python爬虫之selenium4使用(万字讲解)
文章目录
- 一、前言
- 二、selenium的介绍
- 1、优点:
- 2、缺点:
- 三、selenium环境搭建
- 1、安装python模块
- 2、selenium4新特性
- 3、安装驱动WebDriver
- 驱动选择
- 驱动安装和测试
- 基础操作
- 1、属性和方法
- 2、单个元素定位
- 通过id定位
- 通过class_name定位一个元素
- 通过xpath定位
- 通过CSS 选择器定位
- 3、多个元素定位
- 通过xpath定位排行榜的基金代码
- 取数据单个和多个的区别
- 4、元素操作
- 获取元素的文本内容和属性值
- 文本框输入内容和点击按钮
- 5、无头浏览器模式
- 基于chrome 的无头浏览器
- 基于PhantomJS的无头模式(selenium2系列用的多)
- 进阶操作
- 1、切换标签页
- 句柄的数据结构:
- 句柄使用:
- 在不切换句柄的效果
- 切换句柄后的效果:
- 2. iframe窗口的切入
- 不使用switch_to.frame方法测试
- 学习 switch_to.frame的语法
- 最后使用switch_to.frame 方法测试
- 从iframe中切出
- 3. 使用 cookie
- 4. 执行JS
- 5. 页面等待
- 6. 配置代理
- 7. 修改请求头
- 8. 如何从selenium获取请求和响应头
- 注意
一、前言
声明以下的例子,只是来作为测试学习,并不作为真正的爬虫
- 我们在浏览一些网站时,有不少内容是通过 JavaScript动态渲染的,或是 AJAX 请求后端加载数据,这其中涉及到了不少加密参数如 token,sign,难以找规律,较为复杂。像前面的百度贴吧的一个评论的回复,百度翻译等,都是经过ajax动态 加载得到。
- 为了解决这些问题,我们可以直接模拟浏览器运行,然后爬取数据,这样就可以实现在浏览器中看到内容是怎么样了,不用去分析 JS 的算法,也不用去管 ajax 的接口参数了。
- python 提供了多种模拟器运行库,Selenium、Splash、Pyppetter、Playwright 等,可以方便帮我们爬取,很大程度上可以绕过JavaScript动态渲染,获取数据。
二、selenium的介绍
官网中文文档:https://www.selenium.dev/zh-cn/documentation/
其访问比较慢,最好是用 VPN
1、优点:
Selenium 是一个自动化测试工具,历史悠久,功能强大,技术成熟。其优点是能直接在浏览器上操作,利用它可以像人一样完成,输入文本框内容,点击,下拉等操作,它不但能做自动化测试,在爬虫领域也是一把利器,能解决大部分网页反爬问题,Selenium可以根据驱动的代码指令来获取网页内容,甚至是验证码的截屏,或判断网站上的某些动作是否发生。我们这边主要是围绕着爬虫展开。
2、缺点:
1、Selenium 运行比较慢,它需要等待浏览器的元素加载完毕,所以耗时。
2、驱动的适配,浏览器版本不同,浏览器类型不同,得使用不同的驱动器。
3、像一些安全性比较高,比较大型的网站是能检测出是否使用了Selenium来爬取网站
三、selenium环境搭建
我本机是 mac os,浏览器使用 chrome来进行测试
1、安装python模块
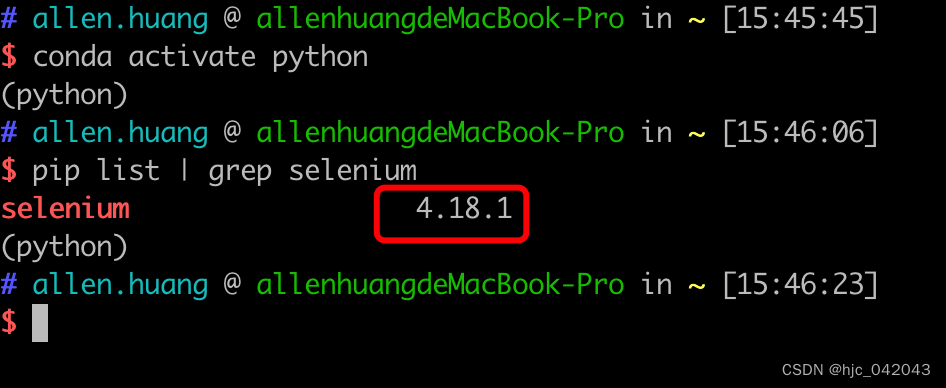
pip install selenium
这里是测试演示用,安装完成后是最新的版本, selenium4,如果是正式使用建议还是使用稳定版本
2、selenium4新特性
selenium增加了一些新特性,也弃用了一些方法,如下简单的列举几个变化:
- executable_path已弃用,使用Service 对象来代替
- Selenium 4 可以自动回收浏览器资源,不需要手动quit()了,像4之前不停止服务会有残留进程,占用内存
- 定位语法方面,Selenium 4引入了新的定位方法,使用By类来替代之前的find_element_by系列方法;
- 放弃了无头浏览器PhantomJS,目前的 chrome,firefox 都是支持无头浏览器
我在这里测试的,也是以4为主,具体看这篇文章
3、安装驱动WebDriver
Selenium库中有个叫WebDriver的 API。WebDriver有点像加载网站的浏览器,但它可以像BeautifulSoup使用 xpath,css选择器来查找页面元素,与页面上的元素进行交互(发送文本,点击等),以及执行其他动作比如调用 JS来下拉页面。
驱动选择
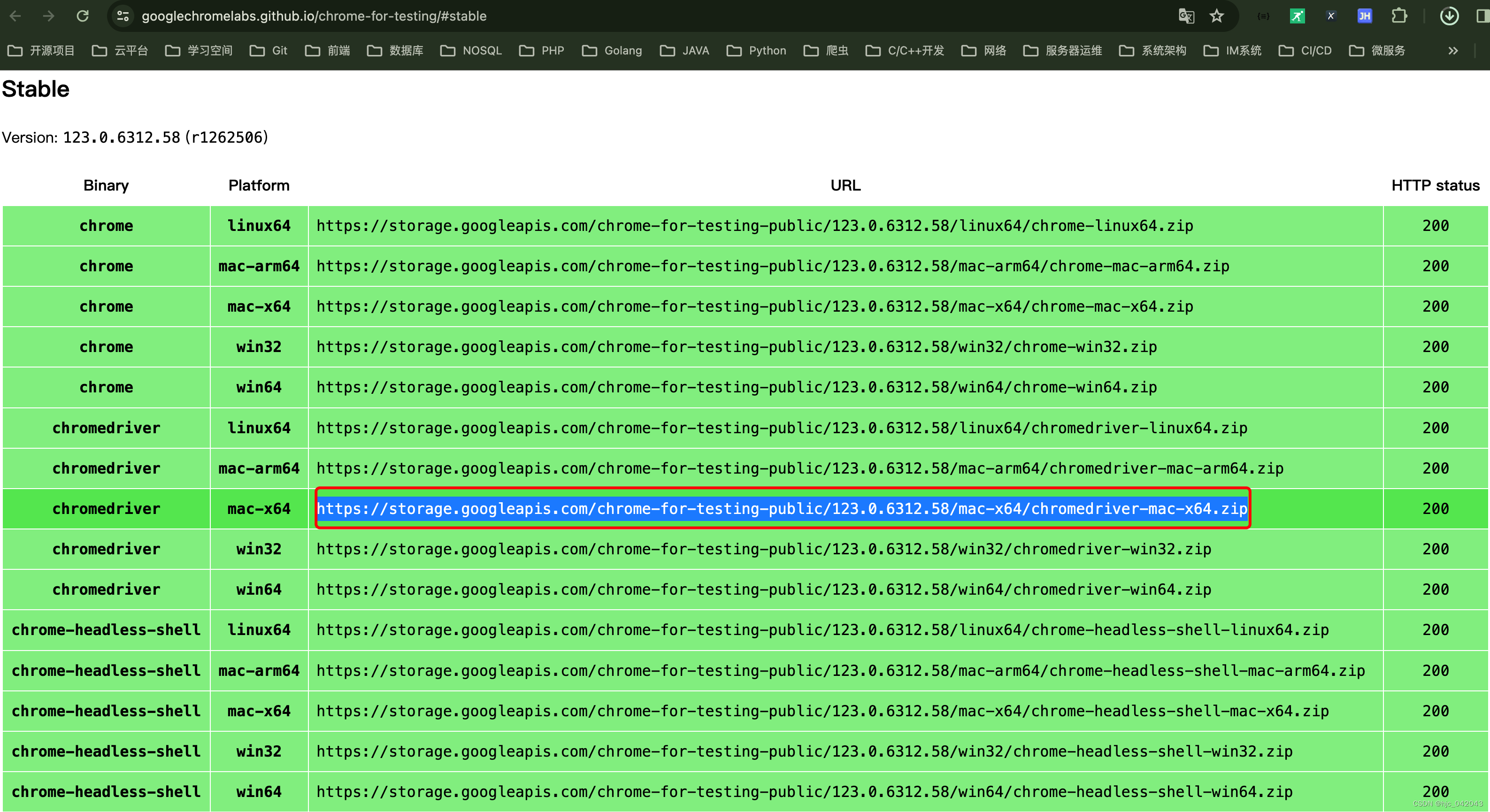
- Chrome浏览器驱动下载地址:
淘宝镜像:https://npmmirror.com/package/chromedriver/versions
google官网:https://googlechromelabs.github.io/chrome-for-testing/#stable
注意:官网需要VPN 翻墙
-
Firefox浏览器驱动下载地址:
https://github.com/mozilla/geckodriver/releases/ -
Edge浏览器驱动下载地址:
这是windows下的浏览器
https://developer.microsoft.com/en-us/microsoftedge/tools/webdriver/#downloads -
无头浏览器
PhantomJs安装教程(无界面浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效),它一般是用在像linux线上服务器,不过现在 chrome(v65以上) 也支持无头浏览器了。 -
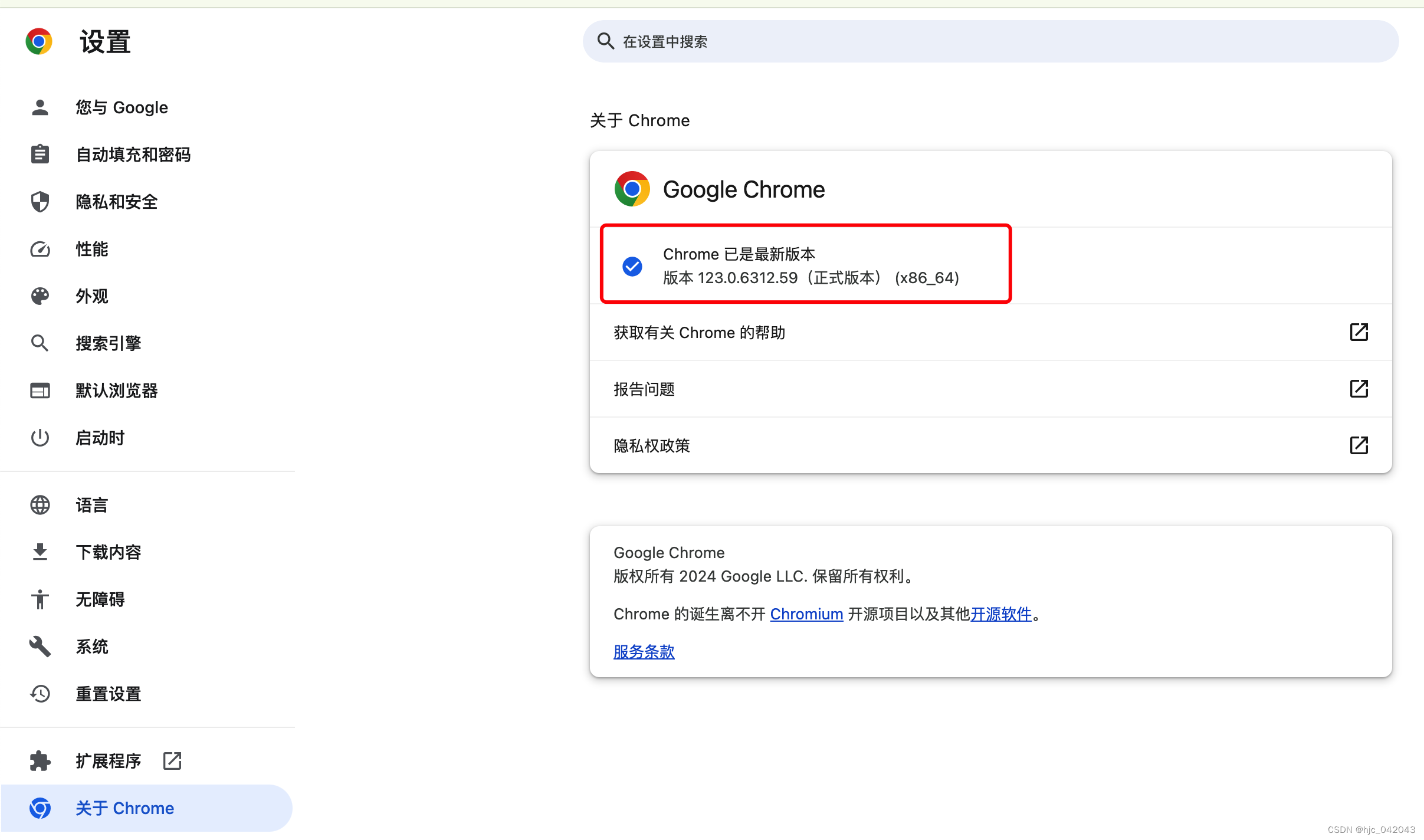
注意: 下载安装步骤如下:需要下对应浏览器版本的驱动
查看 chrome的版本是最新版本123,所以下载对应的驱动
-
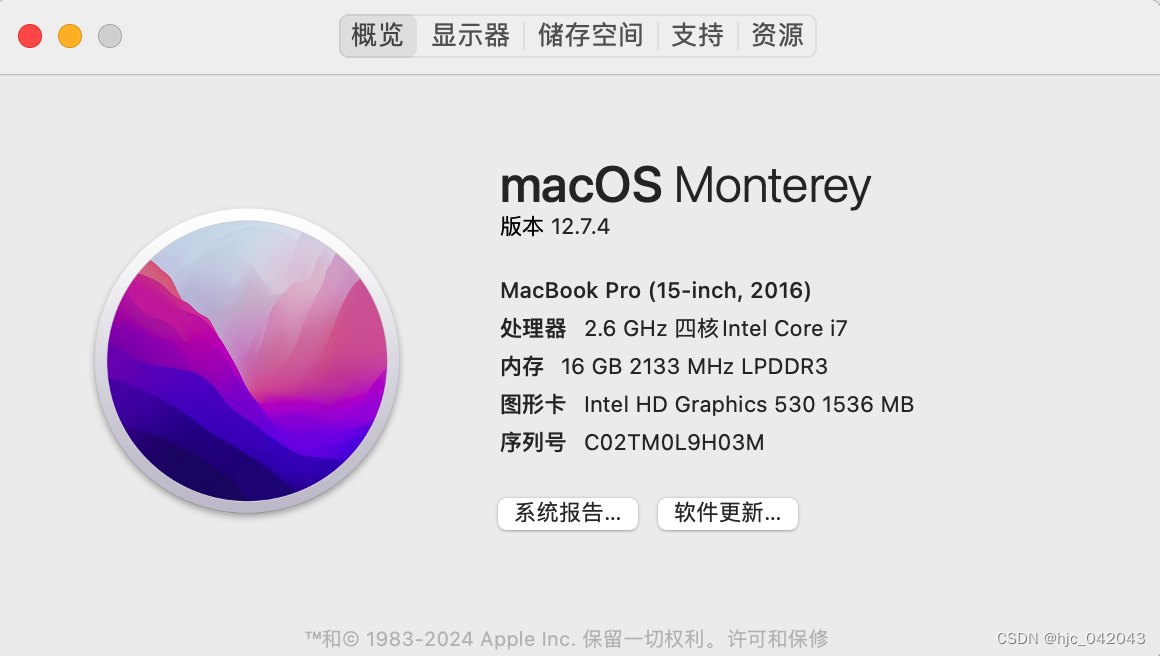
下载对应的版本:
macos 分为 intel 还是arm 的,我因电脑是 intel,所以选择时也要选mac64
