Hive详解(5)
Hive
窗口函数
案例
-
需求:连续三天登陆的用户数据
-
步骤:
-- 建表 create table logins (username string,log_date string ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/login' into table logins; -- 查询数据 select * from logins tablesample (5 rows); -- 按用户分组,将登陆日期进行排序 -- over(partition by xxx order by xxx) -- 获取每一条数据两行之前的数据 select *, lag(log_date, 2) over (partition by username order by log_date) as 2d_log_date from logins; -- 获取连续三天登录的数据 select distinct username from (select *, lag(log_date, 2) over (partition by username order by log_date) as 2d_log_datefrom logins ) t where datediff(log_date, 2d_log_date) = 2;
其他操作
join
-
同MySQL类似,在Hive中也提供了表之间的join,包含:内连接
inner join,左连接left join,右连接right join和全外连接full outer join以及极少使用的笛卡尔积 -
除此之外,Hive还提供了特殊的连接:
left semi join。当a left semi join b,表示获取a表哪些数据在b表中出现过 -
案例
-- 建表 drop table if exists orders; create table orders (order_id int,order_date string,product_id int,number int ) row format delimited fields terminated by ' '; drop table if exists products; create table products (product_id int,product_name string,price double ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/orders' into table orders; load data local inpath '/opt/hive_data/products' into table products; select * from orders; select * from products; -- 需求一:获取每天卖了多少钱 select o.order_date,sum(o.number * p.price) from orders o left join products p on o.product_id = p.product_id group by o.order_date; -- 需求二:获取哪些商品被卖出去过 -- 获取商品表中的哪些数据在订单表中出现过 -- 方式一:left semi join select * from products p left semi join orders oon p.product_id = o.product_id; -- 方式二: select * from products where product_id in (select product_id from orders);
排序
-
不同于MySQL的地方在于,在Hive中,提供了两种排序方式
-
order by:全局排序。在排序的时候,会忽略掉ReduceTask的数量,对所有的数据进行整体的排序 -
sort by:局部排序。这种方式,在每一个ReduceTask内部排序。如果没有指定,那么会根据排序字段,计算字段的哈希码,然后将字段分发到对应到ReduceTask上来进行排序
-
-
案例
-
原始数据
2 henry 84 3 jack 76 1 david 92 1 bruce 78 1 balley 77 2 hack 85 1 tom 79 3 peter 96 2 eden 92 1 mary 85 3 pard 61 3 charles 60 2 danny 94 3 cindy 75
-
案例
-- 建表 drop table if exists scores; create table scores (class int,name string,score int ) row format delimited fields terminated by ' '; -- 加载数据 load data local inpath '/opt/hive_data/scores' into table scores; -- 查询数据 select * from scores tablesample (5 rows); -- order by insert overwrite local directory '/opt/hive_demo/order_by1'row format delimited fields terminated by '\t' select * from scores order by score; -- sort by insert overwrite local directory '/opt/hive_demo/sort_by1'row format delimited fields terminated by '\t' select * from scores sort by score; -- Hive中的SQL默认会转化为MapReduce任务来执行 -- 在MapReduce中,如果不指定,默认只有1个ReduceTask -- 因此也只产生1个结果文件 -- 指定ReduceTask的个数 set mapreduce.job.reduces = 3; insert overwrite local directory '/opt/hive_demo/order_by2'row format delimited fields terminated by '\t' select * from scores order by score; insert overwrite local directory '/opt/hive_demo/sort_by2'row format delimited fields terminated by '\t' select * from scores sort by score; -- 在实际过程中,其实极少单独使用sort by -- sort by一般是结合distribute by来使用 -- 案例:将每一个班的学生按照成绩降序排序 insert overwrite local directory '/opt/hive_demo/distribute_by'row format delimited fields terminated by '\t' select * from scores distribute by class sort by score desc;
-
-
如果
distribute by和sort by的字段一致,那么可以省略为cluster by。注意,cluster by默认只能升序不能降序排序
beeline和JDBC
-
JDBC(Java Database Connection):类似于MySQL,Hive也提供了JDBC操作,代码和MySQL的JDBC操作一模一样
package com.fesco.jdbc; import java.sql.*; public class HiveJDBCDemo { public static void main(String[] args) throws ClassNotFoundException, SQLException { // 注册驱动Class.forName("org.apache.hive.jdbc.HiveDriver");// 获取连接// Hive对外提供的连接端口是10000Connection connection = DriverManager.getConnection("jdbc:hive2://101.36.69.196:31177/demo", "root", "root");// 获取表述Statement statement = connection.createStatement();// 执行SQLResultSet resultSet = statement.executeQuery("select * from products");// 遍历结果集while(resultSet.next()){System.out.println(resultSet.getString("product_name"));}// 关闭resultSet.close();statement.close();connection.close(); } } -
利用Datagrip连接Hive,实际上就是用JDBC的方式连接的Hive
-
Hive提供了原生的远程连接方式:beeline
beeline -u jdbc:hive2://hadoop01:10000/demo -n root
-u表示url,连接地址;-n表示name,用户名 -
注意:如果想要使用JDBC的方式连接Hive,那么必须开启
hiveserver2服务!!!
