是会把输入都padding到同一个长度的,这是搞模型的基操了:保证输入维度不变。同时这也就是下面要提的“最长文本输入”的概念。
训练参数
而在具体的训练中,有一些具体的细节参数还是需要留意的,下面我把主要的参数进行罗列
- 文本的编码采用词级,也就说是一个词一个词的输入。
- 单词输入最长文本为512个token:这就是说一次输入的最长的文本只能是512,如果不够512,也会把它补齐padding到512,如果超过512,也会截断,只保留512个token。
- 单个batch为64个文本序列:如果把第2点输入的512看作一句话的长度,那么这里就是说一次输入到模型中为64句话。
- 优化器选择用adam
- 学习率最开始设置为2.5x10^-4,在前2000个step的时候学习率恒定不变,2000个step之后,学习率会动态减小,直到为0,而这个减小在原文中是用一个余弦函数来实现的。
- 用到dropout的地方,丢弃概率参数为0.1
- 总共训练100个epoch
- 训练时采用L2正则。
预训练数据集
数据集这一块主要是用到了两个数据集
- booksCorpus:这是一些书籍数据。
- 1B Word Benchmark :这是一些连续文本内容。
现在,有了模型、有了优化目标、有了具体模型参数和训练参数、还有了数据。就可以做模型的预训练了,预训练结束后的模型,就会学到词的通用embedding表示啦。
预训练疑问点
在原始论文中,给出了一个计算的公式

从上面可以看得出来,最终自注意力块的输出之后还要和原始输入的词的embedding转置进行相乘,这就是我的疑问点所在。
以我对transformer的decoder的理解,以及在看了minGPT的实现之后,得到的结论是:最后的这个We的转置其实本身就不是We,而是会额外的加入一个线性层进行学习。同时以日常的经验,我认为确实也应该这么做,而不是像GPT-1提出的这么做。这里给朋友们留一个讨论空间。
注:minGPT工程是一个大神对GPT的实现。文章末尾有连接跳转。
模型微调
在预训练阶段,模型学到了如何利用出现的词来预测下一个词。顺带学会了词的embedding表示。按理来说要让他做具体的自然语言理解(NLI)任务是不太可能的,所以也就有了微调这一步,在微调阶段,模型只需要在少量的具体任务的标注数据,就可以达到sota。那对于每一个NLI任务具体该怎么做呢?
模型输入范式
自然语言理解任务(NLI)其实是有很多种的,诸如:情感分析、文本蕴含、相似度计算、多项选择、摘要总结等。对于这么多的任务,输入部分是可大致总结为有两种输入的形式:
- 单文本输入:诸如情感分类这样的任务,其实就是单句话输入进去,判别情感类别。
- 多文本输入:诸如文本蕴含、多项选择,他们是多个连续文本的输入,然后做最终的目标计算。
所以针对这么多的NLI任务,GPT-1统一了输入的范式:
输入的序列(可以是单个或多个)以<s>开头。- 输入序列是多个时,序列之间用$符号做分隔。
输入序列的结尾用<e>作为结束。
以上就是关于输入的范式规定,下面我给出一张官方的图就一目了然了。Start部分就是<s>,Delim部分就是$,而Extract部分就是<e>
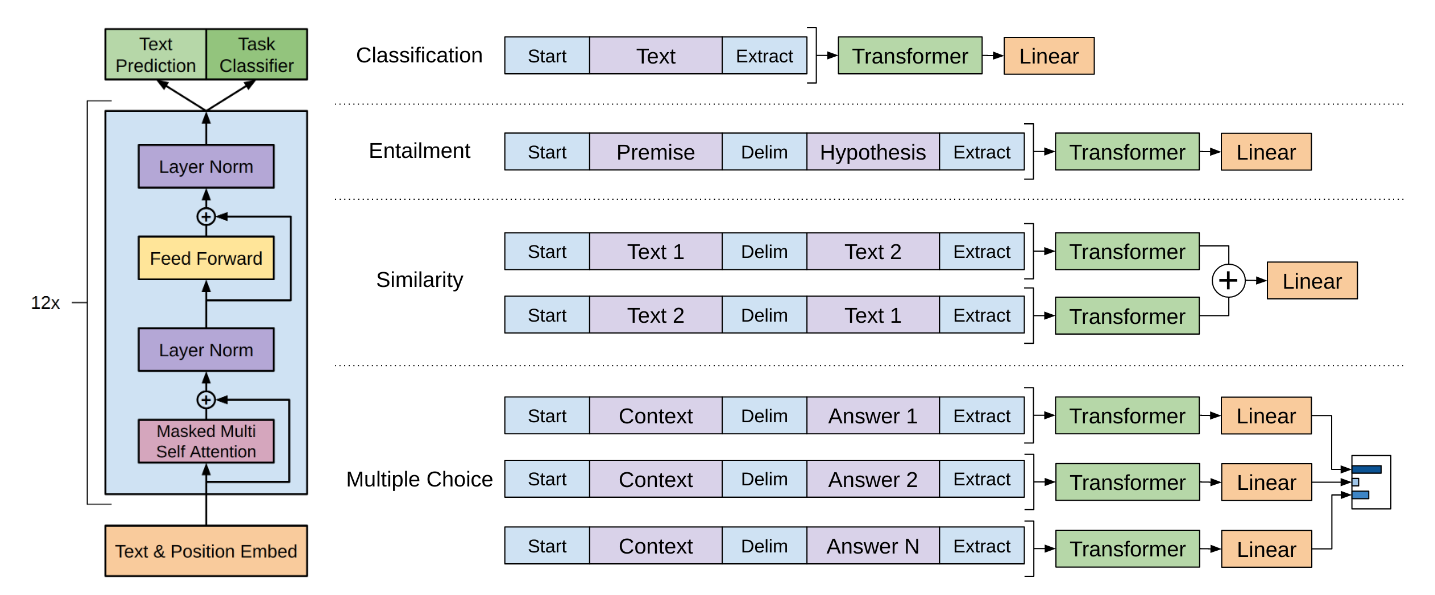
模型训练
在微调部分的训练,其实就是标准的有监督学习,自然要先计算loss,然后根据loss来进行反向BP优化参数。下面我会根据上图来挨个讲解不同NLI任务大概是如何训练的。
单句子分类任务

