通用缓存存储设计实践
目录介绍
- 01.整体概述说明
- 1.1 项目背景介绍
- 1.2 遇到问题记录
- 1.3 基础概念介绍
- 1.4 设计目标
- 1.5 产生收益分析
- 02.市面存储方案
- 2.1 缓存存储有哪些
- 2.2 缓存策略有哪些
- 2.3 常见存储方案
- 2.4 市面存储方案说明
- 2.5 存储方案的不足
- 03.存储方案原理
- 3.1 Sp存储原理分析
- 3.2 MMKV存储原理分析
- 3.3 LruCache考量分析
- 3.4 DiskLru原理分析
- 3.5 DataStore分析
- 3.6 HashMap存储分析
- 3.7 Sqlite存储分析
- 3.8 使用存储的注意点
- 3.9 各种数据存储文件
- 04.通用缓存方案思路
- 4.1 如何兼容不同缓存
- 4.2 打造通用缓存Api
- 4.3 切换不同缓存方式
- 4.4 缓存的过期处理
- 4.5 缓存的阀值处理
- 4.6 缓存的线程安全性
- 4.7 缓存数据的迁移
- 4.8 缓存数据加密处理
- 4.9 缓存效率的对比
- 05.方案基础设计
- 5.1 整体架构图
- 5.2 UML设计图
- 5.3 关键流程图
- 5.4 模块间依赖关系
- 06.其他设计说明
- 6.1 性能设计说明
- 6.2 稳定性设计
- 6.3 灰度设计
- 6.4 降级设计
- 6.5 异常设计说明
- 6.6 兼容性设计
- 6.7 自测性设计
- 07.通用Api设计
- 7.1 如何依赖该库
- 7.2 初始化缓存库
- 7.3 切换各种缓存方案
- 7.4 数据的存和取
- 7.5 线程安全考量
- 7.6 查看缓存文件数据
- 7.7 如何选择合适方案
- 08.其他说明介绍
- 8.1 遇到的坑分析
- 8.2 遗留的问题
- 8.3 未来的规划
- 8.4 参考链接记录
01.整体概述说明
1.1 项目背景介绍
- 项目中很多地方使用缓存方案
- 有的用
sp,有的用mmkv,有的用lru,有的用DataStore,有的用sqlite,如何打造通用api切换操作不同存储方案?
- 有的用
- 缓存方案众多,且各自使用场景有差异,如何选择合适的缓存方式?
- 针对不同场景选择什么缓存方式,同时思考如何替换之前老的存储方案,而不用花费很大的时间成本!
- 针对不同的业务场景,不同的缓存方案。打造一套通用的方案
- 屏蔽各种缓存方式的差异性,暴露给外部开发者统一的API,外部开发者简化使用,提高开发效率和使用效率……
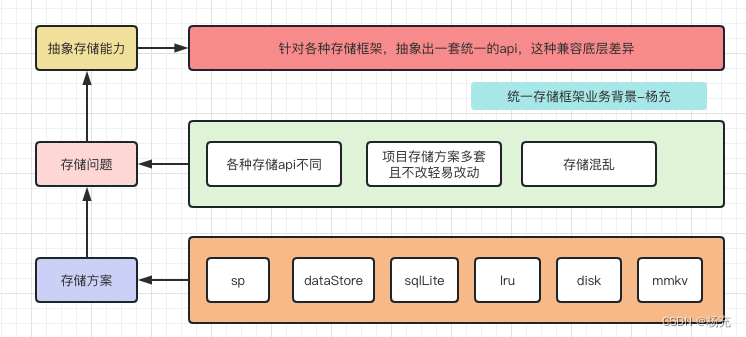
1.2 遇到问题记录
- 记录几个常见的问题
- 问题1:各种缓存方案,分别是如何保证数据安全的,其内部使用到了哪些锁?由于引入锁,给效率上带来了什么影响?
- 问题2:各种缓存方案,进程不安全是否会导致数据丢失,如何处理数据丢失情况?如何处理脏数据,其原理大概是什么?
- 问题3:各种缓存方案使用场景是什么?有什么缺陷,为了解决缺陷做了些什么?比如sp存在缺陷的替代方案是DataStore,为何这样?
- 问题4:各种缓存方案,他们的缓存效率是怎样的?如何对比?接入该库后,如何做数据迁移,如何覆盖操作?
- 思考一个K-V框架的设计
- 问题1-线程安全:使用K-V存储一般会在多线程环境中执行,因此框架有必要保证多线程并发安全,并且优化并发效率;
- 问题2-内存缓存:由于磁盘 IO 操作是耗时操作,因此框架有必要在业务层和磁盘文件之间增加一层内存缓存;
- 问题3-事务:由于磁盘 IO 操作是耗时操作,因此框架有必要将支持多次磁盘 IO 操作聚合为一次磁盘写回事务,减少访问磁盘次数;
- 问题4-事务串行化:由于程序可能由多个线程发起写回事务,因此框架有必要保证事务之间的事务串行化,避免先执行的事务覆盖后执行的事务;
- 问题5-异步或同步写回:由于磁盘 IO 是耗时操作,因此框架有必要支持后台线程异步写回;有时候又要求数据读写是同步的;
- 问题6-增量更新:由于磁盘文件内容可能很大,因此修改 K-V 时有必要支持局部修改,而不是全量覆盖修改;
- 问题7-变更回调:由于业务层可能有监听 K-V 变更的需求,因此框架有必要支持变更回调监听,并且防止出现内存泄漏;
- 问题8-多进程:由于程序可能有多进程需求,那么框架如何保证多进程数据同步?
- 问题9-可用性:由于程序运行中存在不可控的异常和 Crash,因此框架有必要尽可能保证系统可用性,尽量保证系统在遇到异常后的数据完整性;
- 问题10-高效性:性能永远是要考虑的问题,解析、读取、写入和序列化的性能如何提高和权衡;
- 问题11-安全性:如果程序需要存储敏感数据,如何保证数据完整性和保密性;
- 问题12-数据迁移:如果项目中存在旧框架,如何将数据从旧框架迁移至新框架,并且保证可靠性;
- 问题13-研发体验:是否模板代码冗长,是否容易出错。各种K—V框架使用体验如何?
- 常见存储框架设计思考导图
1.3 基础概念介绍
- 最初缓存的概念
- 提及缓存,可能很容易想到Http的缓存机制,
LruCache,其实缓存最初是针对于网络而言的,也是狭义上的缓存,广义的缓存是指对数据的复用。
- 提及缓存,可能很容易想到Http的缓存机制,
- 缓存容量,就是缓存的大小
- 每一种缓存,总会有一个最大的容量,到达这个限度以后,那么就须要进行缓存清理了框架。这个时候就需要删除一些旧的缓存并添加新的缓存。
1.4 设计目标
- 打造通用存储库:
- 设计一个缓存通用方案,其次,它的结构需要很简单,因为很多地方需要用到,再次,它得线程安全。灵活切换不同的缓存方式,使用简单。
- 内部开源该库:
- 作为技术沉淀,当作专项来推动进展。高复用低耦合,便于拓展,可快速移植,解决各个项目使用内存缓存,sp,mmkv,sql,lru,DataStore的凌乱。抽象一套统一的API接口。
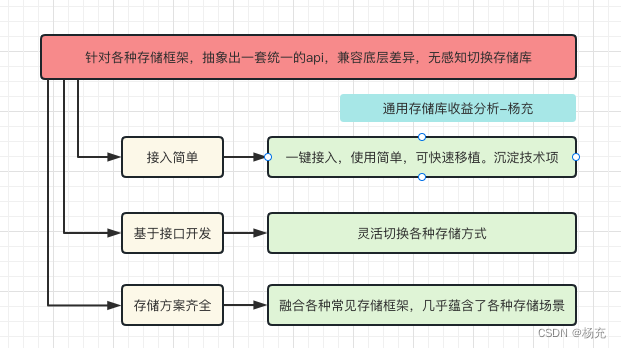
1.5 产生收益分析
- 统一缓存API兼容不同存储方案
- 打造通用api,抹平了sp,mmkv,sql,lru,dataStore等各种方案的差异性。简化开发者使用,功能强大而使用简单!
02.市面存储方案
2.1 缓存存储有哪些
- 比较常见的是内存缓存以及磁盘缓存。
- 内存缓存:这里的内存主要指的存储器缓存;磁盘缓存:这里主要指的是外部存储器,手机的话指的就是存储卡。
- 内存缓存:
- 通过预先消耗应用的一点内存来存储数据,便可快速的为应用中的组件提供数据,是一种典型的以空间换时间的策略。
- 磁盘缓存:
- 读取磁盘文件要比直接从内存缓存中读取要慢一些,而且需要在一个UI主线程外的线程中进行,因为磁盘的读取速度是不能够保证的,磁盘文件缓存显然也是一种以空间换时间的策略。
- 二级缓存:
- 内存缓存和磁盘缓存结合。比如,
LruCache将图片保存在内存,存取速度较快,退出APP后缓存会失效;而DiskLruCache将图片保存在磁盘中,下次进入应用后缓存依旧存在,它的存取速度相比LruCache会慢上一些。
- 内存缓存和磁盘缓存结合。比如,
2.2 缓存策略有哪些
- 缓存的核心思想主要是什么呢
- 一般来说,缓存核心步骤主要包含缓存的添加、获取和删除这三类操作。那么为什么还要删除缓存呢?不管是内存缓存还是硬盘缓存,它们的缓存大小都是有限的。
- 当缓存满了之后,再想其添加缓存,这个时候就需要删除一些旧的缓存并添加新的缓存。这个跟线程池满了以后的线程处理策略相似!
