Hadoop 运行环境搭建(开发重点)
文章目录
- Hadoop 运行环境搭建(开发重点)
- 一、安装JDK
- 二、安装配置 Hadoop
- 1、安装 hadoop
- 2、hadoop 目录结构
- 3、设置免密登录
- 4、完全分布式模式(开发重点)
- 1)分发jdk
- 2)集群配置
- (1) 集群部署规划
- (2) 配置文件说明
- (3) 配置集群
- 4) 集群基本测试
- (1) 上传文件到集群
- 5) 配置历史服务器
Hadoop 运行环境搭建(开发重点)
一、安装JDK
将 hadoop 的安装包和 jdk 的安装包,上传到 hadoop102 的 /opt/software 目录下
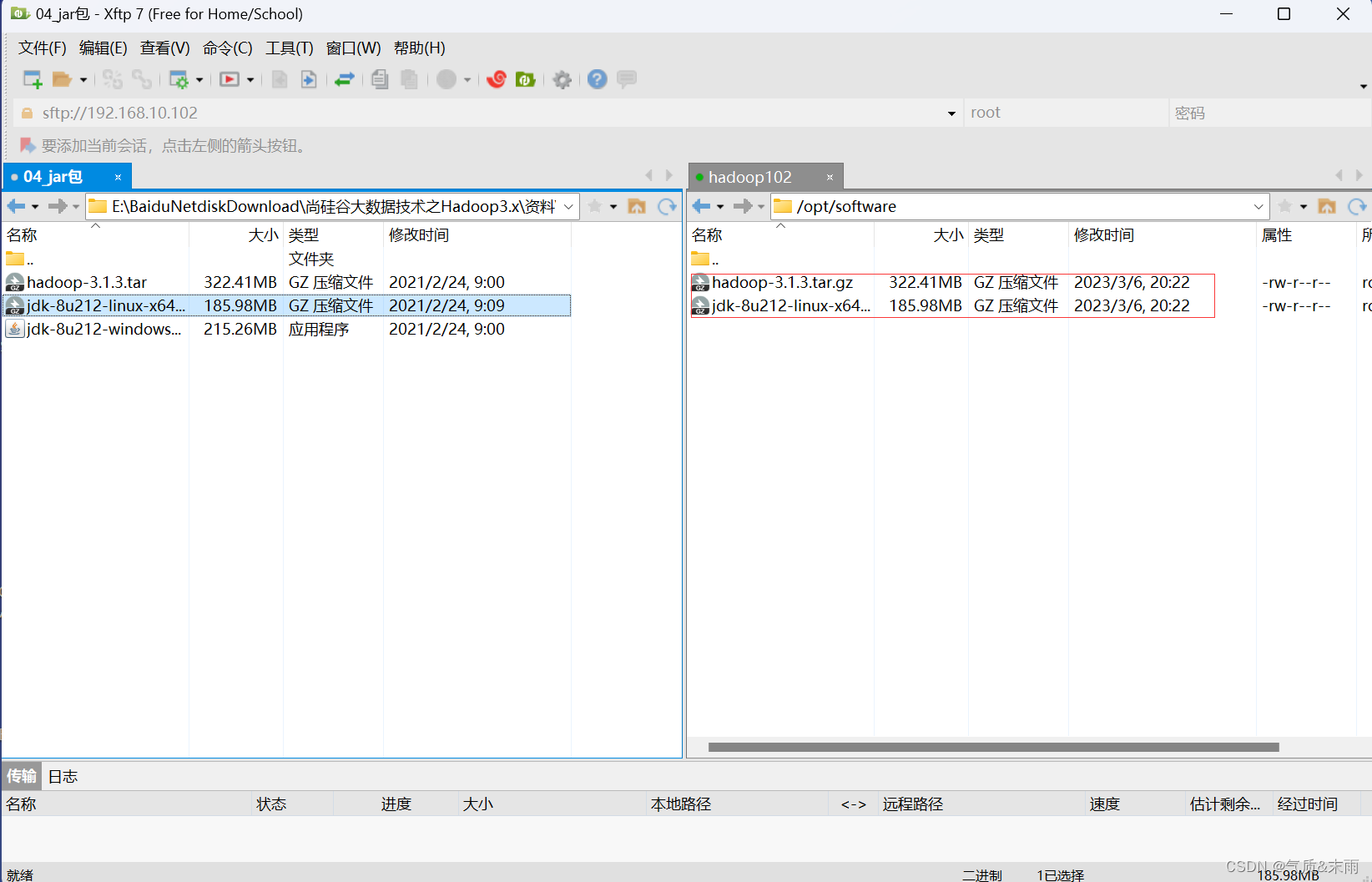
输入命令:tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/ 将jdk压缩包解压到 /opt 目录下
输入命令: mv jdk1.8.0_212/ jdk1.8 包的名字太长了我们给他改成jdk1.8

然后接下来,配置jdk的环境变量
输入命令:vim /etc/profile 添加以下的变量
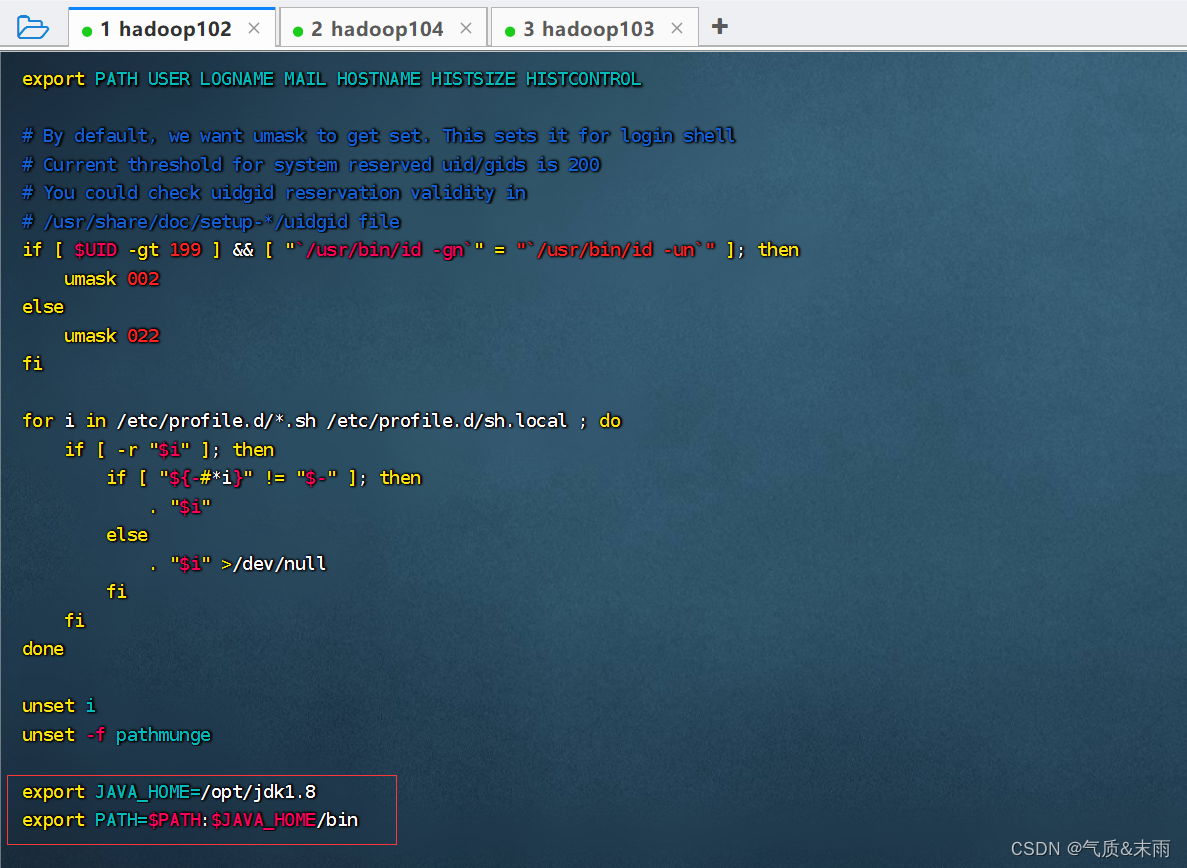
export JAVA_HOME=/opt/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
输入命令:source /etc/profile 保存配置
输入命令:java -version 可以看到jdk安装成功了