SerDe
-
SerDe(Serializar-Deserializar):是Hive中提供的一套用于进行序列化和反序列化操作的机制
-
可以利用SerDe来解决数据的格式问题
-
案例
-- 不使用SerDe -- 1. 建表管理原始数据 create table logs_tmp (log string ); load data local inpath '/opt/hive_data/logs' into table logs_tmp; select * from logs_tmp tablesample (5 rows); -- 2. 建表 create table logs (user_ip string, -- 用户iplog_date string, -- 访问日期和时间timezone string, -- 时区request_way string, -- 请求方式resources string, -- 请求资源protocol string, -- 请求协议state_id int -- 状态码 ) row format delimited fields terminated by '\t'; -- 3. 先将数据替换为规则形式,然后利用split拆分 insert into table logs select arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], cast(arr[6] as int) from (select split(regexp_replace(log, '(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" (.*) \-', '$1 $2 $3 $4 $5 $6 $7'), ' ') arr from logs_tmp ) t; -- 查询数据 select * from logs; -- 使用SerDe -- 建表 drop table if exists logs; create table logs (user_ip string, -- 用户iplog_date string, -- 访问日期和时间timezone string, -- 时区request_way string, -- 请求方式resources string, -- 请求资源protocol string, -- 请求协议state_id int -- 状态码 ) row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'with serdeproperties ('input.regex'='(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" (.*) \-') stored as textfile ; load data local inpath '/opt/hive_data/logs' into table logs; select * from logs;
视图(view)
-
视图是对原表中部分字段进行抽取,可以看作是原表的子表,但是本质上是一个虚拟表
-
当不需要表中所有的字段,而只需要这个表中的部分字段的时候,那么此时就可以使用视图来对数据进行封装
-
视图只能看不能修改!
-
视图的优点
-
简单。使用视图的时候,完全不需要关心视图背后依赖的表结构是否发生变化,是否产生关联。对于用户而言,视图就是已经符合过滤条件的结果集
-
安全。用户只被允许访问视图中已经过滤好的数据,并且视图中的数据只能查不能改,此时不会影响基表的数据
-
数据独立。一旦视图创建,那么此时基表发生结构变化,不会影响视图的操作
-
-
Hive中,在定义视图的时候,需要封装一个select语句。此时,被封装的这个select在创建视图的时候并不会执行;而是会在第一次查询视图的时候才会触发封装的select执行
-
视图分为虚拟视图(只存储在内存中,可以认为是一个虚拟表)和物化视图(会落地到磁盘上,此时就是一个真正的子表)。需要注意的是,Hive只支持虚拟视图不支持物化视图
-
案例
-- 创建视图 create view logs_view as select user_ip, log_date, resources from logs order by log_date; -- 查询视图 select * from logs_view; -- 删除视图 drop view logs_view;
Hive存储
概述
-
Hive中的数据最终是以文件形式落地到HDFS上,目前Hive官方原生的文件格式有6种:
textfile,RCFile,orc,parquet,avro和sequencefile-
avro和sequencefile将文件以序列形式来存储(序列化文件)
-
如果不指定,那么HDFS默认将文件以textfile格式存储
-
textfile,avro和sequencefile是行存储格式,RCFile,orc和parquet是列存储格式
-
textfile不支持修改(delete和update),但是列存储格式都支持delete和update操作,效率非常低
-
textfile
-
Hive中的文件格式默认就是textfile
-
默认情况下,textfile不对数据进行压缩,因此占用磁盘空间相对较大;在进行数据分析的时候,开销相对也较大
-
textfile支持Gzip和Bzip2的压缩格式
orc
-