- 缓存的常见的策略有那些
- FIFO(first in first out):先进先出策略,相似队列。
- LFU(less frequently used):最少使用策略,
RecyclerView的缓存采用了此策略。 - LRU(least recently used):最近最少使用策略,
Glide在进行内存缓存的时候采用了此策略。
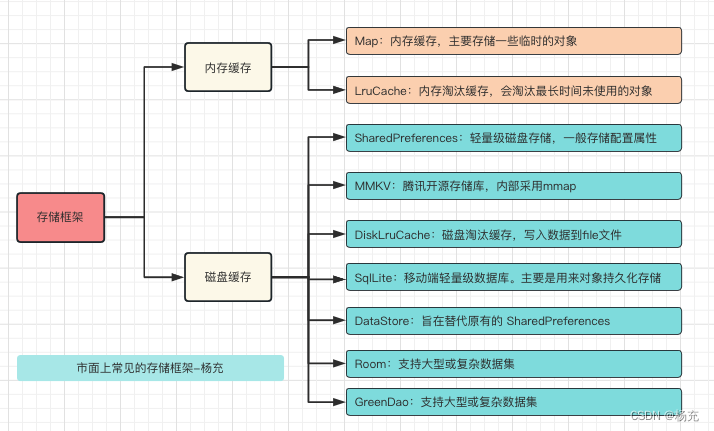
2.3 常见存储方案
- 内存缓存:存储在内存中,如果对象销毁则内存也会跟随销毁。如果是静态对象,那么进程杀死后内存会销毁。
- Map,LruCache等等
- 磁盘缓存:后台应用有可能会被杀死,那么相应的内存缓存对象也会被销毁。当你的应用重新回到前台显示时,你需要用到缓存数据时,这个时候可以用磁盘缓存。
- SharedPreferences,MMKV,DiskLruCache,SqlLite,DataStore,Room,Realm,GreenDao等等
2.4 市面存储方案说明
- 内存缓存
- Map:内存缓存,一般用HashMap存储一些数据,主要存储一些临时的对象
- LruCache:内存淘汰缓存,内部使用LinkedHashMap,会淘汰最长时间未使用的对象
- 磁盘缓存
- SharedPreferences:轻量级磁盘存储,一般存储配置属性,线程安全。建议不要存储大数据,不支持跨进程!
- MMKV:腾讯开源存储库,内部采用mmap。
- DiskLruCache:磁盘淘汰缓存,写入数据到file文件
- SqlLite:移动端轻量级数据库。主要是用来对象持久化存储。
- DataStore:旨在替代原有的 SharedPreferences,支持SharedPreferences数据的迁移
- Room/Realm/GreenDao:支持大型或复杂数据集
- 其他开源缓存库
- ACache:一款高效二级存储库,采用内存缓存和磁盘缓存
2.5 存储方案的不足
- 存储方案SharedPreferences的不足
- 1.SP用内存层用HashMap保存,磁盘层则是用的XML文件保存。每次更改,都需要将整个HashMap序列化为XML格式的报文然后整个写入文件。
- 2.SP读写文件不是类型安全的,且没有发出错误信号的机制,缺少事务性API
- 3.commit() / apply()操作可能会造成ANR问题
- 存储方案MMKV的不足
- 1.没有类型信息,不支持getAll。由于没有记录类型信息,MMKV无法自动反序列化,也就无法实现getAll接口。
- 2.需要引入so,增加包体积:引入MMKV需要增加的体积还是不少的。
- 3.文件只增不减:MMKV的扩容策略还是比较激进的,而且扩容之后不会主动trim size。
- 存储方案DataStore的不足
- 1.只是提供异步API,没有提供同步API方法。在进行大量同步存储的时候,使用runBlocking同步数据可能会卡顿。
- 2.对主线程执行同步 I/O 操作可能会导致 ANR 或界面卡顿。可以通过从 DataStore 异步预加载数据来减少这些问题。
03.存储方案原理
3.1 Sp存储原理分析
- SharedPreferences,它是一个轻量级的存储类,特别适合用于保存软件配置参数。
- 轻量级,以键值对的方式进行存储。采用的是xml文件形式存储在本地,程序卸载后会也会一并被清除,不会残留信息。线程安全的。
- 它有一些弊端如下所示
- 对文件IO读取,因此在IO上的瓶颈是个大问题,因为在每次进行get和commit时都要将数据从内存写入到文件中,或从文件中读取。
- 多线程场景下效率较低,在get操作时,会锁定SharedPreferences对象,互斥其他操作,而当put,commit时,则会锁定Editor对象,使用写入锁进行互斥,在这种情况下,效率会降低。
- 不支持跨进程通讯,由于每次都会把整个文件加载到内存中,不建议存储大的文件内容,比如大json。
- 有一些使用上的建议如下
- 建议不要存储较大数据;频繁修改的数据修改后统一提交而不是修改过后马上提交;在跨进程通讯中不去使用;键值对不宜过多
- 读写操作性能分析
- 第一次通过
Context.getSharedPreferences()进行初始化时,对xml文件进行一次读取,并将文件内所有内容(即所有的键值对)缓到内存的一个Map中,接下来所有的读操作,只需要从这个Map中取就可以
- 第一次通过
3.2 MMKV存储原理分析
- 早期微信的需求
- 微信聊天对话内容中的特殊字符所导致的程序崩溃是一类很常见、也很需要快速解决的问题;而哪些字符会导致程序崩溃,是无法预知的。
- 只能等用户手机上的微信崩溃之后,再利用类似时光倒流的回溯行为,看看上次软件崩溃的最后一瞬间,用户收到或者发出了什么消息,再用这些消息中的文字去尝试复现发生过的崩溃,最终试出有问题的字符,然后针对性解决。
- 该需求对应的技术考量
- 考量1:把聊天页面的显示文字写到手机磁盘里,才能在程序崩溃、重新启动之后,通过读取文件的方式来查看。但这种方式涉及到io流读写,且消息多会有性能问题。
- 考量2:App程序都崩溃了,如何保证要存储的内容,都写入到磁盘中呢?
- 考量3:保存聊天内容到磁盘的行为,这个做成同步还是异步呢?如果是异步,如何保证聊天消息的时序性?
- 考量4:如何存储数据是同步行为,针对群里聊天这么多消息,如何才能避免卡顿呢?
- 考量5:存储数据放到主线程中,用户在群聊天页面猛滑消息,如何爆发性集中式对磁盘写入数据?
- MMKV存储框架介绍
- MMKV 是基于 mmap 内存映射的 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。
- MMKV设计的原理
- 内存准备:通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
- 数据组织:数据序列化方面我们选用 protobuf 协议,pb 在性能和空间占用上都有不错的表现。
- 写入优化:考虑到主要使用场景是频繁地进行写入更新,需要有增量更新的能力。考虑将增量 kv 对象序列化后,append 到内存末尾。
- 空间增长:使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。需要在性能和空间上做个折中。
- MMKV诞生的背景
- 针对该业务,高频率,同步,大量数据写入磁盘的需求。不管用sp,还是store,还是disk,还是数据库,只要在主线程同步写入磁盘,会很卡。
- 解决方案就是:使用内存映射mmap的底层方法,相当于系统为指定文件开辟专用内存空间,内存数据的改动会自动同步到文件里。
- 用浅显的话说:MMKV就是实现用「写入内存」的方式来实现「写入磁盘」的目标。内存的速度多快呀,耗时几乎可以忽略,这样就把写磁盘造成卡顿的问题解决了。
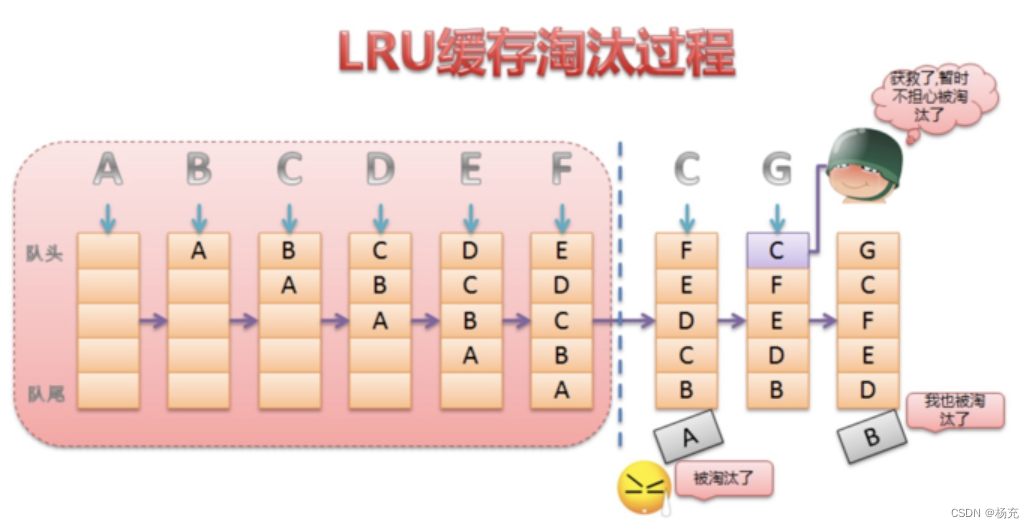
3.3 LruCache考量分析
- 在LruCache的源码中,关于LruCache有这样的一段介绍:
- cache对象通过一个强引用来访问内容。每次当一个item被访问到的时候,这个item就会被移动到一个队列的队首。当一个item被添加到已经满了的队列时,这个队列的队尾的item就会被移除。
- LruCache核心思想
- LRU是近期最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。采用LRU算法的缓存有两种:LrhCache和DiskLruCache,分别用于实现内存缓存和硬盘缓存,其核心思想都是LRU缓存算法。
- LruCache使用是计数or计量
- 使用计数策略:1、Message 消息对象池:最多缓存 50 个对象;2、OkHttp 连接池:默认最多缓存 5 个空闲连接;3、数据库连接池
- 使用计量策略:1、图片内存缓存;2、位图池内存缓存
- 那么思考一下如何理解 计数 or 计量 ?针对计数策略使用Lru仅仅只统计缓存单元的个数,针对计量则要复杂一点。
- LruCache策略能否增加灵活性
- 在缓存容量满时淘汰,除了这个策略之外,能否再增加一些辅助策略,例如在 Java 堆内存达到某个阈值后,对 LruCache 使用更加激进的清理策略。
- 比如:Glide 除了采用 LRU 策略淘汰最早的数据外,还会根据系统的内存紧张等级 onTrimMemory(level) 及时减少甚至清空 LruCache。
/*** 这里是参考glide中的lru缓存策略,低内存的时候清除* @param level level级别*/ public void trimMemory(int level) {if (level >= android.content.ComponentCallbacks2.TRIM_MEMORY_BACKGROUND) {clearMemory();} else if (level >= android.content.ComponentCallbacks2.TRIM_MEMORY_UI_HIDDEN || level == android.content.ComponentCallbacks2.TRIM_MEMORY_RUNNING_CRITICAL) {trimToSize(maxSize() / 2);} }- 关于Lru更多的原理解读,可以看:AppLruCache
3.4 DiskLru原理分析
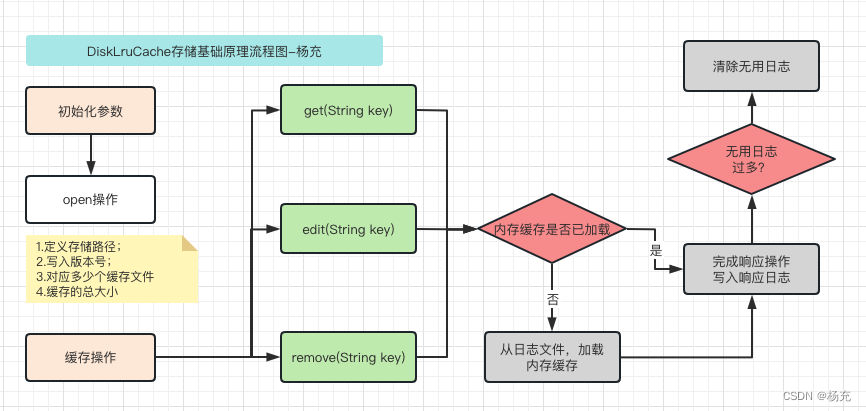
- DiskLruCache 用于实现存储设备缓存,即磁盘缓存,它通过将缓存对象写入文件系统从而实现缓存的效果。
- DiskLruCache最大的特点就是持久化存储,所有的缓存以文件的形式存在。在用户进入APP时,它根据日志文件将DiskLruCache恢复到用户上次退出时的情况,日志文件journal保存每个文件的下载、访问和移除的信息,在恢复缓存时逐行读取日志并检查文件来恢复缓存。
- DiskLruCache缓存基础原理流程图
- 关于DiskLruCache更多的原理解读,可以看:AppLruDisk
3.5 DataStore分析
- 为何会有DataStore
- DataStore 被创造出来的目标就是替代 Sp,而它解决的 SharedPreferences 最大的问题有两点:一是性能问题,二是回调问题。
- DataStore优势是异步Api
- DataStore 的主要优势之一是异步API,所以本身并未提供同步API调用,但实际上可能不一定始终能将周围的代码更改为异步代码。
- 提出一个问题和思考
- 如果使用现有代码库采用同步磁盘 I/O,或者您的依赖项不提供异步API,那么如何将DataStore存储数据改成同步调用?
- 使用阻塞式协程消除异步差异
- 使用 runBlocking() 从 DataStore 同步读取数据。runBlocking()会运行一个新的协程并阻塞当前线程直到内部逻辑完成,所以尽量避免在UI线程调用。
- 频繁使用阻塞式协程会有问题吗
- 要注意的一点是,不用在初始读取时调用runBlocking,会阻塞当前执行的线程,因为初始读取会有较多的IO操作,耗时较长。
- 更为推荐的做法则是先异步读取到内存后,后续有需要可直接从内存中拿,而非运行同步代码阻塞式获取。
3.6 HashMap存储分析
- 内存缓存的场景
- 比如 SharedPreferences 存储中,就做了内存缓存的操作。
3.7 Sqlite存储分析
- 注意:缓存的数据库是存放在/data/data/databases/目录下,是占用内存空间的,如果缓存累计,容易浪费内存,需要及时清理缓存。
3.8 使用缓存注意点
- 在使用内存缓存的时候须要注意防止内存泄露,使用磁盘缓存的时候注意确保缓存的时效性
- 针对SharedPreferences使用建议有:
- 因为 SharedPreferences 虽然是全量更新的模式,但只要把保存的数据用合适的逻辑拆分到多个不同的文件里,全量更新并不会对性能造成太大的拖累。
- 它设计初衷是轻量级,建议当存储文件中key-value数据超过30个,如果超过30个(这个只是一个假设),则开辟一个新的文件进行存储。建议不同业务模块的数据分文件存储……
- 针对MMKV使用建议有:
- 如果项目中有高频率,同步存储数据,使用MMKV更加友好。
- 针对DataStore使用建议有:
- 建议在初始化的时候,使用全局上下文Context给DataStore设置存储路径。
- 针对LruCache缓存使用建议:
- 如果你使用“计量”淘汰策略,需要重写 SystemLruCache#sizeOf() 测量缓存单元的内存占用量,否则缓存单元的大小默认视为 1,相当于 maxSize 表示的是最大缓存数量。
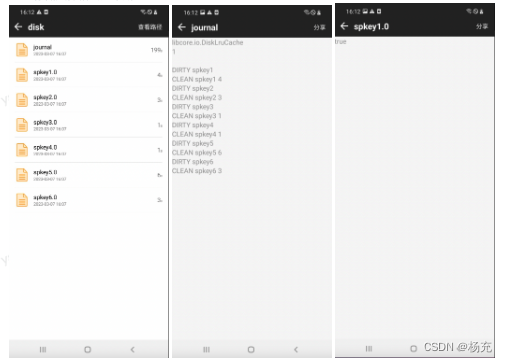
3.9 各种数据存储文件
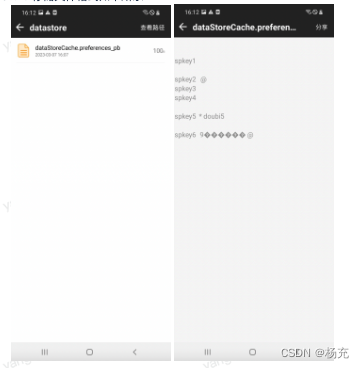
- SharedPreferences 存储文件格式如下所示
<?xml version='1.0' encoding='utf-8' standalone='yes' ?> <map><string name="name">杨充</string><int name="age" value="28" /><boolean name="married" value="true" /> </map> - MMKV 存储文件格式如下所示
- MMKV的存储结构,分了两个文件,一个数据文件,一个校验文件crc结尾。大概如下所示:
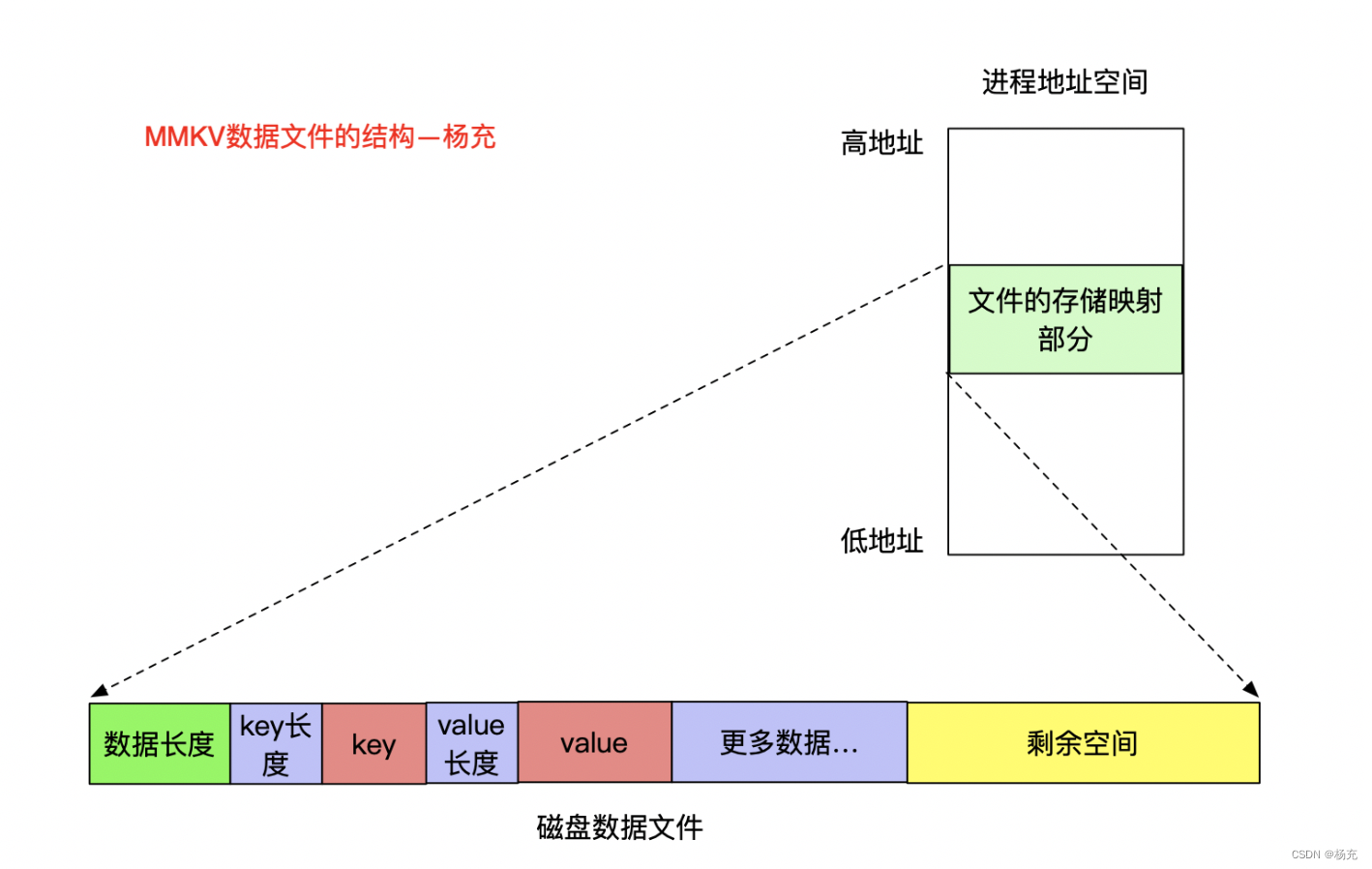

- 这种设计最直接问题就是占用空间变大了很多,举一个例子,只存储了一个字段,但是为了方便MMAP映射,磁盘直接占用了8k的存储。
- LruDiskCache 存储文件格式如下所示
- DataStore 存储文件格式如下所示
04.通用缓存方案思路
4.1 如何兼容不同缓存
- 定义通用的存储接口
- 不同的存储方案,由于api不一样,所以难以切换操作。要是想兼容不同存储方案切换,就必须自己制定一个通用缓存接口。
- 定义接口,然后各个不同存储方案实现接口,重写抽象方法。调用的时候,获取接口对象调用api,这样就可以统一Api
- 定义一个接口,这个接口有什么呢?
