Spark高手之路2—Spark安装配置
文章目录
- Spark 运行环境
- 一、Local 模式
- 1. 下载压缩包
- 2.上传到服务器
- 3. 解压
- 4. 启动 Local 环境
- 5. 命令行工具
- 6. 退出本地模式
- 7. 提交应用
- 二、Standalone 模式
- 1. 解压
- 2. 修改配置文件
- 1)进入解压缩后路径的 conf 目录,复制 workers.template 文件为 workers
- 2)修改 workers文件,添加 work 节点
- 3)复制 spark-env.sh.template 文件名为 spark-env.sh
- 4)修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
- 5)分发 spark-standalone 目录
- 3. 启动集群
- 1)执行脚本命令
- 2)查看三台服务器运行进程
- 3)查看 Master 资源监控 Web UI 界面:http://hadoop001:8080/
- 4. 提交应用
- 5. 提交参数说明
- 6. 配置历史服务
- 1)修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
- 2)启动 hadoop 集群
- 3)创建 directory 文件夹
- 4)修改 spark-default.conf 文件,配置日志存储路径
- 5)修改 spark-env.sh 文件, 添加日志配置
- 6)分发配置文件
- 7)重新启动集群和历史服务
- 8)重新执行任务
- 9)查看历史服务:http://hadoop001:18080
- 7. 配置高可用(HA)
- 1)启动HDFS
- 2)启动 Zookeeper
- 3)修改 spark-env.sh 文件添加如下配置
- 4)分发配置文件
- 5)启动集群
- 6)启动 hadoop002 的单独 Master 节点
- 7)提交应用到高可用集群
- 8)停止 Hadoop001的 Master 资源监控进程
- 9)查看 Hadoop002 的 Master 资源监控 Web UI,稍等一段时间后,Hadoop002节点的 Master 状态提升为活动状态

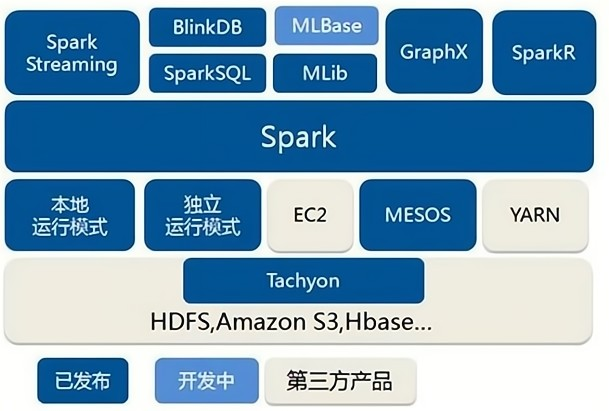
Spark 运行环境
Spark 作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为 Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下 Spark 的运行
一、Local 模式
所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等。
1. 下载压缩包
Spark官网
下载 Spark 安装包
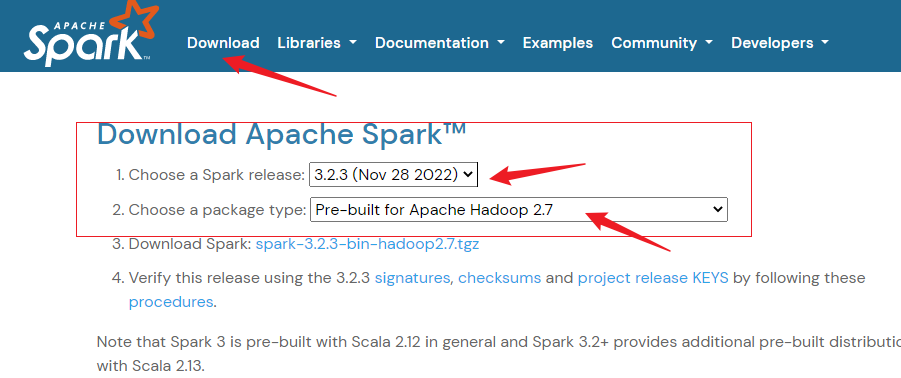
点击下载:
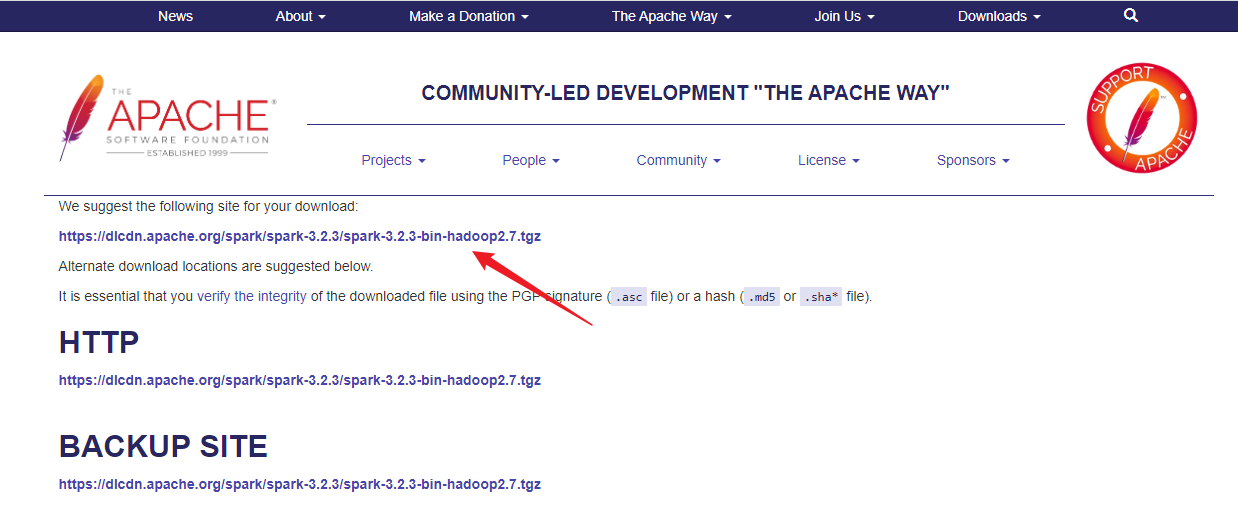