二、安装配置 Hadoop
1、安装 hadoop
将 /opt/software 目录下的hadoop压缩包,解压到 /opt 目录下
输入命令: tar -zxvf hadoop-3.1.3.tar.gz -C /opt 可以看到 opt目录下就有hadoop包了
输入命令:vim /etc/profile 配置Hadoop的环境变量

export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
输入命令:source /etc/profile 让环境生效
输入命令:hadoop version,可以看到hadoop安装成功

2、hadoop 目录结构
查看 hadoop 的目录结构
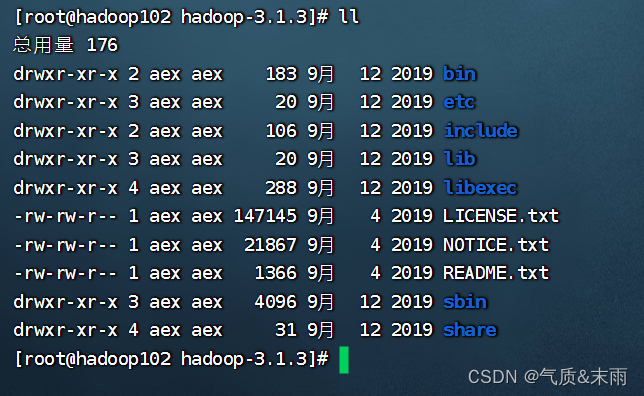
hdfs 是存储的,mapred 是计算的,yarn是资源调度的
hadoop 重要目录:
(1)bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
(3)lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
(4)sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
(5)share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
3、设置免密登录
输入命令:cd .ssh
输入命令:ssh-keygen -t rsa 然后按三次回车
就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
 )将公钥拷将公钥拷贝到要免密登录的目标机器上
)将公钥拷将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
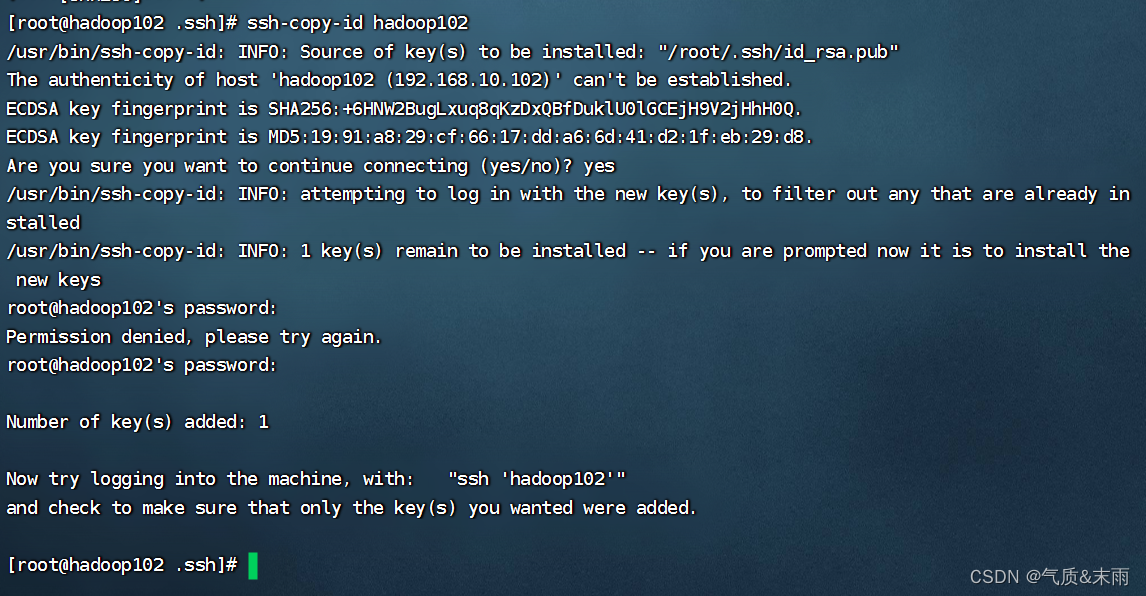
现在登录到其他的虚拟机上就不会输密码了
注意:
还需要在 hadoop103 上采用 root 账号配置一下无密登录到 hadoop102、hadoop103、
hadoop104 服务器上。
还需要在 hadoop104 上采用 root 账号配置一下无密登录到 hadoop102、hadoop103、
hadoop104 服务器上。
还需要在 hadoop102 上采用 root 账号,配置一下无密登录到 hadoop102、hadoop103、
hadoop104
4、完全分布式模式(开发重点)
1)准备三台客户机(关闭防火墙,静态IP,主机名称)
2)安装JDK
3)配置环境变量
4)安装 Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
1)分发jdk
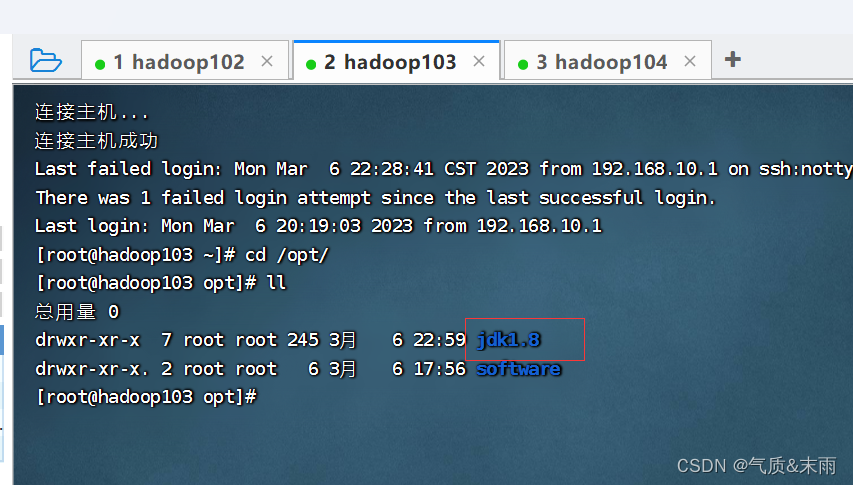
在 hadoop102 上,将hadoop12 中 /opt/jdk1.8 目录拷贝到 hadoop103,hadoop104 上面去
输入命令:scp -r $JAVA_HOME root@hadoop103:/opt
输入命令:scp -r $JAVA_HOME root@hadoop104:/opt
可以看到 hadoop103 和 hadoop104 也有jdk文件了
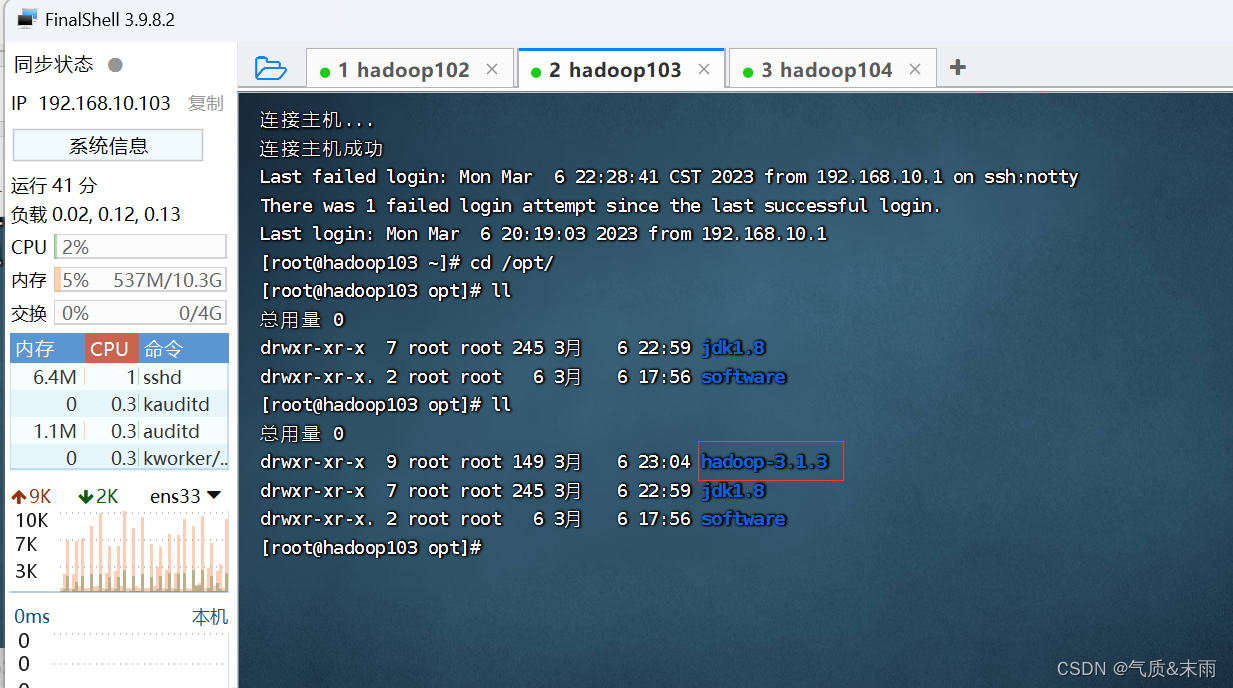
hadoop 也是同样的拷贝,拷贝到 hadoop103 和 hadoop104
输入命令: scp -r $HADOOP_HOME root@hadoop103:/opt
可以看到hadoop103 和 hadoop104 也有hadoop包了
2)集群配置
(1) 集群部署规划
注意:
NameNode 和 SecondaryNameNode 不要安装在同一台服务器
ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在
同一台机器上