orc(Optimized Row Columnar,优化的行列格式),是Hive0.11版本引入的一种文件格式,是基于RCFile格式机型优化,本身是以列存储形式来存放数据
-
每一个ORC文件,由1个File Footer、1个Postscript以及1到多个Stripe来组成
-
Stripe:用于存储数据的。默认情况下,每一个Stripe的大小是250M。Stripe由三部分组成
-
Index Data:索引数据。默认每隔10000行数据形成一次索引,会记录每一列的最小值、最大值、以及每一列中的行索引
-
Row Data:行数据。在存储数据的时候,不是将整个表的列来进行拆分,而是先截取部分行,然后将每一行数据的字段来进行拆分。因为同一列中的字段类型是一致的,所以可以给不同的列来指定的压缩机制进行更好的压缩
-
Stripe Footer:记录每一列的数据类型、每一列的字节长度
-
-
File Footer:记录每一个Stripe中包含的行数以及每一列的数据类型。初次之外,File Footer还可以记录每一列的聚合信息,例如sum、max等
-
Postscript:记录了整个文件的信息,例如文件是否压缩,压缩编码是什么,以及File Footer在orc文件中的从存储位置
-
如果需要在ORC文件中查询某一条数据:
-
首先从文件末尾读取Postscript,从Postscript中获取到File Footer在文件中的存储位置
-
然后读取File Footer,从File Footer中获取这条数据所在的Stripe的位置
-
读取Stripe中的Index Data,锁定这条数据对应的索引位置,最后再通过Row Data获取到这条数据
-
parquet格式
-
parquet格式是从Hive0.10版本开始提供的一种二进制的文件格式,所以不能直接读取
-
每一个parquet文件中,包含了四部分
-
Magic Code:魔数,用于确保当前的文件是一个parquet文件
-
Footer Length:记录元数据的大小。通过这个值以及parquet文件的大小,可以计算出元数据在parquet文件中的偏移量
-
Metastore:元数据存储,记录了当前parquet文件的文件信息,以及文件大小、Row Group的数量
-
Row Group:行组
-
将文件从行方向上进行切分,每一部分就是一个Row Group。默认情况下,Row Group和Block是等大的
-
每一个行组中,又包含了1个到多个Column Chunk(列块)。每一列对应了一个列块。因为同一个列块中的数据类型相同,所以可以给不同的列块指定不同的压缩编码
-
每一个列块中包含了一个到多个Page(页)。Page是parquet文件中数据存储的最小单位
-
Page分为三种
-
数据页:存储数据
-
字典页:存储编码信息
-
索引页:记录存储的数据在文件中的偏移量
-
-
需要注意的是,Hive提供的原生的parquet文件不支持索引页
-
-
-
parquet格式支持LZO和snappy压缩
Hive压缩
-
Hive支持对结果文件进行压缩。其中,经常对orc和parquet文件进行压缩
-
orc文件压缩可以通过属性
orc.compress来配置压缩,可以使用的值:NONE,ZLIB和SNAPPY。NONE表示不压缩create table orc_test (id int,name string,age int ) row format delimited fields terminated by ' 'stored as orc; -- 以orc格式来存储 insert into table orc_test values (1, 'Amy', 15); create table orc_zlib (id int,name string,age int ) row format delimited fields terminated by ' 'stored as orctblproperties ('orc.compress' = 'ZLIB'); insert into table orc_zlib values (1, 'Amy', 15); create table orc_snappy (id int,name string,age int ) row format delimited fields terminated by ' 'stored as orctblproperties ("orc.compress" = "SNAPPY"); insert into table orc_snappy values (1, 'Amy', 15); -
parquet文件压缩可以通过属性
parquet.compression进行配置。可以使用的值:NONE和SNAPPYcreate table parquet_test (id int,name string,age int ) row format delimited fields terminated by ' 'stored as parquet; -- 以parquet形式来存储数据 insert into table parquet_test values (1, 'May', 15); create table parquet_snappy (id int,name string,age int ) row format delimited fields terminated by ' 'stored as parquettblproperties ("parquet.compression" = "SNAPPY"); insert into table parquet_snappy values (1, 'May', 15);