2.上传到服务器
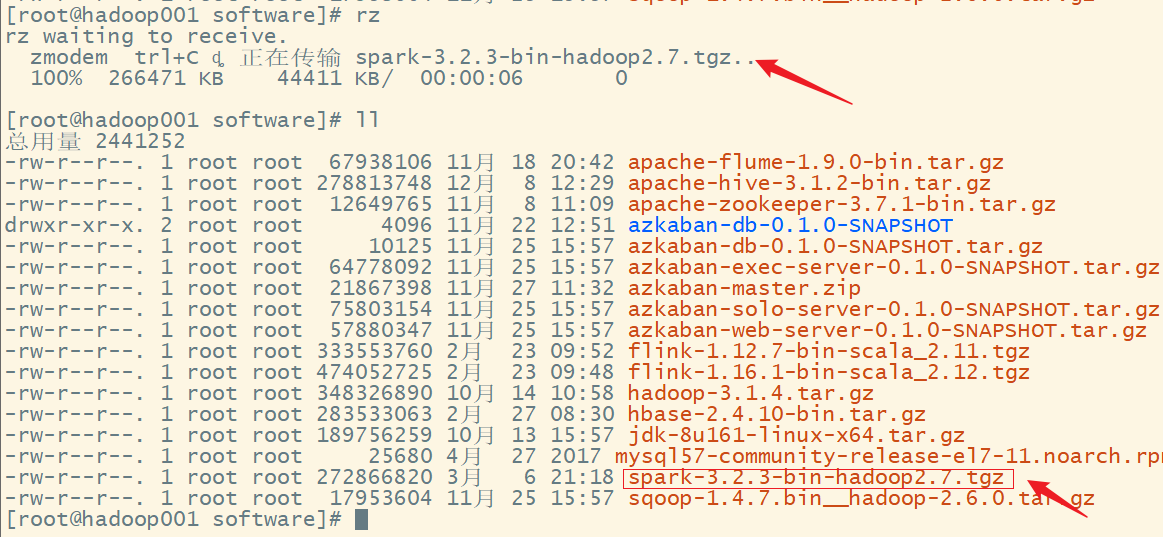
3. 解压

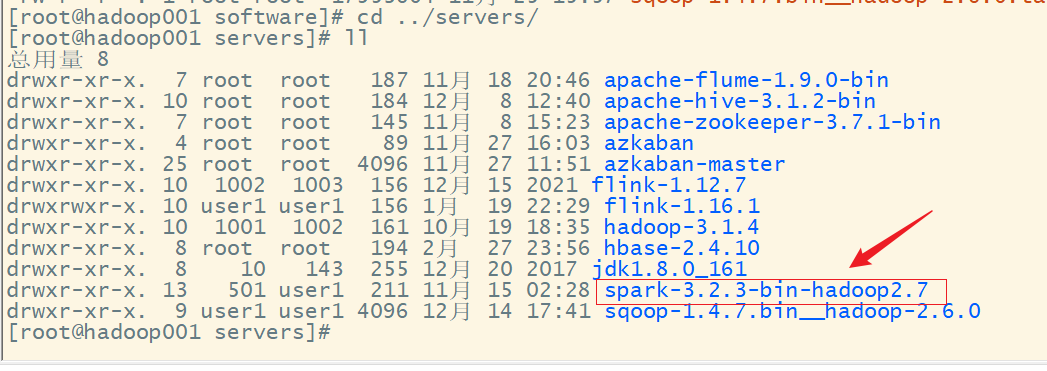
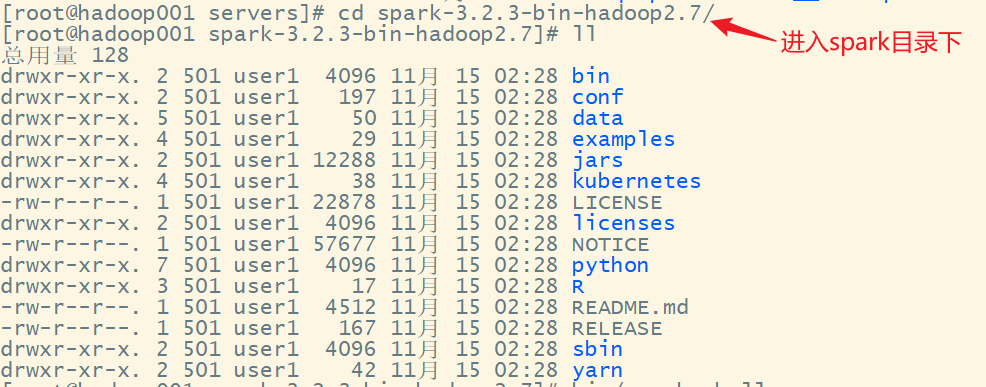
4. 启动 Local 环境
1)进入解压缩后的路径,执行如下指令
bin/spark-shell
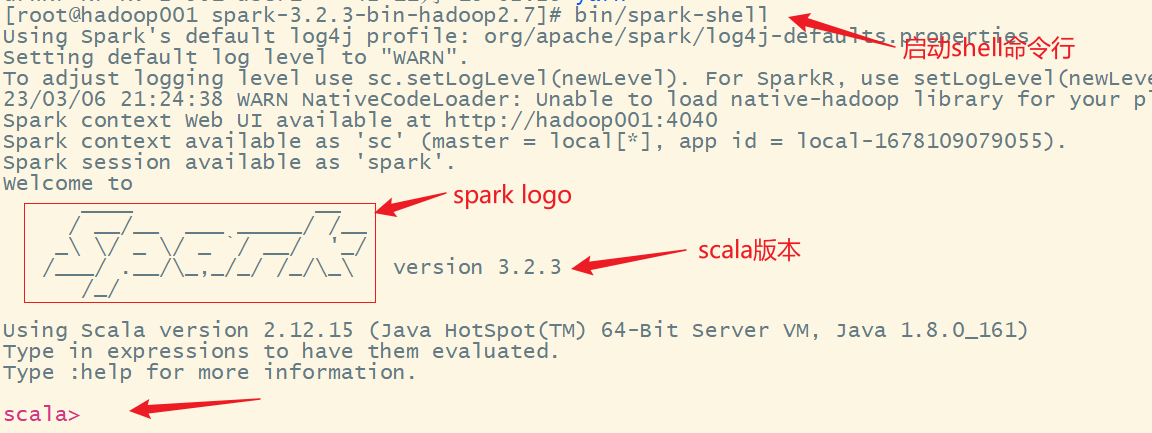
2)启动成功后,可以输入网址进行 Web UI 监控页面访问
5. 命令行工具
在解压缩文件夹下的 data 目录中,添加 a.txt 文件。
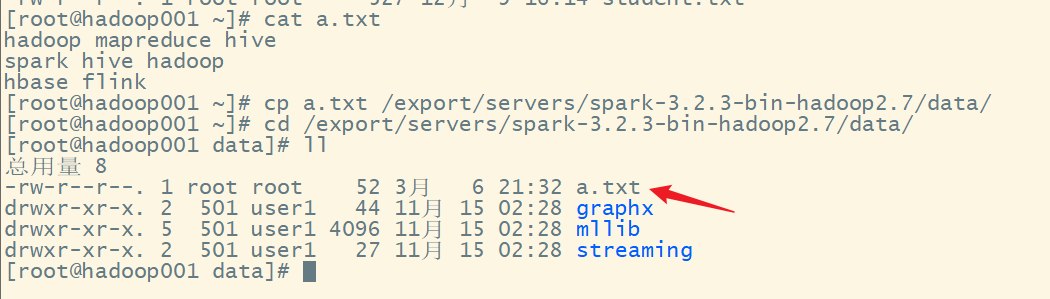
在命令行工具中执行如下代码指令
sc.textFile("data/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

6. 退出本地模式
按键 Ctrl+C 或输入 Scala 指令

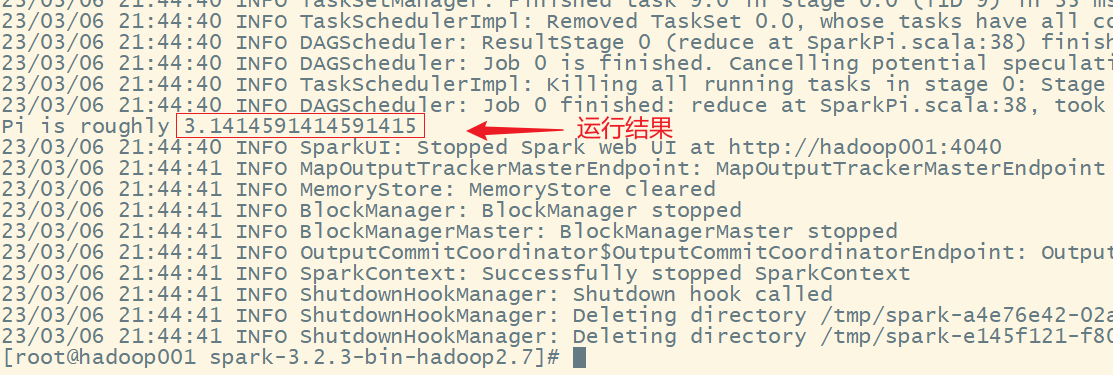
7. 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.2.3.jar \
10
1) --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱们自己打的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
二、Standalone 模式
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。
集群规划:
| Master | Worker | |
|---|---|---|
| hadoop001 | ✅ | ✅ |
| hadoop002 | ❎ | ✅ |
| hadoop003 | ❎ | ✅ |
1. 解压
同上
2. 修改配置文件
1)进入解压缩后路径的 conf 目录,复制 workers.template 文件为 workers
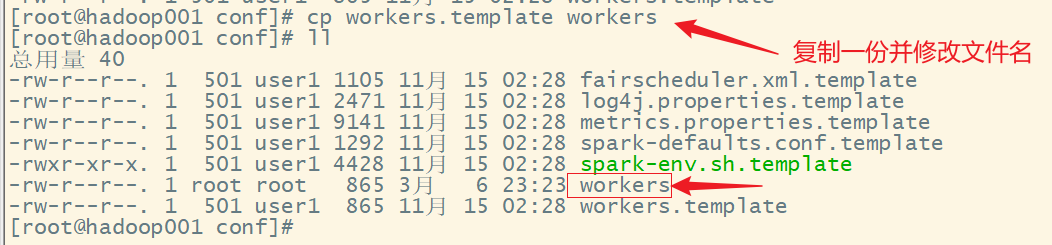
2)修改 workers文件,添加 work 节点
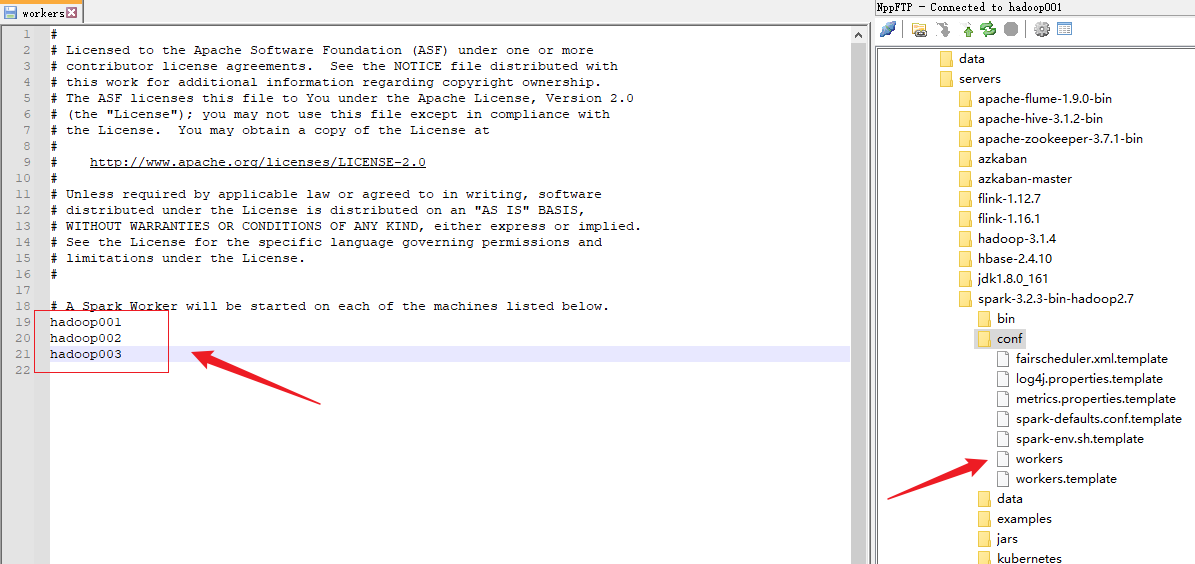
3)复制 spark-env.sh.template 文件名为 spark-env.sh
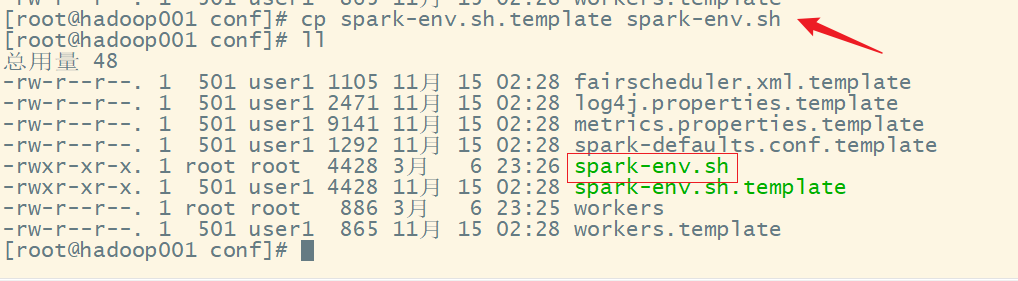
4)修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/export/servers/jdk1.8.0_161/
SPARK_MASTER_HOST=hadoop001
SPARK_MASTER_PORT=7077
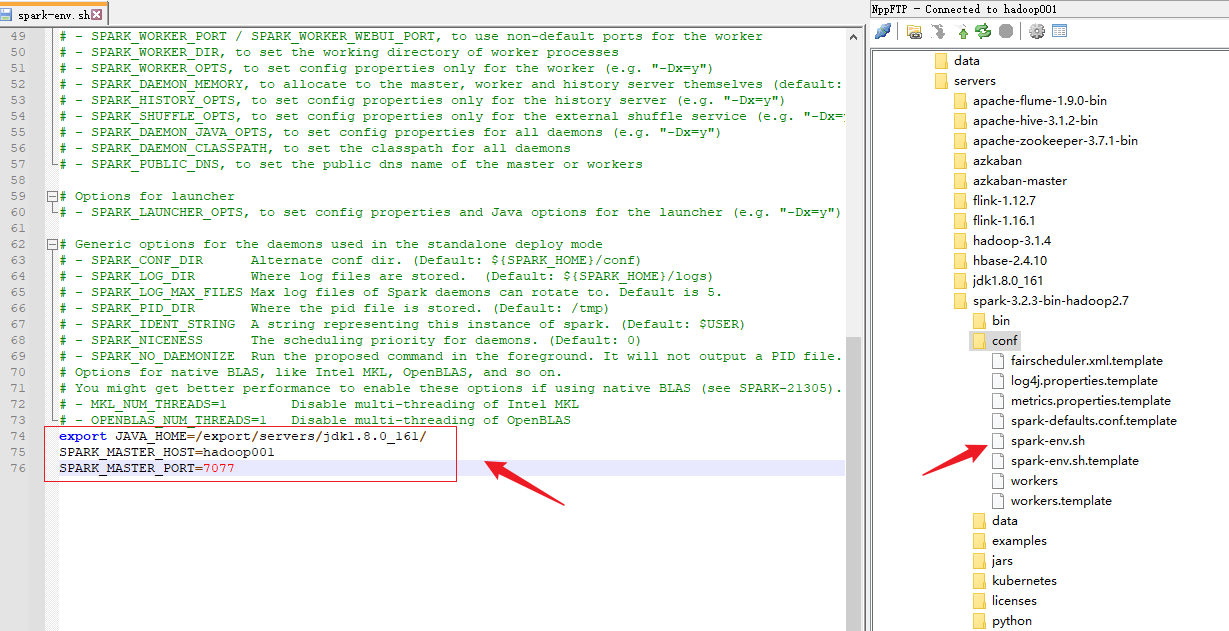
注意:7077 端口,相当于 hadoop3 内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop 配置
5)分发 spark-standalone 目录
分发到hadoop002