浏览器对应的驱动版本
驱动安装和测试
将驱动文件解压,放在环境变量的目录/usr/local/bin 就行
mv Downloads/chromedriver-mac-x64/chromedriver /usr/local/bin/
- 测试
之后的代码都是使用了测试用例,具体代码看码云上的源码,这里先做一个前置操作,设置chrome 驱动的路径,默认在代码中不设置,程序会自动从环境变量中去寻找,但是 selenium启动时会超慢
def setUp(self) -> None:"""@todo: 设置驱动的路径,主要是为了加快selenium的启动速度,不用再去搜索驱动的路径@return:"""self.service = ChromService(executable_path="/usr/local/bin/chromedriver")pass
def test_chrome_driver(self):"""@todo: selenium测试chrome的浏览器@return:"""# 设置驱动的路径,这是 selenium4之后的新写法# 实例化浏览器对象browser = webdriver.Chrome(service=self.service)# 发送请求访问百度browser.get('https://www.baidu.com')# 获取页面标题print("当前页面标题:", browser.title)time.sleep(10)# 退出浏览器browser.quit()pass
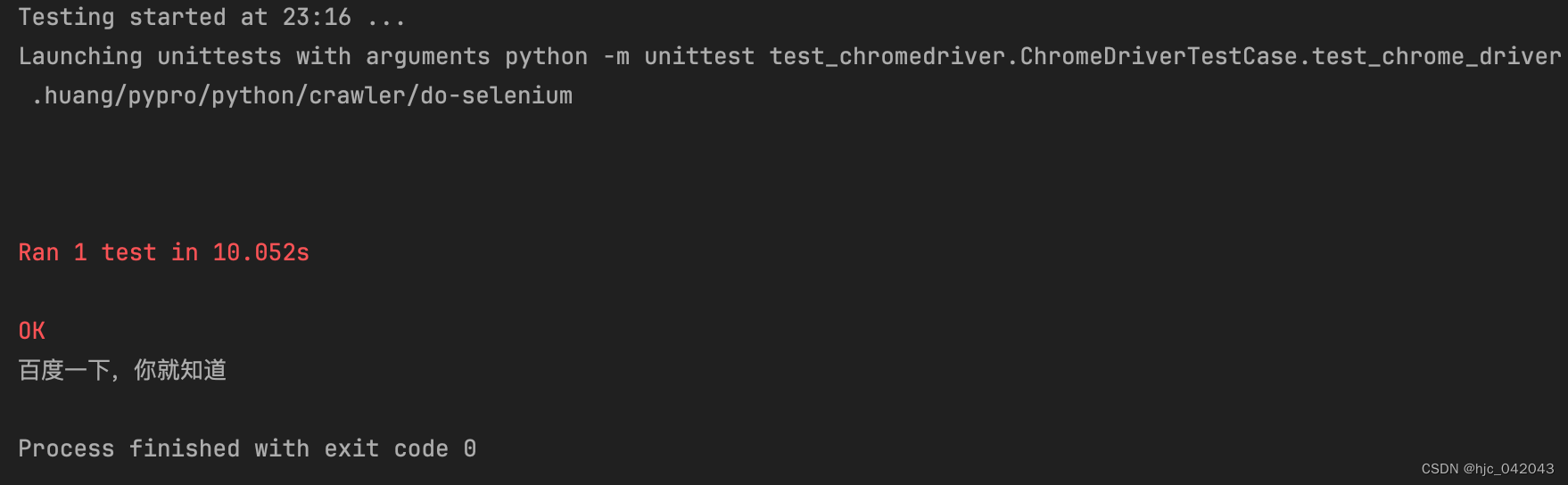
其流程是:
①、开启了一个 新的chrome 窗口,并打开 baidu 网站
②、输出 title 标题
③、关闭浏览器,注意,在 selenium4之前最后一定要手动退出,不然会有残留进程,之后是不用写,自动关闭
基础操作
源码地址:https://gitee.com/allen-huang/python/blob/master/crawler/do-selenium/test_base.py
1、属性和方法
- 常用属性说明:
current_url:当前响应的URLtitle:当前网页的标题page_source:页面源码name:浏览器驱动名称
- 方法说明:
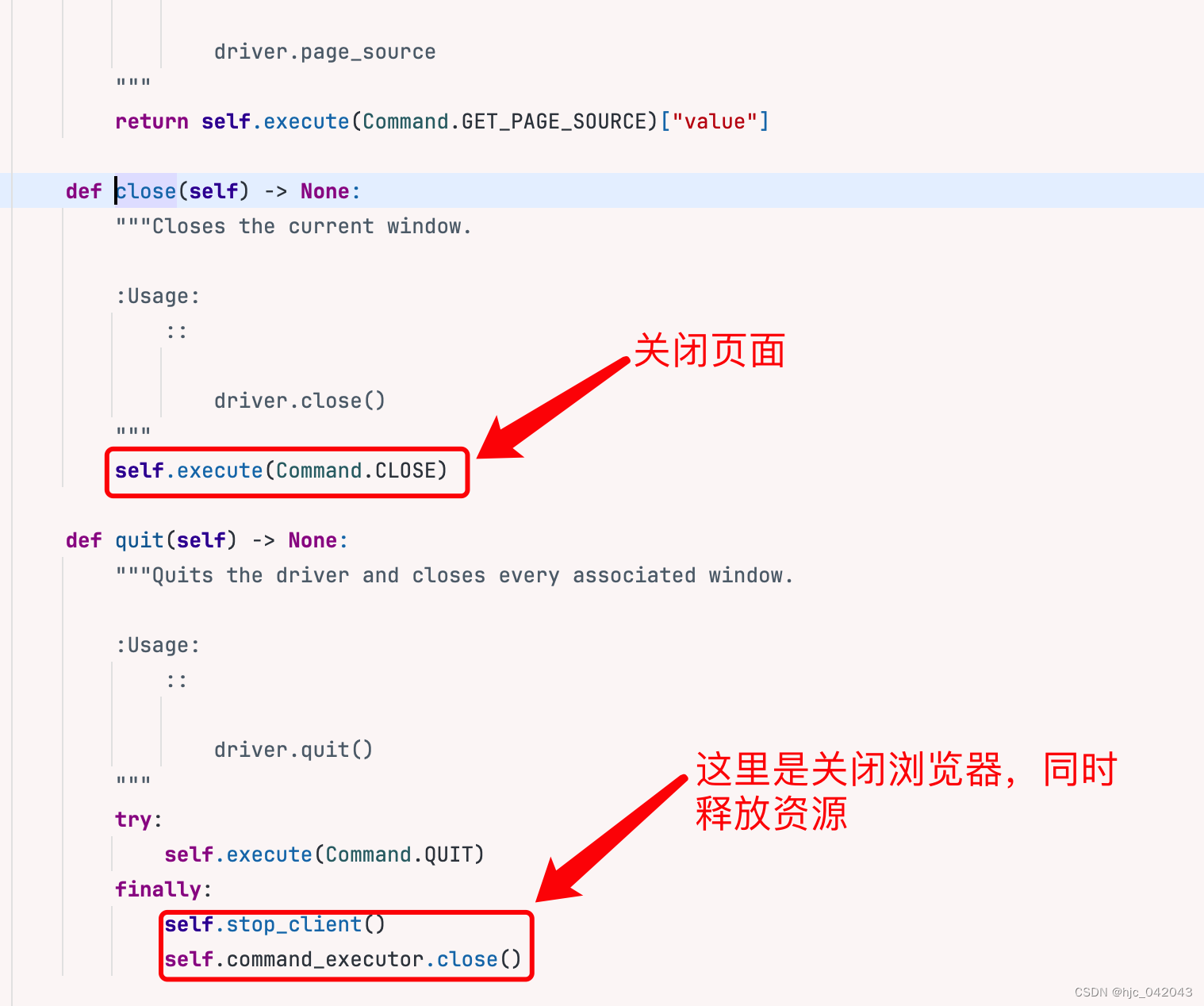
get():打开一个网址,同时会把 response 信息自动保存back():返回上一个网址forward():前进到一个网址refresh():再刷新一个网址save_screenshot():保存当前页面的截屏快照close():关闭当前标签页,不关闭浏览器quit():关闭浏览器,释放进程
cloase()和quit()的区别:
从 selenium4的源码中比较可以看出来
代码展示:
def test_attr_method(self):"""@todo: 测试浏览器的属性和方法@return:"""# 实例化浏览器对象driver = webdriver.Chrome(service=self.service)# 获取浏览器的名称print(driver.name)# 访问百度首页,这里先暂时不使用httpsdriver.get('http://www.baidu.com')# 属性1:打印当前响应对应的URL,之前 http的转换成了 httpsprint(driver.current_url)# 属性2:打印当前标签页的标题print(driver.title)# 属性3:打印当前网页的源码长度print(len(driver.page_source))# 休息2秒,跳转到豆瓣首页,这里的两秒是等当前页面加载完毕,也就是浏览器转完圈后等待的两秒time.sleep(2)driver.get('https://www.douban.com')# 休息2秒,再返回百度time.sleep(2)driver.back()# 休息2秒,再前进到豆瓣time.sleep(2)driver.forward()# 休息2秒,再刷新页面time.sleep(2)driver.refresh()# 保存当前页面的截屏快照driver.save_screenshot("./screenshot.png")# 关闭当前标签页driver.close()# 关闭浏览器,释放进程driver.quit()pass
2、单个元素定位
只罗列常用的几个,其他的可以查下稳定就行,像 xpath 和 css 选择器定位是属于万能定位,尽量用这两个
通过id定位
-
语法格式:
find_element(by=By.ID, value='标签的id属性名) -
测试代码
def test_element_id(self):"""@todo: 通过id定位元素,测试输入框的输入和点击@return:"""# 实例化浏览器对象browser = webdriver.Chrome(service=self.service)# 打开百度首页browser.get('https://www.baidu.com')# 输入关键字内容sora,并赋值给 标签的id属性名来定位;这是新的写法,browser.find_element(by=By.ID, value='kw').send_keys('sora')# 点击搜索按钮browser.find_element(by=By.ID, value='su').click()# 获取搜索结果# 关闭浏览器time.sleep(5)browser.quit()pass
通过class_name定位一个元素
-
语法格式:
find_element(by=By.CLASS_NAME, value='标签的class属性名') -
测试代码:
def test_element_class_name(self):"""@todo: 通过class_name定位元素,测试输入框的输入和点击@return:"""browser = webdriver.Chrome(service=self.service)browser.get('https://www.baidu.com')# 使用class_name定位输入框,并把输入框的内容设置为sorabrowser.find_element(by=By.CLASS_NAME, value='s_ipt').send_keys('sora')browser.find_element(by=By.CLASS_NAME, value='s_btn').click()time.sleep(2)browser.quit()pass