Hive结构和优化
结构

-
Client Interface:客户端端口,包含CLI(Command-line,命令行)和JDBC两种方式
-
客户端连接Client Interface,提交要执行的SQL。这个SQL会被提交给Driver(驱动器)
-
Driver包含了4部分
-
SQL Parser:SQL解析器,SQL提交给Driver之后,会先有SQL Parser进行解析,在解析的时候,先去检查SQL的语法是否正确,会连接元数据库查询/修改元数据,然后将SQL转化为抽象语法树(AST)
-
Physical Plan:物理计划。SQL Parser将SQL解析成AST之后,将AST交给Physical PLAN,将AST编译成具体的执行逻辑
-
Query Optimizer:查询优化器。Physical PLAN将执行逻辑交给Query Optimizer进行优化
-
Execution:执行器。负责将优化之后的执行逻辑转化成具体的执行任务,例如将执行逻辑转化为MapReduce程序
-
优化
-
列裁剪或者分区裁剪。在实际生产环境中,经常需要处理大量的数据,那么此时使用
select * from x的形式,会对整个表进行扫描,从而导致查询效率变低。因此在实际过程中,最好执行列或者指定分区进行查询;如果需要进行按行的查询,那么最好限制查询的行数,例如使用limit n或者tablesample(n rows) -
group by的优化。在进行group by的时候,那么此时相同的键对应的值会被分到一组,会被分发到某一个ReduceTask来处理这一组数据。如果某一个键对应的值比较多,那么此时处理这个键的ReduceTask的任务量就相对较大,此时就产生了数据倾斜。针对这个问题,提供了两种优化方案
-
map combine:map端的聚合,就是将数据在MapTask处先进行一次聚合,然后再将聚合后的结果发送给ReduceTask处理
-- 开启聚合机制 set hive.map.aggr = true; -- 指定聚合的值 set hive.groupby.mapaggr.checkinterval = 10000;
-
二阶段聚合(负载均衡方式):将Hive的执行过程拆分成2个MapReduce任务执行。第一个MapReduce中,先将数据打散之后进行聚合,第二个MapReduce中,再根据实际的要求进行聚合
-- 开启二阶段聚合 set hive.groupby.skewindata = true;
-
-
CBO(Cost based Optimizer,基于花费的优化器)
-
CBO是从Hive0.10开始添加的一种优化机制,从Hive1.1.0开始,CBO优化默认是开启的,可以通过属性
hive.cbo.enable来调节 -
CBO遵循的原则:谁的执行代价最小就是最好的执行计划
-
-
谓词下推。在保证结果不发生改变的前提下,尽量将where条件(谓词)提前执行,来减少下游处理的数据量,这个过程就称之为谓词下推
-- 开启谓词下推 -- ppd是PredicatePushDown,预测/谓词下推 set hive.optimize.ppd = true;
-
map join。当小表和大表进行join的时候, 将小表放入内存中分发给每一个MapTask,MapTask在处理数据时候就直接从内存中获取数据,此时join过程在Map端完成,从而减少了最终交给ReduceTask的数据量
-- 默认是25M set hive.mapjoin.smalltable.filesize = 25000000;
-
SMB join
-
SMB join(sort merge bucket join):基于分桶机制和map join的前提下实现的一种join方式,用于解决大表和大表之间的join问题
-
当大表和大表进行join的时候,可以考虑先将大表的数据进行分桶,每一个桶中都只包含部分数据,此时每一个桶就相当于是一个小表,在此时join的时候,就是小表和大表join,那么可以进行map join。本质上就是"分而治之"的思想
-
SMB join的条件:
A join B-
A表和B表都必须分桶,并且B表的桶数必须是A表桶数的整数倍。例如A分了4个桶,那么B表的桶数必须是4n
-
分桶字段和join字段必须一致。
A join B on a.id = b.id,那么此时A表和B表必须以id字段来进行分桶
-
-
-
启用严格模式
-
hive.strict.checks.no.partition.filter:默认为false,如果设置为true,那么在查询分区表的时候,必须以分区作为查询条件 -
hive.strict.checks.orderby.no.limit:默认为false,如果设置为true,那么进行order by的时候,必须添加limit语句 -
hive.strict.checks.cartesian.product:默认为false,如果设置为true,那么严禁进行笛卡尔积
-
相关文章:
Hive详解(5)
Hive 窗口函数 案例 需求:连续三天登陆的用户数据 步骤: -- 建表 create table logins (username string,log_date string ) row format delimited fields terminated by ; -- 加载数据 load data local inpath /opt/hive_data/login into table log…...