分发到hadoop003

3. 启动集群
1)执行脚本命令
sbin/start-all.sh

2)查看三台服务器运行进程

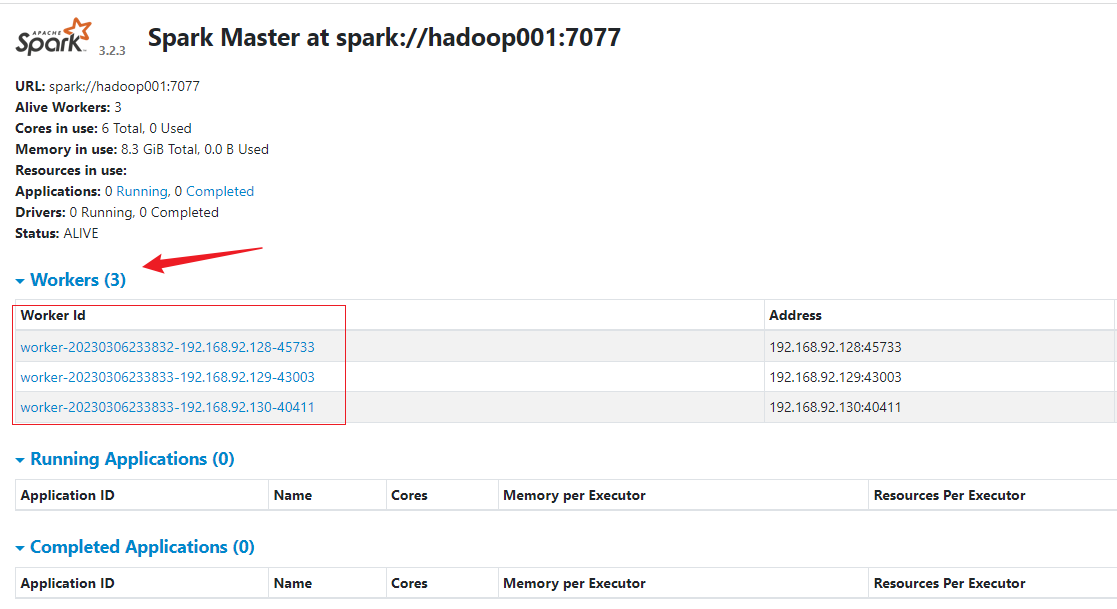
3)查看 Master 资源监控 Web UI 界面:http://hadoop001:8080/
4. 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077 \
./examples/jars/spark-examples_2.12-3.2.3.jar \
10

1)–class 表示要执行程序的主类
2)–master spark://hadoop001:7077 独立部署模式,连接到 Spark 集群
3)spark-examples_2.12-3.2.3.jar 运行类所在的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
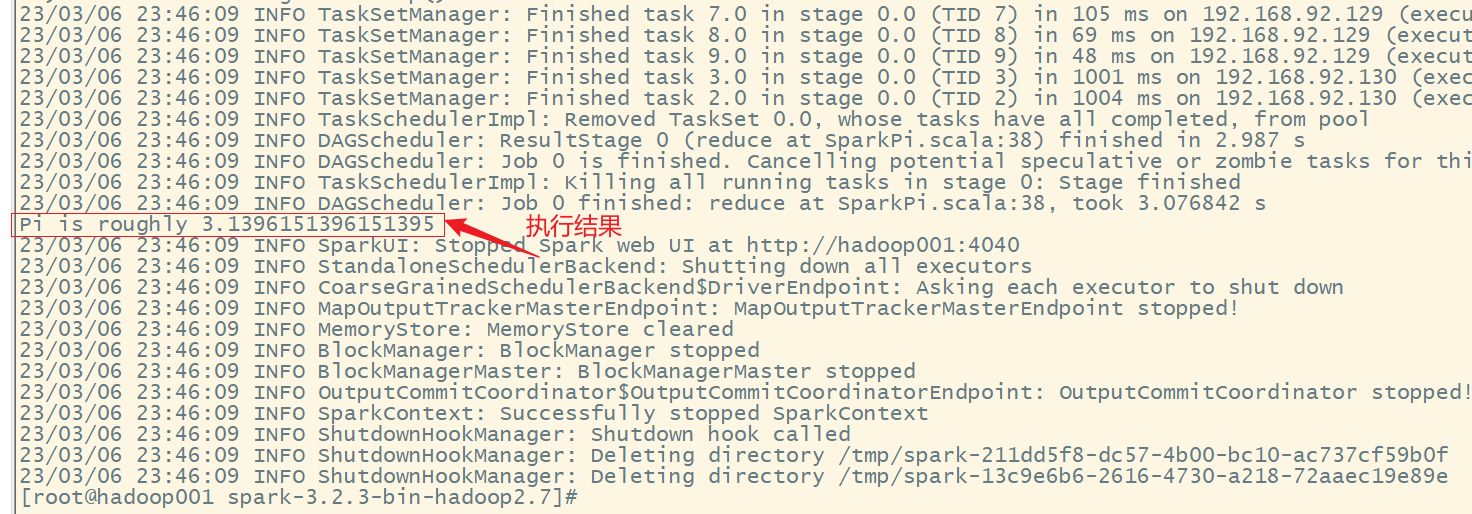
执行任务时,会产生多个 Java 进程
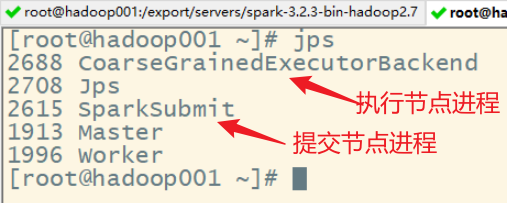