- 主要是存和取各种基础类型数据,比如saveInt/readInt;saveString/readString等通用抽象方法
4.2 打造通用缓存Api
- 通用缓存Api设计思路:
- 通用一套api + 不同接口实现 + 代理类 + 工厂模型
- 定义缓存的通用API接口,这里省略部分代码
interface ICacheable {fun saveXxx(key: String, value: Int)fun readXxx(key: String, default: Int = 0): Intfun removeKey(key: String)fun totalSize(): Longfun clearData() } - 基于接口而非实现编程的设计思想
- 将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低耦合性,提高扩展性。
4.3 切换不同缓存方式
- 传入不同类型方便创建不同存储方式
- 隐藏存储方案创建具体细节,开发者只需要关心所需产品对应的工厂,无须关心创建细节,甚至无须知道具体存储方案的类名。需要符合开闭原则
- 那么具体该怎么实现呢?
- 看到下面代码是不是有种很熟悉的感觉,没错,正是使用了工厂模式,灵活切换不同的缓存方式。但针对应用层调用api却感知不到影响。
public static ICacheable getCacheImpl(Context context, @CacheConstants.CacheType int type) {if (type == CacheConstants.CacheType.TYPE_DISK) {return DiskFactory.create().createCache(context);} else if (type == CacheConstants.CacheType.TYPE_LRU) {return LruCacheFactory.create().createCache(context);} else if (type == CacheConstants.CacheType.TYPE_MEMORY) {return MemoryFactory.create().createCache(context);} else if (type == CacheConstants.CacheType.TYPE_MMKV) {return MmkvFactory.create().createCache(context);} else if (type == CacheConstants.CacheType.TYPE_SP) {return SpFactory.create().createCache(context);} else if (type == CacheConstants.CacheType.TYPE_STORE) {return StoreFactory.create().createCache(context);} else {return MmkvFactory.create().createCache(context);} }
4.4 缓存的过期处理
- 说一个使用场景
- 比如你准备做WebView的资源拦截缓存,针对模版页面,为了提交加载速度。会缓存css,js,图片等资源到本地。那么如何选择存储方案,如何处理过期问题?
- 思考一下该问题
- 比如WebView缓存方案是数据库存储,db文件。针对缓存数据,猜想思路可能是Lru策略,或者标记时间清除过期文件。
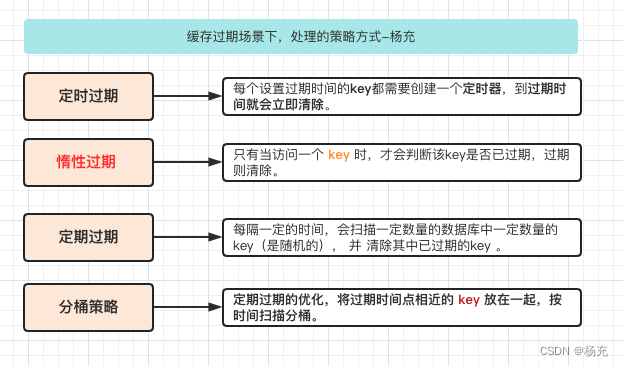
- 那么缓存过期处理的策略有哪些
- 定时过期:每个设置过期时间的key都需要创建⼀个定时器,到过期时间就会立即清除。
- 惰性过期:只有当访问⼀个 key 时,才会判断该key是否已过期,过期则清除。
- 定期过期:每隔⼀定的时间,会扫描⼀定数量的数据库的 expires 字典中⼀定数量的key(是随机的), 并 清除其中已过期的key 。
- 分桶策略:定期过期的优化,将过期时间点相近的 key 放在⼀起,按时间扫描分桶。
4.5 缓存的阀值处理
- 淘汰一个最早的节点就足够吗?以Lru缓存为案例做分析……
- 标准的 LRU 策略中,每次添加数据时最多只会淘汰一个数据,但在 LRU 内存缓存中,只淘汰一个数据单元往往并不够。
- 例如在使用 “计量” 的内存图片缓存中,在加入一个大图片后,只淘汰一个图片数据有可能依然达不到最大缓存容量限制。
- 那么在LRUCache该如何做呢?
- 在复用 LinkedHashMap 实现 LRU 内存缓存时,前文提到的 LinkedHashMap#removeEldestEntry() 淘汰判断接口可能就不够看了,因为它每次最多只能淘汰一个数据单元。
- LruCache是如何解决这个问题
- 这个地方就需要重写LruCache中的sizeOf()方法,然后拿到key和value对象计算其内存大小。
4.6 缓存的线程安全性
- 为何要强调缓存方案线程安全性
- 缓存虽好,用起来很快捷方便,但在使用过程中,大家一定要注意数据更新和线程安全,不要出现脏数据。
- 针对LruCache中使用LinkedHashMap读写不安全情况
- 保证LruCache的线程安全,在put,get等核心方法中,添加synchronized锁。这里主要是synchronized (this){ put操作 }
- 针对DiskLruCache读写不安全的情况
- DiskLruCache 管理多个 Entry(key-values),因此锁粒度应该是 Entry 级别的。
- get 和 edit 方法都是同步方法,保证内部的 Entry Map 的安全访问,是保证线程安全的第一步。
4.7 缓存数据的迁移
- 如何将Sp数据迁移到DataStore
- 通过属性委托的方式创建DataStore,基于已有的SharedPreferences文件进行创建DataStore。将sp文件名,以参数的形式传入preferencesDataStore,DataStore会自动将该文件中的数据进行转换。
val Context.dataStore: DataStore<Preferences> by preferencesDataStore(name = "user_info",produceMigrations = { context ->listOf(SharedPreferencesMigration(context, "sp_file_name"))}) - 如何将sp数据迁移到MMKV
- MMKV 提供了 importFromSharedPreferences() 函数,可以比较方便地迁移数据过来。
- MMKV 还额外实现了一遍 SharedPreferences、SharedPreferences.Editor 这两个 interface。
MMKV preferences = MMKV.mmkvWithID("myData"); // 迁移旧数据 {SharedPreferences old_man = getSharedPreferences("myData", MODE_PRIVATE);preferences.importFromSharedPreferences(old_man);old_man.edit().clear().commit(); } - 思考一下,MMKV框架实现了sp的两个接口,即磨平了数据迁移差异性
- 那么使用这个方式,借鉴该思路,你能否尝试用该方法,去实现LruDiskCache方案的sp数据一键迁移。
4.8 缓存数据加密
- 思考一下,如果让你去设计数据的加密,你该怎么做?