上图中的分类任务是单句子的二分类任务,诸如情感分类。
- 数据准备:
句子开头添加<s>,句子结尾添加<e> - 模型修改,在原有模型上添加二分类头
- 数据训练:数据输入到模型中,预测二分类,根据loss,反向BP更新模型参数
多句子分类任务

上图中的分类任务是多句子的二分类任务,诸如文本蕴含,就是预测一个句子是否含在另一个句子中。
- 数据准备:
句子开头添加<s>,句子结尾添加<e>,句子与句子之间用$分隔 - 模型修改:在原有模型上添加二分类头
- 数据训练:数据输入到模型中,预测二分类,根据loss,反向BP更新模型参数
相似度计算任务

这类任务其实也可以看作是一个二分类任务,以概率来表示他们的相似程度。
5. 数据准备:句子开头添加<s>,句子结尾添加<e>,句子与句子之间用$分隔
6. 在原有模型上添加二分类头
7. 数据训练:数据输入到模型中,预测二分类,根据loss,反向BP更新模型参数
注:在数据输入部分,由于是两段文本,所以谁在前都行,既然谁在前都行,官方的做法就是分别让每一句话都在前一次,然后分别输入到模型,最后将两次的结果进行相加,进行二分类的概率预测。
多项选择任务

多项选择原理上是一个多分类任务,所以同样是用概率来表示选谁,区别与之前的任务的地方在于别的是用sigmoid做二分类任务,而这里是用softmax做多分类任务。但是这里的softmax并不是直接在线性层上去叠加的。
- 数据准备:
句子开头添加<s>,句子结尾添加<e>,句子与句子之间用$分隔,分别将问题和答案做组合,非正确答案的组合的标签就是0,正确答案的组合的标签就是1,这样多个选择就会有多组数据 - 在原有模型上添加二分类头(并不是直接添加多分类头)
- 数据训练:多组数据分别输入到模型中,预测二分类,最后根据多组的二分类输出结果做最终的softmax,再根据loss,反向BP更新模型参数。
注:这里最重要的就是在模型的设计上加入多分类头,比如对于4选项的任务来说,并不是直接在输出层添加一个输出维度为4的线性层,然后再softmax,而是添加了一个二分类头,每一个数据都分别进入模型,得到一个二分类的概率结果,然后再在这4个二分类结果上用softmax归一化,用最终的softmax结果计算loss。结合着图去理解这段话就非常清楚了。
微调建议
有了目标,有了数据,有了模型,就可以微调了。
当然了,官方论文给出了关于一些微调时候训练参数的建议
- 学习率为6.25 x 10^-5
- 每个batch为32
- 训练3个epoch即可
微调疑问点
这个疑问点来自于微调阶段的loss的计算,在原始论文中,给出了一个公式
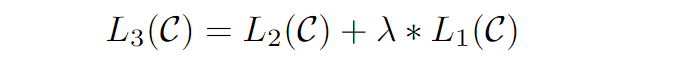
- L3为微调时计算的总的loss,
- L2表示微调时,具体任务的loss,如二分类任务,loss表示二分类结果和真实结果的差距
- L1表示文本生成的loss,也就是说你输入了一句话,这里是会计算文本生成的loss的,这也就是预训练阶段优化的操作依据,但是这里的这个文本生成的loss,并不会计算所有文本的loss,
而是只算开始符号<s>、结尾符号<e>和分隔符$的loss。
个人说明和理解
在微调部分,总的loss是L1和L2的相加。模型会根据总的loss进行反向BP,我想做两点说明:
- 为什么要加上这个L1的loss呢?根据作者在论文中说,他们看到了别人的论文中有这样的做法,就是在微调时加入一个辅助目标,这样训练会让效果更好,而经过验证,他们也觉得这个效果不错,所以就这么做了。
- 而在计算L1的loss时,为什么只计算