阿里云效codeup如何执行github flow工作流
在阿里云效中执行 GitHub 工作流,实质上是在使用 Git 进行版本控制的过程中遵循 GitHub Flow 的原则。GitHub Flow 是一种简洁高效的工作流程,特别适用于追求快速迭代的团队。下面是在阿里云效中执行 GitHub 工作流的基本步骤: 1. 准备工作 …...

node.js的模块化 与 CommonJS规范
一、node.js的模块化 (1)什么是模块化? 将一个复杂的程序文件依据一定的规则拆分成为多个文件的过程就是模块化 在node.js中,模块化是指把一个大文件拆分成独立并且相互依赖的多个小模块,将每个js文件被认为单独的一个模块;模块…...
)
RK3588平台开发系列讲解(PWM开发篇)
目录 前⾔ 驱动文件 DTS 节点配置 PWM 流程 PWM 使⽤ 常⻅问题 PWM 在 U-Boot 与 kernel 之间的衔接问题 PWM Regulator 时 PWM pin 脚上下拉配置问题 前⾔ 脉宽调制( PWM , Pulse Width Modulation )功能在嵌⼊式系统中是⾮常常⻅的…...

宝塔面板操作一个服务器域名部署多个网站
此处记录IP一样,端口不一样的操作方式: 宝塔面板操作: 1、创建第一个网站: 网站名用IP地址,默认80端口。 创建好后,直接IP访问就可以了。看到自带的默认首页 2、接下来部署第二个网站: 仍然是…...

surfer绘制等值线图
surfer介绍 Surfer软件,是美国Golden Software公司编制的一款以画三维图的软件。该软件具有强大的插值功能和绘制图件能力,可用来处理XYZ数据,是地质工作者常用的专业成图软件(来源于百度百科)。 surfer可以用来绘制…...

免费开源的 AI 绘图工具 ImgPilot
免费开源的 AI 绘图工具 ImgPilot 分类 开源分享 项目名: ImgPilot -- 通过提示词及涂鸦生成图片 Github 开源地址: GitHub - leptonai/imgpilot: Turn the draft into amazing artwork with the power of Real-Time Latent Consistency Model 在线地址ÿ…...

Java系统架构设计:构建稳定高效的软件基石
在当今数字化时代,软件系统的稳定性、可扩展性和性能至关重要。Java作为一种广泛应用的编程语言,其系统架构设计对于软件的成功实施具有决定性的影响。本文将探讨Java系统架构设计的重要性以及设计过程中的关键要素。 首先,Java系统架构设计…...

【IntermLM2】学习笔记
微调方式 在大模型的下游应用中,可以有两种微调方式 增量续训 即无监督的方式,让模型学习一些新知识,比如某些垂直领域的新知识 使用的数据有:书籍,文章,代码等有监督微调 为了让模型学会理解指令进行对话…...
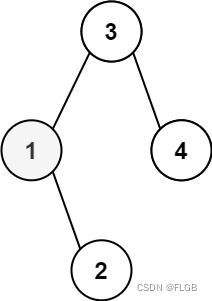
【二叉树】Leetcode 230. 二叉搜索树中第K小的元素【中等】
二叉搜索树中第K小的元素 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。 示例1: 输入:root [3,1,4,null,2], k 1 输出:1 解…...