通过xpath定位
- 语法格式:
find_element(by=By.XPATH, value='xpath的表达式') - 测试代码
def test_element_xpath(self):"""@todo: 通过xpath定位元素,测试输入框的输入和点击@return:"""# 实例化浏览器对象browser = webdriver.Chrome(service=self.service)browser.get('https://www.baidu.com')# 使用xpath定位输入框,并把输入框的内容设置为sorabrowser.find_element(by=By.XPATH, value='//*[@id="kw"]').send_keys('sora')# 点击搜索按钮browser.find_element(by=By.XPATH, value='//*[@id="su"]').click()# 关闭浏览器time.sleep(5)browser.quit()pass
通过CSS 选择器定位
- 语法格式:
browser.find_element(by=By.CSS_SELECTOR, value="选择器表达式") - 测试代码:
def test_element_css_selector(self):"""@todo: 通过css选择器定位元素,测试输入框的输入和点击@return:"""# 实例化浏览器对象,打开百度首页browser = webdriver.Chrome(service=self.service)browser.get('https://www.baidu.com')# 使用css选择器定位输入框,先进行清空文本框,并把输入框的内容设置为sorabrowser.find_element(by=By.CSS_SELECTOR, value="#kw").clear()browser.find_element(by=By.CSS_SELECTOR, value="#kw").send_keys('sora')browser.find_element(by=By.CSS_SELECTOR, value="#su").click()# 关闭浏览器time.sleep(2)browser.quit()pass
3、多个元素定位
天天基金网为例子,如下图:
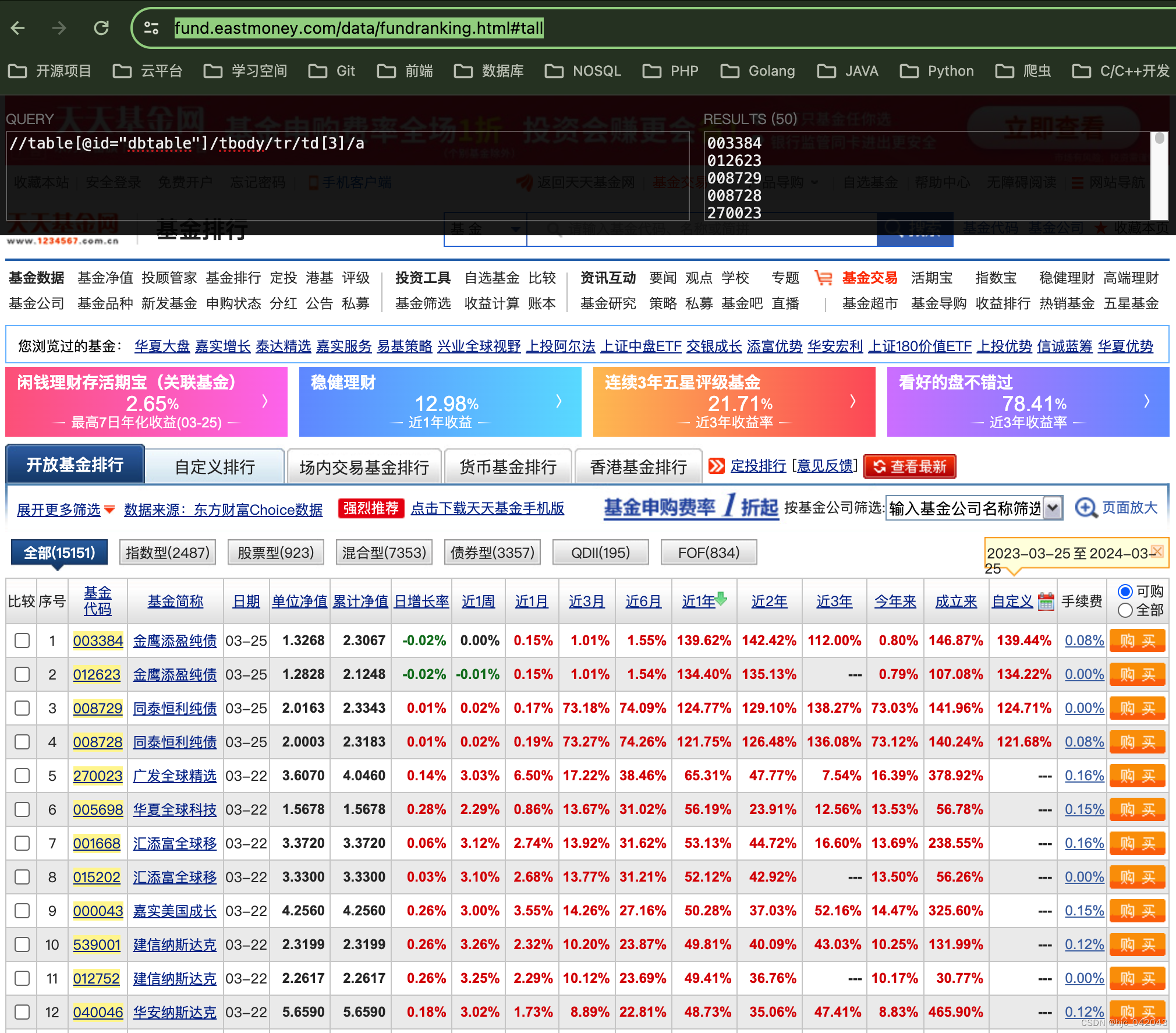
通过xpath定位排行榜的基金代码
-
语法格式:
格式上和单个获取的差不多,唯一有差别的是方法后面多了一个s,使用了find_elements -
测试代码:
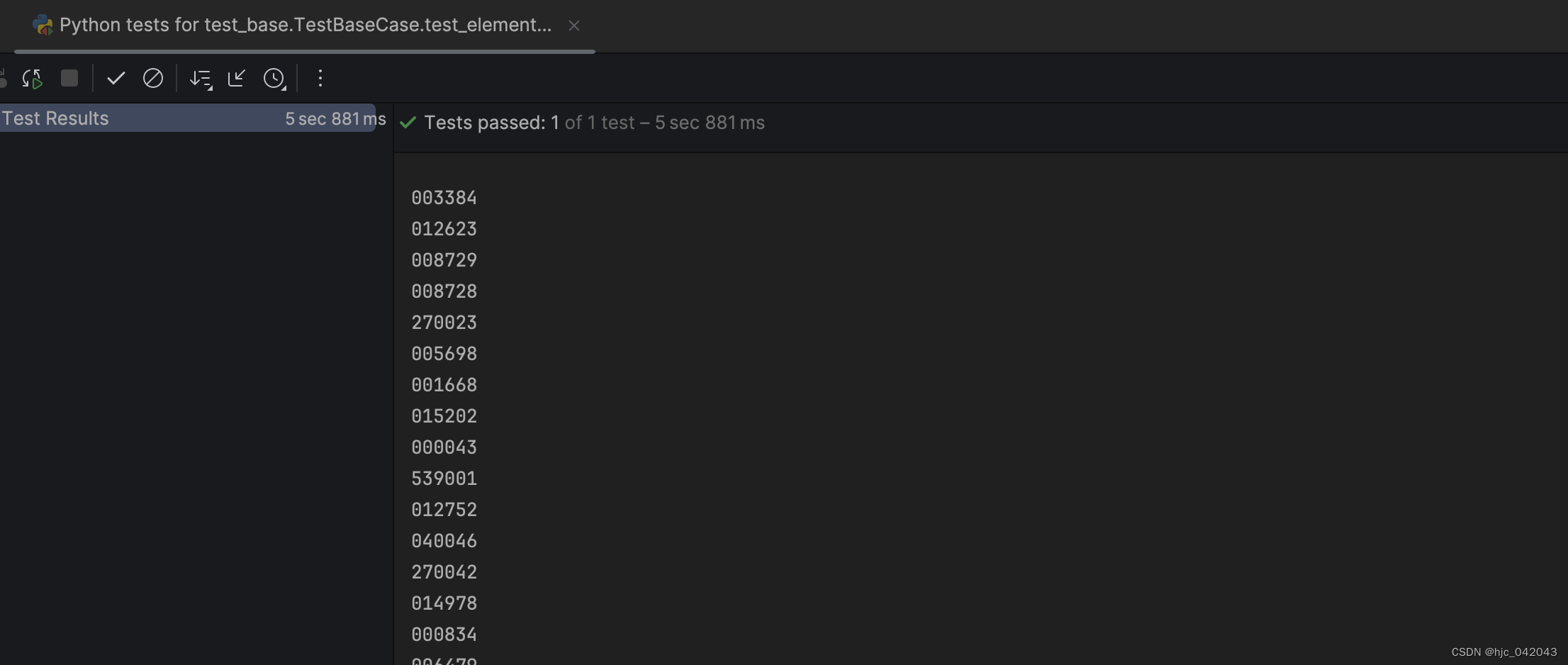
def test_elements_xpath(self):"""@todo: 通过xpath定位元素列表,测试获取列表的数据@return:"""browser = webdriver.Chrome(service=self.service)browser.get('https://fund.eastmoney.com/data/fundranking.html#tall')# 使用xpath定位列表elements = browser.find_elements(by=By.XPATH, value='//table[@id="dbtable"]/tbody/tr/td[3]/a')for elem in elements:print(elem.text)# 页面加载完后,再等待2秒,自动关闭浏览器,这里没有使用quit()方法,也能自动释放time.sleep(2)browser.quit()pass
打印结果:
取数据单个和多个的区别
- find_element:
定位的是元素的对象,定位不到报错
- find_elements:
定位的是列表,列表里面存元素对象,如果定位不到则是空的数据
4、元素操作
获取元素的文本内容和属性值
它这个和 xpath 获取文笔属性值不太一样,这是需要注意的
- 文本内容:
元素对象.text - 属性值:
元素对象.get_attribute(‘属性名’) - 测试用例:
def test_op_element(self):"""测试获取元素的文本内容@return:"""# 实例化浏览器对象browser = webdriver.Chrome(service=self.service)# 天天基金网,查看所有基金,这只是测试,不作为正式的爬虫browser.get('https://fund.eastmoney.com/data/fundranking.html#tall')# 使用xpath定位元素列表,基金代码elems = browser.find_elements(by=By.XPATH, value='//table[@id="dbtable"]/tbody/tr/td[3]/a')for elem in elems:# 代码的内容print(elem.text)# 获取基金的链接print(elem.get_attribute('href'))time.sleep(2)browser.quit()pass
文本框输入内容和点击按钮
send_keys()在使用时,一定要文本框,不然是不生效的,它就是来输入内容用
- 示例:
def test_element_css_selector(self):"""@todo: 通过css选择器定位元素,测试输入框的输入和点击@return:"""# 实例化浏览器对象,打开百度首页browser = webdriver.Chrome(service=self.service)browser.get('https://www.baidu.com')# 使用css选择器定位输入框,先进行清空文本框,并把输入框的内容设置为sorabrowser.find_element(by=By.CSS_SELECTOR, value="#kw").clear()browser.find_element(by=By.CSS_SELECTOR, value="#kw").send_keys('sora')browser.find_element(by=By.CSS_SELECTOR, value="#su").click()# 关闭浏览器time.sleep(2)browser.quit()pass