- 具体可以参考MMKV的数据加密过程。
4.9 缓存效率的对比
- 测试数据
- 测试写入和读取。注意分别使用不同的方式,测试存储或获取相同的数据(数据为int类型数字,还有String类型长字符串)。然后查看耗时时间的长短……
- 比较对象
- SharePreferences/DataStore/MMKV/LruDisk/Room。使用华为手机测试
- 测试数据案例1


- 在主线程中测试数据,同步耗时时间(主线程还有其他的耗时)跟异步场景有较大差别。
- 测试数据案例2

- 测试1000组长字符串数据,MMKV 就不具备优势了,反而成了耗时最久的;而这时候的冠军就成了 DataStore,并且是遥遥领先。
- 最后思考说明
- 从最终的数据来看,这几种方案都不是很慢。虽然这半秒左右的主线程耗时看起来很可怕,但是要知道这是 1000 次连续写入的耗时。
- 而在真正写程序的时候,怎么会一次性做 1000 次的长字符串的写入?所以真正在项目中的键值对写入的耗时,不管你选哪个方案,都会比这份测试结果的耗时少得多的,都少到了可以忽略的程度,这是关键。
05.方案基础设计
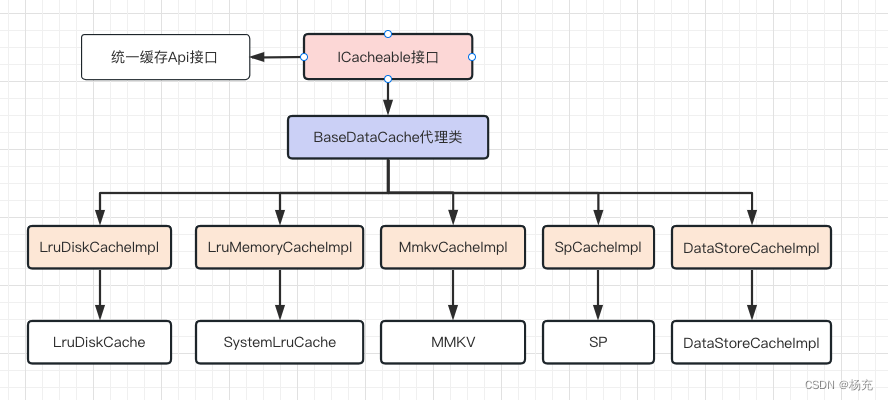
5.1 整体架构图
- 统一存储方案的架构图
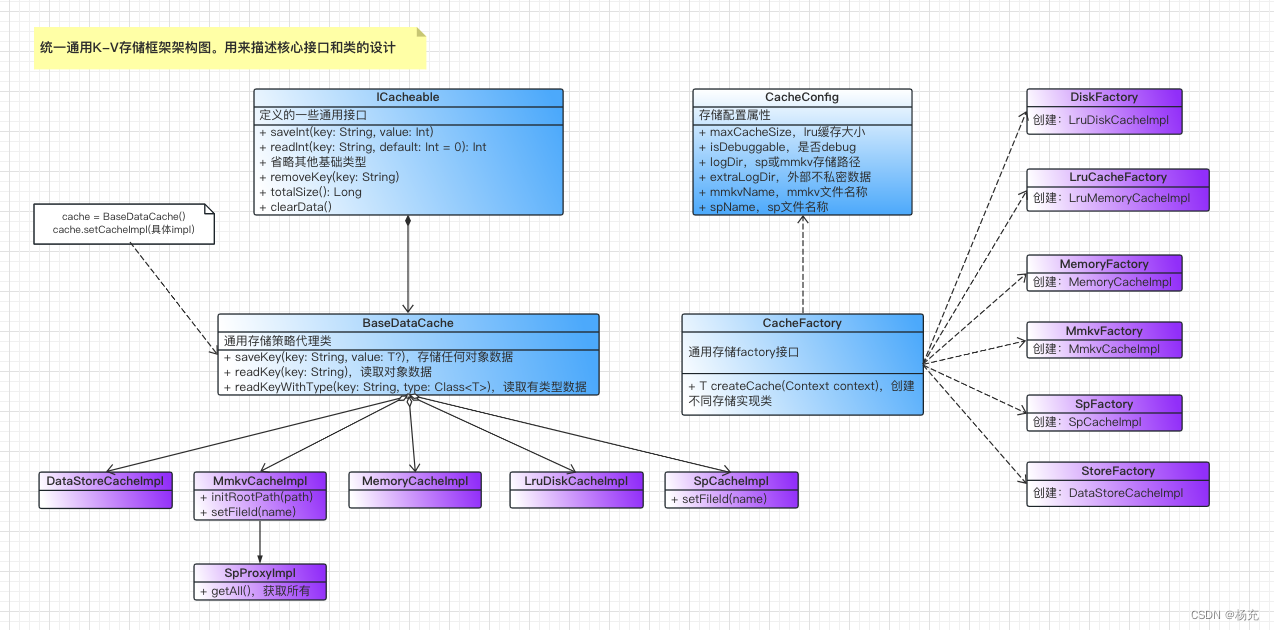
5.2 UML设计图
- 通用存储方案UML设计图
5.3 代码说明图
- 项目中代码相关说明图
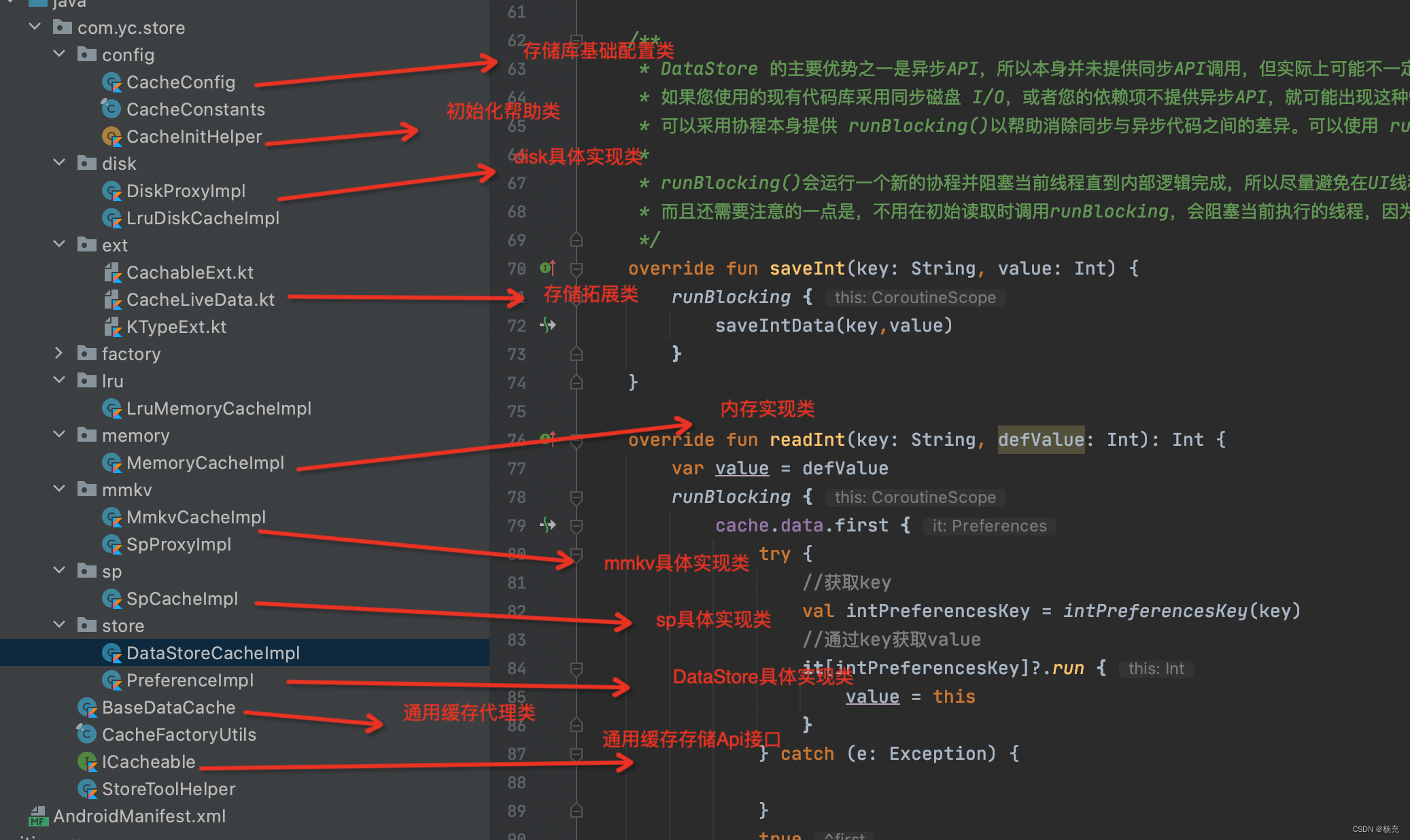
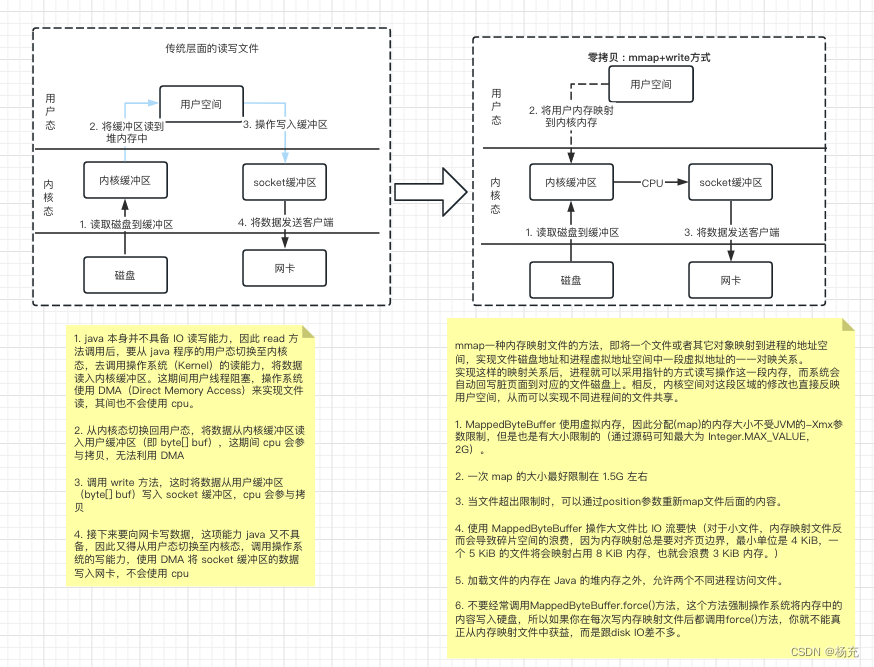
5.4 关键流程图
- mmap的零拷贝流程图
5.5 模块间依赖关系
- 存储库依赖的关系
- MMKV需要依赖一些腾讯开源库的服务;DataStore存储需要依赖datastore相关的库;LruDisk存储需要依赖disk库
- 如果你要拓展其他的存储方案,则需要添加其依赖。需要注意,添加的库使用compileOnly。
06.其他设计说明
6.1 性能设计
- 关于基础库性能如何考量
- 具体性能可以参考测试效率的对比。
6.2 稳定性设计
- 针对多进程初始化
- 遇到问题:对于多进程在Application的onCreate创建几次,导致缓存存储库初始化了多次。
- 问题分析:该场景不是该库的问题,建议判断是否是主进程,如果是则进行初始化。
- 如何解决:思路是获取当前进程名,并与主进程对比,来判断是否为主进程。具体可以参考:优雅判断是否是主进程
6.3 灰度设计
- 暂无灰度设计
6.4 降级设计
- 由于缓存方式众多,在该库中配置了降级,如何设置降级
//设置是否是debug模式 CacheConfig cacheConfig = builder.monitorToggle(new IMonitorToggle() {@Overridepublic boolean isOpen() {//todo 是否降级,如果降级,则不使用该功能。留给AB测试开关return true;}})//创建.build(); CacheInitHelper.INSTANCE.init(this,cacheConfig); - 降级后的逻辑处理是
- 如果是降级逻辑,则默认使用谷歌官方存储框架SharedPreferences。默认是不会降级的!