JS中常用的几种事件
在js中分为多种事件,比如点击事件,焦点事件,加载事件,鼠标事件等等... ... 点击事件 onclick点击事件,ondblclick双击事件 焦点事件 onblur元素失去焦点,onfocus元素获取焦点 加载事件 onload一个页面…...

Android WebView的使用与后退键处理
目录 前言首先,我们需要在布局文件中添加webView组件在Activity中获取webView实例,并加载网页内容 前言 webView是Android中常用的组件之一,用于展示网页内容。它可以加载HTML文件、URL链接等网页内容,并提供交互功能。在使用webV…...

【备忘录】Docker 2375远程端口安全漏洞解决
最近为了项目需要,把docker 的远程端口2375 给开放了。不出意外出意外了。没多久,网站报流量告警,第一反应就是开放2375这个端口问题导致,毫不迟疑直接切换服务器。关闭该台服务器的docker服务,并逐步清理掉挖矿进程&a…...
)
343. 整数拆分(力扣LeetCode)
文章目录 343. 整数拆分题目描述动态规划 343. 整数拆分 题目描述 给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k > 2 ),并使这些整数的乘积最大化。 返回 你可以获得的最大乘积 。 示例 1: 输入: n 2 输出: 1 解释:…...

Spring面试题系列-3