(2) 配置文件说明
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认
配置值时,才需要修改自定义配置文件,更改相应属性值。
1、默认配置文件:

2、自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在
$HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置
(3) 配置集群
1、核心配置文件
配置 core-site.xml
输入命令:cd $HADOOP_HOME/etc/hadoop 进入hadoop的配置的目录
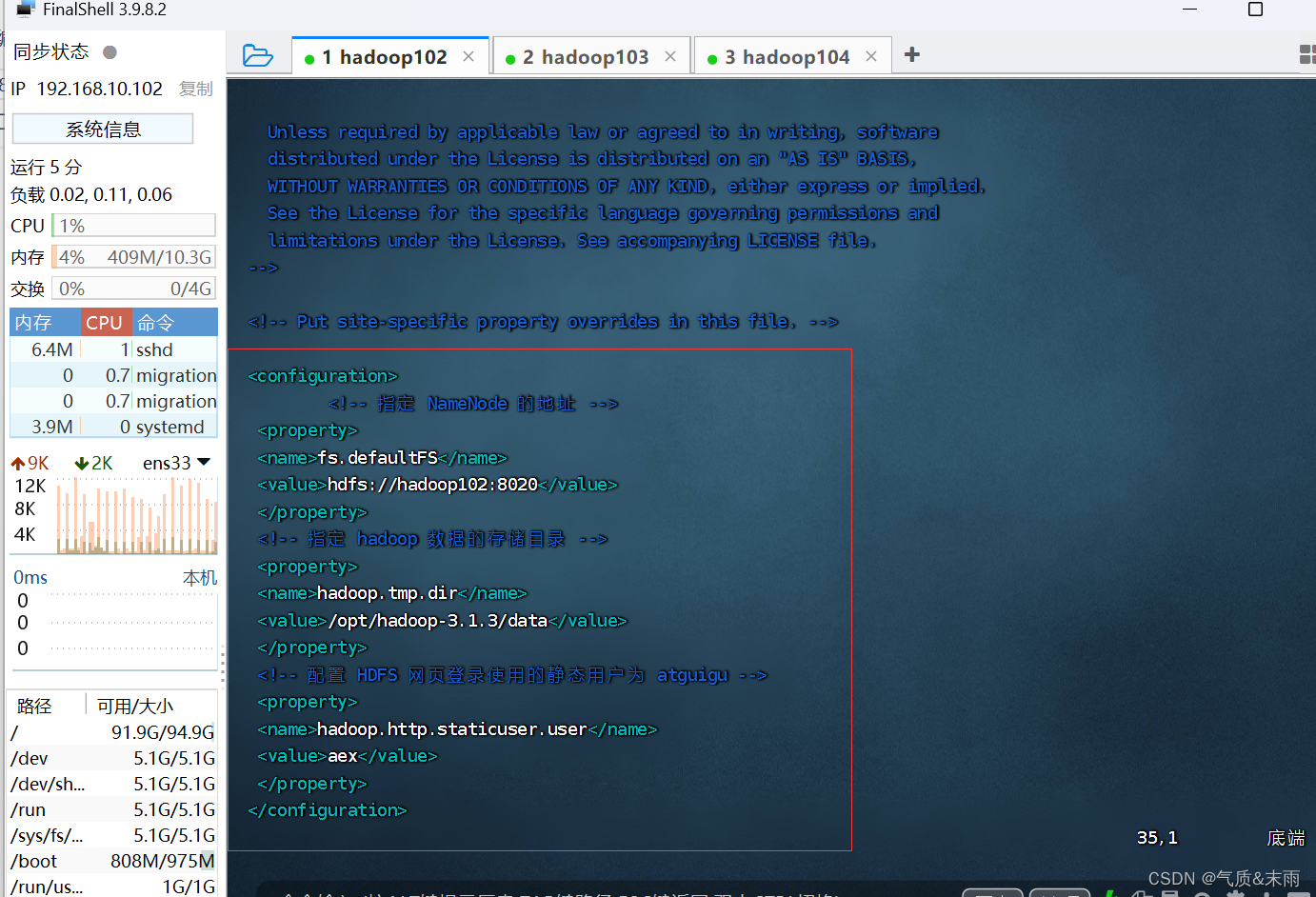
输入命令:vim core-site.xml 配置core-site.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-3.1.3/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为 atguigu --><property><name>hadoop.http.staticuser.user</name><value>aex</value></property>
</configuration>
2、HDFS 配置文件
配置 hdfs-site.xml
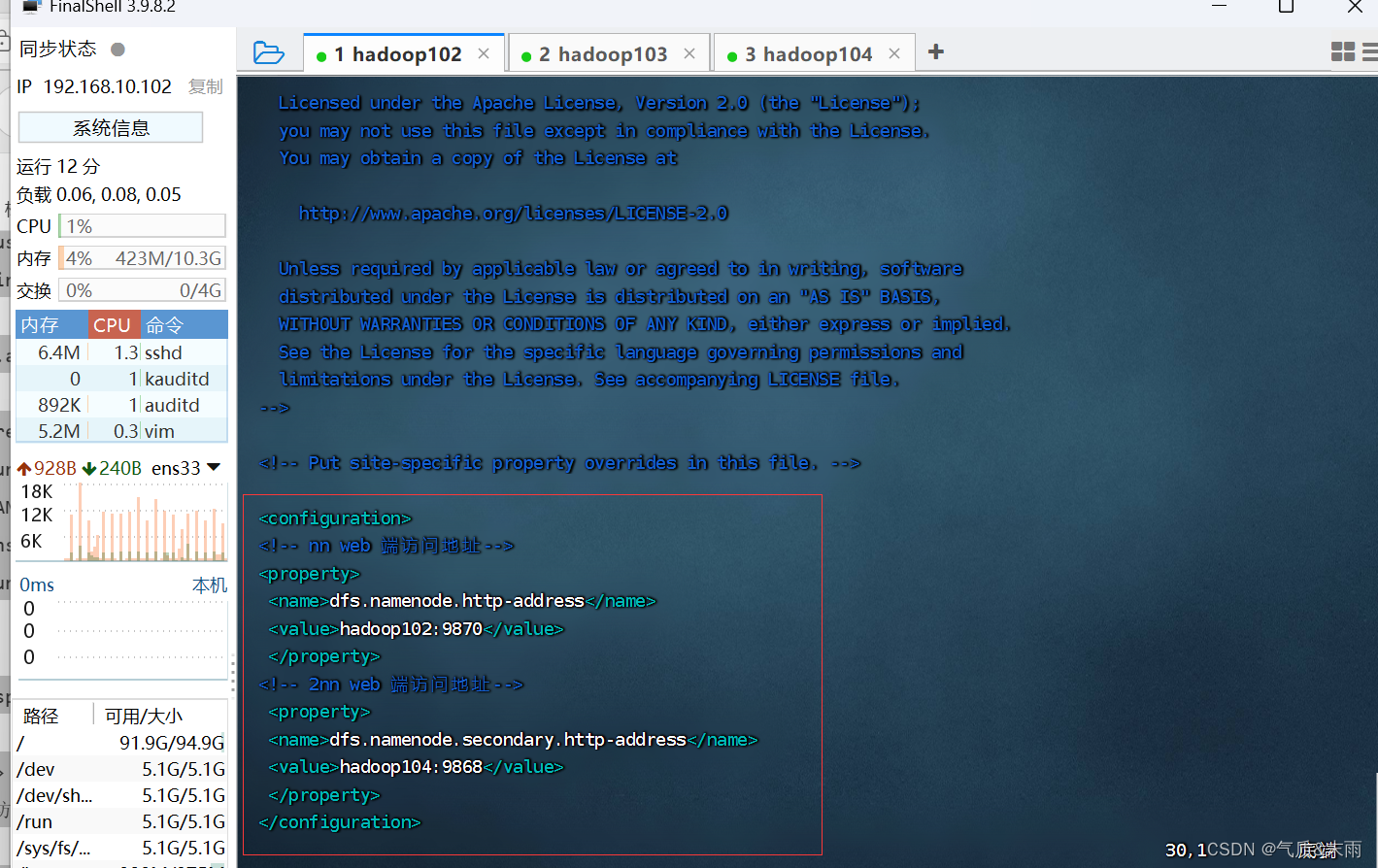
输入命令:vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<!-- nn web 端访问地址-->
<property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property>
<!-- 2nn web 端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
</configuration>
3、YARN 配置文件
配置yarn-site.xml
输入命令:vim yarn-site.xml