5、无头浏览器模式
基于chrome 的无头浏览器
- 1、
webdriver.ChromeOptions(),实例化 chrome 浏览器配置对象- 2、
chrome_options.add_argument('--headless'),开启无头模式- 3、
chrome_options.add_argument('--disable-gpu'),不开启显卡- 4、
browser = webdriver.Chrome(options=chrome_options),实例化浏览器
如下代码展示
def test_headless_driver(self):"""@todo: 测试chrome无头模式浏览器@return:"""# 1.实例化配置对象chrome_options = webdriver.ChromeOptions()# 2.配置对象开启无头模式chrome_options.add_argument('--headless')# 3.配置对象添加无显卡模式,即无图形界面chrome_options.add_argument('--disable-gpu')# 4.实例化浏览器对象browser = webdriver.Chrome(service=self.service, options=chrome_options)browser.get('https://www.baidu.com')# 查看当前页面urlprint(browser.current_url)# 获取页面标题print("页面标题:", browser.title)# 获取渲染后的页面源码print("页面源码-长度:", len(browser.page_source))# 获取页面cookieprint("cookie-data", browser.get_cookies())# 关闭页面的标签页browser.close()time.sleep(5)# 关闭浏览器browser.quit()pass
基于PhantomJS的无头模式(selenium2系列用的多)
在 selenium4开始,phantomJS已经废弃了,建议使用 chrome 和 firefox 的无头浏览器其,这是只是简单的介绍下。
- 下载安装
下载地址:https://phantomjs.org/download.html
选择对应的操作系统即可,我这里是 mac os的
解压出来后,将 bin 目录的phantomjs拷贝到环境变量目录/usr/local/bin 目录下就行
- 验证
出现这个表示安装成功了
代码写法都差不多的
def test_phantjs_driver(self):driver = webdriver.PhantomJS()driver.get('https://www.baidu.com')print(driver.title)driver.quit()pass
进阶操作
源码地址:https://gitee.com/allen-huang/python/blob/master/crawler/do-selenium/test_advanced.py
1、切换标签页
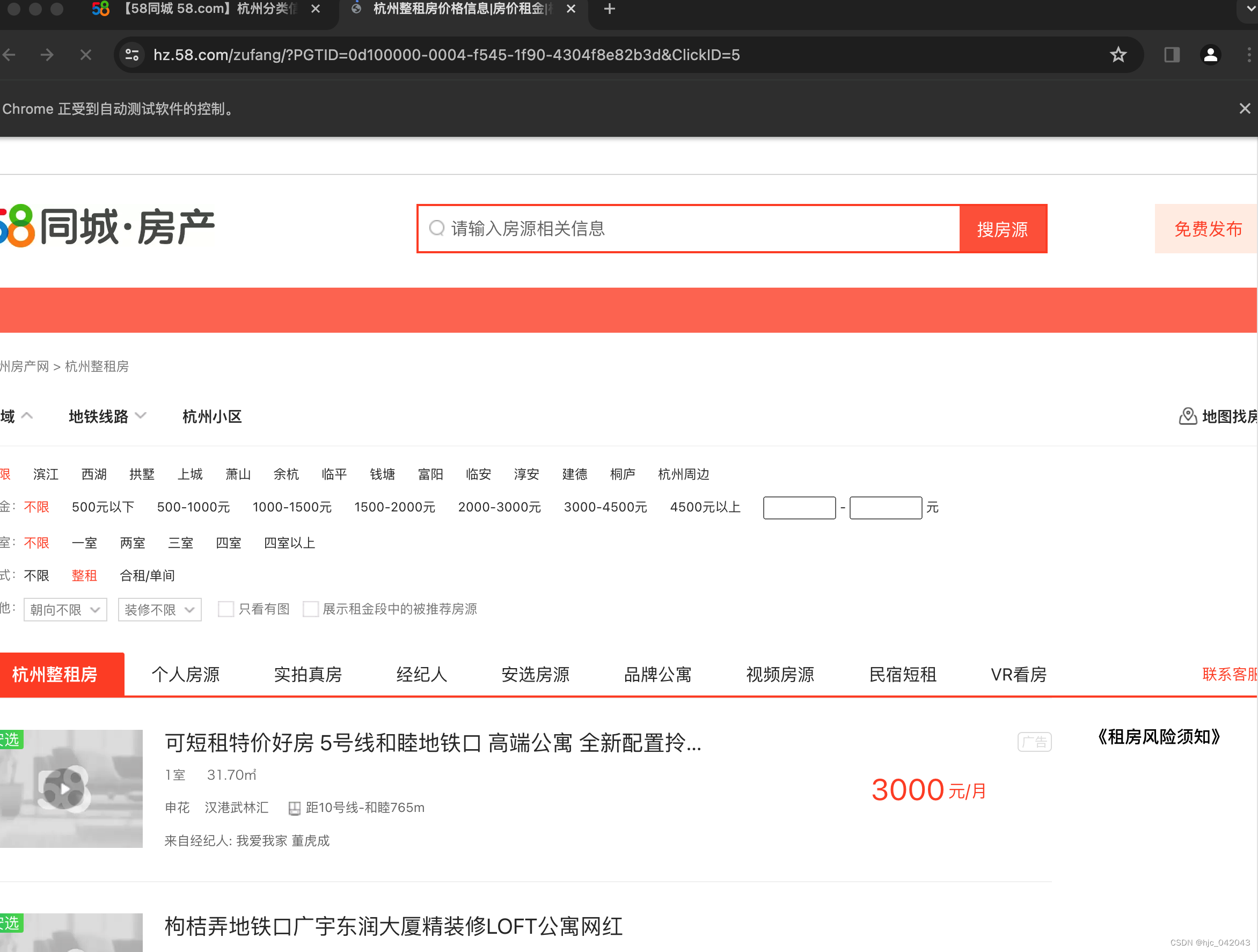
在通过 selenium打开一个页面,通过点击去其他页面获取数据,这个时候,我们切换标签页来实现,但同时不使用句柄,就无法获取目标页面的内容,这句柄相当于是指针的概念。以下以58同城出租网为例
句柄的数据结构:
这是一个列表结构,用来存放所有页面的句柄信息,每打开一个标签的网址,就会存一个,在切换到别的页面时,就去定位对应的索引
driver.window_handles
句柄使用:
就是去指定句柄列表中,具体的句柄值,来切换某个页面的资源,索引 index表示具体哪个页面
driver.switch_to.window(driver.window_handles[index])
在不切换句柄的效果
将
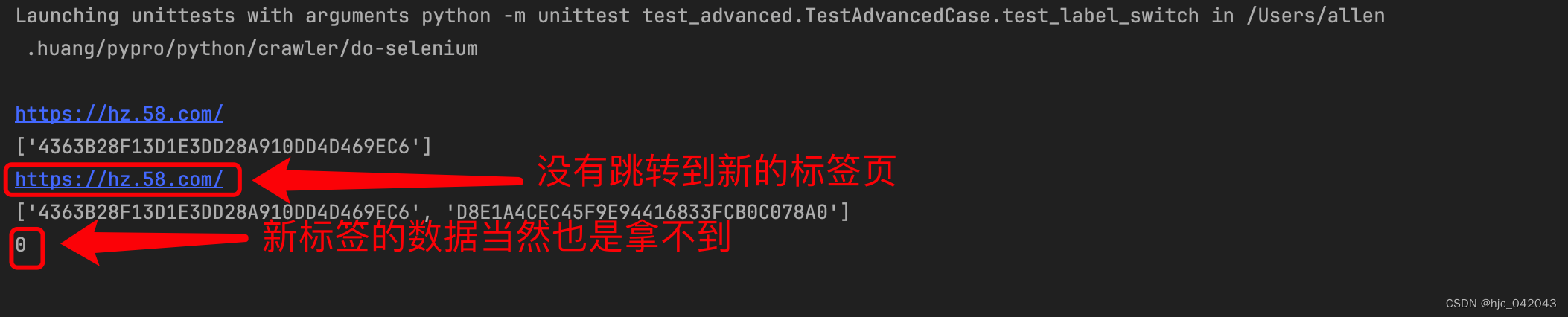
driver.switch_to.window(driver.window_handles[-1])这行代码注释,执行后,新标签页面虽然打开了,但资源并没有切换过去,这里是部分源码,具体看test_label_switch方法
...
driver.get("https://hz.58.com/")# todo 获取当前所有的标签页的句柄构成的列表,这不能提前申明变量,因为句柄相当于是指针,这是动态变化的
# current_windows = driver.window_handles# 获取当前页
print(driver.current_url)
print(driver.window_handles)# 点击整租的链接,打开租房页面
driver.find_element(by=By.XPATH, value="/html/body/div[3]/div[1]/div[1]/div/div[1]/div[1]/span[2]/a").click()# todo 根据标签页句柄,将句柄切换到最新新打开的标签页,这一定要有,不然句柄不会变化,那么下一页内容取不到
# driver.switch_to.window(driver.window_handles[-1])print(driver.current_url)
print(driver.window_handles)elem_list = driver.find_elements(by=By.XPATH, value="/html/body/div[6]/div[2]/ul/li/div[2]/h2/a")
# 统计租房列表的个数
print(len(elem_list))
...