Spring框架是由于软件开发的复杂性而创建的。Spring使用的是基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅仅限于服务器端的开发。从简单性、可测试性和松耦合性角度而言,绝大部分Java应用都可以从Spring中受益。 Spring的属性…...

【比特币】比特币的奥秘、禁令的深层逻辑与风云变幻
导语: 比特币(Bitcoin),这个充满神秘色彩的数字货币,自诞生以来便成为各界瞩目的焦点。它背后所蕴含的Mining机制、禁令背后的深层逻辑以及市场的风云变幻,都让人欲罢不能。今天,我们将深入挖掘比特币的每一个角落&…...
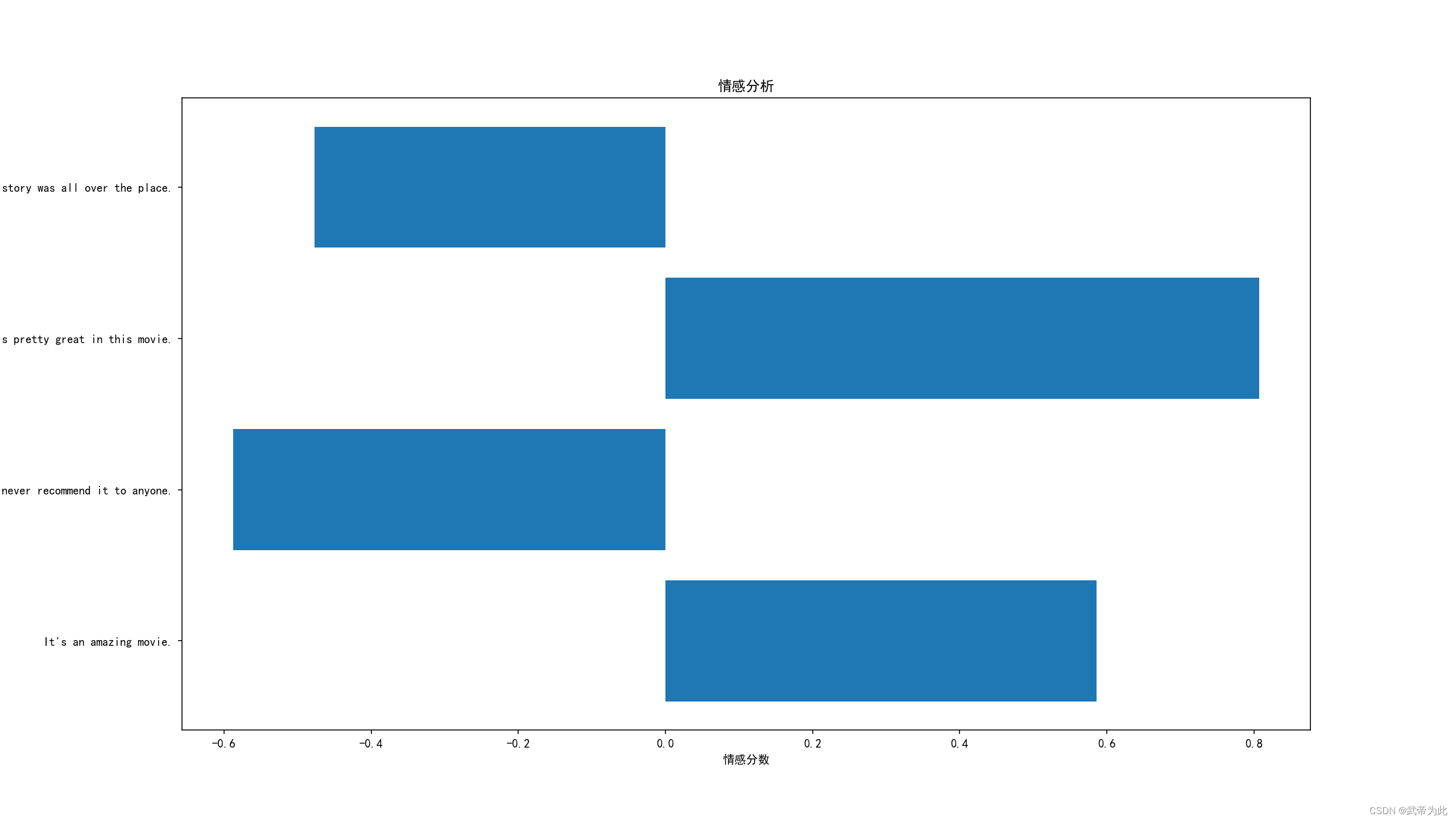
【情感分析概述】
文章目录 一、情感极性分析概述1. 定义2. 情感极性的类别3. 应用场景 二、情感极性分析的技术方法1. 基于规则的方法a. 关键词打分b. 情感词典的使用 2. 基于机器学习的方法a. 监督学习方法b. 深度学习方法 三、Python进行情感极性分析 一、情感极性分析概述 情感极性分析&…...
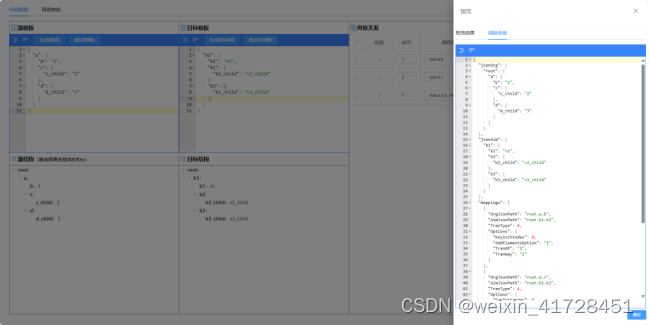
【御控物联】JavaScript JSON结构转换(12):对象To数组——键值互换属性重组
文章目录 一、JSON结构转换是什么?二、核心构件之转换映射三、案例之《JSON对象 To JSON数组》四、代码实现五、在线转换工具六、技术资料 一、JSON结构转换是什么? JSON结构转换指的是将一个JSON对象或JSON数组按照一定规则进行重组、筛选、映射或转换…...