<?xml version="1.0"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
-->
<configuration><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定 ResourceManager 的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value></property>
</configuration>
4、MapReduce 配置文件
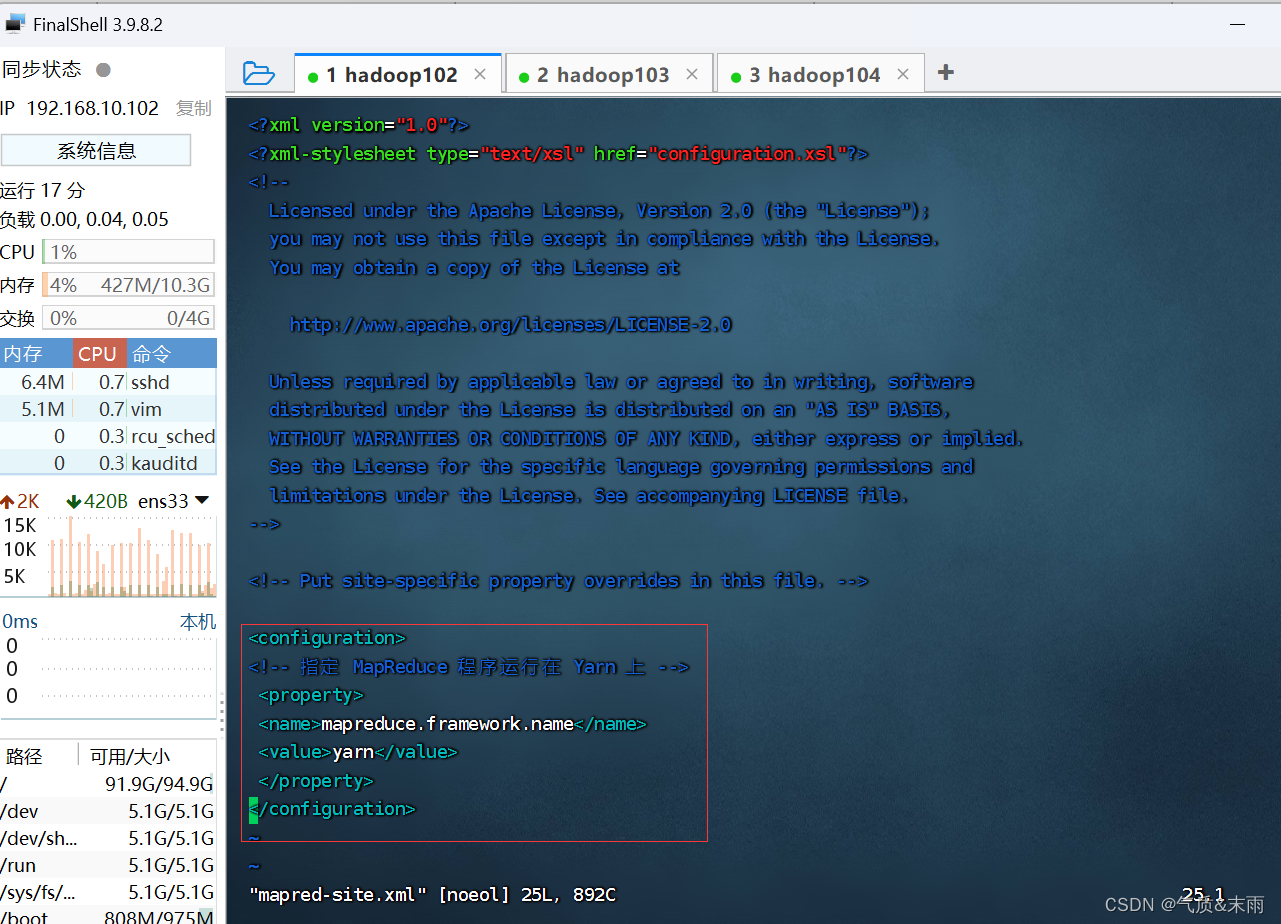