<s>、$、<e>这几个特殊符号的loss呢?我个人理解是,在预训练阶段常规的文本模型都见过了,而这几个特殊符号是在微调阶段为了满足不同的下游任务而设计的输入范式,所以可以理解为模型之前没见过,那这里只计算他们的loss也合理。
个人的困惑和建议
但是在minGPT工程中,以及现在流行的大模型的实现中,其实都不这么做,都是只使用L2来计算loss,然后反向BP。包括在minGPT工程中,也是只用了L2。也就是现在的做法是:在微调阶段就只计算具体微调任务的loss。不会有什么辅助目标了。
这就是论文和实现的差距。同时以我的建议,我建议也是不要像原文一个添加辅助目标了。
实验结果分析
最终作者在很多的NLI任务上做了多次的实验,得出了两个很重要的结论。
- 增加transformer的decoder层数,会对NLI的理解任务有提升。
- 零样本能力:预训练好后的模型本身不需要微调,就具有了一定的NLI解决能力。
关于第1条的结论应该属于顺理成章,而关于第2点,文章作者最开始的本意可能只是想在预训练阶段让模型学到一些词级别或者是短语级别的能力,诸如word2vec能力,而训练完之后,却2发现,这个预训练的模型不仅仅具有简单的词embedding的能力,居然就已经有一些能够解决具体NLI任务的基础能力,只是效果不一定好。这应该是属于意外之喜。
从现在来看,以上的两个结果,指导着当下(2024)年大模型的发展,现在的GPT4,已经完全验证了当初的这两个实验结论了。OpenAI牛逼。
GPT-1缺陷
如果你通读了这篇文章,你会发现一些明显的缺陷:
- 就是在微调阶段,是需要根据不同的NLI任务,添加不同的任务头,这其实和Bert那一套是很像的,可以想象Bert很大概率是借鉴了GPT-1的。好了话说回来,这种添加任务头的形式,无形中是改变了原有的模型的。这可以说是一个缺点吧,因为OpenAI的追求是在不改变模型的情况下得到一个通才。
- 在训练参数这一节提到,在文本输出的时候,是按照词级别进行输入的,这种有一个很大的缺点,如果有些单词没见过,那如何进行编码呢?当然可以有一些平滑处理的手段,但是这确实是一个现存的问题所在,而在minGPT中,则是用了字符级的输入,就是把单词中的字母一个一个的进行编码输入。这虽然解决了问题,但是这个计算量就很大了。所以才有了后来的字节级的编码,诸如bpe,wordpiece等。
后来的Openai也是基于这些个缺点以及实验结论去做迭代,这也是GPT-2和3在寻找的,同时当下的大模型几乎都是不需要更改模型结构的。
好啦,关于GPT-1的讲解就到这,也强烈建议大家看一下论文:Improving Language Understanding by Generative Pre-Training
还有一个是文中提到的:minGPT,他是由一个国外的大佬开发的关于GPT的系列实现,通俗易懂,推荐阅读。
相关文章:
GPT-1原理-Improving Language Understanding by Generative Pre-Training
文章目录 前言提出动机模型猜想模型提出模型结构模型参数 模型预训练训练的目标训练方式训练参数预训练数据集预训练疑问点 模型微调模型输入范式模型训练微调建议微调疑问点 实验结果分析GPT-1缺陷 前言 首先想感慨一波 这是当下最流行的大模型的的开篇之作,由Op…...

web3.0入门及学习路径
Web3是指下一代互联网的演进形式,它涉及一系列技术和理念,旨在实现去中心化、开放、透明和用户主导的互联网体验。Web3的目标是赋予用户更多的控制权和数据所有权,并通过区块链、加密货币和分布式技术来实现。 一、特点 去中心化࿱…...