执行任务时,默认采用服务器集群节点的总核数,每个节点内存 1024M。

5. 提交参数说明
在提交应用中,一般会同时一些提交参数
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| –class | Spark 程序中包含主函数的类 | |
| –master | Spark 程序运行的模式(环境) | 模式:local[*]、spark://hadoop001:7077、Yarn |
| –executor-memory 1G | 指定每个 executor 可用内存为 1G | 符合集群内存配置即可,具体情况具体分析。 |
| –total-executor-cores 2 | 指定所有executor使用的cpu核数为 2 个 | 符合集群内存配置即可,具体情况具体分析。 |
| –executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用 jar,包含依赖。这个 URL 在集群中全局可见。 比如 hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的path 都包含同样的 jar | 符合集群内存配置即可,具体情况具体分析。 |
| application-arguments | 传给 main()方法的参数 | 符合集群内存配置即可,具体情况具体分析。 |
6. 配置历史服务
由于 spark-shell 停止掉后,集群监控 hadoop001:4040 页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
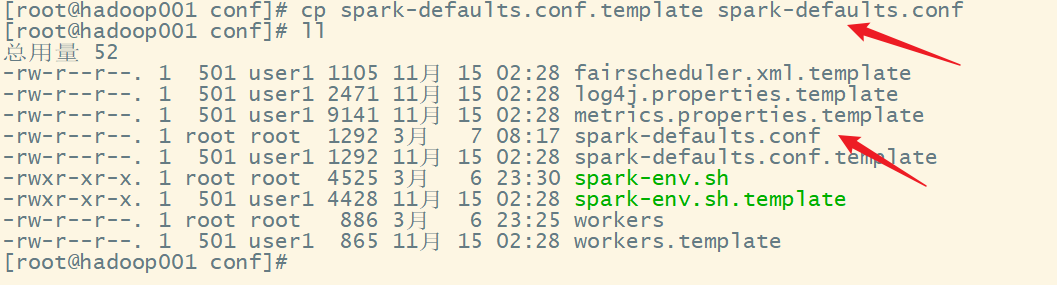
1)修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
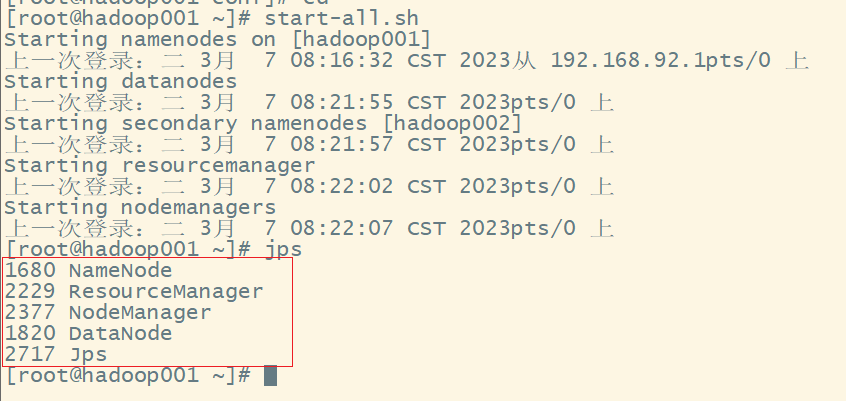
2)启动 hadoop 集群
3)创建 directory 文件夹

集群查看:
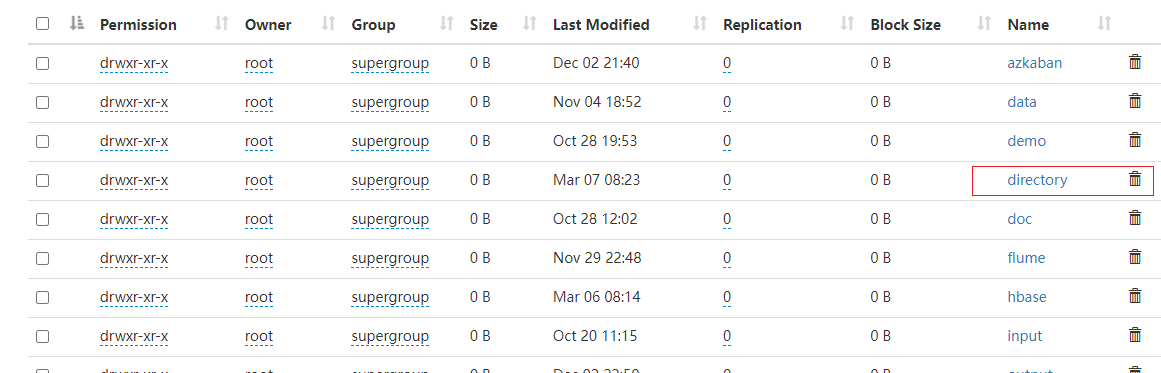
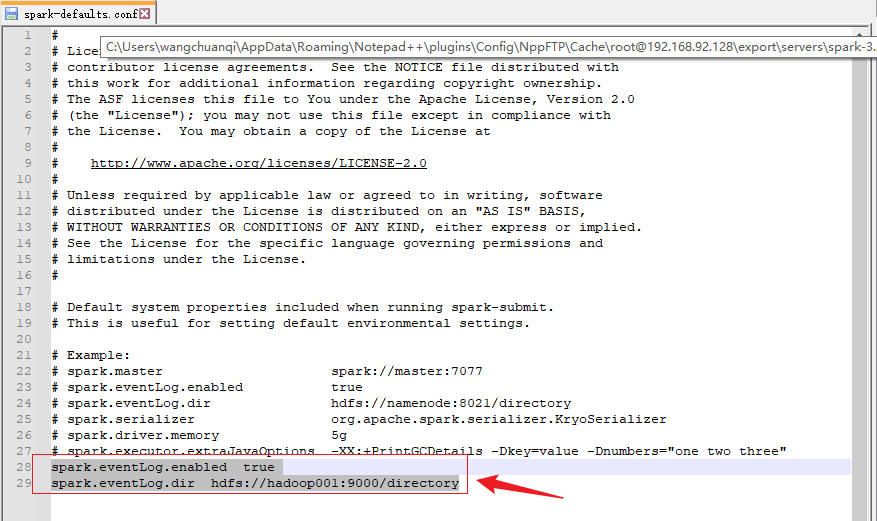
4)修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop001:9000/directory
5)修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop001:9000/directory
-Dspark.history.retainedApplications=30"
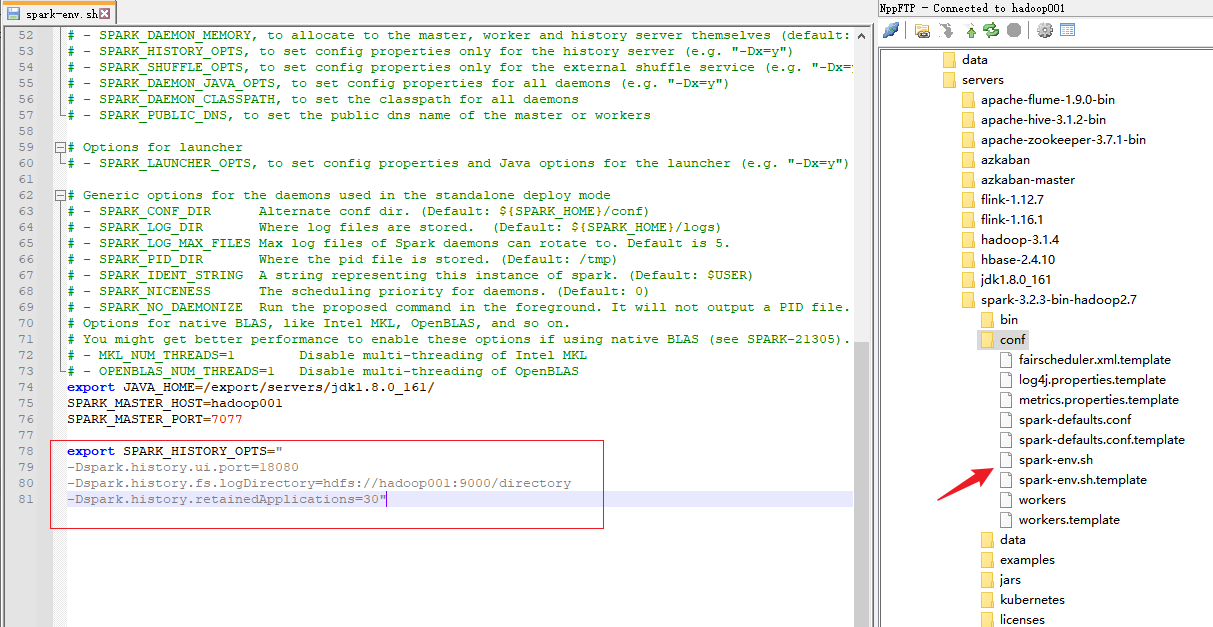
⚫ 参数 1 含义:WEB UI 访问的端口号为 18080
⚫ 参数 2 含义:指定历史服务器日志存储路径
⚫ 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
6)分发配置文件