输入命令:vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
5、在集群上分发1配置好的Hadoop配置文件
输入命令: scp -r $HADOOP_HOME root@hadoop103:$HADOOP_HOME 将配置分发给hadoop103
输入命令: scp -r $HADOOP_HOME root@hadoop104:$HADOOP_HOME 将配置分发给hadoop104
6、配置worekers
输入命令:vim worekers
5、进行初始化
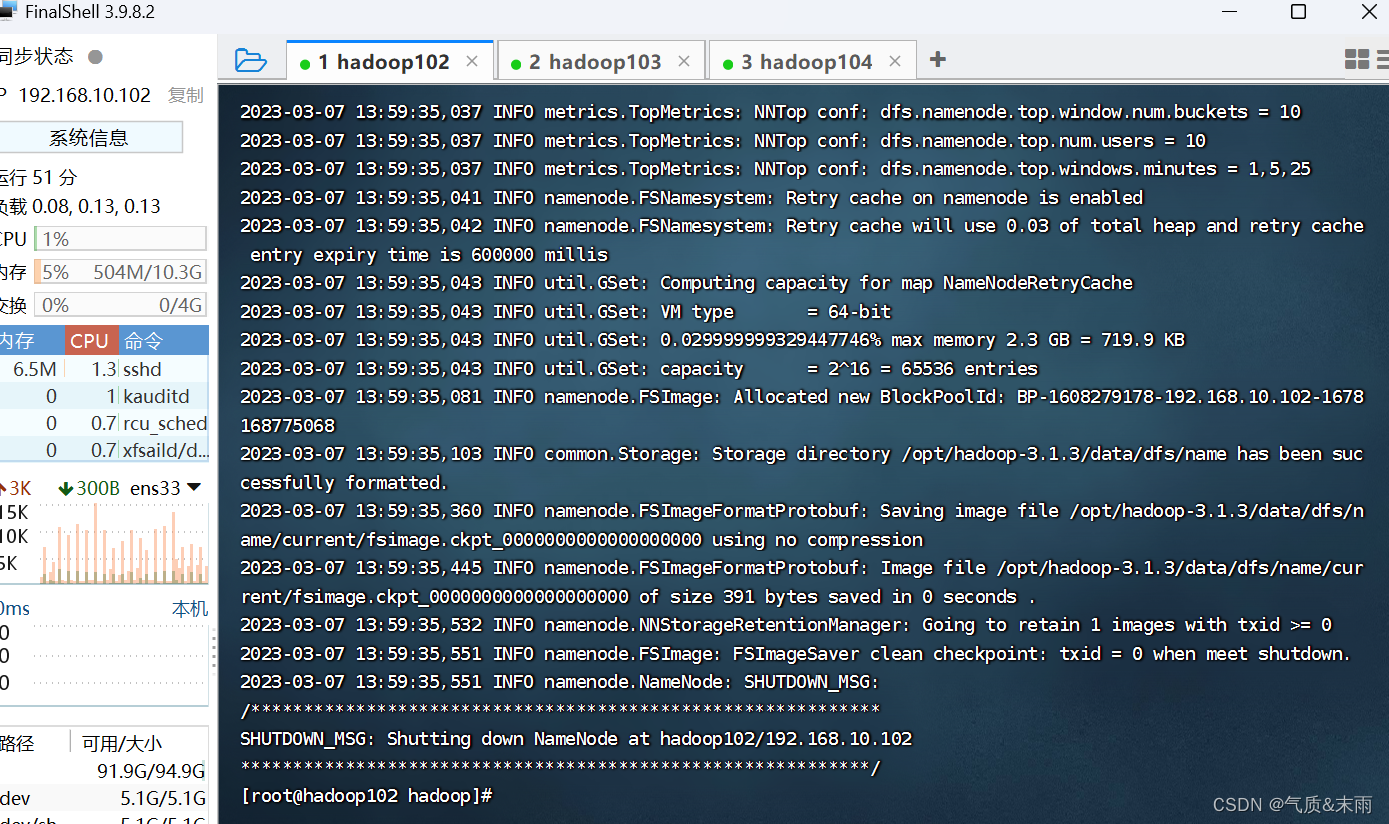