MATLAB 自定义中值滤波(54)
MATLAB 自定义中值滤波(54) 一、算法介绍二、算法实现1.原理2.代码一、算法介绍 中值滤波,是一种常见的点云平滑算法,改善原始点云的数据质量问题,MATLAB自带的工具似乎不太友好,这里提供自定义实现的点云中值滤波算法,具体效果如下所示: 中值滤波前: 中值滤波后:…...
harmonyOS的客户端存贮
什么是客户端存贮 在harmonyOS中,客户端存贮是指将数据存贮在本地设备以供应用程序使用; 注: 和feaureAblity搭配使用,content上下文的获取依赖该API如下: // 引入: import featureAbility from ohos.ability.featureAbility;// 使用: let content featureAbility.getConten…...

安科瑞智慧安全用电综合解决方案
概述 智慧用电管理云平台是智慧城市建设的延伸成果,将电力物联网技术与云平台的大数据分析功能相结合,实现用电信息的可视化管理,可帮助用户实现安全用电,节约用电,可靠用电。平台支持web,app,微…...

Web 前端性能优化之二:图像优化
1、图像优化 HTTP Archive上的数据显示,网站传输的数据中,60%的资源都是由各种图像文件组成的。 **图像资源优化的根本思想,可以归结为两个字:压缩。**无论是选取何种图像的文件格式,还是针对同一种格式压缩至更小的…...

android——枚举enum
在Kotlin中,枚举(Enum)是一种特殊的类,用于表示固定数量的常量。它允许你定义一组命名的常量值,这些值在程序中具有固定的意义。Kotlin的枚举功能强大,支持多种特性,如伴生对象、构造函数、属性…...

Day54:WEB攻防-XSS跨站Cookie盗取表单劫持网络钓鱼溯源分析项目平台框架
目录 XSS跨站-攻击利用-凭据盗取 XSS跨站-攻击利用-数据提交 XSS跨站-攻击利用-flash钓鱼 XSS跨站-攻击利用-溯源综合 知识点: 1、XSS跨站-攻击利用-凭据盗取 2、XSS跨站-攻击利用-数据提交 3、XSS跨站-攻击利用-网络钓鱼 4、XSS跨站-攻击利用-溯源综合 漏洞原理…...

2024年MathorCup数学建模思路C题思路分享
文章目录 1 赛题思路2 比赛日期和时间3 组织机构4 建模常见问题类型4.1 分类问题4.2 优化问题4.3 预测问题4.4 评价问题 5 建模资料 1 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 2 比赛日期和时间 报名截止时间:2024…...
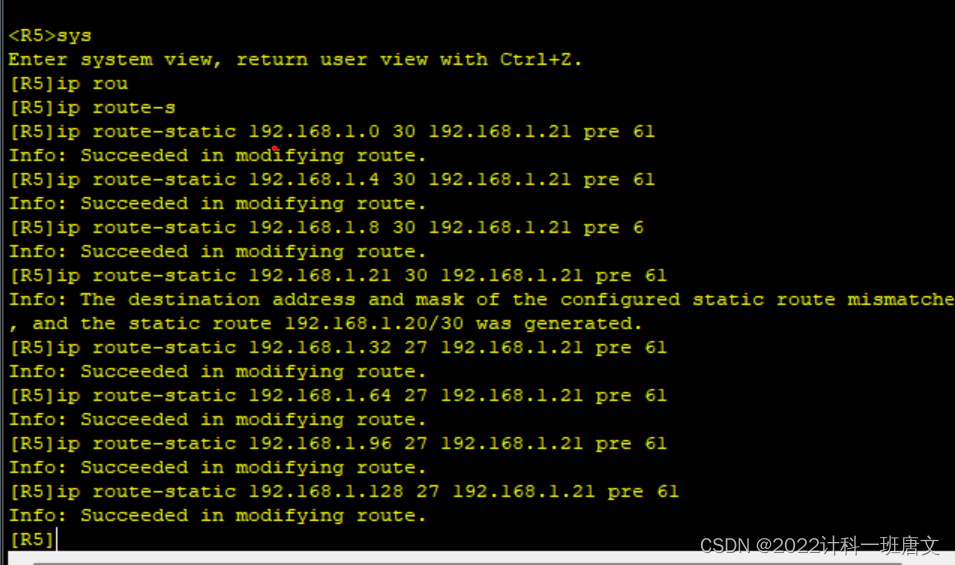
HCIP作业
实验要求: 1、R6为ISP,接口IP地址均为公有地址,该设备只能配置IP地址,之后不能再对其进行任何配置; 2、R1-R5为局域网,私有IP地址192.168.1.0/24,请合理分配; 3、R1、R2、R4&#x…...