这个时候发现,页面并没有跳转
切换句柄后的效果:
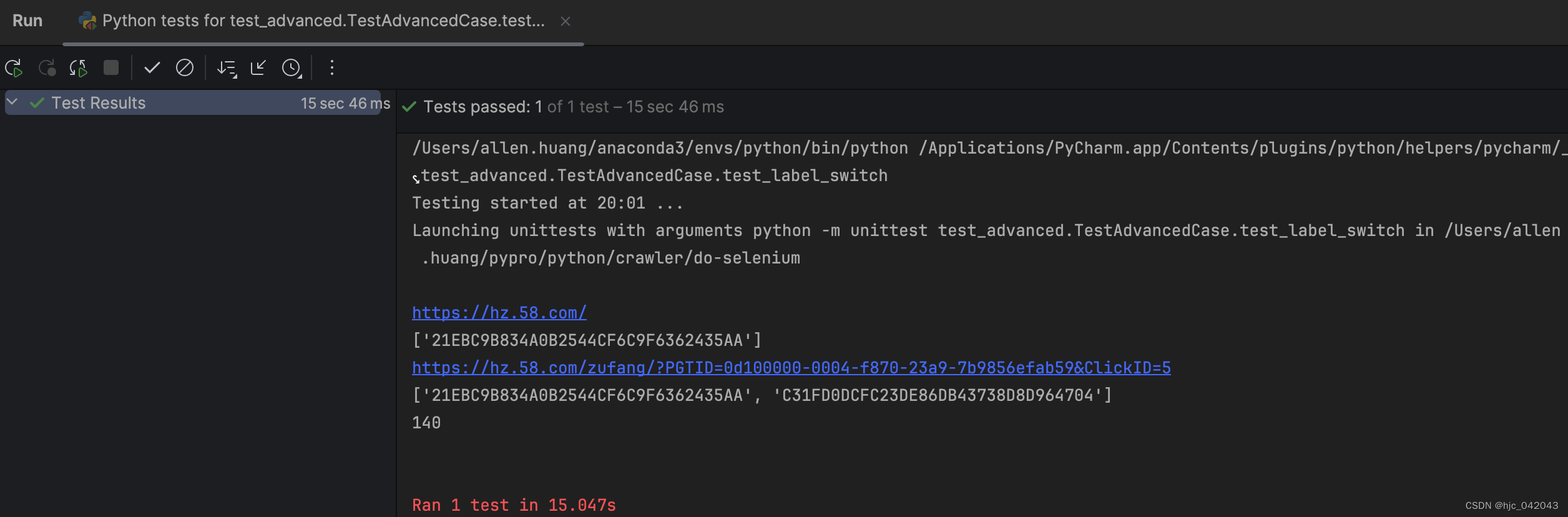
注意: 句柄列表,这不能提前申明为变量,因为句柄随着新便签页的打开,这是动态变化的current_windows = driver.window_handles不能这么赋值。
2. iframe窗口的切入
iframe 即在页面中嵌套子页面,selenium默认是访问不了frame 中的内容的,需要使用
switch_to.frame(frame_element),下面以 qzone为例说明
学习文章参考:https://www.cnblogs.com/lc-blogs/p/17269626.html
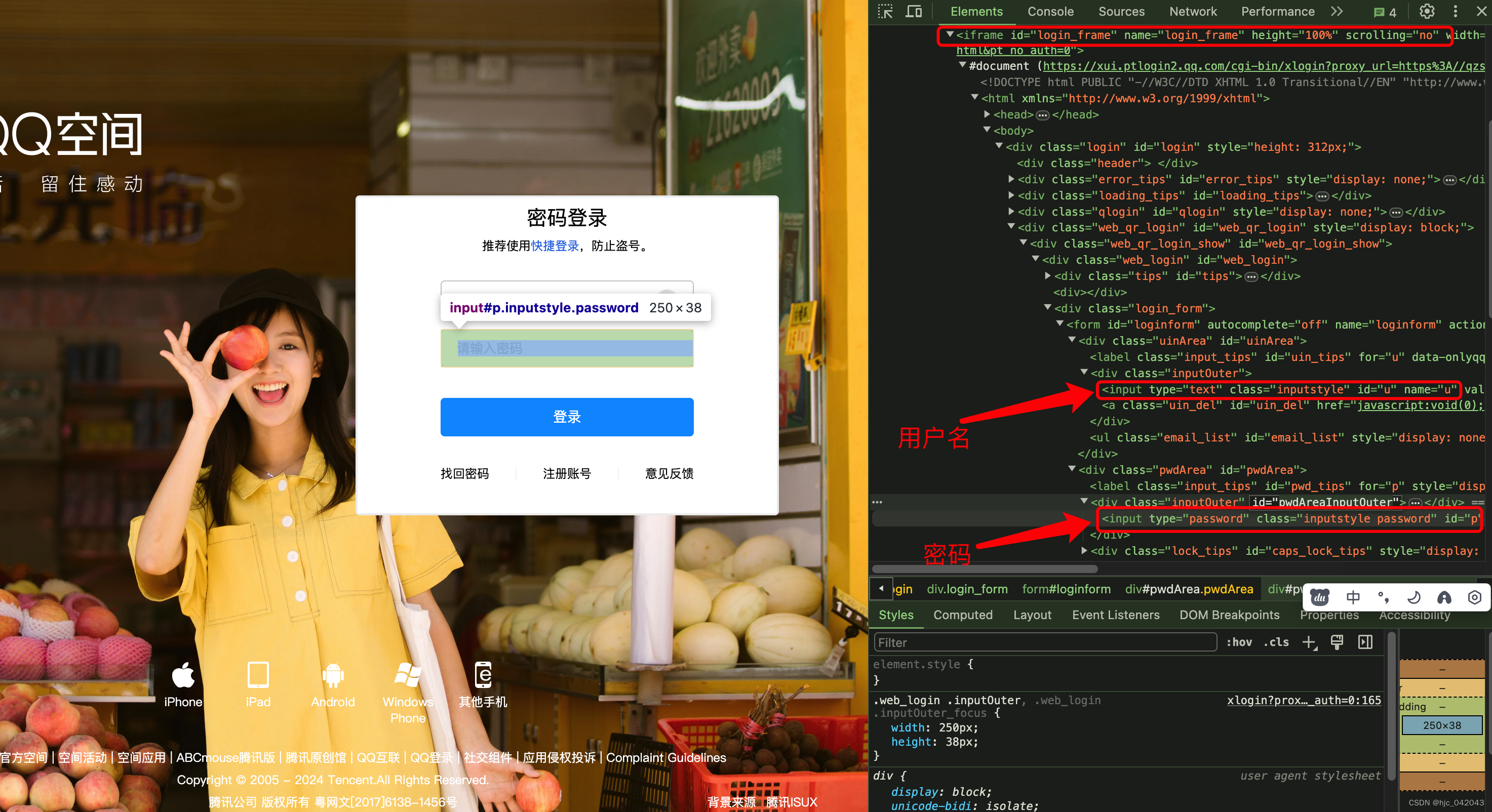
不使用switch_to.frame方法测试
- 测试代码
根据账号,密码的元素属性id 进行定位
def test_no_switchto_frame(self):# 声明浏览器驱动实例driver = webdriver.Chrome(service=self.service)# 打开 qzone 登录页driver.get("https://qzone.qq.com/")# 默认进来是采用扫码,我们这里需要切换成账号密码登录driver.find_element(by=By.ID, value="switcher_plogin").click()# 填写账号driver.find_element(by=By.ID, value="u").send_keys("531881823.qq.com")# 并不是真实的密码driver.find_element(by=By.ID, value="p").send_keys("123456")# 点击登录按钮driver.find_element(by=By.XPATH, value='//*[@id="login_button"]').click()time.sleep(5)driver.quit()pass
- 执行结果
报错的意思是,未能定位id='u’的元素

学习 switch_to.frame的语法
如果所定位的元素是在 iframe 中,那么必须先切入到 iframe 中再对元素进行定位。
- 语法格式:
switch_to.frame(frame_element)
frame_element表示可以传入的元素属性值,用来定位 frame ,可以传入id属性、name、index 以及selenium 的 WebElement 对象,假设有来自某网站的 a.com/index.html,如下 HTML 代码:
<html lang="en">
<head><title>iframetest</title>
</head>
<body>
<iframe src="a.html" id="fid" name="fname">...<div id="test-a"><a href="test.com" class="test-a">打开页面</a></div>...