if (CacheInitHelper.INSTANCE.isToggleOpen()){//如果是降级,则默认使用spreturn SpFactory.create().createCache(); }
6.5 异常设计说明
- DataStore初始化遇到的坑
- 遇到问题:不能将DataStore初始化代码写到Activity里面去,否则重复进入Activity并使用Preferences DataStore时,会尝试去创建一个同名的.preferences_pb文件。
- 问题分析:SingleProcessDataStore#check(!activeFiles.contains(it)),该方法会检查如果判断到activeFiles里已经有该文件,直接抛异常,即不允许重复创建。
- 如何解决:在项目中只在顶层调用一次 preferencesDataStore 方法,这样可以更轻松地将 DataStore 保留为单例。
- MMKV遇到的坑说明
- MMKV 是有数据损坏的概率的,MMKV 的 GitHub wiki 页面显示,微信的 iOS 版平均每天有 70 万次的数据校验不通过(即数据损坏)。
6.6 兼容性设计
- MMKV数据迁移比较难
- MMKV都是按字节进行存储的,实际写入文件把类型擦除了,这也是MMKV不支持getAll的原因,虽然说getAll用的不多问题不大,但是MMKV因此就不具备导出和迁移的能力。
- 比较好的方案是每次存储,多用一个字节来存储数据类型,这样占用的空间也不会大很多,但是具备了更好的可扩展性。
6.7 自测性设计
- MMKV不太方便查看数据和解析数据
- 官方目前支持了5个平台,Android、iOS、Win、MacOS、python,但是没有提供解析数据的工具,数据文件和crc都是字节码,除了中文能看出一些内容,直接查看还是存在大量乱码。
- 比如线上出了问题,把用户的存储文件捞上来,还得替换到系统目录里,通过代码断点去看,这也太不方便了。
- Sp,FastSp,DiskCache,Store等支持查看文件解析数据
- 傻瓜式的查看缓存文件,操作缓存文件。具体看该库:MonitorFileLib磁盘查看工具
07.通用Api设计
7.1 如何依赖该库
- 依赖该库如下所示
//通用缓存存储库,支持sp,fastsp,mmkv,lruCache,DiskLruCache等 implementation 'com.github.yangchong211.YCCommonLib:AppBaseStore:1.4.8'
7.2 初始化缓存库
- 通用存储库初始化
CacheConfig.Builder builder = CacheConfig.Companion.newBuilder(); //设置是否是debug模式 CacheConfig cacheConfig = builder.debuggable(BuildConfig.DEBUG)//设置外部存储根目录.extraLogDir(null)//设置lru缓存最大值.maxCacheSize(100)//内部存储根目录.logDir(null)//创建.build(); CacheInitHelper.INSTANCE.init(MainApplication.getInstance(),cacheConfig); //最简单的初始化 //CacheInitHelper.INSTANCE.init(CacheConfig.Companion.newBuilder().build());
7.3 切换各种缓存方案
- 如何调用api切换各种缓存方案
//这里可以填写不同的type val cacheImpl = CacheFactoryUtils.getCacheImpl(CacheConstants.CacheType.TYPE_SP)
7.4 数据的存和取
- 存储数据和获取数据
//存储数据 dataCache.saveBoolean("cacheKey1",true); dataCache.saveFloat("cacheKey2",2.0f); dataCache.saveInt("cacheKey3",3); dataCache.saveLong("cacheKey4",4); dataCache.saveString("cacheKey5","doubi5"); dataCache.saveDouble("cacheKey6",5.20);//获取数据 boolean data1 = dataCache.readBoolean("cacheKey1", false); float data2 = dataCache.readFloat("cacheKey2", 0); int data3 = dataCache.readInt("cacheKey3", 0); long data4 = dataCache.readLong("cacheKey4", 0); String data5 = dataCache.readString("cacheKey5", ""); double data6 = dataCache.readDouble("cacheKey5", 0.0); - 也可以通过注解的方式存储数据
class NormalCache : DataCache() {@BoolCache(KeyConstant.HAS_ACCEPTED_PARENT_AGREEMENT, false)var hasAcceptParentAgree: Boolean by this }//如何使用 object CacheHelper {//常规缓存数据,记录一些重要的信息,慎重清除数据private val normal: NormalCache by lazy {NormalCache().apply {setCacheImpl(DiskCache.Builder().setFileId("NormalCache").build())}}fun normal() = normal }//存数据 CacheHelper.normal().hasAcceptParentAgree = true //取数据 val hasAccept = CacheHelper.normal().hasAcceptParentAgree
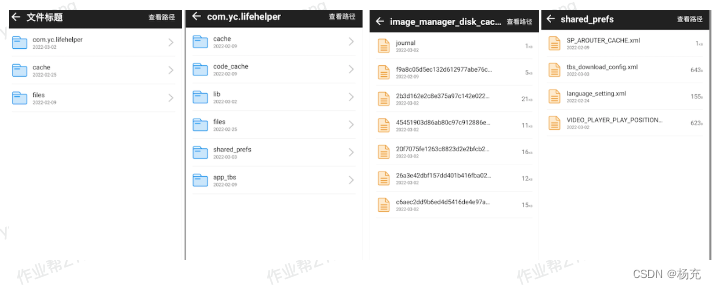
7.5 查看缓存文件数据
- android缓存路径查看方法有哪些呢?
- 将手机打开开发者模式并连接电脑,在pc控制台输入cd /data/data/目录,使用adb主要是方便测试(删除,查看,导出都比较麻烦)。
- 如何简单快速,傻瓜式的查看缓存文件,操作缓存文件,那么该项目小工具就非常有必要呢!采用可视化界面读取缓存数据,方便操作,直观也简单。
- 一键接入该工具
- FileExplorerActivity.startActivity(this);
- 开源项目地址:https://github.com/yangchong211/YCAndroidTool
- 查看缓存文件数据如下所示
7.6 如何选择合适方案
- 比如常见的缓存、浏览器缓存、图片缓存、线程池缓存、或者WebView资源缓存等等
- 那就可以选择LRU+缓存淘汰算法。它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。
- 比如针对高频率,同步存储,或者跨进程等存储数据的场景
- 那就可以选择MMKV这种存储方案。它的核心思想就是高速存储数据,且不会阻塞主线程卡顿。
- 比如针对存储表结构,或者一对多这类的数据
- 那就可以选择DataStore,Room,GreenDao等存储库方案。
- 比如针对存储少量用户类数据
- 其实也可以将json转化为字符串,然后选择sp,mmkv,lruDisk等等都可以。
08.其他说明介绍
8.1 遇到的坑分析
- Sp存储数据commit() / apply()操作可能会造成ANR问题
- commit()是同步提交,会在UI主线程中直接执行IO操作,当写入操作耗时比较长时就会导致UI线程被阻塞,进而产生ANR;
- apply()虽然是异步提交,但异步写入磁盘时,如果执行了Activity / Service中的onStop()方法,那么一样会同步等待SP写入完毕,等待时间过长时也会引起ANR问题。
- 首先分析一下SharedPreferences源码中apply方法
SharedPreferencesImpl#apply(),这个方法主要是将记录的数据同步写到Map集合中,然后在开启子线程将数据写入磁盘
SharedPreferencesImpl#enqueueDiskWrite(),这个会将runnable被写入了队列,然后在run方法中写数据到磁盘
QueuedWork#queue(),这个将runnable添加到sWork(LinkedList链表)中,然后通过handler发送处理队列消息MSG_RUN - 然后再看一下ActivityThread源码中的handlePauseActivity()、handleStopActivity()方法。
ActivityThread#handlePauseActivity()/handleStopActivity(),Activity在pause和stop的时候会调用该方法
ActivityThread#handlePauseActivity()#QueuedWork.waitToFinish(),这个是等待QueuedWork所有任务处理完的逻辑
QueuedWork#waitToFinish(),这个里面会通过handler查询MSG_RUN消息是否有,如果有则会waiting等待 - 那么最后得出的结论是
- handlePauseActivity()的时候会一直等待 apply() 方法将数据保存成功,否则会一直等待,从而阻塞主线程造成 ANR。但普通存储的场景,这种可能性很小。
8.2 项目开发分享
- 通用缓存存储库开源代码
- https://github.com/yangchong211/YCCommonLib/tree/master/AppBaseStore
相关文章:
通用缓存存储设计实践
目录介绍 01.整体概述说明 1.1 项目背景介绍1.2 遇到问题记录1.3 基础概念介绍1.4 设计目标1.5 产生收益分析 02.市面存储方案 2.1 缓存存储有哪些2.2 缓存策略有哪些2.3 常见存储方案2.4 市面存储方案说明2.5 存储方案的不足 03.存储方案原理 3.1 Sp存储原理分析3.2 MMKV存储…...

sheng的学习笔记Eureka Ribbon
Eureka-注册中心Eureka简介官方网址:https://spring.io/projects/spring-cloud-netflixEureka介绍Spring Cloud 封装了 Netflix 公司开发的 Eureka 模块来实现服务注册和发现(请对比Zookeeper)。Zooleeper nacos.Eureka 采用了 C-S 的设计架构。Eureka Server 作为服…...