7)重新启动集群和历史服务
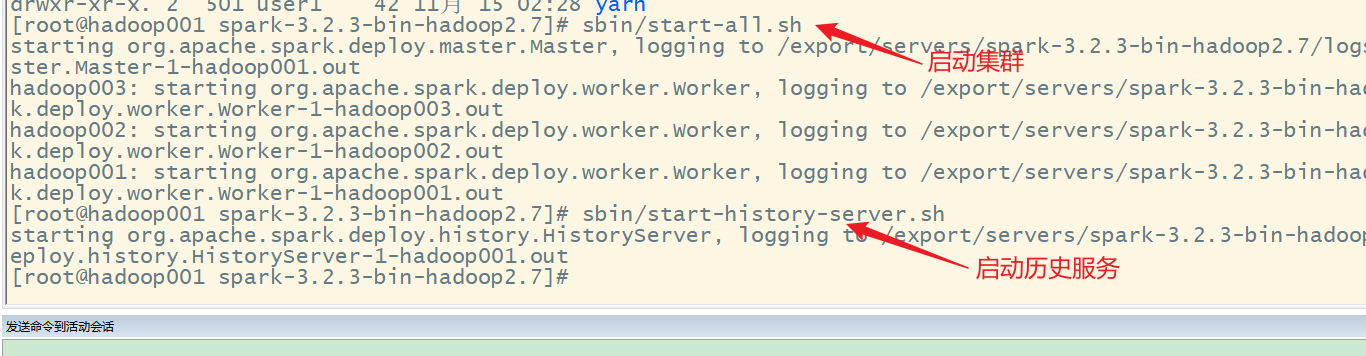
8)重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077 \
./examples/jars/spark-examples_2.12-3.2.3.jar \
10
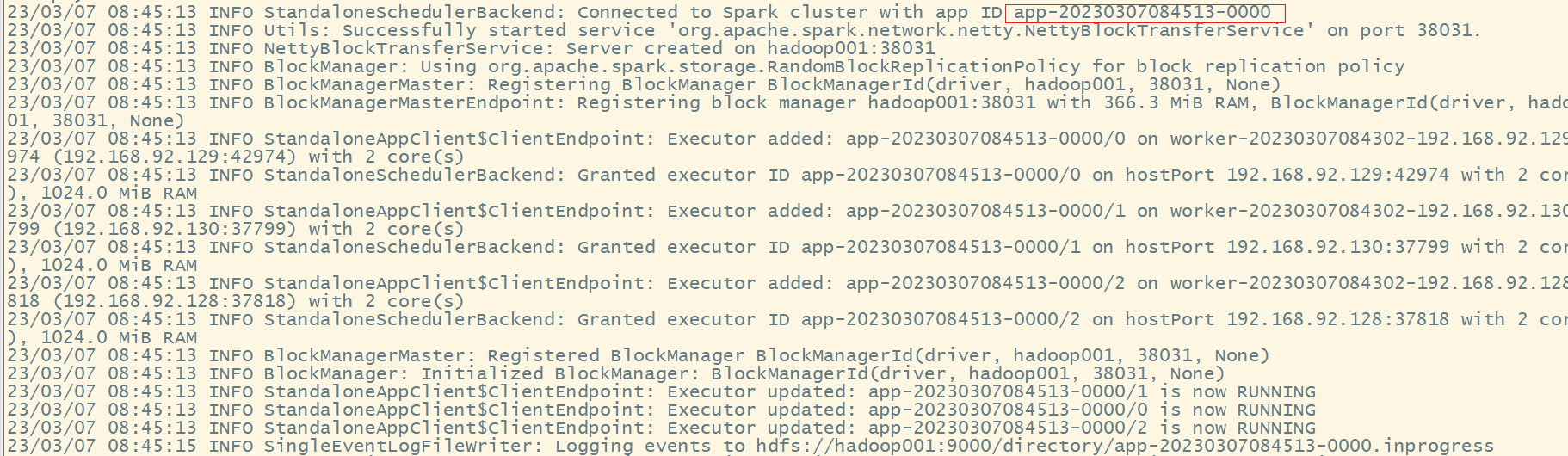
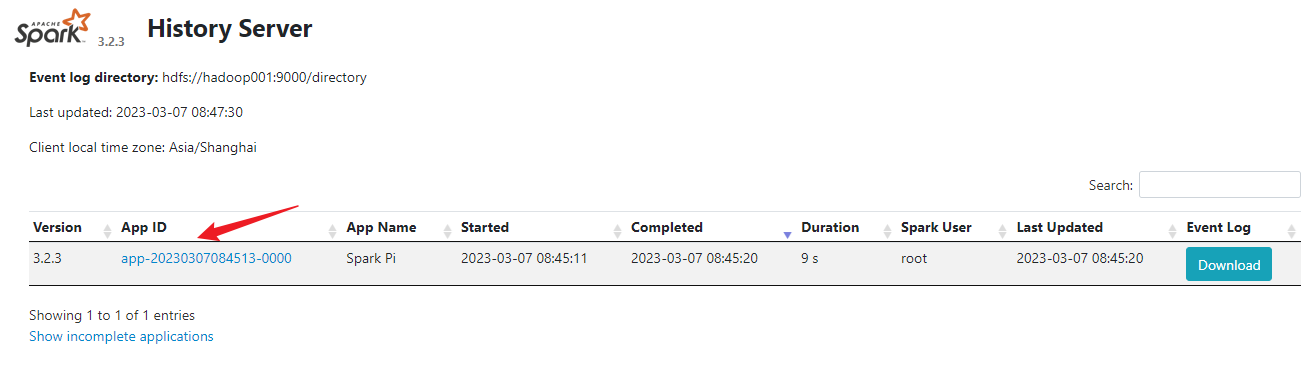
9)查看历史服务:http://hadoop001:18080
7. 配置高可用(HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用
Zookeeper 设置
集群规划:
| Master | Zookeeper | Worker | |
|---|---|---|---|
| hadoop001 | ✅ | ✅ | ✅ |
| hadoop002 | ✅ | ✅ | ✅ |
| hadoop003 | ✅ | ✅ |
1)启动HDFS
2)启动 Zookeeper
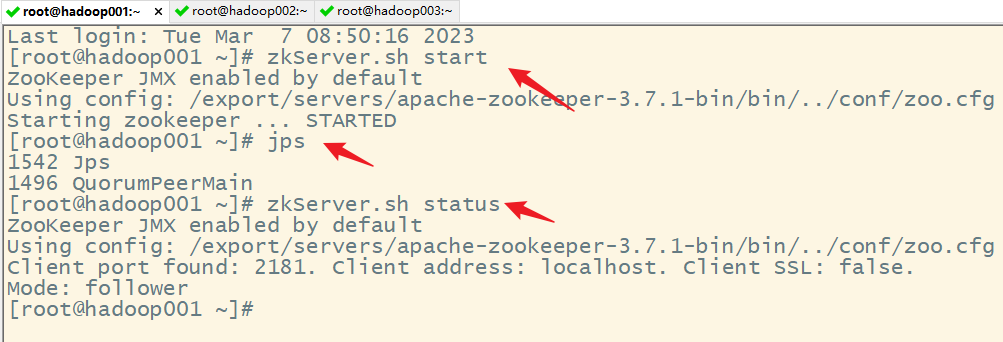
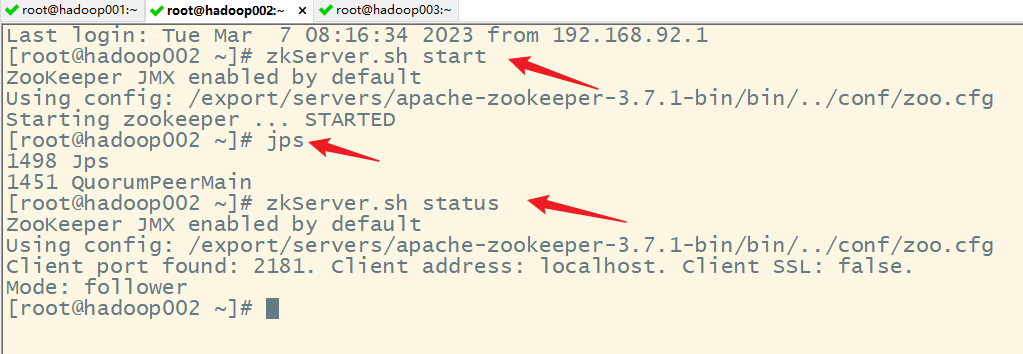
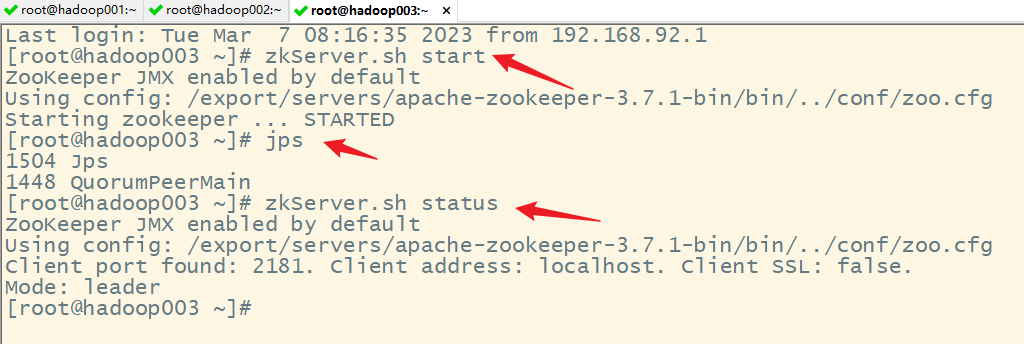
3)修改 spark-env.sh 文件添加如下配置
注释如下内容:
#SPARK_MASTER_HOST=hadoop001
#SPARK_MASTER_PORT=7077添加如下内容:
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop001,hadoop002,hadoop003
-Dspark.deploy.zookeeper.dir=/spark"
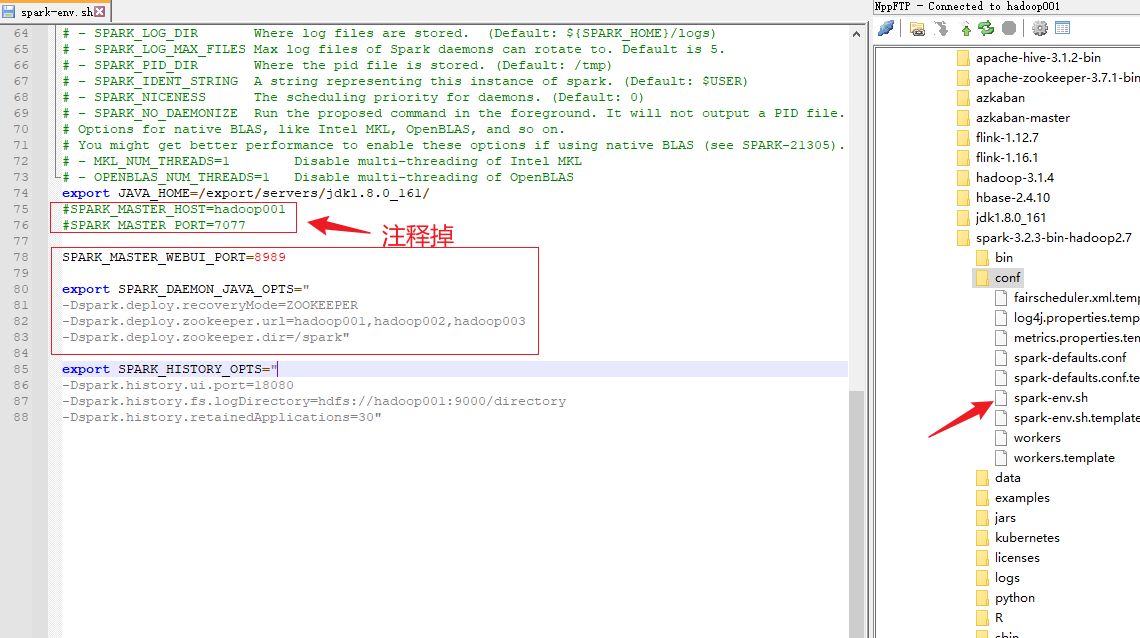
4)分发配置文件