</iframe>
</body>
</html>
可以如下定位:
from selenium import webdriver# 打开Chrome浏览器
driver = webdriver.Chrome()# 浏览器访问地址
driver.get("https://a.com/index.html")# 1.用id来定位
driver.switch_to.frame("fid")# 2.用name来定位
driver.switch_to.frame("fname")# 3.用frame的index来定位,第一个是0
driver.switch_to.frame(0)# 4.用WebElement对象来定位
driver.switch_to.frame(driver.find_element(by=By.XPATH,value='//*[@id="fid"]')
通常采用 id 和 name 就能够解决绝大多数问题。但有时候iframe并无这两项属性,则可以用 index 和 WebElement 来定位:
- index 从 0 开始,传入整型参数即判定为用 index 定位,传入 str 参数则判定为用 id/name 定位
- WebElement 对象,即用 find_element 系列方法所取得的对象,我们可以用 css、xpath 等来定位 iframe 对象
最后使用switch_to.frame 方法测试
def test_switchto_frame(self):driver = webdriver.Chrome(service=self.service)driver.get("https://qzone.qq.com/")# 切入iframedriver.switch_to.frame("login_frame")driver.find_element(by=By.ID, value="switcher_plogin").click()driver.find_element(by=By.ID, value="u").send_keys("531881823.qq.com")driver.find_element(by=By.ID, value="p").send_keys("123456")driver.find_element(by=By.XPATH, value='//*[@id="login_button"]').click()time.sleep(5)driver.quit()pass
从iframe中切出
注:切入到 iframe 中之后,如果想对 iframe 外的元素进行操作,必须先从 iframe 中切出后才能操作元素。
从 iframe 中切出的方法:switch_to.default_content()
driver.switch_to.default_content()
3. 使用 cookie
如果像一些比较大的平台,登录会比较复杂,那么我们可以先用 selenium 进行模拟登录,拿到 cookie之后,就可以使用requests模块来进行操作了。
看如下代码:就是来展示 cookie的测试
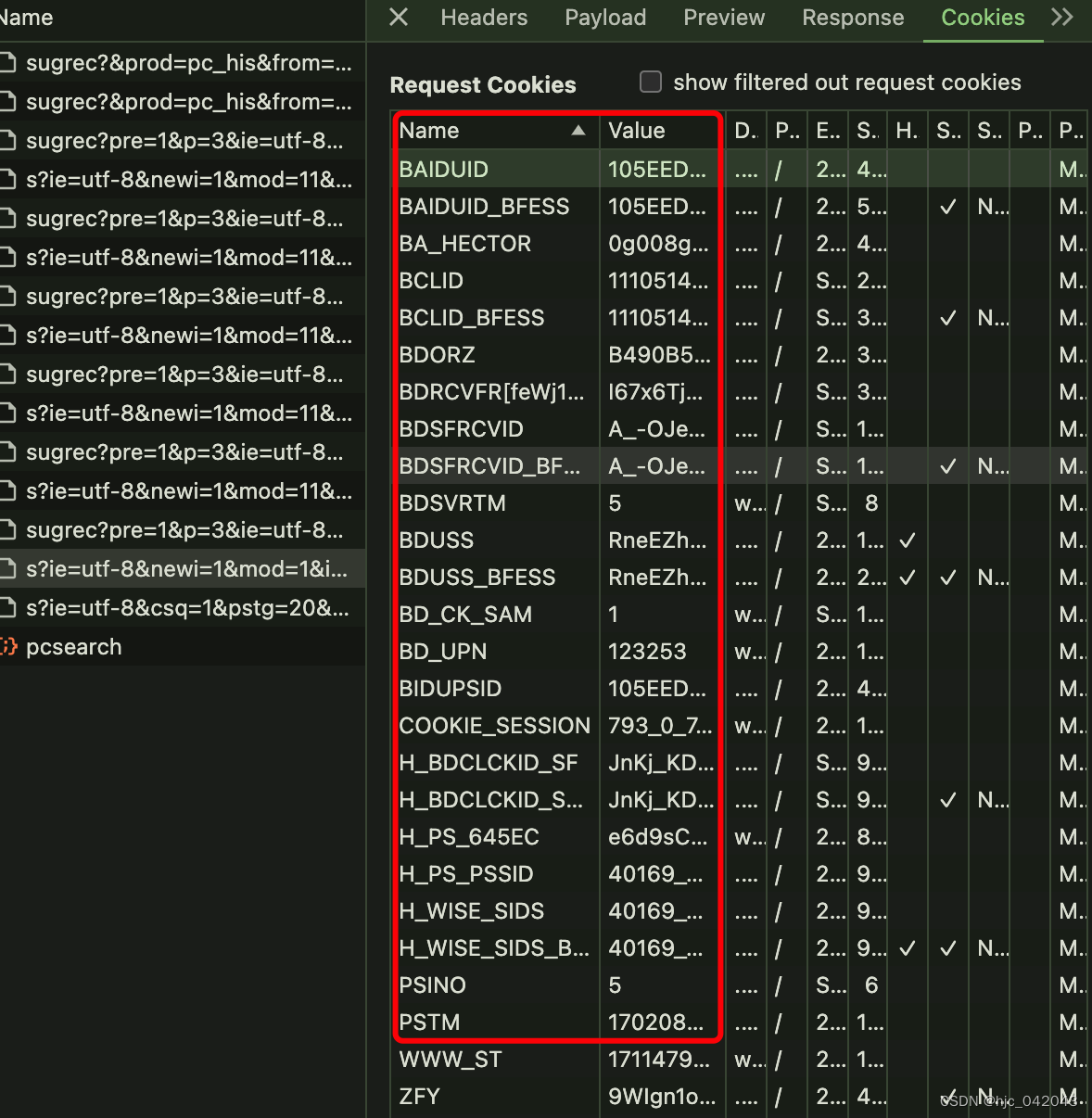
def test_cookie(self):"""获取cookie@return:"""driver = webdriver.Chrome(service=self.service)driver.get("https://baidu.com/")# 获取cookie的值cookie_info = {data["name"]: data["value"] for data in driver.get_cookies()}pprint(cookie_info)time.sleep(2)driver.quit()pass
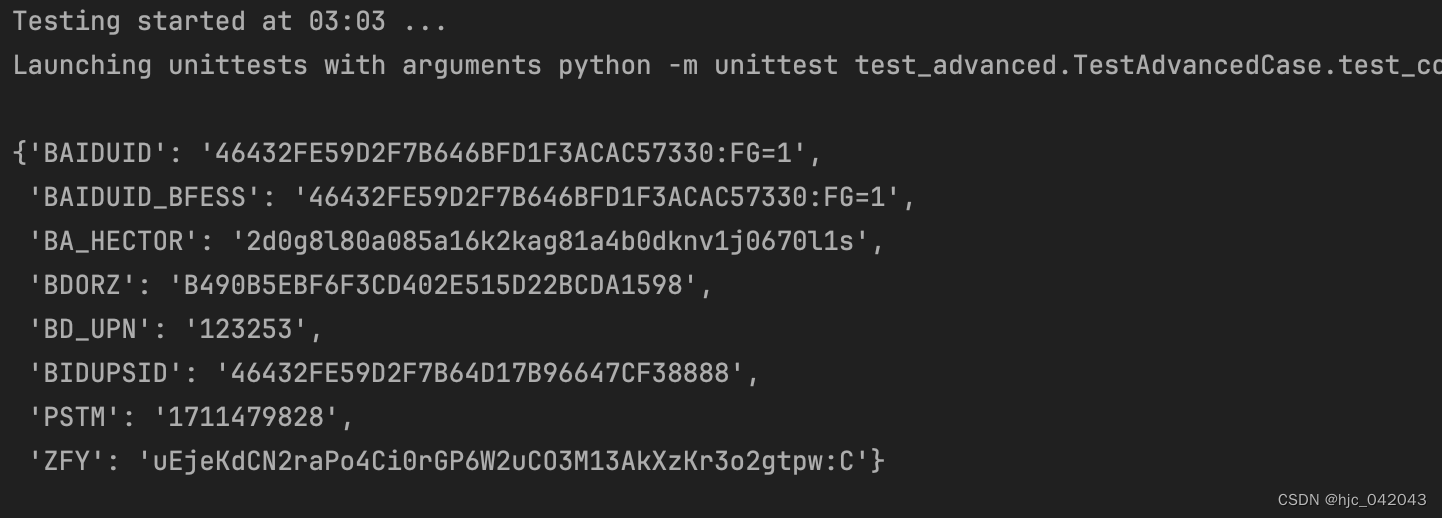
最后打印出的 key,value 对应的值就是在浏览器中的 cookie结构图,如下图所示:
4. 执行JS
selenium可以来执行我们的JS代码
- 语法格式:
driver.execute_script(js)
- 代码例子1:
打开一个新窗口
def test_js(self):"""执行js,打开一个新窗口,跳转到二手房页面@return:"""# 打开浏览器,进到链家首页driver = webdriver.Chrome(service=self.service)driver.get("https://hz.lianjia.com/")# 我想重开一个窗口查看所有的二手房页面js = "window.open('https://hz.lianjia.com/ershoufang/');"# 执行js代码driver.execute_script(js)time.sleep(5)driver.quit()pass
- 代码例子2
滚动到下面去,打开新的页面
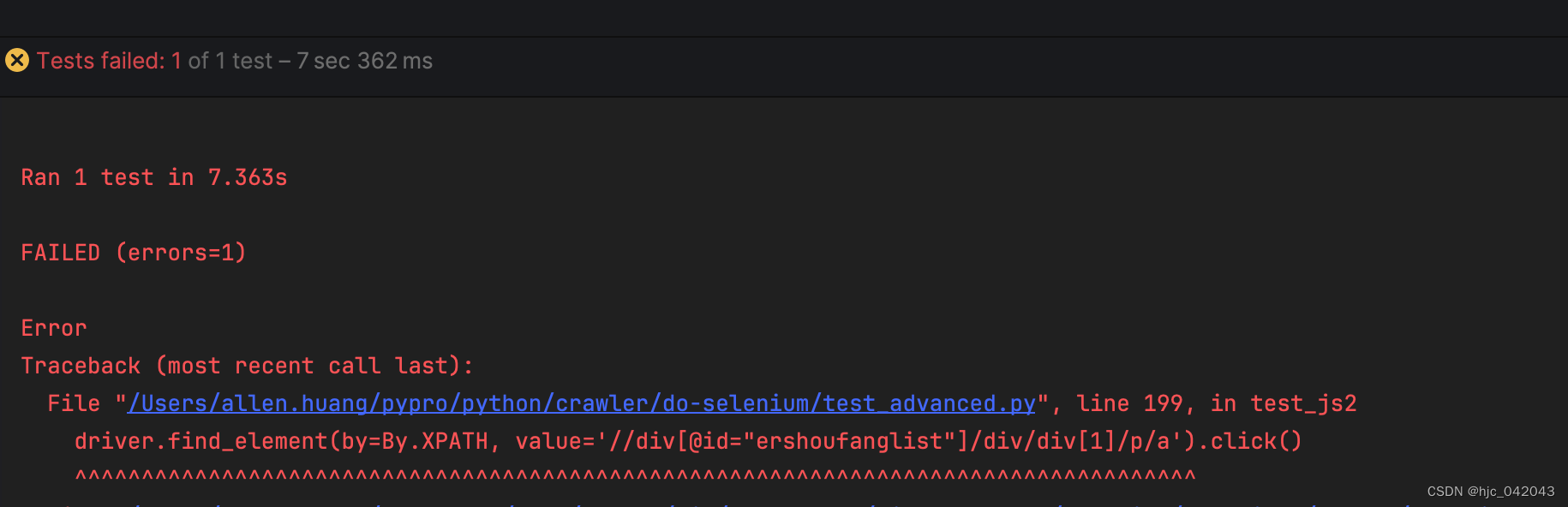
def test_js2(self):"""执行js代码,滚动条往下拉@return:"""driver = webdriver.Chrome(service=self.service)driver.get("https://hz.lianjia.com/")# 执行js代码,滚动条往下拉500像素js = "window.scrollTo(0,1000);"driver.execute_script(js)time.sleep(2)# 然后点击查看更多二手房的按钮driver.find_element(by=By.XPATH, value='//div[@id="ershoufanglist"]/div/div[1]/p/a').click()# 强制等待5秒time.sleep(5)driver.quit()pass
一开始定位不到时,就报错提示找不到元素
滚动正确的位置后,没再报错,能打开新的标签页
5. 页面等待
- 使用场景:
现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待时间过长导致某个dom元素还没出来,但是你的代码直接使用了这个WebElement,这时候就会报定位不到的错误
为了避免这种元素定位不到的问题,所以 Selenium 提供了3种等待方式,强制等待,隐式等待,显式等待。
-
强制等待:
就是 time.sleep(x 秒),即整个页面等待 x秒 -
隐式等待(
较为常用):
针对是元素定位,隐式等待设置了一个时间,在每隔一段时间检查所有元素是否定位成功,如果定位了,就会进行下一步,如果没有定位成功,超时了,就会报超时错误。
假如设置了10秒,在10秒内会定期进行元素定位,但在第5秒钟的时候都加载成功了,那么就会往下执行,它不会一直等到10秒。如果超过了10秒就会报超时错误
driver.implicitly_wait(最大等待时间)
代码:
def test_page_wait(self):"""隐式等待@return:"""# 打开浏览器,进到百度首页driver = webdriver.Chrome(service=self.service)driver.get("https://www.baidu.com/")# 隐式等待,最大等待10秒driver.implicitly_wait(10)# 点击百度的logo图标的src 属性elem = driver.find_element(by=By.XPATH, value='//img[@id="s_lg_img_new"]')print(elem.get_attribute("src"))# 强制等待2秒time.sleep(2)driver.quit()pass
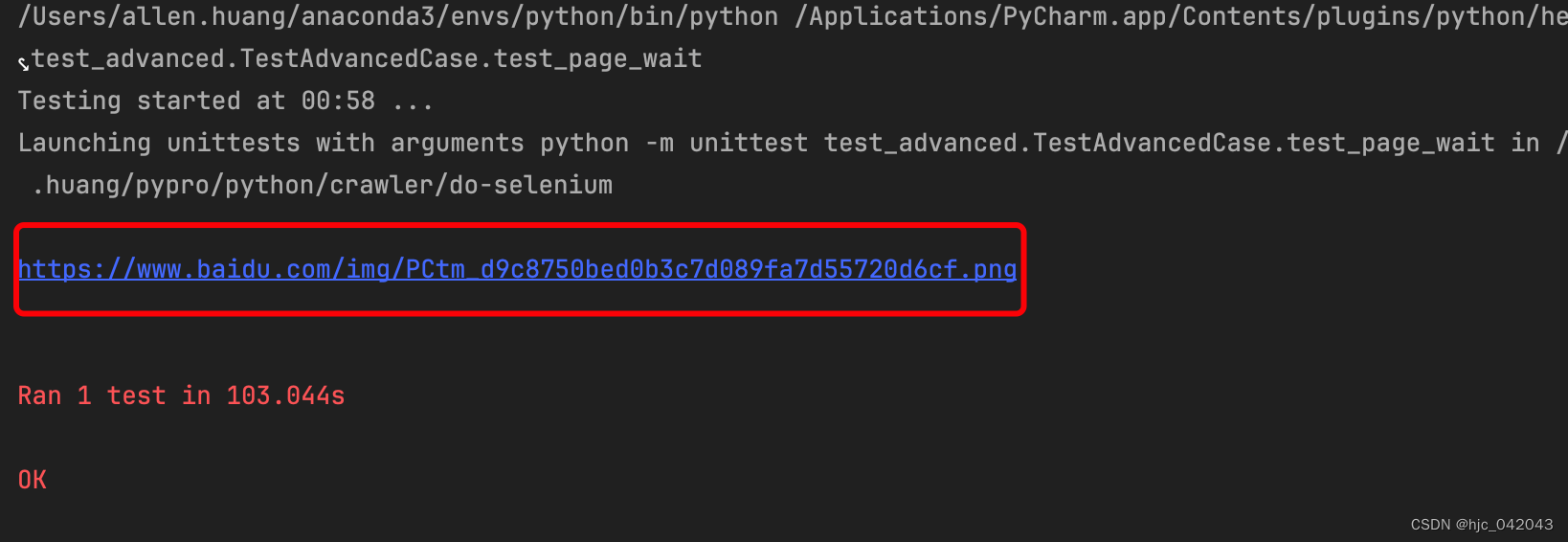
- 显示等待(
了解):
确定等待指定某个元素,然后设置最长等待时间。如果在这个时间还没定位到元素就报错。
在软件测试中使用的比较多,这在爬虫中用的不多,这里就不做过多的介绍
注意: 我们在隐式等待不好使的时候,才使用强制等待。
6. 配置代理
这和requests的代理使用类似,都是避免同一个 IP访问多了,封掉,所以使用代理IP
- 使用格式
# 声明浏览器配置对象
opt = webdriver.ChromeOptions()