如何向sql中插入数据-接上一篇《MySQL数据库的下载和安装以及命令行语法学习》续
接上一篇 《MySQL数据库的下载和安装以及命令行语法学习》续https://blog.csdn.net/tiger_web0/article/details/136903805 在SQL中,要向表中添加数据,您通常使用INSERT INTO语句。 以下是如何使用INSERT INTO语句的基本格式和示例: 基本格式…...

简单的HTML
1.HTML介绍 HTML(HyperText Markup Language,超文本标记语言)是用于创建网页的标准标记语言。它使用一系列的元素来描述网页的结构和内容,包括文本、图像、链接、表格等。 1.1HTML基础结构 HTML文件是一种纯文本文件,由一系列的元素构成。每个元素由一对尖括号<>包围,…...
2024最新 maven 高级用法 (概念自己百度)
#B站看视频学不到的知识# 目录 maven 定义和概念 maven是java构建工具。maven通过远程仓库获取和更新jar包,通过坐标来管理jar文件。 maven核心配置文件 config目录下settings.xml 文件,核心配置详解: localRepository 本地仓库地址&…...

【C++】每日一题 12 整数转罗马数字
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为…...

C++学习建议
C是一门强大且广泛应用的编程语言,特别适合系统级开发、高性能应用和游戏引擎等场景。如果你准备深入学习C,以下是一些关键点和学习路径建议: 1. **基础语法**:首先掌握C的基础语法,如变量声明与赋值、数据类型、运算…...
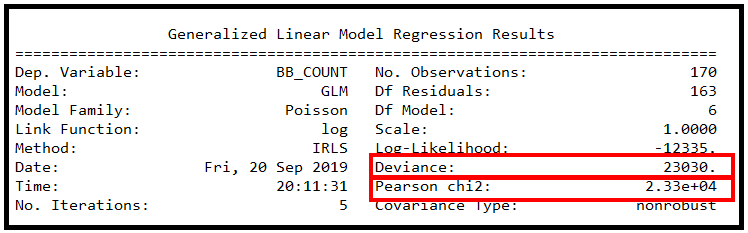
python实现泊松回归
1 什么是基于计数的数据? 基于计数的数据包含以特定速率发生的事件。发生率可能会随着时间的推移或从一次观察到下一次观察而发生变化。以下是基于计数的数据的一些示例: 每小时穿过十字路口的车辆数量每月去看医生的人数每月发现的类地行星数量 计数数…...
软件测试-进阶篇
目录 测试的分类1 按测试对象划分1.1 界面测试1.2 可靠性测试1.3 容错性测试1.4 文档测试1.5 兼容性测试1.6 易用性测试1.7 安装卸载测试1.8 安装测试1.9 性能测试1.10 内存泄漏测试 2 按是否查看代码划分2.1 黑盒测试(Black-box Testing)2.2 白盒测试&a…...

Google人才选拔的独特视角
Google人才选拔的独特视角 独特的人才选拔标准 Google作为全球最大的搜索引擎公司,拥有无数优秀的人才。他们的选拔标准与众不同,有着自己独特的人才观。 重视多元化的背景 Google相信人才的多元化背景能够给公司带来不同的思考角度和创新思维。他们…...

OSPF---开放式最短路径优先协议
1. OSPF描述 OSPF协议是一种链路状态协议。每个路由器负责发现、维护与邻居的关系,并将已知的邻居列表和链路费用LSU报文描述,通过可靠的泛洪与自治系统AS内的其他路由器周期性交互,学习到整个自治系统的网络拓扑结构;并通过自治系统边界的路…...
云数据仓库Snowflake论文完整版解读
本文是对于Snowflake论文的一个完整版解读,对于从事大数据数据仓库开发,数据湖开发的读者来说,这是一篇必须要详细了解和阅读的内容,通过全文你会发现整个数据湖设计的起初原因以及从各个维度(架构设计、存算分离、弹性…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...