5)启动集群
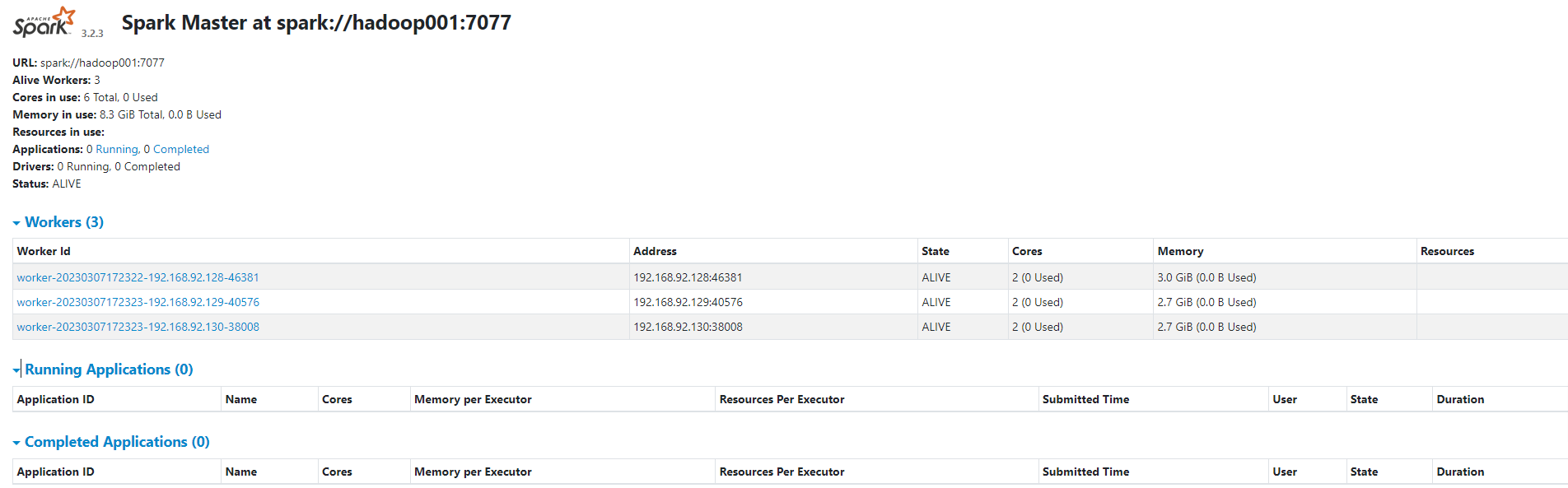
6)启动 hadoop002 的单独 Master 节点

此时 hadoop002 节点 Master 状态处于备用状态
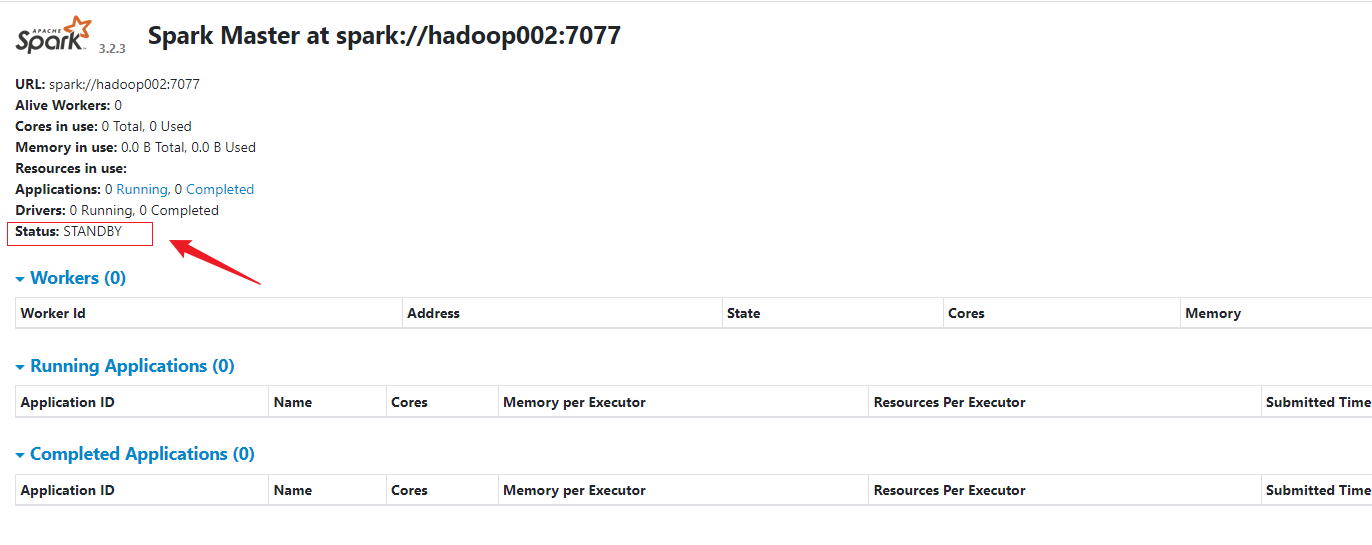
7)提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop001:7077,hadoop002:7077 \
./examples/jars/spark-examples_2.12-3.2.3.jar \
10
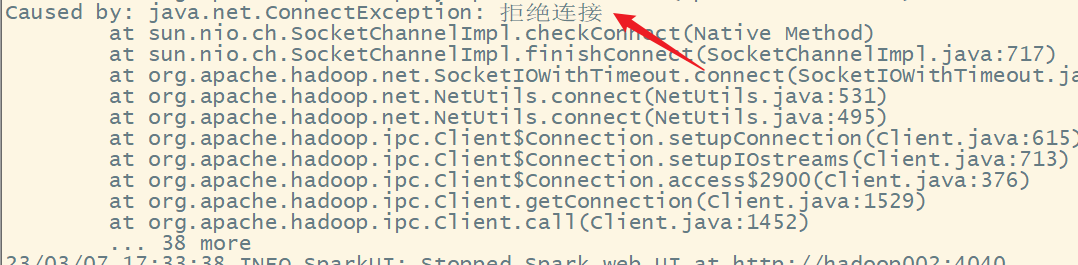
出现错误:
错误原因:没有启动Hadoop集群
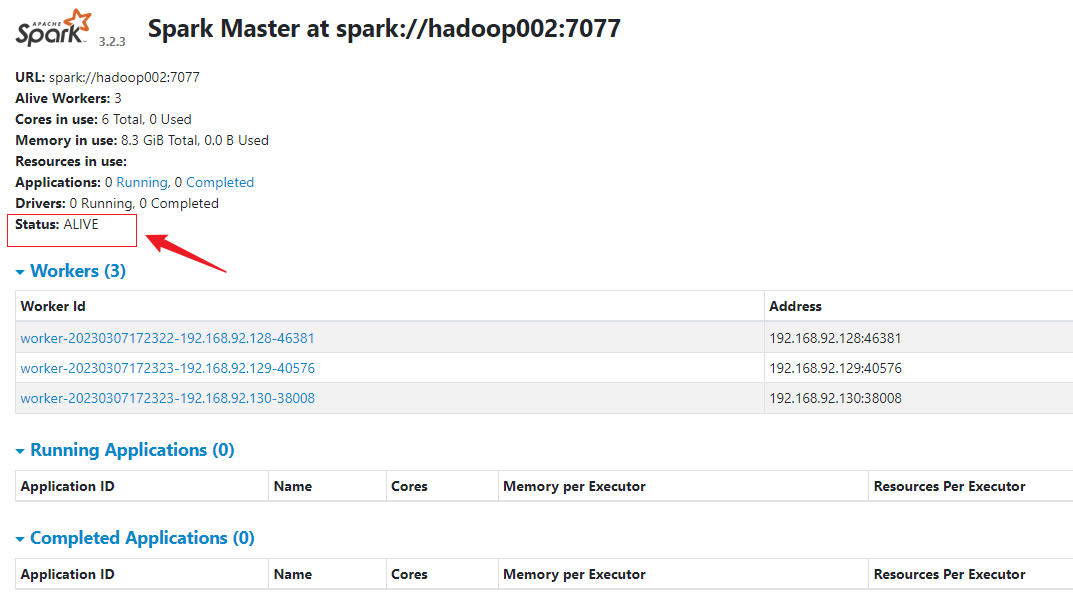
8)停止 Hadoop001的 Master 资源监控进程