# 需要在配置对象中添代理服务器
opt.add_argument("--proxy-server=http://ip地址:端口号")
- 代码实例
def test_proxy(self):"""使用代理测试121.234.119.235@return:"""# 声明浏览器配置对象opt = webdriver.ChromeOptions()opt.add_argument("--proxy-server=http://121.234.119.235:64256")# 打开浏览器,进到百度首页driver = webdriver.Chrome(service=self.service, options=opt)driver.get("https://www.baidu.com/")driver.save_screenshot('baidu.png')time.sleep(5)driver.quit()pass
7. 修改请求头
频繁使用同一个user-agent,也是容易被封,所以需要不定期的更换 user-agent
- 使用格式
# 声明浏览器配置对象
opt = webdriver.ChromeOptions()
# 设置user-agent修改请求头
opt.add_argument("--user-agent=xxxxxxxx")
- 代码示例:
def test_user_agent(self):"""selenium 可以修改请求头,user-agent,模拟成不同的浏览器@return:"""user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15"# 声明浏览器配置对象opt = webdriver.ChromeOptions()# 设置user-agent修改请求头opt.add_argument(f"--user-agent={user_agent}")# 打开浏览器,进到百度首页driver = webdriver.Chrome(service=self.service, options=opt)driver.get("https://www.baidu.com/")time.sleep(5)driver.quit()pass
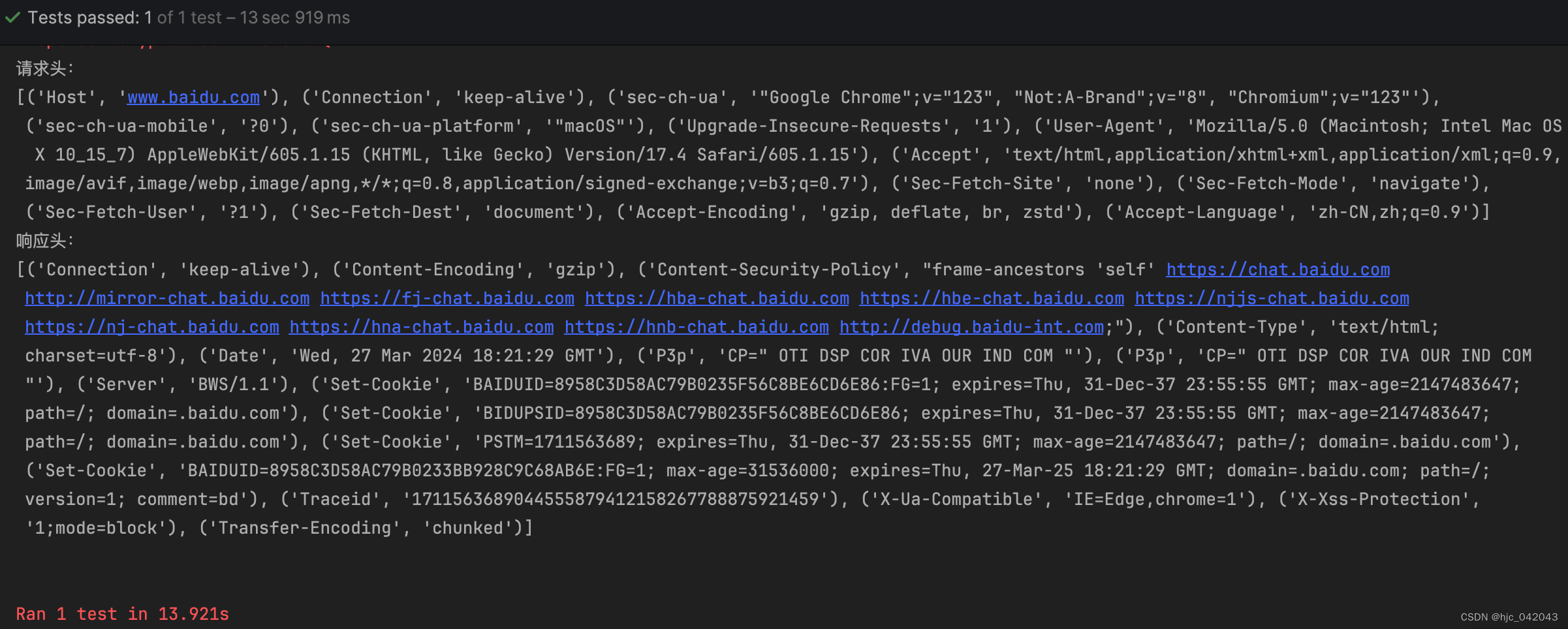
8. 如何从selenium获取请求和响应头
selenium 本是是不能直接获取到请求和响应头,我们还得借助第三方库seleniumwire模块,它可以说是 selenium和requests的结合体。
- 安装模块
pip install selenium-wire
- 代码示例
def test_selenium_headers(self):"""selenium获取请求头和响应头@return:"""user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15"# 导入seleniumwire库from seleniumwire import webdriver# 声明浏览器配置对象opt = webdriver.ChromeOptions()# 设置user-agent修改请求头opt.add_argument(f"--user-agent={user_agent}")# 打开浏览器,进到百度首页driver = webdriver.Chrome(service=self.service, options=opt)driver.get("https://www.baidu.com/")print("请求头:")for request in driver.requests:pprint(request.headers)breakprint("响应头:")for request in driver.requests:pprint(request.response.headers)breaktime.sleep(5)driver.quit()pass
注意
- find_element 底层返回的是WebElement类型,它可以来进行事件操作比如点击 click(),清空clear()等事件
- 对于 send_keys 方法是只有文本框类型才能操作
- selenium在使用 time.sleep()时,是从浏览器转圈结束开始计时算起。
- selenium下元素的属性使用 get_attribute(“src”)等同于 xpath的@href
- selenium为了加快打开chrome驱动,可以显示的把驱动路径设置进去,这样子 selenium就不用再去搜索驱动路径了,这是selenium4之后的新写法:
service = ChromService(executable_path="/usr/local/bin/chromedriver")
driver = webdriver.Chrome(service=service)
相关文章:
python爬虫之selenium4使用(万字讲解)
文章目录 一、前言二、selenium的介绍1、优点:2、缺点: 三、selenium环境搭建1、安装python模块2、selenium4新特性3、安装驱动WebDriver驱动选择驱动安装和测试 基础操作1、属性和方法2、单个元素定位通过id定位通过class_name定位一个元素通过xpath定位…...

【ARM 嵌入式 C 头文件系列 22 -- 头文件 stdint.h 介绍】
请阅读【嵌入式开发学习必备专栏 】 文章目录 C 头文件 stdint.h定长整数类型最小宽度整数类型最快最小宽度整数类型整数指针类型最大整数类型 C 头文件 stdint.h 在 C 语言中,头文件 <stdint.h> 是 C99 标准的一部分,旨在提供一组明确的整数类型…...
LabVIEW专栏三、探针和断点
探针和断点是LabVIEW调试的常用手段,该节以上一节的"测试耗时"为例 探针可以打在有线条的任何地方,打上后,经过这条线的所有最后一次的数值都会显示在探针窗口。断点可以打在程序框图的所有G代码对象,包括结构…...
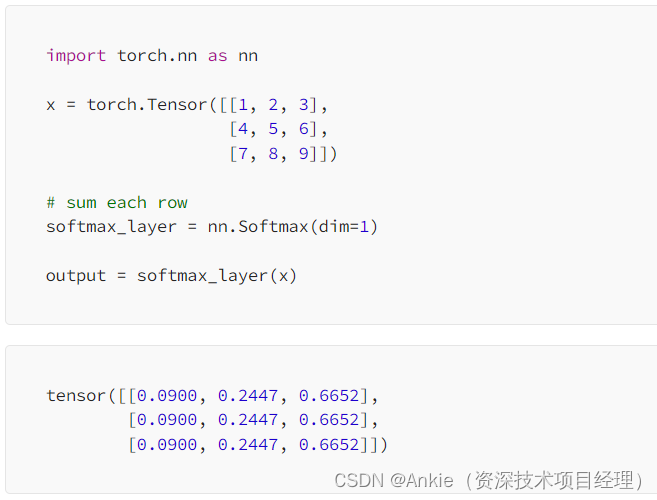
Transformer模型-softmax的简明介绍
今天介绍transformer模型的softmax softmax的定义和目的: softmax:常用于神经网络的输出层,以将原始的输出值转化为概率分布,从而使得每个类别的概率值在0到1之间,并且所有类别的概率之和为1。这使得Softmax函数特别适…...

记录一下做工厂的打印pdf程序
功能:在网页点击按钮调起本地的打印程序 本人想到的就是直接调起方式,网上大佬们说用注册表的形式来进行。 后面想到一种,在电脑开机时就开启,并在后台运行,等到有人去网页里面进行触发,这时候就有个问题&a…...
Linux网络编程一(协议、TCP协议、UDP、socket编程、TCP服务器端及客户端)
文章目录 协议1、分层模型结构2、网络应用程序设计模式3、ARP协议4、IP协议5、UDP协议6、TCP协议 Socket编程1、网络套接字(socket)2、网络字节序3、IP地址转换4、一系列函数5、TCP通信流程分析 第二次更新,自己再重新梳理一遍… 协议 协议:指一组规则&…...
Python读取Excel根据每行信息生成一个PDF——并自定义添加文本,可用于制作准考证
文章目录 有点小bug的:最终代码(无换行):有换行最终代码无bug根据Excel自动生成PDF,目录结构如上 有点小bug的: # coding=utf-8 import pandas as pd from reportlab.pdfgen import canvas from reportlab.lib.pagesizes import letter from reportlab.pdfbase import pdf…...

http: server gave HTTP response to HTTPS client 分析一下这个问题如何解决中文告诉我详细的解决方案
这个错误信息表明 Docker 客户端在尝试通过 HTTPS 协议连接到 Docker 仓库时,但是服务器却返回了一个 HTTP 响应。这通常意味着 Docker 仓库没有正确配置为使用 HTTPS,或者客户端没有正确配置以信任仓库的 SSL 证书。以下是几种可能的解决方案࿱…...