输入命令:hdfs namenode -format 下面会出现很长一串
启动节点
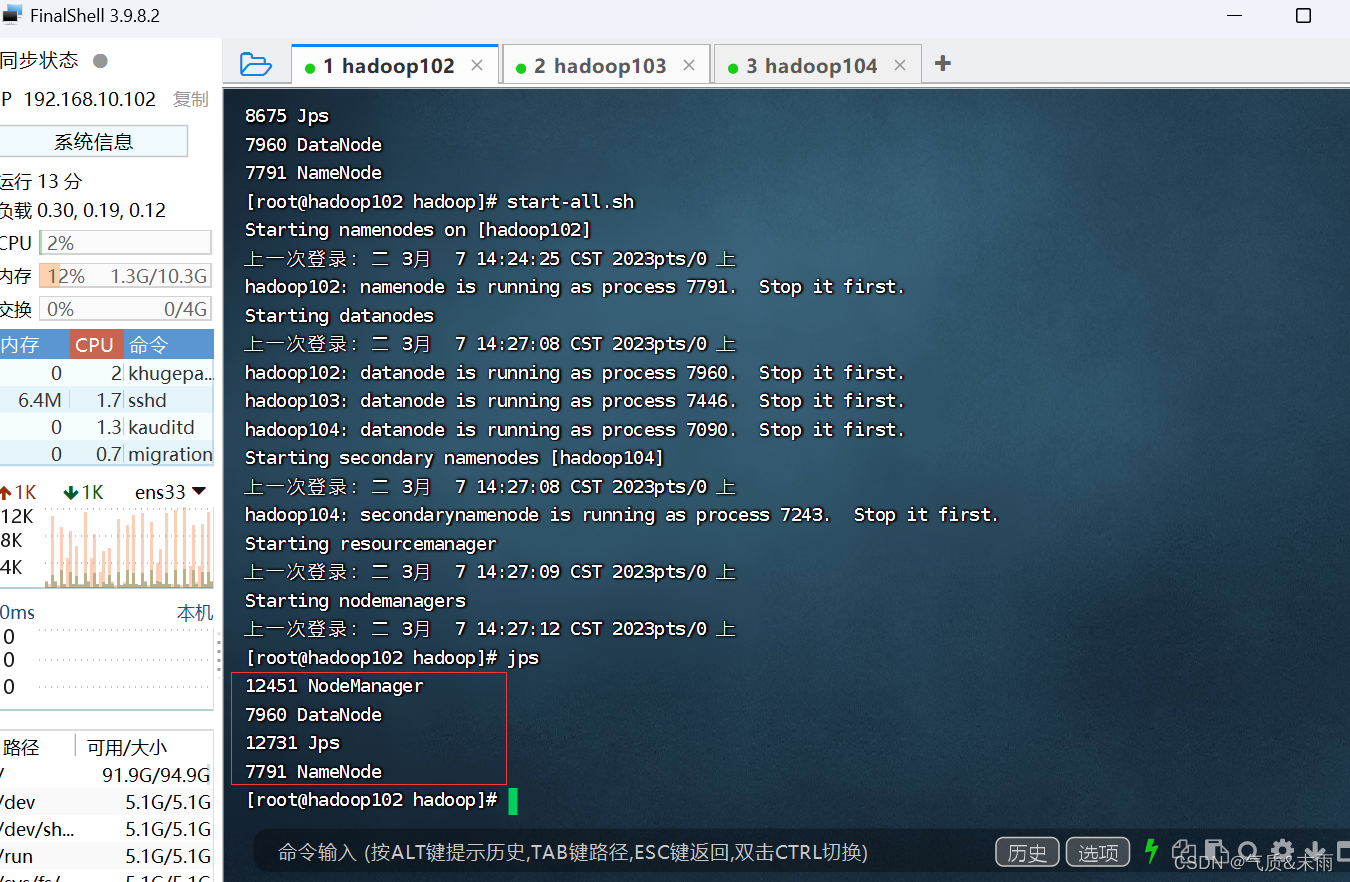
输入命令:start-all.sh
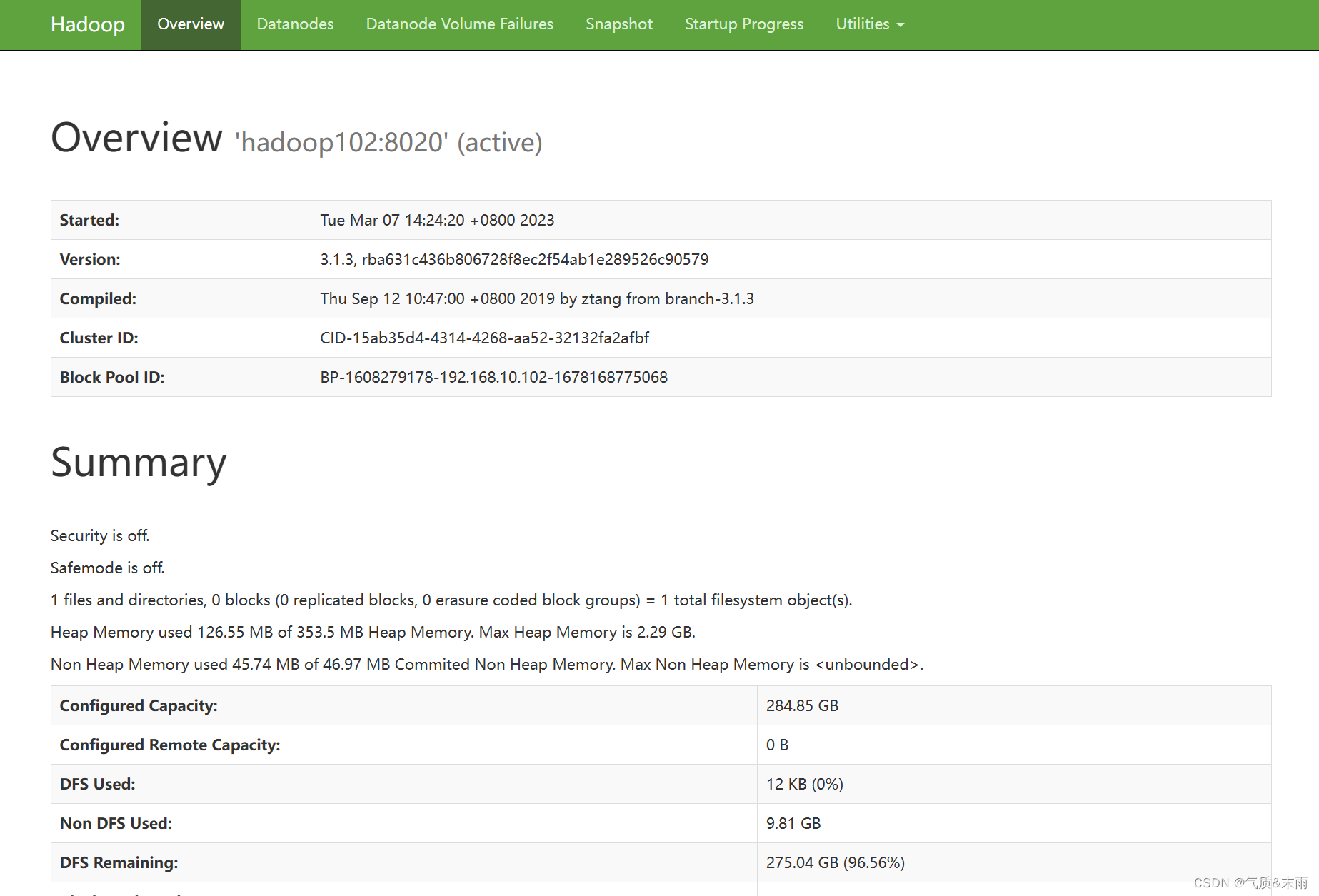
在webUI 界面上查看 hdfs,浏览器输入 hadoop102:9870
4) 集群基本测试
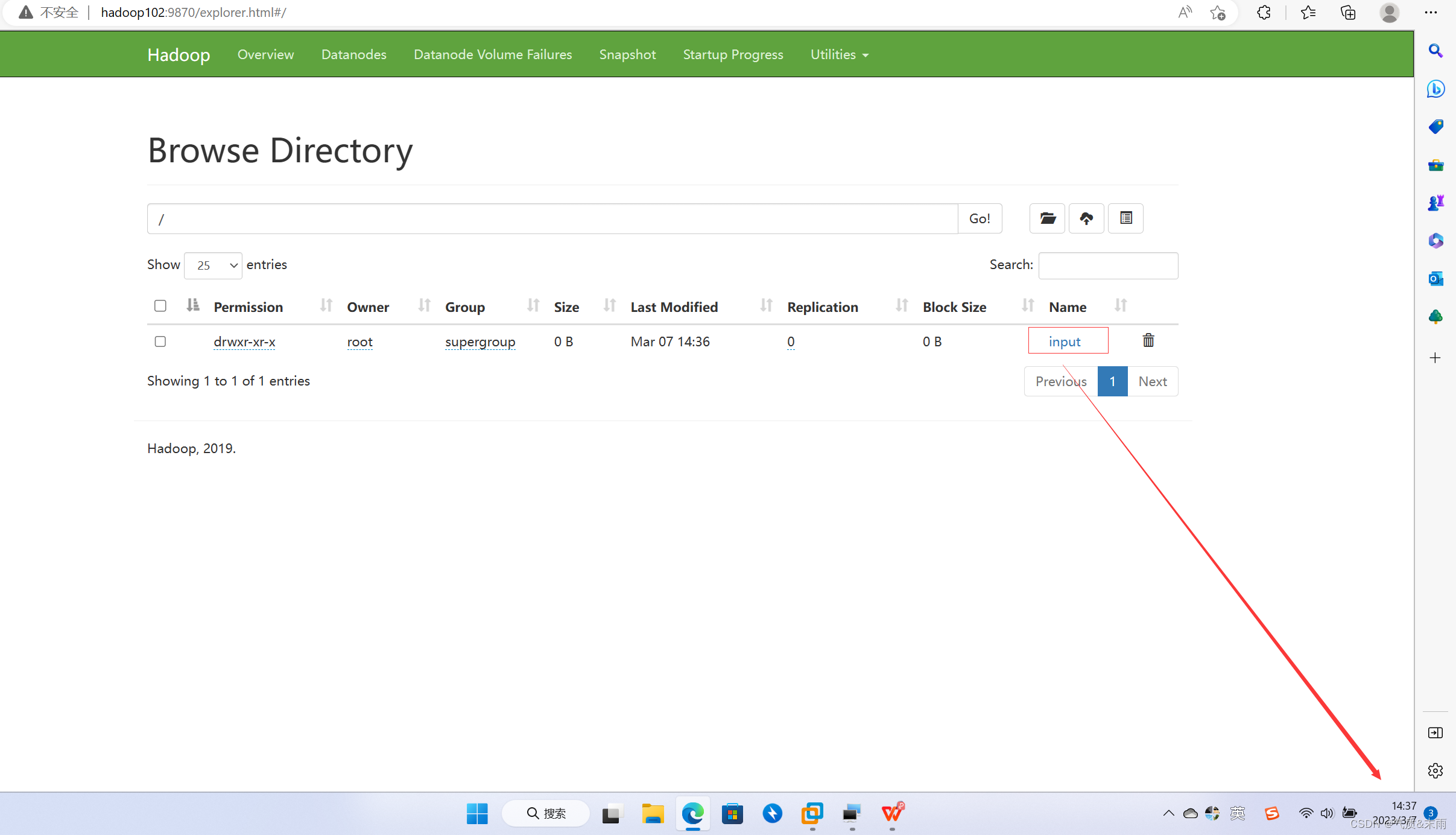
(1) 上传文件到集群
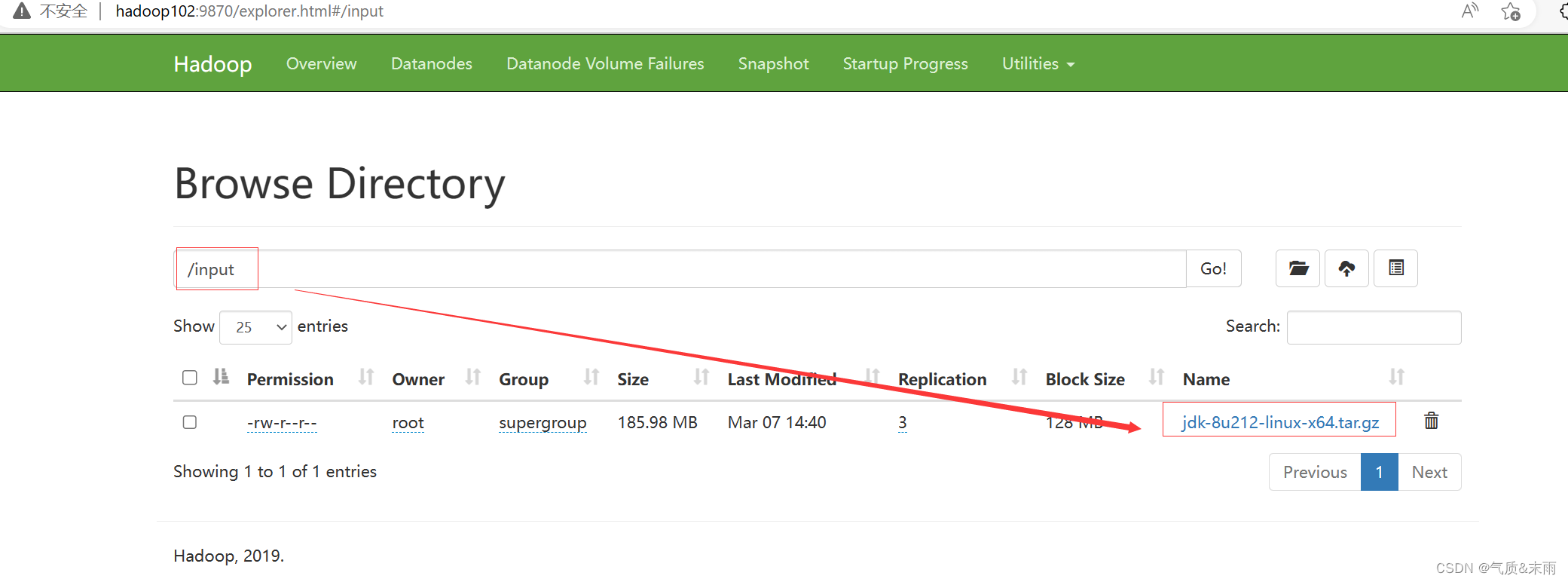
输入命令:hdfs dfs -mkdrir /input 先在hdfs上创建一个 input目录