9)查看 Hadoop002 的 Master 资源监控 Web UI,稍等一段时间后,Hadoop002节点的 Master 状态提升为活动状态
相关文章:
Spark高手之路2—Spark安装配置
文章目录Spark 运行环境一、Local 模式1. 下载压缩包2.上传到服务器3. 解压4. 启动 Local 环境5. 命令行工具6. 退出本地模式7. 提交应用二、Standalone 模式1. 解压2. 修改配置文件1)进入解压缩后路径的 conf 目录,复制 workers.template 文件为 worker…...

Java中对象的比较
目录元素的比较基本类型的比较引用类型的比较1. 覆写基类的equals2. 基于Comparble接口类的比较3. 基于比较器比较三种方法对比元素的比较 基本类型的比较 这里就拿整型, 字符型, 布尔型 为例: public static void main(String[] args) {int a 10;int b 20;System.out.pri…...

Python编程训练题2
1.11 有 n 盏灯,编号 1~n(0<n<100)。第 1 个人把所有灯打开,第 2 个人按下所有编号为 2 的倍数的开关(这些灯将被关掉),第 3 个人按下所有编号为 3 的倍数的开关(其…...

Shifu基础功能:设备管理
设备管理 deviceshifu_configmap.yaml中的telemetries表示自动测量记录传导。Shifu通过telemetries中设置的方法,以指定时间向设备周期性地发送请求,来判断设备的连接情况。如果设备出现故障或者连接出现问题,edgeDevice的状态将发生改变&am…...

交互:可以执行命令行的框架才是好框架
上一节课,我们开始把框架向工业级迭代,重新规划了目录,这一节课将对框架做更大的改动,让框架支持命令行工具。 第三方命令行工具库 cobra obra 不仅仅能让我们快速构建一个命令行,它更大的优势是能更快地组织起有许多…...

eunomia-bpf 和 wasm-bpf 项目的 3 月进展
eunomia-bpf 项目是一个开源项目,旨在提供一组工具,用于在 Linux 内核中更方便地编写和运行 eBPF 程序。在过去一个月中,该项目取得了一些新的进展,以下是这些进展的概述。 首先,eunomia-bpf 动态加载库进行了一些重要…...
Spring框架核心功能手写实现
文章目录概要Spring启动以及扫描流程实现基础环境搭建扫描逻辑实现bean创建的简单实现依赖注入实现BeanNameAware回调实现初始化机制模拟实现BeanPostProcessor模拟实现AOP模拟实现概要 手写Spring启动以及扫描流程手写getBean流程手写Bean生命周期流程手写依赖注入流程手写Be…...

k8s-镜像构建Flink集群Native session
一.Flink安装包下载 wget https://dlcdn.apache.org/flink/flink-1.14.6/flink-1.14.6-bin-scala_2.12.tgz 二.构建基础镜像推送私服 docker pull apache/flink:1.14.6-scala_2.12 docker tag apache/flink:1.14.6-scala_2.12 172.25.152.2:30002/dmp/flink:...

在 k8S 中搭建 SonarQube 7.4.9 版本(使用 PostgreSQL 数据库)
本文搭建的 SonarQube 版本是 7.4.9-community,由于在官方文档中声明 7.9 版本之后就不再支持使用 MySQL 数据库。所以此次搭建使用的数据库是 PostgreSQL 11.4 版本。 一、部署 PostgreSQL 服务 1. 创建命名空间 将 PostgreSQL 和 SonarQube 放在同一个命名空间…...
分析BeanFactory和ApplicationContext)
从getBean()分析BeanFactory和ApplicationContext
本文说了哪些问题: BeanFactory 是啥ApplicationContext 是啥什么时候去实例化一个 bean, BeanFactory 和 ApplicationContext 实例化 bean 都是在什么时候 一个 Bean 什么时候被初始化 任何一个 Bean, 都是在 getBean () 的时候被初始化的.BeanFactory 需要字节手动调用 getb…...

详解Redis的主从同步原理
前言 Redis为了保证服务高可用,其中一种实现就是主从模式,即一个Redis服务端作为主节点,若干个Redis服务端作为主节点的从节点,从而实现即使某个服务端不可用时,也不会影响Redis服务的正常使用。本篇文章将对主从模式…...
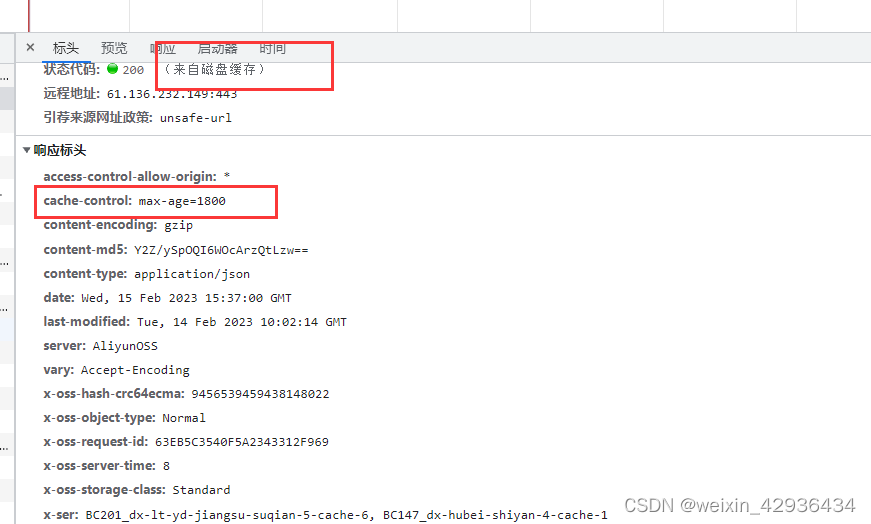
前端项目上线后,浏览器缓存未刷新问题
文章目录问题背景一、解决办法二、实现原理关于缓存强缓存协商缓存刷新页面对浏览器的影响总结问题背景 前端页面开发测试完,要进行上线,某些页面上传更新到服务器之后,浏览器并没有更新,渲染的还是老页面。这是因为浏览器读了缓存…...