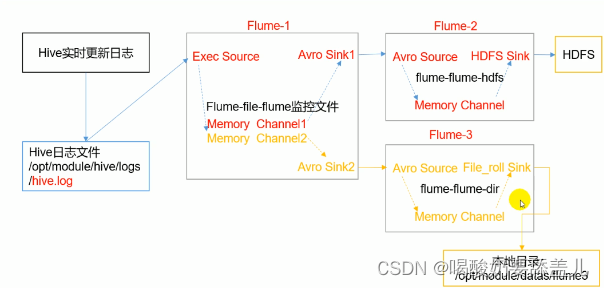
Flume学习笔记
视频地址:https://www.bilibili.com/video/BV1wf4y1G7EQ/ 定义 Flume是一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。 Flume高最要的作用就是实时读取服务器本地磁盘的数据,将数据写入HDFS。 官网:https://flume.apache.org/releases/content/1.9.0/…...
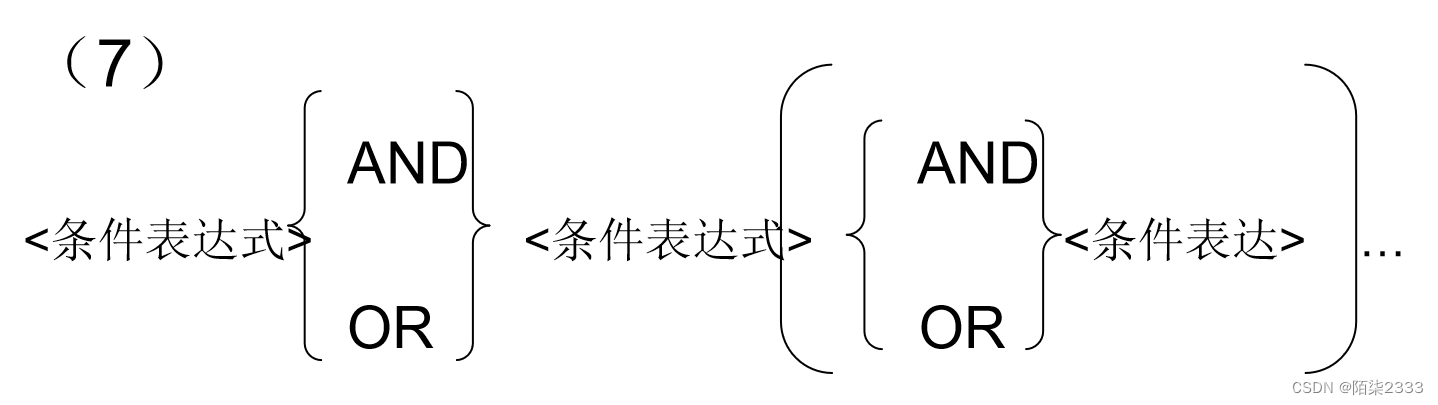
数据库系统概论(超详解!!!) 第三节 关系数据库标准语言SQL(Ⅳ)
1.集合查询 集合操作的种类 并操作UNION 交操作INTERSECT 差操作EXCEPT 参加集合操作的各查询结果的列数必须相同;对应项的数据类型也必须相同 查询计算机科学系的学生及年龄不大于19岁的学生。SELECT *FROM StudentWHERE Sdept CSUNIONSELECT *FROM StudentWHERE Sage&l…...

与谷歌“分家”两年后,SandboxAQ推出统一加密管理平台
3月27日,SandboxAQ宣布其AQtive Guard平台现已全面可用(GA),适用于所有行业,以防范人工智能驱动和量子攻击的威胁。前者是在两年前3月从谷歌母公司Alphabet分拆出来的初创公司,并在当时获得了“九位数”的融…...
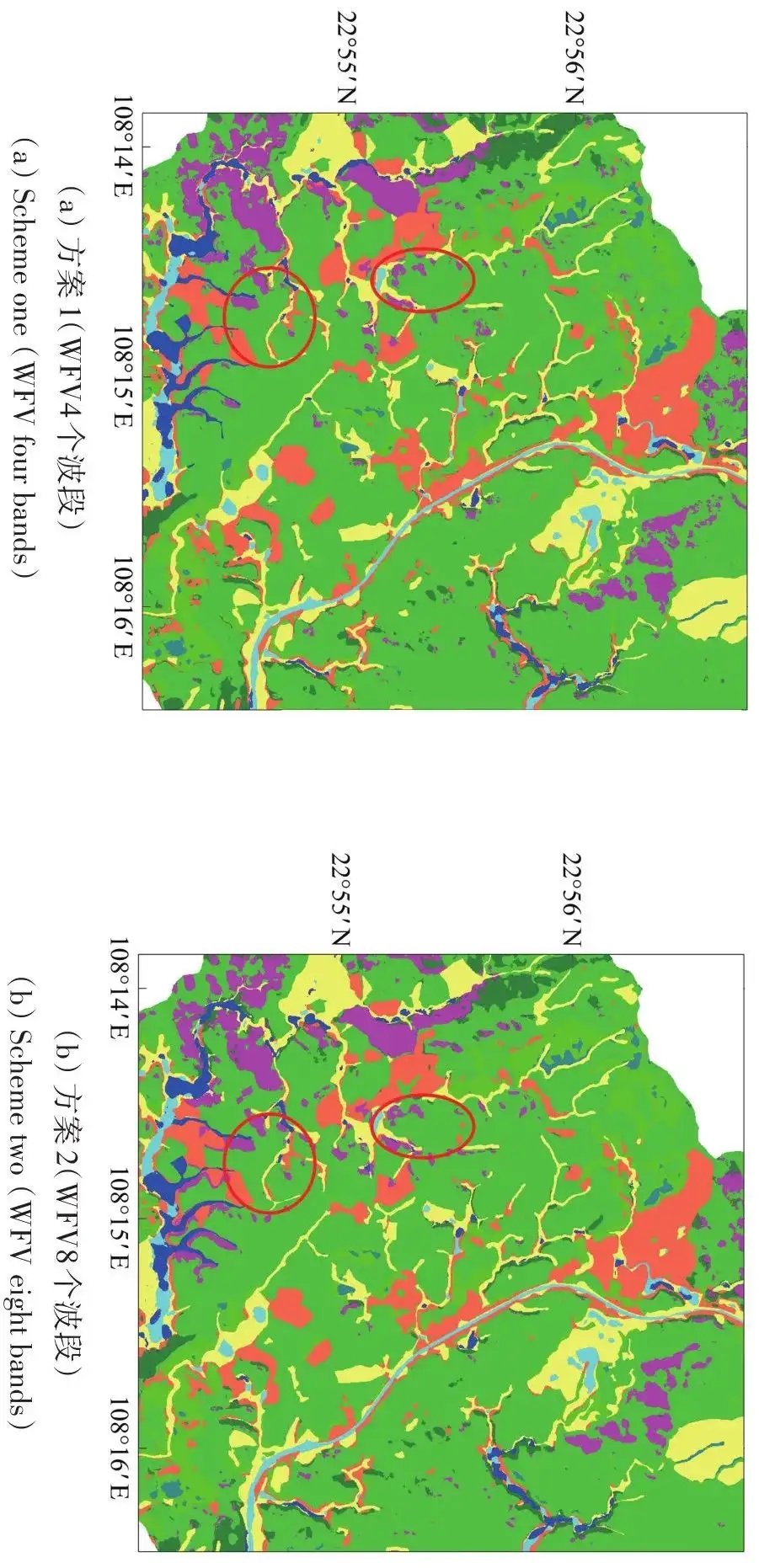
【卫星家族】 | 高分六号卫星影像及获取
1. 卫星简介 高分六号卫星(GF-6)于2018年6月2日在酒泉卫星发射中心成功发射,是高分专项中的一颗低轨光学遥感卫星,也是我国首颗精准农业观测的高分卫星,具有高分辨率、宽覆盖、高质量成像、高效能成像、国产化率高等特…...

XML与Xpath
XML与Xpath XML是一种具有某种层次结构的文件,Xpath则是解析这种文件的工具 接下来将会解释XML文件的结构和Xpath的基本使用,并且用Java语言进行操作展示。 XML结构 XML(可扩展标记语言)文件具有一种层次结构,由标签…...

【c++20】CPP-20-STL-Cookbook 学习笔记
Cpp20-STL-Cookbook-src简单的阅读笔记。c++20更好用了,比如STL 包含了一些这样的辅助函数,比如 make_pair() 和make_tuple() 等。 这些代码现在已经过时了,但是为了与旧代码兼容,会保留这些代码。比如 可以声明是一个std的string:Sum s1 {1u, 2.0, 3, 4.0f }?...

Python 之 Flask 框架学习
毕业那会使用过这个轻量级的框架,最近再来回看一下,依赖相关的就不多说了,直接从例子开始。下面示例中的 html 模板,千万记得要放到 templates 目录下。 Flask基础示例 hello world from flask import Flask, jsonify, url_fora…...
精品丨PowerBI负载测试和容量规划
当选择Power BI作为业务报表平台时,如何判断许可证的选择是否符合业务需求,价格占了主导因素。 Power BI的定价是基于SKU和服务器内核决定的,但是很多IT的负责人都不确定自己公司业务具体需要多少。 不幸的是,Power BI的容量和预期…...
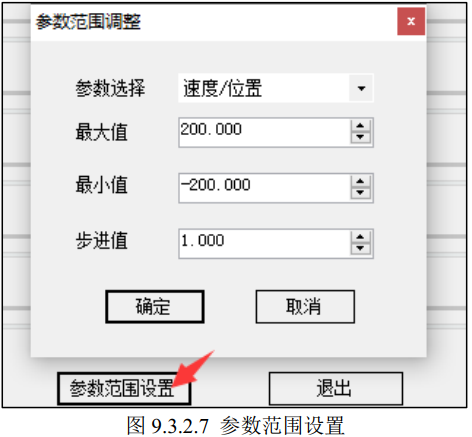
【算法-PID】
算法-PID ■ PID■ 闭环原理■ PID 控制流程■ PID 比例环节(Proportion)■ PID 积分环节(Integral)■ PID 微分环节(Differential) ■ 位置式PID,增量式PID介绍■ 位置式 PID 公式■ 增量式 PI…...
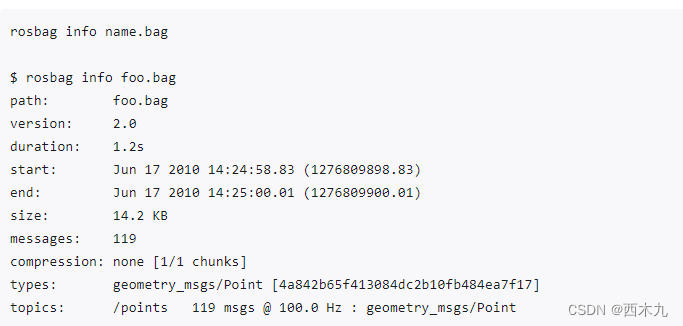
ros rosbag使用记录
rosbag: 1. rosbag record -a 记录当前所有消息(较少用)2. rosbag record -O bag_name.bag /topic 记录指定消息3. rosbag info 查阅bag文件信息4. rosbag play 播放bag文件内容5. python script 查看bag文件内容参考: 1. rosbag record -a 记…...

WebKit结构揭秘:探秘网页渲染的魔法之源
一、WebKit之心:渲染引擎的魔力 WebKit的渲染引擎是其核心所在,它犹如一位技艺高超的魔法师,将HTML、CSS和JavaScript的魔法咒语转化为绚丽的网页画面。它解析代码,绘制页面,让网页内容跃然屏上,展现出无尽…...
VSCode美化
今天有空收拾了一下VSCode,页面如下,个人觉得还是挺好看的~~ 1. 主题 Noctis 色彩较多,有种繁杂美。 我使用的是浅色主题的一款Noctis Hibernus 2. 字体 Maple Mono 官网:Maple-Font 我只安装了下图两个字体,使…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...