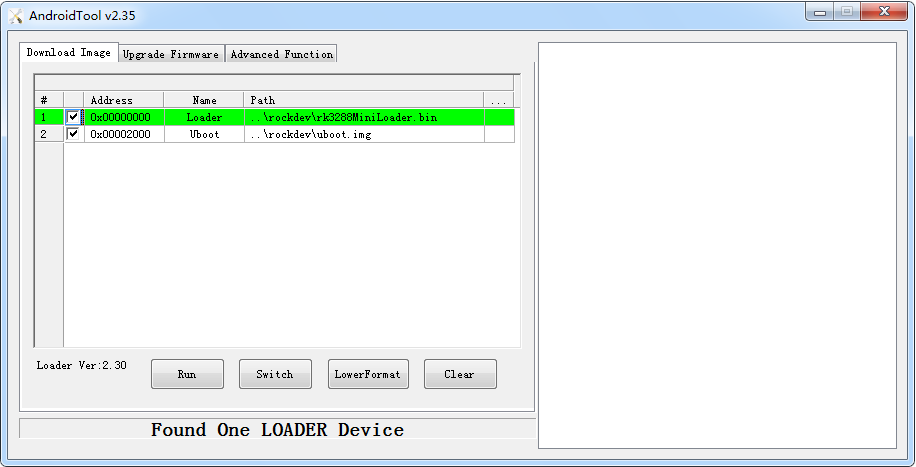
5.6 物联网RK3399项目开发实录-Android开发之U-Boot 编译及使用(wulianjishu666)
物联网入门到项目实干案例下载: https://pan.baidu.com/s/1fHRxXBqRKTPvXKFOQsP80Q?pwdh5ug --------------------------------------------------------------------------------------------------------------------------------- U-Boot 使用 前言 RK U-B…...
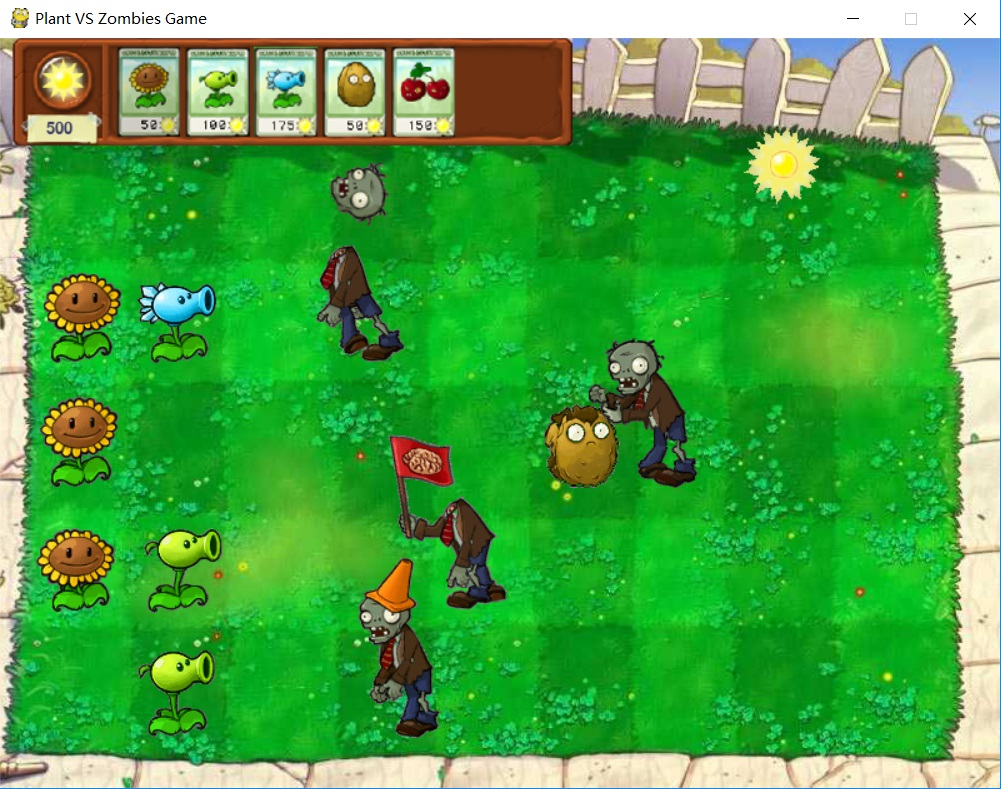
Python版【植物大战僵尸 +源码】
文章目录 写在前面:功能实现环境要求怎么玩个性化定义项目演示:源码分享Map地图:Menubar.py主菜单 主函数:项目开源地址 写在前面: 今天给大家推荐一个Gtihub开源项目:PythonPlantsVsZombies,翻译成中就是…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...