零代码工具我推荐Oracle APEX
云原生时代零代码工具我推荐Oracle APEX 国内的低码开发平台我也看了很多,感觉还是不太适合我这个被WEB抛弃的老炮。自从看了Oracle APEX就不打算看其它的了。太强大了,WEB服务器都省了,直接数据库到WEB页面。功能很强大,震撼到我…...
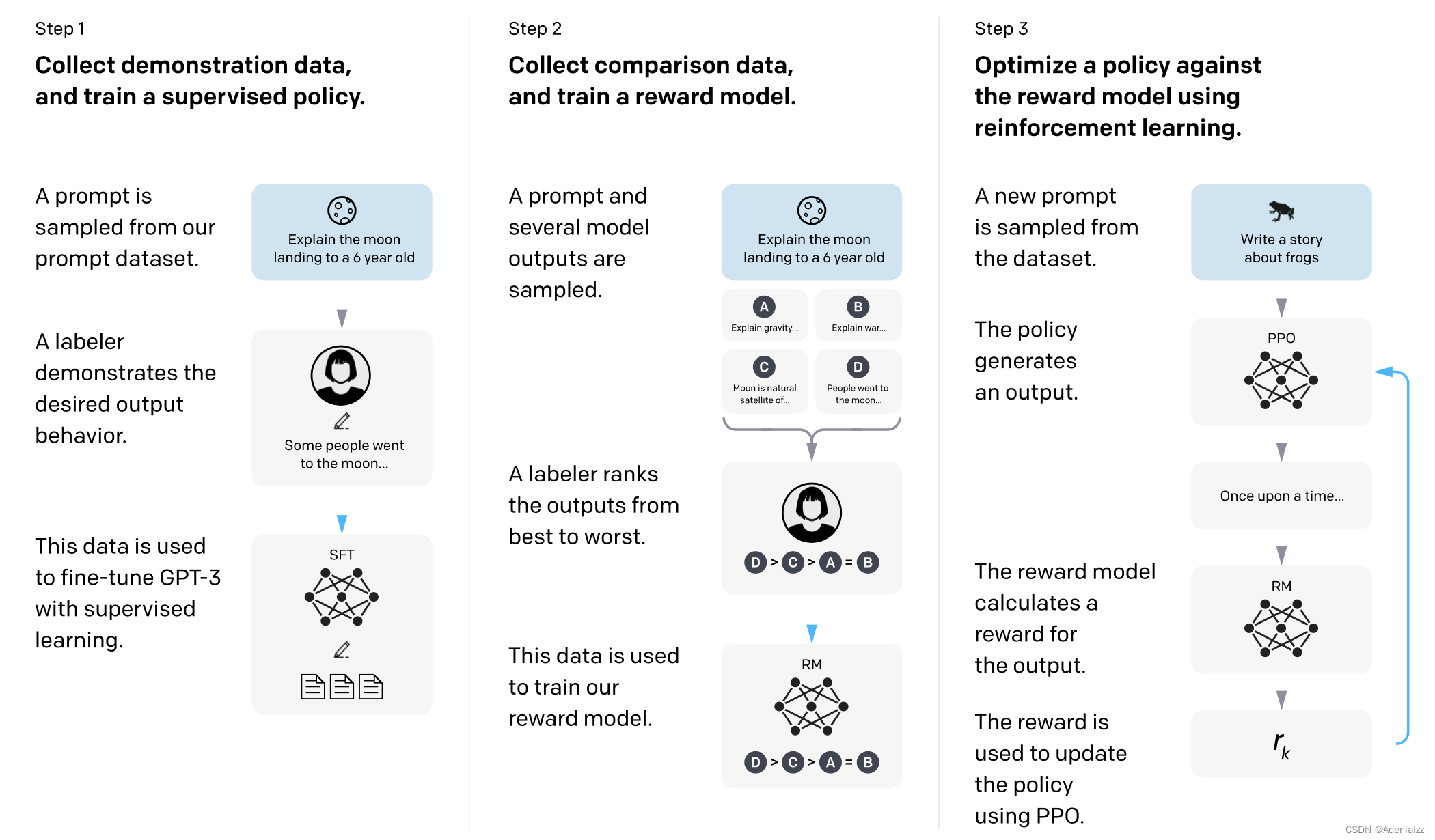
InstructGPT方法简读
InstructGPT方法简读 引言 仅仅通过增大模型规模和数据规模来训练更大的模型并不能使得大模型更好地理解用户意图。由于数据的噪声极大,并且现在的大多数大型语言模型均为基于深度学习的“黑箱模型”,几乎不具有可解释性和可控性,因此&…...

SpringCloud-5_模块集群化
避免一台Server挂掉,影响整个服务,搭建server集群创建e-commerce-eureka-server-9002微服务模块【作为注册中心】创建步骤参考e-commerce-eureka-server-9001修改pom.xml,加入依赖同9001创建resources/application.yml9002的ymlserver: # 修改端口号por…...
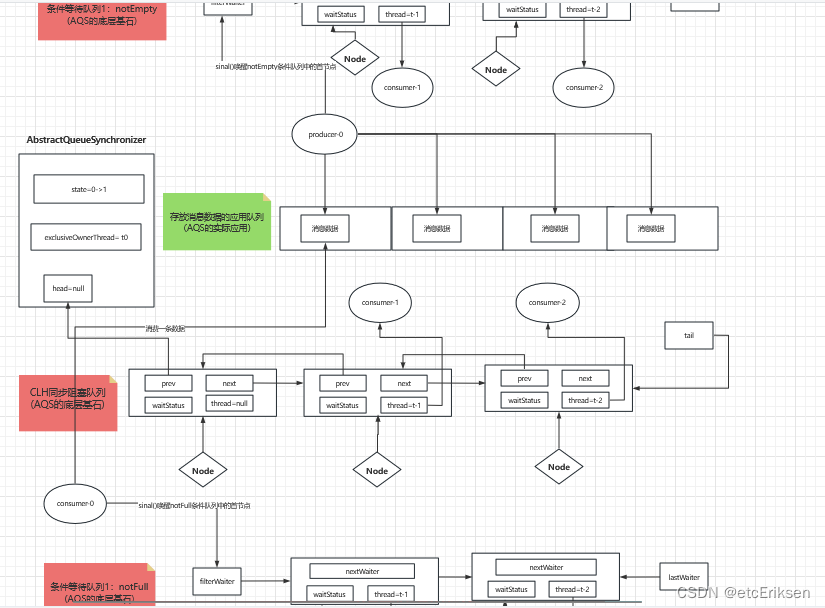
AQS底层源码深度剖析-BlockingQueue
目录 AQS底层源码深度剖析-BlockingQueue BlockingQueue定义 队列类型 队列数据结构 ArrayBlockingQueue LinkedBlockingQueue DelayQueue BlockingQueue API 添加元素 检索(取出)元素 BlockingQueue应用队列总览图 AQS底层源码深度剖析-BlockingQueue【重点中的重…...

Kotlin协程:Flow的异常处理
示例代码如下:launch(Dispatchers.Main) {// 第一部分flow {emit(1)throw NullPointerException("e")}.catch {Log.d("liduo", "onCreate1: $it")}.collect {Log.d("liudo", "onCreate2: $it")}// 第二部分flow …...
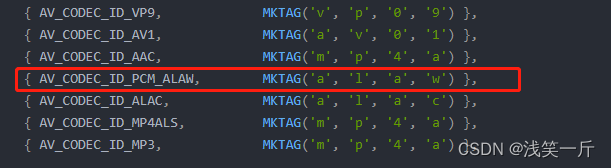
qt下ffmpeg录制mp4经验分享,支持音视频(h264、h265,AAC,G711 aLaw, G711muLaw)
前言 MP4,是最常见的国际通用格式,在常见的播放软件中都可以使用和播放,磁盘空间占地小,画质一般清晰,它本身是支持h264、AAC的编码格式,对于其他编码的话,需要进行额外处理。本文提供了ffmpeg录…...

C#读取Excel解析入门-1仅围绕三个主要的为阵地,进行重点解析,就是最理性的应对上法所在
业务中也是同样的功能点实现。只是多扩展了很多代码,构成了项目的其他部分,枝干所在。但是有用的枝干,仅仅不超过三个主要的!所以您仅仅围绕三个主要的为阵地,进行重点解析,就是最理性的应对上法所在了 str…...
)
一起Talk Android吧(第五百一十八回:在Android中使用MQTT通信五)
文章目录 知识回顾问题描述解决过程经验分享各位看官们大家好,这一回中咱们说的例子是" 在Android中使用MQTT通信五",本章回内容与前后章节内容无关联。闲话休提,言归正转,让我们一起Talk Android吧! 知识回顾 我们在前面章回中介绍了如何使用MQTT通信,包含它…...
100种思维模型之混沌与秩序思维模型-027
人类崇尚秩序与连续性,我们习惯于我们的日常世界,它以线性方式运作,没有不连续或突跳。 为此,我们学会了期望各种过程以连续方式运行,我们的内心为了让我们更有安全感,把很多事物的结果归于秩序,…...
Java开发 - Redis初体验
前言 es我们已经在前文中有所了解,和es有相似功能的是Redis,他们都不是纯粹的数据库。两者使用场景也是存在一定的差异的,本文目的并不重点说明他们之间的差异,但会简要说明,重点还是在对Redis的了解和学习上。学完本…...

Python - 使用 pymysql 操作 MySQL 详解
目录创建连接 pymsql.connect() 方法的可传参数连接对象 conn pymsql.connect() 方法游标对象 cursor() 方法使用示例创建数据库表插入数据操作数据查询操作数据更新操作数据删除操作SQL中使用变量封装使用简单使用: import pymysqldb pymysql.connect(host,user…...