可以看到 hdfs 上已经有这个文件了
上传一个文件上去
输入命令: hdfs dfs -put jdk-8u212-linux-x64.tar.gz /input
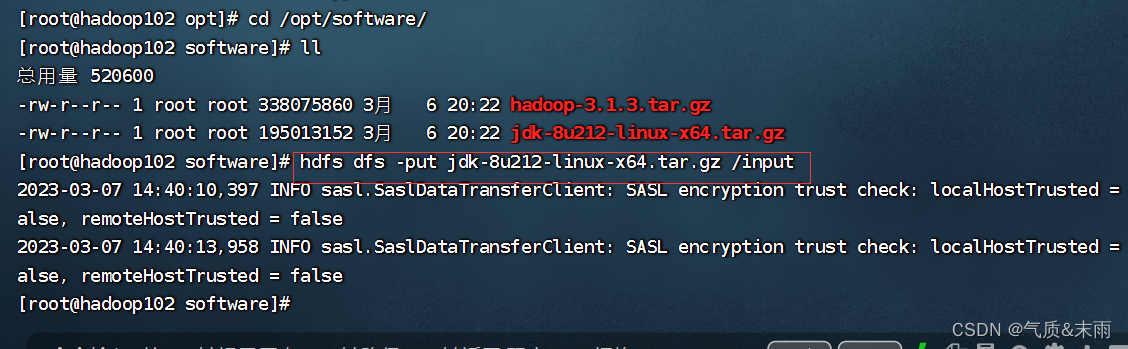
可以看到文件已经上传上去了
5) 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器,具体配置如下:
1、配置 mapred-site.xml
输入命令:vim mapred-site.xml