Vulnhub系列:Raven 1
该篇为Vulnhub系列靶机渗透,本次靶机存在4个flag。下面开始我们今天的渗透之旅。Raven靶机有很多种思路,我将对其进行一一整理。首先进行信息收集,利用arp-scan和nmap,进行靶机的ip及端口扫描发现了22、80、111端口。下面访问80端…...
)
MybatisPlus------多数据源环境(十一)
MybatisPlus------多数据源环境(十一) 生产环境中常常会存在多个数据源。 比如读写分离、一主多从、混合模式等等。 首先再pom文件中需要引入依赖: 多数据源所需要使用到的依赖 <!-- 多数据源所需要使用到的依赖--><depend…...
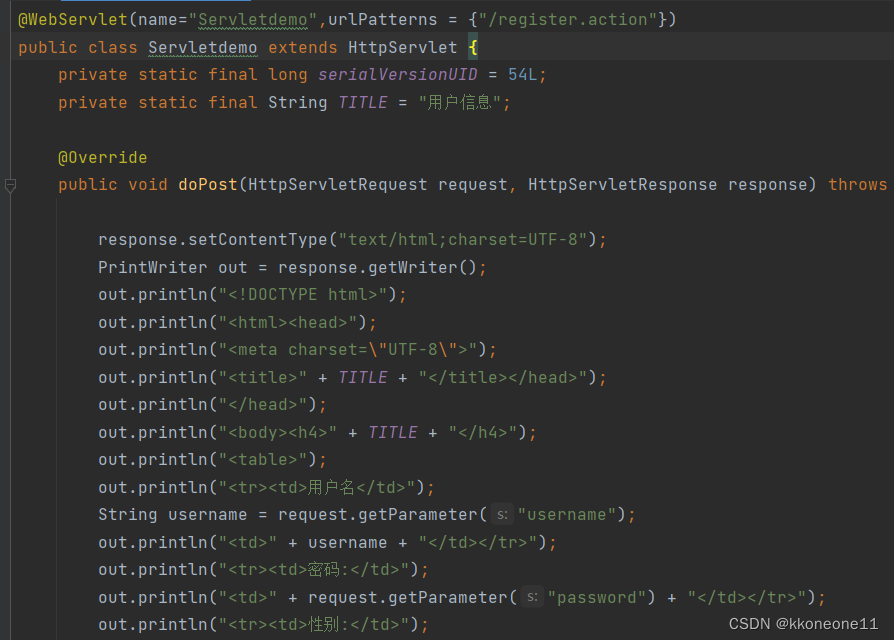
Tomcat+IDEA+Servlet能显示页面但提交form表单出现404问题
问题: 当我们使用tomcat启动,然后输入对应的url路径时候,能出现该html的页面,但提交表单后,却出现了404的问题,这时候我就很疑惑了....然后开始慢慢分析。 思路: 首先我们得知道404状态码是什…...
)
【蓝桥杯集训16】多源汇求最短路——Floyd算法(2 / 2)
目录 Floyd求最短路模板 4074. 铁路与公路 - floyd 脑筋急转弯 Floyd求最短路模板 活动 - AcWing 题目: 给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,边权可能为负数。 再给定 k 个询问,每个询问包含两个整数 x 和…...

simulink stateflow 状态机
系列文章目录 文章目录系列文章目录前言一、基操二、stateflow 数据三、chart动作四、chart的执行五、flow chart / junction六、状态机中的函数 Stateflow Functions七、chart层次结构八、案例——吸尘器机器人的驱动模式前言 一、基操 在tooltrip中选择DEBUG,通过…...

水库大坝安全监测的主要坝体类型介绍
水电站和水库大坝安全的分类中有重力坝、土石坝等不同的大坝形式。就在这里详细水库大坝安全监测按照建造形式,基本上可以分为三类:重力坝、土石坝和拱坝。 (1)重力坝 重力坝,顾名思义就是利用自身重力来维持坝体稳定…...

物理层概述(二)重点
目录前言编码与调制(1)基带信号与宽带信号编码与调制编码与调制(2)数字数据编码为数字信号非归零编码【NRZ】曼斯特编码差分曼彻斯特编码数字数据调制为模拟信号模拟数据如何编码为数字信号模拟数据调制为模拟信号物理层传输介质导…...
成都待慕电商:抖音极速版商品卡免佣扶持政策规则
新规,抖音极速版推出商品卡免佣扶持政策规则,本次抖音规则如何规定?具体往下看:一、政策简介1.1政策介绍为了更好地满足用户消费需求,丰富商家经营模式,降低商家经营成本,现平台针对商品卡场景推…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...
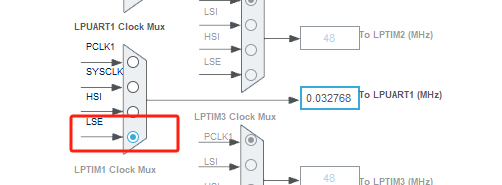
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...
Xcode 16 集成 cocoapods 报错
基于 Xcode 16 新建工程项目,集成 cocoapods 执行 pod init 报错 ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchro…...

门静脉高压——表现
一、门静脉高压表现 00:01 1. 门静脉构成 00:13 组成结构:由肠系膜上静脉和脾静脉汇合构成,是肝脏血液供应的主要来源。淤血后果:门静脉淤血会同时导致脾静脉和肠系膜上静脉淤血,引发后续系列症状。 2. 脾大和脾功能亢进 00:46 …...

深入理解 React 样式方案
React 的样式方案较多,在应用开发初期,开发者需要根据项目业务具体情况选择对应样式方案。React 样式方案主要有: 1. 内联样式 2. module css 3. css in js 4. tailwind css 这些方案中,均有各自的优势和缺点。 1. 方案优劣势 1. 内联样式: 简单直观,适合动态样式和…...
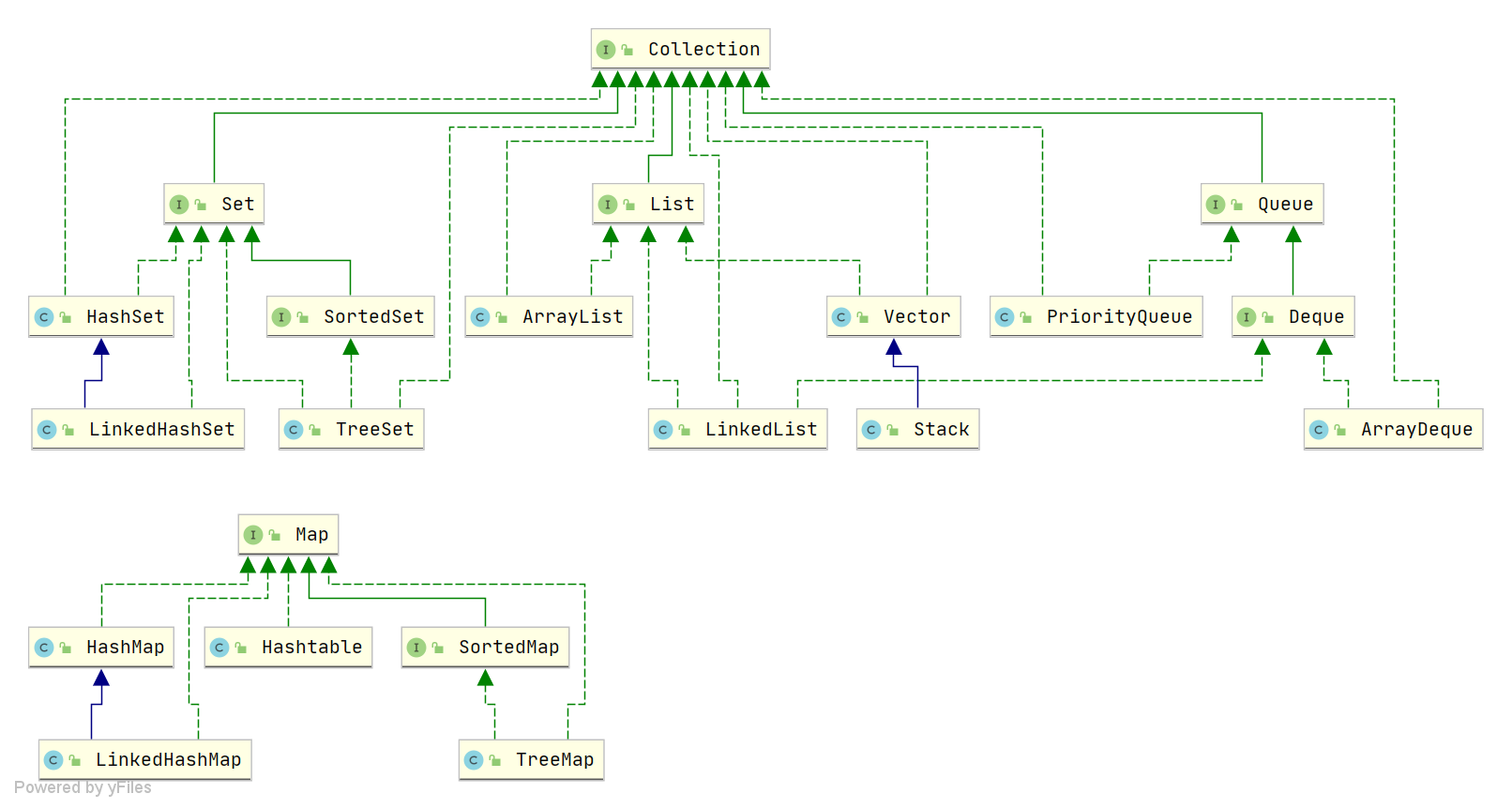
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性 HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,Hash…...