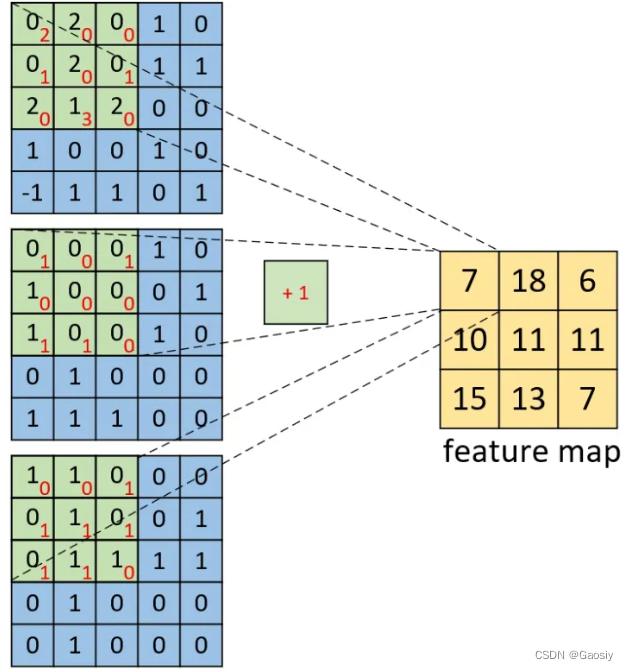
机器学习-卷积神经网络CNN中的单通道和多通道图片差异
背景 最近在使用CNN的场景中,既有单通道的图片输入需求,也有多通道的图片输入需求,因此又整理回顾了一下单通道或者多通道卷积的差别,这里记录一下探索过程。 结论 直接给出结论,单通道图片和多通道图片在经历了第一…...
考研复试——计算机组成原理
文章目录计算机组成原理1. 计算机系统由哪两部分组成?计算机系统性能取决于什么?2. 冯诺依曼机的主要特点?3. 主存储器由什么组成,各部分有什么作用?4. 什么是存储单元、存储字、存储字长、存储体?5. 计算机…...

硬件设计 之摄像头分类(IR摄像头、mono摄像头、RGB摄像头、RGB-D摄像头、鱼眼摄像头)
总结一下在机器人上常用的几种摄像头,最近在组装机器人时,傻傻分不清摄像头的种类。由于本人知识有限,以下资料都是在网上搜索而来,按照摄像头的分类整理一下,供大家参考: 1.IR摄像头: IRinfr…...
)
PTA:C课程设计(2)
山东大学(威海)2022级大一下C习题集(2)2-5-1 字符定位函数(程序填空题)2-5-2 判断回文(程序填空题)2-6-1 数字金字塔(函数)2-6-2 使用函数求最大公约数(函数)2-6-3 使用函数求余弦函…...
第四章:面向对象编程
第四章:面向对象编程 4.1:面向过程与面向对象 面向过程(POP)与面向对象(OOP) 二者都是一种思想,面向对象是相对于面向过程而言的。面向过程,强调的是功能行为,以函数为最小单位,考虑怎么做。面向对象&…...

Linux 安装npm yarn pnpm 命令
下载安装包 node 下载地址解压压缩包 tar -Jxf node-v19.7.0-linux-x64.tar.xz -C /root/app echo "export PATH$PATH:/app/node-v16.9.0-linux-x64" >> /etc/profile source /etc/profile ln -sf /app/node-v16.9.0-linux-x64/bin/npm /usr/local/bin/ ln -…...
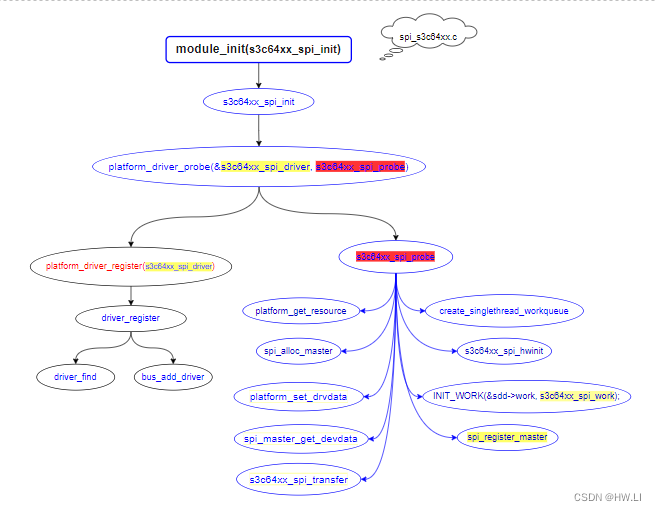
linux SPI驱动代码追踪
一、Linux SPI 框架概述 linux系统下的spi驱动程序从逻辑上可以分为3个部分: SPI Core:SPI Core 是 Linux 内核用来维护和管理 spi 的核心部分,SPI Core 提供操作接口,允许一个 spi master,spi driver 和 spi device 在 SPI Cor…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...
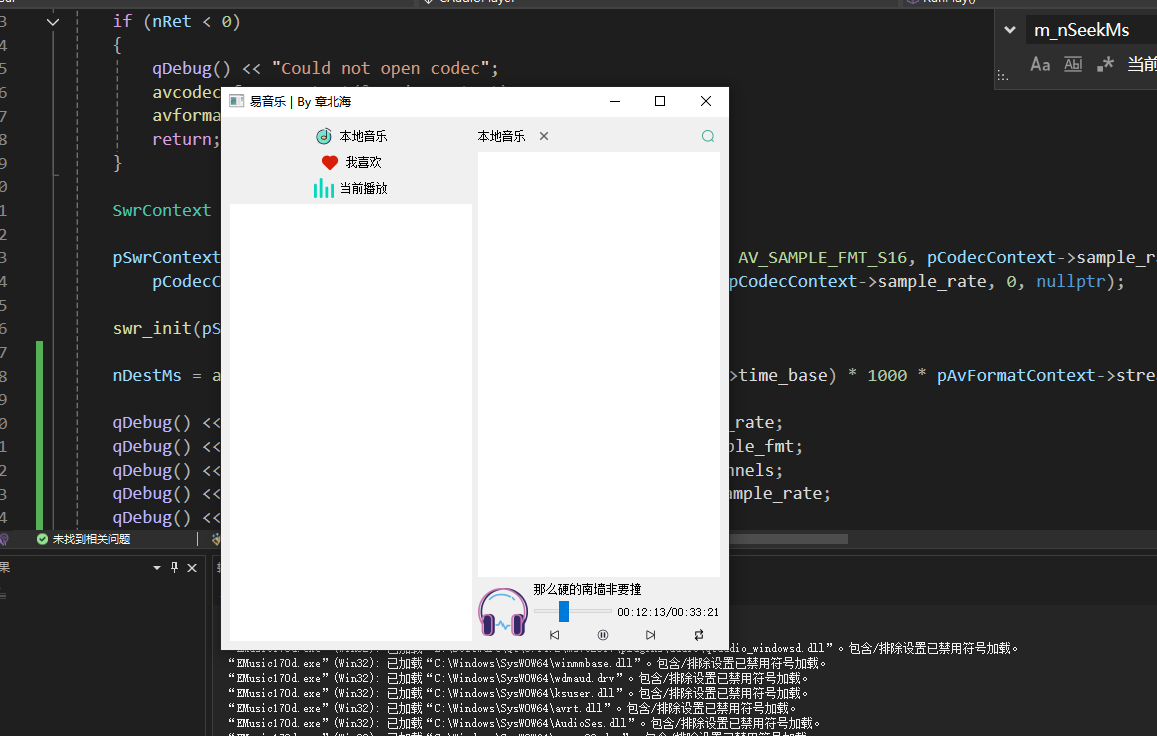
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...
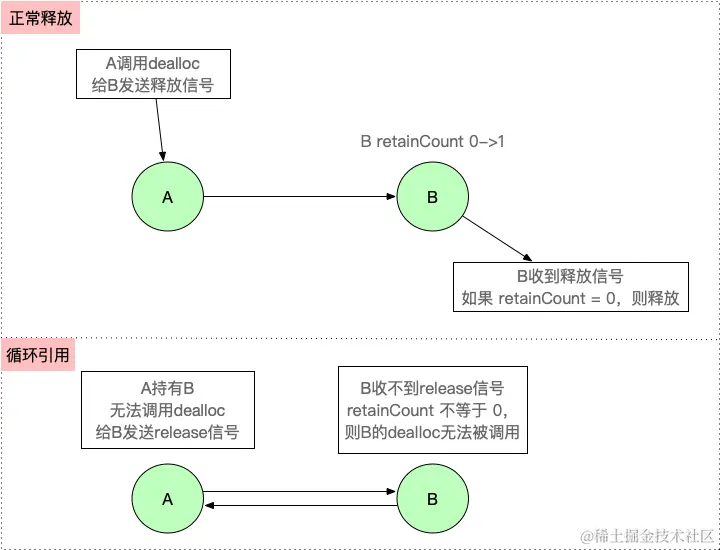
【iOS】 Block再学习
iOS Block再学习 文章目录 iOS Block再学习前言Block的三种类型__ NSGlobalBlock____ NSMallocBlock____ NSStackBlock__小结 Block底层分析Block的结构捕获自由变量捕获全局(静态)变量捕获静态变量__block修饰符forwarding指针 Block的copy时机block作为函数返回值将block赋给…...

边缘计算网关提升水产养殖尾水处理的远程运维效率
一、项目背景 随着水产养殖行业的快速发展,养殖尾水的处理成为了一个亟待解决的环保问题。传统的尾水处理方式不仅效率低下,而且难以实现精准监控和管理。为了提升尾水处理的效果和效率,同时降低人力成本,某大型水产养殖企业决定…...