<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value>
</property>
</configuration>
2、分发配置
输入命令:scp -r /opt/hadoop-3.1.3/etc/hadoop/mapred-site.xml root@hadoop103:/opt/hadoop-3.1.3/etc/hadoop/mapred-site.xml mapred-site.xml
输入命令:scp -r /opt/hadoop-3.1.3/etc/hadoop/mapred-site.xml root@hadoop104:/opt/hadoop-3.1.3/etc/hadoop/mapred-site.xml mapred-site.xml

3、在hadoop102启动历史服务器
输入命令:mapred --daemon start historyserver

相关文章:
Hadoop 运行环境搭建(开发重点)
文章目录Hadoop 运行环境搭建(开发重点)一、安装JDK二、安装配置 Hadoop1、安装 hadoop2、hadoop 目录结构3、设置免密登录4、完全分布式模式(开发重点)1)分发jdk2)集群配置(1) 集群部署规划(2) 配置文件说…...

在社交媒体上行之有效的个人IP趋势
如果您认为无论是获得一份工作、建立一家企业还是推动个人职业发展,社交媒体都是帮助您实现目标的可靠工具,那么个人IP就是推动这一工具前进的燃料。个人IP反映了您是谁,您在所处领域的专业程度,以及您与他人的区别。社交媒体将有…...

Java网络编程
网络编程 什么是网络编程? 可以让设备中的程序与网络上其他设备中的程序进行数据交互(实现网络通信) Java.net. 包下提供了网络编程的解决方案* 基本的通信架构 基本的通信架构有两种方式:CS架构(Client客户端/Se…...
)
PTA:L1-001 Hello World、L1-002 打印沙漏、L1-003 个位数统计(C++)
目录 L1-001 Hello World 问题描述: 实现代码: L1-002 打印沙漏 问题描述: 实现代码: 原理思路: L1-003 个位数统计 题目描述: 实现代码: 原理思路: 过于简单的就不再写题…...

构造HTTP请求
使用formform使用如下:<body><!-- 表单标签,允许用户和服务器之间交互数据 --><form action"https://www.sogou.com" method"get"><!-- 要求提交的数据以键值对的结构来组织 --><input type"text" name"stduent…...
转速/线速度/角速度计算FC
工业应用中很多设备控制离不开转速、线速度的计算,这篇博客给大家汇总整理。张力控制的开环闭环方法中也离不开转速和线速度的计算,详细内容请参看下面的文章链接: PLC张力控制(开环闭环算法分析)_plc的收卷张力控制系统_RXXW_Dor的博客-CSDN博客里工业控制张力控制无处不…...

学习笔记:Java并发编程(补)ThreadLocal
【尚硅谷】学习视频:https://www.bilibili.com/video/BV1ar4y1x727【黑马程序员】学习视频:https://www.bilibili.com/video/BV15b4y117RJ 参考书籍 《实战 JAVA 高并发程序设计》 葛一鸣 著《深入理解 JAVA 虚拟机 | JVM 高级特性与最佳实践》 周志明 著…...

HashMap底层实现原理及面试题
文章目录1. 常见的数据结构有三种结构1.1 各自数据结构的特点2. HashMap2.1 概述2.2 底层结构2.2.1 HashMa实现原理:2.2.1.1 map.put(k,v)实现原理2.2.1.2 map.get(k)实现原理2.2.1.3 resize源码2.2.2 HashMap常用的变量2.2.3 HashMap构造函数2.3 JDK1.8之前存在的问…...
:DMA+ADC实现模拟量检测)
【STM32】进阶(二):DMA+ADC实现模拟量检测
1、简述 DMA:Direct Memory Access,直接内存访问 ADC:Analog to Digital Converter,模数转换器,模拟信号转换成数字信号的电路(采样-量化-编码) 参考博客: STM32DMA功能详解 STM32…...
Lab2_Simple Shell_2020
Lab2: 实验目的:给xv6添加新的系统调用 并理解系统调用是如何工作的,并理解xv6内核的一些内部特征 实验准备: 阅读xv6的第2章以及第4章的4.3,4.3小节熟悉下面的源码 用户态相关的代码:user/user.h和user/usys.pl内核态相关的代…...
2023最全电商API接口 高并发请求 实时数据 支持定制 电商数据 买家卖家数据
电商日常运营很容易理解,就是店铺商品维护,上下架,评价维护,库存数量,协助美工完成制作详情页。店铺DSR,好评率,提升客服服务等等,这些基础而且每天都必须做循环做的工作。借助电商A…...

MySQL 的索引类型
1. 按照功能划分 按照功能来划分,索引主要有四种: 普通索引唯一性索引主键索引全文索引 普通索引就是最最基础的索引,这种索引没有任何的约束作用,它存在的主要意义就是提高查询效率。 普通索引创建方式如下: CREATE…...

< Linux > 进程信号
目录 1、信号入门 生活角度的信号 技术应用角度的信号 前台进程 && 后台进程 信号概念 用kill -l命令察看系统定义的信号列表 信号处理的方式 2、信号产生前 用户层产生信号的方式 3、产生信号 3.1、通过终端按键产生信号 3.2、核心转储core dump 3.3、调用系统函数…...
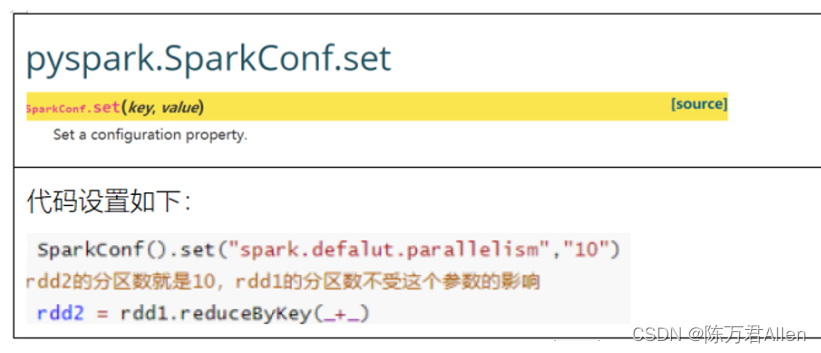
Pyspark基础入门7_RDD的内核调度
Pyspark 注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hi…...

C/C++每日一练(20230307)
目录 1. 国名排序 ★★ 2. 重复的DNA序列 ★★★ 3. 买卖股票的最佳时机 III ★★★ 🌟 每日一练刷题专栏 C/C 每日一练 专栏 Python 每日一练 专栏 1. 国名排序 小李在准备明天的广交会,明天有来自世界各国的客房跟他们谈生意,…...

一条SQL查询语句是如何执行的?
平时我们使用数据库,看到的通常都是一个整体。比如,你有个最简单的表,表里只有一个ID字段,在执行下面这个查询语句时: mysql> select * from T where ID10; 我们看到的只是输入一条语句,返…...
tcsh常用配置
查看当前的shell类型 在 Linux 的世界中,有着许多 shell 程序。常见的有: Bourne shell (sh) C shell (csh) TC shell (tcsh) Korn shell (ksh) Bourne Again shell (bash) 其中,最常用的就是bash和tcsh,本次文章介绍tcsh的…...

YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
前言 前面简单介绍了YOLOv5的项目目录结构(直通车:YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析),对项目整体有了大致了解。 今天要学习的是detect.py。通常这个文件是用来预测一张图片或者一…...

什么叫个非对称加密?中间人攻击?数字签名?
非对称加密也称为公钥密码。就是用公钥来进行加密,撒子意思? 非对称加密 在对称加密中,我们只需要一个密钥,通信双方同时持有。而非对称加密需要4个密钥,来完成完整的双方通信。通信双方各自准备一对公钥和私钥。其中…...

2023.03.07 小记与展望
碎碎念系列全新改版! 以后就叫小记和展望系列 最近事情比较多,写篇博客梳理一下自己3月到5月下旬的一个规划 一、关于毕设 毕设马上开题答辩了,准备再重新修改一下开题报告,梳理各阶段目标。 毕设是在去年的大学生创新训练项目…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...